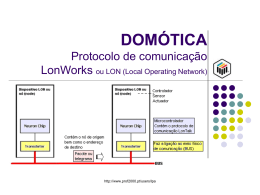
Curso Introdução às Redes Neuronais Parte 2 Prof. Dr. rer.nat. Aldo von Wangenheim Recapitulação: Aspectos Importantes • Modelagem dos Objetos • Implementação dos Algoritmos de Treinamento • Escolha e Gerência dos exemplos para Treinamento • Estes aspectos são independentes do modelo de rede que se deseja implementar. Recapitulação: Modelagem dos Objetos Objetos a serem modelados: • • • • • Rede Camada (Layer) Neurônio Conexão Neuroreceptor (Site) 1.0 0.5 0.0 1.0 0.5 0.0 1.0 0.5 0.0 1.0 1 0.5 0 0.0 0 Backpropagation • Modelo mais utilizado atualmente • Baseia-se em uma extensão dos Perceptrons • Utilizado quando queremos “aprender” uma função y = ?(x) desconhecida entre um conjunto de dados de entrada x e um conjunto de classificações possíveis y para esses. BP é um algoritmo para a implementação de classificadores de dados. Representa teoricamente qualquer função, desde que exista. Perceptrons (1957) • Redes Feed-Forward Treinamento baseado no Erro entre saída e padrão. • 2 Camadas Limitado pque não existiam algoritmos de treinamento. • Dois modelos de Neurônios: Neurônios de Barreira • Representam dados linearmente separáveis Neurônios Lineares • Representam dados linearmente independentes. Aprendizado nos Perceptrons • Através da adaptação dos pesos wik • Mesmo para os dois tipos de neurônios. Entrada: u u Saida: i u Valor de entrada: k u Desejado: Oui = i u Quando a entrada k for aplicada na entrada, teremos como saida: Oui = g( hui ) = g k u wik k Perceptron: Regra de Aprendizado wiknovo = wikvelho + wik onde: wik u my 2 imy my caso ; O i i k = 0 senao ou: u u wik = i - Oimy k e a taxa de aprendizado . Perceptron: Regra de Aprendizado • A regra de aprendizado do Perceptron é chamada de Regra-Delta. A cada passo é calculado um novo delta. • Com a Regra-Delta como foi definida por Rosenblatt havia vários problemas: Só servia para treinar redes onde você pudesse determinar o erro em todas as camadas. Redes com só duas camadas eram limitadas. Nos neurônios lineares, onde era fácil determinar o erro numa camada interna, não fazia sentido incluí-la por causa da dependência linear. Regra de Aprendizado: Minimizar o Erro • Inicializamos a rede com valores aleatórios para os pesos. • A Regra Delta aplicada repetidamente produz como resultado e minimização do erro apresentado pela rede: Erro: 1 u E[w] = i 2 iu 1 O = 2 u i 2 iu u i - k wik u k 2 Pesos Convergem para um Ponto de Erro Mínimo chamado Atrator Problemas: • As vezes o espaço vetorial definido por um conjunto de vetores de pesos não basta, não há um atrator (dados linearmente inseparáveis) • Solução: Rede de mais camadas • Problema: Como definir o erro já que não podemos usar neurônios lineares, onde o erro pode ser definido pela derivada parcial de E em relação a w ? Erro em Camadas Internas • Com neurônios de McCulloch & Pitts podemos representar qualquer coisa. • Como perém treiná-los ? Para a camada de saída é fácil determinar o erro, Para outras impossível. 1 u E[w] = i 2 iu 1 O = 2 u i 2 iu u i - k wik u k 2 Solução (McLelland 1984) • Usamos uma função não-linear derivável como função de ativação. Uma função assim mantém a característica provada por McCulloch e Pitts de representação. • Usamos como medida de erro em uma camada interna, a derivada parcial do erro na camada posterior. • Propagamos esse erro para trás e repetimos o processo: Error Backpropagation. Bacpropagation • Redes de mais de duas camadas. Treinamento: • 2 Passos: Apresentação de um padrão para treinamento e propagação da atividade. Calculo do erro e retropropagação do erro. Treinamento em BP: • Padrão de treinamento é apresentado. • Atividade é propagada pelas camadas. • Erro é calculado na saída e vetores de pesos entrando na última camada são adaptados. • Derivada do erro em relação aos vetores de pesos (antes da adaptação) é calculada e usada para adaptação dos pesos da camada anterior. • Processo é repetido até a camada de entrada. Funções de Ativação Quaselineares: g(h) = tanh(h) 2 com g (h) = (1 - g ) e: -1 f ] g(h) = (h) = [1 + exp(-2 h) com g (h) = 2 g(1 - g) i output layer neuron index j hidden layer neuron index k wij _ > input neuron index w weight i receiving neuron j giving neuron wrec giv input at input- neuron k for pattern u ; the same as activation of neuron k uk ui expected output at neuron i for given input pattern my huj total input of HIDDEN neuron j V uj OUTPUT of neuron j hui total input of OUTPUT neuron i g( ) ACTIVATION FUNCTION of neuron Na apresentaçao de uma padrao u a entrada de um neuronio escondido j huj = w jk u k k my e a saida V j V uj = g( huj ) = g w jk u k k a unidade de saida i recebe: w jk u u hu i = W ij V j = W ij g k k j j my e produz a saida Oi u u Ou i = g( hi ) = g W ij V j j = g W g w u ij jk k k j O erro E[ w ] E[ w ] = 2 1 u u Oi 2 ui i transforma se em: 1 u i - g wij . g w jk u E[ w ] = k 2 ui k j 2 Dos neuronios de saida para os escondidos a regra e a de sempre: E u W ij = - = i - Oui g ( hui )V uj W ij my = ui V uj my = g ( h ) - Oui u i u i u i Para os escondidos para outros escondidos ou para os de entrada: w jk = E E V uj = - = - u w jk my V j w jk ui - Oui g ( hui )W ij g ( huj ) uk myi = ui W ij g ( huj ) k u ui = uj k u com uyj = g ( huj ) W ij ui i e assim aforma geral da regra : w pq = patterns output * V input
Baixar