U NIVERSIDADE F EDERAL DE G OIÁS
I NSTITUTO DE I NFORMÁTICA
M ARCELLO H ENRIQUE D IAS DE M OURA
Comparação entre Desenvolvedores de
Software a partir de Dados Obtidos em
Repositório de Controle de Versão
Goiânia
2013
M ARCELLO H ENRIQUE D IAS DE M OURA
Comparação entre Desenvolvedores de
Software a partir de Dados Obtidos em
Repositório de Controle de Versão
Dissertação apresentada ao Programa de Pós–Graduação do
Instituto de Informática da Universidade Federal de Goiás,
como requisito parcial para obtenção do título de Mestre em
Computação.
Área de concentração: Mineração de Dados.
Orientador: Prof. Dr. Hugo Alexandre Dantas do Nascimento
Co-Orientador: Prof. Dr. Thierson Couto Rosa
Goiânia
2013
Todos os direitos reservados. É proibida a reprodução total ou parcial do
trabalho sem autorização da universidade, do autor e do orientador(a).
Marcello Henrique Dias de Moura
Possui graduação em Sistemas de Informação pela Faculdade Sul-Americana.
É Técnico em Tecnologia da Informação do Centro de Recursos Computacionais da Universidade Federal de Goiás e colaborador da Associação do Software Livre de Goiás. Tem experiência na área de Ciência da Computação,
atuando principalmente nos seguintes temas: Visualização de Informação, Recuperação de Informações, Desenvolvimento de Software, Ensino a Distância
e Gerência de Projetos.
Dedico este trabalho àqueles que direta ou indiretamente contribuíram com seu
resultado, através de momentos de reflexão, apoio ou palavras que me deram força e me
sustentaram nos momentos difíceis.
Em especial dedico a meu filho, quando seus abraços me alimentaram para
batalhas diárias, e a minha esposa, mesmo quando não se continha e me cobrava a atenção
que a privei. Dedico ainda aos meus amigos.
Se sentirem alguma dúvida quando lerem estas linhas, tenham certeza! Vocês são
importantes em minha vida.
Agradecimentos
Agradeço ao Prof. Hugo Alexandre Dantas do Nascimento, um visionário a
frente de seu tempo, que confiou em meu trabalho e em minha força de vontade para
superar os momentos difíceis porém necessários da vida. Sempre dando espaço para
superar minhas deficiências e acreditando em mim, quando eu mesmo já não acreditava.
Ao Prof. Thierson Couto Rosa, uma pessoa extremamente sensata, agradável e
inspiradora com quem tive a oportunidade trabalhar. Me esforço para estar à altura de
suas espectativas. Que nesses momentos difíceis minhas vibrações positivas possam tê-lo
alcançado servindo de alento.
Aos meus amigos Ole Peter, Danilo Inácio, Nícolas Lazarte e Túlio Gonçalves,
quando me ajudaram tecnicamente, quando buscava inspiração ou quando tinham paciência em escutar minhas explicações de ensaio.
Aos gerentes de projeto Leonardo Ribeiro e Euler Sena que participaram nos
estudos de caso realizados para avaliação do presente trabalho.
À Universidade Federal de Goiás que tanto inspira e constrói.
E, por último, a outros amigos e familiares, com quem sinto em sintonia.
“A melhor parte da vida de uma pessoa está nas suas amizades”
16o
Abraham Lincoln,
Presidente dos Estados Unidos.
Resumo
de Moura, Marcello Henrique Dias. Comparação entre Desenvolvedores de
Software a partir de Dados Obtidos em Repositório de Controle de Versão.
Goiânia, 2013. 123p. Dissertação de Mestrado. Instituto de Informática, Universidade Federal de Goiás.
Repositórios de Controle de Versão são sistemas que armazenam mudanças no código
fonte realizadas por desenvolvedores de software. As pesquisas que extraem dados desses
repositórios para análise podem ser classificadas em dois grupos: as que focam no
processo de desenvolvimento e as que focam no desenvolvedor. O presente trabalho
investiga o segundo aspecto contribuindo para o assunto com: (a) a definição de um
histórico de arquivos que sumariza as mudanças realizadas no software em nível de linha
e de arquivo; (b) um conjunto de métricas visando avaliar o trabalho dos desenvolvedores;
e (c) duas propostas de abordagem para comparar os desenvolvedores. Um sistema
computacional que implementa essas métricas e as abordagens foi construído, tendo
sido aplicado em dois estudos de casos envolvendo projetos reais de desenvolvimento de
software. Os resultados obtidos nos estudos foram positivos, coincidindo, em geral, com
a percepção de gerentes de projetos sobre o trabalho dos desenvolvedores e apontando
para novas ideias de evolução da pesquisa. Consideramos que este é um passo no sentido
de entender e caracterizar melhor a forma de trabalho dos desenvolvedores.
Palavras–chave
Desenvolvimento de Software, Comparação entre Desenvolvedores, Repositório
de Código Fonte, Sistema e Controle de Versão, Métricas, Visualização de Informações.
Abstract
de Moura, Marcello Henrique Dias. Comparison of Software Developers from
Data Obtained from Version Control Systems. Goiânia, 2013. 123p. MSc.
Dissertation. Instituto de Informática, Universidade Federal de Goiás.
Version Control Systems are repositories that store source code changes done by software
developers. Research that extracts data from these repositories for analysis can be classified into two groups: those that focus on the development process and the ones that focus
on the developers. The present dissertation investigates the second case and contributes to
the field by providing: (a) the definition of a history file that summarizes changes made to
software in line and file levels, (b) a set of metrics to evaluate the work of the developers;
and (c) two approaches for comparing the developers based on their metrics. A computational system that implements these metrics and approaches was built and applied to
two case studies of real software development projects. The results obtained in the studies were positive. They were consistent with the general perception of project managers
about the work done by the developers. They also leaded to new ideas for improving the
research. We believe that these contributions are a step towards a better understanding and
characterization of the way about how software developers work.
Keywords
Software Development, Comparison Between Developers, Source Code Repositories, Version Control System, Metrics, Information Visualization.
Sumário
Lista de Figuras
11
Lista de Tabelas
13
Lista de Algoritmos
14
1
15
17
17
Introdução
1.1
1.2
2
Revisão Bibliográfica
2.1
2.2
2.3
3
3.3
2.3.1
Trabalhos com foco no processo de desenvolvimento
2.3.2
Trabalhos com foco no desenvolvedor
2.3.3
Aspectos Gerais
Definições básicas
Conjunto de Métricas
3.2.1
Sobre aspectos individuais
3.2.2
Sobre o relacionamento entre desenvolvedores
3.2.3
Ampliação das métricas para análise em arquivo
Comentários gerais
Comparação entre Desenvolvedores
4.1
4.2
5
Dificuldades inerentes ao desenvolvimento de software
Estudo sobre Sistemas de Controle de Versão
Trabalhos que fazem uso de sistemas de controle de versão
Métricas para Desenvolvedores
3.1
3.2
4
Objetivos
Organização da dissertação
Classificação por desempenho
Comparação por similaridade
Sistema Desenvolvido
5.1
5.2
5.3
Tecnologias utilizadas
Etapas de Funcionamento do Sistema
5.2.1
Geração do Histórico
5.2.2
Cálculo das Métricas
5.2.3
Produção dos Dados de Comparação
Visualizações desenvolvidas para análise
5.3.1
Visualização de relacionamento entre desenvolvedores
5.3.2
Visualização de cobertura de métricas
18
18
19
21
21
27
37
42
42
44
44
48
50
53
56
56
58
63
63
64
64
67
68
69
69
70
5.4
6
Dificuldades na Implementação
Avaliação
6.1
6.2
6.3
6.4
Metodologia para os estudos de casos
Estudo de Caso 1
6.2.1
Entrevista
6.2.2
Análise e interpretação dos resultados
6.2.3
Análise para outras métricas
Estudo de Caso 2
6.3.1
Entrevista
6.3.2
Análise e interpretação dos resultados
6.3.3
Análise para outras métricas
Outros Aspectos
71
73
73
76
78
79
80
81
83
84
84
85
Trabalhos Futuros
90
90
Referências Bibliográficas
92
A
Apêndice
98
B
Apêndice
111
7
Conclusão
7.1
Lista de Figuras
2.1
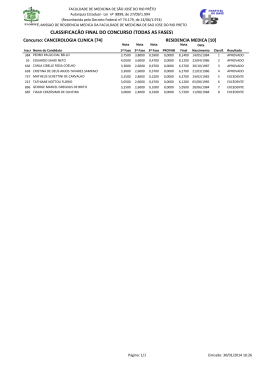
Coeficiente de agrupamento (clustering coefficient) de módulos do projeto
Apache (topo) e Gnome (base) coletadas em fevereiro de 2004.
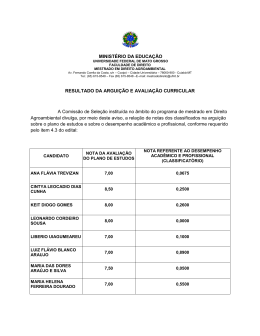
Grafo do projeto Filezilla onde os nós representam os desenvolvedores.
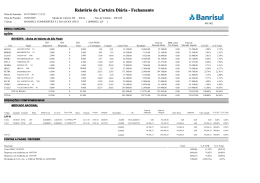
Visualização para identificar especialista em partes do código onde vários
padrões de comportamento são apresentados.
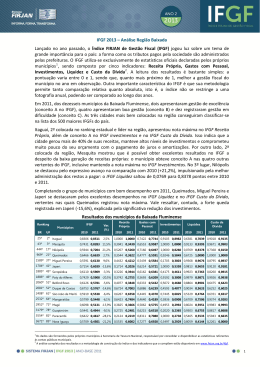
Visualização de evolução de código em nível de arquivos com CVSgrab.
Visualização de evolução de código em nível de linhas com CVSscan.
Visualização denominada Expertise Browser que apresenta especialista
em partes do código fonte em projetos de software.
Papéis geralmente desempenhados por desenvolvedores em projetos de
Software Livre.
Visualização denominada CodeSaw.
Uma caixa de sugestão de especialistas e formas de contactá-los a partir
de dados extraídos de SCV.
Relação entre um grupo de desenvolvedores gerada pela computação de
similaridades, provenientes do desenvolvimento de um componente do
Eclipse.
Apresentação dos clusters do projeto jEdit gerados pelo algoritmo EM
(Expectation Maximization).
Uma extração de informações a partir do SCV, do SAP e do próprio código
fonte.
Rede de desenvolvedores em colaboração no desenvolvimento de software do projeto Eclipse DTP.
36
3.1
Organização dos elementos em um histórico de projeto.
43
4.1
4.2
Exemplo de separação em classes de dominância.
Exemplo do MDS em um agrupamento de pessoas com preferências em
comum.
Exemplo de uma Matrix Scatter Plot.
57
2.2
2.3
2.4
2.5
2.6
2.7
2.8
2.9
2.10
2.11
2.12
2.13
4.3
5.1
5.2
5.3
5.4
5.5
Descrição de cada processo para análise de desenvolvedores a partir da
mineração de repositório.
Apresentação de três painéis de métricas.
Visualização de um processo de identificação de cobertura de métricas.
Problema encontrado no arquivo de diferenças gerado pelo Subversion.
Problema encontrado em operações inconsistentes geradas pelo Subversion.
23
25
26
27
28
29
30
31
32
33
34
35
59
62
64
70
71
72
72
6.1
6.2
6.3
6.4
6.5
6.6
Resultado MDS para o projeto Weby.
Duas imagens comparando o MDS para conjunto distindo de métricas
referentes ao projeto Weby.
Resultado MDS para o projeto Solicite.
Duas imagens comparando o MDS para conjunto distindo de métricas
referentes ao projeto Solicite.
Imagens do MDS para várias configurações de entrada do Algoritmo 4.2.
Imagens do MDS para propostas diferentes de normalização das métricas.
78
80
82
85
88
89
Lista de Tabelas
2.1
2.2
As gerações dos principais Sistemas de Controle de Versão.
Relação dos artigos relacionados.
20
40
3.1
Relação das métricas absolutas definidas.
54
4.1
Exemplo de uso do MDS em um conceito minimalista.
59
6.1
6.2
Formulário utilizado nas entrevistas dos estudos de caso.
Informações gerais sobre o projeto Weby. Total de commits, arquivos e
linhas adicionados, modificados e removidos.
Conjunto de métricas selecionadas e resultados para o projeto Weby.
Resultados da classe de dominância para o projeto Weby.
Informações gerais sobre o projeto Solicite. Total de commits, arquivos e
linhas adicionados, modificados e removidos.
Conjunto de métricas selecionadas e resultados para o projeto Solicite.
Resultados da classe de dominância para o projeto Socilite.
Tabela de informações sobre o resultado de seleção de métricas.
75
6.3
6.4
6.5
6.6
6.7
6.8
77
77
77
81
82
82
87
Lista de Algoritmos
3.1
4.1
4.2
5.1
5.2
Algoritmo Esfo_Dist_Mod(d): produz a métrica de Esforço Distinto de
Modificação.
Algoritmo Divisão_em_Classes(D ): seleciona um conjuto de desenvolvedores em classes onde cada classe não é dominada por outra.
Algoritmo Seleção_de_Métricas(correl, limite, F ): seleciona um conjuto
de métricas não correlacionadas a partir de uma matriz de correlação e um
limiar.
Algoritmo Constrói_Histórico_Projeto(SP ): extrai dos registros de um
Sistema de Controle de Versão e constrói um histórico de projeto.
Algoritmo Atualiza_Histórico(Ha , v, d, X ): atualiza histórico de arquivo.
47
58
61
66
67
CAPÍTULO 1
Introdução
Diante da crise mundial e obviamente dos fatores de produção limitados e recursos naturais finitos, muitos países tem buscado aproveitar melhor seus insumos, otimizando seus processos e reduzindo custos. A tecnologia diretamente ligada a inovação é um
mecanismo para redução de custos e otimização de processos pois permite a ampliação
dos negócios em uma vasta gama de possibilidades. Vários setores da economia utilizam
da tecnologia para ampliar sua participação no mercado e desenvolver mais (produtos)
com menos (recursos).
A Tecnologia da Informação (TI), em especial, deixou de ser luxo para se
tornar necessidade e o desenvolvimento de programas de computador (software) é hoje
essencial, visto a economia e qualidade de vida que potencialmente pode gerar [10].
Empresas privadas utilizam-se de software para fomentar seus processos. Muitas
delas, que antes eram meras usuárias, agora desenvolvem seus próprios software trazendo
diferenciais para o mercado diante da necessidade cada vez mais crescente de personalização para continuar inovando e ter competitividade diante da concorrência.
O governo brasileiro, por sua vez, também vem investindo gradativamente em
tecnologia da informação e identificou gastos financeiro substanciais com o pagamento
de licenças de software a países de primeiro mundo [32]. Para impedir esse escoamento,
o governo decidiu fomentar o uso do Software Livre criando projetos como o Portal do
Software Público 1 , o qual reúne projetos nacionais de inovação tecnológica. Na América
do Norte, em torno de 1,1 milhões de desenvolvedores investem parte do seu tempo no
fomento ao Software Livre [14].
Existe uma certa dificuldade inerente ao processo de desenvolvimento, tanto na
análise do código fonte, que é a matéria prima de todo software, quanto nas relações entre
os desenvolvedores que produzem o código. Alguns fatores complicadores são: a comunicação entre as pessoas ou equipes, a grande quantidade de projetos e os recursos humanos
envolvidos, além da possibilidade dos locais de trabalho estarem geograficamente distribuídos.
1 http://www.softwarepublico.gov.br
16
Quanto ao fator de comunicação, pesquisas estimam que pelo menos 70% do
tempo dos desenvolvedores é usado com essa atividade [12]. Para melhorar o processo de
comunicação e difusão do conhecimento, fábricas de software com alto fluxo de tarefas
investem no trabalho colaborativo através das redes sociais.
As redes sociais já estão bem difundidas, existindo inclusive redes sociais
de pesquisadores 2 e específicas de desenvolvedores de software [34, 19, 8], tendo
os Repositórios ou Sistemas de Controle de Versão (SCVs) como centro de interesse
comum. Os SCVs, comumente chamados de versionadores, são sistemas para auxiliar
o desenvolvimento de outros sistemas através do registro das mudanças ocorridas nos
mesmos durante o processo de desenvolvimento.
Sobre os demais fatores, a elevada quantidade de projetos, de recursos e a
distância, também têm exigido a adoção de ferramentas, sendo os SCVs novamente um
elemento essencial, pela sua capacidade de facilitar o trabalho remoto e a integração dos
resultados produzidos por várias pessoas ou equipes.
Atualmente, os SCVs são alvos de estudos, na tentativa de revelar padrões
ocultos para servir de apoio no processo de desenvolvimento. A importância em conhecer
como o desenvolvedor trabalha para melhor utilizá-lo em projetos futuros é crescente na
medida que a demanda por novos serviços de TI aumenta.
Com o objetivo de compreender esses padrões ocultos, algumas pesquisas relacionam as alterações do código fonte com sistemas de acompanhamento de problemas
(SAP ou também chamados no inglês como Bug Tracking Systems – BTS), para identificar
pontos críticos no software a partir da reincidências de problemas. Em alguns casos, as
pesquisas ajudam a indicar especialistas naquela parte do código com base em correções
prévias feitas pelos desenvolvedores [30, 29]. Outros estudos buscam analisar apenas o
código fonte e as mudanças promovidas pontuando e caracterizando os desenvolvedores [53, 54, 24].
Apesar de interessantes, essas pesquisas focam na evolução do código mais do
que nas pessoas embora façam alguma avaliação individual ou coletiva dos desenvolvedores. Poucos trabalhos abordam as características do desenvolvedor propriamente dito.
Nossa pesquisa vem a contribuir nesse último aspecto, apresentando novas métricas relacionadas ao trabalho dos desenvolvedores e formas de compará-los com o propósito de
verificar a similaridade e o desempenho dos mesmos.
Na presente dissertação propomos novas métricas que foram formalizadas e desenvolvemos um sistema computacional para aplicá-las em projetos de software reais. Os
resultados obtidos com a pesquisa demonstram que é possível, através de métricas extraídas dos SCVs, avaliar os desenvolvedores em vários aspectos de forma a complementar
2 http://www.mendeley.com
1.1 Objetivos
17
ou validar a percepção que os gerentes de projeto de software possuem acerca de sua
equipe.
1.1
Objetivos
O objetivo principal deste trabalho é apresentar um ferramental composto de
históricos, métricas e abordagens comparativas para avaliação de desenvolvedores em
projetos de software, tomando como base as interações residentes em SCVs (Sistemas de
Controle de Versão).
Os objetivos específicos deste trabalho são:
• Propor uma estrutura única que armazena toda a história (as mudanças ocorridas) de
um arquivo de código fonte e um novo conjunto de métricas individuais e coletivas
para avaliar os desenvolvedores.
• Sugerir abordagens para comparação entre desenvolvedores com base nas métricas
propostas.
• Apresentar um sistema computacional que utiliza os conceitos deste trabalho para
aplicá-lo a outros projetos de software.
1.2
Organização da dissertação
O restante desta dissertação está organizada como segue: o Capítulo 2 traz uma
revisão bibliográfica dos principais temas envolvidos no presente projeto. O Capítulo 3
introduz a estrutura de histórico e as novas métricas propostas, baseadas em repositórios
de código fonte. O Capítulo 4 descreve formas de comparação entre desenvolvedores por
desempenho e por similaridade. O Capítulo 5 apresenta um sistema desenvolvido a partir
das métricas identificadas. O Capítulo 6 aborda estudos de casos. Por fim, no Capítulo 7,
encontram-se as conclusões e sugestões para trabalhos futuros.
CAPÍTULO 2
Revisão Bibliográfica
Este capítulo aborda as dificuldades, em geral, inerentes ao desenvolvimento de
software, traz um estudo sobre sistemas de controle de versão e apresenta as pesquisas
afins ao nosso trabalho. Tais pesquisas foram divididas logicamente em dois grupos: as
que focam no processo de desenvolvimento de software e as que focam nos desenvolvedores. Os trabalhos nesse último grupo se preocupam em identificar perfis e/ou papéis
para os desenvolvedores a partir de características individuais ou coletivas. Técnicas de
visualizações de informação aplicadas a esse domínio do conhecimento e pesquisas que
são pertinentes ao assunto são também apresentadas.
2.1
Dificuldades inerentes ao desenvolvimento de software
Em 1968 foi realizada em Garmisch, na Alemanha, uma das primeiras conferências sobre engenharia de software promovidas pelo NATO Science Committee [31]. Entre
os assuntos tratados estava a dificuldade de desenvolver e manter software. A conferência reuniu mais de 50 pessoas de partes diferentes do mundo que lidavam com software,
desde usuários até professores universitários. Foram discutidos temas de grande importância como: a relação entre o software (parte lógica) e o hardware (parte física); desenho
arquitetural, produção, distribuição e serviço de software.
Algumas questões discutidas na conferência, tais como se o preço do software
deveria ser separado do preço do hardware, impulsionou o desenvolvimento de grandes
R
R
empresas conhecidas atualmente (e.g., IBM
, MicroSoft
), embora outros assuntos
ainda permaneçam em aberto.
Já em 1969, na segunda versão da conferência [35], foi relatado que seria
prematuro denominar essa nova área de engenharia, em função da complexidade no
processo de desenvolvimento de software e da existência de diferenças entre a engenharia
comum e a mesma. Algumas dificuldades são: gerir os artefatos produzidos, mensurar
todos os processos envolvidos e ainda garantir a qualidade. Frederic Brooks [6, 5] faz
2.2 Estudo sobre Sistemas de Controle de Versão
19
alusão ao folclore concluíndo que não existe bala de prata quando a questão envolve
desenvolvimento de software.
Todo desenvolvimento de software envolve basicamente três agentes: processos,
pessoas e produtos. Os processos são procedimentos necessários para alcançar um objetivo. As pessoas são desenvolvedores capacitados a produzir, através dos procedimento, o
produto final, o software. Um bom processo de desenvolvimento envolve ferramentas de
apoio, e, entre as várias existentes, destacam-se os Sistema de Controle de Versão.
2.2
Estudo sobre Sistemas de Controle de Versão
O código fonte é o elemento principal de qualquer software [48, 36]. Ele pode ser
interpretado ou compilado para gerar o resultado almejado. Existe sempre uma motivação
para construção de um programa e, seja qual for a finalidade do mesmo, fazer uso de
um repositório de código fonte para gerenciar o projeto é essencial. Os repositórios,
também conhecidos como Sistemas de Controle de Versão (SCV) ou simplesmente
versionadores (e.g., CVS, Subversion, Git), são responsáveis por registrar e facilitar o
controle da evolução do software. Tal evolução consiste em mudanças que podem ser de
três tipos: alterações, inserções e remoções de linhas ou arquivos do código fonte, seja
para acrescentar novas características ao programa ou para corrigir problemas conhecidos
(bugs). Além disso, há recursos mais avançados como ramificar um projeto de software
ou unificar ramos de desenvolvimento.
Para remontar a história dos SCV, voltamos à década de 60 com um marco da
computação, a criação do Sistema Operacional Unix. O Unix foi inicialmente desenvolvido em linguagem Assembly e reescrito em linguagem C anos depois. Na década de 70,
o Unix foi uma grande influência no meio acadêmico que inspirou a maioria dos sistemas
operacionais atuais como BSD, MacOS, Solaris, HP-UX, AIX, Minix, Linux e outros.
No processo de desenvolvimento do Unix, como ainda é o caso até hoje, a
comunicação entre os desenvolvedores acontece indiretamente pela análise das diferenças
entre duas versões de um mesmo arquivo de código fonte. Essa foi a motivação para
a criação de uma ferramenta chamada diff por Malcolm Douglas McIlroy, também
desenvolvedor do Unix, com base em um artigo publicado com James W. Hunt [22].
A questão original sobre o problema do diff é encontrar a maior subsequência comum
ou “Longest Common Subsequence (LCS) Problem”, em inglês, para identificar a posição
correta onde ocorreram as inserções ou remoções em um arquivo.
Logo em seguida, Larry Wall, o mesmo criador da linguagem de programação
Perl, criou uma ferramenta chamada patch para aplicar no código fonte um conjunto de
mudanças baseado nas diferenças geradas pelo programa diff. Como o próprio nome diz,
2.2 Estudo sobre Sistemas de Controle de Versão
20
um “patch” é um remendo ou um ajuste do software original. O diff é usado, internamente,
pela maioria dos SCV até os dias atuais.
O SCCS (Source Code Control System), primeira geração dos SCV, foi desenvolvido nos laboratórios da Bell em 1972 por Marc J. Rochkind [37]. Ele foi massivamente
utilizado até a liberação do RCS (Revision Control System) por Walter F. Tichy [47], em
1982, na Universidade de Purdue. Com o passar do tempo, o SCCS foi gradativamente
sendo substituído pelo RCS. Apesar das melhorias propostas pelo RCS, ele ainda operava somente com um arquivo de cada vez e não existia um caminho trivial para trabalhar
com um projeto (vários arquivos no mesmo contexto). Também, não existia capacidade
de acesso pela rede.
Em 1985, Dick Grune [20] criou um conjunto de scripts para adicionar novas
características ao RCS. Dois anos depois, Brian Berliner [1] reescreveu-os em um único
programa feito em linguagem C, que se tornou a base para o CVS (Concurrent Versions
System). O CVS potencialmente facilitou o trabalho colaborativo na evolução de um
código, permitindo-se trabalhar em um projeto via rede. Inicia-se assim a segunda geração
dos SCV, conhecida como a dos versionadores de código fonte modernos.
Criada em 1999, a CollabNet iniciou um projeto para substituir o CVS por
outro sistema que recebeu o nome de Subversion [33]. A ideia principal era criar
um novo versionador a partir das funcionalidades do CVS, porém livre de bugs e
com mais recursos. Através de uma articulação entre colaboradores que procuravam
algo além das fronteiras do CVS, a CollabNet conseguiu promover uma evolução sem
perder o conhecimento adquirido. Dessa forma, um usuário familiarizado com CVS
facilmente poderia usar o Subversion por sua similaridade intencional prevista por seus
desenvolvedores. Recentemente o Subversion passou a fazer parte do portfólio de projetos
da ASF (Apache Software Foundation) 1 .
Uma das limitações dos versionadores de segunda geração é seu modelo centralizado. A maioria das operações necessitam de acesso a um servidor central. A mudança
desse paradigma permitiu a criação dos versionadores de terceira geração, cuja principal
característica é adotar um modelo distribuído e descentralizado 2 . A Tabela 2.1 apresenta
os principais SCV e algumas de suas características.
Geração
Nome do SCV
Suporte a Rede Tipo de Operação
a
1
SCCS, RCS
N.A.
Acesso Local
a
2
CVS, Subversion
Centralizado
Cliente-Servidor
a
3
Git, Bazaar, Mercurial, BitKeeper
Distribuído
Descentralizado
Tabela 2.1: As gerações dos principais Sistemas de Controle de Versão.
1 http://projects.apache.org
2 http://www.ericsink.com/vcbe/html/history_of_version_control.html
2.3 Trabalhos que fazem uso de sistemas de controle de versão
21
Com o envolvimento de uma grande comunidade de desenvolvedores, os SCV
descentralizados emergiram e já estão sendo usados em vários projetos livres e proprietários.
Os SCV abrem muitas possibilidades para análise e compreensão tanto do código
fonte como do relacionamento entre os desenvolvedores de software, uma vez que estes
sistemas registram todo o trabalho efetuado.
Além de ferramentas SCV isoladas, incubadoras de projetos como Github [34],
GoogleCode [19] e Launchpad [8] fazem uso de SCV internamente. O que então eram
simples sistemas de versionamento, tornaram-se ecossistemas complexos 3 e uma grande
quantidade de dados estão dispostos para serem analisados.
2.3
Trabalhos que fazem uso de sistemas de controle de
versão
Uma das vantagens do uso de um SCV é o registro de toda atividade relacionada
na evolução do código fonte. Esse registro pode ser minerado automaticamente, sem
intervenção humana, para, de alguma maneira, refletir a colaboração no processo de
construção dos artefatos de software. Entende-se como artefatos de um software todos os
componentes criados para o software em questão, os quais podem ser de documentação,
controle, configuração e o código fonte.
Diante das facilidades concedidas pelos SCV em utilizar as informações armazenadas em seus repositórios, muitos artigos científicos exploram essas informações no
sentido de compreender como a evolução do software acontece através de iterações sobre
os artefatos e do relacionamento entre os desenvolvedores.
Foram revisados vários artigos científicos que usam de repositórios de código
fonte. Esses artigos foram classificados em dois grupos: os que focam no processo de
desenvolvimento e os que focam nos desenvolvedores.
Os trabalhos nesses dois grupos são descritos nas próximas seções. Ao final,
apresentamos a Tabela 2.2 listando os artigos citados.
2.3.1
Trabalhos com foco no processo de desenvolvimento
Nesta seção apresentamos as pesquisas que se preocupam com o código fonte
para entender a sua evolução e servir de apoio às equipe de desenvolvimento de software
na melhoria de seus processos.
3 Além
do SCV, tais ambientes possuem também: gerenciador de tarefas, fórum, wiki e outras ferramentas integradas para apoiarem os desenvolvedores no processo de desenvolvimento.
2.3 Trabalhos que fazem uso de sistemas de controle de versão
22
Lopez-Fernandez et al. [28] propuseram uma abordagem de análise de redes
sociais a partir das informações contidas em SCV. A teoria de redes complexas é baseada
na representação de sistemas complexos como grafos. Dois grafos foram construídos. O
primeiro representa a rede de commiters (desenvolvedores do projeto), onde os vértices
correspondem a um particular commiter e dois commiters são ligados quando eles têm
contribuído como pelo menos um módulo em comum. O peso das arestas é dado pelo
número de commits executado por ambos os desenvolvedores para todos os módulos em
comum. No segundo grafo, os vértices representam um módulo do projeto. Nesses termos,
dois módulos são ligados quando pelo menos um commiter tem contribuído para ambos.
Os pesos das arestas é o total de commits executado em ambos os módulos.
Para análise foram consideradas definições comuns em redes sociais como: degree of a vertex, weighted degree of a vertex, distance centrality of a vertex, betweenness
centrality of a vertex, weighted clustering coefficient of a vertex e clustering coefficient
of a vertex. Por exemplo, o coeficiente de agrupamento (clustering coefficient of a vertex),
denotado por,
E(v)
,
(2-1)
Cv =
Kv (Kv − 1)
onde Kv é o número de vizinhos de v e E(v) é o número de arestas entre os vizinhos,
corresponde à medida com que os nós de um grafo tendem a se agrupar. Os autores
realizaram estudos de caso envolvendo grandes projetos de Software como Apache,
Gnome e KDE que possuem milhões de linhas de código. A Figura 2.1 apresenta a
distribuição do coeficiente de agrupamento para comparativo visual entre os módulos do
projeto Apache (topo) e Gnome (base) coletadas em fevereiro de 2004.
Como resultado, concluíram que as características desses projetos são redes
small-world (mundo-pequeno) 4 e que as teorias dessa área podem ser aplicadas. Apesar
deste trabalho verificar o relacionamento entre desenvolvedores o foco ainda permanece
na evolução do software e não nos desenvolvedores propriamente dito.
O trabalho de Huang e Liu [21], semelhante ao anterior quando se trata de
verificar a evolução do código fonte, revisa os históricos de repositórios de projetos
SourceForge 5 . Os desenvolvedores foram divididos em dois grupos: o grupo responsável
pela parte principal e o grupo responsável pela parte periférica do sistema, para descrever
as interações no processo de desenvolvimento. Foi usado um modelo representativo
chamado Legitimate Peripheral Participation (LPP) [27]. A ideia essencial do LPP é a
fixação do aprendizado em situações sociais onde pessoas mais experientes interagem
com os aprendizes na prática diária. Conseguiu-se analisar os relacionamentos entre
4 Uma
rede mundo-pequeno é uma representação gráfica de relacionamentos onde é possível alcançar
um elemento dentro dessa rede, através de um pequeno número de passos.
5 http://sourceforge.net/about
2.3 Trabalhos que fazem uso de sistemas de controle de versão
23
Figura 2.1: Coeficiente de agrupamento (clustering coefficient) de módulos do projeto Apache
(topo) e Gnome (base) coletadas em fevereiro de 2004. O eixo y corresponde a quantidade de módulos (diretórios) e o eixo x ao coeficiente de agrupamento. Extraído de
Lopez-Fernandez [28].
o grupo da equipe principal e o grupo restante no processo de desenvolvimento. Os
autores acreditam que o sucesso de um projeto de Software Livre depende apenas de
uma pequena parte do código que permitiria desenvolvedores comerciais trabalharem com
grupos periféricos em desenvolvimento de produtos, sem a necessidade de liberar todo o
código fonte ao público.
Um método de análise da rede de colaboração foi proposto para perceber a
importância dos desenvolvedores. Definiu-se um conjunto de desenvolvedores D p , onde
p representa um caminho de um diretório afetado no SCV, sendo:
D p = {d|desenvolvedor d modificou caminho p}.
2.3 Trabalhos que fazem uso de sistemas de controle de versão
24
Um grafo simétrico de desenvolvedores Gd é definido como:
Gd = {Vd , Ed }
Vd = {d|d é um desenvolvedor }
Ed = {(d1 , d2 )|∃ caminho p de tal forma que d1 ∈ D p e d2 ∈ D p }.
A distância de centralidade do grafo é apresentada como:
Dc (v) =
1
,
∑t∈G dG (v,t)
onde dG (v,t) é a distância mínima de um vértice v para um vértice t. Dessa forma,
os autores criaram um grafo da rede social dos desenvolvedores de vários projetos
armazenados no SourceForge. A Figura 2.2 mostra o grafo resultante desse processo
para o projeto Filezilla. É percebido que os desenvolvedores que têm um alto valor de
centralidade desempenham papéis importantes no projeto enquanto que os que possuem
baixo valor de centralidade são desenvolvedores periféricos ou corretores.
Os autores comentaram que o grafo pode conter problemas pela característica
do uso de diretórios na geração dos relacionamentos pois dependendo da arquitetura
do projeto, para adicionar uma funcionalidade é requerido alterar vários diretórios do
sistema, portanto, isso poderia implicar em uma equivocada definição de papéis. Foi
possível, ainda, analisar os níveis de colaboração através da intensidade das cores dos
nós que representam os desenvolvedores no grafo e a habilidade de desenvolvedores
periféricos manter a vitalidade e a popularidade do projetos pelas ligações nos limites
do grafo.
Girba et al. [17] investiram na visualização para representar a evolução do software. Para os autores, quando o sistema é grande torna-se difícil conhecê-lo como um
todo e portanto os desenvolvedores acabam conhecendo-o em partes. Diante dessa emblemática, surge a pergunta, "que autores desenvolvem quais partes do sistema?". Motivados
por essa questão, desenvolveram uma representação visual composta da seguinte maneira:
as linhas são arquivos, os círculos são commits e as cores são autores. O que está fora de
contexto durante a visualização permanece em tons de cinza e a linha do tempo está no
sentido da esquerda para direita. Os dados são extraídos de SCV e para ordenação dos
arquivos de uma maneira significativa, utilizaram uma métrica de distância entre os commits baseados em algoritmo de hierarquia de clusters. A Figura 2.3 demonstra a aplicação
da técnica. Alguns padrões de comportamento foram identificados os quais são:
• Monologue – denota o período onde todas as mudanças e a maioria dos arquivos
pertencem a um mesmo autor representado por uma cor que o identifica.
• Familiarization – caracteriza uma acomodação sobre um longo período de tempo.
2.3 Trabalhos que fazem uso de sistemas de controle de versão
25
Figura 2.2: Grafo do projeto Filezilla onde os nós representam os desenvolvedores. O desenvolvedor com maior valor de centralidade aparece em formato retangular. Além disso, a
intensidade das cores representa o valor de centralidade, portanto, cores claras são
baixo valor de centralidade enquanto que cores escuras representam alto valor de
centralidade. Extraído de Huang e Liu [21].
• Takeover – representa o comportamento onde um desenvolvedor faz uma grande
quantidade de código em uma pequena quantidade de tempo.
• Bug-fix – é uma pequena e localizada mudança que não faz muito efeito na imagem
gráfica da linha que representa o arquivo.
• Expansion – demonstra a expansão de arquivos, ou seja, arquivos que são criados.
• Edit – representa o trabalho de um editor que aplica várias mudanças em vários
arquivos ao mesmo tempo.
• Teamwork – é uma colaboração alternada entre desenvolvedores.
Quando um desenvolvedor faz muitas mudanças em um arquivo ele se apropria
daquele arquivo e portanto a partir daquele ponto a cor da linha permanece da sua mesma
cor, ou seja, da cor do seu círculo. A validação feita em vários projetos proprietários (i.e.,
Outsight) e livres (i.e., Ant, Tomcat, JEdit e JBoss). A conclusão que o trabalho é útil na
descoberta de padrões de comportamento e quais desenvolvedores são os especialista em
partes do código.
Kagdi et al. [25] mineraram repositórios de código fonte a partir de um conjunto
de heurísticas a procura de grupos de mudanças que caracterizessem padrões de alterações
em arquivos. A pesquisa tenta descobrir quais arquivos são alterados em conjunto, com
o propósito de dar subsídios para previsões de mudança no software e melhorar o
entendimento de sua evolução. A ordem em que os arquivos são alterados é importante
para esse propósito pois permite inferir que variações no arquivo de interface conduzem
a variações no arquivo de persistência, ambos do código fonte de um mesmo módulo.
2.3 Trabalhos que fazem uso de sistemas de controle de versão
26
Figura 2.3: Visualização para identificar especialista em partes do código onde vários padrões
de comportamento são apresentados. Extraído de Girba et al. [17].
Voinea et al. [49] propõem um conjunto de ferramentas e técnicas de visualização
para avaliar diferentes níveis de detalhe da evolução de software armazenados em SCV.
Eles criaram duas ferramentas de visualização em duas dimensões: o CVSgrab, que
explora a evolução dos arquivos e o CVSscan que explora a evolução em nível de linhas.
Ambas servem de apoio aos desenvolvedores no entedimento da evolução do código.
As visualizações utilizam as cores em três tipos de configuração: a) linhas –
cor verde escuro são constantes (sem alterações), azuis são inserções, amarelas são
modificações e vermelho claro são exclusões; b) blocos de estruturas – laranja são arquivo
de referência, bloco de aninhamento nível 1, verde são comentários e azul são blocos de
aninhamento nível 2; c) autores – como exemplo, laranja corresponde ao autor1, amarelo
ao autor2 e azul ao autor3, pode ser utilizado uma paleta de cores para diferenciar os
autores.
O CVSgrab [50] busca identificar padrões de comportamento através das manipulações efetuadas pelos desenvolvedores nos arquivos do código fonte e obter informações detalhadas sobre os commits, os desenvolvedores e a evolução dos arquivos. A
Figura 2.4 demonstra a atuação CVSgrab onde cada linha na horizontal corresponde a
um arquivo e vários painéis permitem o controle da visualização. É possível manipular
o tamanho, a transparência e a sobra das linhas além da aproximação (zoom), ordenação
por nome dos arquivos, data de criação, atividade de alterações dentre outros.
O CVSscan apresentado na Figura 2.5, permite um maior nível de detalhes e
explora as interações dos desenvolvedores em um baixo nível de granularidade analisando
as linhas alteradas. Diferente da visualização anterior, agora as linhas horizontalmente
coloridas representam as linhas do código fonte. Na visualização é possível controlar:
os níveis de aproximação (zoom), o intervalo de seleção além de blocos de visão geral e
detalhe. A posição do mouse indicado pelo marcador (1) mostra no bloco (2, 3) a evolução
das linhas no código fonte.
2.3 Trabalhos que fazem uso de sistemas de controle de versão
27
Figura 2.4: CVSgrab é uma ferramenta para visualização da evolução de um código fonte em
nível de arquivos. Extraído de Voinea et al. [50]
2.3.2
Trabalhos com foco no desenvolvedor
Nessa seção apresentamos trabalhos focados no desenvolvedor ou na colaboração entre membros de projetos com o objetivo de identificar o perfil de tais colaboradores.
Mockus e Herbsleb [30] buscam identificar desenvolvedores experientes em
partes do código através do conceito de Experience Atoms (EAs) que são unidades
elementares de experiência. Para os autores, experiência é o resultado direto de uma
atividade pessoal com respeito ao trabalho realizado, que, neste caso, pode ser uma
correção ou melhoramento do código. Neste trabalho não foram revelados detalhes sobre a
computação das EAs, apenas que através de diferenças obtidas a partir do SCV é possível
extrair unidades de experiência pela frequência de alterações nos arquivos.
A Figura 2.6 exibe uma visualização denominada ExB – Expertise Browser, para
apresentar sugestões de pessoas com experiência nos artefatos de código na medida em
que são inspecionados. A visualização pretente responder as seguintes perguntas: “quem
tem perícia em uma unidade do software?” e “qual perfil desse perito?”. A pergunta sobre
a perícia pode respondida pela indicação de especialistas que atuaram naquele fragmento
de código e o perfil pode ser respondido pelo foco onde o especialista trabalhou, se
2.3 Trabalhos que fazem uso de sistemas de controle de versão
28
Figura 2.5: CVSscan é uma ferramenta para visualização da evolução de um código fonte.
Em um baixo nível de granuralidade, painéis apresentam as linhas de código (2,3)
selecionadas pelo mouse (1). É possível interagir selecionando um intervalo de
visualização, controlar o foco e outras configurações. Extraído de Voinea et al. [49].
em arquivos de banco de dados provalvemente um especialista em banco de dados por
exemplo. Em resumo, os autores reconhecem que seu modelo não é infalível, porém, essas
heurísticas, podem prover um caminho fácil para identificar e indicar pessoas experientes
em alguma parte do projeto.
Ye e Kishida [51] intrigados com a possibilidade aprender sobre a motivação
que levam desenvolvedores a promover software sem benefícios monetários, estudaram
as atividades desempenhadas por essas pessoas em comunidades de Software Livre.
Identificaram oito papéis (Figura 2.7), os quais são:
• Project Leader – são pessoas que iniciam, têm uma visão geral e direcionam o
projeto;
• Core Member – são responsáveis por coordenar o desenvolvimento do projeto e
fazem significantes contribuições para a evolução do sistema;
2.3 Trabalhos que fazem uso de sistemas de controle de versão
29
Figura 2.6: Visualização denominada Expertise Browser que apresenta especialista em partes do
código fonte em projetos de software. Extraída de Mockus e Herbsleb [30].
• Active Developer – são pessoas que regularmente contribuem com grande quantidade de novas funcionalidades e correção de problemas;
• Peripheral Developer – são pessoas que ocasionalmente contribuem com novas
funcionalidades ou funcionalidades que ampliam suporte a sistemas de interesse
com envolvimento pequeno e esporádico;
• Bug Fixer – são pessoas que corrigem problemas reportados por outros usuários,
geralmente conhecem pequenas partes do código fonte onde atuam;
• Bug Reporter – são pessoas que descobrem e reportam problemas, muitas vezes
assumem o papel de testadores;
• Reader – são pessoas que leem ativamente o código do projeto para usar e entender
seus conceitos; e
• Passive User – são pessoas que somente usam o sistema e não estão interessadas
em alterar ou entender o código.
Nem todos os papéis existem para todos os projetos e alguns projetos usam
outros nomes para atividades semelhantes como Maintainers em vez de Core Members.
Já algumas comunidades preferem assumir ação combinada de papéis como no caso de
Bug Fixers e Peripheral Developers para os quais a diferença é sutíl.
Os autores não fazem uso direto de SCV mas relataram a forma de interação
no desenvolvimento de um sistema tendo a comunidade de Software Livre como sua
mantenedora. O trabalho relatou que a ascendência de uma pessoa na comunidade se
faz, muitas vezes, por meritocracia e reconhecimento a partir das contribuições efetuadas,
demonstrando a importância em analisar o código fonte através de um SCV para verificar
como a evolução acontece e como os desenvolvedores se relacionam.
2.3 Trabalhos que fazem uso de sistemas de controle de versão
30
Figura 2.7: Papéis geralmente desempenhados por desenvolvedores em projetos de Software
Livre. Os círculos mais internos são mais importantes. Extraído de Ye e Kishida [51].
A definição de papéis em projetos de desenvolvimento de software proprietário
é rígida, ou seja, o empregador define estes papéis, enquanto que em projetos livres é
dinâmica, neste caso, não existe cargos pré-estabelecidos, os desenvolvedores se autoorganizam. Neste sentido é importante a categorização dos desenvolvedores para entender
como os relacionamentos ocorrem na evolução dos artefatos de código, sejam eles de
código fonte ou informacionais (e.g., documentação, tutoriais, referências).
Gilbert e Karahalios [16] procuraram analisar ambos o repositório de código
fonte e a comunicação por correio eletrônico (email) entre os desenvolvedores buscando
evidências de colaboração. Para os autores, a comunicação é de extrema importância e
revela evidências na atividade de alteração no código fonte. Os benefícios está em oferecer
a oportunidade de verificar se existe alguma relação entre as comunicações por mensagens
entre os desenvolvedore e as alterações no código fonte. Também, oferece a chance de
refletir se o processo de comunicação está afetando o desenvolvimento.
Os autores criaram uma visualização do tipo visão geral e detalhe (overview+detail) [11] apresentada na Figura 2.8, denominada CodeSaw. A visualização é
dividida em duas partes. A parte superior do eixo x representa as contribuições no código
fonte e a parte inferior do eixo x a comunicação por email. Na visualização em detalhe, é
possível comparar visualmente os desenvolvedores e obter, em caixa flutuante, informações sobre eles e seus últimos cinco arquivos alterados. Em acréscimo, é possível criar
mensagens flutuantes, chamada spatial messaging sobre a visualização gerada. Sarma et
al. [41] usa abordagem similar a partir de comunicação entres desenvolvedores, embora
sejam geradas visualizações diferentes.
Minto e Murphy [29] criaram o conceito de Emergent Expertise Locator (EEL)
como forma de sugerir outros desenvolvedores especialistas ao desenvolvedor que está
interagindo com o código fonte (Figura 2.9), através de uma IDE no momento da edição
desse código. A computação da EEL é feita utilizando três matrizes (i linhas× j colunas):
2.3 Trabalhos que fazem uso de sistemas de controle de versão
31
Figura 2.8: Visualização denominada CodeSaw. Extraído de Gilbert e Karahalios [16].
• Matriz de dependência (i × j) – indica o número de vezes que o arquivo i e arquivo
j foram modificados juntos.
• Matriz de autoria (i × j) – indica o número de vezes que o desenvolvedor i alterou
o arquivo j.
• Matriz de perícia – representa a perícia baseada na matriz de dependência de
arquivo e na matriz de autoria de arquivo.
A Matriz de perícia é computada pela seguinte equação C = (FA FD )FAT , onde
FA é a matriz de autoria e FD é a matriz de dependência. A extração de dados é feita a
partir da evolução do código armazenados em um SCV e a sugestão de especialista é feita
em tempo de execução. Testes de validação foram feitos com grandes de projetos como
Eclipse, Firefox e Bugzilla e verificou-se uma alta precisão e alta revocação (recall) dos
especialistas indicados.
Schuler e Zimmermann [42] analisaram o desenvolvimento da IDE Eclipse e propusseram uma técnica que permite recomendar desenvolvedores especialistas avaliando
fragmentos da evolução do código fonte armazenados em SCV. Foram levados em consideração códigos fontes de linguagens de programação orientadas a objeto. O trabalho
consiste em analisar o conjunto de mudanças (change-sets) a partir das diferenças (diffs)
entre todos os arquivos alterados entre um par de revisões.
Os autores buscaram, em todos os arquivos, os nomes dos métodos e a quanti-
2.3 Trabalhos que fazem uso de sistemas de controle de versão
32
Figura 2.9: Uma caixa de sugestão de especialistas, através de um Ambiente de Desenvolvimento
Integrado (IDE), e forma de contactá-los é apresentada ao desenvolvedor quando o
mesmo busca forma de interagir. Extraído de Minto e Murphy [29].
dade de parâmetros alterados por cada desenvolvedor utilizando os conceitos de “experiência de implementação”, que significa o conhecimento que o desenvolvedor tem sobre
a implementação propriamente dita, de um determinado método. A “experiência de uso”,
que neste caso é o conhecimento que os desenvolvedores possuem em usar os métodos
porém não se sabe como eles foram implementados. Em outras palavras, uma experiência
de uso consiste nas chamadas dos métodos em outras partes do código, conhecendo as
entradas e saídas do métodos porém não compreendendo suas estruturas internas. Uma
experiência de implementação consiste em um conhecimento mais amplo de um método,
inclusive de suas estruturas internas. A cada desenvolvedor é atribuído um perfil de experiência que consiste na computação feita pela frequência de experiência de implementação
e de uso.
O artigo utiliza informações de um SCV através de árvore de sintaxe abstrata
para identificar a composição e as chamadas dos métodos. Isto significa que a técnica
utilizada apesar de ser precisa para detectar alterações e chamadas de métodos é específica
apenas para um determinado tipo de linguagem. Os autores apresentam um mecanismo de
identificação de especialista em partes de código pela computação de similaridades entre
o perfil de experiência em intervalos de 0 a 1, sendo 0 para perfis totalmente diferentes
e 1 para perfis idênticos. A Figura 2.10 apresenta a computação dessa similaridade entre
desenvolvedores com valor maior ou igual a 0,08.
Zhang et al. [53] afirmam ser os primeiros a especificamente minerar e decompor métricas a partir de projetos de software colaborativo em nível individual de granularidade. Eles utilizaram SAP (Sistema de Acompanhamento de Problemas) e SCV para
apresentar resultados sobre indicadores de desempenho individual dos desenvolvedores.
O processo acontece em três níveis de extração sendo:
1. analisar o código fonte e computar métricas;
2. analisar as mudanças armazenadas nos SCV;
3. analisar as tarefas do SAP.
Para analisar o código fonte, são usadas métricas [39] para projetos de software
orientados a objeto como:
2.3 Trabalhos que fazem uso de sistemas de controle de versão
33
Figura 2.10: Relação entre um grupo de desenvolvedores gerada pela computação de similaridades, provenientes do desenvolvimento de um componente do Eclipse. Os desenvolvedores são os nós e a espessura de cada arestas representam as similaridades entres
eles. Extraído de Schuler e Zimmermann [42].
• CC (Cyclomatic Complexity) – é usado para verificar a complexidade das classes,
por complexidade entende-se a quantidade de condicionais e laços existentes;
• WMC (Weighted Methods per Class) – é a quantidade de métodos implementados ou a soma das complexidades dos métodos utilizando o CC (definido anteriormente);
• DIT (Depth of Inheritance Tree) – é o tamanho máximo de profundidade de uma
classe com a herança hierárquica;
• NOC (Number Of Children) – é número imediato de subclasses subordinadas para
uma hierarquia de classes;
• RFC (Response For a Class) – representa um conjunto de métodos que podem ser
invocados mesmo através da hierarquia de classes;
• CBO (Coupling Between Objects) – é a quantidade de acoplamento entre as classes,
o acoplamento indica nível de dependência entre uma classe e outra;
• LCOM (Lack of Cohesion in Methods) – mede o grau de similaridade dos métodos
através das variáveis ou atributos das classes;
• Lines of Code – quantidade de linhas de código existentes; e
• Comment Percentage – corresponde a quantidade relativa de comentários existentes.
Do SCV foram obtididas as seguintes informações: TLOC (número de linhas de
código adicionadas e excluídas) e NCO (número total de commits). Para o SAP, foram
analisados os campos das tarefas que descrevem os problemas encontrados. Uma vez
2.3 Trabalhos que fazem uso de sistemas de controle de versão
34
identificado o corretor cruza as informações com o SCV.
Foi realizado um experimento com Software Livre jEdit, sendo inspecionados
2.871 commits de 3.677 arquivos de código em linguagem de programação Java, 5.412
classes e 29.192 métodos. Via SAP, analisaram 5.218 bugs reportados; destes 278 eram
duplicados e 472 inválidos sendo descartados. Os resultados são apresentados utilizando
cluster analysis algorithm EM (Expectation Maximization), apresentado na Figura 2.11
com o objetivo de aumentar a compreensão dentro de uma coleção de indicadores.
Os resultados podem beneficiar organizações no entendimento do desempenho de seus
desenvolvedores.
Figura 2.11: Apresentação dos clusters do projeto jEdit gerados pelo algoritmo EM (Expectation
Maximization); o eixo x são os quatro clusters formados, e o eixo y a proporção da
métrica WMC por linhas de código para cada desenvolvedor. Extraído de Zhang et
al. [53].
Em [54], Zhang et al. fazem uso de uma técnica de análise de dados definida
como Data Envelopment Analysis (DEA) 6 . O modelo proposto analisa o SCV, o SAP e
o código fonte. A análise do código fonte é feita por ferramentas automatizadas 7 para
criação de métricas individuais de desempenho dos desenvolvedores.
Após todas as extrações de dados das fontes de informações citadas são produzidos indicadores classificados em dois grupos que são:
1. Métricas de produção:
6 DEA
é um modelo de avaliação de desempenho baseado em programação não parametrizada [9],
técnica aceita em pesquisas de análise comparativa de desempenho. Alguns trabalhos anteriores do autores [52, 40] são baseados em estudos empíricos sobre DEA.
7 http://pmd.sourceforge.net
2.3 Trabalhos que fazem uso de sistemas de controle de versão
35
1.1. Análise de código – métricas de controle de fluxo, número de operações
distintas e declarações, grau de modularidade, número de instância e outros; e
1.2. Técnica de análise estática – violação de estilo ou más práticas como: sobrecarga de memória, ponteiros nulos, uso de variáveis não inicializadas ou
inicialização de variáveis nunca utilizadas dentre outros.
2. Métricas de desenvolvimento:
2.1. Extração de dados do SCV – número de operações por dia, quantidade média
de linhas adicionadas, total de linhas excluídas, qual o último desenvolvedor
fez alterações em alguma parte do código e outras.
2.2. Extração de dados do SAP – número de defeitos registrado com alto grau de
urgência, número de defeitos corrigidos, etc.
Essas métricas servem como entrada para o DEA. A Figura 2.12 ilustra o fluxo
proposto pelos autores. As saídas, por sua vez, mais detalhes em [40], são computadas,
gerando pontuações caracterizando o desempenho individual do desenvolvedor (IDP).
Figura 2.12: Uma extração de informações a partir do SCV, do SAP e do próprio código fonte.
São geradas métricas de entrada para um processo de análise. Extraído de Zhang
et al. [54].
Jermakovics et al. [24] apresentaram uma abordagem para minerar e visualizar a
modularidade em redes de desenvolvedores de software baseadas em alterações efetuadas
em arquivos. Os estudos foram validados em projetos comerciais. Cada desenvolvedor é
tratado como um vetor com pesos para os arquivos. Cada peso de um arquivo f de um
desenvolvedor d é definido usando o número de commits para f efetuado por d, como
2.3 Trabalhos que fazem uso de sistemas de controle de versão
36
segue:
peso f ,d
N
= commits f ,d · log
nf
em que N é o total de desenvolvedores e n f é o número de desenvolvedores que
alteraram f . A similaridade entre dois desenvolvedores é dada pelo coseno do ângulo
entre os seus vetores a e b, respectivamente:
similaridade(a, b) = cos(a, b) =
a·b
∑ ak bk
=q k
|a||b|
∑k a2k ∑k b2k
Outras propostas como similaridade Jaccard e correlação de Pearson foram
testadas, porém a similaridade dos cosenos mostrou melhor desempenho e foi escolhida
como a medida principal.
Pela densidade típica de redes formadas pelos históricos de versionamento
aplicou-se uma proposta de filtros para reduzir o número de arestas e evitar essa densidade. A estrutura revelou grupos de desenvolvedores e demonstrou a modularidade na
visualização da rede de desenvolvedores. Um estudo de caso foi aplicado em um projeto de Software Livre, onde os resultados indicaram que a abordagem exibiu estruturas
ocultas com base nas redes de interação entre grupos de desenvolvedores, conforme apresentado na Figura 2.13.
Figura 2.13: Rede de desenvolvedores em colaboração no desenvolvimento de software do projeto
Eclipse DTP. A rede de colaboração pode ser facilmente percebida pelos destaque
entre os grupos formados. Extraído de Jermakovics et al. [24].
2.3 Trabalhos que fazem uso de sistemas de controle de versão
2.3.3
37
Aspectos Gerais
Nesta seção aprentamos a Tabela 2.2 com informações gerais sobre os trabalhos
pesquisados e comparamos brevemente as pesquisas com nosso trabalho. Essas pesquisas nos serviram de motivação para entender as lacunas existentes que ainda não foram
exporadas. Poucos trabalhos fazem uso de SCV porém acreditamos que será uma tendência extrair e analisar dados armazenados em SCV para melhorar a compreensão das
interações entre os desenvolvedores e o processo de desenvolvimento de software.
Grande parte dos trabalhos científicos que utilizam o SCV não definem novas
medidas de comparação entre os desenvolvedores (métricas). Nossa pesquisa não está
direcionada a métricas gerais da engenharia de software geradas a partir da análise do
código fonte. Criamos algumas métricas pela combinação das operações comuns dos SCV
que não foi exploradas por nenhum outro trabalho pesquisado. Elas são usadas em nosso
processo para comparação dos desenvolvedores.
Lopez-Fernandez [28] e Huang e Liu [21] exploram os repositórios a partir de
análise de redes complexas, aplicando técnicas difundidas nesta área de conhecimento
para verificar padrões de comportamento dos desenvolvedores em relação ao código fonte.
Essa conclusão revela ferramentas potênciais a serem utilizadas no qual se difere de nossa
abordagem focada nas interações entre os desenvolvedores.
Alguns trabalhos como Huang e Liu [21], Kagdi et al. [25] e também Jermakovics et al. [23] extraem dados de repositórios a partir de iterações geradas pelo SCV em
nível de arquivos. Porém, o presente trabalho, focou em resultados em um nível mais fino
de granularidade, ao considerar alterações em linhas de código.
Voinea et al. [49] criaram duas ferramentas de visualização de informação para
evidenciar padrões na evolução do código fonte e auxiliar os desenvolvedores no processo
de desenvolvimento. Embora o foco do nosso trabalho esteja nos desenvolvedores e não
na evolução do código fonte, utilizamos de duas visualizações que nos serviram de guia
para produzir os métodos de escolha e seleção de métricas.
Os trabalhos de Mockus e Herbsleb [30] buscam identificar especialista em
partes do código através da frequência de alterações no código. Em nosso trabalho,
utilizamos a frequência de alterações no código combinada com conceitos de esforço
e efetividade para criação das métricas.
Applying social network analysis to
the information in CVS repositories
Mining version histories to verify
the learning process of Legitimate
Lopez-Fernandez,
L.
Huang, Shih-Kun;
Liu, Kang-min.
2006
sitory querying, analysis and visua-
Telea, Alexandru.
Visual assessment of software evo-
lution
Voinea, L.; Luk-
kien, J.; Telea, A.
lization
An open framework for CVS repo-
from version histories
Lucian;
Voinea,
I.
Maletic, Jonathan
Yusuf, Shehnaaz;
2007
2006
do software
Na evolução
do software
Na evolução
do software
Na evolução
SCV
SCV
SCV
Visualização de Infor-
Mineração de Dados e
oria dos Grafos
Redes complexas e Te-
Mineração de Dados,
Redes Complexas
Mineração de Dados e
Abordagem de Análise
mações
Visualização de Infor-
Mineração de Dados e
mações
Visualização de Infor-
Mineração de Dados e
Análise Combinatória
Mineração de Dados e
Huzefa;
Mining sequences of changed-files
SCV
:w
SCV
SCV
Fonte de Dados
Kagdi,
do software
Na evolução
do software
Na evolução
do software
Na evolução
Foco
mações
Evolution
A.; Seeberger, M.;
2005
2005
2004
Ano
Ducasse, S.
How Developers Drive Software
Girba, T.; Kuhn,
Peripheral Participants
Título
Autor
linhas com visão geral e detalhe.
Visualizações em nível de arquivos e
Visualização em nível de arquivos
N.A.
uma cor específica.
brepostos as linhas, cada um com
nhas e os commits são círculos so-
Visualização onde os arquivos são li-
código fonte.
relacionamentos entre alterações no
volvedores são nós e as arestas são
Desenho de grafos onde os desen-
N.A.
Visualizações Construídas
2.3 Trabalhos que fazem uso de sistemas de controle de versão
38
2002
Recommending Emergent Teams
Minto,
David;
Thomas.
Zimmermann,
Schuler,
Murphy, Gail C.
sion archives
Mining usage expertise from ver-
distributed software development
rahalios, Karrie.
Shawn;
CodeSaw: A social visualization of
2008
2007
2007
dor
velopers
Gilbert, Eric; Ka-
desenvolve-
tivation Open Source Software de-
Kishida, Kouichi.
2003
Toward an understanding of the mo-
Yunwen;
Ye,
SCV
dor
desenvolve-
No perfil do
dor
desenvolve-
No perfil do
SCV
SCV
mações
Visualização de Infor-
Mineração de Dados e
Mineração de Dados
mações
dor
Mineração de Dados e
ware
Engenharia de Soft-
Visualização de Infor-
SCV e Email
N.A.
desenvolve-
No perfil do
No perfil do
dor
desenvolve-
approach to identifying expertise
No perfil do
Herbsleb, J. D.
Expertise browser: a quantitative
Visualização de Infor-
Mineração de Dados e
Abordagem de Análise
Mineração de Dados
A;
SCV e SAP
Fonte de Dados
Mockus,
do software
Na evolução
Foco
mações
truction
2009
Ano
chele.
D.; Lanza, Mi-
Visual software evolution recons-
Ambros,
Marco
Título
Autor
dades entre os desenvolvedores.
Visualização em grafo das similari-
pecialistas
Caixa de texto com indicação de es-
email.
x correspodem a comunicação por
digo fonte e a parte inferior do eixo
respondem as contribuições no có-
onde a parte superior do eixo x cor-
Visualização de gráfico de linhas
N.A.
lista.
Painéis com a indicação de especia-
Visualizações diversas
Visualizações Construídas
2.3 Trabalhos que fazem uso de sistemas de controle de versão
39
Mining Individual Performance In-
Shen;
Yongji;
Zhang,
Wang,
Capability Assessment of Indivi-
dual Software Development Pro-
cesses Using Software Repositories
and DEA
Mining and visualizing developer
networks from version control sys-
tems
Shen;
Yongji;
Zhang,
Wang,
Yang, Ye; Xiao,
Junchao.
Jermakovics, An-
drejs; Sillitti, Al-
berto; Succi, Gi-
ancarlo.
ment Using Software Repositories
Xiao, Junchao.
dicators in Collaborative Develop-
Título
Autor
dor
desenvolve-
No perfil do
dor
desenvolve-
No perfil do
dor
desenvolve-
No perfil do
Foco
SCV
código fonte
SCV, SAP e o
código fonte
SCV, SAP e o
Fonte de Dados
Teoria dos Grafos
Mineração de Dados e
Mineração de Dados
Mineração de Dados
Abordagem de Análise
Tabela 2.2: Relação dos artigos relacionados.
2011
2008
2008
Ano
Visualização em formato de grafos.
N.A.
dades.
volvedores a partir de suas similari-
Gráfico com agrupamento de desen-
Visualizações Construídas
2.3 Trabalhos que fazem uso de sistemas de controle de versão
40
2.3 Trabalhos que fazem uso de sistemas de controle de versão
41
Os trabalhos de Ye e Kishida [51] demostram que a definição de papéis em projetos de Software Livre é feita pela meritocracia e comprometimento dos desenvolvedores
com o projeto. Este conhecimento nos permite considerar a existência de uma estrutura
não evidente porém, ainda, armazenada nos SCV. Em muitos casos, os papéis ou perfis
que os desenvolvedores desempenham em projetos são escusos, ou seja, algumas habilidades dos desenvolvedores são desconhecidas embora armazenadas nos repositórios. Possivelmente, em um trabalho futuro de extração de dados e definição de métricas poderiam
revelar essas habilidades “escondidas”.
Zhang et al. [53] criaram métricas, a partir da análise do código fonte, do SCV
e do SAP para pontuar os desenvolvedores em seus desempenhos. Outro trabalho de
Zhang et al. [54] também faz uso de métricas mas não menciona detalhes formais. Nosso
trabalho define métricas formalmente pela extração de dados unicamente do SCV pela
facilidade na obtenção de dados. Futuramente, pretendemos análisar o código fonte e
prover integração com outros sistemas de apoio ao processo de desenvolvimento.
CAPÍTULO 3
Métricas para Desenvolvedores
Neste capítulo propomos um conjunto de métricas sobre dados armazenados
em SCV para contribuir na identificação da forma como os desenvolvedores trabalham.
Apresentamos uma definição formal de uma nova estrutura de informação para armazenar
os dados oriundos do SCV visando facilitar seu processamento.
Em seguida, descrevemos o conjunto de métricas dividindo-as em aspectos individuais dos desenvolvedores e nos relacionamentos entre desenvolvedores no processo de
desenvolvimento.
Por último, apresentamos uma tabela sumarizada das métricas e concluímos com
comentários sobre nosso modelo e possíveis melhorias para contemplar outras opções
além das propostas neste trabalho.
3.1
Definições básicas
Considere a existência de um sistema de controle de versão (SCV) de projetos de
software. Seja P um projeto de software e D o conjunto de desenvolvedores desse projeto.
Seja também A o conjunto de todos os arquivos criados durante o desenvolvimento de P ,
e A r ⊆ A o conjunto dos arquivos que foram removidos (não chegaram na versão final)
desse projeto. Para cada arquivo a ∈ A que existe ou existiu durante o desenvolvimento de
P , definimos um arquivo de história Ha contendo as operações de criação, modificação
ou remoção feitas nas linhas de a. Um arquivo de história Ha consiste, mais precisamente,
em uma sequência de históricos de linha hhal1 , hal2 , . . . , halt i para t linhas consecutivas que
ocorrem ou já ocorreram em pelo menos uma das versões de a. Cada histórico de linha
hali , por sua vez, é uma sequência de operações ho1 , o2 , . . . , ou i que ocorreram na linha
li do arquivo a. O tamanho u dessa sequência, também dado por |hali |, é menor ou igual
à quantidade de versões do arquivo a que aparecem no projeto P do SCV mais uma
unidade1 . Cada operação o de um histórico de linha possui quatro atributos o.versao,
1 Essa
unidade é decorrente de revisões que removem o arquivo, com todas as suas linhas, como
explicado mais adiante.
3.1 Definições básicas
43
o.desenv, o.tipo e o.texto, os quais são definidos a seguir:
o.versao – número da versão do projeto P na qual a operação o foi realizada;
o.desenv – referência ao desenvolvedor que executou a operação o, com o.desenv ∈ D ;
o.tipo – tipo da operação o, podendo ser: CRI (criação), MOD (modificação) e REM
(remoção);
o.texto – conteúdo da linha na revisão o.versao.
Todo histórico de uma linha sempre começa com uma operação o do tipo CRI,
podendo haver, em seguida, zero ou mais operações com o atributo tipo igual a MOD.
Se uma operação o do tipo REM ocorre em um histórico de linha, ela deve ser a última
a, j
na sequência que forma esse histórico. Definimos a notação oi para indicar a i-esíma
a, j
operação realizada na linha j do arquivo a. A notação o1 refere-se à primeira operação
a, j
a, j
na linha j. Já o|h a | , representado simplesmente por o f im , indica a última operação nessa
lj
linha. Também, por simplicidade de notação, omitiremos a referência ao arquivo a quando
subentendido.
Se um arquivo a é removido em alguma versão do desenvolvimento do projeto,
então considera-se que todas as suas linhas são removidas, sendo isso indicado por uma
operação final do tipo REM no histórico de cada linha de a.
Denominamos histórico do projeto o conjunto de arquivos de história HP =
{Ha1 , Ha2 , . . . , Ham } dos m arquivos do projeto P . A Figura 3.1 ilustra a organização dos
elementos de um histórico de projeto. Tal histórico pode ser construído iterando sobre os
registros no SCV conforme o Algoritmo 5.1 descrito posteriormente na Seção 5.2.1.
Figura 3.1: Organização dos elementos em um histórico de projeto. O conjunto Ha corresponde
a todos os arquivos do projeto. O subconjunto hl corresponde a todas as linhas do
arquivos. O subconjunto o corresponde a todas as operações que as linhas sofreram.
3.2 Conjunto de Métricas
3.2
44
Conjunto de Métricas
Nesta seção, aborda-se métricas para avaliar os desenvolvedores utilizando as
definições apresentadas anteriormente. Algumas métricas possuem o termo efetividade
ou esforço na composição de seus nomes. O termo efetividade indica métricas que
mensuram a quantidade de operações perenes, cujos resultados se mantiveram até a
versão final do arquivo onde ocorreram. Já o termo esforço refere-se ao volume total
de operações independentes da perenidade de seu resultado.
No devido contexto, como exemplo, toda operação de criação de uma linha é
um esforço, mas apenas operações de criação que resultaram em linhas que não foram
modificadas posteriormente por outros desenvolvedores, são consideradas efetivas. Além
disso, sucessivas operações de modificação em uma linha por um mesmo desenvolvedor
são consideradas uma única operação para fins de avaliação de efetividade, porém, não de
esforço.
3.2.1
Sobre aspectos individuais
A seguir, apresentamos métricas que avaliam a efetividade e o esforço do
trabalho dos desenvolvedores individualmente quanto ao tipo de operação realizada nas
linhas dos arquivos.
Efetividade de Criação - Efet_Cri(d)
A métrica Efet_Cri: D → N indica o total de linhas que foram criadas por um
desenvolvedor d e que não foram alteradas por outro desenvolvedor nem removidas
posteriormente pelo próprio d. Essa métrica pode ser definida como:
a, j
1 se o1 .desenv = d e
a, j
|Ha |
∀ os com s 6= 1,
Efet_Cri(d) = ∑ ∑
a, j
a, j
(os .tipo = MOD e os .desenv = d);
a∈(A −A r ) j=1
0 caso contrário.
a, j
(3-1)
Na Equação 3-1, o termo o1 .desenv = d indica que a primeira operação da
linha j do arquivo a foi realizada pelo desenvolvedor d (lembrando que essa operação é
de criação). Os demais termos indicam que qualquer outra operação na mesma linha, se
existir, deve ser de modificação e realizada pelo próprio desenvolvedor d.
3.2 Conjunto de Métricas
45
Efetividade de Criação Relativa - Efet_Cri_Rel(d)
A métrica Efet_Cri, (3-1) definida anteriormente, corresponde a uma medida absoluta da quantidade de linhas de código criadas por um desenvolvedor d ∈ D . Entretanto,
é importante, do ponto de vista gerencial, a possibilidade de aferir a capacidade de criação do desenvolvedor em relação a outros desenvolvedores envolvidos no projeto. Para
tal, definimos a métrica Efetividade de Criação Relativa, Efet_Cri_Rel: D → R de acordo
com a Equação 3-2.
Efet_Cri(d)
(3-2)
Efet_Cri_Rel(d) =
∑x∈D Efet_Cri(x)
Efetividade de Modificação - Efet_Mod(d)
A métrica Efet_Mod: D → N para um desenvolvedor d ∈ D avalia a quantidade
de linhas do projeto P que satisfazem as três condições a seguir:
• a última operação na linha é do tipo MOD;
• essa operação foi efetuada pelo desenvolvedor d;
• existe pelo menos uma operação antes da última cujo desenvolvedor é diferente de
d.
A definição formal da métrica Efet_Mod é dada a seguir:
1 se oa, j .tipo = MOD e oa, j .desenv = d e
f im
f im
|Ha |
a, j
a
Efet_Mod(d) = ∑ ∑
∃w, 1 ≤ w < |hl j |, tal que ow .desenv 6= d;
a∈(A −A r ) j=1
0 caso contrário.
(3-3)
Efetividade de Modificação Relativa - Efet_Mod_Rel(d)
A métrica Efet_Mod (3-3) também corresponde a uma medida absoluta da
quantidade de linhas de código alteradas por um desenvolvedor d ∈ D . Similarmente
à métrica 3-2, porém no contexto de efetividade de modificação, definimos a sua versão
relativa, Efet_Mod_Rel: D → R, como:
Efet_Mod_Rel(d) =
Efet_Mod(d)
∑x∈D Efet_Mod(x)
(3-4)
Esforço de Criação - Esfo_Cri(d)
Definimos a métrica Esforço de Criação: D → N como o total de linhas criadas
pelo desenvolvedor d sobre os arquivos do projeto P . Formalmente, o esforço de criação
3.2 Conjunto de Métricas
46
de um desenvolvedor d é:
|Ha |
Esfo_Cri(d) =
(
∑∑
a∈A j=1
a, j
1 se o1 .desenv = d;
0 caso contrário.
(3-5)
Esforço de Criação Relativo - Esfo_Cri_Rel(d)
Definimos a métrica Esforço de Criação Relativo pela métrica Esfo_Cri_Rel:
D → R do seguinte modo:
Esfo_Cri_Rel(d) =
Esfo_Cri(d)
∑x∈D Esfo_Cri(x)
(3-6)
Esforço de Remoção - Esfo_Rem(d)
Definimos a métrica Esforço de Remoção: D → N como o total de linhas
removidas pelo desenvolvedor d nos arquivos do projeto P :
|Ha |
Esfo_Rem(d) =
∑∑
a∈A j=1
(
a, j
a, j
1 se o f im .desenv = d e o f im .tipo = REM;
0 caso contrário.
(3-7)
Esforço de Remoção Relativo - Esfo_Rem(d)
Definimos Esfo_Rem_Rel: D → R como:
Esfo_Rem_Rel(d) =
Esfo_Rem(d)
∑x∈D Esfo_Rem(x)
(3-8)
Esforço Distinto de Modificação - Esfo_Dist_Mod(d)
A métrica de Esfo_Dist_Mod: D → N procura quantificar o esforço de modificação de um desenvolvedor mas desconsiderando operações MOD consecutivas realizadas
pelo mesmo. Isso é importante pois um desenvolvedor que faz commits frequentemente
acaba por ter mais operações de modificação registradas nas linhas do que outro que só
faz commits quando o novo código desenvolvido está correto e completo. Assim, nessa
métrica. Procura-se minimizar esse efeito registrando apenas uma ocorrência para toda
sequência de modificações feitas por um mesmo desenvolvedor em uma linha.
O Algoritmo 3-9 computa a métrica Esfo_Dist_Mod para um desenvolvedor D .
A fim de apresentarmos também uma definição matemática da função que implementa
essa métrica, precisamos introduzir um novo conceito: a compactação de um histórico
de linha hl , dada por hl . Tal compactação consiste na mesma sequência de operações
de hl exceto que toda subsequência de operações consecutivas de modificação feitas
por um mesmo desenvolvedor são representadas por uma única operação, no caso, pela
3.2 Conjunto de Métricas
47
última operação dessa subsequência. Operações no histórico de linha compactadas são
representadas por o ao invéz do símbolo o. Desta forma, definimos o Esforço Distinto de
Modificação como:
|Ha | |hl j |
Esfo_Dist_Mod(d) =
(
∑∑∑
a∈A j=1 i=1
a, j
a, j
1 se oi .desenv = d e oi .tipo = MOD;
0 caso contrário.
(3-9)
Algoritmo 3.1: Esfo_Dist_Mod(d)
Entrada: Um desenvolvedor do conjunto de desenvolvedores, d ∈ D
Saída: Total de esforço distinto de modificação realizado pelo desenvolvedor d
1
2
3
4
5
total ← 0;
para todo a ∈ A faça /* Para todo arquivo a
para j ← 1 até |Ha | faça /* Para cada linha em a
encontrou_desenv ← falso;
para i ← 1 até |halj | faça /* Para cada operação na linha
se
6
= MOD então
a, j
se encontrou_desenv = falso e oi .desenv = d então
total ← total + 1;
encontrou_desenv ← verdadeiro;
8
9
a, j
senão se encontrou_desenv = verdadeiro e oi .desenv 6= d então
encontrou_desenv ← falso;
fim
10
11
12
fim
13
fim
14
16
17
*/
a, j
oi .tipo
7
15
*/
*/
fim
fim
retorna total;
Esforço Distinto de Modificação Relativo - Esfo_Dist_Mod_Rel(d)
Neste trabalho, de forma similar aos casos anteriores, define-se Esforço Distinto
Relativo por meio da métrica Esfo_Dist_Rel: D → R como segue:
Esfo_Dist_Mod_Rel(d) =
Esfo_Dist_Mod(d)
∑x∈D Esfo_Dist_Mod(x)
(3-10)
Além dessas métricas, existe a possibilidade de construir outras derivadas através
de uma razão entre efetividade e esforço. As próximas duas métricas são, portanto,
3.2 Conjunto de Métricas
48
resultado dessa composição.
Efetividade de Criação dividido pelo Esforço de Criação - Efet_Cri_Div_Esfo_Cri(d)
A razão entre Efetividade de Criação e Esforço de Criação de um desenvolvedor
d gera uma nova métrica definida como:
Efet_Cri_Div_Esfo_Cri(d) =
Efet_Cri(d)
Esfo_Cri(d)
(3-11)
A versão relativa dessa métrica é dada por:
Efet_Cri_Div_Esfo_Cri_Rel(d) =
Efet_Cri_Div_Esfo_Cri(d)
∑x∈D Efet_Cri_Div_Esfo_Cri(x)
(3-12)
As referidas métricas (3-11 e 3-12) computam a taxa de aproveitamento (na versão final do arquivo) das criações feitas por um determinado desenvolvedor. Tais métricas
ajudam a diferenciar desenvolvedores que possuem valores parecidos de Efetividade de
Criação mas cujos Esforços de Criação são distintos.
Efetividade de Modificação dividido pelo Esforço Distinto de Modificação Efet_Mod_Div_Esfo_Dist_Mod(d)
Já a razão Efetividade de Modificação e Esforço Distinto de Modificação leva à
métrica:
Efet_Mod_Div_Esfo_Dist_Mod(d) =
Efet_Mod(d)
Esfo_Dist_Mod(d)
(3-13)
A versão relativa da mesma é:
Efet_Mod_Div_Esfo_Dist_Mod(d)
∑x∈D Esfo_Mod_Div_Esfo_Dist_Mod(x)
(3-14)
As métricas (3-13 e 3-14), por sua vez, procuram diferenciar desenvolvedores
que possuem valores parecidos de “Efetividade de Modificação” mas cujos valores na
métrica “Esforço Distintos de Modificação” são diferentes.
Efet_Mod_Div_Esfo_Dist_Mod_Rel(d) =
3.2.2
Sobre o relacionamento entre desenvolvedores
Em adição às métricas supracitadas, as quais estão associadas a um único
desenvolvedor por vez, são apresentadas a seguir métricas de relacionamento entre
pares de desenvolvedores com base na sequência das ações realizadas pelos mesmos
no desenvolvimento de linhas de código. Essas métricas computam, em geral, quantos
pares de operações do tipo (t1 ,t2 ) em sequência, com t1 ,t2 ∈ {CRI, MOD, REM}, foram
3.2 Conjunto de Métricas
49
realizadas pelos desenvolvedores x, y respectivamente. As métricas consideram todas as
operações nas linhas de código sendo portanto uma medida de esforço.
A métrica apresentada a seguir calcula a quantidade de pares de operações
consecutivas dos tipos (CRI, MOD) em que a primeira é realizada pelo desenvolvedor
x e a segunda pelo desenvolvedor y. Como vimos anteriormente, a operação CRI, que
representa a criação, é a primeira operação em uma linha ou arquivo. Ela pode ser
acompanhada por sucessivos MOD’s e de um REM. A métrica opera apenas sobre
históricos de linhas que possuem pelo menos duas operações.
1 se |hl j | > 1 e
a, j
a, j
|Ha |
o1 .desenv = x e o1 .tipo = CRI e
Linha_Cri_Mod(x, y) = ∑ ∑
a, j
a, j
o2 .desenv = y e o2 .tipo = MOD;
a∈A j=1
0 caso contrário.
(3-15)
As próximas três métricas descritas seguem a mesma estrutura da anterior,
apenas variando a sequência de tipos de operação em pares (CRI, REM), (MOD, MOD)
e (MOD, REM). Note que a métrica para o par (MOD, MOD) é representada sobre o
histórico de linha compactada, a fim de desconsiderar modificações em sequência de um
mesmo desenvolvedor.
1 se |hl j | > 1 e
a, j
a, j
|Ha |
o1 .desenv = x e o1 .tipo = CRI e
Linha_Cri_Rem(x, y) = ∑ ∑
(3-16)
a, j
a, j
o
.desenv
=
y
e
o
.tipo
=
REM;
a∈A j=1
2
2
0 caso contrário.
1 se oa, j .desenv = x e oa, j .tipo = MOD e
|Ha | |hl j |−1
i
i
Linha_Mod_Mod(x, y) = ∑ ∑ ∑
oi+1 .desenv = y e oi+1 .tipo = MOD;
a∈A j=1 i=1
0 caso contrário.
(3-17)
a, j
a, j
1 se oi .desenv = x e oi .tipo = MOD e
Linha_Mod_Rem(x, y) = ∑ ∑ ∑
oi+1 .desenv = y e oi+1 .tipo = REM;
a∈A j=1 i=1
0 caso contrário.
(3-18)
Cada uma das quatro métricas anteriores induz uma matriz de dimensão |D| ×
|D|, cujas células contém as quantidades de pares de operações de um certo tipo realizadas. O somatório das linhas e das colunas dessas matrizes são também métricas para os
|Ha | |hl j |−1
3.2 Conjunto de Métricas
50
desenvolvedores. Dessa forma, podemos criar variações das métricas supracitadas com
base no somatório de uma linha ou de uma coluna, excluíndo-se as células na diagonal
principal, como exemplificado a seguir.
Linha_Cri_ΣMod(d) =
∑
Linha_Cri_Mod(d, y)
(3-19)
∑
Linha_Cri_Mod(x, d)
(3-20)
y∈D −{d}
Linha_ΣCri_Mod(d) =
x∈D −{d}
A primeira equação 3-19, define a quantidade total de modificações imediatamente feitas por outros desenvolvedores em linha criadas pelo desenvolvedor d. Já a
equação 3-20 define a quantidade total de modificações imediatamente realizadas pelo
desenvolvedor d em linha criadas por outros desenvolvedores. Este mesmo conceito pode
ser utilizado para produzir métricas individuais com base nas equações 3-16, 3-17 e 3-18.
Ao todo, oito novas métricas sobre aspectos individuais são obtidos.
3.2.3
Ampliação das métricas para análise em arquivo
As métricas apresentadas nas seções anteriores podem ser expandidas para
computar alterações em arquivos, em um nível mais alto de granularidade. Para tanto,
definimos novos conceitos, em adição aqueles introduzidos na Seção 3.1, os quais são
muito próximos da forma como um SCV armazena a evolução dos artefatos de um projeto.
Uma revisão de projeto é uma tripla (r, d, L), onde:
• r é o rótulo da revisão/versão,
• d é identificador do desenvolvedor que a realizou, com d ∈ D e
• L é uma lista de pares (a,t) onde a é um arquivo e t ∈ {C, M, R}2 descreve a
operação realizada sobre o arquivo a na revisão r.
Uma sequência de revisão de projeto é uma sequência SP =
h(r1 , d1 , L1 ), (r2 , d2 , L2 ), . . . , (rm , dm , Lm )i de triplas definidas acima, de forma a representar todo o histórico das alterações feitas sobre os arquivos do projeto P sem, no
entanto, entrar em detalhe nas modificações realizadas nas linhas individualmente. Todo
arquivo a ∈ A é criado em alguma revisão do projeto e pode ser mantido inalterado,
modificado ou removido nas revisões seguintes. No caso de ser removido, o arquivo não
mais aparece em futuras revisões3 . Se o arquivo não for alterado em alguma revisão i ele
não aparece nos pares da lista Li .
2 Utilizar-se-à
das primeiras letras de CRI, MOD, REM, respectivamente, para diferenciar as operações
sobre arquivos das operações de linhas.
3 A reinclusão deste arquivo no SCV é possível, mais isso é representado pela criação de um outro
arquivo, mesmo que tenha nome idêntico.
3.2 Conjunto de Métricas
51
Com base nesses conceitos, definimos novas métricas a seguir.
A métrica abaixo computa a quantidade de commits4 feitos pelo desenvolvedor
x seguidos imediatamente de um commit do desenvolvedor y.
|SP |−1
Commits(x, y) =
∑
i=1
(
1 se di = x e di+1 = y;
0 caso contrário.
(3-21)
Já a métrica 3-22 indica a quantidade de modificações imediatamente efetuadas
pelo desenvolvedor y em arquivos criados pelo desenvolvedor x. Essa função é uma especificação de maior granularidade para relação entre desenvolvedores dada pela equação
3-15.
1 se existem inteiros i, j ∈ [1, |SP |] com i < j
tal que di = x, d j = y, (a,C) ∈ Li , (a, M) ∈ L j ,
Arquivo_Cri_Mod(x, y) = ∑
e não haja inteiro k, i < k < j, para o qual (a,t) ∈ Lk
a∈A
para qualquer tipo de operação t;
0 caso contrário.
(3-22)
De modo similar, as próximas métricas são variações das equações 3-16, 3-17 e
3-18, definidas anteriormente.
1 se existem inteiros i, j ∈ [1, |SP |] com i < j
tal que di = x, d j = y, (a,C) ∈ Li , (a, R) ∈ L j ,
Arquivo_Cri_Rem(x, y) = ∑
e não haja inteiro k, i < k < j, para o qual (a,t) ∈ Lk
a∈A
para qualquer tipo de operação t;
0 caso contrário.
(3-23)
1 se di = xe e d j = ye (a, M) ∈ Li ∩ L j
∑ ∑ e 6 ∃ k, i < k < y, tal que (a, M) ∈ Lk ;
j=i+1 a∈A
0 caso contrário.
(3-24)
|SP |−1 |SP |
Arquivo_Mod_Mod(x, y) =
∑
i=1
4 O commit corresponde a um conjunto de mudanças (change-sets) que afetam arquivos e uma mensagem
descritiva armazenada pelos SCV.
3.2 Conjunto de Métricas
52
1 se existem inteiros i, j ∈ [1, |SP |] com i < j
tal que di = x, d j = y, (a, M) ∈ Li , (a, R) ∈ L j ,
Arquivo_Mod_Rem(x, y) = ∑
e não haja inteiro k, i < k < j, para o qual (a,t) ∈ Lk
a∈A
para qualquer tipo de operação t;
0 caso contrário.
(3-25)
A métrica Arquivo_Mod_Mod está definida de forma a considerar pares de alterações Mod_Mod consecutivas em todos os arquivos, mesmo daqueles que posteriormente
são excluídos do repositório, caracterizando pois uma medida de esforço. Note que o cálculo da métrica pode ser implementado de forma mais eficiente em termos de tempo de
execução do que aquela implicitamente sugerida pela equação 3-24, para isso é necessário manter atualizada uma lista das últimas ações realizadas sobre cada arquivo a ∈ A na
medida em que avançamos de L1 até Lm , com m = |SP |.
A quantidade total de pares de operações consecutivas sobre arquivos realizados
pelo par de desenvolvedores (x, y) é dada por:
Arquivo_Oper_Oper(x, y) = Arquivo_Cri_Mod(x, y)+
Arquivo_Cri_Rem(x, y)+
Arquivo_Mod_Mod(x, y)+
Arquivo_Mod_Rem(x, y)
(3-26)
Essas métricas de relacionamento induzem matrizes bidimensionais como na
seção 3.2.2. Consequentemente, a somatória de suas linhas ou colunas também geram
métricas individuais dos desenvolvedores conforme definidas abaixo, para as equações
3-21 e 3-22:
Arquivo_Cri_ΣMod(d) =
∑
Arquivo_Cri_Mod(d, y)
(3-27)
∑
Arquivo_Cri_Mod(x, d)
(3-28)
y∈D −{d}
Arquivo_ΣCri_Mod(d) =
x∈D −{d}
Aplicam-se as mesmas regras de somatória para as equações 3-23, 3-24, 3-25 e
3-26.
Para o caso da quantidade total de commits feitas por um desenvolvedor d,
usamos uma definição mais simples:
|SP |
ΣCommits(d) =
∑
i=1
(
1 se di = d
0 caso contrário.
(3-29)
3.3 Comentários gerais
53
Todas essas métricas individuais possuem sua versão relativa (normalizada)
divindo seu valor pela soma das mesmas para todos os desenvolvedores e como feito
no caso das funções: 3-2, 3-4, 3-6, 3-8 e 3-10. As novas métricas relativas são indicadas
pelo uso do sufixo _Rel em seus nomes.
3.3
Comentários gerais
Apresentamos um conjunto de métricas M disposto na Tabela 3.1 que contempla
as métricas absolutas, anteriormente formalizadas. Para cada métrica, existe também sua
versão relativa, que foi utilizada, na prática (veja em Sistema Desenvolvido no Capítulo
5), como forma de normalização no processo de avaliação que será apresentado nos
Estudos de Caso no Capítulo 6.
Identificados alguns problemas decorrentes do modelo de métricas proposto que
são expostos abaixo:
• As alterações de modificação em níveis de linhas não consideram os caracteres
alterados e foi percebido uma grande utilidade semântica para essa abordagem.
Uma vez identificada a natureza da alteração seria possível indicar pontos de falhas
com o objetivo de indicar partes do código que requerem atenção e apoiar os
desenvolvedores em futuras alterações.
• Não consideramos a temporariedade dos commits, todos tem igual importância. Portanto, seria interessante acrescentar essa propriedade para tratar essa característica
criando uma medida configurável para cada alteração de acordo com o tempo.
• Os arquivos e consequentemente as linhas, são tratados com a mesma relevância.
Deste modo, um arquivo do núcleo do sistema tem o mesmo valor que algum
arquivo do componente de visualização menos importante.
• Não se tem definido mecanismos de como adicionar especialistas com experiência
já comprovada seja em outros projetos ou empírica. No presente trabalho, essa
experiência é baseada na meritocracia gerada a partir dos registros armazenados
unicamente no SCV.
Existe a possibilidade de se criar novas métricas a partir dos relacionamentos
mais complexos como, por exemplo, uma relação de três operações sequenciais para
arquivos ou linhas ou pela combinação das métricas já existentes, como foi feito para
“Efetividade de Criação dividida pelo Esforço de Criação”. Vale resaltar, ainda, que
pode ser aplicada alguma operação matemática que faça sentido para obtenção de dados
relevantes.
Outra possibilidade a se considerar é a verificação da cobertura do trabalho realizado por um desenvolvedor. Essa cobertura poderia aferir a distância, no sentido de
Efet_Cri
Efet_Mod
Esfo_Cri
Esfo_Dist_Mod
Esfo_Rem
Efet_Cri_Div_Esfo_Cri
Efet_Mod_Div_Esfo_Dist_Mod
ΣCommits
Linha_ΣCri_Mod
Linha_ΣMod_Mod
Linha_ΣMod_Rem
Linha_ΣCri_Rem
Linha_Cri_ΣMod
Linha_Mod_ΣMod
Linha_Mod_ΣRem
Linha_Cri_ΣRem
Arquivo_ΣCri_Mod
Arquivo_ΣMod_Mod
Arquivo_ΣMod_Rem
Arquivo_ΣCri_Rem
Arquivo_Cri_ΣMod
Arquivo_Mod_ΣMod
Arquivo_Mod_ΣRem
Arquivo_Cri_ΣRem
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
Efetividade de criação de d.
Efetividade de modificação de d
Esforço de criação de d.
Esforço distinto de modificação de d.
Esforço de remoção de d.
Efetividade de criação dividido pelo esforço de criação de d.
Efetividade de modificação dividido pelo esforço distinto de modificação de d.
Somatório de commits feitos por d.
Somatório das linhas adicionadas por d seguidas de modificação por outro desenvolvedor.
Somatório das linhas modificadas por d seguidas de modificação por outro desenvolvedor.
Somatório das linhas modificadas por d seguidas de exclusão por outro desenvolvedor.
Somatório das linhas adicionadas por d seguidas de exclusão por outro desenvolvedor.
Somatório das linhas modificadas por d logo após serem adicionadas por outro desenvolvedor.
Somatório das linhas modificadas por d logo após serem modificadas por outro desenvolvedor.
Somatório das linhas excluídas por d logo após serem modificadas por outro desenvolvedor.
Somatório das linhas excluídas por d logo após serem adicionadas por outro desenvolvedor.
Somatório dos arquivos adicionados por d seguidos de modificação por outro desenvolvedor.
Somatório dos arquivos modificados por d seguidos de modificação por outro desenvolvedor.
Somatório dos arquivos modificados por d seguidos de exclusão por outro desenvolvedor.
Somatório dos arquivos adicionados por d seguidos de exclusão por outro desenvolvedor.
Somatório dos arquivos modificados por d logo após serem adicionados por outro desenvolvedor.
Somatório dos arquivos modificados por d logo após serem modificados por outro desenvolvedor.
Somatório dos arquivos excluídos por d logo após serem modificados por outro desenvolvedor.
Somatório dos arquivos excluídos por d logo após serem adicionados por outro desenvolvedor.
Descrição
Tabela 3.1: Relação das métricas absolutas definidas. Suas versões relativas também existem.
Métricas
No
3.3 Comentários gerais
54
3.3 Comentários gerais
55
proximidade dos arquivos alterados. Por essa aproximidade caracteriza se o desenvolvedor é mais completo, se trabalhou em arquivos espalhados pelo projeto, ou se específico,
quando ele trabalhou somente em arquivos comuns que caracterizam módulos do sistema.
Algumas métricas usam informações que são necessárias para a composição de
outras, portanto, é evidente que existe uma relação entre elas. Fazer uso de métricas que
são altamente correrelacionadas, ou seja, na medida que uma aumenta a outra aumenta
proporcionalmente, influencia negativamente na avaliação que procura destacar aspectos
distintos dos desenvolvedores na tentativa de anular ou minimizar este problema, propomos métodos para detecção de um subconjunto, os quais são discutidos nos próximos
capítulos.
CAPÍTULO 4
Comparação entre Desenvolvedores
Com base nas métricas definidas no Capítulo anterior, são propostas duas abordagens para comparação dos desenvolvedores. A primeira abordagem procura classificar
os desenvolvedores de acordo com o desempenho obtido em algumas métricas. Já a segunda, objetiva demonstrar visualmente quão parecidos ou diferentes os desenvolvedores
são entre si.
4.1
Classificação por desempenho
Para a comparação de desenvolvedores descrita nesta seção, aproveitamos alguns
conceitos comumente utilizados em métodos de resolução de problemas de otimização
multiobjetivos, baseados na ideia de Fronteira de Pareto ou Pareto Ótimo [38, 13]. Três
conceitos são particularmente úteis para o presente trabalho – dominância, soluções
equivalentes e solução eficiente – os quais são definidos a seguir
Sejam fi , i = 1, 2, . . . , k, funções objetivos a serem analizadas, e S o conjunto de
todas as soluções factíveis para um problema de otimização. Dadas duas soluções xa e
xb ∈ S , se fi (xb ) ≤ fi (xa ) para todo i e se a desigualdade é estrita para algum i, então
dizemos que xb domina xa . Se xa não domina xb nem o inverso ocorre, então xa e xb são
ditas soluções equivalentes. Uma solução é considerada eficiente se ela não é dominada
por nenhuma outra solução em S . O conjunto de todas as soluções eficientes em S é o
Pareto Ótimo 1 .
Aproveitamos esses conceitos fazendo uma associação na qual as métricas são
tratadas como funções e os desenvolvedores são as soluções. O objetivo agora é dividir os
desenvolvedores em classes de equivalência hierarquicamente dominadas (c1 , c2 , . . . , cn ),
de tal forma que cada classe seja um conjunto de soluções equivalentes (desenvolvedores
que não se dominam) e cada desenvolvedor em uma classe ci , para i > 1, é dominado por
pelo menos um outro desenvolvedor na classe anterior ci−1 .
1 Encontrar
o Pareto Ótimo está relacionado com o Problema do Vetor Máximo (ou Maximum Vector
Problem em inglês) [43, 18].
4.1 Classificação por desempenho
57
A Figura 4.1 demonstra um exemplo da separação dos desenvolvedores em classes. A primeira classe contém desenvolvedores que não são dominados por nenhum outro
desenvolvedor do conjunto. Em seguida, temos uma classe formada por desenvolvedores
que são dominados por, pelo menos, um desenvolvedor da primeira classe.
Figura 4.1: Exemplo de separação em classes de dominância. O desenvolvedor dc não faz parte
da primeira classe porque é dominado por db . Já da e db não se dominam nem são
dominados por qualquer outro desenvolvedor do conjunto D , fazendo assim parte da
primeira classe (correspondente ao Pareto Ótimo).
A divisão dos desenvolvedores em classes pode ser obtida através de um processo
que iterativamente identifica e extrai todos os desenvolvedores não dominados de um
conjunto inicialmente configurado como igual a D. Uma versão simples desse processo é
apresentado no Algoritmo 4.1.
Consideramos que, quando um desenvolvedor faz parte da primeira classe, ele é
quantitativamente superior aos demais. Essa relação vale para as classes subsequentes.
No entanto, para que o processo comparativo funcione, é preciso que as métricas
tenham um mesmo sentido de valor, por exemplo, quanto maior melhor. A definição do
sentido de interpretação de uma métrica é uma tarefa subjetiva. Como ilustração considere
a métrica de Esforço de Modificação. Um alto valor nessa métrica pode indicar que o
desenvolvedor em questão trabalhou bastante no desenvolvimento de um software, o que
seria algo positivo. Por outro lado, é possível também considerar um grande volume de
esforço como um aspecto negativo, principalmente se ele não gerou resultados efetivos.
Desta forma, cabe ao interessado em comparar os desenvolvedores a definição do sentido
que deve ser dado a cada uma das métricas, bem como, escolher dentre elas as que são
mais adequadas ao contexto.
Note que é possível inverter o sentido de um métrica tormando negativo o seu
valor ou elevando-o à potência -1.
4.2 Comparação por similaridade
58
Algoritmo 4.1: Divisão_em_Classes(D )
Entrada: Conjunto de desenvolvedores D
Saída: Classes de desenvolvedores ci ⊆ D , hierarquicamente dominados.
1
2
3
4
5
6
7
8
9
10
A ← D;
/
R ← 0;
i ← 1;
enquanto A 6= 0/ faça
ci ← todos os desenvolvedores de A que não são dominados por nenhum outro
desenvolvedor nesse conjunto; /* Se A é um conjunto de
desenvolvedores equivalentes, então será retornado o próprio
A.
*/
A ← A − ci ;
R ← R ∪ {ci };
i ← i + 1;
fim
retorna R ;
Alguns cuidados adicionais devem ser tomados quando utilizando as métricas
Efet_Cri_Div_Esfo_Cri e Efet_Mod_Div_Esfo_Dist_Mod. Elas podem produzir injustiças como participações pequenas com alto percentual de aproveitamento. Para estes casos,
antes de produzir as classes de dominiância, deve ser anulado (definida como 0) o valor
nessas métricas para os desenvolvedores cuja a produção for inferior a 10% da soma total
em Esfo_Cri e Esfo_Dist_Mod, respectivamente.
4.2
Comparação por similaridade
Em complementação à abordagem anterior, apresentamos uma comparação por
similaridade que busca identificar se os desenvolvedores são semelhantes na sua forma de
trabalho com base nas métricas. Para tanto, utilizamos uma ferramenta estatística conhecida como Multidimensional Scaling (MDS) [2, 7] que escalona dados multidimesionais
para projetá-los em uma dimensão menor 2 , efatizando as relações de proximidade entre
os mesmos.
O MDS pode ser aplicado em várias áreas do conhecimento como: (a) ciências
sociais, classificando indivíduos por seus desejos; (b) Arqueologia, analisando compatibilidade de objetos encontrados; (c) química, para conformatização molecular, que é um
problema de reconstrução espacial de estruturas moleculares, (d) Computação, desenho
de leiautes de grafos [26] e outros.
2 No
presente trabalho utilizou-se de duas dimensões.
4.2 Comparação por similaridade
59
Para demonstrar o MDS em um exemplo minimalista e hipotético, projetou-se
os critérios de preferência entre seis pessoas pelo gosto por frutas, verduras, carne branca,
carne vermelha e massas em uma escala de 0 a 1, onde 0 representa não gostar e 1 gostar.
A diposição de suas preferências segue o disposto na Tabela 4.1.
Pessoa Frutas Verduras
1
0,50
0,40
2
0,50
0,60
3
0
0
4
0
0
5
0
0
6
0
0
Carne Branca Carne Vermelha Massas
0
0
0
0
0
0
0
0
0,60
0
0
0,50
0,55
0,55
0
0,45
0,45
0
Tabela 4.1: Exemplo de uso do MDS em um conceito minimalista.
Intencionalmente, e apenas a título de ilustração, manipulou-se as pessoas 1 e 2
pelo gosto exclusivo por frutas, as pessoas 3 e 4 pelo gosto por massas e as pessoas 5 e 6
pelo gosto por carnes. Como resultado, espera-se do MDS um agrupamento das pessoas
pelas suas preferências, fato que se confirma, conforme verificado na Figura 4.2.
Figura 4.2: Exemplo do MDS em um agrupamento de pessoas com preferências em comum.
Aplicando esse conhecimento ao nosso problema, cada desenvolvedor possui
valores para um conjunto de métricas, e uma projeção MDS é adotada para destacar
visualmente a similaridade (ou a diferença) entre esses desenvolvedores com base nos
seus valores. Deve-se ter o cuidado, no entanto, para não escolher métricas fortemente
correlacionadas para a análise com o MDS. Se muitas métricas correlacionadas entre
si forem escolhidas para o conjunto de análise, elas tenderão a dominar a projeção e a
4.2 Comparação por similaridade
60
visualização não conseguirá expressar os aspectos distintos dos desenvolvedores (o que
seria desejável). Diante do problema exposto, é necessário um procedimento para verificar
a relação das métricas e escolher, dentre elas, um conjunto não fortemente relacionado
para ser utilizado na análise de similaridade.
A fim de identificar automaticamente métricas não correlacionadas, construiu-se,
neste trabalho, um processo para selecionar boas métricas de avaliação.
Inicialmente, calcula-se o coeficiente de correlação de Pearson que retorna a
correção linear entre duas variáveis x e y em uma escala de -1 a +1, sendo:
-1 – correlação negativamente perfeita entre as duas variáveis (quando uma aumenta a
outra diminui),
0 – não dependem linearmente uma da outra (mas pode existir uma relação não-linear),
e
+1 – correlação perfeitamente positiva entre as duas variáveis (quando uma aumenta a
outra aumenta),
O coeficiente de Pearson é calculado para todo par de métricas, resultando em
uma matriz de métricas de tamanho n × n onde n é a quantidade de métricas. Em seguida,
selecionamos um conjunto de métricas fracamente relacionadas. Isso foi feito através do
Algoritmo 4.2, construído neste trabalho exclusivamente para tal fim. O Algoritmo recebe
a matriz de correlação, um limiar de corte de correlação entre 0 e 1 e uma lista de métricas
fixas, possivelmente vazia.
O Algoritmo retorna o conjunto de métricas fixas acrescido de outras com base
na correlação máxima definida pelo limiar. Caso o limiar seja igual a 0, o conjunto será
adicionado apenas de métricas que não mantêm correlação linear entre si nem com as
métricas fixas. Se o limiar for igual a 1, todas as métricas serão retornadas. Já limiares no
intervalo (0,1) servem para descartar métricas cujo valor absoluto de sua correlação com
outras já consideradas para retorno é superior a esse limite.
A existência da lista de métricas fixas se justifica caso seja necessário escolher
intuitivamente um conjunto de métricas e desconsiderar outras ou quando deseja-se
aumentar um conjunto de métricas pré-selecionadas para reforçar algum critério de
interesse.
4.2 Comparação por similaridade
61
Algoritmo 4.2: Seleção_de_Métricas(correl, limite, F )
Entrada: Matriz de correlação de tamanho n × n, limite para corte da correlação no
intervalo [0, 1], lista F de métricas fixas pertencentes ao conjunto
completo M
Saída: Conjunto de métricas selecionadas de M
1
2
3
4
5
6
7
8
9
Para cada métrica m ∈ M , calcule o somatório da correlação de m com todas as
outras métricas em M ;
Crie um vetor V contendo, no início, as métricas de F seguidas das demais
métricas ordenadas ascendentemente pelo seu somatório;
Marque todas as métricas em M como selecionadas;
para i = 1 até |V | − 1 faça
se a métrica V [i] está marcada em M como selecionada então
para j = i + 1 até |V | faça
se V [ j] ∈
/ F e absoluto(correl[V [i]], V [ j]]) > limite então
Marque V [ j] em M como não selecionada;
fim
fim
10
11
12
13
fim
fim
retorna as métricas de M marcadas como selecionadas;
Existem deficiências em nosso algoritmo a considerar. Por exemplo, ele não detecta correlação não linear. Além disso, embora a verificação da correlação de Pearson das
métricas seja útil, ela não deve ser a única técnica utilizada, uma vez que falsos-positivos
podem existir (por exemplo, correlação alta porém gráfico não linear) e conduzir-nos a
resultados errôneos. Pode ser empregada, portanto, uma Matrix Scatter Plot (MSP) para
confirmar visualmente padrões de correlação entre as métricas.
Dado um conjunto de variáveis X1 , X2 , . . . , Xk , uma MSP é formada pelo emparelhamento de simples Scatter Plots em um formato de matriz. A diagonal principal (onde
k-linha é igual a k-coluna) é descartada uma vez que não tem sentido prático comparar
uma váriavel com ela mesma. A matriz gerada é simétrica. Um exemplo ilustrativo de
uma MSP é apresentado na Figura 4.3.
Foi computada uma MSP sobre as métricas dos desenvolvedores para um
projeto de software estudado (o primeiro estudo de caso descrito no Capítulo 6).
A matriz MSP possui 24 × 24 Scatter Plots descrevendo a relação entre 24 métricas para onze desenvolvedores. Após extensiva análise visual de todos os relacionamentos apresentados nessa matriz e experiência empírica, percebeu-se a utilidade de quatro métricas sendo elas: Efetividade de Criação (Efet_Cri), Efetividade
4.2 Comparação por similaridade
62
Figura 4.3: Exemplo de uma Matrix Scatter Plot onde as variáveis são, largura e altura das
pétalas e sépalas de lírios. Exemplo ilustrativo e não discutido no texto. Extraído
de http://bl.ocks.org/4063663.
de Modificação (Efet_Mod), Efetividade de Criação dividido pelo Esforço de Criação
(Efet_Cri_Div_Esfo_Cri), e Efetividade de Modificação dividido pelo Esforço Distinto
de Modificação (Efet_Mod_Div_Esfo_Dist_Mod). Essas métricas representam a quantidade de criação de um desenvolvedor, o esforço que ele desprendeu para evolução dos
artefatos, e as taxas de aproveitamento de suas criações e modificações respectivamente.
Acreditamos que tais métricas são um ponto de partida para comparação entre os desenvolvedores, devendo as mesmas serem ratificadas ou modificadas por meio de um estudo
para cada projeto de software.
CAPÍTULO 5
Sistema Desenvolvido
Este capítulo apresenta um sistema que implementa as métricas formuladas
no Capítulo 3 e as abordagens de comparação entre os desenvolvedores proposto no
Capítulo 4. A motivação para a criação de um sistema é oferecer uma ferramenta pronta
para aplicar a abordagem em repositórios reais de código fonte.
5.1
Tecnologias utilizadas
Para implementação, foi usada a linguagem de progração Ruby [15, 46] na
versão 1.9.3, além de algumas de suas bibliotecas internas e externas, como listadas a
seguir:
• Bundler – componente facilitador que permite instalar dependências internas de
bibliotecas e componentes necessárias para o funcionamento do sistema. 1
• Awesome_print – biblioteca para impressão amigáveis das estruturas muito utilizado para depuração. 2
• Mime-types – biblioteca que permite a identificação de tipo de arquivos. Em nossa
implementação necessitamos saber se os arquivos são binários ou de texto plano
para aplicar o processo de análise. 3
• Axlsx – componente que permite a geração de planilhas. 4
Foi criada uma aplicação desktop capaz de conectar em um SCV indicado por
parâmetro e extrair todos os dados necessários para análise. Optamos por trabalhar com
o Subversion (svn) que apesar de ser comum é compatível com seu antecessor o CVS e
também bastante utilizado em modelos de softwares livres e proprietários.
1 http://gembundler.com
2 https://github.com/michaeldv/awesome_print
3 http://mime-types.rubyforge.org
4 https://github.com/janhuehne/axlsx
5.2 Etapas de Funcionamento do Sistema
64
Nossa implementação suporta apenas o versionador Subversion porém já está em
desenvolvimento, uma versão inicial para Git. Outros versionadores podem ser utilizados
desde que implementados os drivers adequados.
Além dessas tecnologias, o sistema produz arquivos de saída em formatos para
serem lidos por outros programas como: GGobi [45, 44], uma ferramenta livre para exploração de dados multidimensionais e o D3js [4], um framework de visualização de
informações. O sistema também faz uso do aplicativo diff que é comum em sistemas
operacionais Linux para geração das diferenças entre arquivos. Apesar dos SCV implementarem sua própria versão do diff, usamos a do sistema operacional para solucionar
problemas encontrados que serão comentados no final deste capítulo.
5.2
Etapas de Funcionamento do Sistema
O sistema funciona em três etapas: Geração do Histórico, Coleta das Métricas
e Produção dos Dados de Comparação, como ilustrado na Figura 5.1. Essas etapas são
implementadas na forma de programas separados e são descritos detalhadamente a seguir.
Figura 5.1: Descrição de cada processo para análise de desenvolvedores a partir da mineração
de repositório.
5.2.1
Geração do Histórico
A Geração do Histórico tem por objetivo ler os dados de um SCV e produzir
os históricos de projeto com seus respectivos históricos de arquivos e históricos de
linhas como descritos nas Seções 3.2.2 e 3.2.3. O histórico de projetos no nível de
arquivo (Seção 3.2.3) advém diretamente do Subversion sem grandes alterações. A partir
5.2 Etapas de Funcionamento do Sistema
65
dessa estrutura, criamos os históricos de arquivos e de linhas usando um algoritmo que
desenvolvemos e que está referenciado a seguir como Algoritmo 5.1. O Algoritmo e as
operações efetuados sob os arquivos podem ser descritos da seguinte maneira. 5
• Quando uma alteração do tipo A (correspondente a adicionar) é identificada,
inicializa-se uma estrutura de dados armazenando todas as suas linhas.
• Quando uma alteração do tipo D (correspondente a excluir) é identificada, marca-se
todas as linhas como removidas 6 no arquivo de estrutura de dados.
• Quando uma alteração do tipo M (correspondente a modificar) é identificada,
incrementa-se o arquivo de estrutura (anteriormente adicionado) com as devidas
modificações encontradas após análise das diferenças linha a linha.
A operação nos arquivos do tipo (M) leva a implementação do Algoritmo 5.2
que obtém a diferença de um mesmo arquivo em sua versão anterior e atual. A diferenças,
por sua vez, pode conter alterações nas linhas do tipo CRI, MOD, REM, apesar de parecer
simples quando existe uma operação de CRI (criação) é necessário verificar a posição
precisa no arquivo de história e fazer a inserção correta nas estruturas de dados do sistema.
Para efetuar um inserção deve-se levar consideração as alterações feitas anteriormente.
Por exemplo, se a iteração anterior removeu linhas, então a posição das novas linhas deve
desconsiderar as linhas previamente removidas.
Ao término da iteração de todos os arquivos do projeto, é obtida uma cópia da
árvore de diretórios no mesmo formato da original contendo em cada arquivo toda a sua
história. Portanto é possível restaurar os arquivos em qualquer revisão feita anteriormente.
Um exemplo hipotético criado para demonstrar o formado dos arquivos que serão
gerados é apresentado no Registro 5.1. O devido arquivo foi inicializado com duas linhas
(a primeira coluna representa as linhas) sendo “linha-1” e “linha-2” respectivamente
(revisão 1). Na revisão seguinte é modificada a primeira linha pelo conteúdo “linha-a”
e adicionado linha 3 com conteúdo “linha-4” (revisão 2), na próxima iteração removeuse a linha 3 (revisão 3). A linha zero é reservada para metadados em caso de alguma
necessidade futura.
Entretanto, é necessário considerar mais duas operações sobre os arquivos identificadas no modelo do Subversion que são: C (copiar) e R (substituir).
O primeiro corresponde a uma operação conceitual, ou seja, cria uma referencia
entre arquivos enquanto não são modificados. O teor dos arquivos são os mesmos mas em
locais diferentes. Na prática isso permite uma grande economia de espaço em projetos que
5A
nomeclatura dos tipos estão idênticas ao versionador subversion em questão, que são A,M,D,R que
em nosso modelo corresponde à C,M,R,S respectivamente.
6 Nenhuma remoção é efetivamente efetuada pois é necessário computação das métricas.
5.2 Etapas de Funcionamento do Sistema
66
Algoritmo 5.1: Constrói_Histórico_Projeto(SP )
Entrada: Sequênca de Revisão de Projeto SP
Saída: Histórico de Projeto HP e conjuntos de arquivos A e Ar ⊂ A
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
/
HP ← 0;
/
Cria uma lista com última versão de cada arquivo. Inicialmente A ← 0;
r
/
Cria também uma lista de arquivos A ← 0;
para cada revisão no projeto s ∈ SP faça
/* Obs.: Um revisão de projeto consiste de uma tripla (r,d,L)
com descrito na Seção 3.2.2
*/
para cada (a,t) ∈ s.L faça /*
*/
se t = C então
/* Se a operação é de Criação */
Cria arquivo de historia Ha ← ∅;
para cada linha l de a em sequência faça /*
*/
Cria um histórico de linha hl com operação o = (s.r, s.d,CRI, l);
Adiciona hl no final de Ha ;
fim
Adiciona Ha a HP ;
Adiciona a a A;
senão se t = R então
/* Se a operação é de Remoção */
Recupera Ha de HP ;
para cada histórico de linha hl ∈ Ha faça /*
*/
se hl não termina com a operação REM então
Cria um histórico de linha hl com operação
o = (s.r, s.d, REM, ∅);
Adiciona o no final de hl ;
fim
fim
Adiciona a a Ar ;
senão se t = M então
/* Se a operação é de Modificação */
Recupera a última versão de a ∈ A. Seja a0 essa versão;
Computa uma sequência X de alterações de linha de a com base no
comando di f f (a0 , a). Uma alteracão de linha é da forma
x = (linha,tipo,texto), na qual linha é o número da linha alterada,
tipo ∈ {CRI, MOD, REM} é o tipo de alteração realizada na linha pelo
desenvolvedor, e texto é o conteúdo da linha após a alteração. A lista X
deve conter um sequência de alterações de linha ordenadas pelo
número da linha alterada;
Recupera Ha de HP ;
Hanovo ← Atualiza_Histórico(Ha , s.r, s.d, X ); // Ver Algoritmo 5.2
Substitui Ha ∈ HP por Hanovo ;
Substitui a0 ∈ A por a;
fim
fim
fim
5.2 Etapas de Funcionamento do Sistema
67
Algoritmo 5.2: Atualiza_Histórico(Ha , v, d, X )
Entrada: Histórico de arquivo Ha , versão v, desenvolvedor d, Lista de alterações
X em ordem crescente de linhas.
Saída: Histórico de arquivo Ha , incrementado com a lista de alterações.
1
2
3
4
5
6
7
8
9
10
11
para cada x ∈ X faça /* Para cada alteração da Lista X
*/
p ← Posição no histórico Ha da linha indicada por x.linha, desconsiderando as
linhas do tipo “Rem” existentes;
se x.tipo = “Cri” então
// Se a operação é de Criação
Cria uma operação o (versão = v, desenv = d, tipo = x.tipo, texto = x.texto);
Cria um novo histórico de linha na posição p de Ha , deslocando o restante
dos históricos de linha para baixo;
Insere o no histórico de linha na posição p;
senão se x.tipo = “Mod” ou o.tipo = “Rem” então
// Caso contrário
Acrescenta a operação o no histórico de linha que se encontra na posição p
de Ha ;
fim
fim
retorna Ha ;
tem muitas derivações de um parte principal ou em casos de ramos (branches) e rótulos
(tags), correspondente a liberações de versões baseadas em planejamentos prévios.
O segundo representa uma operação de excluir e adicionar feita de uma única
vez. A não existência dessa operação implicaria a necessidade de duas em sequência que
não é muito prático.
Tratamos o caso R (substituir) como M (modificar) da seguinte maneira: aplicase uma operação D, removendo todas as linhas do arquivo e em seguida aplica-se as
operações C (criar), adicionando as linhas incluídas na referida revisão. O histórico de
arquivos será mantido em uma sequência de tipos no formato A > (M) > D, em outro caso
seria A > (R > A) > D, o sinal > significa “seguido de” em um histórico de arquivo e os
parênteses “()” indicam a posição onde ocorreram as ações que descrevemos.
Os arquivos de histórico mencionados são usados como entrada para a análise
dos resultados obtidos e para a próxima etapa do processo.
5.2.2
Cálculo das Métricas
O processo de cálculo das métricas inicia-se na análise das estrutura dos históricos e procede de acordo com o tipo de cada alteração efetuada. No momento que
os arquivos de histórico são analisados as métricas são computada conforme descrito no
Capítulo 3.
5.2 Etapas de Funcionamento do Sistema
68
[0] [] ,
[1] [
[0] {: versao : 1,
: desenv : " user1 ",
: tipo : " Cri ",
: texto : " linha -1\ n"} ,
[1] {: versao : 2,
: desenv : " user2 ",
: tipo : " Mod ",
: texto : " linha -a\n"} ,
],
[2] [
[0] {: versao : 1,
: desenv : " user1 ",
: tipo : " Cri ",
: texto : " linha -2\ n "}
],
[3] [
[0] {: versao : 2,
: desenv : " user2 ",
: tipo : " Cri ",
: texto : " linha -4\ n"} ,
[1] {: versao : 3,
: desenv : " user1 ",
: tipo : " Rem ",
: texto : " linha -4\ n "}
]
Registro 5.1: Exemplo de registro de histórico processado pelo Algoritmo 5.2.
5.2.3
Produção dos Dados de Comparação
Uma vez que todas as métricas são computadas, o último processo é executado
para gerar os seguintes arquivos como resultado:
1. Classes de equivalência – Um arquivo no formato de dados serializados (yaml) 7
legível contendo as classes de dominância previamente apresentada.
2. Análise MDS – Um arquivo no formato de marcação extendida (xml) 8 preparado
para o GGobi. O referido arquivo possui duas partes, a primeira contendo as
métricas para cada desenvolvedor e a outra com a distância euclidiana entre os
desenvolvedores.
3. Relação das métricas selecionadas – Um arquivo no formato de notação de objeto
JavaScript Object Notation (json) 9 , as estruturas estão definidas para visualização
pelo framework D3js.
7 http://www.yaml.org/spec/1.2/spec.html
8 http://www.w3.org/TR/REC-xml/
9 http://www.ietf.org/rfc/rfc4627.txt
5.3 Visualizações desenvolvidas para análise
69
4. Visualização das relações entre os desenvolvedores – Um arquivo no formato de
notação de objeto (json), as estruturas estão definidas para visualização pelo D3js.
5. Matriz de correlação – Um arquivo no formato planilha (xlsx) 10 contendo o valor
da correlação entre todas as métricas;
6. Métricas selecionadas – Um arquivo no formato planilha (xlsx) contendo todas as
métricas selecionadas em sua versão absoluta e relativa;
7. Métricas de relacionamento entre desenvolvedores – Um arquivo no formato planilha (xlsx) que contém em cada aba as métricas de relacionamento entre os desenvolvedores em sua versão absoluta e relativa;
Alguns dos arquivos gerados foram usados como base para entrevistas com os
gerentes de projetos nos estudo de caso descritos no Capítulo 6.
5.3
Visualizações desenvolvidas para análise
Para facilitar a identificação de padrões no comportamento dos desenvolvedores
e apoiar o processo de escolha de métricas foram contruídas visualizações de informação
utilizado o framework D3js 11 .
As próximas seções descrevem tais visualizações.
5.3.1
Visualização de relacionamento entre desenvolvedores
A visualização de relacionamento entre os desenvolvedores foi a primeira a
ser produzida neste trabalho e teve como meta a verificação do trabalho exercido pelos
desenvolvedores a partir de suas métricas.
Toda planilha de relacionamento entre os desenvolvedores foi transformada para
o formato json, e usada como entrada para geração dessas visualizações. A estrutura
visual consiste em um painel para cada métrica. Cada painel, por sua vez, possui nós
que representam os desenvolvedores e que estão dispostos de modo equidistantes sobre
uma circunferência. O tamanho do nó aumenta quando um desenvolvedor faz iterações
com ele mesmo em sequência, por exemplo, um commit seguido de outro commit, ambos,
feitos pelo mesmo desenvolvedor. Uma aresta existe quando um desenvolvedor interage
com outros desenvolvedores, a cor indica a origem e a espessura indica a quantidade de
iterações com o destino.
10 http://msdn.microsoft.com/en-us/library/dd361853.aspx
11 O
D3js [4] é a evolução do Protovis [3] ambos produzidos por um grupo de visualização da Universidade de Stanford (http://vis.stanford.edu) e utiliza padrões web amplamente adotados pela maioria
dos navegadores.
5.3 Visualizações desenvolvidas para análise
70
Dessa forma um desenvolvedor que interage bastante com outro desenvolvedor
terá uma ligação espessa e facilmente percebida visualmente. É notável, também, quando
existe um grande esforço do desenvolvedor com ele próprio (operações em sequência do
mesmo desenvolvedor) pelo tamanho do nó que representa o desenvolvedor.
A visualização possui interação com o usuário e é possível selecionar quais
painéis se deseja mostrar simultaneamente. Basta um clique em um nó para destacá-lo e
também suas arestas, em todos os painéis. É possível destacar vários nós ao mesmo tempo,
permitindo verificar visualmente as interações entre esses desenvolvedores. A Figura 5.2
apresenta a visualização descrita anteriormente, selecionado apenas três painéis (no caso,
commits, arquivos e linhas) e destacando dois desenvolvedores.
Figura 5.2: Apresentação de três painéis de métricas: commits, arquivos e linhas da esquerda
para direita respectivamente. Os desenvolvedores 1 (azul do lado direito dos painéis)
e 7 (vermelho do lados esquerdo dos painéis) estão destacados.
5.3.2
Visualização de cobertura de métricas
A segunda visualização foi proposta como forma de apoiar a identificação de
métricas altamente correlacionadas. Foi usado um grafo e um sistema de forças no modelo
springs onde cada nó corresponde a uma métrica e uma aresta existe para cada par de nós,
representando a correlação entre as suas respectivas métricas. Os nós são posicionados no
início de forma aleatória e o sistema de força tende a reorganizá-los.
O grafo gerado conduziu-nos a geração da rotina de Seleção de Métricas (Algoritmo 4.2) e portanto os seu dados consideram apenas nós que são superiores a um limiar
pré-estabelecidos. A Figura 5.3 apresenta um conjunto de métricas com limiar 0,1, foram
selecionadas automaticamente as seguintes métricas: Efet_Mod_Div_Esfo_Dist_Mod e
Linha_Mod_ΣDel.
5.4 Dificuldades na Implementação
71
Figura 5.3: Visualização de um processo de identificação de cobertura de métricas onde as
métricas destacadas foram selecionadas automaticamente pelo Algoritmo de Seleção
de Métricas.
5.4
Dificuldades na Implementação
Algumas dificuldades foram encontradas no desenvolvimento do sistema apresentado neste capítulo. Notou-se dois problemas difícies de se identificar no qual foram
gastos tempo com depurações e implementações para contorná-los.
No primeiro caso, o versionador não gerava um arquivo de diferenças válido
para algum código, conforme demonstrado na Figura 5.4. Note na linha 10 que o segundo
contexto é expressado pelos sinais @@. Neste caso, isso diz que aquele bloco se inicia na
linha 2 porém existem três linhas antes, o que é um equívoco.
No segundo caso, operações inconsistentes foram geradas. Confira na Figura 5.5
o registro de atividades de um arquivo. Esse arquivo foi adicionado pela primeira vez
na revisão 975 e alterado nas revisões 988 e 1015. Porém, ele foi adicionado novamente
na revisão 1456 e ainda na revisão 1563, sem antes ter sido removido, confirmando uma
operação de inconsistência. Em contato com o gerente e os desenvolvedores do projeto
percebeu-se uma alteração na codificação de caracteres desses arquivos, algo que o SCV
5.4 Dificuldades na Implementação
72
Figura 5.4: Problema encontrado no arquivo de diferenças gerado pelo Subversion.
não entendeu causando má interpretação das operação ao considerar um novo arquivo.
Para estes casos nenhuma ação foi tomada apenas o avisos de inconsistência são gerados
pelo nosso sistema.
Figura 5.5: Problema encontrado em operações inconsistentes geradas pelo Subversion.
CAPÍTULO 6
Avaliação
Com o intuito de verificar o comportamento das abordagens de comparação entre
desenvolvedores descritas anteriormente, foi realizada uma avaliação qualitativa através
de dois estudos de casos utilizando o sistema implementado em SCV de projetos reais. A
metodologia de avaliação e o resultado dos estudos são apresentados a seguir. No final do
capítulo, discutimos também outros aspectos relacionados com o ajuste de configurações.
6.1
Metodologia para os estudos de casos
Para a realização dos estudos, escolhemos dois projetos de desenvolvimento de
software armazenados em repositórios SCV Subversion sob responsabilidade do Centro
de Recursos Computacionais (Cercomp) 1 da UFG. Tal escolha foi feita com base na
disponibilidade de gerentes que poderiam fornecer informações sobre esses projetos e
analisar as abordagens de comparação apresentadas.
O primeiro estudo de caso foi utilizado para experimentação e validação das
metodologias, sendo que o autor da presente dissertação foi desenvolvedor e gerente
do projeto. O segundo estudo de caso envolveu outra equipe. O gerente da mesma
indicou o projeto no qual tinha interesse na avaliação para conhecer o perfil de seus
desenvolvedores.
A avaliação, para cada estudo de caso, foi realizada em quatro etapas:
1. Execução do sistema descrito no Capítulo 5, utilizando o repositório SCV indicado.
Como mencionado anteriormente, esse sistema produz informações sobre o repositório SCV, métricas, classificação dos desenvolvedores por classes e uma matriz de
dissimilaridade.
1 O Cercomp é o órgão da Universidade responsável pela infraestrutura de TI e desenvolvimento e manu-
tenção dos sistemas acadêmicos e administrativos. Atualmente, há cerca de 50 projetos de desenvolvimento
de software no repositório Subversion do órgão. O acesso aos dados foram cedidos pela direção do Cercomp
para o presente trabalho.
6.1 Metodologia para os estudos de casos
74
2. Realização de uma entrevista com o gerente do projeto de desenvolvimento de
software em questão com o objetivo de avaliar qualitativamente as abordagens de
comparação baseadas em métricas.
3. Análise e interpretação dos resultados obtidos com a entrevista.
4. Repetição dos passos 1 para um novo conjunto de métricas e uma análise geral com
o gerente.
Para a etapa 1, foram escolhidas as quatro métricas citadas no final da Seção 4.2 que são: Efetividade de Criação (Efet_Cri), Esforço de Criação (Esfo_Cri),
Efetividade de Criação dividido pelo Esforço de Criação (Efet_Cri_Div_Esfo_Cri)
e Efetividade de Modificação dividido pelo Esforço Distinto de Modificação
(Efet_Mod_Div_Esfo_Dist_Mod). Após a entrevista e com base nas perguntas finais
respondidas pelo especialista, foi selecionado um novo conjunto de métricas de sua
preferência e gerada novas comparações para análise.
No caso específico das entrevistas, essas consistiram de um conjunto de perguntas previamente elaboradas para verificar se os resultados apresentados são compatíveis
com as percepções de um especialista, que neste caso, é o gerente de projeto. O gerente
de projeto foi escolhido como elemento central na entrevista por desempenhar um papel
importante no processo de desenvolvimento de um software. Ele conhece todos os atores envolvido no desenvolvimento, os objetivos a serem alcançados e a metodologia de
trabalho.
A entrevista seguiu um roteiro de seis passos conforme descritos a seguir e
apresentado em detalhe na Tabela 6.1:
1. Apresentação do objetivo da avaliação (ou seja, comparar desenvolvedores com
base em dados coletados do Subversion e nas métrica geradas).
2. Apresentação da classificação dos desenvolvedores por classe de dominância e seu
significado.
3. Realização de perguntas ao especialista (o gerente de projeto) sobre a interpretação
dos resultados da classificação.
4. Apresentação da visualização em MDS.
5. Perguntas ao especialista sobre a visualização em MDS.
6. Perguntas finais ao avaliador sobre as métricas escolhidas para o projeto.
6.1 Metodologia para os estudos de casos
Formulário de Entrevista
Nome do Entrevistado:
Nome do Projeto:
Cargo:
Formação:
Local e Data:
1 Explicar os dados existentes e as métricas. (Explicar o que o sistema desenvolvido faz)
2
Apresentar a classificação por classe de dominância. (Explicar o significado de cada classe)
3
Perguntas sobre a classe de dominância.
a) “Essa separação faz sentido para você?”
b) “Se você fosse escolher um ou mais desenvolvedores para um projeto futuro, esta classificação ajudaria? Por quê? Quais
os desenvolvedores você escolheria?”
c) “Você classificaria os desenvolvedores dessa mesma forma? Por quê? Se não, como seria sua classificação?”
d) “Tem algum desenvolvedor que você acha que foi classificado equivocadamente?”
4
Apresentar a visualização em MDS. (Explicar o que significa a distância entre dois desenvolvedores)
5
Perguntas sobre a visualização em MDS.
e) “Os desenvolvedores que estão próximos são, de fato, parecidos na sua produção técnica? Eles produzem resultados
semelhantes?”
f) “Como você rotularia (daria nomes com base em alguma característica de similaridade) os “grupos” de pessoas
visivelmente próximas?”
g) “Há alguma discrepância ou semelhança entre os resultados das classes de dominância, apresentadas anteriormente, e a
visualização MDS atual?”
6
Perguntas sobre o conjunto total de métricas.
h) “Você concorda que quanto maior for o valor obtido em cada uma dessas 4 métricas melhor foi o desempenho do
desenvolvedor? Por quê?”
i) “Quais outras métricas (da planilha completa) você acha interessante/útil para uma avaliação dos desenvolvedores? Por
quê?”
Tabela 6.1: Formulário utilizado nas entrevistas dos estudos de caso.
75
6.2 Estudo de Caso 1
6.2
76
Estudo de Caso 1
O primeiro estudo de caso analisou um gerenciador de conteúdo Web chamado
Weby. O nome Weby é uma junção das duas letras iniciais da palavra “Web” mais as duas
letras finais da palavra “Ruby”, linguagem de programação utilizada em sua produção.
O projeto iniciou-se em julho de 2010 pela Equipe Web do Cercomp com o objetivo
de desenvolver um sistema flexível e extensível, com uma linguagem de programação
moderna, e com várias novos recursos que o gerenciador de conteúdo antigo (também
desenvolvido pela instituição e em PHP) da Universidade Federal de Goiás (UFG) não
dispunha. A principal motivação para o projeto disponibilizar conteúdo de maneira
simples, permitindo uma fácil administração da informação. O software é utilizado hoje
para gerenciar mais de 400 sítios da UFG.
O sistema é utilizado para apoiar a instituição no cumprimento a Lei 12.527,
sancionada em 18 de novembro de 2.011, pela Presidente da República, Dilma Roussef,
o qual regulamenta o direito constitucional de acesso dos cidadãos às informações
públicas 2 . Também, instaura um canal de ouvidoria 3 conforme resolução Consuni
03/2009/UFG.
A equipe iniciou o desenvolvimento do projeto com um colaborador e quatro
estagiários. O contrato dos estagiários é de um ano, podendo ser renovado por mais
um ano. O tempo de estágio é considerado pouco, gerando assim, um alto índice de
rotatividade. O projeto foi avaliado considerando o período do seu início até o final de
fevereiro de 2012 (1 anos e 7 meses) chegando a 1.294 revisões hospedadas no SCV
(Subversion) após essa data o sistema foi migrado para outro SCV (Git), para o qual nosso
sistema ainda não tem suporte. Durante o período considerado, onze desenvolvedores
contribuiram para a evolução do software, sendo um servidor público, dois colaboradores
e oito estagiários.
A Tabela 6.2 apresenta informações gerais sobre o projeto como quantidade de
commits, total de arquivos e linhas adicionados, modificados e removidos, em acréscimo,
oferece informações sobre a ação dos desenvolvedores no projeto Weby. A primeira
coluna corresponde aos nomes dos desenvolvedores que foram suprimidos para garantir
suas privacidades evitando a identificação, a segunda coluna corresponde ao total de
commits efetuados, a terceira coluna tríplice o total de arquivos criados, modificados e
removidos e a última coluna tríplice o total de linhas criadas, modificadas e removidas. O
Apêndice A mostra os quadros de métricas completas para esse projeto.
Os resultados dos testes procederam com configuração de métricas conforme
Tabela 6.3 que produziu a classe de dominância conforme Tabela 6.4. Para o MDS,
2 http://www.sic.ufg.br
3 http://www.ouvidoria.ufg.br
6.2 Estudo de Caso 1
Desenv.
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
Total
Commits
474
159
2
170
30
99
61
183
20
24
72
1.294
77
Adicionados
652
3.610
1
378
43
2.142
13
5.883
1
8
7
12.738
Arquivos
Modificados
1.827
496
7
591
79
374
381
786
34
74
203
4.852
Removidos
86
14
0
63
1
35
15
44
0
5
4
267
Adic.
110.204
4.340
26
44.013
1736
51.673
1.116
85.686
102
542
1.190
300.628
Linhas
Mod.
7.026
1.521
31
1.577
142
1.548
923
4.688
398
196
489
18.549
Rem.
54.710
1.587
165
1.224
205
3.220
1.214
5.289
15
476
308
68.413
Tabela 6.2: Informações gerais sobre o projeto Weby. Total de commits, arquivos e linhas adicionados, modificados e removidos.
utilizou-se o GGobi com configurações de análise de dissimilaridade com duas dimensões
que produziu a visualização apresentada na Figura 6.1.
D.
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
Efet_Cri
102.817
3.188
0
41.929
1.185
50.630
483
83.409
55
225
1.053
Efet_Mod
539
294
0
410
21
479
163
1.302
211
43
1.053
Efet_Cri_Div_Esfo_Cri
0,932935903
0,734562212
0,0
0,952628709
0,6826036866
0,9797205774
0,4324082363
0,9735284849
0,5392156863
0,4151291513
0,8848739496
Efet_Mod_Div_Esfo_Dist_Mod
0,2531705026
0,6099585062
0,0
0,4550499445
0,4375
0,8077571669
0,6127819549
0,6326530612
0,8755186722
0,6056338028
1,0096153846
Tabela 6.3: Conjunto de métricas selecionadas e resultados para o projeto Weby.
Classes de dominância
1
2
3
4
5
6
Desenvolvedor
d1, d6 e d8.
d4.
d2 e d11.
d5, d7 e d9.
d10.
d3.
Tabela 6.4: Resultados da classe de dominância para o projeto Weby.
6.2 Estudo de Caso 1
78
Figura 6.1: Resultado MDS para o projeto Weby.
6.2.1
Entrevista
Como mencionado anteriormente, o autor desta dissertação foi desenvolvedor e
gerente do projeto em questão. Assim, outro desenvolvedor foi escolhido para a avaliação
que atualmente é o gerente da equipe 4 . A seguir, apresentamos as perguntas e as respostas
dadas por esse gerente.
A. Perguntas sobre a classe de dominância
1. “Essa separação faz sentido para você?”
Sim.
2. “Se você fosse escolher um ou mais desenvolvedores para um projeto futuro, esta
classificação ajudaria? Por quê? Quais os desenvolvedores você escolheria?”
Ajudaria, porque perceberia o desempenho das pessoas. Os desenvolvedores d1, d6
e d8.
3. “Você classificaria os desenvolvedores dessa mesma forma? Por quê? Se não, como
seria sua classificação?”
Faria algumas pequenas modificações de modo que elevaria o desenvolvedor d4
para classe 1 e o desenvolvedor d10 para classe 4.
4. “Tem algum desenvolvedor que você acha que foi classificado equivocadamente?”
Apesar da mudanças sugeridas na pergunta anterior a classificação não está ruim
está apenas mais definida, ou seja contendo mais classes do que sugeri.
4O
autor desta dissertação é o desenvolvedor d1 e o novo gerente é o desenvolvedor d11.
6.2 Estudo de Caso 1
79
B. Perguntas sobre a visualização em MDS
1. “Os desenvolvedores que estão próximos são, de fato, parecidos na sua produção
técnica?”
Sim, mostrou bem a semelhança entre eles.
2. Eles produzem resultados semelhantes?
Os que estão próximos sim.
3. “Como você rotularia (daria nomes com base em alguma característica de similaridade) os “grupos” de pessoas visivelmente próximas?”
Sim, o grupo (d2, d5, d7, d9, d10 e d11) são alteradores e (d4, d6) são criadores na
parte de interface, o restante (d1 e d8) possui características individuais distintas.
4. “Há alguma discrepância ou semelhança entre os resultados das classes, apresentadas anteriormente, e a visualização MDS atual?”
Sim, há semelhança visível no MDS e nas classes de dominância.
C. Perguntas sobre as métricas
1. “Você concorda que quanto maior for o valor obtido em cada uma dessas métricas
melhor foi o desempenho do desenvolvedor? Por quê?”
Sim, porque como você mencionou estão orientadas (em um mesmo sentido).
2. “Quais outras métricas (da planilha completa, Tabela 3.1) você acha interessante/útil para uma avaliação dos desenvolvedores? Por quê?”
Nenhuma. As atuais parecem caracterizar bem os desenvolvedores.
O entrevistado não mostrou interesse explícito pelo uso de nenhuma outra métrica. No entanto, comentou que, caso as métricas 11, 12, 19 e 20 (vide Tabela 3.1) venham
a ser selecionadas, elas deveríam contar ponto em desfavorecimento do desenvolvedor em
questão, por considerarem o trabalho desse desenvolvedor como alvo de remoções.
6.2.2
Análise e interpretação dos resultados
O desenvolvedor d3 participou inicialmente do projeto e por isso tem pouca produção. Outros desenvolvedores que foram estagiários por pouco tempo também tiveram
uma vaga participação.
Os comentários referentes à direção (sentido) das métricas levou a considerar
a criação de um mecanismos para inverter seus valores quando solicitados, porém isso
ainda não foi implementado.
Pela opinião do entrevistado, os resultados foram satisfatórios e consistentes, em
sua maioria, com as suas impressões como especialista e gerente do projeto.
6.2 Estudo de Caso 1
6.2.3
80
Análise para outras métricas
Após a realização da entrevista, e como o entrevistado havia feito comentários
sobre métricas de remoção, acrescentamos a métrica Esfo_Rem no conjunto de métricas
fixas e utilizamos o algoritmo de seleção de métricas com limiar 0,5. Como resultado,
foram selecionadas, além das métricas cinco métricas fixas sugeridas, as seguintes:
Arquivos_Cri_ΣRem e Arquivos_ΣMod_Rem.
O sistema então gerou o MDS demonstrado na Figura 6.2 (b). A Figura 6.2 (a)
consiste no MDS da primeira avaliação e foi colocada ao lado para fins comparativos. O
novo MDS (b) separou os desenvolvedores d2 e d7 dos desenvolvedores d5, d9, d10 e
d11, afastou consideravelmente os desenvolvedores d4 e d6 e aproximou o desenvolvedor
d8 do d6 em virtude do aumento na quantidade de métricas.
Apesar do Algoritmo de seleção de métricas ter sido elaborado para auxiliar
na comparação por similaridade, resolvemos verificar também como a comparação por
desempenho mudaria com as métricas selecionadas pelo mesmo. No caso, foi considerado
que todas as métricas possuem um sentido positivo (quanto maior melhor). O efeito foi
que a relação de dominância sofreu uma pequena alteração na qual o desenvolvedor d4
subiu da classe 2 para classe 1, e o restante permaneceu conforme disposto na Tabela 6.4.
Esse novo resultando é mais próximo das sugestões que foram mencionadas na entrevista.
(a) MDS da primeira avaliação.
(b) MDS da segunda avaliação.
Figura 6.2: Duas imagens MDS referentes ao projeto Weby. O resultado da primeira avaliação (a)
com quatro métricas fixas em comparação com o resultado da segunda avaliação (b)
com quatro métricas fixas em acréscimo da métricas Esfo_Rem e seleção automática
com limiar 0,5.
6.3 Estudo de Caso 2
6.3
81
Estudo de Caso 2
Para o segundo estudo de caso, utilizamos o Solicite, um sistema desenvolvido
pela divisão de Sistemas do Cercomp com a função de otimizar o processo de solicitação
de bens, serviços e requisições de materiais pelos diversos órgãos administrativos e
unidades acadêmicas da UFG. Sua principal vantagem é o rastreamento de solicitações.
Ele é o módulo inicial destinado a gerenciar todo o processo de compras e prestações de
serviços, atendendo a Lei de Licitações 8.666 de 21 de junho de 1.993.
O Solicite interage ainda com os sistemas financeiro e orçamentário, de tabelas
gerais, de pessoal, de almoxarifado e com o sistema de patrimônios da Universidade.
Uma vez criada a solicitação é possível os usuários interessados monitorar o seu estado
e acompanhar sua evolução. O Solicite foi implantado no final de 2.010 e em janeiro
de 2.011, por determinação da Pró-Reitoria de Administração (Proad) e se tornou uma
ferramenta institucional utilizada intensivamente.
Atualmente é o sistema mais bem estruturado em termos de processo de desenvolvimento de software, possui uma razoável definição de controle de versão, dispõe de
uma equipe para realizar testes e de pessoas bem comprometidas e competentes nas suas
funções. Foi avaliado 1.657 commits com o total de 11 desenvolvedores envolvendo o
período de Setembro de 2.008 a Dezembro de 2.012. A Tabela 6.5 apresenta informações gerais sobre o trabalho dos desenvolvedores nesse período. O Apêndice B mostra os
quadros de métricas completas para esse projeto.
Desenv.
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
Total
Commits
493
106
244
457
12
5
5
142
22
165
6
1.657
Adicionados
943
160
47
942
4
6
2
41
0
29
0
2.174
Arquivos
Modificados
1.822
192
780
1.553
16
2
12
201
0
456
0
5.034
Removidos
75
4
1
5
1
0
0
0
0
0
0
86
Adic.
16.304
2.295
239
89.118
10
0
0
0
0
11.650
0
119.616
Linhas
Mod.
462
84
90
1.339
0
0
0
0
0
5.853
0
7.828
Rem.
1.841
1.315
235
890
10
0
0
0
0
2.195
0
6.486
Tabela 6.5: Informações gerais sobre o projeto Solicite. Total de commits, arquivos e linhas
adicionados, modificados e removidos.
Os resultados dos testes procederam com configuração de métricas conforme
Tabela 6.6 que produziu a classe de dominância conforme Tabela 6.7. Para o MDS,
6.3 Estudo de Caso 2
82
utilizou-se o GGobi com configurações de análise de dissimilaridade com duas dimensões
que produziu a visualização apresentada na Figura 6.3.
D.
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
Efet_Cri
16.167
1.946
196
83.481
10
0
0
0
0
11.509
0
Efet_Mod
0
0
0
188
0
0
0
0
0
4.285
0
Efet_Cri_Div_Esfo_Cri
0,991597154
0,847930283
0,820083682
0,936746785
1,0
0,0
0,0
0,0
0,0
0,987896996
0,0
Efet_Mod_Div_Esfo_Dist_Mod
0,0
0,0
0,0
0,1567973311
0,0
0,0
0,0
0,0
0,0
0,7884084637
0,0
Tabela 6.6: Conjunto de métricas selecionadas e resultados para o projeto Solicite.
Classes de dominância
1
2
3
4
5
Desenvolvedor
d1, d4 e d10.
d2.
d3.
d5.
d6, d7, d8, d9 e d11.
Tabela 6.7: Resultados da classe de dominância para o projeto Socilite.
Figura 6.3: Resultado MDS para o projeto Solicite.
6.3 Estudo de Caso 2
6.3.1
83
Entrevista
A. Perguntas sobre a classe de dominância
1. “Essa separação faz sentido para você?”
Faz sentido [. . .] achei justo a classificação.
2. “Se você fosse escolher um ou mais desenvolvedores para um projeto futuro, esta
classificação ajudaria? Por quê? Quais os desenvolvedores você escolheria?”
Com certeza ajudaria. Primeiramente pelos critérios utilizados pelas rotinas. Os
desenvolvedores d4 e d10.
3. “Você classificaria os desenvolvedores dessa mesma forma? Por quê? Se não, como
seria sua classificação?”
Não, porque conheço pessoalmente o trabalho deles. Adicionaria os desenvolvedores d7 e d8 na classse 4.
4. “Tem algum desenvolvedor que você acha que foi classificado equivocadamente?”
Sim. o desenvolvedor d7 e o d8.
B. Perguntas sobre a visualização em MDS
1. “Os desenvolvedores que estão próximos são, de fato, parecidos na sua produção
técnica?”
Sim.
2. “Eles produzem resultados semelhantes?”
Sim.
3. “Como você rotularia (daria nomes com base em alguma característica de similaridade) os “grupos” de pessoas visivelmente próximas?”
Eu rotularia como: grupo dos que não são programadores (d6, d7, d8, d9 e d11),
grupo dos programadores antigos (d1, d2, d3 e d5) e atuais (d4 e d10).
4. “Há alguma discrepância ou semelhança entre os resultados das classe, apresentadas anteriormente, e a visualização MDS atual?”
Percebi a mesma semelhança de agrupamento presente tanto no MDS quanto na
classe de dominância.
C. Perguntas sobre as métricas
1. “Você concorda que quanto maior for o valor obtido em cada uma dessas 4 métricas
melhor foi o desempenho do desenvolvedor? Por quê?”
Sim, porque estão no mesmo sentido.
2. “Quais outras métricas (da planilha completa, Tabela 3.1) você acha interessante/útil para uma avaliação dos desenvolvedores? Por quê?”
6.3 Estudo de Caso 2
84
Têm várias. A de commit por exemplo é importante porque quanto mais rápido o
desenvolvedor efetuar commits menor será os problemas de conflito. Remoção também é interessante para entender se o escopo do projeto mudou ou se existe muitas
falhas que neste caso deveria fazer uma análise mais refinada pelo fornecedor de
requisitos ou verificar a necessidade de qualificação dos desenvolvedores.
O entrevistado perguntou se existia a implementação de algum mecanismos
para avaliar os pontos de função referente a cada alteração no código fonte, no qual foi
respondido que não possui nenhum mecanismo de análise de sintaxe ou vínculo com
ferramenta de registro de bugs. Existe também, a dificuldades inerentes a integração com
outras ferramentas. Uma sugestão anotada, foi a possibilidade de aplicar a ferramenta em
um intervalo específico de tempo a fim de verificar os resultados em partes.
Ao final da entrevista, o gerente comentou que achou importante as métricas de
esforço dos desenvolvedores para avaliar se existe sinergia entre a equipe. Portanto, em
um eventual pedido de aumento salarial poderia ser aferido o merecimento através dos
indícios comparativos de sua produção e se comprovada a sua qualidade, recompensá-lo
adequadamente ou até mesmo recomendá-lo a participar de outros projetos.
6.3.2
Análise e interpretação dos resultados
Os desenvolvedores d9 e d11, apesar de terem commits, apenas criaram diretórios
no projeto e não possui nenhuma estatística para arquivos e linhas. O desenvolvedor
d6 trabalhou somente com arquivos binário e não possui estatística para linhas. Os
desenvolvedores d7 e d8 foram afetados pelo problema comentados na Seção 5.4 e por
isso não possuem estatísticas para linhas.
Os erros encontrados ao extrair os dados do repositório foram identificados
e serão enviados aos desenvolvedores do SCV em questão (Subversion). Esses erros
afetaram sensivelmente os resultados da avaliação, embora ainda tenham sido satisfatórios
conforme expressado na entrevista pelo gerente do projeto.
6.3.3
Análise para outras métricas
Após a entrevista, ainda na presença do gerente entrevistado e por sua
vontade, ajustamos o Algoritmo de seleção automática de métricas para um limiar
0,4 e nenhuma métrica fixa. Foram selecionadas automaticamente 4 métricas que
são: Linhas_ΣMod_Rem, Arquivo_Mod_ΣRem, Linhas_Cri_ΣMod e Linhas_ΣCri_Mod.
Como no estudo de caso anterior (na Seção 6.2.3), para fins de comparação por desempenho, essas métricas foram consideradas como tendo o mesmo sentido (quanto maior
melhor).
6.4 Outros Aspectos
85
A hierarquia de classe permaneceu apenas com dois grupos sendo: classe 1 (d1,
d2, d3, d4 e d10) e classe 2: (d5, d6, d7, d8, d9 e d11) diminuindo o nível de detalhes em
relação à estrutura a anterior.
Uma comparação entre o MDS anterior e o atual são apresentados na Figura 6.4
e comentados em seguida. Semelhante ao que aconteceu com a camada de dominância,
os agrupamentos do MDS se mostraram menos detalhados que o anterior. Três mudanças
foram percebidas: a primeira, houve um distanciamento dos desenvolvedores d2 e d3 do
agrupamento de desenvolvedores d6, d7, d8, d9 e d11. A segunda, o desenvolvedor d5 se
juntou ao agrupamento (d6, d7, d8, d9 e d11). A terceira, o desenvolvedor d1 afastou-se
consideravelmente dos desenvolvedores d2 e d3.
A primeira avaliação está mais condizente com as impressões do gerente sobre
sua equipe.
(a) MDS da primeira avaliação.
(b) MDS da segunda avaliação.
Figura 6.4: Duas imagens MDS referentes ao projeto Solicite. O resultado da primeira avaliação
(a) com quatro métricas fixas em comparação com o resultado da segunda avaliação
(b) com seleção automática com limiar 0,4.
6.4
Outros Aspectos
Conforme observado na Seção 6.3.3, a seleção totalmente automática de métricas
resultou em um MDS que não refletiu a percepção do gerente de projeto quanto a similaridade dos desenvolvedores na mesma proporção que o MDS com as quatro métricas
fixas pré-selecionadas. Isso reforça o nosso comentário de que a escolha de um conjunto
de métricas é um processo subjetivo e deve ser gerenciado com cuidado pelo interessado
na análise dos dados.
6.4 Outros Aspectos
86
Em função disso, decidimos fazer uma análise mais detalhada da seleção de métricas para a comparação por similaridade usando o Algoritmo 4.2. A análise considerou
o projeto Weby descrito no primeiro estudo de caso, com diferentes valores de limiar (de
/ {E f et_Mod}, as quatro
0,1 a 0,5 com incremento de 0,1) e conjunto de métricas fixas (0,
métricas previamente selecionadas). A Tabela 6.8 apresenta o resultado da seleção gerada
pelo Algoritmo para as diversas configurações de parâmetro. Os resultados com limiar 0,1
foram suprimidos por conterem poucas métricas.
Quando não foi selecionada qualquer métrica, o algoritmo de fato retorna um
conjunto de métricas que considera mais adequado. Esse conjunto tende a aumentar
na medida em que se eleva o limiar. No entanto, o conjunto de métricas resultante
pode deixar de incluir algum aspecto de interesse para comparação dos desenvolvedores.
Assim, o método permite que sejam pré-selecionadas algumas métricas desejáveis. Nos
exemplos identificados como (d), (e) e (f) foi considerada apenas uma métrica fixa, tendo
o algoritmo selecionado outras para os dois últimos casos. Já nos exemplos (g), (h) e
(i), foi pré-selecionado um conjunto maior de métricas desejáveis. Esse conjunto possui
maior correlação com várias outras métricas. Mesmo assim, elevando o limiar, é possível
aumentar gradativamente o conjunto.
Os resultados MDS para as configurações supracitas são apresentados na Figura 6.5. Os rótulos dos gráficos estão relacionados com a coluna (Id.) na Tabela 6.8
indicando a configuração correspondente.
Quando há apenas uma métricas (como é o caso (d)), não é possível fazer uma
diferenciação significativa dos desenvolvedores já que todos eles ficam posicionados visualmente em uma mesma linha. Na figura (e), onde existe apenas duas métricas selecionadas, foi produzida uma comparação visual dos desenvolvedores bastante peculiar,
não presente em nenhum outro gráfico. Na medida em que se aumenta a quantidade de
métricas os desenvolvedores tendem a se distanciar e formar visualmente novos grupos
(clusters) no MDS. Note que, para os casos em que foram selecionadas seis métricas (os
gráficos (c), (f) e (i)), os MDSs são muito parecidos apesar das métricas serem diferentes.
Isso se deve, contudo, ao fato do limiar ser maior, o que faz com que sejam selecionadas
métricas que representam os mesmos aspectos que outras correlacionadas.
Em conclusão, uma maior quantidade de métricas é melhor para caracterizar os
desenvolvedores, mas o resultado é mais efetivo se tais métricas forem não correlacionadas. Várias das 24 métricas propostas neste trabalho possuem uma forte correlação entre
si, não sendo adequadas para uso em conjunto no MDS. Portanto, seria útil a criação de
outras métricas com baixa correlação com as já sugeridas visando complementar ainda
mais a comparação por similaridade.
Além da análise do conjunto selecionado de métricas, procuramos obter melhores medidas de normalização para comparar os desenvolvedores utilizando, ao invés
6.4 Outros Aspectos
Entrada
Métricas pré-selecionadas
87
Limiar
Id.
Total
0.2
(a)
3
0.3, 0.4
(b)
4
0.5
(c)
6
0.2
(d)
1
0.3 e 0.4
(e)
2
0.5
(f)
6
0.2, 0.3
(g)
4
0.4
(h)
5
0.5
(i)
6
0/
Efet_Cri_Div_Esfo_Cri
Efet_Cri
Efet_Mod
Efet_Cri_Div_Esfo_Cri
Efet_Mod_Div_Esfo_Dist_Mod
Saída
Métricas escolhidas
Efet_Mod_Div_Esfo_Dist_Mod
Arquivo_Cri_ΣRem
Efet_Mod
Efet_Mod_Div_Esfo_Dist_Mod
Arquivo_Cri_ΣRem
Arquivo_ΣMod_Rem
Efet_Mod
Efet_Mod_Div_Esfo_Dist_Mod
Arquivo_Cri_ΣRem
Arquivo_ΣMod_Rem
Efet_Mod
Linha_Mod_ΣRem
Esfo_Rem
Efet_Cri_Div_Esfo_Cri
Efet_Cri_Div_Esfo_Cri
Arquivos_ΣMod_Rem
Efet_Cri_Div_Esfo_Cri
Efet_Mod_Div_Esfo_Dist_Mod
Arquivo_Cri_ΣRem
Arquivo_ΣMod_Rem
Arquivo_ΣCri_Rem
Esfo_Rem
Efet_Cri
Efet_Mod
Efet_Cri_Div_Esfo_Cri
Efet_Mod_Div_Esfo_Dist_Mod
Efet_Cri
Efet_Mod
Efet_Cri_Div_Esfo_Cri
Efet_Mod_Div_Esfo_Dist_Mod
Arquivo_ΣMod_Rem
Efet_Cri
Efet_Mod
Efet_Cri_Div_Esfo_Cri
Efet_Mod_Div_Esfo_Dist_Mod
Arquivo_ΣMod_Rem
Arquivo_Cri_ΣRem
Tabela 6.8: Tabela de informações sobre o resultado de seleção de métricas.
da versão relativa das métricas, uma padronização baseado na média e no desvio padrão
(x − x)/σ. No entanto, o MDS resultante, ilustrado na Figura 6.6, sofreu apenas alterações
sutis entre a proximidade dos desenvolvedores.
6.4 Outros Aspectos
88
(a)
(b)
(c)
(d)
(e)
(f)
(g)
(h)
(i)
Figura 6.5: Conjunto de figuras MDS composto por várias configurações de entrada para o
Algoritmo 4.2 como um pequeno teste de sensibilidade.
6.4 Outros Aspectos
89
(a) MDS utilizando métricas relativas.
(b) MDS utilizando métricas com desvio padrão.
Figura 6.6: Outras formas de normalização. (a) MDS utilizando métricas relativas, e (b) MDS
utilizando métricas com desvio padrão.
CAPÍTULO 7
Conclusão
O presente trabalho buscou comparar os desenvolvedores de software para endender sua forma de trabalho. Para tanto, foi realizada uma revisão bibliográfica sobre
pesquisas afins, foram criados: um modelo de históricos de alteração de código e um conjunto de métricas e propostas duas abordagens para comparação entre desenvolvedores.
Foi criado também um sistema computacional para calcular as métricas e gerar os dados
de comparação. As abordagens e as métricas foram avaliadas em dois estudos de casos
envolvendo projetos reais de desenvolvimento de software. A validação com especialistas
foi extremamente importante para averiguar a qualidade das comparações geradas. Em
geral, obtivemos resultados positivos e bons comentários dos avaliadores referentes aos
projetos analisados.
A definição formal das métricas e dos históricos e a sua implementação em um
sistema computacional necessitou de um grande investimento de tempo e concentração.
A escolha das ferramentas foi essencial e ajudou em grande parte do trabalho. Além disso
muitos projetos comerciais utilizam o Subversion, pelo seu modelo centralizado e fluxo
de trabalho mais simples, se comparado a SCV de terceira geração. Assim a ferramenta
desenvolvida pode ser utilizada para a comparação de desenvolvedores em outros projetos
de software. Em particular, sentimos a necessidade de aplicar a avaliação em um Software
Livre de grande porte e coletar, de alguma forma, as opiniões de seus desenvolvedores.
7.1
Trabalhos Futuros
Apesar dos resultados iniciais positivos, encontramos algumas limitações na
nossa abordagem e no sistema apresentado que podem ser atendidas em trabalhos futuros.
São elas:
• não foi levado em consideração o fator tempo. Portanto, todas as alterações têm
igual importância independentemente se foram realizados logo no início do projeto
ou no final;
7.1 Trabalhos Futuros
91
• todos os arquivos e diretórios também tem igual relevância e são tratados igualmente na nossa proposta. No entanto, alguns arquivos, dependendo da arquitetura
do projeto, demandam mais dedicação e/ou conhecimentos específicos dos desenvolvedores do que outros. Inclusive, alguns arquivos podem ter sido gerados automaticamente por ferramentas de desenvolvimento;
• não é possível avaliar mais de um projeto (com o sistema atual) ao mesmo tempo
e integrar os dados coletados. No entando pode ser útil expandir a abordagem
comparativa para incluir métricas extraídas de múltiplos projetos;
• dados de poucos SCV foram analisados neste trabalho e faz-se necessário aplicar
as abordagens descritas para projetos de grande porte;
• poderiam ter sido definidas métricas que avaliam outros aspectos dos desenvolvedores, inclusive métricas subjetivas com base no conhecimento dos membros de
uma equipe de desenvolvimento de software pelo gerente de projeto;
• não é possível utilizar, concomitantemente com o SCV, dados de outros sistemas,
tais como de SAP (Sistemas de Acompanhamento de Problemas);
• o sistema implementado pode ser melhorado através de modificações como:
– disponibilizá-lo para utilização via Web;
– inserir novas métricas através de um mecanismo modular de acoplamento.
Atualmente as métricas estão fortemente acopladas ao sistema central. Se o
sistema fosse modular seria possível a criação de novas métricas de maneira
simples e complementar as já existentes;
– incluir drivers para versionadores de terceira geração;
– suportar novas técnicas de visualização de informações; e
– disponibilizar através de uma interface gráfica todos resultados do sistema de
forma amigável e relatórios estatísticos sobre os dados dos projetos analisados
como por exemplo, quantidade de desenvolvedores, total de arquivos e linhas
de código criadas.
Referências Bibliográficas
[1] B ERLINER , B. CVS II: Parallelizing Software Development. In: Proceedings of
the USENIX Winter 1990 Technical Conference, p. 341–352, Berkeley, CA, 1990.
USENIX Association.
[2] B ORG , I.; G ROENEN , P. Modern Multidimensional Scaling: Theory and Applications. Springer, 2005.
[3] B OSTOCK , M.; H EER , J. Protovis: A Graphical Toolkit for Visualization. IEEE
Transactions on Visualization and Computer Graphics, 15(6):1121–1128, Nov. 2009.
[4] B OSTOCK , M.; O GIEVETSKY, V.; H EER , J. D3 Data-Driven Documents. IEEE Transactions on Visualization and Computer Graphics, 17(12):2301–2309, Dec. 2011.
[5] B ROOKS , F. P.
The Mythical Man-Month: Essays on Software Engineering.
Addison-Wesley, anniversary edition, Aug. 1975.
[6] B ROOKS , F. P. No Silver Bullet: Essence and Accidents of Software Engineering.
IEEE Computer, 20:10–19, 1987.
[7] B UJA , A.; S WAYNE , D. F.; L ITTMAN , M. L.; D EAN , N.; H OFMANN , H.; C HEN , L.
Data Visualization with Multidimensional Scaling. Journal of Computational and
Graphical Statistics, 17(2):444–472, 2008.
[8] C ANONICAL LTD.. Sítio do Launchpad – Plataforma de Colaboração de Software.
https://launchpad.net. [Acesso em 11 de Dezembro de 2012].
[9] C HARNES , A.; C OOPER , W. W.; R HODES , E. Measuring the Efficiency of Decision
Making Units. European Journal of Operational Research, 2(6):429–444, November
1978.
[10] C ÍCERO, J. R. Projetos de Pesquisa e Políticas Nacionais de Ciência, Tecnologia
e Inovação – O Caso do Instituto Nacional de Tecnologia em 2010. Master’s thesis, Centro Federal de Educação Tecnológica Celso Suckow da Fonseca CEFET/RJ,
Rio de Janeiro – Rio de Janeiro, 2011.
Referências Bibliográficas
93
[11] C OCKBURN , A.; K ARLSON , A.; B EDERSON , B. B. A Review of Overview+Detail,
Zooming, and Focus+Context Interfaces. ACM Compututing Surveys, 41(1):2:1–
2:31, Jan. 2009.
[12] D E M ARCO, T.; L ISTER , T. Peopleware: Productive Projects and Teams. Dorset
House Publishing Co., Inc. New York, NY, USA, 1987.
[13] DO N ASCIMENTO, H. A. D. Uma Abordagem para Desenho de Grafos Baseada
na Utilização de Times Assíncronos. Master’s thesis, Instituto de Computação –
UNICAMP, Campinas – São Paulo, 1997.
[14] E VANS DATA C ORPORATION . More than 1.1 million developers in north america
now working on open source projects. http://www.evansdata.com/press/
viewRelease.php?pressID=64, 2013. [Acesso em 27 de Março de 2013].
[15] F LANAGAN , D.; M ATSUMOTO, Y. The Ruby Programming Language. O’Reilly
Media, Incorporated, 2008.
[16] G ILBERT, E.; K ARAHALIOS , K. CodeSaw: A Social Visualization of Distributed
Software Development.
In: Proceedings of the 11th IFIP TC 13 international
conference on Humancomputer interactionVolume Part II, Lecture Notes in Computer
Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes
in Bioinformatics), p. 303–316. Springer-Verlag, 2007.
[17] G IRBA , T.; K UHN , A.; S EEBERGER , M.; D UCASSE , S.
Software Evolution.
How Developers Drive
In: Proceedings of the Eighth International Workshop on
Principles of Software Evolution, IWPSE ’05, p. 113–122, Washington, DC, USA,
2005. IEEE Computer Society.
[18] G ODFREY, P.; S HIPLEY, R.; G RYZ , J. Algorithms and Analyses for Maximal Vector
Computation. The VLDB Journal, 16:5–28, 2007.
[19] G OOGLE C O..
Sítio do Google Code – Projeto de hospedagem que provê
desenvolvimento colaborativo livre em um ambiente de código aberto. https:
//code.google.com. [Acesso em 11 de Dezembro de 2012].
[20] G RUNE , D. Concurrent Versions System, A Method for Independent Cooperation. Technical report, IR 113, Vrije Universiteit, 1986.
[21] H UANG , S.-K.; L IU, K.- M . Mining Version Histories to Verify the Learning Process of Legitimate Peripheral Participants. ACM SIGSOFT Software Engineering
Notes, 30(4):1, jul 2005.
Referências Bibliográficas
94
[22] H UNT, J. W.; M CILROY, M. D. An Algorithm for Differential File Comparison.
Technical Report 41, Bell Laboratories Computing Science, jul 1976.
[23] J ERMAKOVICS , A.; S COTTO, M.; S UCCI , G.
Evolution Patterns.
Visual Identification of Software
In: Ninth international workshop on Principles of software
evolution: in conjunction with the 6th ESEC/FSE joint meeting, IWPSE ’07, p. 27–
30, New York, NY, USA, 2007. ACM.
[24] J ERMAKOVICS , A.; S ILLITTI , A.; S UCCI , G. Mining and Visualizing Developer
Networks from Version Control Systems. In: Proceeding of the 4th international
workshop on Cooperative and human aspects of software engineering - CHASE ’11,
p. 24, New York, New York, USA, may 2011. ACM Press.
[25] K AGDI , H.; Y USUF, S.; M ALETIC, J. I. Mining Sequences of Changed-files from
Version Histories. In: Proceedings of the 2006 international workshop on Mining
software repositories - MSR ’06, p. 47, New York, New York, USA, may 2006. ACM
Press.
[26] K RUSKAL , J.; S EERY, J. Designing Network Diagrams. In: Proc. First General
Conference on Social Graphics, p. 22–50, 1980.
[27] L AVE , J.; W ENGER , E. Situated Learning: Legitimate Peripheral Participation.
Cambridge University Press, 1 edition, sep 1991.
[28] L OPEZ -F ERNANDEZ , L.; R OBLES , G.; G ONZALEZ -B ARAHONA , J. M.
Applying
Social Network Analysis to the Information in CVS Repositories. “International
Workshop on Mining Software Repositories (MSR 2004)” W17S Workshop - 26th
International Conference on Software Engineering, 2004:101–105, 2004.
[29] M INTO, S.; M URPHY, G. C. Recommending Emergent Teams. In: Proceedings
of the Fourth International Workshop on Mining Software Repositories, MSR ’07,
Washington, DC, USA, 2007. IEEE Computer Society.
[30] M OCKUS , A.; H ERBSLEB , J. D. Expertise Browser: A Quantitative Approach to
Identifying Expertise. Proceedings of the 24th International Conference on Software
Engineering ICSE 2002, p. 503–512, 2002.
[31] Naur, P.; Randell, B., editors. Software Engineering: Report of a conference
sponsored by the NATO Science Committee, jan 1968.
[32] PANÇARDES , J. R. R.; DE S OUZA J ÚNIOR , P. R.
Legalidade da adoção pela
administração pública federal do programa de implantação do software livre
Referências Bibliográficas
95
(psl-brasil) e suas consequências nos processos licitatórios. Revista Científica
do Centro Universitário de Barra Mansa, 9(17):98, Jul 2007.
[33] P ILATO, C. M.; C OLLINS -S USSMAN , B.; F ITZPATRICK , B. W. Version Control with
Subversion. O’Reilly Media, 2 edition, Sept. 2008.
[34] P RESTON -W ERNER , T.; WANSTRATH , C.; H YETT, P. Sítio do Github – Ambiente
de compartilhamento de código.
https://github.com. [Acesso em 11 de
Dezembro de 2012].
[35] Randell, B.; Buxton, J. N., editors. Software Engineering Techniques: Report
of a conference sponsored by the NATO Science Committee. Scientific Affairs
Division, Roma - Italy, Oct. 1969.
[36] R AYMOND, D. R. Reading Source Code. In: Proceedings of the 1991 conference of
the Centre for Advanced Studies on Collaborative research, CASCON ’91, p. 3–16.
IBM Press, 1991.
[37] R OCHKIND, M. J. The Source Code Control System. IEEE Trans. Software Eng.,
1(4):364–370, 1975.
[38] R ODRIGUES , R. F.
Times Assíncronos para a Resolução de Problemas de
Otimização Combinatória Multiobjetivo. Master’s thesis, Instituto de Computação
– UNICAMP, Campinas – São Paulo, 1996.
[39] R OSENBERG , L.; H YATT, L. Software Quality Metrics for Object-Oriented Environments. Crosstalk Journal, April, 1997.
[40] RUAN , L.; WANG , Y.; WANG , Q.; L I , M.; YANG , Y.; X IE , L.; L IU, D.; Z ENG , H.;
Z HANG , S.; X IAO, J.; Z HANG , L.; N ISAR , M. W.; DAI , J.
Empirical Study on
Benchmarking Software Development Tasks. In: Wang, Q.; Pfahl, D.; Raffo, D. M.,
editors, ICSP, volume 4470 de Lecture Notes in Computer Science, p. 221–232.
Springer, 2007.
[41] S ARMA , A.; M ACCHERONE , L.; WAGSTROM , P.; H ERBSLEB , J. Tesseract: Interactive Visual Exploration of Socio-technical Relationships in Software Development. In: Software Engineering, 2009. ICSE 2009. IEEE 31st International Conference on, p. 23–33. IEEE, 2009.
[42] S CHULER , D.; Z IMMERMANN , T. Mining Usage Expertise from Version Archives.
In: Proceedings of the 2008 international workshop on Mining software repositories MSR ’08, p. 121, New York, New York, USA, may 2008. ACM Press.
Referências Bibliográficas
96
[43] S TADLER , W. A Survey of Multicriteria Optimization or The Vector Maximum
Problem, part I: 1776–1960. Journal of Optimization Theory and Applications, 29:1–
52, 1979.
[44] S WAYNE , D. F.; B UJA , A.; L ANG , D. T. Exploratory Visual Analysis of Graphs in
GGobi, 2003.
[45] S WAYNE , D. F.; L ANG , D. T.; B UJA , A.; C OOK , D. GGobi: evolving from XGobi
into an extensible framework for interactive data visualization. Computational
Statistics & Data Analysis, 43(4):423–444, August 2003.
[46] T HOMAS , D.; F OWLER , C.; H UNT, A. Programming Ruby 1.9: The Pragmatic
Programmers Guide. Pragmatic Bookshelf, 3rd edition, 2009.
[47] T ICHY, W. F. RCS: A System for Version Control. Software-Practice & Experience,
1985.
[48] T URING , A. Computing Machinery and Intelligence. Mind, 59(236):433–460, 1950.
[49] VOINEA , L.; L UKKIEN , J.; T ELEA , A. Visual Assessment of Software Evolution.
Science of Computer Programming, 65(3):222–248, apr 2007.
[50] VOINEA , L.; T ELEA , A.
An Open Framework for CVS repository Querying,
Analysis and Visualization. In: Proceedings of the 2006 international workshop
on Mining software repositories - MSR ’06, p. 33, New York, New York, USA, may
2006. ACM Press.
[51] Y E , Y.; K ISHIDA , K. Toward an Understanding of The Motivation Open Source
Software Developers. In: Proceedings of the 25th International Conference on
Software Engineering, ICSE ’03, p. 419–429, Washington, DC, USA, 2003. IEEE
Computer Society.
[52] Z HANG , S.; WANG , Y.; TONG , J.; Z HOU, J.; RUAN , L. Evaluation of Project Quality:
A DEA-Based Approach. In: Wang, Q.; Pfahl, D.; Raffo, D. M.; Wernick, P., editors,
SPW/ProSim, volume 3966 de Lecture Notes in Computer Science, p. 88–96.
Springer, 2006.
[53] Z HANG , S.; WANG , Y.; X IAO, J. Mining Individual Performance Indicators in Collaborative Development Using Software Repositories. In: Software Engineering
Conference, 2008. APSEC ’08. 15th Asia-Pacific, p. 247 –254, dec 2008.
[54] Z HANG , S.; WANG , Y.; YANG , Y.; X IAO, J. Capability Assessment of Individual
Software Development Processes Using Software Repositories and DEA. In:
Referências Bibliográficas
97
Wang, Q.; Pfahl, D.; Raffo, D. M., editors, Making Globally Distributed Software Development a Success Story, volume 5007 de Lecture Notes in Computer Science, p.
147–159. Springer Berlin Heidelberg, 2008.
APÊNDICE A
Apêndice
Cada página desse apêndice contem uma tabela de métricas em sua versão
absoluta e relativa de relacionamento entre os desenvolvedores. Os desenvolvedores estão
dispostos nas linhas e colunas formando a matriz de relacionamento. Para interpretação
dos resultados, deve-se considerar os desenvolvedores das colunas como agentes de
mundaça nos desenvolvedores das linhas, ou seja, os desenvolvedores dispostos nas linhas
sofreram alterações do desenvolvedores que estão dispostos nas colunas. Ao final, todas
as métricas que foram formalizadas no Capítulo 3 são apresentadas para o projeto Weby.
Na sequência, existe também, uma tabela de três páginas que revela o valor das métricas
de todos os desenvolvedores. Dessa vez, os desenvolvedores estão disposto nas linhas e
as colunas correspondem as métricas.
Apêndice A
99
Weby Commits
d1 d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
269 41 2 46 10 29 21 33 4
5 14
d2
40 64 0 12 4 7 5 18 4
4
1
d3
1 1 0 0 0 0 0 0 0
0
0
d4
55 13 0 44 2 11 10 29 1
1
4
d5
9 5 0 3 7 2 3 0 1
0
0
d6
26 4 0 11 3 31 9 3 1
2
9
d7
25 5 0 11 2 5 13 0 0
0
0
d8
28 16 0 32 2 5 0 80 1
5 14
d9
3 6 0 1 0 2 0 1 5
1
1
d10
1 3 0 4 0 2 0 5 2
6
1
d11
17 1 0 6 0 5 0 14 1
0 28
Weby Commits_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,2079 0,0317 0,0015 0,0355 0,0077 0,0224 0,0162 0,0255 0,0031 0,0039 0,0108
d2
0,0309 0,0495 0,0000 0,0093 0,0031 0,0054 0,0039 0,0139 0,0031 0,0031 0,0008
d3
0,0008 0,0008 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0425 0,0100 0,0000 0,0340 0,0015 0,0085 0,0077 0,0224 0,0008 0,0008 0,0031
d5
0,0070 0,0039 0,0000 0,0023 0,0054 0,0015 0,0023 0,0000 0,0008 0,0000 0,0000
d6
0,0201 0,0031 0,0000 0,0085 0,0023 0,0240 0,0070 0,0023 0,0008 0,0015 0,0070
d7
0,0193 0,0039 0,0000 0,0085 0,0015 0,0039 0,0100 0,0000 0,0000 0,0000 0,0000
d8
0,0216 0,0124 0,0000 0,0247 0,0015 0,0039 0,0000 0,0618 0,0008 0,0039 0,0108
d9
0,0023 0,0046 0,0000 0,0008 0,0000 0,0015 0,0000 0,0008 0,0039 0,0008 0,0008
d10
0,0008 0,0023 0,0000 0,0031 0,0000 0,0015 0,0000 0,0039 0,0015 0,0046 0,0008
d11
0,0131 0,0008 0,0000 0,0046 0,0000 0,0039 0,0000 0,0108 0,0008 0,0000 0,0216
Apêndice A
100
Weby Arquivo_Cri_Mod
d1 d2
d3 d4 d5 d6
d7 d8
d9 d10 d11
d1
780
34 1 10 1
3 13
15 0
0
0
d2
2 3635 0
0 0
2 2
0 0
0
0
d3
0
0 1
0 0
0 0
0 0
0
0
d4
8
2 0 405 0
0 2
0 0
0
0
d5
1
0 0
4 52
4 0
0 0
0
0
d6
10
3 0
4 0 2162 0
2 0
0
6
d7
1
2 0
0 0
0 17
0 0
0
0
d8
14
7 0
0 1
12 0 5953 0
1
1
d9
0
0 0
0 0
0 0
1 0
0
0
d10
0
0 0
1 0
0 0
2 0 10
0
d11
0
0 0
0 0
0 0
0 0
0 10
Weby Arquivo_Cri_Mod_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,0437 0,0019 0,0001 0,0006 0,0001 0,0002 0,0007 0,0008 0,0000 0,0000 0,0000
d2
0,0001 0,2036 0,0000 0,0000 0,0000 0,0001 0,0001 0,0000 0,0000 0,0000 0,0000
d3
0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0004 0,0001 0,0000 0,0227 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000
d5
0,0001 0,0000 0,0000 0,0002 0,0029 0,0002 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0006 0,0002 0,0000 0,0002 0,0000 0,1211 0,0000 0,0001 0,0000 0,0000 0,0003
d7
0,0001 0,0001 0,0000 0,0000 0,0000 0,0000 0,0010 0,0000 0,0000 0,0000 0,0000
d8
0,0008 0,0004 0,0000 0,0000 0,0001 0,0007 0,0000 0,3334 0,0000 0,0001 0,0001
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0001 0,0000 0,0006 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0006
Apêndice A
101
Weby Arquivo_Cri_Rem
d1 d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
32 7 0 3 1 16 0 2 0
0
0
d2
2 2 0 0 0 0 0 0 0
0
0
d3
1 0 0 0 0 0 0 0 0
0
0
d4
8 0 0 0 0 0 0 0 0
0
0
d5
0 0 0 1 0 0 2 0 0
0
0
d6
0 0 0 0 0 4 0 0 0
0
1
d7
3 0 0 0 0 0 1 0 0
0
0
d8
2 0 0 52 0 0 0 20 0
0
0
d9
0 0 0 0 0 0 0 0 0
0
0
d10
0 0 0 0 0 2 0 0 0
0
0
d11
0 0 0 0 0 0 0 0 0
0
2
Weby Arquivo_Cri_Rem_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,0018 0,0004 0,0000 0,0002 0,0001 0,0009 0,0000 0,0001 0,0000 0,0000 0,0000
d2
0,0001 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d3
0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0004 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d5
0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000
d6
0,0000 0,0000 0,0000 0,0000 0,0000 0,0002 0,0000 0,0000 0,0000 0,0000 0,0001
d7
0,0002 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000
d8
0,0001 0,0000 0,0000 0,0029 0,0000 0,0000 0,0000 0,0011 0,0000 0,0000 0,0000
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001
Apêndice A
102
Weby Arquivo_Mod_Mod
d1 d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
950 131 6 162 33 89 154 144 12 17 27
d2
157 176 0 19 4 19 17 45 5
6
3
d3
5
1 0
0 0
0
0
0 0
0
0
d4
160 15 0 196 2 23 28 83 3
4 28
d5
22
5 0 13 8
6
8
8 0
3
0
d6
76 10 0 21 5 115 17 15 0
1 30
d7
125 27 0 25 13 14 135 13 0
0
0
d8
133 45 0 90 2 27
0 342 4 22 23
d9
9
4 0
3 1
0
0
3 7
3
3
d10
11
7 0
7 0
2
0 21 2 14
4
d11
13
2 0
7 0 36
0 12 1
1 75
Weby Arquivo_Mod_Mod_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,0532 0,0073 0,0003 0,0091 0,0018 0,0050 0,0086 0,0081 0,0007 0,0010 0,0015
d2
0,0088 0,0099 0,0000 0,0011 0,0002 0,0011 0,0010 0,0025 0,0003 0,0003 0,0002
d3
0,0003 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0090 0,0008 0,0000 0,0110 0,0001 0,0013 0,0016 0,0046 0,0002 0,0002 0,0016
d5
0,0012 0,0003 0,0000 0,0007 0,0004 0,0003 0,0004 0,0004 0,0000 0,0002 0,0000
d6
0,0043 0,0006 0,0000 0,0012 0,0003 0,0064 0,0010 0,0008 0,0000 0,0001 0,0017
d7
0,0070 0,0015 0,0000 0,0014 0,0007 0,0008 0,0076 0,0007 0,0000 0,0000 0,0000
d8
0,0074 0,0025 0,0000 0,0050 0,0001 0,0015 0,0000 0,0192 0,0002 0,0012 0,0013
d9
0,0005 0,0002 0,0000 0,0002 0,0001 0,0000 0,0000 0,0002 0,0004 0,0002 0,0002
d10
0,0006 0,0004 0,0000 0,0004 0,0000 0,0001 0,0000 0,0012 0,0001 0,0008 0,0002
d11
0,0007 0,0001 0,0000 0,0004 0,0000 0,0020 0,0000 0,0007 0,0001 0,0001 0,0042
Apêndice A
103
Weby Arquivo_Mod_Rem
d1 d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
20 3 0 1 0 5 0 2 0
2
0
d2
2 2 0 0 0 1 3 7 0
0
0
d3
0 0 0 0 0 1 0 0 0
0
0
d4
3 0 0 1 0 2 0 2 0
0
0
d5
0 0 0 0 0 0 0 0 0
0
0
d6
1 0 0 0 0 4 0 0 0
0
0
d7
9 0 0 4 0 0 9 0 0
0
0
d8
3 0 0 1 0 0 0 9 0
1
0
d9
0 0 0 0 0 0 0 0 0
0
0
d10
0 0 0 0 0 0 0 1 0
2
0
d11
0 0 0 0 0 0 0 1 0
0
1
Weby Arquivo_Mod_Rem_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,0011 0,0002 0,0000 0,0001 0,0000 0,0003 0,0000 0,0001 0,0000 0,0001 0,0000
d2
0,0001 0,0001 0,0000 0,0000 0,0000 0,0001 0,0002 0,0004 0,0000 0,0000 0,0000
d3
0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0002 0,0000 0,0000 0,0001 0,0000 0,0001 0,0000 0,0001 0,0000 0,0000 0,0000
d5
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0001 0,0000 0,0000 0,0000 0,0000 0,0002 0,0000 0,0000 0,0000 0,0000 0,0000
d7
0,0005 0,0000 0,0000 0,0002 0,0000 0,0000 0,0005 0,0000 0,0000 0,0000 0,0000
d8
0,0002 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0005 0,0000 0,0001 0,0000
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0001 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0001
Apêndice A
104
Weby Linha_Cri_Mod
d1
d2
d3 d4
d5
d6
d7
d8
d9 d10 d11
d1
113598 526 31
445
14
139 238
958 89 25
38
d2
110 4451 0
23
5
28
45
109 13 16
1
d3
9
0 26
0
0
0
0
0
0
0
0
d4
211
25 0 44343
2
11
36
170 19
1
73
d5
34
46 0
42 1776
20
59
73
0
6
3
d6
126
30 0
50
6 52088
7
192
0
0
12
d7
111
32 0
8
2
22 1206
25 11
1
4
d8
170 138 0
96
1
272
0 86866 23 16
49
d9
5
8 0
2
1
0
0
9 106
0
2
d10
6
0 0
20
0
12
0
10
1 577
6
d11
1
0 0
17
0
49
0
27
0
0 1270
Weby Linha_Cri_Mod_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,2931 0,0014 0,0001 0,0011 0,0000 0,0004 0,0006 0,0025 0,0002 0,0001 0,0001
d2
0,0003 0,0115 0,0000 0,0001 0,0000 0,0001 0,0001 0,0003 0,0000 0,0000 0,0000
d3
0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0005 0,0001 0,0000 0,1144 0,0000 0,0000 0,0001 0,0004 0,0000 0,0000 0,0002
d5
0,0001 0,0001 0,0000 0,0001 0,0046 0,0001 0,0002 0,0002 0,0000 0,0000 0,0000
d6
0,0003 0,0001 0,0000 0,0001 0,0000 0,1344 0,0000 0,0005 0,0000 0,0000 0,0000
d7
0,0003 0,0001 0,0000 0,0000 0,0000 0,0001 0,0031 0,0001 0,0000 0,0000 0,0000
d8
0,0004 0,0004 0,0000 0,0002 0,0000 0,0007 0,0000 0,2241 0,0001 0,0000 0,0001
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0003 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0015 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0001 0,0000 0,0000 0,0033
Apêndice A
105
Weby Linha_Cri_Rem
d1
d2 d3 d4 d5 d6 d7 d8
d9 d10 d11
d1
51616 341 158 319 84 891 512 773 0 58 38
d2
174 240
0
5 0 50 46 424 0 27
8
d3
5
0
0
0 0 12
0
0 0
0
0
d4
814 23
0 453 0 87 65 357 1
0 76
d5
27 52
0 47 60 48 35
24 0
2
1
d6
246
3
0 16 1 624
2 153 0 50 25
d7
149 11
0 20 0 21 166 169 0
0
0
d8
269 341
0 95 2 256
0 2169 0 154 13
d9
17
1
0
1 0
0
0
1 12
0
0
d10
19
1
0 31 0 130
0
54 0 122
4
d11
0
0
0
0 0 30
0
10 0
0 62
Weby Linha_Cri_Rem_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,1332 0,0009 0,0004 0,0008 0,0002 0,0023 0,0013 0,0020 0,0000 0,0001 0,0001
d2
0,0004 0,0006 0,0000 0,0000 0,0000 0,0001 0,0001 0,0011 0,0000 0,0001 0,0000
d3
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0021 0,0001 0,0000 0,0012 0,0000 0,0002 0,0002 0,0009 0,0000 0,0000 0,0002
d5
0,0001 0,0001 0,0000 0,0001 0,0002 0,0001 0,0001 0,0001 0,0000 0,0000 0,0000
d6
0,0006 0,0000 0,0000 0,0000 0,0000 0,0016 0,0000 0,0004 0,0000 0,0001 0,0001
d7
0,0004 0,0000 0,0000 0,0001 0,0000 0,0001 0,0004 0,0004 0,0000 0,0000 0,0000
d8
0,0007 0,0009 0,0000 0,0002 0,0000 0,0007 0,0000 0,0056 0,0000 0,0004 0,0000
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0001 0,0000 0,0003 0,0000 0,0001 0,0000 0,0003 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0002
Apêndice A
106
Weby Linha_Mod_Mod
d1
d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
1746 221 0 150 22 148 210 323 21 36 20
d2
396 246 0 41 5 31 30 173 29
4
1
d3
7
0 0
0 0
0
0
0
0
0
0
d4
146 19 0 154 1 18 49 343
0
1 17
d5
43
8 0
8 9
5
7
7
0
1
0
d6
81
2 0 22 3 200
8 184
0
0 13
d7
186
9 0 22 16
5 144 22 16
0
6
d8
216 108 0 137 15 136
0 853
0 17 138
d9
3
1 0
1 0
0
0
1 171
0
0
d10
24
1 0
5 0 14
0 16
1 37
6
d11
1
0 0
4 0 23
0 13
0
0 20
Weby Linha_Mod_Mod_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,0045 0,0006 0,0000 0,0004 0,0001 0,0004 0,0005 0,0008 0,0001 0,0001 0,0001
d2
0,0010 0,0006 0,0000 0,0001 0,0000 0,0001 0,0001 0,0004 0,0001 0,0000 0,0000
d3
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0004 0,0000 0,0000 0,0004 0,0000 0,0000 0,0001 0,0009 0,0000 0,0000 0,0000
d5
0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0002 0,0000 0,0000 0,0001 0,0000 0,0005 0,0000 0,0005 0,0000 0,0000 0,0000
d7
0,0005 0,0000 0,0000 0,0001 0,0000 0,0000 0,0004 0,0001 0,0000 0,0000 0,0000
d8
0,0006 0,0003 0,0000 0,0004 0,0000 0,0004 0,0000 0,0022 0,0000 0,0000 0,0004
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0004 0,0000 0,0000
d10
0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0001
Apêndice A
107
Weby Linha_Mod_Rem
d1 d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
839 439 7 56 10 654 241 201 0 18 12
d2
70 60 0 1 0 12 68 39 0
2
2
d3
2
0 0 0 0 22
0
0 0
0
0
d4
57 36 0 88 0 22
7 30 0
1
8
d5
11
2 0 0 1
2
3
5 0
2
0
d6
80
0 0 6 0 250
2 68 0
0 22
d7
180
6 0 16 7
6 68 23 1
0
0
d8
135 27 0 67 40 92
0 751 0 33 17
d9
1
3 0 0 0
1
0
0 1
0
0
d10
3
1 0 3 0
7
0 18 0
7
0
d11
0
0 0 1 0
8
0 11 0
0 20
Weby Linha_Mod_Rem_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,0022 0,0011 0,0000 0,0001 0,0000 0,0017 0,0006 0,0005 0,0000 0,0000 0,0000
d2
0,0002 0,0002 0,0000 0,0000 0,0000 0,0000 0,0002 0,0001 0,0000 0,0000 0,0000
d3
0,0000 0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0001 0,0001 0,0000 0,0002 0,0000 0,0001 0,0000 0,0001 0,0000 0,0000 0,0000
d5
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0002 0,0000 0,0000 0,0000 0,0000 0,0006 0,0000 0,0002 0,0000 0,0000 0,0001
d7
0,0005 0,0000 0,0000 0,0000 0,0000 0,0000 0,0002 0,0001 0,0000 0,0000 0,0000
d8
0,0003 0,0001 0,0000 0,0002 0,0001 0,0002 0,0000 0,0019 0,0000 0,0001 0,0000
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0001
Apêndice A
108
Weby Métricas
commits efet_cri efet_mod esfo_cri esfo_rem esfo_dist_mod efet_cri_div_esfo_cri efet_mod_div_esfo_dist_mod lin_files_add_mod
d1
474 102817
539 110208
54714
2129
0,932935903
0,2531705026
77
d2
159
3188
294
4340
1587
482
0,734562212
0,6099585062
6
d3
2
0
0
26
165
0
0
0
0
d4
170
41929
410
44014
1225
901
0,952628709
0,4550499445
12
d5
30
1185
21
1736
205
48
0,6826036866
0,4375
9
d6
99
50630
479
51678
3225
593
0,9797205774
0,8077571669
25
d7
61
483
163
1117
1215
266
0,4324082363
0,6127819549
3
d8
183
83409
1302
85677
5280
2058
0,9735284849
0,6326530612
36
d9
20
55
211
102
15
241
0,5392156863
0,8755186722
1
d10
24
225
43
542
476
71
0,4151291513
0,6056338028
3
d11
72
1053
315
1190
308
312
0,8848739496
1,0096153846
0
Apêndice A
109
Weby Métricas
lin_files_add_del lin_files_mod_mod lin_files_mod_del col_files_add_mod col_files_add_del col_files_mod_mod col_files_mod_del lin_lines_add_mod
29
775
13
36
16
711
18
2503
2
275
13
48
7
247
3
350
1
6
1
1
0
6
0
9
8
346
7
19
56
347
6
548
3
65
0
2
1
60
0
283
1
175
1
21
18
216
9
423
3
217
13
17
2
224
3
216
54
346
5
20
2
344
13
765
0
26
0
0
0
27
0
27
2
54
1
1
0
57
3
55
0
72
1
7
1
118
0
94
Apêndice A
110
Weby Métricas
lin_lines_add_del lin_lines_mod_mod lin_lines_mod_del col_lines_add_mod col_lines_add_del col_lines_mod_mod col_lines_mod_del
3174
1151
1638
783
1720
1103
539
734
710
194
805
773
369
514
17
7
24
31
158
0
7
1423
594
161
703
534
390
150
236
79
25
31
87
62
57
496
313
178
553
1525
380
826
370
282
239
385
660
304
321
1130
767
411
1573
1965
1082
395
20
6
5
156
1
67
1
239
67
32
65
291
59
56
40
41
20
188
165
201
61
APÊNDICE B
Apêndice
Semelhante ao apêndice anterior, cada página desse apêndice contem uma tabela
de métricas em sua versão absoluta e relativa de relacionamento entre os desenvolvedores. Os desenvolvedores estão dispostos nas linhas e colunas formando a matriz de
relacionamento. Para interpretação dos resultados, deve-se considerar os desenvolvedores das colunas como agentes de mundaça nos desenvolvedores das linhas, ou seja, os
desenvolvedores dispostos nas linhas sofreram alterações do desenvolvedores que estão
dispostos nas colunas. Ao final, todas as métricas que foram formalizadas no Capítulo
3 são apresentadas para o projeto Solicite. Na sequência, existe também, uma tabela de
três páginas que revela o valor das métricas de todos os desenvolvedores. Dessa vez, os
desenvolvedores estão disposto nas linhas e as colunas correspondem as métricas.
Apêndice B
112
Solicite Commits
d1 d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
303 34 73 66 2 1 1 14 0
0
0
d2
34 72
0
0 0 0 0
0 0
0
0
d3
73 0 120 45 3 3 0
0 0
0
0
d4
67 0 47 306 2 0 1 17 0 16
1
d5
1 0
4
2 5 0 0
0 0
0
0
d6
1 0
0
3 0 1 0
0 0
0
0
d7
1 0
0
1 0 0 3
0 0
0
0
d8
13 0
0 17 0 0 0 111 1
0
0
d9
0 0
0
1 0 0 0
0 21
0
0
d10
0 0
0 16 0 0 0
0 0 145
3
d11
0 0
0
0 0 0 0
0 0
4
2
Solicite Commits_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,1829 0,0205 0,0441 0,0398 0,0012 0,0006 0,0006 0,0084 0,0000 0,0000 0,0000
d2
0,0205 0,0435 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d3
0,0441 0,0000 0,0724 0,0272 0,0018 0,0018 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0404 0,0000 0,0284 0,1847 0,0012 0,0000 0,0006 0,0103 0,0000 0,0097 0,0006
d5
0,0006 0,0000 0,0024 0,0012 0,0030 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0006 0,0000 0,0000 0,0018 0,0000 0,0006 0,0000 0,0000 0,0000 0,0000 0,0000
d7
0,0006 0,0000 0,0000 0,0006 0,0000 0,0000 0,0018 0,0000 0,0000 0,0000 0,0000
d8
0,0078 0,0000 0,0000 0,0103 0,0000 0,0000 0,0000 0,0670 0,0006 0,0000 0,0000
d9
0,0000 0,0000 0,0000 0,0006 0,0000 0,0000 0,0000 0,0000 0,0127 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0097 0,0000 0,0000 0,0000 0,0000 0,0000 0,0875 0,0018
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0024 0,0012
Apêndice B
113
Solicite Arquivo_Cri_Mod
d1
d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
1154
4 2
5 0 0 0 0 0
0
0
d2
12 180 2 108 0 0 0 0 0
0
0
d3
0
0 57 37 0 0 0 0 0
0
0
d4
2
0 0 767 0 0 0 0 0 47
0
d5
0
0 1
0 6 0 0 0 0
0
0
d6
0
0 0
0 0 8 0 0 0
0
0
d7
0
0 0
2 0 0 2 0 0
0
0
d8
0
0 0 28 0 0 0 54 0
0
0
d9
0
0 0
0 0 0 0 0 0
0
0
d10
0
0 0
1 0 0 0 0 0 47
0
d11
0
0 0
0 0 0 0 0 0
0
0
Solicite Arquivo_Cri_Mod_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,1582 0,0005 0,0003 0,0007 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d2
0,0016 0,0247 0,0003 0,0148 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d3
0,0000 0,0000 0,0078 0,0051 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0003 0,0000 0,0000 0,1052 0,0000 0,0000 0,0000 0,0000 0,0000 0,0064 0,0000
d5
0,0000 0,0000 0,0001 0,0000 0,0008 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0000 0,0000 0,0000 0,0000 0,0000 0,0011 0,0000 0,0000 0,0000 0,0000 0,0000
d7
0,0000 0,0000 0,0000 0,0003 0,0000 0,0000 0,0003 0,0000 0,0000 0,0000 0,0000
d8
0,0000 0,0000 0,0000 0,0038 0,0000 0,0000 0,0000 0,0074 0,0000 0,0000 0,0000
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0064 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
Apêndice B
114
Solicite Arquivo_Cri_Rem
d1 d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
31 0 0 1 0 0 0 0 0
0
0
d2
2 3 0 0 0 0 0 0 0
0
0
d3
0 0 0 0 0 0 0 0 0
0
0
d4
0 0 0 4 0 0 0 0 0
0
0
d5
0 0 0 0 1 0 0 0 0
0
0
d6
0 0 0 0 0 0 0 0 0
0
0
d7
0 0 0 0 0 0 0 0 0
0
0
d8
0 0 0 0 0 0 0 0 0
0
0
d9
0 0 0 0 0 0 0 0 0
0
0
d10
0 0 0 0 0 0 0 0 0
0
0
d11
0 0 0 0 0 0 0 0 0
0
0
Solicite Arquivo_Cri_Rem_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,0043 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d2
0,0003 0,0004 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d3
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0000 0,0000 0,0000 0,0005 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d5
0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d7
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d8
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
Apêndice B
115
Solicite Arquivo_Mod_Mod
d1
d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
1298 52 140 131 5 0 1 14 0
0
0
d2
58 114 10
3 0 0 0 0 0
0
0
d3
127
0 557 84 7 0 0 3 0
0
0
d4
90
0 50 983 0 0 7 70 0 49
0
d5
4
0
8
2 2 0 0 0 0
0
0
d6
0
0
0
0 0 0 0 0 0
0
0
d7
1
0
0
5 0 0 4 2 0
0
0
d8
17
0
0 69 0 0 0 99 0
0
0
d9
0
0
0
0 0 0 0 0 0
0
0
d10
0
0
0 60 0 0 0 0 0 342
0
d11
0
0
0
0 0 0 0 0 0
0
0
Solicite Arquivo_Mod_Mod_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,1780 0,0071 0,0192 0,0180 0,0007 0,0000 0,0001 0,0019 0,0000 0,0000 0,0000
d2
0,0080 0,0156 0,0014 0,0004 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d3
0,0174 0,0000 0,0764 0,0115 0,0010 0,0000 0,0000 0,0004 0,0000 0,0000 0,0000
d4
0,0123 0,0000 0,0069 0,1348 0,0000 0,0000 0,0010 0,0096 0,0000 0,0067 0,0000
d5
0,0005 0,0000 0,0011 0,0003 0,0003 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d7
0,0001 0,0000 0,0000 0,0007 0,0000 0,0000 0,0005 0,0003 0,0000 0,0000 0,0000
d8
0,0023 0,0000 0,0000 0,0095 0,0000 0,0000 0,0000 0,0136 0,0000 0,0000 0,0000
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0082 0,0000 0,0000 0,0000 0,0000 0,0000 0,0469 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
Apêndice B
116
Solicite Arquivo_Mod_Rem
d1 d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
33 0 0 0 0 0 0 0 0
0
0
d2
3 1 0 0 0 0 0 0 0
0
0
d3
1 0 1 0 0 0 0 0 0
0
0
d4
1 0 0 0 0 0 0 0 0
0
0
d5
0 0 0 0 0 0 0 0 0
0
0
d6
0 0 0 0 0 0 0 0 0
0
0
d7
0 0 0 0 0 0 0 0 0
0
0
d8
0 0 0 0 0 0 0 0 0
0
0
d9
0 0 0 0 0 0 0 0 0
0
0
d10
0 0 0 0 0 0 0 0 0
0
0
d11
0 0 0 0 0 0 0 0 0
0
0
Solicite Arquivo_Mod_Rem_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,0045 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d2
0,0004 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d3
0,0001 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d5
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d7
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d8
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
Apêndice B
117
Solicite Linha_Cri_Mod
d1
d2
d3 d4
d5 d6 d7 d8 d9 d10
d11
d1
16592
21 35
0 0 0 0 0 0
0
0
d2
62 2347
0
0 0 0 0 0 0
0
0
d3
1
0 280
0 0 0 0 0 0
0
0
d4
0
0
0 90223 0 0 0 0 0 4352
0
d5
0
0
0
0 10 0 0 0 0
0
0
d6
0
0
0
0 0 0 0 0 0
0
0
d7
0
0
0
0 0 0 0 0 0
0
0
d8
0
0
0
0 0 0 0 0 0
0
0
d9
0
0
0
0 0 0 0 0 0
0
0
d10
0
0
0
95 0 0 0 0 0 12640
0
d11
0
0
0
0 0 0 0 0 0
0
0
Solicite Linha_Cri_Mod_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,1239 0,0002 0,0003 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d2
0,0005 0,0175 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d3
0,0000 0,0000 0,0021 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0000 0,0000 0,0000 0,6737 0,0000 0,0000 0,0000 0,0000 0,0000 0,0325 0,0000
d5
0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d7
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d8
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0007 0,0000 0,0000 0,0000 0,0000 0,0000 0,0944 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
Apêndice B
118
Solicite Linha_Cri_Rem
d1
d2
d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
1123
9 33 20 0 0 0 0 0
0
0
d2
261 1279
0
0 0 0 0 0 0
0
0
d3
35
0 162
0 0 0 0 0 0
0
0
d4
0
0
0 825 0 0 0 0 0 1258
0
d5
0
0
0
0 10 0 0 0 0
0
0
d6
0
0
0
0 0 0 0 0 0
0
0
d7
0
0
0
0 0 0 0 0 0
0
0
d8
0
0
0
0 0 0 0 0 0
0
0
d9
0
0
0
0 0 0 0 0 0
0
0
d10
0
0
0 36 0 0 0 0 0 883
0
d11
0
0
0
0 0 0 0 0 0
0
0
Solicite Linha_Cri_Rem_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,0084 0,0001 0,0002 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d2
0,0019 0,0095 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d3
0,0003 0,0000 0,0012 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0000 0,0000 0,0000 0,0062 0,0000 0,0000 0,0000 0,0000 0,0000 0,0094 0,0000
d5
0,0000 0,0000 0,0000 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d7
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d8
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0003 0,0000 0,0000 0,0000 0,0000 0,0000 0,0066 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
Apêndice B
119
Solicite Linha_Mod_Mod
d1 d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
100 5 10 0 0 0 0 0 0
0
0
d2
8 6 0 0 0 0 0 0 0
0
0
d3
3 0 4 0 0 0 0 0 0
0
0
d4
0 0 0 46 0 0 0 0 0 26
0
d5
0 0 0 0 0 0 0 0 0
0
0
d6
0 0 0 0 0 0 0 0 0
0
0
d7
0 0 0 0 0 0 0 0 0
0
0
d8
0 0 0 0 0 0 0 0 0
0
0
d9
0 0 0 0 0 0 0 0 0
0
0
d10
0 0 0 93 0 0 0 0 0 485
0
d11
0 0 0 0 0 0 0 0 0
0
0
Solicite Linha_Mod_Mod_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,0007 0,0000 0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d2
0,0001 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d3
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0000 0,0000 0,0000 0,0003 0,0000 0,0000 0,0000 0,0000 0,0000 0,0002 0,0000
d5
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d7
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d8
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0007 0,0000 0,0000 0,0000 0,0000 0,0000 0,0036 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
Apêndice B
120
Solicite Linha_Mod_Rem
d1 d2 d3 d4 d5 d6 d7 d8 d9 d10 d11
d1
333 1 5 0 0 0 0 0 0
0
0
d2
41 26 0 0 0 0 0 0 0
0
0
d3
48 0 35 0 0 0 0 0 0
0
0
d4
0 0 0 4 0 0 0 0 0
1
0
d5
0 0 0 0 0 0 0 0 0
0
0
d6
0 0 0 0 0 0 0 0 0
0
0
d7
0 0 0 0 0 0 0 0 0
0
0
d8
0 0 0 0 0 0 0 0 0
0
0
d9
0 0 0 0 0 0 0 0 0
0
0
d10
0 0 0 5 0 0 0 0 0 53
0
d11
0 0 0 0 0 0 0 0 0
0
0
Solicite Linha_Mod_Rem_Rel
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
d11
d1
0,0025 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d2
0,0003 0,0002 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d3
0,0004 0,0000 0,0003 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d4
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d5
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d6
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d7
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d8
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d9
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
d10
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0004 0,0000
d11
0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000 0,0000
Apêndice B
121
Solicite Métricas
commits efet_cri efet_mod esfo_cri esfo_rem esfo_dist_mod efet_cri_div_esfo_cri efet_mod_div_esfo_dist_mod lin_files_add_mod
d1
493 16167
0
16304
1841
8
0,9915971541
0
11
d2
106
1946
0
2295
1315
3
0,8479302832
0
122
d3
244
196
0
239
235
0
0,820083682
0
37
d4
457 83481
188
89118
890
1199
0,9367467852
0,1567973311
49
d5
12
10
0
10
10
0
1
0
1
d6
5
0
0
0
0
0
0
0
0
d7
5
0
0
0
0
0
0
0
2
d8
142
0
0
0
0
0
0
0
28
d9
22
0
0
0
0
0
0
0
0
d10
165 11509
4285
11650
2195
5435
0,9878969957
0,7884084637
1
d11
6
0
0
0
0
0
0
0
0
Apêndice B
lin_files_add_del
Solicite Métricas
lin_files_mod_mod lin_files_mod_del col_files_add_mod col_files_add_del
1
343
0
14
2
71
3
4
0
221
1
5
0
266
1
181
0
14
0
0
0
0
0
0
0
8
0
0
0
86
0
0
0
0
0
0
0
60
0
47
0
0
0
0
122
2
0
0
1
0
0
0
0
0
0
0
col_files_mod_mod col_files_mod_del lin_lines_add_mod
297
5
56
52
0
62
208
0
1
354
0
4352
12
0
0
0
0
0
8
0
0
89
0
0
0
0
0
49
0
95
0
0
0
Apêndice B
123
Solicite Métricas
lin_lines_add_del lin_lines_mod_mod lin_lines_mod_del col_lines_add_mod col_lines_add_del col_lines_mod_mod col_lines_mod_del
62
15
6
63
296
11
89
261
8
41
21
9
5
1
35
3
48
35
33
10
5
1258
26
1
95
56
93
5
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
36
93
5
4352
1258
26
1
0
0
0
0
0
0
0
Baixar