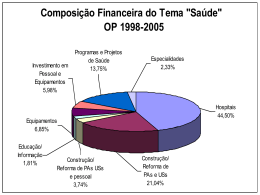
Concorrência:
Sincronização de fina granularidade II
André Santos
CIn-UFPE
©André Santos, 1998-2000
Algorítmo do Tie Breaker
Permite implementar exclusão mútua sem
suporte de instruções especiais do
processador (Test-and-set, exchange etc.).
Garante entrada eventual dos processos na
região crítica mesmo com escalonamento
weakly-fair
Também chamado de algorítmo de Peterson
©André Santos,
1998-2000
Solução de granularidade grossa
int In1=FALSE, In2 = FALSE, last = 1;
void P1 () {
void P2 () {
while (TRUE)
while (TRUE)
{ Non_Cr_S_1;
{ Non_Cr_S_2;
In1=TRUE;last=1;
In2=TRUE; last=2;
<await (!In2 ||
<await (!In1 ||
last==2)>
last==1)>
Crit_S_1;
Crit_S_2;
In1 = FALSE;
In2 = FALSE;
}
}
}
}
©André Santos,
1998-2000
Solução de granularidade fina
int In1=FALSE, In2 = FALSE, last = 1;
void P1 () {
void P2 () {
while (TRUE)
while (TRUE)
{ Non_Cr_S_1;
{ Non_Cr_S_2;
In1=TRUE;last=1;
In2=TRUE; last=2;
while
while
(In2 && last==1)
(In1 && last==2)
{};
{};
Crit_S_1;
Crit_S_2;
In1 = FALSE;
In2 = FALSE;
}
}
}
}
©André Santos,
1998-2000
Algorítmo do Tie Breaker
Para n processos se torna complexo e
pouco eficiente
precisa de um loop de n-1 estágios,
cada estágio com uma instância da
versão para 2 processos.
Complexidade O(n²) ou O(n*m), onde m
é o número de processos querendo
entrar na região crítica em um dado
instante.
©André Santos,
1998-2000
Solução para n processos
void Pi () {
while (TRUE)
{ Non_Cr_S_1;
for (j=1;j<n;j++) { /* proc i in stage j and is last */
In[ i ] = j; last[ j ] = i;
for (k=1;k<n+1;k++) /* wait if proc k is in higher
stage and proc i was the
last to enter this stage */
{ if (i!=k) {while (in[k]>=in[i] && last[j]=i) {}};
};
};
Crit_S_1;
In[i] = 0;
©André Santos,
}}
1998-2000
Algorítmo do Ticket
Funciona como lojas em que se pega
um ticket para esperar sua vez.
Fácil de estender para n processos.
©André Santos,
1998-2000
Solução de granularidade grossa
int number = 1; next = 1,int turn[n] = 0;
void Pi () {
while (TRUE)
{ Non_Cr_S_1;
<turn[i] = number; number++>;
<await turn[i]==next>;
Crit_S_1;
<next ++>;
}
}
©André Santos,
1998-2000
Solução de granularidade fina
int number = 1; next = 1,int turn[n] = 0;
void Pi () {
while (TRUE)
{ Non_Cr_S_1;
turn[i] = FetchAndAdd(number,1)
while (turn[i] != next) {};
Crit_S_1;
next ++; /* need not be atomic */
}
}
©André Santos,
1998-2000
Algorítmo do Ticket
A variável number pode ser resetada
depois que se tornar grande.
Se uma instrução de FetchAndAdd não
estiver disponível, poderia ser usado
algum dos outros algorítmos para
implementar a atomicidade desta
instrução.
©André Santos,
1998-2000
Algorítmo da Padaria
Semelhante ao do ticket, mas não
depende de instruções especiais
Mais complexo
Cada processo pega para si um ticket
que é maior que os dos demais
processos e espera até que o dele seja
o menor de todos os tickets.
A verificação não é centralizada
©André Santos,
1998-2000
Solução de granularidade grossa
int turn[n] = 0;
void Pi () {
while (TRUE)
{ <turn[i] = max (turn) + 1>;
for (j=1;j<=n;j++) {
if (j != i)
{<await (turn[j] == 0 || turn[i] < turn[j]>};
}
Crit_S_1;
<turn[i] = 0>;
Non_Cr_S_1;
}
}
©André Santos,
1998-2000
Tentativa 1 de granularidade fina
int turn1 = 0; int turn2 = 0;
void P1 () {
void P2 () {
while (TRUE)
while (TRUE)
{turn1 =turn2 + 1;
{turn2 = turn1 + 1;
while (turn2 != 0
while (turn1 != 0
&& turn1 > turn2) {}; && turn2 > turn1) {};
Crit_S_1;
Crit_S_2;
turn1 = 0;
turn2 = 0;
Non_Cr_S_1;
Non_Cr_S_2;
}
}
}
}
©André Santos,
1998-2000
Tentativa de granularidade fina 2
int turn1 = 0; int turn2 = 0;
void P1 () {
void P2 () {
while (TRUE)
while (TRUE)
{turn1 =turn2 + 1;
{turn2 = turn1 + 1;
while (turn2 != 0
while (turn1 != 0
&& turn1 > turn2) {}; && turn2 >= turn1) {};
Crit_S_1;
Crit_S_2;
turn1 = 0;
turn2 = 0;
Non_Cr_S_1;
Non_Cr_S_2;
}
}
}
}
©André Santos,
1998-2000
Solução de granularidade fina
int turn1 = 0; int turn2 = 0;
void P1 () {
void P2 () {
while (TRUE)
while (TRUE)
{turn1 = 1;
{turn2 = 1;
turn1 =turn2 + 1;
turn2 = turn1 + 1;
while (turn2 != 0
while (turn1 != 0
&& turn1 > turn2) {}; && turn2 >= turn1) {};
Crit_S_1;
Crit_S_2;
turn1 = 0;
turn2 = 0;
Non_Cr_S_1;
Non_Cr_S_2;
}
}
}
}
©André Santos,
1998-2000
Solução de granularidade fina
int turn[n] = 0;
void Pi () {
while (TRUE)
{turn[i] = 1; turn[i] = max(turn) + 1;
for (j=1;j<=n;j++) {if (j != i) {
while (turn[j] != 0 && (turn[i],i) > (turn[j],j)) {};
}
Crit_S_1;
turn[i] = 0;
Non_Cr_S_1;
}
}
©André Santos,
1998-2000
Sincronização em Barreira
Usada em algorítmos paralelos
iterativos
Custo de criação de processos x custo
de sincronização: mais barato
sincronizar do que criar processos com
freqüência
©André Santos,
1998-2000
Sincronização em Barreira
Usada em algorítmos paralelos
iterativos
Custo de criação de processos x custo
de sincronização: mais barato
sincronizar do que criar processos com
freqüência
©André Santos,
1998-2000
Ineficiente
void Main () {
while (TRUE)
{ co i := 1 to n ->
código para implementar tarefa i;
}
©André Santos,
1998-2000
Sincronização em barreira
void Pi () {
while (TRUE)
{ código para implementar tarefa i;
espera todas as n tarefas completarem;
}
©André Santos,
1998-2000
Sol.1: Contador compartilhado
int count = 0; BOOL passed[n] = FALSE;
void Pi () {
while (TRUE)
{ código para implementar tarefa i;
<count = count + 1>;
<await (count == n) ->
passed[i] = TRUE>;
}
©André Santos,
1998-2000
Sol.1: Contador compartilhado
Dificuldades:
Incremento tem que ser atômico
Como resetar o contador?
Acesso de todos os processos à variável do
contador
©André Santos,
1998-2000
Sol.2: Bandeiras e coordenadores
void Pi () {
while (TRUE)
{ código para implementar tarefa i;
arrive[i] = 1;
<await (continue[i] == 1)>;
continue[i] = 0;
}
©André Santos,
1998-2000
Sol.2: Bandeiras e coordenadores
void Coordinator () {
while (TRUE)
{ for (i=1;i<=n;i++)
{<await arrive[i] == 1>; arrive[i] = 0};
for (i=1;i<=n;i++) { continue[i] = 1};
}
©André Santos,
1998-2000
Sol.2: Bandeiras e coordenadores
Desvantagens:
Um processo a mais
Espera proporcional ao número de
processos
©André Santos,
1998-2000
Sol.2: Bandeiras e coordenadores
Solução: Workers também funcionando
como coordenadores:
Combining Tree Barrier
Worker
Worker
Worker
...
Worker
Worker
...
Worker
Worker
©André Santos,
1998-2000
Princípios de sincronização de
flags
O processo que espera por uma flag
deve ser o mesmo que a resseta
Uma flag não deve ser setada até que se
saiba que ela está ressetada.
©André Santos,
1998-2000
Data Parallel Algorithms
Algorítmo iterativo que manipula um array
compartilhado de forma repetitiva e em
paralelo
Usados em multiprocessadores
síncronos SIMD
MIMD = Multiple Instruction Multiple Data
SIMD = Single Instruction Multiple Data
©André Santos,
1998-2000
Parallel Prefix computations
Usados em vários algorítmos de
processamento de imagem,
processamento de matrizes etc.
Exemplo: cálculo da soma de um array
em log2n passos:
valores iniciais:
[1,2,3, 4, 5, 6]
soma com distância 1: [1,3,5, 7, 9,11]
soma com distância 2: [1,3,6,10,14,18]
soma com distância 4: [1,3,6,10,15,21]
©André Santos,
1998-2000
Algorítmo
int a[n]; int sum[n]; int old[n];
void Sumi () {
d = 1;
sum[i] = a[i]; /* inicializacao da soma */
barrier
while (d < n)
{ old[i] = sum[i] /* guarda valor anterior */
barrier
if ((i - d) >= 1) {sum[i] = old[i – d] + sum[i];};
barrier
d = 2 * d;
}
}
©André Santos,
1998-2000
Implementação de processos
Kernel – estruturas de dados e rotinas
internas do Sistema Operacional ou
sistema de execução da linguagem
Objetivo: criar processadores virtuais que
criam a ilusão de que o processo está
executando em seu próprio processador
©André Santos,
1998-2000
Implementação de processos
Precisamos implementar:
a criação e início de execução de processos
como parar um processo
como determinar que o processo ou um
grupo de processos terminou
Primitivas: rotinas implementadas pelo
kernel de forma que pareça ser atômica
fork - para criar processos
quit - para terminar processos
©André Santos,
1998-2000
Implementação de processos
fork – cria um outro processo, que já
pode entrar em execução, indica onde o
processo começa e seus dados.
quit – termina um processo
©André Santos,
1998-2000
Kernel para um processador
Todo kernel possui estruturas de dados
para representar processos e três tipos
de rotinas
Interrupt handlers
Primitivas
Dispatcher (escalonador)
©André Santos,
1998-2000
Kernel para um processador
Um kernel pode ser organizado:
de forma monolítica – cada primitiva executa
de forma atômica
Coleção de processos especializados que
interagem para implementar as primitivas:
I/O, memória etc.
Como um programa concorrente em que
mais de um processo do usuário pode estar
executando uma primitiva ao mesmo tempo
©André Santos,
1998-2000
Descritor do processo
Estrutura de dados com:
Próxima instrução a ser executada
Conteúdo dos registradores do processador
Está atualizada sempre que o processo
está idle (ocioso)
©André Santos,
1998-2000
Execução de instruções do kernel
Iniciada por uma interrupção
Dois tipos:
Externas, de dispositivos
Internas (traps), do processo em execução.
Ao interromper um processo, o
processador guarda informações sobre o
estado do processo (para que possa
continuar) e executa o interrupt handler
correspondente
©André Santos,
1998-2000
Execução de instruções do kernel
Processo executa uma SVC (supervisor
call) para invocar uma interrupção.
O interrupt handler:
Inibe outras interrupções
Salva estado do processo
Chama primitiva
Chama o escalonador
Habilita novas interrupções
Um (outro) processo é executado
©André Santos,
1998-2000
Execução de instruções do kernel
Listas de descritores de processos:
free list – descritores livres
ready list – processos prontos para executar
executing – indica o processo que está
executando
©André Santos,
1998-2000
Garantindo Justiça (fairness)
Uso de interval timer e de FIFO no
escalonamento dos processos
©André Santos,
1998-2000
Kernel para multiprocessadores
Semelhante, exceto pelo dispatcher
Como fazer melhor uso dos
processadores:
Cada processador ocioso fica verificando
periodicamente a ready list
Ao executar um fork procurar um
processador ocioso
Ter um processo separado para o
dispatcher, que procura processos para
processadores ociosos
©André Santos,
1998-2000
Baixar