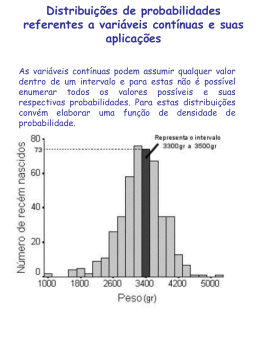
1. Variáveis aleatórias 1. Introdução As distribuições de freqüências de amostras foram tratadas anteriormente. Agora, trataremos das distribuições de probabilidades de populações. A distribuição de freqüência de uma amostra é uma estimativa da distribuição de probabilidade da população correspondente. Se o tamanho da amostra for grande, espera-se que a distribuição de freqüências da amostra tenha uma boa aproximação da distribuição de probabilidade da população. No estudo de pesquisas empíricas e análises de situações reais, a Estatística Descritiva (tabelas de freqüências, média, moda, mediana, desvio padrão, etc) são bastante úteis. Porém, no estudo de uma população, as distribuições de probabilidades, como veremos mais adiante, são preferidas, pois possibilitam a construção de modelos matemáticos que nos auxiliam na compreensão dos fenômenos do mundo real. 2. Variáveis aleatórias Como já vimos no estudo das probabilidades, o conjunto de todos os possíveis resultados de um experimento aleatório é chamado de espaço amostral. Os elementos desse conjunto podem ser numéricos ou não. Por exemplo, o número de filhos de um casal é um exemplo de conjunto numérico. Porém, o grau de escolaridade de um indivíduo é algo não numérico. Dessa forma, em muitas vezes, para podermos trabalhar probabilisticamente com uma variável não numérica, atribuímos valores para cada elemento do espaço amostral. O resultado de um experimento de probabilidade geralmente é uma contagem ou uma medida. Quando isso ocorre, o resultado é chamado de variável aleatória. Definição: uma variável aleatória X representa um valor numérico associado a cada resultado de um experimento de probabilidade. A palavra aleatória indica que os valores assumidos por X são obtidos ao acaso. Notação: geralmente, as variáveis aleatórias são representadas por letras maiúsculas (X), enquanto que os valores assumidos por essas variáveis aleatórias são representadas por letras minúsculas (x). Dessa forma, se escrevermos X=x queremos dizer que a variável aleatória X assume um valor numérico igual a x. As variáveis aleatórias podem ser de dois tipos: discretas ou contínuas. 2.1. Variáveis aleatórias discretas Uma variável aleatória é discreta se ela assume um número finito de valores ou assume um número infinito de valores numeráveis (contáveis). Podemos dizer que uma variável é discreta quando seus valores puderem ser listados. 2 Por exemplo: o número de ligações recebidas por dia em um escritório pode ser um valor igual a 0, 1, 2, 3, 4, ... Assim, definimos a variável aleatória X: X: número de ligações recebidas pelo escritório. Os valores que essa variável pode assumir são x=0, 1, 2, 3, ... Dessa forma, se escrevermos X=3 estamos dizendo que “o número de ligações recebidas pelo escritório (X) é igual a 3 ligações (x)”. 2.2. Variáveis aleatórias contínuas Uma variável aleatória é contínua se ela possui um número incontável de possíveis resultados. Ou seja, uma variável é dita contínua quando os valores que ela pode assumir puderem ser representados como um intervalo na reta dos números reais. Neste caso, os valores assumidos por uma variável contínua, não podem ser listados, visto que são infinitos os possíveis valores dessa variável. Por exemplo: consideremos o tempo de duração de uma ligação recebida em minutos (incluindo frações de minutos). Neste caso, podemos definir uma variável aleatória Y da seguinte forma: Y: tempo de duração de uma ligação em minutos. Perceba que os valores de Y podem assumir qualquer valor em um intervalo real. Suponhamos, para facilitar, que o tempo máximo de uma ligação seja de 120 minutos. Neste caso, os valores y pertencem ao intervalo [0, 120]. 3. Distribuições de probabilidades discretas Para cada valor de uma variável aleatória discreta pode-se determinar uma probabilidade correspondente a esse valor. Ao listar cada valor de uma variável aleatória juntamente à sua probabilidade, você estará formando uma distribuição de probabilidade. Uma distribuição de probabilidades deve satisfazer as seguintes condições: I. A probabilidade de cada valor da variável é um número de 0 à 1. Ou seja: 0 ≤ P( X = x ) ≤ 1 ou, ainda, 0 ≤ P( x ) ≤ 1. II. A soma de todas as probabilidades é igual a 1: ∑ P( X = x ) = 1 , ou ainda, ∑ P( x ) = 1. i i i i Perceba que podemos trabalhar com dois tipos de notação: P(X=x) ou simplesmente P(x). Por exemplo, a probabilidade de a variável X assumir o valor igual a 3 pode ser escrita como P(X=3) ou apenas P(3). 3 Exemplo 1: um psicólogo aplicou um teste para classificar o nível de estresse dos 150 funcionários de uma empresa. Para isso, ele atribuiu cinco possibilidades: muito calmo, calmo, moderado, irritado, muito irritado. Essas características foram pontuadas com valores de 1 à 5, onde 1 indica a qualidade “muito calmo” e 5 indica “muito irritado”. Definindo a variável aleatória X: nível de estresse, podemos dizer que x=1,2,3,4,5. Os resultados da pesquisa estão na tabela a seguir: x frequência 1 24 2 33 3 42 4 30 5 21 total 150 Construir uma distribuição de probabilidade para a variável X. Resolução Utilizando a tabela, podemos calcular as probabilidades: P(X=1) = 24/150 = 0,16 P(X=2) = 33/150 = 0,22 P(X=3) = 42/150 = 0,28 P(X=4) = 30/150 = 0,20 P(X=5) = 21/150 = 0,14 A distribuição de probabilidades está apresentada na tabela a seguir: x 1 2 3 4 5 P(X=x) 0,16 0,22 0,28 0,20 0,14 ou P(x) Graficamente, podemos representar da seguinte forma: 4 Níveis de estresse 0,3 probabilidade 0,25 0,2 0,15 0,1 0,05 0 1 2 3 4 5 escore Exemplo 2: em uma cidade, a distribuição de probabilidade da variável que representa o número de dias de chuva ao longo de uma determinada semana é dada pela tabela: Dias de chuva Probabilidade 0 0,216 1 0,432 2 m 3 0,064 a) defina a variável aleatória X; b) calcule o valor m apresentado na tabela; c) determine P(X=3); d) calcule P(X<2); e) calcule P(X ≥ 2). Resolução a) X: número de dias da semana que chove em certa cidade. b) A soma de todas as probabilidades deve ser igual a 1. Logo: 0,216 + 0,432 + m + 0,064 = 1 E, portanto, m=0,288. c) P(X=3) = P(3) = 0,064 d) P(X<2) = P(X=0) + P(X=1) = 0,216 + 0,432 = 0,648 e) Sabendo que P(X<2) + P(X ≥ 2) = 1, temos que P(X ≥ 2) = 1 – 0,648 = 0,352. Exemplo 3: em uma caixa há 5 peças boas e 3 defeituosas. Duas peças são retiradas ao acaso e sem reposição. Definindo a variável aleatória X como sendo o número de peças boas retiradas, obtenha a distribuição de probabilidades. 5 Resolução Vamos construir a árvore de probabilidades: 4 /7 B 20 / 56 B 5 /8 3 /7 D 15 / 56 5 /7 B 15 / 56 2 /7 D 6 / 56 3 /8 D Definindo: X: número de peças boas retiradas. Note que X poderá assumir valores iguais a 0, 1, ou 2. Logo, a distribuição de probabilidades será dada pela tabela: x P(X=x) 0 6 56 1 30 56 2 20 56 4. Valor Esperado ou Média de uma variável aleatória discreta Seja X uma variável aleatória discreta, com valores x1, x2, ..., xk. O valor esperado de X (ou esperança matemática de X), ou simplesmente a média de X é definida como: k µ = E( X) = ∑ x i .P( x i ) i=1 n Já vimos que a média amostral é dada por x = ∑ fi .x i . A média teórica (ou i=1 populacional) µ é semelhante à média amostral x . À medida que o tamanho da amostra aumenta, a freqüência relativa fi aproxima-se de p(xi), ou seja, a média amostral aproxima-se da média populacional. 6 Observação: embora as probabilidades nunca possam ser negativas, o valor esperado de uma variável aleatória pode ser negativo. Exemplo 4: considere um jogo no qual se lançam três moedas não viciadas e se recebe R$ 2,00 caso apareça 1 cara, R$ 4,00 se aparecerem 2 caras e R$ 8,00 caso apareçam 3 caras. Se nenhuma cara ocorrem, nada se recebe. Quanto se esperaria ganhar caso fizesse esse jogo uma vez? Em outras palavras: qual é o valor esperado de uma jogada? Inicialmente, fazendo o estudo das probabilidades (como a construção de uma árvore de probabilidades, por exemplo), verificamos que a probabilidade de ocorrer uma certo número de caras é dada pela tabela: N° caras 0 1 2 3 Probabilidade 1/8 3/8 3/8 1/8 Se definirmos a variável aleatória X: valor a ser recebido, podemos construir a distribuição de probabilidades de X, conforme tabela a seguir: N° caras 0 1 2 3 xi: valor a ser recebido (R$) 0 2 4 8 Probabilidade: P(X=xi) 1/8 3/8 3/8 1/8 A esperança (ou valor esperado) será: 1 3 3 1 26 E( X) = 0. + 2. + 4. + 8. = = R$ 3,25 . 8 8 8 8 8 O valor esperado é uma média a longo prazo. No caso, após várias jogadas, se esperaria ganhar R$ 3,25. Exemplo 5: em um sorteio, 1500 bilhetes são vendidos a R$ 2,00 cada. Serão 4 prêmios sorteados nos valores de R$ 500, R$ 250, R$ 150 e R$ 75. Você compra um bilhete. Qual o valor esperado do seu lucro? Resolução Para encontrar o lucro para cada prêmio, devemos subtrair o valor do prêmio do valor pago pelo bilhete. Assim, para o prêmio de R$ 500, temos um lucro igual a R$ 500 – R$ 2 = R$ 498. E assim por diante para os demais prêmios. Definindo a variável aleatória discreta X: lucro em reais, construímos a distribuição de probabilidades: 7 Lucro em reais(x) P(X=x) 498 1 1500 248 1 1500 148 1 1500 73 1 1500 –2 1496 1500 Agora, calculamos o valor esperado: E( X) = 408. 1 1 1 1 1496 + 248. + 148. + 73. + ( −2). = −1,35 1500 1500 1500 1500 1500 Logo, como o valor esperado é negativo, você espera perder uma média de R$1,35 por cada bilhete que comprar. 5. Variância e desvio padrão de uma variável aleatória discreta Como já estudamos, a variância é uma medida de dispersão que avalia o grau de homogeneidade dos valores da variável em torno da média. A definição da variância de uma variável aleatória discreta X é dada por: [ σ2 = Var ( X) = E ( x − µ )2 ] Desenvolvendo o quadrado da diferença, obtemos uma fórmula prática para o cálculo da variância: σ 2 ( X) = Var ( X) = E( X 2 ) − E 2 ( X) onde: k E( X) = ∑ x i .P( x i ) e i=1 k E( X 2 ) = ∑ x i2 .P( x i ) i=1 Cuidado: E2(X) = [E(X)]2 que é diferente do valor de E(X2). O desvio padrão da variável X corresponde à raiz quadrada da variância: σ( X) = σ 2 ( X) ou ainda DP( X) = Var( X) . 8 Exemplo 6: uma loja possui a seguinte distribuição de vendas de geladeiras por semana: xi (vendas) 0 1 2 3 4 P(X=xi) 0,20 0,30 0,30 0,15 0,05 Calcular o valor esperado de X: número de vendas por semana e o desvio padrão de X. Utilizando a fórmula para a esperança: E(X) = 0.0,20 + 1.0 ,30 + 2.0,30 + 3.0,15 + 4.0,05 = 1,55 geladeiras. Vamos calcular a variância. Para isto, precisamos determinar, antes, o valor de E(X2): E(X2) = 02.0,20 + 12.0,30 + 22.0,30 + 32.0,15 + 42.0,05 = 3,65. Utilizando a fórmula da variância: Var( X) = E( X 2 ) − E 2 ( X) = 3,65 − (1,55) 2 = 1,25 O desvio padrão será: DP( X) = 1,25 = 1,12 fogões. 6. Exercícios 1) Seja X a variável aleatória correspondente à soma dos pontos obtidos no lançamento de dois dados. Determine: a) a distribuição de probabilidades de X; b) P(3 ≤ X ≤ 10) c) P(X > 7) d) P(X ≤ 5) 2) Uma variável aleatória tem a distribuição de probabilidade dada pela seguinte fórmula: P(xi) = K/x para x = 1, 3, 5, 7. a) Determinar K. b) Calcular P(2 ≤ X ≤ 6). 3) Um vendedor calcula que cada contato resulta em venda com probabilidade de 20%. Certo dia, ele contata dois possíveis clientes. Construa a tabela de distribuição de probabilidade para a variável Y: número de clientes que assinam um contrato de venda. 9 4) Uma variável aleatória discreta pode assumir cinco valores, conforme a distribuição de probabilidade: xi 1 2 3 4 5 P(xi) 0,20 0,25 ? 0,30 0,10 a) Encontre o valor de P(3). b) Calcule a média da distribuição. c) Calcule a variância e o desvio padrão de X. 5) A distribuição de probabilidade de uma variável aleatória X é dada pela fórmula: P(x) = (0,8).(0,2)x–1 para x=1,2,3,... a) Calcular P(x) para x=1, x=2, x=3, x=4 e x=5. b) Some as probabilidades obtidas no item a. O que você pode dizer a respeito das probabilidades para valores de x maiores que 5? 6) O número de chamadas telefônicas recebidas por uma central e suas respectivas probabilidades para um intervalo de um minuto são: N° de chamadas Probabilidades 0 1 2 3 4 5 0,55 0,25 0,10 0,04 0,04 0,02 a) Determinar P(1 ≤ X ≤ 4) e P(X > 1). b) Qual é o número esperado de chamadas em um minuto? c) Lembrando que o coeficiente de variação é o quociente entre o desvio padrão e a média, calcule o coeficiente de variação de X. 7) De acordo com uma pesquisa do Data Journal, 70% das pessoas que trabalham em escritórios utilizam computadores da IBM. Se dois indivíduos que trabalham em escritórios são selecionados ao acaso, encontrar a distribuição de probabilidades da variável X: número de usuários dos computadores da IBM. Calcule a média e o desvio padrão dessa variável. 8) O gráfico mostra a distribuição de furacões que atingiram o território dos EUA divididos por categorias, sendo 1 o nível mais fraco e 5 o mais forte. 10 Para essa variável, calcule: a) a esperança; b) a variância; c) o desvio padrão. 9) O gráfico mostra a distribuição de probabilidades do número de pessoas que moram em cada casa nos EUA: Para essa variável, calcule: a) a esperança; b) a variância; c) o desvio padrão. 10) Em um jogo de roleta americana, há 38 números: 00, 0, 1, 2, 3, ..., 36 marcados em espaços igualmente divididos. Se um jogador aposta $ 1 em um número e ganha, ele continua apostando com o $ 1 e recebe $ 35 adicionais. Caso contrário, ele perde $ 1. Definindo a variável X: lucro obtido em uma rodada, determine a quantidade média de dinheiro, por jogo, que esse jogador pode esperar perder (e não ganhar, visto que se trata de um jogo de azar). 11 Respostas 1) a) xi 2 3 4 5 6 7 8 9 10 11 12 P(xi) 1/36 2/36 3/36 4/36 5/36 6/36 5/36 4/36 3/36 2/36 1/36 b) 8/9 c) 5/12 d) 5/18 2) a) K = 105/176 b) 7/22 3) yi 0 1 2 P(yi) 0,64 0,32 0,04 4) a) 0,15 b) 2,85 c) 1,7275 e 1,31 5) a) xi 1 2 3 4 5 P(xi) 0,8 0,16 0,032 0,0064 0,00128 b) A soma das probabilidades é 0,99968. logo, as probabilidades para valores maiores que 5 são próximas de zero. 6) a) 0,43 e 0,20 b) 0,83 d) CV = 145,8% 7) 0 1 2 xi P(xi) 0,09 0,42 0,49 µ (X) = 1,40 σ (X) = 0,65 8) a) 2,0 b) 1,0 c) 1,0 9) a) 2,5 b) 1,9 c) 1,4 10) $ 0,05 12 2. Modelos Discretos de Distribuições de Probabilidades 2.1. Lei binomial da probabilidade - Ensaios de Bernoulli Consideremos um experimento que consiste em uma seqüência de ensaios ou tentativas independentes, isto é, ensaios nos quais a probabilidade de um resultado em cada ensaio não depende dos resultados ocorridos nos ensaios anteriores, nem dos resultados nos ensaios posteriores. Em cada ensaio, podem ocorrer apenas dois resultados, um deles que chamaremos de sucesso (S) e outro que chamaremos de fracasso (F). À probabilidade de ocorrer sucesso em cada ensaio chamaremos de p; a probabilidade de fracasso chamaremos de q, de tal modo que q=1–p. Tal tipo de experimento recebe o nome de ensaio de Bernoulli. Exemplos de ensaio de Bernoulli 1) Uma moeda é lançada 5 vezes. Cada lançamento é um ensaio, em que dois resultados podem ocorrer: cara ou coroa. Chamemos de sucesso o evento sair uma cara e de fracasso o evento sair uma coroa. Em cada ensaio, p=0,5 e q=0,5. 2) Uma urna contém 4 bolas vermelhas e 6 brancas. Uma bola é extraída, observada sua cor e reposta na urna; este procedimento é repetido 8 vezes. Cada extração é um ensaio, em que dois resultados podem ocorrer: bola vermelha ou bola branca. Chamemos de sucesso o evento sair bola vermelha. Conseqüentemente, fracasso corresponde ao evento sair bola branca. Neste 4 6 caso, p = e q= . 10 10 2.2. Distribuição Binomial Antes de apresentarmos a fórmula e suposições da distribuição Binomial de probabilidades, vamos analisar um exemplo e deduzir a fórmula a partir dele. Exemplo 1: uma prova consta de 10 testes com 5 alternativas cada um, sendo apenas uma delas correta. Um aluno que nada sabe a respeito da matéria avaliada, “chuta” uma resposta para cada teste. Qual é a probabilidade dele acertar exatamente 6 testes? A probabilidade de acertar um teste aleatoriamente é esse teste é de 1 − 1 = 0,2 . Logo, a de errar 5 1 4 = = 0,8 . 5 5 Vamos considerar uma situação bastante específica: o aluno acerta os testes de 1 à 6 e erra os testes de 7 à 10. A probabilidade de isso acontecer é obtida utilizando–se o Princípio Fundamental da Contagem: 0,2 . 0,2 . 0,2 . 0,2 . 0,2 . 0,2 . 0,8 . 0,8 . 0,8 . 0,8 = 13 = (0,2)6 . (0,8)4 ≅ 0,000026 ou 0,0026%. Porém, essa é apenas uma situação de acertos / erros possível. O número total de maneiras que esse aluno pode acertar 6 testes de um total de 10 testes é calculada utilizando–se combinação (visto que a ordem dos acertos NÃO importa): C10,6 = 10! = 210 maneiras. 6!.(10 − 6)! Para cada uma dessas 210 formas, temos uma probabilidade de acerto igual a calculada anteriormente. Logo, a probabilidade de esse aluno acertar 6 testes qualquer é: 210 . (0,2)6 . (0,8)4 ≅ 0,0055 ou 0,55%. Vamos definir a variável aleatória X que representa sucesso como sendo: X: número de testes que o aluno acerta (sucesso). Associada a X, temos a probabilidade de sucesso p=0,2 e, conseqüentemente, a probabilidade de fracasso q=1–0,2=0,8 (probabilidade de errar o teste). 10 Lembrando que C10,6 = , podemos escrever que a probabilidade do aluno 6 acertar 6 testes é: 10 P(X=6) = . (0,2)6 . (0,8)4 6 Generalizando, se em cada uma das n repetições de Ensaios de Bernoulli a probabilidade de ocorrer um evento definido como sucesso é sempre p, a probabilidade de que esse evento ocorra em apenas k das n repetições é dada por: n P( X = k ) = .p k .(1 − p)n−k k Resumindo: um experimento binomial deve satisfazer os seguintes critérios: 1) O experimento é repetido n vezes, onde cada tentativa é independente das demais. 2) Há apenas dois resultados possíveis em cada tentativa: um de interesse, associado à variável X, chamado de sucesso e o seu complementar que é o fracasso. 14 3) A probabilidade de sucesso será denotada por p e é a mesma em cada tentativa (entenda Ensaio de Bernoulli). Logo, a probabilidade de fracasso será denotada por q = 1 – p. Observações importantes: é comum àqueles que estão iniciando os estudos da distribuição Binomial acharem que a variável definida como sucesso precisa ser algo “bom”. Porém, isso não está correto. A variável X, ou seja, o sucesso, deverá ser algo que nos interesse. Por exemplo, poderíamos definir como sucesso: – alunos reprovados em determinado ano; – número de óbitos em uma UTI; – número de fumantes presentes em uma reunião; – acertar um alvo num torneio de tiro; – entrevistados serem do sexo masculino; – sair cara no lançamento de uma moeda; – sair face 5 ou 6 no lançamento de um dado. Ou seja, a variável sucesso pode ser ou pode não ser algo bom! Às vezes, pode ser algo imparcial, como face de uma moeda ou dado, ou sexo de uma pessoa. Exemplo 2: para entender melhor a fórmula, vamos recapitular o cálculo de probabilidades com base em um exemplo. Responda rapidamente a pergunta: um casal deseja ter 4 filhos, 2 homens e 2 mulheres. Supondo que a probabilidade de nascimento de um homem (H) ou uma mulher (M) seja a mesma, qual a probabilidade de tal fato acontecer? Muitas pessoas respondem 50%. Se você foi uma delas, a pergunta seguinte possivelmente será “por quê? Não é???”. A resposta é não! O que mostra que muitas vezes a intuição nos engana, enfatizando a importância da probabilidade (veja, por exemplo, o caso de um médico obstetra ou um laboratório que muitas vezes precisa conhecer cálculos de probabilidades como este). Faremos, inicialmente, um método mais trabalhoso, mas que certamente convencerá o leitor de que tal probabilidade não é 50%. Depois, faremos o cálculo utilizando um modelo probabilístico. Listemos todas as possibilidades de nascimentos: HHHH HHHM HHMH HMHH MHHH HHMM HMHM MHHM HMMH MHMH 15 MMHH HMMM MHMM MMHM MMMH MMMM Das 16 possibilidades listadas, note que em 6 delas ocorrem o nascimento de 2 homens e 2 mulheres. Logo, a probabilidade disso ocorrer é: P= 6 = 0,375 ou 37,5% . 16 Ou seja, a probabilidade é inferior a 50%, mais precisamente, vale 37,5%, o que contradiz a intuição da maioria das pessoas. Uma outra forma de resolver esse mesmo problema é utilizando a Binomial. Agora, para resolvermos essa situação apresentada através da Binomial, vamos determinar que nosso interesse seja o número de homens que nascem. Essa ocorrência será chamada de sucesso. Assim: X: número de homens que nascem (sucesso) Logo, nascer mulher indicaria fracasso. Não é nenhum tipo de preconceito, mas sim, uma questão Estatística. Poderíamos, sem problemas, ter trocado homem por mulher e vice-versa. A probabilidade de sucesso é a probabilidade de em um nascimento qualquer ocorrer um homem, ou seja, p= 1 = 0,5 . 2 Temos interesse que, em 4 nascimentos, 2 sejam homens e 2 sejam mulheres. Como chamamos de sucesso nascer homem, temos interesse no nascimento de 2 homens ou, em linguagem matemática, X=2. Logo, o valor de k é 2 (basta comparar a fórmula X=k com o que acabamos de escrever X=2). Obtemos, portanto: 2 4 1 1 P( X = 2) = . .1 − 2 2 2 4−2 1 1 3 = 6. . = = 0,375 , 4 4 8 que é o mesmo valor obtido utilizando o método anterior. Cabe ressaltar que a fórmula apresentada não tem caráter místico algum. É possível fazer a sua dedução e, para isso, basta utilizarmos a lógica desenvolvida no método anterior. Vejamos: 16 Suponhamos 4 caixas numeradas, e que iremos colocar em cada uma delas um cartão que possui uma letra H ou um cartão que possui uma letra M. Suponhamos que temos um par de cartões “mestre” que serão utilizados na escolha de uma das letras e que tenhamos uma outra pilha de cartões que serão colocados nas caixas. Inicialmente, escolheremos duas delas para colocarmos um cartão que possui a letra H. O número de maneiras que podemos fazer tal escolha não depende da ordem, ou seja, escolher a caixa 1 e 3 é indiferente de escolher a 3 e 1, visto que colocaremos cartas iguais dentro de cada uma delas. Utilizamos a combinação: H 1 M H H 2 3 4 Cartões mestre 4 C 4,2 = = 6 2 Logo, há 6 maneiras de se fazer tal escolha. Fixemos uma das escolhas, como por exemplo, H nas caixas 1 e 3. Nas caixas 2 e 4 colocaremos cartas com a letra M. A probabilidade de tal fato ocorrer pode ser expressa através do princípio multiplicativo. A probabilidade de ocorrer cada H é de 0,5 (pois sorteamos as letras a partir dos cartões-mestre) e de ocorrer M também é 0,5. Assim, a probabilidade de sortearmos H na primeira vez, M na segunda, H na terceira e M na quarta é dada por 0,5.0,5.0,5.0,5 = (0,5)4 = 0,0625. Como tal fato (2 H e 2 M) pode ocorrer de 6 maneiras diferentes temos que a probabilidade final fica P = 6 . 0,0625 = 0,375. Note que 0,5 = 1 – 0,5 = 1 – p. O raciocínio aqui desenvolvido é o mesmo que se faz para deduzir a fórmula da Distribuição Binomial. Exemplo 3: uma urna tem 4 bolas vermelhas (V) e 6 brancas (B). Uma bola é extraída, observada sua cor e reposta na urna. O experimento é repetido 5 vezes. Qual a probabilidade de observarmos exatamente 3 vezes bola vermelha? Inicialmente, vamos definir a variável aleatória de interesse: X: número de bolas vermelhas observadas (sucesso). 17 Logo, a probabilidade de sucesso será p=4/10=0,4. Utilizando a fórmula apresentada, em que n=5 (número de retiradas) e k=3 (número de bolas vermelhas que temos interesse em observar), temos: 5 5 P( X = 3) = .0,4 3.(1 − 0,4)5−3 = .0,4 3.0,6 2 = 0,2304 ou 23,04%. 3 3 Exemplo 4: numa cidade, 10% das pessoas possuem carro de marca A. Se 30 pessoas são selecionadas ao acaso, com reposição, qual a probabilidade de exatamente 5 pessoas possuírem carro de marca A? Definindo X: número de pessoas que possuem o carro da marca A (sucesso), temos associada uma probabilidade de sucesso p=0,10. Sendo n=30 e k=5, temos: 30 30 P( X = 5) = .0,15.(1 − 0,1)30 −5 = .0,15.0,9 25 ≅ 0,1023 ou 10,23%. 5 5 Exemplo 5: admite–se que uma válvula eletrônica, instalada em determinado circuito, tenha probabilidade 0,3 de funcionar mais de 600 horas. Analisando–se 10 válvulas, qual será a probabilidade de que, entre elas, pelo menos 3 continuem funcionando após 600 horas? Seja X: número de válvulas que permanecem funcionando após 600 horas. Temos que a probabilidade de sucesso é p=0,3. Perceba que estamos realizando 10 Ensaios de Bernoulli (n=10). Logo, queremos calcular: P(X≥3) = P(X=3) + P(X=4) + P(X=5) + ... + P(X=9) + P(X=10). Note que teríamos que calcular cada uma das probabilidades envolvidas nessa soma utilizando a fórmula apresentada, ou seja, teríamos que aplicar a fórmula 8 vezes para, em seguida, somar todos os resultados. Neste caso, vamos utilizar uma propriedade, já vista, de eventos complementares: P(X≥3) = 1 – P(X<3) = = 1 – [ P(X=0) + P(X=1) + P(X=2)] = 10 10 10 = 1 − .0,3 0.(1 − 0,3)10 −0 + .0,31.(1 − 0,3)10 −1 + .0,3 2.(1 − 0,3)10−2 = 1 2 0 10 10 10 = 1 − .0,3 0.0,710 + .0,31.0,7 9 + .0,3 2.0,7 8 = 1 2 0 = 1 – 0,3828 = 0,6172 ou 61,72%. 18 Exemplo 6: em uma grande pesquisa com 6000 respondentes, determinou–se que 1500 dos entrevistados assistiam determinado programa de TV. Se 20 pessoas são escolhidas ao acaso, qual a probabilidade de que ao menos 19 assistam a esse programa? Definindo a variável aleatória que indica sucesso: X: número de pessoas que assistem ao programa. Perceba que a probabilidade de sucesso (p) pode ser calculada a partir do enunciado: p= 1500 = 0,25 . 6000 Logo, queremos calcular: P(X≥19) = P(X=19) + P(X=20) = 20 20 = .0,2519.0,75 1 + .0,25 20.0,75 0 = 19 20 –11 ≅ 5,5.10 , ou seja, a probabilidade de 19 ou 20 pessoas assistirem ao programa é muito pequena, quase zero, visto que vale 0,0000000055%. Exemplo 7: vamos supor o lançamento de uma moeda honesta (ou seja, P(cara)=P(coroa)=0,5). Suponhamos que você faça uma aposta com um amigo seu: ganha aquele que obtiver mais caras (no seu caso) ou coroas (no caso dele) em 7 lançamentos. A probabilidade de você ganhar ocorre quando saírem 4 ou 5 ou 6 ou 7 caras. Utilizando o modelo Binomial onde: X: número de caras (sucesso) n = 7 lançamentos k = 4,5,6,7 p = 0,5 temos: P(ganhar) = P(X=4) + P(X=5) + P(X=6) + P(X=7) = 4 7−4 5 7 −5 6 7−6 7 7 −7 7 1 1 7 1 1 7 1 1 7 1 1 = 1 − + 1 − + 1 − + 1 − = 4 2 2 5 2 2 6 2 2 7 2 2 7 7 7 7 1 1 1 1 = 35. + 21. + 7. + 1. = 0,5 2 2 2 2 Resultado interessante, não? Ou seja, ao invés de fazer essa aposta, poderiam ter feito a tradicional aposta de cara x coroa. Exemplo 8: Suponhamos a mesma situação do exemplo anterior, mas agora, você pega, sem seu amigo perceber, uma moeda viciada em que a probabilidade 19 de ocorrer uma cara é de 0,75 ou 3 . Neste caso, p=0,75 e a probabilidade de 4 você ganhar é: P(ganhar) = P(X=4) + P(X=5) + P(X=6) + P(X=7) = 7 3 = 4 4 4 3 1 − 4 7−4 7 3 + 5 4 5 3 1 − 4 7 −5 7 3 + 6 4 6 3 1 − 4 7 −6 7 3 + 7 4 7 3 1 − 4 7 −7 ≅ 0,9294 ou 92,94%. Logo, é muito provável que você ganhe a aposta usando essa moeda viciada. Exemplo 9: Overbooking é prática realizada na aviação do mundo todo. Consiste na empresa aérea vender mais bilhetes do que o disponível no vôo com base na média de desistência dos vôos anteriores. Uma empresa aérea possui um avião com capacidade para 100 lugares. Se para um certo vôo essa empresa vendeu 103 passagens e, admitindo que a probabilidade de um passageiro não comparecer para embarque é de 1%, qual a probabilidade de algum passageiro não conseguir embarcar? Este é um problema clássico resolvido utilizando a Binomial. Aqui, é muito comum haver uma certa confusão na elaboração do que é o sucesso bem como do que se deseja calcular. Assim, vamos definir: X: número de passageiros que comparecem ao embarque (sucesso). Neste caso, p=0,99. Temos, ainda, que n=103, visto que cada um dos 103 passageiros pode comparecer ao embarque (sucesso) ou não comparecer (fracasso). Queremos calcular a probabilidade de que algum passageiro não consiga embarcar, ou seja, de que compareçam ao embarque mais de 100 passageiros: P(X>100) = P(X=101) + P(X=102) + P(X=103) = 103 103 103 .0,99101.0,012 + .0,99102.0,011 + .0,99103.0,010 = = 101 102 103 = 5253.0,99101.0,012 + 103.0,99102.0,011 + 1.0,99103.0,010 = = 0,9150 ou 91,50%. Espantoso? Pois é, a probabilidade de haver problemas devido ao excesso de passageiros para esse vôo é bastante elevada e igual a 91,5%. 2.2.1. Média ou Valor Esperado de uma distribuição Binomial Seja uma variável X com distribuição Binomial de parâmetros n (número de ensaios de Bernoulli) e p (probabilidade de sucesso). A média ou valor esperado de X é dado por: 20 µ = E( X ) = n.p 2.2.2. Variância e Desvio Padrão de uma distribuição Binomial Nas mesmas suposições da média, temos: Variância: σ 2 = Var ( X) = n.p.q ou σ 2 = Var ( X) = n.p.(1 − p) Desvio padrão: σ = DP( X) = n.p.q ou σ = DP( X) = n.p.(1 − p) Exemplo 10: consideremos o exemplo anterior que trata sobre o Overbooking. Determine a média, variância e desvio padrão para a variável X definida anteriormente. Interprete os resultados. Lembrando que: n=103 p=0,99 q=1–0,99=0,01 Então: E(X) = 103 . 0,99 = 101,97 Var(X) = 103 . 0,99 . 0,01 = 1,0197 DP(X) = 1,0197 =1,0098 Logo, em média comparecem ao embarque aproximadamente 102 (101,97) passageiros com um desvio padrão de 1 passageiro. 2.2.3. Exercícios 1) Uma moeda é lançada 6 vezes. Qual a probabilidade de observarmos exatamente duas caras? 2) Um dado é lançado 5 vezes. Qual a probabilidade de que o “4” apareça exatamente 3 vezes? 3) Uma pessoa tem probabilidade 0,2 de acertar num alvo toda vez que atira. Supondo que as vezes que ela atira são ensaios independentes, qual a probabilidade de ela acertar no alvo exatamente 4 vezes, se ela dá 8 tiros? 4) A probabilidade de que um homem de 45 anos sobreviva mais 20 anos é 0,6. De um grupo de 5 homens com 45 anos, qual a probabilidade de que exatamente 4 cheguem aos 65 anos? 21 5) Uma moeda é lançada 6 vezes. Qual a probabilidade de observarmos ao menos uma cara? 6) Um time de futebol tem probabilidade p = 0,6 de vencer todas as vezes que joga. Se disputar 5 partidas, qual a probabilidade de que vença ao menos uma? 7) Uma prova consta de 5 testes com 4 alternativas casa um, sendo apenas uma delas correta. Um aluno que nada sabe a respeito da matéria da prova, “chuta” uma resposta para cada teste. Qual é a probabilidade desse aluno: a) acertar os 5 testes? b) acertar apenas 4 testes? c) acertar apenas 3 testes? d) acertar apenas 2 testes? e) acertar apenas 1 teste? f) errar todos os testes propostos? g) qual o resultado mais provável obtido pelo aluno? 8) Foi realizada uma pesquisa com 500 pessoas para verificar se assistiam determinado programa de televisão. Duzentas pessoas afirmaram assistir. Se, a partir da população, retirarmos 8 indivíduos, qual é a probabilidade de que no máximo 6 assistam o programa? 9) Um aluno tem o domínio de 70% do conteúdo que será cobrado em uma prova. Sabendo–se que essa prova é composta por 10 questões, qual a probabilidade de ele acertar, ao menos, 7 questões para ser aprovado? 10) Em uma UTI, em média 5% dos bebês que nascem prematuros não sobrevivem. Se, atualmente, há 40 bebês prematuros, qual a probabilidade de que no máximo 5% dos bebês não sobrevivam? 11) Em 320 famílias com quatro crianças cada uma, quantas famílias seria esperado que tivessem: a) nenhuma menina? b) três meninos? c) quatro meninos? 2 de probabilidade de vitória sempre que joga. Se X jogar 3 cinco partidas, calcule a probabilidade de: a) X vencer exatamente três partidas; b) X vencer ao menos uma partida; c) X vencer mais da metade das partidas. 12) Um time X tem 13) A probabilidade de um atirador acertar o alvo é 1 . Se ele atirar seis vezes, 3 qual a probabilidade de: a) acertar exatamente dois tiros? b) não acertar o alvo? 22 14) Se 5% das lâmpadas de certa marca são defeituosas, ache a probabilidade de que, numa amostra de 100 lâmpadas, escolhidas ao acaso, tenhamos: a) nenhuma defeituosa; b) três defeituosas; c) mais do que uma boa. 15) Em determinada cidade, 56% dos dias são nublados. Encontre a média, a variância e o desvio padrão para o número de dias nublados durante o mês de junho. 16) Calcule a média, a variância e o desvio padrão da distribuição binomial cujos parâmetros são: a) n=80 e p=0,3; b) n=124 e p=0,26. Respostas 1) 0,2344 2) 0,03215 3) 0,4588 4) 0,2592 5) 0,98439 6) 0,9898 7) a) 1/1024 b) 15/1024 c) 90/1024 d) 270/1024 e) 405/1024 f) 243/1024 g) O resultado mais provável é que o aluno acerte apenas 1 teste. 8) 0,9915 9) 0,6496 10) 0,6767 11) a) 20 b) 80 c) 20 12) a) 80/243 b) 242/243 c) 64/81 13) a) 80/243 b) 64/729 14) a) (0,95)100 b) 100 (0,05)3.(0,95)97 3 100 99 c) 1–(0,05) – 100.(0,95).(0,05) 15) E(X)=16,8 Var(X)=7,4 DP(X)=2,7 16) a) E(X) = 24 Var(X)=16,8 DP(X)=4,1 b) E(X) = 32,2 Var(X)=23,9 DP(X)=4,9 23 2.3. Distribuição Geométrica Muitas situações reais podem ser repetidas até atingir–se o sucesso. Um candidato pode prestar uma prova de vestibular até ser aprovado, ou você pode digitar um número de telefone várias vezes até conseguir completar a ligação. Situações como essas podem ser representadas por uma distribuição Geométrica. Uma distribuição pode ser considerada Geométrica se satisfizer as seguintes condições: 1) Uma tentativa (correspondente a um Ensaio de Bernoulli) é repetida até que o sucesso ocorra, ou seja, ocorrem k–1 fracassos até que ocorra o primeiro sucesso na k–ésima tentativa. 2) As tentativas são independentes umas das outras. 3) A probabilidade de sucesso p é constante em todos os Ensaios de Bernoulli. Logo, a probabilidade de que ocorra sucesso na tentativa k é: P(X=k) = p.(1–p)k–1 com k=1,2,3,4... Ou seja, ocorrem k–1 fracassos com probabilidade 1–p até que ocorra um sucesso na tentativa k com probabilidade p. Exemplo 1: uma linha de produção está sendo analisada para efeito de controle da qualidade das peças produzidas. Tendo em vista o alto padrão requerido, a produção é interrompida para regulagem toda vez que uma peça defeituosa é observada. Se 0,01 é a probabilidade da peça ser defeituosa, determine a probabilidade de ocorrer uma peça defeituosa na 1ª peça produzida, na 2ª, na 5ª, na 10ª, na 20ª e na 40ª. Vamos admitir que cada peça tem a mesma probabilidade de ser defeituosa, independentemente da qualidade das demais. Sendo a ocorrência de peça defeituosa um sucesso, podemos aplicar o modelo Geométrico. Definindo a variável aleatória com distribuição geométrica X: número total de peças observadas até que ocorra a primeira defeituosa, podemos escrever nosso modelo: P(X=k) = 0,01 . 0,99k–1 Assim, podemos aplicar nosso modelo para calcular as probabilidades pedidas: P(X=1) = 0,01 . 0,990 = 0,01 P(X=2) = 0,01 . 0,991 = 0,0099 P(X=5) = 0,01 . 0,994 = 0,0096 P(X=10) = 0,01 . 0,999 = 0,0091 P(X=20) = 0,01 . 0,9919 = 0,0083 P(X=40) = 0,01 . 0,9939 = 0,0068 24 Exemplo 2: por experiência, você sabe que a probabilidade de que você fará uma venda em qualquer telefone dado é 0,23. Encontre a probabilidade de que sua primeira venda ocorra na quarta ou na quinta ligação. X: número da primeira ligação em que ocorre a venda (sucesso). P(X=4) = 0,23 . 0,773 ≅ 0,105003 P(X=5) = 0,23 . 0,774 ≅ 0,080852 Logo, a probabilidade desejada é: P(venda na 4ª ou 5ª ligação) = P(X=4) + P(X=5) = 0,105003 + 0,080852 ≅ 0,186. Embora um sucesso possa, teoricamente, nunca ocorrer, a distribuição geométrica é uma distribuição de probabilidade discreta porque os valores de x podem ser listados – 1,2,3.... Perceba que conforme x se torna maior, P(X=x) se aproxima de zero. Por exemplo: P(X=50) = 0,23 . 0,7749 ≅ 0,0000006306. 2.3.1. Esperança (ou média) da Distribuição Geométrica Seja X uma variável aleatória com distribuição geométrica de parâmetro p (probabilidade de sucesso). A média ou esperança de X é dada por: µ = E( X) = 1 p 2.3.2. Variância da Distribuição Geométrica Nas mesmas condições que as apresentadas para a média, temos que a variância é dada por σ 2 = Var ( X) = 1− p p2 Observação: o desvio padrão é calculado como sendo a raiz quadrada da variância, assim como já estudamos anteriormente. 2.3.3. Exercícios 1) Considere uma variável aleatória X com distribuição Geométrica com parâmetro p=0,4. Calcule: a) P(X = 4). b) P(3 ≤ X < 5). c) P(X ≥ 2). 25 2) Uma moeda equilibrada é lançada sucessivamente, de modo independente, até que ocorra a primeira cara. Seja X a variável aleatória que conta o número de lançamentos anteriores à ocorrência de cara. Determine: a) P(X ≤ 2). b) P(X > 1). c) P(3 < X ≤ 5). 3) Suponha que a probabilidade de que você faça uma venda durante qualquer um dos telefonemas feitos é 0,19. Encontre a probabilidade de que você: a) faça sua primeira venda durante a quinta ligação; b) faça sua primeira venda durante a primeira, segunda ou terceira ligação; c) não faça uma venda durante as três primeiras ligações. 4) Um produtor de vidro descobre que 1 em cada 500 itens de vidro está torcido. Encontre a probabilidade de: a) o primeiro item de vidro torcido ser o décimo item produzido; b) o primeiro item de vidro torcido ser o segundo ou terceiro item produzido; c) nenhum dos dez primeiros itens de vidro estar imperfeito. Respostas 1) a) 0,0864 b) 0,2304 c) 0,6000 2) a) 0,875 b) 0,250 c) 0,047 3) a) 0,082 b) 0,469 c) 0,531 4) a) 0,002 b) 0,004 c) 0,980 26 2.4. Distribuição de Poisson A distribuição de Poisson (fala–se: “Poassom”) é uma distribuição de probabilidade discreta de uma variável aleatória X que satisfaz às seguintes condições: 1) O experimento consiste em calcular o número de vezes, k, que um evento ocorre em um dado intervalo. O intervalo pode ser de tempo, área, volume, etc. 2) A probabilidade de o evento acontecer é a mesmas para cada intervalo. 3) O número de ocorrências em um intervalo é independente do número de ocorrências em outro intervalo. A distribuição de Poisson possui um parâmetro λ (leia–se: “lâmbda”) que chamamos de taxa de ocorrência, que corresponde à freqüência média ou esperada de ocorrências em um determinado intervalo. Além disso, sempre temos que λ >0. A probabilidade é calculada da seguinte forma: P( X = k ) = e − λ .λk k! onde: k=0,1,2,3,... e é o número irracional que vale aproximadamente 2,71828; λ é a taxa de ocorrência (que é igual à média da distribuição). 2.4.1. Esperança e Variância da distribuição de Poisson Sendo X uma variável que segue o modelo Poisson com parâmetro λ , temos que: Média ou esperança: E(X) = λ . Variância: Var(X) = λ . Desvio padrão: DP(X) = λ. Importante: a Poisson, assim como a Geométrica, é uma distribuição que pode assumir infinitos valores. Dessa forma, k assume valores em todo o conjunto dos números naturais. Exemplo 1: a emissão de partículas radioativas tem sido modelada através de uma distribuição de Poisson, com o valor do parâmetro dependendo da fonte utilizada. Suponha que o número de partículas alfa, emitidas por minuto, seja uma variável aleatória seguindo o modelo Poisson com parâmetro 5, isto é, a taxa média de ocorrências é de 5 emissões a cada minuto. Calcular a probabilidade de haver mais de 2 emissões em um minuto. 27 Resolução Pelo enunciado, temos que X: número de emissões em um minuto; λ = 5 emissões/minuto Neste caso, queremos calcular P(X > 2), que é uma soma infinita de valores, pois podemos ter X=3,4,5,6,7,8,... Assim, devemos, obrigatoriamente, trabalhar com o complementar: P(X > 2) = 1 – P(X ≤ 2) = 1 – [ P(X=0) + P(X=1) + P(X=2) ] = e −5 .5 0 e −5 .51 e −5 .5 2 = 1− + + = 0,875. 1! 2! 0! Logo, há uma probabilidade de 87,5% de haver mais que 2 emissões ao longo de um minuto. Exemplo 2: você é o gerente de uma loja e sabe que, fora do horário de pico, entram, em média, 6 clientes a cada 10 minutos. Qual a probabilidade de entrarem: a) 6 clientes na loja em um período qualquer de 10 minutos fora do horário de pico? b) até 2 clientes num período de 10 minutos fora do horário de pico? c) entrarem 3 clientes ou mais fora do horário de pico? Resolução Inicialmente, percebemos que se trata de uma variável com distribuição de Poisson: X: número de clientes que entram num período de 10 minutos; λ =6 clientes a cada 10 minutos a) P(X=6) = e −6 .6 6 = 0,1606. 6! e −6 .6 0 e −6 .61 e −6 .6 2 b) P( X ≤ 2) = P( X = 0) + P( X = 1) + P( X = 2) = + + = 0! 1! 2! 6 0 61 6 2 = e − 6 .25 = 0,0620 = e −6 . + + 0! 1! 2! Perceba que o cálculo ficou bastante simplificado quando colocamos o termo e–6 em evidência (fator comum). c) Vamos utilizar o resultado do item anterior na resolução: P( X ≥ 3) = 1 − P( X < 3) = 1 − P( X ≤ 2) = 1 − 0,0620 = 0,9380 . Note que P(X<3) = P(X=0) + P(X=1) + P(X=2) que é exatamente igual a P(X≤2). 28 Exemplo 3: no pedágio da rodovia dos Imigrantes passam, em média, 3600 carros por hora em vésperas de feriado. Qual a probabilidade de: a) passarem dois carros em um segundo? b) passarem 30 carros em 15 segundos? c) passarem até 5 carros em 10 segundos? Resolução Pelo enunciado, temos que λ =3600 carros/hora. Porém, se você observar as perguntas, poderá perceber que as unidades não correspondem a 1 hora. Assim, devemos recalcular o valor do nosso parâmetro a cada item, de modo a trabalharmos sempre na mesma unidade. Esse cálculo pode ser direto ou através de uma regra de três simples. a) X: número de carros que passam no pedágio por segundo. Nosso parâmetro será recalculado. Lembrando que 1 hora possui 3600 segundos, 3600 temos: λ = = 1 carro por segundo. Agora, podemos calcular a probabilidade 3600 desejada: P( X = 2) = e −1.12 = 0,1839 . 2! b) X: número de carros que passam no pedágio a cada 15 segundos. Vamos trabalhar, agora, com uma regra de três: 3600 carros ––––– 3600 segundos (1h) –––––- 15 segundos λ λ = 15 carros a cada 15 segundos. Assim: P( X = 30) = e −15 .15 30 = 0,00022 . 30! c) X: número de carros que passam no pedágio a cada 10 segundos. Da mesma forma que no item anterior, temos que λ = 10 carros a cada 10 segundos. Portanto: P( X ≤ 5) = P( X = 0) + P( X = 1) + ... + P( X = 5) = e −10 .10 0 e −10 .101 e −10 .10 2 e −10 .10 3 e −10 .10 4 e −10 .10 5 + + + + + = 0! 1! 2! 3! 4! 5! 10 0 101 10 2 10 3 10 4 10 5 = e −10 .1477,6667 = 0,0671 = e −10 . + + + + + 0 ! 1 ! 2 ! 3 ! 4 ! 5 ! = Ou seja, há uma probabilidade de 6,71% de passarem 5 carros ou menos ao longo de 10 segundos. 29 Exemplo 4: suponha que 360 erros de impressão estejam distribuídos aleatoriamente, segundo uma Poisson, em um livro de 180 páginas. Calcule a probabilidade de encontrar uma página com: a) nenhum erro; b) mais de um erro. Resolução Sendo X: número de erros encontrados em 1 página, devemos calcular o valor do nosso parâmetro: λ= 360 = 2 erros / página. 180 a) P( X = 0) = e −2 .2 0 = 0,1353 . 0! e −2 .2 0 e −2 .21 b) P( X > 1) = 1 − P( X ≤ 1) = 1 − [P( X = 0) + P( X = 1)] = 1 − + = 0,5940 . 1! 0! Exemplo 5: experiências passadas indicam que o número de ligações recebidas, no período noturno, em uma central telefônica segue uma distribuição de Poisson. As probabilidades de receber um certo número de chamadas por hora estão apresentadas na tabela a seguir: N° chamadas 0 1 2 3 4 5 Probabilidade 0,0111 0,0500 0,1125 0,1687 0,1898 0,1708 Calcule a probabilidade de que essa central receba 3 ou mais chamadas ao longo de uma hora. Resolução Cuidado! Perceba que queremos calcular P(X≥3) = P(X=3) + P(X=4) + P(X=5) + ... que é uma soma infinita. Muitas vezes, essa tabela nos leva a um erro na hora do cálculo caso você não se lembre que a Poisson é válida para infinitos valores, no caso, do número de chamadas. Devemos, portanto, trabalhar com o complementar: P(X≥3) = 1–P(X<3) = 1- – [P(X=0) + P(X=1) + P(X=2)] = = 1 – [0,0111 + 0,0500 + 0,1125] = 0,8264 ou 82,64%. 30 2.4.2. Exercícios 1) A aplicação de fundo anticorrosivo em chapas de aço de 1 m2 é feita mecanicamente e pode produzir defeitos (pequenas bolhas na pintura), de acordo com uma variável aleatória Poisson de parâmetro λ = 1 defeitos por m2. Uma chapa é sorteada ao acaso para ser inspecionada. Qual a probabilidade de: a) encontrarmos pelo menos 1 defeito? b) no máximo 2 defeitos serem encontrados? c) encontrar entre 2 e 4 defeitos? d) não mais de 1 defeito ser encontrado? 2) Uma indústria de tintas recebe pedidos de seus vendedores através de fax, telefone e Internet. O número de pedidos que chegam por qualquer meio, durante o horário comercial, é uma variável aleatória discreta com distribuição Poisson com taxa de 5 pedidos por hora. a) Calcule a probabilidade de haver mais de 2 pedidos por hora. b) Em um dia de trabalho (8 horas), qual seria a probabilidade de haver 50 pedidos? c) Qual a probabilidade de não haver nenhum pedido em um dia de trabalho? Você diria que isso é um evento raro? 3) O pessoal de inspeção de qualidade afirma que os orlos de fita isolante apresentam, em média, uma emenda a cada 50 metros. Admitindo que a distribuição do número de emendas é dada pela Poisson, calcule a probabilidade de encontrar: a) nenhuma emenda em um rolo de 125 metros; b) no máximo duas emendas em um rolo de 125 metros. c) pelo menos uma emenda num rolo de 100 metros. 4) Certo posto de bombeiros recebe em média 3 chamadas por dia. Calcule a probabilidade de receber, em um dia: a) 4 chamadas; b) 3 ou mais chamadas. 5) A média de chamadas telefônicas numa hora é igual a 3. Qual a probabilidade de: a) receber exatamente 3 chamadas em uma hora? b) receber 4 ou mais chamadas em 90 minutos? 6) Na pintura de paredes, aparecem defeitos em média na proporção de um defeito por metro quadrado. Qual a probabilidade de aparecerem 3 defeitos numa parede de 2 x 2m? 7) Suponha que haja em média dois suicídios por ano numa população de 50000 habitantes distribuídos segundo uma Poisson. Em certa cidade com 100 000 habitantes, qual a probabilidade de que o número de suicídios em determinado ano seja: a) igual a 0? b) igual a 1? c) igual a 2? 31 d) igual a 2 ou mais? 8) Suponha que ocorram 400 erros de impressão distribuídos aleatoriamente em um livro de 500 páginas. Encontre a probabilidade de que uma dada página contenha: a) nenhum erro; b) exatamente dois erros. 9) Certa loja recebe, em média, 5 clientes por hora, segundo o modelo Poisson. Qual a probabilidade de: a) receber dois clientes em 24 minutos? b) receber pelo menos três clientes em 18 minutos? 10) A média de chamadas telefônicas em uma hora é três, segundo o modelo Poisson. Qual a probabilidade de receber: a) três chamadas em 20 minutos? b) no máximo duas chamadas em meia hora? 11) Em uma estrada passam, em média, 1,7 carros por minuto. Qual a probabilidade de passarem exatamente dois carros em dois minutos? Admita válido o modelo Poisson. 12) Uma fábrica produz tecidos com 2,2 defeitos, em média, por peça, segundo o modelo Poisson. Determine a probabilidade de haver ao menos dois defeitos em duas peças. Respostas 1) a) 0,632 b) 0,920 c) 0,261 d) 0,736 –40 2) a) 0,875 b) 0,018 c) Sim, pois a probabilidade é de e . 3) a) 0,0821 b) 0,5440 c) 0,8647 4) a) 0,1680 b) 0,5767 5) a) 0,2241 b) 0,6580 6) 0,1954 7) a) 0,0183 b) 0,0732 c) 0,1464 d) 0,9085 8) a) 0,449 b) 0,1438 9) a) 0,2707 b) 0,1912 10) a) 0,0613 b) 0,8088 11) 0,1929 12) 0,9337 32 3. Modelos Contínuos de Distribuições de Probabilidades Como já vimos, uma variável aleatória pode ser discreta ou contínua. Quando a variável é contínua, ou seja, assume valores em intervalos da reta dos números reais, a distribuição de freqüência de uma amostra de observações pode ser representada através de um histograma. Agora, porém, queremos analisar a população de onde foi retirada essa amostra. Como não temos acesso ao histograma de freqüências relativo à população, não conseguimos determinar, diretamente, o cálculo de qualquer probabilidade. Para o cálculo exato, necessitamos de um modelo para a distribuição de freqüências da população. Estudaremos, aqui, dois dos principais modelos contínuos: a Normal e a Exponencial. Os modelos que serão analisado representam comportamentos de uma extensa série de variáveis do mundo dos negócios e também distribuições teóricas de probabilidades que são fundamentais para os métodos de inferência estatística. Tais modelos são expressos por funções matemáticas denominadas funções densidade de probabilidade. A área sob a curva que expressa a função densidade de probabilidade é igual a 1 (total das probabilidades), sendo que a probabilidade de uma particular observação pertencer a um intervalo é dado pela área sob a curva, correspondente ao intervalo, conforme podemos observar na figura seguinte: 3.1. Distribuição Uniforme A Distribuição Uniforme Contínua é uma das distribuições contínuas mais simples de toda a Estatística. Ela se caracteriza por ter uma função densidade contínua em um intervalo fechado [a,b]. Ou seja, a probabilidade de ocorrência de um certo valor é sempre o mesmo. Embora as aplicações desta distribuição não sejam tão abundantes quanto as demais distribuições que discutiremos mais adiante, utilizaremos a Distribuição Uniforme para introduzirmos as funções contínuas e darmos uma noção de como se utiliza a função densidade para determinarmos probabilidades, esperanças e variâncias. 33 3.1.1. Função densidade de probabilidade A variável aleatória X tem distribuição Uniforme no intervalo [a,b] se sua densidade de probabilidade for dada por: 1 , f ( x) = b − a 0, a ≤ x ≤ b; caso contrário. Usaremos a notação X ~ U[a,b] para indicar que X segue o modelo Uniforme Contínuo no intervalo considerado. Graficamente: f(x) 1 b−a a b x Note que a área compreendida entre a função densidade e o eixo é: Área = base x altura = (b–a) . 1 = 1. b−a Ou seja, de modo simples, podemos dizer que ÁREA = PROBABILIDADE. 3.1.2. Esperança Já vimos que a esperança para variáveis discretas é calculada através da fórmula E( X) = ∑ x i .P( X = x i ) . Quando trabalhamos com variáveis contínuas, utilizamos a i função densidade. Além disso, não podemos trabalhar com o “somatório” visto que se trata de uma função contínua, ou seja, se trata do cálculo de uma área. Logo, utilizaremos integral. 34 Vamos deduzir a fórmula da esperança da distribuição Uniforme contínua: b b 1 1 x2 µ = E( X) = ∫ x.f ( x )dx = ∫ x. dx = . − − b a b a 2 a a b = a b2 − a2 a + b . = 2(b − a) 2 Logo, E( X) = a+b . 2 3.1.3. Variância Assim como já vimos, a variância de uma variável aleatória é obtida através da expressão: σ 2 = Var ( X) = E( X 2 ) − E 2 ( X) = E( X 2 ) − µ 2 . Já calculamos o valor de E(X). Vamos calcular, agora, E(X2): b b 1 1 x3 E( X ) = ∫ x .f ( x )dx = ∫ x . dx = . b−a b−a 3 a a 2 2 b = 2 a b 3 − a 3 b 2 + ab + a 2 = . 3(b − a) 3 Agora, podemos obter a variância: ( ) σ 2 = Var ( X) = E X 2 − E 2 (X ) = b 2 + ab + a 2 a + b (b − a) . − = 3 12 2 2 2 Logo, Var ( X) = (b − a )2 12 . Exemplo: com o objetivo de verificar a resistência à pressão de água, os técnicos de qualidade de uma empresa inspecionam os tubos de PVC produzidos. Os tubos inspecionados tem 6 metros de comprimento e são submetidos a grandes pressões até o aparecimento do primeiro vazamento, cuja distância a uma das extermidades (fixada à priori) é anotada para fins de análise posterior. Escolhe-se um tubo ao acaso para ser inspecionado. Denote por X a variável aleatória que indica a distância correspondente ao vazamento. Assuma que X tem uma distribuição Uniforme Contínua. a) Determine a função densidade de probabilidade. b) Construa o gráfico da função densidade. c) Utilizando apenas a função, determine a probabilidade de que o vazamento esteja, no máximo, a 1 metro das extremidades. 35 d) Utilizando apenas o gráfico construído no item b, determine a probabilidade de que o vazamento esteja, no máximo, a 1 metro das extremidades. Resolução a) Temos, a partir do enunciado, que X ~ U[0,6]. Logo: 1 , f (x) = 6 0, b) 0 ≤ x ≤ 6; caso contrário. f(x) 1 6 x 0 6 c) Utilizando a função densidade: 1 1 6 6 1 1 x x 1 6 5 1 P(0 ≤ X ≤ 1) + P(5 ≤ X ≤ 6 ) = ∫ dx + ∫ dx = + = −0+ − = . 6 6 60 65 6 6 6 3 0 5 Portanto, a probabilidade desejada vale 1 . 3 d) usando apenas o gráfico construído, basta lembrarmos que probabilidade é equivalente a área sob o gráfico da função densidade: 36 f(x) 1 6 x 0 1 5 6 A área hachurada é igual a probabilidade procurada: 1 1 1 P(0 ≤ X ≤ 1) + P(5 ≤ X ≤ 6) = 1. + 1. = , 6 6 3 que é igual ao resultado obtido no cálculo do item c. 3.1.4. Exercícios 1) Sendo X ~ U[0,4], calcule: a) P(X > 2). b) P(X ≥ 2). c) P(1 < X < 2). 2) Admite-se que uma pane pode ocorrer em qualquer ponto de uma rede elétrica de 10 km. a) Qual é a probabilidade de a pane ocorrer nos primeiros 500 metros? E de ocorrer nos 3 km centrais da rede? b) O custo de reparo da rede depende da distância do centro de serviço ao local da pane. Considere que o centro de serviço está na origem da rede e que o custo é de R$ 200 para distâncias até 3 km, de R$ 400 entre 3 e 8 km e de R$ 1000 para as distâncias acima de 8 km. Qual é o custo médio do conserto? 3) O tempo necessário para um medicamento contra dor fazer efeito foi modelado de acordo com a densidade Uniforme no intervalo de 5 a 15 minutos tendo por base experimentos conduzidos em animais. Um paciente, que esteja sofrendo dor, recebe o remédio e, supondo válido o modelo mencionado, qual a probabilidade da dor: a) cessar em até 10 minutos? b) demorar pelo menos 12 minutos até cessar? 37 4) Suponha que o valor esperado de uma variável aleatória com distribuição Uniforme contínua é 1 e a variância é igual a 1/12. Encontre a probabilidade da variável assumir valores menores que 3/4. Respostas 1) a) ½ b) ½ c) ¼ 2) X ~ U[0,10] a) 1/20 e 3/10 b) 460 3) X ~U[5,15] a) ½ b) 3/10 4) Resolva um sistema com os valores da média e da variância para determinar quanto valem os parâmetros a e b. P(X < ¾) = ¼ . 38 3.2. Distribuição Exponencial Há uma estreita relação entre a distribuição Exponencial e a distribuição de Poisson. O modelo de distribuição de probabilidade que descreve o tempo, ou espaço, entre dois sucessos consecutivos de uma variável de Poisson é a distribuição exponencial. Assim, por exemplo, o tempo entre falhas de equipamentos, o tempo entre chegadas de clientes a um shopping, a área entre dois defeitos consecutivos de uma peça de tecido, etc., são descritos pela distribuição Exponencial. Uma variável aleatória contínua X, que assuma todos os valores reais não negativos, terá uma distribuição Exponencial com parâmetro λ >0 se a sua função densidade de probabilidade for dada por: λ.e − λ. x , se t ≥ 0; f (x) = , caso contrário. 0 3.2.1. Média e Variância da Distribuição Exponencial Se uma variável X possui distribuição Exponencial com parâmetro λ , então: Média ou Esperança: E( X) = Variância: Var ( X) = 1 . λ 1 . λ2 Conseqüentemente: Desvio padrão: DP( X) = 1 . λ 3.2.2. Cálculo de Probabilidades Lembrando que a probabilidade é a área compreendida entre o eixo x e a curva do gráfico da função densidade de probabilidade, podemos calcular as probabilidades da distribuição Exponencial utilizando a função densidade juntamente com uma integral definida. Porém, podemos, também, utilizar as seguintes fórmulas para o cálculo: P( X > t ) = e − λ.t . Logo: 39 P( X ≤ t ) = 1 − e − λ.t . Fazendo um esboço gráfico temos: Exemplo 1: suponha que, em determinado período do dia, o tempo médio de atendimento em um caixa de banco seja de 5 minutos. Admitindo que o tempo para atendimento tenha distribuição exponencial, determinar a probabilidade de um cliente: a) esperar mais do que 5 minutos; b) esperar menos do que 4 minutos; c) esperar entre 3 e 8 minutos. Resolução Seja a variável aleatória X: tempo de atendimento. Foi dado que o tempo médio de atendimento é de 5 minutos. Vimos que a média, ou esperança, de uma 1 1 1 variável com distribuição exponencial é E( X) = . Logo: = 5 ⇒ λ = = 0,2 , que λ λ 5 é o parâmetro da distribuição. a) Vimos que: P( X > t ) = e − λ.t . Então: P(X>5) = e-0,2.5 = 0,3679 ou 36,79%. b) Vimos que P( X > t ) = e − λ.t . Logo: P( X ≤ 4) = 1 − e −0,2.4 = 0,5507 ou 55,07%. c) Graficamente, esperar entre 3 e 8 minutos corresponde à região hachurada: 40 Essa área (probabilidade) pode ser calculada da seguinte forma: P(3 < X < 8) = P(X > 3) – P(X > 8) = e–0,2.3 – e–0,2.8 = 0,5488 – 0,2019 = 0,3469. 3.2.3. Distribuição Exponencial aplicada à Teoria da Confiabilidade Na teoria da confiabilidade de componentes, ou sistemas, calculam-se as probabilidades de que o componente, ou sistema, não venha a falhar durante um intervalo [O, t0], ou seja: a probabilidade de que o componente ainda esteja funcionando na época t0. Uma das mais importantes leis de falhas é aquela cuja duração até falhar é descrita pela distribuição exponencial. Admite-se que a taxa de falhas é constante, isto é, depois que a peça (equipamento, sistema etc.) esteja em uso, sua probabilidade de falha não se altera. Logo, não se considera o efeito do desgaste quando o modelo exponencial é admitido. Por exemplo, considerando-se uma taxa de falhas constante, o funcionamento de um rolamento, a qualquer momento, é tão bom quanto novo, e nestes casos o modelo de distribuição de tempo até falhar é exponencial. Exemplo 2: Suponha que a duração da vida de um dispositivo eletrônico seja exponencialmente distribuída com tempo médio entre falhas de 100 horas. a) Qual a probabilidade de o dispositivo não falhar em 150 horas de uso? b) Qual o número de horas para se ter confiabilidade de 90% (isto é, 90% de probabilidade de não falhar)? Resolução Como E( X) = 1 1 1 , então 100 = ⇒ λ = = 0,01. λ λ 100 a) P(X>150) = e–0,01.150 = 0,2231 ou 22,31%. b) Queremos encontrar um valor t de modo que: P(X > t) = 0,90 e–0,01.t = 0,90 Aplicando logaritmo nos dois lados da igualdade temos: 41 ln e–0,01.t = ln 0,90 –0,01.t = ln 0,90 ln 0,90 t=− 0,01 t = 10,54 horas. Ou seja, há 90% de confiabilidade de o dispositivo não falhar antes de 10,54 horas. Exemplo 3: uma indústria fabrica lâmpadas especiais que ficam em operação continuamente. A empresa oferece a seus clientes a garantia de reposição, caso a lâmpada dure menos de 50 horas. A vida útil dessas lâmpadas é modelada através da distribuição exponencial e possui, para t ≥ 0, a seguinte função 1 − .t 1 densidade de probabilidade: f ( t ) = .e 8000 . Qual a porcentagem de lâmpadas 8000 que essa indústria deverá repor a seus clientes, a título de garantia? Comparando com a função densidade da distribuição Exponencial λ.e − λ.x , se t ≥ 0; f (x) = , percebemos que o nosso parâmetro vale , caso contrário. 0 1 . Queremos calcula a seguinte probabilidade: λ= 8000 P(T < 50 ) = 1 − e − 1 .50 8000 = 0,006 . Ou seja, a proporção de trocas por defeito de fabricação será de aproximadamente 0,6%. Esse número é relativamente pequeno, algo natural, visto 1 , a média da distribuição é que como o parâmetro vale λ = 8000 1 1 µ= = = 8000 horas. 1 λ 8000 3.2.4. Exercícios 1) Uma lâmpada tem a duração de acordo com a densidade de probabilidade a seguir: ,t < 0 0 t f(t) = 1 . Determine: − .e 1000 , t ≥ 0 1000 42 a) a probabilidade de que uma lâmpada qualquer queime antes de 1.000 horas; b) a probabilidade de que uma lâmpada qualquer queime depois de sua duração média; c) o desvio padrão da distribuição. 2) O tempo de atendimento numa oficina é aproximadamente exponencial com média de quatro minutos. Qual é a probabilidade de: a) espera superior a quatro minutos? b) espera inferior a cinco minutos? c) espera de exatamente quatro minutos? 3) Sabemos que o intervalo entre ocorrências sucessivas de uma doença contagiosa é uma variável aleatória que tem distribuição exponencial com média de 100 dias. Qual é a probabilidade de não se ter registro de incidência da doença por pelo menos 200 dias a partir da data em que o último caso for registrado? 4) Se as interrupções no suprimento de energia elétrica ocorrem segundo uma distribuição de Poisson com a média de uma interrupção por mês (quatro semanas), qual a probabilidade de que entre duas interrupções consecutivas haja um intervalo de: a) menos de uma semana? b) entre 10 e 12 semanas? c) exatamente um mês? d) mais de três semanas? DICA: calcule o parâmetro da distribuição de Poisson. Ele será o mesmo na Exponencial. 5) A duração de certo tipo de condensador tem distribuição exponencial com média de 200 horas. Qual a proporção de condensadores que duram: a) menos de 100 horas? b) mais de 500 horas? c) entre 200 e 400 horas? 6) Uma companhia fabrica lâmpadas especiais com uma duração média de 100 horas e distribuição exponencial. a) Qual deve ser a garantia do fabricante para repor apenas 5% da produção? b) Qual a probabilidade de uma lâmpada durar de 163 a 185 horas? 7) O tempo necessário para eliminar o perigo de contaminação de certo pesticida, após sua aplicação em um pomar, é uma variável aleatória Exponencial de parâmetro 2 (em anos). O maior ou menor tempo depende de fatores como chuva, vento e umidade da região. Tendo em vista esse comportamento, as autoridades sanitárias recomendam que o contato direto ou indireto com as frutas pulverizadas seja evitado por algum tempo após a aplicação. a) Calcule a probabilidade de uma fruta desse pomar, escolhida ao acaso, não estar mais contaminada após 1 ano da pulverização. b) Qual é a nossa “segurança” se aguardarmos 2 anos para consumir essas frutas? 43 Respostas 1) a) 0,6321 b) 0,3679 c) 1000 horas 2) a) 0,3679 b) 0,7135 c) 0 3) 0,1353 4) a) 0,2212 b) 0,0323 c) 0 d) 0,4724 5) a) 0,3935 b) 0,0821 c) 0,2325 6) a) 5,13 h b) 0,0387 7) a) 0,865 b) A probabilidade da contaminação se encerrar em até 2 anos é 0,982. 44 3.3. Distribuição Normal “O mundo é normal!” Acredite se quiser! Muitos dos fenômenos aleatórios que encontramos na prática apresentam uma distribuição muito peculiar, chamada Normal. Um modelo probabilístico é aquele que nos diz, ou melhor, nos traduz na forma de números o comportamento de uma variável. Por exemplo, já fizemos algumas análises das variáveis altura e peso. Considerando o caso de grandes amostras aleatórias ou mesmo da população, tanto o peso como a altura tem um comportamento muito parecido. Vejamos, por exemplo, a variável altura, considerando-se o sexo masculino e sendo a população os habitantes do Brasil. Essa variável é dita Normal, conforme discutiremos mais adiante. Essa distribuição de freqüência denominada curva normal, considerada um modelo teórico ou ideal que resulta muito mais de uma equação matemática do que de um real delineamento de pesquisa com coleta de dados. A curva normal é um tipo de curva simétrica, suave, cuja forma lembra um sino. Ela é unimodal, sendo seu ponto de freqüência máxima situado no meio da distribuição, em que a média, a mediana e a moda coincidem. Para exemplificarmos, suponhamos 2000 lançamentos de 200 moedas honestas. Utilizando um software de simulação, obtivemos os seguintes resultados: [80 ... 81] [82 ... 83] [84 ... 85] [86 ... 87] [88 ... 89] [90 ... 91] [92 ... 93] [94 ... 95] [96 ... 97] [98 ... 99] 5 6 16 19 39 60 91 111 165 194 45 [100 ... 101] [102 ... 103] [104 ... 105] [106 ... 107] [108 ... 109] [110 ... 111] [112 ... 113] [114 ... 115] [116 ... 117] [118 ... 119] [120 ... 121] [122 ... 123] [124 ... 125] [126 ... 127] 227 220 206 174 155 123 84 49 21 18 6 8 2 1 sample mean = 102.132 sample st dev = 7.238 A partir desses dados, construímos o histograma: 227 Freq 0 79.50 heads 127.50 Observando tal histograma e a tabela anterior, notamos que a média está entre as duas classes com maior freqüências. Além disso, considerando-se a média, percebemos que o histograma parece ser simétrico ao redor dela. A freqüência é menor quanto mais nos afastamos da média, tanto para mais quanto para menos, sendo que as menores freqüências ocorrem nas pontas do gráfico. Note que quanto mais classes usamos, mais fácil fica identificarmos um formato criado pelas colunas do histograma. Esse formato faz lembrar um sino, conforme a figura seguinte: 46 227 Freq 0 79.50 heads 127.50 “Limpando” o gráfico acima, temos: 80.0 90.0 100.0 110.0 120.0 130.0 Média = 102,3 Essa curva que chamamos de sino recebe um nome especial: Curva Normal. A Curva Normal é a representante do modelo normal e é obtida a partir da função densidade que nada mais é do que uma função que origina o gráfico anterior. Assim, se X é uma variável aleatória com distribuição Normal com média µ e variância σ2 (notação: X ~ N(µ, σ2)) então a sua função densidade é dada por f (x) = 1 σ 2π e − ( x − µ )2 2σ2 A Normal apresenta as seguintes propriedades: - é simétrica ao redor da média; - a área sobre a curva é igual a 1; 47 - para valores muito grandes de x, tendendo a infinito (ou muito pequenos, tendendo a menos infinito), a curva tende a zero. Note que conforme o caso, poderemos ter curvas com formatos diferentes, ou seja, mais para a direita, mais para a esquerda, mais ou menos achatadas... enfim, cada caso poderá gerar uma curva diferente. Vejamos mais um caso. Consideremos o lançamento de dois dados não viciados. Estamos interessados em analisar a soma dos resultados obtidos em cada jogada. Realizando uma simulação e construindo o histograma dos resultados, obtemos: 173 Freq 0 1.50 sum 12.50 No caso simulado, obtivemos: sample mean = 7.07200 sample st dev = 2.34282 Ou seja, µ = 7,07 e s = 2,34, onde µ indica a média e s o desvio padrão da amostra. Isolando a curva da normal temos: 48 0.1 −1.0 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 9.0 10.011.012.013.014.015.016.0 Assim, conforme havíamos dito, existem diferentes curvas, que variam conforme os valores da média e do desvio-padrão. Lembramos que a área abaixo desse gráfico vale 1. Ou seja, a área corresponde a uma probabilidade. 3.3.1. Área sob a Curva Normal É aquela região do plano compreendida entre a curva e o eixo das abscissas, que corresponde em qualquer distribuição normal a 100% dos dados considerados. Exemplo 1: consideremos uma população de uma cidade A e de uma outra cidade B. Suponhamos que todas as pessoas tenham informado as respectivas alturas (em centímetros). E deseja-se fazer uma comparação entre tais populações. As principais estatísticas obtidas por essa pesquisa foram: População A População B 174 178 Média (µ) 2 64 1 Variância (σ ) Um pesquisador deseja sortear aleatoriamente pessoas para fazer um teste sobre DNA e crescimento e, para isso, gostaria de coletar (aleatoriamente!) pessoas com mais de 1,80m. Em qual das duas populações será mais fácil achar pessoas com tais características? Para isso, podemos dizer que estamos trabalhando com duas variáveis: XA: altura de 1 pessoa selecionada ao acaso na população A XB: altura de 1 pessoa selecionada ao acaso na população B Nosso objetivo é calcular as seguintes probabilidades: P(XA > 180) e P(XB > 180). 49 Mas antes, calculemos o valor do desvio-padrão (σ) de cada uma das populações. Lembrando que o desvio-padrão nada mais é do que a raiz quadrada da variância. Logo: σ A = 64 = 8 σB = 1 = 1 Utilizando um software é possível calcularmos tais probabilidades. Esse software calcula, na verdade, a área abaixo da curva: P(XA > 180) = 0,2266 ou 22,66%. P(XB > 180) = 0,0228 ou 2,28%. Portanto, o pesquisador terá mais facilidade de achar pessoas com mais de 1,80m na população A. Aleatoriamente falando, tal probabilidade é de 22,66%. Esse resultado pode parecer estranho, visto que a população B possui uma média de alturas superior ao da população A. Porém, tal fato é explicado através da variabilidade dos resultados, ou melhor, pelo desvio-padrão. Exemplo 2: Consideremos, ainda, o exemplo anterior. Só que, agora, temos interesse em obter pessoas que tenham entre 1,75m e 1,80m. Qual população possui um número maior de habitantes nessa faixa de altura? Aqui, queremos calcular as seguintes probabilidades: P(175 < XA < 180) e P(175 < XB < 180) . Novamente, usando um software, obtemos: P(175 < XA < 180) = 0,2236 e P(175 < XB < 180) = 0,9759. Portanto, é evidente que a população B, mais uma vez, representa a melhor escolha, pois a probabilidade de escolhermos uma pessoa nessa faixa de altura na população B é quase 100%, ou seja, quase todos habitantes possuem as alturas procuradas. Meu computador “deu pau”! Como calcular as probabilidades da Normal? USE A NORMAL PADRÃO ! 50 3.3.2. Normal Padrão Em muitos livros de Estatística podemos encontrar uma tabela da Normal Padrão. É uma tabela que nos fornece valores das áreas (= probabilidades) de acordo com o valor de x, exatamente como fizemos nos exemplos anteriores com o auxílio do software Winstats. A maioria dos softwares de Estatística possuem comandos que permitem calcularmos o valor das áreas sobre curvas como a Normal, dentre eles, o SAS, o Excel, o S-PLUS, e outros. Porém, se não temos acesso a um computador, podemos usar a Tabela da Normal. Mas, como dissemos anteriormente, existem diversas curvas da normal, que variam segundo a média e variância. Isso significa que teríamos que ter inúmeras tabelas da normal... o que não parece muito viável. Dessa forma, criou-se uma maneira mais simples de se obter as áreas desejadas. Criou-se uma curva denominada Normal Padrão, que corresponde a uma distribuição normal com média zero e desvio-padrão um. Geralmente a variável aleatória associada à distribuição normal padrão é chamada de Z. Em notação: Z ~ N(0,1), ou seja, µZ = 0 e σZ = 1 A grande vantagem de usarmos tal distribuição é o fato de trabalharmos apenas com uma distribuição e, portanto, com uma única tabela. Tudo é mais fácil! Porém, como fazer para obtermos tal variável Z (padronizada) a partir de uma variável aleatória qualquer X tal que X ~ N(µ, σ2) ? Basta padronizarmos ou normalizarmos a variável X através da fórmula: Z= X−µ σ onde: µ = média de X σ = desvio-padrão de X 3.3.2. Usando a tabela da Normal Padrão Existem algumas variações de apresentação da tabela. No nosso caso, utilizaremos uma tabela tal que P(0 ≤ Z ≤ zc) = p, ou seja, a probabilidade fornecida pela tabela (p) corresponde ao intervalo que vai de 0 até um certo número zc no eixo x. Esquematicamente, a tabela da normal nos fornece a probabilidade correspondente à área a seguir: 51 p 0 zc Leitura da Tabela Veja, esquematicamente, como deve ser a leitura da tabela: 2ª casa decimal de Z Parte inteira e 1ª casa decimal de Z Probabilidade Exemplo 3 – Padronização Voltemos ao caso do exemplo anterior onde tínhamos µ = 174 e σ = 8. Queríamos calcular P(X > 180). Vamos normalizar a variável X (ou seja, transformá-la em Z) e utilizar a tabela para obter a probabilidade desejada. X − µ 180 − 174 P( X > 180 ) = P > = P(Z > 0,75 ) 8 σ Para obtermos a probabilidade desejada, devemos lembrar que a nossa tabela nos fornece a probabilidade de 0 até um certo valor. 52 Consultando a tabela da Normal Dado Z = 0,75, vejamos como obter a probabilidade a partir da tabela da Normal Padrão. Na coluna mais à esquerda, tomamos a parte inteira e a primeira decimal de Z, no caso, 0,7. Na linha superior, observamos o valor da segunda casa decimal, no caso 5 (lembre-se que o número é 0,75). A célula correspondente á linha do número 0,7 e da coluna de 5 é o valor da probabilidade. No caso, p=0,2734. Segunda casa decimal de z Parte inteira e primeira decimal de z 0 1 2 3 4 5 0,0 0,0000 0,0040 0,0080 0,0120 0,0160 0,0199 0,0239 0,0279 0,0319 0,0359 6 7 8 9 0,1 0,0398 0,0438 0,0478 0,0517 0,0557 0,0596 0,0636 0,0675 0,0714 0,0753 0,2 0,0793 0,0832 0,0871 0,0910 0,0948 0,0987 0,1026 0,1064 0,1103 0,1141 0,3 0,1179 0,1217 0,1255 0,1293 0,1331 0,1368 0,1406 0,1443 0,1480 0,1517 0,4 0,1554 0,1591 0,1628 0,1664 0,1700 0,1736 0,1772 0,1808 0,1844 0,1879 0,5 0,1915 0,1950 0,1985 0,2019 0,2054 0,2088 0,2123 0,2157 0,2190 0,2224 0,6 0,2257 0,2291 0,2324 0,2357 0,2389 0,2422 0,2454 0,2486 0,2517 0,2549 0,7 0,2580 0,2611 0,2642 0,2673 0,2704 0,2734 0,2764 0,2794 0,2823 0,2852 0,8 0,2881 0,2910 0,2939 0,2967 0,2995 0,3023 0,3051 0,3078 0,3106 0,3133 0,9 0,3159 0,3186 0,3212 0,3238 0,3264 0,3289 0,3315 0,3340 0,3365 0,3389 1,0 0,3413 0,3438 0,3461 0,3485 0,3508 0,3531 0,3554 0,3577 0,3599 0,3621 Então: 0.4 p=0,2734 0.3 Em vermelho, temos a área (probabilidade) fornecida pela tabela. 0.2 0.1 −3.0 −2.0 −1.0 1.0 2.0 3.0 0,75 53 0.4 0.3 Em laranja, temos a área (probabilidade) que desejamos obter. 0.2 0.1 −3.0 −2.0 −1.0 1.0 2.0 3.0 0,75 Como fazer para calcular o valor desejado a partir do valor da tabela? Bem, é preciso relembrar as propriedades da curva da normal, em especial duas delas: 1) a área abaixo da curva é igual a 1; 2) a curva é simétrica em torno da média (no caso da normal padrão, em torno do zero). Logo, concluímos, que a área correspondente à metade da curva é igual a 0,5: 0.4 0.3 p = 0,5 0.2 0.1 −3.0 −2.0 −1.0 1.0 2.0 3.0 Então, podemos observar que: P(0 ≤ Z ≤ 0,75) + P(Z > 0,75) = 0,5 ⇒ P(Z > 0,75) = 0,5 – P(0 ≤ Z ≤ 0,75) ⇒ P(Z > 0,75) = 0,5 – 0,2734 ⇒ 54 P(Z > 0,75) = 0,2266 Logo, a probabilidade procurada é de 0,2266 que corresponde ao mesmo valor obtido utilizando-se o software (exemplos anteriores). Exemplo 4 – Padronização Consideremos a mesma situação das alturas, ou seja, µ = 178, σ = 1 e queríamos calcular a probabilidade P(175 < X < 180). Normalizando a variável X temos: 175 − 178 X − µ 180 − 178 P(175 < X < 180 ) = P < < = P( −3 < Z < 2) σ 1 1 Graficamente: 0.4 0.3 Em vermelho, temos a área (probabilidade) que desejamos obter. 0.2 0.1 −3.0 −2.0 −1.0 1.0 2.0 3.0 Porém, a nossa tabela só nos fornece os valores: 0.4 0.3 0,4772 0.2 0.1 −3.0 −2.0 −1.0 1.0 2.0 3.0 55 E, também, fornece o valor de: 0.4 0,4987 0.3 Lembre-se que, como a curva é simétrica, a área correspondente ao intervalo de 3 à 0 é igual a área de 0 à 3! 0.2 0.1 −3.0 −2.0 −1.0 1.0 2.0 3.0 Logo, a área procurada corresponde à soma das áreas parciais: P(–3 < Z < 2) = 0,4772 + 0,4987 = 0,9759, que é igual à probabilidade obtida através do software (exemplos anteriores). Assim, mostramos que a tabela pode ser muito útil, principalmente quando não temos um computador ou software adequado por perto. Exemplo 5 – Teste de aptidão Em um certo teste de aptidão para contratação de determinada empresa, os candidatos devem realizar uma seqüência de tarefas no menor tempo possível. Suponhamos que o tempo necessário para completar esse teste tenha uma distribuição Normal com média 45 minutos e desvio-padrão de 20 minutos. Suponhamos que, numa primeira etapa, esse teste foi aplicado com uma amostra de 50 candidatos. Qual a probabilidade de encontrarmos algum candidato que tenha um tempo superior a 50 minutos (candidato muito lento) ou inferior a 30 minutos (que seria impossível completar o teste)? Qual o número aproximado de candidatos com tal perfil? Inicialmente, seja X uma variável que indique o tempo de execução das tarefas tal que X ~ N(45, 202). Desejamos calcular: P(X > 50) + P(X < 35) = X − µ 50 − 45 X − µ 30 − 45 = P > < + P = 20 20 σ σ = P(Z > 0,25) + P (Z < -0,75) = 56 −3.0 −2.0 0.4 0.4 0.3 0.3 0.2 0.2 0.1 0.1 −1.0 1.0 2.0 3.0 4.0 −3.0 −2.0 −1.0 1.0 2.0 3.0 4.0 = (0,5 – 0,0987) + (0,5 – 0,2734) = = 0,6279 ou 62,79% Como 0,6279 . 50 = 31,39, temos que o número de pessoas aproximado que contenham tais característica é de 32 pessoas. Então, nesse teste a empresa já exclui 32 candidatos, restando apenas 18 para continuarem no processo de seleção. 3.3.3. Resumo das Propriedades da Distribuição Normal 1ª) A variável aleatória X pode assumir todo e qualquer valor real. 2ª) A representação gráfica da distribuição normal é uma curva em forma de sino, simétrica em torno da média, que recebe o nome de curva normal ou de Gauss. 3ª) A área total limitada pela curva e pelo eixo das abscissas é igual a 1, já que essa área corresponde à probabilidade de a variável aleatória X assumir qualquer valor real. 4ª) A curva normal é assintótica em relação ao eixo das abscissas, isto é, aproxima-se indefinidamente do eixo das abscissas sem, contudo, alcançá-lo. 5ª) Como a curva é simétrica em torno da média, a probabilidade de ocorrer valor maior que a média é igual à probabilidade de ocorrer valor menor do que a média, isto é, ambas as probabilidades são iguais a 0,5 ou 50%. Cada metade da curva representa 50% de probabilidade. 6ª) Uma variável Normal X com média µ e desvio padrão σ pode ser X−µ transformada em uma variável Normal Padrão Z pela fórmula Z = . σ 57 Exemplo 6: Qual a probabilidade de escolher-se de forma aleatória, numa só tentativa, uma pessoa que tenha renda anual entre US$ 4.000 e US$ 7.000, morador de uma cidade. Sendo a renda média desta cidade US$ 5.000 e o desvio padrão de US$ 1.500? Sabe–se que a renda populacional possui uma distribuição Normal. Sendo X: renda anual de uma pessoa em dólares, temos: 7000 − 5000 4000 − 5000 P( 4000 < X < 7000 ) = P <Z< = P( −0,67 < Z < 1,33 ) 1500 1500 Consultado a tabela da normal, verificamos que a probabilidade entre z=0 e z=1,33 vale 0,1293. A probabilidade entre z=0 e z=–1,33 é igual, devido à simetria da curva, à probabilidade entre z=0 e z=1,33 e vale 0,4082. Logo: P(–0,67<Z<1,33) = 0,1293 + 0,4082 = 0,5375 ou 53,75%. Exemplo 7: Os pesos de 600 estudantes são normalmente distribuídos com média 65,3 kg e desvio padrão 5,5 kg. Determine o número de estudantes que pesam: a) entre 60 kg e 70 kg b) mais que 63,2 kg c) mais que 72 kg Resolução Seja X: peso de um estudante em kg. 80 − 65,3 70 − 65,3 a) P(70 < X < 80 ) = P <Z< = P(0,85 < Z < 2,67 ) = 5,5 5,5 = 0,4962 – 0,3023 = 0,1939. Logo, haverá 0,1939 . 600 = 116,34 ~ 116 estudantes pesando entre 70kg e 80kg. 63,2 − 65,3 b) P( X > 63,2) = P Z > = P( Z > −0,38 ) = 0,5 + 0,1480 = 0,6480 . 5,5 Portanto, espera–se encontrar 0,6480 . 600 = 388,8 ~ 389 estudantes com peso superior a 63,2kg. 72 − 65,3 c) P( X > 72) = P Z > = P( Z > 1,22) = 0,5 − 0,3888 = 0,1112 . 5,5 Assim, devemos encontrar 0,1112 . 600 = 66,72 ~ 67 estudantes com mais de 72kg. 58 Exemplo 8: sendo Z uma variável Normal Padrão, calcule as seguintes probabilidades: a) P (0 < Z < 1,44) b) P (–1,48< Z < 2,05) c) P (Z > –2,03) d) P (Z > 2,03) e) P (0,72 < Z < 1,89) f) P (0,72 ≤ Z < 1,89) g) P (0,72 < Z ≤ 1,89) h) P (0,72 ≤ Z ≤ 1,89) i) P(Z = 0,72) j) P(Z = 1,89) k) P(Z>4,5) l) P(Z<4,5) Resolução Observe que a variável já está padronizada. Logo, basta consultarmos a tabela para efetuar os cálculos. Sugestão: para compreender melhor, sempre faça um esboço da área procurada. a) P (0 < Z < 1,44) = 0,4251 b) P (–1,48< Z < 2,05) = 0,4306 + 0,4798 = 0,9104 c) P (Z > –2,03) = 0,5 + 0,4788 = 0,9788 d) P (Z > 2,03) = 0,5 – 0,4788 = 0,0212 e) P (0,72 < Z < 1,89) = 0,4706 – 0,2642 = 0,2064 Para os itens seguintes, perceba que há apenas a alteração entre os símbolos < e ≤. Pensando que a probabilidade corresponde a área sob a curva e que a área sob um único ponto é uma linha e, portanto, tem área igual a zero, concluímos que a adição ou remoção de um ponto não interfere no resultado final. Ou seja: f) P (0,72 ≤ Z < 1,89) = 0,2064 g) P (0,72 < Z ≤ 1,89) = 0,2064 h) P (0,72 ≤ Z ≤ 1,89) = 0,2064 A área sob um ponto é uma linha, ou seja, a área é igual a zero: i) P(Z = 0,72) = 0 j) P(Z = 1,89) = 0 Note que a tabela não possui valores de probabilidade para z muito grande (geralmente acima de 4, dependendo da tabela utilizada). Ao mesmo tempo, note que para os últimos valores da tabela, a probabilidade se aproxima de 0,5. Então: k) P(Z>4,5) = 0,5 – 0,5 = 0 l) P(Z<4,5) = 0,5 + 0,5 = 1 59 Exemplo 9: Se X é uma variável aleatória tal que X~N(20; 49), Calcule P(X<30). Pela notação da distribuição Normal, X possui média 20 e variância 49. Logo, o desvio padrão vale 7. Assim: 30 − 20 P( X < 30 ) = P Z < = P( Z < 1,43 ) = 0,5 + 0,4236 = 0,9236 . 7 Exemplo 10: o salário semanal dos operários de construção civil de certo país é distribuído normalmente em torno da média de $ 80, com desvio padrão de $5. a) Qual é o valor do salário para escolhermos 10% dos operários com maiores remunerações? b) Qual é o maior salário correspondente aos 20% dos trabalhadores que ganham menos? Resolução Este exemplo é o contrário dos anteriores. Antes, conhecíamos o valor da variável X, padronizávamos para a variável Z e, usando a tabela da Normal Padrão, obtínhamos o valor da probabilidade procurada. Aqui, vamos fazer exatamente o mesmo caminho só que ao contrário. a) Queremos calcular um salário a de modo que: P(X>a) = 0,10. Padronizando: a − 80 P Z > = 0,10 . 5 Ou seja, nosso interesse é procurar um valor de z na tabela de modo que a área da curva a seguir seja 0,10. 60 0,10 z=? Consequentemente, vamos procurar na tabela o valor que mais se aproxima de 0,40 (veja a figura seguinte): 0,40 z=? Observando a tabela, encontramos o valor de z mais próximo à probabilidade 0,40: 61 Ou seja, o valor de z desejado é z=1,28. Isso significa que P(Z>1,28) ≅ 0,10. a − 80 Comparando com a expressão obtida P Z > = 0,10 , temos a seguinte 5 igualdade: a − 80 = 1,28 5 Portanto, a=86,4. Conclusão: existem 10% dos operários que ganham acima de $86,40. Esse é, portanto, o salário procurado. b) Agora, desejamos saber o salário b que separa os 20% que ganham menos dos demais, ou seja: P(X<b)=0,20 b − 80 P Z < = 0,20 5 Graficamente, queremos achar, na tabela da Normal Padrão, o valor de z que satisfaz ao gráfico: 62 0,30 0,20 z=? Observando a tabela da Normal Padrão, devemos procurar a probabilidade mais próxima de 0,30: Ou seja, o valor procurado é z=0,84. Porém, olhando o último gráfico, devemos ficar atento para o fato de que o valor que desejamos está à esquerda do zero, ou seja, é um valor negativo. Devido à simetria da curva da Normal, concluímos que o valor de z que realmente queremos é z=–0,84. Em outras palavras, temos que P(Z<–0,84) ≅ 0,20. Logo: 63 b − 80 = −0,84 e, portanto, b=75,8. 5 Assim, o salário semanal de $ 75,80 separa os 20% dos operários que recebem menos. Exemplo 11: em uma escola, as notas de um exame são normalmente distribuídos com média de 72 pontos e desvio padrão de 9. O professor atribuirá conceito A aos 8% dos melhores alunos. Qual a menor nota (valor inteiro) que um aluno pode tirar de modo a garantir um conceito A? Seja k a nota procurada e seja X a variável que representa a nota de um aluno. Queremos: P(X>k)=0,08 k − 72 P Z > = 0,08 . 9 Buscando na tabela da normal o valor de z que mais se aproxima da probabilidade igual a 0,5–0,08=0,42, encontramos z=1,41. Ou seja, P(Z>1,41)=0,08. Logo: k − 72 = 1,41 ⇒ k = 84,69 . Ou seja, a menor nota que o aluno deve tirar para 9 garantir um conceito A é 85. 3.3.4. Exercícios 1) O tempo necessário em uma oficina para o conserto da transmissão de um tipo de carro segue distribuição normal com média de 45 minutos e desvio-padrão de 8 minutos. O mecânico comunicou a um cliente que o carro estará pronto em 50 minutos. Qual probabilidade do mecânico atrasar o seu serviço? 2) A duração de certo componente eletrônico pode ser considerada normalmente distribuída com média de 850 dias e desvio padrão de 45 dias. Calcular a probabilidade de um componente durar: a) Entre 700 e 1000 dias b) Mais de 800 dias c) Menos de 750 dias 3) Determinado atacadista efetua suas vendas por telefone. Após alguns meses, verificou-se que os pedidos se distribuem normalmente com média de 3.000 pedidos e desvio-padrão de 180 pedidos. Qual a probabilidade de que um mês selecionado ao acaso esta empresa venda menos de 2700 pedidos. 4) O conteúdo líquido das garrafas de 300 ml de um refrigerante é normalmente distribuído com média de 300 ml e desvio padrão de 2 ml. Determine a probabilidade de uma garrafa selecionada ao acaso apresentar conteúdo líquido: a) inferior a 306 ml 64 b) Superior a 305 ml c) entre 302 e 304 ml 5) O lucro mensal obtido com ações de determinada empresa tem distribuição normal com média de 12 mil reais e desvio padrão de 5 mil reais. Qual a probabilidade de que em determinado mês o lucro desta empresa seja: a) superior a 18 mil reais b) inferior a 8 mil reais c) entre 10 e 15 mil reais 6) Durante o mês de dezembro aumenta a procura por concessão de crédito para pessoa física. De acordo com dados históricos é possível verificar que a procura segue uma distribuição aproximadamente normal com média de 12,8 milhões e desvio padrão de 15 milhões. Se as instituições de crédito reservarem 25 milhões para concessão de crédito, qual a probabilidade de faltar dinheiro para emprestar? 7) Suponha que a renda média anual de uma grande comunidade tenha distribuição normal com média de 15 mil reais e com um desvio-padrão de 3 mil reais. Qual a probabilidade de que um indivíduo aleatoriamente selecionado deste grupo apresente uma média salarial anual superior a 18 mil reais? 8) O escore de um estudante no vestibular é uma variável com distribuição normal com média de 550 pontos e desvio padrão de 30 pontos. Se a admissão em certa faculdade exige um escore mínimo de 575 pontos, qual é a probabilidade de um aluno ser admitido nesta faculdade? 9) As vendas de determinado produto têm apresentado distribuição normal com média de 600 unidades e desvio padrão de 40 unidades. Se a empresa decide fabricar 700 unidades naquele mesmo mês, qual é a probabilidade dela não poder atender a todos os pedidos desse mês por estar com o estoque esgotado? 10) O volume de enchimento de uma máquina automática usada para encher latas de bebidas gasosas é distribuído normalmente com uma média de 12,4 onças e um desvio padrão de 0,1 onça. Qual a probabilidade do volume de enchimento ser: a) inferior a 12 onças b) entre 12,1 e 12,6 onças c) superior a 12,3 onças 11) O tempo de reação de um motorista para o estímulo visual é normalmente distribuído com uma média de 0,4 segundos com um desvio-padrão de 0,05 segundos. Qual a probabilidade de que uma reação de um motorista requeira: a) mais de 0,5 segundos b) entre 0,4 e 0,5 segundos 12) O período de falta de trabalho em um mês por causa de doenças dos empregados é normalmente distribuído com uma média de 100 horas e desvio padrão de 20 horas. Qual a probabilidade desse período no próximo mês estar: a) entre 50 e 80 horas 65 b) superior a 90 horas c) inferior a 60 horas 13) X é N(10; 100). Calcular P (12 < X ≤ 20). 14) X é N(30; 16). Calcular P (X < 19). 15) X é N(20; 25). Calcular P (X ≤ 30). 16) X é N(50; 81). Calcular P (40 ≤ X < 60). 17) X é N(10; 16). Calcular P (X ≥ 5). 18) Uma pesquisa indica que as pessoas usam seus computadores por uma média de 2,4 anos antes de trocá–los por uma máquina nova. O desvio padrão é 0,5 anos. Um dono de computador é selecionado de forma aleatória. Encontre a probabilidade de que ele vá usar o computador por menos de 2 anos antes de trocá–lo. Considere uma distribuição normal de probabilidades. 19) Uma pesquisa indica que para cada ida ao supermercado, uma pessoa gasta uma média de 45 minutos, com desvio padrão de 12 minutos naquela loja. Esse tempo gasto na loja é normalmente distribuído. Uma pessoa entra na loja. a) Qual a probabilidade de que essa pessoa fique na loja entre 24 e 54 minutos? b) Qual a probabilidade de que essa pessoa fique na loja mais que 39 minutos? c) Se 200 pessoas entrarem na loja, quantas devem permanecer nela entre 24 e 54 minutos? d) Se 200 pessoas entrarem na loja, quantas devem permanecer nela por mais de 39 minutos? 20) As pontuações para um teste de serviço civil são normalmente distribuídas com uma média de 75 pontos e um desvio padrão de 6,5. Para ser adequado ao emprego de serviço civil. Você deve ter pontuação dentro dos 5% primeiros colocados. Qual é a menor pontuação que você pode obter e ainda assim ser adequado ao emprego? Considere que a pontuação é um valor inteiro. 21) Em uma amostra escolhida aleatoriamente de homens com idade entre 35 e 44 anos, a média do nível de colesterol total era de 210 mg/dl. Suponha que os níveis totais de colesterol sejam normalmente distribuídos. Encontre o nível total de colesterol mais alto que um homem nessa faixa etária pode ter dentre os 1% dos homens com menores níveis de colesterol. 22) Você vende uma marca de pneus de automóveis que tem uma expectativa de vida que é normalmente distribuída com uma vida média de 30.000 milhas e um desvio padrão de 2.500 milhas. Você quer dar uma garantia de troca de pneus grátis que não durem muito. Como você poderia honrar sua garantia se você está disposto a trocar 10% dos pneus que vende? 66 23) Uma máquina de venda automática, distribui café em um copo de 8 decilitros. A quantidade de café no copo é normalmente distribuída com desvio padrão de 0,03. Você pode deixar o café transbordar 1% das vezes. Qual quantidade você deveria marcar como a quantidade média de café a ser distribuído? 24) Os pesos do conteúdo de uma caixa de cereais são normalmente distribuídos com um peso médio de 20 onças e um desvio padrão de 0,07 onça. Caixas nos 5% mais baixos não atendem às condições mínimas de peso e devem ser embaladas novamente. Qual é o peso mínimo exigido para uma caixa de cereais? Respostas 1) 0,2643 2) a) 0,9992 b) 0,8665 c) 0,0132 3) 0,0475 4) a) 0,9987 b) 0,0062 c) 0,1359 5) a) 0,1151 b) 0,2119 c) 0,3811 6) 0,2090 7) 0,1587 8) 0,2033 9) 0,0062 10) a) 0 b) 0,9759 c) 0,8413 11) a) 0,0228 b) 0,4772 12) a) 0,1525 b) 0,6915 c) 0,0228 13) 26,2% 14) 0,3% 15) 97,72% 16) 73,3% 17) 89,44% 18) 21,19% 19) a) 0,7333 b) 0,6915 c) 147 pessoas d) 138 pessoas 20) 86 pontos 21) 120 mg/dl 22) Pneus que gastam antes de completarem 26.800 milhas. 23) 7,93 decilitros. 24) 19,88 onças 67 Distribuição Normal: Valores de p tais que P(0 ≤ Z ≤ z) = p Parte inteira e primeira decimal de z 0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0 1,1 1,2 1,3 1,4 1,5 1,6 1,7 1,8 1,9 2,0 2,1 2,2 2,3 2,4 2,5 2,6 2,7 2,8 2,9 3,0 3,1 3,2 3,3 3,4 3,5 3,6 3,7 3,8 3,9 0 0,0000 0,0398 0,0793 0,1179 0,1554 0,1915 0,2257 0,2580 0,2881 0,3159 0,3413 0,3643 0,3849 0,4032 0,4192 0,4332 0,4452 0,4554 0,4641 0,4713 0,4772 0,4821 0,4861 0,4893 0,4918 0,4938 0,4953 0,4965 0,4974 0,4981 0,4987 0,4990 0,4993 0,4995 0,4997 0,4998 0,4998 0,4999 0,4999 0,5000 1 0,0040 0,0438 0,0832 0,1217 0,1591 0,1950 0,2291 0,2611 0,2910 0,3186 0,3438 0,3665 0,3869 0,4049 0,4207 0,4345 0,4463 0,4564 0,4649 0,4719 0,4778 0,4826 0,4864 0,4896 0,4920 0,4940 0,4955 0,4966 0,4975 0,4982 0,4987 0,4991 0,4993 0,4995 0,4997 0,4998 0,4998 0,4999 0,4999 0,5000 2 0,0080 0,0478 0,0871 0,1255 0,1628 0,1985 0,2324 0,2642 0,2939 0,3212 0,3461 0,3686 0,3888 0,4066 0,4222 0,4357 0,4474 0,4573 0,4656 0,4726 0,4783 0,4830 0,4868 0,4898 0,4922 0,4941 0,4956 0,4967 0,4976 0,4982 0,4987 0,4991 0,4994 0,4995 0,4997 0,4998 0,4999 0,4999 0,4999 0,5000 Segunda casa decimal de z 3 4 5 0,0120 0,0160 0,0199 0,0517 0,0557 0,0596 0,0910 0,0948 0,0987 0,1293 0,1331 0,1368 0,1664 0,1700 0,1736 0,2019 0,2054 0,2088 0,2357 0,2389 0,2422 0,2673 0,2704 0,2734 0,2967 0,2995 0,3023 0,3238 0,3264 0,3289 0,3485 0,3508 0,3531 0,3708 0,3729 0,3749 0,3907 0,3925 0,3944 0,4082 0,4099 0,4115 0,4236 0,4251 0,4265 0,4370 0,4382 0,4394 0,4484 0,4495 0,4505 0,4582 0,4591 0,4599 0,4664 0,4671 0,4678 0,4732 0,4738 0,4744 0,4788 0,4793 0,4798 0,4834 0,4838 0,4842 0,4871 0,4875 0,4878 0,4901 0,4904 0,4906 0,4925 0,4927 0,4929 0,4943 0,4945 0,4946 0,4957 0,4959 0,4960 0,4968 0,4969 0,4970 0,4977 0,4977 0,4978 0,4983 0,4984 0,4984 0,4988 0,4988 0,4989 0,4991 0,4992 0,4992 0,4994 0,4994 0,4994 0,4996 0,4996 0,4996 0,4997 0,4997 0,4997 0,4998 0,4998 0,4998 0,4999 0,4999 0,4999 0,4999 0,4999 0,4999 0,4999 0,4999 0,4999 0,5000 0,5000 0,5000 6 0,0239 0,0636 0,1026 0,1406 0,1772 0,2123 0,2454 0,2764 0,3051 0,3315 0,3554 0,3770 0,3962 0,4131 0,4279 0,4406 0,4515 0,4608 0,4686 0,4750 0,4803 0,4846 0,4881 0,4909 0,4931 0,4948 0,4961 0,4971 0,4979 0,4985 0,4989 0,4992 0,4994 0,4996 0,4997 0,4998 0,4999 0,4999 0,4999 0,5000 7 0,0279 0,0675 0,1064 0,1443 0,1808 0,2157 0,2486 0,2794 0,3078 0,3340 0,3577 0,3790 0,3980 0,4147 0,4292 0,4418 0,4525 0,4616 0,4693 0,4756 0,4808 0,4850 0,4884 0,4911 0,4932 0,4949 0,4962 0,4972 0,4979 0,4985 0,4989 0,4992 0,4995 0,4996 0,4997 0,4998 0,4999 0,4999 0,4999 0,5000 8 0,0319 0,0714 0,1103 0,1480 0,1844 0,2190 0,2517 0,2823 0,3106 0,3365 0,3599 0,3810 0,3997 0,4162 0,4306 0,4429 0,4535 0,4625 0,4699 0,4761 0,4812 0,4854 0,4887 0,4913 0,4934 0,4951 0,4963 0,4973 0,4980 0,4986 0,4990 0,4993 0,4995 0,4996 0,4997 0,4998 0,4999 0,4999 0,4999 0,5000 9 0,0359 0,0753 0,1141 0,1517 0,1879 0,2224 0,2549 0,2852 0,3133 0,3389 0,3621 0,3830 0,4015 0,4177 0,4319 0,4441 0,4545 0,4633 0,4706 0,4767 0,4817 0,4857 0,4890 0,4916 0,4936 0,4952 0,4964 0,4974 0,4981 0,4986 0,4990 0,4993 0,4995 0,4997 0,4998 0,4998 0,4999 0,4999 0,4999 0,5000 68
Baixar