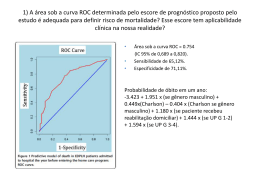
Tratamento de Dados Desbalanceados Sérgio Queiroz Adaptado dos slides do Prof. Ricardo Prudêncio Introdução • É comum nos depararmos com problemas de classificação com dados desbalanceados – I.e., Presença de classes majoritárias com freqüência muito maior que as outras classes minoritárias • Desbalanceamento de classes pode ser prejudicial dependendo do problema e algoritmo Desbalanceamento de Dados • Conseqüência: – Maior tendência para a responder bem para as classes majoritárias em detrimento das minoritárias – Entretanto, em muitos casos, o que importa é ter um bom desempenho para as classes minoritárias!!! • Ver exemplos no próximo slide Desbalanceamento de Dados • Exemplo: Detecção de Fraude – Menos de 1% das transações de cartão de crédito são fraudes – Em um conjunto de exemplos relacionados a transações, teremos: • 99% dos exemplos para a classe negativa (não-fraude) • 1% dos exemplos para a classe positiva (fraude) Desbalanceamento de Dados • Exemplo: Detecção de Fraude – Classificadores terão uma tendência a dar respostas negativas para transações com fraude • I.e. Alto número de falsos negativos – Problema: o custo de um falso negativo é muito maior que o custo de um falso positivo • Falso negativo: fraude que não foi detectada em tempo – I.e., prejuízo a operadora de cartão • Falso positivo: transação normal bloqueada – I.e., aborrecimento para o usuário do cartão Desbalanceamento de Dados • Exemplo: Diagnóstico Médico – Pacientes doentes são em geral menos comuns que pacientes saudáveis – No diagnóstico médico, novamente a classe positiva ( dos pacientes doentes) tem uma freqüência muito menor que a classe negativa (pacientes saudáveis) Desbalanceamento de Dados • Exemplo: Diagnóstico Médico – Classificadores terão uma tendência a classificar doentes reais como supostamente saudáveis • Novamente, alto número de falsos negativos – Conseqüência : • Diagnóstico tardio e dano para o paciente Desbalanceamento de Dados • Observações importantes: – Taxas globais de precisão não são úteis nesses contextos • Use Área Under ROC Curve (AUC) – Processo de construção dos classificadores requer adaptações para evitar um viés para as classes majoritárias ( Revisão: ROC Curves • Exemplo: Diagnóstico de doenças usando um teste Doença presente Doença ausente Teste positivo Positivos verdadeiros (TP) Falsos positivos (FP) Teste negativo Falsos negativos (FN) Negativos verdadeiros (TN) Esta seção de revisão sobre ROC Curves foi baseada no material disponível em: http://gim.unmc.edu/dxtests/ROC1.htm , elaborado por Thomas G. Tape da University of Nebraska Medical Center Revisão: ROC Curves Doença presente Doença ausente Teste positivo Positivos verdadeiros (TP) Falsos positivos (FP) Teste negativo Falsos negativos (FN) Negativos verdadeiros (TN) Definições: • Sensibilidade do teste: proporção de pacientes com a doença que testam positivo. Em notação de probabilidade: P(T+|D+) = TP / (TP + FN). Em classificação chamamos de RECALL. • Especificidade do teste: proporção de pacientes sem doença com teste negativo. Em notação de probabilidade: P (T-| D-) = TN / (TN + FP). • Probabilidade pré-teste: probabilidade estimada da doença antes do teste ser feito. É a mesma coisa que a probabilidade a priori e é frequentemente estimada. Se uma determinada população de pacientes está sendo avaliada, a probabilidade pré-teste é igual à prevalência da doença na população. É a proporção do total de pacientes que têm a doença. Na notação de probabilidade: P (D +) = (TP + FN) / (TP + FP + TN + FN). Revisão: ROC Curves Doença presente Doença ausente Teste positivo Positivos verdadeiros (TP) Falsos positivos (FP) Teste negativo Falsos negativos (FN) Negativos verdadeiros (TN) Definições: • Sensibilidade do teste: proporção de pacientes com a doença que testam positivo. Em notação de probabilidade: P(T+|D+) = TP / (TP + FN). Em classificação chamamos de RECALL. • Especificidade do teste: proporção de pacientes sem doença com teste negativo. Em notação de probabilidade: P (T-| D-) = TN / (TN + FP). • Probabilidade pré-teste: probabilidade estimada da doença antes do teste ser feito. É a mesma coisa que a probabilidade a priorioequão é frequentemente Seentre uma Sensibilidade e especificidade descrevem bem o teste estimada. discrimina determinada população de pacientes está sendo avaliada, a probabilidade pré-teste pacientes com e sem doença. Elas abordam uma questão diferente do que é igual à prevalência da doença na população. É a proporção do total de pacientes queremos responder ao avaliar paciente, no que geralmente que têm a doença. Na notação de um probabilidade: P (Dentanto. +) = (TP +OFN) / (TP + FP + TN + queremos saber é: dado um determinado resultado do teste, qual éa FN). probabilidade de doença? Este é o valor preditivo do teste. Revisão: ROC Curves Doença presente Doença ausente Teste positivo Positivos verdadeiros (TP) Falsos positivos (FP) Teste negativo Falsos negativos (FN) Negativos verdadeiros (TN) Valor preditivo do teste: • Valor preditivo de um teste positivo: é a proporção de pacientes com testes positivos que têm a doença. Em notação de probabilidade: P(D + | T +) = TP / (TP + FP). Esta é a mesma coisa que a probabilidade pós-teste da doença dado um teste positivo. Ele mede o quão bem o teste indica a doença. Em classificação chamamos isso de PRECISÃO • Valor preditivo de um teste negativo: é a proporção de pacientes com testes negativos que não têm a doença. Em notação de probabilidade: P(D-| T-) = TN / (TN + FN). Ele mede o quão bem o teste descarta a doença. Note que isto não é o mesmo que o pós-teste de probabilidade da doença a um teste negativo, que é um menos o valor preditivo de um teste negativo. Fonte: Wikipedia http://en.wikipedia.org/w/index.php?title=Precision_and_recall&oldid=600501669 Índices Revisão: ROC Curves • A sensibilidade e especificidade dependem da definição do que constitui um “teste anormal”. As distribuições dos valores para o teste dos indivíduos de uma classe ou outra normalmente se sobrepõem. Revisão: ROC Curves • Exemplo real: detecção de hipotireoidismo com teste T4. Hypothyroid: hipotireoidismo Euthyroid: normal Revisão: ROC Curves • Suponha que os pacientes com valores de T4 de 5 ou menos sejam considerados com hipotiroidismo. Revisão: ROC Curves • Sejamos menos exigentes com o T4 considerando agora que 7 ou menos sejam considerados com hipotiroidismo. Revisão: ROC Curves • Movendo mais uma vez: 9 ou menos considerados com hipotiroidismo. Tabelando os valores • Observe que você pode melhorar a sensibilidade, movendo a ponto de corte para um valor mais elevado de T4 - ou seja, você pode tornar o critério para um teste positivo menos rigoroso. Você pode melhorar a especificidade, movendo o ponto de corte para um valor mais baixo de T4 - ou seja, você pode tornar o critério para um teste positivo mais estrito. Assim, há um equilíbrio entre sensibilidade e especificidade. Você pode alterar a definição de um teste positivo para melhorar um, mas o outro vai piorar. Curvas ROC: Receiver Operating Characteristic • Taxa de verdadeiros positivos (sensibilidade) x Taxa de falsos positivos Curvas ROC • Uma curva ROC demonstra várias coisas: – Ela mostra o equilíbrio entre sensibilidade e especificidade (qualquer aumento na sensibilidade será acompanhada por uma diminuição na especificidade). – Quanto mais próxima a curva segue a borda esquerda e, em seguida, a borda superior do espaço ROC, mais preciso será o teste. – Quanto mais perto a curva chega de a 45 graus diagonal do espaço ROC, menos preciso o teste. – A inclinação da linha tangente em um ponto de corte dá a razão de verossimilhança (LR) para que o valor do teste. Você pode verificar isso no gráfico acima. Lembre-se que o LR para de T4 <5 é 52. Isto corresponde à extrema esquerda, parte íngreme da curva. A LR para de T4> 9 é de 0,2. Isto corresponde à porção de extremidade direita, quase horizontal da curva. – A área sob a curva é uma medida do poder de discriminação. Área sob curva ROC • Uma área 1 representa um teste perfeito; uma área de 0,5 representa um teste inútil. Um guia geral para classificar a precisão de um teste de diagnóstico é o sistema de notas acadêmicas tradicional: – – – – – 0,90-1 = excelente (A) 0,80-0,90 = bom (B) 0,70-0,80 = razoável (C) 0,60-0,70 = pobre (D) 0,50-0,60 = ruim (F) ) Voltando ao Desbalanceamento de Dados... • Observações importantes: – Diferença entre as freqüências de classes não diz tudo a respeito de um problema – Outros fatores são importantes • Separação linear das classes • Existência de sub-conceitos nas classes – I.e. problemas moderadamente desbalanceados podem ser muito difíceis e; – Problemas fortemente desbalanceados podem não ser tão difíceis assim. Abordagens para Tratamento de Dados Desbalanceados • Resampling aleatório: – Reamostragem dos exemplos de treinamento de forma a gerar conjuntos balanceados – Undersampling • Reduzir número de exemplos da classe majoritária • Pode acarretar em perda de informação – Oversampling • Replicar exemplos da classe minoritária • Se feito aleatoriamente, pode gerar overfitting Abordagens para Tratamento de Dados Desbalanceados • SMOTE (Chawla et al., 2002) – Oversampling usando exemplos sintéticos da classe minoritária – Exemplos sintéticos extraídos ao longo dos segmentos que unem vizinhos mais próximos da classe minoritária • One-side-selection (Kubat & Matwin, 1997) – Undersampling de exemplos redundantes da classe majoritária Abordagens para Tratamento de Dados Desbalanceados • Wilson’s editing (Barandela et al., 2004) – Usa kNN para classificar instâncias da classe majoritária e exclui as classificadas erroneamente • Cluster-based oversampling (Jo & Japkowicz, 2004) – Realizam cluster dos exemplos e replicam exemplos dos clusters mais desbalanceados Abordagens para Tratamento de Dados Desbalanceados • Comparação entre métodos – Undersampling aleatório tem se mostrado superior a oversampling (Chawla et al. 2002) (Hulse et al. 2007) – Entretanto melhor método de sampling depende do algoritmo sendo utilizado e da métrica de avaliação (Hulse et al. 2007) Abordagens para Tratamento de Dados Desbalanceados • Cost-Sensitive Learning – Introdução de custos no processo de aprendizado – Exemplo: Custo Total = FP*CFP + FN*CFN – Adaptação dos algoritmos para tratamento de dados desbalanceados Abordagens para Tratamento de Dados Desbalanceados • Cost-Sensitive Learning vs. Sampling (Weiss et al. 2007) – Nem todos os algoritmos têm versões que lidam com custos e nem sempre é trivial definir custos – Undersampling seria interessante por diminuir o tempo de aprendizado Considerações finais • Em geral, conjuntos de dados tem algum grau de desbalanceamento das classes • Desbalanceamento pode ser um problema difícil dependendo da complexidade das classes • Conjuntos desbalanceados podem ser lidados com técnicas de amostragem ou introduzindo custos diretamente – Não há “o melhor” método
Baixar