UNIVERSIDADE FEDERAL DO RIO GRANDE DO NORTE
U NIVERSIDADE F EDERAL DO R IO G RANDE DO N ORTE
C ENTRO DE T ECNOLOGIA
P ROGRAMA DE P ÓS -G RADUAÇÃO EM E NGENHARIA E LÉTRICA E
DA C OMPUTAÇÃO
Uma aplicação do algoritmo QT clustering para
marcação colaborativa de pontos perigosos em
vias públicas
Adelson Luiz de Lima
Orientador: Prof. Dr. Agostinho de Medeiros Brito Júnior
Dissertação de Mestrado apresentada ao
Programa de Pós-Graduação em Engenharia
Elétrica e da Computação da UFRN como
parte dos requisitos para obtenção do título
de Mestre em Ciências.
Número de ordem PPgEE: M000
Natal, RN, novembro de 2012
Divisão de Serviços Técnicos
Catalogação da publicação na fonte. UFRN / Biblioteca Central Zila Mamede
Lima, Adelson Luiz de.
Uma aplicação do algoritmo QT clustering para marcação colaborativa de
pontos perigosos em vias públicas, Dissertações e Teses no Programa de PósGraduação em Engenharia Elétrica e da Computação da UFRN / Adelson Luiz
de Lima - Natal, RN, 2011
50 p.
Orientador: Agostinho de Medeiros Brito Júnior
Dissertação (mestrado) - Universidade Federal do Rio Grande do Norte. Centro de Tecnologia. Programa de Pós-Graduação em Engenharia Elétrica e da
Computação.
1. Redação técnica - Dissertação. 2. LATEX- Dissertação. I. Brito Júnior,
Agostinho de Medeiros. II. Uma aplicação do algoritmo QT clustering para
marcação colaborativa de pontos perigosos em vias públicas.
RN/UF/BCZM
CDU 004.932(043.2)
Uma aplicação do algoritmo QT clustering para
marcação colaborativa de pontos perigosos em
vias públicas
Adelson Luiz de Lima
Dissertação de Mestrado aprovada em 29 de junho de 2012 pela banca examinadora composta pelos seguintes membros:
Prof. Dr. Agostinho de Medeiros Brito Júnior (orientador) . . . . . . . DCA/UFRN
Prof. Dr. Allan de Medeiros Martins . . . . . . . . . . . . . . . . . . . . . . . . . . . DCA/UFFN
Prof. Dr. Paulo Sergio da Motta Pires . . . . . . . . . . . . . . . . . . . . . . . . . DCA/UFRN
À minha família, pelo apoio e
coragem...
Agradecimentos
Ao meu orientador, professor Agostinho, sou grato pela orientação.
Ao professor Paulo Motta, pelos valiosos comentários que enriqueceram meu trabalho.
Aos meus colegas de pós-graduação, pelas críticas, sugestões e apoio.
À minha família pelo apoio durante esta jornada.
À CAPES, pelo apoio financeiro.
Resumo
O trabalho propõe um sistema colaborativo para marcação de pontos perigosos em
vias de transporte e geração de alertas para motoristas. Ele consistirá de um sistema de
alerta de proximidade de um ponto de perigo, que será alimentado pelos próprios motoristas através de um aparelho móvel equipado com GPS. O sistema deverá consolidar dados
fornecidos por vários motoristas diferentes e gerar um conjunto de pontos comum a ser
usado no sistema de alerta. Embora a aplicação seja destinada à proteção de motoristas, os
dados gerados por ela poderão servir de insumos para os órgãos responsáveis melhorarem
a sinalização e recuperação de vias públicas.
Palavras-chave: Prevenção de acidentes de trânsito, sistema de alerta, sistemas colaborativo, aglomeração de dados, sistemas de informação geográfica.
Abstract
This work proposes a collaborative system for marking dangerous points in the transport routes and generation of alerts to drivers. It consisted of a proximity warning system
for a danger point that is fed by the driver via a mobile device equipped with GPS. The
system will consolidate data provided by several different drivers and generate a set of
points common to be used in the warning system. Although the application is designed to
protect drivers, the data generated by it can serve as inputs for the responsible to improve
signage and recovery of public roads.
Keywords: Prevention of traffic accidents, warning systems, collaborative systems,
data clustering, geographic information systems.
Sumário
Sumário
i
Lista de Figuras
iii
1
Introdução
1.1 Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.1.1 Objetivos Específicos . . . . . . . . . . . . . . . . . . . . . . . .
1.2 Organização do texto . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1
3
3
4
2
Sistemas de Informação Geográfica
2.1 Foursquare . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2 WAZE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.3 WikiMapa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.4 Wikimapia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.5 Comob . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.6 Avaliação das ferramentas pesquisadas no escopo do trabalho proposto
.
.
.
.
.
.
5
6
7
7
8
9
9
3
Aglomeração de dados
3.1 QT clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
11
13
4
Trabalho proposto
4.1 Funcionamento do sistema . . . .
4.2 Marcação de pontos . . . . . . . .
4.3 Processamentos dos dados . . . .
4.4 Remoção de pontos . . . . . . . .
4.5 Alertas de perigo . . . . . . . . .
4.6 Interface desktop . . . . . . . . .
4.7 Sincronização e expurgo de dados
4.8 Modelo do sistema . . . . . . . .
16
16
17
20
21
22
23
24
25
5
Resultados
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
26
i
6
Considerações finais
31
7
Agradecimentos
33
Referências bibliográficas
33
Lista de Figuras
4.1
4.2
4.3
4.4
5.1
5.2
5.3
Arquitetura do sistema proposto para marcação e aglomeração de pontos.
Interface de usuário para dispositivo móvel. . . . . . . . . . . . . . . . .
Exemplo de nuvens formada pela marcação de vários motoristas com seu
ponto representativo e os diferentes tipos de nuvens com pontos de perigo
que podem ser marcados nos cursos das vias. . . . . . . . . . . . . . . .
Protótipo da interface desktop para visualização de centros usando os recursos do Google Maps. . . . . . . . . . . . . . . . . . . . . . . . . . .
17
18
Experimento em zona urbana. . . . . . . . . . . . . . . . . . . . . . . .
Experimento em zona rural. . . . . . . . . . . . . . . . . . . . . . . . . .
Experimento em zona urbana - marcação de falhas nas Avenidas Salgado
Filho e Hermes da Fonseca. . . . . . . . . . . . . . . . . . . . . . . . . .
28
29
iii
20
23
30
Capítulo 1
Introdução
A imperícia e a imprudência no trânsito são, sem dúvida, os principais responsáveis
pela grande maioria dos acidentes nas estradas brasileiras. De fato, a má formação de
condutores para o trânsito brasileiro, junto com a dificuldade de fiscalização e aplicação
de penas mais severas aos infratores, contribui para o estado em que se encontra o trânsito
no nosso país.
É inegável a contribuição da formação humana para a quantidade, a gravidade e o tipo
dos acidentes presentes nas estatísticas oficiais do DNIT - Departamento Nacional de Infraestrutura de Transporte [DNIT 2011]. Entretanto, boa parcela dos acidentes de trânsito
no Brasil são provocados por falhas nas vias de transporte estaduais e federais, sejam essas falhas buracos, ondulações, pavimentos irregulares, valetas, inclinações, depressões,
lombadas e curvaturas mal planejadas. As próprias estatísticas do DNIT relatam que, em
2010, haviam aproximadamente 3.000Km de vias no país que concentravam acidentes.
Informações fornecidas pela Polícia Rodoviária Federal demonstram que, embora reduzidos, acidentes por defeito nas vias ainda são comuns. Os dados fornecidos são apresentados na Tabela 1.11 .
Ano do Acidente
2007
2008
2009
2010
Total geral
Quantidade. de Acidentes
2349
2191
2611
2413
9564
% do total de acidentes
1,83%
1,55%
1,65%
1,32%
1,56%
Tabela 1.1: Estatísticas de acidentes causados por falhas em vias públicas.
Danos físicos e até mortes são consequências comuns em acidentes causados por falhas nas vias, principalmente relacionado a veículos com duas rodas. Ainda, os danos
1 informações
gentilmente cedidas pela Polícia Rodoviária Federal
CAPÍTULO 1. INTRODUÇÃO
2
não se resumem apenas em prejuízo à integridade física dos motoristas e passageiros.
Grande prejuízos financeiro são agregados frequentemente a essas falhas, sejam eles representados por gastos com manutenções ou reparos causados por tais problemas. Dada
a quantidade de impostos pagos pelos contribuintes para criação e manutenção de vias,
geralmente entende-se de responsabilidade do estado os prejuízos causados aos veículos
e passageiros pela má conservação, má sinalização ou má manutenção das vias públicas.
Um caso exemplar de grande prejuízo pode-se imaginar no meio das empresas transportadoras de cargas. A perda da carga no caso de um tombamento ocasionado por uma
falha nas rodovias não só representa o prejuízo, mas também danos ao veículo e atraso
ocasionado pelo reenvio da carga. Em outras palavras, o prejuízo direto será não somente
para a empresa transportadora mas também para a sua contratante.
Embora investimentos públicos sejam feitos constantemente para melhorar a qualidade das estradas brasileiras, a presença de pontos perigosos são inevitáveis. As origens
geralmente são advindas do desgaste natural pelo uso constante, relevo e topologia, e a
própria intempéries da natureza.
diversas soluções comerciais que já são capazes de orientar motoristas no trânsito, que
são os tradicionais sistemas guiados por GPS (Global Positioning System). Alguns deles,
por exemplo, oferecem alertas de proximidade para radares de velocidade, permitindo que
o motorista fique atento aos limites de velocidade e, é claro, às multas impostas pela transgressão destes limites. A eficiência destas soluções dependem do esforço das empresas
em manter sempre atualizados seus bancos de dados e nos mecanismos de repasse destes
dados aos proprietários dos sistemas de navegação. Apesar do sucesso destas ferramentas, nota-se a carência de uma funcionalidade simples que permita aos próprios motoristas
ajudarem uns aos outros a se proteger de falhas e pontos perigosos nas vias públicas, principalmente durante períodos noturnos, quando a visibilidade da via diminui.
É nesse contexto que o presente trabalho é inserido, oferecendo uma forma de atenuar
os problemas decorrentes dos danos causados pelas falhas e pontos perigosos presentes
nas vias de transporte. O trabalho propõe um sistema que alerta aos motoristas da proximidade de algum ponto de perigo, permitindo a tomada de decisões capazes de evitar
danos à saúde ou ao patrimônio.
O sistema proposto consistirá de um programa para dispositivos móveis que poderá ser
instalado em celulares do tipo smartphones equipados com GPS. O sistema será dotado de
uma interface bastante simples, com botões para propor a inserção e remoção de pontos
perigosos, além de exibir alertas visuais e sonoros aos seus usuários. A proposta da implementação em smartphones alia conveniência e custo, haja vista o barateamento de tais
dispositivos no mercado, o uso cada vez mais presente destes dispositivos como meio de
CAPÍTULO 1. INTRODUÇÃO
3
comunicação e a presença de módulos GPS em grande parte deles. Neste contexto, a ferramenta proposta seria apenas mais um aplicativo a ser inserido no smartphone, tornando
os custos da solução bastante reduzidos.
Para que o sistema alerte ao usuário da proximidade de um ponto de perigo é preciso
saber a localização deste ponto. Para isto, os usuários do sistema ao trafegarem pelas
vias e identificarem esses pontos contribuirão com o sistema marcando-os na ferramenta
interativa, para que a coordenada geográfica desse ponto seja transmitida ao servidor para
um futuro processamento.
A fusão das informações fornecidas pelos usuários deverá ser feita através de um
servidor central que coletará, através da Internet, os pontos marcados pelos usuários da
ferramenta e realizará a consolidação destes dados através da catalogação de aglomerados
de pontos sugeridos para trechos comuns. O servidor processará os pontos oferecidos pelos motoristas utilizando algoritmos inteligentes, repassando as informações consolidadas
aos módulos dos smartphones, por requisição dos próprios usuários.
Os dados gerados pelo sistema serão integrados com o sistema de informações geográficas Google maps (http://maps.google.com), acessível através da internet, que
mostrará a localização dos pontos de perigo e poderá disponibilizar estatísticas para que
usuários e governantes possam utilizá-lo de forma a visualizar e colaborar na prevenção
de acidentes. Ainda, a base de dados do sistema poderão servir de insumo para integração
em sistemas de navegação que permitam traçados de rotas mais seguras, evitando assim
possíveis danos ao motorista e ao seu veículo.
1.1
Objetivos
O objetivo geral do trabalho é desenvolver um sistema de alerta que ajude aos motoristas de transportes automotivos a ficarem atentos a falhas nas vias de transporte ou trechos
perigosos, ajudando a evitar acidentes e prejuízos materiais. Sua principal contribuição é
oferecer uma ferramenta voltada especificamente para a realidade brasileira, preenchendo
uma lacuna deixada pela maioria das ferramentas comerciais encontradas.
1.1.1
Objetivos Específicos
Os objetivos específicos do presente trabalho de pesquisa consistem em:
• Fazer uma revisão dos trabalhos existentes que utilizam SIG;
• Realizar estudos sobre algoritmos de aglomeração de dados (clustering);
CAPÍTULO 1. INTRODUÇÃO
4
• Elicitar os requisitos do sistema a ser desenvolvido;
• Modelar a arquitetura do sistema;
• Implementar protótipo de ferramenta para funcionamento em algum modelo de
smartphone;
• Propor uma mecanismo de coleta, distribuição e processamento de dados de usuários;
• Validar o sistema proposto.
1.2
Organização do texto
Este trabalho encontra-se divido da seguinte forma. O Capítulo 2 descreve a ideia
geral do trabalho que se propõe desenvolver no contexto de aplicações correlatas existentes. O Capítulo 3 oferece uma visão geral de algoritmos de aglomeração de dados,
fundamentando a escolha do algoritmo de aglomeração proposto para uso no processamento dos dados fornecidos pelos usuários. O Capítulo 4 descreve o sistema proposto,
seu funcionamento e sua arquitetura. O Capítulo 5 mostra alguns resultados obtidos com
pontos coletados em zonas urbanas e rurais. O Capítulo 6 finaliza o trabalho apresentando algumas considerações acerca do desenvolvimento e traça proposta de tarefas futuras agregadas à temática apresentada.
Capítulo 2
Sistemas de Informação Geográfica
Sistemas de Informação Geográfica (SIG) são ferramentas que permitem sobrepor informações espaciais (geográficas) com vários outros tipos de informações [Clarke 1986].
A sobreposição permite cruzar informações respeitando uma determinada localização geográfica. Deste modo, é possível construir mapas onde aparecem informações úteis para
analisar diversos fenômenos. Esse cruzamento de informações possibilita vários estudos
de análise espacial com base nos parâmetros presentes no SIG.
Devido às suas potencialidades, os SIGs são atualmente utilizados em diversas atividades profissionais, seja em planejamento, em investigação científica, em estudos de impacto ambiental ou compartilhamento de informações genéricas. Os SIGs permitem ainda
realizar diferentes operações de análise, como calcular distâncias, identificar os elementos
que se encontram em determinados locais, ou que tenham determinadas características.
Praticamente não há limitação acerca dos tipos de dados que podem ser utilizados
em um SIG. Embora originalmente tenham sido desenvolvidos para fins de exibição de
informações naturais como relevo, clima e vegetação, a tecnologia atual permite inserir
os mais variados tipos de dados em um SIG. Exemplos de informações presentes em
SIGs atuais incluem imagens, vídeos e pontos de referência. No presente trabalho, o SIG
funcionaria utilizando uma base de dados com as informações geográficas de pontos de
perigo que podem ser mostrados em um mapa digital como a plataforma Google maps.
Os modelos mais comuns em SIG são o raster (ou matricial) e o vetorial. O modelo de
SIG matricial utiliza um mapa de células de tamanho regular, geralmente quadradas, que
armazenam valores de informação para uma dada região do espaço real. Quanto maior
a dimensão da célula, menor é a quantidade de detalhes que se consegue representar no
espaço geográfico. Quanto menor o tamanho da célula, maior a quantidade de detalhes.
No caso do modelo de SIG vetorial, a representação é focada na precisão da localização
dos elementos no espaço. A ferramenta Google maps, por exemplo, apresenta uma mistura destes dois modelos. Em um mesmo mapa, é possível visualizar de forma superposta
CAPÍTULO 2. SISTEMAS DE INFORMAÇÃO GEOGRÁFICA
6
informações de terreno (modelo matricial com fotos de satélite) e desenhos com ruas,
avenidas e pontos de referência (modelo vetorial).
Os campos de aplicação dos Sistemas de Informação Geográfica, por serem muito
versáteis, são muito vastos, podendo-se utilizar na maioria das atividades com um componente espacial, da cartografia a estudos de impacto ambiental ou vigilância epidemiológica de doenças, de prospecção de recursos ao marketing, constituindo o que poderá
designar de Sistemas Espaciais de Apoio à Decisão.
Dada a versatilidade do georeferenciamento de informações, é possível encontrar aplicações dos mais variados tipos à disposição dos usuários. O foco inicial dos SIGs nas
áreas de cartografia e vigilância ambiental está migrando, atualmente, para as áreas de
interação social, disseminação dos mais variados tipos de informação e, notadamente,
comércio, propaganda e logística.
Além da disseminação dos SIGs no comércio, eles estão migrando cada vez mais
do uso em computadores pessoais (desktop) para o uso em dispositivos móveis. Neste
sentido, o mercado vem investindo de forma significativa, dado o potencial associado à
capacidade de geolocalização. Algumas aplicações SIG, como as que serão apresentadas
nas seções seguintes, embora conceitualmente simples, são notáveis em utilidade e funcionalidade, cada qual em sua área de interesse.
2.1
Foursquare
Foursquare é uma plataforma de localização móvel, uma rede social, e um micro blog,
baseada em geolocalização, que permite ao utilizador indicar onde se encontra e procurar
por contatos que estejam próximo desse local. [Foursquare 2011]. A aplicação móvel está
disponível para celulares, através de SMS, ou smartphones, com suporte à iOS, Android,
Windows Mobile, Blackberry e Symbian.
O serviço foursquare recolhe dados pessoais dos utilizadores e partilha-os com outros,
por iniciativa e consentimento do utilizador do serviço. O serviço é baseado na partilha
e comunicação da localização, por vontade própria dos seus utilizadores. Segundo informações da própria Foursquare, havia passado de 100 milhões a quantidade de atualizações
de dados em diferentes locais no mês de julho de 2010. A taxa de crescimento de entrada
de usuários vêm de 1 milhão de atualizações, no ano de 2010, para mais de 40 milhões
nos últimos dois meses de 2010.
A utilização do serviço se dá através de um dispositivo móvel, como celular ou smartphone. O usuário do serviço acessa o site, ativa seu perfil, identifica o local onde está via
CAPÍTULO 2. SISTEMAS DE INFORMAÇÃO GEOGRÁFICA
7
GPS, e informa a informação desejada já georeferenciada. O usuário pode ainda compartilhar sua localização com outras pessoas, via Facebook ou twitter.
2.2
WAZE
Geralmente chamado de GPS social, o Waze é um aplicativo que funciona em smartphones dotados dos sistemas operacionais Android, iOS (iPhone, iPad), Symbian e Windows Mobile. A proposta do sistema é permitir que usuários compartilhem em tempo
real informações de trânsito e tráfego, podendo evitar problemas comuns como acidentes,
engarrafamentos e blitz. [Waze 2010]
O funcionamento do sistema é bem simples. Quando o motorista entra no carro,
deverá ativar o aplicativo do waze em seu smartphone e deixá-lo em funcionamento.
Enquanto dirige, o aplicativo envia pela internet informações sobre a velocidade de seu
veículo e, também, coleta informações da internet acerca da velocidade da via e de outras subjacentes. Se a velocidade da via estiver baixa, o aplicativo marca a via em cores
vibrantes, sugerindo que outros usuários evitem a região.
Outra funcionalidade oferecida pela ferramenta é a comunicação de acidentes. Se o
motorista usuário do Waze estiver preso em um engarrafamento motivado por acidente,
ele pode, tirar uma foto do local e enviá-la através do programa. Os outros usuários da
rede, denominado “wazers”, receberão essa informação na hora e visualizarão a foto.
No Brasil, o serviço ainda é bem limitado, dada a pequena quantidade de usuários.
Como a base de dados é mantida por voluntários, ainda faltam mapas das ruas nas principais cidades. O serviço provido pela Waze, entretanto, é capaz de deduzir possíveis ruas,
melhorar a geometria de ruas existentes e corrigir sentido de ruas.
2.3
WikiMapa
O WikiMapa é um mapa virtual alimentado de forma colaborativa por diversos participantes, por meio do telefone celular ou internet. [WikiMapa 2011]. O projeto foi lançado
em 2009 pelo Programa Rede Jovem, da ONG Comunitas, que atua em comunidades de
baixa renda oferecendo à juventude oportunidades de interação com as novas tecnologias.
Com o WikiMapa é possível inserir informações sobre diferentes lugares de interesse
público (hospitais, escolas, comércios, praças, quadras esportivas, restaurantes, bares,
entre outros) em quaisquer lugar do Brasil e do mundo, como também consultar e editar
comentários e referências sobre os locais já mapeados.
CAPÍTULO 2. SISTEMAS DE INFORMAÇÃO GEOGRÁFICA
8
Esse mapeamento pode ser feito por qualquer pessoa que tenha cadastro no site do
WikiMapa e/ou o programa instalado em um celular com GPS, permitindo a inserção
das informações, coleta da localização e também compartilhamento das experiências em
blogs dentro do site do projeto.
O diferencial do projeto é o mapeamento de ruas e vielas de comunidades de baixa
renda, que até então não tem sido realizados pelos serviços de pesquisa e visualização
de mapas na internet, além do mapeamento dessas comunidades, realizado pelos próprios
moradores.
Em sua fase piloto, cinco comunidades cariocas foram mapeadas: Complexo do Alemão,
Complexo da Maré, Cidade de Deus, Santa Marta e Pavão-Pavãozinho. Em cada uma tem
um jovem morador, responsável por identificar caminhos e locais de interesse, iniciando a
construção do mapa georeferenciado de sua comunidade, tornando sua cultura e geografia
conhecidas por qualquer usuário do WikiMapa.
O Programa Rede Jovem recebeu em 2010 quatro grandes prêmios devido à experiência adquirida com o projeto Wikimapa e foi, ainda, a única iniciativa da América Latina
indicada como finalista ao prêmio Mobile Monday Peer Awards, na categoria Bottom of
the Pyramids.
2.4
Wikimapia
Wikimapia é um sistema de busca e mapeamento na internet que utiliza imagens de
satélite do planeta Terra para identificar os locais mostrados, desde pequenos comércios
até cidades inteiras. O serviço se baseia nas imagens de satélite como as providas pelo
Google mapas. O sistema wiki é aplicado na forma de localização de lugares, pois qualquer pessoa tem a permissão (sendo registrado) de inserir um local no mapa até mesmo
editar os locais já criados. [Wikimapia 2011]
O WikiMapia foi apresentado em 2006 pelos russos Alexandre Koriakine e Evgeniy
Saveliev. A aplicação dispõe várias funcionalidades de edição de mapas, principalmente
através do uso de polígonos que permitem definir precisamente a área do local marcado e ferramentas lineares, como estradas, ferrovias e rios.
No princípio, todos os usuários editavam anonimamente e não havia mecanismos de
monitoramento de usuários problemáticos ou vândalos. Em outubro de 2006, criou-se
o sistema de registro de usuários. Apesar disso, o registro não se tornou obrigatório
e ainda hoje é permitida a colaboração como usuário não registrado. Posteriormente,
adotaram-se diferentes níveis de usuários, permitindo que usuários mais experientes que
sejam considerados confiáveis (chamados de usuários nível 2, ou usuários avançados)
CAPÍTULO 2. SISTEMAS DE INFORMAÇÃO GEOGRÁFICA
9
ganhassem maiores capacidades, como proteger regiões ou banir vândalos.
A marcação dos locais envolve basicamente a definição da área ocupada, título, descrição, endereço, categorias. Um link para artigos da Wikipédia descrevendo o local, é
também incentivado, havendo campos específicos para este fim. Os usuários podem ainda
adicionar fotos dos locais. Na descrição é permitida a inserção de links para páginas da
web e vídeos do Youtube, por exemplo. As categorias são usadas para que se possa filtrar
a visualização, permitindo se ver apenas os locais marcados com certa categoria.
Os locais marcados podem ser descritos em 101 idiomas diferentes, enquanto a interface do usuário já foi traduzida para 56 idiomas.
2.5
Comob
Comob é um projeto de arte digital que explora o potencial do mapeamento colaborativo com a tecnologia GPS. Comob foi desenvolvido como uma ferramenta de pesquisa
para explorar as relações sociais e espaciais entre as pessoas em movimento [Comob
2011]. Ele atualmente é suportado nas plataformas suporta aplicações para iPhone e
Nokia que explora mapeamento colaborativo com a tecnologia GPS. O sistema permite
que os membros de um grupo compartilhado vejam a posição e a movimentação do outro
em tempo real em seus telefones móveis. O grupo é interligado por uma linha que mostra
a sua distribuição espacial relativa.
2.6
Avaliação das ferramentas pesquisadas no escopo do
trabalho proposto
Aplicações como estas que foram descritas nas seções anteriores revelam um aspecto
interessante sobre interações sociais no mundo digital: muitos estão dispostos a colaborar
em prol do bem comum. De fato, quanto mais bem alimentados forem os bancos de dados
de cada ferramenta, mais bem informados estarão seus usuários.
Entretanto, dois aspectos importantes podem ser observado nestas e em outras propostas de sistemas de georeferenciamento colaborativo existentes. Um deles é o fato de
as aplicações estarem cada vez mais voltadas para o mercado de dispositivos móveis.
O outro é que a grande maioria das aplicações são desenvolvida em países de primeiro
mundo, onde as malhas viárias geralmente são bem cuidadas e a educação no trânsito é
realmente levada à sério.
CAPÍTULO 2. SISTEMAS DE INFORMAÇÃO GEOGRÁFICA
10
No Brasil, não são raras as falhas em vias públicas e regiões de perigo. Entenda-se por
regiões de perigo os trechos de rodovia que, embora possam estar livres de falhas na via,
são palco de constantes acidentes de trânsito (ex: trechos com baixa visibilidade, curvas
acentuadas e locais de constantes transgressões de motoristas).
O uso de navegação automotiva assitida por GPS não se faz necessário para os usuários
quando as rotas de chegada ao destino são conhecidas. Exemplos típicos destes usuários
são motoristas de ônibus de linhas interestaduais e caminhoneiros. Para estes usuários, a
existência de uma ferramenta que os lembre de pontos de perigo oferecem grande utilidade em suas viagens de transporte de passageiros e cargas. As ferramentas comerciais
disponíveis, embora sejam capazes de orientar motoristas sobre rotas de viagem, são inúteis para realizar alertas de falhas e pontos de perigo.
Neste sentido, a proposta do trabalho vem preencher esta lacuna, oferecendo um sistema que pode ser usado pelas mais variadas categorias de motoristas para melhorar sua
proteção durante seus deslocamentos entre localidades. Ademais, a ferramenta não deverá
demandar a presença constante de um canal de comunicação para que mapas e pontos de
interesse sejam carregados para o dispositivo móvel. A atualização dos dados poderá ser
feita pelo usuário apenas nos locais onde canais de comunicação estiverem disponíveis.
Tal funcionalidade é útil, tanto no sentido de que nem sempre sinais de rádio estão presentes nas vias de transporte estadual ou interestadual, quanto no sentido da redução de
custos de comunicação, geralmente associados à transmissão de dados por operadoras de
telefonia móvel.
Para desenvolver a proposta do trabalho, que é a marcação de pontos de perigo de
forma colaborativa, é necessário considerar a marcação redundante de pontos pelos usuários
e, inclusive, a remoção de pontos de perigo, por exemplo, em falhas já consertadas em
vias danificadas. Para isso, o uso de algoritmos de aglomeração de dados que reduzam
esta redundância são necessários e valiosos para oferecer ao usuário mapas condensados.
Estes mapas deverão representar as informações de alerta de forma a exigir o mínimo de
recursos de memória para o dispositivo móvel e evitar aborrecer o usuário com repetições
(o que poderia desestimular o uso da ferramenta). A seleção do algoritmo de aglomeração
apropriado será discutida no capítulo seguinte.
Capítulo 3
Aglomeração de dados
Os algoritmos de aglomeração englobam uma categoria de algoritmos que buscam
reunir objetos em grupos homogêneos [Frei 2006]. Eles representam uma das principais
etapas de processos de análise de dados, denominada análise de clusters [Jain et al. 1999].
Aglomeração de dados é um processo de particionamento de uma quantidade de dados
em grupos, ou clusters e, por natureza, operam de forma não supervisionada. Em outras
palavras, algoritmos de aglomeração não requerem conhecimento prévio dos grupos de
dados para poderem agir sobre um conjunto de dados. O critério usado para aglomerar
os grupos é geralmente alguma medida de similaridade ou distância. Como resultado do
processo, elementos originalmente separados são organizados em conjuntos denominados
de clusters. Um exemplo de medida de similaridade é a distância euclidiana.
Os algoritmos de aglomeração colocam no mesmo cluster elementos que têm mais
semelhança entre eles, maximizando então as semelhanças entre elementos dentro do
cluster. De forma concomitante, elementos de diferentes clusters apresentam menor similaridade entre si, minimizando, então, as similaridades entre grupos. Assegurar estas
características é uma importante etapa do processo de análise de dados, tradicionamente
conhecida de análise de clusters [Jain et al. 1999].
Algoritmos de aglomeração podem ser divididos em dois grupos principais: algoritmos hierárquicos e não hierárquicos [Jain et al. 1999, Larose 2005].
Os Algoritmos hierárquicos criam uma hierarquia de clusters, que podem ser representados em uma estrutura de árvore chamada dendrograma. Eles podem ser divididos
em mais duas categorias: algoritmos aglomerativos e divisivos.
O algoritmo hierárquico aglomerativo têm uma abordagem bottom-up, ou seja, o processo inicialmente assume cada elemento de dado como um cluster diferente. Então,
o algoritmo vai juntando de forma iterativa dois clusters, que têm maior semelhança e
prosseguindo neste processo até que no final exista apenas um cluster ou até que outro
critério de parada seja alcançado, como o limite no número de clusters, por exemplo.
CAPÍTULO 3. AGLOMERAÇÃO DE DADOS
12
Diferente do aglomerativo, o algoritmo divisivo apresenta abordagem top-down. Começa
o processo com apenas um cluster contendo todo o conjunto de dados. A cada passo do
algoritmo, esse cluster é dividido recursivamente seguindo métricas de comparação, até
que cada elemento represente o seu próprio cluster. Ao fim do processo, ou o número de
clusters é igual à quantidade de dados ou até algum outro critério de parada ser alcançado,
tal como o número máximo de clusters alcançado.
Os algoritmos não-hierárquicos (ou particionados) normalmente particionam os dados
uma única vez em um determinado número de clusters especifico, ao invés de uma estrutura interligada, como o dendrograma produzido pela técnica hierárquica. Métodos particionados têm vantagens em aplicações que envolvam grandes conjuntos de dados para os
quais a construção de um dendrograma é computacionalmente custosa. Esta característica
coloca a escolha de algoritmos particionados como candidatos naturais para aplicação no
problema proposto neste trabalho. Uma das limitações que geralmente acompanha o uso
de um algoritmo divisivo é a escolha do número de clusters desejado.[Jain et al. 1999].
Entretanto, existem soluções elegantes que conseguem contornar esta limitação.
Dos algoritmos particionados, talvez o mais conhecido seja o algoritmo k-means
[MacQueen 1967]. O algoritmo surgiu em 1967 e sua proposta é processar um conjunto
de dados n-dimensionais agrupando os elementos em uma quantidade pré-determinada de
grupos.
Dado um conjunto n-dimensional, o algoritmo k-means visa particionar o conjunto de
dados em k clusters. Ao final do processamento, o algoritmo encontrará k centros, um para
cada cluster. Cada centro é representado por um elemento n-dimensional ci , i = 1 . . . k,
que é o ponto médio (ou centro) de cada cluster. Os centros obtidos pelo algoritmo kmeans podem ser usados para fazer a classificação de um elemento de prova em busca do
melhor grupo em que esse possa ser inserido. O algoritmo k-means funciona conforme
os seguintes passos:
1 - Dado o valor de k, número de clusters a serem gerados, são escolhidos aleatoriamente k elementos para serem os centros dos clusters, geralmente do próprio
conjunto de entrada.
2 - Para cada elemento do conjunto de dados:
2.1 - Encontrar o cluster que tem a maior similaridade com o elemento, com base
na medida de distância.
2.2 - Definir este elemento como pertencente ao respectivo cluster.
3 - Para cada cluster:
CAPÍTULO 3. AGLOMERAÇÃO DE DADOS
13
3.1 - Atualizar os valores dos centros como sendo a média dos elementos pertencentes ao cluster.
4 - Repetir os passos 2 e 3 até que se atinja a convergência, por exemplo, quando a
distância entre o centro em um passo anterior e o passo atual for menor que um
limiar pré-estabelecido.
Como exemplo de aplicação do algoritmo, considere um sistema de classificação de
tumores de pele. O sistema recebe informações do tipo curvatura, tamanho, textura e
cor e deve ser capaz de orientar seu usuário acerca da melhor classificação do tumor sub
judice. Entretanto, o sistema precisa ser treinado com exemplos previamente rotulados
por especialistas, descrevendo a benignidade ou malignidade dos exemplos.
O algoritmo k-means pode ser usado neste problema para processar os exemplos e
agrupá-los em dois conjuntos (benignos e malignos), gerando centros correspondentes
para cada um. Rotulados os centros com base nas informações fornecidas pelos especialistas, estes podem ser usados para classificar uma nova amostra, usando a mesma medida
de distância escolhida para o treinamento.
Embora seja aplicável a diversos tipos de problemas de aglomeração, o algoritmo
k-means possui uma limitação que o impede de ser usado no problema proposto. O
número de centros deve ser previamente definido. Sendo assim, alternativas que permitam a aglomeração de pontos sem a prévia fixação da quantidade de centros precisam
ser consideradas.
Dos algoritmos pesquisados, um deles chama a atenção pela forma como realiza o processo de aglomeração. A criação do centro se dá pela fixação do seu limite de diâmetro,
que é justamente o que se busca para o caso do sistema de alerta proposto. O algoritmo
é denominado QT clustering e será descrito na seção a seguir, bem como as justificativas
que embasam sua escolha.
3.1
QT clustering
O algoritmo de aglomeração Quality Threshold clustering (ou QT clustering) foi
desenvolvido por Heyer, Kruglyak e Yooseph para aglomeração genes de DNA [Heyer
et al. 1999].
O algoritmo requer um maior custo computacional que o algoritmo k-means, possui
custo exponencial, porém não exige a definição do número de clusters a priori, como no
k-means. Execuções distintas do QT clusering fornecem sempre o mesmo resultado.
CAPÍTULO 3. AGLOMERAÇÃO DE DADOS
14
Ao invés do número de clusters, esse algoritmo recebe como entrada um valor limite
para o diâmetro do cluster. Sendo assim, o foco desse algoritmo é encontrar clusters cujos
diâmetros não ultrapassem o limiar fornecido.
O algoritmo segue os seguintes procedimentos:
1. O primeiro aglomerado candidato é formado começando pelo primeiro elemento
amostrado do conjunto de entradas;
2. Os demais elementos do conjunto são adicionados iterativamente, dado que cada
elemento escolhido minimiza o aumento do diâmetro do aglomerado candidato. O
processo continua até que o diâmetro do aglomerado candidato não ultrapasse o
limiar;
3. Um segundo aglomerado candidato é formado pelo segundo elemento do conjunto
e o mesmo processo de formação descrito na etapa anterior é repetido para todos os
dados do conjunto de entrada;
4. O processo é repetido para todos os elementos do conjunto, de sorte que o número
de aglomerados candidatos seja igual ao número de elementos no conjunto de entrada;
5. O aglomerado candidato com maior número de dados é selecionado como um
aglomerado titular e os dados contidos nele são removidos dos outros aglomerados candidatos;
6. O processo de seleção de titulares é repetido para todos os aglomerados candidatos
até o último aglomerado;
7. O centro de cada aglomerado é assumido como sendo posição do elemento que o
originou.
Um possível critério de parada é quando o cluster restante contiver menos que um
número de elementos especificado. O Algoritmo 1 mostra o funcionamento do QT clustering.
A idéia do algoritmo, embora simples, possui aplicação direta no problema proposto.
Considere a situação onde o sistema de alerta precise avisar um motorista de um ponto de
perigo que se encontra adiante no curso da via. Emitido o alerta, o motorista deveria ser
capaz de reagir ao alerta, iniciar o processo de frenagem e parar, antes de atingir o ponto
de perigo, para se por em segurança.
A distância percorrida entre o início da reação e a parada do veículo é denominada distância de parada e, usando cálculos simples, pode ser estimada conforme a velocidade
do veículo e tipo de pista. Para um veículo se deslocando a 110 km/h em pista seca, a distância de parada pode ser estimada em aproximadamente 150m [Seguras 2011]. Criando
CAPÍTULO 3. AGLOMERAÇÃO DE DADOS
15
Algoritmo 1 QT clustering(G, d). Recebe como dados de entrada o conjunto G e um
diâmetro d, e retorna um conjunto de clusters limitados em tamanho pelo diâmetro
fornecido. Fonte: [Heyer et al. 1999]
1:
2:
3:
4:
5:
6:
7:
8:
9:
10:
11:
12:
13:
14:
15:
16:
17:
18:
19:
if |G| ≤ 0 then
return G
else
for all i ∈ G do
f lag ← T RUE
Ai ← {i}
while ( f lag = T RUE)&(Ai 6= G) do
Encontre j ∈ (G − Ai ) em que o diâmetro de (Ai ∪ { j}) é mínimo
if diâmetro de (Ai ∪ { j}) > d then
f lag ← FALSE
else
Ai ← Ai ∪ { j}
end if
end while
end for
end if
Identifique o conjunto C ∈ {A1 , A2 , ..., A|G| } com a máxima cardinalidade
return C
QTclustering(G −C, d)
clusters, por exemplo, com limite de diâmetro de 300m, seria possível marcar pontos de
perigo representativos de aglomerados que estejam a aproximadamente 150m de distância
de um motorista posicionado no limite do aglomerado. Assim, motoristas se deslocando
a 110 km/h se avisados quando estiverem a 150m de distância do ponto representativo,
poderiam reduzir a velocidade com segurança até atingir o obstáculo. Embora possa ser
estimado um valor mínimo para essa distância de alerta, esta grandeza poderá também ser
definida pelo próprio usuário da ferramenta, através do estabelecimento de parâmetros em
uma interface de usuário.
Estudos heurísticos podem ser realizados usando, por exemplo, opiniões e dados coletados dos próprios usuários da ferramenta para determinar um diâmetro adequado para
os centros dos aglomerados e distância padrão para alertas, nem tão pequena que irrite os
motoristas com alertas excessivos, nem tão grande que instrua o sistema a realizar alertas
demasiadamente antecipados.
Capítulo 4
Trabalho proposto
O presente trabalho propõe o desenvolvimento de um Sistema Informação Geográfica
(SIG) colaborativo capaz de agregar tecnologias muito difundidas e de fácil acesso, como
as ferramentas localização geográfica, cartografia digital e interatividade com a Internet,
usando smartphones.
São agregados um sistema de geração de alertas, através de um dispositivo móvel,
que avisa da proximidade de pontos de perigo nas vias de transporte, e um sistema de
aglomeração de dados para coletar e processar informações dos seus diversos usuários.
Para funcionar, o sistema precisa ter a priori as coordenadas geográficas desses pontos
cadastradas em uma base de informações. Estas coordenadas deverão ser fornecidas pelos
usuários enquanto estiverem trafegando nas vias. Os pontos deverão ser enviados a um
servidor que irá processá-los e gerar uma lista representativa de pontos de perigo. Uma
vez recuperada esta lista, o usuário poderá utilizá-la durante a navegação em conjunto
com a lista dos pontos por ele marcados.
4.1
Funcionamento do sistema
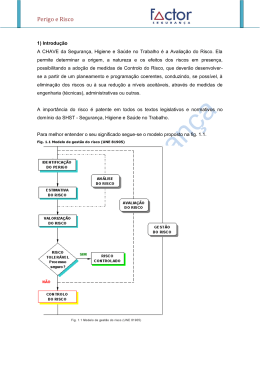
Uma visão geral do sistema proposto é apresentada na Figura 4.1. Nesta figura, cada
número identifica uma fase do processo de armazenamento, tratamento e recuperação de
informações do servidor SIG. O processo de construção da base de informações tem início
pela iniciativa dos seus usuários, que alimentam o sistema marcando nos dispositivos
móveis os pontos de perigo e os enviam ao servidor SIG(1) . O servidor armazena os pontos
fornecidos em um banco de dados(2) , relacionando as marcações realizadas pelos usuários.
Os pontos presentes na base de dados de usuários são enviados para processamento e
geração periódica dos aglomerados através do algoritmo QT clustering(3) . O resultado
do processamento é armazenado no banco de dados(4) para consultas(5) e atualização de
pontos de perigo (centros dos aglomerados) nos clientes móveis(6) . Os dados presentes
CAPÍTULO 4. TRABALHO PROPOSTO
17
no servidor de banco de dados também podem ser acessíveis de forma integrada com
clientes desktop(6) , no caso da necessidade de visualização ou manipulação dos pontos
superpostos com mapas digitais em um computador.
LCD-Pro
CARD
READER
PHONE
MIC
LINE-IN
AUDIO
SATA
USB
EJECT
-RW
DVD
POWER
SELECT
+
-
MENU
1
Cliente
móvel
NumLock
~
`
!
F4
F3
F1 F2
Esc
1
@
Tab
2
#
F7 F8
F11 F12
F9 F10
+
_
-
ScrollLock
PrintScrn
SysRq
Pause
$
4
%
|
\
Home
NumLock
PageUp
Delete
}
ScrollLock
CapsLock
Break
Insert
=
End
PageDown
Shift
-
*
/
7
9
8
Home
]
) 0
{ [
F6
( 9
" '
* 8
O P
& 7
L : ;
?
^
U I
5 6 T Y
J K M < , > . /
G H
N
E R
D F C V B
Q W
A S
CapsLock
Z X
F5
3
4
PgUp
+
6
5
1
End
3
2
0
PgDn
.
Enter
Del
Ins
Ctrl
Alt Gr
Alt
Shift
Ctrl
6
Cliente
desktop
Internet
4
5
Banco de
dados
2
4
Servidor SIG
3
QT clustering/
Processamento
auxiliar
Figura 4.1: Arquitetura do sistema proposto para marcação e aglomeração de pontos.
4.2
Marcação de pontos
Em se tratando de um sistema de alerta colaborativo, o usuário deve ser capaz de marcar de forma simples e rápida a presença de algum ponto de perigo na via em que estiver
trafegando. A marcação deverá ser feita no dispositivo móvel através de botões presentes
CAPÍTULO 4. TRABALHO PROPOSTO
18
na interface do aplicativo. Da mesma forma que a marcação de pontos candidatos a inclusão na base de informações é permitida, também será permitida a marcação de pontos
candidatos a remoção da base de dados. Esta situação poderá ocorrer, por exemplo, para
falhas na via marcadas pelos usuários e já foram reparadas.
A interface de usuário proposta para o sistema é mostrada na Figura 4.2.
(10:30h)
(10:40h)
(10:42h)
(10:53h)
(10:55h)
(14:00h)
GPS ok! Iniciando navegação
Inserida falha na via
Trecho perigoso a 200m
Zona livre marcada
Inserida falha na via
Base de dados sincronizada
TRECHO
PERIGOSO
FALHA
NA VIA
ZONA
LIVRE
Figura 4.2: Interface de usuário para dispositivo móvel.
Na tela da interface do usuário são propostas quatro regiões principais: uma região
superior para apresentação de informações (distância para pontos de perigo, iterações
com o aplicativo, etc) e três regiões sensíveis ao toque, sendo dois botões centrais para
marcação de pontos de perigo e um botão inferior para a marcação de zonas livres.
Os pontos de perigo serão classificados em duas categorias: falhas na via (caracterizadas pela associação a buracos e ondulações, por exemplo) e zonas de perigo (associadas a curvas fechadas e pontos de ultrapassagem perigosos, por exemplo). Cada
categoria poderá gerar um alerta diferenciado para o usuário, bem como prover às entidades govenamentais dados para melhorarem a sinalização e manuntenção das vias, dadas
as opiniões dos próprios motoristas acerca do que consideram trechos perigosos.
A marcação de zonas livre, associada à remoção de pontos, é feita pelo acionamento
do botão zona livre.
CAPÍTULO 4. TRABALHO PROPOSTO
19
A interface oferece alertas sonoros para não desviar a atenção visual do motorista
enquanto percorre o curso da rodovia. Com isso, a ferramenta desenvolvida não oferece
insumos que motivem os motoristas a desobedecer a legislação de trânsito, desviando o
foco da atenção. Dessa forma, a interação entre usuário e ferramenta funciona de forma
semelhante à do navegador GPS convencional, onde este vai ditando as informações ao
motorista.
A alimentação da plataforma móvel com as marcações se dá quando o usuário acionar
as regiões correspondentes no seu smartphone. Entenda-se como usuário, durante procedimento de marcação, aquele que vai manipular a plataforma móvel (que pode ser um
dos passageiros que acompanham o motorista durante a viagem). Para cada ponto marcado são armazenadas as suas coordenadas geográficas, latitude e longitude, data e hora
da marcação, bem como o tipo de ponto selecionado(falhas na via ou zonas de perigo).
O envio dos pontos da plataforma móvel para o servidor SIG não é imediata. Parte-se do
princípio que, em zonas rurais, normalmente sinais de rádio que permitiriam conexões de
dados estão indisponíveis. Portanto, os pontos podem ser enviados para o servidor SIG
para futuro processamento através de um processo de sincronização, quando uma conexão
com a Internet estiver disponível.
O envio das informações para o servidor SIG é feito em lote, quando então as informações dos novos pontos presentes no smartphone são transferidos. Quando os dados
chegam ao servidor, estes são submetidos a técnicas de processamento inteligente para
escolher os pontos de alerta.
Pressupõe-se que a marcação do ponto de perigo na via não deva ser exatamente a
mesma para todos os motoristas. Quando um usuário passa por um ponto de perigo e
realiza a marcação no seu aparelho móvel, esta poderá ocorrer em pontos aproximados
ao ponto de perigo real, devido ao retardo ou antecipação associados à ação do usuário,
ou precisão do receptor GPS do dispositivo móvel. A falha pode ser marcada, portanto,
antes ou depois de o veículo passar pelo ponto. Além disso, vários usuários podem marcar a mesma falha mais de uma vez, resultando em redundância de informações em torno
dos pontos de perigo. Sendo assim, ocorre a necessidade de consolidar estes vários pontos marcados e selecionar um único ponto de perigo associado às marcações sugeridas.
Exemplos de nuvens de pontos que podem ser marcadas no processo colaborativo são
mostradas na Figura 4.3. Nesta figura, os pontos marcados pelos usuários são representados com uma cruz e o ponto representativo de uma aglomerado gerado após tratamento
por técnicas inteligentes é destacado com um círculo.
CAPÍTULO 4. TRABALHO PROPOSTO
20
Ponto
representativo
Pontos de perigo
Curso da via
Cursos das vias
Falhas nas vias
Trechos perigosos
Figura 4.3: Exemplo de nuvens formada pela marcação de vários motoristas com seu
ponto representativo e os diferentes tipos de nuvens com pontos de perigo que podem ser
marcados nos cursos das vias.
4.3
Processamentos dos dados
É no contexto da Figura 4.3 que o processamento dos pontos colhidos pelos usuários
do aplicativo torna-se necessário para produzir apenas pontos de perigo significativos.
Para problemas dessa natureza, algoritmos de aglomeração são candidatos naturais para
uso no sistema de marcações. A geração dos pontos representativos dos aglomerados
de marcações fornecidas pelos usuários deve ser feita de modo a remover as possíveis
redundâncias que porventura sejam fornecidas por diferentes usuários.
No caso desse trabalho, demanda-se um algoritmo de aglomeração que não exija a
determinação a priori da quantidade de aglomerados a serem formados, visto que não
existe a possibilidade de saber de antemão quantos pontos de perigo poderão existir em
uma via.
CAPÍTULO 4. TRABALHO PROPOSTO
21
Os aglomerados de pontos deverão ser formados nas proximidades dos pontos de
perigo, conforme as marcações dos usuários, devendo esta condição se repetir para cada
ponto de perigo real (ver Figura 4.3). Acredita-se que o diâmetro dessas nuvens tenda a
ser regular, devendo assumir forma geralmente elíptica. Tais conjecturas são baseadas no
tempo de observação e reação média dos usuários, promovendo a forma do eixo maior da
elipse, e na precisão do GPS, promovendo a expansão do eixo menor.
Diante das peculiaridades do sistema proposto, o algoritmo QT clustering apresentado
na seção 3.1 foi escolhido como candidato à criação dos centros que marcam os pontos de
perigo. O servidor SIG, em atividades escalonadas periodicamente, determina os centros
dos aglomerados via QT clustering, e torna estes centros disponíveis aos usuários para
atualização das bases de informação móveis.
O uso do algoritmo de aglomeração QT clustering possibilita amenizar a redundância
de marcações, oferecendo para um usuário apenas os pontos mais significativos de perigo,
de modo a orientá-lo sem excesso de informações. Neste trabalho, foi escolhida uma
distância de 300 metros como diâmetro máximo dos aglomerados, assumindo que, para
este diâmetro, é oferecido um limite mínimo para alertar o motorista com segurança.
4.4
Remoção de pontos
Para os aglomerados formados em torno dos ponto de perigo, centros correspondentes
serão determinados pelo próprio algoritmo de aglomeração. O processo de criação ou atualização destes pontos de perigo deve prever, também, a situação onde a existência de
determinados pontos de perigo não seja mais necessária. Um exemplo típico dessa situação é propiciada pelo reparo de um buraco na rodovia que fôra marcado como ponto de
perigo. Em casos como esses, os usuários da ferramenta poderão realizar uma marcação
do tipo zona livre (ver Figura 4.2), indicando a inexistência de fatores capazes de gerar
perigos na região marcada.
Os pontos marcados como zona livre também participam do processo de aglomeração, influindo negativamente na inclusão ou manutenção de centros novos ou existentes,
respectivamente. O processamento desses pontos pelo algoritmo de aglomeração leva em
conta informações tais como o momento em que os pontos foram inseridos na base de
dados de pontos de perigo e a quantidade de marcações do tipo zona livre. Os pontos
marcados como zona livre não provocam a criação de novos aglomerados. Eles servem
apenas para decidir se os aglomerados dos quais participam são ou não candidatos à remoção.
Para decidir a remoção de um aglomerado da base de dados foi utilizada uma heurís-
CAPÍTULO 4. TRABALHO PROPOSTO
22
tica simples com base em um limiar K preestabelecido. Calcula-se a idade média dos
pontos de perigo mais recentes no aglomerado e dos pontos de zona livre mais recentes
no mesmo aglomerado e compara-se as duas médias. Caso a média de idade dos pontos de
zona livre supere a média de idades dos pontos de perigo e o número de pontos de zona
livre atinja o limiar K, todo o aglomerado é removido da base de dados. No protótipo
desenvolvido, escolheu-se um limiar K = 3 como parâmetro para controlar a remoção de
aglomerados.
A heurística proposta foi escolhida com base em algumas suposições acerca do uso da
plataforma móvel. Caso um usuário receba um alerta de ponto de perigo e o ponto realmente exista, dificilmente ele marcará novamente este ponto na ferramenta como sendo
ponto de perigo, uma vez que foi avisado corretamente da presença do ponto. Neste caso,
as idades das marcações dos pontos de perigo tendem a ser mais antigas que as idades das
marcações de zona livre. Caso um usuário receba um alerta de ponto de perigo e o ponto
não exista, a realimentação natural será marcar aquele ponto como zona livre, para evitar
futuros alertas. O limiar para remoção de aglomerados mencionado no parágrafo anterior
visa impedir a remoção prematura de pontos de perigo, requerendo que alguns usuários
colaborem na confirmação da zona livre marcada. É importante observar que o mesmo
limiar inexiste para a marcação de um ponto de perigo, justamente para que prevaleça o
zelo na marcação de possíveis perigos presentes nas vias.
4.5
Alertas de perigo
O sistema de alerta para o dispositivo móvel oferece alerta sonoros, informando ao
motorista da proximidade de algum ponto de perigo na via em que ele estiver trafegando. Para chamar atenção do motorista, o alerta sonoro pode sintetizar fala para informar ao motorista a distância para o ponto de perigo e o tipo de perigo que está eminente. A plataforma de testes na qual o protótipo da ferramenta foi criado, a plataforma
Android(http://www.android.com), já dispõe deste recurso para o desenvolvedor.
Para gerar os alertas, o programa em execução na plataforma móvel deverá constantemente recuperar as coordenadas geográficas locais via GPS, calcular a distância do
usuário para o ponto de perigo mais próximo, e avisar o usuário conforme os alertas programados na interface de usuário. Embora os aglomerados sejam gerados com diâmetro
fixo, a distância mínima de alerta poderá ser definida pelo próprio usuário.
CAPÍTULO 4. TRABALHO PROPOSTO
4.6
23
Interface desktop
A visualização das posições dos pontos pode ser feita na própria plataforma móvel
utilizando os recursos de apresentação de mapas disponibilizados pela Google. Apesar
desta comodidade, uma interface desktop é também disponibilizada para possibilitar a
exibição dos pontos de perigos juntamente com a ferramenta Google Mapas. A interface desktop é capaz de oferecer uma interação visual mais rica e poderá servir como
fonte de insumos para os órgãos responsáveis pela conservação e manutenção das vias
de transporte realizarem procedimentos de recuperação ou melhor sinalização das vias.
Cruzando informações fornecidas pelas marcações geradas pela ferramenta proposta com
informações do próprio DNIT, medidas colaborativas entre cidadãos e o Estado podem ser
tomadas para melhorar a qualidade das vias públicas e diminuir a quantidade de acidentes.
A exibição dos centros gerados pelo algoritmo pode ser feita diretamente através de
uma página web pela integração com a ferramenta Google Mapas. Os recursos de desenvolvimento disponibilizados pela Google permite que os pontos seja exibidos na forma
de uma camada (layer) integrada ao próprio navegador. Com isso, o usuário poderá visualizar a representação dos pontos de perigo juntamente com fotos de satélite contemplando a região onde são situados. O protótipo desenvolvido para este trabalho é ilustrado
na Figura 4.4.
Figura 4.4: Protótipo da interface desktop para visualização de centros usando os recursos
do Google Maps.
CAPÍTULO 4. TRABALHO PROPOSTO
4.7
24
Sincronização e expurgo de dados
A sincronização entre as marcações presentes na plataforma e as marcações fornecidas
a esta pelo servidor SIG é outro aspecto importante que precisou ser considerado. Ao
enviar ou receber informações, a ferramenta presente no dispositivo móvel precisa estar
alerta para não enviar dados repetidos ou desnecessários ao servidor SIG. Da mesma
forma, precisa ser capaz de evitar possíveis redundâncias oriundas dos dados recebidos
deste servidor.
Visando contornar tais problemas, estratégias de rotulação e processamento adicionais
foram também incorporadas à ferramenta móvel. Para fins de sincronização, os pontos de
perigo receberam os seguintes rótulos adicionais (além dos rótulos de trecho perigoso e
falha na via):
Novo: Ponto marcado pelo usuário, mas que ainda não foi comunicado ao servidor SIG.
Sincronizado: Ponto marcado pelo usuário e que já foi comunicado ao servidor SIG.
Centro: Ponto recebido pelo servidor SIG, resultado do processamento dos aglomerados
via algoritmo QT clustering.
Na interface da ferramenta móvel, são providas funcionalidades para permitir que o
usuário envie os pontos para o servidor remoto. Nesta etapa, os pontos dotados do rótulo
Novo têm seus rótulos substituídos por Sincronizado e são então enviados ao servidor
SIG, evitando assim o envio redundante de marcações ao servidor. A recuperação dos
centros gerados também é feita por intervenção do usuário na interface da ferramenta
móvel. Durante o processo, os pontos locais marcados como centro são substituídos pelos
novos centros recuperados.
O processo de marcação de zonas livres também sofre processamento adicional na
ferramenta móvel e possui processo de sincronização ligeiramente diferente dos pontos
de perigo. Cada marcação de zona livre realizada pelo usuário inicia duas ações a serem
tomadas. A primeira ação, realizada imediatamente, consiste em marcar para remoção
na base de dados local todos os pontos de perigo marcados dentro de um raio igual à
metade do diâmetro estipulado para o tamanho máximo dos aglomerados. A segunda
ação consiste em comunicar ao servidor SIG, durante a etapa de recuperação de centros,
os pontos marcados como zona livre. Uma vez enviados, eles são então removidos da
base de dados local, posto que sua presença torna-se inútil na ferramenta.
CAPÍTULO 4. TRABALHO PROPOSTO
4.8
25
Modelo do sistema
O sistema proposto foi desenvolvido utilizando uma confluência de diversas tecnologias diferentes.
O módulo embarcado na plataforma móvel foi desenvolvido em Java, dadas as exigências do sistema operacional Android.
O módulo servidor foi implementado parte em PHP, nos procedimentos de interação
com usuário, e parte em C++, para o processamento numérico do algoritmo QT clustering.
Neste caso, o uso da linguagem C++ é justificado pelo alto custo computacional exigido
pelo algoritmo de aglomeração. Além disso, esta linguagem permite que versões futuras
do algoritmo que executem em arquiteturas paralelas sejam mais facilmente acopladas ao
módulo servidor.
A transferência dos dados entre a plataforma móvel e o servidor é feita através de um
web service desenvolvido em PHP.
O módulo desktop do sistema foi desenvolvido parte em linguagem Javascript para
composição de cenários, haja vista as funcionalidades providas pela biblioteca de programação Google Maps disponibiliza para o desenvolvedor, e parte em PHP para a recuperação dos pontos da base de dados.
Capítulo 5
Resultados
Para testar a ferramenta proposta foram feitos experimentos utilizando um smartphone
Samsung Galaxy S II executando sistema operacional Android 4.0.3 (ice cream sandwich). Nos experimentos realizados os usuários foram instruídos a marcarem os pontos
de perigo que lhes conviesse, sendo apenas informados o que poderia ser caracterizado
como trechos perigosos e falhas na via.
O primeiro experimento visava contemplar uma zona urbana. Vários deslocamentos
foram realizados na Avenida Senador Salgado Filho, na cidade de Natal, no Estado do
Grande do Norte, e foi pedido a diferentes usuários que marcassem todos as posições
dos 9 semáforos presentes em um trecho de 3km escolhido nesta avenida como sendo do
tipo trecho perigoso. Nesse experimento, 6 usuários marcaram um total de 61 pontos.
Os pontos marcados pelos usuários são ilustrados na Figura 5.1a. Com a base de dados
abastecida com os pontos recolhidos da marcação, o algoritmo QT clustering foi executado utilizando limite de diâmetro de 300 metros. Os centros gerados são apresentados na
Figura 5.1b. Para este experimento, constatou-se a formação de 10 centros, 9 dos quais
marcando corretamente a posição real dos semáforos para fins de navegação automotiva.
O segundo experimento visava contemplar uma zona rural. Para isso, 2 usuários diferentes foram instruídos a marcar na ferramenta todos os ponto de perigo numa rodovia de
15 km situada entre o centro da cidade de Nísia Floresta até a praia de Barra de Tabatinga,
no Estado do Rio Grande do Norte. Um dos usuários dirigiu-se da cidade à praia e o outro
da praia à cidade.
Realizadas as marcações em ambos os sentidos, os dados gerados pelos usuários foram
processados, gerando os centros para as zonas de perigo marcadas. De posse destes centros, foi pedido a cada usuário que percorresse o mesmo trecho no sentido contrário ao
que haviam percorrido e que verificasse se a ferramenta gerava corretamente os alertas. O
resultado constatado pelos usuários foi o de que todos os alertas foram gerados corretamente, e contemplaram praticamente a totalidade de falhas na via que haviam encontrado.
CAPÍTULO 5. RESULTADOS
27
Um dos experimentos no trecho que liga o centro de Nísia Floresta à praia de Barra
de Tabatinga foi realizado à noite, para testar uma situação onde o usuário desconhece a
via onde trafega e a visibilidade é curta. A experiência relatada pelo usuário foi de que a
ferramenta tornou-se bastante útil no sentido de que pôde ficar mais alerta na proximidade
de pontos de perigo desconhecidos. Os alertas o ajudaram na navegação, permitindo
que tomasse decisões seguras com antecedência, sem ser supreendido por um obstáculo
no curso da rodovia. Uma das atitudes mais presenciadas durante o experimento foi a
redução de velocidade do motorista ao ser alertado.
Os 68 pontos marcados pelos dois usuários na zona rural e os 31 centros gerados
pelo QT clustering são ilustrados nos mapas das Figuras 5.2a e 5.2b, respectivamente.
Observando-se os mapas, pode-se questionar o fato de os pontos encontrarem-se ligeiramente desalinhados das marcações das rodovias fornecidas pelo Google Maps. Entretanto, a inconsistência encontra-se no mapa gerado pela Google e não na posição dos
pontos marcados pelo usuários. Embora estas inconsistências possam ser inconvenientes,
a Google vem se esforçando para melhorar seus serviços de mapas e, para o motorista
usuário da ferramenta, o mais importante é ser alertado da presença de pontos de perigo.
Outro experimento foi realizado para marcar pontos de falha na via nas Avendidas
Salgado Filho e Hermes da Fonseca, em Natal, RN. A marcação foi realizada no dia
27 de setembro de 2012 com o objetivo de marcar as principais falhas da via em um
precurso de 5.400 metros que abrangem estas duas avenidas ao todo. Na época da escrita
desse documento, a sociedade natalense presenciou sérios problemas de desgaste nestas
duas vias (entre outras várias) e, neste experimento, procurou-se demonstrar a viabilidade
da ferramenta para mostrar (em números) problemas encontrados, servindo assim como
instrumento de cobrança de ações públicas. Foram marcados, nessa época, 38 pontos de
falha, que são ilustrados no mapa da Figura 5.3. Para esta situação, os centros gerados
poderiam ser usados como insumo logístico para os órgãos responsáveis determinarem
regiões de atuação.
CAPÍTULO 5. RESULTADOS
28
(a) Pontos marcados
(b) Centros gerados
Figura 5.1: Experimento em zona urbana.
CAPÍTULO 5. RESULTADOS
29
(a) Pontos marcados
(b) Centros gerados
Figura 5.2: Experimento em zona rural.
CAPÍTULO 5. RESULTADOS
30
(a) Pontos marcados
(b) Centros gerados
Figura 5.3: Experimento em zona urbana - marcação de falhas nas Avenidas Salgado
Filho e Hermes da Fonseca.
Capítulo 6
Considerações finais
O presente trabalho propôs a criação de uma ferramenta de geração de alertas para
proteção de motoristas em vias públicas. Os alertas gerados visam indicar ao motorista
pontos caracterizados como falhas e trechos perigosos na via. A marcação dos pontos
pode ser feita pelos usuários da ferramenta de forma colaborativa, sendo a escolha dos
melhores pontos candidatos realizada por um algoritmo de aglomeração.
O processo de aglomeração de pontos e escolha de centros para os aglomerados foi
realizada utilizando o algoritmo QT clustering, haja vista sua capacidade de gerar centros
com base na limitação de um diâmetro máximo para os centros. A imposição do limite
de diâmetro se ajusta perfeitamente à proposta da geração dos alertas, uma vez que é
necessário alertar os motoristas a uma distância razoável do perigo iminente.
Os experimentos realizados mostraram que a ferramenta embarcada em uma plataforma
móvel foi considerada satisfatória para os usuários em zonas urbanas e, principalmente,
em zonas rurais, atendendo às necessidades de cada situação. Uma das principais utilidades constatadas para ferramenta são os alertas gerados durante o período noturno.
Verificou-se que, durante a noite, os alertas gerados pela plataforma móvel tornaram o
usuário mais atento e precavido na presença de pontos de perigo desconhecidos.
Dada a carência de uma ferramenta de proteção a motoristas moldada nos aspectos
discutidos ao longo do texto, é razoável considerar que a ferramenta desenvolvida pode
ser aplicada à realidade nacional, onde boa parte das vias públicas de transporte, principalmente de longa distância, acumulam regiões de perigo.
Alguns aspectos acerca do gerenciamento dos dados fornecidos pelos usuários e da
geração de aglomerados são objetos de estudo futuro:
• O diâmetro do aglomerado diferente do estabelecido em 300 metros pode ser testado na medida em que mais pessoas puderem ter acesso à plataforma.
• O valor do limiar K = 3 que regula a influência de pontos do tipo zona livre pode
ser melhor avaliado.
CAPÍTULO 6. CONSIDERAÇÕES FINAIS
32
• Mecanismos que meçam a qualidade dos pontos baseados na reputação dos usuários
da plataforma podem ser inseridos.
• Inserir na ferramenta móvel a possibilidade de usar mapas com centros gerados por
outros usuários.
• Estratégias baseadas no compartilhamento de mapas via Google Mapas estão sendo
elaboradas, pois podem ser capazes de dispensar mecanismos mais complexos de
autenticação de usuários e prevenir eventuais envenenamentos das bases de dados
por usuários maliciosos.
• Mecanismos de geração de aglomerados apenas entre grupos de usuários também
podem ser considerados no futuro, visando a aplicação da ferramenta em comunidades fechadas (por exemplo, usuários de empresas transportadoras de cargas).
Por fim, acredita-se que a base de dados do sistema possa servir de insumo inclusive
para integração em sistemas de navegação que permitam traçados de rotas mais seguras,
evitando assim possíveis danos ao motorista e ao seu veículo.
Capítulo 7
Agradecimentos
Os autores gostariam de agradecer à CAPES pelo suporte financeiro dispensado e ao
Núcleo de Estatísticas da PRF, pelos dados estatísticos que ajudaram a fundamentar este
trabalho.
Referências Bibliográficas
Clarke, Keith C. (1986), ‘Advances in geographic information systems’, Computers, Environment and Urban Systems 10(3-4), Pages 175–184.
Comob (2011), Comob’s homepage, Página na internet, acessado em junho de 2011.
URL: http://www.comob.org.uk/
DNIT (2011), ‘Estatísticas de acidentes’, Disponível em: <http://www.dnit.gov.br/
rodovias/operacoes-rodoviarias/estatisticas-de-acidentes >. Acesso
em julho de 2011.
Foursquare (2011), Foursquare’s homepage, Página na internet, acessado em junho de
2011.
URL: https://foursquare.com
Frei, Fernando (2006), Introdução à análise de agrupamentos: teoria e prátic, Editora
UNESP, São Paulo.
Heyer, Laurie J., Semyon Kruglyak & Shibu Yooseph (1999), ‘Exploring expression
data:identification and analysis of coexpressed genes’, Genome Research 9, 1106–
1115.
Jain, Anil Kumar, M Narasimha Murty & Patrick Joseph Flynn (1999), ‘Data clustering:
A review’, Acm Computing Surveys 31, 264–323.
Larose, Daniel T. (2005), DISCOVERING KNOWLEDGE IN DATA : An Introduction to
Data Mining, John Wiley and Sons, Hoboken.
MacQueen, J. B. (1967), Some methods for classification and analysis of multivariate
observations, em L. M. L.Cam & J.Neyman, eds., ‘Proc. of the fifth Berkeley Symposium on Mathematical Statistics and Probability’, Vol. 1, University of California
Press, pp. 281–297.
Seguras, Associação Por Vias (2011), ‘Velocidade e distância de parada’, Disponível
em:
<http://www.vias-seguras.com/publicacoes/aulas_de_educacao_
34
REFERÊNCIAS BIBLIOGRÁFICAS
35
no_transito/aula_09_velocidade_e_distancia_de_parada>. Acesso em
julho de 2011.
Waze (2010), Waze’s homepage, Página na internet, acessado em outubro de 2010.
URL: http://www.waze.com/
WikiMapa (2011), WikiMapa’s homepage, Página na internet, acessado em junho de
2011.
URL: http://wikimapa.org.br/
Wikimapia (2011), Wikimapia’s homepage, Página na internet, acessado em abril de
2011.
URL: http://wikimapia.org
Download