Sumarização de Dados
1. Qual índice de tendência central deveria ser usado para informar:
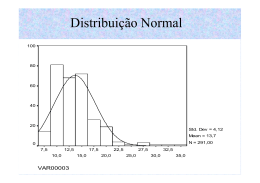
a. O tempo de resposta (FDP simétrica) . A distribuição não é enviesada e os
dados não são categóricos, então usamos a média.
b. Número de pacotes por dia (FDP simétrica). Idem anterior.
c. Número de pacotes por segundo (FDP skewed) Se a distribuição é enviesada,
então devemos usar a mediana.
d. Frequência de palavras-chave numa linguagem. Palavras chave são dados
categóricos, assim usamos a moda.
2. Como sumarizar uma configuração de um computador pessoal típico:
a. Tipo de CPU. Através da moda, poi strata-se de dado categórico.
b. Tamanho de memória. Tamanho de memória é tipicamente enviesado. A
maioria dos computadores têm mais ou menos a mesma quantidade, mas
existem uns poucos que têm muita muita memória. Assim, a melhor opção
seria usar a mediana.
c. Tipo de disco. Dado categórico, usar moda.
d. Número de periféricos. Tipicamente enviesado. Resposta semelhante à dada
para memória.
e. Custo. Usando a mesma lógica usada para tamanho de memória e numero de
periféricos, escolheria a mediana.
3. Os tempos de CPU em milissegundos para 11 workloads num processador são 0.74,
0.43, 0.24, 2.24, 262.08, 8960, 4720, 19740, 7360, 22440 e 28560. Qual índice de
tendência central você escolheria e por quê? Mediana, pois trata-se de uma
distribuição bastante enviesada. Se observarmos a razão Maximo/mínimo veremos
que é enorme.
4. O número de operações de IO de disco realizados por certos programas foram
medidos como segue:
{23,33,14,15,42,28,33,45,23,34,39,21,36,23,34,36,25,9,11,19,35,24,31,29,16,23,34,24,
38,15,13,35,28}. Qual índice de tendência central você usaria e por quê? Usaria média
pois a distribuição parece simétrica (histograma aparentemente simétrico e quantilquantil plot com a normal aproxima-se de uma reta com inclinação 1.
5. Para os 2 problemas acima, calcule todos os índices de dispersão. Qual índice de
dispersão você usaria e por quê? Quando usa a mediana usaria IQR ou SIQR. Quando
usa a média, usaria desvio padrão.
6. Trace um gráfico quantil-quantil para a seguinte amostra de erros:
-0.04444
-0.02569
-0.01565
-0.00083
0.00162
0.01026
0.02134
0.03259
-0.04439 -0.04165 -0.03268 -0.03235 -0.03182
-0.02358 0.02330 0.02305 0.02213 0.02128
-0.01509 0.01432 0.00978 0.00889 0.00687
-0.00048 0.00024 0.00079 0.00082 0.00106
0.00181 0.00280 0.00379 0.00411 0.00424
0.01085 0.01440 0.01562 0.01975 0.01996
0.02252 0.02414 0.02568 0.02682 0.02855
0.03754 0.04263 0.04276
0.02771
0.01793
0.00543
0.00110
0.00553
0.02016
0.02889
0.02650
0.01668
0.00084
0.00132
0.00865
0.02078
0.03072
Os erros são normalmente distribuídos? Não. Parecem ter cauda longa negativa e cauda
curta positiva
7. Demonstre que a média aritmética pode ser usada como métrica de tendência central
para dados da escala intervalar.
8. Mostre que, para métricas de escala nominal, a mediana não faz sentido para
expressar a tendência central, mas que a moda faz sentido.
9. Que aspectos do desempenho de um computador seria razoável sumarizar com um
número único?
10. Já foi dito que a média geométrica é consistente, isto é, consistentemente errada. Já
que uma média é calculada de acordo com uma fórmula matemática clara, em que
sentido poderia estar errada?
11. Que métrica de tendência central (média, mediana, moda) deveria ser usada para
sumarizar os seguintes tipos de dados:
a) Tamanho de uma mensagem numa rede de computadores
b)
c)
d)
e)
f)
g)
h)
i)
j)
k)
Número de hits e misses numa cachê
Tempo de execução
MFLOPS
MIPS
Banda passante
Latência
Speedup
Preço
Resolução de imagem
Vazão de comunicação
12. A tabela abaixo mostra os tempos de execução medidos para diferentes programas de
benchmark quando executados em 3 sistemas diferentes. A última coluna mostra o
número de instruções executadas por cada programa de benchmark. Supondo que cada
benchmark deve receber peso igual, calcule:
a) A média do tempo de execução
b) A taxa média de MIPS
c) O speedup e a mudança relativa, usando S3 como sistema de base.
d) Esses valores médios são bons sumários dos dados? Explique.
Programa
S1
S2
S3
# instruções
1
33.4
28.8
28.3
1.45 x 1010
2
19.9
22.1
25.3
7.97 x 109
3
6.5
5.3
4.7
3.11 x 109
4
84.3
75.8
80.1
3.77 x 1010
5
101.1
99.4
70.2
4.56 x 1010
A média aritmética deve ser usada para tempos e a média harmônica para taxas (como
MIPS).
Programa S1
S2
1
33,4
2
19,9
3
6,5
4
84,3
5
101,1
tempo de execução médio
MIPS
MIPS médio
S3
28,8
22,1
5,3
75,8
99,4
28,3
25,3
4,7
80,1
70,2
49,04
46,28
41,72
434,1317
400,5025
478,4615
447,2123
451,0386
503,4722
360,6335
586,7925
497,3615
458,7525
512,3675
315,0198
661,7021
470,6617
649,5726
440,7802 469,3196
485,3651
# instruções
14500000000
7970000000
3110000000
37700000000
45600000000
média
geral
45,68
média
geral
464,414
Speedup
Mudança relativa
0,908142 0,966942
-0,09186 -0,03306
1
0
A média de tempo de execução não é um bom sumário devido à grande variação presente nos
dados. Para MIPS, há pouca variação e a média é um bom sumário.
13. Repita o problema acima quando os programas P1, P2, P3, P4 e P5 representam 40%, 35%,
15%, 5% e 5% da carga esperada.
14. Determine o coeficiente de variação dos tempos de execução de cada sistema ta tabela
acima. s1.cv= 0.8442748, s2.cv = 0.8549862, s3.cv = 0.7677976
15. Dado o seguinte conjunto de dados: {7, 8, 6, 10, 5, 9, 4, 12, 7, 8}, calcule a média (7,6), o
desvio padrão (2,366), a mediana (7.5) e os quartis (6.25 e 8.75).
16. Calcule a média e o desvio padrão da seguinte distribuição de freqüências, a qual se
refere ao número de defeitos encontrados em placas de circuito integrado.
Número de defeitos
Frequência
0
30 (30/72)
1
25 (25/72)
2
10 (10/72)
3
5 (5/72)
4
2 (2/72)
Temos taxas em que todos os denominadores são iguais (72) e os numeradores são as
freqüências em que um certo numero de defeitos foi encontrado. Com denominadores
iguais, podemos usar a própria media aritmética das taxas para identificar a média (0,2).
A variância é 0,03.
17. Com o objetivo de direcionar campanhas de marketing, uma livraria virtual está
registrando o número de acessos diários em algumas de suas páginas da web, nos últimos
três meses. A tabela abaixo mostra medidas descritivas desses registros, em páginas de
três categorias de livros.
a) Quais as diferenças das três distribuições em termos de posição central e dispersão?
Ao plotar um boxplot (sem mínimos e máximos) percebemos que todas as
distribuições são enviesadas, com viés positivo. Sendo assim, elas devem ser
comparadas usando-se mediana e IQR ou SIQR. Segundo o índice de tendência
central os livros de romance parecem ser, em média, os mais acessados por dia,
seguidos dos livros de não-ficção e, por fim, livros de ficção. Em termos de variação,
os seguintes IQRs foram calculados para os números de acesso a livros de romance,
não ficção e técnicos respectivamente: 1088, 878 e 1385. Isto significa que a
distribuição de número de acessos com valores mais dispersos é a de livros técnicos,
seguida de livros de romance e por fim livros de não-ficção. É interessante observar
como a análise seria diferente caso tivéssemos usado média e desvio padrão. Neste
caso, teríamos concluído que livros técnicos são em média mais acessados que livros
de não ficção, pois a média é influenciada pela enorme quantidade de dados que se
encontra na cauda da distribuição de acessos a livros técnicos (maior dispersão).
Também teríamos concluído, erroneamente, que a distribuição de acessos a livros
técnicos apresentam menor dispersão que a distribuição de acessos a livros de
romance, o que também difere da análise anterior realizada com as métricas mais
indicadas para o caso de distribuições enviesadas.
b) As medidas sugerem distribuições simétricas? Não, as distâncias entre Q1-Q2 e Q2Q3 não são semelhantes.
Livro
Média
Desvio
padrão
Q1
Mediana
Q3
Romance
910
690
412
650
1500
Não-Ficção
220
180
145
398
1023
Técnico
630
480
115
190
1500
18. Os dados a seguir são leituras de pressão do homogeneizador de um laticínio. Para cada
conjunto de dados, calcule as medidas descritivas que você conhece. Com bases nessas
medidas, comente as principais diferenças entre os dois conjuntos de valores.
Leite tipo c
Leite UHT
3,0 3,1 3,0 3,0 3,0 2,9 2,9 3,0 3,1 2,9 3,0 3,0
3,0 3,0 3,0 3,0 3,0 3,0 3,0 3,0 2,9
2,2 2,2 2,3 2,2 2,2 2,2 2,4 2,4 2,2 2,4 2,6 2,6
2,4 2,2 2,2 2,8 2,6 2,2 2,6 2,4 2,0
As distribuições não parecem enviesadas, fazendo mais sentido caracterizá-las pela
média e desvio padrão. Para leite tipo c, a média e o desvio padrão calculados foram
respectivamente 2.990476 e 0.05389584. Para leite tipo UHT foram calculados média e
desvio padrão de 2.347619 e 0.1990453, respectivamente. Se fôssemos “comparar”
estas distribuições usando estes valores descritivos, diríamos que o homogeneizador do
leite tipo UHT tem pressão média menor, porém maior dispersão. O outro grupo de
métricas descritivas que pode ser usado para descrever dados tem a mediana como
índice de medida central e o IQR ou SIQR como índice de dispersão. Para estes dados,
não faz sentido calcular tais métricas.
Baixar