☰
Explorar
Assinar em
Inscrever-se
Envio
×
Baixar
Sem categoria
TESE Uma solução via bootstrap paramétrico para o
Comissão Eleitoral Nacional
III/III/IIIII - Freelance Now
Planta Maria Diva PDF
MARIA APARECIDA FAUSTINO PIRES
Anexo II- Retificado
De: Serviços Administrativos Para: Juntas Regionais, Juntas de
resultado da apuração
resultado da apuração - Câmara Municipal de Campanário
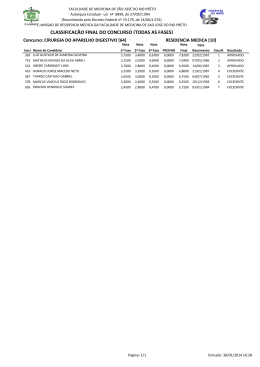
Cirurgia Aparelho Digestivo
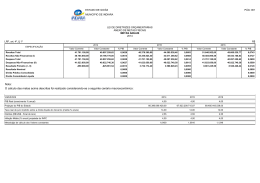
Nota: O cálculo das metas acima descritas foi realizado