☰
Explorar
Assinar em
Inscrever-se
Envio
×
Baixar
Sem categoria
Felipe da Costa Noguez
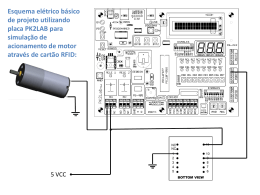
Sistema de acesso usando cartão RFID
Utilização de RFDI em processos de gerenciamento de estoques
Apresentação
Apresentação do PowerPoint
Fundador do Wireless Media Lab da UCLA afirma que a
RFID - IDENTIFICAÇÃO DE RÁDIO-FREQUENCIA UMA
Filosofia da Arte_ Estetica2 (963584)
A Fiscalização do Trânsito de Mercadorias no Futuro
Apresentação do PowerPoint