REDES NEURAIS
ARTIFICIAIS
Prof. Wilian Soares Lacerda
Depto. Ciência da Computação
UFLA
Lavras, novembro de 2006
Sumário
Introdução
Inspiração biológica
Histórico
Neurônio artificial
Treinamento do neurônio
Redes de neurônios
Treinamento da rede
Aplicações
Extração de regras
2
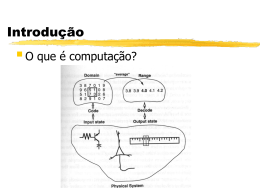
Introdução
3
Inteligência Computacional
A Inteligência Computacional busca,
através de técnicas inspiradas na
Natureza, o desenvolvimento de
sistemas inteligentes que imitem
aspectos do comportamento humano,
tais como: aprendizado, percepção,
raciocínio, evolução e adaptação.
4
5
Redes Neurais Artificiais (RNA)
Definições:
1. Técnica inspirada no funcionamento
do cérebro, onde neurônios artificiais,
conectados em rede, são capazes de
aprender e de generalizar.
2. Técnica de aproximação de funções
por regressão não linear.
6
Capacidade de Generalização
Isso significa que se a rede aprende a lidar
com um certo problema, e lhe é apresentado
um similar, mas não exatamente o mesmo,
ela tende a reconhecer esse novo problema,
oferecendo a mesma solução.
7
Aproximador de funções
A característica mais significante de redes
neurais está em sua habilidade de
aproximar qualquer função contínua ou não
contínua com um grau de correção
desejado. Esta habilidade das redes neurais
as tem tornado útil para modelar sistemas
não lineares.
8
Mapeamento Entrada-Saída
para Aproximação de Funções
Objetivo da Aprendizagem: descobrir a função
f() dado um número finito (desejável
pequeno) de pares entrada-saída (x,d).
9
Teorema da Projeção Linear
Objetivo da aproximação de funções: em uma área compacta
S do espaço de entrada descrever uma função f(x), pela
combinação de funções i(x) mais simples:
N
fˆ x, w wi i x
i 1
onde wi são elementos reais do vetor w=[w1,…,wN] tais que
f x fˆ x, w
e pode ser arbitrariamente pequeno.
A função fˆ x, w é chamada de aproximante e as funções
{i(x)} são chamadas de funções elementares.
10
Redes Neurais Artificiais (RNA)
Devido à sua estrutura, as Redes Neurais
Artificiais são bastante efetivas no
aprendizado de padrões a partir de dados:
não-lineares,
incompletos,
com ruído e até
compostos de exemplos contraditórios.
11
Inspiração biológica
12
Técnica x Natureza
Técnica Computacional
Inspiração na Natureza
Redes Neurais Artificiais
Neurônios biológicos
Computação
Evolucionária
Evolução biológica
Lógica Fuzzy
Processamento lingüístico
Sistemas Especialistas
Processo de Inferência
13
14
Os principais componentes dos neurônios são:
Os dentritos, que tem por função, receber os
estímulos transmitidos pelos outros neurônios;
O corpo de neurônio, também chamado de soma,
que é responsável por coletar e combinar
informações vindas de outros neurônios;
E finalmente o axônio, que é constituído de uma
fibra tubular que pode alcançar até alguns metros,
e é responsável por transmitir os estímulos para
outras células.
Em média, cada neurônio forma
entre mil e dez mil sinapses.
O cérebro humano possui cerca de
1011 neurônios, e o número de
sinapses é de mais de 1014,
possibilitando a formação de redes
muito complexas.
17
Cérebro humano
18
Quadro comparativo entre
cérebro e o computador
Parâmetro
Cérebro
Computador
Material
Orgânico
Metal e plástico
Velocidade
Milisegundos
Nanosegundos
Tipo de Processamento
Paralelo
Seqüencial
Armazenamento
Adaptativo
Estático
Controle de Processos
Distribuído
Centralizado
Número de elementos
processados
1011 à 1014
105 à 106
Eficiência energética
10-16 J/op./seg.
10-6 J/op./seg
Ligações entre elementos
processados
10.000
<10
19
Histórico
20
Histórico (1943)
O neurofisiologista McCulloch e matemático
Walter Pitts (1943), cujo trabalho fazia uma
analogia entre células vivas e o processo
eletrônico, simulando o comportamento do
neurônio natural, onde o neurônio possuía
apenas uma saída, que era uma função do
valor de suas diversas entradas.
21
O neurônio de McCulloch e Pitts
Consiste basicamente de
um neurônio que executa
conexões
uma função lógica.
excitatórias
Os nós produzem somente
x2
resultados binários e as
conexões transmitem
xn
exclusivamente zeros e
uns.
As redes são compostas
de conexões sem peso, de
y1
tipos excitatórios e
inibitórios.
Cada unidade é
conexões
caracterizada por um certo
inibitórias
limiar (threshold) q.
x1
ym
22
Histórico (1949)
O psicólogo Donald Hebb, demostrou que a
capacidade da aprendizagem em redes neurais
biológicas vem da alteração da eficiência sináptica,
isto é, a conexão somente é reforçada se tanto as
células pré-sinápticas quanto as pós-sinápticas
estiverem excitadas;
Hebb foi o primeiro a propor uma lei de
aprendizagem específica para as sinápses dos
neurônios.
23
Histórico (1951)
Construção do primeiro neuro computador,
denominado Snark, por Mavin Minsky. O
Snark operava ajustando seus pesos
automaticamente.
24
Histórico (1956)
Surgimento dos dois paradigmas da
Inteligência Artificial:
– Simbólica: tenta simular o comportamento
inteligente humano desconsiderando os
mecanismos responsáveis por tal.
– Conexionista: acredita que construindo-se um
sistema que simule a estrutura do cérebro, este
sistema apresentará inteligência, ou seja, será
capaz de aprender, assimilar, errar e aprender
com seus erros.
25
Histórico (1958)
Rosemblatt (1958) mostrou em seu livro
(Principles of Neurodynamics) o modelo
dos "Perceptrons".
Nele, os neurônios (Perceptrons) eram
organizados em camada de entrada e
saída, onde os pesos das conexões
eram adaptados a fim de se atingir a
eficiência sináptica usada no
reconhecimento de caracteres.
26
Perceptron Clássico – Rosenblatt (1958)
área de
projeção
área de
associação
respostas
retina
conexões
locais
conexões
aleatórias
27
associação
retina
resposta
28
Histórico (1960)
Em 1960 surgiu a rede ADALINE
(ADAptative LInear NEtwork) e o MADALINE
(Many ADALINE), proposto por Widrow e
Hoff.
O ADALINE/MADALINE utilizou saídas
analógicas em uma arquitetura de três
camadas.
29
Histórico (1969)
• Foi constatado por Minsky & Papert que um
neurônio do tipo Perceptron só é capaz de
resolver problemas com dados de classes
linearmente separáveis.
30
Histórico (1960-1970)
Muitos historiadores desconsideram a
existência de pesquisa nessa área nos
anos 60 e 70.
31
Histórico (1982)
Retomada das pesquisas com a
publicação dos trabalhos do físico e
biólogo Hopfield relatando a utilização de
redes simétricas para otimização, através
de um algoritmo de aprendizagem que
estabilizava uma rede binária simétrica
com realimentação.
32
Histórico (1986)
Rumelhart, Hinton e Williams introduziram
o poderoso método de treinamento
denominado “Backpropagation”.
Rumelhart e McClelland escreveram o
livro “Processamento Paralelo Distribuído:
Explorações na Microestrutura do
Conhecimento”.
33
Histórico (1988)
Broomhead e Lowe descreveram um
procedimento para o projeto de uma rede
neural (feedforward) usando funções de
base radial (Rede de Base Radial – RBF).
34
Neurônio artificial
35
Componentes do neurônio artificial
– As sinapses (entradas), com seus pesos
associados
– A junção somadora; e
– A função de ativação.
36
wk0=bk (bias)
entrada fixa
x0=+1
wk0
x1
wk1
sinais
de
entrada
x2
wk2
função
de ativação
uk
yk
f(uk)
saída
junção
aditiva
xm
wkm
pesos
sinápticos
Função
degrau
37
Princípio de funcionamento
A operação de um neurônio artificial se resume em:
Sinais são apresentados à entrada (x1 à xm);
Cada sinal é multiplicado por um peso que indica sua
influência na saída da unidade (wk);
É feita a soma ponderada dos sinais que produz um nível
de atividade (uk);
A função de ativação f(uk) tem a função de limitar a saída e
introduzir não-linearidade ao modelo.
O bias bk tem o papel de aumentar ou diminuir a influência
do valor das entradas.
É possível considerar o bias como uma entrada de valor
constante 1, multiplicado por um peso igual a bk.
Expressão matemática do neurônio
artificial
Matematicamente a saída pode ser expressa por:
m
yk f (uk ) f wkj x j bk
j 1
ou considerando o bias como entrada de valor x0=1 e
peso wk0=bk,
m
y k f (u k ) f wkj x j
j 0
39
Funções de ativação
40
Função de ativação tangente hiperbólica
e puk e puk
f (u k ) tanh(puk ) puk
e e puk
(a)
f
p(1 u k2 ) 0
u k
(b)
Tangente hiperbólica (a) e sua derivada (b).
41
Função de ativação logística (sigmóide)
e puk
1
f (u k ) puk
e 1 1 e puk
f
puk (1 u k ) 0
u k
(a)
(b)
Sigmóide (a) e sua derivada (b).
42
Função de ativação semi-linear
se
puk 1
1
f (uk ) puk se 0 puk 1
0
se
puk 0
p constantee positivo
(a)
(b)
Função de ativação semi-linear (a) e sua derivada (b).
43
Resposta do neurônio (saída)
Considerando um neurônio artificial com duas
entradas (x1, x2) e função de ativação sigmóide:
44
Separação Linear
Sabe-se que se formarmos uma combinação linear de duas
variáveis, e igualá-la a um número, então os pontos no espaço
bidimensional podem ser divididos em três categorias:
a) pontos pertencentes à linha com coordenadas tais que
w1. x1 + w2 . x2 = q
b) pontos em um lado da linha tem coordenadas tais que
w1 . x1 + w2 . x2 < q
c) pontos no outro lado da linha tem coordenadas tais que
w1 . x1 + w2 . x2 > q .
Nota: bias b = - q, pois:
y f (w1 x1 w2 x2 w0 ), onde w0 b
45
Exemplo
Pontos
2x1+3x2 posição
(x1 , x2 )
(0.0, 2.0)
6
linha
(1.0, 1.0)
5
abaixo
(1.0, 2.0)
8
acima
(2.0, 0.0)
4
abaixo
(2.0, 0.66) 6
linha
(2.0, 1.0)
7
acima
x2
2.0
(0.0,2.0)
(1.0,2.0)
linha
2 x1 + 3 x2 = 6
1.5
1.0
(1.0,1.0)
(2.0,1.0)
(2.0,0.66)
0.5
(2.0,0.0)
0.0
0.0
0.5
1.0
1.5
2.0
2.5
3.0
x1
Posição dos pontos em função da linha 2 x1 + 3 x2 = 6 de delimitação.
Linha:
2 x1 + 3 x2 = 6
Acima:
2 x1 + 3 x2 > 6
Abaixo:
2 x1 + 3 x2 < 6
q=6
46
w0=b
x0=+1
w0
f(u)
u
x1
w1
x2
w2
y
f (u) 1 se u 0
y f (w1 x1 w2 x2 w0 ), sendo
f (u) 0 se u 0
Com os parâmetros w0, w1 e w2, a função f(u) separa o espaço
de entradas em duas regiões, usando uma linha reta dada por:
w1x1 + w2x2 + w0 = 0
47
Perceptron de limiar
O perceptron de limiar é chamado separador
linear
– Porque traça um plano entre os pontos de entrada
onde a saída é zero ou um
Funções linearmente separáveis (a) e (b)
48
Treinamento do neurônio
49
Exemplo: um neurônio para a função AND
de 2 entradas
Iniciamos o neurônio com os pesos 0.5 e 0.6
para as duas entradas, e -0.3 para o limiar (w0).
Isso é equivalente à equação:
u = 0.5 x1 + 0.6 x2 - 0.3 x0
onde x0 é a entrada estável sempre igual a 1.
Assim, a saída y deve disparar quando u >= 0).
50
x1
w1
= 0.5
w2 = 0.6
x2
u = xi wi
w0 = -0.3
Função de
transferência
(ativação)
u
Saída y =(u)
pesos
x0
=1
entradas
x1 x2
0
0
0
1
1
0
u
-0.3
0.3
0.2
y
0
1
1
1
0.8
1
1
a saída é 1 para os padrões 01,
10 e 11, enquanto desejamos que
a saída seja 1 somente para o
padrão 11.
51
Seqüência de passos na aplicação do algoritmo
Inicio
Entrada 0 0
u = - 0.3
y = 0 correta
Entrada 0 1
u = 0.3
y = 1 incorreta
Correção dos pesos de 0.1 para baixo
Entrada 1 0
u = 0.1
y = 1 incorreta
Correção dos pesos de 0.1 para baixo
Entrada 1 1
u = 0.4
y = 1 correta
Entrada 0 0
u = - 0.5
y = 0 correta
Entrada 0 1
u= 0
y = 1 incorreta
Correção dos pesos de 0.1 para baixo
Entrada 1 0
u = - 0.2
y = 0 correta
Entrada 1 1
u = 0.2
y = 1 correta
Entrada 0 0
u = -0.6
y = 0 correta
Entrada 0 1
u = - 0.2
y = 0 correta
Entrada 1 0
u = - 0.2
y = 0 correta
Entrada 1 1
u = 0.2
y = 1 correta
Fim
w1 = 0.5 w2 = 0.6 w0 = -0.3
w1 = 0.5 w2 = 0.5 w0 = -0.4
w1 = 0.4 w2 = 0.5 w0 = -0.5
w1 = 0.4 w2 = 0.4 w0 = -0.6
w1 = 0.4 w2 = 0.4 w0 = -0.6
52
Resultado do aprendizado
x1
x2
w1
= 0.4
w2 = 0.4
w0 = -0.6
u = xi wi
Função de
transferência
(ativação)
u
Saída y =(u)
pesos
x0
=1
entradas
53
x2
1.5
1.0 0,1
1,1
0.5
0,0
0.0
1,0
0.5
1.0
x1
1.5
A reta 0.4 x1 + 0.4 x2 - 0.6 = 0 separa os pontos 00, 01 e
10, do ponto 11.
54
Exemplo: um neurônio para a função XOR
55
No caso do XOR, não existe uma única reta que divide os
pontos (0,0) e (1,1) para um lado, e (0,1) e (1,0) do outro
lado.
x
2
(1,0)
(1,1)
(0,0)
(1,0)
Função xor:
x1
y=0
y=1
Conclui-se que um neurônio do tipo Perceptron não
implementa uma função ou-exclusivo (constatado por Minsky
& Papert, em 1969).
56
Algoritmo de treinamento do Perceptron
Para classificação padrões de entrada como
pertencentes ou não a uma dada classe,
considere o conjunto de treinamento formado
por N amostras {x1,d1}, {x2,d2}, ..., {xN,dN},
onde xj é o vetor de entradas e dj a saída desejada
(classe), que em notação vetorial tem-se {X,d},
onde:
X
mxN
d
1 xN
57
58
Aprendizagem de Perceptrons
O algoritmo
– Executa os exemplos de treinamento através da rede;
– Ajusta os pesos depois de cada exemplo para reduzir o
erro;
– Cada ciclo através dos exemplos é chamado de época;
– As épocas são repetidas até que se alcance algum
critério de parada.
Em geral, quando as mudanças nos pesos forem pequenas.
59
Se os padrões de entrada forem
linearmente separáveis, o algoritmo de
treinamento possui convergência
garantida, i.é, tem capacidade para
encontrar um conjunto de pesos que
classifica corretamente os dados.
60
Perceptrons de limiar
Algoritmo de aprendizagem simples:
– Adaptará o perceptron de limiar a qualquer conjunto de
treinamento linearmente separável
– Idéia: ajustar os pesos da rede para minimizar alguma
medida de erro no conjunto de treinamento
– Aprendizagem = busca de otimização no espaço de
pesos
– Medida clássica de erros = soma dos erros quadráticos
61
Procedure [w] = perceptron (max_it, E, a, X,d)
inicializar w // para simplicidade, com zeros
inicializar b
// para simplicidade, com zero
t1
while t < max_it & E > 0 do
for i from 1 to N do
// para cada padrão de entrada
yi f(w xi + b)
// determinar a saída
ei di – yi
// determinar o erro
w w + a ei xi
// atualizar o vetor peso
b b + a ei
// atualizar o bias
end for
E sum (ei)
//quantidade de erros
t t+1
end while
end procedure
62
Adaline
• Na
mesma época em que Rosenblatt propôs o
Perceptron, Widrow e Hoff propuseram o algoritmo
dos mínimos quadrados (regra delta) para a rede
Adaline (Adaptive Linear Element), similar ao
Perceptron, porém com função de ativação linear
ao invés de função degrau.
• O objetivo do algoritmo de treinamento é minimizar
o erro quadrático médio (MSE) entre a saída de
rede e a saída desejada.
63
• A soma dos erros quadráticos para um determinado
padrão é dada por:
n
n
E e (d i yi )
i 1
2
i
2
i 1
•O
gradiente de E, também denominado de índice de
desempenho ou função custo, fornece a direção de
crescimento mais rápido de E.
• Portanto, a direção oposta ao gradiente de E é a direção
de• maior decrescimento.
64
Adaline (cont.)
O erro pode ser reduzido ajustando-se os pesos da
rede de acordo com:
E
wIJ wIJ a
wIJ
onde wIJ é o peso específico para o neurônio póssináptico I, da entrada J, e a é a taxa de aprendizagem.
65
Como wIJ influencia apenas o neurônio I,
E
wIJ wIJ
2
(
d
y
)
(
d
y
)
i
i
I
I
wIJ
i 1
n
2
Como
y I f (w I .x) f ( wIj x j ) wIj x j
j
j
E
y I
2 ( d I y I )
2(d I y I ) x J
wIJ
wIJ
66
Regra delta
Portanto a regra delta para o Adaline resume-se em:
wIJ wIJ a (d I y I ) x J
bI bI a (d I y I )
Em notação vetorial tem-se:
W W aei x i
T
b b aei
onde:
W oxm , xi mx1 , i 1,..., N ,
ei ox1 , e b ox1
67
68
Aprendizagem com Momento
Aprendizagem com momento usa uma
memória (incremento anterior) para aumentar
a velocidade e estabilizar a convergência
Equação de correção dos pesos:
wij n 1 wij n a ei nx j n wij n wij n 1
onde é a constante de momento
Normalmente, é ajustada entre 0,5 e 0,9
69
Exemplo de Momento
70
Momentum
71
Redes de neurônios
72
Arquitetura das RNAs
Uma rede neural artificial é composta por várias
unidades de processamento (neurônios), cujo
funcionamento é bastante simples.
Essas unidades, geralmente são conectadas por
canais de comunicação que estão associados a
determinado peso.
As unidades fazem operações apenas sobre seus
dados locais, que são entradas recebidas pelas
suas conexões.
O comportamento inteligente de uma Rede Neural
Artificial vem das interações entre as unidades de
processamento da rede.
73
Características Gerais das RNAs
São modelos adaptativos treináveis
Podem representar domínios complexos (não
lineares)
São capazes de generalização diante de
informação incompleta
Robustos
São capazes de fazer armazenamento
associativo de informações
Processam informações Espaço/temporais
Possuem grande paralelismo, o que lhe
conferem rapidez de processamento
74
Tipos de Redes Neurais Artificiais
Existem basicamente 3 tipos básicos de arquitetura
de RNAs:
– Feedforward de uma única camada
– Feedforward de múltiplas camadas e
– Redes recorrentes.
75
Usualmente as camadas são classificadas em três
grupos:
– Camada de Entrada: onde os padrões são
apresentados à rede;
– Camadas Intermediárias ou Ocultas: onde é feita a
maior parte do processamento, através das conexões
ponderadas; podem ser consideradas como extratoras
de características;
– Camada de Saída: onde o resultado final é concluído e
apresentado.
camada
de entrada
camada
escondida
camada
de saída
77
Rede feedforward de uma única camada
o
Os neurônios da camada
de entrada correspondem
aos neurônios sensoriais
que possibilitam a entrada
de sinais na rede (não
fazem processamento).
Os neurônios da camada
de saída fazem
processamento.
neurônio sensorial
neurônio de
processamento
78
Rede feedforward de Múltiplas Camadas
(Multilayer Perceptron - MLP)
Essas redes tem uma ou mais camadas intermediárias
ou escondidas.
79
Redes recorrentes
Essas redes possuem pelo menos uma interconexão
realimentando a saída de neurônios para outros neurônios
da rede (conexão cíclica).
Exemplo: Rede de Hopfield
80
A rede neural de Hopfield apresenta
comportamento dinâmico e fluxo de dados
multidirecional devido à integração total dos
neurônios, desaparecendo assim a idéia de
camadas bem distintas.
81
Rede de Kohonen
82
Topologias das redes neurais
83
Rede de Elman &
Rede de Jordan
84
Redes de Base Radial (RBF)
85
Exemplo: Problema do XOR
x2
(1,0)
(1,1)
(0,0)
(1,0)
Função xor:
x1
y=0
y=1
86
A função XOR está além da capacidade de um Perceptron simples.
Contudo, um Perceptron simples pode implementar funções lógicas
elementares: AND, OR e NOT.
Assim, se uma função pode ser expressa como uma combinação
dessas funções lógicas elementares, então essa função pode ser
implementada usando mais neurônios (RNA).
Por exemplo, XOR pode ser expressa por:
(x1 or x2 ) and (not (x1 and x2 ))
x1
x1 OR x2
y
AND
NOT
x2
x1 AND x2
87
x2
(0,1)
( 1,1)
C
1
D
Linha L2
Linha L1
A
(1,0)
( 0,0 )
x1
0
0
x1
B
1
x1 OR x2
y
AND
NOT
x2
x1 AND x2
88
A parte acima da linha L1 corresponde à função OR, e a
parte abaixo da linha L2 corresponde à função NOT
AND.
A área entre as duas linhas corresponde à função XOR,
o que corresponde à área ABCD, que contem os pontos
(0,1) e (1,0).
89
Superfícies de separação
90
Treinamento da rede
91
Treinamento
A propriedade mais importante das redes neurais é a
habilidade de aprender de seu ambiente e com isso
melhorar seu desempenho. Isso é feito através de um
processo iterativo de ajustes aplicado a seus pesos, o
treinamento. O aprendizado ocorre quando a rede
neural atinge uma solução generalizada para uma
classe de problemas.
Denomina-se algoritmo de aprendizado a um conjunto
de regras bem definidas para a solução de um
problema de aprendizado. Existem muitos tipos de
algoritmos de aprendizado específicos para
determinados modelos de redes neurais. Estes
algoritmos diferem entre si principalmente pelo modo
como os pesos são modificados.
92
Modelos de Aprendizagem
Os principais modelos (paradigmas) de aprendizagem são:
1) supervisionado;
2) não-supervisionado; e
3) com reforço.
93
Supervisionado
Também conhecida com aprendizagem com professor, consiste em que o
professor tenha o conhecimento do ambiente, e fornece o conjunto de
exemplos de entrada-resposta desejada.
Com esse conjunto, o treinamento é feito usando a regra de aprendizagem
por correção de erro.
Vetor de estado
do ambiente
ambiente
professor
Resposta
desejada
Resposta
real
+
Sistema
de aprendizagem
-
Sinal de erro
94
Não supervisionado
Neste caso não há um professor para supervisionar o processo de
aprendizagem. Isso significa que não há exemplos rotulados da função a
ser aprendida pela rede.
Nesse modelo, também conhecido como auto-organizado, são dadas
condições para realizar uma medida da representação que a rede deve
aprender, e os parâmetros livres da rede são otimizados em relação a essa
medida.
Para a realização da aprendizagem não-supervisionada pode-se utilizar a
regra de aprendizagem competitiva.
Vetor de estado
do ambiente
ambiente
Sistema de
aprendizagem
95
Aprendizagem por reforço
Pode ser visto como caso particular de aprendizagem supervisionada.
A principal diferença entre o aprendizado supervisionado e o aprendizado por
reforço é a medida de desempenho usada em cada um deles.
No aprendizado supervisionado, a medida de desempenho é baseada no conjunto
de respostas desejadas usando um critério de erro conhecido, enquanto que no
aprendizado por reforço a única informação fornecida à rede é se uma determinada
saída está correta ou não.
A idéia básica tem origem em estudos experimentais sobre aprendizado dos
animais. Quanto maior a satisfação obtida com uma certa experiência em um
animal, maiores as chances dele aprender.
crítico
reforço/
penalidade
RNA
resposta
96
Definição da Arquitetura da rede
A quantidade de neurônios na camada de entrada
e saída é dada pelo problema a ser abordado.
No entanto, a quantidade de neurônios nas
camadas de processamento são características
do projeto.
97
Aumentando-se o número de neurônios na camada
escondida aumenta-se a capacidade de mapeamento
não-linear da rede.
No entanto, quando esse número for muito grande, o
modelo pode se sobre-ajustar aos dados, na presença de
ruído nas amostras de treinamento. Diz-se que a rede
está sujeito ao sobre-treinamento (overfitting).
98
99
100
Por outro lado, uma rede com poucos neurônios na
camada escondida pode não ser capaz de realizar o
mapeamento desejado, o que é denominado de
underfitting.
O underfitting também pode ser causado quando o
treinamento é interrompido de forma prematura.
101
102
Normalização dos dados de entrada
Uma característica das funções sigmoidais é a saturação, ou
seja, para valores grandes de argumento, a função opera
numa região de saturação.
É importante portanto trabalhar com valores de entrada que
estejam contidos num intervalo que não atinjam a saturação,
103
por exemplo: [0,1].
Inicialização dos vetores de pesos e bias
A eficiência do aprendizado em redes multicamadas
depende da:
- especificação de arquitetura da rede,
- função de ativação,
- regra de aprendizagem e
- valores iniciais dos vetores de pesos e bias.
Considerando-se que os três primeiros itens já foram
definidos, verifica-se agora a inicialização dos vetores
de pesos e bias.
104
Inicialização aleatória dos pesos
A atualização de um peso entre duas unidades depende da derivada da função de
ativação da unidade posterior e função de ativação da unidade anterior.
Por esta razão, é importante evitar escolhas de pesos iniciais que tornem as funções de
ativação ou suas derivadas iguais a zero.
Os valores para os pesos iniciais não devem ser
muito grandes, tal que as derivadas das funções
de ativação tenham valores muito pequenos
(região de saturação). Por outro lado, se os
pesos iniciais são muito pequenos, a soma
pode cair perto de zero, onde o aprendizado é
muito lento.
Um procedimento comum é inicializar os pesos e bias a valores randômicos entre 0.5 e 0.5, ou entre -1 e 1. Os valores podem ser positivos ou negativos porque os
pesos finais após o treinamento também podem ser positivos ou negativos
105
Treinamento da MLP
Algoritmo de aprendizagem – backpropagation
– Regra de aprendizagem baseada na correção do
erro pelo método do Gradiente
– O algoritmo de aprendizagem é composto de
duas fases:
– Cálculo do erro (forward)
– Correção dos pesos sinápticos (backward)
106
Algoritmo de Retropropagação
(Backpropagation)
• Erro
no j-ésimo neurônio da camada de saída no instante t.
e j t d j t y j t
t = iteração, t-ésimo padrão de treinamento apresentado à rede.
• Ajuste
dos pesos:
wji t 1 wji t a j t xi t
Para camada de saída:
j (t ) f [u j (t )].e j (t )
'
j
Para camada oculta:
q
j (t ) f [u j (t )] k (t ).wki
'
j
k 1
107
Durante o treinamento com o algoritmo
backpropagation, a rede opera em uma sequência de
dois passos:
• Primeiro, um padrão é apresentado à camada de
entrada da rede. A atividade resultante flui através
da rede, camada por camada, até que a resposta
seja produzida pela camada de saída.
• Segundo passo, a saída obtida é comparada à
saída desejada para esse padrão particular. Se
esta não estiver correta, o erro é calculado. O erro
é propagado a partir da camada de saída até a
camada de entrada, e os pesos das conexões das
unidades das camadas internas vão sendo
modificados conforme o erro é retropropagado.
108
Algoritmo de backpropagation
Procedure [W] = backprop (max_it, min_err, a, X, R)
for m from 1 to M do
inicializa Wm e bm // valores pequenos escolhidos aleatoriamente
end // for
t1
while t < max_it & MSE > min_err do
for i from 1 to N do
// para cada padrão de treinamento
y0 xi
// propagação progressiva do sinal
ym+1 fm+1 (Wm+1ymi + bm+1), m = 0, 1, …, M-1
i
Mi
mi
.M
F (uMi ) (yi - ri)
.m
F
// retro-propagação das sensibilidades
(umi ) (Wm+1)Tm+1
, m = M-1, …, 2,1
i
Wm Wm - ami (yim-1)T, m = 1, …, M
// atualização dos pesos
bm bm - ami , m = 1, …, M
Ti ei T ei = (ri - yi )T (ri - yi )
end // for
MSE 1/N. sum(Ti)
t t+1
end // while
end // procedure
// cálculo do erro para o padrão i
109
Algoritmo Backpropagation
Treinamento é feito em duas fases:
Fase forward
Fase backward
110
Entrada é apresentada à primeira
Fase forward
camada da rede e propagado em
direção às saídas.
Camadas intermediárias
Camada de
entrada
Camada de
saída
111
Os neurônios da camada i calculam
Fase forward
seus sinais de saída e propagam
à camada i + 1
Camadas intermediárias
Camada de
entrada
Camada de
saída
112
A última camada oculta calcula
Fase forward
seus sinais de saída e os envia
à camada de saída
Camadas intermediárias
Camada de
entrada
Camada de
saída
113
A camada de saída calcula
Fase forward
os valores de saída da rede.
Camadas intermediárias
Camada de
entrada
Camada de
saída
114
Fase backward
Camadas intermediárias
Camada de
entrada
Camada de
saída
115
Fase backward
A camada de saída
calcula o erro da rede: j
Camadas intermediárias
Camada de
entrada
Camada de
saída
Erro (j)
116
Calcula o termo de correção dos pesos
Fase backward
(a atualização será feita depois)
Dwji = ajxi
Camadas intermediárias
Camada de
entrada
Camada de
saída
Erro (j)
117
Fase backward
Envia o erro para a
última camada oculta
Camadas intermediárias
Camada de
entrada
Camada de
saída
Erro (j)
118
A camada oculta calcula o seu erro
Fase backward
j = f’(uj). kwlk
Camadas intermediárias
Camada de
entrada
Camada de
saída
Erro (j)
Erro (k)
119
Calcula o termo de correção dos pesos
Fase backward
(a atualização será feita depois)
Dwij = ajxi
Camadas intermediárias
Camada de
entrada
Camada de
saída
Erro (j)
120
A camada oculta calcula o seu erro
Fase backward
j = f’(uj). kwlk
Camadas intermediárias
Camada de
entrada
Erro (j)
Camada de
saída
Erro (k)
121
Calcula o termo de correção dos pesos
Fase backward
(a atualização será feita depois)
Dwij = ajxi
Camadas intermediárias
Camada de
entrada
Erro (j)
Camada de
saída
122
Cada unidade atualiza seus pesos
Fase backward
wij(novo) = wij(velho) + Dwjk
Camadas intermediárias
Camada de
entrada
Camada de
saída
123
Repete-se o processo enquanto
Backpropagation
enquanto a rede não aprender
o padrão de entrada
Camadas intermediárias
Camada de
entrada
Camada de
saída
124
Desvantagens do algoritmo de aprendizagem
backpropagation:
– Normalmente o tempo de processamento é
elevado
– A arquitetura da rede deve ser fixada a priori
125
Aspectos do treinamento de redes MLP
O aprendizado é resultado de apresentação repetitiva de
todas as amostras do conjunto de treinamento.
Cada apresentação de todo o conjunto de treinamento é
denominada época.
O processo de aprendizagem é repetido época após
época, até que um critério de parada seja satisfeito.
É recomendável que a ordem de apresentação das
amostras seja aleatória de uma época para outra. Isso
tende a fazer com que o ajuste de pesos tenha um
caráter estocástico ao longo do treinamento.
126
Atualização local ou por lote
Atualização dos pesos pode ser de duas maneiras básicas: local e
por lote.
Local: a atualização é feita imediatamente após a apresentação de
cada amostra de treinamento.
- é também chamado de método de atualização on-line ou padrão a
padrão.
- requer um menor armazenamento para cada conexão, e apresenta
menos possibilidade de convergência para um mínimo local.
Lote: a atualização dos pesos só é feita após a apresentação de todas
as amostras de treinamento que constituem uma época.
- é também conhecido como método de atualização off-line ou batch.
- o ajuste relativo a cada apresentação de uma amostra é acumulado.
- fornece uma melhor estimativa do vetor gradiente.
127
Critérios de parada
O processo de minimização do MSE (função custo) não
apresenta convergência garantida e não possui um critério
de parada bem definido.
Um critério de parada não muito recomendável, que não
leva em conta o estado do processo iterativo é o da prédefinição do número total de iterações.
Apresenta-se a seguir um critério de parada que leva em
conta o processo iterativo.
128
Critérios de parada (cont.)
Consideremos um critério que leva em conta informações a respeito do
estado iterativo. Considera-se nesse caso a possibilidade de existência
de mínimos locais.
Seja * o vetor de pesos que denota um ponto mínimo, local ou global.
Uma condição para que * seja um mínimo é que o gradiente
da função custo, seja zero em *.
( ),
Como critério tem-se as seguintes alternativas de parada:
1 - quando a norma euclidiana da estimativa do vetor gradiente
atinge um valor suficientemente pequeno.
( )
2 - quando a variação do erro quadrático médio (MSE) de uma época para outra
atingir um valor suficientemente pequeno.
3 - quando o erro quadrático médio atingir um valor suficientemente pequeno
ou seja, med ( )
onde é um valor suficientemente pequeno.
129
Critérios de parada (cont.)
Nota-se que se o critério é de valor mínimo de MSE então não se
garante que o algoritmo irá atingir esse valor.
Por outro lado, se o critério é o mínimo valor do vetor gradiente
deve-se considerar que o algoritmo termina no mínimo local mais
próximo.
MSE
Mínimo
local
Mínimo
Global
130
Critérios de parada (cont.)
Outro critério de parada, que pode ser usado em conjunto
com um dos critérios anteriores é a avaliação da
capacidade de generalização da rede após cada época
de treinamento.
O processo de treinamento é interrompido antes que a
capacidade de generalização da rede fique restrita.
131
132
Overfitting
– Depois de um certo ponto do treinamento, a rede piora
ao invés de melhorar
– Memoriza padrões de treinamento, incluindo todas as
suas peculiaridades (ruído)
Solução:
– Encerrar treinamento cedo
– Adoção das técnicas de pruning (eliminação de pesos e
nodos irrelevantes)
133
Dilema Bias-Variância
Com poucos parâmetros o desempenho no conjunto
de treinamento (e de teste) é ruim, pois as superfícies
de separação não são adequadamente colocadas.
Com muitos parâmetros, há um ajuste exato
(memorização) ao conjunto de treinamento, mas o
resultado no conjunto de teste não é aceitável
A diferença entre o desempenho sobre os conjuntos
de treinamento e teste é uma medida da variância do
modelo
O objetivo da aprendizagem não deve ser o erro igual
a zero no conjunto de treinamento
134
Esquecimento catastrófico
– Ao aprender novas informações, a rede
esquece as informações previamente
aprendidas
135
Aplicações
136
As aplicações de redes neurais artificiais
podem ser divididas em:
–
–
–
–
–
–
Reconhecimento de padrões e Classificação;
Agrupamento ou categorização (clustering);
Aproximação de funções e modelagem;
Previsão;
Otimização;
Controle.
137
Classificação de padrões
A tarefa de classificação de padrões é atribuir a um
padrão de entrada (como forma de onda vocal, ou
símbolo manuscrito) representado por um vetor de
fatores, a uma das classes pré-especificadas.
138
Clustering/agrupamento
Em clustering ou agrupamento, também conhecido
como classificação de padrões não-supervisionada, não
existem dados para treinamento com classes
conhecidas.
Um algoritmo de clustering explora a similaridade entre
os padrões e coloca os padrões similares num grupo.
139
Aproximação de função
Supondo que um conjunto de n padrões de treinamento
(pares entrada-saída), (x1, y1), (x2,y2), ..., (xn,yn), tenham
sido gerados de uma função desconhecida f(x) (sujeito a
ruído).
A tarefa da aproximação de função é achar uma
estimativa, digamos f’(x) da função desconhecida.
140
Previsão(forecasting)
Dado um conjunto de n amostras (y(t1), y(t2), ..., y(tn)) em
uma sequência de tempo t1, t2, ...,tn, a tarefa é de prever
a amostra y(tn+1) num futuro tn+1.
141
Otimização
Uma grande variedade de problemas em matemática,
estatística, engenharia, ciência, medicina e economia
podem ser classificadas como problemas de otimização.
A meta de um algoritmo de otimização é achar uma
solução que consiste numa “função objetiva” gerada por
um conjunto de restrições que seja maximizada ou
minimizada.
142
Controle
Considerando um sistema dinâmico definido por um
(u(t), y(t)), onde u(t) é a entrada do sistema de controle e
y(t) é a saída, no tempo t.
No controle adaptativo referenciado por padrão, a meta
é gerar uma entrada u(t) tal que o sistema siga uma
trajetória desejada determinada por um padrão de
referência.
143
Aplicações
reconhecimento ótico de caracteres (OCR)
análise de pesquisa de mercado
controle de processos industriais
aplicações climáticas
identificação de fraude de cartão de crédito
diagnóstico médico
análise e processamento de sinais;
robótica;
144
Aplicações
classificação de dados;
reconhecimento de padrões em linhas de montagem ;
filtros contra ruídos eletrônicos;
análise de imagens;
análise de voz;
avaliação de crédito;
análise de aroma e odor (nariz eletrônico);
145
Previsão
Definição da janela de entrada
Definição do horizonte de previsão
Definição de outras variáveis explicativas
146
147
Previsão de Séries Temporais
Séries temporais
valor
alvo
janela
Entradas
da rede =
n valores
passados
Ex: 5 valores
passados
Saída
Desejada =
valor da série
k passos à
frente
tempo
Definição da
janela de entrada
Definição da
janela de saída
Ex: valor um
passo à frente
148
Exemplo: previsão utilizando apenas a série histórica
como entrada.
Séries temporais
alvo
janela
Entradas
da rede
Ajuste dos pesos
a partir do erro
Erro= alvo - previsto
Saída da rede:
Valor previsto
um passo à frente
149
Exemplo: previsão utilizando apenas a série histórica como entrada.
Séries temporais
alvo
janela
Entradas
da rede
Ajuste dos pesos
a partir do erro
Erro= alvo - previsto
Saída da rede:
Valor previsto
um passo à frente
150
Exemplo: previsão utilizando apenas a série histórica como entrada.
Séries temporais
alvo
janela
Entradas
da rede
Ajuste dos pesos
a partir do erro
Erro=alvo - previsto
Saída da rede:
Valor previsto
um passo à frente
151
Exemplo: previsão utilizando apenas a série histórica como entrada.
Séries temporais
janela
alvo
Entradas
da rede
Saída da rede:
Valor previsto
um passo à frente
Ajuste dos pesos
a partir do erro
Erro=alvo previsto
152
Exemplo: previsão utilizando apenas a série histórica como entrada.
Séries temporais
alvo
janela
Entradas
da rede
Ajuste dos pesos
a partir do erro
Erro=alvo - previsto
Saída da rede:
Valor previsto
um passo à frente
153
Exemplo: previsão utilizando apenas a série histórica como entrada.
Séries temporais
janela
previsto
Saída da rede:
Valor previsto
154
Exemplo: previsão utilizando apenas a série histórica como entrada.
Séries temporais
janela
previsto
Entradas da rede:
inclui valores
previstos pela Rede
Saída da rede:
Valor previsto
155
Exemplo: previsão utilizando apenas a série histórica como entrada.
Séries temporais
previsto
janela
Entradas da rede:
inclui valores
previstos pela Rede
Saída da rede:
Valor previsto
156
Aplicações de Previsão
Previsão de Carga Elétrica
– Mensal, horária, 10 em 10 min, horário de pico
Previsão de Vazão
– Horária e semanal
157
Previsão de Carga Horária
(CEMIG)
Previsão Horária Topologia da Rede
Camada de entrada: 11 neurônios.
5 últimos valores de carga.
Carga 24 horas atrás.
Codificação binária do horário.
Camada escondida: 20 neurônios.
Camada de saída: 1 neurônio.
158
Topologia da Rede
5 valores
passados
Valor da Carga
24 horas antes
Valor previsto
da carga
Codificação
Binária da hora
Da previsão
159
Gráficos Comparativos
Março/93
168 horas a frente
01/08/93
24 horas a frente
____ Valores Reais
- - - - Valores Previstos
160
Previsão de Vazão com Informações
de Precipitação - ONS
Hidroelétricas são as principais fontes de
geração de energia no Brasil
Dois modelos de previsão de vazão natural
média:
– Previsão da vazão diária (12 dias a frente);
– Previsão da vazão semanal.
– Dados utilizado do período de 1996 a 2001
161
Definição dos Modelos para Previsão de Vazão
Diária – Itaipu
Topologia das Redes Neurais
Vazões
Naturais
Incrementais
Chuva
Média de
Thiessen
Chuva
Prevista
Vt
...
Vt-6
ChTt
...
ChTt-6
.
.
.
Vazão Prevista
V t+1
ChETA
t
...
ChETAt-10
Postos
Fluviométricos
P1
...
P3
162
Resultados Previsão de Vazão
Diária - Itaipu
Previsão de Vazão Diária - Redes Neurais MLP
Período Anual
Período Seco
Período Úmido
Previsão 1º Dia com 6 Neurônios; MAPE = 4,2604
163
Reconhecimento de expressão da face
NUMBER OF
RECOGNITION RATE
MEMBERS
Bootstrap
9
82.69%
Bootstrap
15
80.77%
Bootstrap
25
80.77%
Bootstrap
50
84.62%
Bootstrap
75
86.54%
Bootstrap
100
90.38%
ARC-x4
9
84.62%
ARC-x4
15
84.62%
ARC-x4
25
84.62%
ARC-x4
50
88.46%
ARC-x4
75
92.31%
ARC-x4
100
90.38%
Reference: 84.62%
COMMITTEE
164
Identificação de Área
Baía de
Guanabara
(Rio de Janeiro)
Acidente onde
1.300 m3 de óleo
foi derramado em
18/01/2000
165
Datiloscopia
É o processo de identificação humana por
meio das impressões digitais. Identidade, em
um conceito mais amplo, é a identificação
única e imutável dos indivíduos.
166
Pré-Processamento
A imagem não pode ser identificada pela RNA
como nós identificamos a olho nu, a RNA deve
receber um arquivo com informações em bit, ou
seja, 0’s e 1’s, por isso é necessário um préprocessamento da imagem.
167
Arquitetura da Rede Neural
1
1
2
2
3
3
400
50
=
401
51
52
402
53
403
100
800
Impressão Digital
Camada de
Entrada
Camada
Oculta
Camada de
Saída
168
Reconhecimento de caracter
169
Dados de treinamento
170
Dados de teste
171
Extração de regras
172
Extração de Regras
É a tarefa de converter modelos de
redes neurais treinadas em
representações mais facilmente
compreensíveis
173
Técnicas de Extração de
Conhecimento de RNAs
Decomposicional
– Extração a nível de associações
escondidas e de saída
Pedagógica
– RNA vista como “caixa preta” e a extração
ocorre sobre arquiteturas sem restrições
Eclética
174
Características dos Métodos
de Extração de Regras
Compreensibilidade
– Quanto são humanamente compreensíveis
Fidelidade
– Quanto modela a RNA da qual foi extraída
Precisão
– Previsão precisa sobre exemplos não vistos
Escalabilidade
– Grandes espaços de entrada, unidades e conexões
Generalidade
– Treinamento especial e/ou restrições
175
176
Fim
Obrigado!
Perguntas?
177
Cópia da apresentação:
www.dcc.ufla.br/~lacerda/download/palestras/rna/palestra_01.ppt
178
Baixar