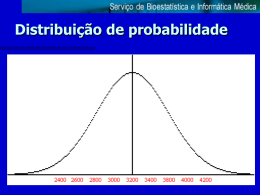
Estatística Aplicada Prof. Antonio Sales/ 2013 DESVIO PADRÃO E ERRO PADRÃO DA MÉDIA As inferências sobre uma população podem ser baseadas em observações a partir de amostras de populações. Como a amostra, a maior parte das vezes, é menor do que a população a média de uma amostra pode não ser a mesma que a média da população total. Uma forma de aproximação seria a retirada de várias amostras de uma população obtendo vários valores de médias (várias distribuições de frequências). Se essas médias tiverem distribuição normal estarão próximas ao verdadeiro valor da média populacional. Nesse caso pode-se encontrar a média de médias e seu desvio padrão. Esse desvio padrão das médias é chamado de erro padrão da média (EP). Quanto menor for o valor do EP uma média qualquer estará bem próxima do valor verdadeiro da média populacional. No entanto, essa tarefa não seria nada cômoda. Além de trabalhosa poderia ser impraticável. Felizmente podemos dispensar todo esse trabalho e estimar o EP a partir de uma única amostra, fazendo EP= desvio padrão n = s , sendo n= fi n Exemplo: Uma amostra de 60 indivíduos onde a massa corpórea, em kg, tiver média 42kg e um desvio padrão de 3,5 o Erro Padrão da Média será: EP 3,5 3,5 = 0,45 60 7,74 Mas, o que significa isso? Significa que podemos ter confiança que 68% ( valores arredondados)da população considerada terá massa corpórea entre os valores 41,55kg e 42,45kg _ ( x EP _ e x EP ) . Se quisermos ampliar o intervalo de confiança podemos afirmar que 95% está com massa corpórea entre os valores 41,2kg e 42,9kg. _ Para determinar esse intervalo de 95% de confiança fizemos x 1,96.EP , que neste caso é 42- 1,960,45 e 42+1,960,45 (os valores finais foram arredondados). Talvez haja a pergunta: de onde veio esse valor de 1,96? Não se pode confundir Desvio Padrão com Erro Padrão, também chamado de erro padrão da média. -Desvio Padrão (DP), ou s, é a variabilidade ou dispersão de observações com relação à média -Erro Padrão (EP) é a variabilidade ou dispersão de valores médios de uma distribuição de médias . Esse é o valor, denominado z, que é encontrado em tabelas estatísticas presentes em quase todos os livros dessa disciplina. A seguir parte de um quadro (LEVIN; FOX, 2003, p. 462) z Área ente Significado a média e z : : 1,92 47,26 1,93 47,32 1,94 47,38 1,95 47,44 1,96 47,50 47,50% dos indivíduos estão à direita (acima) da média e _ abaixo de x +z. EP, ou seja, 95% estão entre a média e z.EP 1,97 47,56 1,98 47,61 1,99 47,67 2,00 47,72 2,01 47,78 2,02 47,83 : : Você consegue agora entender quando, em período de eleições, é anunciado que o candidato X tem 43% dos votos com erro de 2% para mais ou para menos? A curva ilustrativa abaixo foi extraída da internet, mas é facilmente encontrada em livros de Estatística.(Obs. 2SD=2 desvios-padrão) 2 Repetindo: Formula para calcular o intervalo de confiança de 95% Limite inferior: média - 1,96.(EP) Limite superior: média + 1,96.(EP) DETERMINAÇÃO DO TAMANHO DA AMOSTRA Um problema normalmente enfrentado pelo pesquisador consiste em determinar o tamanho da amostra. Numa população de 400 profissionais, quantos devem ser tomados para compor uma a mostra estatisticamente significativa? E se a população for de 5000 elementos? E no caso de uma cidade como Campo Grande que tem cerca de 800 000 habitantes? Alguns critérios podem ajudar na decisão, dependendo do intervalo de confiança (IC) que queremos para o trabalho. O mais comum é admitir IC=95% . Podemos então aplicar uma das seguintes fórmulas: Fórmula (1). Sendo Ez n temos que z n E 2 Onde z=1,96 para IC=95%, E* é o erro esperado ou estimado pelo pesquisador e que deve variar de 1% a 7%, no máximo. O é o desvio padrão da população ( na falta deste usa-se ¼ da amplitude total, isto é, AT ) ( ANDERSON; SWEENEY; WILLIAMS. 2003. p. 300) 4 Esta alternativa é aplicada quando já se conhece alguns dados sobre a população ou, na falta deste, faz-se um projeto piloto utilizando arbitrariamente alguns elementos. Fórmula (2). Não tendo o desvio padrão ou amplitude total pode-se desenvolver um projeto piloto com uma pequena amostra e fazer n z 2 p(1 p) E2 onde p é a proporção do fator a ser pesquisado, na pequena amostra. Suponha que se queira saber o percentual de pessoas com olhos verdes numa certa população. Escolhe-se uma pequena amostra, arbitrária, conta-se o número de pessoas de olhos verdes, n * diríamos 15%, o que significa dizer que p=0,15 e então teremos: (1,96) 2 (0,15)(1 0,15) . Fizemos z=1,96 para ter um IC=95% e podemos arbitrar E=4%=0,04. E2 Quanto maior o erro esperado ou admitido menor o número de elementos na amostra. 3 Nesse n caso teríamos: n (1,96) 2 (0,15)(1 0,15) (0,04) 2 n (3,8416)(0,15)(0,85) 0,0016 (3,8416)(0,1275) 0,5 n = 312,5 0,0016 0,0016 Trezentos e treze indivíduos seria uma amostra estatisticamente significativa com 95 de confiança e com um erro previsto de 4% para mais ou para menos. Quando não há a possibilidade de um projeto piloto pode-se arbitrar p=0,5=50% (também chamada de proporção perversa porque é exagerada e requer uma amostra bem maior) Fórmula (3). Neste caso temos, na realidade, duas fórmulas: a) n Se a população for infinita ( mais de 100.000 elementos) usa-se a mesma fórmula: z 2 pq z 2 p(1 p) , como q=1-p então a fórmula pode ser expressa como n E2 E2 b) Se a população for finita (até 100 000 elementos) usa-se: n z 2 pqN E 2 ( N 1) z 2 pq Nos dois casos E é o erro esperado ou admitido (de 1% a 7%, no máximo), p é o percentual observado uma pequena amostra arbitrária, q é o complemento de p, isto é 1-p, enquanto N é o tamanho da população total. O valor de z será 1,96 sempre que quisermos um IC de 95%. Exemplos: a) Da população de Campo Grande ( 800 000 habitantes) queremos extrair uma amostra com um erro permitido de 3% (E=0,03), um intervalo de confiança de 95% ( z=1,96) para a uma pesquisa eleitoral. Vamos supor que numa pequena amostra de 30 pessoas detectamos que 30% (p=0,30) preferem o candidato A. Vamos agora determinar a amostra para a pesquisa: N= 800 000 (considerada população infinita porque maior que 100 000) Z=1,96 E=0,03 P=0,3 Fórmula: n n z 2 p(1 p) 1,96 2.0,3(1 0,3) n E2 0,032 n 3,8416.0,3.0,7 0,03 2 0,80674 =896,34896 0,0009 Uma amostra de 896 pessoas fornecerá um percentual com 3% de erro para mais ou para menos e um intervalo de confiança de 95% 4 b) Vamos supor agora que queiramos fazer a mesma pesquisa numa cidade interiorana com apenas 70 000 habitantes. Nesse n caso usaríamos a fórmula n z 2 pqN E 2 ( N 1) z 2 pq (1,96) 2 .0,3.0,7.70000 (0,03) 2 (70000 1) (1,96) 2 .0,3.0,7 n n (1,96) 2 .0,3.0,7.70000 (3,8416).(0,3).(0,7).70000 n 2 2 (0,0009)(69999) (3,8416).(0,3).(0,7) (0,03) (70000 1) (1,96) .0,3.0,7 56471,5 56471,5 n n 885,05885 62,999 0,8067 63,8057 Com uma amostra de 885 habitantes teríamos uma pesquisa com 95% de confiança e 3% de erro para mais ou para menos. Exercícios: 1. Os valores de glicose em mg/dl, obtidos em 9 homens de 33 a 39 anos, em jejum, foram: 90, 86, 78, 90, 98, 90, 82, 76, 84. Determine: a) a média b) o desvio padrão c) o erro padrão da média ( obs. Não esqueça de organizar os dados) 2. As alturas de 15 crianças que frequentam a escola na turma M são, em cm: 140, 135, 145, 138, 138, 143, 145, 145, 144, 143, 140, 142, 146, 143, 141. Determine: a) a média b )o desvio padrão c) o erro padrão da média d) uma amostra estatisticamente significativa (α=0,05e E=0,05) 3. Uma empresa tem 250 funcionários e uma equipe de saúde quer fazer um levantamento relativo à massa corpórea desse funcionários. Sabe-se que o mais gordo tem 120kg de massa e o mais magro tem 62 kg. Qual será o tamanho da amostra que representa 95% dessa população e a um erro de 2%? E a um erro de 6%? 4. No problema anterior se 100 dos funcionários forem mulheres e 150 forem homens, quantas mulheres e quantos homens deverão fazer parte da amostra? 5. Se, no problema 3, a maior massa fosse 120kg e a menor fosse 80kg, quantos indivíduos deveriam compor a amostra? 6. O serviço de controle de zoonoses pretende fazer uma pesquisa no município XPTO para analisar o índice de prevalência de leishimaniose em caninos da região. Estima-se que haja 2500 animais no município e como não há nenhum levantamento prévio está-se trabalhando com a proporção exagerada ou perversa de 50%. Quantos cães devem compor a amostra para se 5 ter um erro máximo de 2%? E se já houver uma estimativa confiável de que 15% da população está infectada, com erro admitido de 4%). 7. No mesmo problema anterior se fosse conhecido o índice de prevalência em uma pequena amostra e se soubesse que p=0,2, qual deveria ser o tamanho da amostra? Respostas: 1. a) 86 b)6,5 c)2,2 (valores arredondados) 2. a) 142 b)3 c)0,8 (valores arredondados) 3. 200. (Usamos a amplitude total dividido por 4, uma vez que não temos o desvio padrão. Admitimos um erro máximo de 2 e um intervalo de confiança de 95%). 4. 80 mulheres e 120 homens 5. 96 6. 1225 7. 951 ( para um erro de 5% o número da amostra seria bem menor) Bibliografia ANDERSON, David R., SWEENEY, Dennis J., WILLIAMS, Thomas A. Estatística Aplicada à Administração e Economia. São Paulo: Pioneira Thomson Lerning, 2003. p. 300 LEVIN, J; FOX, J.A. Estatísticas para Ciências Humanas. 9. ed. São Paulo: Prentice-Hall, 2004. p. 462. ENSINO INTERATIVO. Disponível em http://www.anhembi.br/testes/ lo_lu/metodologia_pesquisa/lu10/lo2/index.htm acesso em 03/09/2005 Pode-se ver também: FONSECA, Jairo Simon da; MARTINS, Gilberto de Andrade. Curso de Estatística. 6.ed. São Paulo: Atlas, 2009. 6
Baixar