☰
Explorar
Assinar em
Inscrever-se
Envio
×
Baixar
Sem categoria
Outliers
Apresentação - DECOM-UFOP
Conclusões e Perspectivas de Análise Futura
texto completo
Regressao Linear Multipla_tarefa
Detecção de Outliers em Dados Micrometeorológicos
Slides
Detecção de Outliers Multivariados em Redes de Sensores
Document
Avaliaç ˜ao do poder e taxas de erro do tipo I de testes de
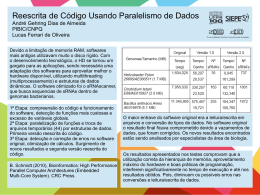
André Gehring Dias de Almeida
Data mining
SERVIÇOS COMPLEMENTARES CDI