Adaline
Perceptron: ajuste de pesos não leva em conta distância entre saída e resposta desejada
Rede Adaline (ADAptive LINEar)
Proposta pôr Widrow e Hoff em 1960
Função de ativação é linear
21/11/11
Mais usada em problemas de regressão
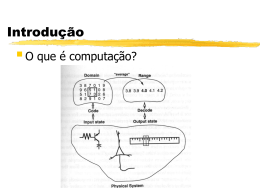
Redes Neurais - André Ponce de Leon F. de
61
Adaline
Estado de ativação
1 = ativo
0 = inativo (ou -1)
Função de ativação linear
fa(u) = u = ∑
21/11/11
i=0:d
x iw i
Termo θ é considerado também (w0 = θ )
Redes Neurais - André Ponce de Leon F. de
62
Adaline
corresponde a um grau de liberdade a mais
Deslocamento da função de ativação em relação
à origem do sistema de coordenadas
Em Perceptron era limiar de ativação do neurônio
f(x) = ∑
i=0:n
xiwi = w .x
Para uma Adaline de d entradas a saída f(x) é:
f(x) = w0 + w1x1 + w2x2 + ... + wdxd
Adaline
Logo, saída corresponde a uma combinação
linear das entradas xi
Pesos da combinação obtidos por meio de
treinamento
y = w0 + w1x1 + w2x2 + ... + wdxd
x0 = +1
x
1
x2
w0 =θ
w1
w2
.
.
.
xd
wd
y
Adaline
Treinamento
Supervisionado
Correção de erro (regra Delta)
Δ w = η x (y - y)
i
i d
Δw
i
≠y)
(yd = y)
Reajuste gradual do peso
21/11/11
=0
(yd
Leva em conta distância entre saída e resposta desejada
Redes Neurais - André Ponce de Leon F. de
65
Aprendizado
Seja um par de treinamento (x, yd)
Erro quadrático: e2 = (yd – w.x)2
Encontrar o w que leve a menor e2
e2 = (yd)2 –2ydw.x + (w.x)2
Superfície de erro
Na realidade deseja-se encontrar o mínimo da
superfície correspondente à soma das superfícies
de erro de todos os dados de treinamento
Aprendizado
Para o conjunto de treinamento com n dados
Função de erro (custo):
J = ½ ∑ i=1:n(ydi – w.xi)2
Algoritmo de treinamento deve atualizar os
pesos visando atingir o mínimo de J
Aprendizado
Dada uma condição inicial w(0), qual a direção
do ajuste a ser aplicado para que w se
aproxime do mínimo de J?
Pelo gradiente da função de custo no ponto
Gradiente possui a mesma direção da maior variação de
erro
ajuste deve ser na direção contrária
Δw(t)α-J
Aprendizado
Gradiente
Aprendizado
η
= taxa de aprendizado
Define velocidade com que o vetor de pesos é
modificado
Equação de ajuste:
w(t+1) = w(t) + η e x(t)
Algoritmo de treinamento
Algoritmo de treinamento de RNA Adaline
Entrada: Conjunto de treinamento D = {(xi ,yi), i = 1,...n}
Saída: Rede Perceptron com pesos ajustados
Iniciar pesos da rede com valores baixos
repita
para cada xi faça
Calcular valor da saída produzida pela rede f(xi)
erro e = yi - f(xi)
se e > então
Ajustar pesos do neurônio w(t+1) = w(t) + ex(t)
até que erro <
21/11/11
Redes Neurais - André Ponce de Leon F. de
71
Algoritmo de teste
Uso da RNA treinada
Algoritmo de teste de RNA Adaline
Entrada: Exemplo de teste x e RNA Adaline com pesos ajustados
Saída: previsão para x
Apresentar x à entrada da RNA
Calcular a saída f(x)
Retorne f(x)
21/11/11
Redes Neurais - André Ponce de Leon F. de
72
Problemas com redes de uma
única camada
Redes de uma camada geram apenas
fronteiras lineares
Grande número de aplicações importantes
são não lineares
Exemplo: XOR
Problemas com Perceptron
0, 0
0, 1
1, 0
1, 1
0
1
1
0
Ex. XOR
1
Problemas com Perceptron
Solução: utilizar mais de uma camada
Camada 1: uma rede Perceptron para cada
grupo de entradas linearmente separáveis
Camada 2: uma rede combina as saídas das
redes da primeira camada, produzindo a
classificação final
Como treinar?
Problemas com Perceptron
1
3
2
Rede multicamadas
Modelo de rede mais popular
Resolvem problemas mais complexos do que o
Perceptron simples e Adaline
Possuem uma ou mais camadas intermediárias
Funções de ativação não-lineares em pelo menos uma
das camadas intermediárias
Sempre vai existir uma rede com uma camada equivalente a uma multicamadas com funções de ativação lineares
Transformações não-lineares sucessivas
Rede multicamadas
Grande Funcionalidade
Uma camada intermediária aproxima:
Duas camadas intermediárias aproximam:
Qualquer função contínua ou Booleana
Qualquer função
Qualidade da aproximação depende da complexidade da
rede
Usar muitas camadas e/ou neurônios
Risco de overfitting!
Perceptron multicamadas
MLP – Multilayer Perceptron
Uma ou mais camadas intermediárias de neurônios
Função de ativação Sigmoide ou Tangente Hiperbólica
Arquitetura mais comum: completamente conectada
Cada neurônio realiza uma função específica
Função implementada é uma combinação das funções realizadas pelos neurônios da camada anterior conectados a ele
Termo θ usado para desvio da função em relação à origem
Todos neurônios vão ter um w0 = θ (ou - θ ) com entrada fixa -1 (ou
+1)
Perceptron multicamadas
MLPs
Função implementada por cada neurônio
Formada pela combinação das funções
implementadas por neurônios da camada anterior
Camada 1: hiperplanos no espaço de entradas
Camada 2: regiões convexas
Número de lados = número de unidades na camada
anterior
Camada 3: Combinações de figuras convexas,
produzindo formatos abstratos
Número de figuras convexas = número de unidades da
camada anterior
Funções cada vez
mais complexas
MLPs
Combinação
das funções
desempenha
das por cada
neurônio
define a
função
associada à
RNA
MLPs
Camada de saída: um neurônio para cada um
dos rótulos presentes
Classificação: função de ativação Sigmoide ou
tangente hiperbólica
Regressão: função de ativação linear
Saída para um objeto x: y = [y1, y2, ..., yk]t, k = número de rótulos
Classificação: vetor y para cada objeto de entrada tem valor 1
na posição associada à classe do objeto e 0 nas demais posições
MLPs
Treinamento por correção de erros
Camada de saída: comparação entre vetor de saída
dos neurônios e vetor de valores desejados
Classificação: rede classifica objeto corretamente quando
a saída mais elevada é a do neurônio correspondente à
classe correta do exemplo
Se valores são baixos ou mais de um neurônio dá valor de
saída alto, a rede não tem condições de prever
Camadas intermediárias: Qual a saída desejada de
uma camada itermediária?
Algoritmo Backpropagation (retropropagação de erros)
MLPs
Algoritmo Backpropagation
Estimar o erro das camadas intermediárias por efeito
que elas causam no erro da camada de saída
Erro da saída é retroalimentado para as camadas
intermediárias
Requer funções de ativação contínuas e diferenciáveis
Regra Delta generalizada
Backpropagation
Treinamento: iteração de duas fases
Cada fase percorre a rede em dois sentidos
Sinal (forward)
Erro (backward)
Backpropagation
Treinamento: iteração de duas fases
Fase Forward
Fase backward
“Para frente”
Cada objeto de entrada é
apresentado à rede
Neurônios são percorridos
da primeira camada
intermediária até a saída
Valores de saída são
comparados aos
desejados
“Para trás”
Erro de cada neurônio da
camada de saída é
usados para ajustar seus
pesos de entrada
Ajuste prossegue até a
primeira camada
intermediária
Rede MLP
camadas intermediárias
camada de
saída
camada de
entrada
conexões
21/11/11
Sistemas Inteligentes - André Ponce de Leon
88
Back-propagation
André Ponce de Leon de Carvalho
100
Back-propagation
Treinamento
Derivada parcial define ajuste dos pesos: mede
contribuição de cada peso no erro da rede
Derivada positiva
peso está provocando aumento na
diferença entre a saída produzida e a desejada
Sua magnitude deve ser reduzida para baixar o erro
Derivada negativa
peso está contribuindo para que
saída produzida seja mais próxima da desejada
Seu valor deve ser aumentado
André Ponce de Leon de Carvalho
101
Treinamento
Algoritmo Back-propagation
Iniciar todas as conexões com valores aleatórios
Repita
para cada par de treinamento (x, y)
para cada camada i := 1 a N
para cada neurônio j := 1 a Mi
Calcular a saída f (x)
ij
erro = y - f (x)
ij
para cada camada i := N a 1
para cada neurônio j:= 1 a Mi
Atualizar pesos
até que erro < (ou número máximo de ciclos)
André Ponce de Leon de Carvalho
102
Treinamento
André Ponce de Leon de Carvalho
103
Treinamento
André Ponce de Leon de Carvalho
104
Treinamento
André Ponce de Leon de Carvalho
105
Treinamento
André Ponce de Leon de Carvalho
106
Treinamento
André Ponce de Leon de Carvalho
107
Teste
Algoritmo de teste de RNA MLP
Apresentar dado x a ser reconhecido
para cada camada i := 1 a N
para cada neurônio j := 1 a Mi
Calcular a saída f (x)
ij
Se classificação: discretizar a saída
(verifica o maior valor produzido; se valores forem baixos ou muito
próximos, rejeitar)
Termo momentum
Para reduzir influência da escolha do valor de η
Adiciona uma fração α do valor anterior
de
atualização dos pesos ao atual
Quantifica grau de importância da variação do ciclo anterior
Quando o gradiente se mantém apontando na
mesma direção, o tamanho dos passos na direção
do mínimo crescerá
Atenção: se ambos η e α forem muito
grandes,
há o risco de passar pelo mínimo
Termo momentum
Caminho seguido
utilizando momento
Solução original de
convergência (lenta)
(lenta
Variações
Versão padrão: ajuste de pesos para cada
objeto individualmente
Variação batch: pesos são ajustados uma
única vez para cada ciclo
Variações
Mínimos locais: solução estável que não é a melhor
solução
Incidência pode ser reduzida
Empregando taxa de aprendizado decrescente
Adicionando nós intermediários
Utilizando termo de momentum
Backpropagation é muito lento em superfícies
complexas
Utilizar métodos de segunda ordem
Outros algoritmos
Ex.: RPROP, Newton, etc.
Critérios de parada
Diferentes critérios podem ser usados:
Número máximo de ciclos
Taxa máxima de erro
Early stop: estratégia para evitar overfitting
Separa parte dos dados de treinamento para
validação
Dados de validação são apresentados à rede a
cada l ciclos
Treinamento é finalizado quando erro em validação
começa a aumentar
Critérios de parada
Early stop
Convergência do algoritmo
Superfície de erro apresenta mínimos locais e
global para problemas complexos
Objetivo é atingir mínimo global
Não há teorema de convergência
Rede pode convergir para mínimo local ou demorar
muito para encontrar solução adequada
Projeto da arquitetura de RNA
Escolhas de função de ativação e topologia da
rede
Número de camadas e neurônios, padrão das
conexões
Geralmente empíricas (tentativa e erro)
Problema de busca
Projeto da arquitetura de RNA
Abordagens:
Empírica
Meta-heurística
Busca cega, tentativa e erro
Diversas arquiteturas são
testadas e comparadas
Mais utilizada, mas com
elevado custo de tempo
Gera conjunto de variações
de RNAs e combina as
que apresentam melhores
resultados
Geralmente usa Algoritmos
Genéticos na busca e
variações
Grande custo computacional
Algumas heurísticas: testar
apenas uma camada
intermediária, pois já tem
bastante poder expressivo
Projeto da arquitetura de RNA
Abordagens:
Poda (pruning)
Construtiva
Começa com uma RNA com
um grande número de
neurônios
Poda remove conexões ou
neurônios redundantes ou
irrelevantes
Gradualmente insere novos
neurônios e conexões a
uma RNA inicialmente
sem neurônios intermediários
Observações
Atributos devem ser numéricos
Categóricos devem ser pré-processados
É necessário normalizar os dados
Similar a k-NN
Relacionado também a ter crescimento muito grande
dos valores de peso
Vantagens RNAs
Várias soluções de sucesso em problemas
práticos (principalmente percepção e controle)
Tolerância a falhas e ruídos
Desvantagens RNAs
Capacidade preditiva ainda está aquém à do
cérebro
Dificuldade de interpretação do modelo gerado
(caixas-pretas)
Escolha de melhor conjunto de parâmetros
Referências
A
Slides de:
Prof Dr André C. P. L. F. de Carvalho
Prof Dr Ricardo Campello
Prof Dr Marcilio Carlos Pereira de Souto
Livro: A. P. Braga, A. C. P. L. F. Carvalho, T. B. Ludermir, Redes
Neurais Artificiais: teoria e aplicações, 2007, Ed LTC
Baixar