UNIVERSIDADE FEDERAL DA BAHIA
INSTITUTO DE MATEMÁTICA
DEPARTAMENTO DE CIÊNCIA DA COMPUTAÇÃO
LORENA SANTOS ERDENS
Um algoritmo de análise de pré-condições e efeitos
para descoberta de serviços Web semânticos
Salvador
2010.2
LORENA SANTOS ERDENS
Um algoritmo de análise de pré-condições
e efeitos para descoberta de serviços Web
semânticos
Monografia apresentada ao Curso de
graduação em Ciência da Computação,
Departamento de Ciência da Computação,
Instituto de Matemática, Universidade Federal da Bahia, como requisito parcial para
obtenção do grau de Bacharel em Ciência da
Computação.
Orientadora: Dra Daniela Barreiro Claro
Salvador
2010.2
RESUMO
O crescimento do uso de serviços Web, tanto na academia, como na área comercial, demanda atenção no desenvolvimento de aplicações compatíveis com esse tipo de tecnologia. Os
serviços Web mostram-se como uma solução promissora para o problema de interoperabilidade, pois apresentam baixo acoplamento entre aplicações. A utilização de tais serviços está
condicionada à sua descoberta, ou seja, os serviços Web precisam ser encontrados, para depois serem invocados e executados. Informações ambíguas dificultam a automatização desta
tarefa, por isso, a adição de técnicas provindas da Web Semântica proporcionou a descoberta
automática. As informações mais usadas na descoberta são os conjuntos de entrada e saída do
serviço. Entretanto, a descoberta que se baseia somente nestas informações não é eficiente o suficiente. Para muitos serviços, é essencial a análise das pré-condições e efeitos no momento da
descoberta, para assegurar a correta execução do mesmo. O presente trabalho propõe um algoritmo de busca, que utiliza correspondência semântica de termos para a análise de pré-condições
e efeitos dos serviços Web semânticos. Tal algoritmo utiliza a análise de pré-condições e efeitos
dos serviços Web semânticos e foi implementado sobre as bases da ferramenta OWL-S Discovery, provendo uma nova ferramenta chamada OWL-S Discovery 2.0.
Palavras-chave: Descoberta de Serviços Web, OWL-S, Serviços Web Semânticos, Précondições e efeitos.
ABSTRACT
The growing use of Web services both in academia as in the commercial area demand attention in developing applications compatible with this type of technology. Web services are
shown as a promising solution to the interoperability problem, since they have low coupling
between applications. The use of such services is subject to its discovery, i.e. Web services
need to be found before beeing invoked and executed. Ambiguous information difficult the automation of this task, so the addition of techniques that come from the Semantic Web provided
that the automatic discovery could be more precise. The most used information in the discovery
are the sets of input and output of the service. However, the discovery that is based exclusively
on this information is not efficient enough. For many services, it is essential to analysis of preconditions and effects at the time of discovery to garantee the correct execution of the service.
This paper proposes a search algorithm that uses semantic matching of terms with the objective
of providing a more accurate way of discovering semantic Web services. This algorithm uses
the analysis of preconditions and effects of semantic Web services and was implemented on the
basis of OWL-S Discovery tool providing a new tool called OWL-S Discovery 2.0.
Keywords: Web Service Discovery, OWL-S, Semantic Web Service, Preconditions and
Effects.
LISTA DE FIGURAS
1
Ciclo de vida de um serviço Web . . . . . . . . . . . . . . . . . . . . . . . . .
11
2
Esrtutura da ontologia Service (MARTIN et al., 2004) . . . . . . . . . . . . . . .
14
3
Representação gráfica de uma ontologia para o termo CARRO . . . . . . . . .
16
4
Visão geral do funcionamento do OWL-S Discovery 2.0 . . . . . . . . . . . .
20
5
Funcionamento do Algoritmo Semântico P/E . . . . . . . . . . . . . . . . . .
21
6
Solução espacial para S e R (BELLUR; VADODARIA, 2008) . . . . . . . . . . . .
31
7
Arquitetura do OWL-S Discovery 2.0 (AMORIM, 2009) . . . . . . . . . . . . .
35
8
Campos obrigatórios para descoberta de serviços Web utilizando a análise de
pré-condições e efeitos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
38
9
Campos selecionados e resultado obtido . . . . . . . . . . . . . . . . . . . . .
39
10
Campos Limpar e Exportar . . . . . . . . . . . . . . . . . . . . . . . . . . . .
40
11
Ontologia para o predicado temConta . . . . . . . . . . . . . . . . . . . . . .
43
12
Gráfico Quantidade de Pré-condições e Efeitos X Tempo de Execução . . . . .
49
LISTA DE TABELAS
1
Tabela comparativa dos algoritmos de descoberta de serviço Web . . . . . . . .
2
Tabela comparativa de retorno da execução para 10 requisições e 100 serviços
dos algoritmos de Paolucci e as versões 1.0 e 2.0 desta ferramenta . . . . . . .
3
42
Tabela comparativa de tempo de execução somente do algoritmo de análise de
entrada e saída e do algoritmo de entrada, saída, pré-condições e efeitos. . . . .
4
34
47
Tabela comparativa de tempo de execução somente do algoritmo de análise de
entrada e saída e do algoritmo de entrada, saída, pré-condições e efeitos, para
as requisições r1 e r2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5
48
Tabela comparativa de tempo de execução somente do algoritmo de análise de
entrada e saída e do algoritmo de entrada, saída, pré-condições e efeitos, para
as requisições r3, r4, r7 e r8. . . . . . . . . . . . . . . . . . . . . . . . . . . .
6
48
Tabela relacional entre a quantidade total de pré-condições e efeitos e o tempo
médio de execução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
49
SUMÁRIO
1
Introdução
2
Serviços Web
11
2.1
Serviços Web semânticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
12
2.2
Descoberta Semântica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
14
3
4
5
6
8
Algoritmo proposto
19
3.1
Visão geral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
19
3.2
Funcionamento do algoritmo de análise semântica . . . . . . . . . . . . . . . .
20
3.3
Um exemplo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
24
Análise e correlação com trabalhos existentes
27
4.1
Análise de entradas e saídas dos serviços Web . . . . . . . . . . . . . . . . . .
27
4.2
Análise complementar com pré-condições e efeitos . . . . . . . . . . . . . . .
29
4.3
Análise Comparativa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
32
Implementação no OWL-S Discovery 2.0
35
5.1
Arquitetura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
35
5.2
Ferramentas utilizadas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
36
5.3
Exemplo de utilização . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
37
Análise e Validação
41
6.1
Precisão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
41
6.2
Complexidade . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
44
6.3
7
Tempo de execução . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Conclusão e trabalhos futuros
46
50
Apêndice A -- Serviço Web
52
Referências
54
8
1
INTRODUÇÃO
O grande crescimento do uso de serviços Web, tanto na academia, como na área comercial,
demanda atenção no desenvolvimento de aplicações orientadas a serviços. Segundo a W3C,
um serviço Web é uma aplicação identificada por uma URI, cujas interfaces são passíveis de
serem definidas, descritas e descobertas por artefatos XML e suportam interação direta com
outras aplicações que usam mensagens XML através de protocolos baseados na internet(W3C,
2002). Uma outra definição que completa a anterior é que um serviço Web é uma maneira de
expor a funcionalidade de um sistema de informação e fazê-lo disponível através de padrões
de tecnologias na Web. Os serviços Web se mostram como uma solução promissora para o
problema de interoperabilidade, pois apresentam baixo acoplamento entre aplicações, uma vez
que seu funcionamento se baseia em troca de mensagens XML.
A utilização de tais serviços está condicionada a sua descoberta, ou seja, os serviços Web
precisam ser encontrados, para depois serem invocados e executados. Atualmente os serviços
são descobertos através da WSDL (Web Services Description Language) (CHRISTENSEN et al.,
2001), e utiliza um processonão automático baseado em busca de palavras chaves. A automação
da descoberta envolve, dentre outros aspectos, a adição de técnicas provindas da Web semântica,
como a incorporação de uma linguagem de marcação com informações sobre os serviços Web.
Esta linguagem de marcação com características semânticas utiliza ontologias com a finalidade
de descrever o serviço Web.
Uma ontologia é a especificação de uma conceituação, isso é, uma ontologia é a descrição
de conceitos e relações que podem existir para um agente ou comunidade de agentes (GRUBER,
1993). Na Web Semântica, uma ontologia permite a formalização, o compartilhamento
e a definição de conceitos, restrições, relacionamentos e axiomas de um domínio de conhecimento. Assim, ela é usada para classificar termos usados por uma aplicação, realizar inferências
baseadas em propriedades, relações e axiomas do domínio que ela representa.
A OWL (Web Ontology Language) (MCGUINNESS; HARMELEN, 2004) é uma linguagem
para definir e instanciar ontologias na Web (W3C, 2004b). Em relação aos serviços Web, a OWL-
9
S (MARTIN et al., 2004) é uma linguagem, baseada na OWL, que provê aos serviços Web um
conjunto de propriedades para descrever tais serviços de forma não ambígua e computavelmente
interpretável. A OWL-S facilita a automação de tarefas, que envolvem serviços Web, incluindo
a busca e descoberta automática, execução e composição de serviços.
Na descoberta de serviços Web, as buscas são realizadas fazendo um comparativo entre as
informações requisitadas e as informações do serviço. No caso dos serviços Web semânticos,
inferências podem ser utilizadas na busca por similaridade semântica entre os termos do serviço
e os parâmetros da busca. As informações mais usadas nesta tarefa são os conjuntos de entrada
e saída do serviço. Para tal, o usuário que busca um serviço informa quais os dados que serão
fornecidos por ele, usados como entrada para execução do serviço, e quais os dados que ele
deseja que sejam retornados pelo serviço, ou seja, o conjunto de saída do serviço. Assim, a
descoberta dos serviços Web semânticos compara semânticamente os termos fornecidos pelo
usuário com os termos do serviços e retorna a similaridade entre o serviço desejado e o serviço
encontrado.
Entretanto, a descoberta que se baseia somente nos conjuntos de entrada e saída não tem
a eficiência necessária. Para muitos serviços, existe um conjunto de condições que devem ser
atendidas para que o serviço seja executado corretamente. Esse conjunto é chamado de précondições. Uma descoberta que analisa apenas as entradas e saídas, não é capaz de determinar
se as pré-condições do serviço em questão serão atendidas. Sendo assim, o serviço descoberto
está propenso a falhas de execução. Outra informação relevante no momento da descoberta é
o conjunto de efeitos do serviço. Esse conjunto informa quais as consequências da execução
do serviço. Os serviços retornados na descoberta, que não considera os efeitos, podem gerar
consequências indesejadas ao usuário ou deixar de produzir algum efeito esperado.
Devido ao crescimento da utilização dos serviços Web semânticos em diversos ramos da
tecnologia atual e da carência de aplicações para descoberta desses serviços, o presente trabalho propõe um algoritmo de busca, que realiza a correspondência semântica de termos. Tal
algoritmo utiliza a análise de pré-condições e efeitos dos serviços Web semânticos e foi implementado sobre as bases da ferramenta OWL-S Discovery (AMORIM, 2009) provendo uma nova
ferramenta chamada OWL-S Discovery 2.0. Também foi feito um estudo da complexidade,
do tempo de execução e da precisão deste algoritmo que permitiu analisar sua eficiência e sua
utilização.
Os próximos capítulos estão organizados da seguinte maneira: o capítulo 2 apresenta os
métodos de descoberta dos serviços Web; o capítulo 3 descreve o algoritmo proposto; o capítulo
4 expõe os trabalhos relacionados; o capítulo 5 faz uma análise dos teste realizados e resultados
10
obtidos; o capítulo 6 apresenta a ferramenta OWL-S Discovery 2.0 e, por fim, no capítulo 7
seguem as conclusões e considerações finais.
11
2
SERVIÇOS WEB
O ciclo de vida de um serviço Web é composto de 5 fases, como apresentado na Figura
cicloVida.
Figura 1: Ciclo de vida de um serviço Web
Inicialmente um serviço web é publicado em um servidor. O processo de publicação é o
ato de tornar um serviço Web acessível, com a finalidade de que outros serviços Web possam
invocá-lo, ou até mesmo usuários possam utilizá-lo (AMORIM, 2009). Essa publicação é feita
utilizando uma linguagem de anotação, que descreve informações relevantes ao uso do serviço.
Uma vez realizada a publicação, a etapa seguinte é a descoberta do serviço Web. A descoberta do serviço é a busca por serviços, os que possuem características similares aos requisitos
informados pela entidade que o invoca, podendo esta entidade ser um usuário ou outros serviços
Web com a finalidade de compor novos serviços.
A etapa seguinte refere-se a seleção do serviço. Baseado em métricas pré-definidas, o
12
agente seleciona, dentre os serviços descobertos, aqueles cujas características se assemelham
mais às desejadas. A composição é o passo seguinte. Ela acontece porque muitos serviços,
quando isolados, podem não atender aos requisitos do cliente. Neste caso, torna-se necessário
combinar determinados serviços a fim de que o objetivo seja alcançado (CLARO; MACEDO,
2008). Porém, quando somente um serviço é capaz de atender por completo o que o cliente
deseja, esta etapa é ignorada.
Por fim, tem-se a invocação do serviço Web. É nesta etapa que o serviço é efetivamente
executado.
A descoberta dos serviços Web é um passo determinante para a realização das etapas
seguintes. A realização defeituosa desta tarefa compromete todas as outras etapas do ciclo
de vida do serviço Web e pode gerar erros de execução e efeitos indesejados na invocação do
serviço. Para fazer a descoberta, o agente responsável por essa atividade começa sua busca no
servidor de serviços, comparando as informações que foram passadas pelo usuário com as informações de cada serviço disponível no servidor. Utilizando o método adequado, o algoritmo
seleciona qual, ou quais, serviços são compatíveis com a requisição em questão e retorna tais
serviços ao usuário.
O grande problema da descoberta é o fato de que não é real assumir que as necessidades do
usuário e os serviços sempre irão se relacionar de forma idêntica. Adotar uma decisão lógica
rígida resultaria em ignorar diversos serviços que são parcialmente similares com os requisitos
informados (AMORIM, 2009). Para atingir esse objetivo, esforços foram realizados no intuito de
atribuir semântica ao termos utilizados na descrição do serviço Web. As técnicas desenvolvidas
permitiram que os descritores dos serviços Web pudessem ser analisados de acordo com a sua
semântica ao invés de serem analisados meramente pela sintática. A adição de semântica à
descrição dos serviços Web deu origem aos serviços Web semânticos.
2.1
SERVIÇOS WEB SEMÂNTICOS
Para adicionar semântica aos serviços Web, alguns mecanismos foram criados para que tais
serviços oferecessem interfaces computavelmente interpretáveis. Dentre eles estão a WSMO
(Web Service Modeling Ontology) (LAUSEN; ROMAN; POLLERES, 2005) , a SAWSDL (FARRELL;
LAUSEN,
2007) e a OWL-S (MARTIN et al., 2004). A linguagem utilizada neste trabalho foi a
OWL-S devido a sua ampla utilização, tanto em ferramentas presentes no mercado, quanto na
área acadêmica, bem como sua fácil integração com a OWL.
O objetivo da OWL-S é fornecer informações no que diz respeito à estrutura de funciona-
13
mento, o fluxo de execução e detalhes da implementação do serviço Web. Todo serviço descrito
em OWL-S deverá possuir uma instância da ontologia Service que irá fazer referências, através
de seus recursos, às ontologias Profile, Process Model e Grounding. A Listagem 2.1 exemplifica
parte do código de um serviço Web descrito em OWL-S.
Listagem 2.1: Serviço Web descrito em OWL-S
< s e r v i c e : S e r v i c e r d f : ID =" S88_SERVICE" >
< s e r v i c e : p r e s e n t s r d f : r e s o u r c e ="# S88_PROFILE " / >
< s e r v i c e : d e s c r i b e d B y r d f : r e s o u r c e ="#S88_PROCESS_MODEL" / >
< s e r v i c e : s u p p o r t s r d f : r e s o u r c e ="#S88_GROUNDING" / >
</ s e r v i c e : S e r v i c e >
A ontologia Profile especifica o serviço na perspectiva do cliente, descrevendo as entradas,
saídas, pré-condições e efeitos do serviço. Em termos gerais, esta ontologia especifica "o que
o serviço faz", fornecendo o tipo de informação necessária para a descoberta do serviço. A ontologia Process Model descreve a execução, o fluxo de dados e informações sobre a invocação
do serviço. Esta ontologia apresenta "como o serviço funciona", descrevendo o comportamento
do serviço quando este é executado. A ontologia Grounding informa como outras aplicações
podem interagir com o serviço, povendo, por exemplo, detalhes sobre protocolos de comunicação.
Em resumo, a ontologia Profile é usada para publicação e descoberta do serviço. Uma vez
que o serviço foi encontrado por um agente, as ontologias Process Model e Grounding, juntas,
fornecem as informações necessárias para que o agente possa fazer uso deste serviço.
A Figura 2 ilustra a estrutura da ontologia Service.
14
Figura 2: Esrtutura da ontologia Service (MARTIN et al., 2004)
2.2
DESCOBERTA SEMÂNTICA
A maior parte dos algoritmos utiliza as informações da ontologia Profile para realizar a descoberta de serviços Web semânticos. Dentre tais informações, as mais empregadas nesta tarefa
são: o Conjunto de Entrada, (Input) que determina quais os dados necessários para realização
do serviço; o Conjunto de Saída, (Output) que lista o retorno do serviço; as Pré-condições,
(Preconditions) que são os requisitos que devem ser satisfeitos para a realização de tal serviço,
e os Efeitos, (Effects) que são as consequências geradas pela invocação do serviço. As quatro
informações acima descritas formam o conjunto conhecido como IOPE (Input, Output, Preconditions e Effects).
Para a descoberta de serviços Web semânticos, autores em (PAOLUCCI et al., 2002) propuseram um algoritmo baseado na capacidade semântica dos termos analisados. O algoritmo
realiza a correspondencia entre os atributos do conjunto de entrada e do conjunto de saída da
requisição, com os atributos do conjunto de entrada e do conjunto de saída do serviço respectivamente. O grau de similaridade entre os termos é baseado no relacionamento que os mesmos
possuem numa determinada ontologia, isto é, de acordo com seus descendentes 1 e seus ascendentes2 .
1 Termos
2 Termos
que, na árvore taxonômica, estão abaixo do termo analisado
que, na árvore taxonômica, estão acima do termo analisado
15
Paolucci apresentou 4 graus de similaridade para os inputs e outputs. Abaixo estão relacionados os graus para o conjunto de saída:
• Exact - Dois outputs são Exact se são exatamente iguais ou se o output do serviço é
descendente direto do output da requisição.
• Plug-in - Dois outputs serão Plug-in se o output do serviço possuir como descendente o
output da requisição (exceto no caso de descendência direta).
• Subsumes - Dois outputs serão Subsumes se o output da requisição possuir como descendente o output do serviço (exceto a descendência direta).
• Fail - Dois outputs serão Fail se não há relacionamento semântico entre eles.
O grau de similaridade para o conjuto de entrada é calculado de maneira inversa para a
requisição e o serviço. Assim, dois inputs serão Plug-in se o input da requisição possuir como
descendente o input do serviço, serão Subsumes se o input do serviço possuir como descendente
o input da requisição e serão Exact se o input da requisição é descendente direto do input do
serviço.
Em complemento aos graus de similaridade definidos por Paolucci, foi proposto por (SAMPER et al., 2008) o Sibling.
Seu objetivo é determinar se dois inputs ou outputs têm o ascendente
direto comum, ou seja, são irmãos.
Assim, em ordem decrescente de similaridade tem-se:
Exact > Plug-in > Subsumes > Sibling > Fail
Considere uma ontologia cujo termo raiz é "COISA", que tem como filhos diretos os termos ESCOLA e VEÍCULO. O primeiro tem como filho direto o termo ENSINO MÉDIO e o
segundo tem como filhos diretos os termos CARRO e MOTO. O termo CARRO tem os termos
ESPORTE e LUXO como filhos diretos. ESPORTE por sua vez tem CORSA e FIESTA como
filhos diretos e LUXO tem LIMOUSINE como filho direto. Destacando o termo CARRO, as
relações dos outros termos com ele é: COISA e VEÍCULO são Subsumes. MOTO é Sibling.
ESCOLA e ENSINO MÉDIO são Fail. ESPORTE e LUXO são Exact. Finalmente, CORSA,
FIESTA e LIMOUSINE são Plugin.
A Figura 3 ilustra a ontologia descrita.
16
Figura 3: Representação gráfica de uma ontologia para o termo CARRO
Há hoje uma grande quantidade de pesquisas e trabalhos acadêmicos voltados ao descobrimento de serviços web semânticos que utilizam os filtros de Paolucci para a análise dos
conjuntos de entrada e saída. Porém, verifica-se que há poucos esforços no que diz respeito à
descoberta de serviços Web semânticos que utilizam as informações de pré-condições e efeitos
de maneira relevante. A análise do conjunto de pré-condições e efeitos no descobrimento de
serviços Web semânticos se faz relevante porque essas informações são essenciais para a correta
execução do serviço.
Para ilustrar a importância dessa análise, consideremos um serviço que tem com input um
filme e o número do cartão de crédito e como output o ingresso para a sessão de cinema. Para
este mesmo serviço, a pré-condição é que o comprador seja maior de 21 anos e o efeito é a
realização da compra pelo usuário.
Supondo que um adolescente deseje comprar um ingresso para tal filme. A descoberta
de serviços Web semânticos que considera apenas entrada e saída retorna esse serviço como
compatível com a requisição do adolescente. Porém, quando invocado, o serviço não será
executado corretamente, pois, ao constatar que a pessoa que requisita o serviço não tem idade
suficiente para comprar o ingresso, o serviço gerará erro. Por outro lado, uma descoberta que
faça a análise de pré-condições e efeitos, não retornará esse serviço como compatível pois, no
momento da descoberta, já consegue perceber que a pré-condição do serviço não foi atendida.
As versões atuais de OWL-S podem usar diversas linguagens para descrever as pré-condições
e efeitos. Atualmente, a linguagem mais usada é a SWRL (HORROCKS et al., 2004) e, por este
motivo, ela foi escolhida para o presente trabalho.
17
A SWRL é uma combinação das sublinguagens da OWL: OWL-DL e OWL Lite, com
a DataLog RuleML, sublinguagem do RML(Rule Markup Langage) (INITIATIVE, 2004). A
proposta da linguagem SWRL é estender os axiomas da OWL para incluir regras do tipo Horn
(W3C, 2004a), permitindo que essas regras sejam combinadas com uma base de conhecimento
OWL. As regras propostas são da forma de uma implicação entre um antecedente (corpo) e
um consequente (cabeça), ambos formados por um conjuntos (possivelmente vazio) de átomos.
Assim quando as condições especificadas no antecedente forem verdadeiras, as condições do
consequente devem ser verdadeiras (HORROCKS et al., 2004). Ou seja:
Antecedente ⇒ Consequente
Como exemplo, suponha uma regra para validar se um usuário tem cartão de crédito. Para
tal, é necessário verificar se existe um usuário com uma conta do tipo cartão.
Antecedente((Usuário) ∧ (ContaCartão)) ⇒ Consequente(temCartão)
Para simplficar, a regra acima pode ser descrita da seguinte maneira:
temCartão(Usuário, ContaCartão)
Em SWRL, a regra acima é dividida em Predicado: temCartão e Atributos: Usuário e
ContaCartão. A Listagem 2.2 exemplifica o código desta regra.
Listagem 2.2: Exemplo de uma condição em SWRL
< e x p r :SWRL−C o n d i t i o n r d f : ID ="_TEMCARTAO" >
< r d f s : l a b e l >temCartao ( _Usuario , _ContaCartao ) </ r d f s : l a b e l >
< e x p r : e x p r e s s i o n L a n g u a g e r d f : r e s o u r c e ="& e x p r ; #SWRL" / >
<expr : expressionObject >
< s w r l : AtomList >
<rdf : first >
<swrl : IndividualPropertyAtom >
<swrl : propertyPredicate rdf : resource=
" h t t p : / / 1 2 7 . 0 . 0 . 1 / o n t o l o g y / c r e d i t c a r d . owl # t e m C a r t a o " / >
< swrl : argument1 r d f : r e s o u r c e =
" h t t p : / / 1 2 7 . 0 . 0 . 1 / o n t o l o g y / m o d i f i e d _ b o o k s . owl # U s u a r i o " / >
< swrl : argument2 r d f : r e s o u r c e =
" h t t p : / / 1 2 7 . 0 . 0 . 1 / o n t o l o g y / Mid−l e v e l −o n t o l o g y . owl # C o n t a C a r t a o " / >
</ s w r l : I n d i v i d u a l P r o p e r t y A t o m >
</ r d f : f i r s t >
</ s w r l : AtomList >
</ e x p r : e x p r e s s i o n O b j e c t >
</ e x p r :SWRL−C o n d i t i o n >
18
Assim, através da SWRL é possível descrever as pré-condições e efeitos dos serviços Web
ampliando as possibilidades de descobertas mais precisas.
O próximo capítulo apresenta o algoritmo desenvolvido com o intuito de recuperar serviços
Web semânticos através da SWRL.
19
3
ALGORITMO PROPOSTO
O algoritmo proposto acrescenta a verificação de pré-condições e efeitos ao OWL-S Discovery (AMORIM, 2009). Os graus de similaridade propostos por Paolucci (PAOLUCCI et al.,
2002) para os conjuntos de entrada e saída são estendidos para os termos dos conjuntos de
pré-condições e efeitos respectivamente.
No presente trabalho, foi usada a OWL-S 1.2 (MARTIN et al., 2010) para descrição dos
serviços, pois esta versão tem suporte à SWRL (HORROCKS et al., 2004) como linguagem de
representação de pré-condições e efeitos. No apêndice A é exibido o exemplo de um serviço
escrito em OWL-S 1.2 cujas pré-condições e efeitos estão escritos em SWRL.
3.1
VISÃO GERAL
A correta execução do algoritmo é condicionada à existência de um diretório contendo os
serviços Web, descritos em OWL-S e a requisição do cliente, também descrito em OWL-S. A
Figura 4 apresenta uma visão geral do funcionamento do algoritmo.
20
Figura 4: Visão geral do funcionamento do OWL-S Discovery 2.0
Inicialmente, o algoritmo realiza um mapeamento das interfaces de cada um dos serviços,
armazenando as entradas, saídas, pré-condições e efeitos em listas encadeadas distintas. Em
seguida, realiza a análise das entradas e saídas retornando o grau de similaridade para esses
conjuntos. O próximo passo é a execução do algoritmo proposto, que faz a análise semântica
para cada termo dessas listas e retorna o grau de similaridade entre as pré-condições e efeitos
do serviços e da requisição.
3.2
FUNCIONAMENTO DO ALGORITMO DE ANÁLISE
SEMÂNTICA
Após a comparação das entradas/saídas feita pelo algoritmo já existente no OWL-S Discovery, o algoritmo proposto começa a comparação entre as pré-condições e efeitos do serviço
e da requisição. Como apresentado no Capítulo 2, uma regra em SWRL é composta por um
predicado e dois atributos. Para efetivar a comparação entre pré-condições e efeitos, o algoritmo
usa a análise semântica dos predicados e seus respectivos atributos cujos termos estão descritos
numa ontologia. A Figura 5 mostra detalhadamente o funcionamento do algoritmo proposto
para uma pré-condição.
21
Figura 5: Funcionamento do Algoritmo Semântico P/E
O algoritmo compara cada pré-condição do serviço com cada pré-condição da requisição.
Este comportamento se deve ao fato de que, se as pré-condições do serviço não forem atendidas,
os serviços podem gerar falhas de execução, o que não acontece com a requisição já que ela não
é executada. Então, o algoritmo parte de cada uma das pré-condições dos serviços em busca de
uma pré-condição similar na requisição. A análise dos efeitos é feita de maneira semelhante,
porém, a diferença consiste em, ao invés de comparar cada termo do serviço com o termo da
requisição, o algoritmo faz a comparação de maneira inversa, ou seja, cada termo da requisição é
comparado com cada termo do serviço. Isto porque o objetivo do algoritmo proposto é encontrar
um serviço que gere todos os efeitos desejados pelo cliente. Assim, o algoritmo parte dos efeitos
da requisição em busca de um efeito similar no serviço. O algoritmo de análise semântica está
descrito na Listagem 3.1.
Listagem 3.1: Algoritmo de Análise de termos semânticos
1
2
3
4
5
6
análiseSemantica ( Serviço , Requisição )
{
FOR( i t e m L i s t a P r e c o n d i c o e s S e r v i c o ; f i n a l L i s t a P r e c o n d i c o e s S e r v i c o ) DO {
FOR( i t e m L i s t a P r e c o n d i c o e s R e q u i s i ç ã o ; f i n a l L i s t a P r e c o n d i c o e s R e q u i s i c a o ) DO
resultadoPredicado=calculaGrauSimilaridade
( predicadoPrecondicaoServico , predicadoPrecondicaoRequisicao ) ;
calculoAtributos=calculaGrauSimilaridade
{
22
7
8
9
10
11
12
13
14
15
( atributosPrecondicaoServiço , atributoPrecondicaoRequisicao );
r e s u l t a d o A t r i b u t o s =melhorCombinacaoAtributos ( c a l c u l o A t r i b u t o s ) ;
}
r e s u l t a d o s P r e c o n d i c a o . add ( c a l c u l a G r a u S i m i l a r i d a d e P r e c o n d i c a o
( resultadoPredicado , resultadoAtributos ) ) ;
}
resultadoFinal = calculaGrauSimilaridadeFinal ( resultadosPrecondicao );
}
retorna resultadoFinal ;
O algoritmo exposto na Listagem 3.1 começa comparando cada pré-condição do serviço
com cada pré-condição da requisição, como está evidenciado nas linhas 1 e 2. Nas linhas 3 e
4, o algoritmo executa o método calculaGrauSimilaridade para o predicado da pré-condição do
serviço e o predicado da pré-condição da requisição.
Listagem 3.2: Método calculaGrauSimilaridade
1
2
3
4
5
6
7
8
9
10
11
12
13
calculaGrauSimilaridade ( argumentoRequisicao , argumentoServico )
{
i f ( f i l h o s D i r e t o s ( argumentoRequisicao , argumentoServico ) ) {
r e t u r n EXACT ;
e l s e i f ( f i l h o s I n d i r e t o s ( argumentoRequisicao , argumentoServico ) )
r e t u r n PLUGIN
e l s e i f ( f i l h o s I n d i r e t o s ( argumentoServico , argumentoRequisicao ) )
r e t u r n SUBSUMES
e l s e i f ( paisEmComum ( a r g u m e n t o R e q u i s i c a o , a r g u m e n t o S e r v i c o ) )
r e t u r n SIBLING
else
r e t u r n FAIL
}
}
O método calculaGrauSimilaridade, descrito na Listagem 3.2, compara os dois argumentos
recebidos e retorna o grau de similaridade entre eles. Para obter o grau de similaridade entre os
dois termos1 em análise, o algoritmo percorre a ontologia, verificando os ascendentes e descendentes dos parâmetros em questão, para definir o relacionamento entre eles. Então, o algoritmo
retorna qual o grau de similaridade entre os termos segundo os filtros descritos no capítulo 2.
Por exemplo, se os dois termos analisados forem iguais ou descendentes diretos o algoritmo
retorna Exact. O retorno do método calculaGrauSimilaridade é guardado na variavel resultadoPredicado que contém o grau de similaridade resultante da comparação dos dois predicados
entre si. Nas linhas 5 e 6 (Listagem 3.1) é chamado o mesmo método, desta vez para os atributos das pré-condições. Como cada condição tem 2 atributos, o resultado da execução deste
método retorna 4 graus de similaridade, resultantes da comparação entre si dos dois atributos da
condição do serviço com os dois atributos da condição da requisição, valor guardado na variável
1 No
caso das pré-condições e efeitos, os termos são os predicados ou os atributos.
23
calculoAtributos. A linha 7 (Listagem 3.1) apresenta a variável resultadoAtributos que recebe
o retorno da chamada ao método melhorCombinacaoAtributos.
Listagem 3.3: Método melhorCombinacaoAtributos
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
melhorCombinacaoAtributos ( c a l c u l o A t r i b u t o s ) {
i f ( Grau do p r i m e i r o i t e m da l i s t a de c a l c u l o A t r i b u t o >
Grau do s e g u n d o i t e m da l i s t a c a l c u l o A t r i b u t o {
a r g u m e n t o 1 = Grau do p r i m e i r o i t e m da l i s t a c a l c u l o A t r i b u t o
} else
a r g u m e n t o 1 = Grau do s e g u n d o i t e m da l i s t a c a l c u l o A t r i b u t o
i f ( Grau do t e r c e i r o i t e m da l i s t a de c a l c u l o A t r i b u t o >
Grau do q u a r t o i t e m da l i s t a de c a l c u l o A t r i b u t o {
a r g u m e n t o 2 = Grau do t e r c e i r o i t e m da l i s t a de c a l c u l o A t r i b u t o
}
else
a r g u m e n t o 2 = Grau do q u a r t o i t e m da l i s t a de c a l c u l o A t r i b u t o
A d i c i o n a ao r e s u l t a d o o a r g u m e n t o 1 e o a r g u m e n t o 2
return resultado ;
}
O método melhorCombinacaoAtributos está descrito na Listagem 3.3 e sua execução retorna, para os dois atributos do serviço, quais os dois atributos da requisição que têm o melhor
grau de compatibilidade2 em relação a ele, segundo a ordem dos filtros descritos no capítulo
anterior. O argumento do método melhorCombinacaoAtributos é uma lista contendo 4 elementos: as duas primeiras contém o grau de Similaridade entre o primeiro atributo do serviço e os
dois atributos da requisição, e as duas seguintes contém o grau de similaridade entre o segundo
atributo do serviço e os dois atributos da requisição. O método verifica qual o maior grau entre
os dois primeiros itens da lista e depois verifica o maior grau entre os dois últimos itens da
lista. Por exemplo, se o primeiro item da lista tem grau Subsumes e o segundo item da lista tem
grau Exact, o algoritmo retorna Exact. Assim, a variável resultadoAtributos guarda 2 graus de
similaridade, cada um referente a um atributo da condição do serviço. Por último, o algoritmo
apresentado na Listagem 3.1 executa o método calculaGrauSimilaridadeFinal, como pode ser
visto nas linhas 10 e 11, e atribui o resultado deste método à variável resultadoPrecondicao.
Listagem 3.4: Método calculaGrauSimilaridadePrecondicao
1
2
3
4
calculaGrauSimilaridadePrecondicao ( resultadoPredicado , resultadoAtributos ) {
r e t u r n ( Menor Grau de s i m i l a r i d a d e e n t r e
resultadoPredicado e resultadoAtributos )
}
O método calculaGrauSimilaridadePrecondicao descrito na Listagem 3.4 retorna o menor
2 Os
termos ’grau de similaridade’ e ’grau de compatibilidade’ serão usados de maneira intercambiável neste
documento.
24
grau de similaridade entre os argumentos recebidos. Ou seja, se a variável resultadoPredicado
tem valor Subsumes, e a variável resultadoAtributos tem valores Plug-in e Sibling, o método
retorna Plug-in. Este valor representa o grau de compatibilidade entre toda a pré-condição do
serviço e toda a pré-condição da requisição e é adicionado à lista resultadosPrecondicao. À essa
lista é adicionado o grau de similaridade da pré-condição do serviço com cada pré-condição da
requisição. Por fim, na linha 13 da Listagem 3.1, a variável resultadoFinal recebe o valor
retornado pelo método calculaGrauSimilaridadeFinal.
Listagem 3.5: Método calculaGrauSimilaridadeFinal
1
2
3
calculaGrauSimilaridadeFinal ( resultadosPrecondicao ) {
r e t u r n ( Maior g r a u de s i m i l a r i d a d e e n t r e o s r e s u l t a d o s da P r e c o n d i c a o )
}
O método calculaGrauSimilaridadeFinal descrito na Listagem 3.5 retorna o maior grau de
similaridade da lista recebida como parâmetro. O objetivo deste método é verificar todas as
comparações entre uma dada pré-condição do serviço e todas as pré-condições da requisição e
retornar qual delas é tem maior grau de similaridade, isto é, qual das pré-condições da requisição
é mais compatível com a pré-condição do serviço.
3.3
UM EXEMPLO
Para ilustrar um exemplo, suponha uma pré-condição do serviço e uma pré-condição da
requisição. Como uma condição em SWRL segue a estrutura Predicado(Atributo1,Atributo2),
temos:
• Serviço: PS(A1 S, A2 S), onde PS é o predicado da condição e A1 S e A2 S são os dois
atributos do Serviço.
• Requisição: PR(A1 R, A2 R), onde PR é o predicado da condição e A1 R e A2 R são os dois
atributos da Requisição.
De posse das pré-condições do serviço e da requisição, o algoritmo proposto utiliza o
método calculaGrauSimilaridade para obter o grau de similaridade dos termos das condições.
Os predicados e atributos são analisados separadamente, assim, não há comparação entre predicados e atributos, somente entre predicados entre si e atributos entre si. A execução deste
método gera um conjunto de tuplas composto por um termo do serviço, um termo da requisição
e o grau de similaridade (Gi) associado aos dois elementos anteriores, como descrito abaixo.
25
{(PR,PS,G1),(A1 S,A1 R,G2),(A1 S,A2 R,G3),(A2 S,A1 R,G4),(A2 S,A2 R,G5)}
Então, o algoritmo utiliza o método melhorCombinacaoAtributos para definir qual das 4
tuplas dos atributos contém o maior grau de similaridade para cada um dos atributos do serviço.
Suponha G2 > G3 e G4 > G5. Assim, o método melhorCombinacaoAtributos retorna as tuplas
(A1 S,A1 R,G2) e (A2 S,A1 R,G4). Após a execução deste método, o resultado obtido é o conjunto
abaixo:
{(PR,PS,G1),(A1 S,A1 R,G2),(A2 S,A1 R,G4)}
É importante observar que se permite que um atributo seja usado mais de uma vez (A1 R),
ou que um atributo não seja usado (A2 R), porque é mais eficiente usar mais de uma vez um
atributo que tem maior grau de similaridade em detrimento de um com menor grau.
Para obter o grau total de compatibilidade entre as condições, o algoritmo executa o método
calculaGrauSimilaridadeFinal, que recebe como parâmetro a tupla referente a análise do predicado da pré-condição do serviço e um conjunto com as duas tuplas referentes à análise dos
respectivos atributos. Este método retorna o menor grau de similaridade entre os presentes nos
parâmetros. Suponha G4 > G1 > G2. O método calculaGrauSimilaridadeFinal retornaria G2
como grau de similaridade final da pré-condição do serviço e da requisição.
Esse algoritmo é executado para todas as pré-condições do serviço com todas as précondições da requisição. O mesmo se aplica para os efeitos. Assim, ao final da execução, é
gerado um conjunto contendo o grau de similaridade para todas as pré-condições do serviço e
um outro conjunto contendo o grau de similaridade para todos os efeitos da requisição.
Seja Pi R uma pré-condição da requisição e E j R um efeito da requisição e Pl S uma précondição do serviço e Ek S um efeito do serviço, com i, j, l, k ≥ 0. Sejam Gh e Gf graus de
similaridade. Há compatibilidade entre o serviço e a requisição se ambas as condições descritas
abaixo são satisfeitas.
• ∀ Pl S : ∃ (Pl S, Pi R,Gh) | Gh 6= Fail
• ∀ E j R : ∃ (E j R, Ek S,Gf) | Gf 6= Fail
Ou seja: Para todas as pré-condições do serviço, existe ao menos uma tupla, cujo grau de
compatibilidade é diferente de Fail, e para todos os efeitos da requisição existe ao menos uma
tupla, cujo grau de similaridade é diferente de Fail.
26
Sendo assim, garante-se que todas as pré-condições necessárias para a correta execução do
serviço serão correspondidas e todos os efeitos desejados pelo usuário serão atendidos.
O próximo capítulo apresenta a análise e correlação do presente trabalho com os trabalhos
existentes.
27
4
ANÁLISE E CORRELAÇÃO COM
TRABALHOS EXISTENTES
A grande utilização dos serviços Web gerou estímulo no que diz respeito ao desenvolvimento de algoritmos de descoberta. Este capítulo apresenta os algoritmos estudados juntamente
com comentários sobre eles e, ao final, faz uma análise comparativa com o algoritmo proposto
no presente trabalho.
4.1
ANÁLISE DE ENTRADAS E SAÍDAS DOS SERVIÇOS
WEB
O algoritmo de descoberta proposto por (PAOLUCCI et al., 2002) foi um dos pioneiros no
descobrimento de serviços Web semânticos. Sua abordagem contribuiu para o desenvolvimento
de métodos que se baseiam na similaridade semântica entre informações extraídas da requisição
e do serviço. Sua abordagem fica a cargo de apenas analisar os parâmetros de entrada e saída
do serviço Web e retornar o grau de similaridade entre eles. Para tal, o algoritmo compara todas
as entradas do serviço com todas as entradas da requisição e todas as saídas da requisição com
todas as saídas do serviço. A proposta de Paolucci é usar a semântica para determinar o quanto
um serviço é "suficientemente similar"a uma dada requisição. O conceito de "suficientemente
similar"é exatamente o ponto atacado pelo trabalho de (PAOLUCCI et al., 2002). Para isso, é
proposto um algoritmo que realiza comparações mais flexíveis, isto é, comparações que reconhecem o grau de similaridade entre o termo da requisição e do serviço, ao invés de somente
determiná-las estritamente como iguais ou diferentes. Esta semelhança entre os termos de entrada e saída fica atrelada à distância entre esses termos na árvore taxonômica da ontologia de
domínio utilizada, seguindo o modelo proposto por Paolucci que está descrito no capítulo 2.
Outro algoritmo de descoberta baseado em entradas e saídas é o OWLS-Discovery (AMORIM,
2009). Este é um aplicativo que permite ao usuário a busca de serviços Web semânticos através
dos inputs e outputs. Baseado na OWL-S, o OWL-S Discovery tem o propósito de facilitar
28
buscas por serviços Web semânticos na Internet, além de prover interfaces para acoplamento de
outros módulos presentes no ciclo de vida de um serviço Web (AMORIM, 2009).
O OWL-S Discovery é composto de duas etapas na realização da descoberta dos serviços. A
primeira delas é a semântica funcional que tem como base os trabalhos de Paolucci (PAOLUCCI
et al., 2002) e (SAMPER et al., 2008), os quais utiliza filtros semânticos para efetuar correspondên-
cia entre os termos da requisição e dos serviços descritos em uma ontologia. A segunda
etapa baseia-se nos trabalhos de (LOPES; HAMMOUDI; ABDELOUAHAB, 2005), que utiliza um
dicionário de sinônimos para a classificação dos termos em questão, e nos trabalhos de (LOPES
et al.,
2006), que executa uma análise dos vizinhos estruturais de classes em uma ontologia.
A correta execução do aplicativo exige a existência de três entidades: um diretório com os
arquivos que descrevem os serviços Web, um meio de acesso às ontologias referenciadas e a
requisição do cliente. De posse desses três elementos, o algoritmo semântico funcional realiza
uma busca no diretório que contém os serviços e em cada um deles realiza um mapeamento das
interfaces, que resulta em duas listas encadeadas: uma contendo os termos de entrada e outra
contendo os termos de saída. Em seguida, cada lista é comparada com as entradas e saídas
da requisição. Esta comparação é feita aplicando os filtros de Paolucci. Ao final do processo,
tem-se um montante de todas as correspondências entre cada um dos parâmetros dos serviços
e cada um dos parâmetros da requisição fornecida pelo usuário. Neste ponto, é realizada uma
maximização dos resultados para obter a melhor combinação entre os parâmetros. Esse método
busca todos os relacionamentos entre a requisição e cada um dos serviços que foram analisados
e em seguida escolhe os melhores relacionamentos encontrados. A resposta final dessa etapa é
resultado de uma nova filtragem realizada no montante de correspondências. Essa filtragem tem
o objetivo de retornar o quão similar semanticamente são os parâmetros da requisição e de cada
serviço. Esse processo retorna o menor grau de similaridade entre todas as correspondências
dos parâmetros.
O algoritmo semântico descritivo é executado somente quando o semântico funcional retorna incompatibilidade semântica entre a requisição e o serviço. O semântico descritivo consiste em utilizar um operador Match(Ma,Mb), que toma duas classes de metamodelos como
entrada e retorna o relacionamento entre elas. A comparação entre duas classes é feita através
de nomes e estruturas. O algoritmo utiliza a função Ψ, que retorna 1 se as classes forem idênticas, 0 se as classes forem diferentes e 0.5 se as classes forem sinônimas. Uma melhoria que
propõe um cálculo de similaridade estrutural entre as classes e seus vizinhos também foi implementada.
Assim como o algoritmo semântico funcional, o semântico descritivo também utiliza um
29
diretório com os arquivos que descrevem os serviços Web, um meio de acesso às ontologias
mencionadas e a requisição do cliente. Em adição a isso, este algoritmo precisa de um dicionário
para o cálculo da similaridade. De modo análogo ao algoritmo funcional, são criadas duas listas
contendo os parâmetros de entrada e saída de cada um dos serviços. Então, o algoritmo analisa
uma classe da requisição do usuário e calcula a similaridade básica com uma classe de um dado
serviço. Em seguida, é calculado o valor da similaridade estrutural das duas classes. Assim, são
retornados ao usuário os valores das similaridades calculadas entre a requisição e cada serviço
presente no diretório.
4.2
ANÁLISE COMPLEMENTAR COM PRÉ-CONDIÇÕES
E EFEITOS
O SAM+ (BENER; OZADALI; ILHAN, 2009) é um algoritmo que utiliza análise de pré-condições
e efeitos escritos em SWRL para realizar a descoberta de serviços Web semânticos. Após a
análise dos inputs e outputs, o algoritmo lista todas as pré-condições e efeitos da requisição e
dos serviços e compara-as entre si. Esta comparação é feita usando 3 métodos que atribuem
pesos de maneira independe aos pares comparados e que depois são combinados para o cáculo
do peso final. São eles:
• Subsumption - Neste método, as pré-condições e os efeitos são comparados segundo os
conceitos dos argumentos, isto é, aplica-se o filtro de Paolucci nas classes dos argumentos
e obtém-se o grau de compatibilidade entre tais classes. Aos pares que se relacionam pelo
grau Exact é atribuído peso 1. Aos pares com grau Plug-in é atribuído peso 0.6 se o par
é de pré-condições e peso 0.4 se o par é de efeitos. Se o grau é Subsumes é atribuído
peso 0.4 se o par é de pré-condições e 0.6 se o par é de efeitos (ou seja, o inverso do
Plug-in). Por último, se o par tem grau Fail é atribuído peso 0. Este método retorna a
varável PesoSubsumption.
• Semantic Distance - Esse método calcula a distância semântica entre os dois termos
pareados dentro de uma ontologia. O peso desta etapa é calculado de acordo com a
quantidade de subclasses que envolvem os termos pela seguinte formula:
Peso(x,y) = 1/NumeroDeSubClasses(x)
Esse método retorna a variável PesoDistânciaSemântica.
30
• WordNet - Essa etapa calcula o peso usando o WordNet como base. WordNet é o dicionário de sinônimos e o objetivo de sua utilização é encontrar termos que não estão
na mesma ontologia mas referem-se à mesma entidade. Esse método atribui um peso no
intervalo [0,1] de acordo com a similaridade das classes. Esse método retorna a varável
PesoWordNet.
De posse das variáveis de retorno desses três métodos, O peso total do par de termos analisados é calculado segundo a fórmula:
PesoTotal = PesoSubsumption + (PesoDistânciaSemântica + PesoWordNet)
Então, o algoritmo gera um grafo bipartite o qual de um lado estão os parâmetros do serviço
e do outro os parâmetros da requisição e os arcos são ponderados de acordo com o PesoTotal
calculado acima. Note que, como todos os parâmetros da requisição são comparados com todos
os parâmetros do serviço, neste grafo, os nodos de um lado estão ligados a todos os nodos
do lado oposto. Se a quantidade de pré-condições da requisição e do serviço são diferentes,
o algoritmo já descarta o serviço em questão. O mesmo comportamento é observado para
os efeitos. Em seguida, é usado o algoritmo húngaro para obter a melhor combinação entre os
parâmetros do serviço e requisição gerando um conjunto de pares de parâmetros. Esse algoritmo
garante que todos os nodos de um lado estarão conectados a um, e somente um, nodo do lado
oposto, de modo que a soma dos pesos dos arcos é a maior possível. Aplicado a comparação de
parâmetros, isso quer dizer que estes serão pareados de maneira a obter a melhor combinação
possível entre os termos. O par que tem o menor peso dentre os pertencentes ao conjunto
gerado, é o resultado do matching entre a requisição e o dito serviço.
Um outro algoritmo realiza a descoberta dos serviços Web Semânticos utilizando os parâmetros de inputs/outputs e pré-condições/efeitos foi o proposto por (BELLUR; VADODARIA, 2008).
Esse algoritmo também se utiliza dos filtros de Paolucci para classificar o grau de compatibilidade dos parâmetros analisados. Após a análise dos inputs e outputs, é feita a análise das
pré-condições e efeitos (escritos em SWRL) que é divida em três partes:
• Parameter Compatibility - Nesta etapa, o algoritmo checa se os parâmetros são equivalentes. Isto é, usando os filtros de Paolucci para comparar os termos, para todos os
parâmetros da requisição, existe ao menos com relacionamento com um parâmetro do
serviço com grau de similaridade diferente de Fail.
• Condition Equivalence - Esta etapa refere-se à similaridade estrutural entre as duas
condições. Para tal, se a condição especificada na requisição contém todos os parâmetros
31
da condição do serviço e a relação entre os parâmetros da condição do serviço são retidos nos parâmetros da condição da requisição, então as condições podem ser marcadas
como equivalente. Em outras palavras, se a condição da requisição for denotada por R e
a condição do serviço por S, é preciso que R ⇒ S (relação A). Então, o espaço em que R
é verdadeiro é um subconjunto do espaço em que S é verdadeiro.
A Figura 6 ilustra a relação A:
Figura 6: Solução espacial para S e R (BELLUR; VADODARIA, 2008)
Isso é verdadeiro para a análise de pré-condições. Para os efeitos, a relação é inversa: S ⇒
R pois mapeia-se cada efeito da requisição com um efeito do serviço enquanto o mapeamento
da pré-condição é inversa. Note, que nesta etapa, o foco é somente a semelhança estrutural entre
as condições. Por isso, só será analisada a parte do lado direito da condição. A parte do lado
esquerdo é sempre associada à parte do lado direito e é analisada na próxima etapa.
A relação A também pode ser descrita como: (¬ R) ∨ (S) (relação B). Se a relação B
for verdadeira para todos os possíveis valores dos parâmetros de R e S, então a relação A é
satisfeita. Isso é equivalente a dizer que ¬((¬ R) ∨ (S)) (relação C) é falsa em todos os casos.
Se for possível provar que a relação C não é satisfazível para qualquer combinação de valores
de parâmetros usados em ambas as condições, pode-se provar que A é uma tautologia.
Nesta etapa tem-se um SAT (Satisfiability Problem). SAT é o problema de determinar, para
uma fórmula de cálculo proposicional, se há uma atribuição de valores verdadeiros para suas
variáveis de maneira que a fórmula seja verdadeira (DU; GU; PARDALOS, 1996). SAT é um problema NP-Completo (provado por Stephen Cook em 1971). Existem hoje alguns algoritmos de
alto desempenho capazes de reduzir a complexidade desses problemas. O SMT - Satisfiability
Modulo Theories (TINELLI, 2002) provê solução para esta instância de SAT. O algoritmo proposto usa, então, o STM para checar se a relação C é verdadeira ou não e assim, determinar a
equivalência entre as condições da requisição e do serviço.
• Condition Evaluation - Esta etapa associa valores aos diferentes parâmetros usados na
32
condição para checar se uma condição realmente satisfaz a outra. Após esta etapa, podese concluir se a condição do serviço satisfaz a condição da requisição. Por exemplo:
Condição da Requisição: Número de Quartos > 4 e aluguel > 5.000
Condição do Serviço 1: Número de Quartos > 4 e aluguel > 4.0000
Condição do Serviço 2: Número de Quartos > 5 e aluguel > 2.0000
Após a realização das duas etapas anteriores, pode-se concluir que a requisição é compatível
com ambos os serviços. Porém, somente depois da Condition Evaluation, pode-se ter certeza
que a requisição somente satisfaz todas as necessidades do serviço 1, mas não do serviço 2.
Depois de realizadas as etapas descritas acima, o algoritmo compara todas as pré-condições
do serviço e da requisição entre si e os classifica de acordo com os filtros de Paolucci. Em
seguida, assim como no SAM+ (BENER; OZADALI; ILHAN, 2009), é feito um grafo bipartite
onde os nodos de um lado são as pré-condições do serviço, os nodos do outro lado são as
pré-condições da requisição e os arcos que os unem são ponderados de acordo com o grau de
compatibilidade apontado pelo filtro de Paolucci. Em seguida é utilizado o algoritmo húngaro
para gerar o conjunto de pares com as melhores combinações possíveis entre os termos. Do
conjunto gerado, o par que tiver a o menor grau de compatibilidade é o resultado da comparação
entre a requisição e o serviço em questão no quesito pré-condição.
A comparação entre efeitos da requisição e do serviço é feita de maneira análoga.
4.3
ANÁLISE COMPARATIVA
Existem grandes diferenças entre os alogitmos estudados e o presente trabalho. O algoritmo
proposto utiliza os filtros propostos por (PAOLUCCI et al., 2002) na comparação dos termos do
conjunto IOPE. Porém adiciona mais uma análise a esses filtros que retorna o caso de dois
parâmetros terem a superclasse em comum, ou seja, o caso de dois parâmetros serem "irmãos",
conforme proposto por (SAMPER et al., 2008). Essa é uma vantagem desta ferramenta em relação
à abordagem proposta por Paolucci, uma vez que introduz mais um nível de similaridade a
termos que, pelo algoritmo de Paolucci, seriam incompatíveis.
Em relação ao OWL-S Discovery, o trabalho desenvolvido adiciona a análise de pré-condições
e efeitos à descoberta. Esta adição faz a descoberta ser mais precisa uma vez que analisa informações cruciais para a correta execução do serviço retornado.
Muitos aspectos diferem o algoritmo desenvolvido dos algoritmos de pré-condições e efeitos
33
estudados.O primeiro deles é que, tanto (BENER; OZADALI; ILHAN, 2009) quanto (BELLUR;
VADODARIA, 2008), ao analisar um serviço que tem uma quantidade diferente de pré-condições
e efeitos em relação à requisição, já descartam esse serviço como um serviço em potencial. O
algoritmo proposto neste trabalho prossegue com a análise dos termos mesmo quando a quantidade de pré-condições e efeitos entre o serviço e a requisição é diferente. Esse comportamento
é defendido porque se uma requisição fornece mais pré-condições do que o serviço necessita,
descarta-se esse excesso de informações e utiliza-se apenas as pré-condições necessárias para a
execução do serviço. Para os efeitos, se um serviço tem mais efeitos que os desejados, não há
restrição porque visa-se atender a todas as necessidades do usuário não do serviço. Em adição
a isso, se existe compatibilidade entre as condições, uma pré-condição ou um efeito pode ser
usado mais de uma vez para satisfazer uma pré-condição do serviço ou para corresponder um
efeito da requisição.
Outra diferença é que os algoritmos propostos por (BENER; OZADALI; ILHAN, 2009) e (BELLUR; VADODARIA,
2008) utilizam o algoritmo Húngaro para realizar a seleção dos pares de
maior peso. Esse algoritmo seleciona para cada nodo de um lado, um e somente um nodo do
outro lado. Com isso, cada parâmetro só pode ser utilizado uma vez. O algoritmo proposto neste
trabalho faz a reutilização de parâmetros. Caso algum dos atributos de uma condição tenha um
grau de similaridade maior com os outros dois atributos da condição que está sendo comparada,
este atributo é utilizado mais de uma vez. Esse método aumenta o grau de similaridade total entre as condições e, consequentemente, aumenta a compatibilidade entre a requisição e o
serviço.
Por fim, o algoritmo proposto neste trabalho utiliza ontologias também para os termos do
predicado da condição, enquanto os algoritmos propostos por (BENER; OZADALI; ILHAN, 2009) e
(BELLUR; VADODARIA, 2008) utilizam ontologias somente para os atributos. Isso contribui para
um melhor mapeamento da condição, uma vez que se utilizam inferências e análises semânticas
para todos os termos da condição e não somente os atributos.
Uma outra diferença pode ser destacada em relação ao algoritmo proposto por (BENER;
OZADALI; ILHAN,
2009). Este utiliza um conjunto de análises para gerar diferentes pesos aos
casamentos dos termos. O presente trabalho propõe apenas a classificação baseada em filtros
semânticos por defender que é mais eficiente a análise do grau de compatibilidade entre termos
baseado exclusivamente na similaridade semântica.
A tabela 1 compara os trabalhos de descoberta de serviços Web existentes e o presente
trabalho. A primeira coluna apresenta a característica analisada, e as seguintes mostram a presença (coluuna marcada com um X) ou ausência (coluna vazia) da característica nos trabalhos
34
de (PAOLUCCI et al., 2002), (AMORIM, 2009), (BENER; OZADALI; ILHAN, 2009), (BELLUR; VADODARIA,
2008) e o algoritmo proposto.
Característica
Paolluci
Amorim
Bener
Bellur
Uso do OWL-S 1.1
X
X
X
X
Uso do OWL-S 1.2
Algo. Proposto
X
Análise de
Pré-condições e Efeitos
X
X
X
Independência da
quantidade de parâmetros
X
Reutilização de
Pré-condições e Efeitos
X
Predicado Semântico
X
Tabela 1: Tabela comparativa dos algoritmos de descoberta de serviço Web
A tabela 1 mostra que, nem OWL-S Discovery 1.0 nem os trabalhos de (PAOLUCCI et al.,
2002) realisam a análise de pré-condições e efeitos. A tabela exibe também que, dos algorítmos estudados que analisam pré-condições e efeitos, somente o OWL-S Discovery realiza a
reutilização de pré-condições. O OWL-S Discovery 2.0 também é o único que analisa as précondições e efeitos independente das suas quantidades, o único que utiliza predicados semânticos e o único a utilizar a versão 2.0 do OWL-S.
O próximo Capítulo apresenta detalhes da arquitetura do OWL-S Discovery 2.0.
35
5
IMPLEMENTAÇÃO NO OWL-S
DISCOVERY 2.0
Esse capítulo apresenta o OWL-S Discovery 2.0, atualização realizada no aplicativo já existente OWLS-Discovery (AMORIM, 2009). As mudanças realizadas no aplicativo original têm
como objetivo inserir a descoberta de serviços Web semânticos com análise das pré-condições
e efeitos dos serviços.
5.1
ARQUITETURA
O OWLS-Discovery 2.0 foi desenvolvido em Java e, assim como o OWLS-Discovery,
fornece interfaces de comunicação com outros módulos que por ventura precisem se integrar ao
aplicativo. Foi mantido no aplicativo o alto grau de escalabilidade possibilitando a inclusão de
novos filtros e métodos de busca que venham a ser desenvolvidos e acoplados ao aplicativo no
futuro.
A estrutura da ferramenta está ilustrada na Figura 7, onde os módulos estão apresentados
em quadrados e as setas representam os fluxos de dados.
Figura 7: Arquitetura do OWL-S Discovery 2.0 (AMORIM, 2009)
O módulo DATA é uma parte da aplicação que encapsula toda a leitura dos arquivos OWL-
36
S dos serviços. Através de Bussiness Objects 1 , este módulo do software fornece ao módulo
ENGINE uma abstração de todos os arquivos necessários para a execução do cálculo da similaridade. Os dados trafegados para a ENGINE são: listas encadeadas com as interfaces de
entrada, saída, pré-condições e efeitos de cada um dos serviços disponíveis para a execução da
descoberta e os requisitos dos usuário encapsulados também em listas encadeadas.
De posse dos dados, o ENGINE os envia para o módulo MATCHER, que é o responsável
por efetuar o cálculo da similaridade entre os termos que lhes foram enviados. Em relação à
escalabilidade, uma interface denominada IMatcher foi criada no sistema a fim de forçar que
todas suas instâncias tenham um comportamento padronizado tanto na entrada quanto na saída
dos dados.
A chamada dos filtros foi encapsulada em um só método e a implementação de cada filtro foi feita via métodos privados que têm a mesma interface de entrada e saída. Para uma
possível inclusão de filtros, basta implementá-lo na referida classe, obedecendo as interfaces já
utilizadas, e efetuar sua chamada no método que os trata.
Uma vez que os dados já foram tratados pelo MATCHER, os resultados, os quais mais uma
vez são encapsulados em Bussiness Objects, são transferidos novamente para a ENGINE. Assim
como existe uma interface para o MATCHER, existe também uma interface para a ENGINE,
seguindo os mesmos mecanismos do MATCHER. A ENGINE tem o papel de classificar, ou
seja, filtrar os resultados de acordo com os parâmetros solicitados pelo usuário do sistema. Por
fim, com a classificação dos dados realizada pela ENGINE, os mesmos são então apresentados
ao usuário final e encapsulados em outros Bussiness Objects para que outras aplicações possam,
por ventura, utilizá-los em sua computação (AMORIM, 2009).
5.2
FERRAMENTAS UTILIZADAS
No desenvolvimento do OWL-S Discovery 2.0, foi necessária a utilização de algumas ferramentas para a leitura e análise dos documentos descritos em OWL-S e OWL. Para tal, foi
utilizado o Jena 2.6.3 (JENA, 2000), o PELLET 2.2.2 (CLARKPARSIA, 2010) e o OWL-S API
3.1-SNAPSHOT (OSIRISNEXT, 2010), que é a última versão disponível desta API.
O Jena é um framework desenvolvido em linguagem Java para desenvolvimento de aplicações que se utilizem do paradigma de Web semântica. Ele provê um ambiente para manipulação de RDF, RDFS, SPARQL e OWL. Neste projeto, foi utilizada a API para manipulação
de OWL. Outra utilidade da mesma API foram os métodos de varredura de ontologias, o que
1 Classes
responsáveis pelo encapsulamento de informações referentes a um objeto do sistema
37
facilitou a busca de forma hierárquica de uma classe.
O Jena também inclui o motor de inferência Pellet. Um motor de inferência é um software
capaz de realizar inferências lógicas referentes a um conjunto de axiomas presente em uma
ontologia. O Pellet foi desenvolvido em Java, com código aberto, e foi utilizado na manipulação
das ontologias.
O sistema desenvolvido também faz uso da OWL-S API 3.1-SNAPSHOT. Esta API provê
suporte para criar, ler, escrever e executar arquivos OWL-S. Para descrição de condições (précondições e efeitos), a API suporta as linguagens SPARQL e SWRL. A OWL-S API 3.1SNAPSHOT transforma os elementos do documento OWL-S em objetos Java e foi utilizada
na leitura dos descritores dos arquivos OWL-S para obtenção das informações relativas aos
conjuntos de entrada, saída, pré-condições e efeitos.
5.3
EXEMPLO DE UTILIZAÇÃO
Esta seção exemplifica uma maneira de utilizar a ferramenta desenvolvida. Uma condição
necessária para a correta utilização da mesma é que todos os serviços, a requisição e as ontologias estejam acessíveis à ferramenta. Com o objetivo de se alcançar as ontologias, o uso de um
servidor Web tornou-se necessário uma vez que as ontologias fazem referências entre si através
de URLs.
A figura destaca os campos obrigatórios para a descoberta de serviços Web considerando a
análise de pré-condições e efeitos.
38
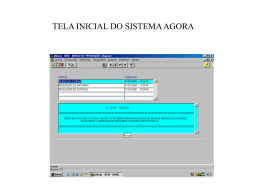
Figura 8: Campos obrigatórios para descoberta de serviços Web utilizando a análise de précondições e efeitos
Na Figura 8, o primeiro campo Requisição é um arquivo em formato OWL-S que descreve
o serviço Web requerido pelo cliente, podendo este caminho ser local ou uma URL. O campo
seguinte indica um diretório contendo todos os serviços disponíveis para a busca. Assim como
a requisição do usuário, uma URL pode ser passada informando o local onde se encontra o
repositório. Então, o usuário deve selecionar quais os filtros que ele deseja que sejam apresentados para as pré-condições e efeitos. O usuário deve selecionar também quais os filtros que ele
deseja que sejam realizados para as entradas e saídas. Por fim, o usuário deve clicar no botão
BUSCAR para dar início a descoberta.
Caso o usuário não informe todos os campos acima mencionados, uma mensagem de erro
é apresentada solicitando que o mesmo informe os campos obrigatórios para a pesquisa.
39
Figura 9: Campos selecionados e resultado obtido
A Figura 9 mostra um exemplo, onde foi utilizada a requisição "r2.owls"e o diretório de
serviços "transp". Para as pré-condições e efeitos foram selecionados os filtros EXACT e FAIL
e para as entradas e saídas os filtros SUBSUMES e SIBLING. No campo "Saída" é possível
visualizar o resultado da busca que retorna o nome da requisição e os serviços encontrados
com seu respectivo grau de similaridade de acordo com os filtros selecionados. Neste exemplo,
para a requisição em questão, a ferramenta retornou para o serviço "s88"o grau EXACT para as
pré-condições e efeitos e SIBLING para as entradas e saídas.
40
Figura 10: Campos Limpar e Exportar
A figura 10 destaca os botões Limpar e Exportar. O botão Limpar é utilizado para apagar as
informações exibidas no campo Saída, já o botão Exportar, copia o conteúdo do campo Saída
para um arquivo .txt e salva o mesmo na máquina em que está sendo executada a aplicação.
Assim, o OWL-S Discovery 2.0 realiza a descoberta de serviços Web semânticos analisando
os conjuntos de entrada, saída, pré-condições e efeitos.
41
6
ANÁLISE E VALIDAÇÃO
Apesar do crescimento acelerado do uso de serviços Web semânticos, existem poucos esforços no que diz respeito a testes experimentais e comparativos entre os métodos de descoberta
destes serviços. Uma coleção pública de testes acessível atualmente chama-se OWL-S Test
Collection 2, mas a mesma não inclui pré-condições e efeitos. Autores em (BENER; OZADALI;
ILHAN,
2009) modificaram esta coleção acrescentando pré-condições e efeitos descritos em
SWRL. Além destas alterações, para validar o trabalho proposto, foram necessárias outras modificações para a atualização dos arquivos OWL-S e para adequação dos mesmos aos padrões e
técnicas utilizadas no presente projeto.
A primeira alteração realizada diz respeito à versão da OWL-S. Os arquivos no Test Collection 2 estavam descritos em OWL-S 1.1 e foram alterados para OWL-S 1.2. O formato
de descrição do efeito também sofreu alteração para que este fosse apresentado como uma
condição SWRL. A maneira de descrever os predicados das pré-condições e efeitos também foi
alterada para que estes apresentassem a ontologia a qual este conceito está inserido, juntamente
com suas relações. A fim de testar os filtros semânticos também nos predicados, alguns deles
foram mudados para conterem outros termos, por exemplo, um predicado temCartaoCredito foi
alterado para temCartaoDebito.
6.1
PRECISÃO
O teste do algoritmo utilizou 10 requisições e um repositório contendo 100 serviços. A
Tabela 2 contém um quadro comparativo dos serviços retornados entre algoritmos que utilizam
somente entrada e saída e o algoritmo proposto. A coluna da esquerda apresenta cada uma
das requisições (r1...r10) e as colunas seguintes mostram a quantidade de serviços retornados
para cada requisição usando os algoritmos de Paolucci, o OWL-S Discovery 1.0 e o OWL-S
Discovery 2.0 respectivamente.
42
Requisição
Paolucci
OWL-S Discovery 1.0
OWL-S Discovery 2.0
r1
14
47
47
r2
15
16
12
r3
15
16
16
r4
45
51
51
r5
3
25
25
r6
15
16
13
r7
33
47
37
r8
42
47
37
r9
3
27
23
r10
15
16
14
Tabela 2: Tabela comparativa de retorno da execução para 10 requisições e 100 serviços dos
algoritmos de Paolucci e as versões 1.0 e 2.0 desta ferramenta
A diferença entre os serviços retornados pelo algoritmo de Paolucci e o OWL-S Discovery
1.0 deve-se ao fato que Paolucci não usa o filtros Sibling. Por exemplo, para a requisição r2, o
OWL-S Discovery 1.0 retorna 16 serviços enquanto o algoritmo proposto por Paolucci retorna
15. O OWL.S Discovery retorna um serviço a mais que o algoritmo de Paolucci. Este serviço,
quando analisado pelo OWL-S Discovery 1.0, tem grau Sibling, mas, analisado pelo algoritmo
de Paolucci, tem grau Fail porque este não utiliza o Sibling. Assim. o OWL-S Discovery 1.0
retorna, além de todos os serviços retornados pelo algoritmo de Paolucci, os serviços que têm
Sibling como grau de similaridade.
A diferença entre a quantidade de serviços retornados pelo OWL-S Discovery 1.0 e o OWLS Discovery 2.0 deve-se à análise de pré-condições e efeitos. Como a análise de pré-condições
e efeitos é feita somente após a análise de entradas e saída e se, somente se, esta análise retornar
um grau de similaridade diferente de Fail, a quantidade de serviços retornados pelo OWL-S
Discovery 1.0 será sempre maior ou igual à retornada pelo OWL-S Discovery 2.0. Os serviços
que foram retornados pela versão 1.0 desta ferramenta mas não foram retornados pela versão
2.0, uma vez invocados, resultarão em um dos dois problemas seguintes:
• O serviço não será corretamente executado pois suas pré-condições não foram totalmente
correspondidas.
• O serviço não gerará os efeitos requisitados ou gerará os efeitos indesejados pela requisição.
43
O OWL-S Discovery 2.0 evita a ocorrência dos dois problemas citados acima uma vez que
não retorna como compatíveis serviços cujas pré-condições e efeitos não são similares às précondições e efeitos da requisição.
Para fazer um estudo comparativo com o algoritmo de (BENER; OZADALI; ILHAN, 2009)
foram criados 2 estudos de caso:
• Primeiro: Quando há reutilização de pré-condições e efeitos.
• Segundo: Quando os predicados do serviço e da requisição não são exatamente iguais.
Para exemplificar o primeiro caso, suponha um serviço e uma requisição com suas respectivas pré-condições:
• Serviço: temConta(Usuário, Número) e temContaPoupança(Usuário, Número)
• Requisição: temConta(Usuário, Número) e temEndereço(Usuário, CEP)
Suponha também uma ontologia que contém temContaPoupança e temContaCorrente como
descendentes de temConta, assim como mostra a Figura 11.
Figura 11: Ontologia para o predicado temConta
O algoritmo proposto por (BENER; OZADALI; ILHAN, 2009) faria o casamento das précondições temConta(Usuário, Número) do serviço e da requisição, porém, ao tentar encontrar
uma pré-condição na requisição compatível com a pré-condição temContaPoupança(Usuário,
Número) do serviço, este algoritmo retornaria este serviço como imcompatível pois a précondição restante na requisição, temEndereço (Usuário, CEP), não é similar a temContaPoupança
(Usuário, Número). Diferente do comportamento descrito acima, o OWL-S Discovery 2.0 faz
uso da técnica de reutilização de pré-condições. Sendo assim, o OWL-S Discovery 2.0 faria o
casamento das pré-condições temConta(Usuário, Número) do serviço e da requsição e, ao buscar uma condição similar a temContaPoupança(Usuário, Número), este retornaria novamente a
44
pré-condição temConta(Usuário, Número), uma vez temContaPoupança e temConta são similares segundo a ontologia suposta. Esse caso demonstra a vantagem da abordagem do OWL-S
Discovery 2.0 em relação à proposta por (BENER; OZADALI; ILHAN, 2009), que eliminaria este
serviço como resultado quando, na verdade, ele é similar ao requisitado.
Finalmente, para o estudo da última situação, suponha que a pré-condição de um serviço
seja temContaCorrente(Usuário,Conta) e a pré-condição da requisição seja temContaPoupança
(Usuário,Conta). Suponha ainda a existência da ontologia do predicado temConta assim como
apresentado na figura 9.
O algoritmo proposto por (BENER; OZADALI; ILHAN, 2009) definiria o grau de similaridade
entre as pré-condições como Fail porque este não faz uso de predicados descritos em ontologias.
Assim, ao concluir que temContaCorrente(Usuário,Conta) e temContaPoupança(Usuário,Conta)
são diferentes, o algoritmo já descarta este serviço como um serviço em potencial. O OWL-S
Discovery 2.0 tem um comportamento diferente em relação ao descrito anteriormente. Como
este utiliza predicados descritos em uma ontologia, ao pesquisar os dois predicados temContaPoupança e temContaCorrente na ontologia correspondente, concluiria que eles tem um grau
de similaridade, neste caso o Sibling, e retornaria esse serviço como compatível com a requisição.
Este comportamento do OWL-S Discovery 2.0 demonstra um ganho em relação ao algoritmo proposto por (BENER; OZADALI; ILHAN, 2009) porque traz mais resultados compatíveis
com a requisição evitando que sejam eliminados serviços potencialmente úteis ao usuário.
6.2
COMPLEXIDADE
Como mencionado anteriormente, a análise de pré-condições e efeitos utiliza filtros semânticos com a finalidade de classificar a similaridade entre os termos presentes nas condições. Para
cada pré-condição do serviço, o algoritmo realiza uma comparação com cada pré-condição da
requisição, e para cada efeito da requisição, o algoritmo realiza a comparação com cada efeito
do serviço. Na Listagem 6.1, está descrito o algoritmo que realiza esta tarefa.
Listagem 6.1: Algoritmo de análise das pré-condições
1
2
3
4
5
6
7
p u b l i c A r r a y L i s t < S i m i l a r i t y D e g r e e > m a t c h e r P r e C o n d i t i o n s ( S e r v i c e s e r v i c e , Query r e q u e s t ) {
foreach ( service . getPreconditionList ( ) ) {
foreach ( request . getPreconditionList ( ) ) {
predicateMatch = caculateDegreeConditions
( servicePredicate , requestPredicate );
atributeMatch = caculateDegreeConditions
( serviceAtributes , requestAtributes );
45
8
9
10
11
12
13
14
atributeResult =
bestAtributesMatch ( atributeMatch );
}
m a t c h R e s u l t . add ( b e s t C o n d i t i o n s M a t c h ( c o n d i t i o n R e s u l t ) ) ;
}
r e s u l t P r e c o n d i t i o n s = calculateFinalDegree ( matchResult ) ;
return r e s u l t P r e c o n d i t i o n s ;
}
Para o processamento de cada instrução, tem-se um custo de Tx ≥ 0, onde x é a linha
da instrução. O processamento da linha 2 ocorrerá T2 (n+1) vezes, onde n é a quantidade de
pré-condições do serviço. O processamento da linha 3 ocorrerá T3 (m+1) vezes onde m é a
quantidade de pré-condições da requisição. O melhor caso seria um serviço sem pré-condições
e uma requisição sem efeitos, ou seja, n = m = 0. Para calcular o pior caso, considere m =
c*n, onde c é uma constante. A execução das linhas de 4 a 11, envolve a busca de dois termos
em uma ontologia. Para tal será fixado um valor g que corresponderá ao custo envolvido nesta
computação. Assim, tem-se a expressão:
T2 (n+1)*T3 (c*n+1)*g
Seja K uma constante de valor maior ou igual a T2 e T3 .
T2 (n+1)*T3 (c*n+1)*g ≤ K(n+1)*K(cn+1)*g
= K 2 (n+1)*(c*n+1)*g = K 2 g(n*c*n + n + c*n +1)
= K 2 g(c*n2 + n + c*n +1) = K 2 g*c*n2 + K 2 g*n + K 2 g*c*n + K 2 g
O termo de maior grau do polinômio é K 2 g*c*n2 . Desta forma, baseado em (CORMEN et
al., 2001), conclui-se que, independente da complexidade de g, a computação do algoritmo é da
ordem quadrada. Ou seja, no pior caso, a complexidade envolvida neste algoritmo é O(n2 ). O
algorítmo de análise dos efeitos funciona de maneira análoga ao de pré-condições, então, sua
complexidade também é O(n2 ). Por sua vez, o algorítmo que analisa entradas se saídas, segundo
afirmado por (AMORIM, 2009), tem complexidade O(n2 ).
Como descrito no capítulo 3, o fluxo do algoritmo segue a seguinte ordem:
Análise de entradas (O(n2 )) → Análise de saídas (O(n2 )) → Análise de pré-condições (O(n2 ))
→ Análise de Efeitos (O(n2 )).
Desta forma, a complexidade total do algorítmo utilizado é:
O(n2 ) + O(n2 ) + O(n2 ) + O(n2 ) = O(n2 )
46
6.3
TEMPO DE EXECUÇÃO
Para testar o tempo de execução do algoritmo, foi realizado um experimento com 20 requisições e um repositório com 100 serviços. As 20 requisições utilizadas continham os mesmos
conjuntos de entrada e saída. Isso foi feito para garantir que a diferença entre as pré-condições
e efeitos fosse o único fator variável entre as requisições, e assim, calcular a influência disso no
tempo de execução do algoritmo.
O experimento consistiu em, para cada uma das 20 requisições, foi calculado duas vezes o
tempo de execução, em segundos, quando realizada somente a análise de entradas e saídas. Em
seguida foi calculada a médias desses dois tempos de execução. Para cada uma das 20 requisições, foi calculado, também duas vezes, o tempo de execução do algoritmo quando analisadas
além das entradas e saídas, as pré-condições e efeitos. Dos tempos obtidos, foi calculado o valor
médio. De posse da média do tempo de execução dos algoritmos, foi calculada a proporção do
aumento do tempo de execução da versão 2.0 em relação à versão anterior. A Tabela 3 apresenta
os resultados obtidos no experimento.
47
Requisição
IO(s)
IOPE(s)
Proporção IO/IOPE
Pré-Condições
Efeitos
Total P/E
r1
1,82
1,95
1,07
0
0
0
r2
2,39
2,39
1,00
0
0
0
r3
2,38
40,07
16,86
1
0
1
r4
2,49
40,73
16,39
1
0
1
r7
1,84
14,61
7,95
0
1
1
r8
2,40
19,36
8,08
0
1
1
r5
1,96
45,13
23,04
2
0
2
r6
1,81
44,72
24,66
2
0
2
r9
1,82
44,55
24,47
1
1
2
r10
1,98
32,85
16,56
1
1
2
r13
1,77
24,64
13,95
0
2
2
r14
1,91
23,40
12,23
0
2
2
r11
1,73
62,02
35,92
2
1
3
r12
1,73
63,75
36,93
2
1
3
r15
2,09
73,31
35,11
1
2
3
r16
2,63
67,44
25,63
1
2
3
r17
1,90
73,59
38,78
2
2
4
r18
1,96
78,38
39,98
2
2
4
r19
1,49
75,84
50,85
2
2
4
r20
1,66
81,68
49,08
2
2
4
Tabela 3: Tabela comparativa de tempo de execução somente do algoritmo de análise de entrada
e saída e do algoritmo de entrada, saída, pré-condições e efeitos.
A primeira coluna, da Tabela 3, lista as 20 requisições utilizadas. Nas colunas 2 e 3, a Tabela
exibe a média do tempo de execução quando analisados somente os inputs e outputs e quando
analisados todo o conjunto IOPE, isto é, todo conjunto de entradas, saídas, pré-condições e
efeitos. A coluna 4 apresenta a proporção do tempo de execução entre os dois algoritmos. As
colunas 5 e 6 mostram, respectivamente, a quantidade de pré-condições e efeitos existentes
na requisição. Finalmente, a última coluna contém a soma da quantidade de pré-condições à
quantidade de efeitos.
Para uma análise mais detalhada, a Tabela 4 destaca as linhas requisições r1 e r2 da Tabela
3.
48
Requisição
IO(s)
IOPE(s)
IO/IOPE
Pré-Condições
Efeitos
Total P/E
r1
1,82
1,95
1,07
0
0
0
r2
2,39
2,39
1,00
0
0
0
Tabela 4: Tabela comparativa de tempo de execução somente do algoritmo de análise de entrada
e saída e do algoritmo de entrada, saída, pré-condições e efeitos, para as requisições r1 e r2.
Na Tabela 4 pode-se observar que, para requisições r1 e r2, que não têm pré-condições e
efeitos, o tempo de execução do algoritmo quando analisadas somente as entradas e saídas foi
praticamente igual ao tempo de quando analisadas também as pré-condições e efeitos. Assim,
pode-se concluir que a verificação da existência de pré-condições e efeitos na requisição e no
serviço não consome tempo relevante.
A Tabela 5 destaca as requisições r3, r4, r7 e r8 da Tabela 3.
Requisição
IO(s)
IOPE(s)
Proporção IO/IOPE
Pré-Condições
Efeitos
Total P/E
r3
2,38
40,07
16,86
1
0
1
r4
2,49
40,73
16,39
1
0
1
r7
1,84
14,61
7,95
0
1
1
r8
2,40
19,36
8,08
0
1
1
Tabela 5: Tabela comparativa de tempo de execução somente do algoritmo de análise de entrada
e saída e do algoritmo de entrada, saída, pré-condições e efeitos, para as requisições r3, r4, r7 e
r8.
A Tabela 5 mostra que o tempo de execução para as requisições r3 e r4 é consideravelmente
maior em relação às requisições r7 e r8 apesar das quatro requisições conterem a mesma quantidade total de pré-condições e efeitos. A diferença entre as requisições é que r3 e r4 têm uma
pré-condição e nenhum efeito, e as requisições r7 e r8 têm um efeito e nenhuma pré-condição.
A diferença do tempo computacional dessas requisições pode ser explicado pelo fluxo do algorítmo de análise de pré-condições e efeitos. Suponha um serviço s1 que tem uma pré-condição
e um efeito. Para realizar a comparação entre r3 e s1, primeiramente o algoritmo analisa se r3
tem pré-condições. Como o resultado é positivo, é realizada a análise das pré-condições entre
r3 e s1. Em seguida, o algoritmo verifica se r3 tem efeitos, obetendo resultado negativo. Então,
o algoritmo para a execução. O mesmo se aplica à requisição r4. Agora suponha a comparação
entre r7 e s1. Primeiramente o algoritmo verifica se r7 tem pré-condições. Como o resultado
é negativo, o algoritmo para a execução. O mesmo acontece com a requisição r8. Assim, para
49
as requisições r3 e r4, o algoritmo realiza a comparação das pré-condições, mas nao realiza a
comparação dos efeitos. Para requisições r7 e r8 o algoritmo não executa nem a comparação
de pré-condições nem a comparação dos efeitos. Isso explica porque o tempo de execução do
algoritmo para requisições que têm pré-condições é maior que o tempo para requisições que
não têm.
A Tabela 6 relaciona a quantidade total de pré-condições e efeitos da requisição e tempo
médio de execução.
Quantidade de P/E
Tempo Médio de Execução(s)
0
1,03
1
12,32
2
19,15
3
33,40
4
47,67
Tabela 6: Tabela relacional entre a quantidade total de pré-condições e efeitos e o tempo médio
de execução
Do exame da Tabela 6 pode-se observar que, com o aumento da quantidade de pré-condições
e efeitos, o tempo médio de execução também aumenta. Ou seja, o tempo de execução é proporcional à quantidade de pré-condições e efeitos. A Figura 12 mostra o gráfico que descreve o
comportamento do tempo de execução com a variação da quantidade de pré-condições e efeitos.
Figura 12: Gráfico Quantidade de Pré-condições e Efeitos X Tempo de Execução
50
7
CONCLUSÃO E TRABALHOS
FUTUROS
A grande utilização de serviços Web nas diversas áreas da tecnologia exige a necessidade
de mais estudos e pesquisas relacionadas a esse tema. A descoberta automática dos serviços
Web é uma etapa relevante na execução desses serviços, uma vez que um serviço não poderá
ser executado sem antes ser descoberto. Por isso, o desenvolvimento de métodos eficientes
para descoberta de serviços Web é uma atividade indispensável no contexto da utilização dos
serviços Web.
Uma técnica eficiente de descoberta de serviços Web é uma técnica que demanda baixo
tempo computacional e gera resultados eficazes, ou seja, que retorna serviços relevantes para a
requisição do usuário. O presente trabalho propôs um algoritmo, que faz uma análise semântica
dos conjuntos de pré-condições e efeitos dos serviços Web semânticos, visando a melhoria
do método de descoberta já realizado pela ferramenta OWL-S Discovery. Como fruto deste
trabalho, foi gerada uma nova versão da ferramenta chamada de OWL-S Discovery 2.0.
O presente trabalho incorporou a análise de pré-condições e efeitos ao OWL-S Discovery
aumentando a precisão dos serviços retornados, além de desenvolver uma análise de predicados
presentes em uma ontologia e realizar uma abordagem que reutiliza as pré-condições e efeitos na
descoberta de serviços Web. Em adição, este trabalho deixa como legado uma ferramenta cuja
arquitetura permite acoplamento de novos métodos de descoberta de serviços Web semânticos.
Como trabalho futuro, diversas possibilidades podem ser destacadas:
• Incorporação de mecanismos para realizar composição de serviços Web ao algoritmo de
descoberta.
• Desenvolvimento de métodos de análise de termos presentes em ontologias diferentes.
• Incorporação do mecanismo proposto por (PRAZERES; TEIXEIRA; PIMENTEL, 2009) ao
OWL-S Discovery 2.0 para a composição de serviços.
51
• Incorporação do algoritmo proposto ao OWL-S Composer (FONSECA, 2008).
52
APÊNDICE A -- SERVIÇO WEB
Alistagem A.1 apresenta o código de um serviço Web.
Listagem A.1: Serviço Web semântico escrito em OWL-S 2.0 com pré-condições e efeitos
escritos em SWRL
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
[...]
<owl : O b j e c t P r o p e r t y r d f : ID= "DELIVERY" >
< r d f s : comment > d e l i v e r y < / r d f s : comment >
< r d f s : domain r d f : r e s o u r c e = " # A i r T r a n s p o r t a t i o n " / >
< r d f s : range r d f : r e s o u r c e ="# Address " / >
</ owl : O b j e c t P r o p e r t y >
<owl : O b j e c t P r o p e r t y r d f : ID= "HASACCOUNT" >
< r d f s : comment > h a s A c c o u n t < / r d f s : comment >
< r d f s : domain r d f : r e s o u r c e = " # U s e r " / >
< r d f s : range r d f : r e s o u r c e ="# J o u r n a l s " / >
</ owl : O b j e c t P r o p e r t y >
< s e r v i c e : S e r v i c e r d f : ID= " S88_SERVICE " >
< s e r v i c e : p r e s e n t s r d f : r e s o u r c e = " #S88_PROFILE " / >
< s e r v i c e : d e s c r i b e d B y r d f : r e s o u r c e = " #S88_PROCESS_MODEL" / >
< s e r v i c e : s u p p o r t s r d f : r e s o u r c e = " #S88_GROUNDING" / >
</ s e r v i c e : S e r v i c e >
< p r o f i l e : P r o f i l e r d f : ID= " S88_PROFILE " >
< s e r v i c e : i s P r e s e n t e d B y r d f : r e s o u r c e = " #S88_SERVICE " / >
< profile : hasInput
< p r o f i l e : hasOutput
r d f : r e s o u r c e = " #_COMIC" / >
r d f : r e s o u r c e = " #_BOOK" / >
< p r o f i l e : h a s P r e c o n d i t i o n r d f : r e s o u r c e = " #_HASACCOUNT" / >
< p r o f i l e : h a s R e s u l t r d f : r e s o u r c e = " #_DELIVERY" / >
< p r o f i l e : h a s _ p r o c e s s r d f : r e s o u r c e = " S88_PROCESS " / > < / p r o f i l e : P r o f i l e >
< p r o c e s s : P r o c e s s M o d e l r d f : ID= "S88_PROCESS_MODEL" >
< s e r v i c e : d e s c r i b e s r d f : r e s o u r c e = " #S88_SERVICE " / >
< p r o c e s s : h a s P r o c e s s r d f : r e s o u r c e = " #S88_PROCESS " / >
</ p r o c e s s : P r o c e s s M o d e l >
< p r o c e s s : A t o m i c P r o c e s s r d f : ID= " S88_PROCESS " >
<process : hasInput
<process : hasOutput
r d f : r e s o u r c e = " #_COMIC" / >
r d f : r e s o u r c e = " #_BOOK" / >
< p r o c e s s : h a s P r e c o n d i t i o n r d f : r e s o u r c e = " #_HASACCOUNT" / >
< p r o c e s s : h a s R e s u l t r d f : r e s o u r c e = " #_DELIVERY" / >
</ p r o c e s s : A t o m i c P r o c e s s >
53
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
< p r o c e s s : I n p u t r d f : ID= "_COMIC" >
< p r o c e s s : p a r a m e t e r T y p e r d f : d a t a t y p e = " h t t p : / / www. w3 . o r g / 2 0 0 1 / XMLSchema# anyURI " >
h t t p : / / 1 2 7 . 0 . 0 . 1 / o n t o l o g y / m o d i f i e d _ b o o k s . owl # Comic </ p r o c e s s : p a r a m e t e r T y p e >
</ p r o c e s s : I n p u t >
< p r o c e s s : O u t p u t r d f : ID= "_BOOK" >
< p r o c e s s : p a r a m e t e r T y p e r d f : d a t a t y p e = " h t t p : / / www. w3 . o r g / 2 0 0 1 / XMLSchema# anyURI " >
h t t p : / / 1 2 7 . 0 . 0 . 1 / o n t o l o g y / m o d i f i e d _ b o o k s . owl # Book </ p r o c e s s : p a r a m e t e r T y p e >
</ p r o c e s s : O u t p u t >
< e x p r :SWRL−C o n d i t i o n r d f : ID= "_HASACCOUNT" >
< r d f s : l a b e l > h a s A c c o u n t ( _User , _ J o u r n a l s ) < / r d f s : l a b e l >
< e x p r : e x p r e s s i o n L a n g u a g e r d f : r e s o u r c e = "&e x p r ; #SWRL" / >
<expr : expressionObject >
< s w r l : AtomList >
<rdf : first >
<swrl : IndividualPropertyAtom >
< s w r l : p r o p e r t y P r e d i c a t e r d f : r e s o u r c e = " h t t p : / / 1 2 7 . 0 . 0 . 1 / o n t o l o g y / c r e d i t c a r d . owl # h a s A c c o u n t " / >
< s w r l : a r g u m e n t 1 r d f : r e s o u r c e = " h t t p : / / 1 2 7 . 0 . 0 . 1 / o n t o l o g y / m o d i f i e d _ b o o k s . owl # U s e r " / >
< s w r l : a r g u m e n t 2 r d f : r e s o u r c e = " h t t p : / / 1 2 7 . 0 . 0 . 1 / o n t o l o g y / m o d i f i e d _ b o o k s . owl # J o u r n a l s " / >
</ s w r l : I n d i v i d u a l P r o p e r t y A t o m >
</ r d f : f i r s t >
< r d f : r e s t r d f : r e s o u r c e = "&r d f ; # n i l " / >
</ s w r l : AtomList >
</ e x p r : e x p r e s s i o n O b j e c t >
</ e x p r :SWRL−C o n d i t i o n >
< p r o c e s s : R e s u l t r d f : ID= "_DELIVERY" >
<process : hasEffect >
< e x p r :SWRL−C o n d i t i o n r d f : ID= "_DELIVERY" >
< r d f s : label > d e l i v e r y ( _ A i r T r a n s p o r t a t i o n , _Address ) </ r d f s : label >
< e x p r : e x p r e s s i o n L a n g u a g e r d f : r e s o u r c e = "&e x p r ; #SWRL" / >
<expr : expressionObject >
< s w r l : AtomList >
<rdf : first >
<swrl : IndividualPropertyAtom >
<swrl : propertyPredicate rdf : resource=
" h t t p : / / 1 2 7 . 0 . 0 . 1 / o n t o l o g y / d e l i v e r y t r a n s p o r t . owl # d e l i v e r y " / >
< swrl : argument1 r d f : r e s o u r c e =
" h t t p : / / 1 2 7 . 0 . 0 . 1 / o n t o l o g y / Mid−l e v e l −o n t o l o g y . owl # A i r T r a n s p o r t a t i o n " / >
< swrl : argument2 r d f : r e s o u r c e =
" h t t p : / / 1 2 7 . 0 . 0 . 1 / o n t o l o g y / Mid−l e v e l −o n t o l o g y . owl # A d d r e s s " / >
</ s w r l : I n d i v i d u a l P r o p e r t y A t o m >
</ r d f : f i r s t >
< r d f : r e s t r d f : r e s o u r c e = "&r d f ; # n i l " / >
</ s w r l : AtomList >
</ e x p r : e x p r e s s i o n O b j e c t >
</ e x p r :SWRL−C o n d i t i o n >
</ p r o c e s s : h a s E f f e c t >
</ p r o c e s s : R e s u l t >
[...]
54
REFERÊNCIAS
AMORIM, R. A. de. Um algoritmo híbrido para descoberta de serviços Web semânticos.
[S.l.], 2009. Trabalho de Conclusão de Curso (Graduação).
BELLUR, U.; VADODARIA, H. On extending semantic matchmaking to include preconditions
and effects. IEEE International Conference on Web Services, p. 120–128, 2008.
BENER, A. B.; OZADALI, V.; ILHAN, E. S. Semantic matchmaker with preconditions and
effects matching using swrl. An International Journal: Expert Systems with Applications, p.
9371–9377, 2009.
CHRISTENSEN, E. et al. Web Services Description Language (WSDL). 2001. Último acesso
em 01 de outubro de 2010. Disponível em: <http://www.w3.org/TR/wsdl>.
CLARKPARSIA. Pellet 2.2.2 Release. 2010. Último acesso em 02 de novembro de 2010.
Disponível em: <http://clarkparsia.com/pellet>.
CLARO, D. B.; MACEDO, R. J. de A. Dependable web service compositions using a semantic
replication scheme. Proceedings of the XXVI Brazilian Symposium of Networks and Distributed
Systems (SBRC 08), 2008.
CORMEN, T. et al. Introduction to algorithms. [S.l.]: MIT press, 2001. ISBN 0-262-03293-7.
DU, D.; GU, J.; PARDALOS, P. Satisfiability Problem: Theory and Applications. [S.l.]:
American Mathematical Society, 1996.
FARRELL, J.; LAUSEN, H. Semantic Annotations for WSDL and XML Schema. 2007. Último
acesso em 02 de novembro de 2010. Disponível em: <http://www.w3.org/TR/sawsdl/>.
FONSECA, A. OWL-S Composer. [S.l.], 2008. Trabalho de Conclusão de Curso (Graduação).
GRUBER, T. A translation approach to portable ontologies. Knowledge Acquisition, 1993.
HORROCKS, I. et al. SWRL: A Semantic Web Rule Language Combining OWL
and RuleML. 2004. Último acesso em 13 de fevereiro de 2010. Disponível em:
<http://www.daml.org/2003/11/swrl/>.
INITIATIVE, T. R. The Rule Markup Initiative. 2004. Último acesso em 30 de novembro de
2010. Disponível em: <http://ruleml.org/>.
JENA. Jena - A Semantic Web Framework for Java. 2000. Último acesso em 02 de novembro
de 2010. Disponível em: <http://jena.sourceforge.net/>.
LAUSEN, H.; ROMAN, D.; POLLERES, A. Web service modeling ontology
(WSMO). 2005. Último acesso em 02 de novembro de 2010. Disponível em:
<http://www.w3.org/Submission/WSMO/>.
55
LOPES, D.; HAMMOUDI, S.; ABDELOUAHAB, Z. Schema matching in the context
of model driven engineering: From theory to practice. Proceedings of the International
Conference on Systems, Computing Sciences and Software Engineering, 2005.
LOPES, D. et al. Metamodel matching: Experiments and comparison. Software Engineering
Advances, International Conference, 2006.
MARTIN, D. et al. OWL-S 1.2 Release. 2010. Último acesso em 01 de outubro de 2010.
Disponível em: <http://www.ai.sri.com/daml/services/owl-s/1.2/>.
MARTIN, D. et al. OWL-S: Semantic Markup for Web Services. 2004. Último acesso em 08 de
janeiro de 2010. Disponível em: <http://www.w3.org/Submission/OWL-S/>.
MCGUINNESS, D.; HARMELEN, F. van. OWL Web Ontology Language Overview. 2004.
Último acesso em 20 de novembro de 2010. Disponível em: <http://www.w3.org/TR/owlfeatures/>.
OSIRISNEXT. OWL-S API 3.1-SNAPSHOT. 2010. Último acesso em 02 de novembro de 2010.
Disponível em: <http://on.cs.unibas.ch/owls-api/>.
PAOLUCCI, M. et al. Semantic matching of web services capabilities. Lecture Notes in
Computer Science, 2002.
PRAZERES, C.; TEIXEIRA, C.; PIMENTEL, M. Semantic web services discovery and
composition: paths along workflows. ECOWS 09 Proceedings of the 7th IEEE European
Conference on Web Services, IEEE Computer Society Press, p. 58–65, 2009.
SAMPER, J. J. et al. Improving semantic web service discovery. Journal of networks, 2008.
TINELLI, C. A dpll-based calculus for ground satis¯ability modulo theories. Proc of JELIA’02,
Springer, 2002.
W3C. Web Services Architecture Requirements. 2002. Último acesso em 6 de dezembro de
2010. Disponível em: <http://www.w3.org/TR/2002/WD-wsa-reqs-20020429>.
W3C. Horn Rules Semantics. 2004. Último acesso em 18 de novembro de 2010. Disponível
em: <http://www.w3.org/2005/rules/wg/wiki/HornRulesSemantics.html>.
W3C. OWL Web Ontology Language Guide. 2004. Último acesso em 20 de outubro de 2010.
Disponível em: <http://www.w3.org/TR/owl-guide/>.
Download