Variáveis aleatórias contínuas e distribuiçao
Normal
Henrique Dantas Neder
Definições gerais
I
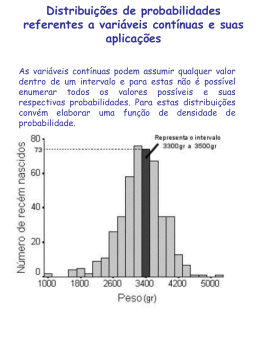
Até o momento discutimos o caso das variáveis aleatórias
discretas. Agora vamos tratar das variáveis aleatórias
contínuas. Começaremos com a variável aleatória contínua
mais simples que é chamada de variável aleatória contínua
uniforme. Suponhamos que temos um relógio com um
ponteiro que funcione como uma roleta de cassino. Giramos
aleatoriamente este ponteiro e verificamos em que posição ele
para. De um ponto de vista matemático, temos um número
infinito de pontos na circunferência do relógio. Então
teóricamente a probabilidade do ponteiro parar exatamente
em um ponto é igual a zero, porque aquele ponto é
matematicamente infinitesimal. Ou seja, ele é apenas um
ponto dentro do conjunto infinito de pontos que estão
contidos na circunferência do relógio.
I
No entanto se quisermos calcular a probabilidade de que o
ponteiro do relógio pare em um determinado intervalo de
pontos, por exemplo, caia entre o número 12 e o número 3 do
relógio, teremos um valor distinto de zero para esta
probabilidade. A probabilidade do ponteiro parar neste
intervalo é numericamente igual a 1/4 porque sabemos que
este intervalo corresponde a esta fração do conjunto total de
pontos do relógio (mesmo que este seja infinito!).
I
Desta forma, qualquer intervalo de pontos finito tem uma
probabilidade associada distinta de zero. E a probabilidade do
ponteiro parar em exatamente um ponto (digamos o número
12 exatamente) é igual a zero. Porque este é apenas um
“pequeno ponto” infinitesimal diante de um número infinito
de pontos ao redor da circunferência do relógio. Quando
estamos afirmando isto, estamos seguindo a definição clássica
de probabilidade, que afirma que a probabilidade de um
evento é o número de eventos favoráveis dividido pelo número
de eventos possíveis e equiprováveis do espaço amostral. O
número de eventos favoráveis neste caso é igual a 1 e o
número de eventos possíveis e equiprováveis é igual a ∞ e a
divisão de 1 por ∞ é (pelo menos no limite) igual a zero.
I
Para representar tudo isto temos que usar o conceito de
função densidade de probabilidade (ou simplesmente função
densidade). Para uma variável aleatória contínua não
podemos usar uma função de probabilidade, tal como no caso
de uma variável aleatória discreta. Para esta última, a variável
aleatória só assume um determinado número supostamente
finito de valores. Desta forma podemos associar valores de
probabilidade para cada valor da variável aleatória. Isto não
ocorre com as variáveis aleatórias contínuas. Neste caso,
como vimos no exemplo do relógio, temos um número infinito
de valores para uma variável aleatória contínua. Não temos
como associar um valor de probabilidade para cada valor da
variável aleatória e sabemos que todos estes valores são nulos.
I
Podemos definir uma função matemática que será chamada
de função densidade cujas propriedades serão:
ˆ +∞
f (x )dx = 1
(1)
e
ˆ
P(a ≤ X ≤ b) =
b
f (x )dx
(2)
a
I
No caso do experimento aleatório do relógio temos uma
função densidade:
f (x ) = 1/12 para qualquer valor de x no intervalo 0 ≤ X ≤ 12.
Se quisermos calcular a probabilidade de que o ponteiro do relógio
pare no intervalo ´que vai de 6 a´ 8, teremos:
8
8 1
x 8
1
P(6 ≤ X ≤ 8) = 6 f (x )dx = 6 12
dx = 12
|6 = 8−6
12 = 6
I Então podemos dizer que uma função densidade é um
instrumento matemático definido para variáveis aleatórias
contínuas e que pode ser usada para calcular probabilidade de
ocorrência destas variáveis em determinados intervalos.
Estamos aqui definindo um exemplo de função densidade,
chamado de função densidade uniforme que está associada a
uma variável aleatória contínua uniforme.
I De uma forma geral uma função densidade uniforme pode ser
qualquer função constante que respeite as condições (1) e (2).
O valor constante da ordenada desta função irá depender do
intervalo de variação definido para esta função. Digamos, de
uma forma geral que a função é definida no intervalo fechado
1
de números reais [a,b]. Então f (x ) = b−a
. Especificamente,
1
no caso do relógio, quando a = 0 e b = 12, f (x ) = 12
.
Esperança matemática e variância de uma variável
aleatória contínua
I
De uma forma análoga ao caso de uma variável aleatória
discreta, para o caso de uma variável aleatória contínua X
com função densidade f (x ), definimos esperança matemática
de X como sendo:
ˆ +∞
E (X ) =
Xf (x )dx
(3)
−∞
No caso de uma variável aleatória contínua uniforme na sua
1
temos:
forma geral, com função densidade igual a f (x ) = (b−a)
´ +∞
´b
1
x2
b 2 −a2
E (X ) = −∞ Xf (x )dx = a X (b−a)
dx = 2(b−a)
|ba = 2(b−a)
= a+b
2
I
A variância de uma variável aleatória contínua pode ser
definida
como sendo:
ˆ +∞
ˆ +∞
2
(X − E (X )) f (x )dx = (
X 2 f (x )dx ) − E (X )2
var (X ) =
I
−∞
−∞
(4)
I
Novamente, no caso de uma variável aleatória contínua
uniforme na sua forma geral, com função densidade igual a
1
temos:
f (x ) = (b−a)
var (X ) = (
b 3 −a3
3(b−a)
I
−
´ +∞
−∞
2
( a+b
2 )
1
2
X 2 (b−a)
dx ) − ( a+b
2 ) =
x3
b
3(b−a) |a
2
− ( a+b
2 ) =
Podemos ter uma variável aleatória contínua com uma função
densidade com forma triangular:
(
cx /k para 0 ≤ x ≤ k
2c − cx /k para k ≤ x ≤ 2k
Exercício: Determine as condições para c e k de forma que f(x)
seja uma função densidade e determine as expressoes para a
esperança matemática e variância para esta variável aleatória.
f (X ) =
Variável aleatória Normal
Uma variável aleatória normal é uma variável aleatória contínua
que tem a seguinte função densidade:
(X −µ)2
1
f (x ) = √ e − 2
σ 2π
I
I
I
I
I
(5)
A mais importante (e mais utilizada na prática) variável
aleatória contínua é a variável aleatória normal.
A variável aleatória normal tem uma função densidade de
probabilidade (chamada de curva normal) que apresenta a
forma de um sino e é unimodal no centro exato da
distribuição.
A média, mediana e a moda da distribuição normal são iguais
e localizadas no pico da distribuição.
Metade da área sob a curva está acima do ponto central
(pico) e a outra metade está acima dele.
A distribuição de probabilidade normal é simétrica em relação
a sua média.
I
Ela é assintótica: a curva aproxima-se cada vez mais do eixo
X mas nunca toca efetivamente ele.
I
Para desenhar a função de densidade da variável aleatória
normal vamos usar alguns recursos gráficos do Stata, de
acordo com a segueinte sequência de comandos:
scalar sigma = 1
scalar mu = 0
twoway function y = (1/(sigma*sqrt(2*_pi)))*exp(-(x-mu)^2/2),
range(-3 3)
.4
.3
y
.2
.1
0
−4
−2
0
x
2
4
Figura : Função densidade da variável normal padrão
I
De propósito, definimos que a nossa função densidade normal
tem como parâmetros µ = 0 e σ = 1. Este é um caso
particular de função densidade normal, chamado de função
densidade normal padrão associada a variável aleatória normal
padrão.
I
A maior parte dos livros de Estatística apresentam tabelas que
contem as probabilidades observadas em diversos intervalos de
valores para a variável normal padrão. Vamos aproveitar o
Stata para calcular valores de probabilidades para
determinados intervalos da variável normal padrão. Por
exemplo, desejamos calcular a probabilidade de que a variável
normal padrão esteja contida no intervalo [1,3]. Para isto
usamos o seguinte comando Stata:
I
disp normal(3) - normal(1)
I
O resultado é .15730536, o que significa que
P(1 < X < 3) = 0.1573. Como é uma função densidade
(associada a uma variável aleatória contínua), podemos dizer
que:
P(1 < X < 3) = P(1 ≤ X < 3) = P(1 < X ≤ 3) = 0.1573 e
que P(X = 1) = P(X = 3) = 0.
I
Vamos agora construir dois gráficos de função densidade
justapostos - um com desvio padrão 2 e outro com desvio
padrão 4, ambos com média 2:
twoway (function X1 = (1/(2*sqrt(2*_pi)))*exp(-(x-2)^2/2),
range(-3 8)) (function X2 = (1/(4*sqrt(2*_pi)))*exp(-(x-2)^2/2),
range(-3 8))
.2
.15
.1
.05
0
−5
0
5
10
x
X1
X2
Figura : Duas funções densidade para variáveis aleatórias normais com
distintos desvios padrões
I
O mais interessante deste último gráfico é que nele é
mostrado que a função densidade com desvio padrão menor
(curva em azul) abarca (“encompasses”) a distribuição com
maior (curva em vermelho) desvio padrão.
I
Poderiamos querer calcular o valores de probabilidades para as
duas variáveis aleatórias normais do ultimo gráfico.
Chamemos a variável normal que tem desvio padrão igual a 2
de X1 e a variável normal que tem desvio padrão igual a 4 de
X2 . Para calcularmos P(3 < X1 < 5) temos que fazer a
seguinte transformação:
5−2
P(3 < X1 < 5) = P( 3−2
2 < z < 2 ) = P(0, 5 < z < 1, 5) =
.24173034
O comando Stata para fazer este último cálculo é:
disp normal(1.5)-normal(.5)
Da mesma forma podemos calcular:
5−2
P(3 < X2 < 5) = P( 3−2
4 < z < 4 ) = P(0, 25 < z < 0, 75) =
.17466632
Estes resultados estão bastante coerentes com o que mostra o
último gráfico: a distribuição com maior desvio padrão tem uma
probabilidade menor (para o mesmo intervalo da variável aleatória
normal X).
Temos que explicar dois pontos importantes:
1) Porque fizemos a transformação anterior?
2) Podemos igualar probabilidades a áreas abaixo da função
densidade?
5−2
Fizemos a transformação P(3 < X1 < 5) = P( 3−2
2 <z < 2 )
porque as probabilidades não sçao calculadas diretamente para
qualquer variável normal, mas indiretamente a partir de
probabilidades para a variável normal padrão. Assim podemos
converter qualquer variável aleatória normal em uma normal
padrão através da seguinte expressão de transformação:
X −µ
(6)
σ
Utilizamos esta expressão para converter a probabilidade de uma
variável normal qualquer estar contida em um determinado
intervalo para achar o correspondente intervalo para a variável
normal padrão. Todas as funções densidade de variáveis aleatórias
normais (sejam o não padrão) devem ter uma área total sob a
z=
curva da função densidade igual a 1, ou seja, devem cumprir a
condição (1) para uma função densidade.
Vimos que a propriedade (2) de uma função densidade f(x) é:
´b
P(a ≤ X ≤ b) = a f (x )dx . Como a integral definida da função
densidade é numericamente igual a área abaixo da curva (e
delimitada no intervalo [a,b]), podemos dizer que probabilidades
de ocorrência de uma variável aleatória contínua podem ser
medidas como sendo a área abaixo da curva correspondente a
função densidade.
Podemos definir função de distribuição cumulativa F(x), como
sendo:
ˆ x
F (x ) =
f (x )dx
(7)
−∞
Particularmente, para a função densidade normal padrão temos a
função de distribuição cumulativa da normal padrão que é
simbolizada por φ(x ). Então, se P(−∞ < z < 1) = .84134475
então podemos dizer que φ(1) = .84134475e que
P(a < z < b) = φ(b) − φ(a) onde z é a variável aleatória normal
padrão.
Exemplos
1) Numa distribuição normal, 30% dos elementos são menores que
45 e 10% são maiores que 64. Calcular os parâmetros que definem
a distribuição (média e desvio-padrão).
Solução:
P(X < 45) = 0, 30
P(X > 64) = 0, 10
X
P(z < 45−µ
σx ) = 0, 30
Determinamos um valor de z = z’ de tal forma que
P(z < z 0 ) = 0, 30. Isto corresponde a função inversa da
distribuição normal cumulativa da normal padrão. No Stata basta
digitar o comando:
disp invnormal(.30)
O resultado é:
-.52440051
Ou seja P(z < −.52440051) = 0, 30
x
Desta forma descobrimos que 45−µ
= −.52440051
σx
De forma análoga obtemos que P(z > 1.2815516) = 0, 10 através
do comando disp invnormal(.90) e descobrimos que:
64−µx
= 1.2815516
σx
Agora basta resolver o seguinte sistema de duas equações a duas
incógnitas:
45−µx
= −.52440051
σx
64−µx
= 1.2815516
σx
Que resultarão em:
.52440051 × σx − µx = −45
−1.2815516 × σx − µx = −64
Multiplicando a primeira equação por (-1) e somando-se a segunda
equação, temos:
(−.52440051 − 1.2815516) × σx = −64 + 45
σx = 10.520766
µx = −1.2815516 × 10.520766 + 64 = 50.517095
2) O tempo de vida de transistores produzidos pela Indústria
Zeppelin Ltda. tem distribuição aproximadamente normal, com
valor esperado e desvio-padrão igual a 500 horas e 50 horas,
respectivamente. Se o consumidor exige que pelo menos 95% dos
transistores fornecidos tenham vida superior a 400 horas,
pergunta-se se tal especificação é atendida. Justifique!
Solução:
P(X > 400) = P( X −500
> 400−500
) = P(z > −2) = 1 − φ(−2) =
50
50
1 − .02275013 = .97724987
A especificação é atendida já que 97,72% dos transístores atende a
especificação.
3) Seja X normalmente distribuída com média µX = 100 e desvio
padrão σX = 7 (daqui a diante indicaremos tal distribuição como
X ~ N(100;7) ). Determinar: a. P(X = 80) b. P(X > 100) c.
P(|X − 95| < 5)d. P(|X − 100| < 10)
Solução:
a. P(X = 80) = 0
b. P(X > 100) = P( X −100
> 100−100
) = P(z > 0) = 0.50
7
7
c. Se X − 95 ≥ 0 então
P(|X − 95| < 5) = P(X − 95 < 5) = P(X < 100) = 0.50
Se X − 95 < 0 então P(|X − 95| < 5) = P(95 − X < 5) =
P(−X < −90) = P(X > 90) = P( X −100
> 90−100
) = P(z >
7
7
−1.4285714) = 1 − φ(−1.4285714) = .92343627
4). Os pesos de certos produtos em quilogramas são normalmente
distribuídos com média µX = 180 e desvio padrão σX = 4. Se
uma unidade deste produto é escolhida aleatoriamente, qual é o
peso desta unidade se a probabilidade de ocorrência: a. De um
peso maior é igual a 0,10? b. De um peso menor é igual a 0,05?
Solução:
0
) = 0.10
a. P(X > x 0 ) = 0.10 Portanto P(z > x −180
4
Temos que achar no Stata o valor de z tal que φ(z) = 0.90 Isto
pode ser feito através do comando:
disp invnormal(.90)
Resultado: 1.2815516
0
Portanto: x −180
= 1.2815516 e
4
x 0 = 1.2815516 × 4 + 180 = 185.12621
5) Se uma distribuição normal tem média 200 e desvio padrão 20,
ache K tal que a probabilidade de que um valor amostral seja
menor do que K é 0,975.
Solução:
P(X < k) = 0.975 Portanto P(z < k−200
20 ) = 0.975
Através do comando disp invnormal(.975) achamos o valor
1.959964. Portanto k−200
= 1.959964e
20
k = 1.959964 × 20 + 200 = 239.19928
Uma alternativa ao Stata para fazer cálculos de probabilidades
correspondentes a variáveis aleatórias normais é o Excel. Por
exemplo se quisermos calcular φ(1.2815516) colocamos em
qualquer célula a função =DIST.NORMP(1.2815516) e retorna o
resultado 0.90. Para a função inversa da distribuição normal
cumulativa da normal padrão se quisermos calcular φ−1 (.90)
colocamos em uma célula a função =INV.NORMP(0.9) e
retornamos ao valor anterior 1.281552.
Vamos gerar no Stata uma Tabela da Função de Distribuição
Cumulativa da Variável Normal Padrão φ(x ), através da seguinte
sintaxe (do file):
* SINTAXE PARA GERAR UMA TABELA PARA A FUNÇÃO
DISTRIBUIÇÃO phi(x)
matrix C = J(31,11,0)
forvalues j = 2(1)11 {
matrix C[1,‘j’] = ‘j’ - 2
}
forvalues i = 2(1)31 {
matrix C[‘i’,1] = (‘i’ - 2)/10
}
forvalues i = 2(1)31 {
forvalues j = 2(1)11 {
scalar x = (‘i’-2)/10 + (‘j’-2)/100
scalar phi = normal(x)
matrix C[‘i’,‘j’] = phi
}
}
matrix list C
svmat C, names(C)
format C2-C11 %5.4f
xmlsave "D:\ECN26\APOSTILA DE ESTATISTICA\TABELA
DISTRIBUIÇÃO NORMAL.xml", doctype(excel) replace
Tabela da distribuição cumulativa da variável normal padrão φ(x )
0
1
2
3
4
5
6
7
8
9
0.0
0.5000
0.5040
0.5080
0.5120
0.5160
0.5199
0.5239
0.5279
0.5319
0.5359
0.1
0.5398
0.5438
0.5478
0.5517
0.5557
0.5596
0.5636
0.5675
0.5714
0.5753
0.2
0.5793
0.5832
0.5871
0.5910
0.5948
0.5987
0.6026
0.6064
0.6103
0.6141
0.3
0.6179
0.6217
0.6255
0.6293
0.6331
0.6368
0.6406
0.6443
0.6480
0.6517
0.4
0.6554
0.6591
0.6628
0.6664
0.6700
0.6736
0.6772
0.6808
0.6844
0.6879
0.5
0.6915
0.6950
0.6985
0.7019
0.7054
0.7088
0.7123
0.7157
0.7190
0.7224
0.6
0.7257
0.7291
0.7324
0.7357
0.7389
0.7422
0.7454
0.7486
0.7517
0.7549
0.7
0.7580
0.7611
0.7642
0.7673
0.7704
0.7734
0.7764
0.7794
0.7823
0.7852
0.8
0.7881
0.7910
0.7939
0.7967
0.7995
0.8023
0.8051
0.8079
0.8106
0.8133
0.9
0.8159
0.8186
0.8212
0.8238
0.8264
0.8289
0.8315
0.8340
0.8365
0.8389
1.0
0.8413
0.8438
0.8461
0.8485
0.8508
0.8531
0.8554
0.8577
0.8599
0.8621
1.1
0.8643
0.8665
0.8686
0.8708
0.8729
0.8749
0.8770
0.8790
0.8810
0.8830
1.2
0.8849
0.8869
0.8888
0.8907
0.8925
0.8944
0.8962
0.8980
0.8997
0.9015
1.3
0.9032
0.9049
0.9066
0.9082
0.9099
0.9115
0.9131
0.9147
0.9162
0.9177
1.4
0.9192
0.9207
0.9222
0.9236
0.9251
0.9265
0.9279
0.9292
0.9306
0.9319
1.5
0.9332
0.9345
0.9357
0.9370
0.9382
0.9394
0.9406
0.9418
0.9429
0.9441
Tabela da distribuição cumulativa da variável normal padrão φ(x )
(cont.)
0
1
2
3
4
5
6
7
8
9
1.6
0.9452
0.9463
0.9474
0.9484
0.9495
0.9505
0.9515
0.9525
0.9535
0.9545
1.7
0.9554
0.9564
0.9573
0.9582
0.9591
0.9599
0.9608
0.9616
0.9625
0.9633
1.8
0.9641
0.9649
0.9656
0.9664
0.9671
0.9678
0.9686
0.9693
0.9699
0.9706
1.9
0.9713
0.9719
0.9726
0.9732
0.9738
0.9744
0.9750
0.9756
0.9761
0.9767
2.0
0.9773
0.9778
0.9783
0.9788
0.9793
0.9798
0.9803
0.9808
0.9812
0.9817
2.1
0.9821
0.9826
0.9830
0.9834
0.9838
0.9842
0.9846
0.9850
0.9854
0.9857
2.2
0.9861
0.9864
0.9868
0.9871
0.9875
0.9878
0.9881
0.9884
0.9887
0.9890
2.3
0.9893
0.9896
0.9898
0.9901
0.9904
0.9906
0.9909
0.9911
0.9913
0.9916
2.4
0.9918
0.9920
0.9922
0.9925
0.9927
0.9929
0.9931
0.9932
0.9934
0.9936
2.5
0.9938
0.9940
0.9941
0.9943
0.9945
0.9946
0.9948
0.9949
0.9951
0.9952
2.6
0.9953
0.9955
0.9956
0.9957
0.9959
0.9960
0.9961
0.9962
0.9963
0.9964
2.7
0.9965
0.9966
0.9967
0.9968
0.9969
0.9970
0.9971
0.9972
0.9973
0.9974
2.8
0.9974
0.9975
0.9976
0.9977
0.9977
0.9978
0.9979
0.9979
0.9980
0.9981
2.9
0.9981
0.9982
0.9983
0.9983
0.9984
0.9984
0.9985
0.9985
0.9986
0.9986
Download