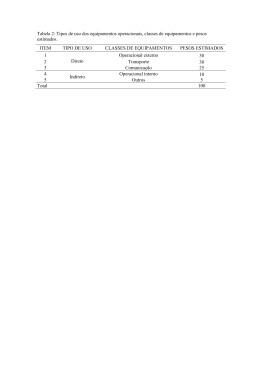
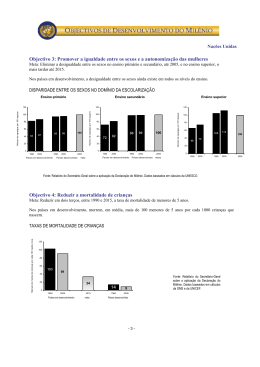
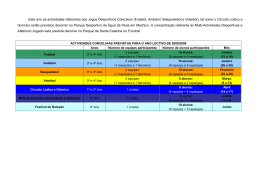
1334 INTRODUÇÃO ÀS PROBABILIDADES E ESTATÍSTICA 2003 Informações: relembra-se os alunos interessados que a realização de acções presenciais só é possível mediante solicitação vossa, por escrito, à assistente da cadeira. A realização da acção fica condicionada à inscrição de um número mínimo de 15 alunos. Relatório do 1º teste formativo 1. População ou universo, é um conjunto de indivíduos ou objectos que apresentam uma ou mais características em comum, que se pretende analisar. A amostra é um segmento (subconjunto) da população, recolhida com o objectivo de se obter informação sobre características desconhecidas da população. A variável é qualquer característica (populacional) da unidade que constitui a população, susceptível de ser expressa por meio de um número. Considerando o seguinte exemplo: Foi feito um inquérito a um grupo de 40 compradores de carros novos, de determinada marca, para determinar quantas reparações ou substituições de peças foram feitas durante o primeiro ano de utilização dos carros. Neste caso, a população será constituída por todos os compradores de carros novos, de determinada marca, a amostra o grupo dos 40 compradores de carros novos da mesma marca e a variável o nº correspondente às reparações ou substituições de peças, feitas durante o primeiro ano de utilização dos 40 carros. 2. Ao estudar uma população, usualmente o que se pretende estudar são algumas das suas características numéricas, normalmente desconhecidas que designamos por Parâmetros. Enquanto que o parâmetro populacional pode ser considerado um valor exacto, mas desconhecido, a Estatística amostral é conhecida, é um número que descreve a amostra. Calcula-se o valor de uma estatística a partir dos valores observados na CMM-2003/2004 1/11 Rel-1º TF-1334 1334 amostra, variando o valor desta de amostra para amostra. Utiliza-se a estatística para estimar o parâmetro desconhecido da população, também por isso muitas vezes conhecido por Estimador. 3. Uma vez recolhida a amostra procede-se ao seu estudo. Este consiste em resumir a informação contida na amostra em tabelas, gráficos, e calculando algumas características amostrais – estatísticas . Este é o objectivo da Estatística descritiva. O objectivo da Inferência Estatística é, utilizando-se técnicas estatísticas convenientes permitir com base numa amostra tirar conclusões acerca da população. Pois num estudo estatístico pretende-se, de uma maneira geral, conhecer o mais possível sobre a população, estimar um parâmetro ou testar uma hipótese. 4. Ao resultado da observação da variável, chamamos dado estatístico ou simplesmente dado. Estes podem ser de dois tipos: ? ? ? Qualitativ os ? Dados ? ? ? discretos ? Quantitativos?? ?? ?contínuos Dados qualitativos, representam a informação que identifica alguma qualidade, categoria ou característica, não susceptível de medida. Dados quantitativos, representam a informação resultante de características susceptíveis de serem medidas, apresentado-se com diferentes intensidades que podem ser de natureza discreta, se só pode tomar um nº finito ( ou infinito numerável) de valores distintos, ou de natureza contínua se toma valores numéricos compreendidos num determinado intervalo de variação. 5. A. População constituída por todos os agregados familiares da cidade em estudo; Amostra de dimensão 20, constituída por alguns (20) dos agregados familiares da referida cidade; Variável, nº de pessoas de cada agregado familiar, quantitativa discreta. B. População constituída por todos os países da comunidade; Amostra de dimensão 3, constituída por alguns (3) dos países da comunidade; Variável, nº de pessoas de cada país, quantitativa discreta. C. População constituída por todos os funcionários da fábrica; CMM-2003/2004 2/11 Rel-1º TF-1334 1334 Amostra constituída por todos os funcionários da fábrica; Variável, tempo de percurso entre a casa e a fábrica, quantitativa contínua. D. População constituída por todos os carros que passam na Ponte Vasco da Gama; Amostra constituída pelos carros observados durante uma hora; Variável, característica dos carros: pequeno, médio, grande, qualitativa. E. População constituída por todas as famílias Portuguesas; Amostra de dimensão 1024, constituída por algumas (1024) das famílias Portuguesas; Variável, valor pago mensalmente por cada família, quantitativa continua. F. População constituída por todos os Estudantes da Universidade, 3500; Amostra de dimensão 1280, constituída por alguns (1280) dos estudantes da Universidade inquiridos; Variável, qualitativa, dicotómica (porque só assume dois valores possíveis); 6. A seguinte tabela apresenta as respostas de 38 alunos de uma Escola, a um inquérito, em que se pedia que indicassem: Sexo, Idade, Nº de irmãos, se tinham ou não Cartão de crédito, Altura (cm), Peso (kg) e Desporto preferido: a) Sexo: variável qualitativa; dicotómica. Idade: variável quantitativa contínua; Nº de irmãos: variável quantitativa discreta; Cartão de crédito: variável qualitativa; dicotómica. Altura: variável quantitativa contínua; Peso: variável quantitativa contínua; Desporto preferido: variável qualitativa. b) Variável Sexo Sexo Freq. abs. Freq. relat. F 22 0.579 M 16 0.421 M F Da análise do diagrama circular, verifica-se que nos alunos seleccionados existem mais raparigas que rapazes. Variável Idade CMM-2003/2004 3/11 Rel-1º TF-1334 1334 Esta variável é de tipo quantitativo e contínuo, uma vez que a idade pode assumir qualquer valor de um intervalo, passando-se de um valor a outro continuamente, embora seja usual apresentá-la de forma discreta. Vamos construir uma tabela de frequências, para posteriormente construir o histograma, considerando 4 classes de amplitude 1: Classes Freq. abs. Freq. relat. [14, 15[ 10 0.263 [15, 16[ 17 0.447 [16, 17[ 10 0.263 [17, 18[ 1 0.026 Freq. rel. 0.447 0.263 0.026 14 15 16 17 18 Da análise do histograma, verifica-se que a distribuição das idades é aproximadamente simétrica (apresentando um ligeiro enviesamento para a direita) em torno de um valor que anda à volta dos 15 anos e meio. Obs: Na construção do histograma tivemos em consideração a Nota 1 da página 58 do manual. Variável Número de irmãos Sendo uma variável de tipo quantitativo discreto, para construir a tabela de frequências, consideramos como classes os diferentes valores que surgem na amostra: Freq.abs. Freq. rel. 7 12 12 4 2 0 1 0.184 0.316 0.316 0.105 0.053 0.000 0.026 Freq. relativa 30% Nº de irmãos 0 1 2 3 4 5 6 20% 10% 0% 0 1 2 3 4 5 6 nº irmãos CMM-2003/2004 4/11 Rel-1º TF-1334 idade 1334 Do diagrama anterior verifica-se que os alunos seleccionados têm entre 0 e 6 irmãos, predominando os alunos com 1 ou 2 irmãos. Há ainda a destacar o facto de nenhum dos 38 alunos ter 5 irmãos. Variável Cartão Freq. rel. Ter Cartão Freq. abs. Freq. rel. Sim 19 0.5 Não 19 0.5 0.5 Sim Não De entre os alunos seleccionados a percentagem dos que dispõem ou não de cartão é idêntica. Variável Altura Para construir a tabela de frequências, considerámos a amplitude da amostra 165–150=15, que foi dividida por 6, que é o número de classes sugerido pela regra empírica utilizada nestas circunstância s (pag. 56 manual). O quociente de 15/6 é 2.5, pelo que pareceria lógico considerarmos para amplitude de classe este valor. No entanto, se procedessemos deste modo, ao construir as classes utilizando sempre a mesma metodologia, que no nosso caso é considerar intervalos fechados à esquerda e abertos à direita, iríamos obter as classes [150, 152.5[, [152.5, 155.0[, [155.0, 157.5[, 157.5, 160.0[, [160.0, 162.5[, [162.5, 165.0[. Então haveria um valor da amostra, o 165, que não pertenceria a nenhuma das classes, pelo que temos efectivamente de considerar para amplitude de classe um valor aproximado por excesso do quociente amplitude da amostra número de classe . Este facto levou-nos a considerar, por exemplo, para amplitude de classe o valor 2.6: Classes Freq. abs. Freq. rel. [150, 152.6[ 1 0.026 [152.6, 155.2[ 6 0.158 0.289 [155.2, 157.8[ 7 0.184 [157.8, 160.4[ 11 0.289 0.211 0.184 0.158 0.132 [160.4, 163.0[ 8 0.211 0.026 [163.0, 165.6[ 5 0.132 Freq. rel. CMM-2003/2004 150 5/11 152.6 155.2 157.8 160.4 163.0 165.6 Rel-1º TF-1334 altura 1334 Da análise do histograma verificamos que a distribuição de frequências é aproximadamente simétrica, com um ligeiro enviesamento para a esquerda. Obs: Na construção do histograma tivemos em consideração a Nota 1 da página 58 do manual. Variável Peso Para a construção da tabela de frequências procedemos de forma análoga à descrita para a variável altura, considerando para amplitude de classe o valor 3.7, que é um valor aproximado por excesso, do quociente Classes Freq. abs. Freq. rel. [43, 46.7[ 5 0.132 [46.7, 50.4[ 13 0.342 [50.4, 54.1[ 7 0.184 [54.1, 57.8[ 3 0.79 [57.8, 61.5[ 6 0.158 [61.5, 65.2[ 4 0.105 65 ? 43 ? 3.666 ? . 6 Freq. rel. 0.342 0.079 43 46.7 50.4 54.1 57.8 61.5 O histograma anterior apresenta uma forma que sugere a existência de uma mistura de duas populações, uma distribuindo-se à volta do valor 48.5, aproximadamente, e outra à volta do valor 59.5, aproximadamente. Tendo em conta os dados que estamos a analisar não nos surpreende os resultados obtidos, pois estamos perante observações resultantes das Populações constituídas pelos pesos dos rapazes e a constituída pelos pesos das raparigas, que de um modo geral são inferiores. Variável Desporto Do mesmo modo que as variáveis Sexo e Cartão, também esta variável é de tipo qualitativo, pelo que para proceder ao agrupamento dos dados consideramos as diferentes categorias que a variável assume: Basket V ólei Desporto Vólei Natação Futebol Andebol Ginástica Ténis Basket Freq. abs. 3 7 8 3 5 9 3 Freq. rel. 0.079 0.184 0.211 0.079 0.132 0.237 0.079 Natação Ténis Ginástica Futebol Andebol CMM-2003/2004 6/11 Rel-1º TF-1334 65.2 peso 1334 Da análise do diagrama anterior sobressaem algumas modalidades como as preferidas dos alunos, nomeadamente o Futebol, o Ténis e a Natação. c) Para comparar os pesos dos rapazes e das raparigas, podemos utilizar diagramas em caule e folhas ou diagramas de extremos e quartis. Vamos utilizar os dois tipos de representação: Para construir a representação gráfica Rapazes Raparigas 3 4 anterior consideramos para cada caule 4, 5 e 999887665 4 679 422110000 5 012 as folhas 0, 1, 2, 3 e 4 e no outro as folhas 5, 7 5 678 6, 7, 8 e 9 (página 68 do manual). 6 111233 Como se verifica, os pesos das raparigas são, 6 5 de um modo geral, inferiores aos dos rapazes. 00 6, dois sub-caules e pendurámos num deles Para construir as representações raparigas anteriores tivemos de calcular algumas medidas, tanto para os pesos das raparigas, como para os pesos dos rapazes rapazes, que exemplificámos ao lado 40 45 50 raparigas 55 60 65 manual). rapazes mínimo 43 46 máximo 60 65 mediana 50 57.5 1º quartil 48 50.5 3º quartil 52 61.5 (consultar páginas 74 e 75 do Esta representação realça o que já havia sido observado com os caules e folhas e podemos ainda observar a maior variabilidade pesos referentes existente nos aos rapazes, relativamente aos pesos das raparigas Chamamos a atenção para que as características observadas nas representações gráficas anteriores, já haviam sido sugeridas pelo histograma da variável Peso, obtido na alínea b). 7. a) Substituindo o F por um 0 e o M por um 1, obtemos 22 zeros e 16 uns. Como a variável sexo é de tipo qualitativo, podemos usar qualquer etiqueta para representar as categorias. Então, uma vez que temos um conjunto de números vamos calcular a sua média: CMM-2003/2004 7/11 Rel-1º TF-1334 1334 média = um 22 ? 0 ? 16 ? 1 ? 0.42 . Substituindo agora o F por 1 e o M por 2, obteremos 38 conjunto média = de números de que vamos também calcular a média: 22 ? 1 ? 16 ? 2 ? 1.42 . Não podemos dizer que os valores obtidos sejam a 38 média da variável sexo, pois sendo uma variável de tipo qualitativo, não tem sentido calcular a média . Como acabámos de ver, conforme as etiquetas utilizadas para representar as classes, assim obteríamos uma média diferente! b) Média dos pesos dos 16 rapazes = 56.4 Média dos pesos das 22 raparigas = 50.3 Média dos pesos dos alunos = 16 ? 56.4 ? 22 ? 50 .3 ? 52.9 38 Consegue-se obter o total dos de pesos e a média global dos pesos dos 38 alunos. c) A mediana das idades dos alunos é 15 e a média é 15.05. Estes valores são aproximadamente iguais, o que era aliás sugerido pelo histograma – aproximadamente simétrico- obtido para a variável Idade, num exercício anterior. d) O histograma apresentado não é simétrico e apresenta um enviesamento para a direita, o que sugere que a média dos pesos deva ser superior à mediana. O cálculo destas características confirma esta suposição, já que se obtém para a média o valor aproximado de 52.9, enquanto que a mediana é 51 (consultar páginas 90 e 91 do manual). e) Desvio padrão dos pesos dos 16 rapazes = 6.3 Desvio padrão dos pesos das 22 raparigas = 4.4 Os pesos dos rapazes apresentam maior variabilidade que os pesos das raparigas. Esta característica já havia sido realçada, quando apresentámos anteriormente, os diagramas de extremos e quartis, para comparar as distribuições dos pesos dos rapazes e das raparigas. f) A média obtida para os pesos dos alunos é aproximadamente 52.9, e o desvio padrão é aproximadamente 6.0. Então, se os dados tivessem uma distribuição aproximadamente normal, o que já vimos não ser verdade, esperaríamos obter no intervalo [46.9, 58.9], aproximadamente 2/3 dos dados, ou seja aproximadamente 25 ou 26 (consultar página 99 do manual). g) A moda é o Futebol, pois é a categoria predominante. Não se podem calcular outras características amostrais. CMM-2003/2004 8/11 Rel-1º TF-1334 1334 8. a) Nº do sapato Freq. Absoluta Freq. Relativa F. A. Acumulada F. R. Acumulada Xi ni fi Ni Fi 28 2 0,05 2 0,05 29 5 0,125 7 0,175 31 16 0,4 23 0,575 32 14 0,35 37 0,925 33 3 0,075 40 1 ni ? frequência absoluta da i - ésima observação N i ? frequência absoluta acumulada n f i ? i ? frequência relativa n f Fi ? i ? frequência relativa acumulada n n? k ? ni ? nº de observaçõe s da amostra i? 1 5 b) x? 1 ? f i xi ? n i? 1 k ? ni x i i? 1 n ? n1 x1 ? ? ? n5 x5 2 ? 28 ? ? ? 3 ? 33 ? ? 31,1 n 40 Moda é o valor com maior frequência absoluta, neste caso será 31. x?n ? ? x? n Como n é par ( n =40) Me ? ? ? ? 1? ?2 ? ? ? ? 2? 2 = x ?20 ? ? x ?21? 2 ? 31 Comparando a média, a moda e a mediana podemos concluir que a distribuição é simétrica. c) 2 8899999 3 1... ? 122 ... ? 22333 14? 10? 9. CMM-2003/2004 9/11 Rel-1º TF-1334 1334 a) População é um conjunto de indivíduos ou objectos que apresentam uma ou mais características em comum, que se pretende analisar, neste caso, constituída por todas as crianças da escola primária em estudo; Amostra, é um subconjunto da população, recolhida com o objectivo de se obter informação sobre características desconhecidas da população, neste caso, de dimensão 60, constituída pelo número animais domésticos de algumas (60) crianças da referida escola primária. b) Variável, nº de animais domésticos de cada criança que respondeu ao inquérito, quantitativa (característica susceptível de ser medida) discreta (só pode tomar um nº finito ( ou infinito numerável) de valores distintos). c) d) c) d) g) Xi ni fi Ni Fi ni X i 1 20 0.333 20 0.33 20 2 20 0.333 40 0.67 40 3 15 0.250 55 0.92 45 4 5 0.083 60 1 20 125 e) n 2 ? n3 ? n 4 ? 40 , 40 crianças. f) F2 ? 0.67 , 67% das crianças têm menos de 3 animais em casa. 4 g) 1 x? n 4 ? i ?1 fi x i ? ? i? 1 ni x i n ? n1 x1 ? ? ? n4 x4 125 ? ? 2.08 n 60 Moda é o valor com maior frequência absoluta, neste caso temos dois valores para a moda, 1 e 2, diz-se que é bimodal. x?n ? ? x?n Como n é par ( n =60) Me ? ? ? ? 1? ?2 ? ? ? ? 2? 2 = x?30? ? x ?31? 2 ?2 Comparando a média e a mediana podemos concluir que a distribuição é aproximadamente simétrica. CMM-2003/2004 10/11 Rel-1º TF-1334 1334 h) Mínimo da amostra X ?1? ? 1 Máximo da amostra X ?60? ? 4 AI ? Q3 ? Q1 ? 3 ? 1 ? 2, amplitude inter - quartil Q1 = Q3 = x?15? ? x ?16? 2 x?45? ? x ?46? 2 ? 1? 1 ?1 2 ? 3?3 ?3 2 10. a) Como os dados nos são fornecidos agrupados, para calcular as médias, vamos escolher como elementos representativos das classes os seus pontos médios: média da Turma 1 = 2 ? 5 ? 3 ? 7 ? 5 ? 9 ? 7 ? 11 ? 6 ? 13 ? 4 ? 15 ? 2 ? 17 ? 11.2 29 média da Turma 2 = 0 ? 5 ? 3 ? 7 ? 5 ? 9 ? 6 ? 11 ? 5 ? 13 ? 4 ? 15 ? 0 ? 17 ? 11.2 23 b) O facto de termos obtido os mesmos valores para a média não nos permite afirmar que as turmas tenham tido comportamento semelhante. Para caracterizar um conjunto de dados é necessário utilizar medidas de localização e dispersão. Vejamos o que se passa com os desvios padrão dos dois conjuntos de dados: Desvio padrão Turma 1 = (5 - 11.2) 2 ? 2 ? (7 - 11.2) 2 ? 3 ? (9 - 11.2) 2 ? 5 ? (11 - 11.2) 2 ? 7 ? ? ? (17 - 11.2) 2 ? 2 = 29 ? 1 10.67 =3.27 Desvio padrão Turma 2 = (5 - 11.2) 2 ? 0 ? (7 - 11.2) 2 ? 3 ? (9 - 11.2) 2 ? 5 ? (11 - 11.2) 2 ? 6 ? ? ? (17 - 11.2) 2 ? 0 = 6.88 23 ? 1 CMM-2003/2004 11/11 Rel-1º TF-1334 1334 Como vemos, a dispersão foi muito maior na turma 1 do que na turma 2, o que significa que os alunos desta turma são mais homogéneos: não há tendência para haver alunos muito maus nem muito bons. CMM-2003/2004 12/11 Rel-1º TF-1334
Baixar