Under the Hood - Estrutura Base
Neste primeiro tutorial da série Under the Hood vamos conhecer
e compreender a estrutura base que persiste os modelos de
dados associados a um processo. Sem este conhecimento, e sem
que esteja bem cimentado, o entendimento dos tutoriais
seguintes torna-se mais difícil, pelo que aconselhamos a perder
algum tempo sobre esta matéria, e, porque não, derivar sobre o
exemplo aqui exposto ou criar outros alternativos para que a
matéria aqui explicada fique bem presente.
1
Tutorial | Plataforma Masterlink
Under the Hood - Estrutura Base
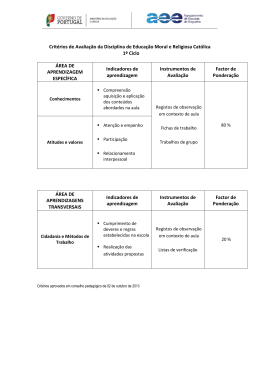
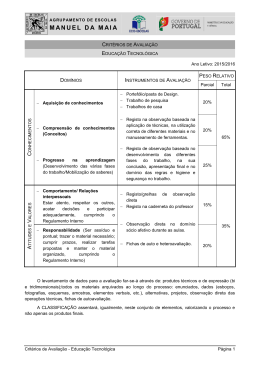
1. A estrutura comum a todos os processos
Este tutorial é uma introdução à estrutura base da MWE. Numa primeira fase vamos conhecer o
tronco comum a todos os processos, ou seja, a estrutura identificativa de um processo. É ela que
estabelece o relacionamento dos dados (registos) com estágios e processos, e que identifica
correctamente os campos da base de dados onde esses dados são guardados. Essa estrutura tem
uma nomenclatura própria, e é precisamente por ela que vamos começar.
Cada campo da base de dados, portanto, cada propriedade do nosso modelo de dados, existe no
âmbito de um grupo.
Este, por seu turno, vive num processo, o qual, à sua vez, determina um fluxo de dados definido
pelos seus estágios.
Processo => Fluxo de Dados = { Grupos, em que Grupos = { Campos } }
Assim sendo, para definirmos o nosso modelo de dados temos primeiro que reunir os campos
em grupos. Cada campo deve ser visto como uma propriedade do modelo de dados. Já os grupos
mais não são do que uma abstracção na forma como se pretende compartimentar a informação.
O que liga estes indivíduos, os campos e os grupos, é o processo. É também o processo que define
os estágios por onde a informação navega.
Como se materializa esta informação na base de dados?
Na prática o processo define uma tabela na base de dados onde os respectivos registos são
guardados, registos esses que contêm informação respeitante aos campos que espelham o
modelo de dados – o processo, na verdade.
1
Tutorial | Plataforma Masterlink
Under the Hood - Estrutura Base
Essa tabela obedece à nomenclatura PR_x, em que x é o identificador do processo (Processo ID).
Quando se procede à criação de um grupo, e consequentemente de um campo, está-se na
realidade a alterar a tabela do processo a que respeita esse grupo por forma a acomodar o novo
campo. Esse campo fica assim disponível pelo número do grupo e o número do campo, cuja
nomenclatura é do tipo GxCy.
Como esse campo existe de facto na tabela do processo – recordamos que a nomenclatura é do
tipo PR_x –, é legítimo pensar que a consulta do campo na base de dados, ou uma eventual
intervenção sobre esse campo, se pode fazer por meio de uma query SQL. Dito isto, vamos supor
que criámos o seguinte campo:
2
Tutorial | Plataforma Masterlink
Under the Hood - Estrutura Base
E que esse campo pertence ao processo indicado na figura:
Para conhecermos os pormenores do campo em causa podíamos fazê-lo por acesso ao painel de
Administração, e em SQL Manager ditar a seguinte query (1):
SELECT GxCy AS [Nome da Escola]
FROM TABELA_DO_PROCESSO
ORDER BY [Nome da Escola] ASC
Em que a que a query substituída no nosso caso é:
SELECT G5773C7453 AS [Nome da Escola]
FROM PR_5152
ORDER BY [Nome da Escola] ASC
3
Tutorial | Plataforma Masterlink
Under the Hood - Estrutura Base
Dito isto, vamos analisar como é que um registo num determinado processo e para um certo
estágio guarda informação sobre eventuais ligações – dependências ou não – a outros registos de
um processo diferente, e como é que esse ou esses registos “filhos” mantêm uma referência válida
para o registo “pai”.
Mas antes disso é vital compreender a estrutura base que assegura esse conjunto de referências,
e quais os campos que actuam nesse sentido.
Vamos analisar como é que um registo de um processo, e para um certo estágio, guarda
informação sobre eventuais ligações – dependências ou não – a outros registos de um processo
diferente, e como é que esse ou esses registos “filhos” mantêm uma referência válida para o
registo “pai”.
De forma a identificar na base de dados o modelo de dados envolvido no processo, e tudo o que
a ele se relaciona, a MWE cria e revela para cada um desses processos uma ‘chapa’ identificativa.
Essa dog tag tem sempre agregada informação relevante, como o identificador do processo (ID), a
tabela correspondente (PR_x), a tabela de histórico (zPRH_x) e a tabela temporária (PRT_x):
Em detalhe, nada como consultar a base de dados de um processo.
Seja a query (2) SELECT * FROM PR_5152 referente ao ‘processo escolas’:
O que é que nos diz este resultado em primeira mão?
4
Tutorial | Plataforma Masterlink
Under the Hood - Estrutura Base
Desde logo que há dois territórios de dados distintos: um que abrange os campos que modelam
os dados, cada qual referenciado por um GxCy único e irrepetível na instância da MWE; e outro
território composto por 15 campos comuns que suportam a base de qualquer tabela que reflita
um processo na MWE. Chamemos a esse conjunto de campos a estrutura base.
Para já, vamos concentra-nos numa parcela particular da estrutura base. O seu campo mais
relevante é o Num_Processo, pois é ele o identificador único do registo. Do mesmo modo, o
campo RespostaID é também uma referência única do registo, embora a sua função se pretenda
com o histórico do registo. Já lá iremos.
5
Baixar