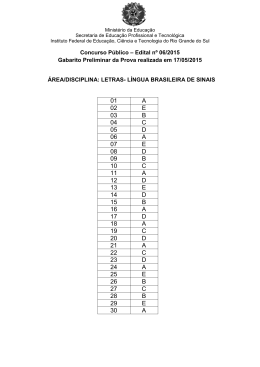
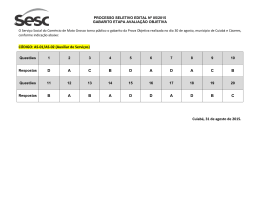
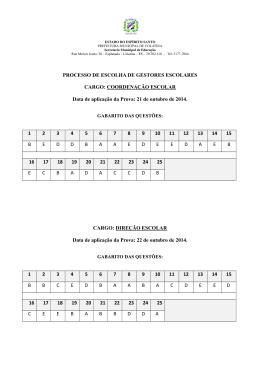
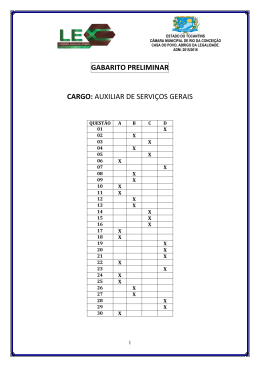
MAE5778 - Teoria da Resposta ao Item Fernando Henrique Ferraz Pereira da Rosa Robson Lunardi 11 de janeiro de 2005 Lista 1 1. Realize uma análise, utilizando o programa ITEMAN, de cada um dos itens e do teste como um todo, segundo a Teoria Clássica. No Anexo I, temos a saı́da da análise do questionário completo no ITEMAN, utilizando a opção de correlação ponto-bisserial. A análise das saı́das para cada uma das questões, revelou como merecedoras de destaque as questões 7, 12 e 17. O item 7 apresentou uma correlação ponto-bisserial razoavelmente baixa (39%), além de apresentar uma correlação ponto-bisserial positiva para uma alternativa incorreta (C). A questão 12 foi a que mostrou piores resultados, tendo um coeficiente de correlação ponto-bisserial negativo e próximo de zero, além de um ı́ndice de discriminação 0, indicando que o item não está discriminando entre os grupos de alunos. Pode ser possı́vel que houve um erro no gabarito, tendo que a alternativa (D) apresenta resultados mais coerentes que a do gabarito (B). A questão 17 teve um coeficiente de correlação bisserial muito baixo (19%), além de um ı́ndice de discriminação também bem fraco (20%), indicando que ela não está discriminando bem os grupos e que não há uma boa correlação entre acertos e erros dessa questão com o escore total do teste. Outras questões que chamaram a atenção por razões similares foram a 8 e a 15, mas as evidências de que elas são inadequadas são mais fracas. A análise das estatı́sticas globais do teste revela que no geral ele está apresentando um desempenho razoável, com um α de 0.802 e um EPM de 2.01, consideravelmente menor que o desvio bruto dos scores, de 4.752. 2. Refaça a análise, após a eliminação de itens que você julgou não terem “funcionado”. Compare os resultados obtidos com aqueles do exercı́cio anterior. Começamos tirando os items que apresentaram os piores resultados: 7, 12 e 17. No Anexo II, temos a saı́da do ITEMAN para esse caso. Nesta saı́da 1 podemos observar uma pequena melhora nos coeficientes de correlação ponto bisserial e ı́ndice de discriminação na maioria dos itens que ficaram. Notamos também uma queda nos valores do EPM (1.842) e da variância bruta dos scores (20.470) e um aumento no valor de α (0.834) indicando que houve uma melhora geral da prova. Procedemos então com a retirada dos dois itens que apresentaram os piores resultados (depois dos 3 já retirados) devido aos seus coeficientes de correlação ponto bisserial e ı́ndice de discriminação: 8 e 15. No Anexo III, temos a saı́da do ITEMAN para esse caso. Verificamos que em muitos itens que ficaram houve uma diminuição dos valores do coeficiente de correlação ponto bisserial e ı́ndice de discriminação. Observamos também que o valor de α com esta eliminação caiu um pouco (0.830) em relação ao último resultado obtido, apesar do EPM e da variância bruta dos escores terem caı́do um pouco. Devido a essa leve queda no desempenho geral do teste obtida com a retirada das questões 8 e 15, concluı́mos que que a prova que só considera a primeira eliminação (Anexo II) é a mais adequada. 3. Construa um programa para estimar: (a) os 5 primeiros itens, os seguintes parâmetros: ı́ndice de dificuldade, ı́ndice de discriminação, coeficiente de correlação ponto bisserial (para cada alternativa de resposta) e coeficiente de correlação bisserial (para cada alternativa de resposta). (b) o coeficiente alfa de fidedignidade e o erro padrão de medida (EPM) do teste. Construı́mos um conjunto de funções em R para realizar a análise clássica de itens. O código fonte segue no Anexo IV. Basicamente construı́mos uma classe trianal, uma função construtura para esse método e funções para imprimir os resultados e ler os dados. Para usar o programa, deve-se abrir uma sessão do R no diretório em que se encontra o arquivo fonte, e executar: > source(’tri_class.R’) Com isso carrega-se as funções na memória. Lê-se então um conjunto de dados com a função le.dados(): > le01 <- le.dados(’le_01.dat’) E gera-se um objeto de análise com a função analise() : > an1 <- analise(le01) 2 Como argumentos opcionais para analise(), pode-se especificar um gabarito alternativo ou ainda um subconjunto de questões que devem ser consideradas. Essas informações já estão disponı́veis no arquivo de entrada, entretanto, para que possa-se fazer a análise mudando o gabarito e/ou as questões consideradas na análise sem a necessidade de se editar o arquivo de dados, foi adicionada essa funcionalidade. O comando abaixo por exemplo faz a análise das 4 primeiras questões somente: > an2 <- analise(le01,usa.questao=c(T,T,T,T,rep(F,18))) Para trocar o gabarito, procede-se da mesma forma. Para trocar o gabarito da questão 12 para ’D’, por exemplo, fazemos: > gabarito <- le01$gabarito > gabarito[12] [1] "B" > gabarito[12] <- "D" > gabarito[12] [1] "D" > an3 <- analise(le01,gabarito=gabarito) Onde temos armazenados em an3 os resultados da análise. Por fim, basta imprimirmos o objeto resultante da análise para verificar os resultados. No item a) pede-se a análise para os 5 primeiros itens do teste. Para fazermos isso, basta usarmos a função print() no objeto adequado, especificando as questões que queremos observar: > print(an1,mostrar.questoes=1:5,global=FALSE) Question 1 key prop.correct disc.index pt.biss biss A 0.4653179 0.7207283 0.5882265 0.7382484 A B C D E NULO ind.dif 0.46531792 0.25722543 0.10404624 0.02312139 0.13005780 0.02023121 end.low 0.17142857 0.32380952 0.14285714 0.03809524 0.27619048 0.04761905 end.high 0.892156863 0.098039216 0.000000000 0.000000000 0.009803922 0.000000000 3 pt.biss 0.5882265 -0.2091873 -0.2034865 -0.0860195 -0.3127053 -0.1543285 biss key 0.7382484 * -0.2834648 -0.3439407 -0.2362007 -0.4970636 -0.4444033 Question 2 key prop.correct disc.index pt.biss biss D 0.3583815 0.6305322 0.5226652 0.6709724 A B C D E NULO ind.dif 0.09826590 0.08959538 0.20809249 0.35838150 0.18786127 0.05780347 end.low 0.1428571 0.1142857 0.3333333 0.1047619 0.1904762 0.1142857 end.high 0.00000000 0.02941176 0.10784314 0.73529412 0.10784314 0.01960784 pt.biss -0.2044972 -0.1075186 -0.2371712 0.5226652 -0.0616127 -0.1658558 biss key -0.3513267 -0.1897306 -0.3358655 0.6709724 * -0.0893056 -0.3345741 Question 3 key prop.correct disc.index pt.biss biss C 0.5433526 0.780112 0.6484235 0.8144313 A B C D E NULO ind.dif 0.19364162 0.10404624 0.54335260 0.05491329 0.09248555 0.01156069 end.low 0.35238095 0.15238095 0.19047619 0.13333333 0.13333333 0.03809524 end.high 0.009803922 0.009803922 0.970588235 0.000000000 0.009803922 0.000000000 pt.biss -0.3488436 -0.1895415 0.6484235 -0.2272230 -0.1952886 -0.1771125 biss key -0.5021019 -0.3203703 0.8144313 * -0.4659082 -0.3414341 -0.6261054 Question 4 key prop.correct disc.index pt.biss biss E 0.66763 0.5210084 0.4611645 0.5981478 A B C D E NULO ind.dif 0.08381503 0.12427746 0.02601156 0.08959538 0.66763006 0.00867052 end.low 0.18095238 0.21904762 0.06666667 0.13333333 0.38095238 0.01904762 end.high 0.009803922 0.029411765 0.000000000 0.058823529 0.901960784 0.000000000 4 pt.biss -0.2533451 -0.2228462 -0.1520366 -0.1330749 0.4611645 -0.1219972 biss key -0.4559380 -0.3585800 -0.4005295 -0.2348280 0.5981478 * -0.4807907 Question 5 key prop.correct disc.index pt.biss biss A 0.5635838 0.5565826 0.4516993 0.5687642 A B C D E NULO ind.dif 0.563583815 0.063583815 0.052023121 0.161849711 0.153179191 0.005780347 end.low 0.25714286 0.06666667 0.10476190 0.22857143 0.32380952 0.01904762 end.high 0.81372549 0.04901961 0.02941176 0.07843137 0.02941176 0.00000000 pt.biss 0.45169926 -0.05409001 -0.13577451 -0.17468867 -0.29247666 -0.14493139 biss key 0.5687642 * -0.1058914 -0.2832665 -0.2624581 -0.4455333 -0.6679198 Para fazer o item b, basta chamarmos a função print no mesmo objeto de análise, mas com o parâmetro global setado para verdadeiro: > print(an1,mostrar.questoes=NULL,global=TRUE) questoes.efetivas N media variancia desvio mediana alpha SEM max.low N.low min.high N.high Global Statistics 22.0000000 346.0000000 9.5317919 22.6439139 4.7585622 9.0000000 0.8207448 2.0147056 6.0000000 105.0000000 13.0000000 102.0000000 4. Para cada um dos 5 primeiros itens, construa um gráfico de dispersão para representar a relação entre a proporção de acerto e o escore médio, medidos em 7 classes de escore. Para esse fim, criamos a função triplot, com argumentos: > args(triplot) function (quest, obj, classes = 7) NULL Ela recebe o número de uma questão, um objeto de análise e o número de classes que desejamos dividir os dados. Ela então retorna um objeto da 5 classe triplot, que pode ser guardado ou no caso do método default em modo interativo (print), é feito o gráfico na tela. Com essa função, para gerar os gráficos pedidos, basta fazer: triplot(1,an1) triplot(2,an1) triplot(3,an1) triplot(4,an1) triplot(5,an1) Obtendo as Figuras: 6 Observamos que os gráficos dos itens analisados apresentam o comportamento esperado, com a curva lembrando uma curva logı́stica com a > 0. Devido a generalidade do programa, é possı́vel facilmente obter-se análises mais completas, assim como variar o número de classes de escore para os gráficos acima. No Anexo V temos uma análise completa das 22 questões, obtida com o comando: > print(an1) Temos também os gráficos de escore médio por proporção de acerto pra 7 as questões que retiramos do teste no Exercı́cio 2 (Itens 7, 12 e 17). Em particular, observamos graficamente porque esses itens não foram apropriados. Para o item 12, temos que conforme o escore médio aumenta, não há crescimento algum na proporção acerto. Para a questão 17, temos que o crescimento da curva é muito lento, e para a questão 7, temos uma situação parecida. Temos ainda os gráficos de escore médio por proporção de acerto para a questão 1, mas com diferentes classes de escore (5, 7 e 12), respectivamente. O aumento no número de classes reflete em uma curva cada vez menos suave, conforme esperado. Por final temos o histograma dos escores, e o gráfico de barras das proporções de acertos, obtidos com os comandos: > hist(an1$outros$score) > barplot(an1$outros$prop.acerto) Sobre A versão eletrônica desse arquivo pode ser obtida em http://www.feferraz. net Copyright (c) 1999-2005 Fernando Henrique Ferraz Pereira da Rosa. É dada permiss~ ao para copiar, distribuir e/ou modificar este documento sob os termos da Licença de Documentaç~ ao Livre GNU (GFDL), vers~ ao 1.2, 8 publicada pela Free Software Foundation; Uma cópia da licença em está inclusa na seç~ ao intitulada "Sobre / Licença de Uso". 9
Baixar