Aula 03
Aritmética
Computador de von Neumann
Unidade lógica e aritmética
Diz respeito a:
Desempenho (segundos, ciclos, instruções)
Abstrações:
Arquitetura do Conjunto de Instruções
Linguagem Assembly e Linguagem de Máquina
Para que serve:
Implementar a Arquitetura
operation
a
32
ALU
result
32
b
32
Aritmética MIPS
•
•
Todas as instruções usa 3 registradores
A ordem dos registradores é fixa (primeiro o registrador destino)
Exemplo:
C code:
A = B + C
MIPS code:
add $s0, $s1, $s2
(associado às variáveis pelo compilador)
Fluxo de Controle
•
Instrução slt – set on less than
if
slt $t0, $s1, $s2
$s1 < $s2 then
$t0 = 1
else
$t0 = 0
Números
Bits são apenas bits (sem nenhum significado inerente)
— convenções definem a relação entre bits e números
Números Binários (base 2)
0000 0001 0010 0011 0100 0101 0110 0111 1000 1001...
decimal: 0...2n-1
Naturalmente resultam em algumas sofisticações:
números são finitos (overflow)
números fracionários e reais
números negativos
p.ex., no MIPS não existe instrução de subtração imediata - addi
pode adicionar um número negativo)
Como representamos números negativos?
i.e., que padrões de bits representam os números?
Possíveis Representações
Sinal e Magnitude Complemento de 1 Complemento
de 2
000 = +0
000 = +0
000 = +0
001 = +1
001 = +1
001 = +1
010 = +2
010 = +2
010 = +2
011 = +3
011 = +3
011 = +3
100 = -0
100 = -3
100 = -4
101 = -1
101 = -2
101 = -3
110 = -2
110 = -1
110 = -2
111 = -3
111 = -0
111 = -1
Comparações: balanceamento, número de zeros, facilidade de
operações
Qual é o melhor? Por que?
MIPS
Números sinalizados de 32 bits:
0000
0000
0000
...
0111
0111
1000
1000
1000
...
1111
1111
1111
0000 0000 0000 0000 0000 0000 0000two = 0ten
0000 0000 0000 0000 0000 0000 0001two = + 1ten
0000 0000 0000 0000 0000 0000 0010two = + 2ten
1111
1111
0000
0000
0000
1111
1111
0000
0000
0000
1111
1111
0000
0000
0000
1111
1111
0000
0000
0000
1111
1111
0000
0000
0000
1111
1111
0000
0000
0000
1110two
1111two
0000two
0001two
0010two
=
=
=
=
=
+
+
–
–
–
2,147,483,646ten
2,147,483,647ten
2,147,483,648ten
2,147,483,647ten
2,147,483,646ten
1111 1111 1111 1111 1111 1111 1101two = – 3ten
1111 1111 1111 1111 1111 1111 1110two = – 2ten
1111 1111 1111 1111 1111 1111 1111two = – 1ten
maxint
minint
Operações em Complemento de 2
Negar um número em complemento de 2: inverter todos os bits e
somar 1
lembrança: “negar” e “inverter” são diferentes!
Convertendo um número de n bits em números com mais de n
bits:
Um dado imediato de 16 bits do MIPS é convertido para 32 bits em
aritmética
Copiar o bit mais significativo (o bit de sinal) para outros bits
0010
-> 0000 0010
1010
-> 1111 1010
"sign extension"
Adição & Subtração
Como no curso primário (carry/borrow)
0111
+ 0110
0111
- 0110
0110
- 0101
Operações em complemento de 2
subtração usando soma de números negativos
0111
+ 1010
Overflow (resultado muito grande para um computador de tamanho
de palavra finito):
P.ex., somando dois números de n-bits não resulta em n-bits
0111
+ 0001
1000
note que o bit de overflow é enganoso,
ele não significa um carry de transbordo
Detectando Overflow
Não ocorre overflow
quando se soma um número positivo e um negativo
quando os sinais são os mesmos para a subtração
Overflow ocorre quando o valor afeta o sinal:
quando somando dois positivos resulta num negativo
ou, somando dois negativos resulta num positivo
ou, subtraindo um negativo de um positivo e dá um negativo
ou, subtraindo um positivo de um negativo e dá um positivo
Considerar as operações A + B, e A – B
Pode ocorrer overflow se B é 0 ?
Pode ocorrer overflow se A é 0 ?
Efeitos do Overflow
Uma exceção (interrupt) ocorre
A instrução salta para endereço predefinido para a rotina de
exceção
O endereço da instrução interrompida é salvo para possível
retorno
Nem sempre se requer a detecção do overflow
— novas instruções MIPS: addu, addiu, subu
nota: addiu still sign-extends!
nota: sltu, sltiu for unsigned comparisons
Revisão: Álgebra Booleana & Portas
Problema: Considerar uma função lógica com 3 entradas: A, B, e C.
A saída D é “true” se pelo menos uma entrada é “true”
A saída E é “true” se exatamente duas entradas são “true”
A saída F é “true” somente se todas as três entradas são “true”
Mostrar a tabela verdade para essas três funções.
Mostrar as equações Booleanas para as três funções.
Mostrar uma implementação consistindo de portas inversoras, AND, e
OR.
Uma ALU (arithmetic logic unit)
Seja uma ALU para suportar as instruções andi e ori
Projetar uma ALU de 1 bit, e replicá-la 32 vezes
operation
a
op a
b
result
b
Possível implementação (soma-de-produtos):
res
Revisão: Multiplexador
Seleciona uma das entradas para a saída, baseado
numa entrada de controle
S
A
0
B
1
C
nota: mux de 2-entradas
embora tenha 3 entradas!
Seja construir a nossa ALU usando um MUX:
Implementação de ALU de um bit
Não é fácil decidir a “melhor” forma para construir algo
Não queremos muitas entradas para uma única porta (fan-in)
Não queremos distribuir para muitas portas (fan-out)
Para o nosso propósito, facilidade de compreensão é importante
Seja a ALU de 1-bit para soma:
CarryIn
a
Sum
cout = a b + a cin + b cin
sum = a xor b xor cin
b
CarryOut
Como construir uma ALU de 1-bit para soma, AND e OR?
Como construir uma ALU de 32-bits?
Construindo uma ALU de 32 bits
CarryIn
a0
Operation
b0
CarryIn
ALU0
Result0
CarryOut
CarryIn
a
Operation
a1
0
b1
CarryIn
ALU1
Result1
CarryOut
1
Result
a2
2
b2
b
CarryIn
ALU2
Result2
CarryOut
CarryOut
a31
b31
CarryIn
ALU31
Result31
E sobre subtração (a – b) ?
Técnica do complemento de 2: apenas negar b e
somar.
Como negar?
Solução:
Operation
Binvert
CarryIn
a
0
1
b
0
2
1
CarryOut
Result
Outras operações da ALU do MIPS
Deve suportar a instrução set-on-less-than (slt)
lembrar: slt é uma instrução aritmética
produz um 1 se rs < rt, e 0 caso contrário
usar subtração: (a - b) < 0 implica a < b
Deve suportar o teste para igualdade (beq $t5, $t6, $t7)
usar subtração: (a - b) = 0 implica a = b
Suportando slt
Binvert
Operation
CarryIn
a
0
1
Result
b
0
2
1
Less
3
a.
CarryOut
Desenhando a idéia?
Binvert
Operation
CarryIn
a
0
1
Result
b
0
2
1
Less
3
Set
Overflow
detection
b.
Overflow
Binvert
CarryIn
a0
b0
CarryIn
ALU0
Less
CarryOut
a1
b1
0
CarryIn
ALU1
Less
CarryOut
a2
b2
0
CarryIn
ALU2
Less
CarryOut
Operation
Result0
Result1
Result2
CarryIn
a31
b31
0
CarryIn
ALU31
Less
Result31
Set
Overflow
Teste de igualdade
Bnegate
•Nota: zero é 1 quando o
resultado é zero!
Operation
a0
b0
CarryIn
ALU0
Less
CarryOut
Result0
a1
b1
0
CarryIn
ALU1
Less
CarryOut
Result1
a2
b2
0
CarryIn
ALU2
Less
CarryOut
Result2
a31
b31
0
CarryIn
ALU31
Less
Zero
Result31
Set
Overflow
Linhas de controle
Operation
Binvert
000
001
010
110
111
=
=
=
=
=
and
or
add
subtract
slt
Conclusão
Podemos construir uma ALU para suportar o conjunto de
instruções MIPS
-- usando multiplexador para selecionar a saída desejada
realizando uma subtração usando o complemento de 2
replicando uma ALU de 1-bit para produzir uma ALU de 32-bits
Pontos importantes sobre o hardware
Todas as portas estão sempre trabalhando
A velocidade de uma porta é afetada pelo número de entradas da
porta
A velocidade de um circuito é afetado pelo número de portas em
série
(no caminho crítico ou nivel mais profundo da lógica)
Mudanças inteligentes na organização pode melhorar o
desempenho
Problema: somador ripple carry (vai-um
propagado) é lento
Uma ALU de 32-bits é tão rápida quanto uma ALU de 1-bit?
Existem mais de uma forma de somar?
dois extremos: ripple carry e soma-de-produtos
Voce pode ver a propagação do vai-um? Como resolvê-lo?
c1
c2
c3
c4
=
=
=
=
a0c0
a1c1
a2c2
a3c3
+
+
+
+
b0c0
b1c1
b2c2
b3c3
+
+
+
+
a0b0 = (a0 + b0)c0 + a0b0
a1b1
a2b2
a3b3
Somador de vai-um antecipado (Carry-lookahead) - CLA
Uma técnica intermediária entre dois extremos
Motivação:
Se não sabemos o valor do carry-in, o que fazemos?
Quando sempre geramos um carry?
Quando propagamos um carry?
gi = ai bi
pi = ai + bi
Resolvemos o ripple calculando o vai-um antecipadamente, usando
as equações:
c1
c2
c3
c4
=
=
=
=
g0
g1
g2
g3
+
+
+
+
p0c0
p1c1
p2c2
p3c3
CarryIn
a0
b0
a1
b1
a2
b2
a3
b3
CarryIn
Result0--3
ALU0
P0
G0
pi
gi
Carry-lookahead unit
C1
a4
b4
a5
b5
a6
b6
a7
b7
a8
b8
a9
b9
a10
b10
a11
b11
a12
b12
a13
b13
a14
b14
a15
b15
Construção de
somadores
grandes
ci + 1
CarryIn
Result4--7
ALU1
P1
G1
pi + 1
gi + 1
C2
ci + 2
CarryIn
Result8--11
usar o princípio de
CLA novamente!
ALU2
P2
G2
pi + 2
gi + 2
C3
ci + 3
CarryIn
Result12--15
ALU3
P3
G3
pi + 3
gi + 3
C4
CarryOut
ci + 4
Multiplicação
Mais complicado que soma
Realizado via deslocamento e soma
Mais tempo e mais área
Vejamos 3 versões baseados no algoritmo
0010
__x_1011
(multiplicando)
(multiplicador)
Números negativos: converter e multiplicar
Multiplicação:
Implementação
Start
Multiplier0 = 1
1. Test
Multiplier0
Multiplier0 = 0
1a. Add multiplicand to product and
place the result in Product register
Multiplicand
Shift left
64 bits
2. Shift the Multiplicand register left 1 bit
Multiplier
Shift right
64-bit ALU
32 bits
Product
Write
64 bits
3. Shift the Multiplier register right 1 bit
Control test
32nd repetition?
No: < 32 repetitions
Yes: 32 repetitions
Done
Start
Segunda
Versão
Multiplier0 = 1
1. Test
Multiplier0
Multiplier0 = 0
1a. Add multiplicand to the left half of
the product and place the result in
the left half of the Product register
Multiplicand
32 bits
Multiplier
Shift right
32-bit ALU
2. Shift the Product register right 1 bit
32 bits
Product
Shift right
Write
Control test
3. Shift the Multiplier register right 1 bit
64 bits
32nd repetition?
No: < 32 repetitions
Yes: 32 repetitions
Done
Versão
Final
Start
Product0 = 1
1. Test
Product0
Product0 = 0
1a. Add multiplicand to the left half of
the product and place the result in
the left half of the Product register
Multiplicand
32 bits
32-bit ALU
2. Shift the Product register right 1 bit
Product
64 bits
Shift right
Write
Control
test
32nd repetition?
No: < 32 repetitions
Yes: 32 repetitions
Done
Multiplicação Paralela
a5
a4
a3
a2
a1
a0 = A
x b5 b4 b3 b2 b1 b0 = B
___________________________________
a5b0 a4b0 a3b0 a2b0 a1b0 a0b0 = W1
a5b1 a4b1 a3b1 a2b1 a1b1 a0b1
= W2
a5b2 a4b2 a3b2 a2b2 a1b2 a0b2
= W3
a5b3 a4b3 a3b3 a2b3 a1b3 a0b3
= W4
a5b4 a4b4 a3b4 a2b4 a1b4 a0b4
= W5
a5b5 a4b5 a3b5 a2b5 a1b5 a0b5
= W6
_________________________________________________________________
P11 P10 P9 P8 P7 P6 P5 P4 P3 P2 P1 P0 = AxB=P
Somadores
CPA – Carry Propagation Adder
Faz a adição de 2 números A e B para produzir o resultado A + B.
CSA – Carry Save Adder
Faz a adição de 3 números A, B e D, produzindo dois resultados:
soma S e
vai-um C.
Matematicamente, tem-se A + B + D = S + C.
A = 1 1 1 1 0 1
B = 0 1 0 1 1 0
D = 1 1 0 1 1 1
__________________________
C = 1 1 0 1 1 1
S =
0 1 1 1 0 0
__________________________
A+B+D=S+C = 1 0 0 0 1 0 1 0
B
A
Circuito de
Multiplicação
Paralela
Gerador de multiplicandos deslocados
CSA1
CSA2
CSA3
CSA4
CPA
P=AxB
A
B
111011
110111
gerador de multiplicandos deslocados
111011
111011
5
Exemplo
000000
4
111011
111011
2
1
3
CSA1
01100100
111011
CSA2
10011010
01111110
4
3
10100001
1
CSA3
01100100
00011110000
4
10010001101
1
CSA4
010011000000
001100101101
1
CPA
110010101101
AxB
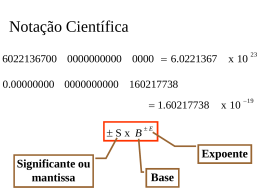
Ponto Flutuante
Necessitamos de uma forma para representar
Números com frações, p.ex., 3.1416
Números muito pequenos, p.ex., .000000001
Números muito grandes, p.ex., 3.15576 109
Representação:
Sinal, expoente, significando:
(–1)sinal significando 2expoente
Mais bits para o significando dá mais resolução
Mais bits para o expoente aumenta o intervalo (range)
Padrão ponto flutuante IEEE 754:
Precisão simples: expoente de 8 bits, significando de 23 bits
Precisão dupla: expoente de 11 bits, significando de 52 bit
Padrão de ponto flutuante IEEE 754
O primeiro bit (leading bit), “1” do significando é implícito
Expoente é “polarizado” para fazer a separação facilmente
bias de 127 para precisão simples e 1023 para precisão dupla
Resumo: (–1)sinal (1+significando) 2expoente – bias
Exemplo:
decimal: -.75 = -3/4 = -3/22
binário: -.11 = -1.1 x 2-1
Ponto flutuante: expoente = 126 = 01111110
Precisão simples IEEE:
10111111010000000000000000000000
Complexidade do Ponto Flutuante
Além do overflow tem “underflow”
Precisão pode ser um grande problema
IEEE 754 mantem dois extra bits, guard e round
Quatro modos de arredondamento
positivo dividido por zero resulta em “infinito”
zero dividido por zero resulta em “not a number”
Outras complexidades
A Implementação do padrão pode ser complicado
Não usar o padrão pode ser mesmo pior
Representação ponto flutuante
Formato
s
exp
frac
s é o bit de sinal
s = 0 positivo
s=1 negativo
exp é usado para obter E
frac é usado para obter M
Valor representado
(-1)s M 2E
Significando M é um valor fracionário no intervalo [1.0,2.0),
para números normalizados e [0 e 1) para números
denormalizados
Exponente E fornece o peso em potência de dois
Valores numéricos Normalizados
Condição
exp 000…0 e exp 111…1
Expoente codificado como valor polarizado (biased)
E = exp – bias
exp : valor não sinalizado
bias : valor da polarização
Precisão Simples: 127 (exp: 1…254, E: -126…127)
Precisão dupla: 1023 (exp: 1…2046, E: -1022…1023)
Em geral: bias = 2e-1 - 1, onde e e´ o numero de bits do expoente
Significando codificado com bit 1 mais significativo (leading bit)
implicito
M = 1.xxx…x2
xxx…x: bits da frac
Minimo quando 000…0 (M = 1.0)
Maximo quando 111…1 (M = 2.0 – )
O bit extra (leading bit 1) e´ obtido “implicitamente”
Valores denormalizados
Condição
exp = 000…0
Valor
Valor do Expoente E = –Bias + 1
Valor do Significando M = 0.xxx…x2
xxx…x: bits de frac
Casos
exp = 000…0, frac = 000…0
Representa valor 0
Nota-se que existem valores distintos +0 e –0
exp = 000…0, frac 000…0
Numeros muito próximos de 0.0
Perde precisão à medida que vai diminuindo
“ underflow gradual”
Valores especiais
Condição
exp = 111…1
Casos
exp = 111…1, frac = 000…0
Representa valor(infinito)
Operação que transborda (overflow)
Ambos positivo e negativo
P. ex., 1.0/0.0 = 1.0/0.0 = +, 1.0/0.0 =
exp = 111…1, frac 000…0
Not-a-Number (NaN)
Nenhum valor numérico pode ser determinado
P. ex., sqrt(–1),
Resumo da codificação de números
reais em ponto flutuante
NaN
-Normalizado
+Denorm
-Denorm
0
+0
+Normalizado
+
NaN
Representação ilustrativa de 8 bits
Representação ponto flutuante de 8 bits
O bit de sinal e´ o bit mais significativo.
Os seguintes quatro bits são expoente, com bias de 7.
Os últimos três bits bits são frac
Semelhante a forma geral no formato IEEE
normalizado, denormalizado
Representação de 0, NaN, infinito
7 6
s
0
3 2
exp
frac
Valores Relativos ao Expoente
exp
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
E
2E
-6
-6
-5
-4
-3
-2
-1
0
+1
+2
+3
+4
+5
+6
+7
n/a
1/64
1/64
1/32
1/16
1/8
1/4
1/2
1
2
4
8
16
32
64
128
(denorms)
(inf, NaN)
Intervalo
s exp
0
0
0
números
denormalizados …
0
0
0
0
…
0
0
números
0
Normalizados 0
0
…
0
0
0
frac
E
Valor
0000 000
0000 001
0000 010
-6
-6
-6
0
1/8*1/64 = 1/512
2/8*1/64 = 2/512
Mais perto de zero
0000
0000
0001
0001
110
111
000
001
-6
-6
-6
-6
6/8*1/64
7/8*1/64
8/8*1/64
9/8*1/64
=
=
=
=
6/512
7/512
8/512
9/512
maior denorm
menor norm
0110
0110
0111
0111
0111
110
111
000
001
010
-1
-1
0
0
0
14/8*1/2
15/8*1/2
8/8*1
9/8*1
10/8*1
=
=
=
=
=
14/16
15/16
1
9/8
10/8
7
7
n/a
14/8*128 = 224
15/8*128 = 240
inf
1110 110
1110 111
1111 000
perto de 1 abaixo
perto de 1 acima
maior norm
Distribuição de valores
Formato de 6-bits tipo IEEE
e = 3 bits de expoente
f = 2 bits de fracao
bias e´ 3
Notar como a distribuição fica mais densa perto de zero.
-15
-10
-5
Denormalized
0
5
Normalized Infinity
10
15
Distribuição de Valores perto de zero
Formato de 6-bits, tipo IEEE
e = 3 bits de expoente
f = 2 bits de fração
Bias igual a 3
-1
-0,5
Denormalized
0
Normalized
Infinity
0,5
1
Numeros interessantes
exp
frac
Zero
00…00 00…00
menor Pos. Denorm. 00…00 00…01
Descrição
valor numérico
0.0
2– {23,52} X 2– {126,1022}
Single 1.4 X 10–45
Double 4.9 X 10–324
maior Denorm.
00…00 11…11
(1.0 – ) X 2– {126,1022}
Single 1.18 X 10–38
Double 2.2 X 10–308
menor Pos. Norm. 00…01 00…00
Um
01…11 00…00
maior Normalized 11…10 11…11
Single 3.4 X 1038
Double 1.8 X 10308
1.0 X 2– {126,1022}
1.0
(2.0 – ) X 2{127,1023}
Operações em ponto flutuante
Conceitualmente
Primeiro computar o resultado exato
Fazê-lo enquadrar na precisão desejada
transborda se o expoente for muito grande
arredonda para caber no frac
Modos de arredondamento
1.40
1.60
1.50
Zero
1
1
1
Round down (-)
1
1
1
Round up (+)
2
2
2
Nearest Even (default) 1
2
2
2.50
2
2
3
2
–1.50
–1
–2
–1
–2
Nota:
1. Round down: resultado e´perto mas não maior que o resultado verdadeiro.
2. Round up: resultado e´perto mas não menor do que o resultado verdadeiro.
Multiplicação em FP
Operandos
*
(–1)s1 M1 2E1
(–1)s2 M2 2E2
Resultado exato
(–1)s M 2E
Sinal s: s1 xor s2
Significando M:
M1 * M2
Expoente E:
E1 + E2
Representação final
se M ≥ 2, deslocar à direita M, incrementar E
se E fora do intervalo, overflow
Arredonda M para caber em frac
Adição FP
Operandos
(–1)s1 M1 2E1
E1–E2
(–1)s2 M2 2E2
(–1)s1 M1
Assumir E1 > E2
(–1)s2 M2
+
Resultado exato
(–1)s M 2E
(–1)s M
Sinal s, significando M:
Resultado de alinhamento e adição
Expoente E:
E1
Representação final
Se M ≥ 2, deslocar à direita M, incrementa E
Se M < 1, deslocar à esquerda M de k posições, decrementar E de k
Overflow se E fora do intervalo
arredonda M para caber em frac
Ariane 5
Explodiu 37 segundos após
decolagem
Por que?
Foi computada a velocidade
horizontal como número em
ponto flutuante
Convertido para inteiro de
16-bits
Funcionou bem para Ariane
4
Ocorreu Overflow para
Ariane 5
Foi usado o mesmo
software
Baixar