Probabilidade
E Estatística
Elaborado por Paul CHEGE
Traduzido para Português por Paulo Diniz
African Virtual university
Université Virtuelle Africaine
Universidade Virtual Africana
_ Africana
Universidade Virtual
Nota
Este document é publicado sob as condições da Creative Commons
http://en.wikipedia.org/wiki/Creative_Commons
Atribuição
http://creativecommons.org/licenses/by/2.5/
Licenca (abreviada “cc-by”), Versão 2.5.
Por CC
São reservados alguns direitos
_ Africana
Universidade Virtual
Índice
I.
Probabilidade e Estatística............................................................................... 3
II.
Conhecimentos prévios (Pre-requisitos)
III.
Tempo............................................................................................................... 3
IV.
Materiais............................................................................................................ 3
V.
Justificativa/Filosofia do módulo............................................................3
VI.
Conteúdos......................................................................................................... .4
6.1
6.2
6.3
Visão geral......................................................................................................... .4
Plano/Esboço..................................................................................................... .5
Diagrama de organização dos conteúdos....…………………………………. 6
VII.
Objectivos do módulo……………………………………………………….. 7
VIII.
Actividades específicas de aprendizagem………………………………….... 7
IX.
Actividades de ensino e aprendizagem..............................................................9
X.
Lista de conceitos chaves (Glossário).............................................................. 12
XI.
Lista de materiais de leitura obrigatória
XII.
Lista de recursos……………………………….…………………………… 19
XIII.
Lista de Links (Sítios da Internet) úteis…………………………………….. 20
XIV.
Actividades de aprendizagem............................................................................21
XV.
Síntese do modulo………………………………………………………….. 112
........................................................ 3
........................................................ .18
XVI. Avaliação sumativa........................................................................................... 113
XVII. Referencias…………………………………………………………………… 121
XVIII. Registos de estudantes....................................................................................... 122
XIX. Principal Autor do módulo................................................................................ 123
Univeridade
Africana
Virtual_
I. Probabilidade e Estatística
Por Paul Chege
II. Conhecimentos prévios (Pre-requisitos)
Para frequentarem este modulo, os estudantes precisam ter conhecimentos sobre
Probabilidade e Estatística do Ensino Secundário
III. Tempo
O tempo total para este modulo é de 120 horas de estudo.
IV. Material
Os estudantes deverão ter acesso aos textos nucleares de leitura que estão especificados
Também precisarão de usar o computador para terem acesso total aos textos nucleares de leitura.
em diante.
Adicionalmente, os estudantes deverão estar aptos para instalar e usar o Sofware wx Maxima para
exercitarem conceitos algébricos
V. Importância do Módulo/Filosofia do Módulo
Probabilidade e Estatística, para além de ser uma área chave para o ensino de matérias
do ensino secundário, constitui uma base muito importante para o ensino da Matemática do
nível superior. A Estatística é uma área fundamental da Matemática com aplicação em muitas
outras disciplinas e é útil em análise de processos em produção industrial. O estudo da
Estatística providencia especialistas (Estatísticos) capazes de recolher e analisar dados
referentes a uma determinada
população e fazer as respectivas inferências sobre certas
características desta. Os Estatísticos providenciam aos governos e organizações instrumentos
concretos que podem ajudar aos gestores na tomada de decisão perante uma determinada
situação. Por exemplo, com base na Probabilidade e Estatística, pode-se analisar a taxa de
expanção de doenças, as alterações da densidade populacional, pode-se fazer a previsão
meteorológica, etc.
O estudo da da teoria de Probabilidade ajuda na tomada de decisão dos agentes
governamentais e das organizações, usando como base a teoria de chances. Por exemplo,
pode-se predizer a quantidade de crianças de sexo masculino e de sexo feminino nascidas
dentro de um determinado período e também projectar a quantidade de chuva que uma
determinada região pode esperar, com base em alguns dados históricos sobre as
regularidades/padrões de chuva dessa região.
A teoria de Probabilidade também tem sido extensivamente usada na determinação de
qualidade (alta, média e baixa) de produtos industriais, por exemplo, para prever o número de
peças defeituosas num processo de produção industrial.
_
African Virtual University
VI. Conteúdos
6.1 Visão geral
Este módulo é composto por três unidades:
Unidade 1: Estatística Descritiva e Distribuição de Probabilidades
A Estatística descritiva é uma unidade que é desenvolvida ou como uma extensão da
matemática do nível secundário ou como uma introdução para estudantes que se iniciam no
estudo da Estatística. Introduzem-se nesta unidade as medidades de tendência central e de
dispersão e também o conceito de probabilidade e o seu tratamento teórico.
Unit 2: Variáveis aleatórias e Distribuições
Esta unidade exige como pre-requisito a unidade 1. É desenvolvida a desde o conceito de
Momento e função geradora de Momento, desiguladades de Markov e de Chebychev, algumas
distribuições univariadas, distribuições bivariadas de probabilidade e probabilidades condicionais.
Esta unidade dá algum subsídio para a análise de coeficientes de correlacão e para funções de
distribuição de variáveis aleatórias, tais como a distribuição qui-quadrado, distribuição T e a
distribuição F
Unit 3: Teoria de Probabilidade
Esta unidade é desenvolvida a partir da unidade 2. Nesta unidade faz-se a análise de
Probabilidade usando funções de indicadores. Introduz-se a desigualdade de Bonferoni, funções
geradoras, função característica e independência estatística de amostras aleatórias. Desenvolve o
conceito de função para diferentes variáveis aleatórias e termina com o tratamento dos teoremas de
convergência e de limite central.
_
African Virtual University
6.2 Plano: Programa
Unidade 1 ( 40 horas): Estatística Descritiva e Distribuição de Probabilidades
Nível 1. Prioridade A. Sem pre-requisitos.
Distribuição de frequências relativas, distribuição de frequências acumuladas, curvas de
frequências, média moda e mediana. Quartís e percentís, desvio padrão, distribuições simétricas
e assimétricas. Probabilidade, espaço amostral, evento, definição de probabilidade, propriedades
da probabilidade, variáveis aleatórias, distribuição de probabilidades, valor esperado (média) de
uma variável aleatória, algumas distribuições particulares: distribuição de Bernoulli, distribuição
Binomial, de poisson, Geométrica, Hipergeométrica, Uniforme, Exponencial e distribuição
Normal. Distribuição de frequências bivariadas, tabelas de probabilidades conjuntas e
probabilidades marginais
Unidade 2 ( 40 horas): Variáveis Aleatórias e Distribuições de Testes
Nível 2. Prioridade B. O pre-requisito é a Estatística 1
Momentos e funções geradoras de Momentos, desigualdades de Markov e de
Chebychev, distribuições univariadas especiais. Distribuição de probabilidades bivariadas,
distribuições de probabilidades conjuntas, condicionais e marginais. Independência, regressão e
correlação de dados bivariadas, cálculo de coeficientes de regressão e de correção, função
distribuição de variáveis aleatórias, distribuição normal bivariada. Distribuições derivadas, tais
como qui-quadrado, T e F.
Unidade 3 ( 40 horas): Teoria de Probabilidade
Nível 3. Prioridade C. O pre-requisito é Estatística 2.
Probabilidade: Uso de funções indicadoras. Desigualdade de Bonferoni de vectores aleatórios. Funções
geradoras. Função característica. Independência estatística de amostras aleatórias. Distribuição multinomial.
Função de várias variáveis aleatórias. Independência de X e de S2 em amostras normais, estatísticas de ordem,
convergência e teorema de limite. Exercícios práticos.
6.3. Diagrama de organização dos conteúdos
_
African Virtual University
VII. Objectivos
No fim deste modulo, os estudantes deverão ser capazes de calcular as medidas de
tendência central e de dispersão em estatística e resolver tarefas de probabilidade baseadas
nas leis probabilisticas e fazer testes de hipóteses usando a teoria de probabilidades
VIII. Objectivos específicos de aprendizagem
(Objectivos instrucionais)
Unidade 1: Estatística Descritiva e Distribuição de Probabilidades ( 40 Horas)
No fim desta unidade, os estudantes deverão ser capazes de:
Desenhar várias curvas de frequência;
Calcular a média, moda, mediana, quartís, decís, percentís e desvio padrão de dados
agrupados ou não;
Definir e enunciar as propriedades da Probabilidade;
Ilustrar as variáveis aleatórias, distribuição de probabilidades e valor esperado de uma
variável aleatória;
Ilustrar as distribuições de Bernoulli, Binomial, Poisson, Geométrica, Hipergeométrica,
Uniforme, Exponencial e Normal;
Unidade 2: Variáveis Aleatórias e Distribuição de Testes ( 40 Horas)
No fim desta unidade, os estudantes deverão ser capazes de:
Ilustrar Momentos e funções geradoras de Momentos;
Analisar as desigualdades de Markov e de Chebychev;
Examinar algumas distribuições univariadas de probabilidade, distribuições
bivariadas de probabilidades, probabilidades conjuntas, marginais e condicionais;
Mostrar a independência de variáveis, correlação e regressão;
Calcular os coeficientes de correlação e regressão para dados bivariados;
Mostrar a função distribuição de varíáveis aleatórias;
Examinar a distribuição normal bivariada;
Ilustrar as distribuições derivadas, tais como a qui-quadrado, a T e a distribuição F.
_
African Virtual University
Unidade 3: Teoria de Probabilidade ( 40 Horas)
No fim desta unidade, os estudantes deverão ser capazes de:
•
•
•
•
Usar as funções de indicadores em Probabilidades;
Mostrar a desigualdade de Bonferoni;
Ilustrar funções geradora e característica;
Examinar a independência estatistica de amostras aleatórias e a distribuição multinomial;
•
•
•
•
•
Avaliar funções de várias amostras aleatórias;
Illustrar a independência de X e S2 em amostras normais de estatísticas de ordem;
Mostrar a distribuição normal multivariada;
Illustrar os teoremas de convergência e de limite;
Resolver exercícios práticos.
_
African Virtual University
IX. Actividades de Ensino e de Aprendizagem
9.1 Pre-Avaliação
A Matemática Básica é um pre-requisito para a Probabilidade e Estatística.
Tarefas
1. Se jogarmos um dado, a probabilidade de se obter um número maior que 4 é:
2. Uma carta é extraida aleatoriamente de um baralho de 52 cartas. A probabilidade de ser
Rainha é:
3. São dados 100 números, dos quais 20 são 4s, 40 são 5s, 30 são 6s e os restantes são 7s.
Encontre a média aritmética desses números.
_0
African Virtual University
4) Calcule a média dos seguintes dados.
5) Encontre a moda dos seguintes dados: 5, 3, 6, 5, 4, 5, 2, 8, 6, 5, 4, 8, 3, 4, 5, 4, 8,
2, 5 e 4.
A.
B.
C.
D.
4
5
6
8
6) O valor da probabilidade pode variar:
A. de 0 a 1
B. de -1 a +1
C. de 1 a 100
D. de 0 a
1
2
7) Encontre a mediana dos seguintes dados: 8, 7, 11, 5, 6, 4, 3, 12, 10, 8, 2, 5, 1, 6, 4.
A.
B.
C.
D.
12
5
8
6
8) Encontre a amplitude total dos seguintes valores: 7, 4, 10, 9, 15, 12, 7, 9.
A.
B.
C.
D.
9
11
7
8.88
__
African Virtual University
9) Se jogarmos duas moedas e verificarmos as faces voltadas para cima, o espaço amostral será:
A.
B.
C.
D.
C, K e CK
CC, CK, KC, KK
CC, CK, KK
C, K
10) Se uma letra for escolhida aleatoriamente da palavra “Mississippi”, encontre a probabilidade
De que seja um “i”
Chave de respostas
1. B 2. A 3. D 4. C 5. B
6. A 7. D 8. B 9. B 10. D
Comentários Pedagógicos para estudantes
Esta pré-avaliação destina-se a dar aos estudantes uma visão sobre o que devem lembrar
sobre Probabilidade e Estatística. Uma pontuação inferior a 50% nesta pre-Avaliação
indica que o estudante precisa de rever os conteúdos de Probabilidade e Estatística do
nível secundário. A pré-avaliação abrange os conceitos básicos com os quais os
estudantes precisam de se familiarizar antes de avançar com este módulo. Faça a revisão
da Probabilidade e Estatística do ensino secundário para dominar o básico se tem
problemas com esta pré-avaliação.
__
African Virtual University
X. Conceitos Chaves ( Glossário)
Eventos mutuamente exclusivos: Dois eventos dizem-se mutuamente exclusivos se não podem
ocorrer ao mesmo tempo.
Variância de um conjunto de dados é definida como a raiz quadrada do desvio padrão, isto é, Var =
S2.
Experimento aleatório: é o processo de observação ou de acção cujos resultados, embora possam
ser descritos no seu conjunto, não são determináveis à prior, antes da realização da experiência. Ex:
tirar aleatoriamente uma carta de um baralho ou lançar um dado e verificar o número obtido.
Espaço amostral: é o conjunto de todos resultados possíveis de um experimento. Ex., se lançarmos
uma moeda e verificarmos a face de cima esperamos dois resultados possíveis (cara ou coroa).
Portanto, o espaço amostral é (C; K).
Variável aleatória: é uma função que assume valores reais para todos resultados possíveis de um
experimento aleatório.
Amostra aleatória: aquela que é construida por métodos envolvendo uma componente imprevisível.
Distribuição de Bernoulli: é uma distribuição de probabilidade discreta, que assume o valor 1 com
probabilidade p de sucesso e valor 0, com probabilidade de fracasso q = 1- p.
Distribuição Binomial: é uma distribuição de probabilidade discreta, que dá conta do número de
sucessos em n experimentos aleatórios independentes, cada um com apenas dois resultados possíveis
(um correspondendo ao sucesso e outro, ao fracasso). A probabilidade de sucesso p, é sempre a
mesma para cada experimento.
Distribuição Hipegeomátrica: é uma distribuição de probabilidade discreta que descreve o número
de sucessos em uma amostra de tamanho n, retirada de uma população finita de tamanho N, sem
reposição.
Distribuição de Poisson: é uma distribuição de probabilidade discreta, que expressa a
probabilidade de vários eventos que ocorrem em um determinado período de tempo, se
esses eventos ocorrerem com uma taxa média conhecida, e independentemente do
intervalo de tempo.
Correlação: é uma medida de associação entre duas variáveis.
Regressão: é uma medida usada para examinar a relação entre uma variável dependente
e uma independente.
Teste qui-quadrado: é um teste de hipótese estatística em que a estatística de teste tem
uma distribuição qui-quadrado quando a hipótese nula é verdadeira, ou qualquer teste em
que a distribuição de probabilidades da estatística de teste (assumindo que a hipótese nula
é verdadeira) pode ser aproximada a uma distribuição qui-quadrado, tanto quanto melhor,
fazendo o tamanho da amostra suficientemente grande.
Distribuição Normal multivariada: é uma distribuição de probabilidade específica, que pode ser
considerada uma generalização da distribuição normal univariada, para dimensões mais grandes.
teste-t é qualquer teste de hipótese estatística para dois grupos, em que a estatística de teste tem uma
distribuição t de Student se a hipótese nula é verdadeira.
__
African Virtual University
Termos estatísticos
1.
Dados
brutos:
são
dados
não
organizado
numericamente.
2. Rol: é um arranjo dos dados numéricos em ordem crescente de magnitude.
3. Amplitude total: é a diferença entre o maior e o menor valor dos dados.
4. Intervalos de classes: Em uma série de dados agrupados por exemplo, 21-30, 31-40 etc, o
intervalo
21-30
é
chamado
de
intervalo
de
classe.
5. Limites da Classe: Em um intervalo de classe, por exemplo, 21-30, 21 e 30 são chamados de
limites
de
classe.
6. Limites inferior de classe (Lic): No intervalo da classe 21-30, o limite inferior da classe é
21
7. Limite superior de classe (Lsc): no intervalo da classe 21-30, o limite superior da classe é
30
8. Fronteiras dos Limites inferior e superior da classe: No intervalo da classe 21-30, a
fronteira do limite inferior de classe é de 20,5 e a do limite superior é 30.5. Essas fronteiras
garantem, teoricamente, todos valores do intervalo de 21-30 estão incluidos no intervalo de
20,5-30,5.
9. Amplitude de classe: É a diferença entre o limite superior e o inferior. Exemplo, para o
intervalo de 21-30, a amplitude é 9 e para o intervalo 20,5-30,5 a amplitude é 10.
10. Marca de classe ou ponto médio: é a média aritmética dos limites da classe. Para o intervalo
de 21-30, o ponto médio é
11. Distribuição de frequências: Um grande número de dados brutos, pode ser representado
na forma tabular, com as suas respectivas frequências. Por exemplo:
Esta representação dos dados chama-se distribuição de frequências ou tabela de frequências
12. Frequências acumuladas: A frequência acumulada até um certo valor ou dado, é a soma as
frequências individuais precedentes incluindo a do próprio valor ou dado. Por exemplo:
13. Distribuição de frequências relativas. Na tabela seguinte,
A soma das frequências é
A freqência relativa da classe 25-29 é calculada dividindo a frequência desta classe pela soma
das frequências. Exemplo: A frequência relativa do intervalo de 25-29 é dada por
__
African Virtual University
14. Curva de frequências acumuladas (Ogiva). Dada a tabela de frequências abaixo,
Podemos construir o gráfico das frequências acumuladas versus fronteiras dos limites superiores
das classes.
Nota: No gráfico de frequências acumuladas, o primeiro ponto marcado é (24,5; 4). Se
começássemos o gráfico neste ponto, este ficaria pendurado no eixo-0y. Para evitar
isso, criamos outro ponto (19,5, 0) como ponto de partida. 19,5 é a fronteira do limite
superior da classe (projectada) anterior.
__
African Virtual University
Formas de curvas de frequência
__
African Virtual University
XI. Lista de material de leitura obrigatória
Leitura 1:
Wolfram MathWorld Acedido em 06.05.07)
Referência completa :http://mathworld.wolfram.com/Probabilty
Resumo: Esta referência fornece o material de leitura muito necessário em
Probabilidade e Estatística. A referência tem uma série de ilustrações que
capacitam o estudante através de diferentes metodologias de abordagem.
Wolfram MathWorld é uma enciclopédia matemática online especializada.
Justificação/Filosofia: Ele fornece as referências mais detalhadas para qualquer
tópico matemático. Os estudantes devem começar por utilizar o mecanismo de
Leitura 2:
Wikipedia (visitado em 06.05.07)
Referência Completa :
http://en.wikipedia.org/wiki/statistics
Resumo: Wikipédia é uma enciclopédia on-line. É escrita pelos próprios leitores.
Está sempre renovada, já que novas entradas são continuamente revistas. Além
disso, tem-se revelado extremamente precisa. Os assuntos matemáticos que dão
entrada
são
muito
detalhados.
Justificação/Filosofia: A Wikipédia dá definições, explicações e exemplos que os
estudantes não podem acessar facilmente em outros recursos. Pelo facto de a
Wikipedia ser atualizada com freqüência dá-se ao estudante a possibilidade de
MacTutor History of Mathematics (Acedido em 03.05.07)
Leitura 3:
Referência complete: http://www-history.mcs.standrews.ac.uk/Indexe s
Resumo: O Arquivo MacTutor é a história mais abrangente da matemática na
internet. Os recursos são organizados tendo em conta os temas históricos.
Justificação/Filosofia: Os estudantes devem pesquisar o arquivo MacTutor por
palavras-chave nos tópicos estão a estudar (ou pelo nome do módulo em si). É
importante
ter
uma
visão
geral
de onde a matemática que está a ser estudada se encaixa na história da
matemática.
Quando
o estudante termina o curso e vai ensinar a matemática do ensino secudário, terá de
traser
o
assunto
para
seus
alunos.
Em particular, o papel das mulheres na história da matemática deve ser bem
estudado para ajudar os alunos a compreenderem que dificuldades as mulheres têm
enfrentado ainda que estejam a traser uma contribuição importante. Do mesmo
modo,
o
papel
do
continente
Africano
deve
ser
estudado
para compartilhar com os alunos nas escolas, nomeadamente os primeiros
dispositivos de contagem (por exemplo, o osso Ishango) e também o papel da
matemática egípcia deve ser bem estudado.
__
African Virtual University
XII. Lista de recursos obrigatórios
Recurso 1: Maxima.
Referência Completa: Uma cópia do Maxima em disco faz parte do material para este
curso
Os estudantes do ensino à distância são ocasionalmente confrontados com dificuldades
no ensino da matemática devido a falta de recursos que os possam guiar. A falta de
aulas presenciais orientadas por um docente pode levar os estudantes a uma estagnação
total, se não estiverem devidamente equipados de recursos que os ajudem a resolver
seus problemas de aprendizagem da matemática. Este impedimento pode ser resolvido
através de uso de recurso acompanhante: Maxima.
Justificação/Filosofia: Maxima é um software do grupo das fontes abertas que pode
permitir os estudantes a resolver equações lineares e quadráticas, sistemas de equações,
integração
e
diferenciação,
executar
manipulações
algébricas:
factorização,
simplificação, etc. Iste recurso é obrigatório para estudantes do ensino à distância
porque possibilita uma aprendizagem rápida usando as habilidades em TIC’s já
adquiridas.
Recurso 2: Graph
Referência Completa: Uma cópia de Graph, também acompanha este curso
É relativamente difícil desenhar gráficos de funções, especialmente funções
complicadas com funções em três dimensões. Os estudantes à distância,
inevitavelmente encontrarão situações em que precisarão de algum recurso para
desenhar gráficos em matemática. Este curso é acompanhado de um software chamado
Graph para ajudar os estudantes no desenho de gráficos. Contudo, os estudantes
precisam de estar familiarizados com este software para o poderem usar facilmente.
Justificação/Filosofia: Graph é um software, dinâmico, do tipo fonte aberta, que os
estudantes podem ter acesso através do disco que lhes é disponizado. Este ajuda aos
estudantes de matemática a desenhar gráficos que de outro modo seriam bastante
difíceis. É fácil usar este software, desde que os estudantes invistam algum tempo para
aprenderem como funciona. Os estudantes sairão em vantagem porque poderão usar
este recurso em outras disciplinas durante e mesmo depois do curso. Notarão que é
muito útil quando forem ensinar a matemática no ensino secundário.
_0
African Virtual University
XIII. Lista de Links úteis
Link 1
Títlo :Wikipedia
URL:http://en.wikipedia.org/wiki/Statistics
Descrição: Wikipedia é dicionário de todos matemáticos. É um recurso-aberto que
freqüentemente é atualizado. A maioria dos estudantes, de quando em vez, encontrará
problemas de referências para materiais de consulta. A maioria dos livros disponíveis
só cobre partes ou seções dos conteúdos de Probabilidade e Estatística. Esta escassez
de materiais pode ser superada com o uso de Wikipedia. É fácil aceder por pesquisa no
“Google”.
Justificação/Filosofia: A disponibilidade de Wikipedia resolve problemas cruciais de
falta de materiais de aprendizagem em várias áreas de matemática. Estudantes
deveriam ter experiência, em primeira mão, de Wekipedia para os ajudar nas suas
aprendizagens. É um recurso grátis muito útil que não só resolve os problemas de
estudante de materiais de referência mas também dirige os estudantes para outro
websites relativamente úteis, bastando clicar nos ícones indicados. A sua utilidade é de
reconhecida importância.
Link 2:
Título: Mathsguru
URL: http://en.wikipedia.org/wiki/Probability
Descrição: Mathsguru é um website que ajuda os estudantes a compreender várias da
Teoria de Números. É fácil acerder através de pesquisa no Google e disponibiliza
informações detalhadas sobre várias questões de Probabilidade. Oferece explicações e
exemplificações que facilmente os estudantes podem entender.
Justificação/Filosofia: Mathsguru oferece vias alternativas para estudantes acederem a
outros tópicos correlacionados, sugestões e soluções, podendo constituir uma grande
ajuda para os que encontram frustrações em obter livros que ajudem na aprendizagem
de Probabilidade. Oferece abordagens bastante úteis, tendo em consideração as várias
áreas do módulo de Probabilidade.
Link 3.
Título: Mathworld Wolfram
URL: http://mathworld.wolfram.com/Probability
Descrição: Mathworld Wolfram é um website cheio de soluções para problemas de
Probabilidade. Os estudantes podem aceder a este recurso através de pesquisa no
Google. Wolfram também orienta os estudantes para outros websites úteis para
aprimorar as suas compreensões sobre os mesmos tópicos. Mathworld Wolfram é um
site que também providencia alguns subsídios sobre a Teoria de Números, desafios e
algumas orientações metodológicas. Ajuda também na Modelagem Matemática e é
fortemente recomendado para estudantes interessados em aprender a Teoria de
Números e outras áreas da Matemática. Ajuda a fazer ligação para outros websites
fornendo uma vasta gama de informações necessárias para estudantes compreenderem
os conteúdos de Probabilidade e Estatística.
__
African Virtual University
XIV. Actividades de Aprendizagem
Unidade 1
40 Horas
Estatística Descritiva e Distribuição de Probabilidades
Uma fazendeira desenvolveu as seguintes actividades na sua fazenda:
1. Ela planta 80 mudas no primeiro dia de Março. No primeiro dia de Dezembro mede as
alturas das plantas.
2. Ela pesa todas as vacas da fazenda e regista os pesos no seu diário.
3. Faz o registo da produção de ovos da secção de avícula.
4. Faz o registo do tempo levado até entregar o leite à fábrica de processamento.
Os resultados dos registos estão indicados a seguir:
1. Alturas das plantas em cm
2. Pesos de vacas em kg
__
African Virtual University
3. Número de Ovos
4. Tempo gasto até que o leite chegue ao processamento
CASO 1:
Uma empresa local que lida com serviços de extensão agrícola visita a fazendeira. Ela
orgulhosamente produziu seus registos. O gestor agrícola ficou muito impressionado com
registos mas percebe claramente que a fazendeira precisa de algumas habilidades em
gestão de dados para permitir que ela tome boas decisões com base nos dados provenientes
da sua fazenda. O gestor agrícola projeta um curso sobre processamento de dados para
todos os farmeiros rurais. Durante a fase de planeamento do curso, são definidos os
seguintes conceitos:
a) Dados: São resultados de uma observação. Por exemplo, alturas de mudas
b) Freqüência: taxa de ocorrência de um dado. Por exemplo, número de vacas pesadas.
c)
d)
Média:
Moda:
O
valor
Dado
médio
que
de
um
ocorre
conjunto
com
maior
de
dados
frequência.
e) A mediana: Postos os dados em ordem crescente, a mediana é o elemento da posição
Aula 1: Introdução à Estatística
A Estatística Descritiva é utilizada para designar qualquer das várias técnicas
utilizadas para sumarizar um conjunto de dados. Tais técnicas são geralmente
classificadas em:
1. Descrição gráfica, em que usamos gráficos para sumarizar os dados.
2. Descrição Tabular, em que se usam tabelas para sumarizar os dados.
3. Descrição Paramétrica, em que se estimam os valores de determinados
parâmetros que assumimos que completam a descrição do conjunto de dados.
Em geral, os dados estatísticos podem ser descritos como uma lista de indivíduos
ou unidades e os dados associados a cada um deles.
1. Pretende-se
neste
momento
alcançar
dois
objectivos:
Pretende-se mostrar estatisticamente o quanto certas medidas são parecidas. Em
manuais de Estatística esta questão é respondida com base nas medidas de tendência
central.
__
African Virtual University
Quando estamos resumindo uma certa quantidade de dados, como o
comprimento, o peso ou a idade, é comum responder-se à primeira
questão com o cálculo da média aritmética, a mediana, ou a moda. Às
vezes, pode-se calcular os quartís, decís ou percentís.
As medidas mais comuns de variabilidade para dados quantitativos
são a variância; a sua raiz quadrada, o desvio-padrão, a amplitude
total; o intervalo interquartil, e o desvio absoluto.
Aulas para os farmeiros
Aos farmeiros é lhes ensinado como calcular:
a) A Média
A Média de um conjunto de dados é a soma de todos valores dividida pelo número
total de dados.
Exemplo:
Calcule a média dos seguintes conjuntos de dados
__
African Virtual University
Aula 2
Média de dados discretos
Exemplo: Encontre a media dos seguintes dados
__
African Virtual University
__
African Virtual University
FAÇA O SEGUINTE
Calcule a media de:
Respostas
__
African Virtual University
Aula 3
Moda
Exemplo
1) Encontre a moda dos seguintes dados: 1,3,4,4,5,6,1,3,3,2,2,3,3,5
Solução:
A moda deste conjunto é o element que aparece mais vezes. Concretamente é o 3,
com frequência igual a 5.
2) Encontre a moda dos seguintes dados: 22, 24, 25,22, 27, 22, 25, 30, 25, 31
Solução:
.22 e 25 ocorrem três vezes cada um. Portanto, as modas são 22 e 25. Neste caso, o
conjunto de
dados diz-se bimodal
3) Encontre a moda dos seguintes dados:
Olhando para a distribuição de frequências, na tabela, conclui-se que a moda do conjunto
de dados é X = 3, com frequência 16.
4) Encontre a classe modal dos seguintes dados:
Neste caso, a classe modal é 70 – 74, porque apresenta a frequência mais alta 15.
__
African Virtual University
FAÇA O SEGUINTE:
Determine a moda ou a classe modal dos seguintes dados:
Respostas
__
African Virtual University
Aula 4
Mediana
A mediana é o valor que se encontra no centro da distribuição de dados, quando estes estão
dispostos na ordem crescente ou decrescente. Por exemplo, no conjunto 1; 2; 3; 4; 5, a
mediana é 3 porque aparece no centro. Isto é, o 3 divide o conjunto em duas partes iguais.
Nos dados 1; 2; 2; 3; 4; 5; 6; 7; 7; 8, temos 10 elementos e não existe um único no centro.
Ou seja, existem dois valores que formam o centro e, neste caso, a mediana é determinada
calculando a média aritmética destes dois valores.
Exemplo:
Cálculo de mediana para dados agrupados em classes
Exemplo: Encontre a mediana dos seguintes dados em classes
_0
African Virtual University
Definição: Limite superior e limite inferior de uma classe.
Limite inferior de classe (Li) ou a fronteira inferior de classe e Limite superior de classe (Ls) ou a
fronteira superior de classe. Exemplo, para o intervalo 20 – 24 a fronteira inferior é 19.5 e a superior é
24.5 e para o intervalo 35 – 39 as fronteiras inferior e superior são respectivamente 34.5 e 39.5.
Observa a tabela seguinte:
Para determinar a mediana destes dados segue os seguintes passos:
1. Identificar a classe que contém a mediana. Neste caso, a mediana ocorre no intervalo 30 – 34,
onde se encontra o dado da posição 20.5.
2. Encontrar as fronteiras desta classe. Neste caso, são Li = 29.5 e s = 34.5.
3. Determinar as frequências acumuladas.
4. Determinar a amplitude desta classe. Faz-se Ls – Li = 34.5 – 29.5 = 5
5. Calcular a mediana fazendo:
Amplitude total de um conjunto de dados
A amplitude total de um conjunto de dados determina-se fazendo a diferença entre o valor
máximo e o mínimo do conjunto.
Exemplo: Para o conjunto 23,26,34, 47,63, a amplitude é 63 – 23 = 40 e para o conjunto 121,
65, 78, 203, 298, 174, a amplitude é 298 – 65= 233.
__
African Virtual University
Aula 5: Medidas de posição ou de Localização e de dispersão
1) Quartís
Dados ordenados Segundo a sua magnitude, podem ser divididos em 4 partes iguais. As
posições extremas destas divisões são os quartís. Assim, o primeiro quatil (Q 1 ), deixa 25% de
elementos à esquerda. O segundo quatil (Q 2 ), deixa 50% de elementos à esquerda. Portanto, o
segundo quartil coincide com a mediana. O terceiro quartil, deixa 75% de elementos à esquerda.
2) Semi-amplitude interquartil
A semi-amplitude interquartil é definida como
3) Decís
Quando os dados estão ordenados, podem ser subdivididos em 10 partes iguais, contendo, cada
uma, 10% do total de elementos. Cada parte corresponde a um decil e se denotam por D 1 , D 2 ,
D 3 , ..., D 8 e D 9
4) Percentís
Os percentís dividem o conjunto de dados em 100 partes iguais. Assim, podemos identificar 99
percentís, P 1 , P 2 , P 3 , ...., P 98 e P 99
5) Desvio médio absoluto
O desvio médio absoluto de um conjunto de N dados, X 1 , X 2 , X 3 , ..., X N , é definido como a
média dos desvios absolutos dos valores X j em relação à média, isto é,
__
African Virtual University
Exemple
Encontre o desvio médio absolute dos seguintes dados 3, 4, 6, 8, 9.
Solução
A média aritmética dos valores dados é
E, portanto, o desvio médio absoluto é
Dada uma tabela de frequências
O desvio médio absoluto é determinado usando a fórmula
__
African Virtual University
5) Desvio Padrão
O desvio padrão de um conjunto de N dados X 1 , X 2 , ...., X N , é definido como a média
dos desvios quadráticos, ou seja,
Para uma tabela de frequências,
O dessvio padrão calcula-se fazendo
6) Variância
A variância de um conjunto de dados é definida como o quadrado do desvio padrão.
Geralmente usa-se o S2 para denotar a variância calculada com base numa amostra de
uma população e
para denotar a variância populacional. De mesmo modo podemos
considerar os respectivos desvios padrão.
__
African Virtual University
Exemplos
Encontre a media e a amplitude dos seguintes dados: 5,5,4,4,4,2,2,2
Solução
E a amplitude é A = 5 – 2 = 3
Mediana
Exemplo
Dadas 13 observações 1,1,2,3,4,4,5,6,8,10,14,15,17, identifique a media
Neste caso, há que identificar a posição da media. Como o número total de dados é ímpar,
existe um só elemento no centro. Este elemento encontra-se na posição
N 1 13 1
= 7.
2
2
Daí que basta identificar o elemento que está na posição 7, nos dados ordenados.
Concretamente, a mediana é 5.
Mas quando o N é par, a mediana é calculada com base na média aritmética dos dois valores
da posição central.
Exemplo: No conjunto 1,1,2,2,3,4,4,5,6,8,10,14,15,17, o N = 14 e a mediana é calculada
fazendo a média aritmética dos números das posições
são 4 e 5. Portanto a mediana é
45
= 4.5
2
N
N
=7e
+1 = 8. Estes números
2
2
__
African Virtual University
FAÇA ISSO
Encontre a mediana dos seguintes dados:
A Variância é a média dos desvios quadráticos
Onde N é o número de observações e a diferença X - X é o desvio em relação à média.
S2 é a variância e a sua raíz é o desvo padrão.
__
African Virtual University
Exemplo
Dado o conjunto 2,4,5,8,11. Determine a variância e o desvio padrão.
Na tabela seguinte estão apresentados os cálculos até a soma dos desvios quadráticos
Portanto, a variância S2 =
50
= 10 e o desvio padrão S = 10
5
FAÇA ISSO
1) Calcule a amplitude dos seguintes dados: 1,1,1,2,2,3,3,3,4,5
10) Calcule a variância e o desvio padrão dos seguintes dados: 1,2,3,4,5
Assimetria
Dada uma distribuição, podemos determinar um coeficiente que mede o quanto a
distribuição é assimétrica. Podemos considerar dois tipos de assimetria: Positiva ou
assimetria à direita e negativa ou assimetria à esquerda. Numa distribuição simétrica, a
média é igual a moda e a mediana. Na distribuição assimétrica positiva ou à direita, a
média é maior do que a moda e a mediana. Na distribuição assimétrica negativa ou à
esquerda, a média é menor do que a moda e a mediana.
Pode-se ver a seguir alguns exemplos:
__
African Virtual University
Primeiro coeficiente de Assimetria de Pearson
Este coeficiente é definido como:
Segundo coeficiente de Assimetria de Pearson
Este coeficiente é definido como:
O coeficiente de Assimetria determinado a partir dos quartís.
Coeficiente de Assimetria determinado a partir dos percentís.
__
African Virtual University
Exemplo: Encontre o percentil de ordem 25, para os seguintes dados: 1, 2, 3, 4, 5, 6,
7, 9
Solução: Como o N = 8, faz N.(0,25) = 8.(0,25) = 2. O elemento da posição 2 é o 2 e o da
posição 3 é o 3. O percentil pedido está entre 2 e 3. Como a diferença entre estes dois
valores é 1, para encontrar o tal percentil faz (0,25).1 + 2 = 2,25
Encontre o percentil de ordem 50 dos dados do exercício anterior
Solução: 8.(0,50) = 4. O tal percentil entre o quarto e o quinto elemento, 4 e 5,
respectivamente. Como a diferença entre estes valor é 1, faz (0,50).1 + 4 = 4,5 que é o
percentil de ordem 50
__
African Virtual University
FAÇA ISSO
Encontre os percentís de ordem 25, 50 e 90 dos seguintes dados:
46,21,89,42,35,36,67,53,42,75,42,75,47,85,40,73,48,32,41,20,75,48,48,32,52,61
49,50,69,59,30,40,31,25,43,52,62,50
Respostas
a) 36 b) 48
c) 73
Curtose
O coeficiente de curtose mede o grau de achatamento de uma distribuição quando se
compara a uma distribuição normal.
Exemplos:
_0
African Virtual University
FAÇA ISSO
Encontre a moda dos seguintes dados:
1) 1,3,4,4,2,3,5,1,3,3,5,4,2,2,2,3,3,4,4,5
2) Número de casamentos em cada 1000 pessoas na população Africana para os anos de
1965 a 1975
__
African Virtual University
3) Número de mortes em cada 1000 pessoas ano a ano de 1960 e de 1965 – 1975
1960
1965
1966
1967
1968
1969
1970
1971
1972
1973
1974
1975
Soluções
1. 3
2. 10.6
3. 9.5
9.5
9.4
9.5
9.4
9.7
9.5
9.5
9.3
9.4
9.3
9.1
8.8
__
African Virtual University
Probabilidade
Conceitos importantes para o cálculo das probabilidades Para começarmos com o cálculo das probabilidades é importante que definamos três conceitos básicos: 1. Experimento ou fenómeno aleatório 2. Espaço amostral (conjunto fundamental ou espaço de resultados ou espaço de acontecimentos)
3. Evento ou acontecimento I) Experimento Aleatório Chama‐se Experimento Aleatório ao processo de observações ou de acção cujos resultados, embora podendo ser descritos no seu conjunto, não são determináveis à priori, antes da realização da experiência. Um experimento Aleatório tem as seguintes características: ‐ A possibilidade de repetição do experimento em condições similares; ‐ Não se poder dizer à partida qual o resultado do experimento a se realizar, mas poder descrever‐
se o conjunto de todos resultados possíveis; ‐ A existência de regularidades quando o experimento é repetido muitas vezes. Ex: Consideremos os seguintes experimentos E1: largar uma pedra de certa altura e verificar o que vai acontecer Para este experimento, uma questão é certa! A pedra vai cair E2: Lançar uma moeda, ao ar, e verificar a face voltada para cima quando a moeda já estiver no chão Aquí, porque a moeda (honesta ou não viciada) tem duas faces, não sabemos à prior qual estará voltada para cima! Existem duas possibilidades. Portanto, E1 é um experimento não aleatório enquanto que E2 é um experimento aleatório Outros experimentos aleatório que podemos considerar, são por exemplo: E3: Lançar duas moedas, ao ar, e verificar as faces de cima. Neste experimento, os resultados possíveis são: (C,C); (C,K); (K,C) e (K,K) em que C é a face coroa e K é a face cara. E4: Lançar um dado (de 6 faces) e verificar a face voltada para cima Para este experimento os resultados esperados são 1 ; 2 ; 3; 4; 5; 6 II) Espaço Amostral ou Espaço de Resultados ou Espaço de acontecimentos ou Conjunto Fundamental (S) ‐ É o conjunto de todos resultados possíveis de um certo experimento Ex: Para o experimento anterior (E2), o espaço amostral é S = (K , C) Para o experimento E3 o conjunto fundamental é S = (C,C); (C,K); (K,C); (K,K) Para o E4 o espaço de resultados é S = 1 ; 2 ; 3; 4; 5; 6 III) Evento ou acontecimento Chama‐se Evento à qualquer subconjunto de S Ex: Consideremos para o experimento E3 o acontecimento A: Saida da face cara pelo menos uma __
African Virtual University
Definições ou Conceitos de Probabilidade
Vamos destacar, aqui, três definições ou conceitos de probabilidades: I. Conceito Clássico de Probabilidade (Teoria Clássica de Laplace) ‐ Se a uma experiência aleatória se podem associar N resultados possíveis, mutuamente exclusivos e igualmente prováveis, e se n(X) desses resultados tiverem o atributo X, então a n( X )
n( X )
; Isto é P(X) = onde n(X) é o nº de resultados probabilidade de X é a fracção N
N
favoráveis a X e N é o nº de resultados possíveis para o experimento Ex: No experimento que consiste em lançar duas moedas e verificar a face de cima, o espaço amostral (S) tem 4 elementos ( resultados possíveis). Então N = 4. E os casos favoráveis ao evento A são 3. Portanto n(A) = 3. Então P(A) = n( A) 3
= N
4
II. Conceito frequencista de Probabilidade ou abordagem empírica ‐ Se em N realizações de uma experiência, o acontecimento A se verificou n vezes, diz‐se que a n
frequência relativa de A nas N realizações é f(A) = N
P(A) = limf(A) n
(quando N ∞) N
Para o caso do exemplo anterior, o número de realizações do experimento é N = 4 e a n
n 3
3
frequência relativa de A é é f(A) = = . Portanto a probabilidade de A é P(A) = N
4
N 4
Portanto, aqui, a probabilidade aproxima‐se à frequência relativa do evento. III. Conceito subjectivo ou personalista de probabilidade ‐ Utilizando este conceito, a probabilidade de um acontecimento é dada pelo grau de credibilidade ou de confiança que cada pessoa dá à realização de um acontecimento. Baseia‐se na informação quantitativa (ex: frequência de ocorrência de um acontecimento) e/ou qualitativa (ex: informação sobre experiência passada em situações semelhantes) que o decisor possui sobre o acontecimento em causa. Diferentes decisores podem atribuir diferenmtes probabilidades ao mesmo acontecimento decorrentes da experiência, atitudes, valores, etc, que possuem. Exemplo: O João diz ao Manuel: Manuel, se tu passares da rua ao lado daquela casa a probabilidade de seres corrido por um cão‐guarda (dessa casa) é de 90%. Mas O Paulo diz ao Manuel: Manuel, se tu passares da rua ao lado daquela casa a probabilidade de seres corrido por um cão‐guarda (dessa casa) é de 50%. Aqui, o João e o Paulo dão a mesma informação ao Manuel mas podes ver que eles atribuem probabilidades diferentes ao evento “ ser corrido...” Pode ser que de 10 vezes que o João passou daquela rua foi corrido 9 vezes e que o Paulo teve uma sorte diferente e foi corrido apenas 5 vezes! Portanto, cada um está usando as suas experiências passadas para definir a probabilidade de alguém ser corrido ao passar daquela rua. Então as probabilidades por eles atribuídas ao evento acima são subjectivas. __
African Virtual University
Regras de Contagem
1) Factorial
Definição: Factorial 4 ! = 4 x 3 x 2 x 1 and 7! = 7 x 6 x 5 x 4 x 3 x 2 x 1
2) Permutação
__
African Virtual University
FAÇA ISSO
.
Resolva
as seguintes tarefas:
__
African Virtual University
Exemplo:
Axiomas da teoria de probabilidades ‐ Da necessidade de sistematização dos conceitos empregues na teoria das probabilidades e da construção de um corpo teórico coerente surgem os três axiomas em que se baseiam todos os desenvolvimentos posteriores do campo das probabilidades. Assim consideramos que P( ) é uma função que associa a todo o acontecimento A definido em S um nº compreendido no intervalo ; e que satisfaz os seguintes axiomas: I.
II.
III.
P(A) , A S (onde S é o espaço amostral) P(S) = 1, ( S é um acontecimento certo) Sendo A e B acontecimentos mutuamente exclusivos definidos em S, ou seja A B
, tem‐se que P(AB) = P(A) P(B) Em geral, se A 1 , A 2 , A 3 , ..., A n são acontecimentos mutuamente exclusivos definidos em S, então n
P(A 1 A 2 A 3 ... A n ) = P(A 1 ) P(A 2 ) P(A 3 ) ... P( A n ) = P(Ai) i=1
Exemplo: Se lançarmos um dado, qual a probabilidade de obtermos 3 pontos ou 5 pontos? 1
1
1 1 2 1
Solução: P(3) = ; P(5) = e, portanto, P(3 ou 5) = + = = 6
6
6 6 6 3
PROBABILIDADE DA MULTIPLICAÇÃO Em probabilidades, há uma regra análoga ao princípio fundamental da contagem (estudado na análise combinatória), denominada regra do produto ou regra de multiplicação de probabilidades. Enunciado: Se um acontecimento é composto por vários eventos sucessivos e independentes, de tal modo que: O 1º evento é A e a sua probabilidade é P(A) O 2º evento é B e a sua probabilidade é P(B) O 3º evento é C e a sua probabilidade é P(C) . . . . . . . . . O K‐ésimo evento é K e a sua probabilidade é P(K), Então a probabilidade de que os eventos A, B, C, ..., K, ocorram nessa ordem é P(A B C ... K) = P(A).P(B).P(C).....P(K) Dois acontecimentos A e B, por exemplo, são independentes se e somente se a probabilidade de A ocorrer após B ter ocorrido é igual a probabilidade de A. Isto é, P(A após B) = P(A) ou P(B após A) = P(B) NOTA: Axiomas são proposições aceites sem demonstração d) Alguns teoremas importantes Os teoremas sempre precisam de ser demonstrados! Teorema 1. Dado um acontecimento A com probabilidade P(A), a probabilidade do seu complementar (acontecimento contrário) obtém‐se subtraíndo à unidade, a probabilidade de A; isto é P( A ) = P(Ac ) = 1 – P(A) Temos (B A) (B – A) = . Então os acontecimentos (B A) e (B – A) são mutuamente exclusivos __
African Virtual University
Teorema 2. Aprobabilidade do acontecimento impossível; isto é P( ) = 0 Teorema 3. Dados dois acontecimentos A e B quaisquer, a probabilidade do acontecimento diferença B – A é P(B ‐ A) = P(B) – P(A B) Demonstração: FIGURA: Da figura podes ver que (B A) (B – A) = . Então os acontecimentos (B A) e (B – A) são mutuamente exclusivos Mas (B A) (B – A) = B Então P(B) = P(B A) (B – A)] = P (B A) P(B – A) P(B – A) = P(B) ‐ P (B A) c.q.d Teorema 4. ‐ A probabilidade da união de dois acontecimentos quaisquer (não necessariamente mutuamente exclusivos), A e B é P(A B) = P(A) P(B) ‐ P (B A) Consideremos alguns exemplos: a) De um baralho de 52 cartas é escolhida aleatoriamente uma carta. Qual a probabilidade de ser um 10 ou coração. 4
; a probabilidade de ser coração é 52
13
1
P(coração) = e a probabilidade de ser 10 e coração P(10 e coração) = . 52
52
Solução: A probabilidade de ser um 10 é P(10) = Portanto, a probabilidade pedida é P(A B) = P(A) P(B) ‐ P (B A) = P(10) + P(coração) – P(10 4 13 1
16
e coração) = P(10) + P(coração) – P(10 e coração) = + ‐ = 52 52 52 52
b) No lançamento de um dado, encontre a probabilidade de que se tenha obtido o número 4 sabendo que sabendo que o número obtido no lançamento foi par. Solução: Trata‐se, aquí, de uma probabilidade condicional. Para dois eventos A e B, em geral, a probabilidade de ocorrência simultânea é dada por P(A B) = P(A/B).P(B) e, portanto, P(A/B) = (A B)
P(B)
Sendo A: Saida do número 4 no lançamento de um dado e B: Saida de um número par no lançamento de um dado 1
1
3
1
(A B)
= 6 = = então P(A B) = e P(B) = . Portanto, P(A/B) = 3
6
6
P(B)
3
6
c) Uma caixa contém 3 bolas cor de laranja, 3 cor amarela e 2 cor branca. Três bolas são seleccionadas aleatoriamente sem reposição. Achar a probabilidade de sairem duas amarelas e uma branca. 3
Sejam, A 1 : Saida de bola amarela na primeira extracção. Então, P(A 1 ) = 8
A 2 : Saida de bola amarela na segunda extracção após ter saido amarela na primeira. Então, 2
P(A 2 ) = 7
B 3 : Saida de bola branca na terceira extracção após terem saido amarelas nas duas extracções 2
anteriores. Então, P(A 2 ) = 6
3 2 2
1
Então, a probabildade de sairem duas amarelas e uma branca será: x x = 8 7 6 28
EXERCÍCIOS 1. De quantas maneiras diferentes 7 pessoas podem estar dispostas numa fila? 2. De quantas maneiras diferentes 3 canetas podem ser escolhidas de 12 canetas? 3. Se de um baralho de 52 cartas escolhermos 3, qual a probabilidade de todas serem ouro? RESPOSTAS 1. (5040) 2. (220) 3. (0,013) LEIA
An Introduction to Probability and Rondam
Processes by Kenneth B & Gian-Carlo, páginas 1.
1. 20-1.22
* Capítulo 1 de exercícios: Sets, Events &
Probability pg 1.23-1.28 Números 1-12 & 14-20
2. 2.1-2.33
* Capítulo 2 de exercícios: Finite Processes pag.
2.33 Números 1, 2, 3, 13-20
3. Itroduction to Probability , by Charles M
Grinstead páginas 139-141
Variáveis Aleatórias
Variáveis Aleatórias (v. a)
Definição: Uma variável aleatória é uma função que associa a cada resultado possível de um
experimento aleatório um número real.
(Harry Frank & Steve C Althoen, CUP, 1994, pág. 155).
Uma variável Aleatória é uma variável no sentido de que ela pode ser usada como um substituto de
um número nas equações ou inequações. Sua aleatoriedade é completamente descrita pela sua função
de distribuição acumulada que pode ser usada para determinar a probabilidade que ela toma para certos
valores particulares.
Formalmente, uma variável aleatória é uma função mensurável de um espaço de probabilidades ao
conjunto de números reais. Por exemplo, uma variável aleatória pode ser usada para descrever o
processo de lançamento de um dado perfeito e os possíveis resultados {1, 2, 3, 4, 5, 6}. A
representação mais óbvia é tomar estes conjunto como espaço amostral, a medida de probabilidade
como sendo uma medida uniforme, e a função sendo a função identidade.
Variável Aleatória
Alguns consideram variável aleatória um nome inapropriado, uma vez que variável aleatória não é
variável mas sim uma função que transforma resultados (de um experimento) em números reais. Seja A
uma -álgebra e o espaço amostral de resultados relevantes ao experimento a ser levado a cabo. No
exemplo de lançamento do dado, o espaço de resultados é = {1, 2, 3, 4, 5, 6}, e A seria a potência do
conjunto. Neste caso, uma variável aleatória apropriada seria a função identide X() = , tal que se o
resultado é um “1” então a variável aleatória é tabém 1. Um exemplo igualmente simples mas menos
trivial é o exemplo no qual poderíamos lançar uma moeda: um espaço amostral adequado de resultados
possíveis é = {H, T} (para cara ou coroa), e A igual ainda à potência de . Uma entre muitas
variávis aleatórias possíveis definidas neste espaço é:
0 , se H
1 , se T
X() =
Matematicamente, uma variável aleatória é definida como uma função mensurável de um espaço
amostral para algum espaço mensurável
Convergência de Variáveis Aleatórias
Na teoria de probabilidade, existem várias noções de convergência para variáveis aleatórias. Elas são
listadas abaixo em ordem da sua força, isto é, qualquer noção de convergência subsequente na lista
implica convergência de acordo com todas as noções de convergência precedentes.
Convergência em distribuição: Como o nome diz, uma sequência de variáveis aleatórias X 1 , X 2 , ...
converge para a variável aleatória X em distribuição se as suas respectivas funções de distribuição
acumuladas F 1 , F 2 , ... convergem para a função de distrbuição acumulada F, de X, sempre que F é
contínua.
Convergência Fraca: A sequência de variáveis aleatórias X 1 , X 2 , ... é dita convergir fracamente para
uma variávela aleatória X se lim P(| X n X | ) = 0 para cada > 0. A Convergência Fraca é também
n
chamada deconvergência em probabilidade.
Convergência Forte: A sequência de variáveis aleatórias X 1 , X 2 , ... é dita convergir fortemente para
uma variávela aleatória X se lim P(| X n X ) = 1
n
A convergência Forte é também conhecida como convergência quase certa.
Intuitivamente, convergência forte é uma versão mais forte da convergência fraca, e em ambos casos
as variáveis aleatórias X 1 , X 2 , ... mostram uma correlação crescente com X. Todavia, no caso da
convergência em distriubuição, os valores realizados das variáveis aleatórias não precisam de
convergir, e qual qualquer possível correlação entre eles é imaterial.
Lei dos Grandes Números
Se uma moeda perfeita é atirada para cima, sabemos que aproximadamente metade de vezes terá cara
virada para cima, e outra metade terá coroa virada para cima. Também parece que quanto mais
lançarmos a moeda, mais provável é que a razão de cara:coroa aproximará a 1:1. A probabilidade
moderna permite-nos chegar formalmente ao mesmo resultado, apelidada de Lei de Grandes
Números. Este resultado é notável porque em parte alguma foi assumido durante a construção da
teoria e é completamente um ramo da teoria. Ligando teoricamente-deduzidas as probabilidades à sua
frequência real de ocorrência no mundo real, este resultado é considerado como um pilar na história da
teoria estatística.
A Lei forte de grandes números (SLLN – strong law of large numbers) afirma que se um evento de
probabilidade p é observado repetidamente durante experimentos independentes, a razão entre a
fraquência observada do tal evento e o número total de repetições converge fortemente para p em
probabilidade.
Em outras palavras, se X 1 , X 2 , ... são variáveis aleatórias independentes de Bernoulli tomando valores
1 com probabilidade p e 0 com probabilidade 1 – p, então a sequência de números aleatórios
X
n
n
converge para p quase certamente, isto é,
n X i
P lim i 1
n
n
p 1
Teorema Central do Limite
O teorema central do limite é a razão de ocorrência omnipresente da distribuição normal, para a qual
é um dos teoremas mais celebrados em probabilidade e estatística.
O teorema afirma que a média de muitas variáveis aleatórias independentes e identicamente
distribuidas tende para uma distribuição normal independentemente da qual distribuição original as
variáveis aleatórias seguem. Formalmente, seja X 1 , X 2 , ... variáveis aleatórias independentes com
médias 1 , 2 , ..., e variâncias .. Então, a sequência das variâveis aleatórias
n
(X
Zn =
i
i )
i 1
n
2
i
i 1
converge em distribuição para uma variável aleatória normal padrão.
Funções de Variáveis Aleatórias
Se temos uma variável aleatória X em e uma função mensurável f: R R, então Y = f(X) será
também uma variável aleatória em , uma vez que a composição de uma função mensurável é uma
função mensurável. O memso procedimento que nos permitiu sair do espaço de probabilidade (, P)
para (R, dF X ) pode ser usado para obter a distribuião de Y. A função acumulada de probabilidade de Y
é
F Y (y) = P(f(X) y).
Exemplo
Seja X tomando valores reais, uma variável aleatória contínua e seja Y = X2. Então
F Y (y) = P(X2 y).
Se y < 0, então P(X2, y) = 0, assim
F Y (y) = 0 se y < 0
Se y 0, então
P(X2 y) = P(|X| y) = P ( y X y ),
Assim, F Y (y) = F X ( y) – F X (- y) se y 0
Distribuições de Probabilidade
Certas variáveis aleatórias ocorrem muitas vezes na teoria de probabilidade devido a muitos processos
naturais e físicos. Suas distribuições portanto, ganharam importância especial na teoria de
probabilidade. Algumas distribuições discretas fundamentais são a uniforme, a de Bernoulli, a
binomial, a binomial negativa, de Poisson e a geométrica. Distribuições contínuas importantes incluem
a uniforme contínua, a normal, exponencial, gamma e a distribuição beta.
Funções de Distribuição
Uma variável aleatória X: R definida no espaço de probabilidade (, A, P) é dada, podemos
colocar as questões do tipo “Quão provável é que o valor de X seja maior que 2?”. Esta questão é a
mesma que a probabilidade do evento {s : X(s) > 2} que muitas vezes é escrito como P(X > 2), de
forma mais breve.
Registando todas estas probabilidades para valores reais de X resulta a distribuição de probabilidade de
X. A distribuição de probabilidade “esquece” do espaço particular de probabilidade usado para definir
X e somente regista as probabilidades dos diferentes valores de X. Tal distribuição de probabilidade
pode sempre ser capturada pela sua função acumulada de probabilidade
F X (x) = P(X x)
e algumas vezes também se usa uma função de densidade de probabilidade. Em termos de teoria de
medidas, usamos a variável aleatória X para “puxar-a-diante” a medida P em a uma medida dF em
R. O espaço de probabilidade subjacente é um dispositivo técnico usado para garantir a existência de
variáveis aleatórias, e algumas vezes para construí-las. Na prática, se dispõe juntamente do espaço e
somente se atribui a uma medida em R que associa medida 1 a toda recta real, isto é, trabalhamos com
distribuições de probabilidade em vez de variáveis aleatórias.
Teoria de Probabilidade discreta
A teoria de probabilidade discreta lida com eventos que ocorrem em espaços amostrais enumeráveis.
Exemplos: Lançamento de um dado, experimentos com baralhos de cartas, e uma caminhada aleatória.
Definição clássica: Inicialmente a probabilidade de um evento a ocorrer foi definida como um número
de casos favoráveis ao evento, sobre o número total de resultados possíveis. Por exemplo, se o evento é
“ocorrência de um número par quando o dado é lançado”, a probabilidade é dada por
3 1
uma vez
6 2
que 3 faces das 6 têm números pares.
Definição moderna: a definição moderna começa com um conjunto chamado de espaço amostral que
relaciona ao conjunto de todos resultados possíveis no sentido clássico, denotado por = {x 1 , x 2 , ... }.
E depois é assumido que para cada elemento x , um número intrínseco de “probabilidade” f(x) é
associado, que satisfaz as seguintes propriedades:
1. f(x) [0, 1] para todo x
f ( x) 1
x
Um evento é definido como qualquer subconjunto E do espaço amostral . A probabilidade do
evento
P(E) =
f ( x)
xE
Assim, a probabilidade de todo espaço amostral é 1, e a probabilidade do evento nulo é 0.
A função f(x) que transforma um ponto no espaço amostral ao valor da “probabilidade” é chamada
uma função de massa de probabilidade abreviada como fmp (= pmf-probability mass function). A
definição moderna não tenta responder como as funções de massa de probabilidade são obtidas, em vez
disso constrói uma teoria que assume sua existência.
Teoria de Probabilidade Contínua
A teoria de probabilidade contínua lida com eventos que ocorrem num espaço amostral contínuo.
Se o espaço amostral é um conjunto de números reais, então uma função chamada de função
acumulada de probabilidade ou fadF (=cdfF – cumulative distribution function) é assumida a
axistir, que resulta em P(X x) = F(x)
fadF deve satisfazer as seguintes propriedades:
1. F é uma função monótona não decrescente e contínua à direita
2.
lim F ( x) 0
x
3. lim F ( x) 1
x
Se F é diferenciável, então a variável aleatória é dita ter uma função de desnsidade de probabilidade
ou fdp ou simplesmente densidade f(x) =
dF ( x)
dx
Para um conjunto E R, a probabilidade da variável aleatória em E é definida como
P(X E) =
xE
dF ( x)
No caso da densidade existir, então a função anterior pode ser escrita como
P(X E) =
xE
f ( x)dx
Enquanto que a fdp existe somente para variáveis aleatórias contínuas, a fad existe para todas variávis
aleatórias (incluíndo para variáveis aleatórias discretas) que tomam valores em R.
Estes conceitos podem ser genaralizados para casos de espaços multidimensionais ou seja em Rn.
Função de Densidade de Probabilidade
Distribuição discreta
Se X é uma variável que pode assumir um conjunto discreto de valores X 1 , X 2 , X 3 , ..., X k com respeito
a probabilidades p 1 , p 2 , p 3 , ...., p k , onde p 1 + p 2 + p 3 + ....... + p k = 1 dizemos que uma distribuição
discreta de probabilidade para X foi definida. A função p(X), com os valores respectivos p 1 , p 2 , p 3 , ...,
p k para X = X 1 , X 2 , X 3 , ..., X k é chamda de função de probabilidade, ou função de frequência, de X.
Porque X pode assumir certos valores com probabilidades dadas, esta função é muitas vezes chamada
uma variável aleatória discreta. Uma variável aleatória é também conhecida como uma variável de
chance ou variável estocástica. {Murray R, 2006, pág. 130).
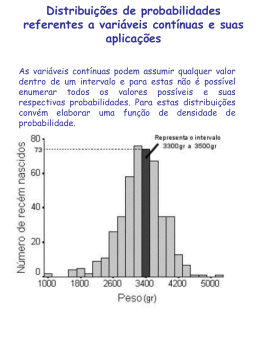
Distribuição Contínua
Supõe que X é uma variável aleatória contínua. Uma variável aleatória contínua X é especificada pela
sua funçao de densidade de probabilidade que é escrita f(x) quando f(x) 0 em todo intervalo de
valores para os quais x é válido. Esta função de densidade de probabilidade pode ser representada por
uma curva, e as probabilidades são dadas pela área por baixo da curva.
A área total por baixo da curva é igual a 1. A área por baixo da curva entre as rectas x = a e x = b
(sombreada) corresponde a probabilidade de X entre a e b, que pode ser denotada por P(a < X < b).
P(X) é chamada uma função de densidade de probabilidade e a variável X é muitas vezes chamada de
uma variável aleatória contínua.
Uma vez que a área total por baixo da curva é igual a 1, segue a probabilidade do espaço entre a e b é
dada por
P(a X b) =
b
f ( x)dx
a
que é a área sombreada.
Nota: ao calcular a área entre a e b, não distinguimos as desigualdades ( e ) e (< e >). Assumimos
que as rectas em a e b não têm grossura e a sua área é igual a zero.
Exemplos resolvidos:
1) Uma variável aleatória X está distribuida com a função densidade de probabilidade f definida
por
f(x) = kx(16 – x2), para 0 < x < 4
Avalie
a). O valor da consatante k
b). A probabilidade do espaço P(1 < X < 2)
c). A probabilidade P(X 3)
Solução
Para qualquer função f(x) tal que
f(x) 0, para a X b,
b
e
f ( x)dx = 1
a
pode ser tomada como a função de densidade de probabilidade (f. d. p) de uma variável aleatória
contínua no intervalo a X b.
Procedimento
Passo 1: Em geral, se X é uma variável aleatória contínua (v. a. c.) com f. d. p. f(x) válida no
intervalo a X b, então
f ( x)dx 1 , isto é
a || X
b
f ( x)dx = 1
a
Passo 2:
a) Para determinar k, usamos o facto de que f(x) = kx(16 – x2), para 0 X 4, então
4
kx(16 x
2
)dx 1
0
4
k (16 x x 3 )dx 1
0
k=
1
64
Passo 3
b). Determinar P(1 < X < 2)
Solução
2
P(1 < X < 2) =
f ( x)dx
1
=
Passo 4
1
64
2
(16 x x
1
3
)dx =
81
256
c). Determinar P(X 3)
1
P(X 3) =
64
4
(16 x x
3
)dx =
3
49
256
Exemplo 2
2). X é a variável aleatória contínua ‘a massa de uma substância, em kg, por minuto num processo de
produção industrial’, onde
1
x (6 x )
(0 X 3)
0
em outros casos
f(x) = 12
Determinar a proabilidade de que a massa seja mais que 2 kg.
Solução
X pode tomar valores somente de 0 a 3. Esboçamos o gráfico de f, e sombreamos a área requerida.
3
P(X > 2) =
1
12 x(6 x)dx
2
3
=
1
(6 x x 2 ) dx
12 2
3
1 2 x3
=
3x
12
3 2
= 0,722 (3 casas decimais)
A probabilidaade de que a massa seja mais do que 2 kg é de 0,722
Exemplo resolvido
3). Uma variável aleatória contínua tem fdp f(x) onde
f(x) = kx2, 0 X 6
a). Determinar o valor de k
b). Determinar P(2 X 4).
Solução
a) Uma vez que X é uma variável aleatória, a probabilidade total é igual 1, isto é,
f ( x)dx 1
a ||
6
kx 2 dx = 1
0
6
kx 3
1
3 0
216k
1
3
k=
3
216
3 2 1 2
x
x ,0X6
216
72
Portanto, f(x) =
b)
4
1
72 x
P(2 X 4) =
2
dx
2
4
1 3
=
x
216 2
= 0,259
Portanto, a probabilidade P(2 X 4) = 0,259
Exemplo resolvido
4). Uma variável aleatória contínua (v. a c) tem a função de densidade de probabilidade f. d. p. f(x),
onde
k
f(x) = k (2 x 3)
0
0 X 2
(2 X 5)
em outros casos
a) Determinar o valor de k
b) Esboçar y = f(x)
c) Determinar P(X 1)
d) Determinar P(X > 2,5)
Solução
a) Uma vez que X é uma variável aleatória, então
f ( x)dx 1
a || X
Portanto,
2
5
kdx k (2 x 3)dx 1
0
2
kx 0 k x 2 3x 2 = 1
2
5
2k + 19k = 1
k=
1
21
b) Assim a f. d. p de X é
1
21
1
f(x) = (2 x 3)
21
0
0 X 2
(2 X 5)
em outros casos
Esboço do gráfico de f:
c) P(X 1) = área por baixo do gráfico entre zero e 1 = C L = 1
1
1
=
= 0,048
21
21
d) Determinar P(X > 2,5) = área do rectângulo + área do trapézio
=(
1
1
1
2
11
2) + ( {0,5}{
+
}) =
0,131
21
21
21
21
84
Reflexão: Os professores podem encontrar o software de produção de gráficos úteis no ensino da estatística. Um exemplo do software da Fonte Aberta é o Graph. Veja na página http://www.padowan.dk/graph/ Se tem acesso ao computador, faça o download graph e explore as suas ferramentas estatísticas A seguir está um exemplo de diferentes curvas que podem ser desenhadas com o recurso a Graph. RESOLVE
1). A variável aleatória contínua X tem a f. d. p f(x) onde f(x) = k, 0 X 3.
a) Esboce y = f(x)
b) Determine o valor da constante k
c) Determine P(0,5 X 1)
2) A variável aleatória contínua X tem a f. d. p f(x) onde f(x) = kx2, 1 X 4
a) Determine o valor da constante
b) Determine P(X 2)
c) Determine P(2,5 X 3,5)
3) A variável aleatória contínua X tem a f. d. p f(x) onde
k
f(x) = k (2 x 1)
0
0 X 2
(2 X 3)
em outros casos
Determine o valor da constante k
a) Esboce y = f(x)
b) Determine P((X 2)
c) Determine P(1 X 2,2)
Esperança
Definição
Se X é uma variável aleatória contínua com a função de densidade de probabilidade (f. d. p) f(x), então
a esperança de X é E(X) onde
Xf ( x)dx
E(X) =
a || X
NB: E(X) é muitas vezes denotada por e referida como a média de X
Exemplo
1) Se X é uma variável aleatória contínua com f. d. p f(x) =
1 2
x , 0 X 3, determine E(X).
16
Solução
Xf ( x)dx
E(X) =
a || X
3
1
1 x4
81
{ X } X 2 dx =
= 1,265
16
16 4 0 64
0
3
2) Se a variável aleatória contínua X tem f. d. p.
f(x) =
2
(3 + x)(x – 1), 1 X 3, determine E(X).
5
E(X) =
Xf ( x)dx
a || X
3
2 x 4 2 x 3 3x 2
608
1
= 10,13
{ X }(3 x)( x 1) dx =
5 4
3
2 1 60
16
0
3
Generalização
Se f(x) é uma função qualquer da variável aleatória contínua X tendo a f. d. p. f(x), então
E[g(X)] =
g ( x) f ( x)dx
a || X
e em particular
E(X2) =
X
2
f ( x)dx
a || X
A seguinte conclusão é consistente
1. E(a) = a
2. E(aX) = aE(X)
3. E(aX + b) = aE(X) + b
4. E[f 1 (X) + f 2 (X)] = E[f 1 (X)] + E[f 2 (X)]
Exemplo
1) Uma variável aleatória contínua X tem f. d. p. f(x) onde f(x) =
Determine
a) E(X)
b) E(X2)
c) E(2X + 3)
Solução
1
x,0X3
2
3
a) E(X) =
Xf ( x)dx =
a || X
0
3
1 2
1 x3
x dx = = 4,5
2
2 3 0
3
3
1 3
1 x4
81
x dx = =
b) E(X ) = X f ( x)dx =
= 10,125
8
20
2 4 0
a || X
2
2
c) E(2X + 3) = E(2X) + 3 = 2E(X) + 3 = 2(4,5) + 3 = 12 (a partir de a) acima)
RESOLVE
1) A variável aleatória contínua X tem a f. d. p. f(x), onde
kx
k
f(x) =
k ( 4 x )
0
0 X 1
1 x 3
(3 X 5)
em outros casos
a) Determine k
b) Calcule E(X)
2) A variável aleatória contínua X tem a f. d. p f(x) onde f(x) =
1
( x 3) , 0 X 5
10
Determine
a) E(X)
b) E(2X + 3)
c) E(X2)
d) E(X2 + 2X – 1)
Distribuição de Bernoulli
Na teoria de probabilidade e estatística, a distribuição de Bernoulli, assim chamada em homenagem
ao cientísta Suiço Jacob Bernoulli, é uma distribuição discreta de probabilidade, que toma o valor 1
com a probabilidade de sucesso p e valor 0 com a probabilidade de fracasso q = 1 – p. Assim se X é
uma variável aleatória com esta distribuição, temos
P(X = 1) = 1 – P(X = 0) = p.
A função f de massa de probabilidade desta distribuição é:
p
f(k; p) = 1 p
0
se k 1
se k 0
em outros casos
O valor esperado de uma variável aleatória de Bernoulli X é E(X) = p, e sua variância Var(X) = p(1 –
p).
A curtose tende para o infinito para os valores altos e baixos de p, mas para p =
1
a distribuição de
2
Bernoulli tem a curtose mais baixa do que qualquer outra distribuição, nomeadamente -2.
A distribuição de Bernoulli faz parte da família da distribuição exponencial.
Distribuição Binomial
Na teoria de probabilidade e estatística, a distribuição binomial é uma distribuição discreta de
probabilidade do número de sucessos numa seuqência de n experimentos independentes do tipo
sim/não cada um dos quais resulta em sucesso com probabilidade p. Um tal experimento de sucesso
/fracasso é também chamado de experimento de Bernoulli ou ensaio de Bernoulli. De facto, quando n
= 1, a distribuição binomial é uma distribuição de Bernoulli. A distribuição binomial é a base para o
teste popular binomial da significância estatística.
Exemplos
Um exemplo elementar é o seguinte: lançar um dado para cima dez vezes e contar o número de 1s
como resultado. Então este número aleatório segue uma distribuição binomial com n = 10 e p =
1
6
Por exemplo, assume que 5% da população tem olhos verdes. E você retira 500 pessoas
aleatoriamente. O número de pessoas de olhos verdes você retira é uma variável aleatória X que segue
uma distribuição binomial com n = 500 e p = 0,05 (quando a retirada de pessoas é com reposição).
Exemplos
1). Uma moeda é lançada para cima 3 vezes. Determine a probabilidade de obter 2 caras e uma coroa
em qualquer ordem dada.
Fórmula
Podemos usar a fórmula C x p 1 p
n x
x
n
Onde n = ao número total de lançamentos
x = número de sucessos (1, 2, ...)
p = probabilidade de sucessos
1º
C xn determina o número de possbilidades em que um sucesso pode ocorrer
2º
p
3º
1 p
x
é a probabilidade de obter x sucessos
n x
é a probabilidade de obter n – x fracassos.
Solução
Lançar 3 vezes significa n = 3
Duas caras significa x = 2
P(Cara) =
1
;
2
P(Coroa) =
1
P(2 caras) = C
2
3
2
2
1
1
2
1
2
3 2
=3
1 1 3
=
4 2 8
RESOLVE
1) Determine a probabilidade de obter exactamente um 5 quando um dado é lançado 3 vezes.
2) Determine a probailidade de obter 3 caras quando 8 moedas são lançadas para cima.
3) Uma urna contém 4 bolas vermelhas e 2 bolas verdes. Uma bola é extraída da urna e reposta na urna
4 vezes. Qual a probabilidade de obter exactamente 3 bolas vermelhas e 1 bola verde?
Resposta
1
2
1
1 5 25
1) P(um 5) = C
= 0,347, isto é n = 3, x = 1 e p =
6
6 6 72
3
1
1
2) P(3 caras) = C
2
8
3
3
5
7
1
1
= 0,218, isto é n = 8, x = 3, p =
2
2 32
3
1
2
2 1 32
= 0,395 isto é n = 4, x = 3, p =
3) P(3 bolas vermelhas) = C
3
3 3 81
4
3
LEIA
1. Lectures on Statistics, By Robert B. Ash, , page 1-4
• Exercícios Nos.1, 2 e 3 na pág 4.
2. An Introduction to Probability & Random Processes By
Kenneth B & Gian-Carlo R, pág. 3.1-3.63
• Exercício Capítulo 3: Variáveis aleatórias (Random Variables) pág 3.64-3.82
Nrs. 1-7, 11-17, 20-24, 34-36
3. An Introduction to Probability By Charles M. Grinstead
Pág. 96-107, & 184
• Exercícios nas pág. 113-118
Nrs. 1,2,3,4,5,8,9,10,19,20
Ref: http://en.wikipedia.org/wiki/measurable_space
Ref: http://en.wikipedia.org/wiki/Probability_theory
Ref: http://en.wikipedia.org/wiki/Bernoulli_distribution
Distribuição de Poisson
Na teoria de probabildade e estatística, a distribuição de Poisson é uma distribuição discreta de
probabilidade que exprime a probabilidade de um número de eventos ocorrendo em um período de
tempo fixo se tais eventos ocorrem com uma taxa média conhecida, e são independentes do tempo a
partir do último evento.
A distribuição foi descoberta por Siméon-Denis Poisson (1781-1840).
A distribuição de Poisson algumas vezes é chamada uma distribuição Poissonian, análogo ao termo
Gaussiano para a distribuição de Gauss ou distribuição normal.
A distribuição de Poisson é usada quando a variável ocorre num período de tempo, volume, área, etc.
... e pode ser usada para chegadas de aviões em aeroportos, o número de chamadas telefónicas por hora
num estação, o número de glóbulos vermelhos no sangue numa certa área.
A probabilidade de X sucessos é:
e x
onde e é uma consatante matemática = 2,7183
X!
é a média ou valor esperado das variáveis.
Trabalho em grupo 1. Estude o cálculo da probabilidade e resolve a quesão que se segue Exemplo
Se ocorrem 100 erros tipográficos distribuidos aleatoriamente em 500 páginas manuscritas, determine
a probabilidade de uma página dada tenha exactamente 4 erros.
Solução
Determinar a média de erros =
100 1
= 0,2
500 5
Em outras palavras, existe uma média de 0,2 erros por cada página. Neste caso x = 4, assim a
probabilidade de escolher uma página com exactamente 4 erros é
e x 2,7183 0,2
=
= 0,00168
4!
X!
0 , 2
Cerca de 0,2%
4
Exemplo Resolvido
Uma linha telefónica gratis recebe uma média de 4 chamadas por hora para qualquer hora dada.
Determine a probabilidade de que ela receba exctamente 5 chamadas.
e x 2,7183 0,2
=
= 0,1001
X!
5!
3
5
Que é 10%
RESOLVE
Uma Companhia de Marketing de telefone obtém uma média de 5 encomendas em cada 1000
chamadas. Se a companhia liga para 500 pessoas, determinar a probabilidade de obter 2 encomendas
Solução
0,26
Que é 26%
LEIA
1. An Introduction to Probability & Random Processes By
Kenneth B & Gian-Carlo R, pág. 187-192
2. Robert B. Ash, Lectures on Statistics, pág. 1 e respostas dos problemas 1,2,3 na pág 15.
Ref: http://en.wikipedia.org/wiki/Normal_distribution
Distribuição Geométrica
Na teoria de probabilidade e estatística, a distribuição geométrica é uma das duas distribuições
discretas:
a distribuição de probabilidade do número X de ensaios de Bernoulli necessárias para obter um
sucesso, realizadas no conjunto {1, 2, 3, ...} ou
a distribuição de probabilidade do número Y = X – 1 de fracassos antes do primeiro sucesso,
sobre o conjunto {0, 1, 2, 3, ... }
Uma destas distribuições chamamos “a” distribuição geométrica por uma meras questão de convecção
e conveniência.
Se a probabilidade do sucesso em cada um dos experimentos é p 1 , então a probabilidade de que k
experimentos sejam necessários para obter um sucesso é
P(Y = k) = (1 – p 0 )k.p 0
para k = 1, 2, 3, ...
Equivalentemente, se a probabilidade de sucessos em cada ensaio é p 0 , então a probabilidade de que
haja k fracassos antes do primeiro sucesso é
P(Y = k) = (1 – p 0 )k.p 0
para k = 0, 1, 2, 3, ...
Em cada um dos casos, a sequência de probabilidades é uma sequência geométrica.
Por exemplo, supõe que um dado perfeito é lançado para cima repetidamente até que pela primeira vez
apareça “1”. A distribuição de probabilidade do número de vezes o dado é lançado ocorre no conjunto
infinito {1, 2, 3, ...} é uma distribuição geométrica com p 1 =
1
6
Soluções Usando a Fórmula da Distribuição Geométrica
A fórmula da probabilidade de que o primeiro sucesso ocorra no en-ésimo experimento é
(1 – p)n – 1p ou simplesmente P(X = k) = (1 – p 1 )k-1p 1 , onde p é a probabilidade de um sucesso e n é o
número de experimentos até ao primeiro sucesso.
Exemplo
1) Determine a probabilidade de que a primeira coroa ocorra no terceiro lançamento no lançamento de
uma moeda.
Solução
O resultado de uma coroa no terceiro lançamento significa CCK. De (1 – p)n – 1p, n = 3 e p =
1
e
2
31
1 1 1 1 1 1
portanto P(CCK) = 1
2 2 2 2 2 8
Exemplos na Distribuição Geométrica
Rolando uma moeda várias vezes, aplicamos a distribuição geométrica para obter a resposta de rolar
uma moeda várias vezes.
Exemplo
1) Uma moeda é lançada para cima, determine a probabilidade de que ocorra a primeira cara no
terceiro lançamento.
Solução
O resultado é KKC
n=3ep=
1
2
A probabilidade de obter 2 coroas e uma cara é
1 1 1 1
2 2 2 8
Ou pela fórmula
31
2
1 1 1 1 1
1
2 2 2 2 8
2) Um dado é rolado; determine a probabilidade de obter o primeiro 3 no quarto lançamento.
Solução
n=4
p=
4 1
1
6
3
1 1 5 1 125
1
= 0,096
6 6 6 6 1296
Exemplo 2
Se cartas são seleccionadas dum baralho e repostas no baralho, quantos ensaios seriam necessários em
média, para obter um nipe de paus?
P(nipe de paus) =
13 1
52 4
Número esperado de ensaios para seleccionar 2 nipes de paus será
2
4
2 = 8
1
1
4
RESOLVE
1) Uma carta de um baralho normal é seleccionada e a seguir resposta no baralho, e mais uma
carta é seleccionada e assim por diante. Determine a probabilidade de o primeiro pau ocorrer na
4ª extracção.
2) Um dado é lançado para cima até que 5 ou 6 seja obtido. Determine o valor experado de
lançamentos.
Resposta
1)
2) 3
Distribuição Hipergeométrica
Na teoria de probabilidade e estatística, a distribuição hipergeométrica é uma distribuição discreta
de probabilidade que descreve o número de sucessos numa sequência de n extracções sem reposição a
partir de um número finito da população.
Um exemplo típico é ilustrado pela tabela de contingência abaixo: há um carregamento de N objectos
nos quais D são defeituosos. A distribuição hipergeométrica descreve a probabilidade de que numa
amostra de n objectos distintivos extraídos do carregamento exatamente k são defeituosos.
Em geral, se uma variável aleatória X segue uma distribuição hipergeométrica com paramétros N, D e
n, então a probabilidade de obter exactamente k sucessos é dada por
D N D
k n k
f(k; N, D, n) =
N
n
A probabilidade é positiva se k está entre max{0, D + n – N} e mín{n, D}.
N
possíveis amostras (sem reposição).
n
A fórmula pode ser entendida da seguinte maneira: existem
D
formas de obter k objectos defeituosos e existem
k
Existem
N D
formas de preencher o resto
n
k
da amostra com objectos não defeituosos.
Quando o tamanho da população é maior comparado com o tamanho da amostra (isto é, N é muito
maior do que n) a distribuição hipergeométrica é razoavelmente aproximada pela binomial com
parámetros n (número de experimentos, ensaios) e p =
experimento).
Fórmula da distribuição hipergeométrica
D
(probabilidade de sucesso num único
N
Se existem dois grupos de itens tais que haja “a” itens no primeiro grupo e “b” itens no segundo grupo,
de modo que o número total de itens seja (a + b), a probabilidade de seleccionar x itens do primeiro
grupo e (n – x) itens do segundo grupo é
C xa C nb x
, onde n é o número total de itens selecionados sem reposição.
Cna b
Exemplos
1. Uma urna contém 3 fichas azuis e 3 fichas verdes. Se duas fichas são seleccionadas aleatoriamente,
determine a probabilidade de que ambas sejam azuis.
Solução
C xa C nb x
Da fórmula
; a = 3, b = 3, x = 2, n = 2, n – x = 2 – 2 = 0
C na b
C 23 C 232 3 1 1
= 0,2
Probabilidade de ambas serem azuis =
C 233
15 5
2. Um comité de 3 pessoas é seleccionado ao acaso sem reposição a partir de um grupo de 6 homens e
3 mulheres. Determinar a probabilidade de que o comité consista de 2 homens e 2 mulheres.
Solução
a = 6, b = 3, n = 6 + 3 = 9
dado que o comité consiste de 2 homens e 2 mulheres, teremos
x=2
n–x=3–2=1
C 26 C13 15 3 15
P(2 homens e 2 mulheres) =
= 0,536
C39
84
28
3. Num total de 10 tanques, 3 são tanques defeituosos. Se 4 tanques são aleatoriamente seleccionados e
testados, determinar a probabilidade de que exactamente um tanque seja defeituoso.
Solução
3 defeituosos
7 são bons
a=3
b=7
P(um tanque ser defeituoso)
n=4 x=1
n–x=4–1=3
C13 C37 105
0,5
P(exactamente um ser defeituoso) =
210
C 410
RESOLVE
1. Numa caixa de 10 folhas existem 5 folhas defeituosas. Se 5 folhas são vendidas aleatoriamente,
determinar a probabilidade de que exactamente duas folhas sejam defeituosas.
2. Numa carregamento de 12 cadeiras 8 são castanhas e 4 são azuis. Se 3 cadeiras são
aleatoriamente vendidas, determinar a probabilidade de que todas sejam castanhas.
Resposta
Trabalho em grupos 1.
a) 0,397
b) 0,255
Faça a revisão das seguintes questões de probabilidade e as respostas 2.
Discuta quaisquer deficuldades encontradas nos cálculos das probabilidades 1) Determine a probabilidade de escolher 5 mulheres de um comité de 15 mulheres
P(Escolher 5) =
1
1
15
C5
3003
2) Qual a probabilidade de extrair um as ou uma espada de um baralho de cartas de jogo.
P(As) =
4
P(A B) = P(A) +P(B) – P(A B)
52
P(espada) =
13 4 13 1 16 4
52 52 52 53 52 13
3). Existem problemas de conceber para mulheres. A probabilidade de morrer é de
1
qual a
51
probabilidade de que pelo menos uma vai morrer em cada 5 mulheres?
5
50
P(pelo menos uma vai morrer) =
= use calculadora
51
1
P(A) =
51
P(A) = 1 -
1 50
=
51 51
Aplicação e Exemplo
Uma aplicação clássica da distribuição hipergeométrica é amostragem sem reposição. Pense numa
urna com dois tipos de caramelos, pretos e brancos. Defina extrair um caramelo branco como sucesso e
a extracção de um caramelo preto como fracasso (análogo à distribuição binomial). Se a variável N
descreve o número de todos caramelos na urna (veja a tabela de contingência abaixo) e D descreve o
número de caramelos brancos (chmados defeituosos no exemplo acima), então N – D corresponde ao
número de caramelos pretos. Agora, assuma que existem 5 caramelos brancos e 45 pretos na urna.
Estando perto da urna, feche os olhos e extrai 10 caramelos sem reposição. Qual a probabilidade P (k =
4) de que você extraia exactamente 4 caramelos brancos (e – naturalmente – 6 caramelos pretos)?
Este problema é resumido na seguinte tabela de contingência
extraidos
Não extraidos
total
caramelos brancos
4(k)
1 = 5 – 4 ( D – k)
5(D)
caramelos pretos
6 = 10 – 4 (n – k)
39 = 50 + 4 – 10 – 5 (N + k – n – D)
45(N-D)
total
10(n)
40(N – n)
50(N)
A probabilidade P(k = x) de extrair exactamente x caramelos brancos (= número de sucessos) pode ser
calculada pela fórmula
D N D
k
n
k
P(k = x) = f(k; N, D, n) =
N
n
Por isso, neste exemplo x = 4, calcule
5 45
4 6 = 0,003964483....
P(k = 4) = f(4; 50, 5, 10) =
50
10
Assim, a probabilidade de extrair exactamente 4 caramelos brancos é bastante baixa (aproximadamente
igual 0,004) e o evento é muito improvável. Isto significa que, se você repetisse seu experimento
aleatório (extraindo da urna 10 caramelos dos 50 sem reposição) 1000 vezes você simplesmente
esperaria obter um tal resultado 4 vezes.
Mas qual a probabilidade de extrair mesmo (todos) 5 caramelos brancos? Você irá intuitivamente
concordar que este resultado é mesmo muito improvável do que extrair 4 caramelos.
Vamos calcular a probabilidade para um tal evento extremo:
Tabela de contingência
extraidos
Não extraidos
total
caramelos brancos
5(k)
0 = 5 – 5 ( D – k)
5(D)
caramelos pretos
5 = 10 – 5 (n – k)
40 = 50 + 5 – 10 – 5 (N + k – n – D)
45(N-D)
total
10(n)
40(N – n)
50(N)
Podemos calcular a probabilidade como se segue (note que o denominador fica sempre o mesmo):
5 45
5 5 = 0,0001189375....
P(k = 5) = f(5; 50, 5, 10) =
50
10
Como esperado, a probabilidade de extrair 5 caramelos brancos é mesmo mais baixa do que extrair 4
caramelos brancos.
Conclusão
Consequentemente, podemos expandir a questão inicial como se segue: Se você extrai 10 caramelos de
uma urna (contendo 5 caramelos brancos e 45 pretos), qual a probabilide de extrair pelo menos 4
caramelos? Ou seja, qual a probabilidade de extrair 4 caramelos brancos e o resultado do extremo
como de extrair 5 caramelos? Isto corresponde a calcular a probabilidade acumulada P(k 4) e pode
ser calculda pela função de probabilidade acumulada (f.p.a). Uma vez que a distribuição
hipergeométrica é uma distribuição discreta de probabilidade a probabilidade acumulada pode ser
calculada facilmente adicionando todos valores das probabilidades individais.
No nosso exemplo, podemos simplesmente somar P( k = 4) e P(k = 5):
P(k 4) = 0,003964583 + 0,0001189375 = 0,004083520
LEIA
1. An Introduction to Probability & Random Processes por
Kenneth B & Gian-Carlo R, pág. 184-195
Distribuições de Frequências Bivariadas
A distribuição normal bivariada é uma distribuição estatística com função de probabilidade
P(X 1 , X 2 ) =
onde
1
2 1 2
z
exp
,
2
2
(
1
)
1 2
z
( X 1 1 ) 2
12
= cor(X 1 , X 2 ) =
2 ( X 1 1 )( X 2 2 )
1 2
( X 2 2 )2
22
12
1 2
é a correlação de X 1 e X 2 (Kenny e Keeping 1951, pp 92 e 202-205; Whittaker and Robinson 1967, p.
32)
11
12
12 1 2
22 22
são comummente usados no lugar de 1 e 2 .
As probabilidades marginais sã então
P(X 1 ) =
1
P
x
x
dx
e
(
,
)
1 2 2
1 2
( x1 1 ) 2
2 12
e
P(X 2 ) =
1
P( x1 , x2 )dx1
2 2
e
( x2 2 ) 2
2 22
Tabelas de Probabilidade Conjunta
Esta tabela é uma tabela correctamente formatada como tabela de probabilidade conjunta
Dias anotados até ser vendido
Abaixo de 30
31-90
Acima de 90
Total
Abaixo de $5.,000
0,06
0,05
0,01
0,13
$5.,000-99.999
0,03
0,19
0,10
0,31
$100.000-150.000
0,03
0,35
0,13
0,50
Acima de $150.000
0,01
0,04
0,01
0,06
Total
0,13
0,63
0,25
1,00
Preço Inicial de Procura
Probabilidades Marginais
Seja S partido em r s de conjuntos disjuntos E i e F j onde o subconjunto geral é denotado por E i
F j . Então a probabilidade marginal de E i é
S
P(E i ) =
P( E F ).
j 1
i
j
LEIA
1. An Introduction to Probability & Random Processes por
Kenneth B & Gian-Carlo R, pág. 142-150
2. Exercícios pág. Nrs 1, 2, 3, 4, 5, 6, 7, 8, 9, 14, 15, 16, 17, 26
REFLEXÃO: As fontes das TICs (ICT) são difíceis para seu acesso. O link abaixo abre uma via para professores de Matemática acessar as fontes das TICs http://www.tsm‐resources.com/suppl.html
Unidade 2
(40 horas)
Variáveis Aleatórias e Teste de Distribuições
Momentos
A distribuição de probabilidade de uma variável aleatória é muitas vezes caracterizada por um pequeno
número de parámetros, que tamém tem uma interpretação prática. Por exemplo, muitas vezes é
suficiente conhecer qual é seu “valor médio”. Esta ideia é captada pelo conceito matemático de valor
esperado de uma variável aleatória, denotada por E[X]. Note que em geral, E[f(x)] não é mesma coisa
que f(E[X]). Uma vez que o “valor médio” é conhecido, pode-se perguntar quão distante os valores
típicos de X estão desse valor médio, uma questão que é respondida pela variância e desvio padrão de
uma variável aleatória.
Matematicamente, este assunto é conhecido como o problema (generalizado) de momentos: tal que
para uma classe dada de variáveis aleatórias X, se determina uma colecção {f i } de funções tais que os
valores esperados E[f i (X)] caraterizam completamente a distribuição da variável aleatória X.
Equivalência de Variáveis Aleatórias
Há vários sentidos diferentes em que as variáveis aleatórias podem ser consideradas para serem
equivalentes. Duas variáveis aleatórias podem ser iguais, iguais quase certamente, iguais em média, ou
iguais em distribuição.
No sentido crescente de força (poder), a definição precisa destas noções de equivalência é dada abaixo.
Equivaléncia em distribuição
Duas variáveis aleatórias X e Y são iguais em distribuição se elas têm as mesmas funções de
distribuição
P(X x) = P(Y x) para todo x.
Duas variáveis aleatórias tendo funções geradoras de momentos iguais têm a mesma distribuição.
Igualdade em média
Duas variáveis aleatórias X e Y são iguas em p-ésima média se o p-ésimo momento de |X – Y| é zero,
isto é,
E (| X Y | p ) 0
Igualdade em p-ésima média implica igualdade em q-ésima média para todo q < p. Como no caso
anterior, existe uma distância relativa entre variáveis aleatórias, nomeadamente,
d p (X, Y) =
E (| X Y | p ) .
Igualdade
Finalmente, duas variáveis aleatórias X e Y são iguais se elas são iguais como funções nos seus espaços
de probabilidade, isto é,
X() = Y() para todo .
Função geradora de Momentos
Na teoria de probabilidade e estatística, a função geradora de momentos de uma variável aleatória X
é
t i;R
M X (t) = E(etX),
onde esta esperança existe.
A função geradora de momentos gera os momentos da distribuição de probabilidade.
Para o vector das variáveis aleatórias X, com componentes reais, a função geradora de momentos é
dada por
M X (t ) E e t , X
onde t é um vector e t, X é o produto interno.
Dado que a função geradora de momentos existe num intervalo por volta de t = 0, o n-ésimo momento
é dado por
dn
E ( X ) M X (0) n
dt
(n)
n
M X (t )
t 0
Se X tem uma função de densidade de probabilidade contínua f(x) então a função geradora de
momentos é dada por
M X (t ) e tx f ( x)dx
=
t 2 x2
... f ( x)dx
1 tx
2!
= 1 + tm 1 +
t 2 m2
+ ...,
2!
onde m i é i-ésimo momento. M X (-t) é simplesmente a transformação de Laplace de dois lados de f(x).
Independentemente se a distribuição de probabilidade é contínua ou não, a função geradora de
momentos é dada pela integral de Riemann-Stieltjes
M X (t ) e tx dF ( x)
onde F é a função de probabilidade acumulada.
Se X 1 , X 2 , ..., X n é uma sequência de variáveis aleatórias independentes (e não necessariamente
identicamente distribuidas), e
n
S n ai X i ,
i 1
onde a i são constantes, então a função de densidade de probabilidade para S n é a convolução das
funções de densidade de probabilidade de cada um dos X i e a função geradora de momentos para S n é
dada por
M S (t ) M X (a1t ) M X (a2t )...M Xn (an t ).
n
1
2
Relacionadas a função geradora de momentos está uma série de transformações que são comuns na
teoria de probabilidade, incluíndo a função característica e a função geradora de probabilidade.
Desigualdade de Markov
A desigualdade de Markov dá um limite superior para a probabilidade de que X esteja dentro de
{X|f(x) }
Na teoria de probabilidade, a desigualdade de Markov dá um limite superior para a probabilidade de
que uma função não negativa de uma variável aleatória é maior ou igual a alguma constante. O nome é
em homenagem ao matemático Russo Andrey Markov, embora tenha aparecido antes no trabalho de
Pafnuty Chebyshev (professor de Markov).
A desigualdade de Markov (e outras desigualdades similares) relaciona probabilidades às esperanças,
fornece (frequentemente) o alargamento dos limites mas ainda úteis para a função de probabilidade
acumulada de uma variável aleatória.
Caso especial: Teoria de probabilidade
Para qualquer envento E seja I E variável aleatória indicadora de E, isto é, I E = 1 se E ocorre e = 0, em
outro caso. Assim I (|X| a) = 1 se o evento |X| a ocorre, e I (|X| a) = 0 se |X| < a.
Então, dado a > 0
aI (|X| a) |X|.
Portanto,
E(aI (|X| a) ) E(|X|).
Agora observe que o lado esquerdo da desigualdade é o mesmo que
aE(I (|X| a) ) = aP(|X| a).
Assim temos
aP(|X| a) E(|X|) e uma vez que a > 0, podemos dividir a ambos lados da desigualdade por a.
LEIA
1. Robert B. Ash, Lectures on Statistics, pág. 9-13
2. An Introduction to Probability & Random Processes
By Kenneth B & Gian-Carlo R, pages 366 -374 & 404 - 407
• Exercícios nas pág 376 -376 Nrs. 1,3,7,8
• Exercícios na pág 442 Nrs. 1,2,3,4,5
Ref:
• http://en.wikipedia.org/wiki/Moment-generating_
function
• http://en.wikipedia.org/wiki/characteristic_function_
%28probability_theory%29.
• http://en.wikipedia.org/wiki/Integral_transform
Desigualdade de Chebyshev
Na teoria de probabilidade, a desigualdade de Chebyshev (também conhecida como desigualdade de
Chebysheff, teorema de Chebyshev ou desigualdade de Bienaymé-Chebyshev) em homenagem a
Pafnuty Chebyshev, quem primeiro provou essa desigualdade, a afirmação de que em qualquer amostra
de dados, ou distribuição de probabilidade, aproximadamente todos valores estão perto do valor médio,
fornece uma descrição quantitativa de “aproximadamente todos” e “perto de”. Por exemplo nada mais
que
1
1
dos valores estão mais do que 2 desvios padrão fora da média, nada mais do que são mais do
4
9
que 3 desvios padrão fora, não mais do que
1
estão mais do que 5 desvios padrão fora da média, e
25
assim por diante.
Afirmação Probabilística
Seja X uma variável aleatória com valor esperado e a variância finita 2. Então para qualquer número
real k > 0,
P(|X - )
1
.
k2
Somente os casos k > 1 fornecem informação útil.
Como exemplo, usando k =
2 , +
2 mostra que pelo menos metade dos valores se situam no intervalo ( -
2 ).
Tipicamente, o teorema fornecerá os limites um pouco inflados. Todavia, os limites fornecidos pela
desigualdade de Chebyshev não podem, em geral (permanecendo conforme para variáveis de
distribuição arbitrária), ser melhorados. Por exemplo, para k > 1, o seguinte exemplo (onde =
satisfaz os limites exactamente.
P(X = -1) =
1
2k 2
1
)
k
P(X = 0) = 1
P(X = 1) =
1
k2
1
2k 2
O teorema pode ser útil apesar da inflação dos limites porque o teorema é aplicável para variáveis
aleatórias de qualquer distribuição, e porque estes limites podem ser calculados conhecendo da
distribuição nada mais do que a média e a variância.
A desigualdade de Chebyshev é usada para provar a lei fraca dos grandes números.
Exemplo de aplicação
Para ilustração, assuma que temos um extenso corpo de texto, por exemplo artigos duma publicação.
Assuma que conhecemos que os artigos são em média de 1000 caracteres em extensão com um desvio
padrão de 200 caracteres. Da desigualdade de Chebyshev podemos então deduzir que pelo menos 75%
dos artigos têm um comprimento entre 600 e 1400 caracteres (k = 2).
Prova probabilística
A desigualdade de Markov afirma que para qualquer variável aleatória Y que toma valores reais e para
E (| Y |)
. Uma forma de provar a desigualdade de
a
qualquer número positivo a, temos P(|Y| > a)
Chebyshev é aplicar a desigualdade de Markov à variável aleatória Y = (X - )2 com a = (k)2.
Também pode ser provado directamente. Para qualquer evento A, seja I A uma variável aleatória
indicadora de A, isto é, I A é igual a 1 se A ocorre e 0 em outro caso. Então
X 2 1 E X 2
1
P(|X - ) = E(I |X - | k) = E I [( X ) /( k )]2 1 E
2
2
2
k k
k
A prova directa mostra porquê os limites são bastante inflados nos casos típicos: o número 1 a
esquerda de “” é substituído por ( X ) /(k ) à direita de “” sempre o último excede 1. Em
2
alguns casos este último excede 1 por uma margem muito grande.
LEIA
1. An Introduction to Probability & Random Processes
por Kenneth B & Gian-Carlo R, pp 305-318
* Exercícios na pág. 309 nrs 1, 2, 3, 4, 5.
* Exercícios nas pp 320-324. Nrs 1, 3, 10, 12
Tipos de Correlações
Correlação é uma medida de associação entre duas variáveis. As variáveis não são designadas como
dependentes ou independentes. Os dois coeficientes de correlação mais populares são o coeficiente de
correlação de Spearman (rho) e o coeficiente de correlação de momento-produto de Pearson.
Quando se calcula um coeficiente de correlação de dados ordinais, escolhe a técnica de Spearman. Para
o intervalo ou dados do tipo razão, use a técnica de Pearson.
O valor de um coeficiente de correlação pode variar de menos um a mais um. Um menos um indica
uma perfeita correlação negativa, enquanto que mais um indica uma perfeita correlação positiva. Uma
correlação de zero significa que não há relação entre as duas variáveis. Quando há uma correlação
negativa entre duas variáveis, significa que enquanto o valor de uma variável cresce, o valor de outra
variável decresce, e vice-versa. Em outras palavras, para uma correlação negativa, as variáveis
trabalham opostas uma da outra. Se há uma correlação positiva entre duas variáveis, significa que
quando o valor de uma variável cresce o valor da outra variável também cresce. As variáveis movemse juntas.
O erro padrão de um coeficiente de correlação é usado para determinar os intervalos de confiança por
volta de uma correlação verdadeira de zero. Se o coeficiente de correlação cai fora do intervalo, então
o coeficiente de correlação é significativamente diferente de zero. O erro padrão pode ser calculado
para o intervalo ou dados do tipo razão (isto é, somente para a correlação do momento-produto de
Pearson).
A singificância (probabilidade) do coeficiente de correlação é determinada da estatística t. A
probabilidade da estatística t indica se o coeficiente de correlação observado ocorreu por acaso se a
correlação verdadeira é zero. Em outras palavras, procura-se saber se a correlação é significativamente
diferente de zero. Quando a estatística t é calculada para coeficiente de correlação da diferença
carecterística de Spearman, deve haver pelo menos 30 casos antes que a distribuição t possa ser usada
para determinar a probabilidade. Se há menos do que 30 casos, deve-se recorrer a uma tabela especial
para determinar a probabilidade do coeficiente de correlação.
Exemplo
Uma companhia quis saber se há uma relação significativa entre o número total de vendedores e o
número total de vendas.
Variável 1
Variável 2
207
6907
180
5991
220
6810
205
6553
190
6190
Coeficiente de correlação = 0,921
Erro padrão de coeficiente = 0,068
Teste-t para significância do coeficiente = 4,100
Graus de liberdade = 3
Probabilidade bi-caudal = 0,0263
Outro Exemplo
Respondentes a uma pesquisa foram solicitados a julgar a qualidade de um produto numa escala Likert
de quatro pontos (excelente, bom, apreciável, pobre). Foram também solicitados a julgar a reputação
da companhia que fabricara o produto numa escala de três pontos (bom, apreciável, pobre). Há uma
relação significativa entre a percepção dos respondentes sobre a companhia e suas percepções da
qualidade do produto?
Uma vez que todas variáveis são ordinais, o método de Spearman é escolhido. A primeira variável é a
classificação da qualidade do produto. As respostas são codificadas como 4 = excelente, 3 = bom, 2 =
apreciável e 1 = pobre. A segunda variável é a reputação percebida da companhia e é codificada como
3 = bom, 2 = apreciável e 1 = pobre.
Variável 1
Variável 2
4
3
2
2
1
2
3
3
4
3
1
1
2
1
Coeficiente de correlação = 0,830
Teste-t para significância do coeficiente = 3,332
Número de pares = 7
A probabildade deve ser determinada a partir de uma tabela por causa do pequeno tamanho da amostra.
Regressão
Regressão simples é usada para examinar a relação entre uma variável dependente e uma variável
independente. Depois de realizar uma análise, a regressão estatística pode ser usada para predizer a
variável dependente quando a variável independente é conhecida. A regressão vai para além da
correlação por adicionar a capacidade de predição.
As pessoas usam regressão num nível intuitivo diariamente. No negócio, um homem bem trajado é tido
como financeiramente bem sucedido. Uma mãe sabe que muito açúcar na dieta dos seus filhos resulta
em níveis de energia muito altos. A facilidade de acordar nas manhãs depende de como atrasou de ir a
cama na noite anterior. A regressão quantitativa aumenta a precisão por desenvolver uma fórmula
matemática que pode ser usada para os propóstos preditivos.
Por exemplo, um pesquisar médico pode querer usar o peso do corpo (variável independente) para
predizer a dose mais apropriada para uma nova droga (varável dependente). O propósito de descrever a
regressão é de determinar uma fórmula que se adequa à relação entre as duas variáveis. Então pode-se
usar tal fórmula para predizer valores para a variável dependente quando somente a variável
independente é conhecida. O médico pode pre-escrever uma dose apropriada baseando-se no peso do
corpo de uma pessoa.
A linha de regressão (conhecida como a linha de quadrados mínimos) é a representação gráfica do
valor esperado da variável dependente para todos valores da variável independente. Tecnicamente, é a
linha que “minimiza os resíduos quadráticos”. A linha de regressão é a linha que melhor ajusta os
dados numa rede de pontos.
Usando a equação da regressão, a variável dependente pode ser predita da variável independente. O
declive da linha de regressão (b) é definido como sendo a variação da ordenada dividida pela variação
correspondente da abscissa.
O intercepto no eixo dos y (a) é o ponto no eixo das ordenadas onde a linha de regressão intercepta o
eixo y. O declive e y intercepto são incorporados na equação de regressão. O intercepto é geralmente
chamado de constante, e o declive é referido como coeficiente. Dado que o modelo de regressão não é
usualmente uma predição perfeita, existe também um termo de erro na equação.
Na equação de regressão, y é sempre a variável dependente e x é sempre a variável independente.
Existem três formas equivalentes para matematicamente descrever um modelo linear de regressão.
y = intercepto + (declive . x) + erro
y = constante + (coeficiente . x) + erro
y = a + bx + e
O significado do declive da linha de regressão é determinado pela estatística t. É a probabilidade de
que o coeficiente de correlação observado ocorreu pelo acaso se a correlação verdadeira é zero. Alguns
pesquisadores preferem dizer a razão-F em vez da estatísitica t. A razão-F é igual a estatística t ao
quadrado.
A estatística t para significância do declive é essencialmente um teste para determinar se o modelo de
regressão (equação) é utilizável. Se o declive é significativamente diferente de zero, então podemos
usar o modelo de regressão para predizer a variável dependente para qualquer valor da varável
indepndente.
Por outro lado, tome um exemplo onde o declive é zero. Não tem nenhuma habilidade de predição
porque para qualquer valor da variável independente, a predição para a variável dependente será a
mesma. Conhecendo o valor da variável independente não melhora nossa habilidade de predizer a
variável dependente. Assim, se o declive não é significativamente diferente de zero, não use o modelo
para fazer predições.
O coeficiente de determinação (r-quadrado) é o quadrado do coeficiente de correlação. Seu valor pode
variar de zero a um. Este valor tem a vantagem em relação ao coeficiente de correlação no sentido de
que pode ser interpretado directamente como a proporção da variância na variável dependente que
pode ser considerada para a equação de regressão. Por exemplo, um valor r-quadrado de 0,49 significa
49% da variância na variável dependente pode ser explicada pela equação da regressão. Outros 51%
são não explicados.
O erro padrão da estimativa para regressão mede a quantidade da variabilidade nos pontos a volta da
linha de regressão. É o desvio padrão de pontos dos dados da maneira como eles se distribuem a volta
da linha de regressão. O erro padrão da estimativa pode ser usado para determinar intervalos de
confiança por volta de uma predição.
Exemplo
Uma companhia pretende saber se há uma relação significativa entre suas despesas de publicidade e
seus volumes de venda. A variável independente é o orçamento de publicidade e a variável dependente
é o volume de vendas. Um intervalo de tempo de um mês será usado porque as vendas são esperadas a
ficarem atrás das despesas actuais de publicidade. Os dados foram colectados para um período de seis
meses. Todos números estão em milhares de dolares. Há uma relação significativa entre o orçamento
de publicidade e volume de vendas?
Variável independente
Variável dependente
4,2
27,1
6,1
30,4
3,9
25,0
5,7
29,7
7,3
40,1
5,9
28,8
Modelo: y = 10,079 + (3,700 . x) + erro
Erro padrão da estimativa = 2,568
Teste-t para a significância do declive = 4,095
Graus de liberdade = 4
Probabilidade bi-caudal = 0,0149
r-qaudrado = 0,807
Num relatório pode-se fazer uma afirmação como esta: Uma regressão linear simples foi realizada
sobre os dados de 6 meses para determinar se havia uma relação significativa entre as despesas em
publicidade e o volume de vendas. A estatítica-t para o declive foi significante em 0,05 nível crítico de
alfa, t(4) = 4 . 10, p = 0,15. Assim, rejeita-se a hipótese nula e conclui-se que houve uma relação
significante positiva entre as despesas em publicidade e volume de vendas. Além disso, 80,7% da
variabilidade no volume de vendas podia ser explicada.
LEIA
1) An Introduction to Probability & Random Processes
por Kenneth B & Gian-Carlo, pág. 18-30, 212-215, 300303
2) Robert B Ash, Lectures on Statistics, pág. 28-29
Ref: http://en.wikipedia.org/wiki/Correlation
Ref: http://en.wikipedia.org/wiki/Regression
O teste de Qui-quadrado
Um teste qui-quadrado é qualquer teste da hipótese estatística no qual o teste estatístico tem uma
distribuição qui-quadrado quando a hipótese nula é verdadeira, ou qualquer teste no qual a distribuição
de probabilidade do teste estatístico (assumindo que a hipótese nula é verdadeira) pode ser feito para
aproximar uma distribição qui-quadrado tão perto quanto desejarmos por fazer o tamanho da amostra
suficiente grande.
Especificamente, um teste qui-quadrado para independência avalia estatisticamente diferenças
significativas entre proporções para dois ou mais num conjunto de dados.
Teste qui-quadrado de Pearson, também conhecido como o teste Qui-quadrado da bondade de
ajuste.
também conhecido como correlcção de Yates paraa continuidade.
Teste qui-quadrado de Mantel-Haenszel
Teste qui-quadrado de associação linear-por-linear
Na teoria de probabilidade e estatística, a distribuição qui-quadrado (também qui-quadrado ou
distribuição) é uma das mais usadas distribuições teóricas de proabilidade na estatística inferencial,
isto é, em testes estatísticas de significância. Ela é útil porque, sub hipóteses razoáveis, quantidades
facilmente calculadas, podem ser provadas como tendo distribuições que se aproximam à distribuição
qui-quadrado se a hipótese nula é verdadeira.
Se X i são k variáveis aleatórias normalmente distribuidas com média 0 e variância 1, então a variável
aleatória
k
Q=
X
i 1
2
i
é distribuida segundo a distribuição qui-quadrado. Esta expressão é usualmente escrita
Q ~ k2 .
A distribuição qui-quadrado tem único parámetro: k – um inteiro positivo que especifica o número de
graus de liberdade (isto é, o número de X i ).
A distribuição qui-quadrado é um caso especial da distribuição gama.
As situações bem conhecidas nas quais a distribuição qui-quadrado é usada são os estes comuns de
qui-quadrado da bondade de ajuste de uma distribuição observada no contexto teórico, e da
independência de dois critérios de classificação de dados qualitativos. Totavia, muitos outros testes
estatísticos conduzem ao uso desta distribuição.
Função Característica
A função característica da distribuição qui-quadrado é
(t ; k ) (1 2it ) k / 2
Propriedades
A distribuição qui-quadrado tem numerosas aplicações na estatistica inferencial, por exemplo, em
testes qui-quadrado e na estimação de variâncias. Ela entra nos problemas de estimação da média duma
população normalmente distribuida e o problema de estimação do declive de uma linha de regressão
através do seu papel na distribuição t-Student. Ela entra em todos problemas de análise de variância
através do seu papel na distribuição-F, que é uma distribuição da razão de duas variáveis aleatórias
independentes qui-quadrados divididas pelos seus respectivos graus de liberdade.
Várias distribuições qui e qui-quadrado
Nome
Estatística
Distribuição qui-quadrado
X i i
i
i 1
Distribuição qui-quadrado não central
Xi
i 1 i
k
k
2
Distribuição qui-quadrado
X i i
i
i 1
Distribuição qui não central
Xi
i 1 i
k
k
2
2
2
LEIA
Ref: http://en.wikipedia.org/wiki/pearson%chi-square_test
Ref: http://en.wikipedia.org/wiki/Chi-Square _test
Teste T-Student
Um teste t é um teste de hipótese estatística para dois grupos nos quais o teste estatítico tem
distribuição T-Student se a hipótese nula é verdadeira.
História
A esstatística t foi introduzida por William Sealy Gosset para de forma barata controlar a fermentação
de bebidas. “Student” era o nome de sua caneta. Gosset foi um estatístico que trabalhava para
fermentadora Guinness em Dublin, Irlanda, e foi contratado na sequência da implementação da política
inovativa de Claude Guinness de recrutar os melhores graduados de Oxford e Canbridge para aplicar a
bioquímica e estatística nos processos industriais da Guinness. Gosset publicou o teste t em Biometrika
em 1908, mas foi forçado pelo seu patrão que considerou o facto de que eles estavam usando estatística
como um negócio secreto, a usar um nome de sua caneta. De facto, a identidade de Gosset foi
desconhecida não somente para os seus colegas de estatística mas também para seu patrão-a
companhia insistia no pseudónimo por forma que podia ocultar a revelação das suas regras.
Hoje em dia, é geralmente usado para a confiança que pode ser substituída em julgamentos feitos das
amostras pequenas.
Utilidade
Entre os testes t muito frequentemente usados são:
* Um teste da hipótese nula de que a média de duas populações normalmente distribuidas são iguais.
Dados dois conjuntos de dados, cada um caracterizado pela sua média, o desvio padrão e o número de
pontos dos dados, podemos usar algum tipo do teste t para determinar se as médias são distintas, dado
que as distribuições subjacentes podem ser assumidas a serem normais. Todos tais testes são
usualmente chamados de testes t-Student, embora estritamente falando, esse nome devia somente ser
usado se as variâncias de duas populações são também assumidas a serem iguais; a forma do teste
usado quando esta hipótese não é usada, é algumas vezes, chamada o teste de Welch. Existem
diferentes versões do teste t dependento se as duas amostras são
- são independentes uma da outra (exemplo, indivíduos aleatoriamente colocados em dois grupos), ou
- pareamento, tal que cada membro de uma amostra tenha uma única relação com um membro
particular da outra amostra(exemplo, as mesmas pessoas medidas antes e depois de uma intervenção,
ou pontuações do teste IQ de um marido e sua esposa).
Se o valor t que é calculado está acima do limiar escolhido para a significância estatística (usualmente
o nível de 0,05), então a hipótese nula de que os dois grupos não diferem é rejeitada a favor de uma
hipótese alternativa, que tipicamente afirma que os grupos são diferentes.
Um teste de que a média de uma população normalmente distribuida tem um valor especificado
numa hipótese nula.
Um teste de que o declive da linha de regresão difere significativamente de 0.
Uma vez que um valor t é determinado, um valor P pode ser encontrado usando uma tabela de valores
da distribuição t-Student.
Intervalos de confiança usando uma amsotra de tamanho pequeno
Considera uma população normalmente distribuida. Para estimar a variância populacional tome uma
amostra de tamenho n e calcule a variância da amostra, s. Um estimador não tendencioso da variância
da população é
2 =
n 2
s
n 1
Claramente para pequenos valores de n esta estimação é incorrecta. Por isso para amostras de
tamanhos pequenos em vez de calcular o valor de z para o número de desvios padrão a partir da média,
z=
x
n
e usar probabilidades basedas na distribuição normal, calcule o valor de t
t=
x
sn 1
n
A probabilidade de que o valor de t esteja num intervalo particular pode ser encontrada usando a
distribuição t. Os graus de liberdade da amostra são o número de dados que precisam de serem
conhecidos antes que o resto dos dados possam ser calculados.
ex:
Uma amostra de coisas tem os pesos:
30,02; 29,99; 30,11; 29,97; 30,01; 29,99
Calcular intervalo de confiança com 95% de confiança para o peso da população.
Assume que a população ~ N(, 2)
A média do peso da amostra é 30,015 com desvio padrão de 0,045. Com a média e os primeiros cinco
pesos é possível calcular o sexto peso. Consequentemente existem 5 graus de liberdade.
A distribuição t diz-nos que, para cinco graus de liberdade, a probabilidade de que t > 2,571 é 0,025.
Também, a probabilidade de que t < -2,571 é 0,025. Usando a fórmula para t = 2,571 um intervalo de
confiança de 95% para a média das populações pode ser encontrada por tomar , o sujeito da equação.
Esto é
30,015 2,571
0,045
0,045
30,015 2,571
6
6
LEIA
1. Introduction to Probability By Charles M. Grinstead, pág.
18-30, 212-215, 300-303
2. Robert B. Ash, Lectures on Statistics, page 23-29.
• Respostas aos problemas 1- 6 na pág 23.
Ref:http://en.wikipedia.org/wiki/Statistical_Hypothesis_testing
Ref: http://en.wikipedia.org/wiki/Null_hypothesis
Reflexão O estudo da Correlação, Regressão, Testes de Hipóteses e outra modelagem matemática pode ser simplicado através das TICs. O seguinte link permite os treinantes aprender modelar com facilidade. http://www.ncaction.org.uk/subjects/maths/ict‐lrn.htm Unidade 3
Teoria de probabilidade
(40 horas)
Na matemática, uma função indicadora ou uma função característica é uma função definida num
conjunto X que indica a pertinência de um elemento num sub-conjunto A de X. Uma função indicadora
de um sub-conjunto A de um conjunto X é uma função
1 A : X {0, 1}
definida como
1 se x A
1 A (x) =
0 se x A
A função indicadora de A é algumas vezes denotada por
A (x) ou 1 A (x) ou mesmo A(x).
Desigualdade de Benferroni
Seja P(E i ) a probabilidade de que E i é verdadeira, e seja P( in1 Ei ) a probabilidade de que pelo menos
um dos E 1 , E 2 , ..., E n é verdadeira. Então “a” desigualdade de Bonferroni, ambém conhecida como a
desigualdade de Boole, afirma que
P( in1 Ei )
onde
n
P( E ),
i
i 1
denota a união. Se E i e E j são conjuntos disjuntos para todo i e j, então a desigualdade torna-
se uma igualdade. Um teorema bonito que exprime a relação exacta entre a probabilidade de uniões e
as probabilidades de eventos individuais é conhecido como o princípio de inclusão-exclusão.
Uma classe ligeiramente larga de desigualdades é conhecida como a de “desigualdades de Bonferroni”.
Função Geradora
Em matemática uma função geradora é uma série formal de potências cujos coeficientes incorporam
informação a cerca de uma sequência a n que é indexada pelos números naturais.
Existem vários tipos de funções geradoras, incluíndo funções geradoras ordinárias, funções
geradoras exponenciais, série de Lambert, série de Bell, e série de Dirichlet; definições e exemplos
são dados abaixo. Cada sequência tem uma função geradora de cada tipo. A função geradora particular
que é mais útil num dado contexto dependerá da natureza da sequência e os detalhes dos problemas a
abordar.
Funções geradoras são muitas vezes expressas na forma fechada como funções de um argumento
formal x. Algumas vezes, uma função geradora é avaliada num valor específico de x. Todavia, deve ser
recordado que funções geradoras são séries formais de potências e elas não precisam ser convergentes
para todos valores de x.
Se a n é a função de massa de probabilidade de uma variável aleatória discreta, então sua função
geradora ordinária é chamada uma função geradora de probabilidade.
A função geradora ordinária pode ser generalizada a sequências com múltiplos índices. Por exemplo, a
função geradora ordinária de uma sequência a m,n (onde n e m são números naturais) é
G(a n,m ; x, y) =
a
m,n 0
m,n
xm yn
Função Característica (Teoria de Probabilidade)
Na teoria de probabilidade, a função característica de qualquer variável aleatória define
completamente sua função de probabilidade. Na recta real, ela é dada pela seguinte fórmula, onde X é
qualquer variável aleatória com distribuiçãi em equação:
X (t ) E e itX
onde t é um número real, i é a unidade imaginária, e E denota o valor esperado.
Se F X é uma função de probabilidade acumulada, então a função característica é dada pela integral de
Riemann-Stieltjes
E e itX e itx dFX (x)
Nos casos em que existe uma função de densidade de probabilidade, f X torna-se
E e itX e itx f X ( x)dx
Se X é um vector cujos componentes são variáveis aleatórias, toma-se o ragumento t a ser um vector e
tX um produto interno.
Cada distribuição de probabilidade em R ou em Rn tem uma função característica, porque intergra uma
função limitada sobre um espaço cuja medida é finita.
O teorema de continuidade
Se uma sequência de funções características de distribuições F n converge para uma função
característica de distribuição F, então F n (x) converge para F(x) para cada valor de x no qual F é
contínua.
Usos das funções características
Funções características são particularmente úteis para lidar com funções de variáveis aleatórias. Por
exemplo, se X 1 , X 2 , ..., X n é uma sequência de variáveis aleatórias independentes (não necessariamente
identicamente distribuidas), e
n
S n ai X i ,
i 1
onde os a i são constantes, então a função característica para S n é dada por
S n (t ) X 1 (a1t )X 2 (a 2 t )...X n (a n t )
Em particular X + Y (t) = X (t) Y (t). Para ver isso, escreve a definição da função característica do
modo seguinte:
X + Y (t) = E e it ( X Y ) = E e itX ) e itY = E e itX ) E e itY = X (t) Y (t).
Observe que a independencia de X e de Y requer estabelecer a igualdade da terceira e quarta
expressões.
Por causa do teorema de continuidade, as funções características são usadas em muitas provas
frequentes do teorema central do limite.
As funções características podem também ser usadas para determinar os momentos da variável
aleatória. Dado que o n-ésimo momento existe, a função característica pode ser diferenciada n vezes e
E(X ) = i
n
n
(n)
X
an
(0) i n X (t )
dt
t 0
n
LEIA
1. Robert B Ash, Lectures in Statistics, pág. 32 de 45
Ref:
http://en.wikipedia.org/wiki/Characteristics_function_%28probability_theory%%29
Independência Estatísitica
Na teoria de probabilidade, dizer que dois eventos são independentes intuitivamente significa que a
ocorrência de um deles não faz com que outro ocorra nem com menos nem com mais probabilidade.
Por exemplo:
O evento de obter um “6” na primeira vez quando um dado é lançado e o evento de obter um “6”
no segundo lançamento são independentes.
Por contraste, o evento e obter um “6” na primeira vez quando um dado é lançado e o evento de
que a soma dos números observados no primeiro e segundo lançamentos é “8” são
independentes.
Se duas cartas são extraídas de um baralho sem reposição, o evento de extracção de uma carta
vermelha no experimento e o evento de extracção da carta vermelha no segundo experimento são
independentes.
Por contraste, se duas cartas são extraídas sem reposição de um baralho de cartas, o evento de
extracção de uma carta vermelha no primeiro experimento e o evento de extracção de uma carta
vermelha no segundo expeerimento são independentes.
De igual modo, duas variáveis aleatórias são independentes se a distribuição de probabilidade de
qualquer valor observado de uma delas é a mesma como se a outra não tivesse sido observada.
Eventos Independentes
Definição padrão:
Dois eventos A e B são independepentes se e somente se P(AB) = P(A)P(B)
Aqui AB) é a intersecção de A e B, isto é, é o evento de que ambos A e B ocorrem.
Mais geral, qualquer colecção de eventos-possivelmente mais do que dois- são mutuamente
independentes-se e somente se para qualquer subconjunto finito A 1 , ..., A n da colecção temos:
P(A 1 ... A n ) = P(A 1 )...P(A n )
Esta relação é chamada a regra de multiplicação para eventos independentes.
Se dois eventos A e B são independentes, então a probabilidade condicional de A dado que B ocorreu é
a mesma como se B não tivesse ocorrido, ou seja é a mesma probabilidade “incondicional” (ou
marginal) de A, isto é
P(A|B) = P(A)
Há pelo menos duas razões porquê esta afirmação não é tomada como definição de idenpendência: (1)
os dois eventos A e B não jogam o papel de simetria nesta afirmação, e (2) problemas surjem com esta
afirmação quando eventos de probabilidade 0 são envolvidos.
Se dizemos que a probabilidade condicional P(A|B) é dada por
P(A|B) =
P( A B)
(para P(B) 0)
P( B)
estamos a dizer que a afirmação acima é equivalente a
P(AB) = P(A)P(B)
que é a definição padrão dada acima.
Amostragem Aleatória
Uma amostra é um sub-conjunto escolhido de uma população para investigação. Uma amostra
aleatória é um subconjunto da população escolhido por um método com um compontente imprevisto.
Amostragem aleatória pode também referir-se a tomar uma série de observações independentes da
mesma distribuição de probabilidade, sem envolver qualquer população real. Uma probabilidade
amostral é a probabilidade em que cada item tem uma probabilidade conhecida de estar na amostra.
A amostra usualmente não será completamente representativa da população da qual ela foi extraída-
esta variação aleatória nos resultados é conhecida como erro de amostragem (erro amostral). Assim,
estimativas obtidas de amostras aleatórias podem ser acompanhadas pelas medidas de incerteza
associada com a estimativa. Esta pode tomar a forma de um erro padrão, ou se a amostra é
suficientemente grande para o teorema do limite central ter efeito, os intervalos de confiança podem
ser calculados.
Tipos de amostras aleatórias
Uma amostra aleatória simples é seleccionada tal que cada amostra possível tem igual
possibilidade de ser escolhida.
Uma amostra auto-ponderada, ..., é uma amostra na qual cada indivíduo, ou objecto, na
população de interesse tem igual oportunidade de ser seleccionado para amostra. Amostras
aleatórias simples são amostras auto-ponderadas.
Amostragem estratificada envolve a seleccção de amostras independentes de uma série de subpopulações (ou estratos) dentro da população. Os grandes ganhos na eficiência são algumas
vezes possíveis a partir de uma estratificação judiciosa.
Amostragem por cluster envolve a selecção de unidades amostrais em grupos. Por exemplo, uma
amostra de chamadas telefónicas pode ser colectada por tomar primeiro uma colecção de linhas
telefónicas e colectar todas chamadas nas linhas seleccionadas. A análise de amostras por cluster
deve tomar em consideração a correlação intra-cluster que reflecte o facto de que unidades no
mesmo cluster são provavelmente a serem mais similares do que duas unidades escolhidas ao
acaso.
Distribuição Multinomial
Na teoria de probabilidade, a distribuição multinomial é uma generalização da distribuição binomial
A distribuição binomial é a distribuição da probabilidade do número de “sucessos” em n ensaios
independentes de Bernoulli, com a mesma probabilidade de “sucessos” em cada ensaio.
Na distribuição multinomial, cada ensaio resulta em exactamente um de alguns números fixos finitos k
de possíveis resultados, com probabilidade p 1 , ..., p k (tal que p i 0 para i = 1, 2, ..., k e
k
p
i 1
i
= 1) , e
onde temos n ensaios independentes. Então sejam X variáveis aleatórias a indicar o número de vezes o
resultado i foi observado durante os n ensaios. X = (X i , ..., X k ) segue uma distribuição ultinomial com
parametros n e p.
Soluções a partir da fórmula da Distribuição Multinomial
Uma versão curta da fórmula multinomial para os três resultados consecutivos é dada abaixo.
Se X consiste de eventos E 1 , E 2 , E 3 , e as probabilidades correspondentes de p 1 , p 2 e p 3 de ocorrências,
onde x 1 é o número de vezes E 1 ocorrerá, x 2 é o número de vezes E 2 ocorrerá e x 3 é o número de
vezes E 3 ocorrerá, então a probabilidade de X é
n!
p1x1 p 2x2 p3x3 onde x 1 + x 2 + x 3 = n e p 1 + p 2 + p 3 = 1
x1! x 2 ! x3 !
Exemplo
1) Numa grande cidade, 60% dos trabalhadores têm transporte próprio para o serviço, 30% tomam
autocarro, e 10% tomam train. Se 5 trabalhadores são seleccionados ao acaso, determinar a
probabilidade de que 2 trabalhadores irão ao serviço de carro próprio, 2 tomarão autocarro e 1 tomará
train.
Solução
n = 5, x 1 = 2, x 2 = 2, x 3 = 1 e p 1 = 0,6; p 2 = 0,3 e p 3 = 0,1
Por isso, a probabilidade de que 2 trabalhadors irão ao serviço de carro próprio, 2 tomarão autocarro e
1 tomará train é:
5!
(0,6) 2 (0,3) 2 (0,1)1 = 0,0972
2! 2! 1!
2) Uma caixa contém 5 bolas vermelhas, 3 bolas azuis e 2 bolas brancas. Se 4 bolas são seleccionadas
da caixa com reposição, determinar a probabilidade de obter 2 bolas brancas, uma bola azul e uma bola
branca.
Solução
N = 4, x 1 = 2, x 2 = 1, x 3 = 1 e p 1 =
5
3
2
; p2 =
e p3 =
10
10
10
Por isso, a probabilidade de obter 2 bolas vermelhas, uma bola azul e uma bola branca é
5! 5
2! 1! 1! 10
2
3
10
1
1
3 9
2
= 0,18
= 12
10
200 50
{Allan G, 2005, pág. 132}
Ordem Estatística
Distribuições de probabilidade para n = 5, ordem estatística de uma distribuição exponencial com
Em estatística, a k-ésima ordem estatística de uma estatística amostral é igual ao seu k-ésimo menor
valor. Juntamente com a característica estatística, a ordem estatística é entre os instrumentos na
estatística não paramétrica e inferência.
Casos especiais importantes da ordem estatística são o mínimos e o máximo valor duma amostra, e
(com algumas qualificações discutidas abaixo) a median amostral e outros quartis amostrais.
Quando usamos a teoria de probabilidade para analisar a ordem estatística de amostras aleatórias de
uma distribuição contínua , a função de probabilidade acumulada é usada para reduzir a análise ao caso
da ordem estatística da função de distribuição.
LEIA
1. Robert B Ash, Lectures in Statistics, pág. 25-26 e
respostas dos problemas 1-4 nas pág. 26/27
Ref: http://en.wikipedia.org/wiki/probability_distribution
Ref: http://en.wikipedia.org/wiki/Ranking
Ref: http://en.wikipedia.org/wiki/non_parametric_Statistics
Notação e exemplos
Por exemplo, supõe que 4 números são observados ou registados, resultando numa amostra de tamnaho
n = 4. Se os valores amostrais são
6, 9, 3, 8
estes números usualmente serão denotados por
x 1 = 6, x 2 = 9, x 3 = 3, x 4 = 8
onde o sub-índice i em x i indica simplesmente a ordem na qual s observações foram registadas e
usualmente assumido não ser significante. Um caso quando é significante é quando as observações são
partes de uma série temporal.
A ordem estatística será denotada
x (1) = 3, x (2) = 6, x (3) = 8, x (4) = 9
onde o sub-índice (i) dentro de parénteses indica a i-ésima ordem estatística da amostra.
A primeira ordem estatística (ou a menor ordem estatística) é sempre o mínimo da amostra, isto é,
X (1) = mín{X 1 , ..., X n }
onde seguindo a convenção comum, usamos letras maúsculas para referir a variáveis aleatórias, e letras
minúsculas (como em cima) para referir aos seus valores reais observdos.
De igual modo, para uma amostra de tamanho n, a n-ésima ordem estatística (ou maior ordem
estatísitca) é o máximo, tal que
X (n) = máx{X 1 , ..., X n }
A amplitude da amostra é a diferença entre a máxima e mínima ordem estatística. É claramente uma
função da ordem estatística
Amplitude{X 1 , ..., X n } = X (n) – X (1)
Uma importância similar na análise exploratória de dados que é simplesmente relacionada à ordem
estatística é a amplitude amostral interquartílico.
A mediana amostral pode ser ou não uma ordem estatística, uma vez que existe um único ponto médio
somente quando o número n de observações é ímpar. Mais precisamente, se n = 2m + 1, para algum m,
então a mediana amostral é X (m + 1) e assim é uma ordem estatística. Por outro lado, quando n é par, n =
2m e existem dois valores médios, X (m) e X (m + 1) , e a mediana amostral é alguma função de duas
variáveis (usualmente a média) e por isso não é uma ordem estatística. Observações similares se
aplicam para todos quantis amsotrais.
Distribuição Normal Multivariada
Na teoria de probabilidade e estatística, a distribuição normal multivariada, também algumas vezes
chamada uma distribuição Gaussiana mutltivariada, é uma distribuição específica de probabilidade,
que pode ser pensada como uma generalização a dimensões mais altas da distribuição normal unidimensional (também chamada uma distribuição Gaussian).
Momentos superiores
Os k-ésimos momentos de X são definidos por
def
def
N
1 ,..., N X r1 ,...., rN ( X ) E X rjj
j 1
onde r 1 + r 2 + ... + r N = k
Os momentos centrais de ordem k são dados como se segue
(a) Se k é ímpar, 1 ,..., N X 0
(b) Se k é par com k = 2, então
1 ,..., 2 ( X ) ( ij kl ... XZ )
onde a soma é tomada em todas alocações do conjunto {1, ..., 2} em pares (não odernadas), dando
(2 1)!
termos na soma, cada um sendo o produto de covariâncias. As covariâncias são
(2 ( 1)!)
1
determinadas pela substituição de termos da lista [1, ..., 2] pelos termos correspondentes a lista
consistindo de r 1 uns, então r 2 dois, etc, depois de cada uma das possíveis alocações da primeira lista
em pares.
Em particular, os momentos de ordem 4 são
E X X 3
E X X 2( )
E X X X 2
E X X X X
E X i4 3( ii ) 2
3
i
j
2
i
2
2
i
i
j
j
ii
ij
2
j
ii
k
k
jj
ii
n
ij
jk
ij
ij
kn
ik
ik
jn
in jk
Para o momento de ordem quatro (quatro variáveis) existem três termos. Para o sexto momento de
ordem 6 exitem 3 5 = 15 termos, e para o oitavo momento de ordem oito existem 3 5 7 termos.
XV. Síntese do Módulo
No fim deste módulo os alunos são esperados que saibam calcular várias medidas de dispersão e
aplicar as leis de probabilidade a várias distribuições. Os alunos devem ser capazes de determinar
vários coeficientes de correlação e regressão.
A unidade um de Probabilidade e Estatística cobre distribuições de Frequências relativas e
distribuições acumuladas, várias curvas de frequências, média, moda e mediana, Quartis e Percentis,
Desvios padrão, distrtibuições simétricas e enviasadas. O estudante é introduzido a várias medidas e
exemplos de orientação.
Os exemplos são bem ilustrados e os estudantes podem seguir sem dificuldades. É recomendado que os
estudantes resolvam as avaliações formativas dadas para analisar (avaliar) seu progresso na
compreensão do conteúdo. Os estudantes devem procurar um tempo para estudar o material de
referência em CDs em anexo, abrir as fontes de recurso e os websites recomendados. Muito
importante, os estudantes são encorajados a ler o conteúdo muito extensamente e resolver as questões
que aparecem depois de cada tópico. A unidade dois do módulo leva os estudantes aos conceitos de
Momento e função geradora de momento, às desigualdades de Markov e Chebyshev, às distribuições
especiais de probabilidade Univariadas e Bivariadas; Distribuições Conjuntas, Marginais e
condicionais; Idenpendência; esperanças, regressão e correlação em distribuições bivariadas; Cálculo
de regressão e coeficiente de correlação para os dados bivaridos. Distribuição da função de variáveis
aleatóriaas, distribuição normal bivariada. Dedução das distribuições tais como qui-quadrado, t e F.
A unidade dois tem várias actividades da aprendizagem para ajudar aprendizagem e os estudantes são
aconselhados a dominar o conteúdo de vários sub-tópicos e fazer a auto-avaliação através das
avaliações formativas. Fracasso na resposta das avaliações formativas deve ser um indicador positivo
de que os alunos devem revisar os sub-tópicos antes de prosseguir para outros sub-tópicos. As tarefas
dadas através de várias actividades de aprendizagem exigem que o estudante domonstre um alto nível
de competência e habilidades nas TICs. Os objectivos da aprendizagem estão bem formulados no
início do módulo e devem guir os alunos no nível de espectativas para o módulo.
A unidade três focaliza a teoria de probabilidade e se concentra sobre as várias distribuições de
probabilidade.
A avaliação sumativa será usada para julgar o domínio do módulo pelos estudantes.
É recomendado que os estudantes revisem o módulo antes de realizarem a avaliação sumativa final.
XVI. Avaliação Sumativa
Responda 4 das questões colocadas. Cada questão vale 15 pontos
Questão 1: Estatística Geral
1) Na tabela seguinte, os pesos de 40 bois estão aproximados ao quilograma mais perto.
128
161
135
142
145
156
150
145
157
138
150
147
140
125
144
173
144
146
140
176
154
148
163
164
135
146
142
142
149
119
134
158
165
168
138
147
152
153
136
126
Determine
a) O peso mais alto
b) O peso mínimo
c) A amplitude
d) Construa uma tabela de distribuição de frequências começando com a classe 118-126.
e) Calcule a média dos dados
f) Calcule o desvio padrão
Questão 2: Probabilidade Geral
A) Uma moeda e um dado são lançados para cima juntos. Desenhe um diagrama de espaço de
2)
possibilidades e determine a probailidade de obter:
a) Uma cara
b) Um número maior do que 4
c) Uma cara e um número maior do que 4
d) Uma cara ou um número maior do que 4
B) Eventos M e N são tais que P(M) =
19
2
4
, P(N) = e P(M N) = . Determine
20
5
5
P(M|N).
Questão 3: Distribuição de Poisson
3) Um livro contém 500 páginas e tem 750 erros.
a) Qual é o número médio de erros por página?
b) Determine a probabilidade de que a página 427 contenha
i)
nenhum erro
ii)
exactamente 4 erros
c) Determine a probabilidade de que as páginas 427 e 428 não contenham nenhum erro.
Questão 4: Variável aleatória contínua
4) Uma variável aleatória contínua (v. a c.) X tem a função de densidade de probabilidade f(x) onde
k ( x 2) 2
f ( x ) 4 k
0
2 x0
0 x 1
1
3
nos outros casos
a) Determine o valor da constante k.
b) Esboce y = f(x)
c) Determine P(-1 X 1)
d) Determine P(X > 1)
Questão 5: Probabilidade de um evento
5) Dado que P(AB) =
7
1
5
, P(A|B) = e P(AC ) = , determine os valores de
8
4
8
a) P(A)
b) P(B)
c) P(A|BC )
d) P(AC BC )
e) A probabilidade de que somente um dos enventos A, B vai ocorrer.
Questão 6: Valor esperado
6) A variável aleatória contínua tem a f. d. p.
f(x) = x +
1
2
0X1
Determine
a) E(X)
b) E(24X + 6)
c) E( (1 X )
1
2
Questão 7:
7) As massas, aproximadas, de 50 rapazes estão registadas abaixo
Massa (kg)
60-64
65-69
70-74
75-79
80-84
85-89
2
6
12
14
10
6
Frequência (f)
a) Costrua uma curva de frequência acumulada
b) Use a curva para estimar
i)
Mediana
ii)
Amplitude interquartílico
iii) 7º decil
iv) 60º percentil
Esquema de Correcção da Avaliação Sumativa
1)
a) 176
b) 119
c) 176 – 119 = 57
d) Usando 7 classes dá-nos um intervalo 9
Peso (kg)
Registo
Frequência
118-126
///
3
127-135
/////;
5
136-144
/////; ////
9
145-153
12
/////; /////;
//
154-162
/////;
5
163-171
////
4
172-180
//
2
Total 40
e) Aceite qualquer método do cálculo da média
f) Aceite qualquer método do cálculo do desvio padrão.
2) A) Uma moeda tem ou Cara (C) ou coroa (K) enquanto que um dado tem as faces 1, 2, 3, 4, 5,
6.
Moeda/Dado 1
2
3
4
5
6
Cara (C)
H1
H2
H3
H4
H5
H6
Coroa (K)
T1
T2
T3
T4
T5
T6
Espaço Amostral = 12
a)
6 1
12 2
b)
4 1
12 3
c)
2 1
12 6
d)
8 2
12 3
B) – P(M N) = P(M) + P(N) – P(M N)
4 19 2
P( M N )
5 30 5
P(M N )
19 12 24 7
30 30 30 30
3) Número médio de erros por página
750
= 1,5
500
b) Seja X “o número de erros por página”. Então, assumindo que os erros ocorrem ao acaso, X ~
P O (1,5)
i) P(X = 0) = e-1,5
= 0,2231
P(não haver nenhum erro na página 427) = 0,047 (3 d.p)
(1,5) 4
ii) P(X = 4) = e =
= 0,0470
4!
-1,
P(haver 4 erros na página 427) = 0,047 (3d.p)
c) Esperamos 1,5 erros em cada página e a assim em duas páginas 427 e 428 esperamos 1,5 + 1,5 = 3
erros.
Seja Y o “número de erros em duas páginas”
Y ~P(3), assim P 0 (Y = 0) = e-3
= 0,4421
4) a) Uma vez que X é uma variável aleatória, então
f ( x)dx 1
a|| X
1
0
Portanto
k ( x 2)
2
2
k
( x 2) 3
3
0
2
1
3
dx 4kdx 1
0
1
1
3
0
4k x 1
k
4
(8) 4k = 1
3
3
8k = 1
k=
1
8
a) A f. d. p de X é
0
P(-1 X 0) =
1
8 ( x 2)
2
dx
1
7
24
e
P(0 X 1) = área do rectângulo =
1
2
Portanto
P(-1 X 1) =
7 1 19
24 2 24
P(0 X 1) = área do rectângulo =
1 1 1
3 2 6
Portanto P(X > 1) =
1
6
5) a) P(A) = 1 – P(AC) = 1 -
5 3
=
8 8
b) P(A B) = P(A) + P(B) – P(A B)
1
7 3
P(B) 4
8 8
P(B) =
3
4
c) P(A|BC ) = P(A) - P(A|B)
=
3 1 1
=
8 4 8
d) AC U BC = (A B)C e P(AC U BC) = 1 – P(A B) =
3
4
e) Somente um de A, B ocorre = (A|BC) U (AC|B)
P(somente A, B ocorre) = P(A|BC) + P(AC|B)
= {P(A) – P(A|B)} + {P(B) – P(A|B)}
=
6) a) E(X) =
1 5
1
+
8
2 8
7
8
b) E(24X + 6) = 20
1
1
1
3
c) E (1 X ) 2 1 X 2 x dx
2
5
0
1
7) a) Média = 76,3 kg
b) Amplitude interquartílico = 9 kg
c) Estimativa de
7
50 = 35º decil a partir da curva
10
d) Estimativa de
60
50 = 30º percentil a partir da curva
100
XVII. Referências
http://en.wikipedia.org/wiki/Statistics
A concise Course in A-Level Statistics By J. Crawshaw and J.Chambers, Stanley
Thornes Publishers, 1994
http://en.wikipedia.org/wiki/Probability
Business Calculation and Statistics Simplified, By N.A. Saleemi, 2000
http://microblog.routed.net/wp-content/uploads/2007/01/onlinebooks.html
Statistics: concepts and applications, By Harry Frank and Steven C Althoen, Cambridge
University Press, 2004
http://mathworld.wolfram.com/Statistics
http://mathworld.wolfram.com/Probability
Probability Demystified, By Allan G. Bluman, McGraw Hill, 2005.
http://directory.fsf.org/math/
http://microblog.routed.net/wp-content/uploads/2007/01/onlinebooks.html
Lectures on Statistics, By Robert B. Ash, 2005.
Introduction to Probability, By Charles M. Grinstead and J. Laurie Snell, Swarthmore
College.
http://directory.fsf.org/math/
Simple Statistics, By Frances Clegg, Cambridge University Press 1982.
Statistics for Advanced Level Mathematics, By I. Gwyn Evans University College
of Wales, 1984.
XVIII. Registos do desempenho do estudante
Nome do ficheiro em EXCEL
Matemática: Registos do desempenho do estudante em Probabilidade e Estatísitica
XIX. Autor Principal do Módulo
Mr. Paul Chege (B. Ed (Sc), M. Ed)
[email protected]
O autor do módulo é formador de professores na Universidade de Amoud, Borama, República Somalia
Ele foi formador de professores em Kenya, República das Seychelles e na Somália. Ele tem sido
envolvido no reforço da Matemática e das Ciências nos níveis secundário e universitário através do
programa da Agência da Corporação Internacional Japonesa (Japan International Corporation Agency
– JICA) em quinze países Africanos.
Ele é casado e com três filhos.
XX. Estrutura do ficheiro
Sugestões da Escrita do Módulo. A indicação de ficheiros e estrutura devem seguir o sistema do
Consórcio AVU/PI como definido e explicado pela AVU. Os autores do Módulo ainda precisam de
fornecer o nome de todos ficheiros (módulo e outros ficheiros que acompanham o módulo).
Diariamente cada módulo será carregado no portifólio pessoal criado para cada consultor. Para isso,
treinamento será dado pelo Professor Thierry Karsenti e sua equipa (Salomon Tchamén Ngano e Toby
Harper).
Nome do ficheiro do módulo (WORD): Mathematics: Probability abd Statistics (Word)
Nome de outros ficheiros (WORD, PDF, PPT, etc) para o módulo.
1. Matemática: Registos do desempenho do estudante em Probabilidade e Estatísitica
(Mathematics: Probability and Statistics Student Records (Excel)
2. Porbabilidade e estatística: Esquema de correcção para Avaliação Sumativa (Probability and
Statistics: Marking Scheme for Summative Evaluation (Word))
3. An Introduction to Probability and Random Processes, Textbook by Kenneth Baclawski and
Gian-Carlo Rota (1979) (PDF)
4. Introduction to Probability, Textbook by Charles M. Grinstead and J. Laurie Snell (PDF)
5. Lectures on Statistics, Textbook by Robert B. Ash (PDF).
Baixar