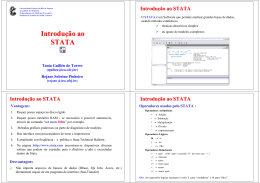
Apostila Stata Programa de Pós-Graduação em Saúde Coletiva Universidade Federal do Maranhão Disciplina: Métodos Estatísticos em Epidemiologia Prof. Antônio Augusto Moura da Silva O que é o Stata O Stata é um programa estatístico potente, capaz de resolver tarefas simples como calcular média, desvio padrão, testes de hipótese para médias e proporções, intervalos de confiança, até estatísticas mais complexas como regressão linear múltipla, análise de variância, regressão logística, análise de sobrevivência, regressão de Cox etc. Tem recursos potentes de tabulação de variáveis e comandos para cálculo das medidas de associação usadas em epidemiologia, como razão de incidências (rate ratio), risco relativo (risk ratio), razão de chances (odds ratio) e risco atribuível. Possui recursos poderosos para manipulação de variáveis, porém as ferramentas para entrada de dados com verificação de erros de digitação são pobres. Usualmente, é melhor criar um programa para entrada de dados no EPIINFO, digitar os dados usando os recursos CHECK e VALIDATE, e depois exportar o arquivo para o STATA usando o STAT TRANSFER. Ou, se forem poucos dados, criar uma planilha Excel e depois cortar e colar os dados no Stata. Quando se carrega o programa na memória, aparece a sua tela, como na figura abaixo: Observa-se a barra do programa (em azul, acima) e os botões do Windows (minimizar, maximizar e fechar). Logo abaixo está a barra de menu, com os recursos File, Edit, Data, Graphics, Statistics, User, Windows e Help. No menu File, existe a opção Open, para abrir um arquivo STATA. Logo abaixo observa-se a barra de botões, com os botões Open (use), Save, Print Results, Log Begin/Close/Suspend/Resume, New Viewer, Bring Graph Window to front, New Do-file Editor, Data Editor, Data Browser, Clear – more – condition e Break. Na área de trabalho há 4 janelas ativas: acima à esquerda, a janela Review, onde vão surgindo os comandos já digitados. Acima à direita, a janela Results, onde vão aparecendo os resultados do processamento. Abaixo à esquerda, a janela Variables, onde ficam todas as variáveis do arquivo em uso e abaixo à direita a janela Command, onde se digitam os comandos. Na penúltima linha da tela, aparece o drive ativo, isto é, onde estão sendo gravados os dados (c:\Arquivos de Programas\Stata10) e a última linha é a barra do Windows, onde estão os botões Iniciar e os botões dos programas ativos no momento. Todos os comandos no Stata podem ser acessados pelo menu ou digitando-se na janela de comandos. Se você optar pelo menu, basta escolher clicando em File, Edit, Data, Graphics, Statistics, User, Windows e Help, depois fazer as seleções, escolher as opções nas caixas de diálogo e clicar OK. Se você optar pela digitação dos comandos, será necessário digitá-los na janela Command. Nesta apostila, todos os comandos que você vai precisar digitar ou escolher do menu estarão destacados em negrito. Apostila Stata 2 Abrindo arquivo no Stata - use Vamos trabalhar agora com o banco de dados dnma.dta. Neste arquivo constam dados dos nascidos vivos no Maranhão em 2009, cadastrados no SINASC (Sistema de Informações Sobre Nascidos Vivos) do Ministério da Saúde. Veja abaixo as variáveis do arquivo que serão utilizadas em exercícios neste curso e a sua codificação. Apostila Stata 3 O primeiro passo é abrir o arquivo. Para tanto é preciso usar o comando File / Open / e em seguida localizar o diretório Stata onde o arquivo dnma está localizado. Em seguida clique em cima do arquivo dnma e escolha a opção Abrir. Observe que o comando use c:\Arquivos de Programas\Stata10\dnma.dta foi copiado para a janela Review e que agora os nomes de variáveis aparecem na janela Variables. Se o arquivo não abrir, é possível que tenha aparecido uma mensagem de erro “no room to add more observations” (não há espaço na memória para carregar o arquivo, numa tradução livre). Se acontecer isto, você precisa aumentar o tamanho da memória disponível para carregar o arquivo, pois o arquivo dnma é muito grande. Digite: set memory 50m (que pode ser abreviado para set memo 50m) E pressione a seguir a tecla ENTER ou RETURN: Pronto, a memória disponível aumentou para 50 mega e agora você vai poder carregar o arquivo. Outra opção digitar o comando na janela de comandos, pressionando a seguir a tecla ENTER ou RETURN: Apostila Stata 4 use dnma.dta use dnma [ENTER] [ENTER] ou (você pode omitir a extensão .dta). Verifique na barra de Status se o drive ativo é c:\Arquivos de Programas\Stata10. Se não for, é preciso digitar o caminho completo das unidades de disco e pastas para que o Stata possa localizar e abrir o arquivo. use c:\Arquivos de Programas\Stata10\dnma.dta Ou você precisa copiar o arquivo dnma.dta para o drive ativo antes de usar o comando use dnma. Ou, ainda, você pode mudar o drive ativo. No menu, escolha File / Change Working Directory e escolha a posta onde você deseja trabalhar (comando disponível a partir da versão 11). Você pode também mudar o drive ou pasta ativa, digitando (não se esqueça de delimitar o caminho usando aspas após o comando cd - abreviatura de change directory). cd “c:\Arquivos de Programas\Stata10” Em seguida, após mudar a pasta ativa, digite: use dnma.dta Observe que, aparece na janela de resultados o comando utilizado após o . Isto nos informa que o que foi digitado se trata de um comando e não do resultado do processamento. O resultado do processamento vai surgir em seguida. . use dnma O Stata está pronto para aceitar um comando quando o ponto . aparece na janela de resultados. Listando variáveis - list Use o comando list para obter uma listagem das variáveis e dos dados gravados no arquivo. Você pode usar o menu de comandos Data / Describe Data / List Data e teclar Ok na janela de diálogo list – list values of variables. Nesta janela de diálogo você pode usar as opções disponíveis, escolhendo apenas algumas variáveis para serem listadas e mudando a largura das colunas para controlar a forma como os dados serão mostrados na tela (janela de Resultados - Results). Alternativamente você pode digitar na janela Command: list Apostila Stata 5 Observe que surgem na tela os dois primeiros registros. Veja também que alguns nomes de variáveis grandes são abreviados e que algumas letras são substituídas por ~, sendo que o Stata preserva a última letra. Por exemplo, a variável codmunnasc se transformou em codmun~c. Observe também que, para continuar a rolar a tela e olhar os próximos registros, é necessário apertar qualquer tecla ou clicar com o mouse em cima de – more- . Como este arquivo armazena dados de 123.635 nascidos vivos, levaríamos muito tempo visualizando todos eles. Desta forma, localize o X vermelho na barra de ferramentas e clique em cima dele para interromper a listagem. Após interromper a listagem, pressione seta para cima e seta para baixo ou [Page Up] e [Page Down] para rolar a tela na janela de resultados. Data Editor (Edit) Variables Manager Log Begin / Close / Suspend / Resume New Do-‐file Editor Interromper Data Editor (Browse) Apenas uma certa quantidade de resultados passados permanece armazenada na janela de resultados. Assim, é possível que você faça o rolamento para cima e parte dos resultados obtidos nesta seção tenham “desaparecido”. Por isso existe a possibilidade de gerar um LOG file. Utilizando o comando log using <nome do arquivo> você grava todo o resultado do processamento em um arquivo que você pode abrir depois. Tudo aquilo que for digitado (comandos) e todos os resultados gerados a partir do momento em que você usa o comando log serão gravados em um arquivo específico. Digite o comando abaixo para gerar um LOG: log using dnma Observe que aparece na janela de resultados: . log using dnma ---------------------------------------------------------------name: <unnamed> log: /Arquivo de programas/Stata10/dnma.smcl log type: smcl opened on: 19 Aug 2011, 07:28:57 De agora em diante, tudo o que você digitar e os resultados do comando serão gravados no arquivo dnna.smcl (smcl é a terminação que o Stata usa para guardar os dados em formato próprio). Digite agora list parto para obter uma listagem apenas da variável tipo de parto. Apostila Stata 6 list parto Vamos abrir agora o arquivo log para verificar que os comandos digitados e os resultados obtidos estão sendo gravados no arquivo dnma.smcl. Identifique o ícone Log Begin / Close / Suspend / Resume e clique nele com o mouse. Na caixa de diálogo selecione a opção View Snapshot of log file e clique em OK. Outra forma de visualizar o conteúdo das variáveis é usar o ícone Data Editor (Browse) para visualizar o conteúdo em forma de planilha. Observe que as variáveis são colocadas nas colunas e as observações nas linhas. Enquanto você estiver no modo Browse você não poderá executar outro comando. Para isso terá que fechar a janela do Browse e retornar para a janela principal do Stata. Se você quiser repetir um comando não precisa digitá-lo de novo. Basta localizar o comando na janela Review e selecioná-lo, clicando em cima dele. Esta ação copiará o comando para a janela Command. Aí basta você teclar [ENTER] para rodar o comando novamente. Ou você também pode rodar o comando novamente clicando duas vezes em cima do comando na janela Review. Ou, ainda, usando as teclas Page Up e Page Down para recuperar na janela Command os últimos comandos digitados. Obtendo frequências simples de variáveis tabulate Para se obter uma tabela de distribuição de frequências de uma variável, utiliza-se o comando tabulate. Vamos obter uma tabela de distribuição de frequências da variável tipo de parto (parto). No menu clique em Statistics / Summaries, tables and tests / Tables / Oneway tables. Surgirá a janela de diálogos tabulate 1 – One-way tables, Escolha em categorical variables a variável parto e tecle OK. Outra alternativa é digitar na janela Command: tabulate tiparto No Stata é possível abreviar os comandos para digitação, usando-se as três primeiras letras do comando. Desta forma você obteria o mesmo resultado digitando: tab tiparto parto | Freq. Percent Cum. ------------+----------------------------------1 | 82,964 67.24 67.24 2 | 40,416 32.76 100.00 9 | 4 0.00 100.00 ------------+----------------------------------Total | 123,384 100.00 Apostila Stata 7 Consultando a tabela de codificação observamos que 1=parto vaginal, 2= parto cesáreo e 9=ignorado. Observe que o total 123.384 não é o mesmo total geral do arquivo 123.635, indicando que alguns casos foram deixados em branco no banco de dados. O Stata usa o código . para indicar dados não digitados. Para se verificar isso é necessário digitar a opção missing após o comando tab, que pode ser abreviada para mis. Note que para se usar uma opção de comando é necessário separar o comando da sua opção por uma vírgula. tab tiparto, mis parto | Freq. Percent Cum. ------------+----------------------------------| 251 0.20 0.20 1 | 82,964 67.10 67.31 2 | 40,416 32.69 100.00 9 | 4 0.00 100.00 ------------+----------------------------------Total | 123,635 100.00 Observe que além de 4 partos codificados como 9, ignorados, existem ainda 251 casos sem informação do tipo de parto. Podemos descartar estes casos prejudicados da análise utilizando o comando recode, para se trabalhar apenas com os casos com informação completa. recode parto 9=. tab parto parto | Freq. Percent Cum. ------------+----------------------------------1 | 82,964 67.24 67.24 2 | 40,416 32.76 100.00 ------------+----------------------------------Total | 123,380 100.00 Podemos verificar agora que a taxa de cesáreas no Maranhão em 2009 foi de 32,76%. Renomeando variáveis - rename Podemos mudar os nomes das variáveis usando o comando rename. Vamos mudar o nome da variável parto para tiparto rename parto tiparto Apostila Stata 8 Rotulando variáveis e valores - label Agora precisamos documentar o arquivo e torná-lo mais fácil de ser entendido, utilizando rótulos (labels). Primeiro vamos documentar as variáveis. Não use acentos ou cedilha pois ficará ininteligível ( o programa não entende símbolos do português). Observe que é necessário colocar o rótulo da variável entre aspas. label variable tiparto “Tipo de parto” Use agora o comando describe para observar o resultado. Veja que agora a variável tiparto tem uma variable label: Tipo de parto describe tiparto storage display value variable name type format label variable label ---------------------------------------------------------------------tiparto float %9.0g Tipo de parto Vamos usar agora o recurso de rotular valores de variáveis numéricas. Por exemplo, vamos dizer que, no caso da variável tiparto, 1 significa parto vaginal e 2 parto cesáreo, usando os comandos label define e label values. No primeiro comando, label define, os rótulos são definidos como 1 para parto vaginal e 2 para parto cesáreo. No segundo comando, os valores do rótulo tipo são colocados na variável tiparto. label define tipo 1 vaginal 2 cesareo label values tiparto tipo Agora, ao pedir uma tabulação observe que o valor 1 é substituído por vaginal e o valor 2 por cesáreo. tab tiparto Tipo de | parto | Freq. Percent Cum. ------------+----------------------------------vaginal | 82,964 67.24 67.24 cesareo | 40,416 32.76 100.00 ------------+----------------------------------Total | 123,380 100.00 Apostila Stata 9 Use agora o comando describe para observar o resultado e verificar que agora a variável tiparto tem um rótulo chamado tipo: describe tiparto storage display value variable name type format label variable label ---------------------------------------------------------------------tiparto float %9.0g tipo Tipo de parto Entretanto, o valor da variável no arquivo não foi modificado. Para observar isto peça uma tabulação omitindo o rótulo, usando a opção nolabel. tab tiparto, nolabel Tipo de | parto | Freq. Percent Cum. ------------+----------------------------------1 | 82,964 67.24 67.24 2 | 40,416 32.76 100.00 ------------+----------------------------------Total | 123,380 100.00 Se você quiser, você pode pedir uma lista dos rótulos e dos seus conteúdos: label list . label list tipo: 1 vaginal 2 cesareo Todas as opções de mudar o nome da variável (rename), colocar um rótulo na variável (label variable), criar rótulos para categorias (label define) e colocar rótulos nas categorias das variáveis (label values) estão também disponíveis no ícone Variables Manager na barra de ícones. Apostila Stata 10 Exercícios Não se esqueça de anotar os comandos utilizados para obter os resultados. Descarte os valores ignorados se os percentuais forem baixos (inferiores a 2%). 1) 2) 3) 4) 5) 6) Apostila Stata Usando os comandos aprendidos acima, verifique a taxa de partos gemelares no Maranhão em 2009. Qual o percentual de mulheres que não realizaram pré-natal? Qual o percentual de nascimentos no domicílio? Use o recurso de rotular valores para a variável estcivmae. Qual o percentual de nascimentos de mulheres solteiras? Qual o percentual de nascimentos de mulheres com nenhuma escolaridade? 11 Criando arquivos no Stata - edit Vamos agora gerar um arquivo simples, contendo 4 campos. Para criar um arquivo no Stata basta clicar no botão Data Editor (Edit) ou digitar na janela de comandos edit. Surge o editor, pronto para se digitar o primeiro registro da primeira variável (var1). Aqui você pode ir digitando nas colunas os conteúdos das variáveis que o Stata vai automaticamente criando as variáveis var1, var2, var3 etc. O programa, a partir do que é digitado, vai automaticamente criando variáveis numéricas ou categóricas, conforme o caso e determinando o tamanho de cada campo. Depois você pode mudar o nome de cada campo, por exemplo de var1 para idade. Quando a casela for deixada em branco o Stata coloca automaticamente o seu código para dado prejudicado (missing) que é o ponto. Vamos começar, criando o arquivo abaixo: Digite inicialmente só os dados nas colunas e depois vamos aprender o comando para gerar o nome da variável. Digite 2350 e tecle ENTER para o cursor se mover para a casela de baixo e assim sucessivamente. Quando digitar o 5o. dado da 1a. coluna passe com as setas ou com o mouse para a 1a. casela da 2a. coluna e assim por diante. Quando terminar feche o editor clicando no botão X, pois enquanto o modo Edit estiver ativo, você não poderá executar comando no Stata. Observe, na janela Variables, que surgem var1, var2, var3, var4 e var5 e na janela Review, edit. pesonasc tiparto 2350 1500 3430 2920 3100 idgest 1 2 1 1 2 idmae 40 33 41 38 39 sexo 30 22 19 33 25 1 1 1 2 2 No Stata os nomes de variáveis são minúsculos. Depois da digitação de dados, a primeira coisa que você deve fazer é salvar os dados. Vá até a janela de comandos e digite, sempre em minúsculas: save rn O Stata avisa e tecle [ENTER] file rn.dta saved (arquivo rn.dta salvo) Aqui você pode observar que o Stata usa .dta como terminação de arquivo. Utilize agora o comando describe para observar os tipos de variáveis criadas pelo Stata. describe Apostila Stata e tecle [ENTER] 12 Contains data from rn.dta obs: 5 vars: 5 size: 50 (100.0% of memory free) ------------------------------------------------------------------1. var1 int %8.0g 2. var2 byte %8.0g 3. var3 byte %8.0g 4. var4 byte %8.0g 5. var5 byte %8.0g ------------------------------------------------------------------Sorted by: Todas as variáveis criadas são numéricas (int e byte) e todas de tamanho 8 (%8.0g). Outros tipos de variáveis numéricas são long, float and double. A diferença entre estes tipos de variáveis numéricas é o seu tamanho e a precisão dos cálculos, determinada pelo número de casas decimais depois da vírgula. Outro tipo de variável que pode ser criada no Stata são as variáveis do tipo caracter, usadas para armazenar informação não numérica, ou seja, endereço, nome, telefone. Estas variáveis podem conter números, mas não vamos realizar operações matemáticas com estes números, eles servem apenas como identificadores. Vamos pedir agora uma listagem do arquivo. list 1. 2. 3. 4. 5. var1 2350 1500 3430 2920 3100 var2 1 2 1 1 2 var3 40 33 41 38 39 var4 30 22 19 33 25 var5 1 1 1 2 2 Estatística descritiva E agora peça uma estatística descritiva destes campos. summarize Variable | Obs Mean Std. Dev. Min Max ---------+----------------------------------------------------var1 | 5 2660 757.5949 1500 3430 var2 | 5 1.4 .5477226 1 2 var3 | 5 38.2 3.114482 33 41 var4 | 5 25.8 5.718391 19 33 var5 | 5 1.4 .5477226 1 2 Apostila Stata 13 O Stata mostra o número de observações, a média (mean), o desvio padrão (Std. Dev.), o valor mínimo e o valor máximo. Note que no caso das variáveis tiparto e sexo, a média não tem valor algum, pois estas variáveis estão codificadas. No caso de tiparto (1=parto vaginal; 2=parto cesáreo) e no caso de sexo (1=masculino; 2=feminino). Renomeando variáveis - rename O próximo passo é mudar os nomes das variáveis. rename rename rename rename rename var1 var2 var3 var4 var4 pesonasc tiparto idgest idmae sexo Rotulando variáveis e valores - label Agora vamos rotular as variáveis. label label label label label variable variable variable variable variable pesonasc “Peso ao nascer no HU em 1998” tiparto “Tipo de parto” idgest “Idade gestacional em semanas-DUM” idmae “Idade da mae em anos completos” sexo “Sexo do recem-nascido” Use agora o comando describe para observar o resultado: describe Contains data from rn.dta obs: 5 vars: 5 size: 50 (99.9% of memory free) ------------------------------------------------------------------------------1. pesonasc int %8.0g Peso ao nascer no HU em 1998 2. tiparto byte %8.0g Tipo de parto 3. idgest byte %8.0g Idade gestacional semanas-DUM 4. idmae byte %8.0g Idade da mae em anos completos 5. sexo byte %8.0g Sexo do recem-nascido ------------------------------------------------------------------------------Sorted by: Note: data has changed since last save Para salvar as alterações feitas digite: Apostila Stata 14 save, replace (salva, grava por cima do arquivo antigo com o mesmo nome rn) Vamos usar agora o recurso de rotular valores de variáveis numéricas. Por exemplo, vamos dizer que no caso da variável tiparto 1 significa parto vaginal e 2 parto cesáreo, usando os comandos label define e label values. label define tipo 1 vaginal 2 cesareo label values tiparto tipo Distribuição de frequências - tabulate Peça agora a distribuição de freqüências da variável tiparto para observar o que ocorreu: tabulate tiparto Tipo de | parto | Freq. Percent Cum. ------------+----------------------------------vaginal | 3 60.00 60.00 cesareo | 2 40.00 100.00 ------------+----------------------------------Total | 5 100.00 Salve novamente as alterações, usando a opção replace para substituir (gravar por cima) o arquivo anterior: save, replace Outro recurso importante é ordenar o conteúdo de um campo com o comando sort: sort tiparto list Para fechar o arquivo e limpar a memória digite: clear Para abrir novamente o arquivo use o menu File e, em seguida, Open. Clique no arquivo rn e no botão abrir. Ou, alternativamente, digite: use rn Apostila Stata 15 Criação de novas variáveis – generate e recodificação – replace Vamos recodificar o peso ao nascer em baixo peso (aquelas crianças com menos de 2500 gramas ao nascer) e não baixo peso (2500 gramas e mais). O primeiro passo é criar uma nova variável através do comando generate. Toda variável criada no Stata tem que ser inicializada com um valor específico. No caso criaremos a variável peso=0 e recodificaremos pesonasc < 2500, criando peso=1 nestes casos. generate peso=0 replace peso=1 if pesonasc < 2500 tabulate peso peso | Freq. Percent Cum. ------------+----------------------------------0 | 3 60.00 60.00 1 | 2 40.00 100.00 ------------+----------------------------------Total | 5 100.00 Da mesma forma vamos recodificar idade gestacional em prematuro (<37 semanas) e não prematuro (37 semanas e mais). generate premat=0 replace premat=1 if idgest < 37 tabulate premat premat | Freq. Percent Cum. ------------+----------------------------------0 | 4 80.00 80.00 1 | 1 20.00 100.00 ------------+----------------------------------Total | 5 100.00 Operadores de comparação (usados após o if) == != > < >= <= Apostila Stata igual a diferente de maior do que menor do que maior ou igual menor ou igual 16 Tabelas 2 x 2 - tabulate Peça agora uma tabela de peso com idade gestacional, com a opção row (para o cálculo dos percentuais das linhas) tabulate premat peso, row | peso premat | 0 1 | Total -----------+----------------------+---------0 | 3 1 | 4 | 75.00 25.00 | 100.00 -----------+----------------------+---------1 | 0 1 | 1 | 0.00 100.00 | 100.00 -----------+----------------------+---------Total | 3 2 | 5 | 60.00 40.00 | 100.00 Observe que a taxa de baixo peso nesta população é de 40%. Dentre os prematuros (codificados como 1), 100% têm baixo peso e que dentre os não prematuros (codificados como 0), 25% têm baixo peso. Vamos pedir agora a tabela diferente, isto é, peso e prematuridade, com os percentuais das colunas, colocando a variável resposta (peso ao nascer) nas linhas e a exposição (idade gestacional) nas colunas. tabulate peso premat, col | premat peso | 0 1 | Total -----------+----------------------+---------0 | 3 0 | 3 | 75.00 0.00 | 60.00 -----------+----------------------+---------1 | 1 1 | 2 | 25.00 100.00 | 40.00 -----------+----------------------+---------Total | 4 1 | 5 | 100.00 100.00 | 100.00 Operadores lógicos: & | ! Apostila Stata e ou não 17 Selecionando registros para processamento – keep / drop Às vezes se precisa limitar o processamento a determinados registros. Digamos que se queira processar apenas os registros do sexo masculino (1). Pode-se usar o comando keep, selecionado sexo==1 ou drop, desprezando-se sexo==2. Note que após o if você precisar usar dois símbolos de igual == keep if sexo==1 drop if sexo==2 Cuidado com o uso destes comandos, pois os registros serão apagados definitivamente! Por isso recomendamos que, toda vez que você usar drop ou keep, salve o arquivo com outro nome em seguida, preservando o arquivo original. Gravando o processamento em um arquivo log Quando se processa grande quantidade de informação, a saída de dados vai rolando para cima na janela Results e você vai deixando de observar os resultados. Para isto grave a saída em um arquivo .log, usando o comando abaixo: log using rn.txt, text Os resultados do processamento de dados serão gravados no arquivo rn.txt, em formato texto. Este arquivo poderá depois ser aberto em um processador de textos e as tabelas utilizadas nos seus relatórios. Apostila Stata 18 Exercícios – arquivo dnma.dta Anote os comandos utilizados para obter os resultados. Descarte os valores ignorados se os percentuais forem baixos (inferiores a 2%). 1) Use o comando keep para trabalhar apenas com os dados de mães residentes no município de São Luís. O código de São Luís é 211130. 2) Recodifique a variável peso ao nascer em <2500 e maior ou igual a 2500 gramas. 3) Coloque rótulo na variável peso ao nascer. 4) Coloque rótulo nas categorias de peso ao nascer. 5) Peça uma listagem dos rótulos. 6) Qual o percentual de recém-nascidos em São Luís com baixo peso ao nascer? 7) Peça uma tabulação das variáveis tipo de parto e peso ao nascer. Coloque o tipo de parto na linha e o peso ao nascer na coluna. Peça o cálculo da porcentagem da linha. 8) Qual o percentual de baixo peso ao nascer dentre os nascidos de parto vaginal? 9) Qual o percentual de baixo peso ao nascer dentre os nascidos de parto cesáreo? Apostila Stata 19 Gerando programas no Stata – arquivo do Geralmente quando vai processar muitos dados é conveniente, ao invés de ir processando e obtendo resultados de forma interativa, gravar os comandos Stata em um arquivo tipo texto com a extensão .do e depois executar todos os comandos deste arquivo de uma só vez, em lote. Vamos criar um pequeno programa para rodar no Stata. Para isto clique no botão New Do-file Editor e digite as seguintes linhas de comandos. Depois salve o arquivo com o nome rn.do. use rn log using rn.txt, text replace label variable pesonasc "Peso ao nascer no Maranhao em 2009" generate peso=0 replace peso=1 if pesonasc < 2500 tabulate peso Agora execute o programa no Stata. Para isto você tem várias alternativas: a) Escolha, ainda dentro do Do-file Editor a última opção da barra de ícones - Execute (do) b) No menu do Stata, clique em File, escolha a opção Do, clique em cima de rn.do e clique em Abrir. c) Ou digite na janela de comandos: do rn O Stata vai executar de uma só vez todos os comandos acima e gravar os resultados do processamento no arquivo rn.txt, em formato texto. Veja, abaixo, uma descrição de cada comando: use rn Abre o arquivo rn.dta se o arquivo estiver na pasta corrente. Se não será necessário indicar o caminho completo para que o Stata possa abrir o arquivo. log using rn.txt, text replace Passa a graver os comandos e o resultado do processamento no arquivo rn.txt, em format texto. A opção replace é usada para substituir (gravar por cima) do arquivo criado anteriormente com o mesmo nome. label variable pesonasc "Peso ao nascer no Maranhao em 2009" coloca rótulo na variável pesonasc generate peso=0 Apostila Stata 20 cria uma nova variável e coloca o valor zero em todas as obervações replace peso=1 if pesonasc < 2500 Substitui na variável peso 0 por 1, se o peso ao nascer na variável pesonasc for < 2500 gramas tabulate peso Gera uma tabela da nova variável peso O uso do Stata escolhendo os comandos no menu é útil para se descobrir novos comandos que não conhecemos, pois os comandos são copiados para a janela Command e podemos então verificar o que o Stata fez e aprender novos comandos. Entretanto, é um procedimento demorado e que não pode ser automatizado, por meio da geração de arquivo DO, para processamento de vários campos e para realizar análise estatística. Desta forma, para se fazer uma boa análise estatística dos dados é melhor usar o Stata digitando os comandos, ao invés de usar o menu e utilizar a opção de gerar comandos em arquivo DO. Se houver algum erro nos dados ou nos comandos você pode facilmente editar o arquivo DO, corrigir o erro e rodá-lo novamente, poupando tempo. IMPORTANTE: Algumas mensagens de erro podem surgir quando trabalhamos com arquivos DO. 1) no; data in memory would be lost . use dnma no; data in memory would be lost r(4); Quando você tentar abrir um arquivo que foi modificado na memória e não foi salvo, o Stata avisa: não; os dados na memória seriam perdidos (no; data in memory would be lost). Solução para este erro: salvar o arquivo ou usar o comando clear para limpar a memória sem salvar o arquivo. Normalmente não salvamos o arquivo original. O ideal é deixar o arquivo original intacto, gravar os comandos em um arquivo DO e executar os comandos de uma só vez, gerar um arquivo LOG com os resultados e nunca salvar por cima do arquivo original. Se você desejar salvar o arquivo modificado, salve sempre com outro nome, como por exemplo: save rn1 Apostila Stata 21 2) log file already open . log using dnma log file already open r(604); end of do-file r(604); Quando você tentar gerar um arquivo LOG e houver um arquivo LOG aberto, o Stata avisa: arquivo LOG ainda aberto (log file already open). Solução para este erro: digitar log close. 3) file ......... already exists . log using dnma file /Arquivos de Programas/Stata/dnma.txt already exists r(602); end of do-file r(602); Se você tentar gravar por cima de um arquivo existente, o Stata avisa. Se você quiser mesmo gravar por cima é só usar a opção replace, no comando log using. Se quiser preservar o arquivo LOG anterior, basta gravar o resultado em outro arquivo, com outro nome. Apostila Stata 22 Importando dados do Excel Para trabalhar com dados no Stata é necessário inicialmente ter o arquivo disponível em formato .dta. Para isto você pode criar o banco de dados no próprio Stata, importar do Excel ou importar de outro programa. Existe um programa chamado StatTransfer que realiza transferência de arquivos de vários programas entre si. Se você tiver um banco de dados disponível no formato .xls (do Excel) você pode usar o StatTranfer para fazer a transferência. Outra alternativa para importar dados do Excel para o Stata é abrir o banco de dados no Excel, selecionar tudo o que deseja transferir e usar o recurso de corte e cola do sistema operacional (CTRL+C, CTRL+V). Vamos fazer isto passo a passo: Inicialmente abra Excel e, em seguida, o arquivo dcor.xls localizado na pasta do Stata. Selecione todos os dados que deseja transferir. Depois disso copie os dados para a área de trabalho (Editar / Copiar ou CTRL+C). Abra o Stata, e digite edit ou clique o ícone Data Editor (Edit) na barra de ícones. Dentro do editor agora escolha a opção Colar (CTRL+V) ou Edit / Paste. O Stata vai perguntar se você deseja considerar a primeira linha como dados ou como nome de variáveis (treat first row as data / treat first row as variable names). Escolha considerar a primeira linha como nomes de variáveis. Pronto, a planilha foi transferida para o Stata. Só falta agora salvar o arquivo. Feche o editor de dados no X. E agora salve o banco de dados com o nome dcor.dta. Apostila Stata 23 Usando o arquivo dcor.dta Vamos usar os comandos aprendidos acima, desta vez com um arquivo maior, o dcor.dta. Este arquivo armazena as variáveis do estudo “FRAMINGHAM HEART STUDY”, realizado nos Estados Unidos, onde se acompanhou durante 18 anos a população da pequena cidade de Framingham, para estudar os fatores de risco para doença coronariana, realizando exames periódicos de 2/2 anos. Abra o arquivo dcor.dta e peça describe, summarize e depois clique no botão Browse, para ver as variáveis do banco de dados. Compare com a descrição abaixo: sex chd age sbp sbp10 dbp chol frw cig yrs_chd yrs_dth death cause Apostila Stata 1=masculino 0=feminino diagnóstico de doença coronariana 0=não tem 1= doença coronariana presente ao primeiro exame (casos prevalentes) 2-10 = número do exame em que foi feito o diagnóstico (casos incidentes). idade em anos ao exame inicial (45-62 anos) pressão arterial sistólica em mmHg no primeiro exame (90-300 mmHg) pressão arterial sistólica em mmHg no décimo exame (94-264 mmHg). Em 635 casos a informação está prejudicada. pressão arterial diastólica em mmHg no primeiro exame (50-160 mmHg) colesterol sérico em mg/100 ml no primeiro exame (96-430 mg/100ml) peso relativo em percentual no primeiro exame (11 casos prejudicados – 52222). O peso relativo foi calculado a partir da razão entre o peso da pessoa em relação ao peso mediano para o seu grupo de sexo/altura. número de cigarros fumados por dia 0=não é fumante (1-60, 1 dado prejudicado) pessoas-ano de observação até ocorrer perda ou o primeiro evento de doença coronariana (43 pessoas já tinham doença coronariana ao primeiro exame e, portanto, não estavam mais sob risco, varia de 0 a 18 anos) pessoas-ano de observação para mortalidade (varia de 1 a 18 anos) 0=vivo 2-10 = número do exame em que já estava morto causa do óbito (19 casos prejudicados) 0 vivo ao primeiro exame 1 doença coronariana (súbita) 2 doença coronariana (não súbita) 3 acidente vascular encefálico 4 outra doença cardiovascular 5 câncer 6 outro 24 Recodificação e tabulação – replace, recode, tab Teste do qui-quadrado Vamos recodificar o nível de colesterol sérico em 3 classes: < 220, 220 a 259 e 260 e mais. generate col=0 replace col=1 if chol >=220 & chol <=259 (&=e operador lógico) replace col=2 if chol >= 260 label variable col “colesterol em mg/100ml” label define colest 0 “<220” 1 “220a259” 2 “260+” label values col colest tabulate col colesterol | em mg/100ml | Freq. Percent Cum. ------------+----------------------------------<220 | 531 37.77 37.77 220a259 | 478 34.00 71.76 260+ | 397 28.24 100.00 ------------+----------------------------------Total | 1406 100.00 Você também pode usar ao invés de replace o comando recode. Veja abaixo: generate col2=chol recode col2 96/219=0 220/259=1 260/430=2 label variable col2 “colesterol em mg/100ml” label values col2 colest tabulate col2 Vamos recodificar a pressão arterial sistólica em 0 (risco basal pA menor que 165 mmHg) e 1 (risco, pA igual ou maior que 165 mmHg). generate pas=. replace pas=1 if sbp>=165 replace pas=0 if sbp<165 label variable pas "pA sistolica - mmHg" label define pressao 0 "<165" 1 "165+" label values pas pressao tabulate pas Apostila Stata 25 pA sistolica| - mmHg | Freq. Percent Cum. ------------+----------------------------------<165 | 313 22.26 22.26 165+ | 1093 77.74 100.00 ------------+----------------------------------Total | 1406 100.00 Vamos recodificar número de cigarros fumados em 0 (não fumante) e 1 (fumante), excluindo 1 caso prejudicado (cig=99): generate fumo=0 replace fumo=1 if cig!=0 replace fumo=. if cig==99 label define cigarro 0 "nao" 1 "sim" label values fumo cigarro tabulate fumo ( != diferente de) fumo | Freq. Percent Cum. ------------+----------------------------------nao | 772 54.95 54.95 sim | 633 45.05 100.00 ------------+----------------------------------Total | 1405 100.00 Qual o percentual de fumantes nesta população ? Vamos agora recodificar chd, considerando 0 como não tendo doença coronariana e de 2 a 10 como casos de doença coronariana, excluindo 1 (casos prevalentes, isto é, pessoas que já tinham doença coronariana ao primeiro exame. Observe que transformamos 1 em . (missing – prejudicado). Desta forma o programa não processará mais estes registros nas saídas posteriores. generate dc=chd recode dc 0=0 1=. 2/10=1 label variable dc “doenca coronariana” label define doenca 0 “nao" 1 “sim” label values dc doenca tabulate dc doenca | coronariana | Freq. Percent Cum. ------------+----------------------------------nao | 1095 80.34 80.34 sim | 268 19.66 100.00 ------------+----------------------------------Total | 1363 100.00 Qual a incidência de doença coronariana nesta população ? Apostila Stata 26 Vamos pedir agora uma tabulação de colesterol e doença coronária, para verificar se o colesterol é um fator de risco para doença coronariana, pedindo percentuais de linha e o cálculo do Qui-quadrado. tabulate col dc, row chi2 colesterol | doenca coronariana em mg/100ml| nao sim | Total -----------+----------------------+---------<220 | 423 96 | 519 | 81.50 18.50 | 100.00 -----------+----------------------+---------220a259 | 377 81 | 458 | 82.31 17.69 | 100.00 -----------+----------------------+---------260+ | 295 91 | 386 | 76.42 23.58 | 100.00 -----------+----------------------+---------Total | 1095 268 | 1363 | 80.34 19.66 | 100.00 Pearson chi2(2) = 5.3202 Pr = 0.070 Observe a taxa de incidência de doença coronariana nos diversos níveis de colesterol sérico. O valor de p do Qui-quadrado foi de 0.070, portanto maior que o nível crítico de 0.05. Diz-se, então, baseado no teste de hipótese, que não há diferença estatisticamente significante entre ter colesterol elevado e sofrer de doença coronariana. Em outras palavras, as diferenças nas taxas de incidência, 18,5% naqueles com colesterol menor que 220 mg/100ml, 17,7% naqueles com colesterol sérico de 220 a 259 mg/100ml e de 23,6% naqueles com colesterol de 260 mg/100ml e mais, não são estatisticamente significantes. Peça agora a tabulação da pressão sistólica e doença coronariana. tabulate pas dc, row chi2 pA | doenca coronariana sistolica -| mmHg | nao sim | Total -----------+----------------------+---------<165 | 894 173 | 1067 | 83.79 16.21 | 100.00 -----------+----------------------+---------165+ | 201 95 | 296 | 67.91 32.09 | 100.00 -----------+----------------------+---------Total | 1095 268 | 1363 | 80.34 19.66 | 100.00 Pearson chi2(1) = Apostila Stata 36.9959 Pr = 0.000 27 Observe a diferença nas taxas de incidência de doença coronariana entre aqueles com pA sistólica abaixo de 165 mmHg (16,2%) comparados com aqueles com pA sistólica muito elevada (32,1%). O valor de p para o Qui-quadrado foi de 0.000, portanto considera-se a diferença amostral observada estatisticamente significante. Desse modo, a pA muito elevada é considerada um fator de risco para doença coronariana. tabulate fumo dc, row chi2 | doenca coronariana fumo | nao sim | Total -----------+----------------------+---------nao | 614 134 | 748 | 82.09 17.91 | 100.00 -----------+----------------------+---------sim | 480 134 | 614 | 78.18 21.82 | 100.00 -----------+----------------------+---------Total | 1094 268 | 1362 | 80.32 19.68 | 100.00 Pearson chi2(1) = 3.2612 Pr = 0.071 Interprete os resultados da tabela acima. Baseado nestes resultados há associação entre fumo e doença coronariana ? Apostila Stata 28 Exercícios - arquivo dnma.dta 1) 2) 3) 4) 5) 6) 7) 8) 9) Crie um arquivo DO para processar os dados do arquivo dnma.dta. No arquivo Do dê um comando para gravar o processamento em um arquivo LOG, formato texto. Use o comando keep para trabalhar apenas com os dados de mães residentes no município de São Luís. O código de São Luís é 211130. Recodifique a variável peso ao nascer em <2500 e maior ou igual a 2500 gramas, usando o comando recode Coloque rótulo na variável peso ao nascer. Coloque rótulo nas categorias de peso ao nascer. Peça uma listagem dos rótulos. Qual o percentual de recém-nascidos em São Luís com baixo peso ao nascer? Recodifique a variável idade materna em 3 níveis < 20 anos, 20 a 34 anos e 35 anos e mais. Coloque rótulo na variável idade materna. Coloque rótulo nas categorias de idade materna. Peça uma listagem dos rótulos. Peça uma tabulação das variáveis idade materna e peso ao nascer. Coloque a materna na linha e o peso ao nascer na coluna. Peça o cálculo da porcentagem da 10) 11) 12) 13) idade linha. 14) Quais os percentuais de baixo peso ao nascer de acordo com as categorias de idde materna? 15) Peça uma tabela com o qui-quadrado e verifique se há associação entre idade materna e baixo peso ao nascer. Apostila Stata 29
Baixar