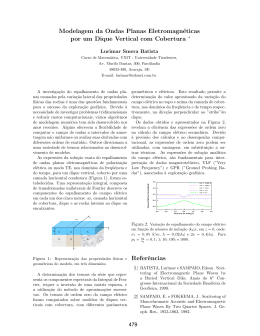
REGISTRO DIRETO DE IMAGENS PARA SLAM VISUAL Geraldo Silveira∗, Ezio Malis†, Patrick Rives† ∗ CTI Renato Archer – Divisão DRVC Rod. Dom Pedro I, km 143,6, Amarais CEP 13069-901, Campinas/SP, Brasil † INRIA Sophia Antipolis – Projeto ARobAS 2004 Route des Lucioles, BP 93 06902 Sophia-Antipolis, França Emails: [email protected], [email protected], [email protected] Resumo— The overwhelming majority of visual SLAM approaches consider feature (e.g., points, lines) correspondences as an input to the joint process of estimating the camera pose and the scene structure. This work proposes a new approach for simultaneously obtaining these parameters, all directly using image intensities as observations. In this way, all possible image information can be exploited, even from areas where no features exist. The visual SLAM problem is here formulated as an image registration task, where new photo-geometric transformation models and optimization methods are applied. Our technique simultaneously enforces several structural constraints, namely the cheirality, the rigidity and those related to the lighting variations. All these factors significantly contribute to obtain accurate visual SLAM results. This is confirmed through various experiments under general camera motion, different types of scenes and of real-world perturbations. Palavras-chave— Monocular SLAM, image registration, direct methods, illumination changes. Resumo— A maioria das técnicas de SLAM visual requerem a extração e associação de primitivas geométricas (e.g., pontos, retas) como entrada para os seus processos de estimação simultânea da pose da câmera e da estrutura da cena. Este trabalho propõe uma nova abordagem para calcular esses parâmetros diretamente a partir dos valores de intensidade dos pixels. Assim, toda a informação possı́vel da imagem pode ser explorada, mesmo de onde não há primitivas. A técnica proposta é baseada em registro de imagens, onde um novo modelo foto-geométrico de transformação e um método de otimização eficiente são aplicados. Essa técnica garante robustez a variações genéricas de iluminação e explora várias restrições simultaneamente na resolução do problema, e.g., rigidez da cena. Todos esses fatores contribuem para obter resultados precisos de SLAM visual. Isto é confirmado em diversos experimentos sob movimentos genéricos da câmera, diferentes tipos de cenas e de perturbações frequentemente presentes em cenários reais. Palavras-chave— 1 SLAM monocular, registro de imagens, métodos diretos, mudanças de iluminação. Introdução O problema de SLAM visual consiste em estimar simultaneamente a localização relativa da câmera e a estrutura do ambiente onde a mesma se desloca. Essa tarefa é tradicionalmente dividida em três etapas principais. Inicialmente, um conjunto adequado de primitivas geométricas (e.g., pontos, retas) é extraı́do e, em seguida, associado nas imagens. Importante salientar que esta associação de dados é raramente perfeita e as falsas correspondências (i.e., outliers) devem ser rejeitadas posteriormente utilizando uma técnica robusta (e.g., RANSAC). O objetivo é encontrar um conjunto coerente de primitivas em correspondência nas imagens que vai permitir estimar os parâmetros desejados através de um processo apropriado de filtragem. O leitor pode se referir às técnicas propostas, por exemplo, em (Broida et al., 1990; Davison, 2003; Eade e Drummond, 2006). Este trabalho segue uma linha diferente dessa abordagem tradicional, dita baseada em primitivas geométricas. De fato, nós propomos uma nova técnica de SLAM monocular onde a pose da câmera e a estrutura da cena são obtidas diretamente (e daı́ sua classificação como tal) a partir dos valores de intensidade dos pixels. Dessa forma, ao invés de se limitar à informação contida em primitivas geométricas particulares, é possı́vel explorar toda informação disponı́vel nas imagens. A técnica proposta também é diferente dos métodos diretos existentes. A estratégia descrita em (Molton et al., 2004), sensı́vel às mudanças de iluminação, não considera o forte acoplamento entre o movimento da câmera e a estrutura da cena que são estimados separadamente. O método proposto em (Jin et al., 2003), bem que as estima simultaneamente, requer movimentos relativos muito lentos da câmera. A abordagem unificada aqui apresentada permite maiores deslocamentos dos objetos entre imagens sucessivas. A técnica proposta neste artigo é baseada em um novo modelo foto-geométrico de transformação e utiliza uma técnica de otimização eficiente para registrar (i.e., alinhar) imagens. Esse modelo generativo garante robustez a variações genéricas de iluminação e impõe, também durante o pro- cesso de otimização, o fato de que a cena está sempre situada em frente à câmera (i.e., profundidades devem ter valores estritamente positivos). A hipótese de movimento global único é suposta verdadeira durante o procedimento de minimização. Com isso, a restrição de rigidez da cena é também satisfeita simultaneamente. A exploração de toda informação possı́vel e dessas restrições estruturais aumentam a precisão e a robustez intrı́nseca do algoritmo com respeito às medidas aberrantes. Entretanto, por motivos de eficiência computacional, apenas algumas regiões da imagem são exploradas pela técnica, que as seleciona automaticamente. Também por esses motivos, a estrutura da cena é aproximada localmente por superfı́cies planares. Diversos resultados experimentais são fornecidos utilizando uma variedade de cenas, incluindo cenas de exterior e urbanas, sob movimentos genéricos da câmera e diferentes tipos de perturbações frequentemente presentes em cenários reais (e.g., pedestres e carros em movimento). 2 2.1 Fundamentação teórica Notações Seja I ∗ uma imagem capturada de uma cena rı́gida. Após o deslocamento da câmera por uma rotação R ∈ SO(3) e uma translação t ∈ R3 , uma outra imagem I é adquirida. Permita que esse deslocamento seja representado por uma matriz homogênea T ∈ SE(3), que p = [u, v, 1]⊤ ∈ P2 denote o vetor homogêneo de coordenadas de um pixel, e que I(p) ≥ 0 represente o seu valor de intensidade. Ademais, utilizaremos υ, υ b, υ ◦ , υ e, e υ ′ para representar, respectivamente, o valor exato de υ, uma estimativa deste valor, o valor ótimo (relativo a uma dada função custo), um valor incremental e uma alteração dessa variável. 2.2 Geometria epipolar entre duas imagens Considere o modelo de câmera de orifı́cio para descrever a projeção geométrica de objetos na imagem. Neste caso, a relação entre as projeções p ↔ p∗ do mesmo ponto 3D em duas imagens calibradas é dada por p ∝ K R K−1 p∗ + (z ∗ )−1 K t, (1) onde K ∈ R3×3 representa os parâmetros intrı́nsecos da câmera, z ∗ > 0 é a profundidade do ponto em relação ao sistema de referência, e o sı́mbolo ‘∝’ indica proporcionalidade. Para o caso particular de um objeto planar, a inversa da profundidade de qualquer ponto pertencente a esse plano é dado por −1 ∗ (z ∗ )−1 = n∗⊤ p , d K (2) onde n∗d ∈ R3 corresponde ao vetor normal desse plano dividido pela sua distância perpendicular à origem do sistema de coordenadas de referência. Nesse caso, a relação genérica expressa em (1) se reduz então a p ∝ G p∗ (3) com ¢ −1 ¡ K . (4) G(T, n∗d ) = K R + t n∗⊤ d 2.3 Registro direto de imagens para localização Considere ainda o caso de um objeto (aproximadamente) planar no que segue. Uma função de transformação geométrica (do inglês, warping) pode então ser definida a partir de (3) como w : R3×3 × P2 → P2 (G, p∗ ) 7→ p = w(G, p∗ ). (5) (6) A equação em (6) pode ser reescrita como p= » g11 u∗ + g12 v ∗ + g13 g21 u∗ + g22 v ∗ + g23 , ,1 g31 u∗ + g32 v ∗ + g33 g31 u∗ + g32 v ∗ + g33 –⊤ onde {gij } denota os elementos da homografia G dada por (4). No caso de imagens calibradas e em que n∗d (i.e., o modelo métrico) é previamente conhecido, tem-se que G = G(T). O problema de registro direto geométrico pode ser formulado como a busca da matriz T ∈ SE(3) que transforma todos os pixels da região da imagem corrente I tal que suas intensidades correspondem da melhor forma possı́vel àquelas na imagem de referência I ∗ . Como objetivamos encontrar a pose da câmera T dado o modelo métrico do objeto n∗d , esse método pode portanto ser interpretado como uma técnica de localização. Um procedimento não-linear de otimização local deve ser aplicado para resolver este problema dado que, em geral: (i) a intensidade I(p) é não-linear em p; e (ii) métodos globais não respeitam as restrições de tempo-real dos sistemas robóticos. A técnica clássica para resolvê-lo consiste em desenvolver a função custo em série de Taylor, permitindo escrevê-lo como um problema de mı́nimos quadrados linear. Dado que essa solução corresponde a apenas uma aproximação, iterações são conduzidas até a convergência dos parâmetros. b ∈ SE(3) de T. Assim, seja uma estimativa T Considere a parametrização dessa variável através da álgebra de Lie respectiva se(3) (Warner, 1987), e = T(e i.e., T = T(v). O incremento ótimo T v) será obtido através da resolução do problema i2 ¢´ ¢ 1 Xh ³ ¡ ¡ b , p∗ − I ∗ (p∗ ) , I w G T(e v) T i i ṽ∈R 2 i (7) com atualização dos parâmetros a cada iteração: min6 b ←− T(e b T v) T ∈ SE(3). (8) A convergência dos parâmetros pode ser estabelecida quando o deslocamento incremental for arbitrariamente pequeno, i.e., ke vk < ǫ. A pose ótima , obtida pode ser utilizada para inicializar o mesmo processo quando uma nova imagem é capturada. Uma solução eficiente para o problema de localização (7) está descrita em (Benhimane e Malis, 2006). Neste trabalho, mostraremos como estendê-lo para a estimação simultânea do modelo métrico do objeto n∗d , bem como relaxarmos a hipótese presente em (7) de que nenhuma variação de iluminação ocorreu entre as imagens. 3 Registro de imagens para SLAM visual A técnica consiste em um novo modelo fotogeométrico de transformação de imagens, e de um método eficiente de otimização não-linear para a obtenção dos parâmetros relativos aos modelos. 3.1 Modelo foto-geométrico de transformação Em primeiro lugar, como desejamos realizar também mapeamento e não somente localização, é imprescindı́vel a inclusão do modelo métrico nd ∈ R3 como variável de otimização. Para representá-la, propomos utilizar a inversa da profundidade (2) de três pontos pertencentes à região ¤⊤ £ z∗ = 1/z1∗ , 1/z2∗ , 1/z3∗ , (9) e parametrizá-los por z∗ = z∗ (y) = exp(y) > 0, y ∈ R3 . (10) Essa parametrização da estrutura é motivada por duas razões fundamentais: (i) impõe o fato de que a cena está sempre em frente à câmera, i.e., zi∗ > 0, ∀i; e (ii) não restringe o método a cenas planares por partes, já que utilizaremos diretamente a profundidade de pontos e não o vetor normal como variável de otimização. Entretanto, por motivos de eficiência computacional, ainda utilizare¡ ¢ mos n∗d = n∗d z∗ (y) . Outro aspecto importante consiste em assegurar robustez à variações genéricas de iluminação. Recentemente, Silveira e Malis (2007) propuseram o seguinte modelo de variação de iluminação: I ′ (S, β) = S · I + β, (11) onde β ∈ R, S é interpretado como uma superfı́cie variante no tempo e o operador ‘·’ denota multiplicação elemento-por-elemento, e o aplicaram ao registro de imagens parametrizado no espaço projetivo. Mostraremos aqui que (11) pode também ser aplicado quando o registro é parametrizado no espaço Euclideano. Assim, tem-se que o modelo foto-geométrico de transformação incremental proposto é dado por ¡ ¢ b p∗ = b, h(e I ′ g(e zg ) ◦ g zh ) ◦ h, ¢ ¡ ¢ ¡ b (12) b, p∗ ) + βe ◦ β, e◦γ b , p∗ · I w(g(e zg ) ◦ g S γ © ª com variáveis geométricas g = T, (z ∗ )−1 , parametrizadas por zg = {v, y}, e fotométricas h = {S, β}, parametrizadas por zh = {γ, β}. O operador de composição ‘◦’ depende do grupo de Lie envolvido. 3.2 Método de otimização não-linear Utilizando o modelo (12), o problema de SLAM visual pode então ser formulado como ¢ ¤2 1 X X £ ′¡ b, p∗ij − I ∗ (p∗ij ) , I x(e z) ◦ x e z={e zg ,e zh } 2 | {z } j i min dij (x(e z)◦b x) onde x = {g, h}, parametrizado por z = {zg , zh }, e d = {dij } representa o conjunto de diferenças de intensidade de cada pixel, para todas as regiões j = 1, 2, . . . , n consideradas. Para a solução iterativa desse problema, uma expansão em série de Taylor é inicialmente efetuada. De forma a obtermos altas taxas e domı́nios de convergência, realizamos a aproximação de segunda ordem eficiente (Malis, 2004) d(x(e z)◦b x) ≈ d(b x)+ ¢ 1¡ z, (13) J(b x)+J(x(e z)◦b x) e 2 onde, em nosso caso, os Jacobianos J(·) são relativos aos parâmetros de movimento, da estrutura da cena, e das mudanças de iluminação. Para que e z corresponda a um extremo da função custo, uma condição de otimalidade necessária fornece de (13) ¢ 1¡ z = −d(b x), J(b x) + J(x) e 2 (14) onde J(b x) é completamente determinada a partir de dados correntes. Porém, somente uma parte do Jacobiano na solução (desconhecida) J(x) pode o ser (já que a imagem de referência é conhecida). A outra parte deve ser aproximada usando, e.g., dados correntes. A solução e z obtida do sistema linear retangular (14) deve ser iterativamente utilizada até a convergência. 4 4.1 Gerenciamento da informação Seleção das regiões De forma a satisfazer critérios de tempo real, apenas algumas regiões da imagem podem ser consideradas para processamento. Neste trabalho, essas regiões são automaticamente selecionadas baseado em um ı́ndice (i.e., score) apropriado, conforme definido abaixo. No caso de métodos diretos, altos ı́ndices devem refletir fortes gradientes em diferentes direções na imagem. Seja R∗ ⊂ I ∗ uma região de imagem com dimensões w × w, e G ∗ uma imagem baseada no gradiente de I ∗ . Uma matriz de ı́ndices S ∗ pode ser obtida como uma somatória de todos os valores de G ∗ contidos em blocos de dimensões w × w (a) (b) (c) (d) (e) Figura 1: (a), (b), (c) Imagens adquiridas a 25 Hz utilizando uma câmera de vı́deo convencional. As regiões exploradas pela técnica estão registradas em vermelho. Observe em (c) a inserção de uma nova região de imagem (a da parede lateral do imóvel). As poses da câmera e a estrutura da cena reconstruı́das estão mostradas sob diferentes pontos de vista em (d) e (e). centrados em cada pixel. Um segundo critério a ser considerado, possivelmente com um peso diferente, é baseado na quantidade de extremos locais de G ∗ (representadas por E ∗ ) dentro de cada bloco. Todas essas operações por bloco podem ser efetuadas eficientemente através de uma convolução com um kernel Kw = 1 de dimensões w × w: S ∗ = λ G ∗ ⊗ Kw + η E ∗ ⊗ Kw . (15) Pesos tı́picos são λ = kG ∗ ⊗ Kw k−1 e η = 1. A quantidade de regiões a serem exploradas (definidas em torno de altos ı́ndices) depende somente dos recursos computacionais disponı́veis. 4.3 Rejeição das regiões Para métodos diretos, medidas aberrantes correspondem a regiões que não satisfazem aos modelos adotados, e.g., às regiões da imagem relacionadas com objetos que se deslocam de forma independente. Essas regiões devem ser detetadas e excluı́das do processo de estimação automaticamente. Com essa finalidade, duas métricas são definidas abaixo para avaliar a j-ésima região: uma medida fotométrica e outra geométrica. O ı́ndice fotométrico é definido diretamente a partir da função custo da otimização: ε2j (x◦ ) = 4.2 Inserção das regiões Dado que as regiões exploradas podem sair do campo visual ou eventualmente serem rejeitadas do processo de estimação, o sistema deve ser capaz de inserir automaticamente novas regiões sempre que recursos computacionais estiverem disponı́veis. Neste trabalho, a inicialização de novas regiões segue a sequência natural de especialização. Isto é, primeiramente a transformação da região é caracterizada no espaço projetivo utilizando a técnica descrita em (Silveira e Malis, 2007). Utilizando esta informação e o resultado incremental do SLAM estimado, a melhor descrição Euclideana possı́vel até o momento é obtida via método descrito em (Silveira et al., 2008). X 1 d2 (x◦ ), ∗ card(Rj ) i ij (16) onde card(·) indica a cardinalidade do conjunto. Observe que as variações de iluminação já estão compensadas nessa métrica. Por outro lado, o ı́ndice geométrico indica o grau de deformação (i.e, redução ou alongamento) entre os lados de cada região em duas imagens consecutivas. Grandes deformações podem significar que a região não possui informação suficiente para restringir todos os graus de liberdade, podendo assim ser descartada do processo de otimização. Note também que, enquanto (16) é avaliado depois de obtermos a solução ótima, o ı́ndice geométrico pode o ser durante as iterações. Isso pode prevenir que medidas aberrantes perturbem a solução final. (a) (b) (c) (d) (e) Figura 2: (a), (b), (c) Imagens urbanas sobrepostas com as regiões registradas (em vermelho) pela técnica. As poses da câmera e a estrutura da cena reconstruı́das estão mostradas sob diferentes pontos de vista em (d) e (e). Observe o paralelismo e/ou perpendicularidade entre as paredes dos imóveis. 5 Resultados experimentais Esta seção relata os experimentos que foram conduzidos a fim de validar a técnica proposta, e avaliar sua performance, em diversos cenários reais. Enfatizamos que nenhum ajuste em bloco (do inglês, bundle adjustment) ou fase de aprendizagem foram efetuados, assim como apenas uma única câmera é empregada como sensor. Considerando imagens em nı́veis de cinza no intervalo [0, 255], a j-ésima região é declarada neste trabalho como aberrante se seu erro fotométrico εj > 20 nı́veis, ou se seu erro geométrico for maior que 50%. Por fim, consideramos que o RMS do ruı́do da imagem é de 0.6 nı́vel de escala de cinza. 5.1 Sequência Hangar Essa sequência de exterior visa principalmente demonstrar o grau de precisão da abordagem e sua robustez a vários tipos de ruı́do, dentre eles: movimentos erráticos da câmera, imagens borradas, pequenas oclusões, etc. Essas últimas perturbações não afetaram de forma significativa os resultados dado que elas possuem substancialmente menos informação comparada com outras partes da mesma região (vide a árvore na Fig. 1). Para esses resultados, a técnica efetuou uma mediana de 5 iterações por imagem, obtendo um erro fotométrico de 13.37 nı́veis de escala de cinza. O ângulo obtido entre as duas paredes reconstruı́das foi de 89.7◦ , utilizando uma mediana de 22.59% do total de pixels de cada imagem (320 × 240 pi- xels). Essa medida geométrica fornece uma boa indicativa do grau de precisão da técnica (considerando que as paredes são realmente perpendiculares), dado que pose e estrutura são intimamente relacionados. O deslocamento total da câmera foi de aproximadamente 50 m, e as imagens foram capturadas por uma câmera convencional a 25 Hz. 5.2 Sequência Urbana A técnica também foi aplicada a uma sequência urbana representativa, a qual foi capturada a aproximadamente 12 Hz. Essa sequência é bastante desafiadora na medida em que: relativamente grandes deslocamentos dos objetos entre imagens são observados; os objetos se encontram a diferentes distâncias da câmera; assim como existe uma mudança significativa na escala (zoom). Outra importância desse cenário decorre do fato que, nesse caso, posições a partir de GPS não estão disponı́veis ou não são suficientemente precisas. A aplicação de câmeras torna-se portanto ainda mais relevante nessa situação. Os resultados obtidos são mostrados na Fig. 2. Para a precisão requisitada, a técnica efetuou uma mediana de 12 iterações por imagem, obtendo um erro fotométrico de 10.77 nı́veis de escala de cinza, na utilização de uma mediana de 34 regiões de imagem de tamanho 31×31 pixels (no momento em que foram selecionadas), explorando uma mediana de 17.01% do total de pixels de cada imagem (760 × 578 pixels). O deslocamento total da câmera é de aproximadamente 60 m. (a) (b) (c) (d) (e) (f) Figura 3: (a), (b), (c) Imagens urbanas capturadas a 12 Hz e sobrepostas com as regiões registradas (em vermelho) pela técnica. As poses da câmera e a estrutura da cena reconstruı́das estão mostradas sob diferentes pontos de vista em (d) e (e). Uma imagem de satélite do cenário está mostrada em (f). 5.3 Sequência Rotatória Esta sequência permite observarmos a robustez da técnica a outros tipos de ruı́dos, e.g., pedestres e veı́culos, os quais possuem movimentos independentes. Algumas imagens e resultados correspondentes são mostrados na Fig. 3. Para a precisão requisitada, a técnica efetuou uma mediana de 10 iterações por imagem, obtendo um erro fotométrico de 11.37 nı́veis de escala de cinza, na utilização de uma mediana de 37 regiões de imagem de tamanho 31×31 pixels (no momento em que foram selecionadas), explorando uma mediana de 10.84% do total de pixels de cada imagem (760 × 578 pixels). Esta sequência foi capturada a aproximadamente 12 Hz por uma câmera abordo de um veı́culo, cujo deslocamento medido pelo Google Earth é de aproximadamente 150 m. 6 Conclusões Este artigo propõe um método eficiente e robusto de registro de imagens como solução para o problema de SLAM visual. Diferentemente dos métodos tradicionais, o método proposto não se baseia em primitivas geométricas para resolver esse problema. De fato, ele consiste em calcular a estrutura da cena, o deslocamento da câmera e as variações de iluminação em relação a um sistema de coordenadas de referência diretamente a partir das intensidades dos pixels. Trabalhos futuros nesta linha podem ser realizados no fechamento do laço (do inglês, loop closing), que consiste em identificar locais previamente já visitados pelo robô. Agradecimentos Este trabalho também foi parcialmente financiado pela CAPES. Referências Benhimane, S. e Malis, E. (2006). Integration of Euclidean constraints in template based visual tracking of piecewise-planar scenes, Proc. of the IEEE/RSJ IROS, China, pp. 1218–1223. Broida, T. J., Chandrashekhar, S. e Chepalla, R. (1990). Recursive 3-D motion estimation from a monocular image sequence, IEEE Trans. on Aerosp. and Electronic Systems 26(4): 639–656. Davison, A. (2003). Real-time simultaneous localization and mapping with a single camera, Proc. of the IEEE Int. Conf. on Computer Vision. Eade, E. e Drummond, T. (2006). Scalable monocular SLAM, IEEE Comp. Vision and Pattern Recogn. Jin, H., Favaro, P. e Soatto, S. (2003). A semi-direct approach to structure from motion, The Visual Computer 6: 377–394. Malis, E. (2004). Improving vision-based control using Efficient Second-order Minimization techniques, Proc. of the IEEE ICRA, USA. Molton, N. D., Davison, A. J. e Reid, I. D. (2004). Locally planar patch features for real-time structure from motion, Proc. of the BMVC. Silveira, G. e Malis, E. (2007). Real-time visual tracking under arbitrary illumination changes, IEEE Comp. Vision and Pattern Recogn. Silveira, G., Malis, E. e Rives, P. (2008). The efficient E-3D visual servoing, International Journal of Optomechatronics 2(3): 166–184. Warner, F. W. (1987). Foundations of differential manifolds and Lie groups, Springer Verlag.
Baixar