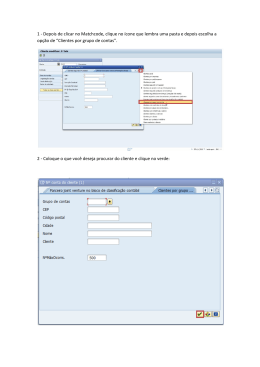
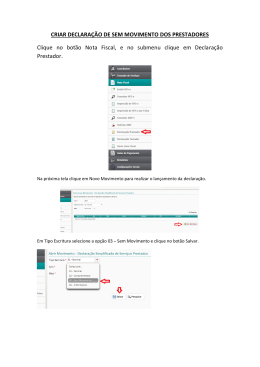
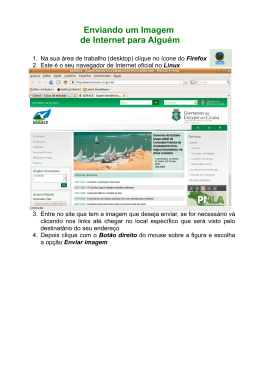
CENTRO ESTADUAL DE EDUCAÇÃO TECNOLÓGICA PAULA SOUZA FACULDADE DE TECNOLOGIA DE LINS PROF. ANTONIO SEABRA CURSO SUPERIOR DE TECNOLOGIA EM BANCO DE DADOS GUSTAVO HENRIQUE RODRIGUES DE JESUS AVALIAÇÃO DE DESEMPENHO EM UM AMBIENTE DE BANCO DE DADOS DISTRIBUÍDO CONSIDERANDO O TRÁFEGO DE PACOTES LINS/SP 1º SEMESTRE/2013 CENTRO ESTADUAL DE EDUCAÇÃO TECNOLÓGICA PAULA SOUZA FACULDADE DE TECNOLOGIA DE LINS PROF. ANTONIO SEABRA CURSO SUPERIOR DE TECNOLOGIA EM BANCO DE DADOS GUSTAVO HENRIQUE RODRIGUES DE JESUS AVALIAÇÃO DE DESEMPENHO EM UM AMBIENTE DE BANCO DE DADOS DISTRIBUÍDO CONSIDERANDO O TRÁFEGO DE PACOTES Trabalho de Conclusão de Curso apresentado à Faculdade de Tecnologia de Lins para obtenção do Título de Tecnólogo (a) em Banco de Dados. Orientador: Prof. Me. Mário Henrique de Souza Pardo LINS/SP 1º SEMESTRE/2013 Jesus, Gustavo Henrique Rodrigues de J58Avaliação de desempenho em um ambiente de banco de dados distribuído considerando o tráfego de pacotes / Gustavo Henrique Rodrigues de Jesus.–Lins, 2013. 135f.: il. Monografia (Trabalho de Conclusão de Curso de Tecnologia em Banco de Dados) – Faculdade de Tecnologia de Lins Prof. Antônio Seabra, 2013. Orientador: Prof. Me. Mário Henrique de Souza Pardo 1.Banco de dados distribuído.2.JMeter. 3.Avaliação de desempenho. 4.Replicação. 5.Linked server. 6.Microsoft SQL server 2008.I.Pardo, Mário Hnrique de Souza. II.Faculdade de Tecnologia de Lins Prof. Antônio Seabra. III.Título. CDD 005.73 Ficha elaboradora pela Biblioteca da Faculdade de Tecnologia de Lins GUSTAVO HENRIQUE RODRIGUES DE JESUS AVALIAÇÃO DE DESEMPENHO EM UM AMBIENTE DE BANCO DE DADOS DISTRIBUÍDO CONSIDERANDO O TRÁFEGO DE PACOTES Trabalho de Conclusão de Curso apresentado à Faculdade de Tecnologia de Lins Prof. Antonio Seabra, como parte dos requisitos necessários para a obtenção do título de Tecnólogo em Banco de Dados sob orientação do Prof. Me. Mário Henrique de Souza Pardo. Data de aprovação: 17 de junho de 2013 __________________________________________________ Orientador: Prof. Me. Mário Henrique de Souza Pardo __________________________________________________ Prof. Me. Anderson Pazin __________________________________________________ Prof. Me. Luiz Fernando de Oliveira Silva Dedicatória Dedico este trabalho, primeiramente, a Deus, pela força dada para superar todas as dificuldades. Em segundo lugar, dedico a minha mãe por todo o apoio que sempre me dá. Dedico também a meu irmão, que faz parte da minha vida e me deu algumas dicas e a minha amiga Rebeca, pelo companheirismo e pela motivação quando tive meus momentos de desânimo. Gustavo Henrique Rodrigues de Jesus AGRADECIMENTOS Neste momento ao qual alcanço um objetivo muito importante para minha vida, quero agradecer as pessoas que fizeram parte durante todo o tempo de estudo e aprendizagem. Agradeço ao prof. Mário Henrique de Souza Pardo, que me orientou e deu dicas importantíssimas para a elaboração deste trabalho e pela amizade durante todos os momentos. Agradeço ao prof. Santarém, o qual tive a honra de conhecer e ter sido aluno. Agradeço ao professor Fábio Lucio Meira, não só pelo fato de ter sido professor, mas mais do que tudo, pela amizade. Ao professor Anderson Pazin, não só pelo profissionalismo e conhecimentos passados durante este período de estudos, mas também pela compreensão e ajuda em um momento difícil na elaboração deste trabalho. Ao professor Alexandre Ponce, por ser um ótimo docente e dar dicas para a composição deste estudo, além dos apontamentos gramaticais e de formatação do mesmo. Ao professor Naylor por se dispor prontamente a ajudar em uma parte deste trabalho. Aos amigos Felipe Maciel e Rafael Hamamura, além da amizade, auxiliaram e muito na parte de montagem do ambiente de testes e disponibilidade para a utilização do mesmo. Ao amigo e chefe Sandro Zamian, que não se opôs a minha ausência quando havia a necessidade de eu realizar testes para este trabalho. Enfim, aos amigos que durante todos os anos de estudos, me permitiu crescer e muito, além da ajuda e amizades verdadeiras. Gustavo Henrique Rodrigues de Jesus “A mente que se abre a uma nova idéia jamais voltará Einstein) ao seu tamanho original” (Albert RESUMO Este trabalho visa avaliar o desempenho em um ambiente de banco de dados distribuído analisando o tráfego dos dados que tramitam em uma rede que integra os hosts deste tipo de ambiente. Para tanto foram realizadas um grande número requisições de dados em tal banco, através de usuários virtuais, a fim de determinar os fatores que influenciam no tráfego desta rede. Houve uma variação, também, no número de hosts. Desta forma, o tráfego gerado permitiu avaliar o comportamento de um banco de dados deste tipo, levando em consideração todos os fatores que compuseram esta pesquisa.Este trabalho expõe conceitos sobre banco de dados distribuído, ferramentas de testes e avaliação de desempenho. Palavras-chave: Banco de dados distribuído. JMeter. Avaliação de desempenho. Replicação. Linked Server. Microsoft SQL Server 2008. ABSTRACT This study aims to evaluate the performance in an environment of distributed databases by analyzing the traffic data that move across a network that integrates the hosts of this type of environment. Therefore, we performed a large number of requests such data bank via virtual user in order to determine the factors that influence the traffic of the network. There was also variation in the number of hosts. Thus, the traffic generated allowed us to evaluate the behavior of a database of this kind, taking into account all factors that composed this search. This work presents concepts on distributed database tools, testing and performance evaluation. Keywords: Database distributed. JMeter. Performance evaluation. Replication. Linked Server. Microsoft SQL Server 2008. LISTA DE ILUSTRAÇÕES FIGURA 1.1 – ARQUITETURADEUM SGBDD HOMOGENÊO ................................ 21 FIGURA 1.2 – ARQUITETURA DE UM SGBDD HETEROGÊNEO .......................... 22 FIGURA 1.3 – FRAGMENTAÇÃO HORIZONTAL ..................................................... 24 FIGURA 1.4 – FRAGMENTAÇÃO VERTICAL .......................................................... 24 FIGURA 1.5 – FRAGMENTAÇÃO MISTA ................................................................. 25 FIGURA 1.6 – REPLICAÇÃO SNAPSHOT ............................................................... 36 FIGURA 1.7 – REPLICAÇÃO TRANSACIONAL ....................................................... 37 FIGURA 1.8 – REPLICAÇÃO MERGE ...................................................................... 39 FIGURA 1.9 – CONFIGURAÇÃO DE SERVIDORES VINCULADOS ....................... 42 FIGURA 2.1 – EQUAÇÃO PARA FATORIAL SIMPLES ........................................... 50 FIGURA 2.2 – EQUAÇÃO PARA FATORIAL COMPLETO ....................................... 51 FIGURA 3.1 – MODELO DE DADOS RELACIONAL ................................................ 55 FIGURA 3.2 – AMBIENTE DE TESTES .................................................................... 57 FIGURA 3.3 – MONITORAMENTO DE PACOTES RECEBIDOS (GRÁFICO) ......... 58 FIGURA 3.4 – MONITORAMENTO DE PACOTES ENVIADOS E RECEBIDOS (TABELA) .................................................................................................................. 59 FIGURA 3.5 – MONITORAMENTO DE PACOTES ENVIADOS E RECEBIDOS ...... 60 FIGURA 3.6 – AMBIENTE FATOR NÚMERO DE HOSTS NÍVEL 3 ......................... 62 FIGURA 3.7 – AMBIENTE FATOR NÚMERO DE HOSTS NÍVEL 6 ......................... 63 FIGURA 4.1 – COMBINAÇÕES DOS NÍVEIS DOS FATORES E RESPOSTAS ...... 72 LISTA DE GRÁFICOS GRÁFICO 4.1 – COMPARATIVO ENTRE OS VALORES MÉDIOS DE CADA EXPERIMENTO ........................................................................................................ 69 GRÁFICO 4.2 – COMPARATIVO LEVANDO EM CONTA O NÚMERO DE USUÁRIOS................................................................................................................ 69 GRÁFICO 4.3 – COMPARATIVO LEVANDO EM CONTA O NÚMERO DE REQUISIÇÕES ......................................................................................................... 70 GRÁFICO 4.4 – COMPARATIVO LEVANDO EM CONTA O NÚMERO DE HOSTS 71 GRÁFICO 4.5 – INFLUÊNCIA DOS FATORES ........................................................ 75 LISTA DE QUADROS QUADRO 2.1 – NÍVEIS, FATORES E RESPOSTAS DE UM PROJETO 22.................... 53 QUADRO 3.1 – QUALIFICAÇÕES DOS HOSTS...................................................... 61 QUADRO 3.2 – FATORES E NÍVEIS PARA AVALIAÇÃO ........................................ 62 QUADRO 3.3 – COMBINAÇÕES ENTRE FATORES E NÍVEIS ............................... 62 QUADRO 4.1 – INTERVALOS DE CONFIANÇA ...................................................... 65 QUADRO 4.2 – ATRIBUIÇÃO DE VARIÁVEIS PARA OS FATORES ...................... 67 QUADRO 4.3 – ATRIBUIÇÃO DE VALORES PARA AS VARIÁVEIS ....................... 67 QUADRO 4.4 – NÍVEIS, FATORES E RESPOSTAS DE UM PROJETO 23.................... 68 QUADRO 4.5 – QUADRO DE COMBINAÇÕES DOS NÍVEIS DOS FATORES ....... 68 QUADRO 4.6 – INFLUÊNCIA DOS FATORES ......................................................... 73 QUADRO 4.7 – SOMA DOS QUADRADOS ............................................................. 74 QUADRO 4.8 – INFLUÊNCIA DOSFATORES .......................................................... 74 LISTA DE ABREVIATURAS E SIGLAS ALM - Application Level Multicasting ANSI-SPARC - American National Standards Institute-Standards Planning and Requirements Committee BDD - Banco de dados distribuído CPU - Central Process Unit DBMS - Databasse Manager System DCE – Distributed Computing Environment DLL - Dynamic Link Library HTTP - HyperText Transfer Protocol HTTPS - HyperText Transfer Protocol Secure IBOPE - Instituto Brasileiro de Opinião Pública e Estatística IC - Intervalo de confiança IP - Internet Protocol JDBC - Java Database Connectivity LDAP - Lightweight Directory Access Protocol MFLOPS - milhões de operações de pontos-flutuantes por segundos MIPS - milhões de instruções por segundo MOM – Message-oriented Middleware MPI – Message-Passing Interface NOWs - network of Workstations ODBC - Open Database Connectivity OSI - Open System Interconnection PC - Personal Computer pps - pacotes por segundo RMI - Remote Method Invocation RPC - Remote Procedure Call SBDD - Sistema de Banco de Dados Distribuído SGBD - Sistema de gerenciamento de banco de dados SGBDD - Sistema de gerenciamento de banco de dados distribuído SO - Sistema Operacional SOAP - Simple Object Access Protocol SQL - Structured Query Language SQT - Soma dos quadrados totais SSH - Secure Shell SST - Sum of Square Total TI - Tecnologia da informação VM - Virtual Machine VMM - Virtual Machine Monitor WANs – Wide Area Networks LISTA DE SÍMBOLOS @ - Arroba ™ - Exactamente ® - Registrado % - Porcentagem SUMÁRIO INTRODUÇÃO .......................................................................................................... 16 1 FUNDAMENTAÇÃO TEÓRICA .............................................................................. 18 1.1 BANCO DE DADOS DISTRIBUÍDOS ................................................................. 18 1.2 ARQUITETURA DE BANCO DE DADOS DISTRIBUÍDOS ................................. 19 1.3 BANCOS DE DADOS HOMOGÊNEOS E HETEROGÊNEOS............................ 20 1.4 TÉCNICAS DE ARMAZENAMENTO DE DADOS DISTRIBUÍDOS .................... 23 1.4.1 Replicação........................................................................................................ 23 1.4.2 Fragmentação .................................................................................................. 23 1.4.3 Fragmentação Mista ......................................................................................... 25 1.5 COMUNICAÇÃO EM BANCO DE DADOS DISTRIBUÍDOS ............................... 25 1.6 ANÁLISE DE TRÁFEGO DE REDE .................................................................... 30 1.7 FERRAMENTAS DE ANÁLISE DE TRÁFEGO DE REDE E PUTTY .................. 31 1.7.1 Putty ................................................................................................................. 32 1.8 VIRTUALIZAÇÃO ................................................................................................ 32 1.8.1 VMware ............................................................................................................ 33 1.9 FERRAMENTAS DE TESTES ............................................................................ 34 1.9.1 JMeter .............................................................................................................. 34 1.10 MICROSOFT SQL SERVER ............................................................................. 34 1.10.1 Tipos de replicação ........................................................................................ 35 1.10.1.1 Replicação Snapshot................................................................................... 35 1.10.1.2 Replicação Transacional ............................................................................. 37 1.10.1.3 Publicação Oracle ....................................................................................... 38 1.10.1.4 Publicação peer-to-peer .............................................................................. 38 1.10.1.5 Replicação Merge........................................................................................ 39 1.10.1.6 Agentes de Replicação................................................................................ 40 1.10.2 Linked Server ................................................................................................. 41 2 AVALIAÇÃO DE DESEMPENHO DE SISTEMAS COMPUTACIONAIS E PLANEJAMENTO DE EXPERIMENTO .................................................................... 43 2.1 AVALIAÇÃO DE DESEMPENHO ........................................................................ 43 2.1.1 Métodos para evitar problemas em projetos de avaliação de desempenho ..... 44 2.1.2 Erros em avaliação de desempenho ................................................................ 45 2.2 PLANEJAMENTO DE EXPERIMENTO............................................................... 46 2.2.1 Terminologia..................................................................................................... 47 2.2.2 Medidas de desempenho ................................................................................. 47 2.2.2.1 Tempo de resposta........................................................................................ 48 2.2.2.2 Throughput .................................................................................................... 48 2.2.3 Carga de trabalho ............................................................................................. 48 2.2.3.1 Tipos de carga de trabalho ............................................................................ 49 2.2.4 Estratégias de projetos de experimentos ......................................................... 49 2.2.4.1 Fatorial simples ............................................................................................. 49 2.2.4.2 Fatorial completo ........................................................................................... 50 2.2.4.3 Fatorial fracionário ......................................................................................... 51 2.2.5 Projetos fatoriais 2k .......................................................................................... 51 2.2.5.1 Projeto fatorial 22 ........................................................................................... 52 2.2.5.2 Soma dos quadrados totais – SQT ............................................................... 53 3 DESENVOLVIMENTO ........................................................................................... 55 3.1 METODOLOGIA .................................................................................................. 55 3.2 AMBIENTE DE TESTES ..................................................................................... 56 3.3 PLANEJAMENTO DE EXPERIMENTOS ............................................................ 61 3.4 RESULTADOS ESPERADOS ............................................................................. 64 4 RESULTADOS E DISCUSSÃO.............................................................................. 65 4.1 INTERVALO DE CONFIANÇA ............................................................................ 65 4.2 QUADRO DE COMBINAÇÕES PARA FATORIAL COMPLETO 23 .................... 67 4.3 RESULTADOS DOS EXPERIMENTOS .............................................................. 68 4.4 INFLUÊNCIA DOS FATORES ............................................................................ 72 CONSIDERAÇÕES FINAIS ...................................................................................... 77 REFERÊNCIAS BIBLIOGRÁFICAS .......................................................................... 79 ANEXO A .................................................................................................................. 83 ANEXO B .................................................................................................................. 90 ANEXO C ................................................................................................................ 105 ANEXO D ................................................................................................................ 130 16 INTRODUÇÃO Inevitavelmente a busca por informações tende a aumentar cada vez mais com o passar dos anos. Pessoas conectadas a Internet buscam a todo o momento notícias, informações, realizam pesquisas e, com isso, o fluxo de dados limita-se por vários fatores. Dentre estes fatores destacam-se o limite máximo que pode ser alcançado nas redes de computadores e a configuração dos mesmos, que fazem parte dessa rede. Outro fator importante é a disponibilidade das informações para os requisitantes das mesmas. Tais dados são obtidos das bases de dados e estas devem sempre estar disponíveis. Há anos os bancos de dados (ou bases de dados) se tornaram de suma importância para as empresas por armazenarem informações pertencentes a estas. Com a união de um software que gerencia banco de dados, uma base de dados e aplicativos, informações são obtidas facilmente. (SILVA, 2001) De acordo com Elmasri, Navathe (2006, p. 04), "Um banco de dados é uma coleção de dados que se relacionam". Complementando essa informação, Silberschatz, et al. (2006, p. 01) afirmam: "Um sistema de gerenciamento de banco de dados (DBMS) é uma coleção de dados inter-relacionados e um conjunto de programas para acessar esses dados." No início, os sistemas de banco de dados eram centralizados e o acesso a estes eram feitos através de terminais. Com o passar do tempo, os computadores pessoais tiveram uma melhora significativa de velocidade e o custo destes foram reduzindo gradativamente. Assim, estes ocuparam o lugar dos terminais que eram conectados aos sistemas centralizados. (SILBERSCHATZ, et al. , 2006) Segundo Silberschatz, et al. (2006), a interface com os usuários ficaram por conta dos computadores pessoais, enquanto que os sistemas centralizados ficaram responsáveis por atender as solicitações dos sistemas clientes, ou seja, os sistemas centralizados tornaram-se sistemas servidores. Entretanto, problemas com hardwares podem ocorrer e os sistemas servidores podem deixar de atender as requisições dos usuários e, caso não exista uma opção que faça com que o serviço volte a funcionar rapidamente, tais requisições ficam prejudicadas. 17 Mesmo que esse tipo de banco de dados seja utilizado até os dias de hoje, devido aos problemas mencionados anteriormente e devido a grande necessidade de armazenar um número cada vez maior de dados, gerenciar estes de forma centralizada tornou-se uma tarefa árdua a ser realizada. (SHIBAYAMA, 2004) Uma alternativa utilizada atualmente para solucionar estes tipos de problemas é o uso de um banco de dados configurado como um sistema distribuído que, por ter a base em vários computadores, caso um deixe de funcionar, as requisições de dados serão supridas, pois os outros computadores ainda estarão ativos na rede. De acordo com Shibayama (2004), os dados são distribuídos em vários computadores, sendo que cada nó tem autonomia dos dados armazenados em si próprios e, mesmo assim, consegue compartilhar estes com outros nós. O presente trabalho tem como objetivo avaliar o desempenho em um sistema de banco de dados distribuído levando em consideração o tráfego de rede deste sistema computacional. Este estudo se faz necessário pois através das coletas de dados foram feitas análises que evidenciaram quais dos três fatores (número de usuários,número de requisições e número de hosts) que compõem o ambiente de testes devem ser levados mais em conta por um administrador de banco de dados distribuídos. Neste trabalho, a fundamentação teórica é descrita no primeiro capítulo, evidenciando o que vem a ser um banco de dados distribuídos, sua arquitetura e como é feita a comunicação em um banco de dados deste tipo. Ainda neste mesmo capítulo são descritas as ferramentas de análise de tráfego de rede, bem como a análise de tráfego em si e o sistema gerenciador de banco de dados SQL Server 2008. No segundo capítulo é descrita a avaliação de desempenho de sistemas computacionais e como elaborar um planejamento de experimento. No terceiro capítulo é apresentado o desenvolvimento do projeto com a descrição do ambiente de testes e o planejamento dos experimentos, a metodologia adotada e os resultados esperados. No quarto capítulo são expostos os resultados obtidos e elaborada uma discussão com base nos valores e gráficos gerados sobre os resultados dos experimentos. Por fim são dispostas as conclusões sobre o trabalho. 18 1 FUNDAMENTAÇÃO TEÓRICA 1.1 BANCO DE DADOS DISTRIBUÍDOS Banco de Dados Distribuídos, segundo Bell e Grimson (1992, p. 44), "[...] pode ser definido como uma coleção logicamente integrada de dados distribuídos que é distribuída fisicamente através dos nós de uma rede de computadores". De acordo com Shibayama (2004, p. 13), “[...] banco de dados distribuído é definido como uma coleção de vários bancos logicamente inter-relacionados (integração lógica significa que qualquer nó tem acesso potencial a todo o banco de dados), distribuídos ao longo de um sistema de redes de computadores [...]”. Segundo Pukdesree et al (2010, p. 01), "as informações contidas em um ambiente de dados distribuídos são decompostas em pequenos pedaços e, em seguida, distribuídas para serem armazenadas em vários computadores”. Reforçando esta informação, Elmasri e Navathe (2005) pontuam que "sistemas de computação distribuídos dividem um problema grande e intratável em partes menores e os resolvem eficientemente de maneira coordenada". Em sistemas de banco de dados distribuídos existem dois tipos de transações: as locais e as globais. Nas transações locais os dados acessados são aqueles que estão no próprio computador em que a requisição foi feita. Já nas globais, os dados acessados não estão no computador de onde saiu a requisição, mas sim em um ou vários que compõem a rede de computadores deste sistema (SILBERSCHATZ et al, 2006) De acordo com Banerjee et al (1993), o aumento de capacidade ou largura de banda das redes de computadores ocasionou avanços nos estudos em sistemas de banco de dados distribuídos. Existem várias vantagens para a utilização de banco de dados distribuídos. Dentre estes estão disponibilidade, autonomia, confiabilidade, controle e compartilhamento de dados. Os conceitos de autonomia e compartilhamento, segundo Silberschatz et al (2006), são: Compartilhamento de dados: um usuário consegue acessar os dados que estão em outros computadores da rede; 19 Autonomia: refere-se à distribuição do controle sobre os dados armazenados localmente. Isso quer dizer que existe um administrador de banco de dados global, responsável pelo sistema inteiro e existem os administradores de banco de dados locais, que possuem graus de autonomia local diferenciados entre eles. Já sobre a disponibilidade de um sistema distribuído, Tanenbaum e Steen (2008, p. 02) dizem: [...] um sistema distribuído estará continuamente disponível, embora algumas partes possam estar temporariamente avariadas. Usuários e aplicações não devem perceber quais são as partes que estão sendo substituídas ou consertadas, ou quais são as novas partes adicionadas para atender a mais usuários ou aplicações. Para gerenciar um banco de dados distribuídos existem sistemas de gerenciamento de banco de dados distribuídos (SGBDD) que tornam a distribuição de dados transparente para o usuário (Shibayama, 2004). De acordo com Elmasri e Navathe (2005), o usuário deste tipo de banco de dados não sabe onde estão fisicamente os dados requisitados ou onde ficarão armazenados os dados enviados por este, devido a essa característica de transparência de distribuição. Processamento distribuído, porém, possui suas desvantagens, dentre as quais se destacam os custos, que são maiores, e o desenvolvimento, que é mais demorado, pois coordenar e controlar os dados são tarefas mais árduas. De acordo com Silberschatz et al (2006, p. 538), deve-se também tomar cuidado com a atomicidade das transações, pois “[...] uma transação executada por dois computadores, em uma ela pode confirmar algo e em outra ela pode abortar, ocasionando um estado inconsistente”. Com relação aos tipos de redes, existem duas: redes locais e redes remotas. Nas locais, os computadores estão localizados fisicamente próximos, podendo estar localizados em um mesmo prédio ou em prédios próximos. Já nas remotas, os nós estão geograficamente separados por grandes distâncias (ELMASRI; NAVATHE, 2005). A comunicação em banco de dados distribuídos é melhor detalhada no subtópico 1.5 – Comunicação em BDD. 1.2 ARQUITETURA DE BANCO DE DADOS DISTRIBUÍDOS 20 Silberschatz et al (2006) dizem que um sistema distribuído é formado por nós ou hosts interligados, por exemplo, por redes, onde os dados são armazenados de forma replicada ou fragmentada nesses nós, e que nesse tipo de sistema não há o compartilhamento de memória principal ou discos. Sanches (2005) define a arquitetura de banco de dados distribuídos da seguinte maneira: As informações estão distribuídas em diversos setores, os quais cada um destes atua como no sistema cliente-servidor, ou seja, o servidor executa as consultas nos sistemas de gerenciamento de banco de dados e retorna os resultados ao cliente, porém as consultas vindas dos aplicativos são feitas para qualquer servidor indistintamente. O sistema de gerenciamento de banco de dados deste tipo é baseado na arquitetura ANSI-SPARC (American National Standards Institute-Standards Planning and Requirements Committee), que define uma arquitetura em três níveis independentes: interno, conceitual e externo. O nível interno é o que mais se aproxima do armazenamento físico dos dados onde, segundo Elmasri e Navathe (2005, p. 22), “descreve detalhes complexos de armazenamento de dados e caminhos de acesso ao banco de dados.” O nível externo ou lógico é o nível mais alto, sendo mais próximo dos usuários, onde Elmasri e Navathe (2005, p. 23) colocam que este “[...] descreve a parte do banco de dados que um dado grupo de usuários tem interesse e oculta o restante do banco de dados desse grupo”. De acordo com Tanenbaum e Steen (2008, p. 02), “o nível mais alto é composto por usuários e aplicações”. Por fim, o nível conceitual ou lógico comunitário ou simplesmente indireto, é o nível intermediário entre os níveis interno e externo. 1.3 BANCOS DE DADOS HOMOGÊNEOS E HETEROGÊNEOS Bancos de dados distribuídos são classificados em dois tipos: homogêneos e heterogêneos. Nos bancos de dados homogêneos, todos os computadores utilizam os mesmos SGBDs de mesmo fabricante. Casanova e Moura (1999, p.03) exprimem que “um sistema de gerenciamento de banco de dados distribuídos é homogêneo se todos os seus SGBDs locais 21 oferecerem interfaces idênticas ou, pelo menos, da mesma família; fornecem os mesmos serviços aos usuários em diferentes nós”. Ainda sobre um sistema de banco de dados distribuído homogêneo, Silberschatz et al (2006, p. 561) dizem que “todos os sites possuem software de sistema de gerenciamento de banco de dados idêntico, conhecem um ao outro e concordam em cooperar nas solicitações dos usuários do processamento”. A seguir uma ilustração da arquitetura de um sistema de gerenciamento de banco de dados distribuídos (Figura 1.1). Baseando-se nessa figura, Bell e Grimson (1992, p. 45) afirmam que em um SGBDD “[...] não existem usuários locais, todos acessam a base de dados através de uma interface global”. Figura 1.1 – Arquitetura de um SGBDD homogêneo Fonte: Bell; Grimson, 1992, p.46 Nos bancos de dados distribuídos heterogêneos, os sistemas gerenciadores utilizados nos computadores são diferentes, podendo “ser baseados no mesmo modelo de dados (ORACLE, por exemplo) ou em modelo de dados diferentes (relacional, hierárquico ou rede).” (BELL; GRIMSON, 1992, p. 52) Complementando essa informação, Silberschatz et al (2006) ainda afirmam que os computadores que compõem o sistema distribuído podem não estar cientes da existência dos outros deste mesmo sistema e, ao contrário da contribuição nos 22 sistemas homogêneos, aqui pode ocorrer uma cooperação limitada no processamento de transações. Bell e Grimson (1992, p. 52) dizem que “tais computadores podem possuir diferentes hardwares, sistemas operacionais dos mais variados e diferentes protocolos de rede”. Silberschatz et al (2006) afirmam que para a manipulação dos dados em um banco de dados heterogêneo existe a necessidade de uma camada de software adicional conhecida como middleware, a qual, ilusoriamente, integra a lógica de banco de dados diferentes neste tipo de sistema, sem a necessidade de haver a integração física dessa base de dados. Figura 1.2 – Arquitetura de um SGBDD heterogêneo Fonte: Bell; Grimson, 1992, p.49 Existem usuários locais e globais neste tipo de sistema. De acordo com Bell e Grimson (1992, p. 48), SBDD heterogêneo “integra recursos de dados heterogêneos pré-existentes, embora sistemas homogêneos possam ser adequados também e que uma importante característica deste sistema é que os usuários locais continuam acessando suas bases de dados locais sem afetar a existência da multibase de dados”, como disposto na Figura 1.2. 23 1.4 TÉCNICAS DE ARMAZENAMENTO DE DADOS DISTRIBUÍDOS Com o uso de banco de dados distribuídos, existem duas formas para armazenar dados no banco. Estas são: replicação e fragmentação, com suas variações. Tais técnicas são descritas nos sub-tópicos a seguir. 1.4.1 Replicação De acordo com Silberchatz et al (2006, p.562), a técnica de replicação ocorre quando "o sistema mantém várias réplicas (cópias) idênticas da relação e armazena cada uma em um site (computador) diferente." Partindo deste princípio, utilizando-se replicação aumenta-se a disponibilidade e o paralelismo, ou seja, referente a disponibilidade, caso um computador que compõem o sistema distribuído sofra algum problema, as informações requeridas podem ser obtidas em outro computador deste tipo de sistema. Já em relação ao paralelismo, consultas podem ser processadas em vários computadores e a informação necessária pode ser obtida no site no qual a consulta está sendo executada, diminuindo assim o tráfego de dados entre os sites. (SILBERCHATZ et al, 2006) Esta técnica privilegia operações de leitura, mas tem problemas em operações de escrita, pois as atualizações devem ser feitas em todas as replicações existentes. De acordo com Siqueira (2012), sobre atualizações de réplicas, o mesmo diz que estas podem ocorrer de três formas: instantâneo (snapshot), incremental e transacional. Sobre snapshot, as cópias das tabelas são feitas de forma completa, tendo ou não atualizações periódicas. Já sobre incremental, a transferência dos dados alterados são feitos em um horário programado. Por fim, sobre transacional, as atualizações são feitas instantaneamente nas réplicas, ou seja, no momento de sua modificação. 1.4.2 Fragmentação Fragmentação ocorre quando uma tabela é dividida em vários fragmentos. Sobre fragmentação, Silberchatz et al (2006, p.562) dizem que "estes fragmentos contém informações suficientes para permitir a reconstrução da relação original." 24 Existem dois tipos básicos de fragmentação: a horizontal e a vertical. Sobre a horizontal, Mesquita (1998, p.22) diz que este tipo de fragmentação "consiste no particionamento das tuplas de uma relação global em subconjuntos." Cada tupla desta relação deve pertencer a pelo menos um dos servidores e para que a relação completa seja obtida, faz-se necessário a união destes fragmentos. A Figura 1.3 evidência um exemplo deste tipo de fragmentação, levando em consideração a cidade e os dados a ela referentes. Figura 1.3 – Fragmentação horizontal Fonte: elaborado pelo autor Ainda sobre fragmentação horizontal, Silberchatz et al (2006) dizem que esse tipo de fragmentação é bastante usada para manter tuplas em sites nos quais elas são mais utilizadas, para que ocorra a diminuição de tráfego de dados. Sobre fragmentação vertical, Shibayama (2004) a define como a divisão vertical de uma relação, através de colunas, em que um fragmento vertical de uma relação mantém apenas alguns atributos desta relação. Figura 1.4 – Fragmentação vertical Fonte: elaborado pelo autor 25 Complementando essa informação, Mesquita (1998, p.23) diz que a vertical “é realizada considerando-se que os atributos a serem agrupados têm características desejáveis em comum.” A Figura 1.4 demonstra como este tipo de fragmentação ocorre, considerando a mesma relação inteira da Figura 1.3. 1.4.3 Fragmentação Mista De acordo com Silberchatz et al (1996), fragmentações horizontal e vertical podem ser aplicadas, juntamente, sobre um mesmo esquema. Fragmentação mista é um tipo de fragmentação onde os fragmentos são resultantes da aplicação de operações de fragmentos sobre fragmentos, e não sobre relações globais. Estas operações podem ser aplicadas recursivamente, contanto que as regras de fragmentação sejam seguidas. (MESQUITA, 1998, p.24) Ainda sobre fragmentação mista, Mesquita (1998) diz que esta pode ser representada por uma árvore de fragmentação, exemplificada na Figura 1.5, na qual a raiz é representada pela relação EMP. Tal relação é fragmentada, verticalmente, em duas partes. Desta fragmentação é constituído o nó folha EMP 2. A outra parte sofre fragmentação horizontal, gerando outros três nós folhas: EMP3, EMP4 e EMP5. Figura 1.5 – Fragmentação mista Fonte: Mesquita, 1998, p.26 1.5 COMUNICAÇÃO EM BANCO DE DADOS DISTRIBUÍDOS Em um ambiente de banco de dados distribuídos, os computadores são conectados de tal maneira que pareçam como se fossem somente um computador com um desempenho bem mais elevado do que se tais computadores estivessem trabalhando de forma isolada (PUKDESREE et al, 2010). De acordo com Siqueira (2012), o tempo de comunicação pela rede é um fator que pesa diretamente em um sistema distribuído. 26 Em um banco de dados distribuído existem dois tipos básicos de redes de comunicação: as locais e as remotas. De acordo com Silberschatz et al (2006), as redes locais (LANs – Local Area Networks) são normalmente utilizadas em pequenos ambientes tais como departamentos dentro de uma mesma empresa. Com o surgimento deste tipo de conexão, verificou-se que para muitas empresas era mais barato ter um tipo de rede assim, com pequenos computadores interligados, cada qual com suas aplicações, do que um sistema grande. Ainda mais que neste tipo de rede, a comunicação é mais rápida e com uma taxa de erros menor, se comparada a uma rede remota. De acordo com Kurose e Ross (2006, p. 347), “[...] a velocidade de transmissão da maioria das LANs é muito alta”. Em algumas redes mais antigas, a velocidade era de 10Mbps. Atualmente a de 100Mbps tornou-se comum e tem-se velocidades na ordem de 1Gbps e 10Gbps. Já as redes remotas (WANs – Wide Area Networks) ou redes geograficamente distribuídas abrangem uma grande área geográfica, tais como estado ou país. A rede remota mais conhecida nos dias de hoje é a Internet. De acordo com CISCO (2012a), “as WANs geralmente utilizam meios de transmissão fornecidos por prestadoras de serviços de telecomunicações tal como uma companhia telefônica“. Ainda de acordo com CISCO (2012a, p.03), as WANs são utilizadas para conectar diversas redes locais e “uma WAN opera na camada física e na camada de enlace do modelo de referência OSI.” Tanenbaum (2003) diz que os computadores que compõem este tipo de rede são conectados por uma sub-rede de comunicação, ou seja, uma sub-rede. Essa sub-rede é composta por dois componentes diferentes: linhas de transmissão e elementos de comutação. “As linha de transmissão transportam os bits entre as máquinas”. Já os elementos de comutação, estes “são computadores especializados que conectam três ou mais linhas de transmissão onde, quando dados chegam a uma linha de entrada, o elemento de comutação deve escolher uma linha de saída para encaminhá-los.” (Tanenbaum, 2003, p. 31) CISCO (2012a, p. 04) diz que WANs “permitem a opção por conexões seriais de baixo custo e de baixa velocidade, mas conexões de altas velocidades podem ser obtidas por, por exemplo, uma conexão em fibra ótica, porém com um custo mais alto”. 27 Com relação a aplicações, de acordo com Tanenbaum e Steen (2007), devido a necessidade de haver comunicação entre diferentes aplicações, diferentes tipos de comunicação foram gerados. “A principal idéia era que aplicações existentes pudessem trocar informações diretamente [...]” (TANENBAUM; STEEN, 2008, p. 14). Dessa necessidade nasceu um modelo chamado middleware de comunicação. Partindo desse princípio, o Open Group1 desenvolveu “uma tecnologia de software a qual permite a criação de aplicações distribuídas utilizando sistemas heterogêneos chamada Ambiente de Computação Distribuída (DCE – Distributed Computing Environment)” (GOULART, 2002, p. 30). Tem-se incluídos nessa tecnologia “serviços de software que residem acima do sistema operacional, fornecendo interface (middleware) para os recursos de baixo nível do sistema operacional e recursos de rede.” (GOULART, 2002, p. 31) Com a utilização desses serviços, dados e processamento são distribuídos através de toda uma organização. Dentre os serviços DCE, existe a RPC (Remote Procedure Call - Chamada Remota de Procedimento) que, segundo Tanenbaum e Steen (2007, p. 14), “[...] um componente de aplicação pode efetivamente enviar uma requisição a outro componente de aplicação executando uma chamada de procedimento local [...]”. Assim “[...] uma aplicação pode efetivamente acessar recursos distribuídos através da rede.” (GOULART, 2002, p. 31) Sobre o funcionamento da RPC, Tanenbaum e Steen (2007) descrevem que uma chamada de procedimento realizada por uma aplicação empacota os parâmetros do procedimento como uma mensagem e a envia ao servidor. O servidor, por sua vez, recebe essa mensagem, obtêm os parâmetros da mesma e gera um resultado, enviando este à aplicação invocadora como uma mensagem de resposta. Com a crescente utilização da tecnologia de objeto criou-se as RMI (Remote Method Invocation - Invocações de Método Remoto), que permite que objetos em computadores diferentes se comuniquem via chamadas de método remoto. “Essas 1 The Open Group é um consórcio global que possibilita a realização dos objetivos de negócio através de standards de TI. Com mais de 350 organizações como membros, The Open Group tem várias categorias de afiliação que compreendem todos os setores da comunidade de TI – clientes, fornecedores de sistemas e soluções, vendedores de ferramentas, integradores e consultores, bem como acadêmicos e pesquisadores que trabalham em conjunto focando na construção de tecnologia de sistemas abertos. (THE OPEN GROUP, 2012). 28 chamadas parecem invocar métodos em um objeto no mesmo programa, mas na realidade elas têm recursos de rede integrados que comunicam as chamadas de método para outro objeto em um computador separado.” (Deitel; Deitel, 2005, p. 929) Tanenbaum e Steen (2007) afirmam que RMI possui o mesmo princípio de funcionalidade que uma RPC, entretanto, ao invés de funcionar com aplicações, funciona com objetos. Estes tipos de middlewares possuem a desvantagem de que no ato da comunicação, tanto o invocador quanto o servidor devem estar ligados e em funcionamento, alem do que ambos devem saber como interagir um com o outro, causando um forte acoplamento. Devido a isto, foi criado o middleware orientado a mensagem (MOM – Message-oriented Middleware). (TANENBAUM; STEEN, 2007). Tanenbaum e Steen (2007, p. 14) resumem o funcionamento de MOM da seguinte maneira: [...] as aplicações apenas enviam mensagens a pontos lógicos de contato [...]. Da mesma forma, as aplicações podem indicar seu interesse por um tipo específico de mensagem, após o que o middleware de comunicação cuidará para que todas as mensagens sejam entregues a essas aplicações. Os serviços de enfileiramento de mensagens têm o conceito básico de que aplicações se comunicam retirando e colocando mensagens em filas específicas. Estes tipos de serviços “oferecem a capacidade de armazenamento de médio prazo para as mensagens trocadas, sem a necessidade de que o remetente ou o receptor estejam ativos durante a transmissão da mesma.” (TANENBAUM; STEEN, 2007, p. 87) Existe também a interface de passagem de mensagens (MPI – MessagePassing Interface), que é uma biblioteca de troca de mensagens projetada para aplicações paralelas de alto desempenho, redes heterogêneas, ambientes de memória distribuída e NOWs (network of Workstations – rede de estações de trabalho). Essa plataforma nasceu da necessidade de criação de uma plataforma padrão para troca de mensagens que fosse independente do hardware. Por ser projetada para aplicações paralelas, a comunicação é transiente, o que significa que, enquanto remetente e receptor estiverem em atividade, a mensagem é armazenada no sistema. 29 Segundo Tanenbaum e Steen (2007, p. 86), “A MPI considera que a comunicação ocorre dentro de um grupo conhecido de processos”, onde cada grupo recebe um identificador e cada processo dentro de um grupo recebe um identificador. O par formado pelo id do grupo e id de um processo (groupID, processID) identifica a fonte ou o destinatário de uma mensagem. “Vários grupos de processos [...] poderão estar envolvidos em um serviço de computação”, podendo estar em execução simultaneamente. (TANENBAUM; STEEN, 2007, p. 86) Outro tópico importante sobre comunicação em sistemas distribuídos é o multicast (transmissões do tipo um-para-muitos). Conforme Tanenbaum e Steen (2007), a idéia básica do multicasting no nível de aplicação é que os computadores se organizem em uma rede de sobreposição a qual é utilizada para distribuir informações para os seus membros. Porém, o roteamento na rede de sobreposição pode ser menos eficiente que o roteamento no nível de rede, pois os computadores na rede podem transpor vários enlaces físicos. Sobre multicast existem duas abordagens: ALM (Application Level Multicasting ou multicasting na camada de aplicação) e Protocolos Epidêmicos. ALM utiliza uma rede virtual e, segundo Tanenbaum e Steen (2007), existem duas definições essenciais para este tipo de abordagem. Na primeira, os nós se organizam na forma de uma árvore, no qual há um único caminho entre cada par de nós. Na segunda, os nós se organizam na forma de uma malha, na qual cada nó terá vários vizinhos, no que resulta em vários caminhos entre cada par de nós. Esta última abordagem oferece maior confiança na transmissão das informações, pois aqui, caso haja um interrupção em uma conexão, tais informações podem atingir o seu destino utilizando-se de outro caminho. Sobre protocolos epidêmicos, Tanenbaum e Steen (2007, p. 102) dizem que “o principal objetivo deste tipo de protocolo é disseminar informações rapidamente entre um grande conjunto de nós usando somente informações locais, ou seja, não há nenhum componente central que coordena essa propagação de informações.” Aqui existem três tipos de nós. O nó infectado, que é considerado assim se este contiver dados os quais está propenso a emitir para os outros nós. O nó suscetível é o nó que não sabe da existência destes dados. Finalmente, o nó removido, que é o nó já atualizado, mas que não é disposto ou não é capaz de divulgar os dados. (TANENBAUM; STEEN, 2007). 30 Uma das várias formas deste tipo de protocolo é a propagação de boato (gossiping). Sobre o seu funcionamento, Tanenbaum e Steen (2007, p. 103) o descrevem da seguinte maneira: Se o nó P acabou de ser atualizado com o item de dado x, ele contata outro nó arbitrário Q e tenta enviar a atualização a Q. Contudo, é possível que Q já tenha sido atualizado por um outro nó. Nesse caso, P pode perder o interesse em levar adiante a propagação da atualização [...]. Analisando esta descrição, percebe-se que alguns nós poderão não receber as atualizações justamente porque P talvez perca o interesse em levar uma atualização adiante. 1.6 ANÁLISE DE TRÁFEGO DE REDE A análise de fluxo de dados é uma técnica para coleta de informações sobre o possível conjunto de valores calculados em vários pontos em um programa de computador. De acordo com Mark Meiss (2004), “fluxo de rede consiste de um ou mais pacotes enviados de uma fonte (IP, porta) para um destino (IP, porta) usando um certo protocolo de transporte durante algum intervalo de tempo.” A análise de tráfego de rede visa analisar os dados que trafegam em uma rede com o intuito principal de aperfeiçoar a utilização da largura da banda. Potter (2008) define que uma análise de rede, em sua essência, da verificação de evidências da rede, procura determinar informações em relação à segurança, desempenho, integridade, disponibilidade, entre outros fatores relativos a esta rede. Segundo Potter (2008, p.07), “uma análise envolve basicamente a coleta e armazenamento de dados; disseminação e excitação dos dados na rede e, por fim, uma análise dos resultados destes na rede.” Sobre a representação de um fluxo de dados como um vetor, Lucas (2010, p. 10) diz o seguinte: Um vetor de fluxo é um resumo das informações sobre um fluxo, contendo a gravação de quais hosts comunicaram entre si, quando esta comunicação ocorreu, como o tráfego foi transmitido e outras informações básicas sobre a conversação na rede. 31 Existem vários dispositivos para a conexão de redes. Dispositivos como hubs, roteadores e switches atuam nas três primeiras camadas do modelo OSI, (Open System Interconnection) transmitindo dados, cada um da sua maneira. No início não existia um sistema de gerenciamento de redes, ou seja, as decisões do roteamento de pacotes eram feitas, geralmente, pelo próprio hardware. Porém, por volta de 1996, a CISCO inventou um método pelo qual as decisões sobre os roteamentos eram instruídas por fluxos. Desta maneira foi possível obter informações sobre o valor do fluxo que trafegava na rede e disponibilizar as mesmas para um sistema-administrador chamado NetFlow. (LUCAS, 2010). 1.7 FERRAMENTAS DE ANÁLISE DE TRÁFEGO DE REDE E PUTTY Sobre sistema de análise de fluxo, Lucas (2010, p. 11) diz que este tipo de sistema “coleta informações de fluxo e dá ao gerenciador do sistema de análise opções de funcionalidades como as de pesquisa, filtros e imprime para este usuário do sistema as informações do fluxo.” Um sistema de gerenciamento de fluxo básico é composto por três componentes: um sensor, um coletor e um sistema que relata as informações colhidas. (LUCAS, 2010) “Sensores podem ser roteadores, switches, firewall com capacidade integrada para exportar fluxo. Sensores também podem ser um software capaz de ouvir o tráfego que ocorre na internet”. (LUCAS, 2010, p. 11) Conhecidos também como sondas, os sensores tem como funcionalidade ouvir o tráfego na rede e coletar dados da mesma. (LUCAS, 2010) Lucas (2010) define o coletor como um software que recebe as gravações do sensor e os armazena em um disco. Por fim, o sistema de comunicação é o responsável por ler os arquivos gerados pelo coletor e transpô-los em relatórios os quais os usuários deste sistema consigam compreender tais informações. (LUCAS, 2010) Várias são as ferramentas de gerenciamento (administração) de fluxo de dados existentes no mercado, dentre as quais se encontram Cisco IOS NetFlow, Zabbix, ntop, etc. Sobre Cisco IOS NetFlow, o mesmo é descrito por CISCO (2012) da seguinte maneira: 32 CISCO IOS NetFlow fornece de forma eficiente um conjunto essencial de serviços para aplicações IP, incluindo contagem de tráfego de rede, planejamento e segurança de rede, serviço de monitoramento de permissões e de rede. NetFlow fornece informações sobre usuários e aplicações de rede, horários de pico de utilização e roteamento de tráfego. Sobre o software Zabbix, Zabbix (2012) o descreve da seguinte maneira: Zabbix é um software que monitora vários parâmetros de uma rede; a saúde e a integridade dos servidores. Zabbix usa um mecanismo de notificação flexível que permite aos usuários configurar e-mail alertas baseados em praticamente todos os eventos. Isto permite uma reação rápida aos problemas do servidor. Zabbix oferece relatórios e visualização de dados com excelentes características baseado nos dados armazenados. Isso faz do Zabbix ideal para o planejamento de capacidade. 1.7.1 Putty Putty é definido como “uma implementação livre de protocolos de rede Telnet e SSH (Secure Shell) para plataformas Windows e Unix, junto com um emulador de terminal xterm. É escrito e mantido principalmente por Simon Tatham.” (PUTTY, 2013) Basicamente este software é utilizado para se faça conexões com servidores remotos fazendo uso de protocolos de rede SSH e Telnet. Então, este será utilizado para acesso ao sistema de gerenciamento do switch, em seu modo texto. 1.8 VIRTUALIZAÇÃO Sobre virtualização, RedHat (2012, p.01) diz que a “virtualização permite que várias instâncias do sistema operacional sejam executadas simultaneamente em um computador. É uma forma de abstrair o hardware de um único sistema operacional.” Complementando essa informação, IBM Global Education (2007, p.03) diz que “um computador virtual é uma representação lógica de um computador em software.” Conforme RedHat (2012), os sistemas operacionais virtualizados são controlados e monitorados por um VMM (Virtual Machine Monitor), conhecidos também por hypervisor. IBM Global Education (2007) afirma que em um ambiente de virtualização, um computador físico, através da execução de softwares, obtém recursos desta 33 máquina física para que estes possam ser utilizados entre os vários computadores virtuais que compõem este ambiente virtual. RedHat (2012) fala que nos sistemas virtualizados (convidados), para que estes utilizem apenas os recursos necessários para sua execução, o controle é feito por um operador que consegue controlar o uso da CPU, armazenamento, memória e outros recursos desse sistema convidado. IBM Global Education (2007) afirma que cada máquina virtual pode rodar diferente sistema operacional de outras máquinas virtuais que estão instaladas em um mesmo computador físico. As formas de virtualização podem ser desktop e servidor. A virtualização de desktop pode ser utilizada para estudos e testes sem que haja alteração nos registros do sistema operacional da máquina física. Já em relação a virtualização de servidores, IBM Grobal Education (2007, p.04) afirma que este tipo de virtualização “permite que um servidor físico possa ser particionado para rodar múltiplos servidores virtuais seguros.” Ainda sobre virtualização de servidores, IBM Global Education (2007) diz que utilizando-se esta técnica reduz-se o custo de aquisição de novas máquinas. Atualmente existem várias ferramentas para a virtualização de computadores. Dentre elas, as mais conhecidas são VirtualBox e VMware. Para a elaboração e execução deste projeto, foi utilizada a ferramenta VMware. 1.8.1 VMware Como ferramenta de virtualização, a VMware possui uma variedade de produtos. Dentre estes produtos estão VMware Workstation, VMware Server e VMware Player. O VMware Workstation encontra-se em sua nona versão e é voltado para o uso em desktops. Este produto é pago, mas pode ser usado gratuitamente por um período, para testes. Ele permite que as várias máquina virtuais instaladas em um computador pessoal possam interagir umas com as outras através da utilização dos recursos de rede que o VMware Workstation traz consigo. Alem dos recursos de rede, a Workstation também inclui recursos de dispositivos e de compartilhamento de arquivos. A instalação pode ser feita em máquinas que possuam tanto arquitetura de 32 bits quanto de 64 bits. 34 O VMware Server é um produto gratuito que foi descontinuado em 2011, ou seja, não existe mais suporte, por parte do desenvolvedor, para este produto. A dona do produto informou que o suporte deste terminou no dia 30 de junho de 2011 e que os usuários são livres para usar o mesmo. Porém, VMware indica que os usuários devem migrar para outros produtos dessa desenvolvedora, que possuem suporte ativo. O VMware Server oferece virtualização de servidores com o intuito de otimizar a utilização de suas máquinas da área de TI. O terceiro produto aqui citado, de nome VMware Player, é gratuito para uso pessoal e permite a fácil criação e implementação de máquinas virtuais em um computador. Segundo VMware (2012c), “VMware Player é a maneira mais fácil de executar diversos sistemas operacionais ao mesmo tempo em seu PC.” Esta versão também tem sua versão para uso comercial. 1.9 FERRAMENTAS DE TESTES 1.9.1 JMeter “A aplicação desktop Apache JMeter é um software de código aberto, desenvolvido 100% em Java, projetado para carregar testes funcionais de comportamento e medição de desempenho.” (JMETER, 2012) Ainda de acordo com o desenvolvedor, JMeter foi inicialmente elaborado para testar aplicações web, mas atualmente pode ser utilizado para outras funções de testes. “A aplicação pode ser usada para testar desempenho de recursos dinâmicos e estáticos” (JMETER, 2012). De acordo com JMETER, a aplicação pode avaliar e testar desempenho de recursos de diferentes tipos de servidores, tais como: em relação a Web – HTTP e HTTPS, SOAP (Simple Object Access Protocol), Base de dados via JDBC, LDAP (Lightweight Directory Access Protocol), entre outros. JMeter pode ser usado para testes de cargas pesadas em servidores, rede ou objetos, para testar a força destes ou para analisar o desempenho do sistema como um todo, com o uso de diferentes tipos de carga. (JMETER, 2012). 1.10 MICROSOFT SQL SERVER 35 SQL Server é um sistema gerenciador de banco de dados utilizado por uma grande variedade de profissionais para realizar diferentes tipos de funções. “SQL Server 2008, versão 10, é uma evolução natural do SQL Server, acrescentando gerenciamento baseado em políticas, compreensão de dados, administrador de recursos, alem de novos tipos de dados relacionais.” (NIELSEN et al, 2009, p.13). SQL Server é muitas vezes necessário em todas as organizações nacionais ou globais, e replicação SQL Server é frequentemente utilizada para mover os dados. Serviços de replicação podem movimentar transações one-way ou atualizações merge de múltiplas localidades, utilizando uma topologia publicador-distribuidorassinante. (NIELSEN et al, 2009, p.11) De acordo com Nielsen et al (2009), os servidores da topologia de replicação são de três tipos: Publicador: servidor de origem; Distribuidor: em replicações transacionais e replicações peer-to-peer, o distribuidor é o local onde as mudanças são armazenadas até as mesmas serem replicadas para o servidor de destino. Já para replicação merge, o distribuidor é apenas um repositório; Subscritor: servidor de destino. 1.10.1 Tipos de replicação Nielsen et al (2009) dizem que o SQL Server 2008 oferece cinco tipos de replicação, cada qual atendendo a um determinado objetivo. Tais tipos são: replicação snapshot, replicação transacional, publicação Oracle, replicação peer-topeer e replicação merge. 1.10.1.1 Replicação Snapshot Na replicação snapshot, uma imagem dos objetos do banco de dados é feita como se fosse uma foto tirada em um determinado momento e esta imagem é copiada do servidor de origem para o servidor de destino. Conforme Nielsen et al (2009), a geração e implantação de imagens podem ser agendadas. 36 Figura 1.6 – Replicação Snapshot Fonte: Lima, 2011, p.28 O SQL Server utiliza alguns componentes para implementar esse tipo de replicação. Um dos componentes é o Snapshot Agent, que é responsável por preparar os arquivos da replicação, armazená-los na pasta de distribuição e registrar uma nova replicação no banco de dados do Distribuidor. A pasta de distribuição é escolhida assim que é configurado o Distribuidor, podendo ser uma pasta local ou remota. Geralmente, os Snapshots são gerados e replicados assim que a publicação é assinada. Em seguida, um outro serviço é acionado, o Distribution Agent. Esse serviço também executa no Distribuidor e é responsável por propagar a distribuição em todos os Assinantes. (LIMA, 2011, p.27) Conforme MSDN (2013c), a replicação de instantâneo pode ser usada de forma isolada, porem, o processo de instantâneo, o qual MSDN (2013c) diz que é “o 37 processo que cria uma cópia de todos os objetos e dados especificados por uma publicação” é regularmente utilizado para fornecer “o conjunto inicial dos dados e dos objetos do banco de dados para publicações de mesclagem e transacionais” (MSDN, 2013c) Este tipo de replicação é mais bem utilizada quando a maioria dos dados raramente mudam. Quando isto ocorre, a mudança ocorre ao mesmo tempo em todas as replicações. (NIELSEN et al., 2009) 1.10.1.2 Replicação Transacional Conforme Nielsen et al (2009), neste tipo de replicação, as transações que ocorrem no servidor de origem são capturadas de forma assíncrona e armazenadas em um repositório, e então são aplicadas, também de forma assíncrona, no servidor de destino. Figura 1.7 – Replicação transacional Fonte: Lima, 2011, p.30 38 Nielsen et al (2009) dizem que o repositório em que são armazenadas as transações é chamado de banco de dados de distribuição. Nessa replicação, o SQL Server utiliza, além dos componentes Snapshot Agent e Distribution Agent, o componente Log Reader Agent. O Snapshot agente só é executado quando a assinatura é iniciada e executa as mesmas operações da replicação Snapshot. Em seguida o Distribution Agent se encarrega de fazer a distribuição para todos os Assinantes. Com todos os Assinantes sincronizados, o serviço Log Reader Agent é acionado. Esse serviço monitora o log de transações de cada banco de dados configurado para a replicação Transactional e copia as transações marcadas para replicação do log de transações no banco de dados de distribuição, que atua como uma fila confiável para armazenar e avançar. Sempre que o Log Reader Agent identifica uma nova atualização e armazena no banco de dados do Distribuidor, essa atualização já pode ser distribuída pelo Distribution Agent aos Assinantes, de acordo com o intervalo de tempo que foi configurado no Distribuidor. Os Assinantes recebem as transações na mesma ordem em que foram aplicados no Publicador. Se uma assinatura estiver marcada para validação, o Distribution Agent também verificará se os dados do Publicador e do Assinante coincidem. A Figura 1.7 demonstra como o Transactional Replication funciona. (LIMA, 2011, p.29) No sub-tópico a seguir será disposto como a publicação Oracle funciona e as suas particularidades de funcionamento. 1.10.1.3 Publicação Oracle De acordo com Nielse et al (2009), publicação Oracle é uma variação da replicação transacional, ou seja, ao invés de o servidor origem ser um SQL Server, este será um servidor Oracle, e as mudanças que ocorrerem são replicadas do servidor Oracle para o SQL Server. Ainda de acordo com os autores, este tipo de publicação está disponível somente na versão SQL Server Enterprise Edition e versões superiores. 1.10.1.4 Publicação peer-to-peer Este tipo de publicação também é uma variação da replicação transacional e é usada para replicar dados para um ou mais nós (computadores). Nielsen et al (2009) dizem que neste tipo de publicação, cada nó pode publicar dados para os nós que são membros em uma topologia de replicação peer-to-peer. Ainda de acordo 39 com os autores, quando ocorre alguma mudança e um nós está desligado, a alteração nesse nó será feita quando o mesmo estiver ativo. As mudanças neste tipo de publicação ocorrem de maneira bi-direcional, ou seja, alterações feitas em um determinado nó são replicadas para os outros, bem como este nó recebe as alterações efetuadas nestes outros nós. Os autores ainda dizem que este tipo de replicação pertence a versão Enterprise Edition e que é escalável para aproximadamente dez nós. 1.10.1.5 Replicação Merge A replicação merge é utilizada para mesclar mudanças que ocorrem tanto nos servidores de destino quanto nos servidores de origem. Figura 1.8 – Replicação merge Fonte: Lima, 2011, p.31 40 A replicação to tipo Merge Replication inicia como a replicação to tipo Transactional, fazendo primeiro uma replicação do tipo Snapshot do Publicador para os Assinantes, sincronizando todas as bases. A partir daí, todas as alterações feitas no Publicador passam a ser rastreadas. Sempre que o Assinante está conectado à rede, as alterações feitas após a última sincronização são replicadas do Publicador para o Assinante. A Figura 1.8 demonstra o funcionamento da Merge Replication. Essa replicação utiliza o componente Snapshot Agent para criar o arquivo de instantâneo e o componente Merge Agent para distribuir as Publicações entre os Assinantes. O Merge Agent mescla as alterações de dados que ocorrem no Publicador com os dados dos Assinantes quando os mesmos estão disponíveis. (LIMA, 2011, p.30) “Com replicação merge, existe uma administradora central para mudanças que determina quais mudanças serão feitas nas bases de dados.” (NIELSEN et al, 2009, p.816) Conforme descrito neste capítulo, as replicações fazem uso de alguns programas chamados agentes. No sub-tópico a seguir serão expostos estes agentes. 1.10.1.6 Agentes de Replicação De acordo com MSDN (2013a), “a replicação usa um número de programas autônomos chamados agentes, para executar as tarefas associadas ao rastreamento de alterações e dados de distribuição.” Ainda segundo MSDN (2013a), tais agentes rodam como tarefas agendadas sob o Agente SQL Server e que o Agente SQL Server deve estar rodando para os trabalhos que ainda virão a ser executados. Nielsen et al. (2009, p. 816) dizem que para realizar toda a carga de trabalho requerida na troca de dados entre os vários servidores em uma publicação, a replicação SQL Server faz uso de três agentes: Snapshot Agent (Agente de Instantâneo), Distribution Agent (Agente de distribuição) e o Merge Agent (Agente de mesclagem). Conforme MSDN (2013a), o agente de instantâneo é “normalmente usado com todos os tipos de replicação.” Ainda conforme MSDN (2013a), este tipo de agente é o que “prepara o esquema e os arquivos de dados iniciais das tabelas publicadas e de outros objetos, armazena os arquivos snapshot e registra as 41 informações sobre a sincronização no banco de dados de distribuição.” Tal agente roda no distribuidor. Já o agente de distribuição é “utilizado com a replicação de instantâneo e replicação transacional” (MSDN, 2013a). Segundo Nielsen et al, (2009, p.816) “usa a replicação de instantâneo inicialmente no Assinante e utiliza a replicação transacional para replicar mudanças subseqüentes que ocorrem no publicador para o subscritor.” Por fim o agente de mesclagem que, conforme Nielsen et al. (2009, p.817), “detecta mudanças que ocorreram no publicador e no subscritor desde a última vez que os agentes rodaram e os mesclam para formar um conjunto consistente em ambos publicador e subscritor.” 1.10.2 Linked Server Muitas vezes existe a necessidade de obter dados de uma base de dados que está em um servidor diferente. Dito isto, com a utilização do Linked Server (Servidores Vinculados), é possível realizar o acesso a base de dados que não somente estão em servidores diferentes, como também podem estar fora da instância do SQL Server, podendo ser outro produto de banco de dados, tal como ORACLE. (MSDN, 2013b) Complementando esta informação, Nielsen et al. (2009, p.693) dizem que “um servidor vinculado pode ser um servidor SQL ou qualquer outra fonte de dados com provedor OLE DB ou drivers ODBC.” De acordo com MSDN (2013b), os Linked Servers oferecem as seguintes vantagens: Capacidade de acesso aos dados de fora do SQL Server. Capacidade de emitir consultas distribuídas, atualizações, comandos e transações em fontes de dados heterogêneos. Capacidade de endereçar de forma semelhante diversas fontes de dados. MSDN (2013b) informa que um servidor vinculado possui os seguintes objetos: um provedor OLE DB e uma fonte de dados OLE DB. “Um provedor OLE DB é uma DLL (Dynamic Link Library – Biblioteca de Vínculo Dinâmico) que gerencia e interage com uma fonte de dados específica. Uma fonte de dados de OLE DB identifica o banco de dados específico que pode ser acessado por meio de OLE DB.” 42 Figura 1.9 – Configuração de Servidores Vinculados Fonte: MSDN, 2013b Normalmente, servidores vinculados são usados para manipular consultas distribuídas. Quando um aplicativo cliente executa uma consulta distribuída através de um servidor vinculado, o SQL Server analisa o comando e envia solicitações ao OLE DB. Essa solicitação de conjunto de linhas pode ser a execução de uma consulta em relação ao provedor ou a abertura de uma tabela base do provedor. Para que uma fonte de dados retorne dados através de um servidor vinculado, seu provedor de OLE DB (DLL) deve estar presente no mesmo servidor da instância do SQL Server. Quando é usado um provedor de OLE DB de terceiros, a conta sob a qual o serviço do SQL Server é executado deve ter permissões de leitura e execução no diretório e em todos os subdiretórios no qual o provedor está instalado. (MSDN, 2013) Este capítulo expôs fundamentações teóricas sobre banco de dados distribuídos, ferramentas de testes e virtualização, e as ferramentas utilizadas para implementar o ambiente de testes deste trabalho. O capítulo seguinte define avaliação de desempenho e como conduzir a mesma para que problemas futuros sejam evitados. No mesmo capítulo também é exposto como deve ser realizado o planejamento de experimentos, os tipos de estratégias para projetos de experimentos, bem como as terminologias e fórmulas utilizadas neste planejamento. 43 2 AVALIAÇÃO DE DESEMPENHO DE SISTEMAS COMPUTACIONAIS E PLANEJAMENTO DE EXPERIMENTO 2.1 AVALIAÇÃO DE DESEMPENHO Desempenho é um critério fundamental na elaboração de um projeto, aquisição e utilização de um sistema de computador, conforme destaca Jain (1991). Sobre sistema, o mesmo diz que é uma coleção de hardware, software e componentes de firmware. Existem duas ferramentas para efetuar a medição de performance de um sistema de computador: uma utilizada para saturar o sistema (gerador de carga) e uma outra para medir os resultados (monitor). Para que uma avaliação de desempenho seja bem sucedida é necessário que o elaborador dos testes tenha um profundo conhecimento do sistema que será avaliado, devendo elaborar uma cuidadosa seleção de metodologia, escolher as ferramentas adequadas e as cargas de trabalho necessárias. (JAIN, 1991) Os critérios usados para avaliar o desempenho de um sistema são conhecidos como métricas. O tempo de resposta (tempo para requisitar um serviço) é um tipo de métrica que pode ser usada para comparar dois sistemas. (JAIN, 1991) Segundo Jain (1991), o conjunto formado por requisições feitas por usuários de sistema são chamadas de workloads (cargas de trabalho). As cargas de trabalho de um sistema de banco de dados consistem de consultas e outras requisições executadas pelos usuários. Simplesmente comparar a média dos resultados de um número de experimentos repetidos não conduz a conclusões corretas, ainda mais se a variabilidade dos resultados é alta. Variações podem ocorrer caso simulações ou medições sejam feitas muitas vezes. Tais variações também podem ocorrer de forma quase imperceptível, o que acaba gerando um resultado diferente para cada teste. Para evitar estes problemas, o mesmo aconselha que uma técnica de estatística apropriada deve ser tomada. Experimentos e simulações devem ser bem elaborados para que o número máximo de informações seja obtido com o mínimo de esforço. Para que simulações sejam realizadas corretamente é necessário escolher uma linguagem para estas simulações, optar por algoritmos para a geração de números aleatórios, decidir o 44 tamanho destas simulações e analisar os resultados gerados por estas simulações. (JAIN, 1991) 2.1.1 Métodos para evitar problemas em projetos de avaliação de desempenho Alguns passos podem ser seguidos para evitar erros que são comuns em projetos de avaliação de desempenho. Primeiramente deve-se definir objetivos de estudo e sistema. Nessa etapa deve-se de definir os objetivos do projeto e delimitar limites do sistema. A escolha dos limites do sistema afeta as métricas adotadas e as cargas de trabalho utilizadas para comparar os sistemas. Por tal fato é importante que se compreenda os limites do sistema. Feito isto, uma lista de serviços e resultados que o sistema fornece deve ser elaborada. Mais tarde serão muito úteis na escolha correta de cargas de trabalho e métricas. Deve-se também selecionar as métricas que, segundo Jain (1991), são os critérios utilizados para comparar desempenho e que estão relacionados à velocidade, precisão e disponibilidade de serviços. Uma lista dos parâmetros que vão afetar o desempenho do sistema deve ser elaborada. Os parâmetros que variam são chamados fatores e os valores destes fatores são chamados níveis. Neste tipo de seleção é importante considerar as restrições econômicas, políticas e tecnológicas que existem, bem como incluir as limitações impostas pelos tomadores de decisões e o tempo para tomar decisões. Isso aumenta as chances de obter uma solução que seja aceitável. Escolhe-se dentre as três técnicas de avaliação (medição, simulação e modelagem analítica), a mais apropriada para que o objetivo seja alcançado. Seleciona-se cuidadosamente a carga de trabalho para que medições sejam significativas. Posteriormente, tendo a lista de fatores e os níveis destes, decide-se a sequência de experimentos que oferecem o maior número de informações com o mínimo de esforço. Por fim, os dados obtidos são analisados e interpretados, gerando resultados os quais serão expostos. 45 2.1.2 Erros em avaliação de desempenho De acordo com Filho (2008), uma série de erros podem ocorrer por aqueles que, no âmbito de conseguirem soluções rápidas, acabam sendo menos cautelosos e esquecem de alguns cuidados que devem tomar com relação à avaliação. Segundo Jain (1991), o analista ou o grupo de analistas que irá realizar os testes e avaliar o desempenho do sistema, antes de fazer qualquer coisa, tal como elaborar um modelo analítico ou estabelecer a medição de um experimento, deve entender o sistema e identificar o problema (ou problemas) a serem solucionados. Desta maneira a metodologia e métricas são escolhidas da forma correta. Outro erro apontado por Jain (1991) é quando um profissional escolhe de forma aleatória parâmetros do sistema, fatores, workloads e métricas. Isto acaba por resultar em conclusões inexatas. O uso da abordagem sistemática, no contexto de desempenho, consiste na identificação de um conjunto de objetivos, parâmetros do sistema, métricas, workloads e fatores. Profissionais também cometem erros quando optam por métricas que podem ser mais fáceis de ser computadas ou medidas do que aquelas que são realmente relevantes para a avaliação. De acordo com Jain (1991), a escolha da métrica correta depende dos serviços fornecidos pelo sistema ou subsistema que estão sendo modelados. Quando o responsável pela avaliação do sistema escolhe a carga de trabalho errada, conclusões erradas são obtidas. A carga de trabalho usada para comparar dois sistemas deve ser representativa do atual sistema a ser comparado. (JAIN, 1991) De acordo com Jain (1991), analistas têm preferência por uma dada técnica de avaliação (medição, simulação e modelagem analítica) que eles usam em todo o problema de avaliação de desempenho, de acordo com o que será avaliado. O analista que irá elaborar e projetar a avaliação deve ter um conhecimento básico das três técnicas, pois o uso de mais de uma técnica pode vir a ocorrer e, com esta união, problemas que antes não existiam, podem vir a surgir. Existe um número de fatores que o analista deve considerar na seleção da técnica certa. Sobre fatores, Jain (1991) diz que estes são parâmetros que sofrem variações no estudo. Nem todos os parâmetros têm um efeito igual no desempenho. O autor diz que é importante identificar os parâmetros os quais, se variados, causarão um 46 impacto significativo na performance. A escolha dos fatores deve ser feita com base em sua importância e não no conhecimento do analista sobre os fatores. 2.2 PLANEJAMENTO DE EXPERIMENTO “O processo ou técnica estatística empregada com o propósito de determinar como o comportamento de um sistema pode ser influenciado pelos possíveis valores de uma ou mais variáveis é o da experimentação.” (FILHO, 2008, p.277) Montgomery (apud FILHO, 2008, p.277) define experimento como “um teste ou uma série de testes, nos quais alterações controladas são realizadas sobre os fatores envolvidos em um sistema ou processo, de tal forma que se possa observar e identificar as razões das mudanças ocorridas sobre as respostas.” Planejamento deve ser utilizado em qualquer experimento. De acordo com Santana e Santana (2012a), planejamento é uma técnica muito importante, pois o seu emprego permite resultados mais confiáveis, economizando dinheiro e tempo. Jain (1991) diz que o planejamento de experimentos relaciona-se com o número de medições ou simulações dos experimentos a serem realizados e os valores dos parâmetros utilizados em cada experimento. Com a utilização de uma seleção adequada destes valores, pode-se obter um maior número de informações com o mesmo número de experimentos. De acordo com Montgomery (apud FILHO, 2008), os objetivos que podem ser buscados no processo experimental são: Determinar quais variáveis têm mais influência sobre as respostas; Determinar que valores associar a essas variáveis, de forma que as respostas permaneçam próximas a seus valores nominais; Determinar que valores associar a essas variáveis, de forma que a variabilidade das respostas seja mínima; Determinar que valores associar a essas variáveis, de forma que a influência dos fatores não controláveis seja minimizada. Filho (2008), com relação a fatores não controláveis, diz que os mesmos podem ser fixados para fins de testes quando estas variáveis estão sendo usadas em modelos de sistemas ou processos. 47 Para que haja compreensão dos termos utilizados, no subtítulo 2.2.1 são apresentados os principais elementos da terminologia utilizada em planejamento de experimentos. Sobre as estratégias mais empregadas, tais serão descritas no item 2.2.4. 2.2.1 Terminologia Segundo Filho (2008), os termos e as explicações destes termos, a seguir, são comumente utilizados em análise e projeto experimental: Variáveis de resposta: resultados de um experimento que permite observar o comportamento de um sistema; Fatores: variáveis controladas pelo experimentador e que podem afetar as variáveis de reposta; Níveis: valores que um fator pode assumir, ou seja, cada nível do fator é uma alternativa para aquele fator; Replicações: repetição de todos ou de alguns experimentos; Projeto experimental: consiste na especificação de uma estratégia de ação que resulta na determinação do número de experimentos (fatores x níveis) a serem realizados, do número de replicações de cada experimento e da forma que serão efetivados. Sobre fatores primários e secundários, Santana e Santana (2012a, p.6) dizem: Fatores primários: fatores que causam um grande impacto em uma variável de resposta e que devem ser considerados; Fatores secundários: fatores cujo impacto na variável de resposta não são significantes ou não se tem interesse em quantificar. 2.2.2 Medidas de desempenho Medidas de desempenho, ou métricas, são, segundo Jain (1991), os critérios utilizados para avaliar o desempenho de um sistema. Ainda segundo o autor, a seleção das métricas é um passo chave em todos os projetos de avaliação de desempenho. 48 Para sistemas computacionais divididos entre vários usuários, devem ser considerados dois tipos de métricas de desempenho: individual e global. Jain (1991, p.48) diz que “as métricas individuais refletem a utilidade de cada usuário, enquanto que as globais refletem a utilidade de todo o sistema.” Citando como exemplos, Jain (1991) afirma que a utilização de recursos, confiança e disponibilidade referem-se a métricas globais. Já tempo de resposta e throughput referem-se a métricas individuais, uma vez que estas podem ser medidas para cada usuário. Nos tópicos a seguir são definidas algumas métricas comumente utilizadas na avaliação de desempenho de um sistema. Ainda sobre essas métricas, Jain (1991) diz que algumas definições dessas medidas precisam ser alteradas para atender a uma determinada aplicação. 2.2.2.1 Tempo de resposta De acordo com Jain (1991, p.51), “tempo de resposta é definido como o intervalo entre uma requisição do usuário e a resposta do sistema.” Ainda de acordo com o autor, esta definição é considerada simplista uma vez que as requisições, bem como as respostas, não ocorram de forma instantânea. 2.2.2.2 Throughput Throughput define a capacidade do computador de processar os dados. Jain (1991, p.53) define throughput como “a taxa (requisições por unidade de tempo) a qual os pedidos podem ser atendidos pelo sistema.” Sobre tal métrica, Jain informa que para sistemas interativos, throughput é medido em requisições por segundo, para CPUs, throughput é medido em milhões de instruções por segundo (MIPS), ou milhões de operações de pontos-flutuantes por segundos (MFLOPS). Já para redes, o throughput é medido em pacotes por segundo (pps) ou bits por segundo (bps). De acordo com Santana e Santana (2012a, p.19), “throughput geralmente aumenta até um certo ponto, depois começa a cair.” 2.2.3 Carga de trabalho 49 “O termo carga de trabalho denota qualquer carga de trabalho utilizada em estudos de desempenho.” (JAIN, 1991, p.60) Carga de trabalho são requisições feitas pelos usuários do sistema. Carga de trabalho pode ser de dois tipos: real e sintética. Tais cargas são descritas no tópico seguinte. 2.2.3.1 Tipos de carga de trabalho Conforme Jain (1991), uma carga de trabalho real é vista em um sistema que é utilizado para operações normais. Por este tipo de carga não poder ser repetida, geralmente não é adequada para uso como carga de testes. Outro tipo de carga de trabalho, a sintética, possui características similares as da carga de trabalho real e pode ser aplicada repetidamente, de uma maneira controlada. Este tipo de carga é desenvolvida e utilizada para estudos. Ainda sobre carga de trabalho sintética, o autor informa que a principal razão para a utilização de uma carga de trabalho deste tipo é que esta é uma representação ou modelo da carga de trabalho real. Conforme Jain (1991), outras razões para a utilização de uma carga de trabalho sintética são que nesta podem existir dados grandes e confidenciais; a carga de trabalho pode ser facilmente modificada, sem afetar as operações. Por possuir tamanho pequeno, a carga de trabalho sintética pode ser facilmente portada para diferentes sistemas, podendo ter recursos de medição internos. (JAIN, 1991) 2.2.4 Estratégias de projetos de experimentos Algumas das estratégias que podem ser adotadas para a execução de um projeto experimental são: planejamento simples, planejamento fatorial completo e planejamento fatorial parcial. No subitem a seguir tais estratégias são descritas. 2.2.4.1 Fatorial simples Este tipo de planejamento é muito utilizado, no qual varia-se um fator por vez, mantendo os demais fixos. 50 Filho (2008) diz que este planejamento desconsidera um elemento fundamental quando se trata de experimentação: a interação entre os fatores. O autor descreve interação como a mútua influência entre dois ou mais fatores. Sobre interação, Santana e Santana (2012a, p.07) dizem que “a interação ocorre quando dois fatores se interagem se o efeito de um depende do nível do outro.” Filho (2008, p.284) ainda diz que, “caso a interação entre os fatores é muito comum, esse tipo de planejamento pode levar a conclusões erradas. O mesmo afirma que, se comprovadamente, não existem interações entre fatores, essa estratégia pode ser uma opção prática.” A equação para este tipo de planejamento é exposta a seguir, K n 1 (ni 1) i 1 Figura 2.1 – Equação para fatorial simples Fonte: Santana; Santana, 2012b, p.06 onde, dados K fatores, com o i-ésimo fator tendo ni níveis, um fatorial simples requer somente n experimentos. Deste modo, caso o experimento contenha quatro fatores, a equação adequada a este seria: n = 1+(3-1)+ (3-1)+ (3-1)+ (3-1) = 9 experimentos 2.2.4.2 Fatorial completo Jain (1991, p.279) diz que “a vantagem de um planejamento fatorial completo é que todas as suas possíveis combinações de configuração e cargas de trabalho são examinadas”, ou seja, todas as possíveis combinações entre fatores e seus diferentes níveis são utilizadas e pode-se encontrar o efeito de todos os fatores, incluindo fatores secundários e suas interações. (FILHO, 2008) Ainda de acordo com Jain (1991), a principal desvantagem deste tipo de planejamento é o custo de estudo. Complementando esta informação, Filho (2008) diz que este custo pode ser muito alto, ainda mais quando se considera a possibilidade de repetir cada experimento várias vezes. De acordo com Filho (2008), existem três maneiras para reduzir o número de experimentos, sendo assim, os custos associados: 51 Reduzir o número de níveis por fator; Reduzir o número de fatores; Usar projetos fatoriais fracionário. Jain (1991, p.279) diz que “a primeira alternativa é a mais recomendada pois, em alguns casos, é possível tentar somente dois níveis por fator e determinar a importância relativa de cada fator.” A seguinte equação expõe o número de experimentos n deste tipo de fatorial. K n ni i 1 Figura 2.2 – Equação para fatorial completo Fonte: Santana; Santana, 2012b, p.10 Desta maneira, caso o experimento contenha quatro fatores e três níveis, a equação para este seria: n = 3 x 3 x 3 x 3 = 81 experimentos 2.2.4.3 Fatorial fracionário Segundo Filho (2008), quando o número de experimentos requeridos para um fatorial completo é muito grande e que a execução do projeto pode se tornar economicamente inviável devido ao tempo e recursos necessários para a sua execução, pode-se utilizar apenas parte ou fração do total de experimentos de um planejamento fatorial completo. Para este tipo de planejamento dá-se o nome de planejamento fatorial fracionário ou fatorial parcial. Ainda de acordo com Filho (2008), com este tipo de planejamento é possível obter boas informações sobre os efeitos causados pelos principais fatores, bem como alguma informação sobre suas possíveis interações. 2.2.5 Projetos fatoriais 2k De acordo com Jain (1991, p.282), “um projeto fatorial tipo 2k é usado para determinar o efeito de k fatores, cada um dos quais com duas alternativas ou níveis.” Complementando, Santana e Santana (2012a) dizem que uma boa alternativa 52 quando ocorre a utilização de estratégia de projeto fatorial em experimentos é iniciar com poucos fatores e 2 níveis por cada fator. Segundo Filho (2008), fatorial tipo 2k merece uma atenção especial pois esta estratégia oferece algumas vantagens tais como: simplicidade de implementação; facilidade de compreensão do que está sendo feito, por parte dos analistas que não possuem tanta experiência; facilidade para entender os efeitos de cada fator sobre as variáveis de resposta; possibilidade de ordenação dos fatores por sua ordem de importância. Jain (1991) diz que, frequentemente, quando são estudados os efeitos de fatores sobre respostas, os efeitos dos fatores são unidirecionais, ou seja, o desempenho diminui ou aumenta continuamente na medida em que os valores dos fatores são alterados, aumentando-os ou diminuindo-os. Assim, Filho (2008) aconselha que, ao invés de realizar um número de experimentos muito grande, o que poderia acarretar em um desperdício de recursos muito grande, pode-se iniciar as experimentações utilizando-se os níveis mínimos e máximos (dois níveis) de cada fator. “Isso ajudará a decidir se a diferença no desempenho é significante o suficiente para justificar exames mais detalhados.” (JAIN, 1991, p.282) Dito isto, o próximo sub-tópico dará uma breve explanação sobre projetos fatoriais do tipo 22, o qual facilita a compreensão dos conceitos utilizados em projetos 2k. 2.2.5.1 Projeto fatorial 22 Fatorial 22 é o caso mais simples de um projeto fatorial. Este é um caso especial de um projeto 2k com k = 2. Deste modo têm-se dois fatores com dois níveis cada. Conforme desdobramento desenvolvido por Jain (1991) considera-se dois fatores, aqui chamados, fator A e fator B e, a partir de experimentos efetuados, serão obtidos os valores y1, y2, y3 e y4. Para cada nível de cada fator é definido um valor. Então, a seguir, estes valores são definidos como: fator A (xA), nível 1 = -1; fator A (xA), nível 2 = 1; fator B (xB), nível 1 = -1; fator B (xB), nível 2 = 1. 53 Desta maneira constrói-se o Quadro 2.1, que demonstra a correspondência entre níveis, fatores e respostas de um fatorial 22. Quadro 2.1- Níveis, fatores e respostas de um projeto 22 Fonte: Santana; Santana, 2012a, p.23 De acordo com Santana e Santana (2012a), a análise do projeto fatorial 2 2 é feita através do modelo de regressão não linear da forma: y = q0 + qAxA + qBxB + qABxAxB Partindo desta equação, Filho (2008) diz que substituindo-se as quatro observações no modelo e os valores dos coeficientes, obtêm-se: y1 = q0 – qA – qB + qAB y2 = q0 + qA – qB – qAB y3 = q0 – qA + qB – qAB y4 = q0 + qA + qB + qAB Em complemento, Filho (2008, p.292) afirma que, partindo dessas equações para qi‟s, as expressões obtidas qA, qB e qAB “são claramente combinações lineares das respostas, com a soma dos coeficientes igual a zero.” Tais expressões (q A, qB e qAB) são evidenciadas a seguir: q0 = ¼ (y1 + y2 + y3 +y4) qA = ¼ (–y1 + y2 – y3 +y4) qB = ¼ (–y1 – y2 + y3 +y4) qAB = ¼ (y1 – y2 – y3 +y4) Estas expressões, de acordo com Jain (1991), são conhecidas como “contrastes”. 2.2.5.2 Soma dos quadrados totais – SQT 54 De acordo com Filho (2008, p.296), é importante que seja determinado a contribuição de cada fator sobre as variações nas variáveis de resposta. “A importância de um fator é medida pela proporção do total da variação na variável de resposta que é por ele explicado.” Santana e Santana (2012a, p.28) dizem que “a partir dos valores q0, qA, qB e qAB, a soma dos quadrados pode ser determinada.” Ainda de acordo com Santana e Santana (2012a, p.28), complementando a afirmação de Filho (2008), “a soma dos quadrados dará a variação total das variáveis de resposta e as variações devido a influência do fator A, do fator B e da interação entre A e B” e que é definida pela seguinte equação: 22 Variância total ou SQT: SST ( yi y ) 2 i 1 Em tal equação, ȳ refere-se a média das respostas dos experimentos realizados. (FILHO, 2008) Ainda de acordo com Filho (2008), a soma dos quadrados totais (SQT), em inglês, Sum of Squares Total (SST), pode ser definida da seguinte forma: SQT = SQA + SQB + SQAB Filho (2008) expõe que as três parcelas do lado direito da equação representam a porção da variação total explicados pelos efeitos de A, B, e da interação AB, respectivamente. Assim, de acordo com as fórmulas descritas anteriormente, atribuindo-a para um projeto 22, a variação pode ser divida em três partes: SSA = 22q2A , porção da soma dos quadrados totais que é explicada pelo fator A. A influência do fator A pode ser expressa pela seguinte fração: A = SQA / SQT; SSB = 22q2B , porção da soma que é explicada pelo fator B, tendo sua influência representada por: B = SBQ / SQT; SQAB = 22q2AB, referente a porção devido a interação entre os fatores A e B, tendo sua influência representada por: AB = SQAB / SQT Por fim, Filho (2008) diz que os fatores que explicam uma alta porcentagem da variação são considerados os mais importantes. 55 3 DESENVOLVIMENTO 3.1 METODOLOGIA Neste tipo de trabalho deve-se adotar o conjunto correto de métodos e técnicas para que o objetivo seja alcançado. Caso a metodologia utilizada nesse tipo de pesquisa não seja a correta, os resultados podem ser obtidos de forma inexata, pois fatores cruciais que influenciam a variável de resposta podem ser deixados de lado. Esta pesquisa tem como variável de resposta a quantidade de pacotes que trafegam em uma rede, por segundo, gerados através de requisições em um banco de dados distribuído. Para esta pesquisa foi utilizado o modelo de dados de um sistema de estacionamento, composto pelas seguintes tabelas: cliente, funcionário, pagamento, ticket e carro. A Figura 3.1 expõe este modelo, dispondo como as tabelas se relacionam, bem como as respectivas colunas e, consequentemente, os tipos destas. Assim pode-se verificar como o banco de dados utilizado neste projeto foi elaborado, fisicamente. Figura 3.1 – Modelo de dados relacional Fonte: Elaborado pelo autor O modelo de dados representado pela Figura 3.1 refere-se a um sistema de controle de estacionamento que permite ao usuário deste sistema usufruir de 56 facilidades de controle de permanência de veículos no estacionamento, possibilitando ao utilizador do sistema gerar o valor do pagamento de um dado veículo, relacionando a permanência deste no pátio com o valor de cada hora. Possibilita também o controle de clientes, mantendo uma base dos referidos veículos pertencentes a este cliente. Através deste modelo foi possível construir o banco de dados distribuído, que foi base deste estudo, contendo o relacionamento entre estas tabelas e, assim, capaz de receber persistência de dados. Dito isto, com a utilização da ferramenta de testes JMeter, foi possível realizar os quatro tipos básicos de requisições (criação, leitura, atualização e exclusão) ao banco de dados, de forma que estas requisições fossem feitas atendendo a um determinado número previamente estabelecido. Ou seja, a ferramenta JMeter permite que uma carga de trabalho seja gerada para que se possa obter os valores para a elaboração de uma análise das respostas a que se quer. No caso deste projeto, JMeter foi utilizado para simular uma certa quantidade de usuários que fizeram uma certa quantidade de requisições ao banco de dados distribuído desta experiência. Essa ferramenta possibilita fazer estes tipos de requisições, simulando usuários reais. Desta maneira foi possível realizar a análise de desempenho deste projeto. 3.2 AMBIENTE DE TESTES O ambiente de testes deste experimento foi baseado em envio e recebimento de requisições a um banco de dados distribuídos que, aqui nesta avaliação de desempenho, teve como base de dados tabelas que compõem um sistema de controle de carros em um estacionamento. Para a parte de infra-estrutura de rede de computadores foi elaborada uma rede local situada na sala 3, contida dentro das dependências da Faculdade de Tecnologia de Lins “Prof Antonio Seabra”, sendo utilizados 8 computadores para a realização dos testes e um notebook para efetuar o bombardeio de requisições, através do JMeter. Em sete destes oito computadores, e no notebook, foi instalado o programa VMware® Workstation, versão 8.0.4 build-744019. Assim foi possível criar uma máquina virtual (VM) em cada uma destas máquinas físicas. Isso propiciou segurança com relação a ter cópias destas VMs, uma vez que um destes 57 computadores poderia vir a ter problemas e, talvez, necessitariam ser formatados, perdendo assim todas as instalações e configurações elaboradas anteriormente para que os testes fossem realizados. Com isto, em sete destas oito máquinas virtuais foram instalados o sistema operacional Windows XP Professional Versão 2002 Service Pack 3 e o SGBD SQL Server 2008 Developer. Desta maneira, o BDD foi composto por sete hosts, sendo que um host representava o publicador e os outros seis representavam os subscritores. No oitavo host, ou seja, no notebook, também foi instalado o Windows XP como sistema operacional, e esta VM ficou disponibilizada para efetuar as requisições ao BDD, com a utilização da ferramenta JMeter. O nono computador foi utilizado para a visualização das portas do switch que compôs a rede deste experimento, através do programa Putty, com o qual foi possível acessar o software nativo do switch, em seu modo texto. A Figura 3.2 representa o ambiente de testes, de uma maneira geral, utilizado nesta avaliação. Figura 3.2 – Ambiente de testes Fonte: Elaborado pelo autor Para a compreensão desta figura, como dito anteriormente, os clientes foram simulados através da utilização do JMeter. Já as requisições que chegavam ao BDD, representadas pela seta nomeada “Dados”, poderiam vir de qualquer lugar, de 58 forma global ou local, a este sistema de banco de dados distribuídos. O visualizador foi utilizado para verificar o tráfego nas portas do switch, como disposto anteriormente. Por fim, os sete hosts, compostos por suas respectivas máquinas virtuais, formando desta forma o banco de dados distribuídos. O notebook utilizado nesta avaliação possui as seguintes características: Processador Intel® Core™ i5-2410M CPU @ 2.30GHz 2.30 GHz, memória RAM 4,00GB, 500GB Hard Disk (HD) e o SO Windows 7 Ultimate 64 Bits. Já os oito computadores utilizados possuem as mesmas características físicas e de sistema operacional: Processador Intel® Core™ i5-2400 CPU @ 3.10GHz 3.10GHz, memória RAM 4,00GB e SO Windows 7 Professional 64 Bits. Com relação às máquinas virtuais, sete das oitos citadas anteriormente, foram configuradas com 1024MB de memória, com um processador de 1 core cada. Já referente a placa de rede, todas foram configuradas para o modo Bridge. Desta maneira a máquina virtual funciona como se estivesse na mesma rede da máquina física. Figura 3.3 – Monitoramento de pacotes recebidos (gráfico) Fonte: D-Link, 2009, p.334. 59 Referente a oitava máquina virtual, como esta funcionou como servidor de rede, a única diferença com relação as outras virtuais foi que esta oitava foi configurada com duas placas de rede, mantendo o modo Bridge. O intuito desta configuração é demonstrar que os hosts além desta máquina virtual não sofreriam interferências diretas da rede sem antes passar por esta máquina. Desta maneira, esta máquina-servidor foi configurada com dois IP‟s diferentes, um para as requisições externas ao banco de dados distribuídos e outro para a rede interna, composta pelas máquinas virtuais que compõem o BDD. O switch utilizado no controle de tráfego da rede e visualzação de pacotes que trafegavam na rede foi um DLink DGS – 3627, tendo como taxa de transferência de dados o equivalente à 1 Gigabits por segundos (GBPS). Este switch possui vinte e quatro portas gerenciáveis, lembrado que para esta avaliação, apenas nove portas foram utilizadas, e o dispositivo não possuía conexão com a Internet. Figura 3.4 – Monitoramento de pacotes enviados e recebidos (tabela) Fonte: D-Link, 2009, p.335. 60 A Figura 3.3 expõe a tela de visualização em forma de gráfico, que o switch disponibiliza para o usuário deste dispositivo. No caso é disposta a tela referente a porta 1, que monitora a chegada de pacotes em tal porta. A Figura 3.4 refere-se a mesma porta (1), porém, disponibiliza as informações transmitidas e recebidas, tanto na forma de pacotes quanto na forma de bytes, na forma de uma tabela. Entretanto, a tela disponibilizada de forma gráfica não atende a necessidade deste projeto, uma vez que só é possível visualizar uma porta do switch por teste e, na transição de uma tela para outra, um tempo considerável era perdido, prejudicando a coleta de informações. Desta maneira, a Figura 3.5 demonstra o total de tráfego de pacotes por porta, fazendo uso do programa Putty. A mudança entre uma porta e outra era feita de forma rápida, apertando a tecla space para acessar a porta seguinte, ou a tecla “p”, para retroceder para a porta anteriormente visualizada. Figura 3.5 – Monitoramento de pacotes enviados e recebidos Fonte: Elaborado pelo autor. Com relação as máquinas utilizadas, para um melhor entendimento destas, virtuais ou física (esta última foi utilizada para visualizar o tráfego de dados do 61 switch), que compuseram esta avaliação, é disposto a seguir o quadro 3.1, contendo o nome do computador físico, o nome da máquina virtual (VM), a porta a que este acessa o switch, qual a atribuição do computador na avaliação de desempenho e o IP atribuído a este computador. Lembrando que o computador que possui máquina virtual, o IP foi atribuído a esta VM, e não à máquina física e que a máquina virtual de nome servidor1 possui dois IPs pois a mesma funcionou como um servidor de rede, tendo em sua configuração duas placas de rede. Quadro 3.1 – Qualificações dos hosts Computador VM Switch (porta) LAB6-M02 servidor1 LAB6-M01 cliente-01 LAB6-M04 cliente-02 LAB6-M03 cliente-03 LAB6-M06 cliente-04 LAB6-M05 cliente-05 LAB6-M08 cliente-06 Gustavo-Notebok JMeter LAB6-M07 ---------Fonte: Elaborado pelo autor 1 2 3 4 5 6 7 9 8 Função Publicador Subscritor 01 Subscritor 02 Subscritor 03 Subscritor 04 Subscritor 05 Subscritor 06 Cliente Virtual-Jmeter Visualizar Tráfego-Switch IP (Protocolo de Internet) 10.1.1.1/192.168.1.1 10.1.1.10 10.1.1.20 10.1.1.30 10.1.1.40 10.1.1.50 10.1.1.60 192.168.1.150 10.90.90.10 3.3 PLANEJAMENTO DE EXPERIMENTOS Para este projeto foi utilizado o planejamento fatorial completo, que leva em consideração os fatores escolhidos e os níveis referentes a estes. O projeto fatorial utilizado aqui foi o 23, o que quer dizer que foram escolhidos 3 (três) fatores, sendo que cada um destes fatores possuem 2 (dois) níveis. Assim, foram efetuados 8 experimentos, pois 23 = 8. A medida de desempenho adotada neste projeto foi a throughput, que como já definido no capítulo 2 deste trabalho, “é a taxa a qual os pedidos podem ser atendidos pelo sistema.“ (JAIN, 1991, p.53). O throughput é medido, neste projeto, em pacotes por segundo (pps), ou seja, a variável de resposta que deve ser adquirida neste experimento é a quantidade média de pacotes que trafegam na rede elaborada, por segundo. Para tal, foi dividido um total de pacotes trafegados por um dado intervalo de tempo, em segundos. Para esta avaliação foram considerados três fatores e cada fator assumiu dois níveis, como exposto no Quadro 3.2. 62 Quadro 3.2 – Fatores e níveis para avaliação Fatores Número de hosts (subscritores) Número de requisições de dados Número de usuários Fonte: Elaborado pelo autor Nível 1 3 8100 45 Nível 2 6 16200 90 O quadro a seguir demonstra as combinações entre os fatores e níveis que resultaram nos oito experimentos realizados neste trabalho, conforme disposto no primeiro parágrafo deste tópico, levando em conta a descrição dos fatores e níveis evidenciados no Quadro 3.2. Quadro 3.3- Combinações entre fatores e níveis Experimentos 1 2 3 4 5 6 7 a Núm. Usuários b Num. Requisições Núm. Hosts 45 45 45 45 90 90 90 90 8100 8100 16200 16200 8100 8100 16200 16200 3 6 3 6 3 6 3 6 8 Fonte: Elaborado pelo autor Figura 3.6 – Ambiente fator número de hosts nível 3 Fonte: Elaborado pelo autor. c 63 A Figura 3.6 demonstra como foi montado o ambiente de testes quando o fator número de hosts foi mantido em 3 (três). Assim, para os outros dois fatores e variações de seus devidos níveis, o ambiente é o mesmo exposto na figura. De acordo com a figura, verifica-se que os clientes são simulados através da utilização da ferramenta JMeter e que as requisições realizadas por esta ferramenta é do tipo de carga de trabalho sintética que, conforme disposto no Capítulo 2, subtópico 2.2.3.1 deste trabalho, tal carga pode ser aplicada repetidamente, de maneira controlada. Esta ferramenta ficou localizada na máquina virtual JMeter, conforme pode ser verificado no Quadro 3.1. Figura 3.7 – Ambiente fator número de hosts nível 6 Fonte: Elaborado pelo autor. Através destas simulações, requisições foram enviadas para o servidor do banco de dados distribuídos, sendo que quem recebeu estas solicitações foi o publicador do BDD, o qual estava sitiado na máquina virtual com o nome servidor1. O servidor1 possui toda a estrutura do banco de dados utilizado neste experimento. Lembrando que o banco de dados foi composto pelas seguintes tabelas: cliente, funcionário, ticket, carro e pagamento. A Figura 3.6 expõe que nesta parte do experimento, o ambiente foi composto pelo publicador (VM servidor1) e por três subscritores: Subscritor 01 (VM cliente-01), Subscritor 02 (VM cliente-02) e Subscritor 03 (VM cliente-03). Desta maneira, o 64 publicador recebeu as requisições e, por meio de linkeds servers, realizou as operações de inclusão, atualização, exclusão e consulta em determinado subscritor ao qual o linked server se referia. Com isto, fazendo uso da replicação merge, o publicador recebeu as atualizações dos subscritores e as publicou para todos os outros subscritores. A Figura 3.7 evidencia que a única alteração que ocorreu ao ambiente anterior foi em relação ao aumento do número de hosts, que nesta parte do experimento, aumentou-se de 3 (três) para 6 (seis). Assim, o BDD deste ambiente foi formado, agora, por sete hosts, sendo que um é o publicador e os outros seis, os subscritores. Os três hosts adicionados foram definidos da seguinte maneira: Subscritor 04 (VM cliente-04), Subscritor 05 (VM cliente-05) e Subscritor 06 (VM cliente-06). 3.4 RESULTADOS ESPERADOS Esperava-se que os resultados sofressem uma boa variação devido aos fatores e a alternância dos seus níveis e que não houvessem ações significantes nesses valores que fossem influenciadas pelos ambientes de teste que, neste trabalho, fizeram uso de máquinas virtuais. Inicialmente, utilizando como primeiro conjunto de configurações foi aplicada ao teste a configuração com os níveis dos fatores em seu máximo, ou seja, o número de usuários simulados será de 90, efetuando um total de 16200 requisições, com 7 (sete) hosts disponíveis no BDD. Com isto, espera-se que o número máximo de pacotes trafegados por segundo, seja obtido. Variando os níveis dos fatores, esperou-se que o número de pacotes que trafegarão pela rede sofresse uma pequena diminuição e, quando utilizada a configuração mínima, ou seja, 45 usuários simulados, com um total de 8100 requisições, tendo o banco de dados composto por 4 (quatro) hosts, supunha-se que a quantidade trafegada seria a mínima neste experimento. No capítulo a seguir são dispostos os resultados dos testes efetuados, em forma de tabelas e gráficos, e como os fatores e as interações entre eles afetaram os resultados. 65 4 RESULTADOS E DISCUSSÃO Para esta avaliação de desempenho foram realizadas 10 repetições para cada um dos oito experimentos. Com isto foi obtido um total de 80 testes. Para o conjunto de testes de cada experimento foi estabelecido o intervalo de confiança dos resultados obtidos. A partir destes verificou-se que as variações dos intervalos foram baixos, garantindo a integridade dos experimentos. Este capítulo expõe valores obtidos com os testes e, a partir destes, a confecção de gráficos. Destes valores e gráficos foram dispostas análises sobre os mesmos, análises estas que são o objetivo deste trabalho. 4.1 INTERVALO DE CONFIANÇA “Os resultados de uma pesquisa devem ser interpretados dentro de um intervalo que estabelece limites em torno da estimativa obtida: o chamado intervalo de confiança.” (IBOPE, 2013) Partindo deste conceito foram realizados cálculos para a obtenção dos intervalos de confiança (IC) para cada experimento. Tais valores são dispostos no Quadro 4.1. Quadro 4.1- Intervalos de confiança Intervalo de Confiança Experimento IC (pps) 1 489,56 674,30 456,85 402,58 314,64 444,12 245,83 402,77 2 3 4 5 6 7 8 Fonte: Elaborado pelo autor Comumente são utilizados intervalos com 95% de confiança. (IBOPE, 2013) Com isto, IBOPE (2013) exemplifica a utilização de intervalo de confiança da seguinte maneira: “Considerando uma margem de erro de 3 pontos percentuais para o candidato A com estimativa de intenção de voto fixada em 30%, o intervalo de confiança dele, com uma confiabilidade de 95%, seria de 27% a 33%.” 66 Assim, os intervalos de confiança obtidos neste trabalho foram alcançados com a utilização de uma fórmula específica do programa de planilha eletrônica Excel, da empresa Microsoft. A seguir a sintaxe da mesma: = INT.CONFIANÇA(alfa; desv_padrão; tamanho) onde, segundo Office (2013a), os parâmetros possuem as seguintes características: “alfa: nível de significância utilizado para calcular o nível de confiança. Desta maneira, o nível de confiança é igual a 100*(1-alfa)%, ou seja, caso alfa seja 0,05, isso indica um nível de confiança de 95%, pois 100*(1-0,05)% será igual a 95%”; “desv_padrão: é o desvio padrão da população para o intervalo de dados, o qual supõe-se que seja conhecido”; “tamanho: é o tamanho da amostra”. Vale lembrar que o desv_padrão foi obtido através de outra fórmula da planilha Excel, a qual deve ser utilizada quando os dados representarem uma amostra da população. (OFFICE, 2013b) A sintaxe da mesma é disposta a seguir: =DESVPAD(núm1,[núm2],...]) onde, segundo Office (2013b), as características dos parâmetros são as seguintes: “núm1: necessário pois é o primeiro argumento numéricos correspondente a uma população”; “núm2,...: opcional. São argumentos numéricos de 2 a 254 correspondentes a uma população”. Para exemplificar a utilização desta fórmula, é disposta a seguir a fórmula utilizada no oitavo experimento: =DESVPAD(B13:U13), a qual demonstra que os valores utilizados nesta fórmula abrangem um intervalo que vai do primeiro ao décimo teste deste experimento, retornando o valor 5008,607232, utilizada na fórmula de IC. Então, exemplificando com valores deste trabalho, mais especificamente com valores do experimento oito, a fórmula de IC é composta da seguinte maneira: = INT.CONFIANÇA(0,05;649,841;10). Desta, o valor 0,05 indica que o nível de 67 confiança utilizado é de 95%, 649,841 é o desvio padrão e o valor 10 é a quantidade de teste realizados neste experimento. 4.2 QUADRO DE COMBINAÇÕES PARA FATORIAL COMPLETO 23 Para elaborar o Quadro 4.4 é necessário, primeiramente, entender como são obtidos os valores desta. Então, para esta compreensão, é necessário expor os fatores e seus níveis desta avaliação de desempenho. Assim, para cada fator será definido uma variável. Quadro 4.2- Atribuição de variáveis para os fatores variáveis Fatores Nível 1 xa xb Número de usuários Número de requisições de dados 45 Nível 2 90 Fonte: Elaborado pelo autor xc Número de hosts (subscritores) 8100 3 16200 6 Conforme o Quadro 4.2, para o número de usuários foi atribuída a variável xa, para o número de requisições, a variável xb e para o número de hosts, a variável xc. Desta maneira, para cada nível dos fatores é atribuído um valor para a variável atribuída a este fator. O Quadro 4.3 torna explicito estas atribuições. Quadro 4.3- Atribuição de valores para as variáveis variáveis Fatores Nível 1 xa xb Número de usuários Número de requisições de dados 45 (1) Nível 2 90 (-1) Fonte: Elaborado pelo autor xc Número de hosts (subscritores) 8100 (1) 3 (1) 16200 (-1) 6(-1) De modo explicativo, a variável xa representa o fator número de usuários. Assim, para o fator número de usuários com nível 1, a variável xa é igual a 1, já para o fator número de usuários com nível 2, a variável xa assume o valor igual a -1. Desta maneira foi possível elaborar o Quadro 4.4, que representa os níveis, fatores e respostas de um projeto fatorial 23, baseando-se no Quadro 2.1, exposto neste trabalho, no capítulo 2. Então, o experimento 1 (um) é composto da seguinte maneira: xa = 1, xb = 1 e xc = 1. Desta maneira se verifica que tal experimento foi composto pelos fatores número de usuários, número de requisições de dados e 68 número de hosts em seu primeiro nível, ou seja, 45 usuários, 8100 requisições e 3 hosts. A variável y1 representa a resposta deste primeiro experimento. Quadro 4.4- Níveis, fatores e respostas de um projeto 23 Experimentos 1 2 3 4 5 6 7 xa Núm. Usuários xb Num. Requisições Núm. Hosts 1 1 1 1 -1 -1 -1 -1 1 1 -1 -1 1 1 -1 -1 1 -1 1 -1 1 -1 1 -1 8 Fonte: Elaborado pelo autor xc Respostas (Y) y1 y2 y3 y4 y5 y6 y7 y8 Por fim, partindo do Quadro 4.4 elaborou-se o Quadro 4.5, que representa as combinações dos níveis de cada fator. Isso se faz necessário para o entendimento dos fatores no ambiente de experimento. Quadro 4.5- Quadro de combinações dos níveis dos fatores Quadro de combinações Experimentos qa qb qc qab qac qbc qabc Resposta (Y) 1 1 1 1 1 -1 -1 -1 -1 1 1 -1 -1 1 1 -1 -1 1 -1 1 -1 1 -1 1 -1 1 1 -1 -1 -1 -1 1 1 1 -1 1 -1 -1 1 -1 1 1 -1 -1 1 1 -1 -1 1 1 -1 -1 1 -1 1 1 -1 y1 2 3 4 5 6 7 8 Fonte: Elaborado pelo autor y2 y3 y4 y5 y6 y7 y8 4.3 RESULTADOS DOS EXPERIMENTOS O Gráfico 4.1 foi construído com as médias obtidas dos valores do conjunto de testes de cada experimento. Neste também é possível visualizar os ICs de cada experimento, os quais estão localizados no topo de cada barra. Só foi possível obter os valores dos testes com o uso da ferramenta JMeter, a qual simulou os usuários 69 que bombardeavam com requisições de inserção, seleção, atualização e exclusão, o banco de dados distribuído deste trabalho. Gráfico 4.1- Comparativo entre os valores médios de cada experimento Fonte: Elaborado pelo autor Através do Gráfico 4.1 é possível verificar que o experimento 8 teve a maior média de tráfego de pacotes por segundo. Este experimento foi composto pelos fatores número de usuários = 90, número de requisições = 16200 e número de hosts = 6. Ao contrário, o experimento 7 teve a menor média de tráfego de pacotes por segundo. Neste experimento o número de usuários foi igual a 90, o número de requisições foi igual a 16200 e o número de hosts igual a 3. As combinações entre os fatores e níveis já foram explanadas no capítulo 3, através do Quadro 3.3. Gráfico 4.2- Comparativo levando em conta o número de usuários Fonte: Elaborado pelo autor 70 Conforme o Gráfico 4.1 e o que foi exposto anteriormente, se comparados os fatores do oitavo e do sétimo experimentos, percebe-se que o oitavo teve um aumento de número de hosts, mantendo o mesmo número de usuários e de requisições. O Gráfico 4.2 demonstra um comparativo dos experimentos levando em consideração o número de usuários. De acordo com Gráfico 4.2, observa-se que conforme ocorre o aumento de número de usuários, diminui-se o tráfego de pacotes pela rede. Isso é evidenciado se comparados os experimentos 1 e 5 , os quais tiveram como fatores o mesmo número de requisições e hosts, ou seja, 8100 requisições e 3 hosts, respectivamente, variando-se apenas o número de usuários, os quais foram simulados 45 para o primeiro experimento e 90 para o segundo. É possível perceber que neste gráfico ocorre uma tendência na qual a medida que ocorre o aumento de número de hosts, mantendo-se o mesmo número de usuários e requisições, tem-se um aumento de tráfego de pacotes por segundo. Isso pode ser observado no nível 2 deste experimento, o qual teve como fator de usuários 90 destes. Fazendo uma comparação entre os experimentos 7 e 8, observa-se que o experimento com menor número de hosts trafegou um menor número de pacotes pela rede. O Gráfico 4.3 evidencia um comparativo que leva em conta o fator representativo número de requisições. Gráfico 4.3- Comparativo levando em conta o número de requisições Fonte: Elaborado pelo autor 71 Este gráfico demonstra que conforme aumenta-se o número de requisições, ocorre uma queda na quantidade de tráfego de pacotes. Isto é visto quando comparados os experimentos 1 e 3, entre os quais o experimento 1 trafega uma média de pacotes de 10728,6 por segundo, sendo que no experimento 3 é trafegado uma média de 9655,8, tendo uma diferença entre eles de 1072,8 pacotes trafegados. Nota-se que neste fator não ocorreu uma grande variação nas médias quando se leva em consideração os níveis 1 e 2, se comparados aos outros fatores, os quais obtiveram uma diferença significativa quando se variou o nível. Este fato, possivelmente, ocorreu porque as máquinas não trabalharam em seus limites e, dessa forma, aceitariam uma carga ainda maior de requisições. O Gráfico 4.4 apresenta um comparativo que teve como fator representativo o número de hosts.Visualiza-se através deste gráfico que conforme aumenta-se o número de hosts (máquinas), aumenta-se o número de pacotes trafegados. Isto é visto quando são adotados os valores de dois experimentos. Desta forma, a exemplificar, compara-se os valores do experimento 5 e 6. No quinto experimento, o tráfego de pacotes foi na média de 8838,7, ou seja, houve um tráfego de 1825,6 pacotes a menos do que o sexto experimento, que trafegou na média de 10664,3 pps. Gráfico 4.4- Comparativo levando em conta o número de hosts Fonte: Elaborado pelo autor 72 Este tópico explanou os resultados obtidos e demonstrou graficamente comparativos entre os níveis de cada fator. A seguir, através dos resultados obtidos, será feita uma análise de quanto cada fator influenciou na variável de resposta. 4.4 INFLUÊNCIA DOS FATORES Primeiramente, para obter os valores de influência dos fatores, foram necessários realizar alguns cálculos baseando-se nas fórmulas explanadas no capítulo 2, a partir do sub-tópico 2.2.5.1. Deste modo, de forma a exemplificar esses cálculos, a fórmula a seguir expõe o cálculo do valor do fator (qa), fazendo uso da ferramenta de planilhas eletrônicas Excel: =(1/8)*((M3*F3)+(M4*F4)+(M5*F5)+(M6*F6)+(M7*F7)+(M8*F8)+(M9*F9)+(M10*F10)) Para compreender esta formula é necessário fazer uso da Figura 4.1, a qual foi baseada no Quadro 4.5 – Quadro de combinações dos níveis dos fatores, mas agora com os valores das variáveis de resposta “y”, representados pela coluna Média (pps). Figura 4.1- Combinações dos níveis dos fatores e respostas Fonte: Elaborado pelo autor Assim, diante da figura anterior, percebe-se que ocorre um cruzamento das colunas F e M, para a obtenção do fator (qa). Desta maneira, multiplica-se a primeira célula da coluna de qa pela primeira célula da coluna da Média (pps), somando com a multiplicação da segunda célula da coluna de qa pela segunda célula da coluna da Média (pps), assim por diante, seguindo a fórmula “qA = ¼ (–y1 + y2 – y3 +y4) “, 73 disposta no sub-tópico 2.2.5.1 do capítulo 2. Percebe-se que esta fórmula refere-se a uma análise de 4 experimentos, sendo necessário realizar algumas adequações. Para este trabalho, expõe-se a fórmula da seguinte maneira: qa = 1/8 (y1 + y2 + y3 + y4 – y5 –y6 –y7 –y8) a qual, adequada a planilha eletrônica, resultou na seguinte: qa=(1/8)*((10728,6*1)+(12783,7*1)+(9655,8*1)+(12097,8*1)+(8838,7*(1))+(10664,3*(-1))+(8652,5*(-1))+(14115,5*(-1))) Diante do exposto na fórmula, qa obteve valor 374,34. Para calcular todos os demais fatores e combinações, tais valores foram obtidos fazendo uso da fórmula da planilha eletrônica exposta anteriormente, resultando no Quadro 4.6. Quadro 4.6- Influência dos fatores Influência dos Fatores qa 374,34 qb -188,27 qc -1473,21 qab 627,96 qac 348,93 qbc 503,02 qabc -406,31 Fonte: Elaborado pelo autor Após isto, calcula-se a porção da soma dos quadrados totais que é explicada pelo fator A, conforme a fórmula “SSA = 22q2A” disposta no sub-tópico 2.2.5.2 do capítulo 2. Desta forma, adequando esta fórmula para a planilha eletrônica, é obtida a seguinte fórmula: =POTÊNCIA(2;3)*POTÊNCIA(B14;2), na qual, em sua primeira parte, POTÊNCIA(2;3), conforme Jose e Silva (2012),o valor 2 se refere a dois níveis e o valor 3 se refere a três fatores, que representam o fatorial fruto deste trabalho. Na segunda parte, POTÊNCIA(B14;2), eleva-se ao quadrado o valor de (qa). Isto resulta na seguinte fórmula: SQA = POTÊNCIA(2;3)*POTÊNCIA(374,34;2) a qual resultou em 1121047,26. Este valor é o que será utilizado na fórmula final para saber qual a influência do fator qa na variável de resposta. Esta fórmula foi adequada para a obtenção de todas as outras porções da soma dos quadrados totais, resultando no Quadro 4.7. 74 Quadro 4.7- Soma dos Quadrados Soma dos Quadrados SST 26241097,22 SSA 1121047,26 SSB 283564,31 SSC 17362805,68 SSAB 3154677,68 SSAC 974013,72 SSBC 2024262,44 SSABC 1320726,12 Fonte: Elaborado pelo autor Posteriormente foi obtido o valor da soma dos quadrados totais, a qual foi sintetizada no sub-tópico 2.2.5.2 do capítulo 2, da seguinte maneira: SQT = SQA + SQB + SQAB Adaptando esta fórmula para a fórmula utilizada na planilha eletrônica, tem-se a seguinte: =POTÊNCIA(2;3)*((POTÊNCIA(B14;2))+(POTÊNCIA(B15;2))+(POTÊNCIA(B16;2))+(PO TÊNCIA(B17;2))+(POTÊNCIA(B18;2))+(POTÊNCIA(B19;2))+(POTÊNCIA(B20;2))) na qual, alterando-se os números das células pelos seus valores, tem-se: =POTÊNCIA(2;3)*((POTÊNCIA(374,34;2))+(POTÊNCIA(-188,27;2))+(POTÊNCIA(1473,21;2))+(POTÊNCIA(627,96;2))+(POTÊNCIA(348,93;2))+(POTÊNCIA(503,02;2) )+(POTÊNCIA(-406,31;2))) resultando em SQT = 26241097,22. Quadro 4.8- Influência dos fatores Influência dos Fatores valor do fator valor em % 0,04272 4,27% 1,08% 66,17% 12,02% 3,71% 7,71% 5,03% 0,01081 0,66166 0,12022 0,03712 0,07714 0,05033 Total: 100,00% Fonte: Elaborado pelo autor Por fim calcula-se a influência do fator qa sobre a variável de resposta da seguinte maneira: qA = SQA / SQT 75 Assim, divide-se SQA por SQT e multiplica-se por 100 para obter o valor de porcentagem de tal fator. Para o fator A, alterando as variáveis pelos valores, é obtido o seguinte: (1121047,26/26241097,22) * 100 = 4,27%. Todos os valores estão dispostos no Quadro 4.8. Após todos os experimentos terem sido realizados e terem os seus fatores transpostos para as tabelas e quadros utilizados neste trabalho, foi gerado o gráfico 4.5. Com isto foi possível calcular a influência que cada fator e as combinações entre eles tiveram nos resultados. Gráfico 4.5- Influência dos fatores Fonte: Elaborado pelo autor Observa-se no Gráfico 4.5 que o fator que teve mais influência na variável de resposta foi o número de hosts (qc). Verifica-se que este fator influenciou em quase 2/3 do valor da variável de resposta, com 66,17%. Essa alta porcentagem de influência na variável de resposta faz sentido pois, em um ambiente de banco de dados distribuídos o qual foi configurado com sincronização de mesclagem, o que gera tráfego na rede deste tipo de banco são as máquinas (hosts) que o compõem. Desta forma, quanto maior o número de hosts que compõem este tipo de ambiente, maior o número de sincronizações e replicações de dados se fazem necessárias. Já o fator número de requisições (qb), quando analisado de forma isolada, foi o que menos influêncou a variável de resposta, com 1,08% do valor total. O fator número 76 de usuários (qa) influênciou 4,27% do total da variável de resposta. O segundo fator que mais influênciou a variável de resposta foi a interação entre os fatores número de usuários (qa) e número de requisições (qb), formando o fator (qab). Isso demonstra que após certo instante, o valor de pacotes por segundo é influenciado pela carga vinda do ambiente externo ao bdd, ou seja, sofre influência da carga que é formada pela quantidade de requisições enviadas pelos usuários deste bd. Na sequência, o fator que mais influênciou a variável foi a combinação entre os fatores número de requisições (qb) e número de hosts (qc), totalizando 7,71% do percentual total da variável de resposta. Depois deste, a combinação entre os três fatores (qabc), influênciou em 5,03% do valor total da variável de resposta. Por fim, o fator formado pela interação número de usuários (qa) e número de hosts (qc) influênciou em 3,71% na variável de resposta. 77 CONSIDERAÇÕES FINAIS Estudos se fazem necessários em todas as áreas de tecnologia, ou para se criar algo novo, ou para aperfeiçoar o que já foi criado ou até mesmo para reinventar algo que já existe. Banco de dados distribuídos é algo relativamente novo no mundo da informática e necessita de muitas pesquisas para aperfeiçoá-lo. Com as suas várias opções de configurações, tais como replicação mesclada ou replicação instantânea, neste ambiente de armazenamento de dados existe a necessidade de serem realizadas várias análises e experimentos que demonstrem a quem for implantar e gerir um BDD, quais as melhores opções de configuração para o ambiente que se quer montar. Este trabalho focou em demonstrar quais dos 3 fatores (número de usuáios, número de requisições e número de hosts) e as variações de seus níveis influenciariam mais no tráfego de dados em um ambiente de banco de dados distribuído. Desta maneira, avaliou-se os resultados obtidos e viu-se que o fator número de hosts é o fator que teve mais influência no tráfego de dados, com um percentual de 66,17% do total. Percebe-se que este é o fator mais influente tanto quando analisa-se os fatores de modo individual ou quando analisa-se os fatores quando ocorre interações entre eles. Entretanto, o segundo fator que mais influenciou no tráfego foi a interação entre os fatores número de usuários com número de requisições, com 12,02% do total. Na sequência, o fator quem mais influênciou o transição de pacotes pela rede do BDD foi a interação entre os fatores número de usuários e número de hosts, obtendo um valor de 7,71%. Desta forma conclui-se que ao se projetar um banco de dados distribuído, deve-se perceber que o fator número de hosts influenciará e muito no tráfego de pacotes, ao contrário do que se possa pensar, que os fatores número de usuários e número de requisições poderiam ser os que mais influenciariam em um ambiente deste. Porém, a combinação destes dois últimos fatores citados é o segundo fator que mais influencia. Então, uma elaboração projetual deve focar em uma boa estruturação na rede deste tipo de ambiente para que não haja sobrecarga neste local, pois existe uma troca muito intensa de dados entre os próprios bancos, para que estes contenham os mesmos dados. Só então se deve pensar nas requisições vindas do ambiente externo, emitidas pelos usuários. 78 Vale lembrar que o ambiente de testes utilizado neste trabalho fez uso de máquinas virtuais e, com isso, o desempenho fica bem reduzido se comparado a um mesmo ambiente, só que fazendo uso de máquinas físicas. Outro fator que pode ter influenciado nos resultados mas que não foi adotado neste trabalho é a capacidade de processamento dos computadores que compõem o ambiente de banco de dados distribuídos. Com isto, caso o ambiente adote uma ótima estrutura de cabeamento de rede, esta capacidade de processamento computacional pode ter uma forte influência nas variáveis de resposta. Diante do exposto anteriormente, novos trabalhos de avaliação de desempenho podem ser realizados adotando outros ambientes e outros fatores. Tais estudos são de suma importância para ampliar o conhecimento e melhora em um sistema de banco de dados distribuídos. 79 REFERÊNCIAS BIBLIOGRÁFICAS BELL, D.; GRIMSON, J. Distributed Database Systems. 1. ed. Virgínia: AddisonWesley Pub. Co., 1992. CASANOVA, M. A.; MOURA, A. V. Princípios de Sistemas de Gerência de Banco de Dados Distribuídos. Campinas, 1999. CISCO. Programa Cisco Networking Academy. 2012a. Disponível em: <http://dc300.4shared.com/doc/Pj2XWRO6/preview.html>. Acesso em: 07 mai. 2012 __________. Cisco IOS NetFlow. 2012b. Disponível em: <http://www.cisco.com/en/US/products/ps6601/products_ios_protocol_group_home.h tml>. Acesso em: 11 jun. 2012. COUTINHO, R. RPC. 2009. Disponível em: <http://www.culturamix.com/tecnologia/rpc>. Acesso em: 24 mai. 2012. CUNHA, S. L. O. Gerenciamento de Dados em Banco de Dados Distribuídos. 2003. Monografia (Bacharelado em Ciência da Computação) – Centro Universitário do Triângulo, Instituto de Ciências Exatas e Tecnológicas, Uberlândia. DEITEL. H.M.; DEITEL. P. J. Java: como programar. Tradução Edson Furmankiewicz. 6. ed. São Paulo: Pearson Prentice Hall, 2005. D-LINK. STACK User Manual. Product Model: xStack DGS-3600 Series. 2009. Disponível em: <http://www.dlink.com/uk/en/support/product//media/Business_Products/DGS/DGS%203627G/Manual/DGS3600SeriesManualv25 _EN.pdf>. Acesso em: 10 out. 2012. ELMASRI, R.; NAVATHE, S. B. Sistemas de Banco de Dados. Tradução Marília Guimarães Pinheiro, Cláudio César Canhette, Glenda Cristina Valim Melo, Claudia Vicei Amadeu e Rinaldo Macedo Morais. 4. ed. São Paulo: Pearson Addison Wesley, 2005. FILHO, P. J. F. Introdução à modelagem e simulação de sistemas com aplicações em Arena. 2. ed. Florianópolis: Visual Books, 2008. GOULART, A. Sistemas Distribuídos e Comunicação em Grupo. 2002, 67p. Apostila da disciplina de Tópicos Especiais em Computação – Sistemas Distribuídos. Universidade do Vale do Itajai. IBM Global Education. Virtualization in Education. 2007. Disponível em: <http://www07.ibm.com/solutions/in/education/download/Virtualization%20in%20Education.pdf>. Acesso em: 15 nov. 2012. 80 IBOPE. Intervalo de confiança. Disponível em: <http://www.ibope.com.br/ptbr/conhecimento/Leitura-de-Pesquisas-Eleitorais/Paginas/Intervalo-deConfianca.aspx>. Acesso em: 01 jun. 2013. JAIN, R. Art of Computer Systems Performance Analysis Techniques For Experimental Design Measurements Simulation And Modeling. New York: Wiley, 1991. JMETER. Apache JMeter. Disponível em: <http://jmeter.apache.org/>. Acesso em: 15 nov. 2012. JOSE, F. P. R.; SILVA, N. S. Avaliação de Desempenho em Banco de Dados Distribuídos considerando o Ambiente de Aplicação WEB. 2012. TCC (Tecnólogo em Banco de Dados) – Faculdade de Tecnologia de Lins Prof. Antonio Seabra, Lins. LIMA, M. S. Aplicação de estratégias de replicação de base de dados em sistemas gerenciadores de banco de dados. 2011. TCC (Bacharelado em Sistemas de Informação) – Departamento de Sistemas de Informação, Universidade Federal de Sergipe, Itabaiana. LUCAS, M. W. Network Flow Analysis. San Francisco: No Starch Press, Inc., 2010. MADRUGA, F. L. Protocolos de Multicast na Camada de Aplicação para Streaming. 2008. TCC (Graduado em Engenharia da Computação) – Fundação Universidade Federal do Rio Grande, Rio Grande. MESQUITA, E. J. S. Projeto de Dados em Bancos de Dados Distribuídos. 1998. Tese (Mestrado em Matemática Aplicada) – Instituto de Matemática e Estatística, Universidade de São Paulo, São Paulo. MSDN. Visão Geral dos Agentes de Replicação. 2013a. Disponível em: <http://msdn.microsoft.com/pt-br/library/ms152501.aspx>. Acesso em: 20 mai. 2013. __________. Servidores vinculados (Mecanismo de Banco de Dados). 2013b. Disponível em: <http://msdn.microsoft.com/pt-br/library/ms188279.aspx>. Acesso em: 25 mai. 2013. __________. Replicação de instantâneo. 2013c. Disponível em: <http://msdn.microsoft.com/pt-br/library/ms151832.aspx>. Acesso em: 29 mai. 2013c. NIELSEN, P. et al. Microsoft SQL Server 2008 Bible. 1. ed. Indianapolis: Wiley Publishing, Inc., 2009. OFFICE. INT.CONFIANÇA. 2013a. Disponível em: <http://office.microsoft.com/ptbr/excel-help/int-confianca-HP005209021.aspx>. Acesso em: 01 jun. 2013. 81 __________. DESVPAD.P (Função DESVPAD.P). 2013b. Disponível em: <http://office.microsoft.com/pt-br/excel-help/desvpad-p-funcao-desvpad-pHP010335772.aspx>. Acesso em: 01 jun. 2013. POTTER, B. Network Flow Analysis. 2008. Disponível em: <http://www.defcon.org/images/defcon-16/dc16-presentations/defcon-16-potter.pdf>. Acesso em: 10 jun. 2012. PUTTY. PuTTY: A Free Telnet/SSH Client. Disponível em: <http://www.chiark.greenend.org.uk/~sgtatham/putty/>. Acesso em: 26 mai. 2013. REDHAT. O que é virtualização? Disponível em: <http://br.redhat.com/pdf/virtualization/whatisvirtualization.pdf>. Acesso em: 15 nov. 2012. SANCHES, A. R. Fundamentos de Armazenamento e Manipulação de Dados. Universidade de São Paulo (IME). 2012. Disponível em: <http://www.ime.usp.br/~andrers/aulas/bd2005-1/aula4.html>. Acesso em: 02 mai. 2012. SANTANA, M. J.; SANTANA, R. H. C. Aula 2: Avaliação de Desempenho. Planejamento de Experimentos 2. Universidade de São Paulo (Instituto de Ciências Matemáticas e de Computação e Departamento de Sistemas de Computação). 2012a. Disponível em <http://lasdpc.icmc.usp.br/disciplinas/posgraduacao/avaliacao-de-desempenho-1/2011/aulas-slides/aula2planeja2.ppt/view>. Acesso em: 01 nov. 2012. __________. Aula 3: Avaliação de Desempenho. Planejamento de Experimentos 2. Universidade de São Paulo (Instituto de Ciências Matemáticas e de Computação e Departamento de Sistemas de Computação). 2012b. Disponível em <http://lasdpc.icmc.usp.br/disciplinas/pos-graduacao/avaliacao-de-desempenho1/2011/aulas-slides/aula3planeja2.ppt/view>. Acesso em: 01 nov. 2012. SHIBAYAMA, E. T. Estudo Comparativo entre Bancos de Dados Distribuídos. 2004. TCC (Bacharelado em Ciência da Computação) – Departamento de Computação, Universidade Estadual de Londrina, Londrina. SILVA, E. K. O. Um estudo sobre Sistemas de Banco de Dados Cliente/Servidor. 2001. Monografia (Graduado em Processamento de Dados) – Faculdade Paraibana de Processamento de Dados, João Pessoa. SIQUEIRA, F. Banco de Dados Distribuídos. Universidade Federal de Santa Catarina (Departamento de Informática e Estatística). 2012. Disponível em: <http://www.inf.ufsc.br/~frank/BDD/BDDIntro.pdf>. Acesso em: 03 mai. 2012. TANENBAUM, A. S. Computer Networks. Tradução Vandenberg D. de Souza. 4. ed. Rio de Janeiro: Elsevier, 2003. 82 TANENBAUM, A. S.; STEEN, M. V. Sistemas distribuídos: princípios e paradigmas. Tradução Arlete Simille Marques. 2. ed. São Paulo: Pearson Prentice Hall, 2007. THE OPEN GROUP. The Open Group Debuts Open Source Licensing of DCE Source Code. 2012. Disponível em: <https://adl.opengroup.org/comm/press/05-0112.htm>. Acesso em: 23 mai. 2012. VMWARE. Conceitos básicos de virtualização. 2012a. Disponível em: <http://www.vmware.com/br/virtualization/virtualization-basics/what-isvirtualization.html>. Acesso em: 15 nov. 2012. __________. VMware Server End of Life Info Center. 2012b. Disponível em: <http://www.vmware.com/br/products/datacenter-virtualization/server/overview.html>. Acesso em: 15 nov. 2012. __________. VMware Player. 2012c. Disponível em: <http://www.vmware.com/br/products/desktop_virtualization/player/overview.html>. Acesso em: 15 nov. 2012. ZABBIX. Manual do Zabbix 1.8. Disponível em: <http://www.zabbix.com/documentation/pt/1.8/complete>. Acesso em: 11 jun. 2012. 83 ANEXO A – Criação e configuração das máquinas virtuais Os exemplos de configurações de máquinas virtuais foram realizados com base no trabalho de conclusão de curso de Jose e Silva (2012). A primeira máquina virtual teve o nome completo do computador alterado após a instalação do sistema operacional Windows XP Professional. Isto foi feito para facilitar o reconhecimento destas VMs dentro do ambiente de testes e conexão no SQL Server 2008, pois tal sistema agrega o nome do computador como o nome do servidor SQL. Figura A.1 – Abrindo Propriedades do Meu computador Para alterar o nome do computador, com o sistema operacional já inicializado e estabilizado, é necessário clicar em Iniciar e em seguida clicar com o botão direito do mouse em Meu computador. Um sub-menu será disponibilizado. Neste seleciona-se a opção Propriedades, conforme a Figura A.1. Feito isto, uma nova janela será disponibilizada. Nesta nova janela clica-se na aba Nome do computador. Após clica-se no botão Alterar, conforme a Figura A.2. Na próxima janela (Alterações de nome de computador) disponibilizada, no campo Nome do computador: insira o nome o qual será definido para tal máquina e clique em “OK”. Para este exemplo, foi definido o nome cliente-02, conforme a Figura A.3. 84 Figura A.2 – Alterar nome do computador Figura A.3 – Inserir nome do computador Quando o botão “OK” é clicado, o sistema operacional disponibiliza uma janela informando que o computador deve ser reinicializado para que as alterações realizadas tenham efeito, conforma a Figura A.4. Clique em “OK”. 85 Figura A.4 – Primeiro aviso para reinicializar o sistema Feito isto já é possível visualizar o novo nome do computador, conforme a Figura A.5. Nesta tela, clique em “OK” novamente. Figura A.5 – Nome do computador já alterado Por fim uma última tela é disponibilizada, sugerindo que o computador seja reinicializado. Clique em “OK”, conforme a Figura A.6. 86 Figura A.6 – Segundo aviso para reinicializar o sistema O próximo passo é desabilitar o firewall para que as máquinas virtuais consigam transmitir informações entre si. Para isso, clique em Iniciar Painel de controle e dentro da janela Painel de controle, clique sobre o ícone Firewall do Windows. Na janela Firewall do Windows, aba Geral, selecione a opção Desativado (não recomendável), conforme a Figura A.7. Feito isso, clique em “OK”. Figura A.7 – Desativar firewall 87 A seguir será necessário definir os IPs de cada máquina virtual, em uma mesma faixa de valores, para que estas consigam transmitir dados umas para as outras. Para isto dê dois cliques no atalho Meus locais de rede e na janela que será disposta, selecione a opção Exibir conexões de rede, conforme a Figura A.8 Figura A.8 – Exibir conexões de rede Figura A.9 – Propriedades do Protocolo TCP/IP 88 Na nova janela, clique com o botão direito sobre o ícone Conexão local e selecione Propriedades no sub-menu que será exposto. Na nova janela, na caixa de diálogo Esta conexão usa estes itens:, selecione Protocolo TCP/IP e clique no botão Propriedades, conforme a Figura A.9. Figura A.10 – Endereço de IP e máscara de sub-rede Figura A.11 – Confirmação do endereço de IP e máscara de sub-rede 89 Os endereços de IP configurados nas máquinas virtuais foram fixados na faixa 10.1.1.xx. Já a máscara de sub-rede foi configurada com o valor 255.255.255.0, em todas as VMs. Na máquina virtual utilizada neste exemplo foi definido o IP 10.1.1.20, conforme a Figura A.10. Para comprovar se o endereço de IP foi configurado corretamente, clique em Iniciar Todos os programas Acessórios Prompt de comando. Dentro da janela do Prompt de comando digite a linha de comando ipconfig e tecle Enter. Nesta mesma janela serão dispostos o endereço de IP e a Máscara de sub-rede definidos. A Figura A.11 demonstra isto. O presente trabalho fez uso de oito máquinas virtuais. Para verificar se uma máquina consegue transmitir dados para a outra basta abrir o prompt de comando e efetuar um “ping” de uma VM para a outra. Para isto, basta digitar a linha de comando ping tendo o número do endereço de IP da VM destino na frente. Assim, tal linha de comando tem a seguinte sintaxe: ping <endereço de IP>. Pacotes serão enviados para a máquina destino e, caso não ocorra nenhum erro, a máquina destino envia respostas à VM requisitante. 90 ANEXO B – Instalação e configuração do banco de dados Microsoft SQL Server 2008 Developer Para instalar o SQL Server, primeiramente é necessário que seja instalado o software Windows Installer 3.1. Baixe-o e o instale. Depois de instalado deve-se reiniciar o computador que, no caso deste trabalho, é uma máquina virtual. Feito isto, quando se inicia a instalação do SQL Server, tal software aponta que há a necessidade que seja instalada a ferramenta de desenvolvimento de software Microsoft .NET e que o Windows Installer precisar ser atualizado para uma versão mais nova. Clique em “Ok”, conforme a Figura B.1. Figura B.1 – Instalação do Microsoft .NET requerida A próxima tela exibe o termo licença. Selecione a opção “Eu li e Aceito os termos do Contrato de licença”. Após clique no botão “Instalar”, conforme a Figura B.2. Depois de instalado, na tela de “Instalação concluída”, clique em “Sair“, conforme a Figura B.3. 91 Figura B.2 – Termos de Licença Figura B.3 – Instalação do Microsoft .NET concluída Na Figura B.4, clique em “Avançar”. A Figura B.5 exibe uma tela de aceitação de licença para uso da empresa Microsoft. Selecione a opção “Concordo” e clique em “Avançar”. 92 Figura B.4 – Assistente para atualização de software Figura B.5 – Contrato de licença Na Figura B.6, clique em “Concluir”. Feito isto, uma nova tela aparecerá informando que o sistema operacional precisa ser reinicializado pois um dos prérequisitos instalados requer que seja feito isto, conforme demonstra a Figura B.7. Então, clique em “Ok” e reinicialize a máquina. 93 Figura B.6 – Instalação do assistente concluída Figura B.7 – Reinicialização do sistema operacional Após o sistema operacional ser reinicializado, prossiga com a instalação do SQL Server 2008, conforme a Figura B.8. Na Figura B.9 clique na primeira opção. 94 Figura B.8 – Retorno à instalação do SQL Server 2008 Figura B.9 – Instalação e configuração do SQL Server 2008 Na Figura B.10, clique em “Ok”. A Figura B.11 demonstra que é necessário inserir a chave de validação do produto. Após inserí-la, clique em “Ok”. 95 Figura B.10 – Visualização parcial dos resultados da instalação Figura B.11 – Inserção da chave de validação Quando chegar à Figura B.12, clique no botão “Select All” e clique em “Next”. Na Figura B.13, selecione a opção “Default Instance” e clique em “Next”. 96 Figura B.12 – Seleção de características Figura B.13 – Seleção de instância Na Figura B.14 selecione todas as opções como AUTORIDADE NT/SYSTEM e clique em “Next” Na figura B.15, selecione a opção Mixed Mode, insira nos campos requeridos e clique na opção Add Current User. Feito isto, clique em “Next”. 97 Figura B.14 – Conta de serviço Figura B.15 – Adicionando usuário corrente Na Figura B.16, clique em Add Current User e após, clique em “Next”. Na Figura B.17, selecione a opção Install the native mode default configuration e clique em “Next”. 98 Figura B.16 – Configuração de análise de serviços Figura B.17 – Configuração dos serviços de relatório A Figura B.18 demonstra o fim da instalação. Verifica-se que no final da instalação ocorreu um erro. Porem, este erro não influenciou nos resultados. Clique em “Close”. 99 Figura B.18 – SQL instalado com sucesso Após instalado o SQL Server é necessário configurar o firewall do sistema operacional, para que o mesmo não barre o acesso de requisições através da porta 1433. Para isto, adicione uma porta no firewall, dê o nome 1433, com número da porta 1433, selecionando a opção TCP. Feito isto, configure o SQL Server acessando o SQL Server Configuration Manager, conforme demonstra a Figura B.19. Figura B.19 – SQL Server Configuration Manager 100 Na Figura B.20, cliquem em “TCP/IP” e selecione “Propriedades” no submenu que será disposto. Figura B.20 – Propriedades do TCP/IP Figura B.21 – Propriedades do TCP/IP Na figura B.21, mude para Yes a opção Enabled. Habilite também a opção Named Pipes, conforme a Figura B.22. 101 Figura B.21 – Habilitando Named Pipes Feito isto, acesse o SQL Server Management Studio, conforme a Figura B.22. Figura B.22 – SQL Server Management Studio Após acessar o SQL Server, clique com o botão direito sobre a instância CLIENTE-02, fruto desta configuração, e selecione a opção Facets, conforme a Figura B.23. 102 Figura B.23 – Opção Facets Na próxima tela, em Facet, selecione a opção Surface Area Configuration, conforme a Figura B.24. Figura B.24 – Surface Area Configuration Em Facet properties, selecione RemoteDacEnabled e mude sua opção para True, conforme a Figura B.25. 103 Figura B.25 – RemoteDacEnabled O próximo passo e reiniciar o SQL Server e o SQL Server Agent, conforme as Figuras B.26 e B.27, respectivamente. Figura B.26 – Reinicializando o SQL Server 104 Figura B.27 – Inicializando o SQL Server Agent 105 ANEXO C – REPLICAÇÃO MERGE SQL SERVER CONFIGURANDO O DISTRIBUIDOR MICROSOFT SQL SERVER 2008 Para a criação do distribuidor, após acessado o SQL Server, clique com o botão direito em Replication e selecione a opção Configure Distribuition, conforme a Figura C.1 Figura C.1 – Configuração de distribuição Figura C.2 – Tela inicial 106 Na tela inicial, clique em “Next”, conforme a figura C.2. Na próxima etapa é escolhido o distribuidor que, no caso, será a própria máquina. Nesta etapa, clique em “Next”, conforma a Figura C.3. Figura C.3 – Escolha do distribuidor Na Figura C.4, clique em “Next”. Figura C.4 – Escolha do distribuidor 107 O próximo passo é escolher o nome do banco de dados distribuidor. Mantenha o nome indicado e clique em “Next”, conforme a Figura C.5. Figura C.5 – Escolha do nome do distribuidor Na figura C.6, clique em “Next”. Figura C.6 – Permissão para distribuição quando for publicador 108 Na Figura C.7 clique em “Next”. Por fim, a Figura C.8 exibe as configurações que serão aplicadas ao servidor. Nesta tela, clique em “Finish”. Figura C.7 – Configurar distribuidor Figura C.8 – Configurações que serão aplicadas 109 A Figura C.9 exibe uma tela informando que o distribuidor foi configurado com sucesso e que tal servidor foi habilitado para funcionar também como publicador. Figura C.9 – Configuração realizada com sucesso CRIANDO UMA PUBLICAÇÃO Nesta etapa será configurada uma publicação. Figura C.10 – Nova publicação 110 Clique em Replication e com o botão direito, clique na opção Local Publications, selecionando New Publication, conforme Figura C.10. Na tela inicial, clique em “Next”, conforme a Figura C.11. Figura C.11 – Tela inicial Figura C.12 – Banco de dados escolhido 111 Na próxima etapa é escolhido o banco de dados que terá seus dados publicados, conforme a Figura C.12. A seguir deve ser escolhido o tipo de publicação que será feita. Para este trabalho foi adotada a publicação do tipo mesclagem, conforme a Figura C.13. Figura C.13 – Publicação Merge Na Figura C.14, clique em “Next”. Figura C.14 – Versão do SQL Server 112 A próxima etapa é a escolha das tabelas que serão publicadas. Selecione a opção Tables e clique em “Next” Figura C.15 – Seleção de tabelas a serem publicadas Na Figura C.16 clique em “Next”. Figura C.16 – Adição de filtros 113 A Figura C.17 expõe a opção para configurar o Agente de Instantâneo. Selecione as opções Create a snapshot immediately e Schedule the Snapshot Agent to run at the following times:. Após isto, clique em Change… Na janela que é disponibilizada, conforme a Figura C.18, configure para que a aplicação do instantâneo seja feita diariamente, adotando o intervalo mínimo permitido pelo SQL Server, que é de 10 segundos. Figura C.17 – Especificação de execução do Agente de Instantâneo Figura C.18 – Agendamento de execução do Snapshot Agent 114 A Figura C.19 exibe as configurações escolhidas. Clique em “Next” nesta etapa. Figura C.19 –Confirmação das configurações Na Figura C.20, clique em Security Settings para configurar a conexão do Agente. Figura C.20 – Configuração da conexão do Agente 115 Na próxima etapa, selecione as opções conforme disposto na Figura C.21 e, em Login, insira o usuário “sa” e nos campos Password e Confirm Password, insira do servidor publicador, que no caso, é o própria máquina fruto deste exemplo. Figura C.21 – Configuração de segurança do Agente Na Figura C.22, clique em “Next”. Figura C.22 – Confirmação das configurações da conexão do Agente 116 Na Figura C.23, clique em “Next”. Figura C.23 – Criar a publicação Na Figura C.24, clique em “Next” novamente. Figura C.24 – Confirmação das configurações que serão aplicadas 117 A Figura C.25 demonstra que as configurações foram aplicadas com sucesso. Clique em “Close”. Figura C.25 – Configurações aplicadas com sucesso Na Figura C.26 é possível visualizar a nova publicação criada. Figura C.26 – Nova publicação já disponível 118 CRIANDO UM ASSINANTE Para criar um assinante, clique com o botão direito em Local Subscriptions e selecione New Subscriptions..., conforme a Figura C.27 Figura C.27 – Criando um novo assinante Na Figura C.28, cliquem em “Next”. Figura C.28 – Tela inicial de criação do assinante 119 A próxima etapa é escolher para qual publicação será criado o novo assinante. Na Figura C.29 foi escolhida a publicação “Exemplo_publicacao_3”. Clique em “Next”. Figura C.29 – Escolha da publicação Na Figura C.30, clique em “Next” Figura C.30 – Agentes rodarão no distribuidor 120 A próxima etapa é escolher um novo assinante. Na Figura C.31, clique em Add SQL Server Subscriber... Figura C.31 – Adicionando um servidor como assinante A exemplificar, o servidor de nome CLIENTE-03 será o novo assinante da publicação, conforme a Figura C.32. Insira o nome do usuário administrador (sa) e a senha do mesmo. Clique em “Connect”. Figura C.32 – Acesso ao servidor CLIENTE-03 121 O próximo passo é criar um banco de dados no CLIENTE-03, o qual receberá as tabelas e dados do publicador. Então, na Figura C.33, selecione CLIENTE-03 e crie um novo banco de dados para ele. Para isto, selecione a opção <New database...>, conforme a Figura C.33. Figura C.33 – Novo banco de dados Na nova tela, dê um nome para o banco de dados e clique em “Ok”, conforme a Figura C.34. Figura C.34 – Acesso ao servidor CLIENTE-03 122 A Figura C.35 expõe o servidor e o banco de dados escolhidos para receber as tabelas e dados do publicador. Clique em “Next”. Figura C.35 – Servidor e banco de dados do assinante A Figura C.36 expõe a opção para que sejam informadas as configurações de acesso e segurança do Merge Agent do servidor CLIENTE-03. Clique no botão “...”. Figura C.36 – Inserir opções de acesso e segurança 123 Na próxima etapa, selecione as opções conforme dispostas na Figura C.37, inserindo o nome do super administrador (sa) e a senha do mesmo. Figura C.37 – Inserir opções de acesso e segurança A Figura C.38 exibe parcialmente as configurações realizadas. Clique em “Next”. Figura C.38 – Confirmação de configurações, parcial 124 Na Figura C.39, selecione a opção de agendamento para rodar continuamente. Figura C.39 – Agente em funcionamento contínuo Na Figura C.40, selecione a opção para inicializar imediatamente a assinatura. Clique em “Next”. Figura C.40 – Inicializar imediatamente Na Figura C.41, cliquem em “Next”. 125 Figura C.41 – Tipo de subscrição: Server Na Figura C.42, clique em “Next”. Figura C.42 – Criar a nova assinatura Na Figura C.43 confirme as configurações que serão aplicadas e clique em “Finish”. A Figura C.44 exibe que a criação do assinante foi realizada com sucesso. 126 Figura C.43 – Confirmação de configurações Figura C.44 – Assinatura criada com sucesso CONFIGURANDO LINKED SERVER Para este trabalho foram configurados Linked Servers (servidores vinculados) para cada assinante. Isto se fez necessário pois o servidor principal teria que funcionar apenas como uma ponte entre a conexão externa ao ambiente do banco de dados distribuídos e os hosts (máquinas) que compõem o bdd. Desta forma, a 127 Figura C.45 dispõe o primeiro passo para a criação um novo Linked Server, para o host de nome CLIENTE-03 Figura C.45 – Novo Linked Server... O próximo passo é dar um nome para este Linked Server e inserir o IP do host CLIENTE-03, conforme a Figura 46. Figura C.46 – Configurações do Linked Server 128 O próximo passo é inserir as informações de usuário e senha de acesso ao host CLIENTE-03. Para isto, clique em “Add”, conforme a Figura C.47. Figura C.47 – Configurações do Linked Server Na linha azul, como disposto na Figura C.48, clique abaixo de Local Login e insira o nome do usuário do servidor CLIENTE-03. Em Remote User, insira o mesmo nome. Por fim, insira a senha deste usuário. Selecione também a opção “Be made without using a security context”. Após, clique em “Ok”. Figura C.48 – Usuário e senha do servidor acessado remotamente 129 A Figura C.49 expõe um comando de seleção de dados já fazendo uso do Linked Server criado. Pode-se observar que a requisição dos dados é feita para o host CLIENTE-03 e não para o servidor o qual está realizando a requisição. Figura C.49 – Exemplo de uso do Linked Server 130 ANEXO D – Elaboração de um plano de teste com a ferramenta JMeter Para poder utilizar normalmente esta ferramenta, cabe algumas explicações. Primeiramente, esta ferramenta funciona sem a necessidade de instalá-la, apenas é necessário executar o “ApacheJMeter.jar”, que encontra-se dentro da pasta “bin”, contida no pacote baixado “jakarta-jmeter-2.5”. Contudo, ainda houve a necessidade de apontar para cada teste, na tela inicial dos mesmos, a localização da biblioteca “jtds-1.3.0.jar”, pois sem isto, a ferramenta não funcionava. A adição desta biblioteca pode ser visualizada na Figura D.1, na parte inferior da mesma. Vale lembrar que a ferramente JMeter foi obtida fazendo o download da mesma, de forma compactada. Assim, este arquivo deve ser descompactado no local escolhido pelo usuário. Figura D.1 – Tela inicial do JMeter, adição da biblioteca jtds-1.3.0.jar O segundo passo é adicionar o Grupo de Usuários. Para isto, clique com o botão direito do mouse no Plano de teste, vá em Adicionar -> Threads (Users) -> Grupo de usuários. A Figura D.2 expõe a tela que será aberta. Nesta tela é onde serão feitas as configurações com relação a quantidade de usuários que serão simulados e quantas vezes estes usuários irão executar uma requisição de dados junto ao banco de dados distribuído. Ainda nesta tela, em “tempo de inicialização”, configure-o para zero. Desta forma o não haverá intervalos entre a execução de um usuário e outro. 131 Figura D.2 – Configuração de Grupo de usuários A próxima etapa é a configuração da conexão com o banco de dados, através do JDBC. Nesta fase temos que configurar o nome da Variável. Este nome deverá ser o mesmo nome que será dado quando houver a configuração da Requisição JDBC, que será explicada através da Figura D.4. Para este exemplo, deu-se o nome de “csv_01”. A outra parte da configuração é a que contem os parâmetros que realizam efetivamente a conexão com o banco de dados. Desta forma, em “URL do banco de dados”, passa-se o caminho da seguinte maneira: jdbc://sqlserver://<número do IP do servidor que será acessado>:1433;InstanceName=<instânciaSQL>;databaseName=<nome do banco de dados>. Para este exemplo, essa linha pode ser verificada através da Figura D.4. Em “Classe do Driver JDBC”, adicione a linha “com.microsoft.sqlserver.jdbc.SQLServerDriver”, que se refere ao driver de conexão JDBC. Já em nome de usuário, adicione o usuário “sa” e passe a senha do mesmo. Desta forma, a ferramenta JMeter consegue efetuar requisições de dados junto ao servidor SQL Server. 132 Figura D.3 – Configuração da Conexão JDBC Na Figura D.4 será realizada a configuração da requisição JDBC. Nesta tela, em “Nome de Variável”, adicione o mesmo nome dado quando foi configurada a conexão JDBC que, para este exemplo, recebeu o nome de “csv_01”. É este nome que faz a “amarração” entre as requisições feitas ao banco de dados e a configuração para que estas requisições cheguem ao bdd. Figura D.4 – Configuração da Requisição JDBC 133 No campo “Tipo de consulta:”, selecione a opção “Callable Statement”. Este tipo de consulta faz com que qualquer tipo de consulta ao banco de dados seja aceita, fazendo uso do arquivo CSV, o qual será explicado na Figura D.6. Para tanto, ainda há a necessidade de no campo “Consulta”, passar o parâmetro “$(SQLSmt)” A Figura D.5 demonstra as configurações necessárias para que seja possível a utilização do arquivo do tipo CSV. Este arquivo do tipo CSV é um arquivo de planilha, o qual contem dados em cada linha, que são separados por um caractér. Desta maneira várias linhas podem ser passadas como requisições, para o JMeter, que as dispara junto ao bdd. Para que a ferramenta JMeter consiga ler esse arquivo, deve-se colocar este dentro da pasta “bin”, que neste exemplo, pode ser acessada através do caminho “C:\jakarta-jmeter-2.5\bin”. No campo “Nome do arquivo” deve ser colocado o mesmo nome do arquivo CSV que foi alocado na pasta “bin”. Aqui, tal arquivo foi nomeado “CSV_JMETER_teste_02.csv”. Em codificação do arquivo, insira a informação “UTF8”. Já em “Nome das variáveis (separados por vírgula), coloque “SQLStmt”. No campo “Separador (usar „t\‟ para tabulações)”, insira o ponto-e-vírgula (;). Todas as outras configurações são mantidas as padrões. Figura D.5 – Configuração dos dados CSV A Figura D.6 expõe as linhas de requisições ao banco de dados, contidas no arquivo CSV utilizado neste exemplo. 134 Figura D.6 – Arquivo CSV A Figura D.7 exibe as informações logo após a execução de um plano de testes elaborado no JMeter. Para adicionar o “Gráfico Agregado” clique com o botão direito do mouse sobre o plano de teste, selecione Adicionar -> Ouvinte -> Gráfico Agregado, conforme a Figura D.8. Figura D.7 – Gráfico Agregado Figura D.7 – Inserção do Gráfico Agregado 135 Verifica-se através da Figura D.7 que foram executadas 4 requisições ao banco de dados, através da coluna “#Amostras” e que não houve nenhum erro com estas requisições, ou seja, todas obtiveram respostas as suas requisições, conforme a coluna “%erro” demonstra.
Download