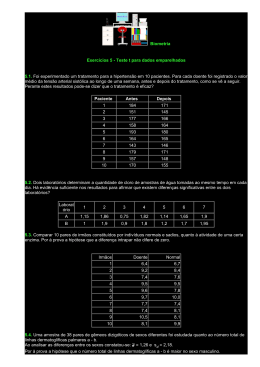
Caros Alunos, Para desenvolver a atividade abaixo vocês precisarão de um computador conectado à internet banda larga, do arquivo .txt (bloco de notas) disponível no “Constructore” e deste arquivo com as coordenadas para o trabalho. “Explorar o resultado” significa observar o máximo possível de detalhes a partir dos resultados gerados com a ferramenta de trabalho que vocês estão utilizando. Não se preocupem, porque links explicando o princípio e/ou o significado dos termos estarão disponíveis em quase todas as etapas. Vale destacar que as coordenadas descritas abaixo representam apenas uma das milhares de formas de desenvolver esta tarefa. Fiquem completamente à vontade para explorarem outros recursos disponíveis na web. Informações relevantes obtidas por caminhos diferentes dos apresentados poderão favorecer o aprendizado e o rendimento final. Nome da atividade: Identificação de uma proteína a partir da sua seqüência nucleotídica e determinação da sua estrutura e função Seção 1: Identificação da proteína e aquisição de dados Copie a seq de interesse a partir do arquivo .txt fornecido > Entre em http://blast.ncbi.nlm.nih.gov/Blast.cgi > link blastx > cole a seq em “Enter query sequence” > clique em “Blast” > clicar na identificação (ID) do primeiro item dos resultados (ex.: gb|BCD95476.1|) > explorar os dados disponíveis (qual é a proteína, organismo de origem...copie e guarde tudo!) > na parte superior da página em “format” escolher “FASTA” > copie o resultado (desde gi|BCD95476.1| até o final da seq) > criar um arquivo novo no bloco de notas (.txt) > colar a seq no arquivo .txt. Esta seq corresponde à seq da proteína codificada pela seq de interesse. Representa a tradução da seq nucleotídica em um seq de aminoácidos. Retorne ao resultado do Blast > copie outras 4 seqs > a última seqüência da lista e outras 3 seqs intermediárias na lista > para cada seq copie a origem do organismo e outras informações que acharem necessárias > colar todas as seqs no mesmo arquivo .txt Ao final desta sessão vocês terão: 1) Identificação da proteína 2) Organismo e local de origem 3) um arquivo .txt contendo 5 seq em formato Fasta Guarde este arquivo para uso posterior Seção 2: Informações de estrutura primária da proteína Copie a primeira seq a partir do arquivo.txt gerado na Seção 1 > Entre em http://www.expasy.ch/tools/ > link “ProtParam” > cole a seq de interesse na caixa indicada “Or you can paste your own sequence in the box below” > clique em “compute parameters” > explorar os dados disponíveis (no de aminoácidos da proteína, pI...copie e guarde tudo!) Ao final desta Seção vocês terão: 1) informações de seqüência primária da seq de interesse 2) alguns parâmetros físico-químico da seq de interesse Seção 3: Ocorrência de peptídeo sinal/Predição de localização subcelular Copie a seq de interesse > retorne em http://www.expasy.ch/tools/ > link “SOSUI” > link SOSUIsignal > cole a seq de interesse em “Enter your sequence with...” > clique em “Exec” > explorar os dados disponíveis (se a proteína tem ou não peptídeo sinal, se é solúvel ou não...copie e guarde tudo!) Ao final desta Seção vocês terão: 1) existência de peptídeo sinal 2) se a proteína é solúvel ou de membrana Seção 4: Alinhamento das seq de interesse Entre em http://www.mbio.ncsu.edu/BioEdit/bioedit.html#downloads > no final da página, escolha “Version 7.0.7” > salve no seu computador > abra e execute o programa > File > Open > encontre o arquivo .txt gerado ao final da Seção 1 > as 5 seq salvas aparecerão em ordem no programa > vá em “Accessory application” > “ClustalW Multiple alignment” > aparece uma caixa de diálogo > clique em “Run ClustalW” > uma outra caixa de diálogo aparece > clique em ok > a nova janela aberta apresenta as 5 seqs alinhadas > mantenham esta janela aberta, ela deve ser o local de partida para os três caminhos seguintes: Caminho 1: determinação das regiões de maior e menor hidrofobicidade da proteína: localize a sua seq de interesse entre as 5 seqs na janela do alinhamento anterior > selecione a seq de interesse clicando sobre a identificação dela (gi|954761|) > vá em “Sequence” > opção “protein” > escolha “Kyte & Doolitle Mean hydrophobicity Profile” > clique em “Run Plot” > salvar o gráfico de hidrofobicidade da seq (observar que o eixo “position” do gráfico equivale à posição do aminoácido representado pelos números que aparece nas seqs alinhadas > no gráfico, encontrar as regiões de maior e menor hidrofobicidade (picos superior e inferior) > encontrar na seq primária o trecho de aminoácidos responsável por elas. Caminho 2: montagem da figura final do alinhamento: Na janela do alinhamento anterior > selecionar as 5 seqs alinhadas clicando na identificação de cada uma delas (tem que estar com o Ctrl pressionado) > vá em “File” > opção “Graphic View” > preencha a janela que foi aberta exatamente como segue: copiar a figura do alinhamento em “Edit” > opção “Copy Page as an enhanced Windows metafile” > colar em arquivo .doc ou .ppt para montagem do trabalho final (caso a figura do alinhamento seja muito grande, vai ser necessário copiar em duas partes e montar uma figura final única) > explorar os dados disponíveis (se existe algum aminoácido diferente na seq de interesse) > analisar esta diferença levando-se em conta a natureza do aminoácido diferente comparado com a natureza do aminoácido que ocorre na mesma posição nas outras seqs (copie e guarde tudo!) Caminho 3: Determinação de regiões conservadas Na janela do alinhamento anterior > selecionar as 5 seqs alinhadas clicando na identificação de cada uma delas (tem que estar com o Ctrl pressionado) > vá em “Alignment” > opção “Find Conserved Regions” > uma caixa de diálogo vai ser aberta > clique em “Start” > explorar os dados disponíveis (encontrar os trechos indicados como conservados no alinhamento e checar a correspondência entre os aminoácidos das seqs alinhadas para aqueles trechos...copie e guarde tudo!) Ao final desta Seção, vocês terão: 1) os principais trechos responsáveis pelo caracter hidrofóbico e hidrofílico da proteína 2) o quanto as proteínas se parecem, se existe alguma diferença na composição de aminoácido entre elas 3) quais seriam os trechos conservados da proteína Seção 5: Avaliação do grau de parentesco Retorne em http://www.expasy.ch/tools/ > opção “CLUSTAL W” > link “EBI”> na nova página > na opção “Upload a file” clique em “Procurar” > localize o arquivo .txt gerado na Seção 1 > clique em “Run” > aguarde enquanto o arquivo é processado > uma página com vários resultados vai ser gerada > vá até o final da página no item “Cladogram” > clique em “Show as Phylogram Tree > voltar ao final da página > para copiar a figura da árvore filogenética vocês usarão o recurso “Print Screen” do computador (tecla PrtSc) > abrir qualquer programa de foto disponível no seu computador > colar a imagem > selecionar apenas a parte da imagem que equivale à árvore filogenética > copiar > colar em arquivo tipo .doc ou .ppt para a montagem do trabalho final > observar se agrupamento feito entra as seqs tem alguma correlação com o país de origem de cada seq Ao final desta Seção, vocês terão: 1) Uma figura informativa do agrupamento das seqs de acordo com as semelhanças entre elas Seção 6: Avaliação da estrutura terciária/quaternária da proteína Copie a primeira seq a partir do arquivo .txt gerado na Seção 1 (somente as letras que correspondem aos aminoácidos) > retorne em http://www.expasy.ch/tools/ > opção “CPHmodels” > cole a seq na opção “Paste a single sequence or several sequences in FASTA format into the field below:” > aguarde o processamento do arquivo > no final da página de resultados vocês encontrarão uma caixa preta, ela contem o modelo da estrutura para a seq de interesse > observem que vocês podem rodar (segure o botão esquerdo do mouse e movimente) ou alterar a escala da imagem (segure o botão direito e arraste para direita ou esquerda) > para copiar a figura do modelo estrutural vocês usarão o recurso “Print Screen” do computador (tecla PrtSc) > abrir qualquer programa de foto disponível na seu computador > colar a imagem > selecionar apenas a parte da imagem que equivale à árvore filogenética > copiar > colar em arquivo tipo .doc ou .ppt para a montagem do trabalho final Ao final desta Seção, vocês terão: 1) O modelo da estrutura terciária da seq de interesse Seção 7: Busca por estrutura semelhantes à proteína de interesse Entre no site http://www.rcsb.org/pdb/home/home.do > escreva o nome da proteína de interesse (em inglês, ex.: hemoglobin) ou a seqüência (obtida após o Blast da seção 1). Se utilizar a busca pelo nome: clique “Search” > entre os resultados observar pelo nome da proteína aquela que estaria mais relacionada com a sua proteína de interesse (dar preferência para proteínas que cuja estrutura foi determinada na presença de um ligante, isso pode lhes ajudar a determinar a região chave na estrutura da proteína) > clique no link “download PDB file” como abaixo (seta vermelha) > salve o arquivo .pdb Se utilizar a busca pela seqüência: clique “Adv. search” > “Choose a query type” > Sequence (Blast/Fasta) > cole sua seq na caixa em branco > evaluate query. a estrutura salva poderá ser visualizada em um programa chamado “RasMol” > para fazer o download dele, vá em http://www.bernstein-plus-sons.com/software/RasMol_2.7.2/ > no final da página tem um link “RasWin.exe” > salve em seu computador > execute o programa > abra o arquivo .pdb salvo anteriormente > utilize as ferramentas do programa para movimentar a estrutura > copie as imagens que vocês acharem mais interessantes > cole em arquivo .doc ou .ppt para montagem do trabalho final. Ao final desta Seção, vocês terão: 1) O modelo da estrutura terciária de uma proteína semelhante à proteína de interesse Seção 8: Agrupamento de informações Baseado nos conceitos gerais sobre estrutura e função de proteínas desenvolvidos em sala e nas informações específicas obtidas nas Sessões acima, monte uma apresentação (ex.: no PowerPoint) objetivando contar a estória específica da proteína de interesse. Lembrando que toda estória precisa ter princípio (“informações de estrutura primária), meio (“informações de estrutura secundária”) e fim (“informações de estrutura terciária e quaternária e função”). Bom trabalho!
Baixar