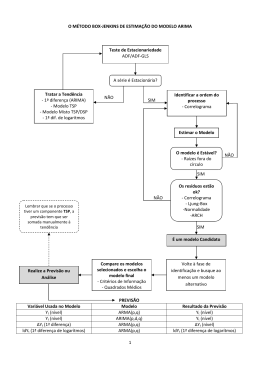
10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil THE USE OF TIME SERIES AS A PREDICTION TOOL FOR PROVISIONING IN CLOUD COMPUTING ENVIRONMENTS Tatiana Fernanda Mousquer dos Santos (Universidade Federal de Santa Maria, Rio Grande do Sul, Brasil) – [email protected] Carlos Oberdan Rolim (Universidade Federal do Rio Grande do Sul, Rio Grande do Sul, Brasil) – [email protected] Raul Ceretta Nunes (Universidade Federal de Santa Maria, Rio Grande do Sul, Brasil) – [email protected] Adriano Mendonça Souza (Universidade Federal de Santa Maria, Rio Grande do Sul, Brasil) – [email protected] Cloud Computing systems needs to ensure the distribution of resources for processing services within acceptable levels of Quality of Service - QoS. One problem that exists in this context is how to use available computational resources avoiding bottlenecks and wastage. This paper aims to determine if there is a statistical method able to predict the amount of resources that should be used for new virtual servers. Thus, we used a time series model named ARIMA (autoregressive moving average) as underlying technique for provisioning of new virtual machines in Cloud Computing environments. The results evidence the feasibility of use of such models in this context. Sistemas baseados em computação em nuvem necessitam assegurar a distribuição de recursos para processamento dos serviços dentro de níveis aceitáveis da qualidade de serviços – QoS. Um problema que existe neste contexto é como utilizar os recursos computacionais de forma a evitar gargalos e desperdício destes recursos. O presente artigo tem como objetivo verificar, se há um método estatístico capaz de apontar de forma preditiva a quantidade de recursos que deverão ser utilizados por novos servidores virtuais. Para isso foi definida a utilização de séries temporais e resultados demonstraram que o modelo de série temporal ARIMA (auto-regressivo de médias móveis), é viável como técnica base para um mecanismo de provisionamento de novas máquinas virtuais em ambientes de nuvem computacional. Palavras-Chave: séries temporais, ARIMA, Cloud. 2060 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil 1. Introdução A partir do avanço da sociedade, surgiram novas tecnologias. Serviços como email, acesso à Internet e vendas on-line, tornaram-se essenciais na vida diária das pessoas. A Computação em Nuvem, do inglês Cloud Computing é uma tecnologia já disseminada em todo o mundo e permite a entrega de tais serviços, a qualquer lugar e hora, bastando apenas que o usuário possua conexão à Internet. A Computação em Nuvem é um termo para descrever um ambiente de computação baseado em uma grande rede de servidores, na maior parte das vezes tais servidores são virtuais, porém também podem ser físicos (Taurion, 2009). Ainda de acordo com (Armbrust, 2009), a computação em nuvem é um conjunto de serviços de rede ativados, proporcionando escalabilidade, qualidade de serviço, infra-estrutura barata de computação sob demanda e que pode ser acessada de uma forma simples e pervasiva. Nessa nova forma de arquitetura, os recursos de Tecnologia da Informação (TI) são fornecidos como um serviço, possibilitando assim que os usuários os acessem sem possuir o conhecimento sobre a tecnologia (hardware/software) utilizada. Tanto usuários como empresas acessam os serviços sob demanda, sem ter a necessidade de saber a localização destes. Assim, estes movem suas informações e aplicações para a nuvem, acessando-as de forma simples, sem a necessidade de investimento ou instalação de uma estrutura física local, pois todo o processamento é efetuado remotamente por um conjunto de servidores virtuais que são escalonados conforme a necessidade da aplicação. Um problema que existe nesse tipo de arquitetura está relacionado justamente a essa necessidade de escalonamento de novos servidores virtuais. Conforme (Chirigati, 2009), as aplicações desenvolvidas para uma nuvem precisam ser escaláveis, de forma que os recursos utilizados possam ser ampliados ou reduzidos de acordo com a demanda. Se forem alocados poucos servidores às aplicações, elas irão apresentar gargalos, se forem alocados demais, recursos computacionais que poderiam ser utilizados de forma mais efetiva por outras aplicações serão desperdiçados. Além disso, existe ainda a necessidade que essa alocação de recursos seja efetuada de forma próativa, visando assim, garantir a qualidade de serviço para as aplicações. Neste contexto, este artigo visa responder a seguinte questão: Existe um método estatístico que seja capaz de apontar de forma preditiva os recursos computacionais que serão utilizados para a alocação de novos servidores virtuais? Dessa forma, este artigo analisa o modelo baseado em séries temporais chamado de ARIMA, que é um modelo auto-regressivo de médias móveis, visando investigar a possibilidade de utilizá-lo como técnica básica para um mecanismo de provisionamento de ambientes de nuvem computacional. O ARIMA foi aplicado em dados históricos que caracterizam o ambiente para então se verificar a capacidade deste modelo em fornecer corretamente as configurações de memória, disco e processamento de novos servidores que serão alocados deverão possuir. Com isso, situações atípicas que necessitem de grande capacidade de recursos computacionais, como por exemplo, ataques de negação de serviços a servidores web ou de bancos de dados, podem ter seus reflexos amenizados uma vez que se alocará recursos que consigam suprir a demanda nos momentos de ataques. 2061 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil A principal contribuição desse artigo está justamente na análise e definição de uma técnica baseada em séries temporais como base para um mecanismo de escalonamento de máquinas virtuais em ambientes de nuvem computacional. O trabalho está organizado da seguinte forma: na seção 2 são apresentados os trabalhos relacionados; na seção 3 são apresentados alguns conceitos envolvendo séries temporais; na seção 4 são apresentados alguns tipo de ataques DoS; na seção 5 é abordado o modelo proposto para a predição de recursos computacionais; já na seção 6 são demonstrados os resultados obtidos a partir do modelo ARIMA encontrado; e por fim na seção 7 são apresentadas as conclusões e trabalhos futuros. 2. Trabalhos relacionados A computação em nuvem é um paradigma, que surgiu a partir da necessidade de se reduzir custos e de se ter maior escalabilidade na infraestrutura. Ainda de acordo com (Nist, 2012), computação em nuvem é um modelo que possibilita acesso, de modo conveniente e sob demanda, a um conjunto de recursos computacionais configuráveis que podem ser rapidamente adquiridos e liberados com mínimo esforço gerencial ou interação com o provedor de serviços. Ambientes de computação em nuvem levam a uma maior integração de recursos de armazenamento escalável, possuindo alto poder de processamento. Sendo que estas características são de extrema importância, uma vez, que a enorme quantidade de informações geradas pelas empresas e usuários, torna necessária a procura de soluções que visam oferecer serviços de informação que tratem um grande volume de dados com um menor custo e com um SLA aceitável. Já que muitas transações comerciais acontecem de forma on-line e a parada parcial ou total destes serviços pode levar uma empresa a ter prejuízos incalculáveis. Segundo a literatura, a computação em nuvem é composta por camadas diferentes chamadas de SaaS, PaaS e IaaS, as quais são representadas na Figura 1 e descritas mais abaixo: Figura 1 – Camadas da Computação em Nuvem SaaS (Software as a Service) – é a camada de mais alto nível, em que as aplicações são oferecidas aos usuários através de serviços ofertados por provedores de internet, sendo acessíveis em qualquer horário e local através de aplicações como o browser. Exemplos de implementações SaaS são os serviços prestados pela Google (Google Docs, Google Agenda, Google Mail). 2062 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil PaaS (Plataform as a Service) – é a camada intermediária, sendo que é a capacidade disponibilizada pelo provedor para que o usuários desenvolva suas aplicações que serão hospedadas e executadas em nuvem. Atualmente serviços como Google AppEngine e Microsoft Azure são exemplos de PasS. IaaS (Infraestructure as a Service) - encontra-se em um nível mais baixo. Nesta camada o provedor fornece aos usuários uma infraestrutura de processamento e armazenamento, sendo que o cliente não tem acesso à estrutura física do serviço, mas através de ferramentas de virtualização consegue ter controle sobre os sistemas operacionais, aplicações e armazenamento. Exemplo da utilização deste serviço é Amazon EC2, Google Cloud Storage. A camada IaaS é de extrema importância, pois esta serve de base para a prestação de serviços pelas outras camadas. Assim a capacidade de existir SLAs confiáveis de acordo com requisitos de QoS estabelecidos em um nível mais baixo na nuvem, é de total importância e possui forte dependência dessa camada. Por este motivo o presente trabalho possui como objetivo investigar um método estatístico que seja capaz de ser utilizado como técnica básica para um mecanismo de provisionamento de servidores virtuais na camada IaaS. Como se pode imaginar, o provisionamento de recursos é uma das mais importantes características da computação em nuvem, e um dos maiores desafios também. De acordo com (Taurion, 2009:09) a Computação em Nuvem, aparece como uma alternativa, pois aloca recursos computacionais à medida que eles sejam demandados. A qualidade do serviço prestado na nuvem é um dos aspectos mais importantes, essa qualidade depende da capacidade da nuvem se auto gerenciar para assim disponibilizar aos seus usuários recursos necessários de acordo com a demanda, autores como (Armbrust, 2009) dizem que esta característica chama-se elasticidade, que é um termo que vem sendo bastante utilizado devido à popularização da computação em nuvem. O objetivo da elasticidade é criar um ambiente que se adapte às diferentes cargas de trabalho que são impostas ao sistema. Pois normalmente uma máquina real possui recursos alocados de maneira estática, sendo que qualquer variação na alocação, como adição ou remoção, implica na perda de desempenho deste ambiente. A partir da utilização de virtualização a alocação se torna mais flexível, principalmente quando o recurso em questão é o processador. A alocação estática de recursos possui problemas como a falta ou ainda o desperdício de recursos. Sendo que ao se projetar um ambiente para satisfazer demandas que ocorrem no cotidiano sem prever momentos de pico de utilização destes recursos, faz com que ocorra a falta de recursos deste ambiente. Já quando se faz o provisionamento de recursos em um ambiente, para suportar uma maior carga, mas quando isso ocorre de forma esporádica, aí ocorre o desperdício de recursos. Sendo que desperdício ou falta de recursos Uma das principais dificuldades ao se otimizar a alocação de recursos é manter o ambiente com um desempenho aceitável. Sistemas baseados em computação em nuvem, necessitam determinar a distribuição necessária para processamento dos serviços, e assim atingir níveis aceitáveis da qualidade dos serviços, chamados QoS (Quality of Service). Porém existem algumas variáveis que podem por em risco a QoS de serviço. Ataques de Denial-of-Service (DoS) e suas variantes (como Distributed Denial of Service) são exemplos de iniciativa que visam estressar o consumo de recursos nos servidores de forma que estes parem de atender requisições, consequentemente os serviços atendidos ficam comprometidos. 2063 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil Neste contexto algumas iniciativas foram desenvolvidas por alguns autores. Pode-se apresentar o trabalho de (Sladescau, 20012) que apresenta sobrecarregar um ambiente em nuvem e fazer com que os indicadores de QoS permaneçam em níveis aceitáveis. Ainda pode ser citado o trabalho de (Khan, 2012), que é utiliza Modelos Ocultos de Markov para fazer correlações temporais em cluster de servidores e com isso fazer a predição de variações nos padrões de carga do ambiente. Em (Sladescau, 2012), os autores propõem um framework chamado de Event Aware Prediction (EAP) o qual a proposta é lidar com rajadas de sobrecarga de um ambiente de nuvem de forma a manter os indicadores de QoS em níveis aceitáveis. Tal framework utiliza uma estratégia baseada em histórico de eventos passados para predizer cargas associadas com eventos similares no futuro. O trabalho é interessante, pois além do framework proposto é efetuada uma análise de diversos modelos matemáticos com foco em predição. Entretanto, os autores se limitam somente a questões preditivas de eventos e não e fornecer indicativos de configurações quantitativas que os servidores que serão escalonados precisam possuir para lidar com a sobrecarga do ambiente. Já o trabalho de (Khan, 2012) apresenta um método baseado em Modelos Ocultos de Markov (HMM, do inglês Hidden Markov Modeling) para caracterizar correlações temporais em clusters de servidores e predizer variações nos padrões de carga do ambiente. Apesar de demonstrar interessantes resultados relacionados à predição a partir da aplicação do método proposto não é abordada a questão de recursos computacionais que deveriam ser alocados para lidar com essas mudanças de carga do ambiente. O trabalho de (Araújo, 2011) que apresenta uma abordagem para lidar com questões relacionadas ao rejuvenescimento de recursos em ambientes de nuvem computacionais relacionados à degradação do estado interno dos softwares devido ao seu uso operacional. O trabalho apresenta a aplicação de diferentes tipos de séries temporais, porém o seu foco está em questões de rejuvenescimento de recursos e não na detecção de violação de SLAs e predição de recursos computacionais que deverão ser alocados. Como se percebe, nenhuma dessas iniciativas é capaz de proporcionar de forma preditiva indicativos de ataques que estariam ocorrendo, violando assim os Acordos de Nível de Serviço (ou SLAs, do inglês Sevice Level Agreement), e nem mesmo conseguem fornecer quais as configurações necessárias aos novos servidores virtuais para suprirem as demandas. Com isso existe uma lacuna no estado da arte apontando para uma necessidade de uma técnica que seja capaz de ser utilizada como base para um mecanismo para escalonamento de servidores virtuais em um ambiente de nuvem computacional. Assim, conforme mencionado na seção anterior o presente trabalho aborda uma solução viável para alocar recursos computacionais adequadamente e para isso foi utilizada séries temporais. 3. Séries Temporais Uma série temporal é definida como um conjunto de observações de uma variável ordenadas no tempo (Morretin & Toloi, 1987). A maioria dos problemas encontrados é de não estacionariedade, pois muitas variáveis alteram o seu 2064 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil comportamento através do tempo, ou seja, ocorre muita variabilidade, alterações bruscas e assim não há uma variância constante e isso faz com que a série observada não seja estável ou estacionária ao longo do tempo. Uma série temporal x é representada da seguinte forma: A análise de séries temporais consiste na aplicação de modelos matemáticos e estatísticos nos dados das mesmas, com o objetivo de quantificar e compreender o fenômeno da variação temporal. Essa análise é feita com dois objetivos: (i) Analisar o passado, tentando retirar conhecimento útil do mesmo; (ii) Predizer o futuro, tentando através da análise dos dados, construir um modelo que permita antever a evolução futura da série temporal (Oliveira, 2007:02). Uma metodologia bastante utilizada na análise de uma série temporal é Box e Jenkins, esta consiste em ajustar modelos auto-regressivos (AR) integrados de médias móveis (MA). Conforme (Tápia, 2000), a utilização de séries temporais pelo método Box e Jenkins é representada pelo conjunto de processos estocásticos ARIMA (do inglês Autoregressive Integrated Moving Average) representado pelas letras (p, d, q), em que p é a parte autoregressiva, d representa o número de diferenças efetuadas na série para que se possa tornar estacionária e q representa as médias móveis. A construção do modelo usando séries temporais segue um ciclo iterativo da metodologia de Box e Jenkins, é composto pelas quatro etapas, conforme (Gujarati, 2000): (i) Identificação: descobrir os valores apropriados para os parâmetros. Para determinar suas ordens e valores, a função de autocorrelação (FAC) e a função de autocorrelação parcial (FACP) auxiliam nessa tarefa; (ii) Estimação: estimar os parâmetros dos termos autorregressivos; (iii) Verificação de diagnóstico: nessa etapa procura-se atestar se o modelo identificado e estimado é adequado, ou seja, se ele descreve adequadamente a série de dados. A forma de verificação comumente utilizada é a realização da análise dos resíduos do modelo; (iv) Previsão: consiste em realizar a previsão, mas é importante verificar a potencialidade de previsão do modelo. Ao se modelar uma série temporal se pressupõe a utilização de uma série estacionária, de modo que no período de estimação de seus parâmetros sejam representativos de toda a série que será estimada. Assim há duas características para os modelos, uma é quando a série já se encontra estacionária, representada pelo modelo ARMA, e a outra é quando se faz necessário estacionarizar a série, para após aplicar a modelagem, este se denomina ARIMA, ambos os modelos são designados genericamente por ARIMA (p, d, q). A seguir serão apresentados os modelos ARMA e ARIMA. 3.1 Modelos ARMA (p, q) As aplicações destes modelos seguem as características de que a série comportese estacionária, ou seja, sem a influência das componentes: tendência, sazonalidade, ciclo e variáveis aleatórias. O modelo ARMA (p, q), se dá pela equação abaixo. Zt =ξ +φ1Zt−1 +φ2Zt−2 +φpZt−p +εt −θ1εt−1 −θ2 εt−2 −θq εt−q 2065 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil Onde: φ1, φ 2 , ...φ q são parâmetros autorregressivos e θ1 θ 2 θ p , são parâmetros de médias móveis, ε t considera-se um processo puramente aleatório com média zero e variância constante σ e2 . ξ é um parâmetro relacionado ao nível ou á média da série. Podendo-se reescrever a equação acima como: ~ φ p ( B) Z t = ε t θ ( B) ^ Onde: φ p (Β) = 1 − φ1Β − ... − φ p Β p ^ θ q (Β) = 1 − θ1Β − ... − θ q Β q Segundo (Box & Jenkins, 1970), um processo ARMA (p, q) estacionário tem por caracterização um decaimento exponencial após a defasagem q, enquanto a PACF tem o mesmo comportamento após a defasagem p (Tabela 1): Modelo AR(p) MA(q) ARMA (p, q) FAC Decaimento exponencial Truncada na defasagem q Decai exponencialmente se j > q FACP Truncada na defasagem p Decaimento exponencial Decai exponencialmente se j > q Tabela 1- Identificação dos modelos AR(p) e MA(q) - [Bueno, 2008]. Assim, quando há característica de estacionariedade, isso garante que um parâmetro estimado no modelo seja representativo para toda a série, o que possibilita a realização de previsão de forma mais assertiva. 3.2 Modelos ARIMA (p, d, q) Ao se utilizar séries temporais, se busca um conjunto de observações, as quais devem mostrar um comportamento estável ao longo do tempo, sendo assim busca-se encontrar um conjunto de observações com característica estacionária. Desta maneira, a metodologia proposta por Box & Jenkins, aplica-se a casos em que a série apresenta características não estacionárias, sendo necessário tomar uma ou mais diferenças para estacioná-la sendo nomeada (d), a ordem de integração. A construção da modelagem ARIMA, parte do pressuposto de que as séries temporais envolvidas na análise são geradas por um processo estocástico estacionário, sendo representada a partir de um modelo matemático. Dessa forma se Zt não é estacionária, mas Z t = ∆ Ζ t = Ζ t − Ζ t −1 é estacionária, então Zt é dita integrada de ordem (1). Caso seja necessário efetuar duas diferenças para tornar a série estacionária, então Zt é denominada de ordem (2), assim Ζ t = ∆2 Ζ t = ∆ ( ∆Ζ t ) = ∆ ( Ζ t − Ζ t −1 ) se torna estacionária. 2066 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil O objetivo principal de uma série temporal é a possibilidade de utilizar técnicas de predição a fim de encontrar bons modelos preditivos. Isso se dá pelo fato de que as séries temporais se baseiam na idéia de que observações passadas de um conjunto de dados possuem informações sobre o padrão do comportamento destes dados no futuro. 4. Ataque DoS A segurança de rede está se tornando um grande desafio. Gerenciamento de segurança e fiscalização em grandes redes tornou-se uma tarefa desafiadora (Morin, 2009) visando assegurar a disponibilidade, confidencialidade e integridade dos sistemas de informação (Depren, 2005). Nessa área, um dos desafios encontrados por administradores de redes e sistemas é ataques de Negação de Serviços (DoS do inglês Denial-of-Service) e sua variante distribuída que é ainda mais impactante pois pode envolver até mesmo milhares de computadores atacando um único alvo chamada de Negação de Serviços Distribuída (DDoS do inglês Denial-of-Service). Devido às suas características de atuação serem semelhantes no que se refere à finalidade de esgotar os recursos de um servidor e como o foco aqui não está em questões de como tais ataques são efetuados, este artigo trata ambos, DoS e DDoS, como ataque de Negação de Serviço. Em ataques de Negação de Serviços ao invés de se tentar uma invasão a um servidor são efetuadas diversas requisições simultâneas, por um único computador ou por um conjunto deles, de forma que os recursos disponíveis sejam exauridos e não se consiga mais respondê-las. De forma simples, o servidor fica sobrecarregado e passa a negar a prestação do serviço. Ataques com essas características geralmente são efetuados como forma de protesto, tentativas de fraudes ou até mesmo como demonstração de “poder” entre grupos de ativistas on-line e seu foco geralmente são servidores que atendem serviços web ou de banco de dados. Para a sua execução uma forma bastante conhecida é chamada de SYN Flooding, onde um atacante malicioso implementa de forma errônea o protocolo TCP visando explorar o aperto de mão em três etapas (Three-Way Handshake). SYN SY N + ACK 2067 K AC 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil Figura 2 – Aperto de mãos em três vias (Three-Way Handshake) Na forma normal de funcionamento do aperto de mãos em três vias (Figura 2), o cliente solicita uma conexão através de um SYN (synchronize) ao servidor. Este confirma a requisição enviando um SYN+ACK (acknowledge) de volta ao cliente. Para estabelecer a conexão, o cliente então deve responder com um ACK. Acontece que em ataques desse tipo o atacante não envia esse último ACK e imediatamente inicia requisição de uma nova conexão que também não será completada através do envio do ACK final (Figura 3). O servidor ficará esperando pelos ACKs que jamais serão entregues. Como recursos do sistema são alocados para atender as novas requisições que supostamente estão sendo efetuadas, logo não haverá mais recursos disponíveis e o sistema passa a negar seus serviços. Figura 3 – SYN Flooding Outra forma de ataque que se enquandra na categoria de Negação de Serviço é chamado de UPD Packet Storm. Nele, ao invés de se utilizar o protocolo TCP são enviados diversos pacotes UDP (User Datagram Protocol) com endereços de origem forjados (spoof) para portas randômicas de um servidor. Como resultado, o servidor irá primeiramente verificar se existe um serviço rodando em tal porta, como provavelmente não existirá, será enviado um pacote ICMP Destination Unreachable para o endereço origem. Como o endereço de origem do pacote UDP foi forjado o pacote ICMP não chega de volta ao atacante, que mantêm sua identidade oculta. Se forem mandados vários pacotes UDP o servidor precisará responder a todos com um ICMP e se não houver recursos suficientes disponíveis, isso fará com que ele fique indisponível para outros clientes que desejariam utilizar seus serviços. Esses são somente alguns tipos de ataques de Negação de Serviço que servem para ilustras que simples regras de firewall ou uso de sistemas de detecção de intrusão (IDS do inglês Intrusion Detection System) não são suficientes para lidar com estes tipos de ataques. Uma estrutura de Nuvem é capaz de absorver essa demanda de recursos computacionais. Entretanto, é necessária a existência de um mecanismo que 2068 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil seja capaz de verificar a ocorrência de violação de SLA (que pode indicar um ataque em andamento) e então alocar recursos suficientes para minimizar seus impactos. 5. Modelo escolhido Como exposto anteriormente, ataques de Negação de Serviços visam sobrecarregar o servidor, usando todos os recursos disponíveis, de forma que este passe a negar a prestação de serviços. Uma estrutura de serviços em Nuvem é capaz de diminuir o impacto desse tipo de ataque através do escalonamento de novos servidores virtuais a medida que a demanda aumenta. Assim, é necessária uma técnica que seja capaz de ser utilizada como base para um mecanismo para escalonamento de servidores virtuais em momentos de sobrecarga. Pelo fato da maioria de ataques de Negação de Serviços serem endereçados a servidores web, os dados utilizados no presente trabalho, foram retirados de servidores que prestam serviços de hospedagem de sites. Para um servidor ser capaz de atender requisições de páginas web os recursos utilizados são: memória, disco e processador. Ou seja, no escopo deste artigo a técnica escolhida deverá manipular variáveis que indiquem o uso de cada um destes recursos, identificar se está ocorrendo uma sobrecarga no sistema e então indicar valores que deverão ser usados para escalonar novos servidores que consigam suportar a demanda exigida. Ressalta-se que não foram utilizados dados referentes ao consumo de banda, pois tal análise será efetuada em trabalhos futuros. Os dados foram obtidos de um cluster de servidores de uma empresa de hospedagem de sites. Foram desenvolvidos scripts que coletavam dados referente ao consumo de memória, de disco e de processador em intervalos de 30 segundos. Os dados foram coletados durante um período de 30 dias de forma que ao final desse período foi montado um dataset contendo os seguintes campos: - Consumo de memória (MEM): volume de memória dinâmica volátil - RAM, consumida pelo número de requisições solicitadas ao sistema em um dado momento. - Consumo de disco (DSC): corresponde ao consumo em megabytes das requisições efetuadas em cima do espaço de armazenagem do sistema. - Load do processador (LOAD): indica a soma de todos os processos em um sistema que ficam em execução, ou que estão aguardando na fila, para serem executados. Para ser capaz de manipular esses dados é necessária a definição de um modelo que seja capaz de lidar com o monitoramento e predição de recursos (memória, disco, processador). De acordo com (Box & Jenkins, 1994), o modelo ARIMA (p, d, q) apresentado anteriormente é adequado para a previsão de séries temporais cujo processo estocástico não é estacionário, como é o caso dos dados em questão. Logo, a série original, passará por algumas diferenciações a fim de torná-la estacionária. Modelos Box & Jenkins, consistem em modelos matemáticos que observam o comportamento da série, ou seja, verifica a autocorrelação dos dados passados e assim realizar previsões futuras. Ainda de acordo com (Souza, 2001), o modelo ARIMA apresenta os critérios necessários (i) Ser um modelo parcimonioso; (ii) P valor significativo (p<0,05); (iii) Existência de ruído branco; (iv) Observações do critério AIC. 2069 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil Pelo comportamento das séries atenderem todos os requisitos mencionados pelos autores (Box & Jenkins, 1994) e (Souza, 2001) foi utilizado o modelo ARIMA. Uma vez as séries originais não sendo estacionárias, houve a necessidade de se fazer uma diferenciação de ordem (d). Através da utilização do modelo ARIMA, pode-se verificar uma previsão de recursos computacionais que serão utilizados para alocação de novos servidores virtuais, desta maneira não ocorrerão gargalos e nem desperdícios na utilização de recursos do sistema. Isso significa que recursos como memória, disco e processador serão provisionados a partir da previsão do modelo ARIMA. Assim, a série temporal foi modelada conforme Figura 4, buscando-se definir qual a melhor configuração de parâmetros do modelo que fosse capaz predizer valores de consumo de memória, consumo de disco e também de processador com base nos dados de entrada contidos no dataset. Figura 4 - Variáveis de entrada do modelo ARIMA A próxima seção vai mostrar quais foram melhores modelos estimados para as séries, assim como resultados de predição obtidos a partir dos modelos encontrados. 6. Resultados O objetivo da modelagem ARIMA é observar o comportamento das séries ao longo do tempo em relação aos valores de entrada das variáveis e a partir disso achar o melhor modelo de predição da série temporal para prever comportamentos futuros. Com isso em mente, essa seção visa demonstrar como foram selecionados os parâmetros para definir o melhor modelo a ser usado e também quais foram os resultados preditivos a partir da aplicação de tal modelo com vistas a melhorar a capacidade de um ambiente de nuvem em se adaptar a carga de trabalho. Para se chegar aos resultados deste trabalho, foi utilizado o software R, para modelagem dos melhores modelos ARIMA, e na plotagem dos gráficos o software Statistica versão 9.0. Para verificar o melhor modelo foram analisadas 399 observações em cada variável. O primeiro passo para se modelar as séries foi a plotagem das variáveis. A partir dos gráficos das séries originais, observados na Figura 5, percebe-se que as séries não são estacionárias, uma vez que o gráfico referente à variável MEM possui variabilidade e uma tendência crescente ao longo do tempo, já o gráfico correspondente ao disco, possui alta variabilidade, e por fim o gráfico LOAD, também possui uma tendência crescente com bastante variância. Por estes motivos as séries não são estacionárias, pois não variam em torno da média. Assim foi necessária a aplicação 2070 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil de uma diferença (d) em todas as variáveis (séries), após essa diferença houve a estacionariedade das séries. a) b) c) Figura 5 - Gráficos das séries originais: a) variável MEM (memória) - b) variável DSC (disco) - c) variável LOAD (Load do processador) Outro critério importante em uma modelagem ARIMA, é a verificação da independência dos erros, ou seja, o ruído branco que é os erros do modelo encontrado, neste caso ARIMA (1, 1, 0), isso indica as variáveis têm média zero e variância constante ao longo do tempo. A Figura 6 mostra esta independência, que é a função da autocorrelação dos resíduos (ACF). Através desta função se pode identificar a estrutura do modelo, analisando ainda os valores de p ao nível de 5%, na Figura 6 se percebe que há autocorrelação nas variáveis MEM, DSC e LOAD, isso indica que o modelo ARIMA é indicado para estas variáveis. 2071 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil a) b) c) Figura 6 - Resíduos da série: a) Função de autocorrelação dos resíduos variáveis MEM (memória) - b) variável DSC (disco) - c) variável LOAD (load do processador). Após a modelagem no software R, se obteve os seguintes modelos estimados para cada variável, visualizados nas Tabelas 2, 3 e 4, para as variáveis de entrada memória (MEM), disco (DSC) e load (LOAD): Variável Modelo Coeficiente p-value AIC Ruído branco MEM (memória) ARIMA (1,1,0) Φ= -0,4673 0,0000 4573,07 Sim MEM (memória) ARIMA (2,1,0) Φ= -0,6419 0,0000 0,0000 Sim 4515,66 Tabela 2 - Modelos estimados para a variável memória. 2072 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil Variável Modelo Coeficiente p-value AIC Ruído branco DSC (disco) ARIMA(1,1,0) Φ= 0,4673 0,0000 4573,07 Sim DSC (disco) ARIMA (2,1,0) Φ= -0,5770 0,0000 0,0000 5193,82 Não Tabela 3- Modelos estimados para a variável disco. Variável Modelo Coeficiente p-value AIC Ruído branco Load ARIMA (1,1,0) Φ= -0,4673 0,000000 4573,07 Sim Load ARIMA (2,1,0) Φ= -0,7209 0,00000, 0,00001 3925,36 Sim Tabela 4- Modelos estimados para a variável Load do processador. A partir das informações contidas nas tabelas acima, verifica-se que os modelos de previsão encontrados foram ARIMA auto-regressivos (p), com uma diferenciação (d), já que houve necessidade de dar uma diferença nas séries para que pudessem se tornar estacionárias. O Critério de Informação de Akaike (AIC) é utilizado para comparar modelos diferentes para uma mesma série, este critério aumenta conforme a soma dos quadrados dos resíduos (SQE) aumenta. E o p-value indica o quanto as variáveis são significativas ao nível de 5%, que foi a porcentagem utilizada para se modelar as séries. Ao verificar o melhor modelo, entre os dois estimados nas tabelas 2, 3 e 4, levase em conta a parcimônia, em que o melhor modelo é aquele com o menor número de parâmetros possíveis que é o número de termos autoregressivos e de médias móveis, e número de integrações necessárias para tornar a série estacionária, isso faz com que se tenha menos imprecisão nas estimativas. Portanto o modelo ARIMA (1, 1, 0), com apenas um parâmetro (1), uma diferença (1) e sem média móvel (0), juntamente com os outros critérios já mencionados, foi o modelo que apresentou as melhores configurações de parâmetros, uma vez que a modelagem ARIMA (2, 1, 0), possui dois parâmetros (2), uma diferença (1) e sem média móvel (0) e isso acaba tornando o modelo menos impreciso para predição, sendo assim pouco indicado para o uso nessa situação. Uma vez definido que o modelo ARIMA (1, 1, 0) é o mais adequado para esse tipo de situação, foram aplicados os dados do dataset como entrada do modelo então foi analisada a saída obtida. A Figura 7 esquematiza a aplicação do modelo definido com relação aos dados de entrada e as saídas preditas. 2073 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil Figura 7 - Aplicação do modelo ARIMA escolhido com relação à entrada e saída de dados Após a entrada dos dados no modelo, a saída da série é demonstrada na tabela 5. Nessa tabela pode-se perceber a previsão de cada variável 10 passos à frente, ou seja, conforme mencionado na seção anterior, os dados foram coletados de 30 em 30 segundos, o que significa que os 10 passos de previsão representa o comportamento destas variáveis ao passo futuro de 5 minutos. MEM (memória) DSC (disco) Load (processador) 75.24799 171.6662 36.29016 85.25819 196.4670 40.34235 102.28911 235.1972 48.66944 113.34960 261.5156 53.52885 124.88631 288.1394 59.00580 134.80367 311.3762 63.52031 144.31778 333.4600 67.97103 153.11958 353.9750 72.03244 161.49653 373.4461 75.93289 169.43568 391.9166 79.61498 Tabela 5 - Previsões das séries Ou seja, nos experimentos realizados pode-se perceber que o uso de séries temporais conseguiu apontar antecipadamente tendências que indicam eventuais anomalias de serviço. Com isso, como se sabe o provável comportamento do sistema nos próximos minutos, caso ocorra algum tipo de situação onde os servidores passem a receber um alto número de requisições em um curto intervalo de tempo, pode-se trabalhar de forma pró-ativa para que os serviços não sejam afetados ou ainda que os impactos referentes a gargalos sejam amenizados ao máximo a fim de que os clientes não sintam reflexos de perda de desempenho nos serviços. Por fim, a partir das análises nas séries e com base nos resultados obtidos, verifica-se que a proposta abordada mostrou-se válida. A utilização de uma série temporal, a partir do modelo ARIMA, pode ser uma alternativa ao provisionamento em ambientes dinâmicos, em que há uma constante variabilidade no sistema. 2074 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil 7. Conclusão O provisionamento de recursos em um ambiente dinâmico é um dos desafios da computação em nuvem. O trabalho proposto visou investigar a existência de um método estatístico capaz de apontar de forma preditiva os recursos computacionais necessários para a alocação de novos servidores virtuais. A análise dos resultados demonstra que é viável a utilização de séries temporais, neste caso, o modelo ARIMA (1, 1, 0), para o provisionamento de recursos em ambientes onde há necessidades de uma previsão constante e principalmente caso ocorra um ataque DoS. A partir dos resultados obtidos neste presente trabalho, chega-se a conclusão de que a computação em nuvem pode se beneficiar da utilização de modelos ARIMA. Uma vez que essa modelagem possibilitou analisar as informações contidas no dataset e com isso fazer previsões sobre o padrão do comportamento destes dados no futuro. Assim através da capacidade preditiva desta técnica estatística, consegue-se fornecer indicativos necessários ao provimento da elasticidade de recursos a fim de que o ambiente se adapte as suas necessidades. Uma carência que o trabalho possui é o comparativo de variáveis reais com as variáveis preditivas para verificar o quanto de acerto que a séries trazem em relação a previsões futuras. Como proposta de trabalho futuro está à abordagem dessa carência através de um comparativo entre os valores reais das séries e os valores preditivos, a fim de verificar a margem de erro do modelo ARIMA em cima da predição dos dados estudados. Além disso, pretende-se modelar e aplicar uma rede neural sobre os dados e então fazer um comparativo para verificar qual dessas técnicas é mais adequada para predição de provisionamento de servidores em ambientes virtuais. Referências ARAÚJO, J.; Matos, R.; Maciel, P.; Vieira, F.; Matias, R.; Trivedi, K.S.; , "Software Rejuvenation in Eucalyptus Cloud Computing Infrastructure: A Method Based on Time Series Forecasting and Multiple Thresholds," Software Aging and Rejuvenation (WoSAR), IEEE Third International Workshop on , vol., no., pp.38-43, Nov. 29 2011-Dec. 2, 2011. ARMBRUST, M., Fox, A., Griffith, R., Joseph, A. D., Katz, R. H., Konwinski, A., Lee, G., Patterson, D. A., Rabkin, A., Stoica, I., and Zaharia, M. Above the clouds: A berkeley view of cloud computing. Technical report, EECS Department, University of California, Berkeley. 2009. BOX, G. E. P., Jenkins, G. M. & Reinsel, G. C. Time Series Analysis:Forecasting and Control (Third ed.). Englewood Cliffs NJ: Prentice-Hall, 1994. BOX, G. E. P.; PIERCE, D. A. Distribution of residual autocorrelations in autoregressive-integrated moving average time series models. Journal of the American Statistical Association. v. 65, 1970. P. 1509-1526. 2075 10th International Conference on Information Systems and Technology Management – CONTECSI June, 12 to 14, 2013 - São Paulo, Brazil BUENO, Rodrigo de Losso da Silveira. Econometria das Séries Temporais. São Paulo: Cengage Learning, 2008. CHIRIGATI, Fernando Seabra. Computação em Nuvem. 2009. <http://www.gta.ufrj.br/ensino/eel879/trabalhos_vf_2009_2/seabra/vantagens.html>. Acesso em Jan 2013. DEPREN, O.; TOPALLAR, M.; ANARIM, E.; Ciliz, M. K. An intelligent intrusion detection system (IDS) for anomaly and misuse detection in computer networks. In Expert Systems with Applications, v. 29, issue 4, pages 713-722, 2005. GUJARATI, D. N. Econometria básica, São Paulo: Makron Books, 2000. KHAN, Arijit, Xifeng Yan, Shu Tao, Nikos Anerousis, “Workload Characterization and Prediction in the Cloud: A Multiple Time Series Approach”, IFIP/IEEE International Workshop on Cloud Management (CloudMan), 2012. MORIN B.; Mé L.; ebar H.; Ducassé M. A logic-based model to support alert correlation in intrusion detection. In Information Fusion, v. 10, issue 4, pages 285299, 2009. MORRETIN, P. A.; TOLOI, C. M. C. Previsão de séries temporais. 2. ed. São Paulo: Atual Editora, 1987. NIST. National Institute of Standards and Technology Draft Definition of Cloud Computing <http://csrc.nist.gov/groups/SNS >. Acesso em Dez 2012. OLIVEIRA, P. C. “Séries Temporais: Analisar o Passado, Predizer o Futuro”. In Departamento de Engenharia Informática, Universidade de Coimbra, Portugal, 2007. SLADESCU, Matthew, Alan Fekete, Kevin Lee, and Anna Liu WISE, volume 7651 of Lecture Notes in Computer Science, page 368-381. Springer, 2012. SOUZA, A. M; Lutz, M. R; Cardoso, R. A. Aplicação da metodologia Box & Jenkins na modelagem e previsão da série lucros mensais em uma empresa de ramo alimentício. 2001. TÁPIA, Milena, Redes Neurais Artificiais: Uma Aplicação na Previsão de Preços de Ovos, Dissertação de mestrado, UFSC, 2000. TAURION, Cezar. Cloud Computing: computação em nuvem: transformando o mundo da tecnologia da informação. Rio de janeiro: Brasport, 2009. 2076
Baixar