☰
Explorar
Assinar em
Inscrever-se
Envio
×
Baixar
Sem categoria
Visualizar/Abrir
cusroDeDelphicoltec1
Slides - Estrutura de Dados II
Frente
Paradigmas de Projetos de Algoritmos
Minicurso
3 Bim - Manipulação de Dados
clipper tranportes internacionais completa 30 anos no mercado
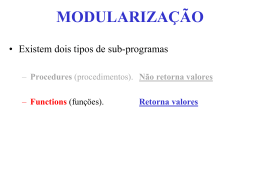
05_Modularizacao_2Funcoes
Var Matriz - Departamento de Computação