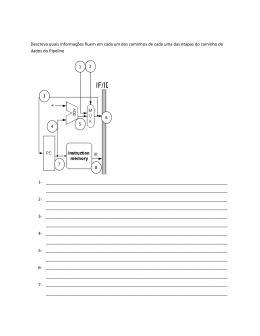
Tópicos Sobre Pipeline e Paralelização à nível de Instrução Diógenes Luiz Oliveira de Azevedo Nicolas Melo de Oliveira Departamento de Estatística e Informática - DEInfo Universidade Federal Rural de Pernambuco - UFRPE Recife, Brasil [email protected] Departamento de Estatística e Informática - DEInfo Universidade Federal Rural de Pernambuco - UFRPE Recife, Brasil [email protected] Resumo — Este artigo tratará dos aspectos que envolvem a técnica de paralelização de instruções conhecida como Pipeline. Serão abordados tópicos como: aplicações paralelas, fases do pipeline, programação paralela, compiladores paralelos, classificação dos modelos de arquiteturas paralelas e desempenho. Palavras-chave – pipeline, arquitetura-paralela, instruções, desempenho. I. INTRODUÇÃO Uma vez que um dos aspectos que são levados em consideração no processo de avaliação do desempenho de processadores trata da questão do tempo de execução das instruções, torna-se importante otimizar o procedimento adotado no processamento das mesmas. Nesse contexto é que se enquadra o pipeline, cujo objetivo é executar, simultaneamente mais de uma instrução por vez, isto, possibilitado pelo fato de que cada instrução passa por uma série de fases até ser completamente executada. Com isso em mente, vários aspectos devem ser considerados. Alguns deles são: quantidade de estágios do pipeline, programação paralela e compiladores capazes de traduzir o código do programador em código de máquina paralelizado. Este último item será descrito ao longo do artigo em termos de sua funcionalidade e das possibilidades de paralelização. Portanto, teremos aqui definições sobre arquitetura paralela, pipeline (estágios e tipos), compiladores (funcionalidades, paralelização) e uma breve análise do desempenho (em termos de tempo de execução de instruções) que o pipeline pode prover. II. ARQUITETURAS PARALELAS Com o objetivo de classificar as arquiteturas paralelas, podem-se tomar vários aspectos [4]. Aqui, essa classificação será analisada com base no nível de paralelismo. Granularidade (nível de paralelismo) fina: paralelismo de baixo nível, paralelismo ligado às instruções e operações, pipeline, superescalar, pipeline múltiplo. Granularidade média: paralelismo em blocos e sub-rotinas que constituem processos médios, threads. Granularidade alta: paralelismo de alto nível, processos e programas, multiprocessadores e multicomputadores. III. PIPELINE Pipeline consiste em uma técnica de hardware, a qual armazena e executa as instruções em uma série de cinco estágios. Trata-se de uma busca antecipada da instrução que se deseja executar bem como das instruções subsequentes, permitindo que o pré-processamento da próxima instrução seja executado antes de concluir a instrução atual. Tal artefato proporciona um aumento na velocidade de execução das instruções em comparação com um hardware sem pipeline através da diminuição do número de ciclos de clock por instrução [2]. Devido ao fato de as instruções possuírem diversas fases de execução no processador, a vantagem do uso de pipeline se dá ao passo que se torna possível sobrepor a execução das instruções em suas múltiplas etapas. [3] A. Etapas: 1. Buscar a instrução na memória 2. Decodificar a instrução 3. Executar a instrução 4. Acessar um operando na memória 5. Escrever o resultado em um registrador latência, entre outros. Como o presente artigo se propõe a explanar um pouco sobre como o pipeline pode reduzir o tempo de execução de um conjunto de instruções, este será o parâmetro utilizado. Com relação ao tempo gasto para executar um conjunto M de instruções utilizando, para isso, um pipeline de K estágios em uma máquina com ciclo de clock igual a T, temos [3]: Tempo = [K + (M - 1)] * T Figura 1. (a) estágios do pipeline e (b) execução dos estágios Fonte: [4]. Para um exemplo de tempo despendido no processamento de instruções: 1. Programa com 10.001 instruções 2. Pipeline de 5 estágios IV. COMPILADORES PARALELIZADOS 3. Clock de 100ns Com pipeline: O compilador é uma ferramenta que, a partir de códigos gerados pelo programador, gera códigos em uma linguagem alvo. Esse é um processo de tradução que mantém a equivalência do código original com a linguagem destino a partir de análises léxica, sintática e semântica[6]. Tempo = [5 + (10.001 - 1)] * 100x10-9 Tempo = (aprox.) 1ms Sem pipeline: No que diz respeito à paralelização, os compiladores podem se deparar com paralelismo implícito e explícito [6]: Paralelismo implícito: mantém a sintaxe da codificação sequencial, o compilador traduz o código para sua forma paralela. O compilador possui alta complexidade devido à necessidade de identificar a paralelização e gerar o código paralelo automaticamente. A análise da dependência entre os dados é feita por parte do compilado. Para um estudo sobre predição de desempenho, análise e modelagem de aplicações paralelas, incluindo modelos baseados em pipeline, recomenda-se a leitura do texto exposto em [1]. Paralelismo explícito: responsabilidade do programador, linguagens utilizam construtores específicos para o paralelismo, necessário especificar quais partes do códigos deverão ser paralelizadas, exige conhecimento profundo da arquitetura paralela, projeto do compilador menos complexo. A partir do que aqui foi exposto, percebe-se a importância de avaliar e estudar a paralelização de arquiteturas e códigos com o objetivo de obter alternativas de desempenho que se adequem aos mais diferentes cenários. O pipeline mostra-se uma importante ferramenta com este propósito no nível de instruções. Porém, algo interessante a ser abordado é seu uso em conjunto com outras técnicas de paralelização em outros níveis, como threads e multiprocessadores. Para exemplificar o que foi dito, tem-se: Tempo = 500ns (relativo à execução de grupos de 5 instruções) * 10.000 Compiladores paralelizadores: paralelismo implícito, requer pouco conhecimento do programador, desempenho modesto. Ex.: Oxygen, OSCAR, Cray. Linguagens concorrentes: criadas especificamente para a paralelização, exige conhecimento profundo da arquitetura, baixa portabilidade. Ex.: Occam, Ada. Tempo = 5ms VI. CONCLUSÃO REFERÊNCIAS [1] [2] [3] V. DESEMPENHO Em computação, desempenho é algo bastante abstrato e requer a análise do objetivo do sistema bem como de fatores como modelo de programação, granularidade das tarefas, [4] [5] Lucas Janssen Baldo, Predição de Desempenho de Aplicações Paralelas para Máquinas Agregadas Utilizando Métodos Estocásticos, Dissertação de Mestrado, Pontifícia Universidade Católica do Rio Grande do Sul, 2007. http://www.eng.uerj.br/~ldmm/Arquiteturas_de_Alto_Desempenho/Pipe line.pdf. Acessado em 06/11/2014. http://www.dcc.ufrj.br/~gabriel/arqcomp2/Pipeline.pdf. Acessado em 06/11/2014. Wesley dos Santos Menenguci, Computação de Alto Desempenho Envolvendo Clusters e Métodos Numéricos, TCC, Centro Universitário Vila Velha, 2008. http://pt.wikibooks.org/wiki/Programa%C3%A7%C3%A3o_Paralela_e m_Arquiteturas_Multi-Core/Compiladores_paralelizadores. Acessado em 06/11/2014. [6] http://pt.wikibooks.org/wiki/Programa%C3%A7%C3%A3o_Paralela_e m_Arquiteturas_Multi-Core/Compiladores_paralelizadores. Acessado em 06/11/2014.
Baixar