☰
Explorar
Assinar em
Inscrever-se
Envio
×
Baixar
Sem categoria
Fernando Manuel Rosmaninho Morgado Ferrão Dias Técnicas de
Mestrado em Ambiente Saúde e Segurança
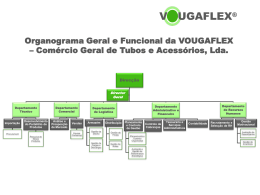
Organograma Geral e Funcional da VOUGAFLEX
Vaga: Empresa O Boticário – sede portuguesa da empresa
REABILITAÇÃO CARDIOVASCULAR
Apresentação Levantamento de Requisitos
Conceitos sobre Realidade Virtual
A proteção de dados pessoais dos trabalhadores e a
Influência do treino EMS adjuvante na composição corporal e nos
KICANDO – COMERCIO GERAL E AGROPECUÁRIA, LDA
Apresentaçao 1