1
Pontifícia Universidade Católica do Rio Grande do Sul
Faculdade de Informática
Programa de Pós-Graduação em Ciência da Computação
Desenvolvimento de Programas Paralelos
para Máquinas NUMA: Conceitos e
Ferramentas
NEUMAR SILVA RIBEIRO
Orientador: Prof. Dr. Luiz Gustavo Leão Fernandes
Monografia apresentada para disciplina de
Introdução à Pesquisa I
Porto Alegre, Junho de 2009.
2
RESUMO
A demanda por poder de processamento está sempre presente no cotidiano das
entidades que trabalham com desenvolvimento de pesquisa e, por conseguinte, é um
desafio para aqueles que produzem essas ferramentas, ou seja, os fabricantes de
computadores. Mas, não se tem interesse apenas em máquinas potentes, se tem buscado
uma boa relação custo/beneficio na aquisição das soluções. Os supercomputadores
foram dando espaço para a utilização de computadores de menor porte como os SMPs
(Symmetric Multiprocessor) que possuem um menor custo. Esses computadores tiveram
então uma grande demanda e começaram a surgir necessidades de aumento do poder
computacional dessas máquinas. Porém encontraram-se limites com relação ao número
de processadores dos computadores SMPs, com relação ao acesso à memória. A partir
dessa dificuldade, surgiu então a utilização da arquitetura NUMA (Non-Uniform
Memory Access) para minimizar esse gargalo. Os computadores NUMA, possuem uma
memória dita local para cada processador, ou seja, o processador não precisa acessar um
barramento compartilhado para acesso a essa porção da memória. Porém, esse
processador não está restrito a essa porção, ele pode acessar a memória de todos os
processadores do sistema, e isso é feito com endereçamento único para toda a memória.
Assim como as máquinas UMA (Uniform Memory Access) as máquinas NUMA
possuem memória compartilhada, o que facilita o desenvolvimento de aplicações,
utilizando OpenMP em conjunto com bibliotecas como LIBNUMA e MAI (Memory
Affinity Interface). Então, esse trabalho busca apresentar alguns conceitos e ferramentas
para o desenvolvimento de programas para máquinas NUMA, visto que essa arquitetura
está em evidência e com grande demanda.
Palavras-Chave: NUMA, UMA, SMP, OpenMP,LIBNUMA, MAI , Memória Compartilhada
3
SUMÁRIO
RESUMO ...................................................................................................... 2
LISTA DE FIGURAS..................................................................................... 5
LISTA DE ABREVIATURAS E SIGLAS....................................................... 6
1
INTRODUÇÃO ........................................................................................ 7
2
ARQUITETURAS PARALELAS E DISTRIBUÍDAS................................ 9
2.1
Arquitetura de von Neumann...............................................................................................11
2.2
Taxonomia de Flynn..............................................................................................................11
2.3
Arquitetura de Memória Compartilhada............................................................................12
2.3.1
UMA (Uniforme Memory Access) ................................................................................12
2.3.2
NUMA (Non-Uniform Memory Access).......................................................................13
2.4
Arquitetura de Memória Distribuída ..................................................................................13
2.5
Arquitetura de Memória Hibrida ........................................................................................14
2.6
Modelos de Programação Paralela ......................................................................................14
2.6.1
Modelo de Memória Compartilhada ..............................................................................14
2.6.2
Modelo de Threads ........................................................................................................15
2.6.3
Modelo de Troca de Mensagens ....................................................................................15
2.7
Plataformas para PPD ..........................................................................................................16
2.7.1
PVP – Processadores Vetoriais ......................................................................................16
2.7.2
MPP – Massive Parallel Processing...............................................................................16
2.7.3
SMP – Symmetric Multiprocessor.................................................................................16
2.7.4
Cluster Computing.........................................................................................................17
2.7.5
Grid Computing .............................................................................................................17
2.7.6
Multicore Computing.....................................................................................................18
2.7.7
GpGPUs.........................................................................................................................18
2.8
Paradigmas de Programação Paralela ................................................................................18
2.8.1
Memória Compartilhada – OpenMP..............................................................................18
2.8.2
Troca de Mensagens – MPI ...........................................................................................19
4
3
ARQUITETURAS NUMA ...................................................................... 21
3.1
Conceitos ................................................................................................................................23
3.1.1
Gerência de Memória em Unix......................................................................................23
3.1.2
Alocação de Memória ....................................................................................................24
3.1.3
Localidade de Dados......................................................................................................24
3.1.4
O problema do Falso Compartilhamento .......................................................................25
3.1.5
Escalonamento ...............................................................................................................26
3.2
Memória em Máquinas NUMA............................................................................................27
3.2.1
Alocação Eficiente .........................................................................................................27
3.2.2
Localidade Ótima: Nó Local..........................................................................................27
3.2.3
Aplicação Multi-Nó .......................................................................................................27
3.2.4
Migração de Memória....................................................................................................28
3.3
Cpusets ...................................................................................................................................29
3.4
Exemplos de Sistemas NUMA ..............................................................................................29
3.4.1
AMD Athlon 64 e AMD Opteron ccNuma Multiprocessor Systems ............................29
3.4.2
HP Integrity Superdome ................................................................................................31
4
FERRAMENTAS PARA UTILIZAÇÃO DE ARQUITETURAS NUMA .. 33
4.1
NUMA API.............................................................................................................................33
4.1.1
NUMACTL....................................................................................................................34
4.1.2
LIBNUMA.....................................................................................................................35
4.2
MAI – Memory Affinity Interface .......................................................................................40
4.2.1
Detalhes da Implementação ...........................................................................................41
4.2.2
Funções de Sistema........................................................................................................42
4.2.3
Funções de Alocação .....................................................................................................42
4.2.4
Funções de Políticas de Memória ..................................................................................43
4.2.5
Funções de Políticas de Threads ....................................................................................45
4.2.6
Funções Estatísticas .......................................................................................................46
5
CONCLUSÃO ....................................................................................... 47
REFERÊNCIAS........................................................................................... 48
5
LISTA DE FIGURAS
Figura 1: Arquitetura de Von-Neumann ....................................................................................................11
Figura 2: Arquitetura UMA .......................................................................................................................12
Figura 3: Arquitetura NUMA.....................................................................................................................13
Figura 4: Arquitetura de Memória Distribuída .........................................................................................14
Figura 5: Modelo Fork-Join – OpenMP ....................................................................................................19
Figura 6: Esquema Máquina NUMA .........................................................................................................22
Figura 7: Falso Compartilhamento ...........................................................................................................25
Figura 8: Processador Dual-Core cc-Numa ..............................................................................................30
Figura 9: Arquitetura HP Integrity Superdome .........................................................................................31
Figura 10: Tabela SLIT..............................................................................................................................31
Figura 11: Exemplo numa_available. ........................................................................................................36
Figura 12: Exemplo numa_alloc_onnode. .................................................................................................37
Figura 13: Exemplo numa_alloc_interleaved. ...........................................................................................37
Figura 14: Exemplo numa_set_interleave_mask .......................................................................................38
Figura 15: Exemplo numa_interleave_memory. ........................................................................................38
Figura 16: Exemplo nodemask_set. ...........................................................................................................39
Figura 17: Arquitetura da Interface MAI...................................................................................................41
Figura 18: MAI - Funções de Sistema........................................................................................................42
Figura 19: MAI – Funções de Alocação ....................................................................................................43
Figura 20: Exemplo Utilização MAI – Funções de Alocação....................................................................43
Figura 21: MAI - Funções de Políticas de Memórias. ...............................................................................44
Figura 22: Exemplo Utilização MAI – Funções de Políticas de Memória. ...............................................45
Figura 23: MAI - Funções de Políticas de Threads. ..................................................................................46
Figura 24: MAI - Funções de Estatísticas..................................................................................................46
6
LISTA DE ABREVIATURAS E SIGLAS
NUMA
Non-Uniform Memory Access
cc-NUMA
cache coehent Non-Uniform Memory Access
SMP
Symmetric Multiprocessor
MPI
Message Passing Interface
API
Application Program Interface
MAI
Memory Affinity Interface
CPU
Central Process Unit
SISD
Single Instruction Single Data
SIMD
Single Instruction Multiple Data
MISD
Multiple Instruction Single Data
MIMD
Multiple Instruction Multiple Data
UMA
Uniform Memory Access
PVP
Parallel Vetor Processor
MPP
Massive Parallel Processor
NoC
Network on Chip
GPU
Graphics Processing Unit
FPGA
Field Programmable Gate Circuits
ASIC
Application Specific Integrated Circuits
ACPI
Advanced Configuration and Power Interface
SLIT
System Locality Information Table
SRAT
System Resource Affinity Table
RAM
Random Access Memory
AMD
Advanced Micro Devices
INRIA
Institut National de Recherche en Informatique
et en Automatique
7
1 INTRODUÇÃO
Uma nova maneira de projetar arquiteturas de computadores multiprocessados
está ganhando cada vez mais espaço no mercado [8] [10]. Sistemas NUMA (NonUniform Memory Access) ou sistemas com acesso não uniforme à memória, estão
sendo utilizados para proporcionar um maior poder computacional às novas arquiteturas
de computadores. A arquitetura que é geralmente utilizada pela maioria dos fabricantes
de computadores e supercomputadores é a cc-NUMA (cache coehent Non-Uniform
Memory Access) onde a arquitetura prove um mecanismo de coerência de cache para a
Memória. O que diferencia uma arquitetura NUMA das demais arquiteturas é que os
processadores do nó de um sistema NUMA possuem um tempo de acesso à memória
local inferior ao tempo de acesso que aqueles processadores possuem com relação à
memória de outros nós. No entanto, toda a memória da arquitetura compartilha um
único espaço de endereçamento com todo o sistema. Isso é possível pela interconexão
dos nós através de uma rede especializada.
A arquitetura NUMA está ganhando espaço em função da limitação dos
processadores SMP (Symmetric Multiprocessor), pois esses sistemas possuem como
característica a interconexão dos vários processadores com a memória através de um
barramento único. Isto limita a velocidade de comunicação entre os processadores e a
memória, pelo fato de todos os processadores disputarem acesso ao barramento para
comunicação com a memória. Sendo assim, esses sistemas tendem a ter uma limitação
quanto ao número de processadores, ou seja, possuem uma baixa escalabilidade.
Por outro lado, as arquiteturas de computadores, como os Clusters [27], possuem
um processamento distribuído, onde cada nó possui sua memória local. Porém a
comunicação entre os nós é feita por troca de mensagens, o que aumenta a
complexidade para o desenvolvimento de aplicações.
Portanto, os sistemas NUMA possuem as características de um menor tempo de
acesso à memória, quando acessa a memória local do nó e também utiliza o paradigma
de programação de memória compartilhada. Essas características facilitam e agilizam o
desenvolvimento de aplicações por ser um padrão mais próximo do modelo seqüencial
tradicional, ao contrário do paradigma por troca de mensagens.
Nesse contexto, o objetivo desse trabalho é apresentar os conceitos e as
ferramentas necessárias para o desenvolvimento de programas paralelos para máquinas
com arquitetura NUMA. Com foco nas ferramentas LIBNUMA e MAI, que utilizadas
com OpenMP são utilizadas para programação dessas máquinas, conforme os trabalhos
[2] e [29] desenvolvidos pelo GMAP (Grupo de Modelagem de Aplicações Paralelas)
da FACIN (Faculdade de Informática) da PUCRS (Pontifícia Universidade Católica do
Rio Grande do Sul).
8
O trabalho está organizado em cinco capítulos, onde o capítulo um é a
introdução, já o capítulo dois busca apresentar algumas informações históricas e
conceituais com relação ao processamento paralelo e distribuído de maneira objetiva,
ainda apresentam as plataformas mais comuns de processamento paralelo e distribuído,
e por fim, cita os paradigmas de programação paralelo de memória compartilhada,
utilizando OpenMP, e o paradigma de memória distribuída, utilizando MPI. O capítulo
três busca, num primeiro momento apresentar alguns conceitos de gerenciamento de
memória no ambiente Linux, escalonamento de processos e localidade de dados, depois
descreve as características de utilização de memória em máquinas NUMA, assim como
mostra a alocação de processos em máquinas NUMA. Já no capítulo quatro são
apresentadas as ferramentas para desenvolvimento de programas paralelos em máquinas
NUMA: NUMA API, uma biblioteca que disponibiliza chamadas de sistemas para
alocação de recursos de maneira otimizada para aplicações; e a interface MAI (Memory
Affinity Interface) que oferece facilidades para utilização da NUMA API. Por fim, no
capítulo cinco é feita uma conclusão, buscando o fechamento de uma opinião sobre o
desenvolvimento de programas paralelos para máquinas NUMA.
9
2 ARQUITETURAS PARALELAS E DISTRIBUÍDAS
Tradicionalmente, programas têm sido desenvolvidos para serem processados de
modo serial, isso devido a origem do modelo de computação, onde havia uma unidade
de entrada, uma unidade processadora e uma unidade de saída. Nesse modelo, o
problema é quebrado em séries discretas de instruções de maneira a serem processadas
uma após a outra, podendo uma operação seguinte depender de dados de uma operação
anterior. A idéia é que apenas uma instrução seja executada a cada momento.
Esse modelo evoluiu adicionando-se uma memória interligada ao processador, e
após algum período, os recursos avançaram ainda mais, de maneira a deixar o acesso à
memória e aos demais dispositivos de entrada e saída mais rápidos. Isso também
ocorreu buscando desonerar a unidade de processamento com a parte de controle,
possibilitando acelerar o processamento de dados.
Mesmo com essas melhorias ainda necessitava-se maior poder de
processamento, então partiu-se para o desenvolvimento de arquiteturas especiais ou
arquiteturas paralelas e distribuídas, utilizando-se múltiplas unidades de processamento.
De modo mais simples, uma computação paralela e ou distribuída se dá quando
utiliza-se múltiplas unidades de processamento para obter-se o resultado final. Isso
acontece quebrando-se um problema em partes discretas de modo que cada uma dessas
partes possa ser processada paralelamente, ou seja, cada uma dessas partes pode ser
processada em uma unidade de processamento diferente ao mesmo tempo.
Essas unidades de processamento paralelo podem ser compostas por um único
computador com múltiplos processadores, por múltiplos computadores interligados por
uma infra-estrutura de rede ou ainda por uma combinação de ambos [13] [18]. Algumas
Arquiteturas Paralelas:
•
Pipeline Superescalar
•
Máquinas Vetoriais
•
Multiprocessadores
•
Multicomputadores
Sendo assim, pode-se dizer que computação paralela é uma evolução natural da
computação serial, e realmente parece adaptar-se muito melhor aos problemas a serem
resolvidos no mundo real, ou seja, temos muitos acontecimentos complexos e interrelacionados que ocorrem ao mesmo tempo.
10
Computação paralela vem sendo considerada “o topo da computação” [13] e,
então, sendo utilizada para resolver problemas de difíceis modelos científicos e ou de
engenharia encontrados no cotidiano. Contudo, a utilização de computação paralela
também está crescendo em aplicações comerciais, em função do grande volume de
dados que deve ser processado para a obtenção de informações úteis ao negócio.
Utilizando computação paralela pode-se economizar, diretamente, tempo e
dinheiro, ou seja, teoricamente disponibilizando mais recursos para a solução de um
problema tende-se a resolvê-lo em menor tempo. Ou ainda, pode-se resolver grandes
problemas com a utilização da computação paralela, que certamente levaria um tempo
impraticável ou inaceitável para ser resolvido no modelo serial.
Outro grande motivo, para a utilização do modelo paralelo é a capacidade de
processamento concorrente. Logo, enquanto uma unidade de processamento pode fazer
apenas uma operação de cada vez, tendo-se múltiplas unidades de processamento,
consegue-se múltiplas operações. Ainda, deve-se considerar que essas unidades de
processamento não necessariamente precisam estar no mesmo local, ou seja, podemos
utilizar recursos que estejam em qualquer lugar do mundo, desde que estejam
interconectados.
Outra situação que está norteando a todos para a utilização de recursos paralelos
são as limitações físicas e práticas para o aumento da capacidade de processamento que
os projetistas de computadores estão enfrentando [13]. A velocidade de transmissão de
informações dentro de um computador já está encontrando limite no barramento e na
memória, ou seja, mesmo que a unidade de processamento possua poder para um
melhor desempenho essa unidade fica “parada” durante algumas unidades de tempo,
esperando os dados que são acessados na memória para poderem ser processados [3]
[8]. Também temos os limites de miniaturização, os transistores estão cada vez
menores, e certamente encontrarão um limite [10]. Ainda, tem-se um problema
relacionado com a alta freqüência dos processadores seriais e o calor dissipado por eles,
ou seja, para que processadores alcancem altos desempenhos é necessária uma alta
freqüência, o que por sua vez produz um calor inaceitável para um projeto de
computador de custo razoável.
Durante os últimos anos as arquiteturas de computadores estão cada vez com um
maior nível de paralelismo em hardware [24], e isso já está incrementando o
desempenho dessas máquinas com os seguintes recursos: múltiplas unidades de
execução, pipeline de instruções e multicores. E tudo indica que não tem mais como
fugir da realidade da computação paralela, hoje até os computadores de mesa, já
possuem capacidade para processamento paralelo.
Para fazermos um estudo, ainda que resumido, do histórico de arquiteturas
paralelas precisamos conhecer alguns conceitos relacionados a esse assunto.
11
2.1 Arquitetura de von Neumann
O matemático húngaro John von Neumann, foi o primeiro autor a citar em seus
artigos os requisitos gerais para um computador eletrônico em 1945[30]. Desde então,
todos os computadores estão seguindo esse modelo.
Composto por quatro componentes principais: Memória, Unidade de Controle e
Unidade Lógica e Aritmética, que formam a UCP (unidade central de processamento)
ou CPU (Central Process Unit) e, por fim, a unidade de entrada e saída. Conforme
figura a seguir, retirada de [13]:
Figura 1: Arquitetura de Von-Neumann
A memória é utilizada para armazenar instruções de programas e dados, e é
acessada aleatoriamente para leitura e escrita. A unidade de controle busca as instruções
ou os dados da memória, decodifica a instrução e então de forma seqüencial executa a
tarefa, a unidade aritmética é responsável pelas operações aritméticas básicas e as
unidades de entrada e saída são as interfaces com o operador.
2.2 Taxonomia de Flynn
Existem diferentes maneiras de classificar arquiteturas de computadores, uma
das mais clássicas é a Taxonomia de Flynn, que é uma classificação de arquiteturas de
computadores proposta por Michael J. Flynn em 1966 e publicada pela IEEE em 1972
[20].
A Taxonomia de Flynn distingue as arquiteturas de computadores de acordo com
o fluxo de instruções e de dados. Cada um desses fluxos pode ser simples ou múltiplo.
•
SISD (Single Instruction, Single Data)
É um computador serial, o qual processa uma única instrução em cima de um
único dado. É uma execução determinística e é encontrado nos computadores mais
antigos e nos computadores pessoais que não são multicore.
•
SIMD (Single Instruction, Multiple Data)
É um tipo de computador paralelo, porém executa apenas uma instrução sobre
múltiplos dados, ou seja, a mesma instrução é executada em todas as unidades de
12
processamento ao mesmo tempo. Nessa classificação enquadram-se os computadores
Vetoriais. Apesar de ser um assunto insipiente, já estão sendo utilizadas GPUs
(Graphics Processor Units ou Unidades de Processamento Gráfico) para o
processamento paralelo e elas empregam SIMD [19].
•
MISD (Multiple Instruction, Single Data)
Um único fluxo de dados é processado por múltiplas unidades de
processamento. Esse tipo de computador não é muito comum.
•
MIMD (Multiple Instruction, Multiple Data)
Atualmente, esse é o tipo mais comum de computador, os mais modernos
computadores são caracterizados por poderem aplicar múltiplas instruções sobre
múltiplos fluxos de dados. As execuções podem ser: síncronas ou assíncronas e
determinística ou não-determinística. Os supercomputadores, cluster, grids
computacionais, os computadores multiprocessados e os microcomputadores multicore
pertencem a esse grupo.
2.3 Arquitetura de Memória Compartilhada
O compartilhamento de memória em computadores paralelos pode variar
bastante: pode-se ter todos os processos que estão executando no computador
compartilhando o mesmo espaço de endereçamento global, ou pode-se ter múltiplos
processadores operando de maneira independente mas compartilhando os mesmos
recursos de memória. Máquinas com memória compartilhada podem ser divididas em
dois tipos, baseado no tempo de acesso a memória: UMA e NUMA.
2.3.1 UMA (Uniforme Memory Access)
São computadores que possuem acesso à memória com tempo uniforme. Os
representantes mais comuns desse tipo de computador são as máquinas SMP. Estas
possuem processadores iguais e cada um dos processadores do computador possui o
mesmo tempo de acesso à memória. A Figura 2, com base em [27], mostra uma
simplificação de uma arquitetura UMA.
Figura 2: Arquitetura UMA
13
2.3.2 NUMA (Non-Uniform Memory Access)
São computadores que possuem um acesso à memória com tempo não uniforme.
Esses sistemas, por exemplo, podem ser formados por computadores SMPs ligados por
uma conexão especial. Dessa maneira um computador pode acessar à memória do outro,
porém o tempo de acesso à memória vai ser maior do que o tempo de acesso à memória
local desse computador. Um ponto importante é que o espaço de endereçamento é único
para todos os computadores, não importando quantos nós possui o sistema. A figura
abaixo, com base em [27], busca mostrar de maneira simplificada, uma arquitetura
NUMA.
Figura 3: Arquitetura NUMA
2.4 Arquitetura de Memória Distribuída
Assim como em computadores de memória compartilhada, computadores com
memórias distribuídas também são muito utilizada, e ainda possuem algumas
características comuns aos primeiros. Computadores com memória distribuída precisam
de uma rede de interconexão para comunicação entre os processos. Os processadores
possuem sua própria memória local e essa memória é endereçada apenas pelo
processador local, de modo que um processador não consiga acessar à memória de outro
computador diretamente. Com essas características cada processador opera
independentemente dos demais. Quando um processador precisa acessar os dados que
estão localizados na memória de outro processador, esse acesso é feito através da rede
de interconexão dessas máquinas por troca de mensagens. Essa rede pode ser uma rede
especializada ou até mesmo uma simples rede Ethernet. A Figura 4, com base em [27],
esboça um exemplo de arquitetura de memória distribuída.
14
Figura 4: Arquitetura de Memória Distribuída
2.5 Arquitetura de Memória Hibrida
Ainda podemos ter a união dos dois tipos de arquitetura para formar um
computador paralelo. Os maiores e mais potentes computadores do mundo empregam
ambas as arquiteturas de memória: Distribuída e Compartilhada.
Por exemplo, podemos tem um computador paralelo formado por vários
computadores SMPs interligados por uma rede de comunicação.
2.6 Modelos de Programação Paralela
Existem diversos modelos de programação paralela de uso comum: Memória
Compartilhada, Threads, Troca de Mensagens.
Modelos de programação paralela existem como uma forma de abstrair as
arquiteturas de hardware e organização da memória. O modelo a ser utilizado depende
do tipo de computador paralelo e também da escolha pessoal do profissional. Não existe
o melhor modelo, mas certamente há modelos que se adaptam melhor para
determinados computadores.
2.6.1 Modelo de Memória Compartilhada
No modelo de programação de memória compartilhada, as tarefas compartilham
um mesmo espaço de endereçamento, o qual é lido e escrito de maneira assíncrona.
Vários mecanismos como os semáforos podem ser utilizados para o controle de acesso a
memória compartilhada.
15
Do ponto de vista do programador, esse modelo traz alguns benefícios e
facilidades para o desenvolvimento das aplicações, pois os vários processos podem
comunicar-se através da memória.
Uma desvantagem desse modelo é que o programador precisa gerenciar e
controlar o acesso e a coerência dos dados que serão acessados por vários processos
diferentes e também contornar ou tentar minimizar os problemas de desempenho em
função disso.
2.6.2 Modelo de Threads
No modelo de threads, um processo simples pode ter múltiplos e concorrentes
caminhos de execução. Uma simples analogia pode ser feita para descrever o conceito
de threads: tendo um programa seu código principal, ele pode ter chamadas de subrotinas, quando uma sub-rotina é chamada normalmente o programa espera o retorno
dela para seguir o fluxo de execução, no caso das threads o programa faz uma chamada
e tanto o programa quanto a thread seguem seus fluxos de execução concorrentemente.
Essas threads podem comunicar-se através da memória, visto que compartilham um
mesmo espaço de endereçamento.
As threads podem ser implementadas de diferentes maneiras, as mais utilizadas
são POSIX (Portable Operation System Interface for Unix) Threads e OpenMP [7].
Posix Threads é baseada na biblioteca, especificada pela IEEE (Institute of Eletrical and
Electronics Engineers), IEEE POSIX 1003.1c standard, é utilizada com a linguagem C
e normalmente referida como Pthreads. Já OpenMP é baseada em diretivas de
compilação e pode ser utilizada em códigos seriais. OpenMP pode ser utilizada com
Fortran ou com C/C++ e também é multiplataforma [13].
2.6.3 Modelo de Troca de Mensagens
No modelo de troca de mensagem geralmente tem-se um conjunto de
computadores interconectados em rede e uma tarefa a ser feita, essa tarefa é dividida em
pequenas partes de modo a ser executada em cada um dos computadores utilizando seus
recursos locais, como por exemplo, sua memória local. Desse modo, se as tarefas
necessitarem trocar informações devem fazer isso por trocas de mensagens, visto que
um processo executando em um computador não pode acessar a memória de um outro
computador.
Para implementação do modelo por troca de mensagens, geralmente é utilizada a
biblioteca MPI (Message Passing Interface) [11], apesar de existirem outras bibliotecas,
como PVM [14].
16
2.7 Plataformas para PPD
Computadores Paralelos podem ser classificados seguindo diversos critérios. A
seguir serão apresentadas algumas plataformas onde estão sendo ou já foram obtidos
resultados em computação paralela, esse texto não tem por objetivo detalhar o estudo de
nenhuma dessas plataformas, muito pelo contrário, a idéia é apenas fazer um apanhado
dos principais tipos de arquiteturas paralelas existentes.
2.7.1 PVP – Processadores Vetoriais
Processadores Vetoriais (Vector Processors) são computadores desenvolvidos
inicialmente para área de computação científica, e foi com base nessa plataforma que
surgiram os primeiros supercomputadores na década de 80. Um processador vetorial é
uma CPU desenvolvida de modo que uma instrução possa executar uma operação
matemática em cima de um conjunto de dados simultaneamente. Esses computadores
podem ser classificados na taxonomia de Flynn como computadores SIMD (Single
Instruction, Multiple Data). A presença desses computadores no mercado está cada vez
menor, muito em função do alto custo para o desenvolvimento de uma máquina com
uma arquitetura especial, mas também pelo crescimento do desempenho das CPUs de
propósitos gerais. Um exemplo recente e famoso de implementação de um processador
vetorial foi a criação do processador Cell [31]. Um consórcio entre IBM, Toshiba e
Sony possibilitou o desenvolvimento desse processador que foi inicialmente utilizado
nos consoles de jogos Play Station 3. Esse processador possui um processador escalar e
oito processadores vetoriais, destinados ao processamento gráfico.
2.7.2 MPP – Massive Parallel Processing
Computadores com processamento maciçamente ou massivamente paralelo.
Essa arquitetura de computadores possui unidades de processamento e memórias locais
independentes umas das outras. O massivamente se justifica porque geralmente são
milhares de unidades de processamento, que podem ser computadores, interconectados
para formar um desses sistemas.
Atualmente, muitos dos supercomputadores possuem arquiteturas MPP, alguns
exemplos são Earth Simulator e Blue Gene. Todas essas máquinas estão interconectadas
por redes de altíssimo desempenho, formando um único e grande computador.
2.7.3 SMP – Symmetric Multiprocessor
Symmetric Multiprocessor, ou computador com multiprocessadores simétricos, é
uma arquitetura que apresenta dois ou mais processadores conectados por um
barramento a uma memória principal compartilhada. A maioria dos computadores
multiprocessados utiliza a arquitetura SMP. Nos sistemas SMP, os processos
comunicam-se através da memória.
17
Em função de estarem todos os processadores interconectados por intermédio de
um barramento, e também utilizarem esse mesmo caminho para acesso à memória,
esses sistemas possuem uma baixa escalabilidade. Esse barramento também atribui a
esse sistema a característica de que todos os processadores levam o mesmo tempo para
acessarem a memória, dessa forma temos um sistema UMA.
Buscando aumentar um pouco o tamanho desses computadores, novas
arquiteturas SMPs, estão sendo desenvolvidas de modo que cada processador possua
uma memória local, sem, no entanto, deixar de possuir um espaço único de
endereçamento, possibilitando assim máquinas com um maior número de
processadores. Esses sistemas são denominados de NUMA, ou seja, cada processador
pode acessar sua memória local muito mais rápido, visto que nesse caso o acesso não se
dará pelo barramento compartilhado com todos os demais processadores do sistema. No
capítulo 3 será detalhado o funcionamento de computadores NUMA, os quais esse
trabalho tem por objetivo detalhar.
2.7.4 Cluster Computing
Cluster ou Computadores Agregados, ou ainda Computadores Aglomerados são
um conjunto de computadores/servidores interconectados trabalhando cooperativamente
para resolver um problema. Cada computador, no entanto, trabalha de maneira
independente executando uma pequena tarefa de modo a auxiliar na resolução do
problema. Esses computadores geralmente estão conectados através de uma rede local
rápida, porém isso não é uma regra. Em Clusters mais simples, podemos até mesmo ter
os computadores ligados através de um simples hub, ou em Clusters mais robustos
podemos ter redes de fibras ópticas.
Os programas paralelos desenvolvidos para executarem em Clusters utilizam o
paradigma de troca de mensagens para trocar informações entre os processos, visto que
um computador não consegue acessar diretamente à memória de outro computador. A
biblioteca de troca de mensagens mais difundida é MPI (Message Passing Interface)
[11].
2.7.5 Grid Computing
Uma das idéias principais da Computação em Grade é utilizar os recursos
computacionais de computadores que estão sendo subutilizados. Os computadores são
adicionados à grade e recebem as tarefas a serem executadas, conforme os
processadores desses computadores vão ficando ociosos.
De maneira geral, os computadores participantes de uma Grade podem estar em
qualquer lugar, desde que possuam conectividade com a grade. Isto possibilita que se
tenham grades computacionais com milhares de computadores. No entanto, quanto
maior a grade, maior são os problemas de gerenciamento. Essa é uma das diferenças
entre grades e clusters, as grades computacionais tendem a ser menos acopladas que os
clusters.
18
2.7.6 Multicore Computing
Computação Multicore é realizada hoje até mesmo nos computadores de uso
pessoal, pois atualmente os processadores oferecidos já apresentam dois ou mais cores.
Esses processadores implementam multiprocessamento em um único microprocessador.
É como se existissem dois processadores na arquitetura SMP, no caso de um
processador com dois cores. Geralmente esses processadores implementam coerência de
cache na L2 ou ainda podem ter diferentes caches.
Assim como na arquitetura SMP, esses cores compartilham a mesma
interconexão com o resto do sistema. Cada um desses cores pode implementar
independentemente otimizações como execução superescalar, pipeline e multithreading.
Também estão sendo propostos processadores com um número bastante grande de
cores, e estão sendo denominados de processadores Many-Cores [24]. Esses
processadores Many-Core estão apresentando soluções para comunicação interna
bastante sofisticadas, chegando ao ponto de implementarem redes dentro do chip. Essas
rede são conhecidas como NoC (Network on Chip).
2.7.7
GpGPUs
General-purpose Computing on Graphics Processing Units, ou computação de
propósito geral com unidades de processamento gráfico. Com o desenvolvimento das
GPUs chegando a um poder computacional bastante interessante, começou-se a buscar
maneiras de utilizar essa capacidade de processamento para resolução de problemas que
até então eram resolvidos por computadores de grande porte. Para isso está sendo
desenvolvida uma arquitetura de computação paralela de propósito geral – a CUDA
(Compute Unified Device Architecture), que servirá de interface para a utilização do
poder computacional das GPUs [19].
2.8 Paradigmas de Programação Paralela
Atualmente, dois paradigmas para programação paralela estão em destaque.
Quando se trata de programação em arquiteturas de memória compartilhada
normalmente utiliza-se OpenMP, enquanto que para programação em arquiteturas de
memória distribuída utiliza-se MPI. A seguir serão apresentadas algumas informações
básicas para uma melhor compreensão desses dois paradigmas.
2.8.1 Memória Compartilhada – OpenMP
OpenMP [7] é uma API (Application Program Interface) para programação em
C/C++ e Fortran, que oferece suporte para programação paralela em computadores que
possuem uma arquitetura de memória compartilhada. OpenMP é mantido por um grupo
formado pelos maiores produtores de software e hardware [7]. O Modelo de
programação adotado pelo OpenMP é bastante portável e escalável podendo ser
utilizado numa gama de plataformas que variam desde um computador pessoal até
19
supercomputadores [7][15][16] OpenMP é baseado em Diretivas de compilação, rotinas
de bibliotecas e variáveis de ambiente
O OpenMP provê um padrão suportado por quase todas as plataformas ou
arquiteturas de memória compartilhada. Um detalhe interessante e importante é que isso
é conseguido utilizando-se um conjunto simples de diretivas de programação. Em
alguns casos, o paralelismo é implementado usando 3 ou 4 diretivas. É, portanto, correto
afirmar que o OpenMP possibilita a paralelização de um programa serial de forma
amigável.
Como o OpenMP é baseado no paradigma de programação de memória
compartilhada, o paralelismo consiste então de múltiplas threads. Assim, pode-se dizer
que OpenMP é um modelo de programação paralelo explicito, oferecendo controle total
ao programador [15].
O modelo de Fork-Join é utilizado pelo OpenMP. Basicamente, todo programa
OpenMP inicializa-se como um processo simples, que pode ser chamado de thread
principal, e sua execução serial vai até encontrar a primeira região de paralelismo, nesse
momento são criados os processos (threads) paralelos, através de uma primitiva Fork.
Então a execução concorrente segue até que todos os processos concorrentes terminem.
Nesse momento ocorre o sincronismo de todos os processos, o Join, e conclui-se a
execução do programa com um único processo. A figura a seguir, retirada de [14],
exemplifica o funcionamento do fork-join.
Figura 5: Modelo Fork-Join – OpenMP
2.8.2 Troca de Mensagens – MPI
MPI (Message-Passing Interface) [11] é uma especificação de uma biblioteca de
interface de passagem de mensagens. MPI representa um paradigma de programação
paralela no qual os dados são movidos de um espaço de endereçamento de um processo
para o espaço de endereçamento de outro processo, através de operações de troca de
mensagens [11]. MPI é uma especificação para uma biblioteca de interface, então não
pode ser caracterizada com uma linguagem de programação, e todas as operações do
MPI são expressas como uma função, sub-rotina ou método, de acordo com a
linguagem de programação à qual o MPI esta sendo associada [14] [17].
As principais vantagens do estabelecimento de um padrão de troca de mensagens
são a portabilidade e a facilidade de utilização. Em um ambiente de comunicação de
memória distribuída ter a possibilidade de utilizar rotinas em mais alto nível ou abstrair
a necessidade de conhecimento e controle das rotinas de passagem de mensagens,
soquetes, por exemplo, é um benefício bastante razoável. E como a comunicação por
20
troca de mensagens é padronizada por um fórum de fabricantes bastante respeitável
[14], é correto assumir que será provido pelo MPI eficiência, escalabilidade e
portabilidade.
MPI possibilita a implementação de programação paralela em memória
distribuída em qualquer ambiente. Além de ter como alvo de sua utilização as
plataformas de hardware de memórias distribuídas (como Cluster) MPI também pode
ser utilizado em plataformas de memória compartilha como as arquiteturas
SMP/NUMA. E ainda, torna-se mais aplicável em plataformas Híbridas, como Cluster
de Máquinas NUMA.
Todo o paralelismo em MPI é explicito, ou seja, de responsabilidade do
programador, e implementado com a utilização dos construtores da biblioteca no
código.
21
3 ARQUITETURAS NUMA
Nesse capítulo serão apresentadas com maiores detalhes principais as
características de máquinas NUMA. Assim como os conceitos básicos necessários para
o desenvolvimento de programas paralelos para máquinas NUMA, como melhores
práticas de alocação e gerência de memória e alocação e gerência de processos.
Os últimos anos marcaram o lançamento de inúmeras novas tecnologias devido a
busca por um maior poder computacional. Já existiam muitos esforços no sentido da
criação de supercomputadores, porém esses recursos tinham um custo muito elevado, e
ficavam restritos a poucos usuários. Em seguida, foram feitas tentativas com os clusters,
visto que esses poderiam ser formados por equipamentos de prateleira. Outras tentativas
foram a construção de computadores SMPs e mais recentemente computadores
multicore. Os clusters se tornaram bastante populares, pois podiam alcançar um bom
poder computacional a um custo relativamente baixo, porém tinham contra si a
dificuldade para o desenvolvimento de aplicações, em função do paradigma de
programação por troca de mensagens. Por outro lado, os processadores SMPs se
tornaram mais acessíveis em comparação com os supercomputadores, e apresentando
um bom poder computacional. Além disso, esses sistemas utilizam o paradigma de
programação por memória compartilhada, que é mais próximo do modelo de
programação que os programadores utilizam normalmente. Porém, os sistemas SMPs
também possuem suas desvantagens: existe uma limitação com relação ao número de
processadores, visto que todos os processadores disputam o acesso à memória através
do mesmo barramento.
Mais uma vez posta de frente a um novo desafio, a indústria buscou uma nova
solução, e começou a construir computadores com a arquitetura NUMA, a qual busca
exatamente contornar as limitações dos sistemas SMPs e multicore. Na verdade, os
sistemas que estão sendo implementados são sistemas cc-NUMA, ou seja, são sistemas
NUMA que possuem coerência de cache, e que desse ponto em diante será tratado
simplesmente por sistemas NUMA.
Os sistemas NUMA são compostos por nós, que possuem um processador,
multicore ou não, e uma memória local, todos esses nós estão interconectados por uma
rede especializada, o que oferece um único espaço de endereçamento da memória para
todo o sistema, proporcionando inclusive a coerência da cache dos diversos
processadores [3] [4] [5].
Em sistemas SMP o acesso à memória é uniforme, o que significa que o custo de
acesso a qualquer local da memória é o mesmo. Já nos sistemas NUMA, o tempo de
22
acesso a memória é não uniforme, visto que quando o processador acessa os dados que
estão na memória local experimenta uma latência bastante inferior do que quando
acessa os dados que estão na memória de outro nó [6].
Nos sistemas NUMA, esse custo para acesso à memória varia de acordo com a
Distância NUMA ou Fator NUMA. Essa distância é basicamente a razão entre o tempo
de acesso á memória de um nó local e o tempo de acesso à memória de um nó remoto.
As distâncias NUMA são reconhecidas pelos sistemas operacionais em unidades
definidas pela ACPI (Advanced Configuration and Power Interface) [21] SLIT ( System
Locality Information Table). De acordo com o padrão ACPI, a distância NUMA é
armazenada na tabela SLIT e é um valor normalizado por 10. Também é definido pelo
padrão a tabela SRAT (System Resource Affinity Table) que é utilizada pelo sistema
operacional de modo a auxiliar que nas tarefas de alocação de memória os dados sejam
postos na memória do nó local do processo.
Na Figura 6 tem-se um modelo de um esquema de um sistema NUMA retirado
de [3]:
Figura 6: Esquema Máquina NUMA
23
Nesse exemplo, tem-se um sistema com quatro nós. Cada nó possui dois
processadores, uma memória local e sua cache. Imaginando que existe um processo
executando no processador 4, no nó 2, então à distância NUMA para o acesso a
memória local é 10. No entanto, se esse processo precisar acessar dados na memória
localizados no nó 1, então esse acesso terá uma latência maior, e esse valor pode ser
expresso pela distância NUMA, que nesse exemplo pode ser colocada como 14, que é
um valor hipotético. Então esses dois valores expressam a diferença entre os acessos à
memória local e a memória remota.
É importante, salientar que esses valores dependem sempre das tecnologias
envolvidas na construção do sistema NUMA.
3.1 Conceitos
Alguns conceitos referentes à gerência e localidade de dados na memória e
escalonamento de processos pelo kernel precisam ser apresentados de modo a
possibilitar um melhor entendimento dos demais conceitos e fundamentos referentes aos
Sistemas NUMA.
3.1.1 Gerência de Memória em Unix
Um processo Unix pode, teoricamente, ocupar até quatro gigabytes. Entretanto, o
espaço em memória física (RAM) é um recurso escasso e o sistema operacional deve
dividi-lo entre os vários processos em execução. Quando é necessário carregar um novo
processo em memória, o sistema operacional traz do disco apenas as porções
necessárias à sua execução e não o processo inteiro. Se ao executar, o processo acessa
uma posição de memória que não está carregada em memória, o sistema operacional
bloqueia esse processo, realiza a carga da porção que está faltando e, na seqüência,
torna o processo novamente apto a executar. Esse esquema de gerenciamento de
memória desvincula o tamanho lógico do processo do espaço disponível em RAM, já
que o sistema operacional mantém em memória física apenas as porções necessárias à
execução do programa. Isso é a base do que é denominado de memória virtual [26].
Existem duas técnicas fundamentais para definir as porções de memória:
segmentação e paginação. Na segmentação, o espaço de endereçamento do processo é
dividido em porções de tamanhos variáveis denominados de segmentos. Já na
paginação, essas porções possuem tamanhos fixos e são denominados de páginas. A
maioria dos sistemas operacionais emprega paginação por seu gerenciamento ser mais
simples. A paginação é uma técnica de gerenciamento de memória que consiste em
dividir tanto o espaço de endereçamento lógico do processo quanto o espaço físico em
memória RAM em porções de tamanho fixo denominadas de página e quadros (frames),
respectivamente. O sistema operacional mantém uma lista de quadros livres e os aloca a
páginas à medida que os processos vão sendo carregados em memória (paginação por
demanda). Qualquer página pode ser alocada a qualquer quadro. A vinculação entre
páginas e quadros é feita a partir de uma tabela de páginas.
24
3.1.2 Alocação de Memória
Sempre que um processo é criado, é definido um espaço de endereçamento
lógico que pode ser visto como uma espécie de ambiente de execução contendo código,
dados e pilha. O procedimento de criação de processos em Unix é baseado nas
chamadas de sistema fork e exec. Um processo, denominado de processo pai, quando
executa a chamada de sistema fork cria um novo processo, atribuindo um novo pid
(process identifier) e um espaço de endereçamento lógico, uma cópia quase exata do
seu próprio espaço de endereçamento [23] [26]. Na prática, isso é feito com que o
processo filho receba uma cópia da tabela de páginas do processo pai. Entretanto, na
maioria das vezes o processo filho é criado para executar um código diferente do
processo pai. Assim, na seqüência o processo filho executa a chamada de sistema exec
para substituir as cópias das páginas do processo pai por páginas próprias provenientes
de um arquivo executável. A partir desse ponto, os processos pai e filho, se diferenciam.
Nesse ponto, ocorre uma alocação de memória para as páginas do processo filho.
Os processos, uma vez em execução, podem alocar memória adicional a partir da
área de heap de seu espaço de endereçamento lógico. Isso é feito adicionando novas
páginas ao seu espaço de endereçamento virtual, ou seja, aumentando o número de
entradas em sua tabela de páginas, através da chamada de sistema malloc. Entretanto,
normalmente, no Unix, a vinculação de uma nova página (endereço lógico) a um quadro
(memória real) só acontece quando essa página for acessada pela primeira vez. Essa
política é conhecida como first touch [23]. Posto de outra forma, ao se realizar uma
primitiva malloc se obtém um espaço de endereçamento lógico proporcional à
quantidade solicitada pelo malloc, porém a memória física correspondente só será
realmente alocada quando for feito o primeiro acesso a ela.
3.1.3 Localidade de Dados
É o principal mecanismo utilizado em caches para agrupar posições contíguas
em blocos, quando um processo referencia pela primeira vez um ou mais bytes em
memória, o bloco completo é transferido da memória principal para a cache. Desta
forma, se outro dado pertencente a este bloco for referenciado posteriormente, este já
estará presente na memória cache, não sendo necessário buscá-lo novamente na
memória principal. Portanto, sabendo-se o tamanho dos blocos utilizados pela cache e a
forma com que os dados são armazenados pelo compilador é possível desenvolver uma
aplicação paralela que possa melhor utilizar essa característica.
Blocos são utilizados em cache devido a características básicas em programas
seqüenciais: localidade espacial e localidade temporal [22] [25]. Na primeira um
determinado endereço foi referenciado, há uma grande chance de um endereço próximo
a esse também ser referenciado em um curto espaço de tempo. Já na localidade
temporal, um programa é também normalmente composto por um conjunto de laços.
Cada laço poderá acessar um grupo de dados de forma repetitiva. Por causa disto, se um
endereço de memória foi referenciado, há também a chance deste ser referenciado
novamente em pouco tempo.
25
3.1.4 O problema do Falso Compartilhamento
As características de localidade de dados descritas podem representar uma
grande desvantagem quando utilizadas em Sistemas Multiprocessados. O problema é
que mais de um processador pode necessitar de partes diferentes de um bloco. Se um
determinado processador escreve somente em uma parte de um bloco em sua cache
(somente alguns bytes), cópias deste bloco inteiro nas caches dos demais processadores
devem ser atualizadas ou invalidadas, dependendo da política de coerência de cache
utilizada. Este problema é conhecido como Falso Compartilhamento [6] [22], podendo
reduzir o desempenho de uma aplicação paralela. A Figura 7 busca mostrar um possível
esquema, para exemplificar esse problema.
Figura 7: Falso Compartilhamento
Em máquinas NUMA, estas questões referentes à localidade dos dados e Falso
Compartilhamento se agravam, pois os dados podem pertencer à memória remota, ou
seja, a memória de um nó vizinho, assim o tempo de acesso à memória vai ser onerado
pelo Fator NUMA do sistema.
Existem mecanismos que permitem ao programador definir em que módulo de
memória um determinado dado deverá ser armazenado. Em grande parte das
arquiteturas NUMA, um dado é armazenado no nó em que acessou primeiro. Outra
26
estratégia possível é permitir que o sistema operacional mantenha esse controle sobre a
localidade dos dados.
Sabendo destas características é importante que o programador tenha
conhecimento dos cuidados a serem tomados para o desenvolvimento de aplicações
paralelas em máquinas NUMA de modo a conseguir um bom desempenho.
3.1.5 Escalonamento
O mecanismo responsável por determinar qual processo executará em um
determinado processador e por quanto tempo deverá permanecer no processador é
denominado escalonador. O objetivo deste mecanismo é permitir que a carga do sistema
possa ser balanceada da melhor maneira entre todas as CPUs do sistema. Tratando-se de
arquiteturas paralelas o escalonamento pode ser tratado em dois níveis: aplicação ou
como entidade externa a aplicação [26].
No primeiro caso, a solução paralela para um problema é desenvolvida levandose em consideração as características da arquitetura alvo, como por exemplo, número de
processadores, rede de interconexão e memória disponível. O mecanismo de
escalonamento estará presente dentro da aplicação, distribuindo as tarefas a serem
executadas de forma a melhor utilizar o sistema.
O segundo caso, o esforço na programação é reduzido, porém também é comum
o desempenho nesse caso ser pior. Isso ocorre porque o mecanismo de escalonamento
tem conhecimento do sistema, mas não da aplicação.
Quando se trata de máquinas NUMA, há uma questão importante relacionada ao
balanceamento de carga. Se um processo p1, em um determinado processador
localizado em um nó n1, aloca dados em memória e os utiliza com freqüência, é
bastante provável que esses dados estejam alocados na memória local do nó n1.
Contudo, para manter o sistema balanceado o processo p1 pode ser enviado para outro
processador. Assim se esse outro processador estiver em outro nó que não o n1, todo o
acesso que o processo p1 necessitar fazer à memória que está alocada no nó n1 terá uma
maior latência, prejudicando certamente o desempenho do processo.
Nesses casos, é importante o programador avaliar o sistema NUMA utilizado
para saber qual a melhor alternativa na seqüência de execução do programa. Pode-se
seguir utilizando os dados armazenados na memória do nó, então, remoto. Ou pode-se,
fazer a migração das páginas de memória do nó original para o nó em que o processo
está sendo executado. Portanto, aplicações paralelas em máquinas NUMA somente
terão resultados ótimos levando em consideração todos os detalhes referentes ao
escalonamento e o balanceamento de carga do sistema.
27
3.2 Memória em Máquinas NUMA
Em sistemas NUMA, a memória é gerenciada separadamente para cada nó.
Essencialmente, existe um pool de páginas em cada nó. Assim, cada nó tem uma thread
de swap que é responsável pelo memory reclaim do nó [3]. Cada faixa de endereço de
memória no nó é chamada de zona de alocação. A estrutura da zona de alocação
contém listas que possuem as páginas disponíveis. Também existem listas informando
quais as páginas estão ativas e inativas de modo a auxiliar no processo de limpeza ou
“recuperação” da memória.
Se uma requisição de alocação é feita para um sistema NUMA, então é
necessário decidir em qual pool e em qual nó será alocada a memória. Normalmente,
são utilizados os padrão do processo que esta fazendo a requisição e é alocado a
memória no nó local. No entanto, pode-se utilizar funções de alocação específicas de
modo a poder alocar a memória em nós diferentes [4] [5].
3.2.1 Alocação Eficiente
A Alocação de Memória em sistemas NUMA lida com novas considerações na
comparação com um sistema com tempo de acesso à memória uniforme. A existência
de nós eficientes significa que o sistema possui muitas partes com mais ou menos
autonomia, assim os processos podem rodar melhor quando os dados são alocados
levando em consideração essas características.
3.2.2 Localidade Ótima: Nó Local
A localidade ótima de alocação de memória para o processo se dá ao alocar a
memória no nó local do processo. Nesse caso o processo terá o menor custo possível no
sistema NUMA para acesso aos dados da memória e não terá tráfego na interconexão
NUMA.
No entanto, essa estratégia de alocação somente será a melhor se o processo
continuar acessando os dados de maneira regular e local.
3.2.3 Aplicação Multi-Nó
Uma situação mais complexa ocorre quando a aplicação precisa de mais recursos
que um nó pode oferecer. Quando não é possível alocar toda a memória necessária para
a aplicação num mesmo nó, então é necessário fazer uma avaliação quanto ao
desempenho da aplicação, levando-se em conta a forma como a aplicação utiliza esse
recurso [3].
A seguir tem-se o tipo de aplicação e a melhor forma de alocação:
1. Dados especificados pela thread: alocação no nó local, desde que os dados
28
sejam acessados pelo processador local.
2. Dados compartilhados para leitura/escrita: se os dados são acessados de
forma igual entre todos os processos dos diferentes nós, a forma mais
apropriada é a alocação de memória de maneira entrelaçada entre todos os
nodos.
3. Dados compartilhados somente leitura: se os dados são apenas acessados
para leitura, então estes dados podem ser replicados para todos os nós, tendo
cada um sua própria cópia.
Aplicações multi-nó podem ter poucas threads, porém essas threads podem
utilizar mais memória física que o nó tem disponível. Nesse caso, mais memória pode
ser alocada automaticamente de outros nós do sistema NUMA. É verdade que o
desempenho dessa aplicação sofrerá perdas em função de aumentar o tempo de acesso
aos dados que estão em memória remota.
3.2.4 Migração de Memória
A necessidade de migrar páginas de memória entre nós aparece quando um
processo que estava executando em um determinado nó é movido pelo escalonador do
sistema operacional para outro nó. Nessa situação, para evitar o tempo de acesso à
memória remota pode ser justificado migrar as páginas de memória alocadas para esse
processo para a memória local do nó [3] [9].
Outro momento em que a migração de páginas de memória se mostra vantajosa é
para refazer o balanceamento de acesso à memória entre todos os nós que estão
acessando dados na memória de maneira entrelaçada. Imagine uma aplicação rodando
sobre vários nós, utilizando cada thread os dados em sua memória local. Após o
encerramento de uma thread, os dados daquele nó devem ser acessados pelas outras
threads. Nesse caso, é melhor migrar as páginas do nó que já encerrou o processamento
para os demais nós, conforme a necessidade da aplicação.
Para ocorrer a migração de páginas, todas as referências a essas páginas devem
ser desfeitas temporariamente e depois movidas para o novo endereço das páginas. Se
não for possível remover todas as referências, a tentativa de migração é abortada e as
antigas referências são re-estabelecidas. Esse tipo de problema pode ocorrer se
existirem vários processos que acessam a mesma área de memória.
A migração ocorre em quatro etapas:
•
•
•
•
As páginas a serem migradas são removidas da lista de LRU (Last Recently
Used);
Todas as entradas da tabela de páginas são movidas da referência antiga para a
nova;
É verificada a quantidade de referências de páginas e a quantidade de páginas
alocadas, para ter certeza que o kernel não tem outras referências para as
páginas;
Se tudo estiver certo, então todas as referências são refeitas e as páginas são
novamente disponibilizadas para utilização.
29
3.3 Cpusets
Cpusets provê um mecanismo para associar um conjunto de CPUs e memória de
um nó a um conjunto de tarefas. Assim, é restringido a dada aplicação utilizar apenas os
recursos disponibilizados pelo cpuset corrente. Ele forma uma hierarquia aninhada
dentro de um sistema de arquivos virtual, e essas informações são necessárias para a
gerência do sistema.
Cada tarefa tem um apontador para um cpuset, e múltiplas tarefas podem
referenciar o mesmo cpuset. Requisições de tarefas utilizam a chamada de sistema
sched_setaffinity para incluir CPUs na máscara de afinidade. Também são utilizadas as
chamadas de sistemas mbind e set_mempolicy para configurar a afinidade de alocação
de memória.
O escalonador não irá escalonar tarefas para CPUs que não estiverem no vetor
de cpus_allowed e o alocador de páginas do kernel não irá alocar memória de outro nó
que não esteja no vetor mems_allowed.
Se o cpuset é CPU ou memória exclusivo,
nenhum outro cpuset poderá referenciar aqueles recursos já uma vez referenciados.
Cpuset é extremamente valioso para o gerenciamento de um sistema complexo,
com muitos processadores (CPUs) e com sistema de memória que é composto por
partes em nós separados. No caso, os sistemas NUMA,se encaixam bem nessa
definição. Isso, porque nesses sistemas é extremamente importante ter domínio de onde
serão alocadas as páginas de memória e em quais CPUs serão executadas as tarefas, de
modo que a aplicação tenha o melhor desempenho possível.
3.4 Exemplos de Sistemas NUMA
Atualmente, já temos vários sistemas NUMA presentes no mercado, e a cada dia
teremos mais sistemas desse tipo, visto que os sistemas multicore estão cada vez mais
presentes nas máquinas do nosso cotidiano, e esses sistemas estão utilizando a
arquitetura NUMA para melhorar o desempenho.
Nessa seção serão apresentadas dois exemplos de arquiteturas NUMA: o
processador AMD Opteron que implementa sistema NUMA no chip e o computador HP
Integrity Superdome.
3.4.1 AMD Athlon 64 e AMD Opteron ccNuma Multiprocessor Systems
Os processadores das famílias Athlon 64 e AMD Opteron de sistemas
multiprocessados são baseados na arquitetura ccNUMA. Nessa arquitetura, cada
processador tem acesso a sua memória local, com baixa latência, por outro lado, o
30
acesso feito à memória dita remota possui um tempo de acesso maior em função de ter
que acessar a memória através do outro processador. Essa arquitetura NUMA é
desenvolvida para manter a coerência da cache de todo o espaço de endereçamento de
memória compartilhado. O recurso utilizado para isso é o HyperTransport [10], uma
tecnologia de interconexão entre os processadores que garante a coerência dos dados da
memória e os acessos de dados da memória entre os processadores [10].
Em sistema SMPs tradicionais vários sistemas compartilham o mesmo
barramento para acesso à memória, esse barramento é um gargalo para os processadores
que precisam obter dados da memória, e em função disso, esses sistemas não são muito
escaláveis. Essa estrutura proposta pela AMD busca suprir esses problemas,
possibilitando a criação de sistemas NUMA com um número bastante grande de CPUs.
O sistema apresentado a seguir é baseado no Quartet, um sistema não comercial
da AMD, que possui quatro AMD Opteron Dual-Core 2.2GHz, retirado de [10]:
Figura 8: Processador Dual-Core cc-Numa
A Figura 8 mostra quatro processadores cada um composto por dois cores
(denominado C0 e C1). A AMD utiliza o termo hop para descrever a distância de acesso
em sistemas NUMA. Quando uma thread acessa a memória do seu próprio processador
então o tempo de acesso é local ou tem 0-hop de acesso. Já se a thread que acessar a
memória de outro processador, então o tempo de acesso remoto pode ser de 1-hop, caso
o processador seja vizinho ou de até 2-hops caso o acesso seja feito em um processador
que esteja na diagonal, esses detalhes dizem respeito a esse exemplo.
Na Figura 8, as caixas descritas como cHT (coherent HyperTransport) são a
implementação da tecnologia HyperTransport que garante um único espaço de
endereçamento para a memória compartilhada e a coerência das caches.
31
3.4.2 HP Integrity Superdome
A fabricante de computadores HP (Hewlett-Packard), possui uma linha de
computadores chamada Superdome, que são computadores de alto desempenho e alta
disponibilidade que implementam arquiteturas NUMA [8]. O exemplo abaixo foi
retirado de [28]
, e foi colocado por ser um computador que muitas empresas
possuem em seus datacenters, isso busca mostrar que as arquiteturas NUMA já estão
sendo utilizadas em grande escala.
A Figura 9, retirada de [28] mostra uma arquitetura com dois níveis de acesso à
memória, com 4 nós e 16 processadores. Assim esse computador possui dois diferentes
valores de latência para o acesso à memória.
Figura 9: Arquitetura HP Integrity Superdome
Como visto no capítulo 3, a ACPI é o padrão que provê informações sobre a
configuração do hardware e possibilita que o sistema operacional gerencie da melhor
maneira os recursos. Essas informações são hierarquicamente organizadas e são
disponibilizadas em tabelas. Uma dessas tabelas que a ACPI prove é a SLIT, que
descreve a distância relativa entre o processador e a memória, ou seja, a latência para
acesso à memória para determinado processador.
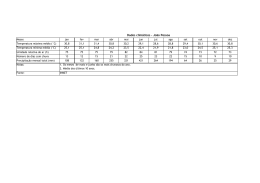
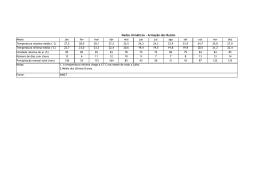
A Figura 10 mostra uma possível tabela SLIT para o computador mostrado na
figura 9. De acordo com essa tabela, a distância do nó 1 para o nó 2 equivale a 1.7 vezes
da distância local, ou seja, o processador do nó 1 leva setenta por cento (70%) mais
tempo para acessar a memória do nó 2 do que para acessar a sua memória local.
Figura 10: Tabela SLIT
32
Assim, podemos observar o quanto é importante a utilização dos recursos dos
sistemas NUMA de maneira apropriada. E para isso existem ferramentas que
possibilitam a alocação dos recursos de maneira a retirar o máximo desempenho dos
computadores que implementam a arquitetura NUMA, essas ferramentas serão
apresentadas a seguir.
33
4 FERRAMENTAS PARA UTILIZAÇÃO DE
ARQUITETURAS NUMA
Observando-se as limitações de escalabilidade dos servidores SMPs em função do
problema de disputa entre os processadores por acesso ao barramento, quando do acesso
à memória. Surgiram alternativas como as arquiteturas NUMA. No entanto, para a
utilização correta das melhorias trazidas por esse novo sistema foi necessário a criação
de recursos nos ambientes de modo a viabilizar esse processo. Os primeiros passos,
foram a criação da Biblioteca LibNuma e do Numactl que são as partes mais relevantes
da NUMA API [1], que possibilitam ao programador especificar os parâmetros
necessários de maneira que a aplicação faça a alocação dos recursos de modo mais
correto possível, dado certo comportamento da aplicação. Como a utilização dessas
ferramentas vem crescendo, justamente pelo crescimento das plataformas NUMA no
mercado, existem algumas propostas de novas bibliotecas ou interfaces para facilitarem
a utilização da NUMA API, visto que as funções disponibilizadas por ela são bastante
complexas. A MAI (Memory Affinity Interface), desenvolvida em um laboratório na
França [12], busca oferecer uma interface mais simples para a implementação de
aplicações que devem utilizar os recursos das arquiteturas NUMAs.
A seguir, será feita uma apresentação da NUMA API, assim como da MAI.
4.1 NUMA API
Os sistemas Unix possuem maneiras de escalonar os processos para as unidades de
processamento disponíveis na arquitetura. No caso do Linux, esse processado
tradicionalmente é feito utilizando as chamadas de sistema sched_set_affinity e
schedutils [1]. NUMA API estende essas chamadas de sistema permitindo que os
programas possam especificar em qual nodo a memória será alocada e ou em qual CPU
será colocada para executar determinada thread. NUMA API é normalmente distribuída
de um pacote RPM e segundo [1] já está disponível no SUSE desde a versão Enterprise
9, atualmente estamos na versão 10, com lançamento da versão 11 do SUSE Enterprise.
NUMA API consiste de diferentes componentes: existe uma parte que trabalha junto
ao kernel gerenciando as políticas de memória por processos ou especificando o
mapeamento da memória. Essa parte é controlada por três novas chamadas de sistema.
Temos a libnuma, que é uma biblioteca compartilhada no espaço de usuário do sistema,
34
que pode ser “ligada” a aplicação, e é a interface recomendada para utilização das
políticas NUMA. Tem-se também a numactl, um utilitário de linha de comando, que
permite controlar as políticas NUMA para uma determinada aplicação e os processos
que essa aplicação gerar. Como utilitários auxiliares têm-se o numastat, que coleta
estatísticas sobre alocação de memória, e o numademo, que mostra os efeitos das
diferentes políticas no sistema.
A principal tarefa da NUMA API é a gerência das políticas NUMA. As políticas
podem ser aplicadas aos processos ou a áreas de memória. São suportadas quatro
diferentes políticas:
•
default: aloca no nó local;
•
bind: aloca num conjunto especificado de nós;
•
interleve: entrelaça a alocação de memória num conjunto de nós;
•
preferred: tenta alocar primeiro num determinado nó.
A diferença entre as políticas bind e preferred é que a primeira vai falhar
diretamente, quando o nodo não conseguir alocar a memória, enquanto que a segunda,
no caso de falha, vai tentar alocar em outro nodo. As políticas podem ser por processos
ou por regiões de memória, levando sempre em consideração que os processos filhos
sempre herdam as políticas dos processos pais. E também que a política sempre é
aplicada a toda a memória alocada no contexto do processo.
4.1.1 NUMACTL
NUMACTL é uma ferramenta de linha de comando para rodar aplicações com
determinadas políticas NUMA especificadas, assim essa ferramenta possibilita que seja
definido um conjunto de políticas sem que a aplicação precise ser modificada e
compilada novamente.
A seguir são apresentados alguns exemplos retirados do [1] que mostram alguns
comandos:
numactl --cpubind=0 --membind=0,1 program
Nesse caso, é executado o program na CPU do nodo 0, e apenas é alocada memória
dos nodos 0 e 1.
numactl --preferred=1 numactl –show
Aqui é especificado a política preferred para o nodo 1 depois mostrado o resultado.
numactl –interleave=all numbercruncher
Executa um programa (number cruncher) que tem uso intensivo de memória, de
modo a alocar a memória de maneira entrelaçada entre todos nos nodos disponíveis.
35
Algumas opções do comando numactl são importantes e merecem destaque. Muitas
dessas opções requerem uma máscara para especificar o nodo (node-mask), isto é, uma
lista separada por vírgulas de números dos nodos. O comando numactl --hardware,
mostra a lista de nodos disponíveis no sistema e numactl --show, mostra estado dos
processos correntes e seus filhos.
As políticas mais utilizadas são as destinadas aos processos:
•
membind=nodemask: aloca memória apenas nos nodos especificados;
•
interleave=nodemask: entrelaça toda alocação de memória entre os nodos
especificados;
•
cpubin=nodemask: executa os processos apenas nas CPUs especificadas na
mascara de nodos;
•
preferred=node: aloca memória preferencialmente no nodo especificado.
A seguir, será apresentada uma maneira de gerenciar a alocação de memória
compartilhada com o numactl, visto que até agora foi visto apenas a opções que tratam
da alocação de processos.
Algumas aplicações podem ter seu desempenho melhorado quando utilizam a
melhor política de alocação de memória, levando em consideração suas características.
Por exemplo, imagine uma aplicação multiprocessada, que esteja alocando um único
segmento de memória que é compartilhada por todos os processos. Se essa alocação for
feita de modo entrelaçada entre as memórias de todos os nodos, é bastante razoável
imaginar que o desempenho irá melhorar. Assim, segue um exemplo das opções que
podem ser passadas para o numactl de modo a escolher uma política de alocação de
memória.
numactl --length=1G --fila=/dev/shm/interleaved --interleave=all
O comando acima configura um tmpfs, filesystem temporário, de um gigabyte para
entrelaçar a memória sobre todos os nodos do sistema.
Muitas outras opções podem ser encontradas na Man Pages do Linux sobre numactl.
4.1.2 LIBNUMA
O numactl pode fazer o controle de políticas numa, porém sempre que aplicada a
política ela é válida para todo o processo. Já a libnuma, que é uma biblioteca
compartilhada, pode aplicar políticas para área de memória especifica ou até mesmo
para uma thread.
A libnuma pode ser “linkada” aos programas e então oferecer ao programador uma
API confiável para utilização das políticas NUMA, a biblioteca também é considerada a
36
melhor maneira de se utilizar os recursos da NUMA API. Um exemplo de compilação
de um programa com a libnuma é:
cc ... –lnuma
As funções e macros da NUMA API são declaradas no arquivo de include numa.h.
Antes de qualquer função da libnuma ser utilizada, o programa deve chamar a função
numa_available(), quando essa função retorna um valor negativo, significa que o
suporte a API NUMA não está disponível. Exemplo da Figura 11 foi retirado de [1]:
#include <numa.h>
...
if (numa_available() < 0) {
printf(‘‘Your system does not support NUMA API\n’’);
...
}
...
Figura 11: Exemplo numa_available.
A seguir, deve-se chamar a função numa_max_node(), essa função descobre e
informa o número de nodos disponíveis no sistema.
Sendo assim, serão apresentadas algumas funções da libnuma, com exemplos de
utilização.
A libnuma armazena numa estrutura de dados abstrata chamada nodemask_t, que
representa o conjunto de nodos que pode ser gerenciado pela API. Cada nodo do
sistema tem um único número, o maior número corresponde ao valor retornado pela
função numa_max_node(). A máscara de nodos é inicializada com a função
nodemask_zero().
Exemplo:
nodemask_t mask;
nodemask_zero(&mask);
Um único nodo pode ser configurado na máscara com as funções: nodemask_set e
nodemask_clr. A função nodemask_equal, compara duas máscaras. E a função
nodemask_isset testa se um bit esta configurado na máscara.
37
Existem duas máscaras de nodos pré-definidas: numa_all_nodes e numa_no_nodes,
que respectivamente representam uma máscara com todos os nodos e outra sem nodos.
A libnuma possui funções para a alocação de memória com políticas especificadas.
Essas funções de alocação são relativamente lentas e não devem ser utilizadas para a
alocação de porções pequenas da memória [1]. Quando uma alocação for solicitada e
não for possível, então será retornado o valor NULL. Toda a memória alocada com as
funções da família numa_alloc deve ser liberada com a função numa_free.
A função numa_alloc_onnode aloca memória no nodo especificado, na Figura 12
tem-se um exemplo:
void *mem = numa_alloc_onnode(MEMSIZE\_IN\_BYTES, 1);
if (mem == NULL)
/* report out of memory error */
... pass mem to a thread bound to node 1 ...
Figura 12: Exemplo numa_alloc_onnode.
Por padrão, a função ira tentar alocar a memória no nodo, caso tenha problema
poderá tentar alocar a memória em outro nodo, a menos que a função
numa_set_strict(1), tenha sido chamada. Para se ter a informação de quanta memória o
nodo tem disponível pode ser chamada a função numa_node_size.
A função numa_alloc_interleaved aloca a memória de maneira entrelaçada entre
todos os nodos do sistema, conforme exemplo da Figura 13.
void *mem = numa_alloc_interleaved(MEMSIZE\_IN\_BYTES);
if (mem == NULL)
/* report out of memory error */
... run memory bandwidth intensive algorithm on mem ...
numa\_free(mem, MEMSIZE_IN_BYTES);
Figura 13: Exemplo numa_alloc_interleaved.
É importante, ressaltar que nem sempre a alocação de memória entre todos os
nodos garante um bom desempenho a aplicação, em muitas arquiteturas NUMA o ideal
é a alocação entre apenas alguns nodos vizinhos, nesse caso pode-se utilizar a função
numa_alloc_interleaved_subset. Ainda tem-se a função numa_alloc_local, a qual aloca
38
memória no nodo local e a função numa_alloc que aloca a memória conforme a política
do sistema como um todo.
A biblioteca libnuma também pode gerenciar as políticas de processos. A função
numa_set_interleaved_mask habilita entrelaçamento para a thread corrente, assim todas
as futuras alocações serão feitas utilizando-se do Round-Robin entrelaçado entre os
nodos contidos na máscara. A Figura 14, apresenta um exemplo.
numamask_t oldmask = numa_get_interleave_mask();
numa_set_interleave_mask(&numa_all_nodes);
/* run memory bandwidth intensive legacy library that allocates memory */
numa_set_interleave_mask(&oldmask);
Figura 14: Exemplo numa_set_interleave_mask.
O parâmetro numa_all_nodes informa que é para entrelaçar entre todos os nodos. A
função numa_no_nodes desabilita a alocação entrelaçada. E a função
numa_get_interleaved_mask retorna a política.
A função numa_set_prefered configura o nodo como preferencial para a thread
corrente. Assim, é tentado alocar a memória no nodo local, caso tenha-se um problema
é então alocado a memória em outro nodo. A função numa_set_membind configura a
alocação de memória de maneira estrita aos nodos definidos na máscara. A função
numa_set_localalloc configura a política de alocação para o padrão local.
Em alguns casos não é possível utilizar as função da família numa_alloc para a
alocação de memória, então são utilizadas as funções como mmap( )e shmat(). A
libnuma disponibiliza funções para configurar as políticas de gerenciamento das áreas
de memórias já existentes. A função numa_interleave_memory configura a política de
entrelaçamento conforme a máscara de nodos, assim como mostrado na Figura 15.
void *mem = shmat( ... ); /* get shared memory */
numa_interleave_memory(mem, size, numa_all_nodes);
Figura 15: Exemplo numa_interleave_memory.
A função numa_tonode_memory irá alocar a memória nos nodos especificados,
enquanto que numa_tonodemaskmemory coloca a memória na máscara de nodos. Já a
39
função numa_setlocal_memory dá à área de memória a política de alocação do nodo
corrente. A numa_police_memory use a política corrente de alocação de memória, essa
função é muito utilizada quando a política é trocada anteriormente.
As políticas apresentadas até aqui, especificam os nodos onde serão alocadas as
memórias. Outra característica da libnuma é alocar os threads nos nodos conforme
especificado. Isso é feito com a função numa_run_on_node, que especifica com a
numa_run_on_node_mask em quais nodos as threads serão executadas.
A numa_bind é outra função de configuração para a alocação de processos.
nodemask_t mask;
nodemask_zero(&mask);
nodemask_set(&mask, 1);
numa_bind(&mask);
Figura 16: Exemplo nodemask_set.
Na Figura 16, a configuração é feita para permitir a execução dos processos no nodo
“1”. Essa configuração pode ser desfeita utilizando a função numa_run_on_node_mask
com a máscara numa_all_nodes.
A função numa_get_run_node_mask retorna a máscara com os nodos para os quais
os processos correntes estão sendo alocados.
Ainda é possível obter informações sobre o ambiente no qual os processos estão
sendo executados. A função numa_node_size retorna o tamanho da memória do nodo. A
função numa_node_to_cpus retorna o número de CPUs de todas as CPUs no nodo. O
tratamento de erros da libnuma é relativamente simples. Isso porque os erros de
configuração das políticas podem ser ignorados, o único problema é que as aplicações
irão ser executadas com menor desempenho. Quando um erro ocorre é chamada a
função numa_error, e como padrão ela imprime um mensagem de erro para o stderr,
quando a variável global numa_exit_on_error esta configurada e ocorre um erro da
libnuma no programa, então o programa é finalizado.
A libnuma ainda possui funções como: numa_hit, numa_miss, numa_foreign e
interleaved_hit. Essas funções entre outras, disponibilizam informações estatísticas da
libnuma.
Assim como mencionado anteriormente, não é objetivo desse texto detalhar todos os
pontos da NUMA API, sendo relevante buscar maiores detalhes na referencias.
40
4.2 MAI – Memory Affinity Interface
Essa Interface de Afinidade de Memória foi desenvolvida pela estudante de
doutorado Christiane Pousa Ribeiro sob a orientação do Prof. Dr. Jean-François Méhaut
no LIG (Laboratoire d'Informatique de Grenoble, ligado ao INRIA ( Institut Nacional de
Recherche en Informatique et en Automatique ) em Grenoble. O objetivo é permitir ao
maior facilidade ao desenvolvedor na gerência da Afinidade de Memória em
Arquiteturas NUMA. A unidade de afinidade na MAI é um vetor (array) de aplicações
paralelas. O conjunto de políticas de memória da MAI podem ser aplicadas a esses
vetores de maneira simples. Assim, as funções em alto nível implementadas pela MAI
reduzem o trabalho do desenvolvedor, se comparados com as funções disponibilizadas
pela NUMA API.
MAI é uma biblioteca desenvolvida em C que define algumas funções de alto nível
para lidar com afinidade de memória. Com essa biblioteca o desenvolvedor poderá
gerenciar a afinidade de memória das estruturas mais importantes da aplicação. Isso
facilita bastante para o desenvolvedor, por que, ao contrário da NUMA API, a MAI
dispensa os cuidados com ponteiros e endereços de páginas. Além disso, a MAI permite
um ajuste fino sobre a afinidade de memória, podendo trocar a política de alocação de
memória no código.
As principais características da MAI são: simplicidade no uso, menos complexa que
outras soluções como libnuma e numactl, e controle fino da memória; portabilidade,
essa biblioteca funciona em diferentes plataformas com diferentes compiladores; e
desempenho, funciona com melhor desempenho que soluções padrão.
A biblioteca possui sete políticas de memória: cyclic, cyclic_block, prime_mapp,
skew_mapp, bind_all, bind_block e random. Na política cyclic as páginas de memória
que contém os vetores são colocados na memória física formando um “circulo” com os
blocos de memória. A diferença entre cyclic e cyclic_block é a quantidade de páginas de
memórias que são utilizadas. Na prime_mapp as páginas de memórias são alocadas em
nodos de memória virtual. O número de nodos de memória virtual é escolhido pelo
usuário e tem que ser primo. Essa política tenta espalhar as páginas de memória pelo
sistema NUMA. Na skew_mapp, as páginas de memórias são alocadas utilizando o
modo round-robin, por todo o sistema NUMA. A cada “volta” do round-robin é feito
um deslocamento com o número de nodos. Ambos as políticas prime_mapp e
skew_mapp, podem ser utilizadas com blocos, assim como cyclic_block, sendo um
bloco um conjunto de linhas e colunas de um array. Em bind_all e bind_block a política
de páginas de memória aloca os dados em nodos especificados pelo desenvolvedor. A
diferença entre os dois, é que o bind_block aloca os blocos de memória com os
processo/threads que estão fazendo uso deles. A última política é a random. Nessas
políticas as páginas de memórias são alocadas em uma distribuição aleatória e uniforme.
O principal objetivo dessas políticas é diminuir a contenção de acesso à memória das
arquiteturas NUMA.
Para desenvolver aplicações usando a MAI os programadores precisam apenas de
algumas funções de alto nível. Essas funções são divididas em cinco grupos: sistema,
41
alocação, memória, threads e estatísticas. Na seção 4.2.1 serão apresentados alguns
detalhes sobre a implementação da MAI, e nas seções a seguir desse capítulo serão
apresentadas as funções.
4.2.1
Detalhes da Implementação
A MAI é implementada em C para Linux baseados em sistemas NUMA.
Programadores que quiserem utilizar a MAI devem utilizar o modelo de programação
de Memória Compartilhada. As bibliotecas de Memória Compartilhada que podem ser
utilizadas são Pthreads e OpenMP para C/C++. Com pré-requisito para a MAI tem-se a
NUMA API.
A Figura 17 mostra a arquitetura da interface MAI:
Figura 17: Arquitetura da Interface MAI
Para garantir afinidade de memória, todo o gerenciamento de memória deve ser feito
utilizando-se as estruturas da MAI. Essas estruturas são carregadas na inicialização da
interface, função mai_init(), e são usadas durante a execução da aplicação.
42
4.2.2 Funções de Sistema
As funções de sistema são divididas em funções para configurar a interface e
funções para obter algumas informações sobre a plataforma. A funções de configuração
podem ser chamadas no inicio (mai_init()) e no final (mai_final()) do programa. A
função mai_init() é responsável por inicializar os Ids dos nodos e threads que irão ser
usados para políticas de memória e threads. Essa função recebe como parâmetro o
arquivo de configuração da MAI, que contém as informações sobre os blocos de
memória e processadores/cores da arquitetura. Se não for passado o arquivo como
parâmetro, a MAI escolhe quais blocos de memória e processadores/cores usará. A
função mai_final() é usada para liberar quais dados alocados pelo programador. Na
Figura 18, tem-se exemplos.
void mai_init (char filename [] ) ;
void mai_final ( ) ;
int mai_get_num_nodes ( ) ;
int mai_get_num_threads ( ) ;
int mai_get_num_cpu ( ) ;
unsigned long * mai_get_nodes_id ( ) ;
unsigned long * mai_get_cpus_id ( ) ;
void mai_show_nodes ( ) ;
void mai_show_cpus ( ) ;
Figura 18: MAI - Funções de Sistema
4.2.3 Funções de Alocação
Essas funções permitem ao programador alocar vetores (arrays) de tipos primitivos
da linguagem C (char,int,Double e float) e tipos não primitivos como estruturas. A
função precisa do número de itens e do tipo em C. O retorno é um ponteiro para os
dados alocados. A memória é sempre alocada seqüencialmente Essa estratégia permite
um melhor desempenho e faz com que seja mais fácil definir uma política de memória
para o vetor, na Figura 19 são apresentado as funções.
void * mai_alloc_1D( int nx , size_t size_item , int type ) ;
void * mai_alloc_2D( int nx , int ny , size_t size_item , int type ) ;
void * mai_alloc_3D( int nx , int ny , int nz , size_t size_item , int type ) ;
43
void * mai_alloc_4D( int nx , int ny , int nz , int nk , size_t size_item , int type ) ;
void mai_free_array ( void *p ) ;
Figura 19: MAI – Funções de Alocação
No exemplo da Figura 20, tem-se a utilização da função mai_alloc_2D, de modo a
efetuar a alocação de um vetor de duas dimensões por intermédio da MAI.
#include <mai.h>
#define N 1000
int main (int argc, char* argv[])
{
int i,j;
double **tab;
// set information about cpus and nodes
mai_init(argv[1]);
tab = (double**)mai_alloc_2D(N,N,sizeof(double),DOUBLE);
//just some operations
#pragma omp parallel for
for(i=0;i<N;i++)
{
tab[i][j]=......;
}
//finalize structures and library
mai_final();
}
Figura 20: Exemplo Utilização MAI – Funções de Alocação.
4.2.4 Funções de Políticas de Memória
As funções desse tipo permitem ao programador selecionar a política de memória
para a aplicação e migrar dados entre um nodo e outro. Como já citado, são sete
políticas para alocação de memória. A Figura 21 agrupa todas as funções desse tipo.
44
void mai_cyclic ( void *p ) ;
void mai_skew_mapp( void *p ) ;
void mai_prime_mapp( void *p , int prime ) ;
void mai_cycl ic_rows ( void *p , int nr ) ;
void mai_skew_mapp_rows ( void *p , int nr ) ;
void mai_prime_mapp_rows ( void *p , int prime , int nr ) ;
void mai_cyclic_columns ( void *p , int n) ;
void mai_skew_mapp_columns ( void *p , int n) ;
void mai_prime_mapp_columns ( void *p , int prime , int n) ;
/*Bind memory policy − function prototype s */
void mai_bind_all ( void *p ) ;
void mai_bind_rows ( void *p ) ;
void mai_bind_columns ( void *p ) ;
/*Random memory policy − function prototype s */
void mai_random( void *p ) ;
void mai_random_rows ( void *p , i n t nr ) ;
void mai_random_columns ( void *p , int n) ;
/*Migrat ion − function prototype s */
void mai_migrate_rows ( void *p , uns igned long node , int nr , int start ) ;
void mai_migrate_columns ( void *p , unsigned long node , int n, int start ) ;
void mai_migrate_scatter ( void *p , unsigned long nodes ) ;
void mai_migrate_gather ( void *p , uns igned long node ) ;
Figura 21: MAI - Funções de Políticas de Memórias.
O exemplo da Figura 22, mostra a utilização da função de política de memória
mai_bind_columns, ao ser alocado o vetor de uma dimensão com a função
mai_alloc_1D.
45
#include <mai.h>
#define N 1000
struct mydata{
int i;
char *a;
};
int main (int argc, char* argv[])
{
int i,j,k;
// set information about cpus and nodes
mai_init(argv[1]);
t
=
(struct
mai_bind_columns(t));
mydata*)mai_alloc_1D(N,sizeof(struct
mydata),
//just some operations
#pragma omp parallel for
for(i=0;i<N;i++)
{
t[i]=......;
}
//finalize structures and library
mai_final();
}
Figura 22: Exemplo Utilização MAI – Funções de Políticas de Memória.
4.2.5 Funções de Políticas de Threads
Essas funções permitem ao desenvolvedor atribuir ou migrar um processo/thread
para um CPU/core no sistema NUMA. As funções bind_thread usam o id da thread a
máscara da CPU/core para fazer a atribuição. Na Figura 23, são apresentadas as funções
de políticas de threads.
void bind_threads ( ) ;
46
void bind_thread_posix ( int id ) ;
void bind_thread_omp ( int id ) ;
void mai_migrate_thread ( pid_t id , unsigned long cpu ) ;
Figura 23: MAI - Funções de Políticas de Threads.
4.2.6 Funções Estatísticas
As funções estatísticas permitem ao programador coletar algumas informações sobre
a execução da aplicação no sistema NUMA. Existem informações sobre memória e
threads, tanto sobre alocação quanto sobre migração e também informações de
sobrecarga de migrações. Na Figura 24 tem-se exemplos das funções.
/*Page information − function prototype */
void mai_print_pagenodes ( unsigned long * pageaddrs , int size);
int mai_number_page_migration ( unsigned long * pageaddrs , int size) ;
double mai_get_time_pmigration ( ) ;
/*Thread information − function prototype */
void mai_print_threadcpus ( ) ;
int mai_number_thread_migration ( unsigned int * threads , int size) ;
double mai_get_time_tmigration ( ) ;
Figura 24: MAI - Funções de Estatísticas.
Com a utilização da MAI é possível obter o melhor desempenho das máquinas
NUMA, com um menor esforço no desenvolvimento da aplicação.
47
5 CONCLUSÃO
NUMA (Non-Uniform Memory Access) pode-se afirmar que é a arquitetura que
está em destaque no momento. Durante esse trabalho de pesquisa pode-se observar que
a grande maioria dos fabricantes de software está dando destaque para o suporte a
arquiteturas NUMA em seus sistemas de alto desempenho. Enquanto que as empresas
que projetam o hardware estão utilizando a arquitetura em suas implementações.
Os mais diversos sistemas operacionais como: Linux, HP-UX, AIX da IBM, Solaris
da SUN e Windows da Microsoft, estão oferecendo suporte para arquiteturas NUMA,
de modo que as aplicações desenvolvidas para executarem nesses sistemas operacionais
possam utilizar todos os benefícios das máquinas NUMA.
Outro ponto bastante relevante quanto à utilização das máquinas NUMA, refere-se
ao modelo de programação adotado. Os desenvolvedores precisam utilizar um modelo
de programação de memória compartilhada, o que facilita e agiliza bastante o
desenvolvimento da aplicação. Isso se dá pelas facilidades que o OpenMP oferece para
se obter paralelismo, em comparação com a programação em memória distribuída
utilizando MPI.
Ainda, tem-se a MAI, desenvolvida pelo INRIA, que facilita a gerência de alocação
de memória e gerência de processos abstraindo as complicadas chamadas de sistemas
oferecidas pela NUMA API.
Então, pode-se concluir que as arquiteturas NUMA serão cada vez mais utilizadas
pela indústria de hardware e também terão suporte pela indústria de software, visto que
desde os computadores domésticos multicore até os grandes sistemas MPPs usarão
arquiteturas NUMA.
48
REFERÊNCIAS
[1] Kleen,
A.,
A
NUMA
API
for
LINUX
Disponível
www.halobates.de/numaapi3.pdf acessado em: 15 de junho de 2009.
em
[2] CASTRO, M. B., NUMA-ICTM: Uma versão paralela do ICTM explorando
estratégias de alocação de memória para máquinas NUMA, Dissertação de Mestrado
– Pontifícia Universidade Católica do Rio Grande do Sul, 2008.
[3] LAMETER, C., Local and Remote Memory: Memory in Linux/NUMA System.
Disponível
em
http://kernel.org/pub/linux/kernel/people/christoph/pmig/
numamemory.pdf. Acessado em: 15 de junho de 2009.
[4] Bolosky, W. J., Scott, M. L., Fitzgerald, R. P., Fowler, R. J., and Cox, A. L. NUMA
policies and their relation to memory architecture. In Proceedings of the Fourth
international Conference on Architectural Support For Programming Languages
and Operating Systems. Santa Clara, California, United States, 1991. ASPLOS-IV.
ACM, New York, NY, 212-221.
[5] Joseph Antony, Pete P. Janes, and Alistair P. Rendell, Exploring thread and memory
placement on NUMA architectures: Solaris and Linux, UltraSPARC/FirePlane and
Opteron/HyperTransport". In Proceedings International Conference on High
Performance Computing, LNCS 4297, 2006, Bangalore,India. pages: 338-352.
[6] Carissimi A., Dupros F., Mehaut J, Polanczyk R., Aspectos de programação paralela
em arquiteturas NUMA. WSCAD 2007: VIII Workshop em Sistemas
Computacionais de Alto Desempenho, 2007. Gramado, RS.
[7] OpenMP Application Program Interface Version 3.0 Complete Specifications. May,
2008. Disponível em http://www.openmp.org/mp-documents/specs30.pdf. Acessado
em 15 de junho de 2009.
[8] Gostin, G., Collard, J., and Collins, K. 2005. The architecture of the HP Superdome
shared-memory multiprocessor. In Proceedings of the 19th Annual international
Conference on Supercomputing. Cambridge, Massachusetts, 2005. pp. 239-245.
[9] Goglin, Brice and Furmento, Nathalie, Enabling high-performance memory
migration for multithreaded applications on Linux. In Workshop on Multithreaded
Architectures and Applications, held in conjunction with IPDPS 2009, Disponível
em : http://hal.inria.fr/inria-00358172/en/ acessado em : 15 de junho de 2009.
49
[10] Performance Guidelines for AMD Athlon™ 64 andAMD Opteron™ ccNUMA
Multiprocessor
Systems.
Disponível
em:
www.amd.com/usen/assets/content_type/white_papers_and_tech_docs/40555.pdf. Acessado em: 15 de
Junho de 2009.
[11] MPI: A Message-Passing Interface Standard Version 2.1. Disponível em:
www.mpi-forum.org/docs/mpi21-report.pdf. Acessado em: 15 de Junho de 2009.
[12] Pousa Ribeiro, Christiane and M'ehaut, Jean-Francois, MAI: Memory Affinity
Interface, Laboratoire d'Informatique de Grenoble - LIG - INRIA - Universit'e Pierre
Mend`es-France - Grenoble II - Universit'e Joseph Fourier - Grenoble I - Institut
Polytechnique de Grenoble. Disponível em: http://hal.inria.fr/inria-00344189/en/
Acessado em: 15 de Junho de 2009.
[13] Blaise Barney, Introduction to Parallel Computing. Lawrence Livermore National
Laboratory. Disponível em: https://computing.llnl.gov/tutorials/parallel_comp/
Acessado em: 15 de Junho de 2009.
[14] Blaise Barney, Message Passing Interface (MPI). Lawrence Livermore National
Laboratory. Disponível em: https://computing.llnl.gov/tutorials/mpi/ Acessado em:
15 de Junho de 2009.
[15] Blaise Barney, OpenMP. Lawrence Livermore National Laboratory. Disponível
em: https://computing.llnl.gov/tutorials/openMP/ Acessado em: 15 de Junho de 2009
[16] Chapman, B., Jost, G., and Pas, R. 2007 Using Openmp: Portable Shared Memory
Parallel Programming (Scientific and Engineering Computation). The MIT Press.
[17] Gropp, W., Lusk, E., and Skjellum, A. 1999 Using MPI (2nd Ed.): Portable
Parallel Programming with the Message-Passing Interface. MIT Press.
[18] Kumar, V. 2002 Introduction to Parallel Computing. 2nd. Addison-Wesley
Longman Publishing Co., Inc.
[19]
NVIDIA
CUDA
Development
Tools.
Disponível
em:
http://www.nvidia.com/object/cuda_develop.html Acessado em: 15 de Junho de
2009.
[20] Flynn, M., Some computer organizations and their effectiveness, IEEE Trans.
Comput., Vol. C-21, pp. 948, 1972.
[21] Advanced Configuration and Power Interface Specificication. Revision 3.0,
September
2,
2004.
Disponível
em
http://www.acpi.info/DOWNLOADS/ACPIspec30.pdf. Acessado em: 15 de Junho
de 2009.
[22] TORRELAS, J.; LAM, H. S.; HENNESSY, J. L. False sharing and spatial locality
in multiprocessor caches. IEEE Trans. Comput., IEEE Computer Society,
Washington, DC, USA, v. 43 n. 6, p. 651-663, 1994.
[23] Vahalia, U. UNIX Internals. Prentice-Hall, 1996.
50
[24] ERAD 2009 – IX Escola Regional de Alto Desempenho – Arquiteturas Multicore.
Março de 2009, Caxias do Sul, RS.
[25] SNIR, M.; YU, J. On the Theory of spatial and temporal locality. Department of
Computer Science, Technical Report. University of Illinois at Urbana-Champaign,
2005. Disponível em http://hdl.handle.net/2142/11077. Acessado em: 15 de Junho de
2009.
[26] Oliveira, R.; Carissimi, A.; Toscani, S.; Sistemas Operacionais. Série Didática da
UFRGS. Sagra-Luzzato. Vol. 11, 2004.
[27] De Rose, C.; Navaux, P. ; Arquiteturas Paralelas. Série Didática da UFRGS.
Sagra-Luzzato. Vol. 15, 2002.
[28] Zorzo, A.; Corrêa, M; Scheer, R. 2006 Operating system multilevel load balancing.
In Proceedings of the 2006 ACM Symposium on Applied Computing (Dijon, França,
2006). SAC ´06. ACM, New York,NY, 1467-1471.
[29] CASTRO, M. B., Explorando o paralelismo em máquinas NUMA em Nível de
Aplicação, Trabalho Individual I – Pontifícia Universidade Católica do Rio Grande
do Sul, 2007.
[30] KOWALTOWSKI, T. Von Neumann: suas contribuições à Computação. Estud.
Av. [online]. 1996, vol. 10, n. 26, 237-260.
[31] IBM Cell Broadband Engine resource center.
Disponível em
http://www.ibm.com/developerworks/power/cell/. Acessado em 30 de junho de 2009.
Baixar