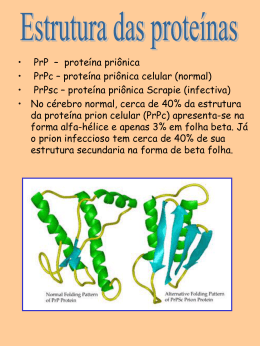
Proteínas
Predição de Estrutura Secundária
Marcilio Souto
DIMAp/UFRN
1
Somos seres protéicos
• A vida está intimamente ligada às proteínas
– Estas moléculas especiais realizam as mais
variadas funções no nosso organismo
• Transporte de nutrientes e metabólitos,
catálise de reações biológicas
– Apesar da complexidade de suas funções, as
proteínas são relativamente simples:
• Repetições de 20 unidades básicas, os
aminoácidos
2
Aminoácido
• Um aminoácido consiste em um caborno “central”
com uma ligação a grupo amino (-NH2), outra a um
grupo carboxila (-COOH), a terceira a um átomo de
hidrogênio e a quarta a uma cadeia lateral variável
COO|
H3N+--C--H
|
R
3
Aminoácidos
• Single- & three-letter amino acid codes
–
–
–
–
–
–
–
–
–
–
G
A
L
M
F
W
K
Q
E
S
Glycine
Alanine
Leucine
Methionine
Phenylalanine
Tryptophan
Lysine
Glutamine
Glutamic Acid
Serine
Gly
Ala
Leu
Met
Phe
Trp
Lys
Gln
Glu
Ser
P
V
I
C
Y
H
R
N
D
T
Proline
Valine
Isoleucine
Cysteine
Tyrosine
Histidine
Arginine
Asparagine
Aspartic Acid
Threonine
Pro
Val
Ile
Cys
Tyr
His
Arg
Asn
Asp
Thr
• Additional codes
– B Asn/Asp
Z Gln/Glu
X Any amino acid
4
Definição
• As proteínas são macromoléculas complexas,
compostas de aminoácidos, e necessárias para os
processos químicos que ocorrem nos organismos
vivos
• São os constituintes básicos da vida: tanto que seu
nome deriva da palavra grega "proteios", que
significa "em primeiro lugar”
• Nos animais, as proteínas correspondem a cerca de
80% do peso dos músculos desidratados, cerca de
70% da pele e 90% do sangue seco. Mesmo nos
vegetais as proteínas estão presentes.
5
Importância
• A importância das proteínas, entretanto, está
relacionada com suas funções no organismo, e não
com sua quantidade
• Todas as enzimas conhecidas, por exemplo, são
proteínas
– Muitas vezes, as enzimas existem em porções muito
pequenas.
– Mesmo assim, estas substâncias catalisam todas as reações
metabólicas e capacitam aos organismos a construção de
outras moléculas - proteínas, ácidos nucléicos, carboidratos
e lipídios - que são necessárias para a vida.
6
Polipeptídeos
• As proteínas também são chamadas de polipeptídeos, porque os
aminoácidos que as compõe são unidos por ligações peptídicas
– Uma ligação peptídica é a união do grupo amino (-NH2) de
um aminoácido com o grupo carboxila (-COOH) de outro
aminoácido, através da formação de uma amida
7
Estrutura da Proteínas
• Embora sejam quase inúmeras, todas as proteínas são formadas
exclusivamente por apenas 20 aminoácidos, que se repetem
numa seqüência característica para cada proteína
– Esta seqüência, conhecida como estrutura primária, é que,
de fato, determina a forma e a função da proteína.
– A estrutura primária é somente a sequência dos amino
ácidos, sem se preocupar com a orientação espacial da
molécula
– As interações intermoleculares entre os aminoácidos das
proteínas fazem com que a cadeia protéica assuma uma
estrutura secundária e uma estrutura terciária.
8
Estrutura Secundária
• A estrutura secundária é uma função dos ângulos formados
pelas ligações peptídicas que ligam os aminoácidos
– "The secondary structure of a segment of polypeptide chain
is the local spatial arrangement of its main-chain atoms
without regard to the conformation of its side chains or to its
relationship with other segments".
– A conformação espacial é mantida graças as interações
intermoleculares (ligação hidrogênio) entre os hidrogênios
dos grupos amino e os átomos de oxigênio dos outros amino
ácidos.
9
Estrutura Secundária
• Em geral, estas ligações forçam a proteína a assumir
uma forma helicoidal, como uma corda enrolada em
torno de um tubo imaginário.
– Esta forma, a mais comum, é chamado de alfa hélice.
– Outras duas formas na estrutura secundária são as betasheets e turns. Nas beta-sheets, um segmento da cadeia
interage com outro, paralelamente.
10
-Hélice
• É a forma mais comum de estrutura
secundária regular
• Caracteriza-se por uma hélice em
espiral formada por 3,6 resíduos de
aminoácidos por volta
• As cadeias laterais dos aminoácidos
se distribuem para fora da hélice
• A principal força de estabilização da a
- Hélice é a ponte de hidrogênio.
11
-Folhas
• Envolve 2 ou mais segmentos
polipeptídicos da mesma molécula
ou de moléculas diferentes,
arranjados em paralelo ou no sentido
anti-paralelo
• Os segmentos em folha da
proteína adquirem um aspecto de
uma folha de papel dobrada em
pregas.
• As pontes de hidrogênio mais uma
vez são a força de estabilização
principal desta estrutura
12
Estrutura Terciária
• A estrutura terciária relaciona-se com os loopings e
dobraduras da cadeia protéica sobre ela mesma.
• É a conformação espacial da proteína, como um
todo, e não de determinados segmentos particulares
da cadeia protéica.
• A forma das proteínas está relacionada com sua
estrutura terciária.
• Existem, por exemplo, proteínas globulares (que tem
forma esférica).
13
Estrutura Terciária
• O que determina a estrutura terciária são as cadeias
laterais dos aminoácidos
– Algumas cadeias são tão longas e hidrofóbicas que perturbam a
estrutura secundária helicoidal, provocando a dobra ou looping
da proteína.
• Muitas vezes, as partes hidrofóbicas da proteína
agrupam-se no interior da proteína dobrada
– Longe da água e dos íons do ambiente onde a proteína se
encontra, deixando as partes hidrofílicas expostas na superfície
da estrutura da proteína.
• Regiões como "sítio ativos", "sítios regulatórios" e
módulos são propriedades da estrutura terciária
14
Estrutura Terciária
15
Estrutura Quaternária
• Existe, finalmente, a estrutura quaternária
– Ccertas proteínas, tal como a hemoglobina, são compostas
por mais de uma unidade polipeptídica (cadeia protéica).
– A conformação espacial destas cadeias, juntas, é que
determina a estrutura quaternária. Esta estrutura é mantida
pelas mesmas forças que determinam as estruturas
secundárias e terciárias. A figura ao lado mostra uma
imumoglobulina que é, na verdade, um tetrâmero, isto é,
constituída por 4 cadeias protéicas (polipeptídeos).
16
Estrutura Quaternária
• A figura ao lado mostra uma imumoglobulina que é, na verdade,
um tetrâmero, isto é, constituída por 4 cadeias protéicas
(polipeptídeos).
17
Proteínas Conjugadas
• As proteínas podem ser simples
– Constituidas somente por aminoácidos
• ou conjugadas
– Contêm grupos prostéticos, isto é, grupos não aminoácidos,
tais como carbohidratos, íons, pigmentos, etc.
– A hemoglobina é um exemplo de proteína conjugada:
contém 4 grupos prostéticos, cada um consistindo de um íon
de ferro e a porfirina. São justamente estes grupos que
habilitam a hemoglobina a carregar o oxigênio através da
corrente sanguínea. As liproproteínas, tal como LDL e HDL,
são também exemplos de proteínas conjugadas - neste caso,
com lipídeos.
18
Proteínas Conjugadas
19
Outras Classificações
• Uma outra forma de classificar as proteínas é baseado na sua
função.
• Sobre este prisma, elas podem ser divididas em dois grupos:
– proteínas estruturais e proteínas biologicamente ativas
– Algumas proteínas, entretanto, podem pertencer aos dois
grupos
– A maioria das proteínas estruturais são fibrosas - compostas
por cadeias alongadas. Dois bons exemplos, nos animais,
são o colágeno (ossos, tendões, pele e ligamentos) e a
queratina (unhas, cabelos, penas e bicos).
20
Outras Classificações
• A grande maioria das proteínas biologicamente ativas são
globulares, e sua atividade funcional é intrínsica a sua
organização espacial
– Exemplos são as enzimas, hormônios protéicos (que atuam
como mensageiros químicos), proteínas de transporte (como
as lipo-proteínas, que podem carregar o colesterol) e
imunoglobulinas (ou anticorpos), que protegem o corpo de
microorganimos invasores.
– Muitas proteínas biologicamente ativas ficam na região da
membrana celular, e atuam de diversas maneiras
21
Outras Classificações
•
A figura ao lado mostra uma porina, uma proteína trans-membrana,
que atua como um canal iônico em bactérias. Existe um "buraco" na
estrutura protéica, de cerca de 11 angstrons de diâmetro, onde os íons
passam, seletivamente
22
Enzimas
•
•
•
•
As enzimas são uma classe muito importante de proteínas
biologicamente ativas.
Elas são responsáveis pela catálise de diversas reações em nosso
organismo. Reações que, sem o auxílio das enzimas, jamais
aconteceriam ou, ainda, gerariam indesejados produtos colaterais.
Em uma proteína enzimática, existe um certo domínio chamado de
"sítio ativo", que liga-se ao substrato - a molécula reagente - e diminui
a energia do estado de transição que leva ao produto desejado.
A ligação entre o sítio ativo e o substrato é extremamente específica:
– a molécula precisa ter certas características eletrônicas e espaciais
que permitam o seu "encaixe" com a proteína. Por isso esta relação
tem sido chamada de lock'n'key, ou seja, chave-fechadura.
23
Enzimas: Sítio Ativo
•
No exemplo da figura, uma determinada região da proteína liga-se à
um substrato, que se adapta ao sítio ativo da enzima tal como uma
chave faz a sua fechadura.
24
Enzimas: Inibidor
• A atividade de uma enzima pode ser bloqueada pela ação de
outra molécula, um inibidor.
• Quando um inibidor interage com uma determinada região da
enzima, chamado de sítio regulatório, provoca uma alteração na
sua conformação e uma desativação do sítio catalítico.
• A atividade enzimática, portanto, pode ser controlada, pelo
organismo, através da liberação ou captação de inibidores.
25
Enzimas: Inibidor
26
Caso tenham esquecido
•
•
•
A sequência dos amino ácidos em todas as proteínas - fator que é
responsável por sua estrutura e função - é determinado geneticamente
a partir da sequência dos nucleotídeos no DNA celular.
Quando uma proteína em particular é necessária, o código do DNA
(gene) para esta proteína é transcrito em uma sequência
complementar de nucleotídeos ao longo de um segmento de RNA chamado de RNA mensageiro.
Este segmento de RNA serve como uma forma para a síntese da
proteína subsequente: cada grupo de 3 nuclueotídeos especifica um
determinado aminoácido;
– estes aminoácidos são ligados na sequência codificada pelo RNA. No final
do processo, obtém-se a proteína completa, cuja sequência de aminoácidos
foi ditada pelo RNA mensageiro. Desta maneira, o organismo é capaz de
sintetizar as várias proteínas com as funções mais diversas de que precisa.
27
Previsão de Estrutura de Proteínas
• Experimental
– Cristalização
• Raios X
• Ressonância nuclear magnética
– Cerca de 10 a 12 mil estruturas em repositórios públicos
– Processo caro e demorado
• Teórico
–
–
–
–
Homologia
Ab Inition
Threading
Aprendizado de Máquina
28
Modelagem por Homologia
•
•
A ferramenta mais bem sucedida de predição de estruturas
tridimensionais de proteínas é a modelagem por homologia, também
conhecida como modelagem comparativa.
Esta abordagem baseia-se em alguns padrões gerais que têm sido
observados, em nível molecular, no processo de evolução biológica:
– homologia entre seqüências de aminoácidos implica em
semelhança estrutural e funcional;
– proteínas homólogas apresentam regiões internas conservadas
(principalmente constituídas de elementos de estrutura secundária:
hélices-a e fitas-b);
– as principais diferenças estruturais entre proteínas homólogas
ocorrem nas regiões externas, constituídas principalmente por alças
("loops"), que ligam os elementos de estruturas secundárias.
29
Modelagem por Homologia
• Outro fato importante é que as proteínas agrupam-se em um
número limitado de famílias tridimensionais. Estima-se que
existam cerca de 5.000 famílias protéicas.
• Conseqüentemente, quando se conhece a estrutura de pelo
menos um representante de uma família, é geralmente possível
modelar, por homologia, os demais membros da família.
30
Modelagem por Homologia
• A modelagem de uma proteína (proteína-problema) pelo
método da homologia baseia-se no conceito de evolução
molecular.
–
Isto é, parte-se do princípio de que a semelhança entre as
estruturas primárias desta proteína e de proteínas homólogas de
estruturas tridimensionais conhecidas (proteínas-molde) implica em
similaridade estrutural entre elas.
• Os métodos correntes de modelagem de proteínas por
homologia implicam basicamente em quatro passos sucessivos:
– identificação e seleção de proteínas-molde;
– alinhamento das seqüências de resíduos;
– construção das coordenadas do modelo;
– validação.
31
Threading
• Esta técnica é baseada na comparação da proteína em questão
com modelos descritivos dos enovelamentos de proteínas
homólogas
• Nesses modelos são descritas:
– a distância entre os resíduos de aminoácidos
– a estrutura secundária de cada fragmento
– as características fisico-químicas de cada resíduo
32
Ab Initio
• Entretanto, um grande desejo dos que trabalham com proteínas
é o desenvolvimento de programas realmente eficientes para a
modelagem ab initio
– Um programa que seja capaz de predizer a estrutura
terciária de uma proteína, tendo como informação apenas a
seqüência dos resíduos de aminoácidos e suas interações
fisico-químicas, entre si e com o meio.
– Programas assim existem hoje mas têm muito a melhorar
para que possamos confiar unicamente no seu resultado.
33
Predição de Estrutura
• Decomposição em três problemas:
– Da Estrutura Primária para a Estrutura
Secundária e outras Características
Estruturais
– Da Estrutura Primária e Características
Estruturais para Representações
Topológicas
– De Representações Topológicas para
Coordenadas 3D.
34
Protein Structure Terms
Protein Folds: The core 3D structure of a domain is called a fold. There are
only a few thousand possible folds.
Motif: A short conserved region in a protein sequence. Motifs are
frequently highly conserved parts of domains.
Domain: An independently folded unit within a protein, often joined by a
flexible segment of the polypeptide chain.
Class:used to classify protein domains according to their secondary
structural content and organization
Core:portion of the folded protein molecule that compromises the
hydrophobic interior of the helices and sheets.
Profile:a scoring matrix that represents a multiple sequence alignment of a
protein family
35
Protein Structure Terminology
helix – the most abundant type of secondary structure
in proteins. The helix has an average of 3.6 amino acids
per turn with a hydrogen bond formed about every fourth
residue. Average length is 10 amino acids
sheet- formed by hydrogen bonds between an average
of 5-10 consecutive amino acids in one portion of the
chain with another 5-10 further down the chain. The
interacting regions may be adjacent, with a short loop in
between or far apart with other structures in between.
36
Alpha Helix
37
38
Beta Sheet
39
40
41
Secondary Structure and Folding
Classes
In the absence of “known” information about secondary
structure, there are methods available for predicting the ability of
a sequence to form helices and strands.
Methods rely on observations made from groups of proteins
whose three-dimensional structure has been experimentally
determined
Classification system based on the order of secondary structural
elements within a protein
42
Secondary Structure Prediction
• Predict the secondary structural conformation of each
residue of protein sequences in general - making use of
global rules applying across all sequence families (not
those within individual families).
• Prediction programs are trained on data sets of nonhomologous proteins of known structure (eg all sequence
identity < 25%)
43
Estruturas Secundárias
DSSP classes:
•
•
•
•
•
•
•
•
H = alpha helix
E = sheet
G = 3-10 helix
S = kind of turn
T = beta turn
B = beta bridge
I = pi-helix (very rare)
C = the rest
CASP (harder) assignment:
•
•
•
α = H and G
β = E and B
γ = the rest
Alternative assignment:
•
•
•
α= H
β= B
γ = the rest
44
Algorithms:
• Nearest Neighbour - find the most similar sub-sequences
of known structure (eg Levin, Robson, Garnier, 1986)
• Statistical, such as pairwise frequencies of amino acids as a
function of separation and secondary structure (Garnier,
Osguthorpe, Robson, 1978)
• Neural Networks, (eg PHD - Rost and Sander, 1993)
• Hybrid methods, eg using statistics, physico-chemical
properties such as hydrophobic moments and others (eg
DSC, King and Sternberg, 1996)
45
History:
• The first generation prediction methods following in the
60's and 70's all based on single amino acid propensities
• The second-generation methods dominating the scene until
the early 90's utilised propensities for segments of 3-51
adjacent residues
– It seemed that prediction accuracy stalled at levels
slightly above 60%
– The reason for this limit was the restriction to local
information
– Can we introduce some global information into local
stretches of residues
46
Traditional
47
48
Secondary structure prediction profits
from divergence
• Early on Dickerson [1976] realised that information
contained in multiple alignments can improve predictions
• However, the breakthrough of the third generation
methods to levels above 70% accuracy required a
combination of larger databases with more advanced
algorithms
• The major component of these new methods was the use of
evolutionary information. All naturally evolved proteins
with more than 35% pairwise identical residues over more
than 100 aligned residues have similar structures
49
New database searches extend
family divergence found
• The breakthrough to large-scale routine searches has been
achieved by the development of PSI-BLAST [Altschul, S.
et al. (1997)] and Hidden Markov models [Eddy, S. R.
(1998); Karplus, K., Barrett, C. & Hughey, R. (1998)]
• More data + refined search = better prediction
• Prediction accuracy peaks at 76% accuracy. The currently
best methods reach a level of 76% three-state per-residue
accuracy ( Table 1 ). This constitutes a sustained level
more than four percentage points above last century's best
method not using diverged profiles (PHD in Table 1 )
50
51
Method
Q3
Description
PROF
77.2
PSIPRED
76.6
divergent profile-based neural network prediction
trained and tested with PSI-BLAST
divergent profile (PSI-Blast) based neural network
prediction
SSpro
76.3
profile-based advanced neural network prediction
method
JPred2
75.2
divergent profile (PSI-BLAST) based neural network
prediction
PHDpsi
75.1
divergent profile (PSI-BLAST) based neural network
prediction
PHD
71.9
simple profile-based neural network prediction
Cop
78
advanced neural network prediction method
SAM
HMMSTR
76
74
neural network prediction, using Hidden Markov
models as input
52
Caution: over-optimism
• Seemingly improve accuracy by ignoring short segments.
There are many ways to publish higher levels of accuracy
• Comparing apples and oranges, or too few apples with one
another
– There is NO value in comparing methods evaluated on
different data sets
– For example, 16 new protein structures are clearly too
few! For that set, JPred2, PHD, PROF, PSIPRED, SAMT99sec and SSpro are indistinguishable
•
Seemingly achieve 100% accuracy by using correlated sets
• EVA: automatic evaluation of automatic prediction servers
53
Clever methods can be more accurate 1/4
• SSpro: advanced recursive neural network system
– The only method published recently that appears to improve
prediction accuracy significantly not through more divergent profiles
but through the particular algorithm is SSpro [Baldi, P., Brunak, S.,
Frasconi, P., Soda, G. & Pollastri, G. (1999)]
– The system never learns that secondary structure correlates between
adjacent residues
– PHD addressed this problem by a second level structure-to-structure
network that was trained on the predicted secondary structure from
the first level sequence-to-structure network [Rost, B. & Sander, C.
(1993)]. PSIPRED and JPred2 as well.
– Pierre Baldi and colleagues deviated substantially from this concept.
Instead of using an additional network, they embedded the
correlation into one single recursive neural network
54
Clever methods can be more accurate 2/4
• HMMSTR: hidden Markov models for connecting library of
structure fragments
– Can we predict secondary structure for protein U by local sequence
similarity to segments of known structures {S} even when overall U
differs from any of the known structures {S}?
– Yes, as shown by many nearest-neighbour-based prediction methods,
the most successful of which seems to be NSSP [Salamov, A. A. &
Solovyev, V. V. (1997)]
– A conceptually quite different realisation of the same concept has
been implemented in HMMSTR by Chris Bystroff, David Baker and
colleagues (2000)
55
Clever methods can be more accurate 3/4
• HMMSTR: hidden Markov models for connecting library of
structure fragments
– Firstly, build a library of local stretches (3-19) of residues with 'basic
structural motifs' (I-sites)
– Secondly, assemble these local motifs through Hidden Markov
models introducing structural context on the level of super-secondary
structure
– Thus, the goal is to predict protein structure through identification of
'grammatical units of protein structure formation’
– Although HMMSTR intrinsically aims at predicting higher order
aspects of 3D structure, a side-result is the prediction of 1D
secondary structure
56
Clever methods can be more accurate 4/4
• Copenhagen: a Danish group developed a neural network-based method
that is most amazing in many respects Petersen, T. N. et al. (2000).
– The authors estimate the method to yield levels above 77% prediction
accuracy
– If true, this is the best current method
– Like PSIPRED, JPred2, and PROF, the method uses PSI-BLAST
profiles as input, and like most methods since PHD a two-level
approach addressing the problem of predicting short segments
– It replaces the standard 3 output units (for helix, strand, other), by 9
output units
– Also new is the particular way of weighting the average over different
networks by the overall reliability of the prediction for that network,
and the mere number of different networks considered (up to 800!)
57
Combining mediocre and good
methods is best
• Combination improves on non-systematic errors
– Systematic errors, e.g., through non-local effects
– White noise errors caused by, e.g., the succession of the examples
during training neural networks
– Theoretically, combining any number of methods improves
accuracy as long as the errors of the individual methods are
mutually independent and are not only systematic
• PHD - and more recently others [Chandonia, JPred2,
Copenhagen] - utilised this fact by combining different
neural networks.
58
Discussion
• Methods improved significantly over last two years
– Growing databases and improved search techniques predominantly through the iterated PSI-BLAST tool - yielded a
substantial improvement in secondary structure prediction
accuracy over the last two years.
– State-of-the-art methods now reach sustained levels of 76%
prediction accuracy
• What is the limit of prediction accuracy?
– 88% is the limit, but shall we ever reach close to there?
– Larger databases may get us six percentage points higher, and it
may not. The answer remains nebulous
59
References
•
•
•
•
•
B. Rost (2001) Protein secondary structure prediction continues to rise.
Journal of Structural Biology, 134, pp. 204-218 (Columbia University).
Bystroff, C., Thorsson, V. & Baker, D. (2000). HMMSTR: a hidden Markov
model for local sequence-structure correlations in proteins. J. Mol. Biol., 301,
173-190 (University of Washington)
Cuff, J. A., Clamp, M. E., Siddiqui, A. S., Finlay, M. & Barton, G. J. (1998).
JPred: a consensus secondary structure prediction server. Bioinformatics, 14,
892-893 (JPred – Oxford/Cambridge)
Cuff, J. A. & Barton, G. J. (2000). Application of multiple sequence alignment
profiles to improve protein secondary structure prediction. Proteins, 40, 502511 (JPred2)
Rost, B. (1996). PHD: predicting one-dimensional protein structure by profile
based neural networks. Meth. Enzymol., 266, 525-539. (PHD – Heidelberg –
Germany)
60
References
•
•
•
•
•
Przybylski, D. & Rost, B. (2000). PSI-BLAST for structure prediction: plug-in
and win. Columbia University (PHDPsi)
Rost WWW, B. (2000). Better secondary structure prediction through more
data. Columbia University, WWW document
(http://cubic.bioc.columbia.edu/predictprotein) (PROF)
Altschul, S., Madden, T., Shaffer, A., Zhang, J., Zhang, Z. et al. (1997).
Gapped Blast and PSI-Blast: a new generation of protein database search
programs. Nucl. Acids Res., 25, 3389-3402. (PSI-BLAST – USA)
Jones, D. T. (1999). Protein secondary structure prediction based on positionspecific scoring matrices. J. Mol. Biol., 292, 195-202 (PSIPRED – Warwick)
Karplus, K., Barrett, C. & Hughey, R. (1998). Hidden Markov models for
detecting remote protein homologies. Bioinformatics, 14, 846-856 (SAMT99Sec – University of California Sta. Cruz)
61
References
•
•
•
Baldi, P., Brunak, S., Frasconi, P., Soda, G. & Pollastri, G. (1999). Exploiting
the past and the future in protein secondary structure prediction.
Bioinformatics, 15, 937-946. (Sspro – University of California at Irvine and
Italy)
Petersen, T. N., Lundegaard, C., Nielsen, M., Bohr, H., Bohr, J. et al. (2000).
Prediction of protein secondary structure at 80% accuracy. Proteins, 41, 17-20
– Denamark, including Brunak)
Salamov, A. A. & Solovyev, V. V. (1997). Protein secondary structure
prediction using local alignments. J. Mol. Biol., 268, 31-36 (nearest-neigbour
method)
62
Baixar