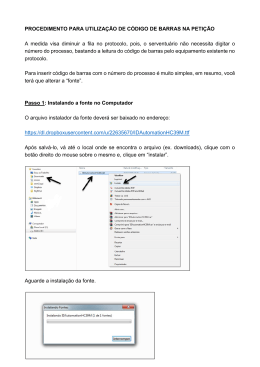
JOÃO PAULO GONÇALVES PEREIRA HEURÍSTICAS COMPUTACIONAIS APLICADAS À OTIMIZAÇÃO ESTRUTURAL DE TRELIÇAS BIDIMENSIONAIS Dissertação de Mestrado 1 JOÃO PAULO GONÇALVES PEREIRA HEURÍSTICAS COMPUTACIONAIS APLICADAS À OTIMIZAÇÃO ESTRUTURAL DE TRELIÇAS BIDIMENSIONAIS Dissertação apresentada ao Curso de Mestrado em Modelagem Matemática e Computacional do Centro Federal de Educação Tecnológica de Minas Gerais, como requisito parcial à obtenção do título de Mestre em Modelagem Matemática e Computacional. Área de concentração: Sistemas Inteligentes. Orientador: Prof. Dr. Gray Farias Moita Belo Horizonte Centro Federal de Educação Tecnológica de Minas Gerais Diretoria de Pesquisa e Pós-Graduação 2007 2 P436h 2007 Pereira, João Paulo Gonçalves Heurísticas computacionais aplicadas à otimização estrutural de treliças bidimensionais. – 2007. 120 f. Orientador: Gray Farias Moita Dissertação (mestrado) – Centro Federal de Educação Tecnológica de Minas Gerais. 1. Programação heurística. – 2. Otimização combinatória. 3. Análise estrutural. I. Moita, Gray Farias. II. Centro Federal de Educação Tecnológica de Minas Gerais. III. Título. CDD 519.6 3 Folha de aprovação. Esta folha será fornecida Graduação página. pelo e Programa deverá de substituir Pósesta 4 “O rio sempre segue seu curso porque aprendeu a contornar os obstáculos“. (Provérbio chinês). 5 AGRADECIMENTOS A Deus por me conceder a honra e o privilégio de estar vivendo este momento. Obrigado! Ao meu orientador, Prof. Dr. Gray Farias Moita, pela amizade, paciência, orientação e por acreditar em mim. Ao Prof. Dr. Roque Pitangueira da UFMG, por fornecer o software INSANE para a realização deste trabalho. À minha família, especialmente minha avó Helena, fonte de ensinamentos; meu avô José, por todo o carinho e apoio, meus tios Maria Helena e Victor, pelo ombro nas horas difíceis, e aos meus pais pelo incentivo. Aos meus sogros Wamberto e Margareth, a vocês toda minha gratidão por me receberem como o quarto filho da família e pela confiança depositada em mim. A Linkcom Informática LTDA, por possibilitar a realização deste projeto, permitindo conciliar trabalho e estudo. Aos professores do Cefet, aos meus colegas de mestrado Alexandre, João Paulo Xará, Jeferson, Magela, Manoel e aos demais; todos os amigos e companheiros do trabalho, obrigado pelo incentivo. E à minha noiva Carolina, futura esposa, amiga e eterna companheira, a você eu dedico cada página, pela sua paciência, pelo seu carinho, pelo seu amor. Dizem que, na história, por trás de todos os grandes homens existiu sempre uma grande mulher. Eu posso não ser um grande homem, mas com certeza você é uma grande mulher. De todo meu coração, muito obrigado. “A vida é como o mar, incansável na busca pela onda perfeita, até descobrir que a perfeição está na própria busca”. 6 SUMÁRIO LISTA DE FIGURAS ...................................................................................................7 LISTA DE TABELAS ................................................................................................10 LISTA DE QUADROS...............................................................................................11 LISTA DE ABREVIATURAS E SIGLAS ...................................................................12 RESUMO...................................................................................................................13 ABSTRACT...............................................................................................................14 1 INTRODUÇÃO .......................................................................................................15 1.1 Considerações iniciais.........................................................................................16 1.2 Introdução às Heurísticas....................................................................................17 1.3 Motivação e Objetivos do Trabalho .....................................................................18 1.4 Organização do Trabalho ....................................................................................20 2 HEURÍSTICAS COMPUTACIONAIS .....................................................................21 2.1 Algoritmos Genéticos ..........................................................................................22 2.2 VNS .....................................................................................................................26 2.3 GRASP................................................................................................................29 2.4 Simulated Annealing ...........................................................................................31 2.5 Busca Tabu .........................................................................................................33 2.6 Colônia de Formigas ...........................................................................................36 3 MODELAGEM E IMPLEMENTAÇÃO DOS ALGORITMOS..................................40 3.1 Modelagem do Problema ....................................................................................41 3.2 Implementação dos Algoritmos ...........................................................................42 3.2.1 Algoritmos Genéticos .................................................................................................. 42 7 3.2.2 VNS ............................................................................................................................. 48 3.2.3 GRASP ........................................................................................................................ 51 3.2.4 Simulated Annealing ................................................................................................... 52 3.2.5 Busca Tabu .................................................................................................................. 54 3.2.6 Colônia de Formigas.................................................................................................... 57 4 DESENVOLVIMENTO ...........................................................................................62 4.1 O Software INSANE e sua Integração ................................................................63 4.2 Inicialização de variáveis.....................................................................................65 5 ANÁLISE DOS RESULTADOS OBTIDOS ............................................................72 5.1 Estrutura de 10 Barras ........................................................................................74 5.1.1 Descrição do Problema................................................................................................ 74 5.1.2 Resultados.................................................................................................................... 75 5.1.3 Análise dos Resultados................................................................................................ 77 5.2 Estrutura de 18 Barras ........................................................................................84 5.2.1 Descrição do Problema................................................................................................ 84 5.2.2 Resultados.................................................................................................................... 86 5.2.3 Análise dos Resultados................................................................................................ 90 5.3 Estrutura de 47 Barras ........................................................................................96 5.3.1 Descrição do Problema................................................................................................ 96 5.3.2 Resultados.................................................................................................................... 99 5.3.3 Análise dos Resultados.............................................................................................. 100 5.4 Análise Comparativa entre os métodos.............................................................107 6 CONCLUSÃO ......................................................................................................109 6.1 Considerações Gerais .......................................................................................110 6.2 Conclusões........................................................................................................110 6.3 Sugestões para Trabalhos Futuros ...................................................................112 REFERÊNCIAS.......................................................................................................114 ANEXO A – CONFIGURAÇÃO DO AMBIENTE DE DESENVOLVIMENTO..........119 7 LISTA DE FIGURAS FIGURA 2.7: Otimização por Colônia de Formigas. .............................................38 FIGURA 3.1: Funcionamento dos operadores de Crossover utilizados no AG. 45 FIGURA 3.8: Esquema da matriz de feromônio. ...................................................59 FIGURA 4.1: Interface do software INSANE. .........................................................64 FIGURA 4.2: Exemplo do arquivo de inicialização IniFile.XML. ..........................66 FIGURA 4.3: Executando o sistema OtimoEstrutura. ..........................................66 FIGURA 4.4: Interface gráfica do sistema OtimoEstrutura. .................................67 FIGURA 4.5: Exemplo do arquivo de inicialização do AG. ..................................67 FIGURA 4.6: Padronização de nomenclatura da modelagem de problemas no INSANE...............................................................................................................69 FIGURA 4.7: Seqüência de eventos e intercâmbio de dados com o software INSANE...............................................................................................................70 FIGURA 5.1: Topologia da estrutura com 10 barras. Fonte: Yokota et al. (1998). ............................................................................................................................74 FIGURA 5.2: Gráfico de Peso (lbs) x Tempo (s) do AG (10 Barras). ...................77 FIGURA 5.3: Gráfico de Peso (lbs) x Tempo (s) do VNS (10 Barras). .................78 FIGURA 5.4: Gráfico de Peso (lbs) x Tempo (s) do GRASP com VNS (10 Barras). ............................................................................................................................79 8 FIGURA 5.5: Gráfico de Peso (lbs) x Tempo (s) do SA (10 Barras).....................79 FIGURA 5.6: Gráfico de Peso (lbs) x Tempo (s) da BT (10 Barras). ....................80 FIGURA 5.7: Gráfico de Peso (lbs) x Tempo (s) do AC (10 Barras). ...................81 FIGURA 5.8: Melhores resultados de cada algoritmo (10 Barras). .....................81 FIGURA 5.9: Topologia da estrutura com 18 barras. Fonte: Fawaz et al. (2005). ............................................................................................................................85 FIGURA 5.10: Topologia da estrutura de 18 barras otimizada. Fonte: Fawaz et al. (2005). ............................................................................................................86 FIGURA 5.11: Gráfico de Peso (lbs) x Tempo (s) do AG (18 Barras). .................90 FIGURA 5.12: Gráfico de Peso (lbs) x Tempo (s) do VNS (18 Barras). ...............91 FIGURA 5.13: Gráfico de Peso (lbs) x Tempo (s) do GRASP com VNS (18 Barras)................................................................................................................91 FIGURA 5.14: Gráfico de Peso (lbs) x Tempo (s) do SA (18 Barras)...................92 FIGURA 5.15: Gráfico de Peso (lbs) x Tempo (s) da BT (18 Barras). ..................93 FIGURA 5.16: Gráfico de Peso (lbs) x Tempo (s) do AC (18 Barras). .................93 FIGURA 5.17: Melhores resultados de cada algoritmo (18 Barras). ...................94 FIGURA 5.18: Topologia da torre de 47 barras. Fonte: Castro (2001). ...............97 FIGURA 5.19: Gráfico de Peso (lbs) x Tempo (s) do AG (47 Barras). ...............101 FIGURA 5.20: Gráfico de Peso (lbs) x Tempo (s) do VNS (47 Barras). .............102 9 FIGURA 5.21: Gráfico de Peso (lbs) x Tempo (s) do GRASP com VNS (47 Barras)..............................................................................................................103 FIGURA 5.22: Gráfico de Peso (lbs) x Tempo (s) do SA (47 Barras).................103 FIGURA 5.23: Gráfico de Peso (lbs) x Tempo (s) da BT (47 Barras). ................104 FIGURA 5.24: Gráfico de Peso (lbs) x Tempo (s) do AC (47 Barras). ...............105 FIGURA 5.25: Melhores resultados de cada algoritmo (47 Barras). .................105 10 LISTA DE TABELAS TABELA 5.1: Restrições de projeto e valores de coeficientes. Fonte: Yokota et al. (1998). ............................................................................................................74 TABELA 5.2: Melhores resultados obtidos em dez execuções para a treliça de 10 Barras. ...........................................................................................................76 TABELA 5.3: Tensão máxima e deslocamento máximo das soluções para a treliça de 10 Barras. ..........................................................................................76 TABELA 5.4: Melhores resultados obtidos em dez execuções para a treliça de 18 Barras. ...........................................................................................................88 TABELA 5.5: Tensão máxima e deslocamento máximo das soluções para a treliça de 18 Barras. ..........................................................................................88 TABELA 5.6: Melhores resultados obtidos em dez execuções para a treliça de 47 Barras. ...........................................................................................................99 TABELA 5.7: Tensão máxima e deslocamento máximo das soluções para a treliça de 47 Barras. ........................................................................................100 TABELA 5.8: Análise comparativa entre os algoritmos implementados. ........108 11 LISTA DE QUADROS QUADRO 3.1: PSEUDOCÓDIGO DO AG IMPLEMENTADO. .................................48 QUADRO 3.2: PSEUDOCÓDIGO DO MÉTODO VNS. ............................................50 QUADRO 3.3: PSEUDOCÓDIGO DO MÉTODO GRASP. .......................................52 QUADRO 3.4: PSEUDOCÓDIGO DO MÉTODO SIMULATED ANNEALING..........53 QUADRO 3.5: PSEUDOCÓDIGO DO MÉTODO BUSCA TABU. ............................57 QUADRO 3.6: PSEUDOCÓDIGO DO MÉTODO COLÔNIA DE FORMIGAS. .........61 12 LISTA DE ABREVIATURAS E SIGLAS AC – Ant Colony – Colônia de Formigas. AG – Algoritmos Genéticos. BT – Busca Tabu. JDK – Java Development Kit. SA – Simulated Annealing. VNS – Variable Neighborhood Search - VNS. WWW – World Wide Web. XML – Extensible Markup Language. 13 RESUMO Este trabalho visa mostrar o funcionamento de métodos computacionais, conhecidos como Heurísticas, na pesquisa de boas soluções para problemas de análise estrutural. O problema de otimização estrutural foi tratado estudando estruturas com treliças bidimensionais para obter as dimensões mínimas suficientes para as áreas de seção transversal de cada barra, obedecendo às restrições impostas pelo projeto. As heurísticas computacionais implementadas aqui são utilizadas com o intuito de fornecer métodos alternativos para minimizar o peso e, conseqüentemente, o custo destas estruturas. As vantagens e desvantagens de cada heurística implementada são descritas, analisando os resultados obtidos por meio de sua aplicação em três problemas com configurações estruturais distintas. Espera-se, através da análise de comportamento de cada heurística e dos resultados alcançados em cada problema, contribuir para fornecer métodos auxiliares à engenharia como forma de aprimorar projetos de construção de estruturas e ao mesmo tempo incorporar um arcabouço de conhecimentos em heurísticas computacionais e suas aplicações. PALAVRAS-CHAVE: Otimização estrutural, Heurísticas computacionais, Treliças bidimensionais. 14 ABSTRACT The present work is focused on demonstrating the functioning of the computational method known as heuristics, as used on the search of a solution for structural analysis. The problem of structural optimization was approached by optimizing plane trussed structures to obtain their minimal cross sectional area, restricted to the limitations imposed by the project. Computational Heuristics was used with the goal of finding alternative shapes to minimize the weight - and therefore the costs - of such structures. The advantages and drawbacks of each method are demonstrated, including the analysis of the results obtained in three different structural problems, as compared to the results of the methods applied on the different tests. This work and its results are aimed to contribute to the use of auxiliary methods in the field of Engineering as a mean to improve the structural projects, and to simultaneously compile a knowledge base on heuristics and its applications. KEY WORDS: Optimization, Computational heuristical, Plane trusses. 15 1 INTRODUÇÃO 1 INTRODUÇÃO 16 Este capítulo contém uma introdução ao estudo do problema de pesquisa tratado neste trabalho, que se refere à avaliação de métodos computacionais, conhecidos como heurísticas, aplicados a uma classe específica de problemas de otimização: projetos estruturais. Neste trabalho foi estudado um modelo específico, conhecido como Treliça. A Seção 1.1 descreve uma breve introdução contendo os conceitos relacionados com o problema tratado. A Seção 1.2 contém um pequeno resumo sobre heurísticas computacionais. A Seção 1.3 apresenta os principais motivos que idealizaram este estudo e a Seção 1.4 descreve a organização deste trabalho. 1.1 CONSIDERAÇÕES INICIAIS Nos dias atuais é muito comum utilizar estruturas treliçadas em projetos de grandes construções. Tais estruturas podem ser encontradas em diversos locais, como por exemplo, ginásios cobertos, estádios de futebol, viadutos, frutos da criatividade e inteligência humana. Treliças são estruturas compostas por barras articuladas nas extremidades - interligadas por rótulas – e, por isso, unicamente sujeitas a esforços axiais. Essa configuração faz com que a estrutura seja leve e ao mesmo tempo resistente. Sendo assim, a idéia deste trabalho consiste em diminuir os custos de projetos que utilizam treliças em suas construções, reduzindo a quantidade de material empregado nestas estruturas, com o intuito de diminuir seu peso, mas de acordo com as restrições impostas pelo projeto. Para realizar o processo de otimização estrutural proposto foi utilizado um conjunto de métodos conhecidos como heurísticas computacionais. A seção seguinte descreve como tais métodos são utilizados na busca pela diminuição do peso estrutural e, principalmente, como estes métodos podem atingir boas soluções a um baixo custo computacional. 17 1.2 INTRODUÇÃO ÀS HEURÍSTICAS Segundo Castro (2001), “o conceito de otimização de qualquer tarefa ou processo está diretamente ligado à sua realização, do modo mais eficiente possível. Esta eficiência pode ser avaliada de inúmeras maneiras, como por exemplo, a minimização de tempo gasto na limpeza de um jardim, a maximização de velocidade de processamento de um chip, dentre outros”. Existem várias formas de realizar a otimização. A primeira linha de métodos desenvolvidos para este fim foi a Programação Matemática. Esta linha de pesquisa trata o problema de maneira iterativa e determinista, através de operações matriciais, gradientes, etc. A programação matemática é mais adequada para problemas que possuem um espaço de soluções viáveis bem definido, suavidade da função objetivo e convexidade do problema. Sua desvantagem é que ainda não existe nenhum método que possibilite a busca de soluções ótimas globais, ou seja, a busca pode convergir e se prender a qualquer solução ótima local. Sendo assim, devido a estas características, a programação matemática não é indicada para a classe de problemas estudada neste trabalho. Uma outra linha de métodos desenvolvidos para realizar a otimização é formada por um conjunto de técnicas compostas de algoritmos conhecidos como heurísticas computacionais. Para compreender melhor a idéia por trás dos métodos heurísticos veja a descrição a seguir: “O desafio é produzir, em tempo reduzido, soluções tão próximas quanto possível da solução ótima. Muitos esforços têm sido feitos nessa direção e heurísticas muito eficientes foram desenvolvidas para diversos problemas. Entretanto, a maioria dessas heurísticas desenvolvidas é muito específica para um problema particular, não sendo eficiente (ou mesmo aplicável) na resolução de uma classe mais ampla de problemas”. (SOUZA, 2005, p.2) Analisando a citação anterior, podem-se perceber dois conceitos distintos: o primeiro revela que as heurísticas podem atingir bons resultados, mas não garante em nenhum momento que a solução encontrada é a melhor solução global para o problema (porém, diferentemente da programação matemática, existem estratégias 18 que permitem escapar de ótimos locais). O segundo, e não menos importante, demonstra a necessidade da experimentação. Como cada heurística é desenvolvida para um problema em particular, a mesma pode não ser tão eficiente para outros problemas de explosão combinatória1. Neste caso, os métodos devem ser calibrados para o problema em questão, e tal calibragem somente é possível por meio de inúmeros e variados testes, ajustando os parâmetros de cada uma das heurísticas, a fim de obter os melhores resultados. 1.3 MOTIVAÇÃO E OBJETIVOS DO TRABALHO A decisão de se trabalhar com métodos heurísticos reside nas respostas de duas perguntas: a) Tempo é considerado primordial? b) É preciso atingir boas soluções com um custo baixo de processamento? Estas duas perguntas descrevem exatamente as vantagens de se utilizar métodos heurísticos na resolução de problemas de pesquisa operacional. Com o objetivo de analisar o comportamento dos métodos heurísticos foi escolhida a área de otimização estrutural, utilizando treliças planas, por ser extremamente ampla e largamente utilizada atualmente. A utilização de heurísticas computacionais neste tipo de problema mostra-se muito vantajosa, podendo inclusive encorajar aqueles que buscam formas alternativas de reduzir os custos de seus projetos com um baixo tempo computacional. Contextualizando estas vantagens é possível, por exemplo, produzir a diminuição dos custos de um projeto de estruturas por meio de métodos heurísticos, visando diminuir a área da seção transversal das barras de aço utilizadas no projeto inicial. Uma redução de 30%, por exemplo, poderia significar uma grande redução nos custos totais da obra e, ainda assim, os requisitos de sustentação continuariam 1 Problemas classificados na literatura como NP-Dificeis, que não podem ser resolvidos em tempo polinomial, de maneira que um computador pode levar vários anos para encontrar a melhor solução. 19 sendo atendidos. O mesmo processo poderia ser empregado em outra variável, por exemplo, o tipo de material, ou até mesmo permitir a alteração das coordenadas dos nós que compõem a estrutura, permitindo que sua topologia seja modificada. Tal otimização poderia ainda inferir que determinadas barras que compõem o projeto poderiam ser removidas e, ainda assim, os requisitos de sustentação continuariam sendo atendidos. Estes são apenas alguns exemplos das inúmeras possibilidades que este processo de aperfeiçoamento pode oferecer. Para aplicar tal processo foram selecionadas algumas das principais heurísticas computacionais utilizadas atualmente. Dentro deste contexto, o presente trabalho possui os seguintes objetivos: • Analisar cada heurística aplicada com o intuito de descobrir, para a classe de problemas analisada, quais os métodos mais eficientes, os métodos menos eficientes, e os métodos de melhor relação custo / benefício, onde o custo está relacionado à facilidade de implementação e o benefício diretamente ligado à eficiência e qualidade das soluções obtidas; • Determinar a importância da modelagem do problema e sua direta influência no desempenho do algoritmo; • Analisar o papel do operador de Mutação no processo de pesquisa do Algoritmo Genético; • Executar testes de experimentação e calibração para determinar fatores como eficiência e facilidade de implementação de cada método, aplicados em problemas existentes na literatura. Muitos trabalhos vêm sendo realizados com relação à utilização de métodos heurísticos na resolução de problemas das mais diversas áreas. Na área de otimização aplicada à engenharia de estruturas, pode-se citar Castro (2001), Yang (2002), Fonseca e Pitangueira (2004), Dimou e Koumousis (2003), entre outros. 20 Espera-se que, por meio da análise dos algoritmos e dos resultados obtidos, este trabalho possa fornecer um arcabouço de conhecimentos àqueles que lidam diariamente com projetos estruturais. 1.4 ORGANIZAÇÃO DO TRABALHO O capítulo 2 introduz as heurísticas computacionais por meio de uma revisão de sua bibliografia. As heurísticas empregadas neste trabalho são detalhadas, fornecendo a teoria necessária para a compreensão de suas aplicações. O capítulo 3 descreve em detalhes como, a partir dos conceitos relacionados no capítulo 2, os algoritmos foram implementados e adaptados para o tipo de problema proposto. O capítulo 4 descreve o ambiente de desenvolvimento, bem como a maneira como foi realizada a integração do sistema aqui desenvolvido com o software INSANE, e suas variáveis de inicialização. O capítulo 5 exibe os problemas estruturais utilizados para a aplicação dos métodos heurísticos, juntamente com suas restrições e resultados obtidos para cada algoritmo implementado. Ainda neste capítulo é realizada uma análise dos resultados obtidos em cada problema através da aplicação de cada algoritmo, citando as vantagens e desvantagens de cada heurística utilizada. O capítulo 6 descreve as conclusões obtidas com este trabalho, bem como as contribuições e sugestões para futuros trabalhos na área de otimização estrutural. 21 2 HEURÍSTICAS COMPUTACIONAIS 2 HEURÍSTICAS COMPUTACIONAIS 22 Este capítulo contém uma revisão da bibliografia das diversas Heurísticas Computacionais utilizadas ao longo deste trabalho. Exemplos de aplicações que utilizam tais métodos, suas funcionalidades e suas características individuais serão detalhadas com o intuito de fornecer um embasamento teórico que será um facilitador para o entendimento dos algoritmos implementados neste trabalho. A Seção 2.1 descreve em detalhes as características e o funcionamento do método Algoritmos Genéticos. A Seção 2.2 detalha o método de Pesquisa em Vizinhança Variável, também conhecido como Variable Neighborhood Search – VNS. A Seção 2.3 explica o método GRASP - Busca Gulosa e Randomizada. A Seção 2.4 descreve o método de Recozimento Simulado, conhecido como Simulated Annealing. A Seção 2.5 detalha o método Busca Tabu e a Seção 2.6 descreve o método Colônia de Formigas. 2.1 ALGORITMOS GENÉTICOS Dimou e Koumousis (2003) descrevem esta heurística de maneira simples e clara: “Algoritmos genéticos são algoritmos de busca baseados nos conceitos de seleção natural e sobrevivência do indivíduo mais apto”. São compostos por uma seqüência de rotinas computacionais, elaboradas com o intuito de simular o comportamento da evolução natural por meio do computador. Para compreender melhor seu funcionamento são descritos brevemente alguns conceitos associados à seleção natural e à genética, facilitando assim o entendimento do algoritmo ao perceber sua semelhança com a biologia. Charles Darwin (1809-1882) revolucionou as idéias acerca da evolução da vida e da origem das espécies. Durante suas pesquisas, Darwin observou que nem todos os organismos que nascem se reproduzem ou até mesmo sobrevivem. Darwin percebeu que os organismos que conseguiam sobreviver o faziam pelo fato de possuírem determinadas características que facilitavam sua adaptação ao ambiente. Tais organismos, devido a essas características que os permitia sobreviver, teriam uma probabilidade maior de se reproduzir, deixando descendentes. Desta maneira, 23 as características que proporcionavam maior adaptabilidade do organismo ao ambiente seriam passadas de geração a geração, garantindo a sobrevivência da espécie. De modo semelhante, as características que dificultavam a adaptabilidade iam sendo extintas, pois dificultavam a sobrevivência dos organismos que as possuíam e, por isso, não eram passadas de geração a geração. Zimmer (2003) relata que, segundo Darwin, este processo de evolução é lento, contínuo e aleatório, pois surge por meio de várias gerações, cada qual contribuindo para diversificar as características genéticas da espécie. Sua grande contribuição para a teoria da evolução foi o conceito de “Seleção Natural”, sendo esta composta das seguintes premissas (maiores detalhes podem ser encontrados nos livros de Darwin: “Sobre a Origem das Espécies por Meio da Seleção Natural” e “A Descendência do Homem e Seleção em Relação ao Sexo”), segundo suas observações: 1. Indivíduos de uma mesma espécie exibem modificações aleatórias tanto em sua fisiologia quanto em sua forma; 2. Parte de tais modificações é transmitida aos seus descendentes; 3. Nem todos os indivíduos de uma mesma espécie se reproduzem. Caso isto ocorresse, as populações de inúmeras espécies cresceriam de forma exponencial; 4. Os seres de uma população lutam pela sua sobrevivência, pois os recursos disponíveis no meio ambiente são limitados; 5. Desta maneira, somente os indivíduos mais aptos (e que nem sempre são os mais fortes, e sim mais adaptados às condições ambientais) sobrevivem, possuindo mais chance de se reproduzirem; 6. Por conseguinte, as espécies de gerações futuras passam a ser compostas por indivíduos cada vez mais adaptados ao meio ambiente; 24 O processo de evolução realiza-se por meio de modificações, totalmente aleatórias, das características genéticas dos indivíduos que compõem a população. Ainda neste mesmo processo, a presença de uma ou mais características vantajosas à adaptação dos indivíduos aumenta de forma gradual à medida que os indivíduos mais adaptados se reproduzem. Este processo ocorre na natureza por meio da ação da Seleção Natural. Segundo Mitchell (1998), o primeiro passo em busca de um modelo matemático que representasse a teoria de Darwin surgiu com a obra “The Genetic Theory of Natural Selection”, elaborado pelo biólogo evolucionista R. A. Fisher. Logo em seguida, John H. Holland elaborou os Algoritmos Genéticos, juntamente com seus alunos e colegas da Universidade de Michigan em meados dos anos 60 e 70. Como resultado deste trabalho, Holland publica o livro “Adaptation in Natural Systems” e, no ano de 1989, David Goldberg (1989) publica “Genetic Algorithms in Search, Optimization and Machine Learning”, considerado até hoje um dos livros mais importantes sobre os Algoritmos Genéticos. De acordo com Mitchell (1998), baseado nas informações acima descritas tornase mais fácil descrever o Algoritmo Genético: é um conjunto de técnicas computacionais, normalmente empregadas na resolução de problemas de otimização, dotadas de uma plausibilidade biológica que se relaciona com a genética e as teorias de evolução e seleção natural. As variáveis dos problemas são representadas como genes em um cromossomo (também chamado de “indivíduo”). Uma “população“ é composta de vários indivíduos. Novos indivíduos são gerados por meio de operadores genéticos como Mutação, Seleção, Cruzamento e Clonagem, dando origem a uma nova população. A cada geração uma nova população é construída e esta, por sua vez, corresponde a um conjunto de possíveis soluções para um dado problema. A cada geração é aplicado o princípio da Seleção Natural, de maneira que somente os indivíduos mais aptos (que representam as melhores soluções para o problema naquele momento) sofrerão ação dos operadores genéticos (podendo 25 sofrer Mutação, Cruzamento, Clonagem, entre outros), enquanto os demais (menos aptos) serão descartados. Desta maneira pode-se compreender a evolução de um Algoritmo Genético como um processo de busca pela melhor solução para o problema tratado. Apesar de existirem diferentes implementações de Algoritmos Genéticos, algumas características são comuns entre elas: • A partir de uma população inicial (geração zero), inicia-se a construção de novas populações (gerações futuras) pela aplicação dos operadores genéticos. Os operadores mais utilizados são: Mutação, Cruzamento e Clonagem. • Podem existir algumas diferenças na maneira como os operadores são implementados, mas basicamente as regras são as mesmas: a Mutação seleciona um gene do indivíduo e modifica este gene, introduzindo assim uma nova característica na população; o Cruzamento é realizado entre dois indivíduos (pais), cruzando seus genes para a construção de novos indivíduos (filhos); e a Clonagem copia um indivíduo gerando outro novo idêntico a ele, que irá fazer parte da nova população. A Seleção, como o próprio nome sugere, seleciona os indivíduos mais aptos da população que irão sofrer ação destes operadores, como forma de produzir novos indivíduos para a próxima geração; • Apresentam muita flexibilidade, no sentido de permitir, sem muita dificuldade, uma grande quantidade de modificações em sua implementação, permitindo fácil hibridização. O alto grau de flexibilização permite testar situações diversificadas no intuito de observar como ocorre a evolução até a resposta. Por outro lado, torna difícil a calibração do método uma vez que permite um número elevado de combinações entre os parâmetros. 26 Cada indivíduo da população recebe o nome de cromossomo e, segundo Souza (2005), “cada cromossomo está associado a uma solução do problema e cada gene está associado a um componente da solução”. Desta maneira, cada cromossomo da população é considerado um ponto entre os vários pontos existentes no espaço de busca. O fato de que cada cromossomo está associado a uma solução do problema não significa que esta solução seja viável. O processo de avaliação e seleção dos indivíduos está diretamente relacionado com a análise de viabilidade destas soluções, de maneira que indivíduos considerados de baixa ou nenhuma adaptabilidade são aqueles estão associados a soluções inviáveis ou de baixa qualidade. Para maiores detalhes é recomendada a leitura de Goldberg (1989). 2.2 PESQUISA EM VIZINHANÇA VARIÁVEL Este método, do inglês – VNS (Variable Neighborhood Search), foi proposto por Mladenovic e Hansen (1997). É um método de busca local que realiza modificações sistemáticas das estruturas de vizinhanças para explorar o espaço de soluções. Sua idéia mais interessante reside no fato de que ele não segue uma trajetória específica em busca da solução. Ele explora vizinhanças cada vez mais distantes da solução corrente e redireciona a busca por uma nova solução se e somente se acontecer uma melhora na qualidade da solução encontrada. A busca se inicia da mesma maneira que os Algoritmos Genéticos: partindo de uma solução inicial, buscando novas soluções a partir desta e terminando quando atingir um critério de parada. A diferença é que o AG inicia sua pesquisa com uma população inicial (ou seja, vários cromossomos que representam várias soluções candidatas), enquanto o VNS parte de uma única solução inicial que, a partir desta, soluções vizinhas são geradas dentro da estrutura de vizinhança corrente. Para compreender melhor o funcionamento da pesquisa nas estruturas de vizinhança, torna-se necessário utilizar um problema de otimização como exemplo. Sendo assim, considere o problema do Caixeiro Viajante. Partindo de uma 27 determinada cidade, o viajante deverá visitar as demais cidades uma única vez e retornar à cidade de origem, de maneira a percorrer a menor distância possível. Trata-se de um problema de minimização de distâncias, em que o principal objetivo é diminuir os custos reduzindo a distância total percorrida. Considere um trajeto qualquer elaborado aleatoriamente. Este trajeto, por ser o primeiro, pode ser melhorado, mas serve de ponto de partida para a geração de um novo trajeto (nova solução) através de seu refinamento. Sendo assim, considere a elaboração de vários trajetos partindo do trajeto inicial, em que cada novo trajeto é construído modificando a ordem de visitação entre apenas duas cidades simultaneamente. Desta maneira, várias novas soluções são elaboradas e avaliadas, em que a única regra consiste na modificação da ordem de visitação de apenas duas cidades por vez. Sendo assim foi estabelecida uma estrutura de vizinhança do projeto inicial, composta por todos os trajetos elaborados a partir do trajeto inicial, modificando-se apenas a ordem de visitação entre somente duas cidades simultaneamente. De modo semelhante, uma outra estrutura de vizinhança poderia ser composta por todos os trajetos elaborados modificando-se a ordem de visitação entre somente quatro cidades por vez. Deste modo, trajetos cada vez mais distintos serão elaborados, diversificando a pesquisa e ampliando de forma gradual o espaço de soluções. A compreensão acerca do funcionamento das estruturas de vizinhança se faz necessária para o entendimento do método como um todo. A partir do trajeto inicial, o método inicia sua pesquisa gerando novas soluções, que estão contidas em uma determinada estrutura de vizinhança. A cada solução gerada é aplicado um método de busca local (que será explicado posteriormente). Se a solução resultante desta busca for melhor que a melhor solução encontrada até o momento, o método atualiza a melhor solução e redireciona a busca para a primeira estrutura de vizinhança. Caso contrário, o método modifica a estrutura de vizinhança e pesquisa uma nova solução dentro da nova estrutura. O processo é repetido até atingir um critério de parada, conforme será explicado posteriormente. 28 Neste trabalho foi desenvolvido o método VNS tradicional, que utiliza como busca local o método VND (Variable Neighborhood Descent ou Descida em Vizinhança Variável). Este método foi proposto por Nenad Mladenovic e Pierre Hansen (1997) e também utiliza o conceito de estruturas de vizinhança no seu processo de busca. A diferença é que, a partir de uma solução inicial, o método pesquisa a melhor solução vizinha dela e, caso não encontre, modifica a estrutura de vizinhança e recomeça a pesquisa. O processo é repetido até atingir um critério de parada, que pode ser o número máximo de iterações ou então o tempo máximo de processamento. O melhor valor para este critério é determinado por meio do processo de experimentação, que é detalhado no capítulo seguinte. É importante salientar que a pesquisa pelo melhor vizinho da solução inicial pode ser muito cara computacionalmente e, dependendo do tipo de problema, até inviável de ser realizada. A busca pelo melhor vizinho de uma solução pode se tornar uma tarefa árdua caso a estrutura de vizinhança contenha um número extremamente elevado de soluções possíveis. Em um dos problemas tratados neste trabalho (a estrutura de 10 barras), a área de seção transversal das barras possui uma precisão de seis casas decimais. Isto torna a pesquisa pelo melhor vizinho inviável devido à grande quantidade de combinações possíveis para se obter as estruturas. Para resolver tal inconveniente, faz-se necessário retornar o primeiro melhor vizinho encontrado ou restringir a quantidade de vizinhos gerados, reduzindo o espaço de busca da estrutura de vizinhança. Com relação aos parâmetros de calibração, diferentemente dos Algoritmos Genéticos que são extremamente flexíveis, o VNS possui apenas um parâmetro, que corresponde a um valor para determinar seu critério de parada. Este parâmetro pode ser definido como um número máximo de iterações ou um valor de tempo máximo de processamento (que foi o critério adotado neste trabalho para colher os resultados de cada algoritmo). A inferência do valor deste parâmetro é realizada pelo processo de experimentação (executando o algoritmo várias vezes, modificando seus parâmetros e analisando os resultados obtidos), que tem por objetivo calibrar o algoritmo para que este apresente os melhores resultados para o problema tratado. Vale lembrar que cada tipo de problema deve passar pelo processo de 29 experimentação, pois problemas diferentes muitas vezes requerem parâmetros distintos. Existem vários métodos que podem realizar o procedimento de busca local. Sendo assim, torna-se interessante utilizar um parâmetro que defina qual método de busca local utilizar. Como este trabalho utiliza apenas o VND como busca local, tal parâmetro não se fez necessário, mas é uma ferramenta muito útil que aumenta um pouco mais a flexibilidade do algoritmo. Vale lembrar que cada tipo de problema requer uma modelagem diferente das estruturas de vizinhança. Tal modelagem deve ser bem estudada, pois influencia diretamente na qualidade dos resultados encontrados. O método VNS desenvolvido neste trabalho será mostrado em detalhes, incluindo seu pseudocódigo, no capítulo seguinte. 2.3 GRASP O método GRASP (Greedy Randomized Adaptive Search Procedure), também conhecido por busca adaptativa gulosa e randomizada, foi proposto por Feo (1995). É um procedimento que consiste em duas fases: uma fase de construção da solução inicial e uma fase de busca local a partir dessa solução gerada. Na fase de construção, cada elemento gerado é adicionado a uma lista de candidatos, com uma ordenação pré-determinada. O processo de seleção destes candidatos é realizado por uma função gulosa e adaptativa, regulada por um único parâmetro de ajuste, que varia entre 0 e 1. Quanto mais próximo de zero, mais guloso se torna o algoritmo, ou seja, se movendo sempre em direção à primeira melhor solução encontrada (cada nova solução gerada é comparada com a solução inicial. A primeira melhor, passa a ser a nova solução corrente), intensificando a busca. Quanto mais próximo de um, mais aleatório se torna o algoritmo, diversificando a busca. A fase de construção de uma solução inicial é realizada elemento por elemento. Para facilitar a compreensão, imagine que a solução de um determinado problema é 30 representada por um vetor de n posições. Cada posição do vetor é calculada da seguinte maneira: é gerada uma quantidade t de valores candidatos para a posição. Estes valores são armazenados em uma lista de maneira ordenada (esta ordenação se faz pelo critério de interesse do problema. Se o objetivo é minimizar, ordena-se pela ordem crescente, caso contrário, decrescente). A partir da lista de valores candidatos, uma nova lista é preenchida. Esta nova lista é chamada de Lista de Candidatos Restrita (LCR). O tamanho desta lista é determinado pelo parâmetro α (seu valor varia de 0 a 1). Deste modo, seu tamanho pode, por exemplo, ser calculado multiplicando o valor de α por n. Na LCR são inseridos os melhores candidatos contidos na lista de candidatos e dela é selecionada, de maneira aleatória, o valor que ocupará uma posição no vetor. Desta maneira observa-se que, um valor de α = 0 faz o com que a geração de soluções seja puramente gulosa (escolhe sempre o primeiro melhor), enquanto um valor de α = 1 gera soluções totalmente aleatórias. Portanto, é extremamente importante passar pelo processo de experimentação com o objetivo de calibrar este parâmetro em busca de um valor que retorne os melhores resultados. O processo de construção citado acima é repetido para cada posição do vetor até que todas as posições possuam seus valores estabelecidos, formando assim uma solução inicial. Neste ponto inicia-se o processo de busca local a partir da solução gerada. Ao finalizar a busca local, compara-se a solução resultante com a melhor solução encontrada até o momento, atualizando-a caso seja necessário. O processo de construção de uma nova solução inicial recomeça passando novamente pela busca local e atualizando a melhor solução caso necessário. O procedimento é repetido até que se atinja um determinado critério de parada, que pode ser um número máximo de iterações ou um valor de tempo máximo de processamento. O método GRASP desenvolvido neste trabalho será mostrado em detalhes, incluindo seu pseudocódigo, no capítulo seguinte. Cabe ao pesquisador realizar a calibração do parâmetro α baseado na experimentação, levando em consideração o tipo de problema tratado. Este método tem-se mostrado bastante eficiente na resolução de diversos tipos de problema, 31 principalmente por proporcionar a calibração do nível de gulosidade e aleatoriedade na fase de construção da solução inicial. Além do mais, outras heurísticas podem ser utilizadas para realizar a busca local como forma de testar sua eficiência para cada tipo de problema. Alguns exemplos de aplicações GRASP com outras heurísticas podem ser encontrados em Costa (2003), Silva (2004) e Trindade (2004). Alguns procedimentos mais sofisticados incluem um processo dinâmico para a definição do valor de α (seu valor é modificado durante a execução do problema, alterando o tamanho da LCR dinamicamente), o que promove resultados melhores do que procedimentos com valores fixos de α. 2.4 RECOZIMENTO SIMULADO Este método, do inglês - Simulated Annealing, foi proposto originalmente por Kirkpatrick et al. (1983) e, da mesma maneira que o método Algoritmos Genéticos, faz uma analogia a uma outra área: a Termodinâmica. O método desenvolve uma simulação do processo de resfriamento de um conjunto de átomos aquecidos, operação que deu origem ao seu nome: Recozimento Simulado. Esta heurística inicia sua busca a partir de uma solução inicial qualquer e a partir daí gera aleatoriamente, a cada iteração, uma única solução vizinha. Considerando um problema de minimização (como é o caso deste trabalho), o método se move para a solução gerada caso sua função objetivo possua um valor menor que o valor calculado para a solução anterior. No entanto, este método trabalha com uma possibilidade de aceitação de soluções de piora baseada na avaliação de uma expressão matemática. Tal expressão é calculada por meio de um parâmetro existente no método, onde tal probabilidade é resultante da avaliação da expressão e-∆/T, onde T é a temperatura, que é ajustada durante o processo de experimentação. De acordo com Kirkpatrick et al. (1983), este método possui boa flexibilidade, uma vez que trabalha com os seguintes parâmetros de ajuste: 32 • Valor da temperatura inicial (T0); • Valor de α (que varia de 0 a 1); • Número máximo de iterações ou critério de parada por tempo máximo de processamento. Para compreender melhor seu funcionamento, considere uma solução inicial qualquer. A partir desta solução o método inicia sua busca, e o faz enquanto o valor da temperatura for maior que zero. Neste ponto já se percebe a importância da calibragem do valor da temperatura inicial, pois a cada iteração a temperatura é atualizada multiplicando seu valor por α. Como α varia de 0 a 1, T estará sempre diminuindo e, desta maneira, seu valor inicial influencia diretamente na execução do método. Prosseguindo com sua execução, o método verifica se já atingiu o número máximo de iterações (parâmetro de ajuste). Caso não tenha atingido, inicia a construção de uma solução vizinha da solução inicial. A partir daí, o método avalia a solução inicial, a solução vizinha gerada e a melhor solução encontrada até o momento (que neste ponto é a própria solução inicial). A avaliação das soluções consiste em pontuar cada solução de acordo com o critério objetivo do problema. De posse destes valores, o método calcula a diferença entre os valores da solução vizinha e da solução inicial (valorvizinho - valorinicial). Caso o resultado desta diferença seja menor que zero, o método verifica se o valor da solução vizinha é menor (caso o problema seja de minimização) que o valor da melhor solução encontrada até o momento. Caso seja, atualiza a melhor solução. Caso não seja, o método inicia a avaliação da expressão e-∆/T, gerando um valor entre 0 e 1 e verificando se este valor é menor que o valor de e-∆/T. Caso seja, atualiza a solução inicial atribuindo a esta a solução vizinha. Este processo é repetido até atingir o número máximo de iterações. Quando este valor é atingido, atualiza-se o valor da temperatura inicial, multiplicando-o pelo valor de α e reiniciando o contador de iterações. O fluxo de execução recomeça verificando novamente se o valor de T é menor do que zero. O método prossegue até que a temperatura atinja o valor zero. 33 Porém, é importante ressaltar que, matematicamente, jamais o valor de T chegará ao valor zero, uma vez que T é multiplicado por α (onde α varia de 0 a 1), portanto, seu valor poderá chegar muito próximo a zero, mas nunca tal valor. Este inconveniente é solucionado modificando a condição (ao invés de comparar com o valor zero, compara-se com um valor muito próximo a zero). No caso deste trabalho, os algoritmos foram desenvolvidos na linguagem Java, de maneira que T possui o tipo de dado de dupla precisão. Este tipo de dado, assim como todos os tipos de dados numéricos, possui um tamanho máximo para sua representação. Desse modo, quando o valor de T atinge um valor extremamente pequeno, de maneira a ocupar o tamanho máximo de representação deste tipo, ao executar a próxima divisão é retornado o valor zero e o método encerra sua execução. A eficiência deste método, aliada à flexibilidade fornecida pelos seus parâmetros, faz com que ele seja empregado em vários tipos de problemas de otimização, inclusive combinando suas funcionalidades com outros algoritmos. Alguns exemplos podem ser encontrados em Kincaid (1992), Kincaid (1993) e Salajegheh (2004). 2.5 BUSCA TABU Originado dos trabalhos independentes de Glover (1986) e Hansen (1986), este método tem como sua principal característica aceitar movimentos de piora como estratégia para fugir de ótimos locais. Porém, o que realmente caracteriza este método é a manutenção de uma lista de movimentos proibidos conhecida como Lista Tabu, reduzindo o risco de ciclagem (execução em ciclo infinito) do algoritmo. O tamanho da lista Tabu é calibrado de acordo com testes de experimentação, buscando o melhor desempenho e eficiência para cada tipo de problema em particular. Este método possui apenas dois parâmetros de calibração: o tamanho máximo da lista tabu e o número máximo de iterações (que também pode ser definido em função do tempo máximo de processamento). 34 A lista tabu exerce um papel fundamental no processo de pesquisa de soluções. Para compreender melhor sua utilidade torna-se necessário detalhar seu fluxo de execução. Para isto, considere uma solução inicial qualquer para um determinado problema. Enquanto o número de iterações sem melhora não atingir o valor máximo (passado como parâmetro) o método pesquisa pelo melhor vizinho da solução inicial, de maneira que o movimento realizado para gerar a solução vizinha não esteja contido na lista tabu. Antes de prosseguir torna-se necessário elucidar o conceito de “movimento”. Um “movimento” consiste em uma modificação sistemática de uma solução, de maneira a gerar outra solução diferente desta. Esta modificação deverá seguir uma regra ou modelo pré-estabelecido. Por exemplo, considere o problema de minimização de uma função de x, de modo que seu objetivo é encontrar o valor mínimo. Para isto, os valores são convertidos em números binários. Considere uma solução inicial de valor 100101. A modelagem de um movimento consiste em modificar um bit deste valor, para gerar uma nova solução. Desta maneira, pode-se gerar o valor 100100, que é obtido por meio do movimento de modificação da última posição. A modelagem do movimento influencia diretamente na eficiência do método. Inclusive, o método de Busca Tabu implementado neste trabalho teve sua modelagem de movimento alterada durante os testes de experimentação. Os motivos e detalhes desta modificação são demonstrados no capítulo seguinte. Após compreender o conceito de movimento torna-se mais fácil seguir o fluxo de execução do algoritmo. A pesquisa da melhor solução vizinha da solução inicial deve retornar a melhor solução gerada por um movimento que não esteja na lista tabu. Porém, existe ainda um critério conhecido como função de aspiração. Esta função possibilita aceitar o melhor vizinho gerado mesmo que o movimento que o originou esteja na lista tabu. Uma maneira de implementar a função de aspiração é considerar que, se a melhor solução vizinha gerada for melhor que a melhor solução encontrada até o momento, esta solução vizinha é aceita, mesmo que o movimento que a originou esteja na lista tabu. Deste modo, o critério de aspiração é conhecido como aspiração por objetivo. 35 Prosseguindo com o fluxo, após retornar o melhor vizinho o método atualiza a lista tabu (adicionando a esta o movimento que gerou o melhor vizinho). Neste ponto é importante ressaltar que a lista tabu possui um tamanho fixo, determinado através de um parâmetro do método. As inserções e retiradas desta lista funcionam como uma fila com a política FIFO (first-in, first-out), de maneira quando um novo valor entra, o valor mais antigo na lista é removido (quando a lista estiver cheia). Caso o melhor vizinho retornado tenha sido aceito pelo critério de aspiração, a lista tabu não é atualizada, pois o movimento já estará contido na lista. Após atualizar a lista tabu, o método verifica se a solução vizinha gerada é melhor do que a melhor solução encontrada até o momento. Caso seja, atualiza a melhor solução encontrada. A partir daí, o método atualiza o contador de iterações e recomeça o processo novamente até que a condição de parada seja satisfeita, retornando a melhor solução encontrada. O método Busca Tabu desenvolvido neste trabalho será mostrado em detalhes, incluindo seu pseudocódigo, no capítulo seguinte. A quantidade de iterações do método é determinada pelo número de iterações sem melhora ou estipulando um tempo máximo para execução do método. O número de iterações sem melhora corresponde à quantidade máxima de iterações executadas sem que haja melhoria na qualidade da melhor solução encontrada. Para calcular o valor de iterações sem melhora, basta armazenar a última iteração que produziu uma solução melhor do que a melhor solução corrente. Existem ainda algumas implementações que utilizam técnicas mais elaboradas de maneira a determinar o tamanho da lista tabu de forma dinâmica (modificando seu tamanho durante a própria execução). Para maiores detalhes é recomendada a leitura de Dammeyer (1993). Este método é extremamente eficiente, sendo amplamente utilizado em diversas áreas de pesquisa. Porém, a calibração do parâmetro que define o tamanho da lista tabu deve ser cuidadosamente realizada por meio dos testes de experimentação, uma vez que não existe um tamanho ideal e, inclusive, o valor ideal varia de acordo com o tipo de problema. 36 Alguns exemplos de aplicações do método de Busca Tabu podem ser encontrados em Kincaid (1993), Bland (1995) e Costa (2003). 2.6 COLÔNIA DE FORMIGAS Este método foi proposto por Dorigo (1992) e simula o comportamento de um grupo de formigas que trabalham em conjunto para resolver um determinado problema. Os parâmetros deste método são: a) ponderação do feromônio; b) parâmetro de evaporação do feromônio; c) quantidade de formigas; d) número máximo de iterações. As formigas possuem um mecanismo natural de orientação por meio de uma substância que é depositada por cada agente ao percorrer um determinado percurso. Esta substância é conhecida pelo nome de “feromônio”. Os valores relacionados com a quantidade de feromônio depositada por cada formiga, assim como o percentual de evaporação do feromônio, são regulados através dos parâmetros citados anteriormente. Tais parâmetros devem ser calibrados para cada problema específico e seu funcionamento ocorre da seguinte forma: quanto mais vezes um determinado caminho for percorrido, maior será a quantidade de feromônio deixada nesse rastro, indicando a direção que a pesquisa tenderá a percorrer. O procedimento de busca é repetido até que um número máximo de iterações seja atingido ou não se verifica melhoria na qualidade das soluções obtidas após um determinado número de iterações. 37 Do mesmo modo que os métodos anteriormente citados, a implementação de um mesmo algoritmo pode variar dependendo do tipo de problema tratado (pois cada problema pode necessitar de uma modelagem distinta), de maneira que podem surgir outros parâmetros ou até mesmo trabalhar com alguns destes parâmetros de forma fixa (por exemplo, fixando a quantidade de formigas em um determinado valor baseado em alguma referência, e modificando apenas os demais parâmetros). O parâmetro de ponderação do feromônio determina qual a quantidade desta substância que será depositada no caminho percorrido por cada formiga. O parâmetro de evaporação está relacionado com a velocidade com que os caminhos percorridos terão suas quantidades de feromônio reduzidas. A quantidade de formigas determina quantas formigas farão parte do processo de busca pelo alimento. E, por último, o número máximo de iterações determina a condição de parada do método. O funcionamento deste método, assim como o método de Algoritmos Genéticos, é baseado no comportamento de um agente (ou um conjunto de agentes) existente na natureza. Da mesma forma que os Algoritmos Genéticos se referem à geração de novos indivíduos na natureza por meio de seus modificadores evolutivos, o método “Colônia de Formigas” se refere ao comportamento de formigas em busca de alimento. A Figura 2.1 demonstra três possíveis caminhos para que uma formiga consiga chegar até seu alimento. Inicialmente, como nenhuma formiga percorreu nenhum caminho (não existindo ainda nenhum rastro de feromônio), cada um dos três possíveis caminhos demonstrados possui igual probabilidade de ser percorrido. Sendo assim, imagine que a primeira formiga percorra o caminho três até chegar ao seu alimento. A segunda formiga terá uma probabilidade maior de escolher o mesmo caminho da primeira formiga, uma vez que este caminho já possuirá um rastro de feromônio depositado nele. 38 FIGURA 2.1: Otimização por Colônia de Formigas. Deste modo, todas as formigas, a partir da primeira, poderiam seguir sempre o mesmo caminho que esta. Mas isto não acontece porque o feromônio possui um determinado grau de evaporação, diminuindo sua intensidade com o tempo. Além disso, o fato de existir um rastro de feromônio não significa que todas as demais formigas seguirão este caminho, uma vez que alguma pode, aleatoriamente, escolher um novo caminho. Deste modo, outros caminhos vão sendo descobertos até que, em determinado momento, o melhor caminho (neste caso, aquele de menor distância) é descoberto. Uma vez percorrido, por ser o menor caminho, os caminhos de ida e volta ao alimento são percorridos mais rapidamente, reforçando cada vez mais o rastro de feromônio e atraindo cada vez mais formigas, que também reforçarão o caminho com seu feromônio e assim sucessivamente. A explicação deste mecanismo natural facilita a compreensão do método aqui implementado. Ainda assim, algumas adaptações foram necessárias de modo a adequar o funcionamento do algoritmo com o tipo de problema a que este trabalho se refere. O método Colônia de Formigas desenvolvido neste trabalho será mostrado em detalhes, incluindo seu pseudocódigo, no capítulo seguinte. A quantidade de formigas também influencia diretamente no método, uma vez que um número muito baixo de formigas poderá não ser suficiente para descobrir soluções consideradas de boa qualidade. E números muito elevados podem influenciar diretamente no tempo de pesquisa. Este método tem se mostrado muito eficiente em diversas áreas de pesquisa. Porém, seu número elevado de parâmetros torna o processo de experimentação uma tarefa um pouco mais árdua. Ainda assim, sua aplicação é encontrada em 39 áreas diversificadas, tais como problemas para aplicações de atribuição quadrática Coelho (2004), roteirização de veículos para pessoas portadoras de deficiência Baba (2004), dentre outros. Conhecendo o funcionamento básico de cada método heurístico utilizado neste trabalho torna-se mais fácil compreender a modelagem do problema tratado e a adaptação de cada algoritmo, que são devidamente detalhados no capítulo seguinte. 40 3 MODELAGEM E IMPLEMENTAÇÃO DOS ALGORITMOS 3 MODELAGEM E IMPLEMENTAÇÃO DOS ALGORITMOS 41 Este capítulo descreve de maneira detalhada como cada algoritmo citado no capítulo anterior foi adaptado e implementado para o tipo de problema tratado neste trabalho. É importante destacar que nem todo método heurístico é diretamente aplicável a uma determinada classe de problemas. Portanto, este capítulo é dedicado ao detalhamento sobre a implementação de cada método e como os mesmos foram adaptados de maneira a produzir os melhores resultados. As seções seguintes descrevem os detalhes de cada método heurístico utilizado neste trabalho e, para cada um, é detalhado um pseudocódigo para facilitar a compreensão. 3.1 MODELAGEM DO PROBLEMA O principal objetivo do processo de otimização, aplicado na classe de problemas estudada neste trabalho, consiste em minimizar o peso de uma estrutura composta por treliças bidimensionais, obedecendo às restrições impostas pelo projeto. Tais restrições são diferentes para cada problema e são devidamente detalhadas no Capítulo 5. Com o intuito de facilitar a compreensão do tipo de problema tratado e da adaptação dos algoritmos descritos a seguir, torna-se necessário descrever como foi realizada a modelagem do problema. Um projeto estrutural composto por n barras foi representado por um vetor de n posições, onde cada posição do vetor corresponde à área de seção transversal de cada barra que compõe a estrutura. Por exemplo, uma estrutura composta por quatro barras é representada por um vetor de quatro posições, de maneira que a primeira posição armazena a área de seção transversal da barra 1, a segunda posição armazena a área de seção transversal da barra 2, e assim sucessivamente. Esta modelagem foi utilizada na implementação e adaptação de cada um dos algoritmos utilizados neste trabalho. A seção seguinte descreve detalhadamente a implementação de cada um dos métodos, incluindo seus parâmetros de calibração. 42 3.2 IMPLEMENTAÇÃO DOS ALGORITMOS No capítulo anterior, os algoritmos utilizados neste trabalho foram descritos em sua forma genérica, sem nenhuma adaptação ou especialização com relação a algum problema específico, de maneira a descrever apenas o funcionamento básico de cada método. Os algoritmos adaptados ao tipo de problema tratado neste trabalho, bem como os detalhes de implementação, são detalhados a seguir. 3.2.1 Algoritmos Genéticos Os principais conceitos do Algoritmo Genético, detalhados no capítulo anterior, foram mantidos no algoritmo desenvolvido neste trabalho. Porém, com o intuito de melhorar a qualidade das soluções encontradas durante sua execução, alguns operadores genéticos foram ligeiramente modificados e a construção da população inicial foi alterada. A implementação clássica do AG utiliza a representação binária, ou seja, o cromossomo é representado por um vetor de bits, contendo apenas os valores 0 e 1. Neste trabalho, a representação utilizada foi a representação real, de maneira que cada posição do cromossomo é um valor real e não um número binário. A decisão de utilizar a representação real está diretamente relacionada com o desempenho dos algoritmos para o tipo de problema tratado, uma vez que realizar a conversão de valores para cada gene de um cromossomo, para várias populações de várias gerações, aumentaria consideravelmente o custo computacional. Um estudo interessante relacionado com o desempenho dos algoritmos utilizando representação binária e real pode ser encontrado em Catarina (2003). Os parâmetros de calibragem utilizados inicialmente foram idênticos a Yokota et al. (1998), uma vez que, em um primeiro momento, o objetivo era analisar o comportamento dos operadores genéticos e estudar a influência da qualidade da população inicial no processo de pesquisa. Em seguida, a alteração dos parâmetros foi realizada durante os testes de calibração. Sendo assim, o tamanho da população foi mantido em 20 indivíduos, o número máximo de gerações foi definido em 1500, e 43 as probabilidades de ocorrer Mutação e Crossover foram inferidas, respectivamente, em 0,3 e 0,6. Neste trabalho, o cromossomo foi representado por um conjunto de valores, de maneira que cada valor corresponde à área da seção transversal de uma determinada barra da estrutura tratada. Vale ressaltar que nem todo cromossomo é considerado uma solução viável para o problema. Neste trabalho, devido às restrições de projeto, as primeiras gerações possuem um determinado número de cromossomos não viáveis que vai se reduzindo gradualmente a cada geração. Isto ocorre porque as soluções não viáveis são consideradas como indivíduos de pouca aptidão, que vão perecendo pela ação da Seleção Natural. Desta maneira, as gerações posteriores reduzem gradativamente a ocorrência destes cromossomos, até que eles se extinguem. O alto grau de flexibilidade apresentado deve-se à quantidade de parâmetros de calibração presentes no método. Apesar de existir implementações diversas deste método, existem alguns parâmetros que são comuns. Neste trabalho os seguintes parâmetros foram considerados: 1) Tamanho da população: especifica a quantidade de cromossomos existentes em uma população; 2) Tamanho do cromossomo: define o comprimento do cromossomo. Neste trabalho, o comprimento do cromossomo equivale ao número de barras existentes na estrutura tratada; 3) Probabilidade de cruzamento: estabelece a probabilidade de realizar um cruzamento entre dois indivíduos selecionados; 4) Probabilidade de mutação: define a probabilidade de realizar mutação em um indivíduo selecionado; 44 5) Número máximo de gerações: estabelece a quantidade máxima de gerações que o método irá produzir, funcionando como critério de parada. O parâmetro relacionado à maneira como ocorre a Seleção não foi considerado, pois foi desenvolvido do seguinte modo: para cada geração o operador de Seleção seleciona a metade dos indivíduos da população, escolhendo os mais aptos. Esta técnica é conhecida como Elitismo. Algumas implementações utiliza o operador de Seleção parametrizado, de maneira que é possível calibrar esta operação, aumentado a flexibilidade do método. Porém, contribui para dificultar a calibração do método por aumentar a quantidade de possíveis combinações na tentativa de obter os parâmetros ideais. Após os testes iniciais foi possível perceber que o algoritmo se mostrava muito sensível à construção de uma população inicial de boa qualidade. Tal fato foi constatado ao partir de uma população inicial aleatória, gerando grande quantidade de indivíduos infactíveis (que não satisfazem aos requisitos impostos pelo projeto). Ao partir desta população, a melhor solução encontrada não obteve uma qualidade satisfatória. Após alguns testes de experimentação, o processo de geração da solução inicial foi aperfeiçoado, de maneira que não produzisse indivíduos infactíveis. Desse modo, ao partir de um conjunto de soluções possíveis para o problema, o algoritmo obteve uma melhora significativa na qualidade das soluções encontradas. Buscando melhorar ainda mais os resultados obtidos, os operadores genéticos de Seleção, Mutação e Crossover sofreram algumas adaptações. No caso da Mutação, quando um indivíduo é selecionado para sofrer a ação deste operador, o mesmo poderá tornar-se infactível. Sendo assim, o operador de mutação foi alterado para que, ao realizar a mutação em um indivíduo e o mesmo se tornar infactível, realizará outra mutação e assim sucessivamente, até que a factibilidade seja atingida. Com isso, garante-se a qualidade do indivíduo gerado por meio da mutação. 45 O operador genético Crossover foi adaptado com o intuito de aprimorar as características herdadas dos pais do indivíduo gerado. Com o operador de Crossover clássico, escolhe-se um mesmo ponto nos cromossomos pais, e a partir deste ponto, a metade inicial do primeiro pai, com a metade final do segundo pai gera um filho. Na mesma linha, a metade inicial do segundo pai com a metade final do primeiro pai gera o segundo filho. Em termos práticos funciona muito bem, mas, para a classe de problemas estudada neste trabalho, gera muitos indivíduos semelhantes em uma mesma geração. Sendo assim, foi adicionado um operador Crossover adicional para funcionar da seguinte maneira: escolhem-se dois pontos nos cromossomos pais, divindo-os em três partes que, para facilitar a compreensão recebem o nome de X, Y e Z. A parte X do primeiro pai, se junta com a parte Y do segundo pai e adiciona a parte Z do próprio filho gerado (pois neste caso, o filho já possui todas áreas de seção transversal inicializadas de acordo com o intervalo encontrado nas restrições de projeto, possuindo assim características próprias dele mesmo). Do mesmo modo gera-se o segundo filho, invertendo X e Y dos pais e mantendo Z do segundo filho. O operador clássico continua sendo utilizado, porém o sistema determina, com uma probabilidade de 50% para cada operador, qual dos dois será utilizado em cada cruzamento efetuado. A inserção de um novo operador fez com que o algoritmo obtivesse um ganho significativo na qualidade das soluções encontradas, uma vez que a variabilidade da mutação, somada com a diversidade de informações herdadas dos pais e aquelas aproveitadas dos filhos ampliou o espaço de soluções geradas. O funcionamento do operador de Crossover clássico (i) e do operador adicionado (ii) podem ser visualizados na Figura 3.1 a seguir. FIGURA 3.1: Funcionamento dos operadores de Crossover utilizados no AG. 46 Inicialmente o operador de seleção utilizado baseava-se nos princípios da roleta russa (selecionando aleatoriamente os pais e realizando as operações obedecendo às probabilidades de cada operador, garantindo apenas o não cruzamento de um indivíduo com ele mesmo). Visando aprimorar este operador a idéia da roleta russa foi substituída por uma política conhecida como Elitismo: dentre os n indivíduos produzidos a cada geração, selecionam-se os n/2 mais aptos (neste problema, os mais aptos são aqueles com menor peso) e realizam-se as operações nestes para produzir os indivíduos da próxima geração. Ao implantar o “Elitismo” no operador de Seleção, mesmo partindo de soluções iniciais de qualidade inferior, o método atingiu ótimos resultados. Esta modificação fez com que o método encontrasse a melhor solução mais rapidamente, utilizando um número menor de gerações. Ao combinar soluções iniciais de boa qualidade com a política de Elitismo, a melhor solução é encontrada mais rapidamente, aumentando consideravelmente a eficiência do algoritmo. Vale lembrar que as modificações e adaptações realizadas estão especificamente relacionadas com a classe de problemas tratadas neste trabalho, podendo ou não atingir os mesmos resultados em outras classes de problemas. Após vários testes de experimentação, os valores dos parâmetros foram alterados considerando os melhores resultados obtidos durante a calibração. Os novos valores atribuídos foram: probabilidade de mutação (0,3), probabilidade de crossover (0,6) e o número de gerações (1500). A quantidade de indivíduos por população foi mantida em 20 indivíduos. A necessidade de gerar indivíduos mais diversificados ocorreu durante os testes, onde a partir de uma geração aleatória, muitos indivíduos começavam a se repetir. Neste caso, o aumento da probabilidade de mutação promoveu uma diversidade maior dos indivíduos. Outra alternativa utilizada para melhorar a qualidade das soluções foi manter o melhor indivíduo gerado dentro de cada geração. Isto porque ele possui características (áreas de seção transversal) que podem ser herdadas por gerações futuras, aprimorando a qualidade dos próximos indivíduos. O funcionamento se deu 47 da seguinte maneira: cada geração é ordenada (por ordem de peso) para garantir a seleção dos n/2 indivíduos pelo operador de Seleção. Antes da ordenação, substituise o pior indivíduo da geração pelo melhor indivíduo gerado até o momento. Ao ordenar, o melhor indivíduo sobe para o topo de lista, substituindo aquele de qualidade inferior a ele. Suas características serão aproveitadas pelas futuras gerações. Realizadas as modificações acima citadas, e passando pelos testes de experimentação, sentiu-se a necessidade de ampliar o espaço de soluções pesquisadas. Foi introduzido um parâmetro de inicialização no sistema que recebeu o nome de “tolerância_k”. Este parâmetro é utilizado para considerar aquelas soluções que não satisfazem aos requisitos do problema, mas que estão muito próximas de atendê-los. Isto faz com que um novo espaço de soluções seja considerado na busca. Vale ressaltar que tais soluções não podem ser consideradas melhores do que aquelas que satisfazem os requisitos de projeto. Elas apenas são introduzidas na população por possuírem características que poderão ser herdadas por gerações futuras, contribuindo para produzir melhores indivíduos. O pseudocódigo do algoritmo implementado é mostrado no Quadro 3.1 a seguir. 48 (1) Constrói população inicial (tamanho = n); (2) Ordena a população pela função objetivo (peso); (3) Enquanto não alcançar o número máximo de gerações faça: a. Seleciona os n/2 melhores indivíduos que passarão ou pela mutação ou pelo crossover ou pela clonagem (); b. Até alcançar o tamanho da nova população repita: i. Selecione dois indivíduos distintos (); ii. Tenta realizar mutação (indivíduo) verificando a probabilidade de mutação; //se um sofre mutação, o outro também sofrerá; iii. Caso não realizou mutação, tenta realizar crossover (individuo i1, individuo i2), verificando a probabilidade de crossover; iv. Caso não realizou mutação nem crossover, clona ambos indivíduos (); v. Verifica se cada indivíduo é melhor que a melhor solução encontrada ou pior que a pior solução encontrada () através do cálculo da função objetivo () e atualiza o melhor e o pior se necessário; vi. c. Insere os novos indivíduos na nova população (); Remove o pior indivíduo da população e insere o melhor encontrado até o momento (); d. Incrementa o contador de gerações (); e. Ordena a população (); (4) Apresenta o melhor indivíduo encontrado (); QUADRO 3.1: Pseudocódigo do AG implementado. 3.2.2 Variable Neighborhood Search O princípio básico deste método consiste em gerar uma solução inicial para o problema e, a partir desta solução pesquisar novas soluções vizinhas buscando melhorar a qualidade da solução inicial gerada. Porém, a busca por soluções vizinhas não segue uma trajetória específica. Para entender melhor como isto ocorre, considere uma possível solução s ' para o problema estudado em Yokota et al. (1998). Este problema está devidamente detalhado no capítulo 5, seção 1, Figura 5.1 deste trabalho. A solução s ' , portanto, terá o formato de um vetor contendo 10 posições onde cada posição corresponde a área da seção transversal de uma determinada barra da estrutura. Um vizinho de s ' ( s ' ' ) seria gerado, por exemplo, 49 modificando uma posição aleatória do vetor (obedecendo ao limite inferior e superior da área da seção transversal da barra selecionada). Desse modo, define-se um espaço de vizinhança de s ' como todos aqueles vizinhos que são gerados a partir da modificação da área de apenas uma única barra da estrutura. Nessa mesma linha, uma outra estrutura de vizinhança seria formada pelas soluções obtidas ao efetuar a modificação da área de duas barras de s ' simultaneamente, e assim sucessivamente. Seguindo os conceitos demonstrados no capítulo anterior, foram definidas quatro estruturas de vizinhança distintas: k=1 (modificação de apenas uma única barra), k=2 (modificação de duas barras simultaneamente), k=3 (modificação de três barras simultaneamente) e k=4 (todas as barras da estrutura são modificadas). Após gerar s ' ' a partir de s ' , o método efetua uma busca local em s ' ' . Este procedimento de busca local pode utilizar qualquer tipo de vizinhança, pois o objetivo aqui é encontrar uma solução vizinha de qualidade superior a s ' ' . O método VNS tradicional utiliza um procedimento para realizar a busca local conhecido como Método de Descida em Vizinhança Variável, também chamado de VND (HANSEN, 1997). O presente trabalho utiliza também o VND para realizar a busca local. Desta maneira, o método efetua uma busca local em s ' ' . Se o resultado da busca local não melhorar a qualidade de s ' ' , incrementa-se o valor de k, alterando a estrutura de vizinhança da próxima iteração. Se a busca local obtiver uma solução melhor que s ' ' , o sistema atualiza a melhor solução e atribui a k o valor 1. Este processo é repetido até que o método atinja o número máximo de iterações. O modo pelo qual este valor foi calculado é explicado a seguir. Os testes de experimentação foram realizados utilizando um único parâmetro de ajuste: o número máximo de iterações do método VNS: VNSMAX. Este parâmetro pode ser modificado para obedecer a um determinado tempo de processamento ou ainda, um número pré-determinado de iterações sem melhora da solução. No entanto, após passar pelo processo de experimentação, o método foi calibrado para trabalhar com o parâmetro VNSMAX igual a 60 iterações. 50 É importante destacar que a geração de um determinado vizinho é realizada de maneira totalmente aleatória, ou seja, sorteia-se uma determinada barra e, aleatoriamente, sorteia-se um valor de área que satisfaça o intervalo permitido da barra selecionada. Assim, garante-se que não ocorra ciclagem no método, o que poderia acontecer caso alguma regra determinística fosse empregada nesta geração. A construção da solução inicial foi implementada, em um primeiro momento, utilizando uma geração aleatória de soluções. Porém, durante os testes de experimentação, foi detectado que este tipo de geração, para o tipo de problema tratado neste trabalho, gera muitos indivíduos infactíveis. Sendo assim, o processo de geração da solução inicial foi modificado e passou-se a utilizar o método GRASP. Sua aplicação foi implementada de maneira a produzir sempre soluções factíveis. Ou seja, caso a primeira solução gerada não seja factível, o algoritmo executa o procedimento GRASP novamente, até que uma solução factível seja gerada. O Quadro 3.2 a seguir exibe o pseudocódigo do método VNS. Vale lembrar que a etapa (1) demonstrada na figura sempre produz uma solução factível. O processo de busca local é realizado pelo método VND. Porém, vale lembrar que qualquer método heurístico pode ser utilizado nesta etapa. O VND foi escolhido por ser o método utilizado na busca local do algoritmo VNS tradicional, conforme detalhado no capítulo anterior. (1) Constrói solução inicial via GRASP (); (2) Enquanto não atingir o número máximo de iterações faça: a. Atribui a variável k de controle da estrutura de vizinhança o valor 1; b. Enquanto k <= 4 faça: i. Pesquise uma solução factível na estrutura de vizinhança (k); ii. Aplique busca local (VND) na solução encontrada (); iii. Verifique se a solução resultante da busca local é melhor do que a melhor solução encontrada até o momento através do cálculo da função objetivo (); c. iv. Caso seja, atualiza a melhor solução e faça k=1; v. Caso contrário: k++; Incrementa o contador de iterações; (3) Apresenta o melhor resultado encontrado (); QUADRO 3.2: Pseudocódigo do método VNS. 51 3.2.3 Grasp O funcionamento deste método consiste em construir soluções iniciais utilizando uma lista restrita de soluções candidatas. O tamanho t desta lista é determinado através de um parâmetro de inicialização do método (α), que neste trabalho corresponde ao número de barras do problema multiplicado pelo valor de uma variável α (podendo assumir valores maiores que zero e menores ou iguais a um. Neste trabalho, após passar pelo processo de experimentação, seu valor foi definido em 0,5. Neste caso, o tamanho da lista restrita de candidatos será sempre a metade do número de barras do problema). As soluções são construídas do seguinte modo: para cada barra do problema, o sistema gera uma quantidade t de possíveis áreas de seção transversal, onde t corresponde ao tamanho da lista restrita de candidatos, obedecendo às restrições impostas pelo projeto. A lista é ordenada e, a partir daí, o método sorteia uma dentre as t/2 melhores áreas da lista. Isto ocorre dividindo a lista ordenada pela metade e realizando o sorteio na primeira metade da lista. Este processo é repetido para cada barra até completar uma possível solução. Esta solução é avaliada e, se não for factível, o processo é repetido até atingir a factibilidade. De posse da solução inicial, o método aplica busca local na solução. O método GRASP implementado neste trabalho utiliza o método VNS para aplicar a busca local. Os parâmetros α e o parâmetro GRASPMAX (número máximo de iterações), formam o conjunto de parâmetros de inicialização do método GRASP. Após aplicar a busca local na solução inicial gerada, o método avalia, ao final da busca, se a solução resultante da busca local é melhor (possuindo menor peso) do que a melhor solução encontrada até o momento. Caso seja, o método atualiza a melhor solução encontrada e constrói novamente outra solução inicial para aplicar nova busca local. O processo se repete até que o número máximo de iterações GRASPMAX seja atingido (o valor utilizado neste método, após passar pelos testes de experimentação, foi definido em 50 iterações). 52 A idéia de construir várias soluções iniciais e aplicar buscar local em cada uma delas, armazenando a melhor solução encontrada, faz com que o método GRASP seja de fácil calibragem por possuir poucos parâmetros, garantindo ainda a facilidade de implementação como um todo. O método GRASP também foi utilizado como construtor de solução inicial de outros métodos implementados neste trabalho, garantindo boas soluções iniciais a um baixo custo de processamento e implementação. A seguir o Quadro 3.3 exibe o pseudocódigo do método GRASP. (1) Enquanto não alcançar o número máximo de iterações faça: a. Inicia o processo de construção da solução inicial factível utilizando uma lista restrita de candidatos de tamanho (n x α); b. Aplica a busca local na solução gerada (VNS); c. Verifica se a solução resultante da busca local é melhor do que a melhor solução encontrada até o momento através do cálculo da função objetivo. Caso seja, atualiza a melhor solução; d. Incrementa o contador de iterações; (2) Apresenta a melhor solução encontrada (); QUADRO 3.3: Pseudocódigo do método GRASP. 3.2.4 Simulated Annealing A idéia chave deste método segue alguns princípios da termodinâmica, simulando o resfriamento de um determinado material, operação conhecida como recozimento. O método possui três parâmetros de calibragem, sendo eles: o número máximo de iterações SAMAX (definido em 40 iterações), a temperatura inicial (definido em 1) e o valor de α (que varia de 0 a 1 e foi definido em 0,5) que é utilizado no controle da temperatura. Os valores destes parâmetros foram inferidos durante o processo de experimentação, de maneira que dentre os valores testados foram os que alcançaram os melhores resultados. É importante ressaltar que, se o valor de α for zero, o método será executado apenas em SAMAX iterações. Isto acontece porque, a cada SAMAX iterações, a temperatura é multiplicada por α, repetindo-se o processo até que a temperatura 53 alcance o valor zero ou muito próximo a ele. Sendo assim, após as primeiras SAMAX iterações, ao multiplicar α por T, a temperatura atingirá o valor zero e o método encerrará sua execução. Para construir a solução inicial, neste trabalho foi utilizado o método GRASP, avaliando sempre as soluções geradas para garantir a factibilidade da solução inicial. O Quadro 3.4 a seguir detalha o pseudocódigo do método implementado. (1) Constrói solução inicial factível via método GRASP (s); (2) Enquanto (T > 0) faça: a. Enquanto não atingir número máximo de iterações faça: i. Gera um vizinho da solução inicial (s’); ii. Calcula a função objetivo da solução inicial (s) e do vizinho gerado (s’); iii. Calcula o Delta (função objetivo (s’) – função objetivo (s)); iv. Se (Delta < 0) faça: 1. Se função objetivo (s’) < função objetivo da melhor solução encontrada até o momento, copia (s’) na melhor solução; 2. Caso contrário, gera um número entre 0 e 1 (x); 3. Se (x < e -∆/T ) então copia o vizinho na solução inicial (s = s’); v. Incrementa o contador de iterações; b. Atualiza a temperatura (T = α x T ); (3) Apresenta a melhor solução encontrada (); QUADRO 3.4: Pseudocódigo do método Simulated Annealing. Analisando o Quadro 3.4 torna-se mais fácil seguir a execução do algoritmo: com a solução inicial s gerada, enquanto a temperatura T for maior que zero, o método segue o seguinte fluxo: para cada iteração, o sistema gera uma solução vizinha de s (s’). A partir daí, o sistema calcula a função objetivo de s, s’ e da melhor solução encontrada até o momento. O cálculo da função objetivo deste problema é realizado por meio da análise da solução gerada, calculando seu peso e verificando as restrições de projeto. Caso alguma restrição seja violada, a solução é inviabilizada utilizando uma penalização no cálculo de peso. Baseado nos dados calculados, o sistema calcula o DELTA (que é a diferença entre a função objetivo de s’ e a função objetivo de s). Caso DELTA seja menor que zero, o método copia s’ em s e, se a função objetivo de s’ for menor do que a função objetivo da melhor solução encontrada até o momento, copia s’ em melhor_s. 54 Caso DELTA não seja menor do que zero, o sistema calcula a probabilidade de aceitar um movimento de piora. Isto é feito gerando um número aleatório entre 0 e 1 e verificando se este número gerado satisfaz a expressão a seguir: x < e-∆/T Caso satisfaça, o método copia em s o valor de s’, atualizando assim a solução inicial gerada e recomeçando pela geração do vizinho de s. Após todos estes cálculos durante as SAMAX iterações, o sistema atualiza a temperatura T multiplicando seu valor por α. Todo processo é repetido enquanto (T > 0). Vale ressaltar que, se α é um valor entre 0 e 1 (excluindo o valor 0 para não executar apenas SAMAX iterações), a condição (T > 0) seria sempre verdadeira, portanto a condição deve ser estudada para extrair a melhor execução do método. Após alguns testes de experimentação o método se mostrou bastante eficaz, gerando inclusive ótimos resultados com um baixo computacional. Sua facilidade de implementação aliada ao baixo número de parâmetros de calibragem e à qualidade das soluções obtidas torna este método uma excelente opção para cálculos relacionados com o tipo de problema tratado neste trabalho. 3.2.5 Busca Tabu A idéia básica deste método consiste em gerar uma solução inicial e, a partir desta solução, pesquisar o melhor vizinho de modo que o movimento realizado para obter este melhor vizinho não esteja na lista de movimentos tabu. Este método foi adaptado para o tipo de problema tratado neste trabalho de maneira que a geração de um vizinho por meio de um movimento seria correspondente à alteração do valor da área de seção transversal de uma determinada barra. Porém, logo nas primeiras execuções foi verificado que, por diversas vezes, o algoritmo não conseguia aprimorar uma solução considerada de média qualidade (em relação ao valor de referência do problema tratado). Sendo assim, o método foi alterado de maneira que um “movimento” fosse correspondente 55 às alterações das áreas de x barras simultaneamente. Modelado desta maneira, o algoritmo passou a apresentar resultados consideravelmente melhores, chegando a soluções muito próximas aos valores de referência. Deste modo, a lista tabu conteria um número t de valores (valores estes que correspondem ao número de barras alteradas simultaneamente), onde t é o tamanho da lista tabu que é determinado por um parâmetro do método. Este método possui apenas dois parâmetros de calibragem, sendo eles: o número máximo de iterações BTMAX (que neste trabalho, após vários testes de experimentação, foi calibrado para 200 iterações) e o tamanho da lista tabu t, que neste trabalho foi definido, após passar pelo processo de experimentação, em n/2, onde n é o número de barras do problema de pesquisa. É importante ressaltar que o valor máximo que poderá ser atribuído a t, para a modelagem aqui implementada, é n, afinal t armazena a quantidade de barras modificadas simultaneamente e, portanto, não poderá ter um tamanho maior que o número de barras existentes no problema tratado. A construção da solução inicial utiliza o método GRASP como garantia de qualidade. Com a solução inicial gerada, o método executa a seguinte seqüência de eventos: enquanto o número de iterações sem melhora (corresponde à quantidade de iterações menos a melhor iteração, sendo esta a iteração que gerou a melhor solução encontrada até o momento) for menor que o número máximo de iterações (BTMAX), o algoritmo pesquisa o melhor vizinho da solução inicial corrente de maneira a atender a seguinte condição: o melhor vizinho somente será aceito caso tenha sido gerado a partir da modificação de x barras simultâneas de maneira que x não esteja na lista tabu. Ainda assim, existe um critério mais conhecido como função de aspiração que aceita um vizinho gerado por um movimento que esteja na lista tabu se este melhor vizinho for melhor que a melhor solução encontrada até o momento. Após decidir a escolha do melhor vizinho gerado por meio da solução inicial, o método atualiza a lista tabu adicionando a ela o movimento realizado na geração do 56 vizinho. Vale lembrar que os movimentos de vizinhos aceitos pelo critério de aspiração não são adicionados à lista, pois tais movimentos já existem na mesma. A lista funciona como o tipo de dados fila de forma que o primeiro que entra é o primeiro que sai. Para facilitar a compreensão deste procedimento, considere o seguinte exemplo: em uma lista vazia com tamanho máximo de 4 elementos, o sistema adiciona os valores 1, 4, 2, e por último, o valor 5. Para que o próximo valor seja adicionado, o primeiro da lista (neste caso, o valor 1) será removido e todos os demais valores terão seus índices subtraídos de uma unidade, sendo deslocados para a esquerda na lista, cedendo a última posição para o próximo valor. Com o melhor vizinho gerado, o método analisa se o mesmo é melhor do que a melhor solução encontrada até o momento. Caso seja melhor, o método atualiza a melhor solução e atualiza a variável que armazena a melhor iteração até o momento. Após este cálculo, o sistema incrementa o contador de iterações e recomeça o processo caso o número de iterações sem melhora não tenha atingido BTMAX. O processo de calibragem deste método foi facilitado devido ao baixo número de parâmetros. Sua principal desvantagem reside na implementação, pois a manutenção da lista tabu e a pesquisa por vizinhos exigem um pouco mais de atenção. É importante salientar que nem sempre é possível encontrar qual o melhor vizinho de uma determinada solução. Por exemplo, no caso de um dos problemas tratados neste trabalho, encontrado em Yokota et al. (1998), as soluções são calculadas com uma precisão de seis casas decimais. Sendo assim, devido a grande quantidade de soluções possíveis, é impraticável gerar todos os possíveis vizinhos de uma solução devido ao tamanho do espaço de busca. Sendo assim, o processo de geração do melhor vizinho foi padronizado para construir vizinhos de uma determinada solução até atingir BTMAX iterações sem melhora ou quando o primeiro melhor for encontrado. Sua execução se mostrou rápida, apresentando respostas com excelente qualidade, mas devido à complexidade de sua implementação talvez não seja o 57 método mais indicado àqueles que não estão mais intimamente familiarizados à área computacional. O Quadro 3.5 exibe em detalhes o pseudocódigo do método Busca Tabu implementado neste trabalho. (1) Constrói solução inicial factível via método GRASP (s); (2) Inicializa a lista tabu de tamanho t, onde t é um parâmetro do método (); (3) Enquanto (iterações – melhor iteração) < (número máximo de iterações) faça: a. Selecione o melhor vizinho (s’) de s cujo movimento para gerá-lo não esteja na lista tabu OU função de aspiração (se o melhor vizinho é melhor que a melhor solução, o aceita mesmo que o movimento que o gerou esteja na lista tabu); b. Atualiza a lista tabu adicionando o movimento utilizado na geração do melhor vizinho (); Caso a lista esteja cheia, remove o valor que está há mais tempo na lista (política de fila first-in, first-out); c. Atualiza a solução inicial com o melhor vizinho (s=s’); d. Se o vizinho gerado for melhor que a melhor solução encontrada até o momento, atualiza a melhor solução e armazena a iteração corrente como a melhor iteração (melhor iteração = iteração); (4) Apresenta a melhor solução encontrada (); QUADRO 3.5: Pseudocódigo do método Busca Tabu. 3.2.6 Colônia de Formigas Conforme detalhado no capítulo anterior, este método faz uma analogia ao comportamento de um conjunto de formigas em busca de alimento. Durante esta busca, cada formiga deposita uma substância no caminho percorrido, conhecida como feromônio. Neste trabalho, o ato de percorrer um determinado caminho até o alimento foi primeiramente modelado como o ato de gerar uma solução vizinha a partir de uma solução inicial, modificando um determinado componente (área de seção transversal de uma determinada barra) de uma solução qualquer. Por exemplo, considerando 58 uma solução representada por um vetor, a modificação do valor da barra 1 para gerar a solução vizinha indica que o caminho 1 foi percorrido. Inicialmente, esta modelagem apresentava alguns resultados satisfatórios, porém ainda longe dos resultados esperados. Mesmo após passar pelo processo de calibragem dos parâmetros, os resultados obtidos ainda poderiam ser melhorados. Dessa maneira, a modelagem do “caminho” percorrido foi modificada. Ao invés de considerar a barra modificada equivalente ao caminho percorrido, passou a ser considerado a quantidade de barras alteradas simultaneamente. Por exemplo, o valor 6 armazenado, não indicaria mais que a barra 6 foi modificada, mas sim que seis barras tiveram suas áreas de seção transversal alteradas simultaneamente para gerar a solução vizinha. Desse modo os resultados obtiveram uma melhora significativa, demonstrando que a maneira como um determinado tipo de problema é modelado possui uma importância intrínseca na eficiência e na qualidade das soluções obtidas. Obviamente a importância do processo de experimentação não deverá ser minimizada, uma vez que a necessidade de alteração na modelagem do problema somente foi descoberta por meio dos testes de execução. Por meio do processo de experimentação, os parâmetros foram calibrados com os seguintes valores: número máximo de iterações ACMAX (que foi definido em 50 iterações), quantidade de formigas (definido em 200 formigas), valor de incremento do feromônio (definido com valor 1) e percentual de evaporação do feromônio (definido em 0,5). O valor de incremento significa qual a quantidade de feromônio que será depositada cada vez que uma formiga percorrer um determinado caminho. Sendo assim, de acordo com o valor definido para o parâmetro, cada formiga deposita 1 unidade de feromônio para cada caminho. O percentual de evaporação corresponde ao valor que será multiplicado pela quantidade de feromônio de cada caminho percorrido, simulando o fenômeno de evaporação do feromônio. Para iniciar o processo, o método deverá gerar um caminho a partir de uma determinada solução inicial. A construção de tal solução foi realizada pelo método GRASP, sempre gerando soluções factíveis. 59 Entende-se por “caminho” a alteração de uma determinada área de seção transversal, de uma barra qualquer da solução inicial, que gere uma nova solução factível. Implementado desta maneira, após as primeiras execuções, foi verificado que o método não conseguia aperfeiçoar soluções consideradas de média qualidade em relação ao valor de referência do problema tratado. Sendo assim, o “caminho” passou a ser modelado como a alteração das áreas de x barras simultaneamente. Com esta modificação o algoritmo conseguiu atingir ótimos resultados, gerando soluções de ótima qualidade. Para controlar a quantidade de feromônio do caminho percorrido por cada formiga foi utilizada uma matriz, utilizando como índices a quantidade máxima de barras pela quantidade de formigas. Esta matriz armazena a quantidade de feromônio depositado por cada formiga a cada iteração do método e, antes de iniciar o processo, seus valores são zerados. Para facilitar a compreensão, a Figura 3.2 exibe um esquema dessa matriz. FIGURA 3.2: Esquema da matriz de feromônio. Sendo assim, a partir da solução inicial gerada, na primeira das ACMAX iterações, a primeira formiga do processo sorteia um número n de barras para serem modificadas simultaneamente (escolhendo, assim, um caminho a percorrer). Ao modificar estas áreas, caso a estrutura se torne infactível, sorteia-se novamente uma outra quantidade n de barras para modificação e assim sucessivamente até que uma solução factível seja encontrada. Atingida a factibilidade, o algoritmo verifica se a solução encontrada é melhor que a melhor solução encontrada até o momento. Caso seja o método atualiza a melhor solução. 60 Após percorrer o caminho a matriz de feromônio é atualizada e a próxima formiga entra em ação. A partir daqui já existem caminhos percorridos, onde a quantidade de feromônio de cada caminho (nesse caso, a quantidade de barras modificadas simultaneamente) está armazenada na matriz de feromônios. Porém, se todas as formigas, após a primeira, sempre seguissem o rastro de feromônio, a quantidade de barras modificadas pela primeira formiga seria a mesma quantidade de barras selecionada a todo instante para sofrer a alteração. Para evitar este problema foi definido um percentual de 60% de chance de a próxima formiga seguir o caminho com mais feromônio. Para realizar este controle, é sorteado um valor qualquer entre 1 e 10. Caso o valor sorteado seja maior que 6, ou seja, fora do percentual de chances de seguir o rastro de feromônio, a formiga sorteia um novo caminho para percorrer, modificando a estrutura até atingir a factibilidade. Caso o valor sorteado esteja dentro dos 60%, o algoritmo percorre a matriz de feromônio e retorna uma lista ordenada da quantidade de barras alteradas simultaneamente com maior quantidade de feromônio. A formiga então escolhe alguma quantidade dentre as n/2 quantidade de barras da lista (onde n representa quantidade de barras do problema tratado). O processo é repetido para todas as formigas, cuja quantidade é um valor definido como parâmetro do método. Quando todas as formigas já tiverem percorrido algum caminho, a matriz de feromônio é atualizada, multiplicando todos os valores pelo parâmetro de evaporação. O processo se reinicia para a próxima iteração até atingir ACMAX iterações. Ao final do processo, a melhor solução é retornada. Devido à quantidade de parâmetros de calibragem, requisitando mais tempo nos testes de experimentação e, pelo tamanho da matriz de feromônios ser diretamente proporcional à quantidade de barras do problema, este método pode ter seu custo computacional muito elevado caso a estrutura possua um número muito elevado de barras na sua composição. Entretanto, o método apresentou resultados de qualidade satisfatória e sua implementação, modelada da forma aqui demonstrada, é de fácil compreensão e de simples desenvolvimento. O Quadro 3.6 exibe em detalhes o pseudocódigo do método Colônia de Formigas implementado. 61 (1) Constrói solução inicial factível via GRASP (s); (2) Enquanto não alcançar o número máximo de iterações faça: a. Enquanto não alcançar o número de formigas faça: i. Enquanto não gerar uma solução factível a partir de s, faça: 1. Caso seja a primeira formiga, sorteia uma quantidade de barras (que corresponde a um caminho até uma outra solução); 2. Caso contrário verifica na matriz de feromônio quais as (n/2) quantidade de barras simultâneas com mais feromônio () e sorteia uma entre elas; 3. Verifica a probabilidade da formiga seguir o caminho escolhido entre os n/2 melhores caminhos da matriz de feromônio (); 4. Caso a probabilidade esteja dentro do limite determinado, modifica a quantidade de barras escolhidas em s (gerando s’) e avalia a factibilidade da solução gerada (); 5. Caso contrário sorteia-se uma quantidade de barras (novo caminho), modificam-se as barras de s (gerando s’) e avalia a factibilidade da solução gerada (); ii. Avalia se a solução gerada (s’) é melhor que a melhor solução encontrada até o momento através da função objetivo (); iii. Caso seja, atualiza a melhor solução e atualiza s (s=s’); iv. Atualiza a matriz de feromônios, incrementando o caminho escolhido acima (quantidade de barras alteradas); v. Incrementa o contador de formigas; b. Incrementa o contador de iterações; c. Atualiza a matriz de feromônio baseado no parâmetro de evaporação (); (3) Apresenta a melhor solução encontrada (); QUADRO 3.6: Pseudocódigo do método Colônia de Formigas. 62 4 DESENVOLVIMENTO 4 DESENVOLVIMENTO 63 Este capítulo descreve alguns detalhes relacionados ao desenvolvimento deste trabalho, inclusive a respeito do software utilizado na análise das estruturas geradas pelos métodos heurísticos, bem como a maneira como foi implementada a sua integração com o sistema aqui desenvolvido. As seções seguintes foram dispostas da seguinte maneira: a Seção 4.1 descreve o software utilizado para realizar a análise das estruturas geradas pelas heurísticas, de modo a atestar sua viabilidade quanto aos requisitos de projeto. A Seção 4.2 descreve as variáveis de inicialização do sistema, que são lidas por meio de um arquivo XML, e detalha a maneira pela qual ocorre a troca de informações entre o sistema desenvolvido neste trabalho e o software utilizado na análise das estruturas. O Anexo A, ao final deste trabalho, apresenta em detalhes como instalar e configurar o ambiente de desenvolvimento utilizado. 4.1 O SOFTWARE INSANE E SUA INTEGRAÇÃO Para a análise estrutural dos problemas investigados neste trabalho, o programa escolhido foi o software INSANE, desenvolvido no Departamento de Engenharia de Estruturas da UFMG (Fonseca, 2004). Sua interface gráfica é exibida na Figura 4.1. Sua escolha se deve, principalmente, ao fato de sua implementação ter sido elaborada na mesma linguagem (Java) que este trabalho, o que facilitou a troca de informações entre os dois programas. 64 FIGURA 4.1: Interface do software INSANE. Cada estrutura gerada pelo OtimoEstrutura deve ser analisada com relação à sua viabilidade, ou seja, se a mesma atende os requisitos de projeto como deslocamentos máximos permitidos e tensões máximas suportadas. Como o INSANE trabalha com arquivos XML, a primeira idéia para realizar esta tarefa foi gerar um arquivo XML para cada estrutura. A partir daí o INSANE carregaria tal arquivo e analisaria a estrutura para atestar sua viabilidade, atualizando o arquivo XML para informar ao OtimoEstrutura o resultado da análise. Esta idéia foi logo descartada ao calcular em média a quantidade de soluções geradas pelos algoritmos. Considerando tais empecilhos, a maneira encontrada foi incorporar o INSANE ao OtimoEstrutura, de maneira a executá-lo (em segundo plano) durante a execução do sistema aqui desenvolvido. Para realizar esta tarefa, foi necessário adicionar um novo método principal no INSANE. O método principal, também conhecido como método main(), é o primeiro 65 método invocado ao executar qualquer sistema desenvolvido na linguagem Java. Sendo assim, foi adicionado outro método main(), de modo que o método criado realizasse as mesmas operações do método main() original, exceto a execução do comando que exibe a aplicação na tela. Desse modo, o INSANE aguarda, em segundo plano, as estruturas que serão analisadas. Após configurar o INSANE para executar em segundo plano, foi necessário analisar o modo pelo qual as estruturas seriam transmitidas. A maneira adotada foi utilizar um arquivo XML de inicialização para o OtimoEstrutura. Os detalhes a respeito de seu funcionamento são exibidos na seção seguinte. 4.2 INICIALIZAÇÃO DE VARIÁVEIS O arquivo XML de inicialização foi desenvolvido com o objetivo de fornecer os dados necessários ao INSANE para a análise das soluções geradas. Neste arquivo (IniFile.XML) estão as informações relacionadas à quantidade de barras da estrutura do problema tratado, o deslocamento máximo permitido, a tensão máxima suportada, a densidade do material, o intervalo de áreas de seção transversal permitido para cada barra, o tempo máximo de execução para os algoritmos, a precisão de casas decimais para os cálculos e o caminho do arquivo gerado no INSANE. Para cada problema tratado é necessário modificar este arquivo, de maneira a relacionar os requisitos de projeto e intervalo permitido das áreas de seção transversal correspondentes. A Figura 4.2 exibe um exemplo deste arquivo, relacionado ao primeiro problema avaliado neste trabalho (Yokota et al., 1998). 66 <?xml version="1.0" ?> <IniFile casasdecimais="6" numbarras="10" deslocamentomaximo="5.000" densidade="0.1" stressmax="25000" tempoMaxEmSegundos="480" pathmodelo="C:\java\workspaces\jpgp\OtimoEstrutura\YOKOTA.ISN"> <AREA areamenor="11.5" areamaior="12.5" comprimento="360.0"/> <AREA areamenor="8.0" areamaior="9.0" comprimento="360.0"/> <AREA areamenor="0.1" areamaior="1.0" comprimento="360.0"/> <AREA areamenor="5.5" areamaior="6.5" comprimento="360.0"/> <AREA areamenor="5.5" areamaior="6.0" comprimento="509.12"/> <AREA areamenor="8.0" areamaior="9.0" comprimento="509.12"/> <AREA areamenor="8.0" areamaior="9.0" comprimento="509.12"/> <AREA areamenor="0.1" areamaior="1.0" comprimento="509.12"/> <AREA areamenor="0.1" areamaior="1.0" comprimento="360.0"/> <AREA areamenor="0.1" areamaior="1.0" comprimento="360.0"/> </IniFile> FIGURA 4.2: Exemplo do arquivo de inicialização IniFile.XML. Para aplicar as heurísticas aqui implementadas a um determinado problema estrutural, primeiramente é necessário modelar este problema no INSANE. Um exemplo desta modelagem foi mostrado na Figura 4.1. Após modelar o problema é necessário salvar o arquivo (de extensão “.ISN”). Feito isso, ao executar o OtimoEstrutura, é necessário informar (através do IniFile.XML), qual o caminho do arquivo “.ISN” no disco, juntamente com as restrições de projeto para que, ao executar o INSANE em segundo plano, o mesmo carregue as informações relacionadas ao modelo do problema tratado. Após realizar estes passos, o OtimoEstrutura está pronto para ser executado. A Figura 4.3 abaixo é exibida ao executar o OtimoEstrutura, solicitando que o usuário informe o arquivo de inicialização citado. FIGURA 4.3: Executando o sistema OtimoEstrutura. 67 A Figura 4.4 mostra a interface gráfica do OtimoEstrutura, exibindo o menu onde as heurísticas implementadas são selecionadas para execução. FIGURA 4.4: Interface gráfica do sistema OtimoEstrutura. Cada heurística foi implementada como uma classe, contendo seus atributos e métodos definidos. Ao escolher qualquer heurística para execução, o sistema exibe outra tela idêntica à Figura 4.3, solicitando que o usuário informe o arquivo de inicialização da heurística correspondente. Este arquivo contém os valores dos parâmetros de calibragem de cada um dos métodos. A Figura 4.5 mostra um exemplo de um arquivo de inicialização do AG (IniAG.XML). <?xml version="1.0" ?> <IniAG mutacao="0.3" cruzamento="0.6" numerogeracoes="1500" tamanhoindividuo="10" populacao="20"> </IniAG> FIGURA 4.5: Exemplo do arquivo de inicialização do AG. 68 Logo nos primeiros testes foi detectado que, durante a análise das estruturas, o OtimoEstrutura gradualmente ocupava mais memória, diminuindo seu desempenho e seguindo este padrão até ter sua execução interrompida. Este problema foi solucionado removendo da memória os resultados calculados pelo INSANE a cada análise estrutural. Esta tarefa foi realizada utilizando dois métodos existentes no INSANE: Interface.cleanResults() e Interface.closeModelWithoutSaving(). O primeiro método limpa os resultados da tela. Porém, ao executar somente ele, para cada solução analisada pelo INSANE, este solicitava que o usuário salvasse ou não o modelo analisado. Sendo assim, foi necessário desenvolver o segundo método, implementado a partir de outro método do INSANE, chamado de Interface.closeModel(). Esta implementação foi realizada apenas removendo a opção de salvar o modelo, pois da maneira utilizada anteriormente (sem tais comandos), cada análise estava acumulando os resultados anteriores. As informações contidas no arquivo XML, exibido na Figura 4.2, são utilizadas no OtimoEstrutura durante sua execução. As informações relacionadas aos intervalos de áreas de seção transversal permitidas são utilizadas durante o processo de construção de cada solução. A ordenação em que as áreas estão dispostas no arquivo influenciam diretamente no processo de otimização. Por exemplo, de acordo com a Figura 4.2, os valores de área permitidos para a barra “4” variam de 5,5 a 6,5. Isto porque esta informação está disposta exatamente na quarta linha da seção de informações a respeito dos intervalos de área (que corresponde às tags nomeadas de “<AREA>”). Desse modo, ao modelar qualquer problema no INSANE, deve-se nomear cada barra com seu número correspondente para que o OtimoEstrutura possa relacionar corretamente os valores permitidos para cada elemento da estrutura. Sendo assim, conforme o exemplo acima citado, a barra 4 do modelo deverá ser nomeada por “4”, e assim sucessivamente. A Figura 4.6 exibe um exemplo da nomenclatura que deve ser utilizada para que cada barra possua um valor de área que corresponde ao intervalo permitido, contido no arquivo de inicialização. De acordo com a Figura 4.6, a área de seção transversal da barra selecionada (barra “6”, ligando o nó 4 ao nó 2) possui o nome “6”, e portanto, corresponde à sexta tag <AREA> do arquivo IniFile.XML (permitindo valores de área entre 8,0 in2 a 9,0 in2). Ou seja, no exemplo 69 da Figura 4.6, o valor exibido (8,538694) está corretamente dentro do intervalo permitido para esta barra. FIGURA 4.6: Padronização de nomenclatura da modelagem de problemas no INSANE. O fluxo da transmissão de informações funciona da seguinte maneira: o OtimoEstrutura gera uma determinada configuração de barras (possível solução) e acessa o modelo do INSANE, modificando as áreas de seção transversal do modelo de acordo com a configuração gerada (daí a importância de padronizar a nomenclatura na estrutura). A partir daí, é executado o método analyseModel() da classe StructuralMech do INSANE. Este comando analisa o modelo e retorna os valores necessários para validar a solução. A Figura 4.7 exibe um diagrama de sequência para facilitar a compreensão desta etapa. 70 FIGURA 4.7: Seqüência de eventos e intercâmbio de dados com o software INSANE. O valor relacionado ao deslocamento máximo de cada nó da estrutura é obtido por meio do comando “Math.abs(it.getModel().getDiscreteModel().getDriver(). getSolution().getXVector().getElement(a));”. Este comando é utilizado para verificar o deslocamento no passo 8 da Figura 4.7. A função Math.abs retorna o valor absoluto do deslocamento, uma vez que ele pode ser positivo ou negativo dependendo do sentido em que ocorre. A variável “a” corresponde a cada nó da estrutura. Desse modo, este valor é buscado para cada nó da estrutura e verifica-se se o valor retornado é menor ou igual ao deslocamento máximo permitido no problema. Caso seja maior, o OtimoEstrutura penaliza a solução gerada, associando a ela um valor extremamente elevado para seu peso. Caso contrário a verificação prossegue com o próximo requisito: a tensão máxima. A tensão máxima de cada barra não é obtida diretamente pelo INSANE. O INSANE calcula as ações nas extremidades de cada barra. Desse modo, o valor da tensão é obtido dividindo este valor pela área da seção transversal da barra correspondente. Para obter o valor correspondente às ações nas extremidades para 71 cada barra é utilizada a expressão “Math.abs(((FrameElement)it.getModel(). getDiscreteModel(). getDriver(). getFemModel(). getElementsList(). get(j)). getActionAtExtremity(0));”. A variável “j” corresponde a cada barra da estrutura, de maneira que este comando é executado dentro de uma iteração. E para buscar o valor da área de seção transversal é utilizada a expressão “((FrameElement)it.getModel().getDiscreteModel().getDriver().getFemModel(). getElementsList().get(j)).getCrossSection().getArea();”. Dividindo o valor da ação na extremidade pelo valor da área obtêm-se a tensão máxima suportada pela barra. Este cálculo é realizado no passo 8 da Figura 4.7. Caso o valor esteja dentro do valor máximo permitido, o cálculo do peso da estrutura é realizado. Caso contrário a solução é penalizada, atribuindo a ela um valor extremamente alto para o peso, de maneira que ela seja desconsiderada ao ser comparada com a melhor solução corrente nas iterações seguintes. O valor do peso da estrutura é calculado multiplicando-se a área da seção transversal pelo comprimento (fornecido no IniFile.XML) e pela densidade (fornecido no IniFile.XML). Por meio do arquivo IniFile.XML é possível modificar a densidade do material empregado na estrutura; modificar o intervalo considerado para a área de seção transversal das barras; modificar o deslocamento máximo permitido e a tensão máxima suportada; alterar o tempo máximo de processamento para cada algoritmo e determinar a precisão dos cálculos realizados por cada algoritmo, garantindo flexibilidade para trabalhar com diversos tipos de configurações estruturais. Deste modo, a junção entre os dois sistemas funciona de maneira eficaz, garantindo rapidez e eficiência na troca de informações sobre cada solução gerada, fazendo com que o tempo gasto em cada análise seja muito pequeno, não afetando o desempenho dos algoritmos. 72 5 ANÁLISE DOS RESULTADOS OBTIDOS 5 ANÁLISE DOS RESULTADOS OBTIDOS 73 Este capítulo descreve em detalhes cada um dos problemas utilizados neste trabalho, apresentando os resultados obtidos para cada algoritmo aplicado. Com o objetivo de atestar a eficiência e o desempenho dos métodos heurísticos aqui desenvolvidos foram selecionados três problemas, com configurações estruturais e restrições de projeto distintas. Para cada problema foi elaborada uma análise dos resultados obtidos por meio de gráficos, contendo a evolução da qualidade das soluções obtidas em função do tempo de execução. Durante esta análise, os resultados considerados “excelentes” são aqueles que obtiveram qualidade superior ao valor de referência. Os resultados considerados “bons” são aqueles bem próximos e em alguns casos, até mesmo iguais ao valor de referência. Resultados considerados “satisfatórios” estão próximos ao valor de referência, mas ainda podem ser melhorados. E “ruins” são resultados que não estão sequer próximos do valor de referência, demonstrando que, por algum motivo, o algoritmo não apresentou resultados aceitáveis. Vale ressaltar que cada ponto (X=tempo; Y=peso) considerado em cada execução na construção do gráfico de um determinado algoritmo, corresponde ao melhor resultado obtido durante a pesquisa a cada 10 segundos. A partir deste ponto, com o intuito de facilitar a análise dos resultados, alguns algoritmos serão abreviados da seguinte maneira: Algoritmos Genéticos (AG), Simulated Annealing (SA), Busca Tabu (BT) e Colônia de Formigas (AC). A Seção 5.1 descreve o problema apresentado em Yokota et al. (1998), composto por uma configuração estrutural constituída de dez barras, juntamente com a análise dos resultados obtidos por meio dos algoritmos aplicados. A Seção 5.2 descreve o problema proposto em Fawaz et al. (2005), composto por dezoito barras e adaptado para realizar a otimização apenas das áreas de seção transversal de cada barra. A análise dos resultados obtidos está incluída na mesma seção. E por fim, a Seção 5.3 descreve o problema composto de quarenta e sete barras de Castro (2001), também adaptado para realizar a otimização apenas das áreas de seção transversal e incluindo também uma análise dos resultados obtidos. 74 5.1 ESTRUTURA DE 10 BARRAS 5.1.1 Descrição do Problema A figura 5.1 ilustra a configuração estrutural de barras do problema tratado. FIGURA 5.1: Topologia da estrutura com 10 barras. Fonte: Yokota et al. (1998). A estrutura exibida na Figura 5.1 possui algumas restrições de projeto, as quais são descritas na tabela abaixo: 11,5 in2 ≤ A1 ≤ 12,5 in2 0,1 in2 ≤ A3 ≤ 1,0 in2 5,5 in2 ≤ A5 ≤ 6,0 in2 8,0 in2 ≤ A7 ≤ 9,0 in2 0,1 in2 ≤ A9 ≤ 1,0 in2 E = 107 psi | σ | ≤ 25000 (25 ksi) l1 – 4, 9, 10 = 360 in l5 – 8 = 360√2 in 8,0 in2 ≤ A2 ≤ 9,0 in2 5,5 in2 ≤ A4 ≤ 6,5 in2 8,0 in2 ≤ A6 ≤ 9,0 in2 0,1 in2 ≤ A8 ≤ 1,0 in2 0,1 in2 ≤ A10 ≤ 1,0 in2 ρ = 0,1 lb/in3 | v6 | ≤ 5,0 in P = 105 lbs TABELA 5.1: Restrições de projeto e valores de coeficientes. Fonte: Yokota et al. (1998). As variáveis Ai citadas na tabela correspondem ao intervalo permitido de valores para a área da seção transversal de cada barra envolvida no processo. Por exemplo, a área da seção transversal da barra 1 pode variar entre 11,5 e 12,5. Os coeficientes assinalados na tabela acima são restrições que deverão ser consideradas durante o processo de pesquisa, de maneira que cada estrutura gerada durante o processo 75 deverá obedecer a todos os requisitos estruturais acima citados, caso contrário deverá ser descartada pois é infactível para o problema. Na Tabela 5.1, E é o módulo de elasticidade longitudinal do material, σ é a tensão máxima suportada, li corresponde ao comprimento de cada barra i, ρ corresponde à densidade do material e v6 corresponde ao deslocamento vertical do nó 6, que deverá ser menor ou igual a 5. Note que, no caso do deslocamento, o nó 6 é citado mas a verificação é realizada em todos os nós. A implementação foi realizada desta maneira para que o OtimoEstrutura possa trabalhar com qualquer tipo de configuração estrutural. O nó 6 é citado em particular na tabela devido a sua posição na configuração estrutural do problema, de maneira que ele é o nó que mais se deslocará ao aplicar o peso P. 5.1.2 Resultados Durante o processo de experimentação dos algoritmos foi percebido que nenhum dos métodos utilizados conseguia alcançar a solução de referência, obtida por Yokota et al. (1998). Ao analisar a solução de referência no INSANE, foi constatado que, apesar de satisfazer o requisito de deslocamento máximo permitido, a mesma não satisfazia o requisito de tensão máxima suportada. Para confirmar este fato foi utilizado o software comercial LUSAS (2007), que realiza a análise estrutural utilizando Elementos Finitos. Este software comprovou que a melhor solução encontrada em Yokota et al. (1998) possui uma barra que atinge uma tensão máxima (σ) de valor 27134 psi, de maneira que o máximo permitido, de acordo com as restrições de projeto, seria até 25000 psi. Os demais valores obtidos em Yokota et al. (1998) foram corretamente validados pelo INSANE. Sendo assim, o valor de referência que passou a ser considerado é encontrado em Rozvany (1991). Para a execução dos testes, cada algoritmo foi limitado em 8 minutos de execução. Este valor foi definido durante o processo de experimentação do problema tratado, estabelecido como critério de parada de cada algoritmo. Tal valor foi definido por ter sido considerado o tempo gasto em média para que os algoritmos estabilizem sua busca, de maneira a não melhorar significativamente a qualidade da 76 melhor solução corrente. Os resultados demonstrados na Tabela 5.2 são os melhores obtidos em dez execuções para cada algoritmo. Algoritmo Utilizado Melhor Solução Encontrada Erro Rel. AG [12.184564, 8.765164, 0.1, 6.011111, 5.567187, 8.404665, 8.675727, 0.1, 0.1, 0.1] - Peso: 2139.51531 lbs 0,019% VNS [12.37530, 8.61023, 0.1, 6.25468, 5.56154, 8.21205, 8.71207, 0.15450, 0.12264, 0.1] - Peso: 2144.91843 lbs 0,271% GRASP com VNS [12.16320, 8.28717, 0.1, 6.11155, 5.53106, 8.88064, 8.53061, 0.15408, 0.11889, 0.11336] – Peso: 2144.07353 lbs 0,232% Simulated Annealing [12.21668, 8.737761, 0.1, 6.21331, 5.56808, 8.47098, 8.4574, 0.11148, 0.1, 0.1] - Peso: 2139.85444 0,035% Busca Tabu [12.125599, 8.80142, 0.1, 5.975283, 5.561755, 8.599056, 8.521716, 0.1, 0.1, 0.1] - Peso: 2139.18689 lbs 0,004% Colônia de Formigas [12.04866, 8.903371, 0.10296, 6.01019, 5.56551, 8.64850, 8.43207, 0.1, 0.1, 0.1] - Peso: 2139.5949 lbs 0,022% [12.126576, 8.827450, 0.1, 6.046585, 5.564322, 8.497882, 8.551163, 0.1, 0.1, 0.1] - Peso: 2139.198 lbs 0,004% [12.161174, 8.707029, 0.1, 6.040580, 5.560165, 8.573640, 8.542670, 0.1, 0.1, 0.1] - Peso: 2139.10498 lbs 0,000% [12.161174, 8.707029, 0.1, 6.040580, 5.560165, 8.573640, 8.542670, 0.1, 0.1, 0.1] - Peso: 2139.10498 lbs 0,000% DOC-FSD [YOKOTA,1998] Dual [YOKOTA,1998] DCOC [YOKOTA,1998] [ROZVANY,1991] (valor referência) [12.161174, 8.707029, 0.1, 6.040580, 5.560165, 8.573640, 8.542670, 0.1, 0.1, 0.1] - Peso: 2139.10498 lbs TABELA 5.2: Melhores resultados obtidos em dez execuções para a treliça de 10 Barras. A Tabela 5.3 a seguir exibe os valores obtidos de tensão máxima e deslocamento máximo das melhores soluções obtidas de cada algoritmo. Algoritmo Utilizado Tensão máxima (psi) Deslocamento máximo (in) AG Barra 5: 24989,81 Nó 6: 4,999985944448685 VNS Barra 5: 24936,53 Nó 6: 4.999091569275484 GRASP com VNS Barra 5: 24988,57 Nó 6: 4.999770040553758 Simulated Annealing Barra 5: 24985,03 Nó 6: 4.999953947391877 Busca Tabu Barra 5: 24999,73 Nó 6: 4.999999442826388 Colônia de Formigas Barra 5: 24990,44 Nó 6: 4.999997735144299 [ROZVANY,1991] (valor de referência) Barra 5: 25000,00 Nó 6: 4.999999993084772 TABELA 5.3: Tensão máxima e deslocamento máximo das soluções para a treliça de 10 Barras. 77 5.1.3 Análise dos Resultados Conforme relatado anteriormente, os gráficos foram elaborados utilizando dez execuções para cada algoritmo, com o tempo máximo de processamento de 8 minutos para cada execução. Estes valores foram determinados após os testes de experimentação, levando em consideração o tempo necessário para que cada algoritmo se estabilizasse. A Figura 5.2 exibe o gráfico elaborado por meio dos resultados obtidos em cada execução do método AG, considerando o tempo máximo de 8 minutos. Durante a execução dos testes para a geração dos gráficos, foi constatado que o algoritmo atinge boas soluções, consumindo um baixo tempo computacional. Mesmo utilizando um limite de 8 minutos, o algoritmo já apresenta bons resultados em apenas metade deste tempo. É importante lembrar que o AG é o único método que não utiliza o método GRASP na construção de soluções iniciais. Isto porque a utilização do GRASP neste método implicaria construir todos os indivíduos da população inicial, elevando o tempo computacional gasto. Sendo assim, a construção utilizada apenas garante indivíduos factíveis. 2300 2280 2260 2240 2220 Execução Execução Execução Execução Execução Execução Execução Execução Execução Execução 44 0 36 0 40 0 28 0 32 0 16 0 20 0 24 0 12 0 80 40 2200 2180 2160 2140 2120 2100 0 Peso(lbs) Algoritmos Genéticos Tempo(s) FIGURA 5.2: Gráfico de Peso (lbs) x Tempo (s) do AG (10 Barras). 1 2 3 4 5 6 7 8 9 10 78 A Figura 5.3 exibe o gráfico elaborado por meio dos resultados obtidos pela aplicação do método VNS. Analisando o gráfico nota-se que, mesmo utilizando o método GRASP para as soluções iniciais, o VNS consome todos os 8 minutos para atingir bons resultados. 2300 2280 2260 2240 2220 Execução Execução Execução Execução Execução Execução Execução Execução Execução Execução 1 2 3 4 5 6 7 8 9 10 44 0 36 0 40 0 28 0 32 0 16 0 20 0 24 0 12 0 80 40 2200 2180 2160 2140 2120 2100 0 Peso(lbs) VNS Tempo(s) FIGURA 5.3: Gráfico de Peso (lbs) x Tempo (s) do VNS (10 Barras). A Figura 5.4 exibe o gráfico elaborado por meio dos resultados obtidos pela aplicação do método GRASP com VNS. Analisando suas execuções constata-se que, similar ao VNS, consome todo o tempo disponível para atingir bons resultados. 79 2300 2280 2260 2240 2220 Execução Execução Execução Execução Execução Execução Execução Execução Execução Execução 1 2 3 4 5 6 7 8 9 10 44 0 36 0 40 0 28 0 32 0 16 0 20 0 24 0 12 0 80 40 2200 2180 2160 2140 2120 2100 0 Peso(lbs) GRASP com VNS Tempo(s) FIGURA 5.4: Gráfico de Peso (lbs) x Tempo (s) do GRASP com VNS (10 Barras). A Figura 5.5 exibe o gráfico elaborado por meio dos resultados obtidos pela aplicação do método SA. Pela análise do gráfico nota-se que este algoritmo atinge bons resultados, consumindo baixo tempo computacional. 2300 2280 2260 2240 2220 Execução Execução Execução Execução Execução Execução Execução Execução Execução Execução 44 0 36 0 40 0 28 0 32 0 16 0 20 0 24 0 12 0 80 40 2200 2180 2160 2140 2120 2100 0 Peso(lbs) Simulated Annealing Tempo(s) FIGURA 5.5: Gráfico de Peso (lbs) x Tempo (s) do SA (10 Barras). 1 2 3 4 5 6 7 8 9 10 80 A Figura 5.6 exibe o gráfico elaborado por meio dos resultados obtidos pela aplicação do método BT. Analisando o comportamento deste algoritmo percebe-se ele converge rapidamente para bons resultados, consumindo menos de 80 segundos, que corresponde a menos de 17% do tempo total disponível para a pesquisa. 2300 2280 2260 2240 2220 Execução Execução Execução Execução Execução Execução Execução Execução Execução Execução 1 2 3 4 5 6 7 8 9 10 44 0 36 0 40 0 28 0 32 0 16 0 20 0 24 0 12 0 80 40 2200 2180 2160 2140 2120 2100 0 Peso(lbs) Busca Tabu Tempo(s) FIGURA 5.6: Gráfico de Peso (lbs) x Tempo (s) da BT (10 Barras). A Figura 5.7 exibe o gráfico elaborado por meio dos resultados obtidos pela aplicação do método AC. Analisando seu comportamento nota-se que o mesmo converge rapidamente, utilizando pouco tempo computacional para atingir bons resultados. 81 Colônia de Formigas Peso(lbs) 2300 2280 2260 2240 2220 Execução Execução Execução Execução Execução Execução Execução Execução Execução Execução 12 0 16 0 20 0 24 0 28 0 32 0 36 0 40 0 44 0 80 40 0 2200 2180 2160 2140 2120 2100 1 2 3 4 5 6 7 8 9 10 Tempo(s) FIGURA 5.7: Gráfico de Peso (lbs) x Tempo (s) do AC (10 Barras). Para facilitar a compreensão acerca do comportamento dos algoritmos com relação ao problema em questão, foi elaborado o gráfico da Figura 5.8, reunindo as melhores execuções de cada algoritmo para o problema tratado. Melhor execução de cada algoritmo (10 Barras) 2300 VNS SA GRASP BT AG AC 2240 2220 2200 2180 2160 2140 2120 12 0 16 0 20 0 24 0 28 0 32 0 36 0 40 0 44 0 80 40 2100 0 Peso (lbs) 2280 2260 Tempo (s) FIGURA 5.8: Melhores resultados de cada algoritmo (10 Barras). 82 Analisando o comportamento dos algoritmos pelos gráficos anteriormente exibidos, pode-se perceber que existem algumas características que os assemelham, e que de certa maneira os dividem em dois grupos: o primeiro grupo é composto os algoritmos AG, SA, BT e AC. O segundo grupo é composto pelos algoritmos VNS e GRASP. Esta divisão por semelhança é fácil de ser detectada analisando os gráficos das figuras 6.2 e 6.3 em comparação com os demais gráficos. O comportamento dos algoritmos GRASP e VNS é muito parecido. Isto se deve, principalmente, pelo fato de que o método GRASP utiliza como busca local o próprio VNS. O comportamento dos algoritmos GRASP e VNS se destaca dos demais, considerando o tipo de problema em questão, por um fator muito importante: a maneira pela qual é realizada a modelagem de um “movimento” para a geração de soluções vizinhas. Um “movimento”, conforme já citado anteriormente, consiste em uma modificação sistemática de uma solução, de maneira a gerar outra solução diferente desta. Todos os demais algoritmos possuem em sua implementação a possibilidade de modificar simultaneamente uma quantidade aleatória de barras, enquanto que o método VNS foi modelado de maneira a trabalhar utilizando sua implementação tradicional, com quatro estruturas de vizinhança distintas: modificando uma barra, duas barras, três barras ou todas as barras da estrutura. Isto faz com que a probabilidade de melhorar a qualidade da melhor solução encontrada em um determinado momento seja menor do que nos demais algoritmos, uma vez que o espaço de soluções é um pouco menor. Isto é percebido pela existência de planícies nos gráficos das figuras 5.3 e 5.4. As várias planícies consecutivas significam que o método consome um tempo maior de processamento para conseguir melhorar sua solução devido às restrições de geração de novas soluções impostas pela modelagem. As planícies, citadas anteriormente, são identificadas como sendo pequenas retas paralelas ao eixo X, podendo ser encontradas em cada execução, demonstrando que o método tratado consome um tempo maior de processamento para conseguir melhorar a solução corrente. 83 Neste problema, os métodos VNS e GRASP com VNS, apresentaram regiões de planície em pouco tempo de execução, enquanto os demais métodos somente apresentaram tais regiões ao final de suas execuções, quando as soluções obtidas já estavam muito próximas da solução de referência. No caso do VNS e, consequentemente, do GRASP com VNS, caso fosse modelada uma quantidade maior de estruturas de vizinhança, o tempo necessário para aprimorar a qualidade da melhor solução corrente seria menor, uma vez que o espaço de busca destas soluções seria maior. Porém, não existe uma quantidade ideal de estruturas de vizinhança para um determinado tipo de problema. Mesmo que novas estruturas fossem modeladas, problemas com uma quantidade maior de barras em sua estrutura, por conseguinte, necessitariam de mais estruturas de vizinhança, de maneira que este aumento pode melhorar um problema específico, mas não toda uma classe de problemas. No caso da classe de problemas tratada neste trabalho, a possibilidade de modificação da área da seção transversal de várias barras simultaneamente modelado como um único “movimento”, se mostrou extremamente eficaz, principalmente ao observar o comportamento das heurísticas BT e AC ao modificar a modelagem utilizada nas mesmas durante os testes de experimentação. Conforme citado anteriormente, as heurísticas BT e AC, durante o processo de calibragem dos parâmetros, não apresentavam resultados considerados satisfatórios (sequer próximos da solução de referência do problema). Sendo assim, a modelagem de um “movimento” para a geração de novas soluções nestes algoritmos foi modificada na tentativa de melhorar a qualidade das soluções obtidas. Após tal modificação foi percebido que, nos testes de experimentação, a qualidade das soluções obtidas, tanto na AC quanto na BT, foi consideravelmente maior. Isto demonstra que a modelagem do problema exerce um papel fundamental na eficiência do algoritmo para o tipo de problema tratado. Ainda assim, isto não significa que as heurísticas GRASP e VNS sejam inadequadas, uma vez que tais métodos foram implementados considerando sua modelagem tradicional. A definição de estruturas de vizinhanças mais elaboradas pode ampliar o espaço de busca, contribuindo para a melhoria das soluções obtidas. 84 Ainda assim, para o referido problema, os resultados obtidos foram considerados bons. Os métodos do primeiro grupo (AG, SA, BT e AC) se mostraram muito eficientes. Os gráficos das figuras 5.2, 5.5, 5.6 e 5.7 demonstram que o tempo de processamento consumido para atingir soluções de boa qualidade é muito pequeno. O gráfico da Figura 5.8 ilustra o comportamento semelhante destes métodos. Dentre eles, aquele que melhor obteve uma relação custo / benefício foi o método Simulated Annealing. Sua facilidade de implementação, aliada à simples calibração, faz deste método uma excelente opção, garantindo soluções de boa qualidade consumindo um baixo tempo de processamento. O método que obteve a solução de melhor qualidade dentre todos foi o método Busca Tabu. Lembrando que, antes da modificação realizada na modelagem, tal método atingia soluções consideradas apenas satisfatórias (sequer próximas do valor de referência). É importante destacar que nenhum dos algoritmos obteve o mesmo resultado duas vezes para o problema tratado. Isto ocorre devido à grande diversidade de soluções existentes para o problema, uma vez que os cálculos foram realizados utilizando uma precisão de seis casas decimais, o que torna o espaço de soluções extremamente vasto. 5.2 ESTRUTURA DE 18 BARRAS 5.2.1 Descrição do Problema A estrutura analisada neste exemplo foi retirada de Fawaz et al. (2005). Em seu trabalho, a otimização realizada é chamada de multiobjetiva pelo fato de possuir dois objetivos que podem ter seus valores modificados: a área da seção transversal das barras e as coordenadas de alguns nós da estrutura (de maneira que sua topologia pode ser modificada durante o processo de otimização). 85 A estrutura inicial em que a otimização foi aplicada é mostrada na Figura 5.9 a seguir. FIGURA 5.9: Topologia da estrutura com 18 barras. Fonte: Fawaz et al. (2005). Os nós 1, 2, 4, 6 e 8 são fixos, ou seja, não podem ter suas coordenadas alteradas. A cada um destes mesmos nós é aplicada uma força externa correspondente a 20000 lbs. Desse modo, as seguintes restrições devem ser consideradas: a) Tensão máxima menor ou igual a 20 ksi (| σ | ≤ 20000); b) As 18 barras são divididas em quatro grupos: o 1º grupo é composto das barras 1, 4, 8, 12 e 16. O 2º grupo é composto pelas barras 2, 6, 10, 14 e 18. O 3º grupo é composto pelas barras 3, 7, 11 e 15. O 4º e último grupo é composto pelas barras 5, 9, 13 e 17. As barras que pertencem a um mesmo grupo devem possuir áreas de seção transversal iguais; c) Somente os nós 3, 5, 7 e 9 podem ter suas coordenadas modificadas; d) As propriedades do material utilizado são: módulo de elasticidade (E) igual a 107 psi e a densidade é igual a 0,1 lb/in3; e) Os valores das áreas de seção transversal podem variar de 0,2 in2 a 30 in2. 86 O resultado do processo de otimização de Fawaz et al. (2005) aplicado na configuração estrutural, considerando as restrições impostas pelo projeto, é exibido na Figura 5.10. FIGURA 5.10: Topologia da estrutura de 18 barras otimizada. Fonte: Fawaz et al. (2005). A otimização aplicada acima foi realizada considerando dois tipos de variáveis: a área da seção transversal e a coordenada dos nós 3, 5, 7 e 9. Porém, o presente trabalho focaliza a otimização de maneira uniobjetiva, utilizando apenas uma variável: a área de seção transversal. Desta maneira, o modelo da Figura 5.10 foi o modelo utilizado para aplicar o processo de otimização através dos algoritmos aqui implementados. 5.2.2 Resultados A otimização é realizada seguindo o mesmo processo do problema anterior: cada estrutura gerada durante o processo de busca é analisada pelo INSANE, que analisa a estrutura fornecida e retorna os resultados referentes à tensão máxima e deslocamento máximo. É importante destacar que este problema não possui nenhuma restrição quanto ao valor do deslocamento máximo. Sendo assim, o valor do deslocamento máximo informado nos parâmetros de inicialização do OtimoEstrutura foi um valor elevado, de maneira que tal restrição jamais fosse ser utilizada durante a pesquisa. Ao analisar a solução otimizada no INSANE com o intuito de verificar os cálculos, o valor do deslocamento máximo corresponde exatamente ao valor descrito em Fawaz et al. (2005). Porém, a tensão máxima encontrada não corresponde ao 87 valor mencionado no referido artigo, que é de 19997 ksi. O valor máximo calculado pelo INSANE foi de 20087,56 ksi, correspondente à barra 17. Sendo assim, para que o OtimoEstrutura pudesse realizar sua pesquisa no mesmo espaço de soluções, o qual a solução otimizada foi encontrada, o limite máximo de tensão foi modificado para 20089 ksi. A definição deste valor foi realizada da seguinte maneira: se o referido artigo, utilizando um limite de tensão máxima de 20000 ksi, obteve a melhor solução com um valor de tensão máxima de 19997 ksi, a diferença entre o limite máximo permitido e o valor máximo encontrado foi de 3 ksi. Deste modo, com o intuito de manter o mesmo espaço de busca da pesquisa para este problema, o limite máximo foi definido em 20089 ksi, uma vez que a tensão máxima calculada pelo INSANE para a solução de Fawaz et al. (2005), foi de 20087,56 ksi. Os resultados descritos na Tabela 5.4 são os melhores obtidos em 10 execuções de dez minutos para cada algoritmo. Este tempo foi estabelecido durante o processo de experimentação, sendo considerado o tempo gasto em média para que os algoritmos se estabilizassem. Este valor foi definido por ter sido considerado o tempo mínimo necessário para que os algoritmos estabilizem sua busca, de maneira a não melhorar significativamente a qualidade da melhor solução corrente. O valor de referência é o valor do peso da estrutura otimizada da Figura 5.10 de Fawaz et al. (2005). Vale ressaltar que o resultado apresentado em Fawaz et al. (2005) é de 390,42 lbs. Entretanto, este valor está incorreto. Deste modo, o peso da estrutura otimizada foi recalculado, de maneira que o valor correto é 3899,22 lbs. É importante notar que os resultados da coluna de Erro Relativo com valores negativos representam o percentual de melhora em relação ao valor de referência. 88 Algoritmo Utilizado AG VNS GRASP com VNS Simulated Annealing Busca Tabu Colônia de Formigas Ref. [FAWAZ, 2005] Melhor Solução Encontrada [11.39, 15.13, 1.93, 11.39, 4.38, 15.13, 1.93, 11.39, 4.38, 15.13, 1.93, 11.39, 4.38, 15.13, 1.93, 11.39, 4.38, 15.13] Peso: 3884,69 lbs [11.49, 15.28, 2.28, 11.49, 4.42, 15.28, 2.28, 11.49, 4.42, 15.28, 2.28, 11.49, 4.42, 15.28, 2.28, 11.49, 4.42, 15.28] Peso: 3943,81 lbs [11.44, 15.15, 2.13, 11.44, 5.09, 15.15, 2.13, 11.44, 5.09, 15.15, 2.13, 11.44, 5.09, 15.15, 2.13, 11.44, 5.09, 15.15] Peso: 3971,72 lbs [11.6, 15.29, 2.05, 11.6, 4.51, 15.29, 2.05, 11.6, 4.51, 15.29, 2.05, 11.6, 4.51, 15.29, 2.05, 11.6, 4.51, 15.29] Peso: 3951,36 lbs [11.39, 15.13, 1.87, 11.39, 4.38, 15.13, 1.87, 11.39, 4.38, 15.13, 1.87, 11.39, 4.38, 15.13, 1.87, 11.39, 4.38, 15.13] Peso: 3880,6 lbs [11.39, 15.13, 1.87, 11.39, 4.38, 15.13, 1.87, 11.39, 4.38, 15.13, 1.87, 11.39, 4.38, 15.13, 1.87, 11.39, 4.38, 15.13] Peso: 3880,6 lbs [11.43, 15.21, 1.92, 11.43, 4.38, 15.21, 1.92, 11.43, 4.38, 15.21, 1.92, 11.43, 4.38, 15.21, 1.92, 11.43, 4.38, 15.21] Peso: 3899.22 lbs Erro Rel. -0,373% 1,143% 1,859% 1,337% -0,478% -0,478% TABELA 5.4: Melhores resultados obtidos em dez execuções para a treliça de 18 Barras. A Tabela 5.5 a seguir exibe os valores obtidos de tensão máxima e deslocamento máximo das melhores soluções obtidas de cada algoritmo. Algoritmo Utilizado Tensão máxima (psi) Deslocamento máximo (in) AG Barra 17: 20087,56 Nó 1: 21,008551584529517 VNS Barra 16: 19905,85 Nó 1: 20,868994635115193 GRASP com VNS Barra 18: 20058,29 Nó 1: 20,960181019938027 Simulated Annealing Barra 18: 19874,63 Nó 1: 20,715979044740270 Busca Tabu Barra 17: 20087,56 Nó 1: 20,996553053334832 Colônia de Formigas Barra 17: 20087,56 Nó 1: 20,996553053334832 [FAWAZ,2005] (valor de referência) Barra 17: 20087,56 Nó 1: 20,915188380539250 TABELA 5.5: Tensão máxima e deslocamento máximo das soluções para a treliça de 18 Barras. 89 Para que a restrição de grupo (barras do mesmo grupo devem possuir o mesmo valor de área de seção transversal) fosse considerada, o método responsável pela análise de cada solução foi modificado para que, antes de avaliar uma solução, a mesma fosse adequada às restrições de grupo. Inicialmente, tal operação foi realizada sorteando uma barra de cada grupo e igualando as demais barras do grupo à área da barra sorteada. Por exemplo, considere que a barra 8 foi sorteada. Esta barra faz parte do primeiro grupo, composto pelas barras 1, 4, 8, 12 e 16. Sendo assim, para adequar a restrição de grupo, a área de seção transversal das barras 1, 4, 12 e 16 eram modificadas, sendo igualadas ao valor da área de seção transversal da barra 8 sorteada. A mesma operação era realizada com os demais grupos. Porém, ao realizar os primeiros testes com o AG, foi detectada a necessidade de um tratamento mais elaborado desta adequação. Isto porque, ao analisar um indivíduo resultante de uma operação de Mutação, muitas vezes a nova característica (nova área de seção transversal proveniente da mutação) era sobrescrita ao realizar a adequação. Por exemplo, considere que o valor da área de seção transversal da barra 4 é proveniente de uma mutação. Ao realizar a adequação, conforme descrito anteriormente, se a barra sorteada do primeiro grupo for, por exemplo, a barra 12, todas as demais barras (inclusive a barra 4) teriam seus valores igualados ao valor da área da barra 12. Deste modo, o valor proveniente da mutação realizada na barra 4 era sobrescrito. Desta maneira, para os indivíduos provenientes de mutação, ao realizar a adequação para a restrição de grupo, a área da barra modificada pela mutação passou a ser propagada para todos os membros de seu grupo, de maneira que a mutação não mais se perdesse. O mesmo foi desenvolvido para as demais heurísticas, de modo a diminuir a perda de novas características pelo processo de adequação da restrição por grupo. 90 5.2.3 Análise dos Resultados Da mesma maneira que o problema das 10 barras, os gráficos deste problema foram elaborados utilizando dez execuções para cada algoritmo, porém com o tempo máximo de processamento de dez minutos para cada execução. Estes valores foram determinados após os testes de experimentação, levando em consideração o tempo necessário para que cada algoritmo se estabilizasse. A Figura 5.11 exibe o gráfico elaborado por meio dos resultados obtidos pela aplicação do método AG. Analisando o gráfico nota-se que o AG converge rapidamente para bons resultados, utilizando em média um terço do tempo disponível para a pesquisa. Ao final de sua pesquisa o algoritmo obteve resultados considerados excelentes (de qualidade superior em relação ao valor de referência do problema tratado). Algoritmos Genéticos 8600 Peso (lbs) 7600 6600 5600 4600 50 10 0 15 0 20 0 25 0 30 0 35 0 40 0 45 0 50 0 55 0 0 3600 Execução 1 Execução 2 Execução 3 Execução 4 Execução 5 Execução 6 Execução 7 Execução 8 Execução 9 Execução 10 Tempo (s) FIGURA 5.11: Gráfico de Peso (lbs) x Tempo (s) do AG (18 Barras). A Figura 5.12 a seguir exibe o gráfico construído por meio das execuções do algoritmo VNS. 91 VNS 8600 Peso (lbs) 7600 6600 5600 4600 50 10 0 15 0 20 0 25 0 30 0 35 0 40 0 45 0 50 0 55 0 0 3600 Execução Execução Execução Execução Execução Execução Execução Execução Execução Execução 1 2 3 4 5 6 7 8 9 10 Tempo (s) FIGURA 5.12: Gráfico de Peso (lbs) x Tempo (s) do VNS (18 Barras). Analisando o gráfico anterior nota-se que o método VNS consome praticamente todo o tempo disponível para alcançar resultados considerados satisfatórios (valores próximos do valor de referência, mas que poderiam ser melhorados). A Figura 5.13 abaixo exibe o gráfico elaborado a partir das execuções do algoritmo GRASP com VNS. GRASP com VNS 8600 6600 5600 4600 50 10 0 15 0 20 0 25 0 30 0 35 0 40 0 45 0 50 0 55 0 3600 0 Peso (lbs) 7600 Execução Execução Execução Execução Execução Execução Execução Execução Execução Execução Tempo (s) FIGURA 5.13: Gráfico de Peso (lbs) x Tempo (s) do GRASP com VNS (18 Barras). 1 2 3 4 5 6 7 8 9 10 92 Analisando o gráfico anterior percebe-se que o algoritmo consome todo o tempo disponível para atingir resultados considerados satisfatórios, de maneira que a qualidade das soluções finais encontradas poderia ser melhorada. A Figura 5.14 abaixo exibe o gráfico construído através das execuções do algoritmo SA. Simulated Annealing 8600 Peso (lbs) 7600 6600 5600 4600 50 10 0 15 0 20 0 25 0 30 0 35 0 40 0 45 0 50 0 55 0 0 3600 Execução 1 Execução 2 Execução 3 Execução 4 Execução 5 Execução 6 Execução 7 Execução 8 Execução 9 Execução 10 Tempo (s) FIGURA 5.14: Gráfico de Peso (lbs) x Tempo (s) do SA (18 Barras). Analisando a Figura 5.14 nota-se que o algoritmo consome pouco tempo computacional para convergir seus resultados. Porém, a qualidade dos resultados alcançados pelo SA, no problema tratado, é considerada satisfatória (de maneira que ainda poderia ser melhorada). A Figura 5.15 a seguir exibe o gráfico construído através das execuções do algoritmo BT. É possível perceber que o algoritmo converge rapidamente, obtendo, ao final de sua pesquisa, resultados considerados excelentes (de qualidade superior em comparação com valor de referência). 93 Busca Tabu 8600 Peso (lbs) 7600 6600 5600 4600 50 10 0 15 0 20 0 25 0 30 0 35 0 40 0 45 0 50 0 55 0 0 3600 Execução 1 Execução 2 Execução 3 Execução 4 Execução 5 Execução 6 Execução 7 Execução 8 Execução 9 Execução 10 Tempo (s) FIGURA 5.15: Gráfico de Peso (lbs) x Tempo (s) da BT (18 Barras). A Figura 5.16 a seguir exibe o gráfico construído por meio das execuções do algoritmo AC. Nota-se que seu comportamento é semelhante ao algoritmo anterior, e, inclusive, atingindo também resultados considerados excelentes (quando comparados com o valor de referência). Colônia de Formigas 8600 6600 5600 4600 50 10 0 15 0 20 0 25 0 30 0 35 0 40 0 45 0 50 0 55 0 3600 0 Peso (lbs) 7600 Execução Execução Execução Execução Execução Execução Execução Execução Execução Execução Tempo (s) FIGURA 5.16: Gráfico de Peso (lbs) x Tempo (s) do AC (18 Barras). 1 2 3 4 5 6 7 8 9 10 94 Para facilitar a compreensão acerca do comportamento dos algoritmos com relação ao problema em questão, foi elaborado o gráfico da Figura 5.17, contendo as melhores execuções de cada algoritmo. Melhor execução de cada algoritmo (18 Barras) 8600 Peso (lbs) 7600 VNS SA GRASP BT AG AC 6600 5600 4600 50 10 0 15 0 20 0 25 0 30 0 35 0 40 0 45 0 50 0 55 0 0 3600 Tempo (s) FIGURA 5.17: Melhores resultados de cada algoritmo (18 Barras). Analisando cada gráfico separadamente é possível perceber a mesma semelhança entre os mesmos métodos, citada na seção anterior. Deste modo, os mesmos dois grupos de algoritmos podem ser evidenciados: o VNS e GRASP com VNS em um mesmo grupo, e os demais em outro grupo. O único parâmetro de inicialização alterado para a execução deste problema em relação à treliça de 10 barras foi a Lista Tabu da Heurística BT, cujo tamanho foi ajustado para seis. Este valor foi definido durante o processo de experimentação, sendo considerado o valor que obteve os melhores resultados durante as execuções do algoritmo. É importante salientar que, para este problema, muitos resultados repetidos foram alcançados. Tal fato se deve à restrição de áreas de seção transversal permitida, fazendo com que a probabilidade de uma mesma área ser escolhida em 95 outras execuções torne-se muito maior do que no problema das 10 barras. Isto porque o intervalo de área deste problema varia de 0,2 in2 a 30 in2 (considerando, no máximo, duas casas decimais). Já o problema das 10 barras, possui intervalos pequenos (por exemplo, de 11,5 a 12,5), porém utilizando uma precisão de seis casas decimais, o que faz com que a probabilidade de encontrar uma mesma solução em diferentes execuções seja bem mais reduzida. Vale notar que o desvio padrão das respostas obtidas entre as execuções de cada algoritmo para este problema é bem maior do que no problema das 10 barras pelo mesmo motivo citado acima. Isto se deve à grande diversidade de áreas de seção transversal permitidas para o problema das 10 barras, que varia em grande parte nas casas decimais de seus valores, de maneira que o peso final em cada execução torna-se muito próximo uns dos outros. Porém, para o caso deste problema, a área da seção transversal pode variar de 0,2 in2 a 30 in2, com precisão de até duas casas decimais. Desta maneira, o valor da área de seção transversal de cada barra pode variar mais nos algarismos inteiros, gerando soluções de peso estrutural com maior desvio padrão entre as dez execuções de cada algoritmo. Os algoritmos de Busca Tabu e Colônia de Formigas chegaram a um mesmo resultado e obtiveram um comportamento muito semelhante durante suas execuções, inclusive atingindo a melhor resposta de cada execução com um tempo gasto bem reduzido. Analisando o comportamento do Simulated Annealing pode-se dizer que o mesmo atingiu um ótimo local. Isto pôde ser constatado ao perceber que a Busca Tabu e a Colônia de Formigas obtiveram um resultado de qualidade superior repetidas vezes, enquanto o SA obteve o mesmo resultado em todas as suas execuções, porém de qualidade inferior. Ainda assim, se observarmos o comportamento dos algoritmos aplicados a este problema apenas pelo gráfico da Figura 5.17, equivocadamente chegar-se-ia a conclusão que o VNS foi superior ao Simulated Annealing. Porém, ao analisar o gráfico de cada algoritmo individualmente, é possível perceber que o SA apresentou um comportamento muito mais constante (baixo desvio padrão entre suas execuções) em seus resultados do que o VNS. Ainda que o melhor resultado do SA seja de qualidade inferior ao melhor 96 resultado obtido pelo VNS, este último consome um tempo muito maior para atingir bons resultados devido à modelagem de suas estruturas de vizinhança. Tal fato é importante para perceber que a eficiência dos algoritmos não pode ser inferida baseada apenas em uma única execução de cada método. É extremamente importante executar o método várias vezes, durante e após o processo de calibração, de modo a qualificar mais precisamente seu comportamento. O Algoritmo Genético, antes de se perceber a falha do processo de adequação citada anteriormente (em que o resultado da mutação muitas vezes se perdia), não obtinha bons resultados. Isto porque, na maioria das vezes, o operador responsável por inserir uma nova característica na população (Mutação) era ineficiente, pois tal característica era sobrescrita pelo processo de adequação das áreas para membros de um mesmo grupo. Esta suposta falha serve para demonstrar a importância do operador de mutação no processo de pesquisa do AG. Sua existência é indispensável, mesmo que sua probabilidade de ocorrer seja extremamente pequena, na continuidade das gerações das populações de indivíduos. Se tal operador não existir, todas as demais gerações de indivíduos serão sempre provenientes de características herdadas da população inicial. Dessa maneira, a mutação é a chave para inserir novas características nos indivíduos e, conseqüentemente, nas futuras gerações. Ao corrigir o processo, os resultados obtidos atingiram um nível de qualidade muito próximo dos resultados da Busca Tabu e da Colônia de Formigas, sendo estes considerados os algoritmos mais eficientes do presente trabalho. 5.3 ESTRUTURA DE 47 BARRAS 5.3.1 Descrição do Problema A configuração estrutural composta por 47 barras foi retirada de Castro (2001) e adaptada para os algoritmos aqui desenvolvidos. A Figura 5.18 ilustra a estrutura a ser otimizada. 97 FIGURA 5.18: Topologia da torre de 47 barras. Fonte: Castro (2001). A otimização realizada em Castro (2001) permite a modificação das áreas de seção transversal das barras e das coordenadas de alguns nós da estrutura, de maneira que a topologia da estrutura poderá ser alterada durante o processo de otimização. 98 O objetivo principal do processo é o mesmo: minimizar o peso estrutural, obedecendo a um conjunto de restrições impostas pelo projeto. Porém, cada problema possui restrições distintas. Sendo assim, as seguintes restrições devem ser consideradas: a) Os nós 18, 19, 21 e 22 são fixos. Os nós 1 e 3 são semi-fixos (pois podem ter suas coordenadas alteradas em relação ao eixo x). Os demais nós são livres para ter suas coordenadas alteradas (adaptado neste trabalho, de maneira que todos os nós são fixos, com o intuito de otimizar apenas a área da seção transversal). b) Nos nós 21 e 18 é aplicado uma força concentrada vertical de Fy= -14000 lbs em Y e horizontal de Fx= 6000 lbs em X. c) O módulo de elasticidade é igual a 3x107 psi, tensão admissível de tração igual a 20000 psi e tensão admissível de compressão igual a -15000 psi (neste trabalho foi considerada somente uma tensão admissível de 20000 psi para compressão ou tração) e massa específica 0,3 lbs / in3. d) Devido a restrições de simetria, as seguintes barras devem possui mesma área de seção transversal: A1=A3; A2=A4; A5=A6; A8=A9; A11=A12; A13=A14; A15=A16; A17=A18; A19=A20; A21=A22; A23=A24; A25=A26; A29=A30; A31=A32; A34=A35; A36=A37; A39=A40; A41=A42; A44=A45; A46=A47; e) As áreas de seção transversal podem variar entre 0,1 in2 a 20 in2. f) Nenhuma restrição é imposta para o deslocamento máximo permitido. Sendo assim, o valor máximo do parâmetro foi inicializado com um valor muito alto para não interferir na busca. 99 5.3.2 Resultados Devido às adaptações realizadas nas restrições da estrutura para sua utilização neste trabalho e pelo fato da otimização aqui aplicada considerar a modificação de apenas uma variável, os resultados obtidos não podem ser comparados com os valores obtidos na referência. Os resultados descritos na Tabela 5.6 são os melhores obtidos em 10 execuções de doze minutos para cada algoritmo. Este tempo foi estipulado após os testes de experimentação, considerando o tempo gasto em média para que os algoritmos se estabilizassem. A coluna de erro relativo foi calculada baseada na melhor solução obtida, que foi encontrada pelo método Busca Tabu. O valor obtido pelo algoritmo original, retirado de Castro (2001) é exibido ao final da Tabela 5.6. Algoritmo Utilizado AG VNS GRASP com VNS Simulated Annealing Colônia de Formigas Busca Tabu (Valor de Referência) [Lemonge,1999] apud [Castro, 2001] Erro Rel. Melhor Solução Encontrada [6.0, 3.1, 6.0, 3.1, 1.5, 1.5, 5.2, 1.1, 1.1, 4.1, 6.3, 6.3, 1.8, 1.8, 5.7, 5.7, 4.0, 4.0, 5.4, 5.4, 6.2, 6.2, 4.9, 4.9, 6.4, 6.4, 6.5, 5.1, 4.2, 4.2, 2.2, 2.2, 6.2, 3.0, 3.0, 0.6, 0.6, 0.5, 3.7, 3.7, 1.6, 1.6, 7.1, 5.6, 5.6, 0.7, 0.7] - Peso: 4331,0 lbs [5.4, 2.7, 5.4, 2.7, 1.3, 1.3, 1.9, 0.6, 0.6, 4.7, 1.9, 1.9, 2.6, 2.6, 6.4, 6.4, 2.8, 2.8, 2.3, 2.3, 2.0, 2.0, 5.3, 5.3, 2.5, 2.5, 6.7, 5.6, 3.2, 3.2, 3.5, 3.5, 3.0, 6.2, 6.2, 1.2, 1.2, 2.3, 6.6, 6.6, 1.9, 1.9, 2.4, 5.5, 5.5, 1.5, 1.5] - Peso: 4165,6 lbs [15.2, 3.4, 15.2, 3.4, 1.1, 1.1, 0.3, 2.6, 2.6, 6.7, 1.6, 1.6, 0.4, 0.4, 3.6, 3.6, 1.7, 1.7, 1.3, 1.3, 17.8, 17.8, 8.1, 8.1, 2.2, 2.2, 10.8, 2.9, 3.0, 3.0, 1.0, 1.0, 2.6, 3.5, 3.5, 1.2, 1.2, 1.8, 4.2, 4.2, 4.8, 4.8, 2.1, 3.4, 3.4, 0.7, 0.7] - Peso: 4205,7 lbs [2.2, 2.2, 2.2, 2.2, 2.2, 2.2, 0.1, 2.2, 2.2, 8.5, 2.2, 2.2, 2.2, 2.2, 2.2, 2.2, 2.2, 2.2, 2.2, 2.2, 0.1, 0.1, 2.2, 2.2, 2.2, 2.2, 10.5, 0.1, 6.4, 6.4, 2.2, 2.2, 2.2, 2.2, 2.2, 2.2, 2.2, 4.3, 4.3, 4.3, 2.2, 2.2, 2.2, 4.3, 4.3, 2.2, 2.2] – Peso: 3508,3 lbs [2.3, 1.5, 2.3, 1.5, 0.5, 0.5, 0.2, 0.9, 0.9, 1.6, 1.8, 1.8, 0.6, 0.6, 1.0, 1.0, 1.6, 1.6, 0.4, 0.4, 0.4, 0.4, 1.9, 1.9, 2.1, 2.1, 1.4, 0.8, 2.4, 2.4, 1.5, 1.5, 1.0, 2.3, 2.3, 0.6, 0.6, 0.1, 2.9, 2.9, 0.5, 0.5, 0.2, 3.5, 3.5, 0.5, 0.5] - Peso: 1686,8 lbs [2.3, 1.5, 2.3, 1.5, 0.5, 0.5, 0.2, 0.6, 0.6, 1.3, 1.7, 1.7, 0.4, 0.4, 0.5, 0.5, 1.6, 1.6, 0.3, 0.3, 0.9, 0.9, 2.2, 2.2, 2.5, 2.5, 1.6, 0.3, 2.4, 2.4, 0.8, 0.8, 0.6, 2.5, 2.5, 0.5, 0.5, 0.1, 3.0, 3.0, 0.5, 0.5, 0.2, 3.4, 3.4, 0.6, 0.6] - Peso: 1608,8 lbs 169,21% 158,93% 161,42% 118,07% 4,85% [3.8, 3.4, 3.8, 3.4, 0.8, 0.8, 0.9, 0.9, 0.9, 1.8, 2.1, 2.1, 1.2, 1.2, 1.6, 1.6, 2.1, 2.1, 0.7, 0.7, 0.9, 0.9, 1.7, 1.7, 1.7, 1.7, 1.4, 0.9, 3.7, 3.7, 1.5, 1.5, 0.7, 2.9, 2.9, 0.7, 0.7, 1.6, 3.7, 3.7, 1.6, 1.6, 0.7, 4.5, 4.5, 1.6, 1.6] - Peso: 2446,8 lbs * * Resultado obtido utilizando valores de tensões admissíveis diferentes. TABELA 5.6: Melhores resultados obtidos em dez execuções para a treliça de 47 Barras. 100 A Tabela 5.7 a seguir exibe os valores obtidos de tensão máxima e deslocamento máximo das melhores soluções obtidas de cada algoritmo. Algoritmo Utilizado Tensão máxima (psi) Deslocamento máximo (in) AG Barra 37: 15275,97 Nó 18: 1.4291726128710256 VNS Barra 9: 17530,52 Nó 18: 1,1495388094475552 GRASP com VNS Barra 45: 19769,12 Nó 18: 1,5776944264699788 Simulated Annealing Barra 3: 19287,86 Nó 18: 1,4900368711744065 Colônia de Formigas Barra 30: 19942,09 Nó 18: 2,2778998069655283 Busca Tabu Barra 30: 19998,79 Nó 18: 2,3514695284451386 [Castro, 2001] Barra 26: 20000,0 Nó 18: 1,6201567782764879 TABELA 5.7: Tensão máxima e deslocamento máximo das soluções para a treliça de 47 Barras. Para realizar a adequação das soluções devido às restrições de simetria deste problema, foi utilizado um processo semelhante à adequação da restrição de grupo do problema anterior. Do mesmo modo, cada solução gerada é modificada e adequada à simetria do problema antes de serem analisadas pelo INSANE. Da mesma maneira que no problema anterior, esta modificação foi implementada no método responsável pela análise das soluções. 5.3.3 Análise dos Resultados Da mesma maneira que o problema anterior, os gráficos deste problema foram elaborados utilizando dez execuções para cada algoritmo, porém com o tempo máximo de processamento de 12 minutos para cada execução. Este valor foi determinado após os testes de experimentação, levando em consideração o tempo necessário para que cada algoritmo se estabilizasse. A utilização deste problema foi muito importante para determinar a eficiência de cada algoritmo ao trabalhar com uma quantidade maior de barras na estrutura. 101 Os gráficos a seguir demonstram que a quantidade de barras existentes na configuração estrutural do problema influencia diretamente no desempenho de alguns algoritmos, como por exemplo, o AG. De acordo com Castro (2001), para cromossomos de tamanho um pouco maiores, é necessário utilizar um operador de cruzamento mais elaborado, o que aumentaria a diversidade entre os filhos gerados, proporcionando um número maior de soluções diferentes provenientes da aplicação do operador de Crossover. Como o objetivo deste trabalho é realizar uma análise comparativa entre os algoritmos, o desenvolvimento de operadores mais elaborados para estes casos é proposto como sugestão para futuros trabalhos. A Figura 5.19 a seguir exibe o gráfico construído por meio das execuções do algoritmo AG. Analisando o gráfico nota-se que, mesmo utilizando todo o tempo disponível para a pesquisa, os resultados obtidos são considerados ruins, sendo sequer próximos do valor de referência. 14500 13500 12500 11500 10500 9500 8500 7500 6500 5500 4500 3500 2500 1500 Execução 1 Execução 2 Execução 3 Execução 4 Execução 5 Execução 6 Execução 7 Execução 8 Execução 9 650 600 550 500 450 400 350 300 250 200 150 100 50 Execução 10 0 Peso (lbs) Algoritmos Genéticos Tempo (s) FIGURA 5.19: Gráfico de Peso (lbs) x Tempo (s) do AG (47 Barras). A Figura 5.20 a seguir exibe o gráfico elaborado por meio das execuções do método VNS. Pelo gráfico é possível perceber que o VNS não atinge resultados sequer satisfatórios. Inclusive, analisando o comportamento do algoritmo em todas 102 as execuções, percebe-se que, mesmo consumindo todo o tempo disponível, o algoritmo não atinge resultados aceitáveis (em comparação com o valor de referência). 14500 13500 12500 11500 10500 9500 8500 7500 6500 5500 4500 3500 2500 1500 Execução 1 Execução 2 Execução 3 Execução 4 Execução 5 Execução 6 Execução 7 Execução 8 Execução 9 650 600 550 500 450 400 350 300 250 200 150 100 50 Execução 10 0 Peso (lbs) VNS Tempo (s) FIGURA 5.20: Gráfico de Peso (lbs) x Tempo (s) do VNS (47 Barras). A Figura 5.21 a seguir exibe o gráfico elaborado por meio das execuções do método GRASP com VNS. Pela análise de suas execuções, percebe-se que, do mesmo modo que o algoritmo anterior, mesmo consumindo todo o tempo disponível para a pesquisa, o método não consegue atingir resultados sequer satisfatórios. 103 14500 13500 12500 11500 10500 9500 8500 7500 6500 5500 4500 3500 2500 1500 Execução 1 Execução 2 Execução 3 Execução 4 Execução 5 Execução 6 Execução 7 Execução 8 Execução 9 650 600 550 500 450 400 350 300 250 200 150 100 50 Execução 10 0 Peso (lbs) GRASP com VNS Tempo (s) FIGURA 5.21: Gráfico de Peso (lbs) x Tempo (s) do GRASP com VNS (47 Barras). A Figura 5.22 a seguir exibe o gráfico das execuções do método SA. 14500 13500 12500 11500 10500 9500 8500 7500 6500 5500 4500 3500 2500 1500 Execução 1 Execução 2 Execução 3 Execução 4 Execução 5 Execução 6 Execução 7 Execução 8 Execução 9 650 600 550 500 450 400 350 300 250 200 150 100 50 Execução 10 0 Peso (lbs) Simulated Annealing Tempo (s) FIGURA 5.22: Gráfico de Peso (lbs) x Tempo (s) do SA (47 Barras). 104 Analisando o gráfico anterior é possível perceber que, para este problema, o método SA não atinge soluções consideradas satisfatórias, mesmo consumindo todo o tempo disponível para a pesquisa. A Figura 5.23 a seguir exibe o gráfico elaborado por meio das execuções da heurística BT. Analisando o gráfico é possível perceber que o algoritmo converge rapidamente para excelentes soluções, consumindo baixo tempo computacional. 14500 13500 12500 11500 10500 9500 8500 7500 6500 5500 4500 3500 2500 1500 Execução 1 Execução 2 Execução 3 Execução 4 Execução 5 Execução 6 Execução 7 Execução 8 Execução 9 650 600 550 500 450 400 350 300 250 200 150 100 50 Execução 10 0 Peso (lbs) Busca Tabu Tempo (s) FIGURA 5.23: Gráfico de Peso (lbs) x Tempo (s) da BT (47 Barras). A Figura 5.24 a seguir exibe o gráfico elaborado por meio das execuções do método AC. Pelo gráfico é possível perceber que o AC apresenta bons resultados em pouco tempo, atingindo, ao final de sua pesquisa, excelentes soluções. 105 14500 13500 12500 11500 10500 9500 8500 7500 6500 5500 4500 3500 2500 1500 Execução 1 Execução 2 Execução 3 Execução 4 Execução 5 Execução 6 Execução 7 Execução 8 Execução 9 650 600 550 500 450 400 350 300 250 200 150 100 50 Execução 10 0 Peso (lbs) Colônia de Formigas Tempo (s) FIGURA 5.24: Gráfico de Peso (lbs) x Tempo (s) do AC (47 Barras). O gráfico da Figura 5.25 contém as melhores execuções de cada algoritmo para o problema proposto. 14500 13500 12500 11500 10500 9500 8500 7500 6500 5500 4500 3500 2500 1500 650 600 550 500 450 400 350 300 250 200 150 100 50 VNS SA GRASP BT AG AC 0 Peso (lbs) Melhor execução de cada algoritmo (47 Barras) Tempo (s) FIGURA 5.25: Melhores resultados de cada algoritmo (47 Barras). 106 Os algoritmos VNS e GRASP, de acordo com o gráfico da Figura 5.25, mais uma vez exibiram resultados semelhantes. Analisando os gráficos individuais de cada método percebe-se a existência de muitas planícies em pouco tempo de execução, o que demonstra um gasto de tempo mais elevado para obter melhores soluções. O AG não obteve bons resultados devido aos operadores genéticos utilizados em sua implementação. Conforme mencionado anteriormente, para cromossomos de tamanho um pouco maior, é necessário desenvolver operadores genéticos capazes de manter a diversificação entre as gerações durante a evolução da população, de maneira que tal diversificação não é atingida ao trabalhar apenas com os operadores clássicos. Pela análise da Figura 5.25 pode-se perceber que o SA não obteve resultados satisfatórios. Entretanto, ao analisar o comportamento das execuções do algoritmo na Figura 5.22, percebe-se que o algoritmo tende a obter resultados mais satisfatórios consumindo um tempo acima do limite estipulado. Deste modo, foi realizado um teste estipulando um tempo máximo de 18 minutos e o resultado obtido foi considerado satisfatório. Mesmo não obtendo bons resultados neste problema, sua facilidade de implementação e calibração, juntamente com os resultados obtidos nos problemas anteriores, faz com que este algoritmo seja uma boa alternativa ao se levar em conta a relação custo / benefício. Já os algoritmos de Busca Tabu e Colônia de Formigas consolidaram a eficiência demonstrada nos problemas anteriores. Analisando o gráfico da Figura 5.25 é fácil perceber um comportamento muito semelhante entre eles. Porém, o algoritmo Colônia de Formigas, ao possuir um número maior de parâmetros, dificulta um pouco mais o processo de calibração em comparação com o algoritmo de Busca Tabu. 107 5.4 ANÁLISE COMPARATIVA ENTRE OS MÉTODOS Ao analisar os gráficos das figuras 5.23 e 5.24 é possível perceber que os algoritmos BT e AC conseguem atingir boas soluções utilizando-se de um tempo computacional muito reduzido, o que demonstra um grande poder de pesquisa. Esta característica, ao ser comprovada nos três problemas aqui estudados, faz destes métodos os mais robustos e eficientes deste trabalho. Sendo assim, o quadro a seguir foi elaborado para comparar os métodos em níveis de dificuldade (definidos em alta, média e baixa) para os quesitos de: • Flexibilidade: neste trabalho este quesito está diretamente relacionado com a quantidade de parâmetros do método, de maneira que uma quantidade elevada de parâmetros indica alta flexibilidade, permitindo testar situações diversificadas no intuito de observar como ocorre a evolução até a resposta; • Calibração: quanto maior a quantidade de parâmetros, mais difícil tornase a tarefa de calibração destes parâmetros devido à quantidade de possibilidades permitidas; • Eficiência: diretamente relacionado com o tempo gasto e a qualidade das respostas obtidas; • Implementação: refere-se à facilidade de implementação e adaptação do método a diversos tipos de problema. Vale lembrar que os conceitos inferidos para cada quesito estão diretamente relacionados com a classe de problemas tratada neste trabalho, juntamente com as implementações aqui desenvolvidas, de maneira que os valores podem ser diferentes para outras classes de problema. Os conceitos descritos na Tabela 5.8 são relacionados com o nível de dificuldade do requisito. “Alta” indica o nível de dificuldade mais elevado, exigindo mais atenção, paciência e, inclusive, bons conhecimentos na área computacional. “Média” indica um nível de dificuldade 108 moderado, exigindo atenção e um nível razoável de conhecimentos em computação. “Baixa” indica um nível de dificuldade baixa, de maneira que é interessante, mas não necessária, uma boa formação computacional. Flexibilidade Calibração Eficiência Implementação AG Alta Alta Alta Média VNS Baixa Baixa Média Baixa GRASP com VNS Média Baixa Média Baixa Simulated Annealing Média Baixa Alta Baixa Busca Tabu Média Média Alta Alta Ant Colony Alta Alta Alta Alta TABELA 5.8: Análise comparativa entre os algoritmos implementados. O método ideal serial aquele que obtivesse os conceitos “Alta”, “Baixa”, “Alta”, “Baixa”, respectivamente na ordem das colunas acima. Analisando o nível de dificuldade de cada quesito da tabela, percebe-se que o único algoritmo que possui alta eficiência e facilidade de implementação é o SA, o que evidencia sua relação custo / benefício. Outro algoritmo que tem sido largamente utilizado nas mais diversas áreas de pesquisa em otimização, por possuir grande eficiência e flexibilidade, aliada a um custo de implementação moderado, é o AG. No caso dos algoritmos VNS e GRASP com VNS, os mesmos não obtiveram bons resultados para os dois últimos problemas tratados. Vale lembrar que tais métodos não obtiveram bons resultados para a classe de problemas aqui propostos, implementados em sua forma tradicional. Tais resultados podem ser ligeiramente diferentes para implementações mais elaboradas ou quando aplicados a uma outra classe de problemas. Os algoritmos BT e AC, mesmo com um grau elevado de implementação, se mostraram os mais eficientes do trabalho, sendo os mais indicados àqueles que primam pela qualidade de resultados, utilizando um tempo computacional reduzido. 109 6 CONCLUSÃO 6 CONCLUSÃO 110 Este capítulo contém as conclusões acerca deste trabalho, bem como sugestões para futuras implementações e estudos na área de otimização estrutural utilizando métodos heurísticos. 6.1 CONSIDERAÇÕES GERAIS Os métodos aqui desenvolvidos, juntamente com a análise realizada por meio da aplicação dos problemas propostos, fornecem um grande arcabouço de experimentos aos profissionais e pesquisadores da área de otimização e aperfeiçoamento de projetos estruturais. A análise dos métodos heurísticos aplicados fornece um embasamento teórico e prático necessário que poderá ajudar na escolha do algoritmo mais adequado ao tipo de problema que se deseja otimizar. 6.2 CONCLUSÕES O método de Algoritmos Genéticos se mostrou bastante eficiente nos dois primeiros problemas e, ainda que os resultados obtidos no último problema não tenham sido satisfatórios, sua utilização não deve ser descartada. Este método é largamente utilizado nas mais diversas áreas de otimização, comprovando sua eficiência e robustez em diversos tipos de problemas, o que pode ser comprovado em Castro (2001), Yang (2002), dentre outros. A utilização da codificação real para os cromossomos na implementação do AG foi fundamental na eficiência deste algoritmo. A utilização de codificação binária para problemas de grande porte (que necessitam de um tamanho elevado para os cromossomos) é desencorajada, uma vez exige um grande esforço computacional para codificação e decodificação de toda uma população. Um estudo sobre 111 vantagens e desvantagens de cada tipo de codificação pode ser encontrado em Catarina e Bach (2003). O operador de Mutação se mostrou extremamente importante no processo de construção de indivíduos para uma nova geração. Mesmo com baixa probabilidade, ele garante novas características aos indivíduos em cada geração, de maneira que tais características não poderiam ser adquiridas utilizando apenas o operador de cruzamento. Os métodos VNS e GRASP, mesmo não apresentando resultados satisfatórios nos dois últimos problemas, são opções interessantes àqueles que desejam ingressar na aplicação de heurísticas, devido a sua facilidade de desenvolvimento e calibração. O método Simulated Annealing comprovou ser o melhor método de relação custo / benefício, por possuir fácil implementação e calibração, além de obter bons resultados com um tempo computacional reduzido. Por meio da implementação dos algoritmos Busca Tabu e Colônia de Formigas, foi possível perceber a importância do papel da modelagem de um problema para a aplicação dos métodos heurísticos. Tais heurísticas se mostraram extremamente eficientes, tornando-se excelentes opções principalmente quando o problema tratado exigir qualidade de respostas e baixo tempo computacional. Os resultados obtidos foram considerados excelentes, principalmente ao comparar os resultados dos Algoritmos Genéticos, Busca Tabu e Colônia de Formigas com os valores de referência de Rozvany (1991) e Fawaz (2005). As soluções encontradas possuem qualidade semelhante e até superior (no caso do segundo problema) ao serem comparados com os valores de referência. 112 6.3 SUGESTÕES PARA TRABALHOS FUTUROS As sugestões apresentadas a seguir são algumas idéias que podem ser abordadas em futuras pesquisas na área de otimização estrutural: • Analisar um estudo comparativo considerando como novo objetivo para a otimização a topologia da estrutura, permitindo a alteração das coordenadas dos nós que compõem a configuração. Um exemplo prático desta otimização pode ser encontrada em Castro (2001); • Estudar o comportamento dos algoritmos quando aplicados a projetos que utilizam treliças tridimensionais ou espaciais, analisando os resultados obtidos; • Desenvolver operadores genéticos mais elaborados que permitam ao AG manter o alto nível de qualidade de suas respostas mesmo quando o problema possuir um número elevado de barras em sua estrutura (necessitando de um cromossomo de maior tamanho); • Estudar o comportamento evolutivo do Algoritmo Genético por meio do conhecimento dos pais e pontos de mutação de cada indivíduo. O desenvolvimento realizado neste trabalho mantém armazenados os pais e, quando ocorre, o ponto de mutação de cada indivíduo, permitindo mapear o momento em que ocorre o surgimento de novas características e até mesmo a construção da árvore genealógica de cada indivíduo; • Desenvolver um algoritmo Simulated Annealing modificado, de maneira a manter o nível de qualidade mesmo quando o problema possuir um número elevado de barras em sua estrutura; • Realizar o processo de otimização em vigas de concreto armado, onde em geral, o custo não é proporcional ao peso, elaborando um estudo comparativo entre as heurísticas implementadas; 113 • Empregar a otimização em problemas considerados “fortemente” multiobjetivo, como por exemplo, estruturas dinâmicas – peso x freqüências naturais de vibração. 114 REFERÊNCIAS 115 BABA, C. M. Otimização da Colônia de Formigas aplicada ao Problema de programação e roteirização de veículos para o transporte de pessoas portadoras de deficiência. XXVI Encontro Nac. de Eng. de Produção – ENEGEP – 03 a 05 de Novembro de 2004 – Florianópolis – SC - Brasil. Pg. 2966-2973, 2004. BLAND, J.A. Discrete-variable optimal structural design using tabu search. Journal Structural and Multidisciplinary Optimization. Publisher Springer Berlin / Heidelberg. Issue Volume 10, Number 2 / October, Pg. 87-93.,1995. CASTRO, R. E. Otimização de Estruturas com Multi-Objetivos Via Algoritmos Genéticos de Pareto. Tese de Doutorado. COPPE / UFRJ. Rio de Janeiro - RJ. Brasil, 2001. CATARINA, A. S. e BACH, Sirlei L. Estudo do efeito dos parâmetros genéticos sobre a solução otimizada e sobre o tempo de convergência em algoritmos genéticos com codificações binária e real. Acta Scientiarum. Technology. Maringá-SP, Brasil, v. 25, no. 2, Pg. 147-152, 2003. COELHO, L. S. e NETO, R. F. T., Colônia de Formigas: Uma Abordagem Promissora para Aplicações de Atribuição Quadrática e Projeto de Layout, XXIV ENEGEP, Florianópolis-SC, Brasil, 2004. COSTA, F. P. Programação de Horários em Escolas via GRASP e Busca Tabu. Monografia de Graduação em Engenharia de Produção pela Universidade Federal de Ouro Preto – MG, Brasil, 2003. DAMMEYER, F. e VOY, S. Dynamic tabu list management using the reverse elimination method. In P.L. Hammer, editor, Tabu Search, volume 41 of Annals of Operations Research, Pg. 31-46, Baltzer Science Publishers, Amsterdan, 1993. DIMOU, C.K. e KOUMOUSIS V.K. Competitive genetic algorithms with application to reliability optimal design. Institute of Structural Analysis and Aseismic Research, National Technical University of Athens, Athens, Greece, 2003. Disponível via http://www.elsevier.com/locate/advengsoft. DORIGO M., Optimization, Learning and Natural Algorithms, Ph.D.Thesis, Politecnico di Milano, Italy, 1992. DORIGO, M. e CARO, G. DI. The Ant Colony Optimization Meta-Heuristic. In D. Corne, M. Dorigo and F. Glover, editors, New Ideas in Optimization, McGraw-Hill, Pg.11-32, 1999. FAWAZ, Z., XU, Y.G. e BEHDINAN K. Hybrid evolutionary algorithm and application to structural optimization. Journal Structural and Multidisciplinary Optimization. Publisher Springer Berlin / Heidelberg. Issue Volume 30, Number 3 – Pg. 219-226 / September, 2005. FEO, T.A. e RESENDE, M.G.C. Greedy randomized adaptive search procedures. Journal of Global Optimization, Volume 6, Pg. 109-133, 1995. 116 FONSECA, F. T. e PITANGUEIRA, R. L. Um Programa Gráfico Interativo para Modelos Estruturais de Barras. Departamento de Engenharia de Estruturas, Universidade Federal de Minas Gerais. Belo Horizonte – MG, Brasil, 2004. Disponível via http://www.dees.ufmg.br/insane/artigos. GLOVER, F. Future paths for Integer Programming and links to Artificial Intelligence. Computers and Operations Research, Volume 5, Pg. 553-549, 1986. GLOVER, F. e LAGUNA, M. Tabu search. In: Colin, R. R. Modern heuristic techniques for combinatorial problems. New York, McGraw-Hill, Pg. 70-150, 1995. GOLDBERG, D.E. Genetic Algorithms in Search, Optimization and Machine Learning. Addison-Wesley, Berkeley, 1989. HANSEN, P. The steepest ascent mildest descent heuristic for combinatorial programming. In Congress on Numerical Methods in Combinatorial Optimization, Capri, Italy, 1986. JIVOTOVSKI, G. A gradient based heuristic algorithm and its application to discrete optimization of bar structures. Journal Structural and Multidisciplinary Optimization. Publisher Springer Berlin / Heidelberg. Issue Volume 19, Number 3 / May, Pg. 237248, 2000. KINCAID, R.K. Minimizing distortion and internal forces in truss structures via simulated annealing. Journal Structural and Multidisciplinary Optimization. Publisher Springer Berlin / Heidelberg. Issue Volume 4, Number 1 / March, Pg. 55-61, 1992. KINCAID, R.K. Minimizing distortion in truss structures: A comparison of simulated annealing and tabu search. Journal Structural and Multidisciplinary Optimization. Publisher Springer Berlin / Heidelberg. Issue Volume 5, Number 4 / December, Pg. 217-224, 1993. KIRKPATRICK, S., GELLAT, D.C. e VECCHI, M.P. Optimization by Simulated Annealing. Science, Number 220, Pg. 671-680, 1983. LEMONGE, A. C. C., “Aplicação de Algoritmos Genéticos em Otimização Estrutural”. Tese de Doutorado do Programa de Engenharia Civil, COPPE / UFRJ, Rio de Janeiro, Junho de 1999. LUSAS, FEA. Engineering Analysis Software. Available: http://www.lusas.com, 2007. MAGALHÃES, J. R. M. e MALITE, M. Treliças metálicas espaciais: alguns aspectos relativos ao projeto e à construção. Cadernos de Engenharia de Estruturas. Departamento de Engenharia de Estruturas – USP, 1998. MITCHELL M. An Introduction to Genetic Algorithms. MIT Press, 1998. 117 MLADENOVIC, N. e HANSEN P. Variable Neighborhood Search. Computers and Operations Research, Volume 24 Pg. 1097 – 1100, 1997. ROZVANY, G.I.N. e ZHON M. A note on truss design for stress and displacement constraints by optimality criteria methods. Journal Structural and Multidisciplinary Optimization. Publisher Springer Berlin / Heidelberg. Issue Volume 3, Number 1 / March, Pg. 45-50, 1991. SALAJEGHEH, E. e HEIDARI, A. Optimum Design of Structures Against Earthquake by Adaptive Genetic Algorithm Using Wavelet Networks. Journal Structural and Multidisciplinary Optimization. Publisher Springer Berlin / Heidelberg. Issue Volume 28, Number 4 / October, Pg. 277-285, 2004. SILVA, E. C. N. Técnicas de Otimização Aplicadas no Projeto de Peças Mecânicas. Departamento de Engenharia Mecatrônica e de Sistemas Mecânicos. Escola Politécnica da USP, 2002. SILVA, G. C. Análise de Heurísticas GRASP para o Problema da Diversidade Máxima. Dissertação de Mestrado submetida ao Programa de Pós-Graduação da Universidade Federal Fluminense – Niterói – RJ, 2004. SOUZA, M. J. F. Apostila da disciplina Inteligência Computacional para Otimização. ICEB-UFOP. Ouro Preto-MG. Disponível via http://www.iceb.ufop.br/decom/~marcone, 2005. TRINDADE, V. A. e OCHI, L. S. Proposta e Avaliação Experimental de Heurísticas GRASP para um Problema de Escalonamento de Veículos. Artigo publicado no XXXVI SBPO – São João Del Rey – MG, 2004. YANG, Y. e SOH, C. K. Automated optimum design of structures using genetic programming. Nanyang Technological University, Singapore, 2002. YOKOTA, T., TAGUCHI T. e GEN, M. A Solution Method for Optimal Weight Design Problem of 10 Bar Truss Using Genetic Algorithms. Department of Industrial and Systems Engineering. Ashikaga Institute of Technology, Ashikaga 326, Japan, 1998. ZIMMER C. Livro de Ouro da Evolução. Ediouro, Pg. 4-9, 2003. 118 ANEXOS 119 ANEXO A – CONFIGURAÇÃO DO AMBIENTE DE DESENVOLVIMENTO O presente trabalho, que recebeu o nome de OtimoEstrutura, foi implementado na plataforma Java (JDK versão 1.6.0), utilizando como ambiente de desenvolvimento o Eclipse versão 3.2. A versão mais recente do pacote JDK pode ser encontrada gratuitamente através do site http://www.sun.com. A versão mais recente da ferramente Eclipse pode ser encontrada em http://www.eclipse.org. A configuração utilizada nesta implementação foi um computador com o processador Intel Core 2 Duo E6300, 2 GB de memória RAM e sistema operacional Windows XP Service Pack 2. Para utilizar a ferramenta Eclipse é recomendável pelo menos 1GB de memória RAM. A configuração do ambiente é bem simples. Após realizar o download dos aplicativos acima citados, é recomendada a criação da pasta C:\java (para melhor organizar todas as ferramentas relacionadas com a aplicação). Antes de instalar o pacote JDK, é necessário verificar (através do painel de controle) se existe na máquina alguma aplicação do pacote JDK já instalada. Caso exista é aconselhável remover, uma vez que poderá causar incompatibilidade de versão com o novo pacote. Após realizar tal operação, basta instalar o pacote JDK de maneira que fique na pasta C:\Java (Ex.: C:\Java\jdk1.6.0). O pacote instalará o JDK e o JRE. Ambos deverão estar em C:\Java. Após instalar o JDK, o próximo passo é a configuração do Eclipse. A versão mais recente do Eclipse já vem com uma versão do JRE integrada. Nas versões mais antigas (em que não é necessário instalar o aplicativo, pois o mesmo vem em um arquivo .zip, que deverá apenas ser descompactado na pasta C:\Java) é obrigatório a instalação do pacote do JDK. Mesmo na versão mais recente, pode-se instalar uma versão do pacote JDK e configurar o Eclipse para que este utilize o pacote instalado e não a versão nativamente integrada. Para todos os 120 casos (instalar ou descompactar) sua instalação deverá ser realizada na pasta C:\Java (C:\Java\Eclipse). Após a instalação da ferramenta, sua configuração é bem simples: basta executar o Eclipse, acessar o menu Window, opção Preferences. Após abrir as opções, clicar no ícone “+” da opção Java na lista à esquerda. Escolher a opção Installed JREs e clicar em “adicionar”. No campo JRE name, basta digitar “jdk<versão de sua instalação>”. Ainda na mesma tela, escolher o diretório em que ele se encontra (C:\Java\jdk<versão>). Após realizar estas operações, basta confirmar clicando em OK e verificar se a opção selecionada em Installed JREs corresponde à opção que foi recentemente adicionada. Caso esteja correto, resta apenas confirmar e reiniciar o Eclipse. Desde modo, o ambiente de desenvolvimento está devidamente configurado.
Download