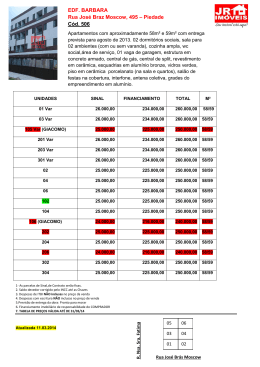
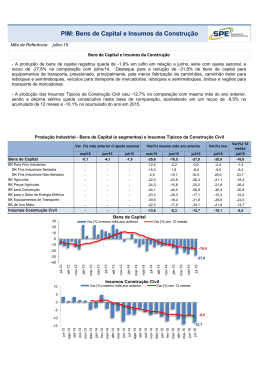
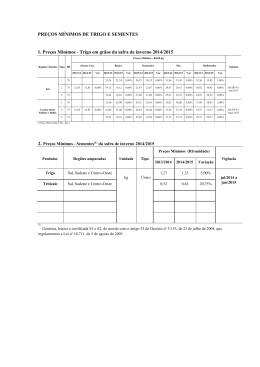
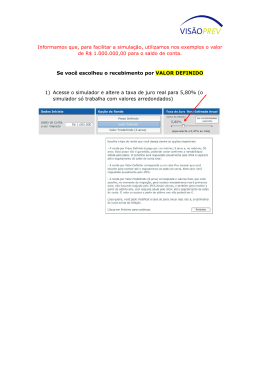
Bruno Vasques Maletta Modelos baseados em Simulação de Monte Carlo: Soluções para o cálculo do Value-at-Risk Dissertação de Mestrado Orientador: Eduardo Saliby, Ph. D. Universidade Federal do Rio de Janeiro Instituto COPPEAD de Administração Abril de 2005 Maletta, Bruno Vasques Modelos baseados em Simulação de Monte Carlo: soluções para o cálculo do Value-a t-Risk / Bruno Vasques Maletta. Rio de Janeiro, 2005. x, 63 f. Dissertação (Mestrado em Administração) – Uni versidade Federal do Rio de Janeiro, Instituto COPPEAD de Administração, 2005. Orientador: Eduardo Saliby 1. Simulação de Monte Carlo. 2. Value-at-Risk. 3. Técnicas de Redução de Variância. 4. Finanças – Teses. I. Saliby, Eduardo. II. Universidade Federal do Rio de Janeiro. Instituto COPPEAD de Administração. III. Título. AGRADECIMENTOS À minha família, pelo apoio e incentivo que sempre me deram. Em especial, à minha mãe, Regina, e minha namorada, Karine, que tiveram a paciência necessária nesta longa trajetória do mestrado. Ao meu orientador, Eduardo Saliby, que foi mais que um professor e orientador, mas se tornou um amigo. A todos os amigos que fiz no COPPEAD. RESUMO MALETTA, Bruno Vasques Maletta. Modelos baseados em Simulação de Monte Carlo: soluções para o cálculo do Value-at-Risk. Orientador: Eduardo Saliby. Dissertação (Mestrado em Administração). Instituto COPPEAD de Administração, Universidade Federal do Rio de Janeiro, Rio de Janeiro, 2005. O Value-at-Risk (VaR) é um dos conceitos mais aceitos no gerenciamento de risco. Sua popularidade se dá, principalmente, pela simplicidade do conceito, sendo capaz de resumir posições de risco em um único valor. Existem diversas metodologias para o cálculo do Var, porém as abordagens mais tradicionais possuem algumas falhas já conhecidas. A metodologia paramétrica necessita supor uma distribuição de probabilidade para o fator de risco. Em geral, a distribuição Normal é utilizada, apesar de vários estudos empíricos mostrarem que as séries financeiras possuem assimetria ou excesso de curtose. Na metodologia histórica, deve-se supor que o comportamento passado do fator de risco irá se repetir no futuro. Outra forma de cálculo, a simulação de Monte Carlo com a Amostragem Aleatória Simples, necessita de intenso uso de recursos computacionais. As conseqüências destes problemas são a subestimação ou superestimação do risco estimado ou lentidão e complexidade nos cálculos. O objetivo deste trabalho é apresentar e avaliar novas formas de cálculo do VaR atra vés da simulação de Monte Carlo e do uso de técnicas de amostragem mais eficientes nos componentes aleatórios da simulação, de forma a eliminar ou minimizar os problemas apresentados nas metodologias mais tradicionais. Uma das metodologias apresentadas usa a mistura de três distribuições para modelar, de forma mais realista, as extremidades da distribuição dos fatores de risco. A outra metodologia apresentada incorpora as técnicas de Amostragem por Importância e Amostragem Descritiva à simulação de Monte Carlo. Os testes foram realizados usando as ações da Petrobrás, Embratel e Telemar para o período de Janeiro de 2002 a Março de 2004, totalizando 557 dias de negociação. A qualidade das metodologias foi mensurada pelo teste de proporção de falhas, CVaR, desvio-padrão dos resultados e percentual de erros de sub -aditividade. Os resultados indicam que as novas formas de cálculo são menos perigosas no gerenciamento de risco que as metodologias tradicionais, principalmente para elevados níveis de confiança. ABSTRACT MALETTA, Bruno Vasques Maletta. Modelos baseados em Simulação de Monte Carlo: soluções para o cálculo do Value-at-Risk. Orientador: Eduardo Saliby. Dissertação (Mestrado em Administração). Instituto COPPEAD de Administração, Universidade Federal do Rio de Janeiro, Rio de Janeiro, 2005. The Value-at-Risk (VaR) is the most popular concept about risk management. However, the traditional methodologies to calculate it present some known problems (the choose of the statistical distribution for the risk factors, the time series used, intense use of computational resources and others). This work intend to present ways, using Monte Carlo Simulation and variance reductions techniques, to solve or minimize those problems. One of the new methodologies intend to mix three statistical distributions to model, in a realistic way, the extremities of the risk factors. The other new methodology introduce the variance reduction techniques in the traditional Monte Carlo Simulation. The tests was realized in the Bra zilian Market, using Petrobrás, Embratel and Telemar shares in the period if January/2002 and March/2004. The quality of the models was measured by the Kupiec's test, CVaR, standard deviation and sub-aditivity failure. The results show that the methodologies presented are better than the traditional, principally on elevated confidence levels. LISTA DE SIGLAS E ABREVIAÇÕES SMC Simulação de Monte Carlo AAS Amostra Aleatória Simples AD Amostragem Descritiva VaR Value-a t-Risk LISTA DE ILUSTRAÇÕES TABELA 1 - ESTATÍSTICAS DESCRITIVAS DA SÉRIE DE RETORNOS DA AÇÃO PETR4 NO PERÍODO DE 02 DE JANEIRO DE 2002 A 31 DE MARÇO DE 2004……………………………..…40 TABELA 2 - ESTATÍSTICAS DESCRITIVAS DA SÉRIE DE RETORNOS DA AÇÃO EBTP4 NO PERÍODO DE 02 DE JANEIRO DE 2002 A 31 DE MARÇO DE 2004……………………………..…42 TABELA 3 - ESTATÍSTICAS DESCRITIVAS DA SÉRIE DE RETORNOS DA AÇÃO TNLP4 NO PERÍODO DE 02 DE JANEIRO DE 2002 A 31 DE MARÇO DE 2004……………………………..…44 TABELA 4 - INTERVALO DE CONFIANÇA PARA A PORCENTAGEM DE FALHAS NO CÁLCULO DO VaR PROPOSTO POR KUPIEC PARA UMA AMOSTRA DE 557 OBSERVAÇÕES……………....46 TABELA 5 - PROPORÇÃO DE FALHAS PARA O CÁLCULO DO VaR DIÁRIO PARA A POSIÇÃO DE COMPRA DE AÇÕES PETR4 NO PERÍODODE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIAÇA E METODOLOGIAS DISCUTIDAS…….46 TABELA 6 - PROPORÇÃO DE FALHAS PARA O CÁLCULO DO VaR DIÁRIO PARA A POSIÇÃO DE VENDA DE AÇÕES PETR4 NO PERÍODODE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIAÇA E METODOLO GIAS DISCUTIDAS……...….46 TABELA 7 - 3 DESVIO PADRÃO (X10 ) DAS SIMULAÇÕES PARA O CÁLCULO DO VaR DIÁRIO DAS AÇÕES PETR4 NO PERÍODO DE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIANÇA……………………………………………..……...……...….47 TABELA 8 - PROPORÇÃO DE FALHAS PARA O CÁLCULO DO VaR DIÁRIO PARA A POSIÇÃO DE COMPRA DE AÇÕES EBTP4 NO PERÍODODE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIAÇA E METODOLOGIAS DISCUTIDAS…….48 TABELA 9 - PROPORÇÃO DE FALHAS PARA O CÁLCULO DO VaR DIÁRIO PARA A POSIÇÃO DE VENDA DE AÇÕES EBTP4 NO PERÍODODE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIAÇA E METODOLOGIAS DISCUTIDAS……...….48 DESVIO PADRÃO (X103) DAS SIMULAÇÕES PARA O CÁLCULO DO VaR DIÁRIO DAS AÇÕES EBTP4 NO PERÍODO DE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIANÇA…………………………………………..………..….48 TABELA 10 - TABELA 11 - PROPORÇÃO DE FALHAS PARA O CÁLCULO DO VaR DIÁRIO PARA A POSIÇÃO DE COMPRA DE AÇÕES TNLP4 NO PERÍODODE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIAÇA E METODOLOGIAS DISCUTIDAS………………………………………………………………………………………………..49 TABELA 12 - PROPORÇÃO DE FALHAS PARA O CÁLCULO DO VaR DIÁRIO PARA A POSIÇÃO DE VENDA DE AÇÕES TNLP4 NO PERÍODODE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIAÇA E METODOLOGIAS DISCUTIDAS……...………………………………………………………………………………………...50 DESVIO PADRÃO (X103) DAS SIMULAÇÕES PARA O CÁLCULO DO VaR DIÁRIO DAS AÇÕ ES TNLP4 NO PERÍODO DE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIANÇA…………………………………………..………..….50 TABELA 13 - TABELA 14 - PROPORÇÃO DE FALHAS PARA O CÁLCULO DO VaR DIÁRIO PARA A POSIÇÃO DE COMPRA DA CARTEIRA NO PERÍODODE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIAÇA E METODOLOGIAS DISCUTIDAS………………………………………………………………………………………………..52 TABELA 15 - DESVIO PADRÃO DAS SIMULAÇÕES PARA O CÁLCULO DO VaR DIÁRIO PARA A POSIÇÃO DE COMPRA DA CARTEIRA NO PERÍODO DE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIANÇA.....……………………………...52 TABELA 16 - PERCENTUAL DE ERROS DE SUB -ADITIVIDADE NO CÁLCULO DO VaR DIÁRIO PARA A POSIÇÃO DE COMPRA DA CARTEIRA NO PERÍODO DE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIANÇA.....……......……...53 TABELA 17 - PROPORÇÃO DE FALHAS PARA O CÁLCULO DO VaR DIÁRIO PARA A POSIÇÃO DE VENDA DA CARTEIRA NO PERÍODODE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIAÇA E METODOLOGIAS DISCUTIDAS………………………………………………………………………………………………..54 TABELA 18 - DESVIO PADRÃO DAS SIMULAÇÕES PARA O CÁLCULO DO VaR DIÁRIO PARA A POSIÇÃO DE VENDA DA CARTEIRA NO PERÍODO DE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIANÇA.....……………………………...54 TABELA 19 - PERCENTUAL DE ERROS DE SUB -ADITIVIDADE NO CÁLCULO DO VaR DIÁRIO PARA A POSIÇÃO DE VENDA DA CARTEIRA NO PERÍODO DE 02 DE JANEIRO DE 2002 ATÉ 31 DE MARÇO DE 2004 PARA OS DIVERSOS NÍVEIS DE CONFIANÇA.....……..............……...54 FIGURA 1 - COMPARAÇÃO DA AMOSTRAGEM ALEATÓRIA SIMPLES COM A AMOSTRAGEM POR IMPORTÂNCIA NA GERAÇÃO DE VALORES DA DISTRIBUIÇÃO NORMAL............……...14 FIGURA 2 - ILUSTRAÇÃO DO CONCEITO DE VALUE- AT-RISK................…...............................…...16 FIGURA 3 - EFEITO DE RS NA DISTRIBUIÇÃO DO FATOR DE RISCO DO MODELO............……...28 FIGURA 4 - EVOLUÇÃO DOS PREÇOS DE FECHAMENTO DA AÇÃO PETR4 NO PERÍODO DE 02 DE JANEIRO DE 2002 A 31 DE MARÇO DE 2004............…...................................................…...39 FIGURA 5 - HISTOGRAMA DA SÉRIE DE RETORNOS DA AÇÃO PETR4 NO PERÍODO DE 02 DE JANEIRO DE 2002 A 31 DE MARÇO DE 2004............……............................................................40 FIGUR A 6 - QQ-PLOT DA SÉRIE DE RETORNOS DA AÇÃO PETR4 NO PERÍODO DE 02 DE JANEIRO DE 2002 A 31 DE MARÇO DE 2004............……............................................................40 FIGURA 7 - EVOLUÇÃO DOS PREÇOS DE FECHAMENTO DA AÇÃO EBTP4 NO PERÍODO DE 02 DE JANEIRO DE 2002 A 31 DE MARÇO DE 2004............…...................................................…...41 FIGURA 8 - HISTOGRAMA DA SÉRIE DE RETORNOS DA AÇÃO EBTP4 NO PERÍODO DE 02 DE JANEIRO DE 2002 A 31 DE MARÇO DE 2004............……............ ................................................42 FIGURA 9 - QQ-PLOT DA SÉRIE DE RETORNOS DA AÇÃO EBTP4 NO PERÍODO DE 02 DE JANEIRO DE 2002 A 31 DE MARÇO DE 2004............……............................................................42 FIGURA 10 - EVOLUÇÃO DOS PREÇOS DE FECHAMENTO DA AÇÃO TNLP4 NO PERÍODO DE 02 DE JANEIRO DE 2002 A 31 DE MARÇO DE 2004............…...................................................…...43 FIGURA 11 - HISTOGRAMA DA SÉRIE DE RETORNOS DA AÇÃO TNLP4 NO PERÍODO DE 02 DE JANEIRO DE 2002 A 31 DE MARÇO DE 2004............……............................................................44 FIGURA 12 - QQ- PLOT DA SÉRIE DE RETORNOS DA AÇÃO TNLP4 NO PERÍODO DE 02 DE JANEIRO DE 2002 A 31 DE MARÇO DE 2004............……............................................................44 ÍNDICE Capítulo 1 - O Problema 1.1 Introdução 1.2 Questões a serem respondidas 1.3 Objetivo 1.4 Relevância do estudo 1.5 Delimitação Capítulo 2 - Referencial Teórico 2 2 5 5 6 6 8 2.1 Simulação de Monte Carlo 8 2.1.1 Variáveis Antitéticas 10 2.1.2 Variável de Controle 10 2.1.3 Hipercubo Latino 11 2.1.4 Amostragem Descritiva 12 2.1.5 Amostragem por Importância 14 2.2 Administração de risco 15 2.3 Metodologias de cálculo do Value-a t-Risk (VaR) 17 2.3.1 VaR Histórico 17 2.3.2 VaR Paramétrico 19 2.3.3 VaR por Simulação de Monte Carlo com incorporação da Amostragem Descrita e Amostragem por Importância 22 2.3.4 Modelo de Mistura de Distribuições 26 2.4 Geração de variáveis aleatórias correlacionadas 29 2.5 Teste de proporção de falhas 31 Capítulo 3 - Metodologia 3.1 Tipo de pesquisa 3.2 Experimento realizado 3.3 Coleta de dados 3.4 Parâmetros estimados 3.5 Tratamento dos dados 3.6 Limita ções dos métodos 3.6.1 Limitações Metodológicas 3.6.2 Limitações de Hardware e Software Capítulo 4 - Resultados 4.1 Análise exploratória dos dados 4.2 VaR individual 4.3 VaR para carteiras 33 33 34 34 35 37 37 37 37 39 39 45 51 Capítulo 5 - Conclusões 56 Capítulo 6 - Referências 59 1. O Problema 1.1 Introdução O risco de mercado tornou-se, ao longo dos últimos anos, uma das maiores preocupações para os participantes do mercado financeiro. Agências reguladoras, bancos comerciais e de investimentos, grandes corporações e investidores estão cada vez mais voltando suas atenções ao nível de risco ao qual sua instituição ou carteira de investimentos estão submetidos. Segundo Jorion (1997), o principal motivo para o crescimento da administração de risco é a imprevisibilidade das variáveis financeiras. Hoje, um dos conceitos mais aceitos para o gerenciamento de riscos é o Valuea t-Risk , ou VaR. Jorion (1997) o define como "um método de mensuração de risco de mercado que utiliza técnicas estatísticas, buscando medir a pior perda esperada de carteira, fundo ou instituição ao longo de determinado intervalo de tempo, sob condições normais de mercado e dentro de determinado nível de confiança". Sabe-se que uma das grandes vantagens do VaR, e possível razão para sua popularidade, é a simplicidade do conceito. A maneira intuitiva de resumir, em um único número, posições de risco de carteiras complexas e difíceis de serem interpretadas também contribui para sua aceitação. Existem diversas metodologias para o cálculo do VaR e cada uma possui vantagens e desvantagens em relação às demais. As principais delas são a paramétrica, histórica e a simulação de Monte Carlo. Todas serão melhor discutidas na seção 2.3. A metodologia paramétrica utiliza métodos estatísticos padronizados para calcular as variações no valor do portfólio. Para isso, baseia -se fortemente em premissas sobre a distribuição de probabilidade dos fatores de risco, em geral, a distribuição Normal. Porém, vários estudos empíricos 1 mostraram que séries de dados financeiros apresentam assimetria e/ou excesso de curtose. Este fenômeno, conhecido como "caudas gordas", 1 Por exemplo: Li (1999) e Zangari (1996) deixa as extremidades da série com maior probabilidade que as extremidades da distribuição Normal teórica, subestimando a exposição ao risco. A metodologia histórica aplica variações observadas em um determinado período histórico nas posições do portfólio atual, levando em consideração o horizonte de tempo escolhido. Assim, deve-se supor que o comportamento passado dos ativos que compõem o portfólio irá se repetir no futuro. O método de Monte Carlo consiste na simulação do valor futuro dos ativos que compõem a carteira através de um modelo. Esta metodologia é indicada quando as abordagens histórica e paramétrica não são apropriadas, principalmente devido ao alto custo computacional de implementação e processamento. Mesmo assim, vem sendo cada vez mais utilizada, não somente no gerenciamento de risco, mas em diversas áreas financeiras (destacam-se os estudos na precificação de derivativos). Sua crescente popularidade se dá, principalmente, pela liberdade na modelagem do problema (passando de "soluções exatas de problemas aproximados" para "soluções aproximadas de problemas exatos"), avaliação de perguntas do tipo "e se?" (permitindo a avaliação de mudanças de cenários ou conseqüências de decisões) e avaliação de problemas em que o conhecimento das variáveis envolvidas é parcial. Além da necessidade de recursos computacionais, por se tratar de estimação de valores futuros, em alguns casos, a baixa precisão dos resultados e a falta de generalidade (solução pontual) reforçou a idéia de que a simulação deva ser utilizada apenas como um "último recurso". A imprecisão é conseqüência do processo de amostragem na seleção dos valores aleatórios de entrada dos modelos, necessários para a simulação de qualquer fenômeno. Em princípio, esta seleção era realizada de forma totalmente aleatória (Amostragem Aleatória Simples). Objetivando um maior controle do processo de amostragem, foram desenvolvidas algumas técnicas denominadas de "técnicas de redução de variância": Variáveis Antitéticas, Amostragem por Importância, Amostragem Estratificada, Variável de Controle, Common Random Numb ers e outras. Ainda assim, nestas técnicas, o controle amostral é parcial, uma vez que ainda persistem valores aleatórios em seus algoritmos. Em 1979, McKay, Beckman e Conover sugeriram uma nova técnica de redução de variância baseada no forte controle do processo de amostragem, o Hipercubo Latino. A base da técnica é a estratificação da distribuição amostral em estratos de igual probabilidade de ocorrência e o sorteio aleatório de um valor em cada um deles. Contemporaneamente e independentemente dos estudos do Hipercubo Latino, uma abordagem alternativa para a simulação de Monte Carlo foi desenvolvida por Saliby (1980), a Amostragem Descritiva. Nesta abordagem, rompe-se completamente a seleção aleatória da amostra, baseando-se em uma seleção determinística de valores (pontos centrais dos mesmos estratos utilizados no Hipercubo Latino) e uma posterior permutação destes. Diferentemente das primeiras técnicas de redução de variância, o Hipercubo Latino e a Amostragem Descritiva apresentam resultados signific ativamente superiores à Amostragem Aleatória Simples em diversos estudos (MARINS, SANTOS e SALIBY, 2003; ARAÚJO, 2001). Apesar da proximidade das técnicas, Moreira (2001) e Saliby (1997) mostraram que a Amostragem Descritiva é um melhoramento do Hipercubo Latino tanto na eficiência estatística quanto na eficiência computacional. Recentemente, muitos trabalhos foram apresentados tentando resolver, ou minimizar, o efeito dos problemas no cálculo do VaR nas diversas metodologias. Li (1999) propôs uma metodologia semiparamétrica baseada nas quatro primeiras estatísticas de ordem, Dowd (2001) também usou as estatísticas de ordem em suas estimativas, Zangari (1996) apresentou um modelo de mistura de duas variáveis gaussianas com estimação via estatística Bayesia na e Glasserman et al (1999) introduziu técnicas de redução de variância na simulação de Monte Carlo. Entretanto, a grande complexidade destas metodologias vai de encontro à simplicidade do conceito de VaR e, em geral, inviabilizam sua utilização. Entre os poucos trabalhos que apresentaram novas formas de calcular o VaR com simplicidade, destaca-se a metodologia de Gibson (2001) com a incorporação de eventos raros (ou saltos) na trajetória dos ativos. Ele propõe uma modelagem da distribuição dos retornos de ativos financeiros como a mistura de três distribuições de probabilidade. Apesar da aparente complexidade, a estimação dos parâmetros utiliza os dados históricos e não cálculos estatísticos avançados. Outro possível caminho com baixa complexidade é a incorporação da Amostragem Descritiva na forma clássica de cálculo do VaR por simulação de Monte Carlo. Esta técnica de amostragem foi muito pouco explorada até hoje e apresentou em diversos estudos (não somente em finanças) um aumento na precisão dos resultados e redução dos esforços computacionais. Também, esta ainda pode apresentar ganhos adicionais quando combinada com outras técnicas de redução de variância, como a Amostragem por Importância. 1.2 Questões a serem respondidas O uso da metodologia proposta por Gibson (2001) e da Amostragem Descritiva combinada com a Amostragem por Importância apresentam realmente melhorias no cálculo do VaR? Caso positivo, será que os resultados apresentados são significativamente superiores aos resultados das metodologias mais tradicionais, sendo válido uma mudança nos procedimentos de cálculo nas instituições financeiras? Existem alguns ativos que melhor se encaixam nas duas novas formas de cálculo? E qual delas é a melhor? 1.3 Objetivo O objetivo deste trabalho é apresentar o modelo sugerido por Gibson (2001), adaptando-o para uma carteira de ações brasileiras e para o uso da simulação de Monte Carlo. Também, será incorporado à metodologia básica de simulação de Monte Carlo a combinação das técnicas de Amostragem Descritiva e Amostragem por Importância. Os dois modelos apresentam simples implementação para o cálculo do VaR e visam eliminar os problemas clássicos já apresentados utilizando o mercado brasileiro de ações. Estas duas formas de cálculo serão com paradas com as formas tradicionais para diferentes carteiras de ativos e diferentes níveis de confiança. A verificação dos resultados será realizada através da proporção de falhas, do intervalo de confiança para esta proporção (conforme sugerido por Kupiec em 1995) e da distância média entre as falhas e o VaR calculado (também conhecida por CVaR). A variabilidade dos resultados também será levada em consideração, assim como a quantidade de erros de subaditividade. 1.4 Relevância do estudo O VaR é uma medida de risco amplamente utilizada por instituições financeiras, investidores institucionais, seguradoras (que assumem posições de risco em vários mercados), órgãos reguladores (que definem a exigência de capital para garantir as operações das empresas em função dos riscos assumidos) e empresas não financeiras (conhecimento do risco para operações de hedge). Assim, formas de cálculo mais precisas, rápidas e de fácil entendimento são importantes no gerenciamento das posições de risco de cada empresa, possibilitando oportunidades de investimento ou operações de proteção mais eficientes. Do ponto de vista teórico, destaca-se a comparação de dois métodos que utilizam a simulação de Monte Carlo com processos de amostragem diferentes. A seleção de valores determinística utilizada na técnica de Amostragem Descritiva ainda é bastante questionada por quebrar o paradigma de que o comportamento natural dos acontecimentos deva ser reproduzido por valores aleatórios. 1.5 Delimitação Como o cálculo do VaR não possui uma resposta correta, ou seja, uma fórmula analítica fechada, a precisão dos métodos será avaliada pela variabilidade de suas respostas e, principalmente, pela proporção de falhas. Estas duas medidas são diretamente afetadas pelo tamanho da amostra de dias utilizados nos experimentos. Alguns autores (por exemplo: Blanco e Ihle em 1998) utilizam outros critérios de avaliação, como a magnitude das falhas. Os resultados apresentados para as carteiras utilizadas indicam, mas não provam, superioridade de uma metodologia frente às demais. A utilização de outras carteiras ou ativos de outra natureza pode apresentar resultados diferentes. Os portfólios desenvolvidos para a comparação dos métodos serão criados especificamente para o trabalho, não pertencendo a nenhuma carteira de instituição financeira ou afim. 2. Referencial Teórico 2.1 Simulação de Monte Carlo Segundo Saliby (1989), a simulação é uma técnica de pesquisa operacional, que corresponde a realização de experimentos numéricos com modelos lógico-matemáticos. Estes experimentos envolvem grandes volumes de cálculos repetitivos, fazendo uso intensivo de recursos computacionais. A origem do método de Simulação de Monte Carlo se deu durante a Segunda Guerra Mundial, ao longo das pesquisas no Labora tório de Los Alamos, que resultaram na construção da primeira bomba atômica. O método foi proposto por Von Neumann e Ulam para solução de problemas matemáticos cujo tratamento analítico não se mostrava viável. Primeiramente, voltava -se à avaliação de integrais múltiplas para o estudo da difusão de nêutrons. Posteriormente, verificou-se que ele poderia ser aplicado em outros problemas matemáticos mais complexos de natureza determinística. O nome Monte Carlo, famoso cassino de Mônaco fundado em 1862, foi adotado por razões de sigilo das pesquisas e pelo fato da presença da aleatoriedade lembrar os jogos de azar. No final da década de 40, os computadores ainda começavam a se tornar realidade e essa era a grande limitação do método. A restrição de recursos computacionais acarretava baixa precisão nos resultados da simulação. Na década de 50, com o desenvolvimento de computadores, programas e linguagens de simulação, a atenção dos pesquisadores voltou-se para a obtenção de resultados mais precisos, mas com o cuidado de não aumentar o tempo de processamento necessário. O esforço destes pesquisadores deu origem às primeiras técnicas de redução de variância: Variáveis Antitéticas, Amostragem por Importância, Amostragem Estratificada, Variável de Controle, Common Random Numbers e outras. O objetivo era um controle parcial do processo de amostragem dos valores aleatórios. Até então, a geração da amostra era totalmente aleatória, chamada de abordagem tradicional ou Amostragem Aleatória Simples. Apesar dos baixos ganhos de precisão, o principal motivo pelo qual as técnicas de redução de variância não foram muito utilizadas foi a concepção de que a amostragem deveria imitar o comportamento aleatório da realidade. Ou seja, o controle do processo de amostragem significava, nesta concepção, a introdução de um viés nos resultados. No final da década de 70 e início dos anos 80, McKay, Beckman e Conover (1979) e Saliby (1980) desenvolveram o que pode ser caracterizado como uma segunda geração das técnicas de redução de variância. As técnicas de Hipercubo Latino e Amostragem Descritiva, diferentemente das primeiras, apresentaram em vários estudos resultados muito superiores à Amostragem Aleatória Simples (MARINS, SANTOS e SALIBY, 2003; ARAÚJO, 2001; OWEN, 1992). É importante mencionar, também, que as barreiras impostas pela limitação de recursos computacionais aos poucos estavam sendo ultrapassadas. A idéia do Hipercubo Latino, apesar de impor um controle maior no processo de amostragem que as primeiras técnicas de redução de variância, ainda manteve vivo o paradigma de que a amostra deve possuir um componente aleatório em seus valores. Nesta técnica de amostragem, é proposta a estratificação da distribuição acumulada de probabilidade das variáveis de entrada do modelo de simulação em n partes de igual probabilidade e, em seguida, a escolha aleatória de um elemento dentro de cada estrato e a permutação destes valores. Assim, fica garantido que todos os estratos serão representados na amostra (MCKAY, BECKMAN e CONOVER, 1979). O paradigma da amostra aleatória só foi totalmente abandonado pela Amostragem Descritiva proposta por Saliby (1980). Esta técnica utiliza os mesmos estratos do Hipercubo Latino, mas seleciona-se o valor central de cada estrato. A permutação na ordem dos valores centrais garante a aleatoriedade da amostra. As seções seguintes detalham as principais técnicas de redução de variância, dando maior ênfase à Amostragem Descritiva e Amostragem por Importância. 2.1.1 Variáveis Antitéticas Esta técnica propõe a redução de variância através da introdução de uma correlação negativa entre as estimativas. Seja X1 e X2 variáveis aleatórias definidas como função da variável u e -u, respectivamente. Ou seja, X1 = f(u) e X2 = f(-u). Observa-se que X1 e X2 possuem a mesma distribuição, sendo porém negativamente correlacionadas. Desta forma, pode-se definir a variância da média aritmética entre os pares de X1 e X2 como: _ Var ( X ) = Var ( X 1 ) + Var ( X 2 ) + 2Cov( X 1 , X 2 ) Var ( X ) = × (1 + ρ) 4 2 (2.1) Onde: Var(X) = Var(X1 ) = Var(X2) ρ : coeficiente de correlação entre X1 e X2 Observa-se que a variância da média aritmética entre as duas variáveis é menor do que a variância das variáveis aleatórias originais devido à correlação negativa introduzida. 2.1.2 Variável de Controle A metodologia usual para o emprego desta técnica é a substituiçã o de um problema que não dispõe de solução analítica por um problema similar mais simplificado, que dispõe deste tipo de solução. A solução do problema simplificado é usada para aumentar a precisão da simulação do problema mais complexo. Utiliza -se o erro de simulação, diferença entre o valor analítico e o valor estimado por simulação para o problema mais simples, como controle na simulação do problema mais complexo. Pode ser mostrado que o coeficiente do erro de simulação que minimiza a variância da var iável ajustada é o coeficiente angular da regressão entre o valor estimado por simulação do problema sem solução analítica e o valor estimado por simulação do problema com solução analítica (BRATLEY, FOX e SCHRAGE, 1987). Var ( X − kY ) = Var ( x) + k 2Var (Y ) − 2Cov( X , Y ) (2.2) Onde: X: valor estimado por simulação do problema sem solução analítica Y: variável de controle (diferença entre o valor analítico e o valor estimado por simulação do problema com solução analítica) K: coeficiente angular da regressão entre o valor estimado por simulação do problema sem solução analítica e o valor estimado por simulação do problema com solução analítica Um exemplo da aplicação desta técnica é a precificação de contratos de Opções do tipo Asiáticas com média aritmética. Neste caso, apresentado por Marins, Santos e Saliby (2003), utiliza -se a solução analítica das opções asiáticas com média geométrica como controle. PAVC = PA + β (C-PG) (2.3) Onde: PAVC: prêmio aritmético estimado por Variável de Controle PA: prêmio aritmético estimado por simulação PG: prêmio geométrico estimado por simulação C: prêmio obtido pelo modelo de Black e Scholes para o caso geométrico β: coeficiente angular da regressão entre PA e PG 2.1.3 Hipercubo Latino Consiste na estratificação da distribuição acumulada de probabilidade das variáveis de entrada da simulação em n partes de igual probabilidade. Em seguida, escolhe-se aleatoriamente um valor dentro de cada estrato. A amostra hipercúbica é composta por estes valores permutados aleatoriamente. A fórmula usada para a geração dos valores hipercúbicos, a serem depois permutados, é: i − Randi xhi = F −1 n (2.4) Onde: i = 1, ..., n xhi: valor que compõem a amostra hipercúbica n: tamanho da amostra F -1: inversa da função de distribuição acumulada Randi : número aleatório entre 0 e 1 2.1.4 Amostragem Descritiva Contemporaneamente e independentemente dos estudos que geraram o Hipercubo Latino, Saliby (1980) questionou a idéia de que a simulação deva ser uma simples imitação da realidade. Segundo o autor, a amostragem aleatória introduz uma variabilidade desnecessária nos problemas de simulação. A Amostragem Descritiva se baseia na idéia de uma seleção totalmente determinística e intencional dos valores de entrada do modelo de simulação. Como no Hipercubo Latino, a Amostragem Descritiva propõe a estratificação da distribuição acumulada de probabilidade das variáveis de entrada do modelo de simulação em n partes de igual probabilidade. Porém, no lugar de uma seleção aleatória, seleciona-se o ponto médio dentro de cada estrato. A permutação aleatória dos pontos médios dos estratos garante a aleatoriedade da amostra. É importante ressaltar que os valores amostrais serão sempre os mesmos dado um determinado número n de simulações. Ou seja, a amostra não varia mais entre diferentes corridas. Este fato significa o fortalecimento do controle no processo de amostragem, enfatizando ainda mais a ruptura com o paradigma vigente. Tanto na amostragem tradicional (Amostra Aleatória Simples) quanto nas demais técnicas de redução de variância (incluindo o Hipercubo Latino) existem duas fontes de variabilidade: a variabilidade da seleção dos valores e a variabilidade da seqüência dos valores. Por possuir a seleção determinística, a Amostragem Descritiva só possui a variabilidade da seqüência, devido a permutação aleatória dos pontos médios. Segundo Moreira (2001), o ponto de maior dificuldade quando este método é sugerido é convencer que, ao contrário da crença comum, não há necessidade de haver seleção aleatória nas amostras de experimentos de simulação de Monte Carlo. Saliby (1990) argumenta que nos experimentos de simulação as amostras são obtidas, por hipótese, de distribuições de probabilidade já conhecidas. Neste caso, o propósito da amostragem é simular certo comportamento aleatório (já realizado pela permutação aleatória dos pontos médios na Amostragem Descritiva) e não realizar inferências sobre a população analisada. Outro bom argumento é a facilidade de implementação: pequeno incremento no tempo de programação e redução no tempo de processamento. A única exigência antes da implementação é conhecer o tamanho da amostra desejada (determinar o número n de estratos). A fórmula proposta para a geração do conjunto único de valores descritivos, que serão posteriormente permutados é: i − 0,5 xdi = F −1 n Onde: i = 1, ..., n xdi: valor que compõem a amostra descritiva n: tamanho da amostra F -1: inversa da função de distribuição acumulada F -1 (R), R ∈ (0,1) (2.5) 2.1.5 Amostragem por Importância A Amostragem por Importância é uma das técnicas da primeira geração das chamadas técnicas de redução de variância. Sua idéia principal é de concentrar a distribuição de probabilidade na área de maior interesse em determinado problema, e assim, aumentar a convergência do método. Pensando novamente no VaR, a área de maior interesse são os extremos da distribuição, onde estão localizadas as possíveis perdas. A Figura 1 mostra o deslocamento do centro de uma distribuição Normal em duas unidades. Observa-se que no método de Monte Carlo básico (utilizando a Amostragem Aleatória Simples) poucos valores foram gerados nas extremidades, enquanto que na metodologia da Amostragem por Importância a maior parte dos resultados encontra-se na área de interesse da distribuição. Figura 1 – Comparação da Amostragem Aleatória Simples com a Amostragem por Importância na geração de valores da distribuição Normal Monte Carlo Básico Amostragem por Importância Logicamente, o deslocamento da curva Normal introduz um viés na amostragem que, felizmente, pode ser corrigido pela razão de Verossimilhança. Neste caso, pode-se calcular a Verossimilhança pela razão das funções de probabilidade entre o valor deslocado e o valor originalmente selecionado. Por exemplo, supondo um deslocamento de 2 unidades para a esquerda na curva Normal padrão e aleatoriamente o valor 0,32 foi selecionado, a razão de Verossimilhança será F (-2,32) / F(0,32), onde F( ) representa a função de densidade da Normal padrão. Os cálculos usando a Amostragem por Importância devem ser ponderados pela razão de Verossimilhança. No caso do VaR, por exemplo, para o nível de confiança de (1-a)% seleciona -se a perda que possuir a razão de Verossimilhança acumulada mais próxima da estatística a x N, onde N é o tamanho da amostra. Existem diversas outras formas de se implementar a Amostragem por Importância. Para isso, consultar Boyle (1997) e Charnes (2000). 2.2 Administração de Risco Segundo Jorion (1997), risco pode ser definido como a volatilidade de resultados inesperados, normalmente relacionada ao valor de ativos ou passivos. As empresas podem estar expostas a três tipos de risco: operacional, estratégico e financeiro. O primeiro deles está relacionado ao setor da economia em que a empresa opera, inovações tecnológicas, desenho de produtos, marketing, etc. O risco estratégico resulta de mudanças fundamentais no cenário econômico e político (por exemplo, a expropriação ou nacionalização de territórios). O risco financeiro está ligado a possíveis perdas nos mercados devido a oscilações de variáveis financeiras (por exemplo, a taxa de juros ou câmbio). Este último pode ser classificado em: - Riscos de mercado: surgem de mudanças nos preços de ativos ou passivos financeiros. - Riscos de crédito: surgem do não cumprimento de obrigações contratuais - Riscos de liquidez: surge quando uma transação não pode ser conduzida pelos preços de mercado, devido a uma atividade insuficiente de mercado. Também, pode referir -se à impossibilidade de cumprir obrigações relativas ao fluxo de caixa. - Riscos operacionais: referem-se às perdas potenciais resultantes de sistemas inadequados, má administração, controles defeituosos ou falha humana na execução das operações da empresa. - Riscos legais: surge quando uma contraparte não possui autoridade legal ou regulatória para se envolver em uma transação. Este trabalho concentra-se no risco financeiro, mais especificadamente no risco de mercado. O principal motivo para o surgimento da administração de risco é a volatilidade das variáveis financeiras. A imprevisibilidade fez com que diversos instrumentos fossem criados para a gestão de risco desde a década de 70, chamados de derivativos. Entre eles estão o futuro de moedas (1972), opções de ações (1973), swaps de moedas (1981), opções sobre swap (1985) e opções credit default (1994). Esses derivativos proporcionam um mecanismo através do qual as instituições financeiras podem hedgear-se com eficácia. Do outro lado dos hedges estão os especuladores, buscando lucro em suas transações. Uma medida de mensuração e controle dos riscos de mercado bastante utilizada é o Value-a t-Risk (VaR), definida como o valor máximo que pode ser perdido, com um certo nível de confiança, em um dado horizonte de tempo. A Figura 2 ilustra bem o conceito de VaR. Figura 2 - Ilustração do conceito de Value-at-Risk α Vt VaR V Valor do Portfolio Inicialmente, esta medida foi utilizada pelos principais bancos e instituições financeiras do mundo, mas seu conceito foi difundido devido, principalmente, a sua simplicidade: um único valor resumindo a exposição de carteiras, muitas vezes complexas, bem como a probabilidade de uma oscilação adversa. Além disso, ele mede o risco na mesma unidade constante nos relatórios de resultados, facilitando o entendimento de acionistas e administradores em geral. Dos diversos propósitos do VaR, pode-se citar o fornecimento de informações gerenciais (informar sobre riscos incorridos em transações e operações de investimentos ou os riscos financeiros de empresas, contribuindo para estabilidade do sistema financeiro), alocação de recursos (estabelecer de limites para traders e onde alocar recursos limitados de capital) e avaliação de performance (ajustar o desempenho de traders ao risco incorrido). Todavia, é importante perceber que o VaR é um procedimento necessário, mas não suficiente para o controle de riscos. Esta medida representa uma estimativa técnica para o risco de mercado, tendo o mesmo valor de outras estimativas em outras áreas científicas. O VaR deve ser complementado por limites e controles, além de uma função independente e centralizada de administração de risco. 2.3 Metodologias de cálculo do Value-at-Risk (VaR) As três metodologias mais utilizadas para cálculo do VaR são: histórica, paramétrica e por simulação de Monte Carlo. Cada uma delas têm suas vantagens e desvantagens e seus usos são indicados em função dos ativos que compõem o portfólio analisado. As duas primeiras metodologias serão apresentadas nas seções seguintes e o cálculo usando a simulação de Monte Carlo será descrito na seção 2.3.3. 2.3.1 VaR Histórico O VaR histórico aplica as variações dos fatores de risco (fatores que afetam o valor de um determinado ativo do portfólio, por exemplo o preço de uma ação, a taxa de juros, o câmbio, etc.) ocorridas no passado nas posições de risco atuais levando em cons ideração o horizonte de tempo escolhido. Define-se um período histórico e a unidade do holding period (diário, mensal, etc.) da qual deseja -se medir o VaR e calcula -se, para cada unidade de tempo, o retorno do portfólio atual, atualizando o valor de cada ativo. Dado um determinado nível de confiança (1-α)%, o VaR será o percentil α% da amostra de retornos históricos. Por exemplo, o VaR de uma posição "comprada" em um determinado portfólio, por esta metodologia, com nível confiança de 95% será o percentil 5% da amostra de retornos. Para uma posição de venda, o VaR será o percentil 95%. As principais vantagens desta metodologia são a simplicidade e o não embasamento em premissas (como a distribuição de probabilidade dos retornos dos ativos), pois os dados são retirados diretamente do mercado financeiro. Além disso, consegue capturar o efeito de uma possível assimetria dos dados. Do lado das desvantagens, por se tratar de dados passados, é necessário acreditar que o futuro se comportará da mesma maneira que o período histórico analisado. Além disso, esta metodologia não permite a realização de análises de sensibilidade. A metodologia do VaR histórico sofre de um grave problema: a sub-aditividade. 2.3.1.1 Propriedade da Sub-aditividade Em 1999, Artzner et al. demonstraram que, em geral, as medidas de risco deveriam satisfazer algumas condições para serem consideradas coerentes. Caso contrário, seus resultados seriam paradoxais e não representariam corretamente o risco incorrido. Uma das condição aprese ntada pelo autor é a propriedade de sub-aditividade: sendo duas variáveis aleatórias X e Y e a função ?(), ?(X + Y) ≤ ?(x) + ?(Y). No caso do VaR, isto significa que o risco de um portfólio deve ser menor que a soma dos riscos individuais dos ativos que o compõe. Este conceito é bastante difundido (a diversificação diminui os riscos) e utilizado em diversas teorias de investimento e alocação de recursos, como o Capital Asset Pricing Model (CAPM). Porém, no artigo de Artzner et al. (1999) e vários outros - Acerbi, Nordio e Sirtori (2001), por exemplo - foi demonstrado que o VaR histórico falha neste critério, ou seja, pode apresentar portfólios com risco maior que a soma do risco de seus ativos. As outras propriedades apresentadas por Artzner et al. (1999) para uma medida de risco coerente são satisfeitas pelo VaR histórico: monotonicidade, homogeneidade e invariância de translação. Devido a esta e outras críticas, diversas variações do VaR já foram apresentadas na literatura, como o Expected Shortfall. 2.3.2 VaR Paramétrico A metodologia do VaR paramétrico utiliza métodos estatísticos padronizados para calcular as variações do portfólio atual. Para isso, baseia -se em fortes premissas: o retorno dos ativos ou fatores de risco seguem uma distribuição estatística (geralmente utiliza-se a distribuição Normal), a variação dos ativos é linearmente proporcional à variação do portfólio, os retornos dos ativos são homocedásticos durante o horizonte de tempo e não há autocorrelação nas séries de retornos. Esta metodologia utiliza uma fórmula analítica para o cálculo do VaR: VaR = M × FS × σ × HP (2.6) Onde: M: montante (em unidade monetárias) aplicado na posição FS: Fator de segurança retirado da distribuição teórica assumida (em geral, a distribuição Normal padrão) referente ao nível de confiança desejado σ: volatilidade HP: horizonte de tempo considerado (Holding Period) A estimativa da volatilidade utilizada na expressão analítica é, geralmente, retirada dos dados históricos. Uma forma simples é considerar a volatilidade como sendo o desvio -padrão dos retornos do portfólio. Porém, desta forma, todas as observações possuirão o mesmo peso, independentemente se ocorreram na véspera do cálculo ou no início do período analisado. Uma forma de capturar a dinâmica da volatilidade, dando ma ior peso para as observações mais recentes, é o alisamento exponencial (conhecido por EWMA). A previsão para a volatilidade em um instante qualquer é a média ponderada da previsão do instante anterior, usando um peso ?, e o quadrado do último retorno, com peso 1- ?. σ t = λσ t −1 + (1 − λ ) rt2−1 (2.7) O fator ? é chamado de fator de decaimento e deve ser menor que 1. O modelo EWMA é considerado como recursivo, pois baseia-se na previsão anterior. Por ter apenas um único parâmetro, este modelo é bastante robusto quanto a erros de estimativ a. O ? pode ser determinado mediante maximização da função de Verossimilhança, mas operacionalmente seria inviável calcular este fator todos os dias para todos os ativos de um grande portfólio. Na prática, o RiskMetrics utiliza o fator 0,94 para todas as séries diárias. O modelo EWMA pode ser considerado um caso especial do processo GARCH, que não será discutido neste trabalho, mas também pode ser utilizado para estimar a volatilidade dos fatores de risco com pesos diferentes para as observações 2. A principal vantagem do VaR paramétrico é a facilidade de implementação e a rapidez do cálculo, visto que o VaR é uma simples multiplicação. Porém, as premissas utilizadas nem sempre são constatadas na prática, principalmente a normalidade dos retornos dos ativos (LI, 1999). Sabe-se que os retornos extremos acontecem com mais freqüência do que os previstos pela distribuição normal. Isso faz com que as estimativas de perda fiquem bastante imprecisas. Também, não é a metodologia indicada para portfólios que contenha m ativos não lineares, como os derivativos (a variação de preço dos derivativos não é proporcional à variação do preço do ativo-objeto). Nesta metodologia, o VaR para as posições "comprada" e vendida" são iguais caso a distribuição assumida para a série de retornos seja simétrica, como é a distribuição Normal. Para o VaR de um portfólio, utiliza-se: VaR ( X + Y ) = VaR ( X ) 2 + VaR (Y ) 2 + 2 × VaR( X ) × VaR(Y ) × ρ ( X ,Y ) 2 Vide Jorion (1997). (2.8) Onde: ?(X,Y): correlação entre o retorno dos ativos X e Y 2.3.2.1 Método Delta -Normal O método Delta-Normal também pode ser considerado como uma forma de mensuração do VaR por solução analítica, pois possui uma fórmula fechada. Sua virtude é a simplicidade. Baseia -se na propriedade de que um portfólio de ativos normalmente distribuídos também é normalmente distribuído e que o valor do portfólio é uma combinação linear do valor dos ativos individuais. A perda potencial para o valor V do portfólio é calculada como: ∆V = β0 × ∆S (2.9) Onde: β 0 : sensibilidade da carteira às mudanças de preço, avaliada a partir do preço atual, que depende dos preços atuais de cada ativo (S0). A suposição de normalidade permite o cálculo do β do portfólio como a média dos β individuais. ∆S: mudança potencial nos preços Um benefício essencial deste método está no fato de requerer o cálculo do valor do portfólio apenas uma vez, a partir da posição atual e dos preços atuais de cada ativo. Logo, o método Delta-Normal adapta-se bem aos portfólios formados por muitos ativos ou fatores de risco. Entretanto, se este possuir opções (ou outro ativo não linear) a abordagem de delta pode apresentar vários problemas: o delta pode mudar muito depressa ou ser diferente para movimentos ascendentes e descendentes e a pior perda pode não corresponder às realizações extremas do preço dos ativos-objetos. Uma aproximação para este método, tentando adicionar ao modelo riscos diferentes do risco de delta, é a utilização da expansão de Taylor e das "gregas" 3. Assim, o VaR de um derivativo pode ser mensurado pela equação: VaRd = ∆ × VaRa − 1 × Γ × VaRa 2 2 (2.10) Onde: ∆ e Γ são as derivadas de primeira e segunda ordem do preço do derivativo em relação ao preço do ativo-objeto oriundas da expansão de Taylor. VaR a: VaR do ativo-objeto de origem do derivativo Este método é indicado para derivativos de um único ativo-objeto, mas torna-se ineficiente para a mensuração dos riscos de um portfólio em que os ativos são correlacionados (devido a não linearidade dos derivativos, não se pode utilizar a matriz de correlação tradicional). 2.3.3 VaR por Simulação de Monte Carlo com incorporação da Amostragem Descritiva e Amostragem por Importância O cálculo de VaR por simulação de Monte Carlo não se prende às premissas da metodologia do VaR paramétrico nem à suposição de que o comportamento futuro irá repetir o comportamento passado, principais desvantagens das outras metodologias. Porém, por se tratar de um método que necessita intensivamente de recursos computacionais e repetições de procedimentos, seus cálculos podem ser lentos e com implementação difícil e cara. Outro ponto importante, é que os fatores de risco devem ser modelados por modelos estocásticos, o que exige profissionais qualificados e a escolha do modelo mais apropriado para cada situação. "Apesar de tudo, os métodos por simulação de Monte Carlo são considerados os mais robustos e os mais poderosos para o cálculo do Value-a t-Risk , pois contempla m uma grande variedade de riscos financeiros. Todas as variáveis dos modelos podem ser tratadas como probabilísticas caso isso venha a ser de interesse." (SALIBY e ARAÚJO, 2001) 3 Vide Hull (2003) O cálculo básico do VaR por simulação de Monte Carlo envolve os seguintes passos: 1. Escolher um processo estocástico para simular os preços futuros de cada ativo ou fator de risco do portfólio; 2. Estimar as volatilidade e correlações entre os ativos e/ou fatores de risco que compõem os modelos estocásticos; 3. Gerar uma pseudo-seqüência Ε 1, ..., Ε N , a partir da qual serão realizadas as simulações; 4. Simular os preços futuros dos ativos ou fatores de risco do portfólio através do processo estocástico já selecionado e com a pseudo-seqüência gerada, levando-se em consideração as correlações dos ativos para o horizonte de tempo de interesse; 5. Caso o portfólio tenha derivativos, utilizar um modelo de precificação para avaliar seus preços em função dos valores encontrados na simulação (passo anterior); 6. Repetir os passos 2 a 5 tantas vezes quanto necessário, até se obter uma amostra suficientemente grande para que se possa gerar a distribuição de probabilidade do valor do portfólio. Ao nível de confiança desejado (1-α)%, o VaR é o valor do percentil α% (para posição "comprada") ou percentil (1-α )% (para posição "vendida") da série de retornos do portfólio gerada pela simulação. Diz-se que uma variável segue um processo estocástico quando seu valor é incerto e variável dependendo de um parâmetro, em geral do tempo. O modelo estocástico de maior utilização no mercado financeiro para representar o retorno de um ativo-objeto é o movimento geométrico browniano - processo inicialmente utilizado na física para descrever o movimento de uma partícula sujeita a choques de outras moléculas. Este modelo pode ser representado pela equação diferencial estocástica a seguir: dSt = µdt + σdz t St (2.11) Onde: St : preço do ativo-objeto no instante t; dSt / St : taxa de retorno do ativo-objeto µ: esperança da taxa de retorno do ativo-objeto dt: intervalo de tempo σ: volatilidade da taxa de retorno do ativo-objeto dzt: variável aleatória com distribuição Normal (0;dt) O movimento geométrico browniano é composto por dois termos: o primeiro (µdt) é determinístico e representa a tendência seguida pelos retornos; o segundo (σdzt) é aleatório com distribuição Normal (0; σ2 dt) e representa a volatilidade em torno da tendência. O termo dzt segue um Processo de Wiener, e pode ser substituído por: dzt = εt dt (2.12) Onde: ε t: variável aleatória Normal padrão dzt é independente para dois intervalos de tempo distintos Para encontrar o valor se St em (2.7) é necessário resolver a equação através de integrais. Contudo, a integração desta equação diferencial estocástica é muito complexa e não segue as regras básicas de cálculo clássico. Uma alternativa é a aplicação da Integral de Itô, que apresenta uma maneira de somar incrementos aleatórios durante o tempo 4. A solução encontrada adotando-se a hipótese de neutralidade de risco (retorno do ativo sendo igual à taxa de juros livre de risco) é: St = St − 1e( Rf −σ 2 / 2) dt +σ dt εt (2.13) Onde: Rf: taxa livre de risco É importante mencionar que a equação (2.13) baseia -se na hipótese de eficiência dos mercados, pois o preço atual reflete toda a informação passada. Além disso, assume-se que os mercados respondem imediatamente ao surgimento de novas informações. No passo 2, a volatilidade pode ser calcula pelo desvio-padrão de retornos anteriores ou utilizando-se o modelo EWMA ou GARCH, como discutido na seção 2.3.2. No passo 3, os valores aleatórios são chamados de "pseudo-aleatórios" porque são gerados a partir de uma função pré-estabelecida e podem ser replicados. Os geradores de valores aleatórios de qualquer software geram valores desta natureza, pois necessitam de algoritmos determinísticos. Na prática, não existem números aleatórios no ambiente computacional, uma vez que o computador é essencialmente determinístico. As técnicas de redução de variância são utilizadas no passo 3 (geração da seqüência pseudo-aleatória) e no processo estocástico utilizado para melhorar a precisão das estimativas resultantes da simulação. A incorporação da Amostragem Descritiva e da Amostragem por Importância (já detalhados em seções anteriores) modificam a expressão 2.13 para: St = St − 1e( Rf −σ 2 / 2 )dt +σ dt (εt' − C ) (2.14) Onde: ε't: variável aleatória Normal padrão gerada pela Amostragem Descritiva C: valor do deslocamento proposto na Amostragem por Importância Com a incorporação destas técnicas o VaR não será mais um determinado percentil como descrito no passo 6, mas sim a perda que tiver sua razão de Verossimilhança acumulada mais aproxima da estatística a x N ou (1- a) x N para uma posição de venda. Pode -se também usar a interpolação para determinar o VaR ao invés da perda mais próxima. O VaR de um portfólio é determinado pela equação (2.8), igualmente ao VaR paramétrico. 4 Uma demonstração completa encontra-se em Hull (2003) 2.3.4 Modelo de Mistura de Distribuições Gibson (2001) apresenta o modelo de mistura de distribuições para a incorporação de eventos raros ou inesperados no cálculo do VaR. Segundo o autor, pouquíssimos modelos capturam o risco dos acontecimentos eventuais, que podem ser, por exemplo, a notícia de um default ou um atentado terrorista. Na prática, o motivo pelo qual se obtém um retorno excessivamente baixo ou alto não é relevante, importando-se apenas suas propriedades estatísticas. Inicialmente, pode-se considerar que um fator de risco deva ser dividido em dois componentes. O primeiro, chamado de ordinário, segue a distribuição dos dados sem a interferência de saltos para cima ou para baixo. O outro componente é a representação dos choques causados pelos saltos. Então, um fator de risco pode ser modelado da seguinte forma: r = r o + rS (2.15) Onde: ro : segue a distribuição ordinária dos dados rS : componente influenciado pelos saltos, segue uma distribuição trinomial definida como: 0, com probabilidade 1-p-q rS = -D, com probabilidade p (2.16) U, com probabilidade q Assim, a distribuição de r é equivalente à mistura de três distribuições: r = (1-p-q) r o + p rD + q rU (2.17) Onde: rD e rU possuem a mesma distribuição ordinária de ro com médias defasadas em -D e U, respectivamente. É importante mencionar que r o e rS devem ser independentes. Este modelo captura a assimetria quando D é diferente de U ou p é diferente de q. Assumindo que a distribuição ordinal é Fr o(x;µ,?), onde µ é a média e ? os demais parâmetros necessários (por exemplo, o desvio-padrão no caso da distribuição Normal), pode -se escrever: Fr(x) = (1-p-q) Fro(x;µ;?) + p Fro(x; µ-D;?) + q Fro (x; µ+U;?) (2.18) Na prática, para o calculo do VaR, é necessário a resolução desta equação numericamente sendo Fr a distribuição que melhor se aproxime dos dados. Assumindo normalidade, tem-se para um nível de 95% de confiança: − ( u− µ )2 1 0,95 = (1 − p − q )∫ e − ∞ σ 2π x 2σ2 − (u− µ −D )2 1 du + p ∫ e −∞ σ 2π x 2σ 2 − ( u− µ +U )2 1 du + q ∫ e − ∞ σ 2π x 2σ 2 du (2.19) O valor de x (limite superior das integrais) é o novo fator de segurança para o cálc ulo do VaR pela metodologia paramétrica. Uma alternativa para a resolução da equação (2.19), utilizada neste trabalho, é o uso da simulação de Monte Carlo diretamente aplicada à equação (2.15), tratando-se de um problema bidimensional: uma variável aleatória é sorteada para o valor de r o segundo a distribuição ordinária e outra variável aleatória para a distribuição trinomial de rS. O efeito da incorporação de rS com distribuição trinomial no modelo é a melhor representação das caudas da distribuição, fazendo com que a mistura das três distribuições, vista na equação (2.16), fique mais próxima da distribuição real dos retornos financeiros. Este efeito pode ser visualizado na Figura 3. Figura 3 - Efeito de rS na distribuição do fator de risco do modelo Distribuição dos dados ordinários Distribuição dos saltos para baixo Distribuição dos saltos para cima A estimação dos parâmetros envolve a estimação de D, U, p e q da equação (2.16) e dos demais parâmetros necessários para o uso da distribuição ordinária. Ao contrário de outros modelos de mistura de distribuições que utilizam cálculos estatísticos avançados, a estimação dos parâmetros neste modelo é bastante simples e intuitiva, baseando-se nos dados históricos. Como a metodologia inicialmente foi apresentada para a incorporação do efeito de eventos raros na distribuição de probabilidade dos fatores de risco, é necessário uma grande quantidade de dados para a estimação dos parâmetros. No Brasil, isso pode ser um problema, pois, apesar da facilidade de se obter séries de dados financeiros, mudanças de regimes e cenários econômicos podem tornar períodos de tempo incomparáveis. Uma sugestão é o agrupamento de ativos com características semelhantes. Primeiramente, deve-se dividir o conjunto de dados em três grupos: saltos para cima, saltos para baixo e retornos sem saltos. Esta divisão pode seguir qualquer critério coerente. Uma sugestão, seguida neste trabalho, é o corte a partir de um número arbitrário de desvios-padrão. Considera-se como salto um valor acima ou abaixo do valor determinado. Vale ressaltar que a qualidade do modelo dependerá muito desta escolha. As probabilidades p e q são estimadas como a porcentagem de retornos nos grupos de saltos para baixo e para cima, respectivamente. Os valores de D e U são estimados como a média dos retornos destes dois grupos. Novamente, para o VaR de um portfólio utiliza -se a equação (2.8). 2.4 Geração de Variáveis Aleatórias Correlacionadas Na prática, os portfólios são compostos por mais de uma fonte de risco ou ativo financeiro. Quando se utiliza a simulação para descrever o comportamento destes fatores de risco, deve -se levar em consideração a correlação entre eles. A fatoração de Cholesky é o método mais conhecido para a incorporação da correlação na geração de seqüências aleatórias. Genericamente, para três variáveis, considere que a estrutura de correlação possa ser representada pela multiplicação das matrizes TT', onde T é triangular inferior. 1 ρ12 ρ13 ρ12 1 ρ23 ρ13 a 11 0 ρ23 = a12 a 22 1 a13 a 23 0 a11 a12 0 x 0 a 22 a33 0 0 a13 a112 a11a12 a 11a13 2 2 a23 = a11a12 a12 a22 a13a12 + a23a 22 2 a33 a11a13 a13 a12 + a 23 a22 a132 + a23 + a 332 E assim tem -se: a11 = 1 a 23 = a12 = ρ12 a13 = ρ13 a 22 = (1 − ρ122 )1 / 2 ρ23 − ρ12 ρ13 (1 − ρ122 ) 1/ 2 2 ρ23 − ρ12 ρ13 2 a 33 = 1 − ρ13 − (1 − ρ122 )1/ 2 1/ 2 Pela fatoração de Cholesky, os valores aleatórios modificados (com a incorporação das correlações) são obtidos pela multiplicação entre a matriz T (com valores encontrados acima) e os valores aleatórios originais. ε1' 1 ' ε2 = ρ12 ε3' ρ 13 0 (1 − ρ122 )1 / 2 ρ23 − ρ12 ρ13 (1 − ρ122 )1 / 2 ε1 0 0 x ε2 2 1/ 2 ρ −ρ ρ ε3 1 − ρ132 − 23 212 1/132 (1 − ρ12 ) (2.20) É importante perceber que a fatoração de Cholesky modifica os valores aleatórios sorteados para gerar a correlação esperada. Assim, as técnicas de amostragem estratificadas (como é o caso da Amostragem Estratificada, do Hipercubo Latino e da Amostragem Descritiva) têm suas características destruídas. Iman e Conover (1982) propuseram um método para induzir a correlação ordinal entre as variáveis aleatórias no qual estas são mantidas, permitindo o uso de qualquer processo de estratificação e amostragem de variáveis aleatórias. Além disso, pode ser aplicada a qualquer distribuição, enquanto que a fatoração de Cholesky deve ser utilizada apenas em casos de Normalidade. Araújo (2001) descreve o método da seguinte forma: Supondo uma matriz U com dimensões n x k, onde as colunas representam variáveis aleatórias distribuídas livremente, seguindo qualquer esquema de estratificação. O objetivo é fazer com que a matriz de correlação de rank de U seja próxima da matriz de correlação desejada (C). Define-se, também, a matriz R de mesmas dimensões de U, onde os valores de cada coluna são uma permutação aleatória de ? -1(i/(n+1)) para i=1,...,n e ? -1 representando a inversa da distribuição Normal padrão acumulada. Observa -se que a matriz de correlação de R é próxima a matriz identidade, uma vez que as colunas são independentes. Em seguida, decompõem-se C em PP', como na fatoração de Cholesky (P é uma matriz triangular inferior). Calcula -se R* = RP' com matriz de correlação ordinal próxima a matriz de correlação C. Finalmente, ordena -se as colunas de U de forma que o valor em cada coluna tenha a mesma ordem de R*. Assim, U apresentará a mesma correlação ordinal que R*, que por sua vez é próxima a C. Em resumo, o algoritmo apresentado ordena os valores estratificados (sem alterá-los) de forma que sua matriz de correlação ordinal seja próxima da matriz de correlação desejada. Outros métodos de geração de variáveis aleatórias correlacionadas são o Singular Value Decomposition (J.P.Morgan, 1996) e o algoritmo de Gram-Schmidt (Owen, 1994). 2.5 Teste de Proporção de Falhas Proposto por Kupiec (1995), o intervalo para a proporção de falhas no cálculo do VaR é baseado na distribuição Qui-Quadrado com 1 grau de liberdade. Define -se como falha no cálculo do VaR o dia em que o retorno observado foi menor (maior) que o VaR calculado para um posição comprada (vendida) no ativo-objeto em questão. Com um nível de confiança de (1-a)%, espera -se a ocorrência de a % de falhas. O teste de proporção de falhas permite a comparação entre as diversas metodologias de cálculo do VaR, sendo a metodologia que mais se aproximar de a % de falhas a mais adequada para os dados utilizados. Vale ressaltar que uma elevada porcentagem de falhas representa a exposição a um nível de risco maior do que se espera, enquanto que uma baixa porcentagem de falhas representa a sub-utilização dos recursos devido ao controle excessivo aos traders. Este teste para a proporção de falhas baseia -se somente na freqüência de erros, ou seja, mede se a quantidade de erros é coerente com a quantidade esperada. Porém, alguns autores (como Blanco e Ihle, 1998; Lopez, 1998) defendem que além da freqüência deve ser medido a magnitude dos erros. Ou seja, a diferença entre a máxima perda esperada (VaR) e o valor verdadeiramente observado. A média destas diferenças é conhecida como CVaR. Neste trabalho, a magnitude dos erros será observada quando houver empate na proporção de falhas. Sendo assim, um critério de desempate para escolha da metodologia de cálculo do VaR mais precisa. As medidas acima referidas são válidas para a comparação das metodologias de cálculo para um mesmo nível de confiança. Ou seja, dado um certo nível de confiança, pode-se decidir qual delas é a melhor. Porém, neste trabalho, analisa-se o comportamento das metodologias paras diversos níveis de confiança, sendo necessário a construção de um índice de desempenho geral. Este índice é calculado como o somatório das diferenças absolutas entre os percentuais de falha observado e esperado normalizadas para os diversos níveis de confiança. Supondo que uma determinada metodologia obtenha os valores 5,20%, 2,75% e 0,80% como proporções de falha para os níveis de confiança de 5%, 2,5% e 1%, tem-se que o índice de desempenho geral é: 5,20 − 5 2 ,75 − 2 ,5 0,80 − 1 + + = 0,34 5 2 ,5 1 Este índice permitirá a comparação geral (para todos os níveis de confiança) das metodologias em análise. É fácil perceber que quanto menor o índice, melhor é o resultado. 3. Metodologia Nesta seção, serão apresentadas as classificações deste trabalho em categorias quanto aos fins e meios empregados, serão discutidos o universo e amostra de dados utilizados para a formação dos portfólios de ativos financeiros e suas formas de coleta e tratamento. Também, são apresentados as principais limitações dos métodos e ferramentas utilizadas. 3.1 Tipo de Pesquisa O estudo a ser realizado consistirá na implementação de dois modelos para o cálculo do VaR: modelo de Mistura de Distribuições e o modelo de simulação de Monte Carlo com a combinação das técnicas de Amostragem Descritiva e Amostragem por Importância. Ambos possuem fácil entendimento e baixa complexidade na estimação de seus parâmetros e forma de cálculo. A comparação entre eles e as formas tradicionais de cálculo do VaR será realizada pelo teste de proporção de falhas, pela variabilidade dos resultados medido pelo desvio-padrão e pela porcentagem de erros de sub-aditividade. Este trabalho pode ser classificado em relação a dois aspectos: quanto aos fins e quanto aos meios empregados. No primeiro aspecto, este trabalho trata -se de uma pesquisa exploratória, visto que o experimento é relacionado à descobertas recentes e será aplicada em uma situação ainda não apresentada na literatura. Quanto aos meios empregados, pode-se classificar este trabalho em duas categorias. É uma pesquisa de laboratório, pois será realizada através de uso intensivo de computador e suas ferramentas (programas de simulação, planilhas de dados, internet, etc.). Também é uma pesquisa experimental, uma vez que permitirá analisar o fenômeno da superioridade de um método ao outro. 3.2 Experimento Realizado O experimento a ser realizado, neste trabalho, será o cálculo do VaR diário para as posições de compra e de venda de uma carteira composta igualmente pelas três ações de maior participação no IBOVESPA (quadrimestre de maio a agosto de 2004): TNLP4 (Telemar), PETR4 (Petrobrás) e EBPT4 (Embratel). Juntas, estas três ações, representam aproximadamente 27% do índice. Também será realizado uma análise descritiva das três ações separadamente. O período selecionado foi de 02 de janeiro de 2002 até 31 de março de 2004, totalizando uma amostra de 557 dias de negociação. O período não foi maior, pois as metodologias para o cálculo do VaR propostas, principalmente o Modelo de Mistura de Distribuição, precisam de um período de dados anterior para estimação dos parâmetros necessários no cálculo. As metodologias utilizadas no cálculo do VaR serão as metodologias apresentadas na seção do "Referencial Teórico": histórica, paramétrica, Modelo de Mistura de Distribuições (utilizando Amostragem Aleatória Simples e Amostragem Descritiva) e por Simulação de Monte Carlo (utilizando a Amostragem Aleatória Simples, a Amostragem Descritiva e a combinação da Amostragem Descritiva com a Amostragem por Importância). Serão utilizados diferentes níveis de confiança: 95%, 97,5%, 99% e 99,5%. Os resultados serão comparados pelo teste de proporção de falhas, magnitude dos erros, variabilidade (para os modelos baseados em simulação), quantidade de erros de sub-aditividade e índice de desempenho geral conforme definido na seção 2.5. 3.3 Coleta de Dados Para o cálculo dos parâmetros de entrada dos modelos utilizados serão necessários os dados históricos das três ações citadas, taxa livre de risco e de um gerador de números aleatórios. Os dados históricos foram coletados no banco de dados do site Yahoo Finance como valores de fechamento diários já ajustados para operações de split, merge, pagamento de dividendos e etc. O valor de taxa livre de risco foi consid erada constante em 16% ao ano durante todo o período de análise. Na geração dos valores aleatórios será utilizado o gerador do software Matlab. 3.4 Parâmetros Estimados Os modelos propostos e os modelos tradicionais de cálculo do VaR baseiam-se na estimação de alguns parâmetros. Esta seção tem como objetivo esclarecer a forma de estimação e os dados utilizados. O modelo de Mistura de Distribuições utiliza dados históricos para a estimação de seus parâmetros. Como foi criado para a incorporação de eventos raros, existe a necessidade de utilizar grande quantidade de dados. Para um melhor ajuste do modelo às mudanças no cenário econômico, as estimativas dos parâmetros p, q, D e U serão calculadas anualmente. Por exemplo, para 2002 serão utilizados os dados de 01 de junho de 1994 (ou 21 de setembro de 1998 para EBTP4 e TNLP4) até 31 de dezembro de 2001 e estas estimativas serão válidas para todos os cálculos do VaR durante o ano de 2002. Para 2003 e 2004, incorporam-se os anos de 2002 e 2003 sem retirar nenhum dos dados iniciais. Neste modelo, também, é necessário determinar o valor do corte que divide os retornos em saltos para cima, baixo ou sem saltos. Como foi mencionado na seção 2.3.4, uma boa medida de corte é determinar uma quantidade de desvios-padrão da média. Evitando simplesmente uma determinação arbitrária e buscando um melhor ajuste do modelo aos dados, será utilizado o corte que otimiza (em relação ao teste de proporção de falhas) a amostra do ano anterior ao cálculo. Ou seja, calcula-se o VaR para todos os dias de negócio de 2001, com as estimativas de p, q, D e U conforme mencionadas acima, com valores de corte variando de 1,5 até 5 desvios-padrão (de 0,5 em 0,5 unidades). Nos cálculos do ano 2002 será utilizado o critério de corte que me lhor se ajustou em 2001. Da mesma forma ocorrerá nos anos subseqüentes. Dessa forma, utiliza-se os dados passados para calibrar o modelo anualmente, possibilitando um ajuste à mudanças e maior precisão no modelo. Exemplo para o ano 2002: utilizando os critérios de corte nos retornos de 1,5, 2, 2,5, ..., 5 desvios-padrão (ou seja, 8 critérios), calcula -se as estimativas de p, q, D e U com os dados de 01 de junho de 1994 até 31 de dezembro de 2001. Usando o teste de proporção de falhas para o VaR de todos os dias de negociação de 2001 (o ano anterior ao ano que estamos interessados) escolhe-se o critério a ser utilizado em 2002. Os parâmetros estimados escolhidos serão utilizados para todos os dias de 2002. Após este período, calcula -se novamente as estimativas de p, q, D e U incorporando os dados reais de 2002 ao período de teste e encontra-se o melhor critério de corte que deveria ter sido usado em 2002. Este critério será utilizado em 2003. Para o modelo de simulação com a técnica de Amostragem por Importância, necessita -se estimar o valor do deslocamento da curva Normal para a esquerda (no caso de posições de compra) ou para a direita (no caso de posições de venda). Da mesma forma que o Modelo de Mistura de Distribuições, utiliza -se o ano anterior ao ano de interesse como período de backtest. Ou seja, otimiza-se em relação ao teste de proporção de falhas o modelo com os dados do ano anterior ao ano de interesse. Para o valor do deslocamento, permite -se a variação na primeira casa decimal. Quanto aos modelos tradicionais: para a metodologia histórica utiliza-se uma janela móvel de 50 dias de negócio para o cálculo do percentil e para a metodologia paramétrica faz-se uso da distribuição Normal. Para as metodologias que utilizam a simulação de Monte Carlo (incluindo o Modelo de Mistura de Distribuições) realizamse 10 corridas de 1.000 simulações cada.Vale lembrar que quando utilizada a técnica de Amostragem Descritiva, os valores de entrada do modelo de simulação são sempre os mesmos. Assim, quando calcula-se o VaR apenas para um ativo, tem-se um problema unidimensional e todas as corridas possuem o mesmo resultado. Porém, para um portfólio, as corridas possuem diferentes resultados dado a permutação dos mesmos valores de entrada entre os ativos que o compõe. Em todos os casos, a volatilidade será estimada pelo desvio-padrão dos retornos diários numa janela móvel de 50 dias de negociação. A geração dos valores aleatórios nas simulações leva em consideração a correlação entre as três ações fazendo uso da fatoração de Cholesky e do algoritmo de Iman e Conover para o caso da Amostragem Descritiva, conforme seção 2.4. 3.5 Tratamento dos Dados As sub-rotinas para simulação das trajetórias dos ativos, geração dos valores pseudo-aleatórios e o cálculo do VaR serão desenvolvidas em linguagem de programação no software Matlab versão 6.5. Os algoritmos desenvolvidos nesta ferramenta possuem processamento bastante rápido, são de fácil manipulação e compreendem todas as funções estatísticas e matemáticas necessárias já pré-definidas. 3.6 Limitações dos Métodos Este trabalho apresenta algumas limitações relativas às metodologias e ferramentas computacionais utilizadas. A seção está dividida nestas duas partes. 3.6.1 Limitações Metodológicas A metodologia exploratória apresenta a limitação da ausência de generalização dos resultados obtidos. Normalmente, os experimentos são casos específicos ou que despertam o interesse do pesquisador. As conclusões obtidas neste trabalho só podem ser aplicadas, com segurança, nos dados aqui analisados. 3.6.2 Limitações de Hardware e Software A simulação é uma técnica que necessita de intenso uso do ferramental computacional, tanto hardware (importante no processamento) como software (importante na programação das sub-rotinas). No início do uso das técnicas de simulação de Monte Carlo, década de 40, a pequena disponibilidade de recursos computacionais era a principal limitação do método. Porém, cada vez mais este fator deixa de ser um limitante para a utilização da simulação. A precisão de um processo de simulação é dependente da quantidade de simulações executadas, ou seja, do número de repetições do experimento ou cálculo. Assim, o hardware utilizado pode representar uma limitação, uma vez que quanto mais repetições maior será o consumo deste recurso. Quanto às limitações do software, pode-se citar a falta de conhecimento e acesso de muitos estudantes e pesquisadores ao software Matlab, que impossibilita uma maior penetração do trabalho (se comparado com o Exc el, por exemplo). No entanto, o Matlab não possui muitas das limitações dos demais programas, como limitações "físicas" de dados, buggs de funções e outras. 4. Resultados 4.1 Análise Exploratória dos Dados Antes de iniciar os cálculos do VaR, é importante fazer uma análise descritiva das séries de dados utilizadas no experimento. Vale lembrar que o período de cálculo do VaR é de janeiro de 2002 até o dia 31 de março de 2004. A Figura 4 apresenta a evolução do preço da ação PETR4. Houve um aumento de 82,4% entre o primeiro e o último dia da amostra. Figura 4 - Evolução dos preços de fechamento da ação PETR4 no período de 02 de janeiro de 2002 a 31 de março de 2004 90,00 80,00 70,00 R$ 60,00 50,00 40,00 30,00 Mar-30-04 Mar-09-04 Feb-13-04 Jan-23-04 Jan-02-04 Dec-08-03 Oct-27-03 Nov-17-03 Oct-06-03 Sep-15-03 Aug-25-03 Jul-14-03 Aug-04-03 Jun-20-03 May-29-03 Apr-14-03 May-08-03 Mar-24-03 Feb-27-03 Feb-06-03 Jan-14-03 Dec-18-02 Nov-27-02 Oct-15-02 Nov-05-02 Sep-24-02 Sep-03-02 Jul-23-02 Aug-13-02 Jul-01-02 Jun-10-02 Apr-25-02 May-17-02 Apr-04-02 Mar-11-02 Feb-18-02 Jan-23-02 Jan-02-02 20,00 Jan/02 a Mar/04 Os valores de assimetria e curtose, mostrados na Tabela 1, indicam que a amostra possui uma ponta assimétrica que se estende em direção dos valores mais negativos e excesso de curtose comparado à distribuição Normal. Estas características são facilmente visualizadas no histograma, Figura 5, e no QQ Plot, Figura 6. Tabela 1 - Estatísticas descritivas da série de retornos da ação PETR4 no período de 02 de janeiro de 2002 a 31 de março de 2004 PETR4 Observações Média 557 0,11% Desvio Padrão 2,16% Mínimo Máximo Assimetria -9,82% 8,43% -0,191 Excesso de Curtose 1,686 Figura 5 - Histograma da série de retornos da ação PETR4 no período de 02 de janeiro de 2002 a 31 de março de 2004 100 80 60 40 20 0 5 ,07 3 ,06 0 ,05 8 ,03 5 ,02 3 ,01 0 ,00 12 -,0 25 -,0 37 -,0 50 -,0 62 -,0 75 -,0 87 -,0 00 -,1 PETR4 Figura 6 - QQ Plot dos retornos da ação PETR4 no período de 02 de janeiro de 2002 a Normal31Q-Q de março Plotdeof2004 PETR4 ,08 ,06 ,04 Expected Normal Value ,02 0,00 -,02 -,04 -,06 -,08 -,2 -,1 Observed Value 0,0 ,1 As características observadas nos dados de retorno da ação PETR4 são compatíveis com as características já mencionadas para o problema das "caudas gordas". Observa-se, na Figura 5, que a curva da distribuição Normal subestima a proporção de valores nas caudas, principalmente no lado esquerdo. Pela Figura 6, observa-se que os pontos das extremidades são os mais distantes da reta que caracteriza a distribuição Normal. Apesar destes desvios, a amostra pode ser considerada Normalmente distribuída pelo teste de Kolmogorov-Smirnov com 95% de confiança (p-valor de 34,2%). Quanto à ação EBTP4, observa -se na Figura 7 dois períodos bastante distintos: primeiramente uma forte queda no preço e depois a recuperação. A diferença entre o primeiro e último dia da amostra é de -10,6%. Figura 7 - Evolução dos preços de fechamento da ação EBTP4 no período de 02 de janeiro de 2002 a 31 de março de 2004 12,00 10,00 R$ 8,00 6,00 4,00 2,00 Mar-30-04 Mar-09-04 Feb-13-04 Jan-23-04 Jan-02-04 Dec-08-03 Oct-27-03 Nov-17-03 Oct-06-03 Sep-15-03 Aug-25-03 Jul-14-03 Aug-04-03 Jun-20-03 May-29-03 Apr-14-03 May-08-03 Mar-24-03 Feb-27-03 Feb-06-03 Jan-14-03 Dec-18-02 Nov-27-02 Oct-15-02 Nov-05-02 Sep-24-02 Sep-03-02 Jul-23-02 Aug-13-02 Jul-01-02 Jun-10-02 Apr-25-02 May-17-02 Apr-04-02 Mar-11-02 Feb-18-02 Jan-23-02 Jan-02-02 0,00 Jan/02 a Mar/04 Observa-se na Tabela 2, que os retornos desta ação possuem uma amplitude muito maior que os retornos da ação PETR4, estando dentro do intervalo de -29,3% e 20,9%. A assimetria e excesso de curtose também são mais acentuados. Tabela 2 - Estatísticas descritivas da série de retornos da ação EBTP4 no período de 02 de janeiro de 2002 a 31 de março de 2004 Ebtp4 Observações Média 557 -0,02% Desvio Padrão 4,93% Mínimo Máximo Assimetria -29,26% 20,85% -0,665 Excesso de Curtose 4,751 Figura 8 - H istograma da série de retornos da ação EBTP4 no período de 02 de janeiro de 2002 a 31 de março de 2004 140 120 100 80 60 40 20 0 -,300 -,200 -,250 -,100 -,150 ,000 -,050 ,100 ,050 ,200 ,150 EBTP4 Figura 9 - QQ Plot dos retornos da ação EBTP4 no período de 02 de janeiro de Normal2002 Q-Q a 31 Plot de março of EBTP4 de 2004 ,2 Expected Normal Value ,1 0,0 -,1 -,2 -,3 -,2 Observed Value -,1 -,0 ,1 ,2 ,3 Através do Histograma, Figura 8, e do QQ Plot, Figura 9, percebe-se que existem alguns retornos, principalmente negativos, bastante diferentes dos valores esperados pela distribuição Normal. Diferentemente do teste realizado com a ação da Petrobrás, não se pode considerar esta série Normalmente distribuída pelo teste de Kolmogorov-Smirnov com 95% de confiança (p-valor de 01,4%). A ação TNLP 4 apresentou um crescimento entre o primeiro e último dia da amostra de 48,3%, conforme Figura 10. Este aumento não foi maior devido a uma queda nos preços a partir do final de janeiro de 2004, quando a série atinge seu máximo de R$ 50,19. Figura 10 - Evolução dos preços de fechamento da ação TNLP4 no período de 02 de janeiro de 2002 a 31 de março de 2004 55,00 50,00 45,00 40,00 35,00 30,00 25,00 20,00 15,00 Mar-17-04 Feb-26-04 Jan-15-04 Feb-04-04 Dec-22-03 Dec-02-03 Oct-23-03 Nov-12-03 Oct-03-03 Sep-15-03 Aug-26-03 Jul-17-03 Aug-06-03 Jun-26-03 Jun-05-03 Apr-25-03 May-16-03 Apr-03-03 Mar-14-03 Jan-30-03 Feb-20-03 Jan-09-03 Dec-16-02 Nov-26-02 Oct-16-02 Nov-05-02 Sep-26-02 Sep-06-02 Jul-30-02 Aug-19-02 Jul-10-02 Jun-19-02 May-29-02 Apr-18-02 May-09-02 Mar-28-02 Mar-06-02 Jan-22-02 Feb-14-02 Jan-02-02 10,00 A Tabela 3 indica que esta é a série que possui valores de assimetria e excesso de curtose mais próximos de zero, ou seja, dos valores teóricos da distribuição Normal. Tabela 3 - Estatísticas descritivas da série de retornos da ação TNLP4 no período de 02 de janeiro de 2002 a 31 de março de 2004 TNLP4 Observações Média 557 0,02% Desvio Padrão 2,45% Mínimo Máximo Assimetria -8,28% 8,90% -0,070 Excesso de Curtose 0,630 Figura 11 - H istograma da série de retornos da ação TNLP4 no período de 02 de janeiro de 2002 a 31 de março de 2004 70 60 50 40 30 20 10 0 1 ,08 9 ,06 6 ,05 4 ,04 1 ,03 9 ,01 6 ,00 06 -,0 19 -,0 31 -,0 44 -,0 56 -,0 69 -,0 81 -,0 Figura 12 - QQ PlotTNLP4 dos retornos da ação TNLP4 no período de 02 de janeiro de Normal Q-Q of TNLP4 2002 a 31Plot de março de 2004 ,08 ,06 ,04 Expected Normal Value ,02 0,00 -,02 -,04 -,06 -,08 -,1 Observed Value 0,0 ,1 Observa-se que das três séries, a ação TNLP4 é a mais próxima da distribuição Normal, apresentando os pontos do Histograma (Figura 11) e QQ Plot (Figura 12) mais próximos dos valores teóricos esperados. No teste de Kolmogorov-Smirnov, seu p-valor é o mais alto (59,8%), confirmando a análise gráfica. Comparando-se as três séries de preços, tem-se que suas trajetórias seguem os mesmos movimentos: uma queda (mais acentuada na EBTP4) seguida de crescimento com maior volatilidade. As séries de retornos apresentaram médias próximas de zero, sendo a maior delas da ação PETR4 com o valor de 0,11%. Quanto ao desvio-padrão, pode-se afirmar que a ação EBTP4 apresentou o maior valor (4,93%), assim como na amplitude. É importante perceber que as três séries de retornos apresentaram assimetria negativa e excesso de curtose positivo, indicando, principalmente, a presença de valores negativos extremos. Sua principal conseqüência seria a subestimação do risco incorrido se calculado sob a suposição de Normalidade. 4.2 VaR Individual Nesta seção, apresenta-se o resultado do cálculo do VaR para os 557 dias de negócio já mencionados para os três ativos selecionados utilizando as diversas metodologias apresentadas: histórica, paramétrica (supondo distribuição Normal), modelo de Mistura de Distribuições e simulação de Monte Carlo com a utilização das técnicas de redução de variância. Estes resultados serão analisados em conjunto com as estatísticas descritivas apresentadas na seção anterior. As próximas tabelas mostram a proporção de falhas para os níveis de confiança de 95%, 97,5%, 99% e 99,5% e o desvio -padrão das simulações utilizando a Amostragem Aleatória Simples e o modelo de Mistura de Distribuições (para o caso unidimensional, o desvio-padrão das simulações utilizando a técnica de Amostragem Descritiva é zero). Para os três ativos, foram calculados os valores do VaR para as posições de compra e venda (lados esquerdo e direito da distribuição). Os valores realçados representam os mais próximos do percentual de falhas esperado em cada nível de confiança (os melhores). Quando ocorrer empate, será destacada a metodologia que apresentar menor CVaR. Os valores marcados com o asterisco estão fora do intervalo proposto por Kupiec (os piores). A última linha de cada tabela, denominada "Índice", mostra os valores do índice de desempenho geral conforme definido na seção 2.5. Tabela 4 - Intervalo de confiança para a porcentagem de falhas no cálculo do VaR proposto por K upiec para uma amostra de 557 observações Nível de Limite Confiança Inferior Superior 95% 3,30% 6,91% 97,5% 1,32% 3,90% 99% 0,30% 1,93% 99,5% 0,05% 1,19% Tabela 5 - Proporção de falhas para o cálculo do VaR diário da posição de compra de ações PETR4 no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança e metodologias discutidas 5,206 3,411 1,975 * 1,975 * 4,488 2,693 1,616 1,616 * 4,668 2,693 1,616 1,616 * 4,488 2,693 1,616 1,616 * 4,488 2,693 0,898 0,718 Mistura de Distribuições (AAS) 4,488 2,513 1,077 0,359 4,331 3,027 2,991 3,027 0,718 0,467 Histórica 95% 97,5% 99% 99,5% Índice Paramétrica Simulação (Normal) (AAS) Simulação (AD) Simulação (AD+AI) Mistura de Distribuições (AD) 4,488 2,513 0,718 0,180 1,031 Tabela 6 - Proporção de falhas para o cálculo do VaR diário da posição de venda de ações PETR4 no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança e metodologias discutidas Histórica 95% 97,5% 99% 99,5% Índice 5,566 3,232 1,975 * 1,975 * 4,331 Mistura de Paramétrica Simulação Simulação Simulação Distribuições (Normal) (AAS) (AD) (AD+AI) (AAS) 6,643 6,463 6,463 6,104 5,386 3,770 3,411 3,232 2,154 1,616 1,257 1,257 1,257 0,898 0,718 0,898 0,898 0,898 0,180 0,359 1,889 1,709 1,637 1,102 0,995 Mistura de Distribuições (AD) 5,386 1,616 0,898 0,359 0,815 Tabela 7 - Desvio-padrão (x 103) das simulações para o cálculo do VaR diário das ações PETR4 no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança Posição de Compra Nível de Simulação Confiança (AAS) 95% 97,5% 99% 99,5% 1,355 1,725 2,392 3,050 Posição de Venda Mistura de Mistura de Distribuições Distribuições (AAS) (AD) 1,505 0,530 2,692 1,771 16,151 15,893 34,919 34,068 Nível de Simulação Confiança (AAS) 95% 97,5% 99% 99,5% 1,362 1,705 2,360 3,053 Mistura de Mistura de Distribuições Distribuições (AAS) (AD) 1,595 0,695 3,454 2,711 9,595 9,212 11,597 10,534 Pode-se observar na Tabela 5 que o Modelo de Mistura de Distribuições usando a Amostragem Aleatória Simples apresentou, para os três maiores níveis de confiança, a proporção de falhas mais próxima do valor esperado e o menor CVaR quando comparado à mesma metodologia com a Amostragem Descritiva. Para o nível de confiança de 95%, a metodologia histórica obteve o melhor valor. Observa-se, também, que esta mesma metodologia apresentou valores fora do intervalo proposto por Kupiec para os dois níveis de confiança mais altos. No nível de 99,5% de confiança, todas as metodologias, exceto as três propostas, ficaram fora do intervalo de Kupiec. Estas mesmas três metodologias, também, apresentaram o índice de desempenho geral bem abaixo das demais. Já na Tabela 6, os melhores resultados foram divididos entre o Modelo de Mistura de Distribuições com os dois processos de amostragem e a simulação de Monte Carlo com a combinação das técnicas de Amostragem Descritiva e Amostragem por Importância. Novamente, a metodologia histórica obteve suas proporções de falhas fora do intervalo de Kupiec para os dois níve is mais altos de confiança. Observando a Tabela 7, percebe-se que o desvio-padrão do Modelo de Mistura de Distribuições é mais elevado que a medida da simulação de Monte Carlo básica, chegando a ser mais de 10 vezes maior. Entre os dois modelos de Mistura de Distribuições, observa-se que o uso da Amostragem Descritiva reduz o desvio-padrão de forma significativa apenas nos níveis de confiança de 95% e 97,5%. Observa-se, também, que o desvio-padrão aumenta conforme aumenta o nível de confiança. Fazendo uma comparação entre as posições de compra e venda, observa -se que para a metodologia clássica de simulação não existem diferenças significativas. Porém, para o outro modelo, existem grandes diferenças nos dois níveis mais elevados de confiança (posição de compra apresenta valores muito superiores a posição de compra).. Tabela 8 - Proporção de falhas para o cálculo do VaR diário da posição de compra de ações EBTP4 no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança e metodologias discutidas 5,745 3,052 1,795 1,795 * 5,925 3,770 1,975 * 1,795 * 5,925 3,770 1,975 * 1,616 * 5,925 3,770 1,975 * 1,795 * 3,914 2,873 1,436 0,898 Mistura de Distribuições (AAS) 4,668 2,693 1,616 0,718 3,755 4,258 3,900 4,258 1,598 1,196 Histórica 95% 97,5% 99% 99,5% Índice Paramétrica Simulação Simulação Simulação (Normal) (AAS) (AD) (AD+AI) Mistura de Distribuições (AD) 4,488 2,693 1,616 0,718 1,232 Tabela 9 - Proporção de falhas para o cálculo do VaR diário da posição de venda de ações EBTP4 no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança e metodologias discutidas 5,925 3,052 1,616 1,616 * 3,411 2,513 1,077 0,718 3,411 2,513 1,077 0,718 3,411 2,513 1,077 0,718 5,745 2,873 1,077 0,359 Mistura de Distribuições (AAS) 3,411 1,975 0,898 0,359 3,254 0,837 0,837 0,837 0,657 0,912 Histórica 95% 97,5% 99% 99,5% Índice Paramétrica Simulação Simulação Simulação (Normal) (AAS) (AD) (AD+AI) Mistura de Distribuições (AD) 3,411 1,975 0,898 0,359 0,912 Tabela 10 - Desvio -padrão (x 103) das simulações para o cálculo do VaR diário das ações EBTP4 no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança Posição de Compra Posição de Venda Mistura de Mistura de Nível de Simulação Distribuições Distribuições Confiança (AAS) (AAS) (AD) 95% 2,974 3,387 1,354 97,5% 3,788 6,070 4,435 99% 5,262 9,381 8,059 99,5% 6,695 14,697 13,697 Mistura de Mistura de Nível de Simulação Distribuições Distribuições Confiança (AAS) (AAS) (AD) 95% 3,063 3,224 1,105 97,5% 3,854 4,812 2,323 99% 5,316 7,062 4,006 99,5% 6,851 19,000 18,388 Na Tabela 8, observa -se novamente a superioridade do Modelo de Mistura de Distribuições usando a Amostragem Aleatória Simples com o melhor resultado em três das quatro situações. Apenas para o nível de 99%, este modelo foi superado pela simulação de Monte Carlo com a combinação das duas técnicas de amostragem. Nos dois níveis de confiança mais elevados, várias das metodologias apresentaram suas proporções de falhas fora do intervalo de Kupiec. As três metodologias propostas apresentaram valores para o índice de desempenho bem melhores que as metodologias tradicionais. Para a posição de venda (Tabela 9) os resultados foram bastante homogêneos entre as metodologias, fazendo com que as proporções de falhas mais próximas do esperado ficassem espalhadas pela tabela (empate em 97,5% de confiança entre 3 metodologias e empate entre 4 metodologias para 99% de confiança). Mesmo com os empates, a metodologia de simulação com as técnicas AD+AI apresentou três dos quatro melhores resultados (levando em consideração o critério de desempate: CVaR) e o menor índice de desempenho. Apenas a metodologia histórica apresentou um valor fora do intervalo de confiança. O comportamento do desvio -padrão (Tabela 10) foi próximo ao observado na Tabela 7 com os dados da ação PETR4, crescimento do menor para o maior nível de confiança e redução pouco significativa nos níveis de confiança mais elevados pelo uso do Amostragem Descritiva. Porém, em 99,5% de confiança, a posição de venda apresenta valores de desvio-padrão mais elevados que a posição de compra. Tabela 11 - Proporção de falhas para o cálculo do VaR diário da posição de compra de ações TNLP4 no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança e metodologias discutidas 6,284 3,770 2,513 * 2,513 * 4,668 3,950 * 2,334 * 0,898 4,668 3,950 * 2,334 * 0,898 4,847 3,950 * 2,513 * 0,898 4,488 3,232 0,718 0,359 Mistura de Distribuições (AAS) 5,565 2,873 1,257 0,359 6,304 2,776 2,776 2,919 0,959 0,801 Histórica 95% 97,5% 99% 99,5% Índice Paramétrica Simulação Simulação Simulação (Normal) (AAS) (AD) (AD+AI) Mistura de Distribuições (AD) 5,386 2,873 1,975 * 0,359 1,483 Tabela 12 - Proporção de falhas para o cálculo do VaR diário da posição de venda de ações TNLP4 no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança e metodologias discutidas 5,745 2,873 1,257 1,257 * 6,104 3,591 1,077 0,718 5,925 3,591 1,077 0,718 5,925 3,411 1,077 0,718 6,104 2,513 0,898 0,359 Mistura de Distribuições (AAS) 5,206 2,693 0,539 0,180 2,069 1,171 1,135 1,063 0,610 1,221 Histórica 95% 97,5% 99% 99,5% Índice Paramétrica Simulação Simulação (Normal) (AAS) (AD) Simulação (AD+AI) Mistura de Distribuições (AD) 5,206 2,334 0,539 0,180 1,210 Tabela 13 - Desvio -padrão (x 103) das simulações para o cálculo do VaR diário das ações TNLP4 no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança Posição de Venda Posição de Compra Nível de Simulação Confiança (AAS) 95% 97,5% 99% 99,5% 1,595 2,035 2,818 3,604 Mistura de Mistura de Distribuições Distribuições (AAS) (AD) 1,701 0,470 5,775 4,803 7,736 6,641 5,706 5,491 Mistura de Mistura de Nível de Simulação Distribuições Distribuições Confiança (AAS) (AAS) (AD) 95% 1,642 1,719 0,571 97,5% 2,057 2,572 1,307 99% 2,840 4,384 3,388 99,5% 3,666 5,808 5,211 Através das Tabelas 11 e 12, confirma-se o que já havia sido constatado nos resultados dos outros dois ativos. Na posição de compra, existe uma clara superioridade do Modelo de Mistura de Distribuições utilizando a Amostragem Aleatória Simples. Na posição contrária, existe a superioridade do modelo de simulação com as técnicas de Amostragem Descritiva e Amostragem por Importância. Na Tabela 11, o modelo de Mistura de Distribuições com Amostragem Descritiva apresentou um valor fora do intervalo de Kupiec, mas índice de desempenho geral baixo. Novamente, vários valores ficaram fora do intervalo de Kupiec no cálculo do VaR para a posição de compra para as metodologias mais tradicionais e a metodologia histórica não obteve nenhum dos melhores resultados. O desvio-padrão foi menor do que nos outros dois casos. Trançando um paralelo entre as estatísticas descritivas e gráficos de histograma e QQ-Plot com os resultados encontrados nas tabelas acima para o teste de proporção de falhas, pode-se afirmar que para os dados que se encontraram mais afastados da distribuição Normal, a melhor metodologia de cálculo foi o Modelo de Mistura de Distribuições com a Amostragem Aleatória Simple s. Da seção 4.1, pode-se constatar que os dados do lado esquerdo da distribuição das três séries de retornos, ou seja, lado dos retornos negativos, são mais dispersos e menos se aderem à distribuição Normal do que os retornos positivos. É fácil perceber isso pelos QQ-Plots (Figuras 6, 9 e 12), os dados na parte inferior possuem maior distância da reta Normal teórica. As conseqüências da não Normalidade são estimativas ruins do VaR pelas metodologias paramétrica e por simulação de Monte Carlo (uma vez que utilizam o pressuposto de Normalidade na simulação da trajetória do ativo), comprovadas nas diversas proporções de falhas fora do intervalo de Kupiec. Para o lado dos retornos positivos, que melhor se aderem à distribuição Normal, a simulação de Monte Carlo com as técnicas AD+AI mostrou-se o melhor modelo para o cálculo do VaR. Apesar de, também, pressupor Normalidade na trajetória dos ativos, a simulação utilizando a Amostragem por Importância se comportou de forma diferente das demais metodologias de simulação, com melhores resultados (nenhuma de suas proporções de falha ficou fora do intervalo de Kupiec tanto na posição de compra como de venda). Isso nos faz pensar que esta técnica de amostragem pode minimizar o problema da não Normalidade dos dados quando concentra os valores selecionados na parte de interesse da distribuição. O uso da Amostragem Descritiva no modelo de Misturas de Distribuição, fez, em geral, com que as proporções de falhas se afastassem dos valores esperados, apresentando até um valor fora do intervalo de Kupiec (posição de compra de TNLP4 com 99% de confiança). A redução esperada no desvio -padrão foi pouco significativa, não justificando o uso desta técnica nestas situações. 4.3 VaR para carteiras Nesta seção, utilizando os três ativos anteriormente analisados (PETR4, EBTP4 e TNLP4), apresenta-se o resultado do teste de proporção de falhas do VaR da carteira formada igualmente por eles para o período de 02 de janeiro de 2002 até 31 de março de 2004. As metodologias utilizadas e os níveis de confiança são os mesmos da seção anterior no cálculo do VaR individual de cada ativo. Na análise do VaR de carteiras, pode-se observar, ainda, a existência do erro de sub-aditividade. Quanto ao desvio-padrão, são apresentados os valores para as metodologias de simulação básica e com Amostragem Descritiva, visto que o problema não é mais unidimensional. A coluna de redução percentual representa a porcentagem do desvio-padrão da AD em relação ao desvio-padrão da AAS. Os valores do desviopadrão do modelo de Mistura de Distribuições não são apresentados, pois o VaR passa a ser determinado pela multiplicação dos valores já encontrados individualmente, conforme a fórmula (2.8). Vale lembrar, que nas tabelas abaixo os valores realçados representam os mais próximos do percentual de falhas esperado em cada nível de confiança (os melhores). Em caso de empate, utiliza-se o critério do menor CVaR. Os valores marcados com o asterisco estão fora do intervalo proposto por Kupiec (os piores). Tabela 14 - Proporção de falhas para o cálculo do VaR diário da posição de compra da carteira no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança e metodologias discutidas 7,002 * 3,591 1,795 1,795 * 6,104 4,488 * 2,154 * 1,436 * 6,822 4,847 * 3,052 * 1,975 * 6,643 4,488 * 2,873 * 2,154 * 5,386 3,411 0,718 0,359 Mistura de Distribuições (AAS) 5,925 2,693 0,539 0,180 4,222 4,042 6,305 6,305 1,005 1,364 Histórica 95% 97,5% 99% 99,5% Índice Paramétrica Simulação Simulação (Normal) (AAS) (AD) Simulação (AD+AI) Mistura de Distribuições (AD) 5,745 3,052 0,539 0,180 1,472 Tabela 15 - Desvio-padrão das simulações para o cálculo do VaR diário da posição de compra da carteira no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança Nível de Simulação Confiança (AAS) 95% 97,5% 99% 99,5% 0,463 0,577 0,789 1,002 Simulação (AD) Redução 0,298 0,389 0,556 0,749 -35,6% -32,6% -29,6% -25,3% Tabela 16 - Percentual de erros de sub-aditividade no cálculo do VaR diário da posição de compra da carteira no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança Nível de Confiança 95% 97,5% 99% 99,5% Histórica 15,440 2,334 0,000 0,000 Observa-se, na Tabela 14, que os melhores resultados se encontram na metodologia de simulação com AD+AI (para 95%, 99% e 99,5% de confiança) e no Modelo de Mistura de Distribuições (para 97,5% de confiança). Nas demais metodologias, vários valores se encontram fora do intervalo de Kupiec. Este resultado já era esperado, devido aos resultados individuais apresentados na seção 4.2. Quanto ao desvio -padrão (Tabela 15), percebe-se o efeito da redução de variância da Amostragem Descritiva em relação à Amostragem Aleatória Simples. O desvio -padrão do primeiro é inferior ao desvio -padrão do segundo nos quatro casos, sendo maior a redução quanto menor é o nível de confiança (de 37,2% no nível de 95% de confiança para 25,8% com confiança de 99,5%). Apenas a metodologia histórica apresentou erros de sub-aditividade (Tabela 16), chegando a aproximadamente 15,4% das 557 observações no nível de 95% de confiança. A não existência deste tipo de problema nas demais metodologias ocorre devido à incorporação dos efeitos da correlação nos cálculos: fatoração de Cholesky na simulação com AAS, algoritmo de Iman e Conover na simulação com AD e com AD+AI e aplicação da fórm ula (2.4) no Modelo de Mistura de Distribuições e VaR paramétrico. Tabela 17 - Proporção de falhas para o cálculo do VaR diário da posição de venda da carteira no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança e metodologias discutidas 4,668 2,693 1,257 1,257 5,027 1,975 0,539 0,180 4,488 1,436 0,180 * 0,180 4,668 1,436 0,180 * 0,180 5,745 1,795 0,359 0,180 Mistura de Distribuições (AAS) 3,950 1,436 0,180 * 0,000 * 1,914 1,318 1,989 1,953 1,713 2,456 Histórica 95% 97,5% 99% 99,5% Índice Paramétrica Simulação Simulação (Normal) (AAS) (AD) Simulação (AD+AI) Mistura de Distribuições (AD) 3,950 1,436 0,180 * 0,000 * 2,456 Tabela 18 - Desvio-padrão das simulações para o cálculo do VaR diário da posição de venda da carteira no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança Nível de Simulação Confiança (AAS) 95% 97,5% 99% 99,5% Simulação (AD) Redução 0,325 0,441 0,647 0,872 -35,8% -33,2% -29,7% -27,7% 0,507 0,660 0,920 1,207 Tabela 19 - Percentual de erros de sub-aditividade no cálculo do VaR diário da posição de venda da carteira no período de 02 de janeiro de 2002 até 31 de março de 2004 para os diversos níveis de confiança Nível de Confiança Histórica 95% 97,5% 99% 99,5% 1,436 0,000 0,000 0,000 Na posição de venda, observa-se na Tabela 17 o resultado inverso ao observado na Tabela 14 para a posição de compra. As metodologias propostas não possuem os melhores resultados em nenhum dos quatro níveis de confiança e possuem valores fora dos limites propostos por Kupiec. Nesta situação, as melhores metodologias são a histórica, paramétrica e simulação com Amostragem Descritiva analisando separadamente cada nível de confiança. Levando em consideração o índice de desempenho, a melhor metodologia é a paramétrica seguida pela simulação com combinação da Amostragem Descritiva com Amostragem por Importância. Na Tabela 18, o efeito de redução da variância da AD sobre a AAS continua presente do menor para o maior nível de confiança. O percentual de redução é bastante semelhante ao apresentado na Tabela 15 para a posição de compra. Entretanto, o percentual de erros de sub-aditividade na metodologia histórica (Tabela 19) é muito inferior, apresentando este tipo de erros apenas no nível de 95% de confiança. Observando a proporção de falhas do VaR desta carteira, tem-se que o problema da subestimação do risco é ainda mais grave que no VaR individual. Espera-se que quanto mais ativos na carteira, maior será a subestimação, uma vez que o erro das estimativas é acumulado. As metodologias clássicas se mostraram bastante ineficientes e perigosas no gerenciamento dos riscos. As metodologias propostas apesar de não apresentarem os melhores valores em todas as situações, ficaram poucas vezes fora do intervalo de Kupiec. A metodologia de Mistura de Distribuições (com as duas formas de amostragem) apenas infringiu o limite inferior, se mostrando conservadora. A simulação com as técnicas de Amostragem por Importância e Amostragem Descritiva não ficou fora do intervalo nenhuma vez. 5. Conclusões Através dos resultados apresentados, pode -se concluir, primeiramente, que os modelos propostos nesse trabalho, a simulação de Monte Carlo com a combinação das técnicas de Amostragem Descritiva e Amostragem por Importância e o Modelo de Mistura de Distribuições (com a Amostragem Aleatória Simples e Amostragem Descritiva), são capazes de realizar os cálculos para o VaR de ativos individuais ou portfólios. A estimação e implementação dos modelos foi bastante simples, não representando limitação aos métodos. Percebeu-se que os modelos apresenta ram os melhores resultados no teste de proporção de falhas. No cálculo do VaR individual, o Modelo de Mistura de Distribuições obteve os melhores resultados quando os ativos não possuíam as características de Normalidade. Como a motivação deste trabalho foi a constatação em diversos estudos que grande parte dos fatores de risco financeiro não seguem a distribuição Normal ou outra distribuição bem definida e conhecida, estes resultados são de grande valia. Nos casos em que os dados se aproximavam da distribuição Normal, a simulação com as técnicas de AD+AI obteve os melhores resultados. Com os testes individuais, também, fica bastante claro que as metodologias clássicas de cálculo do VaR subestimam o risco incorrido em níveis de confiança mais elevados. O pior desempenho ocorreu na metodologia histórica. Quando se formam carteiras, observou-se que o desempenho das diversas metodologias está relacionado com o resultado individual dos ativos. Quando os fatores de risco estão mais distantes da distribuição Normal, como é o caso da posição de compra, o risco é subestimado pelas metodologias clássicas e apenas as metodologias propostas apresentaram bons resultados. Mesmo nos casos em que a Normalidade é mais admissível, as metodologias propostas só ficaram for a do intervalo de Kupiec nos níveis de 99% e 99,5% de confiança. Mesmo assim, ficaram abaixo do limite inferior, apresentando uma posição mais conservadora e não de subestimação do risco. Do ponto de vista da evolução dos métodos de amostragem na simula ção de Monte Carlo, tem-se resultados bastante expressivos. Da simulação básica para a simulação com a técnica de Amostragem Descritiva, observou-se a redução da variabilidade dos resultados e do tempo de processamento, apesar de não apresentar melhorias nos resultados dos testes de proporção de falhas. Com a incorporação da Amostragem por Importância à Amostragem Descritiva, além do ganho de precisão e tempo em relação à Amostragem Aleatória Simples, observou-se melhoria dos resultados dos testes, mostrando que a concentração dos valores selecionados na área de interesse não representa apenas um avanço teórico. Já para o Modelo de Mistura de Distribuições, o uso da Amostragem Descritiva o afastou do resultado esperado com baixo ganho no desvio-padrão. Sendo, então, uma alternativa ruim. Quando a simulação é utilizada, o tempo de processamento é um importante ponto a ser discutido. No Modelo de Mistura de Distribuições, o tempo de processamento foi pouco superior ao tempo da metodologia clássica envolvendo a simulação de Monte Carlo. A técnica de Amostragem Descritiva, com o uso da amostra determinística, permite o cálculo do VaR com apenas uma corrida para ativos individuais (problema unidimensional). No caso das carteiras, o tempo foi compatível com a Amostragem Aleatória Simples. A incorporação da Amostragem por Importância, o VaR das carteiras foi calculado pela multiplicação dos valores individuais e de suas correlações (fórmula 2.8), sendo então a multiplicação de problemas unidimensionais e necessitando apenas do desenvolvimento de uma corrida de simulação. Vale destacar que com o rápido avanço tecnológico, as limitações provenientes dos recursos computacionais são cada vez menos relevantes. Em resumo, os principais problemas no cálculo do VaR eram a subestimação do risco pelas metodologias que necessitavam da suposição de Normalidade e a intensa utilização de recursos computacionais nos modelos de simulação. O primeiro problema foi contornado pelas metodologias propostas (vide resultados do teste de proporção de falhas). O segundo problema foi minimizado pela incorporação das técnicas de redução de variância na modelagem básica de simulação de Monte Carlo. A escolha da metodologia de cálculo do VaR mais adequada dependerá das características dos ativos que compõem o portfólio, sendo possível ou não a suposição de Normalidade. Como sugestão para trabalhos posteriores, tem-se a pesquisa de algoritmos mais refinados para a calibragem dos modelos propostos. Uma forma de otimização do deslocamento 'C' na Amostragem por Importância (fórmula 2.14) e no número de desvios-padrão que determinam os saltos no Modelo de Mistura de Distribuições (influenciando nos parâmetros da fórmula 2.16) que incorporem mais rapidamente as informações passadas podem trazer maior agilidade aos modelos e melhores resultados. Neste trabalho, os modelos foram estimados anualmente, mas algoritmos de ajustes diário são possíveis. 6. Referências ALEXANDER, G.; BAPTISTA, A. CVAR as a measure of risk: implications for portfólio selection. Working paper, fev. 2003. Disponível em: <http://www.gloriamundi.org> ARAÚJO, M.S. Simulação de Monte Carlo para cálculo de VaR: o uso da Amostragem Descritiva. 2001. 97f. Dissertação (Mestrado) - Instituto COPPEAD de Administração, Universidade Federal do Rio de Janeiro, Rio de Janeiro, 2001. ARCEBI, C.; NORDIO, C.; SIRTORI, C. Expected Shortfall as a tool for financial risk management. Working paper, dez. 2001. Disponível em: <http://www.gloriamundi.org> ARTZNER, P.; DELBAEN, F.; EBER, J.; HEATH, D. Coherent measures of risk. Mathematical Finance , v. 9, n. 3, jul. 1999. BLANCO, C.; IHLE, G. How good is your VaR? Using backtesting to assess system performance. 1998. Disponível em <www.fenwes.com\fen11.var.html> BOYLE, P.P.; BROADIE, M.; GLASSERMAN, P. Monte Carlo methods for security princing. Journal of Economic Dynamics and Control, n. 21, 1997. BRATLEY, P.; FOX, B.; SCHRAGE, L. A Guide to Simulation, Nova Iorque: Springer-Verlag, 2 Ed., 1983. CÁRDENAS, J.; FRUCHARD, E.; PICRON J.F.; REYES, C.; WALTERS, K.; YANG, W. Monte Carlo within a day. Risk, fev. 1999. CHARNES, J.M. Using simulation for option princing. Winter Simulation Conference , 2000. DOWD, K. Estimating VaR with order statistics. The Journal of Derivatives, spring, 2001. FLANNERY, B.; TEUKOSLKY, S.; VETTERING, W. Numerical Recipes in C, 2 Ed., Cambridge University Press, 1992. FREY, R.; MCNEIL, A. VaR and Expected Shortfall in portfolios of dependent credit risks: conceptual and practical insights. Working pa per, jan. 2002. Disponível em <www.mathematik.uni-leipzig.de/MI/frey/rome.pdf> FUGLSBJERG, B. Variance reduction techniques for Monte Carlo estimates of Value at Risk. Working paper, 2000. Disponível em: <http://www.gloriamundi.org> GARMAN, M. Improving on VaR. Risk, v. 9, n. 5, mai. 1996. GIBSON, M. Incorporating event risk into Value-at-Risk, Series Board of Governors of the Federal Reserve System, 2001. GLASSERMAN, P.; HEIDELBERGER, P.; SHAHABUDDIN, P. Importance Sampling and Stratification for Value-a t-Risk. Computational Finance , 1999 GLASSERMAN, P.; HEIDELBERGER, P.; SHAHABUDDIN, P. Portfolio Value-a tRisk with heavy-tailed risk factors. Mathematical Finance , 12, No. 3, 2000. GLASSERMAN, P.; HEIDELBERGER, P.; SHAHABUDDIN, P. Variance reduction techniques for Value-at-Risk with heavy-tailed risk factors. Winter Simulation Conference , 2000. HULL, J. Options, Futures and Other Derivatives. Nova Iorque: Prentice-Hall, 2003. IMAN, R.; CONOVER, W. A distribution free approach to inducing correlation rank among input variables. Communications in Statistics , v. 11, n. 3, 1982. INGALLS, R. Introduction to simulation. Winter Simulation Conference , 2002. J. P. MORGAN REUTERS. Technical Document. Nova Iorque: 1996. JORION, P. Value at Risk : A nova fonte de referência para o controle do risco de mercado. São Paulo: Bolsa de Mercadorias e Futuros, 1997. JOY, C.; BOYLE, P.P.; TAN, Q.S. Quasi-Monte Carlo methods in numerical finance. Management Science , n. 42, 1996. KUPIEC, P. Techniques for verifying the accuracy of risk measurement models. The Journal of Derivatives, winter, 1995. LI, D. Value at Risk based on the volatility, skewness and kurtosis . Working paper, mar. 1999. Disponível em: <http://www.gloriamundi.org> LOPEZ, J. Methods for evaluating Value-at-Risk. FRBNY, 1998. MARINS, J.M.; SANTOS, J.F.; SALIBY, E. Comparação de Técnicas de Redução de Variância para Estimação do Prêmio de Opções de Compra do Tipo Asiática. In: CONGRESSO BRASILEIRO DE FINANÇAS, 3., 2003, São Paulo. Anais... São Paulo: 2003. MCKAY, M.D.; BECKMAN, R.J.; CONOVER, W.J. A comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics, v. 21, n. 2, p. 239-245, mai. 1979. MOREIRA, F. Estudo comparativo dos métodos de Quasi-Monte Carlo, Amostragem Descritiva, Hipercubo Latino e Monte Carlo Clássico na análise de risco. 2001. 135f. Dissertação (Mestrado) - Instituto COPPEAD de Administração, Universidade Federal do Rio de Janeiro, Rio de Janeiro, 2001. OWEN, A.B. A Central Limit Theorem for Latin Hypercube Sampling. Journal of Royal Statistical Society Ser. , B54, p. 541-551, 1992. PAPAGEORGIOU, A., PASKOV, S. Deterministic simulation for risk management. Journal of Portfolio Management, p. 122-127, mai. 1999. PASKOV, S.H., TRAUB, J.F. Faster valuation of financial derivatives. The Journal of Portfolio Management, Fall 1996. SALIBY, E. A reappraisal of some simulation fundamentals . 1980. Tese (Doutorado) - University of Lancaster, 1980. __________. Repensando a simulação. São Paulo: Atlas, 1989. __________. Descriptive Sampling: A better approach to Monte Carlo simulation. Journal Operational Research Society, v. 41, n. 12, p.1133-1142, 1990. __________. Descriptive Sampling: an improvement over Latin Hipercube Sampling. Winter Simulation Conference , 1997. __________; ARAÚJO, M.S. Cálculo do VaR através de simulação de Monte Carlo: uma avaliação de uso de métodos amostrais mais eficientes. In: ENCONTRO ANUAL DA ANPAD, 25. Anais... ANPAD, 2001. SCATENA, F.M.; Análise de risco de mercado de carteiras não-lineares, Resenha BM&F, n 152. SILVA, A. Análise da coerência de medidas de risco no mercado brasileiro da ações e críticas ao desenvolvimento de uma metodologia híbrida. 2004. 87f. Dissertação (Mestrado) - Instituto COPPEAD de Administração, Universidade Federal do Rio de Janeiro, Rio de Janeiro, 2004. STAUM, J. Simulation in financial engineering. Winter Simulation Conference , 2001. STAUM, J.; EHRLICHMAN, S.; LESNEVSKI, V. Work reduction in financial simulatio n. Winter Simulation Conference , 2003. ZANGARI, P. An improved methodology for measuring VaR. RiskMetrics Monitor, 1996.
Download