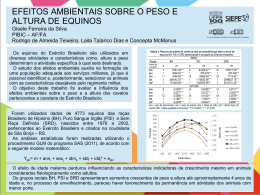
Armazenamento Estável através da Replicação Remota de Dados Tatiana Simas Stanchi [email protected] Francisco Vilar Brasileiro [email protected] Coordenação de Pós-graduação em Informática Departamento de Sistemas e Computação Universidade Federal da Paraíba Av. Aprígio Veloso s/n, Bodocongó 58109-970, Campina Grande, Paraíba ABSTRACT Stable storage of data is an important requirement for many applications. Traditional file systems use synchronous write operations to guarantee the stability of data stored. However, due to the slow speed of disk accesses, writing data synchronously decreases the performance of applications. Other systems are based on the use of special hardware devices that prevent data stored in volatile memory from being lost after a crash. This paper presents a new stable storage technique that substitutes synchronous write operations by remote replication of data that are modified in the cache of the file system. To assure the stability of the information, the technique includes a forward recovery mechanism, which allows it to collect enough remote information to restore the file system to a consistent state after a crash. Since the transfer of data through a high speed network is considerably faster than writing the same quantity of data to disk, the main advantage of the proposed technique is the guarantee of stability, even in the presence of both software and hardware faults, without the need of any special hardware devices, and with a performance that is potentially better than that of those solutions based on synchronous write operations. Keywords: stable storage; replicated processing; file system. RESUMO Armazenamento estável é um requisito importante para muitas aplicações. Os sistemas de arquivo tradicionais realizam a gravação síncrona em disco, como uma forma de garantir a estabilidade dos dados armazenados. Contudo, a gravação síncrona provoca uma degradação no desempenho das aplicações, em decorrência da lentidão dos acessos a disco. Outros sistemas baseiam-se na utilização de hardware especial para garantir a não-volatilidade dos dados armazenados em memória principal. Este artigo apresenta uma nova técnica de armazenamento estável, que substitui a gravação síncrona pela replicação remota de dados alterados na cache do sistema de arquivo. Para assegurar a estabilidade das informações, a técnica proposta inclui um mecanismo de recuperação para frente, capaz de restaurar o sistema de arquivo para um estado consistente, após um crash. Como a transmissão de dados, através de uma rede de alta velocidade, é bem mais veloz do que a gravação da mesma quantidade de dados em disco, o principal benefício oferecido é a garantia de estabilidade dos dados, mesmo na presença de falhas do software e do hardware, com um desempenho potencialmente superior ao de soluções baseadas na gravação síncrona em disco, e sem a necessidade de qualquer hardware especial. Palavras-chaves: armazenamento estável; processamento replicado; sistema de arquivo. 1. INTRODUÇÃO A evolução tecnológica exerce uma forte influência nas pesquisas de sistemas computacionais. À medida que a tecnologia avança, as características dos componentes de hardware mudam, exigindo que os algoritmos utilizados para gerenciar os sistemas sejam reexaminados e que novas técnicas sejam desenvolvidas. As influências tecnológicas são particularmente evidentes nos projetos de sistema de arquivo. O projeto de um sistema de arquivo depende da tecnologia de processador, de memória principal, de disco e, mais recentemente, da tecnologia de rede. Nas duas últimas décadas, as tecnologias de processador, memórias principal e rede melhoraram por várias ordens de grandeza, tanto em desempenho, quanto em capacidade. Por outro lado, a tecnologia de disco não acompanhou esse desenvolvimento, no que tange ao desempenho, em decorrência das limitações impostas pela natureza mecânica dos discos magnéticos. A evolução desigual dos componentes de hardware desafia os sistemas de arquivo a compensarem a lentidão dos discos, permitindo que o desempenho cresça com a tecnologia de processador, de memória e de rede. O aumento do desempenho dos sistemas de arquivo deve superar o dos discos, sob pena de as aplicações serem incapazes de utilizar o rápido aumento da velocidade de processadores e dos demais componentes de hardware, para oferecer um melhor desempenho aos seus usuários. Tradicionalmente, os sistemas de arquivo adotam técnicas de otimização de desempenho baseadas na utilização de caching na memória principal. Porém, essas técnicas reduzem a confiabilidade do sistema, em decorrência da volatilidade da memória. Algumas aplicações necessitam de armazenamento estável de dados, ou seja, não admitem a perda de informações, mesmo nos casos em que ocorram falhas no sistema. Nesse caso, as técnicas de otimização baseadas apenas em memória principal não podem ser utilizadas, porque um crash no sistema apaga todo o conteúdo da memória volátil. Uma solução bastante simples, para crashes provocados pela interrupção do fornecimento de energia, é a utilização de um UPS (Uninterruptible Power Supply) [1]. Entretanto, o contínuo aumento da complexidade dos sistemas operacionais atuais é um fator que tende a aumentar o número de falhas de concepção residuais presentes nesses sistemas, e conseqüentemente a possibilidade de crash do sistema operacional. Além disso, em alguns casos, uma máquina que sofreu um crash não se recupera automaticamente, precisando passar por um processo de manutenção offline antes de entrar novamente em operação. O uso de um UPS não resolve nenhum desses problemas. Dada a grande confiabilidade dos discos, os sistemas de arquivo tradicionais oferecem a gravação síncrona, como uma forma de prover armazenamento estável: a aplicação solicita ao sistema que inicie imediatamente a gravação, em disco, dos dados de uma requisição de escrita e espera pela finalização da operação de saída. Portanto, os sistemas de arquivo tradicionais obrigam as aplicações a pagarem um alto custo pelo armazenamento estável de dados. Outros sistemas (por exemplo, [3, 17]) baseiam-se na utilização de hardware especial para garantir a não-volatilidade dos dados armazenados em memória principal. Neste artigo propomos uma nova técnica de armazenamento estável, baseada na replicação remota dos dados alterados. A idéia fundamental da técnica é garantir a estabilidade de dados, minimizando ao máximo a necessidade de realizar gravações síncronas em disco, e sem recorrer a qualquer hardware especial. Baseando-se no fato de que um acesso à memória principal (na ordem de nanossegundos) é muito mais rápido do que um acesso a disco (na ordem de milissegundos) e de que a latência decorrente de um acesso através de uma rede de alta velocidade é menor do que a latência introduzida pelo acesso a um bloco em um disco local [7, 10, 12, 16], a técnica substitui a gravação síncrona de dados pela replicação remota dos dados e metadados alterados na cache do sistema de arquivo. Dessa forma, o preço a ser pago para se ter uma diminuição da latência das operações de armazenamento estável é apenas um, potencialmente pequeno, aumento no consumo de banda passante na rede de comunicação. Adicionalmente, um mecanismo de recuperação para frente é utilizado para garantir a consistência e estabilidade dos dados armazenados em um sistema de arquivo, caso a máquina que hospeda o sistema de arquivo1 sofra um crash. Para facilitar o entendimento da proposta, esta será apresentada dentro do contexto de um sistema de arquivo específico. Devido a sua popularidade, escolhemos o sistema de arquivo do UNIX [11, 13] para tal fim. Embora a apresentação enfoque um sistema em particular, a replicação remota de informações da cache de sistemas de arquivo, como uma alternativa à gravação síncrona de dados, também pode ser aplicada a outros sistemas de arquivo. Assim, a técnica de armazenamento estável proposta tem um sentido genérico. O restante do artigo está organizado da seguinte forma. Na próxima seção analisamos os trabalhos relacionados, que visam a melhoria do desempenho e da confiabilidade dos sistemas de arquivo. Essa seção evidencia o diferencial da 1 No restante desse documento essa máquina será denominada de hospedeira. 2 técnica de armazenamento estável proposta. Na Seção 3 o Salius2 - Serviço de Armazenamento Estável com Recuperação para Frente Baseado na Replicação Remota de Dados é apresentado. Este serviço é acrescido ao sistema de arquivo UNIX para prover armazenamento estável através da replicação remota de dados. Essa seção apresenta o funcionamento geral do Salius e descreve seus principais componentes: a Interface, o Servidor de Arquivos Complementar e sua interação com o Serviço de Replicação de Dados, além do Procedimento de Recuperação. A Seção 4 apresenta o projeto de um Serviço de Replicação de Dados, descrevendo o modelo de replicação e os protocolos de replicação e recuperação utilizados. Esta seção discute também a corretude dos protocolos propostos. Finalmente, a Seção 5 traz as nossas conclusões. 2. TRABALHOS RELACIONADOS O contexto atual dos sistemas de arquivo exige soluções para que os requisitos de desempenho e confiabilidade sejam atendidos satisfatoriamente. Muitos trabalhos foram desenvolvidos nesse sentido. Os sistemas de arquivo baseados em log – Log File System (LFS), centralizados, como o Sprite LFS [14] e o BDS LFS [15], ou distribuídos, como o Zebra [9] e o xFS [2], conseguem otimizar o desempenho através da utilização mais eficiente dos discos, durante pequenas operações de escrita: os dados e metadados alterados são agrupados em buffers, na memória principal, sendo posteriormente gravados no disco, de forma seqüencial, através de uma operação de saída única e contínua, minimizando, assim, a quantidade de acessos a disco e de posicionamentos da cabeça de leitura e gravação. Porém, essa estratégia diminui a confiabilidade do sistema, pois a ocorrência de um crash pode provocar a perda de dados. Um mecanismo de recuperação para frente leva o sistema a um estado consistente, considerando apenas o conteúdo já gravado no log, antes da falha. O sistema não consegue recuperar os dados que estavam na cache no momento imediatamente anterior ao crash. Portanto, um LFS não consegue prover armazenamento estável de dados. Outros trabalhos sugerem métodos para tornar a memória principal capaz de armazenar dados, de forma persistente. Por exemplo, a adição de memória não-volátil nas caches de servidores e de clientes [3], diminui tanto o tráfego de rede cliente-servidor, quanto o tráfego para disco, decorrentes de operações de escrita, melhorando o desempenho. Adicionalmente, os dados gravados em memória não-volátil sobrevivem a crashes do sistema. Entretanto, se o fluxo de dados das operações de escrita torna-se maior que a capacidade da memória não-volátil, o sistema passa a transferir dados para o disco. Para garantir a estabilidade desses dados, a gravação em disco precisa ser realizada de forma síncrona, como nos sistemas de arquivo convencionais. O sistema eNVy [17] faz uso de memória Flash RAM, para prover armazenamento em memória não-volátil, adotando uma variedade de técnicas para superar as deficiências apresentadas pela tecnologia Flash. Por exemplo, como a programação da memória Flash RAM é uma operação lenta, durante a atualização de uma página de memória, o eNVy cria uma nova versão da página num outro tipo de memória (SRAM, com bateria), simulando para o processador que os dados sobrepõem o conteúdo antigo. À proporção que a SRAM vai atingindo um nível de preenchimento preestabelecido, suas páginas vão sendo gravadas na memória Flash. Se não existir espaço livre na memória Flash, uma operação de limpeza é realizada, transferindo dados para o disco. Por isso, O sistema eNVy foi projetado para aplicações com base de dados de pequeno e médio portes. O desempenho do sistema eNVy está atrelado à taxa de transações por minuto e à quantidade de dados armazenada pela aplicação. Assim, o eNVy não pode ser utilizado de forma genérica. Somente algumas aplicações, com o comportamento previsível, podem beneficiar-se desse sistema. O Rio File Cache [4] consegue tornar a memória RAM capaz de sobreviver a crashes de sistema operacional. Para isso, ele adota duas linhas de ação: impede que a memória seja sobregravada acidentalmente pelo sistema, durante um crash, e provê o sistema de um mecanismo de recuperação do tipo “warm reboot”. Esse sistema, entretanto, além necessitar de uma fonte confiável para alimentação da memória RAM (um UPS, por exemplo), requer também que a memória do sistema e a cache do processador sejam capazes de preservar seus respectivos conteúdos, após um reinício normal do sistema. O sistema de arquivo Harp [10] é um dos primeiros sistemas que provê estabilidade através da substituição de operações de gravação síncronas no disco por operações de comunicação via a rede. Entretanto, diferentemente da técnica proposta neste artigo, o Harp requer um UPS para manter o sistema executando por um pequeno período de tempo após uma falha no fornecimento de energia. Em resumo, a maioria dos trabalhos recentes, que visam aumentar a confiabilidade do armazenamento de dados, depende da utilização de hardware especial. Além disso, nenhuma solução que se baseie em recuperar informação em 2 Salius, é o nome dado, em latim, aos doze sacerdotes de Marte, encarregados da guarda dos escudos sagrados que protegiam a estabilidade da Roma Antiga. 3 memória RAM após um crash pode tolerar falhas do próprio hardware3. O Salius, pelo contrário, resiste a falhas do software e do hardware, além de utilizar apenas a tecnologia atualmente disponível na maioria dos sistemas computacionais e a redundância já presente no sistema. 3. O SALIUS A idéia fundamental do Salius é garantir a estabilidade de dados, minimizando ao máximo a necessidade de realizar gravações síncronas em disco. A estabilidade dos dados é garantida, porque todas as estruturas de dados, mantidas pelo sistema de arquivo na memória principal da hospedeira, são copiadas para as memórias principais de outras máquinas disponíveis. O sistema de arquivo do UNIX mantém em memória a buffer cache, os nós-i e o superbloco [11]; qualquer alteração nessas estruturas é replicada pelo Salius. Essa replicação deve garantir a sobrevivência de, pelo menos, uma cópia dos dados alterados, após a ocorrência de crashes na hospedeira e em outras máquinas usadas para replicar os dados. Dessa forma, o conteúdo replicado pode ser recuperado, a partir de uma outra máquina que não falhou, e gravado no sistema de arquivo em disco. O Salius é constituído de quatro componentes básicos: Interface: é um conjunto de primitivas, incorporadas à interface do sistema de arquivo e utilizadas pelos programas de usuário para requisitar operações ao Salius; Serviço de Replicação de Dados (SRD): é um serviço que provê a replicação confiável de dados, ou seja, garante o armazenamento de cópias das alterações realizadas num sistema de arquivo. Adicionalmente, esse serviço fornece as informações necessárias para restabelecer, após um crash da hospedeira, o sistema de arquivo a um estado consistente, preservando os dados estáveis; Servidor de Arquivos Complementar (SAC): é a implementação das operações invocadas através de primitivas do Salius. O SAC realiza operações sobre arquivos, requisitadas pelos clientes, e interage com o SRD, solicitando a replicação dos dados alterados; Procedimento de Recuperação (PR): é um aplicativo que restabelece a consistência do sistema de arquivo, após um crash da hospedeira. O PR interage com o SRD para recuperar as informações replicadas, necessárias para restaurar a consistência do sistema de arquivo, mantendo as informações estáveis. 3.3. A Interface Existem duas abordagens possíveis para incorporar um serviço de armazenamento estável a um sistema de arquivo: i) substituindo todas as primitivas originais pelas primitivas do serviço; ou ii) adicionando novas primitivas à interface do sistema. Na primeira abordagem, o armazenamento estável passa a ser a única forma possível de manipular dados. O serviço é totalmente transparente ao usuário: ao invocar uma primitiva do sistema de arquivo, o usuário grava dados de forma estável, automaticamente. Na segunda alternativa, a transparência cede lugar à flexibilidade, pois o usuário opta entre utilizar o serviço, ou continuar usando as primitivas tradicionais. O Salius prioriza a flexibilidade, porque muitas aplicações não necessitam pagar os custos do armazenamento estável. Além disso, uma mesma aplicação pode requerer a estabilidade de apenas parte dos dados manipulados. Por exemplo, uma aplicação pode desejar gravar seus arquivos de log e de auditoria, de forma estável, mas pode prescindir da estabilidade para os demais arquivos. Oferecendo suas primitivas como uma alternativa adicional, para a manipulação de arquivos, o serviço propicia ao usuário o benefício de decidir sobre a conveniência de utilizar, ou não, o armazenamento estável. Uma segunda decisão refere-se à granularidade atribuída à unidade de armazenamento estável. O Salius assume que a necessidade de armazenamento estável aplica-se, em geral, a um arquivo inteiro e não a uma fração de arquivo. Por conseguinte, o usuário opta pela utilização do serviço no momento em que abre ou cria um arquivo, indicando explicitamente que o arquivo deve ser manipulado através de primitivas do Salius. As principais primitivas oferecidas são: open A primitiva open é utilizada para abrir um arquivo existente, ou criar e abrir um novo arquivo. Através dela, o usuário pode optar pela utilização do Salius. 3 O procedimento de manutenção necessário para recuperar ou substituir o componente defeituoso (memória, processador, controladoras, etc.) normalmente precisa se realizado off-line, e portanto, não há como salvaguardar a informação armazenada na memória RAM. 4 Sintaxe: fd = open(pathname, flags, mode); onde fd é um descritor de arquivo, que é retornado para a aplicação; pathname é o nome do arquivo; flags é uma combinação de bits, com diretrizes importantes, resumidas na Tabela 1; e mode contém as permissões de acesso associadas ao arquivo; esse parâmetro só é obrigatório para a criação de um arquivo. O_RDONLY O_WRONLY O_RDWR O_APPEND O_CREAT O_STABLE O_EXCL O_TRUNC O_SYNC O_NDELAY O arquivo é aberto apenas para leitura. O arquivo é aberto apenas para escrita. O arquivo é aberto para leitura e escrita. Todas as escritas irão adicionar dados ao final do arquivo. Se o arquivo existir, não tem efeito algum. Caso contrário, o arquivo é criado e o parâmetro mode deve ser especificado. Todas as alterações do arquivo serão realizadas pelo Salius. O arquivo é aberto em modo exclusivo. Se o arquivo existir, seu tamanho é truncado para zero. Indica a gravação síncrona de todas as alterações do arquivo. Se uma operação de leitura, ou escrita, não puder ser realizada, retorna, imediatamente, com erro, sem entrar em uma condição de bloqueio. Tabela 1: Flags da operação open no Salius. A sintaxe do open do UNIX foi ligeiramente alterada, adicionando a opção O_STABLE no parâmetro flags. Quando o O_STABLE é informado, todas as operações de escrita subseqüentes realizam o armazenamento estável, usando a replicação do Salius. O_STABLE também afeta o comportamento da primitiva open quando é associado aos flags O_CREAT ou O_TRUNC: o open só retorna para a aplicação, quando as alterações realizadas estiverem estáveis. s_creat A primitiva s_creat é a versão estável do creat original do UNIX, utilizada para criar um arquivo regular, ou rescrever sobre um existente. Sintaxe: fd = s_creat(pathname, mode); onde fd é um descritor de arquivo, que retorna para a aplicação; pathname é o nome do arquivo; e mode contém as permissões de acesso associadas ao arquivo. A primitiva cria um novo arquivo, com o nome indicado em pathname, e armazena as permissões de acesso, informadas em mode, no nó-i associado. Se o arquivo existe, s_creat trunca o seu tamanho para zero. Após ser criado, com sucesso, o arquivo é aberto exclusivamente para escrita, com a opção O_STABLE, ou seja, indicando que deve ser alterado de forma estável. A primitiva só retorna, após realizar a estabilização dos dados alterados: o superbloco, o nó-i do arquivo e do diretório pai e a entrada do arquivo no diretório pai. Por sua vez, os dados estão estáveis quando ocorre uma das seguintes situações: i) as modificações realizadas no sistema de arquivos estão armazenadas na memória principal e existem cópias dos dados e metadados alterados no SRD; ou ii) todos os dados e metadados alterados já estão gravados no disco da hospedeira. write A primitiva write é utilizada para escrever dados em um arquivo. Sintaxe: num = write(fd, address, nbytes); onde fd é o descritor do arquivo; address é o endereço de uma estrutura, na área de memória da aplicação, contendo os dados que devem ser escritos no arquivo; nbytes indica o número de bytes que deverão ser escritos; e num retorna com o número de bytes gravados. A primitiva write tenta gravar nbytes de um buffer, apontado por address, no arquivo associado ao descritor fd. Se a operação for bem-sucedida, retorna em num o número de bytes efetivamente gravados, normalmente igual ao valor de nbytes. De outro modo, num retorna com o valor -1, indicando um erro. No retorno, write atualiza o apontador da posição corrente do arquivo, adicionando o número de bytes gravados. A primitiva write do UNIX adota, como padrão, a gravação assíncrona de dados. Desse modo, quando write retorna, as modificações realizadas no arquivo ficam armazenadas na memória principal, em estruturas como a buffer cache, a tabela de nós-i e a cópia do superbloco. Posteriormente, essas mudanças são transferidas para o disco, de forma assíncrona. Portanto, o usuário não tem garantias relativas à estabilidade dessas informações, que podem ser perdidas por um crash do sistema. Se o arquivo foi aberto com o bit O_SYNC ligado, write realiza a gravação síncrona de dados, ou seja, só retorna quando todos os dados e metadados do arquivo estiverem gravados em disco. Nesse caso, a aplicação tem a garantia de que as informações gravadas podem sobreviver a crashes. Por outro lado, se o arquivo for aberto com o flag 5 O_STABLE ligado, ou se for criado através da primitiva s_creat, write realiza o armazenamento estável de dados, conforme apresentado na primitiva anterior. PRIMITIVA NO UNIX open write creat mkdir mknod PRIMITIVA NO SERVIÇO open write s_creat s_mkdir s_mknod link unlink chown chmode s_link s_unlink s_chown s_chmode OPERAÇÃO Criação e/ou abertura de um arquivo. Escrita de dados em um arquivo. Criação de um arquivo regular. Criação de um diretório. Criação de um arquivo de qualquer tipo: regular, diretório, especial de caracter, especial blocado ou pipe. Criação de uma nova entrada de diretório para um arquivo existente. Remoção de uma entrada de diretório. Alteração do proprietário de um arquivo. Alteração das permissões de acesso de um arquivo. Tabela 2: Primitivas do Salius. Em resumo, no nível lógico, o serviço possui uma nova versão de cada primitiva de alteração do sistema de arquivo original. As primitivas do serviço realizam praticamente as mesmas ações que as primitivas do UNIX, somando a replicação de dados, para garantir a estabilidade de informações armazenadas. A Tabela 2 relaciona as primitivas do Salius com as primitivas correspondentes do sistema de arquivo do UNIX e descreve, sucintamente, a função de cada primitiva. 3.4. Obtendo Armazenamento Estável O diagrama da Figura 1 mostra como ocorre a manipulação de arquivos no UNIX, com a adição do Salius. A figura mostra que o SAC do Salius é incorporado ao sistema de arquivo, assim como as primitivas do Salius são acrescentadas à interface do sistema. Processos de usuário Primitivas do UNIX Primitivas do Salius Chamadas do UNIX Chamadas do Salius Sistema de arquivo UNIX SAC do Salius Nível do usuário buffer cache Nível do núcleo Nível do hardware Drivers dos dispositivos de E/S Drivers de rede Controladores de disco Controladores de rede Hardware de disco Hardware de rede Figura 1: Diagrama da manipulação de arquivos no UNIX com Salius. O SAC executa uma operação solicitada, interagindo com a buffer cache, para alterar dados na memória, da mesma forma que o sistema de arquivo do UNIX. A seguir, o SAC interage com os drivers de rede para enviar uma mensagem ao SRD, solicitando a replicação dos dados alterados, e receber a confirmação da replicação. O programa de usuário permanece bloqueado, até que a replicação seja confirmada. Uma confirmação só pode ser dada quando o SRD puder 6 garantir, com uma determinada probabilidade, que a informação está estável. Somente após receber a confirmação do SRD, o SAC retorna o controle para o programa de usuário, informando que a operação requisitada foi realizada com sucesso. Se a confirmação não chega dentro de um intervalo de tempo predefinido, o SAC assume que o SRD falhou. Nesse caso, o SAC força a gravação síncrona de todos os dados do sistema de arquivo alterados na memória e ainda não propagados para o disco. Se a replicação é confirmada no tempo esperado, os dados alterados na memória principal permanecem na cache por um certo tempo e depois são gravados em disco, de forma assíncrona, como no funcionamento padrão do sistema de arquivo do UNIX. Assim, o Salius possibilita que o sistema de arquivo do UNIX realize caching de escrita e ofereça armazenamento estável, simultaneamente. A depender da relação entre o volume de dados alterados e a capacidade de memória principal disponível na hospedeira, o tempo de permanência dos dados alterados na cache pode ser aumentado para um valor maior do que o valor padrão, contribuindo para um melhor desempenho do sistema. Como discutido anteriormente, quando uma replicação não é confirmada no tempo esperado, o SAC assume que o SRD falhou. Por isso, realiza a gravação síncrona, garantindo a estabilidade dos dados provenientes da operação de atualização em curso. Porém, essa ação não é suficiente para preservar a semântica de compartilhamento do serviço. Na prática, o SRD pode continuar operacional, e a falha detectada ser decorrente de algum problema na comunicação entre o SAC e o SRD. Se o sistema sofrer um crash logo após a gravação síncrona dos dados, uma posterior execução do PR poderá gravar no disco os dados replicados no SRD, antes do crash. O SRD pode conter dados desatualizados, que irão sobrepor informações mais recentes, armazenadas com a gravação síncrona. A situação descrita pode ser demonstrada com o seguinte exemplo: um bloco x é atualizado e replicado no SRD; em seguida, outra operação modifica o mesmo bloco e tenta realizar a replicação, mas o SRD falha e, portanto, x é gravado de forma síncrona; a seguir, o sistema de arquivo sofre um crash. Neste ponto o administrador do sistema executa o PR, que grava o antigo conteúdo do bloco x, fornecido pelo SRD, violando a semântica de compartilhamento adotada pelo serviço, já que uma atualização antiga vai sobrepor uma atualização mais recente. Para preservar a semântica de compartilhamento, o SAC precisa evitar que dados desatualizados permaneçam no SRD. Para tal, o SRD precisa detectar que falhou e passar por um procedimento de regeneração, que consiste em descartar os dados do log, antes de voltar a atender a novos pedidos de replicação. A forma como o SRD detecta que falhou depende do modo como o SRD é implementado, mais especificamente, do modelo de replicação adotado, da semântica de falha e do protocolo de replicação do serviço. Esses detalhes serão abordados na próxima seção. 3.5. Recuperação de um Sistema de Arquivos após um Crash da Hospedeira Considera-se a ocorrência de um crash toda vez que as estruturas de dados do sistema de arquivo, residentes em memória, são perdidas. Isso pode ser causado por um crash da hospedeira, bem como por um crash do sistema operacional. A recuperação de crash é o ato de restaurar o sistema de arquivo em disco para um estado consistente, de modo que preserve as garantias oferecidas pelo Salius às aplicações. A execução do PR do Salius assegura a estabilidade de todos os dados armazenados através de suas primitivas. O PR utiliza um mecanismo de recuperação para frente: todos os dados e metadados atualizados no sistema de arquivo, que são perdidos em decorrência de um crash, permanecem guardados no SRD; o PR obtém esses dados e providencia a gravação dos mesmos no disco, na mesma ordem em que foram gerados. Assim, o mecanismo de recuperação do Salius garante a durabilidade dos efeitos de operações realizadas antes do crash da hospedeira. As mensagens de replicação contêm informações de controle, indicando a ordem em que as atualizações do sistema de arquivo aconteceram. Por exemplo, a implementação do Salius pode englobar um contador de pedidos de replicação único para cada sistema de arquivo. Assim, toda vez que o SAC executa uma operação de atualização, o contador é incrementado e o número do pedido é enviado na mensagem de replicação, para o SRD. Quando o PR obtém as mensagens de replicação de volta, ele ordena os dados recuperados pelo número do pedido, antes de iniciar a gravação em disco. Como o procedimento de recuperação realiza as atualizações na mesma ordem na qual elas foram originalmente realizadas, a operação de recuperação é idempotente. Assim, mesmo que ocorra um crash durante a recuperação, o procedimento pode ser repetido: mesmo que a recuperação já tenha sido parcialmente realizada, o sistema de arquivo sempre chega ao mesmo estado final. O PR assegura, única e exclusivamente, a recuperação de dados armazenados através de primitivas do Salius. Ele não trata os dados armazenados pelas primitivas tradicionais do sistema de arquivo. Para esse subconjunto de dados, devem ser utilizados os procedimentos de recuperação oferecidos pelo próprio sistema de arquivo. O UNIX, por exemplo, utiliza um programa de recuperação, denominado fsck, para remover inconsistências do sistema de arquivo. O fsck continua sendo necessário, para o subconjunto de dados armazenado com as primitivas originais do UNIX. 7 Existe uma situação especial, que merece ser considerada pelo PR. A explicação de tal situação será feita através de um cenário dividido em cinco partes, cada uma delas apresentando um momento diferente do sistema de arquivo. No tempo t1, um bloco de dados x foi atualizado e replicado por uma primitiva do Salius. No tempo t2 > t1, uma parte do conteúdo de x foi atualizada por uma chamada de sistema original do UNIX. Em t3 > t2, x foi gravado no disco e sua cópia replicada tornou-se desatualizada. Em t4 > t3, ocorreu um crash e o conteúdo da memória da hospedeira foi perdido. Em t5 > t4, o PR foi ativado e gravou no disco a cópia obsoleta de x, enviada pelo SRD, sobrepondo uma atualização mais recente. A situação retratada é rara e pode ser evitada, se a implementação do SRD puder impedir a manutenção de blocos obsoletos. Para tal, o SAC mantém uma tabela de pedidos pendentes em sua memória, para controlar os pedidos que já foram estabilizados. Essa tabela mantém, para cada pedido, uma lista invertida, com os números de todos os blocos de dados replicados pelo pedido. Quando um bloco é gravado no disco, ele é retirado das listas invertidas. Assim, quando a lista de blocos de um pedido torna-se vazia, significa que aquele pedido foi estabilizado. Ao enviar um pedido de replicação, o SAC consulta a tabela de pedidos pendentes, para enviar às réplicas do SRD o número do maior pedido já estabilizado. Essa informação é utilizada pelas réplicas do SRD para descartar de seus logs os pedidos obsoletos. Para o subconjunto de dados armazenados pelo Salius, a recuperação de crash é potencialmente muito rápida. Não é necessário realizar verificações na estrutura de metadados do sistema, porque todos os metadados afetados numa determinada operação são automaticamente replicados, junto com os dados alterados. Se a implementação do SRD puder impedir a situação atípica relatada anteriormente, então, também será capaz de fornecer sempre a versão mais atualizada dos dados e metadados do sistema de arquivo. Nesse caso, a recuperação resume-se em obter os dados replicados antes do crash e gravá-los no disco. 4. PROJETO DE UM SRD O SRD é implementado através de processos, denominados Servidores de Replicação de Dados, executando em várias máquinas do sistema distribuído. Cada processo excuta dois protocolos: um protocolo de replicação que recebe e armazena os dados replicados na execução das primitivas do Salius e envia confirmações para o SAC que enviou um pedido de replicação; e um protocolo de recuperação que fornece a um PR os dados necessários à recuperação da consistência de um sistema de arquivo. 4.1. Modelo do Sistema Considera-se um sistema distribuído assíncrono [8]. Nesse tipo de sistema processadores e processos falham somente por crash. Além disso, não há uma noção global de tempo, nem limites máximos conhecidos do atraso na comunicação entre dois processos operacionais. Dessa forma, temporizadores não podem ser usados para detectar, confiavelmente, a falha de um processo. Considera-se ainda que as mensagens enviadas podem ser perdidas ou recebidas fora de ordem, mas não podem ser corrompidas ou duplicadas. O número de réplicas que implementam o SRD é definido de acordo com o grau de tolerância a faltas desejado. Como a semântica de falha dos processos é crash, o SRD deve ser implementado por pelo menos f+1 réplicas, para que seja possível tolerar f faltas [5]. Nesse caso, cada pedido de replicação do SAC precisa ser confirmado por f+1 réplicas, para que a replicação seja considerada bem-sucedida: se o SAC não receber mensagens de, pelo menos, f+1 réplicas distintas, confirmando o recebimento de um pedido de replicação, num tempo máximo predefinido, então o SAC assume que o SRD falhou. Sendo n o número de réplicas, f o número máximo de falhas a tolerar e freal o número real de replicas que falharam, o SRD pode falhar em duas situações distintas: i) quando n - freal < f+1; ou ii) quando ocorre um particionamento (real ou virtual) entre o SAC e um número suficientemente grande de réplicas do SRD, ou seja, quando o serviço de comunicação falha, temporariamente, impedindo que o SAC receba mensagens de confirmação de pelo menos f+1 réplicas. O SRD precisa atender, de forma equilibrada, a dois requisitos, normalmente conflitantes: i) enviar a mensagem de confirmação de um pedido de replicação, o mais rapidamente possível; e ii) ter uma alta probabilidade de manter estável uma informação, para a qual uma mensagem de confirmação foi enviada a um SAC. O balanceamento entre tais requisitos é obtido através da escolha dos valores de n e f. Quanto maior f, maior é a probabilidade da informação poder ser recuperada, após um crash; por outro lado, quanto menor f+1 (número de respostas para confirmar a estabilidade de um pedido), mais rapidamente a confirmação será recebida pelo SAC. Por outro lado, se n = f+1, então, basta que uma réplica falhe, para que o SRD deixe de atender aos pedidos de replicação e o Salius passe a utilizar a gravação síncrona, deixando de ser vantajoso, em relação às técnicas de armazenamento estável existentes. Assim, quanto maior n - (f+1), maior a probabilidade de, pelo menos, f+1 réplicas 8 não falharem no atendimento a um pedido de replicação, diminuindo a ocorrência de gravações síncronas. Fazendo n = 2f+1, a única possibilidade de falha do SRD será devida a uma falha na comunicação entre o SAC e as réplicas. Considera-se que o SRD é implementado por 2f+1 réplicas. Note que nesse caso, mesmo quando todas as operações de replicação são realizadas com sucesso, algumas réplicas podem ficar desatualizadas: uma falha do serviço de comunicação pode impedir que algumas das réplicas recebam um pedido de replicação, muito embora outras f+1 réplicas do SRD consigam atender ao pedido, enviando mensagens de confirmação ao SAC. Nesse caso, o SAC recebe f+1 mensagens de confirmação para um pedido de replicação, mas algumas réplicas do SRD não contêm os dados daquele pedido. Mesmo assim, ainda é possível recuperar o sistema de arquivo, como será mostrado na Subseção 3.4. 4.2. Protocolo de Replicação Após realizar as alterações de dados e metadados de um sistema de arquivo, na memória principal, o SAC tenta replicar todos os dados alterados, antes de retornar o controle para a aplicação. Para isso, o SAC envia um pedido de replicação ao SRD, usando o protocolo descrito a seguir. Conforme discutido na Subseção 2.3, a identificação de um pedido deve indicar a ordem na qual ele foi gerado. Como sistema de arquivo do UNIX é centralizado, é possível implementar um contador de pedidos, único para cada sistema de arquivo e armazenado numa região crítica da memória. Assim, antes de enviar uma mensagem de replicação, um SAC obtém um número de pedido e monta o identificador do pedido, contendo: o identificador da máquina onde o sistema de arquivo reside, o identificador do sistema de arquivo e o número do pedido. O SAC controla os efeitos das possíveis falhas do SRD através de um mecanismo bastante simples. O SAC monta a mensagem de replicação com os dados e metadados alterados, além de um cabeçalho com informações de controle, dentre as quais: o identificador do pedido e o identificador do último pedido gravado sincronamente pelo SAC. Quando termina de montar a mensagem, o SAC tenta realizar a replicação. Para isso, envia o pedido a todas as réplicas do SRD e espera pela confirmação da replicação, durante um intervalo de tempo predefinido. Se, nesse tempo, chegarem mensagens de confirmação para o pedido de, pelo menos, f+1 réplicas do SRD, o SAC assume que a replicação foi bemsucedida. Caso contrário, o SAC assume que o SRD falhou. Quando o SAC detecta uma falha no SRD durante uma tentativa de replicar dados ele grava sincronamente todas as informações não estáveis e o identificador do último pedido de replicação enviado ao SRD. O pseudocódigo apresentado na Figura 2, descreve as ações realizadas pelo SAC. SAC: altera dados em memória; adquire região crítica; m = (sac_id, último_pedido_estável, ++pedido, dados); envia m para todas as réplicas; inicia temporizador; respostas = 0; faça { receba resposta; se (resposta.pedido == pedido) respostas++; } enquanto (não expirar timporizador) e (respostas < f+1); se (respostas < f+1) { /* SRD falhou */ grava sincronamente todos os dados não estáveis; último_pedido_estável = pedido; grava sincronamente último_pedido_estável; } libera região crítica; Figura 2: Algoritmo do SAC Ao receber um pedido de replicação, uma réplica do SRD verifica o identificador do último pedido estável nele contido. Se o identificador é maior que o valor do último pedido estável associado ao log da réplica, então esta detecta que está desatualizada e inicia um procedimento de regeneração. Este procedimento consiste simplesmente em descartar todas as informações mantidas no log relativo àquele SAC. Em seguida a réplica verifica se o identificador do pedido de replicação é maior que o último pedido estável; se esse for o caso, então trata-se de um pedido antigo e a réplica descarta-o. Caso contrário a informação é armazenada no log da réplica (mantido em memória principal) e uma confirmação é enviada para o SAC correspondente. O pseudocódigo da Figura 3 ilustra o funcionamento de uma réplica. 9 Réplica do SRD: enquanto (verdade) { recebe m; se (m.último_pedido_estável > último_pedido_estável) { descarta log de m.sac_id; último_pedido_estável = m.último_pedido_estável; } se (m.pedido ≤ último_pedido_estável) { descarta m; } senão { armazena m em log de m.sac_id; confirmação = (m.pedido); envia confirmação para m.sac_id; } } Figura 3: Algoritmo de uma réplica do SRD 4.3. Protocolo de Recuperação Quando uma hospedeira reinicia, após um crash, o PR deve ser executado, para restaurar o sistema de arquivo. Para isso, o PR interage com as réplicas do SRD, a fim de obter os dados replicados antes do crash. Para simplificar a descrição do protocolo, vamos assumir que durante a execução do PR não há particionamentos da rede nem perda de mensagens, dessa forma uma mensagem enviada pelo PR é sempre recebida por uma réplica operacional, e vice-versa. Normalmente é possível definir um atraso máximo na transmissão de mensagens em um sistema distribuído (principalmente se a estimativa desse limite máximo pode ser feita de forma conservadora), dentro do qual a maior parte das mensagens são entregues. Na prática os sistemas distribuídos alternam entre longos períodos de estabilidade, onde a troca de mensagens se dá dentro desse limite, e curtos períodos de instabilidade, quando esse limite não é respeitado. Dentro desse contexto, perdas de mensagens podem ser tratadas através de um mecanismo de temporização e retransmissão [6]. O PR envia uma mensagem para cada uma das réplicas, informando o início da recuperação. Cada réplica operacional do SRD envia uma resposta ao PR, informando o seu estado de atualização, ou seja, o identificador do último pedido de replicação atendido. O PR então espera pela resposta de f+1 réplicas e escolhe como pedido base para recuperação aquele com o maior valor entre as respostas recebidas. O PR então lê do disco o valor correspondente ao último pedido gravado sincronamente pelo SAC e compara este valor com o valor calculado com base nas respostas das réplicas; se o valor calculado é menor que o valor armazenado no disco, significa que quando houve o crash na hospedeira, o SAC não estava usando o SRD (por causa de um particionamento na rede, por exemplo) e portanto os dados do sistema de arquivo já foram estabilizados (já que as alterações dos dados foram realizadas através de gravações síncronas – veja Figura 2), não necessitando qualquer intervenção do PR. Caso contrário é preciso recuperar todos os pedidos com identificadores maiores que o daquele gravado em disco e que estão armazenados nas réplicas do SRD. Com base nas informações recebidas o PR envia mensagens de solicitação de retransmissão dos pedidos necessários a todas as réplicas do SRD. O PR inicializa um temporizador e fica esperando pelas mensagens. Se o temporizador espira antes de todas as mensagens serem recebidas (a próxima seção discute quando isso pode ocorrer) o processo é reiniciado. Caso contrário o PR grava os dados de cada pedido de replicação no sistema de arquivo em disco, obedecendo à ordem na qual os pedidos foram originalmente gerados. O pseudocódigo da Figura 4 mostra o funcionamento do PR. 4.4. Considerações sobre a Corretude dos Protocolos Teorema 1: Após um crash da hospedeira, a execução do PR recupera o sistema de arquivo, de tal forma que nenhuma modificação feita através de uma primitiva do Salius é perdida. 10 PR: lê último_pedido_estável do disco; terminou = falso; faça { envia “pedido de recuperação” para todas as réplicas; num_respostas = 0; último_pedido = último_pedido_estável; faça { recebe m; se (m.pedido > último_pedido) último_pedido = m.pedido; } enquanto (++num_respostas < f+1); se (último_pedido > último_pedido_estável) { inicia temporizador; para i (último_pedido_estável+1, último_pedido) faça { envia “quero pedido i” para todas as réplicas; recebe resposta; } grava pedidos ordenados pelo número do pedido; terminou = verdade; } senão terminou = verdade; } enquanto (não expirou temporizador) e (terminou = false); Figura 4: Algoritmo do PR Prova (esboço): Sejam pu o pedido associado com a última ativação de uma primitiva do Salius que retornou com sucesso para a aplicação, antes da hospedeira falhar; pe, pe ≤ pu, o valor do último pedido, cujos dados foram gravado no disco da hospedeira; e pmax o maior valor de último pedido armazenado em um log obtido das primeiras f+1 respostas recebidas pelo PR (veja algoritmo da Figura 4). Como n = 2f+1 e pelo menos f+1 réplicas confirmaram a replicação de pu, então pu ≤ pmax. Se pmax = pe, então, de acordo com o algoritmo da Figura 2, as modificações associadas a pmax estão gravadas no próprio disco da hospedeira, e nehuma operação extra é requerida (veja algoritmo da Figura 4). Caso contrário, temos duas situações: i) pe < pu = pmax; e ii) pe < pu < pmax. Se pmax = pu então, segundo o algoritmo da Figura 2, o SAC recebeu f+1 confirmações de réplicas, indicando que pmax foi armazenado em seus respectivos logs. Como, no máximo, f réplicas podem falhar, existe pelo menos uma réplica operacional que armazenou p em seu log. Por sua vez, o log de uma réplica só é descartado quando ela recebe um pedido de replicação com um identificador de último pedido estável maior do que o identificador de último pedido estável que ela mantém localmente. Além disso, se qe é o identificador do último pedido estável associada a um log que contém p, então qe < p (veja o algoritmo da Figura 4). Para que uma réplica que contém p em seu log descarte esse log, e portanto p, é necessário que esta receba um pedido de replicação com um identificador de último pedido estável re ≥ p. Dessa forma, pmax não pode Ter sido removido do log, já que os pedidos de replicação enviados pelo SAC da hospedeira antes do crash contém identificadores de último pedido estável se, tal que se ≤ pe < pmax (veja o algoritmo da Figura 3). O mesmo raciocínio é valido para qualquer pedido q, pe < q ≤ pmax. Portanto, o PR poderá recuperar todos os pedidos cujas informações podem não ter sido gravadas no disco da hospedeira e pode providenciar as suas gravações na ordem correta. A situação em que pmax > pu ocorre apenas quando a hospedeira falha no meio da execução de uma primitiva do Salius. Mais precisamente, quando um pedido de replicação com um identificador de pedido pmax e identificador de último pedido estável pe é enviado às replicas do SRD e algumas réplicas do SRD recebem o pedido, mas antes de receber a confirmação de f+1 réplicas a hospedeira falha. Note que pela definição de pu o SAC não pode receber f+1 confirmações para o pedido pmax e como nesse caso temos pmax > pe, mesmo que o temporizador para a espera das confirmações tenha expirado, o SAC deve necessariamente ter falhado antes de poder gravar no disco o valor de pmax como sendo o identificador do último pedido estável. Além disso, teremos necessariamente pmax = pu+1. Nesse caso, como o pedido pmax corresponde a uma ativação de uma primitiva do Salius que não retornou com sucesso (a hospedeira falhou antes do retorno da primitiva), o PR não precisa necessariamente recuperar esse pedido. Como não se pode garantir que f+1 réplicas contêm pmax em seus logs, é possível que todas as réplicas que contêm pmax em seus logs falhem e o PR ficará bloqueado esperando por uma mensagem que contenha esse pedido. Nesse caso o temporizador irá expirar e um novo valor para pmax será calculado. Entretanto, após um número finito de tentativas o PR conseguirá recuperar o sistema de arquivo, considerando ou não o pedido pmax. ٱ 11 5. CONCLUSÕES O Salius possibilita que os avanços tecnológicos em curso beneficiem mais o sistema, porque consegue diminuir a influência da tecnologia de disco no desempenho global do sistema, ao eliminar a urgência de gravar dados em disco. O desempenho do sistema passa a depender mais dos processadores, da capacidade de memória disponível, da velocidade de acesso à memória, das taxas de transmissão da rede e da banda passante da rede disponível para esse serviço, enfraquecendo o vínculo existente com a tecnologia de disco. Dessa forma, o serviço permite que o sistema utilize mais agressivamente as técnicas de otimização de desempenho, baseadas em caching em memória principal. Dessa forma, a nova técnica de armazenamento estável apresentada é potencialmente capaz de substituir, de forma vantajosa, as soluções que usam apenas a gravação síncrona em disco. Baseados em nossas próprias medidas preliminares [16] e em outros trabalhos correlatos [7, 12], acreditamos que uma implementação eficiente do Salius deverá levar a um desempenho superior àquele de técnicas baseadas na gravação síncrona em disco. O Salius apresenta a desvantagem de aumentar o consumo da banda passante do meio de comunicação, pois o funcionamento do serviço exige a troca constante de mensagens entre um SAC e o seu SRD. Teoricamente, a utilização de redes de alta velocidade diminuiria a probabilidade de um congestionamento inviabilizar a replicação de dados. Porém, somente a experimentação, através de simulação ou implementação do serviço, permitirá uma avaliação mais precisa dos efeitos do aumento do tráfego de dados na rede, causados pelo Salius. REFERÊNCIAS 1. The Power Protection Handbook. Technical report, American Power Conversion, 1996. 2. Anderson, T. et al. Serverless Network File Systems. Proceedings of the 15th Symp. on Operating Systems Principles, 109-126, dezembro 1995. 3. Baker, M. et al. Non-Volatile Memory for Fast Reliable File Systems. Fifth International Conference on Architectural Support for Programming Languages and Operating Systema (ASPLOS-V), pp. 10-22, outubro 1992. 4. Chen, P.M. et al. The Rio File Cache: Surviving Operating Systems Crashes. Seventh International Conference on Architectural Support for Programming Languages and Operating Systems, SIGPLAN Notices, 31(9): 74-83, setembro 1996. 5. Cristian, F. Understanding Fault-Tolerant Distributed Systems. Communications of the ACM, 34(2): 56-78, fevereiro 1991. 6. Cristian, F., e Fetzer, C. The Timed Asynchronous Distributed System Model. IEEE Transactions on Parallel and Distributed Systems, 10(6): 642-657, junho 1999. 7. Dahlin, M. et al. A Quantitative Analysis of Cache Policies for Scalable Network File Systems. Proceedings of the SIGMETRICS Conference on Measurement and Modeling of Computer Systems, pp. 150-160, maio 1994. 8. Fischer, M.J., Lynch, N.A., e Paterson, M.D. Impossibility of Distributed Consensus with One Faulty Process. Journal of ACM, 32(2): 374-382, abril 1985. 9. Hartman, J., e Ousterhout, J. The Zebra Stripped Network File System. ACM Transactions On Computer Systems, 13(3): 274-310, agosto 1995. 10. Liskov, B. et al. Replication in the Harp File System. Proceedings of the Thirteenth ACM symposium on Operating Systems Principles, pp. 226-238, outubro 1991. 11. McKusick, M. et al. A Fast File System for UNIX. ACM Transactions on Computer Systems, 2(3): 181-197, agosto 1984. 12. Plank, J.S., Li, K., e Puening, M.A. Diskless Checkpointing. IEEE Transactions on Parallel and Distributed Systems, 9(10): 972-986, outubro 1998. 13. Ritchie, D., e Thompson, K. The UNIX Time-Sharing System. The Bell System Thecnical Journal, 57(6): 19051930, julho 1978. 14. Rosenblum, M. e Ousterhout, J. The Design and Implementation of a Log-Structured File System. ACM Transactions on Computing Systems, 10(1): 26-52, fevereiro 1992. 15. Seltzer, M. et al. An Implementation of a Log-Structured File System for UNIX. Proceedings of the Winter 1993 USENIX Conference, pp. 307-326, janeiro 1993. 16. Stanchi, T.S. SALIUS – Serviço de Armazenamento Estável com Recuperação para Frente Baseado em Replicação Remota de Buffers. Dissertação de Mestrado, Coordenação de Pós-Graduação em Informática, Universidade Federal da Paraíba, Campina Grande, fevereiro 2000. 17. Wu, M., e Zwaenepoel, W. eNVy: Non-Volatile, Main Memory Storage Syatem. Proceedings of the 1994 International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), outubro 1994. 12
Download