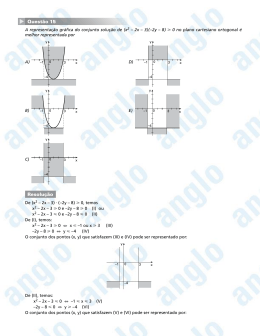
Algoritmos Genéticos
em Mineração de Dados
Descoberta de
Conhecimento
Descoberta do Conhecimento
em Bancos de Dados
Processo interativo e iterativo
para identificar padrões válidos,
novos, potencialmente úteis e
interpretáveis em bases de dados.
1
Aplicações:
Conhecendo o Negócio
• Conhecer Comportamento do Consumidor
• Enriquecimento de Banco de Dados
• Segmentação de Mercado
• Análise de Vendas
• Detecção de Fraude
• Conhecer um processo, um equipamento etc,
a partir de dados armazenados
Processo de Descoberta do
Conhecimento - Fases
Interpretação
Conhecimento
Data Mining
Padrões
Transformação
Pré-Processamento
Seleção
Banco
Dados
2
Fases do Processo de
Descoberta do Conhecimento
• Identificação da tarefa - O que se deseja conhecer/extrair?
• Seleção de dados - Dados e/ou atributos relacionados .
• Limpeza, PréPré -Processamento - Retirada de dados
ambíguos, duplicados, etc.
• Enriquecimento - Agregar informação externa.
• Mineração dos dados - Extrair regras, agrupar.
• Relatório - Histórico, conclusões, informações relevantes, etc.
Tarefas de Data Mining
• Clusterização
– Segmentar registros de um BD em N clusters (grupos, classes)
• Diferenciação
– Regras que diferenciam um cluster de outros
• Classificação
– Identificar o cluster (grupo) ao qual pertence um registro
• Explicação
– Regras que explicam o porque de um conjunto de registros
pertencer a um cluster (classe)
3
Regras
• Regras possuem:
– antecedentes (condições) e
– conseqüentes (classe):
SE COND1 E COND2 E... ENTÃO CLASSE_A
• Condições relacionam valores dos atributos:
– Atributos Quantitativos: idade, salário, etc
– Atributos Categóricos: Sexo, Estado Civil, etc
– Relações: <, >, =. Exemplo:
SE seguro>3000 E sexo=M ENTÃO Não-Fraudador
Mineração
• Inferir uma Regra Y descobrir condições (atributos,
valores/categorias) que satisfazem a uma classe
• Classificar um novo cliente Y presumir a classe a
qual pertence um determinado cliente
• Agrupar clientes Y identificar classes por suas
características
• Explicar Y regras com acurácia que abranjam todos
os elementos de uma classe
4
Detecção de Fraude
• Regra explica sinistros fraudados
SE
06:00hs< hora_sinistro < 08:30hs E
oficina ∈ oficinas_suspeitas
E
prêmio_seguro < R$ 2300
E
registro_policial = NÃO E
...........
custo_sinistro > 2,4 prêmio_seguro
ENTÃO
FRAUDE
Avaliação de uma Regra
• Acurácia:
– mede o quão boa é a sua solução (C) em função do grau de certeza,
ou confiança, obtido através do conjunto de exemplos que pertencem
(P) e não pertencem (P ) à classe;
– mede o quão bem a teoria descoberta (neste caso, uma regra) se
aplica aos dados;
– valor máximo = 100%, indicando que um registro classificado por essa
regra com certeza pertence à classe (P)
• Abrangência:
– percentual de registros cobertos por uma regra ([C^P] / P);
– valor máximo = 100%, significando que todos os possíveis registros de
uma determinada classe meta foram cobertos por essa regra.
5
Medidas de Desempenho
• Subconjunto C: Condição - Registros que satisfazem as
condições da Regra (SE)
• Subconjunto P: Previsão - Registros que satisfazem o objetivo da
Regra (ENTÃO)
• Acurácia de uma Regra (Ac
Ac): Percentual dos registros que
satisfazem C então P dentre todos os registros que satisfazem C.
• Abrangência de uma Regra (Ab
Ab): Percentual dos registros que
satisfazem C então P dentre todos os registros que satisfazem P.
Ac =
C&P
(C & P + C & P )
Ab =
C &P
(C & P + C & P )
Exemplo
• BD contém 100 Registros
• Registros estão segmentados em 2 Grupos:
– 80 regs. do G1 e 20 regs. do G2)
• Procura-se regras (C) para G1 (P≡ pertence a G1)
• Uma determinada regra encontrada, resulta em:
– 60 Registros satisfazem a regra e são do G1 (C&P)
– 20 Registros do G1 não satisfazem a regra
– 12 Registros do G2 satisfazem a regra
Ac =
60
( 60 + 12 )
= 0.833
Ab =
60
( 60 + 20 )
(C & P)
(C & P)
= 0.75
6
Classificação por Algoritmos
Genéticos
Conhece-se a segmentação de um BD em
n Grupos (clusters
(clusters)) ; deseja-se descobrir
a(s) regra(s) que melhor caracterizam
cada Grupo.
As regras podem se usadas para
classificar outros registros que ainda
não tenham sido segmentados.
Modelagem do GA
•
•
•
•
•
Representação
Decodificação
Operadores
Medidas de Desempenho
Avaliação
7
Cromossoma representa
uma Regra
• Regras :=antecedentes + consequentes
Se COND1 ^ COND2 ^...ENTÃO CLASSE_A
Exemplo:
Se 200<salário<3000 ^ sexo=M ENTÃO Bom-Pagador
• Evoluir Regra Y
– descobrir faixa de valores para atributos quantitativos
– descobrir conjunto de categorias para os categóricos
Representação
Atrib(1)
Atrib(2)
Atrib(n)
............
Gene
Cada Atributo é representado por um gene com 2 campos.
Atributos podem ser:
Gene
• Quantitativos (faixas
(
de valores) mim
• Categóricos (código)
máx
Código binário
8
Decodificação
Um cromossoma representa uma regra que
responde a uma pergunta:
Ex: O que caracteriza um estudante da PUC-Rio?
Atributos considerados:
A(1): Idade {15; 90}, A(2) Renda Familiar {200;8000}, A(3): Sexo{M; F}
Exemplo de um
cromossoma:
A(1)
18
25
A(2)
3000
A(3)
8000 M,F
A(1), A(2) são Quantitativos e A(3) é Categórico
Se 18 ≤ Idade
Idade≤
≤ 25 e 3000 ≤ Renda ≤ 8000 e Sexo = M ou F
então Estuda na PUC
Exemplo: Classificação de
Empresas
• Deseja-se identificar padrões de empresas (já agrupadas)
em um BD
• Exemplo: A regra abaixo esclarece qual o padrão das
empresas do Cluster 1?
Se receita_serviço 1 (Instalação)
= 5000<R$<7000 &
receita_serviço 2 (Manutenção) = 7000<R$<8000 &
código_atividade = 13 (Ind. Mat.Elétrico Eletrônico e Comunicação) &
10 < #_Filiais < 50 &
...........
#_Empregados > 100
Então Empresa pertence ao Cluster 1(Prioritárias)
9
Cromossoma ≡ Regra
Genes ≡ atributos do banco de dados
cruzamento
P1
Receita Serviço 1 Receita Serviço 2
COD_ATIV = 13
1000<R$<2000
4000<R$<9000
10<#_Filiais<50
Empregados>100
P2
Receita Serviço 1 Receita Serviço 2
COD_ATIV = 14
5000<R$<7000
7000<R$<8000
30<#_Filiais<60
Empregados>300
F1
Receita Serviço 1 Receita Serviço 2
COD_ATIV = 14
1000<R$<2000
4000<R$<9000
30<#_Filiais<60
Empregados>300
F2
Receita Serviço 1 Receita Serviço 2
COD_ATIV = 13
5000<R$<7000
7000<R$<8000
10<#_Filiais<50
Empregados>100
Operadores
• Crossover
– Sobre Reais: 1 ponto; 2 pontos; Uniforme;
Aritmético
– Sobre Binários (Lógicos): OU, E
• Mutação
– Troca gene por um número aleatório na faixa
do atributo escolhido na mutação
– Sobre Binários (Lógicos): NOT
10
Codificação de Atributos
Categóricos
- Ex: Residência: = {funcional, parente, alugada, própria}
- Cada posição indica ausência (0) ou presença (1) do
símbolo correspondente
Alelo
Decodificação
Tipo Res
1
0001
própria
2
0010
alugada
3
0011
própria ou alugada
…
…
…
15
1111
própria ou alugada ou parente ou
funcional (don’t care)
0
0000
Não informada (Null)
Operadores Lógicos
E, OU, NOT
P1
0011
null
F1
0111
null
F1 = P1 OU P2
P2
0110
null
F2
0010
null
F2 = P1 E P2
P
0011
null
1100
null
NOT P
11
Função de Avaliação
• O objetivo em datamining é obter regras com alta
acurácia e alta abrangência.
• As fórmulas de Acurácia e Abrangência, quando
usadas como funções de avaliação, podem prejudicar a
evolução se as regras na primeira população
apresentam Ac=Ab=0
• É preciso definir funções que forneçam avaliações
diferentes de 0 (zero)
• Existem várias funções propostas, cujo o desempenho
varia com a aplicação (problema)
• Ac e Ab podem recompensar avaliação quando
diferentes de zero
Funções de Avaliação
• Número-Atributos
• Distância-Ótima
• RecompensaAtributos
• CBayesianos
• Número-Registros
•
•
•
•
•
FAcurácia
FAbrangência
Correlação-2-Grupos
Rule-Interest[PIAT91]
Chi-Square[RAD95]
12
Ciclo de um Algoritmo Genético
Avaliação
dos Filhos
Planejamento Cromossoma Aptidão
Regra A
Regra B
Regra C
Regra D
Seleção
86%
44%
69%
7%
f(f( )=acerto%
)=acerto%
Cruzamento
Filhos
Reprodução
Mutação
Otimização da Acurácia da
Regra
30000
100%
25000
20000
50%
15000
10000
49
45
41
37
33
29
25
21
17
13
9
0
5
5000
1
Acurácia
Melhor Padrão
Cromossomas x 2000
Evolução è
13
Baixar