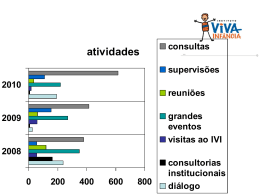
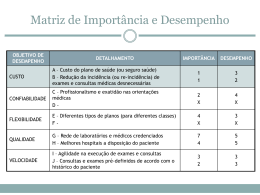
Interoperabilidade Ulrich Schiel [email protected] (C) COPIN - Coordenação de Pós-Graduação em Informática UNIVERSIDADE FEDERAL DE CAMPINA GRANDE Roteiro • Bibliografia • Histórico • Arquiteturas de distribuição • Data Warehouses • Heterogenidade • Conceitos de distribuição • Transparência • Extração e integração • Processamento de consultas • Controle de Concorrência • Data Warehouse-criação e atualização • Seminários • Projeto BIBLIOGRAFIA O. Bukhres& A. Elmagarmid (eds.) Object Oriented Multidatabase Systems, Prentice-Hall, (1996) (capítulos 1-9) SISTEMAS: Pegasus (HP), VODAK/KODIM (GMD-IPSI), OIS/CIS(ESPRIT-Bertino),, EIS/XAIT (Xerox), DOMS (GTE-Labs:Buchman, Ozsu, Brodie), Carnot (MCC-Woelk), Thor (MIT-Liskov), FBASE (Purdue-Mullen), InterBase* (Purdue-Bukhres), A La Carte (U.o.Colorado, HKBMS (Florida-Su) IRO-DB (ESPRIT-Versailles, GMD,)(Caps.10-20) M.T. Özsu, & P. Valduriez Princípios de Bancos de Dados Distribuidos – 2ª Edição, Campus (2001) (Capítulo 4-Arquiteturas DDBMS; Cap. 15 – Interoperabilidade) M.T. Özsu, U. Dayal & P. Valduriez (eds.) Distributed Object Management, Morgan Kaufmann (1994) (Part 6. Interoperability - PP. 304-398 BIBLIOGRAFIA W. Kim (ed.) Modern Database Systems, Addison Wesley (1995) Part II - Interoperating Legacy Systems - Cap. 25-29 SISTEMAS - UniSQL/M, EDA/SQL, Pegasus, ADDS(Cap. 30-33) M. Jarke, M. Lenzerini, Y. Vassiliou & P. Vassiliadis Fundamentals of Data Warehouses, Springer Verlag, 2000 (itens 1.1, 1.2, 1.3, 2.1 e capítulos 3 e 4.1,4.2, 4.3) Os autores coordenam um projeto ESPRIT, denominado DWQ SISTEMAS:Carnot, SIMS, Inf. Manifold, TSIMMIS, Sqirrel, WHIPS) H. Garcia-Molina, J. Ullman & J. Widom Database System Implementation, Prentice-Hall, 2000 (capítulo 11 - Information Integration, §11.1 e 11.2) V. Poe, P. Klauer & S. Probst Building a Data Warehouse for Decision Support -2nd ed. Prentice-Hall, 1998 (Cap. 8 - Data Integration) BIBLIOGRAFIA - cont. [Cea98] D. Calvanese et.al. Information Integration: conceptual modeling and reasoning support, Proc. 6th Intl. Conf. on Cooperative Information Systems -CoopIS, 1998, pp. 280-291 [BLN86] C. Batini, M. Lenzerini, S. Navathe A comparative analysis of methodologies for database schema integration, ACM Comp. Surveys 18(4), 1986 pp. 323-364 [Gea97] H. Garcia-Molina et.al. The TSIMMIS approach to mediation: data models and languages, J. Intell. Information Systems 8:2, 1997, pp.117-132 [HZ96] R. Hull & G. Zhou A framework for supporting data integration using the materialized and virtual approaches, Proc. of ACM SIGMOD Conference, 1996, pp.481-492 [O 97] R.J. Orli Data extraction, transformation, and migration tools, Kismet Corp, http://www.kismeta.com/ex2.com [PGW95] Y. Papakonstantinou, H. Garcia-Molina & J. Widom Object exchanges across heterogeneous information sources, Proc. Intl. Conf on Data Engineering 1995 pp. 251-260 [SL90] A.P. Sheth & J.A. Larson Federated Databases for managing distributed, heterogeneous, and autonomous databases ACM Computing Surveys 22:3, 1990, pp.183-236 [Tra04] R. Traunmüller (ed.) Third Intl. Conf EGOV 2004, LNCS 3183, Zaragoza 2004 Seminários / Projetos Temas para seminários: • • • Projetos – especificação da integração de fontes heterogêneas em: • F-Logic / FLORA • Description Logic •Z HISTÓRICO 1. Dados independentes • problemas de redundância • problemas de inconsistência • novas tecnologias (mainframes,..) 2. Dados Integrados HISTÓRICO 2. Dados Integrados • questões gerenciais • questões políticas • novas tecnologias (micros, comunicação, internet) 3. Dados distribuídos HISTÓRICO 3. Dados distribuídos • heterogeneidade • necessidades gerenciais e estratégicas (históricos, agregados,.) • assincronismo operacional X gerencial 4. Dados operacionais distribuídos e gerenciais centralizados SISTEMAS DISTRIBUIDOS Usuário global Usuário local BANCOS DE DADOS DISTRIBUÍDOS • Banco de Dados Distribuído homogêneo PROJETO TOP-DOWN • Banco de Dados Distribuído heterogêneo = Banco de Dados Federado = Multibanco de Dados PROJETO BOTTOM-UP • Data Warehouse MULTIBANCOS DE DADOS Integrado (não-federado) (sem autonomia local) Fracamente acoplado MDBS (sem esq. Global) Federação simples federado Fortemente acoplado (com esq. Global) Federação múltipla ACESSO AOS DADOS • Com esquema global • Sem esquema global • Com dados globais • Sem dados globais ARQUITETURAS DE DISTRIBUIÇÃO • Aspectos: • Autonomia: – 0 = integração total – 1 = autonomia parcial – 2 = isolamento total • Distribuição: – 0 = centralizado – 1 = sistemas cliente/servidor – 2 = sistemas peer-to-peer • Heterogeneidade: – 0 = homogêneo – 1 = heterogêneo ARQUITETURAS DE DISTRIBUIÇÃO • Combinações: • • • • • • • • • • (A0,D0,H0): sistemas compostos (A0,D0,H1): sistemas heterogêneos (A0,D1,H0): sistema Cliente/servidor (A0,D2,H0): sistemas distribuídos peer-to-peer (A1,D0,H0): federação centralizada de SGBDs específicos (A1,D0,H1): SGBD federado heterogêneo (A1,D1,H1): SGBD federado distribuído heterogêneo (A2,D0,H0): Multidatabase homogêneo (A2,D0,H1): Multidabase federado heterogêneo (A2,D1,H1)&(A2,D2,H1): Multidabase Distribuído ARQUITETURAS DE DISTRIBUIÇÃO • Resumindo temos: • (Ax,D1,Hy): sistemas cliente-servidor • (A0,D2,Hy): Bancos de Dados Distribuídos • (A2,Dx,Hy): Multidatabase Systems ARQUITETURAS DE DISTRIBUIÇÃO • Formas de acesso a fontes heterogêneas: • Migrar todos os dados para o local da consulta (ex. IMS-EXTRACT P/ SQL/DS, DB2, Data Warehousing) • Gateways dois-a-dois (ex. INGRES-DB2; ORACLE-IMS) • Federação de SGBDs (MDBS) baseado em um esquema global ARQUITETURAS DE DISTRIBUIÇÃO Características de um MDBS: • BD global completo (atualização esquema e dados, consultas ad-hoc, integridade, autorização, etc. • necessidades de conversões e migração de uma fonte para a outra • autonomia local • acesso local independente • transparência da heterogeneidade • transações distribuidas • acesso global único • sem efeitos colaterais locais • performance comparável aos BDDs homogêneos ARQUITETURAS DE DISTRIBUIÇÃO MULTIDATABASE SGBD global consultas Controle de globais concorr. Glob. Esquema global Esquema global dos dados locais conversão SGBD local esquema Dados local locais. Esquema global dos dados locais conversão SGBD local esquema Dados local locais. PROCESSAMENTO DE CONSULTAS GLOBAIS Interface global. Definir consulta global Decompor consulta global Distribuir sub-consultas global Traduzir sub-consulta para modelo local SGBD local Traduzir sub-consulta para modelo local SGBD local Data Warehouse no contexto MDBS Data Warehouse Consultas programadas Object Data Store ODS MDBS Agregação Data Warehouse: arquit. tradicional GIS OLAP DSS clientes Data mart Data mart Data Warehouse Meta-BD Mediator wrappers fontes Texto BD Dados externos Data Warehouse: 3 perspectivas CONCEITUAL LÓGICA OLAP Modelo do cliente FÍSICA Dados cliente Esquema do cliente agregação Modelo da empresa Esquema do DW Dados DW conversão OLTP Modelo operacional conversão wrapper Esquema fonte Dados fonte HETEROGENEIDADE • • • • • hardware sistema operacional modelo de dados SGBD formato dos dados Conceitos • Distribuição de bases de dados entre ambientes distintos; •Geografia; •Interligação de ambientes através de protocolos de rede matriz PB TCP/IP filial Recife BD Campina - PB Conceitos •Em cada um dos nós o software do SGBDD consiste minimamente do que se segue: – Um sistema operacional local. – O gerenciador de comunicação, que permite a troca mútua de informação entre programas remotos. – Um Sistema de Gerência de Banco de Dados (SGBD) para atender aos usuários locais. Conceitos • O MDBS possui um ou vários catálogos globais – Atender usuários globais – Determinar quais nós precisam ser acessados para atender uma consulta particular – Integrar os resultados da consulta – Realizar otimização de consultas globais – garantir controle de concorrência global Conceito • Sistema Multidatabase deve prover também: – Gerência de transações globais • Atomicidade, confiabilidade, isolamento e durabilidade das transações. – Funções Administrativas • Autorização, autenticação, definição de restrições de integridade e gerência do dicionário de dados. – Heterogeneidade • Diferenças de Hardware, Sistema Operacional, canais de comunicação, sistema de gerência de dados e modelos de dados. Vantagens de Distribuição de Dados • Associar autonomia local com usuários globais. • Confiabilidade e Disponibilidade – Se um nó falhar em um sistema distribuído, os nós remanescentes podem ser capazes de continuar operando. – Replicação: aumenta a disponibilidade. Vantagens de Distribuição de Dados • Aceleração no Processamento de Consultas – Se uma consulta envolve dados em diversos nós, é possível dividi-la em subconsultas que podem ser executadas em paralelo. Desvantagens de Distribuição de Dados • Custo de desenvolvimento de software – É mais difícil e mais caro. • Maior Potencial para erro – O potencial existe para erros extremamente sutis; • Aumento de overhead de processamento – A troca de mensagens e a computação adicional exigida para se conseguir coordenação interlocal. Reprodução de Dados • O sistema mantém diversas réplicas idênticas (cópias) de uma relação em nós diferentes • Aumenta o desempenho de operações read e a disponibilidade de dados • Transações de atualização ficam sujeitas a baixos desempenhos • Controle de concorrência mais difícil Fragmentação de Dados • Uma relação r é dividida armazenados em nós distintos em fragmentos • Tipos de fragmentação: – Fragmentação Horizontal: divide a relação designando cada tupla de r para um ou mais fragmentos. Recuperação por união. – Fragmentação Vertical: divide a relação decompondo o esquema R da relação r. Recuperação por junção. – Fragmentação Mista: aplicação das duas fragmentações anteriores • Reconstrução: operação união ou junção Sistemas Orientados a Objetos • • Cada fragmento é uma subclasse Tipos de fragmentação: – Fragmentação Horizontal: pode ser • • • – – – primária (= relacional) ou cada sublcasse em um site ou Secundária: baseada em um atributo complexo relacionamento Secundária: baseada em métodos complexos. Fragmentação Vertical: discutível, pois quebra encapsulamento. Gera subclasses unidas por agregação ou o Fragmentação Mista: aplicação das duas fragmentações anteriores Acesso a partes de objetos complexos Sistemas Orientados a Objetos • Replicação: • Alocação de objetos: • • • – – – – objetos, atributos, métodos Comportamento local-objeto local Comportamento local-objeto remoto Comportamento remoto-objeto local Comportamento remoto-objeto remoto Gerenciamento dos OIDs Ponteiros e caminhos Migração de objetos (manter pode estar 1. pronto (pode migrar), 2. ativo ou 3. esperando placeholders): Objeto TRANSPARÊNCIA Separa semântica de alto nível da Implementação de baixo nível • dados (EE x EC) Tipos [Özsu&Valduriez]: • distribuição • replicação • fragmentação Transparência e Autonomia • No esquema global local – Dois nós não devem usar o mesmo nome para itens de dados distintos – Dicionário de dados central – Cada nó pode prefixar seu próprio identificador para qualquer nome que ele gerar Transparência e Autonomia •Transparência de Localização – Criar um conjunto de nomes alternativos ou aliases para cada local •Atualização – Assegurar que todas as réplicas de um item de dado e todos os fragmentos afetados sejam atualizados – Relacionado ao problema de atualização de visões. Topologia de rede •Formas de conexão: – rede totalmente conectada, parcialmente conectada, rede com estruturada em árvore, estrela e anel •Considerações: – custos de instalação e comunicação. – Confiabilidade: a freqüência com que uma ligação ou nó falha. –Disponibilidade: O grau em que os dados podem ser acessados apesar da falha de alguns elos ou nós. Integração FORMAS: 1. Integração de esquemas esquemas fonte Esquema global 2. Integração virtual dos dados dados fonte Especificação de acessos globais 2. Integração materializada dados fonte Visões materializadas Integração 1. Integração de esquemas ETAPAS: • pré-integração análise dos esquemas fonte estratégia de integração técnicas: Description Logic ou BC de terminologia • comparação de esquemas solução de conflitos: - heterogeneidade (de modelo de dados) - conflitos de nomes (homônimos, sinônimos) - conflitos semânticos (níveis de abstração) - conflitos estruturais (representação distinta de conceitos) Integração 1. Integração de esquemas ETAPAS: • homogenização de esquemas - manutenção da capacidade de informação - manutenção da semântica de atualizações • integração de esquemas (schema merging) sobreposição de esquemas deve garantir: completude, corretude, minimalidade e usabilidade Integração 1. Integração virtual dos dados Semelhante às visões em bancos de dados convencionais. As visões são a base para formulação de consultas Integração 1. Integração virtual dos dados • Existe uma visão global ou não • Quais os passos metodológicos QUESTÕES: (decomposição, transporte, reconstrução) • Qual o formalismo de descrição dos dados (arquivos, legados, RDB, ORDB, não-estruturados, ..) • Linguagem para consultas globais • critérios de casamento dos dados (baseados em chave, em tabela look-up, comparações, • Qualidade dos dados (interpretabilidade, credibilidade, .. Integração 1. Integração virtual dos dados SISTEMAS: • Carnot (MCC) - Collete, Huhns - esquemas locais determinam uma ontologia global descrita em GCL - Global Context Language - transformações baseadas em axiomas de articulação - consultas e atualizações são transformadas em GCL • Integração 1. Integração virtual dos dados SISTEMAS: • SIMS (Arens) - múltiplas fontes de dados - a partir de um modelo do domínio da aplicação as fontes são descritas neste modelo - consultas são distribuídas dinamicamente Integração 1. Integração virtual dos dados SISTEMAS: • UniSQL (D’Andrea, Janus) - SGBD OR - Extensão SQL/M para definir visões virtuais Albert D'Andrea , Phil Janus UniSQL's next-generation object-relational database management system, ACM SIGMOD Record , Volume 25 , Issue 3 (September 1996 Integração 1. Integração virtual dos dados SISTEMAS: • Information Manifold (AT&T) - múltiplas fontes de dados - componentes: visão do mundo e descrição das fontes de informação - usa Description Logic para os componentes e regras para otimização de consultas • Consultas em Datalog T. Kirk, A. Y. Levy, Y. Sagiv, and D. Srivastava. The Information Manifold. In Proc. of the AAAI Spring Symposium on Information Gathering in Distributed Heterogeneous Environments, Integração 1. Integração virtual dos dados SISTEMAS: • TSIMMIS (Stanford) - múltiplas fontes de dados - um mediator é uma visão das fontes de informação integradas e processadas - usa o OEM - Object Exchange Model - Descrição do mediator por uma linguagem lógica MSL = Datalog + OEM - não há integração global. Cada mediator atende às consultas a uma certa visão Integração 1. Integração materializada dos dados QUESTÕES: • as mesmas da integração virtual • quais dados são materializados • níveis da participação das fontes (suficiente, restrita, não-ativa) • estratégias de manutenção (incremento local, baseado em polling, refrescamento completo) • timing (imediato, periódico) Integração 1. Integração materializada dos dados SISTEMAS: • Sqirrel (Zhou, Hull) - baseado em um integration mediator com múltiplas fontes - geração automática de novos integradores especificados pela ISL - Integration Specification Language - ISL especifica: esquema local, critérios de casamento de objetos entre classes. Diversos critérios de casamento de OIDs R. Hull and G. Zhou, "A Framework for Supporting Data Integration Using the Materialized and Virtual Approaches,", Proceedings of SIGMOD, June 1996, Montreal, Canada, pgs. 481-492 Integração 1. Integração materializada dos dados SISTEMAS: • WHIPS (Garcia-Molina) - módulos implementados como objetos CORBA - visões criadas por expressões SQL - ;;;; Janet L. Wiener, Himanshu Gupta, Wilburt Labio, Yue Zhuge, Hector Garcia-Molina: The WHIPS Prototype for Data Warehouse Creation and Maintenance. ICDE 1997: 589 Customização Extração e Integração OLAP Data Mart Data Mart Data Warehouse Agregação Meta Esquema ODS Extração e Integração OLTP Extração e Integração WRAPPER, LOADER MEDIATOR Fonte de Informação DW Carregamento, transformação, limpeza, atualização Conflitos, incosistências, integração Extração e Integração FONTES DE INFORMAÇÃO • Bancos de dados (relacionais, OO, OR, hierárquicos, rede, outros) • fontes externas (outras empresas, resultados de pesquisas, ...) • Arquivos (planilhas, arquivos, textos, documentos multimidia) METAESQUEMA/ METADADOS • dicionário de dados • fluxo de dados • transformação dos dados • controle de versões dos metadados •estatísticas de uso •aliases •segurança Extração e Integração TAREFAS • extração (diversas fontes) • limpeza (cleaning) • transformação (formatos, linguagens,..) • carregamento • replicação • análise (p.ex. valores inválido/inesperados) • transferência • cheque da qualidade dos dados (completeza, duplicidade, granularidade, necessidade, ..) • análise dos metadados Solução de Conflitos CONFLITOS ESTRUTURAIS 1. Entidade-vs-entidade (a) entidade 1-1 i. nome: homônimos e sinônimos ii. Estrutura: falta de atributos, atributos implícitos iii. restrições de entidade iv. Inclusão de entidade (generalização) (b) entidades n-m 2. Atributo-vs-atributo (a) atributos 1-1 i. nome ii. Restrições: integridade, domínio, composição iii. Valores default (valores nulos, constantes) iv. Inclusão de atributos (generalização) v. métodos Solução de Conflitos CONFLITOS ESTRUTURAIS 3. Entidade-vs-atributo 4. Relacionamentos i. nomes ii. Cardinalidades 5. Entidade-vs-atributo-vs-relacionamento 6. Abstrações: generalização, agregação, agrupamento (a) agregação-vs-relacionamento-vs-composição 7. Diferentes representações da mesma informação (a) expressões diferentes (b) unidades diferentes (c) níveis de precisão Solução de Conflitos 1. Renomear entidades e atributos TÉCNICAS DE SOLUÇÃO DE CONFLITOS 2. Homogenizar representações (a) expressões diferentes (p.ex. abstrações) (b) unidades diferentes (c) níveis de precisão 3. Homogenizar atributos e relacionamentos (a) valores default (b) cardinalidades 4. Uniões (completar os atributos) 5. Junções verticais (entidades, atributos, agregações) 6. Junções mistas 7. Homogenizar métodos Solução de Conflitos TÉCNICAS DE SOLUÇÃO DE CONFLITOS Criação de classes virtuais Sintaxe (linguagem SQL/M do UniSQL): CREATE VCLASS nome-da-classe-virtual SIGNATURE lista-de-atributos AS SELECT lista-de-seleção FROM lista-de-entidades WHERE condição SELECT ... Solução de conflitos EXEMPLO: MDBS de quatro universidades. UNIVERSIDADE-1 (BD relacional) Est-grad(nome CHAR(25), mat INTEGER, end CHAR(50),curso CHAR(7)) Curso(cnome CHAR(20), cnum INTEGER) Disciplina(dnome CHAR(20), dnum INTEGER, cnum CHAR(7)) Matricula(dnum CHAR(7), mat INTEGER, cre REAL) Est-pós(nome-e CHAR(25), mat INTEGER, curso CHAR(20), tese CHAR(50) aproveitamento CHAR(1)) NOTAÇÃO: Classes começam com maiúsculas, atributos em minúsculas e PALAVRAS-RESERVADAS em maiúsculas. Exemplo UNIVERSIDADE-3 (BD OO ou OR) CLASS Estudante SIGNATURE nome:CHAR(25), mat:INTEGER, curso: CHAR(20), cre:REAL, /*métodos*/ CLASS Est-pós-graduação SUPERCLASS Estudante SIGNATURE orientador: SET-OF Professor CLASS Professor SUPERCLASS Empregado SIGNATURE depto: CHAR(25), nível: CHAR(20) CLASS Empregado ... CLASS Matriculado SIGNATURE curso:Curso, est:Estudante, conceito:REAL Classe virtual CREATE VCLASS Todos-estudantes SIGNATURE nome CHAR(25), matricula INTEGER, curso CHAR(20), cre: REAL AS SELECT eg.nome eg.mat c.cnome eg.cre FROM un1.Est-grad eg, un1.Matricula m, un1.Curso c WHERE eg.mat=m.mat AND c.cnum = eg.curso AS INTEGER SELECT nome-e epg.mat curso valor(aproveitamento) FROM un1.Est-pós epg, un1.Matricula m SELECT nome mat curso cre from un3.Estudante Conflitos - Homogenizar representações Expressões distintas denotam a mesma informação CONFLITO: diferentes valores escalares denotam a mesma informação SOLUÇÃO: definir um isomorfismo que cria classes de equivalência EXEMPLO: “Dr.”, “PhD” ou “DSc” denominam o mesmo nível. Conceitos na pós podem ser A, B, C ou D ou então 1, 2, 3, 4 ou excelente, bom , regular, ruim. “Bach. em C. da Computação” ou “Bacharelado em Ciência da Computação” SELECT nome FROM Todos-estudantes WHERE curso LIKE Bach% em C% da Computação Conflitos - Homogenizar representações Unidades distintas CONFLITO: valores numéricos distintos denotam a mesma quantidade física SOLUÇÃO: definir uma função de conversão EXEMPLO: quilogramas e libras; graus centígrados e graus Farenheit Conflitos - Homogenizar representações Precisões distintas CONFLITO: valores numéricos expressos em granularidades distintas SOLUÇÃO: converter para a granularidade menos precisa EXEMPLO: gramas e quilos; segundos e minutos Conflitos - Homogenizar atributos Conflitos de tipos CONFLITO: domínios distintos para atributos semanticamente equivalentes SOLUÇÃO: em muitos casos é possível converter de um domínio para outro EXEMPLO: INTEGER e CHAR(n); INTEGER e FLOAT; CHAR(n) e CHAR(m) WHERE eg.mat=m.mat AND c.cnum = eg.curso AS INTEGER Conflitos - Homogenizar atributos Conflitos atributo X relacionamento X entidade CONFLITO: o mesmo fato é ora modelado com atributo ora como relacionamento SOLUÇÃO: criar uma classe virtual e converter o atributo em relacionamento EXEMPLO: em Uni-1 Curso é um entidade relacionada com Est-grad enquanto em Uni-3 é um atributo de Estudante CREATE VCLASS Cursos SIGNATURE nome CHAR(25) AS SELECT cnome FROM un1.Curso SELECT curso FROM un3.Estudante Conflitos - Homogenizar atributos Valores default Atributos concatenados (e.g. nome=primeiro nome + sobrenome) Conflitos - Uniões Tabelas união-compatíveis SEM CONFLITOS ESTRUTUAIS SOLUÇÃO fazer a união com o cuidado de não repetir a mesma entidade e considerar possíveis restrições COM CONFLITOS ESTRUTUAIS CONFLITO: uma tabela tem mais atributos SOLUÇÃO: criar atributos ‘fantasma’ ou eliminar os atributos a mais Conflitos - Junções Entidade n-m CONFLITO: as mesmas entidades são espalhadas por vários locais com atributos distintos SOLUÇÃO: processar junções Conflitos - Métodos Entidade n-m CONFLITO: métodos distintos realizam a mesma tarefa SOLUÇÃO: analisar os dois métodos e criar um método genérico que realiza as duas tarefas Conflitos - Navathe & Savasere: A Schema Integration Facility using O-O Data Model Meta-conhecimento para raciocínio aproximado • nomes de objetos (variações, parcial, abreviações, convenções) • nomes de objetos (thesaurus de sinônimos e homônimos) • tipos e domínios (chaves, valores nulos, default) • interação com objetos ao redor • cardinalidades esperadas de classes e relacionamentos • atualidade • descrições textuais Ex. OCL = Object Constraint Language ou Organization Communiste Libertáire Conflitos - Navathe et. al. Casamento (aproximado) de nomes Casamento (aproximado) de atributos Casamento (aproximado) de estruturas Grau de similaridade entre entidades Solução de Conflitos Generalizar E1 E2 G E12 = E1 E2 AE12 = AE1 AE2 E12 L2 L1 E1 E2 OBS: E1 e E2 podem ficar em G ou não Solução de Conflitos Especializar E1 E2 L1 E1 L2 E2 OBS: E1 e E2 podem ficar em G ou não G E12 E12 = E1 E2 AE12 = AE1 AE2 Solução de Conflitos Subordinar E2 a E1 L2 E1 G E1 E2 E2 L1 E2 E1 AE1 AE2 Solução de Conflitos Agregar E1 e E2 G E12 E1 X E2 E12 L1 E1 E2 OBS: E1 e E2 L2 podem ficar em G ou não Solução de Conflitos Agrupar E2 em E1 L2 E1 G E1 E2 E2 L1 E1 P(E2) Solução de Conflitos E1r12E2 = E1r1E2 E1r1E2 Combinar r1 e r2 G r12 E1 E2 L2 L1 E1 r1 E2 E1 r2 E2 Solução de Conflitos r’ = r at Atributo X relacionamento G r’ E1 A L2 L1 E1 at A E1 r A Solução de Conflitos R’ = R r Entidade X relacionamento G R’ E2 E1 R E1 L2 L1 E2 E1 r E2 Solução de Conflitos Entidade X atributo Agregação X relacionamento SISTEMA: • O usuário escolhe esquemas locais • O sistema sugere regras de integração que podem ser aceitas ou não pelo usuário • O usuário pode estabelecer suas próprias regras de integração Integração baseada em agentes FONTE: M. Klusch “Intelligent Information Agents”, Springer Verlag (1999) [749 referências!] TECNOLOGIAS: • Inteligência Artificial • Inteligência Artificial Distribuída • Recuperação da Informação • Ciências cognitivas • Computer Supported Collaborative Work – CSCW • Interação Homem-Máquina Integração baseada em agentes CLASSIFICAÇÃO DE AGENTES (Franklin&Gaesser): Autônomos computacionais • software • virus • aplicativos • vida artificial • de informação biológicos • diversão robóticos • cooperativos • não-cooperativos • adaptivos • racionais • móveis Integração baseada em agentes – cooperação • cooperativos • delegação hierárquica de tarefas • contratação simples e complexa • negociação descentralizada • não-cooperativos Integração baseada em agentes – categorias • racionais (agem e interagem para melhorar seus benefícios) • adaptativos (se alteram de acordo com estados da rede e do ambiente) • móveis (se locomovem autonomamente pela Internet) Agentes de Informação • Agentes de Informação Cooperativos • Agentes de Informação Racionais (agem e interagem para melhorar seus benefícios) • Agentes de Informação Adaptativos (se alteram de acordo com estados da rede e do ambiente) • Agentes de Informação Móveis (se locomovem autonomamente pela Internet) Agentes de Informação Cooperativos • Sistemas de Informação Cooperativos - CIS INTERMEDIAÇÃO (BROKERING) 2.Solicitar serviço Requerente 4.Resultado 3.Solicitar serviço Intermediário Servidor 1.Anunciar serviço Agentes de Informação Cooperativos • Sistemas de Informação Cooperativos - CIS ASSOCIAÇÃO (MATCHMAKING) 2.Solicitar serviço Associador 1.Anunciar serviço 3.Informar servidor Requerente 4.Solicitar serviço 5.Resultado Servidor Agentes de Informação Racionais Aplicação em comércio eletrônico, govêrno eletrônico, turismo • Interfaces conversacionais e perfis •Filtragem colaborativa de informação (agentes antecipam necessidades do usuário no contexto de outros usuários) • Shopping comparativo (agentes selecionam produtos baseado na análise de preços e outras condições) • Mercados baseados em agentes (leilões, múltiplos agentes de informação associando clientes e fornecedores) • Coalizações Agentes de Informação Adaptativos ADAPTAÇÃO Agente simples • Estratégia • Instrução • Exemplo • Analogia • Descoberta •Objetivo • habilidades • cap. do sistema • Decentralização • tipo de distribuição • comp. concorrente Multi-Agentes • Feedback • Supervisão • Reforço • Auto-organização •Interação • Agente-agente • Agente-humano • Ambiente do sistema Agentes de Informação Móveis • Padrões • Mestre-escravo • Itinerário • Descoberta de fontes de informação • Acesso à estrutura das fontes (memória, arquivos, serviços, threads) • Agentes heterogêneos DIA Seminários • • • • • • • A uniform framework for integration of information from the web by W May; G Lausen, Information Systems. 29, no. 1, (2004): 59-91 Combining schema and instance information for integrating heterogeneous data sources, Huimin Zhao , Sudha Ram, Data & Knowledge Engineering 61 (2007) 281–303 An ontology based approach to the integration of entity–relationship schemas, Qi He, Tok Wang Ling, Data & Knowledge Engineering 58 (2006) 299–326 How to act on inconsistent news: Ignore, resolve, or reject, Anthony Hunter, Data & Knowledge Engineering 57 (2006) 221–239 Semantic integration in Xyleme: a uniform tree-based approach, C. Delobel et al. Data & Knowledge Engineering 44 (2003) 267–298 Supporting ontological analysis of taxonomic relations, C. Welty, N. Guarino, Data & Knowledge Engineering 39 (2001) 51-74 DFD – a dialog based integration of concept and rule, M. Balban, A. Eyal, Data & Knowledge Engineering 38 (2001) 301-334 Integração - García-Solaco, Saltor, Castellanos: Semantic Heterogeneity in Multidatabase Systems - uma survey CLASSIFICAÇÃO DE HETEROGENIDADES: • entre classes (diferenças em extensão, nomes, atributos e métodos, domínios (sintático e semântico), restrições) • entre estruturas (inconsistências de generalização/espec., agregação/decomp., dados/metadados, metaclasses • entre instâncias (presença/ausência, atributos multivalorados, valores nulos, valores diferentes nos atributos) Integração - García-Solaco, Saltor, Castellanos: Semantic Heterogeneity in Multidatabase Systems - uma survey 1. DETECÇÃO DE HETEROGENIDADES: TOOLS: SIS-Schema Integration System; Honeywell Testbend MUVIS_Multiuser View Integration System; BERDI-Bellcore Schema Design and Integration Toolkit; MIST of Carnot; CONTRIBUTIONS: Theory of Attribute Equivalence; Common Concept Approach; Semantic Unification Approach; Maximum Spanning Tree Appr.; Semantic Proximity Proposal; Mathematical Model of Meaning; Semantic Abstractions Integração - García-Solaco, Saltor, Castellanos: Semantic Heterogeneity in Multidatabase Systems - uma survey 2. SOLUÇÃO DE HETEROGENIDADES: TOOLS: Multibase; Honeywell Testbend; MUVIS; BERDI ViewSystem; Carnot; Pegasus; UniSQL/M CONTRIBUTIONS: Superview - Integration Operators; Rule Based Approach; Approach that preserves semantic relativism; Semantic Unification Approach; Semantic Abstractions; Structural Integration Integração - Papazoglou, Zahir Tari, Russel: Object-Oriented technology for Interschema and language Mappings Baseado em losely coupled architectures. Troca direta de informações entre as fontes Partially unified schemas Interação usa um Common Object Model denominado KOM Integração - Papazoglou, Zahir Tari, Russel: Object- Oriented technology for Interschema and language Mappings Object wrapper Object wrapper RDB FDB Inforrmation Broker Inforrmation Broker Client Server Interface Interface Client Server Interface Interface Control flow Shared Inf. metadata Thesauri Service desc. Common Object Model Shared Inf. metadata Thesauri Service desc. Data flow Integração - Papazoglou, Zahir Tari, Russel: Object- Oriented technology for Interschema and language Mappings O modelo KOM: ODL - Object Definition Layer FUNCIONAL OTL - Object Transformation Layer RELACIONAL ORIENTADO A OBJETOS Transformação de estruturas e operações Integração - Bertino & Illaramendi: The Integration of Heterogeneous DBMS: Approaches based on the OO Paradigm 1) TRADUÇÃO - características OO • enriquecimento semântico • tradução operacional • correspondência complexa 2) INTEGRAÇÃO - características OO • integração operacional • vários níveis (esquemas) de integração • integração inteligente (detecção de erros na correspondência de objetos} Integração - Bertino & Illaramendi: The Integration of Heterogeneous DBMS: Approaches based on the OO Paradigm Survey dos sistemas: • Pegasus •CIS - Comandos Integration System • OOA • Cyc • Candide • AIMS Integração – Domingos Sávio & U. Schiel: RDF na interoperabilidade de dados entre domínios • Domínios descritos em RDF • Comunicação direta entre domínios Processamento de Consultas Consulta global EG Decomposição e otimização global EGL1 SC1 ... tradutor CL1 BD local SCn CPP1 ... CPPm tradutor ... CLn BD local resultado CPP = consulta de pós-processamento Processamento de Consultas DECOMPOSIÇÃO/TRADUÇÃO: 1) modificação para atender os EGLs 2) decomposição em consultas internas e consultas externas (externas sobre dados intermediários transmitidos) 3) tradução para esquemas locais PASSOS: • Modificação da consulta • Tradução da consulta • otimização global Processamento de Consultas • Modificação da consulta Fatores que afetam complexidade: • linguagem de consulta global e modelo de dados global • métodos de integração dos esquemas de exportação: generalização e outerjoin • replicação de dados • inconsistências e outras incompatibilidades Processamento de Consultas • Modificação da consulta Dada uma classe C: tipo(C) = atributos de C com os domínios extensão(C) = {instâncias de C} mundo(C) = {objetos do mundo real descritos por C} C = generalização(C1,C2) sss tipo(C) = tipo(C1) tipo(C2) extensão(C) = extensão(C1) extensão(C2) C = outerjoin(C1,C2) sss tipo(C) = tipo(C1) tipo(C2) extensão(C) = equi-outerjoin(C1,C2, ID) mundo(C) = mundo(C1) mundo(C2) OBS. Em caso de diferenças, ajustá-las por funções de agregação Processamento de Consultas • Outerjoin Emp1(#e, nome, idade) <1, José, 28> <2, Karla, 22> Emp2(#e, nome, nivel) <1, José, sup> <3, Cintia, méd> Emp1 >< Emp2 = <1,José, 28, sup> Emp1 >o< Emp2 = {<1,José, 28, sup>, <2, Karla, 22, {}>, <3, Cintia, {}, méd> Processamento de Consultas • Outerjoin Emp1(#e, nome, sal, idade) <1, José, 300.-, 28> <2, Karla, 450,-, 22> Emp2(#e, nome, sal, nivel) <1, José, 120.-, sup> <3, Cintia, , méd> Emp1 >o< Emp2 (sum(sal)) = {<1,José, 28, 450.-, sup>, <2, Karla, 22, 450.-, >, <3, Cintia, , , méd> Processamento de Consultas • Modificação da consulta EXEMPLO Emp1(#e, nome, salario, idade) - esquema exportação-local 1 Emp2(#e, nome, salario, nivel) - esquema exportação-local 2 EmpG(#e, nome, salario) - esquema generalização EmpG.nome = Emp1.nome se EmpG está em mundo(Emp1) = Emp2.nome se EmpG caso contrário EmpG.salario = Emp1.salário se EmpG está em mundo(Emp1) - mundo(Emp2) = Emp1.salario+Emp2.salario se EmpG está em mundo(Emp1) mundo(Emp2) ... Processamento de Consultas • Modificação da consulta EXEMPLO EmpOJ(#e, nome, salario, idade, nivel) - esquema outerjoin EmpOJ.idade = Emp1.idade se EmpOL está em mundo(Emp1) = nulo se EmpOJ está em mundo(Emp2) - mundo(Emp1) EmpOJ.nivel = Emp2.nivel se EmpOJ está em mundo(Emp2) = nulo se EmpOJ está em mundo(Emp1) - mundo(Emp2) Processamento de Consultas EmpOJ(#e, nome, salario, idade, nivel) SEJA A CONSULTA: SELECT EmpOJ.nome, EmpOJ.nivel FROM EmpOJ WHERE EmpOJ.salario > 2000 AND EmpOJ.idade = 49 A tabela EmpOJ é dividida em três partições: mundo(Emp2)-mundo(Emp1); mundo(Emp1)-mundo(Emp2); mundo(Emp2) mundo(Emp1); Processamento de Consultas Para o mundo(Emp2)-mundo(Emp1) o atributo idade é nulo; Para o mundo(Emp1)-mundo(Emp2) teremos SELECT Emp1.nome FROM Emp1 WHERE Emp1.salario > 2000 AND Emp1.idade =49 AND Emp1.#e NOT IN (SELECT Emp2.#e FROM Emp2) Para o mundo(Emp2) mundo(Emp1) teremos SELECT Emp1.nome, Emp2.nivel FROM Emp1, Emp2 WHERE sum(Emp1.salario, Emp2.salario) > 2000 AND Emp1.idade =49 AND Emp1.#e = Emp2.#e Uma consulta de pós-processamento irá produzir o resultado final Processamento de Consultas • Tradução da consulta ALGORITMOS CONVENCIONAIS A qualidade da tradução irá depender do poder expressivo da linguagem local Uma única consulta local • otimização local CASOS: Várias consultas locais. • Definir consultas locais de forma a otimizar a performance • otimização local Processamento de Consultas • Otimização global da consulta VOLTEMOS AO EXEMPLO: Para o mundo(Emp2) mundo(Emp1) temos SELECT Emp1.nome, Emp2.nivel FROM Emp1, Emp2 WHERE sum(Emp1.salario, Emp2.salario) > 2000 AND Emp1.idade =49 AND Emp1.#e = Emp2.#e Processamento de Consultas • Otimização global da consulta POSSIBILIDADES: SELECT SELECT SELECT SELECT Emp1 Emp2 SELECT SELECT Result1 + Emp2 Result2 + Emp1 Emp1 SELECT Result1 + Result2 Emp2 Processamento de Consultas • Otimização global da consulta Algoritmos de BDDs homogêneos podem ser aplicados, se • não houver inconsistências • facilidades de transmissão de dados • estatísticas locais comparáveis entre si Árvores de junção: linear fechada Processamento de Consultas • Otimização global da consulta Solução de inconsistências - funções de agregação Seja C global e C1, C2 uma partição horizontal. A operação: C[A op a] = C1[A op a] int-op C2[A op a] usa outerunion: C1 OJ C2 = C1-O OU C2-O OU (C1-C J C2-C) parte privada parte comum Processamento de Consultas • Otimização global da consulta Otimização com funções de agregação f(a1,a2) f(a1,a2) min min max max sum sum op < = > = < = Para os outros casos nenhuma otimização é possível (4) f(a1,a2)op a a1 op a AND a2 op a (1) f(a1,a2)op a f(a1 op1 a, a2 op2 a) op a (2) f(a1,a2)op a a1 op a AND a2 op a (1) f(a1,a2)op a f(a1 op1 a, a2 op2 a) op a (2) f(a1,a2)op a f(a1 op a, a2 op a) op a (3) f(a1,a2)op a f(a1 op1 a, a2 op2 a) op a (2) Processamento de Consultas a1=E1.sal = 500 a2=E2.sal = 600 sal = 600 f(a1,a2) op min min max max sum sum > = < < < = min(E1.sal,E2.sal)> 600 E1.sal > 600 AND E2.sal > 600 (1) min(E1.sal, E2.sal)= 550 min(a1<600, a2<600) = 600 (2) max(a1,a2)< a a1 < 600 AND a2 < 600 (1) max(a1,a2)= a max(a1 > 600, a2 > 600) = 600 (2) sum(a1,a2)< a sum(a1>600, a2>600) < 600 (3) sum(a1,a2)= a sum(sum(a1) > 600, sum(a2) > 600) = 600 (2) (1) = processamento em todos locais (2) = processamento em um local pode resolver (3) = processamento local e global Controle de Concorrência TIPOS DE TRANSAÇÕES • Transações locais • Transações globais AUTONOMIA LOCAL • Autonomia de projeto • Autonomia de execução • Autonomia de comunicação Controle de Concorrência MDBS • locais (s1,...,sm), • Operações básicas: r (read), w (write), c (commit), a (abort) • GTG (Gerente de Transações Globais) • SGBD local • Server (ligação entre GTG e SGBD local) Controle de Concorrência MDBS Ti GTG Server Tl Tj Server Tl SGBD SGBD Controle de Concorrência MDBS - Interface Server/SGBD POSSIBILIDADES •O SGBD aceita operações individuais begin, op.1, op.n, commit • O SGBD aceita serviços na forma de transações locais Controle de Concorrência PROBLEMAS • Serializabilidade global • Atomicidade e recuperação • Deadlock Controle de Concorrência • Serializabilidade global Local s1 com a, b Local s2 com c, d Transações: globais: T1 : r1(a) r1(c) T2 : r2(b) r2(d) locais: T3 : w3(a) w3(b) em s1 T4 : w4(c) w4(d) em s2 Visão global: T1 ,T2 Schedules locais: S1: r1(a) w3(a) w3(b) r2(b) T1 , T3 , T2 S2 : w4(c) r1(c) r2(d) w4(d) r2(d) w4(c) w4(d) r1(c) T2 , T4 , T1 Controle de Concorrência • Atomicidade global e recuperação Local s1 com a Local s2 com c Transações: global: T1 : r1(a) w1(a) w1(c) local: T2 : r2(a) w2(a) em s1 Execução: T1 completa suas 3 ações e manda commit para s1 e s2 s2 recebe e confirma o commit, mas s1 aborta a subtransação original antes do commit T2 é executada e realiza commit GTG resubmete w1(a) s1 considera isto uma nova transação RESULTADO:schedule não serializavel: r1(a) r2(a) w2(a) w1(a) Controle de Concorrência • Atomicidade global e recuperação SOLUÇÃO: Prepare-to-commit reduz heterogenidade Controle de Concorrência • Deadlock global Local s1 com a, b Local s2 com c, d Transações: globais: T1 : r1(a) r1(d) T2 : r2(c) r2(b) locais: T3 : w3(b) w3(a) em s1 T4 : w4(d) w4(c) em s2 Execução: T1 executou r1(a) e T2 executou r2(c) T3 executa w3(b) e submete w3(a) e espera liberação de T1 T4 executa w4(d) e submete w4(c) que espera por T2 T1 e T2 submetem seus restos e o deadlock ocorre Nem os locais nem o global conseguem detectar este deadlock Controle de Concorrência • Serializabilidade global Local s1 com a, b Local s2 com c, d Visão global: T1 ,T2 Transações: globais: T1 : r1(a) r1(c) T2 : r2(b) r2(d) locais: T3 : w3(a) w3(b) em s1 T4 : w4(c) w4(d) em s2 SOLUÇÕES: • evitar transações T1 ,T2 que atuam no mesmo local provocar conflito artificial • identificar schedules como S2 e evita-los Controle de Concorrência • Serializabilidade global Local s1 com a, b Local s2 com c, d , t Transações: globais: T1 :w1(t) r1(a) r1(c) T2 : r2(b) r2(d) r2(t) locais: T3 : w3(a) w3(b) em s1 T4 : w4(c) w4(d) em s2 Visão global: T1 ,T2 Provocar conflito entre T1 ,T2 com um ticket Schedules locais: S1: r1(a) w3(a) w3(b) r2(b) T1 , T3 , T2 S2 : w4(c) w1(t) r1(c) r2(d) w4(d) r2(t) não é serializável r2(d) w4(c) w4(d) r1(c) T2 , T4 , T1 Controle de Concorrência • Serializabilidade global - SGBDs com 2PL rigoroso Local s1 com a, b Local s2 com c, d Transações: globais: T1 : r1(a) r1(c) T2 : r2(b) r2(d) locais: T3 : w3(a) w3(b) em s1 T4 : w4(c) w4(d) em s2 Visão global: T1 ,T2 Schedules locais: S1: r1(a) w3(a) w3(b) r2(b) T1 , T3 , T2 S2 : w4(c) r1(c) r2(d) w4(d) não ocorre, pois c é bloqueado até o final de T4 Controle de Concorrência • Atomicidade global e recuperação PROBLEMA: Falha de subtransação global TIPOS DE TRANSAÇÕES • com redo (operações de write são repetidas) • com retry (toda subtransação é repetida) • com compensação (compensação desfaz ação da transação original) Controle de Concorrência • Atomicidade global e recuperação TIPO DA OPERAÇÃO ler (read) update de troca update relativo COMPENSÁVEL REPETÍVEL sim - (ler de novo) não sim (usar valor) sim sim (reescrever) sim update relativo c/restrição inserção em conjunto entrada em fila inserção em lista condicional condicional sim - (remover) sim sim (remover) sim (remover) sim não (pode ter mudado) não update em textos não EXEMPLO escrever um inteiro incrementar um valor depósito, cancelamento Controle de Concorrência • Outros conceitos em Özsu&Valduriez-Princípos Distrtibuídos de Bancos de Dados CONTROLE DE CONCORRÊNCIA • Bloqueio; centralizado, cópia primária e distribuído •Pessimista: bloqueio e timestamp ordering • Otimista: bloqueio, timestamp ordering, híbrido • Deadlock: prevenção, anulação, detecção e resolução CONTROLE DE CONCORRÊNCIA RELAXADO OU ANINHADO Data Warehousing - Alimentação Projeto do Data Warehouse - FASES: • PROJETO: definição de visões, extratores, revisores, integradores. • ALIMENTAÇÃO: carga inicial. Passos: preparação (Logs, deltas, histories), integração (ODS), agregação (CDW), customização (Datamarts) • ATUALIZAÇÃO: como alimentação, só que o ODS é atualizado e alterações são propagadas - FIGURA 4.1- Data Warehousing - Atualização Considerações • requisitos da aplicação (e.g. atualidade e precisão dos dados, tempo de computação de consultas) • restrições da fonte (disponibilidade, frequência de alterações) • limites do Data Warehouse (espaço, funcionais) Data Warehousing - Atualização ODS - Object Data Store - atualização • atualização imediata - Banco com lançamentos locais e saldo global) • atual - ODS com estatísticas semanais de lançamentos locais e atualização horária) • periódica (assíncrona) - resultados diários, após n lançamentos, sob demanda (saldo, #lançamentos, ..) Semelhante para o Data Warehouse Data Warehousing - Atualização CDW - Data Warehouse - atualização PROBLEMAS CRÍTICOS • volume muito grande de dados - de GB a TB • sobrecarga transacional - transações de carga e acesso pesadas GB/hora, processamento paralelo, transferência compactada • concorrência entre atualização e consulta divisão do tempo entre batch e on-line difícil, conflitos Data Warehousing - Atualização Customização Propagação AGREGAÇÃO INTEGRAÇÃO Integração Histórico PREPARAÇÃO Extração Temporal/ externo Histórico Limpeza Data Warehousing - Atualização • detectar alterações • extrair alterações • registrar alterações • isolar alterações cedo reduz drasticamente massas de dados • integração incremental (limpeza) QUESTÕES AO ODS: • processar dados que alteram o DW • prever informações de outras fontes, antes da atualização • estimar tempo da preparação • estimar tempo de atualização do DW Data Warehousing - Extração arquivos snapshot não-cooperativas logadas BDs, e-mails específicas legados consultáveis BDs relacionais FONTES: replicadas cooperativas ativas BDs c/ replicação callback Ações internas BDs c/triggers externos BDs c/triggers e delta tables Data Warehousing - Limpeza Dados devem ser: precisos, relevantes, consistentes e completos DADOS SUJOS: • diferença de formato • dados relevantes escondidos em textos • mal-entendidos (atributo ‘nome’ de que?) • erros de digitação inconsistências • falta de valores • informação duplicada Data Warehousing - Limpeza módulos de limpeza: • conversão e normalização transformação de formatos heterogêneos • limpeza específica arquivos textuais, uso de dicionários • limpeza independente do domínio algoritmos de casamento de campos • limpeza baseada em regras regras específicas de casamento (business rules) Data Warehousing - Limpeza • conversão e normalização transformação de formatos heterogêneos SQL*Loader Arquivos Oracle Wrappers Dados fonte Data Warehouse NORMALIZAÇÃO Exemplos: • textos sem acentuação • formato do datas Data Warehousing - Limpeza • limpeza específica arquivos textuais, uso de dicionários normalização de nomes próprios • nome farmaceuticos • normalização postal EXEMPLOS: PostalSoftACE SSA(Search Soft America) PostalSoft Library and Mailers Carleton’s Pure Integrator (DW) ETI Data Cleanse Data Warehousing - Limpeza • limpeza independente do domínio algoritmos de casamento de campos PROBLEMA: o mesmo valor descrito de forma distinta • junções aproximadas • valores alternativos • graus de casamento Carlton’s Pure Integrator: • casamento com chaves • casamento sem chaves (fuzzy) Data Warehousing - Limpeza • limpeza baseada em regras regras específicas de casamento (business rules) MERGE/PURGE Problem; • criação de chaves analisando os dados das fontes • ordenar fontes segundo estas chaves • intercalar registros (funções distância) Data Warehousing - Limpeza • limpeza baseada em regras regras específicas de casamento (business rules) Regras explícitas: for(all tuples) boolean similar-nome = compare(nome1, nome2) boolean similar-end = compare(end1,end2) boolean similar-cidade = mesma-cidade(cid1, cid2) boolean similar-cep = mesmo-cep(cid1, cid2) similar-end = (similar-cidade similar-cep) if (similar-nome && similar-end) merge-tuples(pessoa1, pessoa2) Data Warehousing - Limpeza • limpeza baseada em regras Regras geradas automaticamente (baseadas em data mining) regras matemáticas regras IF-THEN A=B*C WHERE A = p-total, B=quant. C=p-unit Rule’s accuracy level: 0.99 rule exists in 1890 records IF Cliente IS “UFCG” AND item IS “Informática” THEN Vendedor=“Chico” Rule’s probability: 0.95 rule exists in 102 records Data Warehousing - Limpeza o estudo das semânticas de limpeza e estratégias de atualização de um DW a partir de diversas fontes é uma área aberta de pesquisa FIM
Baixar