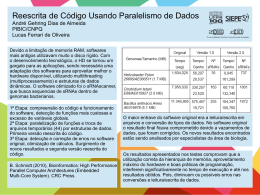
PostgresSQL
Optimização de Interrogações
Francisco Santos
Agenda
Introdução
Processamento Interrogações
Query Tree
Reescrita de Interrogações
Optimização do Plano
Modelo de Custo
Bibliografia
Introdução
O que é o PostgresSQL?
É um sistema de gestão de base de dados, com suporte para o modelo de
dados objecto-relacional.
Surgiu como evolução do SGBD Postgres, desenvolvido pelo Dep. Eng. Inf.
da Universidade da California, em Berkley.
Este projecto foi apresentado, pela primeira vez, na conferência ACM SIGMOD de
1988.
É extensível, permitindo que o utilizador defina:
Tipos de dados
Funções
Operadores
Funções de Agregação
Novos tipos de índices
Processamento Interrogações
Análise
Léxica,
Sintáctica
Análise
Semântica
Reescrita
Interrogações
Optimização
Plano
Execução
Plano
Processamento Interrogações
Análise
Léxica,
Sintáctica
Árvore
derivação
Análise
Semântica
Reescrita
Interrogações
Optimização
Plano
•Análise léxica: leitura sequencial dos
caracteres que constituem a interrogação,
separação dos caracteres em palavras e o
reconhecimento dos vocábulos representados
por cada palavra (ex.: cláusulas SELECT, FROM,
nomes de tabelas, colunas, …).
•Análise sintáctica: agrupamento dos
vocábulos, verificando se formam uma frase
sintacticamente correcta, isto é, composta de
acordo com as regras sintácticas da linguagem
(ex.: formulação completa de uma interrogação).
•Resultado: árvore de derivação.
Execução
Plano
Processamento Interrogações
Análise
Léxica,
Sintáctica
Árvore
derivação
Análise
Semântica
Reescrita
Interrogações
Árvore
interrogação
Optimização
Plano
Execução
Plano
•Análise semântica: verificar se os nomes
alternativos (aliases) das tabelas (inclui vistas) e
colunas correspondem a objectos existentes na
BD, verificar se os operadores são aplicados aos
operandos do tipo adequado.
•Resultado: árvore da interrogação (sintáctica- e
semanticamente correcta).
Processamento Interrogações
Análise
Léxica,
Sintáctica
Árvore
derivação
Análise
Semântica
Reescrita
Interrogações
Árvore
interrogação
Optimização
Plano
Execução
Plano
Árvore
interrogação
•Reescrita interrogações: aplicação das regras
definidas pelos utilizadores, para as operações:
UPDATE, INSERT, DELETE;
as operações anteriores também podem utilizar
operações SELECT. Subsequentemente, todas
as regras relacionadas com operações SELECT
são aplicadas.
•Resultado: árvore da interrogação
Processamento Interrogações
Análise
Léxica,
Sintáctica
Análise
Semântica
Reescrita
Interrogações
•Optimização Plano: geração do método de
obtenção dos registos para satisfazer a
interrogação;
geração de baixo para cima (i.e. parte da subinterrogação interior para a exterior); escolha do
melhor plano
é feita com base noÁrvore
custo (inclui
Árvore
CPU e derivação
I/O);
interrogação
duas formas de determinar a melhor ordem de
junção: algoritmo padrão (Sistema R), algoritmo
genético.
•Resultado: plano de menor custo
Optimização
Plano
Execução
Plano
Plano
Árvore
interrogação
Árvore da Interrogação
Exemplo:
alunos( aid:string, nome:string, idade:integer, email:string, media:real )
inscricoes( aid:string, cid:string, nota:integer )
aid FK Alunos
Q: “Quais são os alunos: aid e nome, cuja nota no TFC é superior à sua
média de curso?”
SELECT Q1.aid, Q1.nome
FROM alunos Q1
WHERE Q1.aid IN
( SELECT Q3.aid
FROM inscricoes Q3
WHERE Q3.nota > Q1.media
AND Q3.cid = ‘TFC’ )
Árvore da Interrogação
Tipo da operação:
SELECT, INSERT, UPDATE ou
DELETE
Lista das colunas:
Lista das tabelas:
Na operação SELECT, representa
todas as tabelas da cláusula FROM
Tabelas são referenciadas por um
identificador numérico
Tabela do resultado:
Nas operações INSERT, UPDATE e
DELETE, representa a tabela onde
vai ser colocado o resultado
Este campo não é usado na
operação SELECT
Expressão de qualificação:
Na operação SELECT: colunas a
partir das quais é feita a projecção
Na operação INSERT: expressões
contidas na cláusula VALUES
Na operação UPDATE: descreve as
novas linhas que substituem as
existentes (SET col = expr)
Na operação DELETE: não é usada
uma vez que esta operação não
produz resultados
Corresponde à cláusula WHERE de
uma operação
Árvore da junção:
Mostra a estrutura da cláusula FROM
Reescrita de Interrogações
Os utilizadores podem definir que regras devem ser
usadas consoante a operação que for aplicada a
uma tabela:
CREATE RULE nome_regra AS
ON { SELECT | INSERT | UPDATE | DELETE }
TO tabela [ WHERE condicao_aplicacao ]
DO [ INSTEAD ] { NOTHING | comando | ( comando; comando …
)}
As regras de reescrita são aplicadas entre a fase da
análise semântica e da optimização do plano.
Reescrita de Interrogações
As vistas sobre as tabelas base são definidas
através do sistema de regras.
CREATE VIEW v_alunos_cadeiras (aid, nome, cid) AS
SELECT a.aid, a.nome, i.cid
FROM alunos a, inscricoes i
WHERE a.aid = i.aid;
Esta operação é desdobrada em duas operações:
CREATE TABLE v_alunos_cadeiras (aid, nome, cid);
CREATE RULE _RETURN AS ON SELECT TO
v_alunos_cadeiras DO INSTEAD
SELECT a.aid, a.nome, i.cid
FROM alunos a, inscricoes i
WHERE a.aid = i.aid;
Reescrita de Interrogações
Resultado da aplicação da regra de reescrita:
SELECT aid,nome,cid FROM v_alunos_cadeiras;
SELECT aid,nome,cid
FROM ( SELECT a.aid, a.nome, i.cid
FROM alunos a, inscricoes i
WHERE a.aid = i.aid ) v_alunos_cadeiras;
A redefinição da interrogação aninhada através de uma
só operação SELECT é feita durante a fase da
optimização do plano
Optimização do Plano
Cada bloco da interrogação é processado isoladamente (bloco =
sub-interrogação)
Geração do plano é feita de baixo para cima:
Optimizador parte da sub-interrogação interior para a exterior
Permite aplicar optimizações durante a geração, ex.: transformar
sub-interrogação numa junção
Escolha do melhor plano é feita com base no custo, inclui custo
de processamento (CPU) e transferência de páginas de disco
para memória (I/O)
Duas formas de determinar a melhor ordem de junção:
algoritmo padrão (Sistema R): programação dinâmica
algoritmo genético: usado quando o número de tabelas na
cláusula FROM é muito elevado (>= 12)
Optimização do Plano
Alg. Programação Dinâmica (clássico):
Para cada par de sub-conjuntos complementares
de ‘S’: ‘S1’ e ‘S - S1’, onde ‘S’ é o conjunto das
relações a juntar:
Encontrar o melhor plano para juntar as tabelas
contidas em ‘S1’, designado P1, e o melhor plano para
juntar as tabelas contidas no conjunto complementar,
designado P2.
A = Melhor algoritmo para juntar P1 e P2.
Custo = Custo(P1) + Custo(P2) + Custo(A)
Se o novo custo for inferior ao anteriormente calculado
para ‘S’, substituir o plano por: “P1, P2, juntar(P1,P2,A)”
Optimização do Plano
No PostgresSQL: são considerados apenas os planos
recursivos à esquerda (left-deep):
r3
r1
r2
Para uma junção n-ária, o sub-plano
esquerdo é uma junção (n-1) ária e o
direito é um acesso a uma tabela
Os acessos podem ser feitos de forma
sequencial ou através de índices
primários ou secundários
As junções são feitas através de um
dos seguintes algoritmos: nestedloops-join, merge-join, hash-join
Optimização do Plano
O alg. nested-loops-join é o mais simples para juntar duas
tabelas.
Pode ser dispendioso se não existir índice sobre os atributos da
junção na tabela interior.
O merge-sort-join é melhor que o método anterior quando não
existe índice sobre a tabela interior.
Pode ser usado quando existe uma cláusula da forma ‘col1 OPR
col2’ onde ‘col1 tabela1’ e ‘col2 tabela2’
O custo de ordenação inicial das relações pode ser eliminado se
existirem índices sobre os atributos da junção em cada tabela
Uma segunda alt. quando não existirem índices é o hash-join: é
aplicada uma função de hash para a relação interior, os atributos
da junção da tabela exterior são usados para pesquisar o índice
hash.
Modelo de Custo
Custo dos Acessos a Tabelas
Custo
P
T
Acesso
Sequencial
NumPaginas
NumRegistos
Índice primário
NumPaginas*F
NumRegistos*F
Índice secundário
F*(NumPaginas + IRegistos)
F*(NumRegistos + IRegistos)
NumPaginas: número de páginas de uma tabela
NumRegistos: número de registos de uma tabela
IRegistos: número de registos no índice
F: factor de selectividade combinado para todas as
condições de selecção
Modelo de Custo
Custo das Junções
Nested Loops Join
Cext + Next * Cint
Sort Merge Join
C ext + Cord_ext + Cint + Cord_int
Hash Join
Cext + Cconst_hash + Next * Chash
Cext: custo para aceder à tabela exterior
Cint: custo para aceder à tabela interior
Cord_ext: custo para ordenar a tabela exterior (igual a zero, caso já
esteja ordenada)
Cord_int: custo para ordenar a tabela interior (igual a zero, caso já
esteja ordenada)
Cconst_hash: custo para construir o índice hash sobre a tabela
interior
Chash: custo de uma pesquisa através do índice hash
Next: tamanho da tabela exterior
Bibliografia
[Post05a] – The PostgresSQL Global Development
Group “PostgresSQL 8.0.0 Documentation”, 2005
[SKS06] – Silberschatz, Korth, Sudarshan, “Database
System Concepts”, Cap. 13, 14, 26, McGraw-Hill, 5th
edition, 2006
[Fong97] – Zelaine Fong, “The Design and
Implementation of the Postgres Query Optimizer”, 1997
[Post05b] – The PostgresSQL Global Development
Group, “PostgresSQL Online Documentation”, 2005,
www.postgresql.org/docs/
Baixar