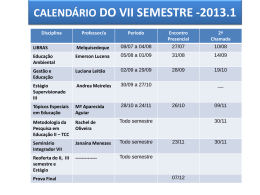
IV – Regressão e correlação IV.4. (cont.) Significância Estatística e Regressão Múltipla Tratamento de Dados 2º Semestre 2005/2006 Significância Estatística Existe uma estatítica, o t-estatístico, associado a cada estimativa O t-estatístico mede a distância do valor estimado a zero em termos de desvio padrão Se o valor do t-estatístico for igual ou superior a 2 em valor absoluto, então o coeficiente associado tem significância estatística Tratamento de Dados 2º Semestre 2005/2006 Cálculo de t-estatístico O t-estatístico é igual ao valor da estimativa do coeficiente a dividir pelo desvio padrão do coeficiente. Porque existe um desvio padrão associado a cada coeficiente da regressão linear? O que significa ter significância estatística? Acreditamos que o coeficiente é diferente de zero para um determinado nível de confiança. Tratamento de Dados 2º Semestre 2005/2006 Exemplo: Golfe e Performance Regressão linear entre performance financeira da empresa e golfe handicap do CEO da empresa (amostra de 51 empresas das 500 maiores da Fortune) Handicaps and Corporate Performance 120 y = -0.1734x + 55.137 R2 = 0.0017 Performance 100 80 60 40 20 0 0 5 10 15 20 25 Handicap Tratamento de Dados 2º Semestre 2005/2006 30 35 40 Excel Output: Golfe e Performance SUM M A RY OUTPUT Regression Statistics M ultiple R 0.042 R Square 0.002 A djusted R Square -0.019 Standard Error 25.38 Observations 51 A NOVA df Regression Residual Total Intercept Handicap Tratamento de Dados 1 49 50 SS MS 55.05295154 55.0529515 31567.65293 644.237815 31622.70588 t Stat CoefficientsStandard Error 55.1373367 9.790428944 5.63175904 -0.17343047 0.593277937 -0.2923258 2º Semestre 2005/2006 Problema Geral em Estatística Os dados provêm de uma amostra retirada da população Usamos características da amostra como estimativa das características da população Uma amostra diferente implica estimativas diferentes Tratamento de Dados 2º Semestre 2005/2006 Caso de Golfe e Performance Com uma amostra diferente de CEOs, não obteríamos uma estimativa de -0.1734 O desvio padrão da estimativa mede a precisão com que a estimativa é feita Existe uma probabilidade de cerca de 95% de que a estimativa esteja até 2 desvios padrão do verdadeiro valor do parâmetro Tratamento de Dados 2º Semestre 2005/2006 Distribuição do valor do coeficiente associado a Handicap 0.6 0.5 0.4 0.3 0.2 0.1 -4 -2 00 2 H 4 Seria uma surpresa se o verdadeiro valor do declive fosse igual a zero? Tratamento de Dados 2º Semestre 2005/2006 Detalhes sobre t-estatístico* Calculado como o valor da estimativa do coeficiente a dividir pelo desvio padrão do coeficiente estimado O t-estatístico tem distribuição t com N - k - 1 graus de liberdade, sendo k o número de variáveis explicativas O valor de t é aproximadamente igual a 2 para um teste a nível de significância de 5% (2-tail) Para obter precisão, verifiquem se o p-value < 0.05 * (nas aulas de estatística irão discutir este tema em teste de hipóteses) Tratamento de Dados 2º Semestre 2005/2006 Regressão Múltipla Regressão linear com mais de uma variável explicativa: ys = b0 + b1 x1s +...+bk xks + ε s xis corresponde ao valor da variável i para a observação s O Excel determina os coeficientes de xis que minimizam a soma dos quadrados dos erros da regressão (SSE) Tratamento de Dados 2º Semestre 2005/2006 Relebrem caso discriminação salarial yˆ = a + bI F Excel Output a = 60,983 b = - 3,166.67 Verificamos que a estimativa do declive corresponde à diferença entre as médias Tratamento de Dados Average of Earnings Gender Total F 57816.67 M 60983.33 Grand Total 59400 2º Semestre 2005/2006 Adicionando Experiência Tabela de Contingência Gender Male/Femal Experience Data F M Grand Total Difference 10 Average of Earnings 57150 59650 57983.33 2500 Count of Earnings 40 20 60 20 Average of Earnings 59150 61650 60816.67 2500 Count of Earnings 20 40 60 Total Average of Earnings 57816.67 60983.33 59400 3166.67 Total Count of Earnings 60 60 120 Experiência medida por anos de trabalho Tratamento de Dados 2º Semestre 2005/2006 Regressão Linear com Experiência SUMMARY OUTPUT Regression Statistics Multiple R 0.39 R Square 0.15 Adjusted R Square 0.14 Standard Error 4389.67 Observations 120.00 ANOVA df Regression Residual Total SS 2.00 407500000.00 117.00 2254500000.00 119.00 2662000000.00 Intercept Experience Female Coefficients Standard Error 57650.00 1525.90 200.00 85.01 -2500.00 850.06 Tratamento de Dados 2º Semestre 2005/2006 MS 203750000.00 19269230.77 F 10.57 t Stat P-value 37.78 0.00 2.35 0.02 -2.94 0.00 Adicionando IQ – Coeficiente de Inteligência Tabela de Contingência IQ 101-110 Data Average of Earnings Count of Earnings 111-120 Average of Earnings Count of Earnings 121-130 Average of Earnings Count of Earnings 131-140 Average of Earnings Count of Earnings 141-150 Average of Earnings Count of Earnings Total Average of Earnings Total Count of Earnings Tratamento de Dados Gender F 51816.66667 12 54816.66667 12 57816.66667 12 60816.66667 12 63816.66667 12 57816.66667 60 M 54983.33333 12 57983.33333 12 60983.33333 12 63983.33333 12 66983.33333 12 60983.33333 60 2º Semestre 2005/2006 Male/Fem. Grand Total Diff. 53400 3166.667 24 56400 3166.667 24 59400 3166.667 24 62400 3166.667 24 65400 3166.667 24 59400 3166.667 120 Regressão Linear com IQ SUMMARY OUTPUT Regression Statistics Multiple R 0.98 R Square 0.96 Adjusted R Square 0.96 Standard Error 954.82 Observations 120.00 ANOVA df Regression Residual Total Intercept Female IQ Tratamento de Dados SS MS F 2.00 2555333333.33 1277666666.67 1401.44 117.00 106666666.67 911680.91 119.00 2662000000.00 Coefficients Standard Error 23333.33 767.08 -3166.67 174.33 300.00 6.03 2º Semestre 2005/2006 t Stat P-value 30.42 0.00 -18.17 0.00 49.73 0.00 Pontos Chave na Interpretação Adicionar uma variável permite controlar o seu efeito na regressão: permite manter a variável a níveis constantes Semelhante a análise através de tabelas de contingência Adicionar uma variável pode alterar a estimativa dos coeficientes de outras variáveis (ex. ao adicionar experiência altera-se a estimativa do coeficiente do indicador ‘female’) Controlar uma variável correlacionada com outra variável explicativa elimina ‘bias’ ou enviezamento na estimativa dos efeitos dessas variávies (ex. experiência e female) Controlar uma variável não correlacionada com outra variável explicativa melhora o “ajustamento” mas não elimina ‘bias’ (por exemplo, IQ e Female) Tratamento de Dados 2º Semestre 2005/2006 Como escolher as variáveis a incluir na regressão? Número de variáveis Critério estatístico Critério lógico Tratamento de Dados 2º Semestre 2005/2006 Número de variáveis Restrição de ordem técnica O número de observações tem deve ser pelo menos igual ao número de variáveis explicativas mais dois Restrição de ordem práctica Devemos ter pelo menos 10 observações por variável explicativa para obtermos estimativas precisas Tratamento de Dados 2º Semestre 2005/2006 Critério estatístico Adicionar uma variável sempre fará o R2 aumentar. Portanto, um aumento do R2 não pode ser usado como base para concluir que uma variável deve ser incluída. O R2 ajustado é uma medida modificada que impõe uma “penalidade” sobre variáveis extras. Tratamento de Dados 2º Semestre 2005/2006 Critério Lógico Adicionar variáveis altera a interpretação dos coeficientes. Exemplo: Preço = b0 + b1 Quartos • b1 mede a diferença entre, por exemplo, apartamentos com 3 quartos e apartamentos com 4 quartos Preço = b0 + b1 Quartos + b2 m2 • b1 mede a diferença entre, por exemplo, apartamentos com 3 quartos e apartamentos com 4 quartos com a mesma àrea em m2 Escolha da variável pode depender do tipo de comparação que se pretende efectuar Tratamento de Dados 2º Semestre 2005/2006 Multicolinearidade As variáveis explicativas podem ter alguma correlação entre elas Uma variável explicativa não pode ser uma função linear de outras variáveis explicativas (correlação linear perfeita) Demasiada correlação entre as variáveis explicativas torna as estimativas imprecisas - (problema com os dados) Tratamento de Dados 2º Semestre 2005/2006 Price How will simple and multiple regression results differ? 450000 400000 350000 300000 250000 200000 150000 100000 50000 0 0 1000 2000 Size Tratamento de Dados 2º Semestre 2005/2006 3000 4000 (1) Intercept Size (2) -66,298.94 145,332.70 -7,423.87 (-4.41) (16.06) (-0.11) 136.92 (22.65) Area R-Squared Tratamento de Dados (3) 98.55 (2.21) 220,276.44 62,592.24 (17.21) (0.87) 0.988 0.980 2º Semestre 2005/2006 0.990
Download