Estatística II Sociologia e Sociologia e Planeamento ISCTE SOCIOLOGIA E SOCIOLOGIA E PLANEAMENTO Ano Lectivo 2003/2004 (2º Semestre) ESTATÍSTICA II (Textos de Apoio das Aulas) Testes de Hipóteses Carlos Lourenço, Dep.º Métodos Quantitativos ([email protected]) Carlos Lourenço ISCTE, 2004 1 Estatística II Sociologia e Sociologia e Planeamento Testes de Hipóteses 1. INTRODUÇÃO Um sociólogo planeia realizar um estudo empírico sobre percepção política em grupos de alunos universitários. No final, através dos dados recolhidos na amostra, o sociólogo espera confirmar a sua hipótese de estudo (para a população universitária portuguesa), a de que nas faculdades de ciências sociais e humanas a proporção de indivíduos com uma propensão política entendida como sendo tradicionalmente à esquerda é superior à proporção de indivíduos com uma propensão política entendida como sendo tradicionalmente à direita ( p esq > p dir ). Nas faculdades de ciências exactas, o sociólogo espera ver igualmente confirmada a sua hipótese, mas agora no sentido oposto: a proporção de indivíduos com uma propensão política entendida como sendo tradicionalmente à direita é superior à proporção de indivíduos com uma propensão política entendida como sendo tradicionalmente à esquerda ( p esq < p dir ). Como já sabemos nesta altura, se o sociólogo se limitar a construir intervalos de confiança para estimar aquelas proporções, pode acontecer que os seus limites não permitam tirar nenhuma conclusão no sentido desejado. Por exemplo, com base nos resultados amostrais, pode acontecer (para um determinado nível de confiança) que o intervalo de confiança para a proporção de indivíduos de esquerda nas faculdades de ciências sociais e humanas seja dado por ]0,488;0,514[ , e o sociólogo não pode afirmar (para o nível de confiança definido) que a verdadeira proporção de indivíduos de esquerda na população universitária é superior aos de direita. O que pode o sociólogo fazer? Se na amostra a proporção de indivíduos de esquerda é, por exemplo, de 0,503, haverá alguma forma de o sociólogo poder testar se na população esta proporção (para um determinado nível de significância) é, de facto, superior a 0,50? Relembremos o ponto onde estamos… Constituindo uma amostra tendo em conta os princípios da teoria da amostragem (representativa e, se possível, aleatória), podemos inferir para a população as conclusões retiradas acerca da amostra. Determinadas características da amostra – estatísticas – podem ser generalizáveis para a população se cumprirem determinadas propriedades. A estas estatísticas chamamos estimadores, os quais, associados a um determinado grau de confiança e com uma determinada probabilidade de erro, e porque conhecemos as suas distribuições amostrais, vão servir para estimar os valores dos verdadeiros e únicos parâmetros da população em estudo. O valor assumido por um estimador numa amostra concreta designa-se por estimativa.1 Existem métodos de estimação pontual (por exemplo, o método dos mínimos quadrados e o método da máxima verosimilhança) e o método de estimação de intervalos de confiança. No último capítulo iniciámos a inferência estatística precisamente através da estimação de intervalos de confiança para os parâmetros populacionais. Tal como vimos, na estimação por intervalos, em vez de se indicar um valor concreto para um parâmetro, constrói-se um intervalo de confiança onde se encontrará esse valor. Associada à estimação desse intervalo impomos um determinado nível de confiança (ou grau de certeza) e um nível de significância (ou probabilidade de erro). Ora, o que neste capítulo vamos fazer é ligeirmente diferente da estimação. Em vez de tentarmos estimar os valores dos parâmetros da população, iremos formular hipóteses sobre esses parâmetros e testá-las. Os testes de hipóteses estatísticos permitem-nos assim rejeitar ou não determinadas hipóteses sobre os parâmetros, hipóteses essas formuladas tendo em conta a teoria – sociológica, biológica, física, económica, etc. – subjacente que estamos a estudar. Tal como na estimação, a rejeição ou a não rejeição das hipóteses faz-se com base em estimativas obtidas em amostras aleatórias e com uma determinada probabilidade de erro associada e fixada a priori pelo analista. 1 Recorde-se que os estimadores são, portanto, variáveis aleatórias que produzem tantas estimativas quanto o número de amostras realizáveis. É por esta razão que para efeitos de estimação necessitamos de conhecer as suas distribuições amostrais. Carlos Lourenço ISCTE, 2004 2 Estatística II Sociologia e Sociologia e Planeamento 2. CONSTRUÇÃO DE UM ENSAIO DE HIPÓTESES A construção de um ensaio de hipóteses segue habitualmente uma metodologia que pode ser definida como se segue: 1. Formulação das hipóteses estatísticas 2. Escolha da estatística de teste (escolha do teste adequado) 3. Fixação do nível de significância 4. Determinação do valor crítico e das regiões de rejeição e de não rejeição 5. Tomada de decisão Iremos percorrer estes passos e ilustrá-los com um exemplo decorrente dos resultados da aplicação do inquérito que nos tem acompanhado. 2.1. Formulação das Hipóteses Estatísticas O primeiro passo para a construção de um ensaio de hipóteses é a formulação das hipóteses. Obviamente, por cada hipótese que queremos testar, existe uma hipótese alternativa. Convencionou-se que a primeira hipótese é por definição a mais restritiva, isto é, corresponde à hipótese que postula não haver efeitos significativos, não haver mudanças de opinião, de a média da população ser igual a um determinado valor, etc., e que se assume ser verdadeira até prova em contrário; a esta hipótese chamamos de hipótese nula: H 0 . A segunda hipótese representa precisamente a situação alternativa à enunciada pela hipótese nula; a esta hipótese chamamos de hipótese alternativa: H a .2 Note-se que, como parece ser óbvio, a formulação das hipóteses antecede a recolha dos dados que serão analisados. Ou seja, para que não haja enviesamentos na recolha da amostra, as hipóteses de estudo devem ser antecipada e claramente definidas. Aplicação… “Em certa aula de Estatística II, os alunos resolvem fazer previsões sobre a média das notas dessa disciplina. Os alunos não estão propriamente de acordo, apesar de estarem todos optimistas. Um grupo de alunos recorda a média obtida em Estatística I: 8,85 valores Descriptive Statistics Que nota obteve em Estatística I? Valid N (listwise) N Mean 114 8,85 114 e afirma (com muita convicção) que a média de Estatística II vai ser positiva e de 13 valores.”3 O grupo de alunos está a tentar “adivinhar” a média das notas a Estatística II, avançando com 13 valores como hipótese. De modo a testarmos se a média da população de alunos inscritos a Estatística II é, de facto, igual a 13 valores, iremos usar os dados de que dispomos na amostra e realizar um ensaio de hipóteses.4 2 É igualmente bastante comum escrever a hipótese alternativa como H 1 . In Helena Carvalho (2004), Interpretação de Outputs do SPSS - Intervalo de Confiança para a Média Populacional e Ensaio de Hipóteses para a Média Populacional, Textos de apoio das aulas, p.5. 4 Assumimos, para efeitos de exemplo, que esta hipótese foi formulada antes da recolha dos dados. 3 Carlos Lourenço ISCTE, 2004 3 Estatística II Sociologia e Sociologia e Planeamento As hipóteses nula e alternativa serão então as seguintes: H 0 : µ = 13 H a : µ ≠ 13 A média da população é representada por µ , e se a informação contida na amostra através da média amostral ( X ) não for significativamente diferente, então existe evidência para não rejeitar a hipótese nula formulada. Se, pelo contrário, a informação contida na amostra através da média amostral for significativamente diferente, então existe evidência para rejeitar a hipótese nula. Vejamos qual a média (e o desvio-padrão) na amostra da nota esperada a Estatística II: Descriptive Statistics N Que nota espera vir a ter em Estatística II? Valid N (listwise) Mean 152 11,69 Std. Deviation 2,232 152 Se o resultado do teste não permitir provar que µ = 13 , ou seja, H 0 é rejeitada, nesse caso a verdadeira média das notas a Estatística II na população poderá ser 10, 12, 9, etc. (precisamente a situação que é enunciada na hipótese alternativa, H a : µ ≠ 13 ), e a melhor estimativa possível que podemos obter (com esta amostra) é de 11,69 valores, estimativa esta que, como iremos ver, estará sujeita a um erro. Note-se que a não rejeição da hipótese nula, não quer dizer que H 0 seja verdadeira. O que podemos dizer é que, provavelmente, a hipótese nula de que a média da nota esperada a Estatística II é de 13 valores, é verdadeira. 2.1.1. Teste bilateral e teste unilateral O modo como escrevemos H a define se estamos na presença de um teste bilateral ou unilateral. Por exemplo, num teste de hipóteses para µ como o que estamos a considerar: - se as nossas hipóteses são H 0 : µ = 13 vs. H a : µ ≠ 13 , então estamos na presença de um teste bilateral. Significa que se rejeitarmos H 0 podemos afirmar que a média da população não é igual a 13, e que nesse caso µ pode ser maior ou menor que 13. - se as nossas hipóteses fossem H 0 : µ = k vs. H a : µ > k ou H 0 : µ = k vs. H a : µ < k , então estaríamos na presença de um teste unilateral, à direita e à esquerda, respectivamente. Significaria que se rejeitássemos H 0 poderíamos afirmar que a média da população não era igual a k, e que nesse caso teríamos apenas uma alternativa para µ (em que µ seria maior que k). Carlos Lourenço ISCTE, 2004 4 Estatística II Sociologia e Sociologia e Planeamento 2.2. Escolha da Estatística de Teste (escolha do teste adequado) Depois de formuladas as hipóteses nula e alternativa e de sabermos se estamos na presença de um teste bilateral ou unilateral, temos de definir um critério que nos auxilie na tomada de decisão sobre rejeitar ou não rejeitar a hipótese nula. No fundo, o que queremos é dispor de um critério que permita averiguar se os resultados da amostra ( X = 11,69 ) são verossímeis, isto é, se podem ser inferidos para a população. Como sempre, esta verosimilhança é quantificada em termos probabilísticos. O critério de decisão será dado por uma estatística de teste. A estatística de teste não é mais que uma fórmula que contém o estimador pontual do parâmetro populacional a testar, e que seguirá uma determinada distribuição. Em seguida, apenas necessitamos de calcular o valor desta estatística de teste com base nos dados amostrais e compará-lo com o seu valor tabelado. Ora, as fórmulas que contêm os estimadores pontuais dos parâmetros – as estatísticas de teste – são precisamente as expressões das suas próprias distribuições amostrais. No nosso caso, como já sabemos, o estimador para a média populacional (o parâmetro sobre o qual estamos a fazer inferência) é a estatística média amostral, a qual fornecerá a informação para podermos executar o teste de hipóteses. A estatística de teste será então dada pela expressão da distribuição da média amostral, assumindo que desconhecemos, para a população, qual o verdadeiro valor do desvio-padrão da nota esperada a Estatística II: X −µ 5 T= . s' n Sob H 0 (isto é, H 0 é verdadeira), esta estatística segue uma t de Student com n-1 graus de liberdade: T ∩ t ( n −1) . No entanto, por aplicação directa do Limite Central, dado que estamos a trabalhar com uma grande amostra ( n = 152 ), a distribuição da média amostral segue uma normal-padrão (a t de Student é aproximadamente igual à normal-padrão em grandes amostras). A estatística de teste vem então : X −µ 6 Z= , a qual, sob H 0 , segue uma normal padrão: Z ∩ N (0;1) . s' n Estamos agora em condições de calcular o valor da estatística de teste, Z, a partir dos dados amostrais e se H 0 for verdadeira ( H 0 : µ = 13 ): Z= X − µ 11,69 − 13 − 1,31 = = = −7,218 s' 2,232 0,181 n 152 Dado que a estatística de teste, Z, (sob H 0 ) segue uma normal-padrão, a partir de que valor se poderá assumir que a média da população é de 13 valores, sabendo que a média na amostra é de 11,69 valores? 5 O facto da distribuição seguir uma t de Student explica a designação largamente conhecida dos testes para a média como os testes T (em inglês T test, a qual é usada pelo SPSS). 6 Note mais uma vez que as distribuições amostrais são, obviamente, e tal como o nome indica, funções dos valores das amostras. Carlos Lourenço ISCTE, 2004 5 Estatística II Sociologia e Sociologia e Planeamento 2.3. Fixação do nível de significância, α Tal como vimos no contexto da estimação de intervalos de confiança, o nível de significância que desejamos associar à estimação corresponde à probabilidade de erro inerente à própria estimação. Dado que estamos sempre a trabalhar com probabilidades e com dados amostrais, existe sempre a probabilidade de errar na inferência estatística que estamos a efectuar, embora controlemos este erro com a fixação de um valor muito baixo (habitualmente, 0,05). No contexto dos testes de hipóteses continua a fazer sentido impor um nível de significância associado a cada teste, isto é, fixar a probabilidade de erro que estamos dispostos a aceitar na tomada de decisão sobre o teste. 2.3.1. Erros associados à decisão nos testes de hipóteses estatísticos: Erro Tipo I e Erro Tipo II De onde vem então o erro na decisão relacionada com um teste de hipóteses? Pensemos num julgamento de um réu que foi acusado. Até prova em contrário, o réu deve ser considerado inocente, isto é, a hipótese nula é que ele é inocente (sendo a hipótese alternativa a de que o réu é culpado). No final do julgamento, e após a apresentação das provas de acusação e de defesa, o réu pode vir a ser julgado como inocente ou como culpado, e esta decisão pode ter sido correcta ou incorrectamente tomada. Vejamos: se o réu era de facto inocente, isto é, a hipótese nula era verdadeira, e ele foi julgado como inocente, então não se rejeitou a hipótese nula e tomou-se a decisão correcta; se, pelo contrário, o réu era de facto inocente (a hipótese nula era verdadeira), mas este foi julgado como culpado, então rejeitou-se a hipótese nula e tomou-se a decisão errada. A este erro chamamos um Erro Tipo I. Se o réu era de facto culpado, isto é, a hipótese nula era falsa, e ele foi julgado como culpado, então rejeitou-se a hipótese nula e tomou-se a decisão correcta; se, pelo contrário, o réu era de facto culpado (a hipótese nula era falsa), mas este foi julgado como inocente, então não se rejeitou a hipótese nula e tomou-se a decisão errada. A este erro chamamos um Erro Tipo II. Realidade Hipótese nula é verdadeira (o réu é de facto inocente) Decisão baseada nas provas Não rejeita a hipótese nula (o réu é julgado como inocente) Decisão correcta Rejeita a hipótese nula (o réu é julgado como culpado) Erro Tipo I: considerar culpado um réu que é inocente Hipótese nula é falsa (o réu é de facto culpado) Erro Tipo II: considerar inocente um réu que é culpado Decisão correcta No nosso caso, podemos cometer o erro de rejeitar a hipótese nula (média igual a 13 valores), quando essa hipótese é verdadeira e portanto a média é, de facto, de 13 valores – Erro Tipo I. Podemos também cometer o erro de não rejeitar a hipótese nula quando essa hipótese é falsa e portanto a média não é de 13 valores – Erro Tipo II. População Decisão baseada na amostra H 0 é verdadeira (a média na população é de 13 valores) H 0 é falsa (a média na população não é de 13 valores) Não rejeita H 0 Decisão correcta Erro Tipo II Rejeita H 0 Erro Tipo I Decisão correcta Carlos Lourenço ISCTE, 2004 6 Estatística II Sociologia e Sociologia e Planeamento Então, resumidamente: Erro Tipo I – rejeitar H 0 quando H 0 é verdadeira; Erro Tipo II – não rejeitar H 0 quando H 0 é falsa. Quais as probabilidades de cometer um e outro erros? A probabilidade de cometer o Erro Tipo I é dada pelo nível de significância, α . Tal como nos intervalos de confiança o nível de significância era a probabilidade de errar na estimação de um determinado intervalo, agora persiste a mesma ideia. Considerando sempre a situação em que existe a presunção de verdade, isto é, a hipótese nula é verdadeira, rejeitar essa verdade é cometer um erro com uma determinada probabilidade. Normalmente, esta probabilidade de erro é fixada em 0,05. Para o nosso caso vamos então fixar 0,05 como o nível de significância. 2.4. Determinação do Valor Crítico e das Regiões de Rejeição e de Não Rejeição Calculada a estatística de teste e conhecendo a sua distribuição amostral, temos de definir o valor crítico da distribuição da estatística de teste que associado a um determinado nível de significância α nos permite rejeitar ou não H 0 . No nosso caso, o valor crítico é o valor a partir do qual se poderá assumir (ou não) que a média da população é de 13 valores, sabendo que a média na amostra é de 11,69 valores. Mas Como se obtém o valor crítico? Teste bilateral O valor crítico do teste é dado pelo valor da distribuição da estatística de teste associado à probabilidade 1 − α 2 ; Teste unilateral O valor crítico do teste é dado pelo valor da distribuição da estatística de teste associado à probabilidade 1 − α . Teste bilateral Carlos Lourenço Teste unilateral à direita ISCTE, 2004 Teste unilateral à esquerda 7 Estatística II Sociologia e Sociologia e Planeamento No nosso exemplo, para um nível de significância de 5%, o valor crítico do teste é dado pelo valor da distribuição normal-padrão para uma probabilidade 1 − 0,05 2 = 1 − 0,025 = 0,975 , ou seja, z 0,975 = 1,960 . E o nosso valor da estatística de teste Z = −7,218 , está situado numa região de rejeição: 2.5. Tomada de Decisão Dado que o valor da estatística de teste “caiu” na região de rejeição ( Z ≤ − z 0,975 ou − 7,218 < −1,960 ), rejeitamos a hipótese nula ( H 0 : µ = 13 ). Ou seja, não existe evidência estatística, através da amostra recolhida, para afirmar que a média da nota esperada a Estatística II, na população, é de 13 valores. Ou, em termos formais: Se Z ≤ −1,960 ou Z ≥ 1,960 , rejeitar H 0 Se − 1,960 < Z < 1,960 , não rejeitar H 0 2.6. A Probabilidade de Significância: o p-value Qual o nível de significância que deve ser fixado num teste de hipóteses? 10%, 5%, 1%? Para contornar este problema, o que podemos fazer é calcular qual o menor valor de α a partir do qual rejeitamos H 0 . A este valor chamamos probabilidade de significância p ou, mais frequentemente, p-value. Quanto menor for a probabilidade de significância (o p-value), menor será o erro de Tipo I (rejeitar H 0 quando H 0 é verdadeira) que estaremos a cometer quando rejeitamos H 0 . Tipicamente, o que se faz é considerar que Como alternativa para a tomada de decisão num teste de hipóteses, basta olharmos para o p-value associado ao teste, e, uma vez que este valor corresponde ao menor valor a partir do qual rejeitaríamos H 0 , compará-lo com o nível de significância definido. Consideremos um nível de significância igual a 0,10 ( α = 0,10 ). Se o p-value for 0,07, então significa que rejeitamos H 0 a partir de 0,07, ou seja, embora tenhamos admitido como 0,10 a probabilidade de rejeitar H 0 quando H 0 é verdadeira – Erro Tipo I –, o que se verifica é que rejeitamos logo H 0 a partir de uma probabilidade de erro admissível ainda mais baixa. Se o p- Carlos Lourenço ISCTE, 2004 8 Estatística II Sociologia e Sociologia e Planeamento value for 0,00, então significa que rejeitamos H 0 mesmo que virtualmente não admitamos qualquer probabilidade de erro (ou uma probabilidade muito residual), e, portanto, é óbvio que aceitando uma probabilidade de erro de 0,10, também iremos rejeitar H 0 . Muito simplesmente, a regra habitual para a decisão num teste de hipóteses usando o p-value, é a seguinte: p − value ≤ α p − value > α rejeitar H 0 não rejeitar H 0 A maioria dos softwares estatísticos, tal como o SPSS, calcula o p-value. No nosso caso, e consultando a tabela da normal, mesmo com um α de 0,00001 o valor crítico de teste que obteríamos seria 4,417 (ou, devido à simetria da distribuição normal, – 4,417), ainda muito longe do valor da estatística de teste ( Z = −7,218 ), o que significa que mesmo assim rejeitaríamos H 0 . Mesmo com uma probabilidade de erro, α , tão baixa estamos ainda muito longe de podermos não rejeitar H 0 . O p-value deve então ser igual a 0,000: One-Sample Test Test Value = 13 Que nota espera vir a ter em Estatística II? t -7,218 df 151 Sig. (2-tailed) Mean Difference ,000 -1,31 95% Confidence Interval of the Difference Lower Upper -1,66 -,95 No SPSS o p-value figura nos outputs como Sig. Neste caso, Sig. (2-tailed) significa que se trata do p-value associado a um teste bilateral (2-tailed = 2 caudas). Carlos Lourenço ISCTE, 2004 9 Estatística II Sociologia e Sociologia e Planeamento 3. TESTES PARAMÉTRICOS Todos os testes de hipóteses serão realizados para um nível de significância de 5% ( α = 0,05 ). 3.1. Testes Para a Média Populacional (com desvio-padrão populacional, σ , desconhecido) Com base nos dados recolhidos para uma amostra, podemos testar se a respectiva média populacional, µ , é significativamente diferente, maior ou menor que um determinado valor k . A forma das hipóteses nula e alternativa e os respectivos critérios de decisão e regiões de rejeição (consoante as estatísticas de teste) apresentam-se no quadro seguinte: Hip. nula, H 0 H0 : µ = k Hip. alternativa, H a Ha :µ ≠ k (teste bilateral) Rejeitar H 0 se Z ≤ −z T ≤ −t α 1− α 2 1− ; ( n −1) 2 Ha : µ < k (teste unilateral à esquerda) Ha : µ > k (teste unilateral à direita) ou Z ≥ z ou T ≥ t Região de rejeição 1− α 2 α 1− ; ( n −1) 2 Z ≤ − z1−α T ≤ −t1−α ;( n −1) Z ≥ z1−α T ≥ t1−α ;( n −1) No caso em que o desvio-padrão é desconhecido, os testes para a média vão depender da dimensão da amostra (e da distribuição da variável na população). 3.1.1. Pequenas amostras, n ≤ 30 (e assumindo que a variável segue uma distribuição normal na população) “Um grupo de alunos da turma SA1 manifesta uma enorme convicção em melhorar a nota média na cadeira do 2º semestre. Defendem que a sua turma vai obter uma nota média de 12 valores. Não obstante, as opiniões dividem-se, pois há quem afirme mesmo que vai ser maior que 12 valores.” 7 Formulação das hipóteses estatísticas H 0 : µ = 12 H a : µ > 12 7 Vai usar-se o exemplo desenvolvido nos textos de apoio às aulas de Interpretação de Outputs do SPSS, op. cit., pág. 9. Carlos Lourenço ISCTE, 2004 10 Estatística II Sociologia e Sociologia e Planeamento Estamos então na presença de um teste unilateral à direita, e dispõe-se da seguinte informação: Descriptive Statisticsa Que nota espera vir a ter em Estatística II? Valid N (listwise) N Mean 25 12,24 Std. Deviation 2,350 25 a. Turma = SA1 Escolha da estatística de teste (escolha do teste adequado) X −µ T= , a qual, sob H 0 segue uma t de Student com n-1 graus de liberdade: T ∩ t ( n −1) . s' n Dado que desconhecemos o desvio-padrão populacional e estamos em pequenas amostras, não podendo aplicar o TLC. E o cálculo da estatística de teste vem: X − µ 12,24 − 12 0,24 0,24 t= = = = = 0,511 8 s' 2,350 2,350 0,47 5 n 25 Determinação do valor crítico e das regiões de rejeição e de não rejeição O valor crítico do teste é dado pelo valor da distribuição t de Student para uma probabilidade 1 − α = 1 − 0,05 = 0,95 e com 24 graus de liberdade ( n − 1 = 25 − 1 = 24 ), ou seja, t1−α ;( n −1) = t 0,95;( 24 ) = 1,711 . E a região de rejeição e a região de não rejeição de H 0 é dada por: Tomada de decisão Dado que o valor da estatística de teste “caiu” na região de não rejeição ( t < t1−α ;( n −1) Z ≥ z 0,95 ou 0,511 < 1,711 ), não rejeitamos a hipótese nula ( H 0 : µ = 12 ). Ou seja, existe evidência estatística, através da amostra recolhida, para não rejeitar que a média da nota esperada a Estatística II na turma SA1, na população, é de 12 valores. 8 Note mais uma vez que s' n = 0,47 corresponde ao erro-padrão da média amostral (do inglês standard error of mean, ou, abreviadamente, std. error mean). Carlos Lourenço ISCTE, 2004 11 Estatística II Sociologia e Sociologia e Planeamento 3.1.2. Grandes amostras, n > 30 (e qualquer que seja a distribuição da variável na população) Vamos usar o mesmo exemplo da parte introdutória. Formulação das hipóteses estatísticas Os docentes de Estatística II estão interessados em saber se os alunos inscritos estão apenas interessados em passar à cadeira, significando que estão a trabalhar apenas para o 10, ou se existem indícios de uma maior motivação. Os docentes vão basear-se no inquérito feito a uma amostra de alunos. As hipóteses nula e alternativa serão então as seguintes: H 0 : µ = 10 H a : µ > 10 Estamos novamente na presença de um teste unilateral à direita, com a seguinte informação: Descriptive Statistics Que nota espera vir a ter em Estatística II? Valid N (listwise) N Mean 152 11,69 Std. Deviation 2,232 152 Escolha da estatística de teste (escolha do teste adequado) X −µ Z= , a qual, sob H 0 , segue uma normal padrão: Z ∩ N (0;1) . s' n E o cálculo da estatística de teste vem: Z = X − µ 11,69 − 10 1,69 = = = 9,337 9 s' 2,232 0,181 n 152 Determinação do valor crítico e das regiões de rejeição e de não rejeição O valor crítico do teste é dado pelo valor da normal-padrão para uma probabilidade 1 − α = 0,95 , ou seja, z 0,95 = 1,645 . A região de rejeição e a região de não rejeição de H 0 é dada por: Tomada de decisão Dado que o valor da estatística de teste “caiu” na região de rejeição ( Z ≥ z 0,95 ou 9,337 ≥ 1,645 ), rejeitamos a hipótese nula ( H 0 : µ = 10 ). Ou seja, não existe evidência estatística, através da amostra recolhida, para afirmar que a média da nota esperada a Estatística II, na população, é de 10 valores. Assim sendo, podemos afirmar que a média é superior a 10 valores. Note mais uma vez que s' n = 0,181 corresponde ao erro-padrão da média amostral (do inglês standard error of mean, ou, abreviadamente, std. error mean). 9 Carlos Lourenço ISCTE, 2004 12 Estatística II Sociologia e Sociologia e Planeamento 3.2. Teste Para a Diferença de 2 Médias Populacionais (com grandes amostras e desvios-padrão populacionais, σ 1 e σ 2 , desconhecidos) Neste ponto vale a pena relembrar os conceitos de amostras independentes e de amostras emparelhadas. Duas (ou mais) amostras dizem-se independentes se os indivíduos das várias amostras são seleccionados de forma independente, ou seja, se estes não estão (propositadamente ou não) relacionados entre si. Duas (ou mais) amostras dizem-se emparelhadas se os indivíduos das várias amostras estão de alguma forma relacionados entre si. Os exemplos mais comuns são as investigações com grupos experimentais: comportamento dos doentes depressivos antes e depois de sujeitos ao tratamento com um novo anti-depressivo; trajectórias de integração de reclusos, em que se constitui uma amostra com reclusos toxicodependentes e uma amostra com reclusos que não consomem drogas; avaliação de agregados familiares em momentos temporais distintos; etc. 3.2.1. Amostras independentes Com base em dados amostrais, podemos testar se as médias entre duas populações, µ1 e µ 2 , são significativamente diferentes, ou se uma delas é maior ou menor que a outra. A forma das hipóteses nula e alternativa apresenta-se no quadro seguinte: Hip. nula, H 0 Hip. alternativa, H a Rejeitar H 0 se Z ≤ −z H a : µ1 ≠ µ 2 ou H a : µ1 − µ 2 ≠ 0 1− α ou Z ≥ z 2 Região de rejeição 1− α 2 (teste bilateral) H 0 : µ1 = µ 2 ou H 0 : µ1 − µ 2 = 0 H a : µ1 < µ 2 ou H a : µ1 − µ 2 < 0 Z ≤ − z1−α (teste unilateral à esquerda) H a : µ1 > µ 2 ou H a : µ1 − µ 2 > 0 Z ≥ z1−α (teste unilateral à direita) Para fazer a exposição deste teste, vai utilizar-se o mesmo exemplo usado para os intervalos de confiança apresentado anteriormente. Carlos Lourenço ISCTE, 2004 13 Estatística II Sociologia e Sociologia e Planeamento “Será que os alunos que frequentam as aulas da noite são, de facto, mais velhos que os alunos que frequentam as aulas durante o dia? Ou seja, será que a diferença entre a média de idades dos alunos “da noite” e a média de idades dos alunos “do dia” é positiva (significando, portanto, que a média dos alunos “da noite” é superior à média de idades dos alunos “do dia”). Na sequência do que é apresentado no exemplo consideram-se os alunos “da noite” como a população 1 e os 10 alunos do dia como a população 2.” Formulação das hipóteses estatísticas H 0 : µ1 − µ 2 = 0 H a : µ1 − µ 2 > 0 (teste unilateral à direita) Temos a seguinte informação: Report Idade Horário (Diurno/Nocturno) Diurno Nocturno Total Mean 20,50 29,50 24,12 N 98 66 164 Std. Deviation 3,077 9,481 7,815 Escolha da estatística de teste (escolha do teste adequado) ( X − X 2 ) − ( µ1 − µ 2 ) 11 Z= 1 s1'2 s 2'2 + n1 n 2 A qual, sob H 0 , segue uma normal padrão, Z ∩ N (0,1) . E o cálculo da estatística de teste vem: Z= ( X 1 − X 2 ) − ( µ1 − µ 2 ) s1'2 n1 + s 2'2 n2 = (29,50 − 20,50) − 0 2 9,481 3,077 + 66 98 2 = 9 1,459 = 9 = 7,45 12 1,208 10 In Carlos Lourenço, (2004), Intervalo de Confiança Para a Diferença de Duas Médias Populacionais, (em grandes amostras e com variâncias desconhecidas), Textos de apoio das aulas, pág.2. 11 A aplicação deste teste tem dois pressupostos: (1) a variável em estudo tem distribuição normal nas duas populações e (2) existe homogeneidade (ou homocedasticidade) das variâncias, isto é, a variância é igual nas duas populações. Para verificar o primeiro pressuposto é normalmente usado o teste K-S (Kolmogorov-Smirnov) com a correcção de Lilliefors, o qual é dispensável no caso de estarmos na presença de grandes amostras e podermos aplicar o Teorema do Limite Central para aproximar as distribuições à normal. Para a verificação do segundo pressuposto é habitualmente usado o teste de Levene, o qual é considerado um dos mais potentes para o efeito. O teste de Levene é apresentado em detalhe no ANEXO do presente texto de apoio. 12 Note mais uma vez que s1'2 s 2'2 + = 1,208 corresponde ao erro-padrão da diferença entre as médias n1 n 2 amostrais (do inglês standard error of mean difference, ou, abreviadamente, std. error difference). Carlos Lourenço ISCTE, 2004 14 Estatística II Sociologia e Sociologia e Planeamento Determinação do valor crítico e das regiões de rejeição e de não rejeição O valor crítico do teste é dado pelo valor da distribuição normal-padrão para uma probabilidade 1 − α = 1 − 0,05 = 0,95 , ou seja, z 0,95 = 1,645 . Tomada de decisão Dado que o valor da estatística de teste “caiu” na região de rejeição ( Z ≥ z 0,95 ou 7,45 ≥ 1,645 ), rejeitamos a hipótese H 0 : µ1 − µ 2 = 0 , isto é, rejeitamos a igualdade das médias populacionais. Ou seja, as médias de idades entre os dois turnos são significativamente diferentes. Carlos Lourenço ISCTE, 2004 15
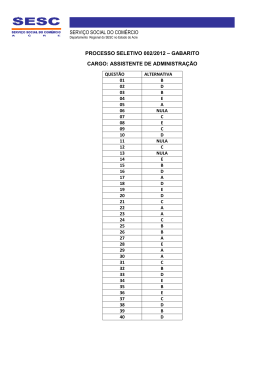
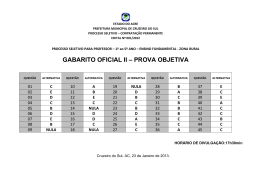
Download