Indução de Árvores e
Regras Proposicionais
de Decisão
Classificação versus Predição (Regressão)
• Classification:
– Afetação a uma classe (rotulo de um atributo categórico)
– Classifica dados (constroi um modelo) baseado em um
conjunto de treinamento previamente rotulado e usa o
modelo para classificar novas observações.
• Previsão (Regressão):
– Modela funções contínuas; previsão de valores
desconhecidos ou ausentes
• Aplicações
– Aprovação de crédito
– Diagnóstico médico
– etc.
Classificação: Um processo em duas etapas
• Construção do Modelo (Aprendisagem): descrição de um
conjunto de classes a priori
– Supõe-se que cada observação é oriunda de uma classe predefinida,
como indicado pelo atributo rótulo da classe
– Conjunto de treinamento: O conjunto de observações usadas para
construir o modelo
– Exemplos de modelos: regras de classificação, árvores de decisão,
fórmulas matemáticas
• Uso do modelo: para classificar observações desconhecidas
– Avaliação da precisão do modelo
• O rótulo conhecido de uma observação é comparado com o
resultado do modelo (conjunto de teste)
• A taxa de erro é a percentagem de observações do conjunto teste
que são classificadas incorretamente pelo modelo
• O conjunto de teste deve ser independente do conjunto de
treinamento, senão poderá ocorrer super ajustamento (over-fitting)
Processo de Classificação (1):
Construção do Modelo
Algoritmos de
Classificação
Dados de
treinamento
NOME
Tonho
Maria
João
José
David
Ana
CATEGORIA
Prof. Assist.
Prof. Assist.
Professor
Prof. Assoc.
Prof. Assist.
Prof. Assoc.
ANOS
3
7
2
7
6
3
Efetivo
não
sim
sim
sim
não
não
Classificador
(Modelo)
IF categoria = ‘professor’
OU Anos > 6
THEN Efetivo = ‘sim’
Processo de Classificação (2): Uso
do modelo para a previsão
Classificador
Dados de
teste
Dados não
(Jeferson, Professor, 4)
NOME
Tonho
Melisa
George
Jose
CATEGORIA
Prof. Assist.
Prof. Assoc.
Professor
Prof. Assist.
ANOS EFETIVO
2
não
7
não
5
sim
7
sim
Efetivo?
Aprendizagem supervisada vs.
Aprendizagem não supervisada
• Aprendizagem supervisada (classificação)
– Supervisão: Os dados de treinamento são rótulados pelas
classes as quais pertencem
– As novas observações são classificadas com base no
conjunto de aprendizagem
• Aprndizagem não supervisada (clustering)
– As classes dos dados de treinamento são desconhecidas
– O objetivo é formar / descobrir classes à partir dos dados
Questões que dizem respeito à classificação e
a previsão (1): Preparação de Dados
• Preparação de Dados
– Pré-processamento dos dados para reduzir o ruído e tratar
os valores ausentes
• Seleção de variáveis
– Remoção dos atributos irrelevantes ou redundantes
• Transformação dos dados
– Generalização e/ou normalização dos dados
Questões que dizem respeito à classificação e
a previsão (2): Avaliação dos métodos
• Previsão da taxa de erro
• Velocidade e escalabilidade
– Tempo para a construção do modelo
– Tempo para o uso do modelo
• Robustes
– Ruido e valores ausentes values
• Escalabilidade
– Eficiencia em grandes base de dados
• Interpretabilidade:
– Compreensão fornecida pelo modelo
• Adequação das regras
– Tamanho das árvores de decisão
– Compacticidade das regras de classificação
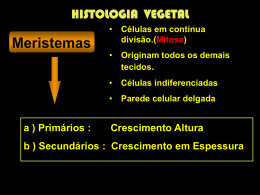
Classificação via Árvores de Decisão
• Árvores de Decisão
–
–
–
–
Estrutura semalhante a uma árvore
Os nós internos representam um teste em um atributo
Os ramos representam o resultado do teste
As folhas representam os rótulos das classes
• Duas fases na geração de uma árvore de decisão
– Construção da árvore
• No início, todos os exemplos de treinamento estão na raíz
• Os exemplos são particionados recursivamente com base nos
atributos selecionados
– Poda da árvore
• Identificar e remover ramos que refletem ruidos e aberrações
• Uso das árvores de decisão: Classificação de uma observação
desconhecida
Conjunto de treinamento
idade
renda
estudante?
crédito
computador?
<=30
alta
não
passavel
no
<=30
alta
não
excelente
no
30…40
alta
não
passavel
yes
>40
média
não
passavel
yes
>40
baixa
sim
passavel
yes
>40
baixa
sim
excelente
no
31…40
baixa
sim
excelente
yes
<=30
média
não
passavel
no
<=30
baixa
sim
passavel
yes
>40
média
sim
passavel
yes
<=30
média
sim
excelente
yes
31…40
média
não
excelente
yes
31…40
alta
sim
passavel
yes
>40
média
não
excelente
no
Saída: Árvore de Decisão para
“compra_computador”
Idade?
<=30
Estudante?
não
sim
não
sim
overcast
30..40
Sim
>40
Crédito?
excelente Passável
não
sim
Algoritmo: Árvores de decisão
• Algoritmo básico
– A árvore é construida recursivamente de cima para baixo no modo
dividir para conquistar
– No início todos os exemplos se encontram na raíz
– Os atributos são discretos (os atributos contínuos são discretizados
previamente)
– Os exemplos são particionados recursivamente com base em atributos
selecionados
– Os atributos são selecionados heuristicamente ou através de uma critério
estatístico (ex., ganho de informação)
• Condições de parada
– Todas as amostras de um dado nó pertencem a mesma classe
– Não há mais atributo disponível para futuras partições – usa-se voto da
maioria para classificar a folha
– Não há mais exemplos disponíveis
Critério para a seleção de atributos
• ganho de informação (ID3/C4.5)
– Supõe-se que todos os atributos são categóriocos
– Pode ser modificado para atributos continuos
• Selecione o atributo com o maior ganho de informação
• Suponha que existem duas classes, P e N
– Seja S o conjunto de exemplos com p elementos da classe P e
n elementos da classe N
Ganho de informação (ID3/C4.5)
– A quantidade de informaçãonecessária para decidir se um
exemplo arbitrário de S pertence a P ou a N é definedo como
p
p
n
n
I ( p, n)
log2
log2
pn
pn pn
pn
Ganho de informação em árvores de decisão
• Suponha que usando-se um atributo A um conjunto S
será particionado em {S1, S2 , …, Sv}
– Se Si contem pi examplos de P e ni examplos de N, a
entropia, ou a informação esperada necessária para
classificar objetoss em todas as sub árvores Si é
p n
E ( A) i i I ( pi , ni )
i 1 p n
• A informação que seria ganha ao ramificar-se por A
Gain( A) I ( p, n) E( A)
Seleção de atributos pelo calculo do
ganho de informação
Classe P: computador? = “sim”
Classe N: computador? = “não”
I(p, n) = I(9, 5) = 0.940
Calculo da entropia para idade:
idade
<=30
30…40
>40
pi
2
4
3
ni I(pi, ni)
3 0,971
0 0
2 0,971
5
4
E(idade )
I( 2,3) I( 4,0)
14
14
5
I(3,2) 0.971
14
Logo
Gain(idade ) I(p, n ) E(idade )
Da mesma forma
Gain(income) 0.029
Gain( student ) 0.151
Gain(credit _ rating ) 0.048
Extração de regras de classificação ‘a partir
de árvores de decisão
• Representa o conhecimento na forma de regras IF-THEN
• Cria-se uma regra para cada caminho ligando a raíz a uma
folha
• Cada par atributo-valor ao lingo de um caminho forma uma
conjunção
• A folha fornece a previsão da classe
• Exemplo
IF idade = “<=30” AND estudante = “não” THEN computador? = “não”
IF idade = “<=30” AND estudante = “sim” THEN computador? = “sim”
IF idade = “31…40”
THEN computador? = “sim”
IF idade = “>40” AND crédito = “excelente” THEN computador? = “sim”
IF idade = “<=30” AND crédito = “passável” THEN computador = “não”
Evitar Overfitting em Classificação
• A árvore gerada pode super ajustar os dados de
treinamento
– Ramos demais, alguns podem ser o resultado de anomalias
devido a ruidos e dados aberrantes
– Taxa de erro maior para as observações desconhecidas
• Duas abordagens para evitar o overfitting
– Pré-Poda: Parar a construção da árvore cedo—não dividir um nó
se isso resultar em um critério abaixo de um limiar
• Difícil escolher o limiar apropriado
– Pos-Poda: Remover ramos de uma árvore completa—obter uma
sequencia de árvores progressivamente podadas
• Usar um conjunto de dados diferente dos dados de
treinamento para decidir qual é a melhor árvore podada”
Abordagens para determinar o tamanho
final da árvore
• Conjuntos de treinamento (2/3) e teste (1/3)
separados
• Usar cross validation, ex., 10-fold cross validation
• Usar todos os dados para treinar
– mas aplicar um teste estatístico (ex., qui-quadrado) para
estimar se a expansão ou a poda de um nó pode ser
realizada
• etc.
Melhoramentos na árvore de decisão básica
• Permitir a manipulação de atributos contínuos
– Definir dinamicamente novos atributos discretos que
particionam os atributos contínuos em um conjunto de
intevalos
• Manipular valores ausentes
– Atribuir o valor mais comum do atributo
– Atribuir o valor mais provável
• Construção de atributos
– Criar novos atributos com base naqueles representados
esparsamente
Regras de classificação
ANTECEDENTES
CONSEQUÊNCIA
•Cada antecedente: teste valor de um atributo da
instância para classificar.
•Conseqüência: classificação da instância.
Ex: IF tempo = sol AND dia = Dom THEN sair
(T = sol) (D = Dom) => sair
Hipótese do Mundo fechado
• Classificação de alvo booleano em um mundo
fechado.
IF tempo = sol AND dia = Dom THEN racha
IF tempo = sol AND dia = Sab THEN racha
Construindo regras
•
• Algoritmo de
Cobertura: selecionar
•
uma classe e procurar
uma forma de
cobrir todas as instâncias.
y
1
b bb a a a a
b b a a
b
b b a b
1.2
x
Passo inicial
– if ? then class = a
Primeiro passo
– if x > 1.2 then class = a
Essa regra cobre, tanto os bs
quanto os as
• Segundo passo
– if x > 1.2 e y > 1 then
class = a
Essa regra cobre somente
a’s.
Algoritmo de cobertura
Para cada classe C
Inicialize E como sendo o conjunto de instâncias
Enquanto E contém instâncias na classe C
Crie uma regra R sem antecedentes que prediz a classe C
Enquanto R não for perfeita e houver mais atributos
Para cada atributo A não mencionado em R e cada valor V
Considere a adição de A=v nos antecedentes de R
Selecione A e v que maximize Heuristic-function()
Adicione A=v nos antecedentes de R
Remova as instâncias cobertas por R de E
Função heurística
Correctness based Heuristic
MAXIMIZAR
Número dessa instâncias
que pertencem à classe da regra
Número de instâncias que
disparam a regra
p
t
Information based Heuristic
MAXIMIZAR
p
P
p log log
t
T
Calcula o ganho de informação levando
em conta o número de instâncias positivas
Comparando os critérios
• Os dois critério classificam corretamente todas as instâncias.
• Correctness Based
– Privilegia regras 100% corretas mesmo com cobertura
baixa
– Trata primeiro os casos especiais
• Information Based
– Privilegia regras de alta cobertura mesmo com precisão
baixa
– Trata primeiro os casos gerais
Exemplo
Idade
receita
astigmatismo lagrimas
lentes
Jovem
Jovem
Jovem
Jovem
Pre-presbiotico
Pre-presbiotico
Pre-presbiotico
Pre-presbiotico
Presbiotico
Presbiotico
Presbiotico
Presbiotico
miope
miope
hipermetropo
hipermetropo
miope
miope
hipermetropo
hypermetropo
miope
miope
hypermetropo
hypermetropo
sim
sim
sim
sim
sim
sim
sim
sim
sim
sim
sim
sim
null
forte
null
forte
null
forte
null
null
null
forte
null
null
reduzido
normal
reduzido
normal
reduzido
normal
reduzido
normal
reduzido
normal
reduzido
normal
Exemplo
Atributo-valor
cbh
ibh
idade = jovem
2/8
0.35
idade = pre-presbiotico
1/8
-0.12
idade = presbiotico
1/8
-0.12
Receita = miope
3/12
0.53
receita = hipermetropia
1/12
-0.3
astigmatismo = não
0/12
0.0
astigmatismo = sim
4/12
1.2
Taxa de produção de lágrimas= reduzida
0/12
0.0
Taxa de produção de lágrimas = normal
4/12
1.2
Regras boas e regras ruins
• Gerar regras que não são perfeitas no conjunto de
treinamento ...
• ... mas que são melhores na generalização do
problema.
• Solução: contrabalançar a precisão de uma regra nos
exemplos e a qualidade de uma regra no problema
• As heurísticas exibidas anteriormente causam overfit
se usados isoladamente
Qualidade de uma regra
T
t
P
p
Probabilidade de uma regra aleatória ter um p igual a
um valor qualquer i:
P[i de t estarem em P] =
p T P
i t i
T
t
Qualidade de uma regra
• A qualidade de uma regra é a probabilidade de
uma regra gerada aleatoriamente ter um
desempenho melhor ou igual à regra.
• Para uma regra R:
min(t , P ) p T P
min(t , P )
M(R) =
i p
P[i de t estarem em P] =
i p
i t i
T
t
Exemplo
IF astigmatismo = sim AND produção de
lagrimas = normal
THEN recomendação = forte
– p/t = 4/6
– P/T = 4/24
4 24 4
4
4 6 4
m( R) P ri,6,4,24
0,0014 0,14%
24
i 4
6
Ou seja, apenas 0,14% de chance de uma regra gerada
aleatoriamente ser melhor do que esta regra.
Gerando boas regras
1. Gerar regras 100% precisas ou perfeitas
– IF A=a AND B=b AND C=c THEN D=d
• Precisão = 100%, qualidade = baixa
2. Os testes do antecedente da regra são tirados gradualmente
para tentar melhorar a qualidade da regra.
– IF A = a AND B=b THEN D=d
• precisão < 100%, qualidade = alta
Dessa forma as regras são melhores na generalização do
problema.
Listas de regras
• Lista ordenada de decisão formada por regras que são
interpretadas seqüencialmente
• A primeira regra disparada leva a instância
• Algoritmo de geração de listas de regras:
Inicialize E com o conjunto de instancias
Até que E esteja vazio
para cada classe C contida em E
-gere uma regra R perfeita para a classe C pelo cobertura
-calcule a medida de valor m(R) para a regra e para a
regra m(R-) com a condição final retirada
-enquanto m(R)<m(R-) retire a condição final da regra e
repita o passo anterior
das regras geradas escolha a que tem o menor m(R)
Imprima a regra R
retire de E as instâncias cobertas por R
continue
Conjunto de teste
• A medida de probabilidade da qualidade de uma
regra é uma forma eficiente de comparar a
qualidade entre duas regras.
• Mas não tem muito valor estatístico porque é
aplicada sobre os mesmo dados usados no
crescimento da regra.
• Solução (Reduced Error-Prunning):
– Dividir os dados de forma que as medida sobre a
qualidade de uma regra sejam feitas em uma
conjunto separado
Usando um conjunto de testes
CONJUNTO DE CRESCIMENTO
– Usado para construir as regras
CONJUNTO DE PODA
– Usado para verificar a qualidade da poda
Problemas ...
• Como separar os conjuntos.
• Instâncias chaves podem ser alocadas para o
conjunto de poda.
Conjuntos
• Variando o conjunto de poda é possível evitar
perda de informação.
Usando um conjunto de testes
Inicialize E com o conjunto de instancias
Divida E em Crescimento S1 e Poda S2 em uma razão 2:1
Para cada classe C para qual S1 e S2 tenham instancia
- Use o algoritmo de cobertura para para criar uma
regra perfeita para a classe C
- Calcule w(R) para a regra em S2, e para a regra
com o ultimo teste retirado w(R-)
- Enquanto w(R-) > w(R-), remova o ultimo teste e
repita o passo anterior
Das regras geradas selecione a que tiver o maior w(R)
Imprima a regra R
Remova as instancias de E cobertas pela nova regra
Continue
Possibilidades:
•W(R) = qualidade da regra
•W(R) = [p+(N - n)] / T
Regras de Classificação vs. Árvores
• Regras de classificação podem ser convertidas em árvores de
decisão e vice-versa
• Porém:
– a conversão é em geral não trivial
– dependendo da estrutura do espaço de instâncias, regras ou
árvores são mais concisas ou eficientes
• Regras são compactas
• Regras são em geral altamente modulares (mas raramente são
completamente modulares)
Vantagens de Árvores de Decisão
Exemplo de conversão árvore -> regras
X > 1.2
não
b
IF x >1.2 AND y > 2.6 THEN
class = a
sim
If x < 1.2 then class = b
Y > 2.6
não sim
b
If x > 1.2 and y < 2.6 then
class = b
a
• Sem mecanismo de interpretação preciso regras podem ser ambíguas
• Instâncias podem “passar através” de conjunto de regras não
sistematicamente “fechado”
Vantagens de Regras de Classificação
Exemplo de conversão regra/árvore
If x=1 and y=1
x
1
2
y
1 2
3
then class = a
a
z
If z=1 and w=1
1 2
3
then class = b
w
b
b
1
3
2
a
b
b
•Árvores são redundantes e não incrementais
•Árvores não são ambíguas e não falham em
classificar
3
O que é previsão
• Previsão é similar a classificação
– Primeiro, constroi-se o modelo
– Depois, usa-se o modelo para prever valores
desconhecidos
• O mais importante método de previsão é a regressão
– Regressão linear e múltipla
– Regressão não linear
• Previsão é diferente de classificação
– Classificação dis respeito a previsão do rótulo de uma
classe
– Previsão é apropriada para modelar funções contínuas
Análise de regressão e Modelo Log-Linear em
previsão
• Regressão linear: Y = + X
– Dois parametros , and espeficicam a reta e devem ser
estimados a partir dos dados disponíveis.
– Em geral aplica-se o critério dos quadrados mínimos aos
valores conhecidos Y1, Y2, …, X1, X2, ….
• Regressão Múltipla: Y = b0 + b1 X1 + b2 X2.
– Muitas funçòes não lineares podem ser expressas na forma
acima.
• Modelos Log-Linear:
– Uma tabela de multiplas entradas com a distribuição de
probabilidade conjunta é aproximada pelo produto de tabelas
de ordem inferior.
– Probabilidade: p(a, b, c, d) = ab acad bcd
Regressão localmente ponderada
• Constrói uma aproximação explicita de uma função f
• em uma região próxima de xq
• Aproximação linear, quadrática, exponencial, ... de f
• Regressão linear: faprox = w0 + w1 y1(x) + … + wp yp(x)
• Escolher os pesos wi
• que minimiza a soma dos quadrados dos erros
• em relação aos k vizinhos mais próximos de xq
E( x q )
f (x ) f
aprox
x aos k vizinhos mais próximos de x q
(x)
2
Baixar