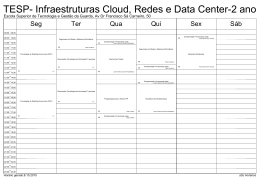
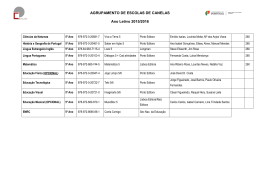
OPTIMIZAÇÃO DE CÓDIGO
PARA PENTIUM 4: SSE2
• Conceito de SIMD
• Evolução das tecnologias
• Aplicações práticas
• Conclusões
Luis Figueiredo - ESTG - Maio de 2003
CONCEITO DE SIMD
Single Instruction, multiple data
• Necessidades de uma nova tecnologia
• Características dos dados a processar
• Possíveis operações
– Operações simples (aritméticas e lógicas)
– Operações compostas (várias operações simples)
Luis Figueiredo - ESTG - Maio de 2003
OPERAÇÕES SIMPLES
+
a0
a1
a2
a3
a4
a5
a6
a7
b0
b1
b2
b3
b4
b5
b6
b7
a0+b0 a1+b1 a2+b2 a3+b3 a4+b4 a5+b5 a6+b6 a7+b7
Luis Figueiredo - ESTG - Maio de 2003
OPERAÇÕES COMPOSTAS
a0
a1
a2
a3
a4
a5
a6
a7
(ai+bi)/2 b0
b1
b2
b3
b4
b5
b6
b7
(a0 +b0)/2
(a7 +b7)/2
Luis Figueiredo - ESTG - Maio de 2003
OPERAÇÕES COMPOSTAS
a0
a1
a2
a3
a4
a5
a6
a7
b0
b1
b2
b3
b4
b5
b6
b7
a0*b0+a1*b1
a2*b2+a3*b3
a4*b4+a5*b5
Luis Figueiredo - ESTG - Maio de 2003
a6*b6+a7*b7
CONCEITO
DE
SIMD
Single Instruction, multiple data
• Necessidades de uma nova tecnologia
• Características dos dados a processar
• Possíveis operações
– Operações simples (aritméticas e lógicas)
– Operações compostas (várias operações simples)
• Operações com Saturação
Luis Figueiredo - ESTG - Maio de 2003
OPERAÇÕES COM SATURAÇÃO
Sem saturação
11111110
+ 00000010
1 00000000
Com saturação
254
+ 2
256
11111110
+ 00000010
1 00000000
11111111
Erro Absoluto sem
saturação
256 - 0 = 256
Erro Absoluto com
saturação
256 - 255 = 1
Luis Figueiredo - ESTG - Maio de 2003
EVOLUÇÃO DAS TECNOLOGIAS
• Tecnologia MMX (Pentium MMX)
• Tecnologia SSE (Pentium III)
• Tecnologia SSE2 (Pentium 4)
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA MMX
Aspectos físicos
Registos da FPU
st7
st6
st5
st4
st3
st2
st1
st0
Registos MMX
MM7
MM6
MM5
MM4
MM3
MM2
MM1
MM0
80 bits
64 bits
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA MMX
Aspectos lógicos
MMX (64 bits)
QUADWORD
DOUBLEWORD
WORD
WORD
DOUBLEWORD
WORD
WORD
Byte Byte Byte Byte Byte Byte Byte Byte
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA MMX
Algumas instruções
• PADDB, PADDW, PADDD
• PADDSB, PADDSW
• PADDUSB, PADUSW
• PSUBB, PSUBW, PSUBD
• São 57 novas instruções
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA MMX
principais limitações
• Não pode ser utilizada em simultâneo com a
unidade de floating point (FPU)
• Não permite qualquer operação de floats
• Latência na passagem de MMX para FPU
• Não permite multiplicações de unsigneds
• Não permite comparações de unsigneds
• Não permite divisões
• Não, não, não...
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA SSE
Aspectos físicos
Novos Registos XMM
XMM7
XMM6
XMM5
XMM4
XMM3
XMM2
XMM1
XMM0
128 bits
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA SSE
Aspectos lógicos
XMM (128 bits)
DOUBLEQUADWORD
FLOAT
FLOAT
FLOAT
Luis Figueiredo - ESTG - Maio de 2003
FLOAT
TECNOLOGIA SSE
Principais novidades
• Novos registos de 128 bits
• Aritmética de floats (precisão simples)
• Novas instruções (MMX e XMM)
• Instruções de controlo da cache
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA SSE
Algumas instruções
• PAVGB, PAVGW (MMX)
• PMINUB, PMINUW (MMX)
• ADDPS, SUBPS, MULPS, DIVPS (XMM)
• MINPS, MAXPS (XMM)
• SQRTPS (XMM)
• São 70 novas instruções
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA SSE
principais limitações
• Os registos XMM de 128 bits não trabalham
com inteiros
• Só permite a utilização de floats de precisão
simples
• Não permite multiplicações de inteiros de 32
bits
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA SSE2
Aspectos físicos
• Nada de novo...
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA SSE2
Aspectos lógicos
XMM (128 bits)
Double float
Double float
float
float
float
float
doublequadword
quadword
doubleword
word
word
quadword
doubleword
word
word
doubleword
word
word
doubleword
word
word
byte byte byte byte byte byte byte byte byte byte byte byte byte byte byte byte
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA SSE2
Principais novidades
• Aritmética de floats (precisão dupla)
• Aritmética de inteiros nos registos XMM
• Novas instruções (MMX e XMM)
• Novas instruções de controlo da cache
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA SSE2
Algumas instruções
• MOVAPD, MOVUPD
• MOVLHPD, MOVHLPD
• PSHUFPD
• PADDQ, PSUBQ
• ADDPD, SUBPD, MULPD, DIVPD
• São 144 novas instruções
Luis Figueiredo - ESTG - Maio de 2003
TECNOLOGIA SSE2
principais limitações
• Limitações do tipo de dados em função das
instruções (soma de 32 bits com saturação)
• Não permite a multiplicação de palavras de 64
bits.
• Os registos têm apenas 128 bits!
Luis Figueiredo - ESTG - Maio de 2003
APLICAÇÕES PRÁTICAS
Média de arrays em C
void media( unsigned char *str1, unsigned char *str2, unsigned char *str3, int n)
{
int x;
for(x=0;x<n;x++)
str3[x]=(str1[x]+str2[x])/2;
}
Luis Figueiredo - ESTG - Maio de 2003
APLICAÇÕES PRÁTICAS
Média de arrays com SSE2
esi ->Ponteiro para 1º array, ebp ->Ponteiro para 2º array
edi ->ponteiro para destino, ecx -> número de elementos
lb1:
shr ecx,4
movapd XMM0,[esi]
add esi,16
movapd XMM1,[ebp]
add ebp,16
pavgb XMM0,XMM1
movapd [edi],XMM0
add edi,16
loop lb1
Luis Figueiredo - ESTG - Maio de 2003
APLICAÇÕES PRÁTICAS
Média de arrays: resultados
Nº Ciclos de Clock por elemento do Array
70
Ciclos Clock
60
50
40
C
XMM
30
20
10
0
18
94
70
45
21
97
72
2
59
4
30
6
01
8
72
0
44
2
15
4
86
Luis Figueiredo - ESTG - Maio de 2003
47
41
36
31
26
20
15
6
57
88
48
42
10
52
0
Tamanho Array
APLICAÇÕES PRÁTICAS
Multiplicação de matrizes
a1
a2
a3
a4
*
Endereços
crescentes
b1
b2
b3
b4
=
a1*b1+a2*b3 a1*b2+a2*b4
a3*b1+a4*b3 a3*b2+a4*b4
a1
b1
a2
b2
a3
b3
a4
b4
Luis Figueiredo - ESTG - Maio de 2003
APLICAÇÕES PRÁTICAS
Multiplicação de matrizes
a1
a2
a3
a4
*
Endereços
crescentes
b1
b3
b2
b4
=
a1*b1+a2*b3 a1*b2+a2*b4
a3*b1+a4*b3 a3*b2+a4*b4
a1
b1
a2
b3
a3
b2
a4
b4
Luis Figueiredo - ESTG - Maio de 2003
APLICAÇÕES PRÁTICAS
Multiplicação de matrizes
• Versão 1: Multiplicação em C
– multiplicar linhas por colunas
• Versão 2: Multiplicação em C com transposta
– transpor 2ª matriz
– multiplicar linhas por linhas
• Versão 3: Multiplicação SSE2 com transposta
– transpor 2ª matriz
– multiplicar linhas por linhas com SSE2
Luis Figueiredo - ESTG - Maio de 2003
APLICAÇÕES PRÁTICAS
Multiplicação de matrizes: Resultados
Nº de ciclos de clock por cada multiplicação e adição
(para matrizes de N*N temos N*N*N multiplicações e adições)
300
Ciclos Clock
250
200
C
CT
150
XMM
100
50
0
24
10
0
96
6
89
Luis Figueiredo - ESTG - Maio de 2003
2
83
8
76
4
70
0
64
6
57
2
51
8
44
4
38
0
32
6
25
2
19
8
12
64
0
Tamanho da matriz
APLICAÇÕES PRÁTICAS
Multiplicação de matrizes: Resultados
Tempo normalizado em relação à multiplicação em C
1,2
Tempo normalizado
1
0,8
C
CT
0,6
XMM
0,4
0,2
0
24
10
0
96
6
89
Luis Figueiredo - ESTG - Maio de 2003
2
83
8
76
4
70
0
64
6
57
2
51
8
44
4
38
0
32
6
25
2
19
8
12
64
0
Tamanho da matriz
APLICAÇÕES PRÁTICAS
Algumas considerações
• Efeito da cache
• Alinhamento da memória (16 bytes)
• Tamanho dos dados
• Organização da memória
Luis Figueiredo - ESTG - Maio de 2003
APLICAÇÕES PRÁTICAS
Organização da memória (exemplo clássico)
Typedef struct{
x
y
z
cor
x
y
z
cor
int x,y,z,cor;
}ponto;
ponto *lista;
lista=malloc(10000*sizeof(ponto));
x
y
z
cor
Luis Figueiredo - ESTG - Maio de 2003
Elemento 0
Elemento 1
Elemento n-1
APLICAÇÕES PRÁTICAS
Organização da memória (exemplo clássico)
int *listax,*listay,*listaz,*listacor;
listax
listax=malloc(10000*sizeof(int));
listay
listay=malloc(10000*sizeof(int));
listaz=malloc(10000*sizeof(int));
listacor=malloc(10000*sizeof(int));
Luis Figueiredo - ESTG - Maio de 2003
listaz
listacor
CONCLUSÕES
• As tecnologias SIMD aumentam substancialmente
a capacidade de cálculo
• O programador tem que repensar alguns
algoritmos
• Os compiladores (actuais) não fazem todo o
trabalho (não fazem quase nenhum)
• O conhecimento de arquitectura de computadores
dá ao programador enormes vantagens
Luis Figueiredo - ESTG - Maio de 2003
Baixar