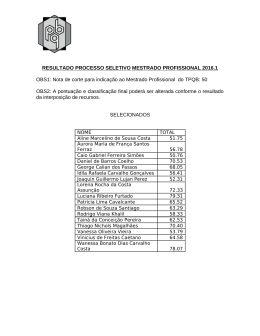
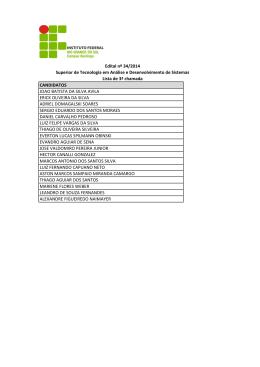
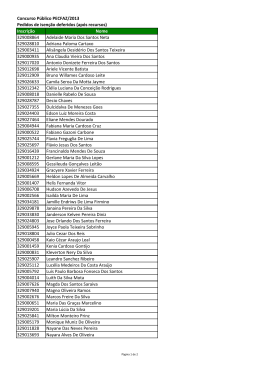
Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Aula 1: Introdução à Modelagem SER-202 Estatística: Aplicações ao Sensoriamento Remoto Thiago S. F. Silva [email protected] 23/04/2013 Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) 1 Apresentações 2 Informações Gerais 3 Modelagem Estatística 4 Discussão - Gigerenzer et al. (2004) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Quem sou eu? Thiago Sanna Freire Silva Graduado em Biologia pela UFRN em 2002 Mestre em Sensoriamento Remoto pelo INPE em 2004 Doutor em Geografia Física pela UVic (Canada) em 2009 Bolsista de Pós-doutorado FAPESP Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Quem sou eu? Thiago Sanna Freire Silva Graduado em Biologia pela UFRN em 2002 Mestre em Sensoriamento Remoto pelo INPE em 2004 Doutor em Geografia Física pela UVic (Canada) em 2009 Bolsista de Pós-doutorado FAPESP Área de Atuação Sensoriamento Remoto Multisensor (Óptico + SAR) Ecologia de Ecossistemas e da Paisagem Áreas Úmidas (Wetlands) Tropicais Impactos Antrópicos e Mudanças Climáticas Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Quem são vocês? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) INFORMAÇÕES GERAIS Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Avaliações Exercícios Semanais: 30% Prova/Trabalho Final: 70% Nota Final NotaFinal = (NotaCamilo + NotaThiago) 2 Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Avaliações Exercícios Semanais: 30% Prova/Trabalho Final: 70% Nota Final NotaFinal = (NotaCamilo + NotaThiago) 2 Obs 1: Please, identifiquem-se no nome do arquivo (ex: thiago_sanna_exercicio_1.pdf) Obs 2: Please x 2, usem o seu e-mail do INPE para enviar o trabalho (filtro de e-mails) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Mudanças de Horários AGU Americas - 14/05/2013 (Ter?a) e 16/05/2013 (Quinta) Concurso - ???? SORRY! Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Por que usar R? R: Pacote para análise e programação estatística Livre, gratuito, tem se tornado “padrão” para análises científicas Difícil no início, mas o tempo é recuperado depois Programação = liberdade Todos os exemplos desta parte do curso serão dados em R Assume-se que todos tenham instalado o R 3.0 e a interface RStudio Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Por que usar R? R: Pacote para análise e programação estatística Livre, gratuito, tem se tornado “padrão” para análises científicas Difícil no início, mas o tempo é recuperado depois Programação = liberdade Todos os exemplos desta parte do curso serão dados em R Assume-se que todos tenham instalado o R 3.0 e a interface RStudio Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Por que usar R? R: Pacote para análise e programação estatística Livre, gratuito, tem se tornado “padrão” para análises científicas Difícil no início, mas o tempo é recuperado depois Programação = liberdade Todos os exemplos desta parte do curso serão dados em R Assume-se que todos tenham instalado o R 3.0 e a interface RStudio Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Por que usar R? R: Pacote para análise e programação estatística Livre, gratuito, tem se tornado “padrão” para análises científicas Difícil no início, mas o tempo é recuperado depois Programação = liberdade Todos os exemplos desta parte do curso serão dados em R Assume-se que todos tenham instalado o R 3.0 e a interface RStudio Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Por que usar R? R: Pacote para análise e programação estatística Livre, gratuito, tem se tornado “padrão” para análises científicas Difícil no início, mas o tempo é recuperado depois Programação = liberdade Todos os exemplos desta parte do curso serão dados em R Assume-se que todos tenham instalado o R 3.0 e a interface RStudio Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que será abordado nas próximas 12 aulas? 1 Introdução (Hoje) 8 Extensões da Regressão: Modelos Lineares Gerais, Generalizados, Mistos 2 Análise Exploratória de Dados e Análise Gráfica 3 Regressão Linear Simples 9 Autocorrelação I - Séries Temporais 4 Regressão Linear Múltipla 5 Diagnóstico e Avaliação do Modelo 10 Autocorrelação II Correlação Espacial 6 Análise e Partição da Variância 11 7 Exemplos de Aplicações Técnicas de Ordenação e Agrupamento - PCA, CCA, Cluster, etc. 12 Em aberto (revisão, reposição, falta de tempo, etc.) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que será abordado nas próximas 12 aulas? 1 Introdução (Hoje) 8 Extensões da Regressão: Modelos Lineares Gerais, Generalizados, Mistos 2 Análise Exploratória de Dados e Análise Gráfica 3 Regressão Linear Simples 9 Autocorrelação I - Séries Temporais 4 Regressão Linear Múltipla 5 Diagnóstico e Avaliação do Modelo 10 Autocorrelação II Correlação Espacial 6 Análise e Partição da Variância 11 7 Exemplos de Aplicações Técnicas de Ordenação e Agrupamento - PCA, CCA, Cluster, etc. 12 Em aberto (revisão, reposição, falta de tempo, etc.) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que será abordado nas próximas 12 aulas? 1 Introdução (Hoje) 8 Extensões da Regressão: Modelos Lineares Gerais, Generalizados, Mistos 2 Análise Exploratória de Dados e Análise Gráfica 3 Regressão Linear Simples 9 Autocorrelação I - Séries Temporais 4 Regressão Linear Múltipla 5 Diagnóstico e Avaliação do Modelo 10 Autocorrelação II Correlação Espacial 6 Análise e Partição da Variância 11 7 Exemplos de Aplicações Técnicas de Ordenação e Agrupamento - PCA, CCA, Cluster, etc. 12 Em aberto (revisão, reposição, falta de tempo, etc.) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que será abordado nas próximas 12 aulas? 1 Introdução (Hoje) 8 Extensões da Regressão: Modelos Lineares Gerais, Generalizados, Mistos 2 Análise Exploratória de Dados e Análise Gráfica 3 Regressão Linear Simples 9 Autocorrelação I - Séries Temporais 4 Regressão Linear Múltipla 5 Diagnóstico e Avaliação do Modelo 10 Autocorrelação II Correlação Espacial 6 Análise e Partição da Variância 11 7 Exemplos de Aplicações Técnicas de Ordenação e Agrupamento - PCA, CCA, Cluster, etc. 12 Em aberto (revisão, reposição, falta de tempo, etc.) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que será abordado nas próximas 12 aulas? 1 Introdução (Hoje) 8 Extensões da Regressão: Modelos Lineares Gerais, Generalizados, Mistos 2 Análise Exploratória de Dados e Análise Gráfica 3 Regressão Linear Simples 9 Autocorrelação I - Séries Temporais 4 Regressão Linear Múltipla 5 Diagnóstico e Avaliação do Modelo 10 Autocorrelação II Correlação Espacial 6 Análise e Partição da Variância 11 7 Exemplos de Aplicações Técnicas de Ordenação e Agrupamento - PCA, CCA, Cluster, etc. 12 Em aberto (revisão, reposição, falta de tempo, etc.) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que será abordado nas próximas 12 aulas? 1 Introdução (Hoje) 8 Extensões da Regressão: Modelos Lineares Gerais, Generalizados, Mistos 2 Análise Exploratória de Dados e Análise Gráfica 3 Regressão Linear Simples 9 Autocorrelação I - Séries Temporais 4 Regressão Linear Múltipla 5 Diagnóstico e Avaliação do Modelo 10 Autocorrelação II Correlação Espacial 6 Análise e Partição da Variância 11 7 Exemplos de Aplicações Técnicas de Ordenação e Agrupamento - PCA, CCA, Cluster, etc. 12 Em aberto (revisão, reposição, falta de tempo, etc.) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que será abordado nas próximas 12 aulas? 1 Introdução (Hoje) 8 Extensões da Regressão: Modelos Lineares Gerais, Generalizados, Mistos 2 Análise Exploratória de Dados e Análise Gráfica 3 Regressão Linear Simples 9 Autocorrelação I - Séries Temporais 4 Regressão Linear Múltipla 5 Diagnóstico e Avaliação do Modelo 10 Autocorrelação II Correlação Espacial 6 Análise e Partição da Variância 11 7 Exemplos de Aplicações Técnicas de Ordenação e Agrupamento - PCA, CCA, Cluster, etc. 12 Em aberto (revisão, reposição, falta de tempo, etc.) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que será abordado nas próximas 12 aulas? 1 Introdução (Hoje) 8 Extensões da Regressão: Modelos Lineares Gerais, Generalizados, Mistos 2 Análise Exploratória de Dados e Análise Gráfica 3 Regressão Linear Simples 9 Autocorrelação I - Séries Temporais 4 Regressão Linear Múltipla 5 Diagnóstico e Avaliação do Modelo 10 Autocorrelação II Correlação Espacial 6 Análise e Partição da Variância 11 7 Exemplos de Aplicações Técnicas de Ordenação e Agrupamento - PCA, CCA, Cluster, etc. 12 Em aberto (revisão, reposição, falta de tempo, etc.) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que será abordado nas próximas 12 aulas? 1 Introdução (Hoje) 8 Extensões da Regressão: Modelos Lineares Gerais, Generalizados, Mistos 2 Análise Exploratória de Dados e Análise Gráfica 3 Regressão Linear Simples 9 Autocorrelação I - Séries Temporais 4 Regressão Linear Múltipla 5 Diagnóstico e Avaliação do Modelo 10 Autocorrelação II Correlação Espacial 6 Análise e Partição da Variância 11 7 Exemplos de Aplicações Técnicas de Ordenação e Agrupamento - PCA, CCA, Cluster, etc. 12 Em aberto (revisão, reposição, falta de tempo, etc.) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que será abordado nas próximas 12 aulas? 1 Introdução (Hoje) 8 Extensões da Regressão: Modelos Lineares Gerais, Generalizados, Mistos 2 Análise Exploratória de Dados e Análise Gráfica 3 Regressão Linear Simples 9 Autocorrelação I - Séries Temporais 4 Regressão Linear Múltipla 5 Diagnóstico e Avaliação do Modelo 10 Autocorrelação II Correlação Espacial 6 Análise e Partição da Variância 11 7 Exemplos de Aplicações Técnicas de Ordenação e Agrupamento - PCA, CCA, Cluster, etc. 12 Em aberto (revisão, reposição, falta de tempo, etc.) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que será abordado nas próximas 12 aulas? 1 Introdução (Hoje) 8 Extensões da Regressão: Modelos Lineares Gerais, Generalizados, Mistos 2 Análise Exploratória de Dados e Análise Gráfica 3 Regressão Linear Simples 9 Autocorrelação I - Séries Temporais 4 Regressão Linear Múltipla 5 Diagnóstico e Avaliação do Modelo 10 Autocorrelação II Correlação Espacial 6 Análise e Partição da Variância 11 7 Exemplos de Aplicações Técnicas de Ordenação e Agrupamento - PCA, CCA, Cluster, etc. 12 Em aberto (revisão, reposição, falta de tempo, etc.) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que será abordado nas próximas 12 aulas? 1 Introdução (Hoje) 8 Extensões da Regressão: Modelos Lineares Gerais, Generalizados, Mistos 2 Análise Exploratória de Dados e Análise Gráfica 3 Regressão Linear Simples 9 Autocorrelação I - Séries Temporais 4 Regressão Linear Múltipla 5 Diagnóstico e Avaliação do Modelo 10 Autocorrelação II Correlação Espacial 6 Análise e Partição da Variância 11 7 Exemplos de Aplicações Técnicas de Ordenação e Agrupamento - PCA, CCA, Cluster, etc. 12 Em aberto (revisão, reposição, falta de tempo, etc.) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) MODELAGEM ESTATÍSTICA Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que é um modelo? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Y = β0 + β1X ? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) ? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) O que é um modelo? Uma representação simplificada da realidade Busca descrever alguns aspectos de interesse, ignorando outros “All models are wrong. Some are useful.” George E. P. Box Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) “Modelo” é um termo bastante genérico Síndrome do “eu trabalho com modelagem” Existem tipos e tipos de modelos Que tipos de modelos nos interessam nesse curso? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Uma taxonomia de modelos Modelos Conceituais Quantitativos Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Uma taxonomia de modelos Modelos Conceituais Quantitativos Matemáticos Estatísticos Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Uma taxonomia de modelos Modelos Conceituais Quantitativos Matemáticos Estatísticos Determinísticos Estocásticos Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Uma taxonomia de modelos Modelos Conceituais Quantitativos Matemáticos Estatísticos Determinísticos Estocásticos Teóricos Thiago S. F. Silva [email protected] Empíricos Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Uma taxonomia de modelos Modelos Conceituais Quantitativos Matemáticos Estatísticos Determinísticos Estocásticos Teóricos Empíricos OBS: Essas são relações “fuzzy”, não “binárias”! Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Outras dicotomias Analítico vs. Numérico (Computacional) Dinâmico vs. Estático Contínuo vs. Discreto Baseado em Populações vs. Baseado em Indivíduos Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Outras dicotomias Analítico vs. Numérico (Computacional) Dinâmico vs. Estático Contínuo vs. Discreto Baseado em Populações vs. Baseado em Indivíduos Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Outras dicotomias Analítico vs. Numérico (Computacional) Dinâmico vs. Estático Contínuo vs. Discreto Baseado em Populações vs. Baseado em Indivíduos Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Outras dicotomias Analítico vs. Numérico (Computacional) Dinâmico vs. Estático Contínuo vs. Discreto Baseado em Populações vs. Baseado em Indivíduos Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Modelos Estatísticos 1 São baseados em probabilidades (estocásticos) Determinístico (matemático):Y = f (X ) Estocástico (estatístico):Y ∼ N(µ, σ) = f (X ∼ N(µ, σ)) 2 Incluem incertezas Y = β0 + β1 X + e 3 Costumam ser derivados empiricamente Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Modelos Estatísticos 1 São baseados em probabilidades (estocásticos) Determinístico (matemático):Y = f (X ) Estocástico (estatístico):Y ∼ N(µ, σ) = f (X ∼ N(µ, σ)) 2 Incluem incertezas Y = β0 + β1 X + e 3 Costumam ser derivados empiricamente Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Modelos Estatísticos 1 São baseados em probabilidades (estocásticos) Determinístico (matemático):Y = f (X ) Estocástico (estatístico):Y ∼ N(µ, σ) = f (X ∼ N(µ, σ)) 2 Incluem incertezas Y = β0 + β1 X + e 3 Costumam ser derivados empiricamente Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Modelos Estatísticos 1 São baseados em probabilidades (estocásticos) Determinístico (matemático):Y = f (X ) Estocástico (estatístico):Y ∼ N(µ, σ) = f (X ∼ N(µ, σ)) 2 Incluem incertezas Y = β0 + β1 X + e 3 Costumam ser derivados empiricamente Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Modelos Estatísticos 1 São baseados em probabilidades (estocásticos) Determinístico (matemático):Y = f (X ) Estocástico (estatístico):Y ∼ N(µ, σ) = f (X ∼ N(µ, σ)) 2 Incluem incertezas Y = β0 + β1 X + e 3 Costumam ser derivados empiricamente Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) 0 2 4 y 6 8 10 Modelos Estatísticos 0 2 4 6 8 10 x Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) 0 2 4 y 6 8 10 Modelos Estatísticos 0 2 4 6 8 10 x Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Por que modelar? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Por que modelar? Dois objetivos principais: Compreensão (explicação) de um fenômeno Predição de um fenômeno Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Por que modelar? Dois objetivos principais: Compreensão (explicação) de um fenômeno Predição de um fenômeno Compreensão Será que a adição de um fertilizante aumenta a produção de biomassa? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Compreensão sem 4 3 2 Call: lm(formula = cont ~ tempo) Coefficients: (Intercept) -0.0286 tempo 0.1983 1 com Com fertilizante Sem fertilizante 0 biomassa (kg m2) 5 6 ## ## ## ## ## ## ## 0 5 10 15 tempo 20 25 30 ## ## ## ## ## ## ## Call: lm(formula = trat ~ tempo) Coefficients: (Intercept) -0.0253 Thiago S. F. Silva [email protected] tempo 0.4054 Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Por que modelar? Dois objetivos principais: Compreensão (explicação) de um fenômeno Predição de um fenômeno Predição Qual a biomassa média de biomassa de uma plantação 10 dias após fertilização? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Previsão com 4 3 Call: lm(formula = trat ~ tempo) Coefficients: (Intercept) -0.0253 tempo 0.4054 2 1 Com fertilizante Sem fertilizante 0 biomassa (kg m2) 5 6 ## ## ## ## ## ## ## 0 5 10 15 20 25 Y = −0.0253 + 0.4054 ∗ X + e 30 tempo Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Previsão com 4 3 Call: lm(formula = trat ~ tempo) Coefficients: (Intercept) -0.0253 tempo 0.4054 2 1 Com fertilizante Sem fertilizante 0 biomassa (kg m2) 5 6 ## ## ## ## ## ## ## 0 5 10 15 20 25 30 Y = −0.0253 + 0.4054 ∗ X + e Y = −0.0253 + 0.4054 ∗ 10 + e tempo Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Previsão com 4 3 Call: lm(formula = trat ~ tempo) Coefficients: (Intercept) -0.0253 tempo 0.4054 2 1 Com fertilizante Sem fertilizante 0 biomassa (kg m2) 5 6 ## ## ## ## ## ## ## 0 5 10 15 tempo 20 25 30 Y = −0.0253 + 0.4054 ∗ X + e Y = −0.0253 + 0.4054 ∗ 10 + e Y = −0.0253 + 4.054 + e Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Previsão com 4 3 Call: lm(formula = trat ~ tempo) Coefficients: (Intercept) -0.0253 tempo 0.4054 2 1 Com fertilizante Sem fertilizante 0 biomassa (kg m2) 5 6 ## ## ## ## ## ## ## 0 5 10 15 tempo 20 25 30 Y Y Y Y = −0.0253 + 0.4054 ∗ X + e = −0.0253 + 0.4054 ∗ 10 + e = −0.0253 + 4.054 + e = 4.0287 + e Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Compreensão vs. Predição Existe uma diferença fundamental entre os dois objetivos. Qual? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Compreensão vs. Predição Existe uma diferença fundamental entre os dois objetivos. Qual? Compreensão/Explicação busca a generalidade Predição busca a especificidade Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Compreensão vs. Predição Existe uma diferença fundamental entre os dois objetivos. Qual? Compreensão/Explicação busca a generalidade Predição busca a especificidade Ao se priorizar um, necessariamente se sacrifica o outro Y = β0 + β1 ∗ X + e Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) A importância do modelo conceitual A modelagem começa antes de qualquer análise numérica Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) A importância do modelo conceitual A modelagem começa antes de qualquer análise numérica Qual o seu modelo conceitual? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) A importância do modelo conceitual A modelagem começa antes de qualquer análise numérica Qual o seu modelo conceitual? O computador sempre vai nos dar uma resposta. . . Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) A importância do modelo conceitual A modelagem começa antes de qualquer análise numérica Qual o seu modelo conceitual? O computador sempre vai nos dar uma resposta. . . . . . independentemente da realidade. Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) fonte: http://thesocietypages.org/socimages/2011/03/18/ illustrating-a-spurious-relationship-passport-ownership-and-diabetes/ Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) fonte: http://thesocietypages.org/socimages/2011/03/18/ illustrating-a-spurious-relationship-passport-ownership-and-diabetes/ Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Concluindo Praticamente todo o conhecimento humano é baseado em modelos Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Concluindo Praticamente todo o conhecimento humano é baseado em modelos Modelos quantitativos são apenas uma ferramenta a mais para adquirir esse conhecimento Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Concluindo Praticamente todo o conhecimento humano é baseado em modelos Modelos quantitativos são apenas uma ferramenta a mais para adquirir esse conhecimento A formalização matemática de modelos nos ajuda a entender a realidade. . . Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Concluindo Praticamente todo o conhecimento humano é baseado em modelos Modelos quantitativos são apenas uma ferramenta a mais para adquirir esse conhecimento A formalização matemática de modelos nos ajuda a entender a realidade. . . . . . mas jamais será um substituto para este entendimento. Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Concluindo Praticamente todo o conhecimento humano é baseado em modelos Modelos quantitativos são apenas uma ferramenta a mais para adquirir esse conhecimento A formalização matemática de modelos nos ajuda a entender a realidade. . . . . . mas jamais será um substituto para este entendimento. Pode ser muito poderosa, mas nada supera o bom-senso e a experiência Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Concluindo Praticamente todo o conhecimento humano é baseado em modelos Modelos quantitativos são apenas uma ferramenta a mais para adquirir esse conhecimento A formalização matemática de modelos nos ajuda a entender a realidade. . . . . . mas jamais será um substituto para este entendimento. Pode ser muito poderosa, mas nada supera o bom-senso e a experiência Com grandes poderes, vêm grandes responsabilidades Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Concluindo Praticamente todo o conhecimento humano é baseado em modelos Modelos quantitativos são apenas uma ferramenta a mais para adquirir esse conhecimento A formalização matemática de modelos nos ajuda a entender a realidade. . . . . . mas jamais será um substituto para este entendimento. Pode ser muito poderosa, mas nada supera o bom-senso e a experiência Com grandes poderes, vêm grandes responsabilidades Os modelos (e a estatística) são o meio, e não o fim Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) The Journal of Socio-Economics 33 (2004) 587–606 Mindless statistics Gerd Gigerenzer∗ Max Planck Institute for Human Development, Lentzeallee 94, 14195 Berlin, Germany Abstract Statistical rituals largely eliminate statistical thinking in the social sciences. Rituals are indispensable for identification with social groups, but they should be the subject rather than the procedure of science. What I call the “null ritual” consists of three steps: (1) set up a statistical null hypothesis, but do not specify your own hypothesis nor any alternative hypothesis, (2) use the 5% significance level for rejecting the null and accepting your hypothesis, and (3) always perform this procedure. I report evidence of the resulting collective confusion and fears about sanctions on the part of students and teachers, researchers and editors, as well as textbook writers. © 2004 Elsevier Inc. All rights reserved. Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) 588 G. Gigerenzer / The Journal of Socio-Economics 33 (2004) 587–606 Página 2 of in psychology. I asked the author why he removed the chapter on Bayes as well as the innocent sentence from all subsequent editions. “What made you present statistics as if it had only a single hammer, rather than a toolbox? Why did you mix Fisher’s and Neyman–Pearson’s theories into an inconsistent hybrid that every decent statistician would reject?” To his credit, I should say that the author did not attempt to deny that he had produced the illusion that there is only one tool. But he let me know who was to blame for this. There were three culprits: his fellow researchers, the university administration, and his publisher. Most researchers, he argued, are not really interested in statistical thinking, but only in how to get their papers published. The administration at his university promoted researchers according to the number of their publications, which reinforced the researchers’ attitude. And he passed on the responsibility to his publisher, who demanded a single-recipe cookbook. No controversies, please. His publisher had forced him to take out the chapter on Bayes as well as the sentence that named alternative theories, he explained. At the end of our conversation, I asked him what kind of statistical theory he himself believed in. “Deep in my heart,” he confessed, “I am a Bayesian.” If the author was telling me the truth, he had sold his heart for multiple editions of a famous book whose message he did not believe in. He had sacrificed his intellectual integrity for success. Ten thousands of students have read his text, believing that it reveals the method of science. Dozens of less informed textbook writers copied from his text, churning out a flood of offspring textbooks, and not noticing the mess. Por que fazemos ciência? 1. The null ritual Textbooks and curricula in psychology almost never teach the statistical toolbox, which contains tools such as descriptive statistics, Tukey’s exploratory methods, Bayesian statisThiago S. F. Silvadecision [email protected] 1: Introdução à Modelagem tics, Neyman–Pearson theory and Wald’sAula sequential analysis. Knowing the contents Página 2 researchers according to the numberOutline of their publications, which reinforced the researchers’ Apresentações attitude. And he passed on the responsibility to his publisher, who demanded a single-recipe Informações Gerais cookbook. No controversies, please. His publisher had forced him to take out the chapter Modelagem Estatística on Bayes as well-as the sentence that(2004) named alternative theories, he explained. At the end of Discussão Gigerenzer et al. our conversation, I asked him what kind of statistical theory he himself believed in. “Deep in my heart,” he confessed, “I am a Bayesian.” If the author was telling me the truth, he had sold his heart for multiple editions of a famous book whose message he did not believe in. He had sacrificed his intellectual integrity for success. Ten thousands of students have read his text, believing that it reveals the method of science. Dozens of less informed textbook writers copied from his text, churning out a flood of offspring textbooks, and not noticing the mess. 1. The null ritual Textbooks and curricula in psychology almost never teach the statistical toolbox, which contains tools such as descriptive statistics, Tukey’s exploratory methods, Bayesian statistics, Neyman–Pearson decision theory and Wald’s sequential analysis. Knowing the contents of a toolbox, of course, requires statistical thinking, that is, the art of choosing a proper tool for a given problem. Instead, one single procedure that I call the “null ritual” tends to be featured in texts and practiced by researchers. Its essence can be summarized in a few lines: The null ritual: 1. Set up a statistical null hypothesis of “no mean difference” or “zero correlation.” Don’t specify the predictions of your research hypothesis or of any alternative substantive hypotheses. 2. Use 5% as a convention for rejecting the null. If significant, accept your research hypothesis. Report the result as p < 0.05, p < 0.01, or p < 0.001 (whichever comes next to the obtained p-value). 3. Always perform this procedure. The null ritual has sophisticated aspects I will not cover here, such as alpha adjustment and ANOVA But these do not changeAula its essence. Often, àtextbooks also teach Thiago S.procedures. F. Silva [email protected] 1: Introdução Modelagem Página 2 Outline to his publisher, who demanded a single-recipe attitude. And he passed on the responsibility cookbook. No controversies,Apresentações please. His publisher had forced him to take out the chapter Informações on Bayes as well as the sentence that Gerais named alternative theories, he explained. At the end of Modelagem Estatística our conversation, I asked himetwhat kind of statistical theory he himself believed in. “Deep Discussão - Gigerenzer al. (2004) in my heart,” he confessed, “I am a Bayesian.” If the author was telling me the truth, he had sold his heart for multiple editions of a famous book whose message he did not believe in. He had sacrificed his intellectual integrity for success. Ten thousands of students have read his text, believing that it reveals the method of science. Dozens of less informed textbook writers copied from his text, churning out a flood of offspring textbooks, and not noticing the mess. 1. The null ritual Textbooks and curricula in psychology almost never teach the statistical toolbox, which contains tools such as descriptive statistics, Tukey’s exploratory methods, Bayesian statistics, Neyman–Pearson decision theory and Wald’s sequential analysis. Knowing the contents of a toolbox, of course, requires statistical thinking, that is, the art of choosing a proper tool for a given problem. Instead, one single procedure that I call the “null ritual” tends to be featured in texts and practiced by researchers. Its essence can be summarized in a few lines: The null ritual: A mecanização dahypothesis ciência 1. Set up a statistical null of “no mean difference” or “zero correlation.” Don’t specify the predictions of your research hypothesis or of any alternative substantive hypotheses. 2. Use 5% as a convention for rejecting the null. If significant, accept your research hypothesis. Report the result as p < 0.05, p < 0.01, or p < 0.001 (whichever comes next to the obtained p-value). 3. Always perform this procedure. The null ritual has sophisticated aspects I will not cover here, such as alpha adjustment and ANOVA procedures. But these do not change its essence. Often, textbooks also teach concepts alien to the ritual, such as statistical power and effect sizes, but these additions tend Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Página 2 attitude. And he passed on the responsibility to his publisher, who demanded a single-recipe Outline cookbook. No controversies, please. His publisher had forced him to take out the chapter Apresentações on Bayes as well as the sentence that named alternative theories, he explained. At the end of Informações Gerais our conversation, I Modelagem asked him what kind of statistical theory he himself believed in. “Deep Estatística in myDiscussão heart,” he -confessed, Bayesian.” Gigerenzer“Ietam al.a (2004) If the author was telling me the truth, he had sold his heart for multiple editions of a famous book whose message he did not believe in. He had sacrificed his intellectual integrity for success. Ten thousands of students have read his text, believing that it reveals the method of science. Dozens of less informed textbook writers copied from his text, churning out a flood of offspring textbooks, and not noticing the mess. 1. The null ritual Textbooks and curricula in psychology almost never teach the statistical toolbox, which contains tools such as descriptive statistics, Tukey’s exploratory methods, Bayesian statistics, Neyman–Pearson decision theory and Wald’s sequential analysis. Knowing the contents of a toolbox, of course, requires statistical thinking, that is, the art of choosing a proper tool for a given problem. Instead, one single procedure that I call the “null ritual” tends to be featured in texts and practiced by researchers. Its essence can be summarized in a few lines: The null ritual: A mecanização dahypothesis ciência 1. Set up a statistical null of “no mean difference” or “zero correlation.” Don’t specify the predictions of your research hypothesis or of any alternative substantive O que é o ritual nulo? hypotheses. 2. Use 5% as a convention for rejecting the null. If significant, accept your research hypothesis. Report the result as p < 0.05, p < 0.01, or p < 0.001 (whichever comes next to the obtained p-value). 3. Always perform this procedure. The null ritual has sophisticated aspects I will not cover here, such as alpha adjustment and ANOVA procedures. But these do not change its essence. Often, textbooks also teach concepts alien to the ritual, such as statistical power and effect sizes, but these additions tend Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Página 2 cookbook. No controversies, please. His publisher had forced him to take out the chapter on Bayes as well as the sentence thatOutline named alternative theories, he explained. At the end of Apresentações our conversation, I asked him what kind of statistical theory he himself believed in. “Deep Informações Gerais in my heart,” he confessed, “I am a Bayesian.” Modelagem Estatística If the author -was telling me the (2004) truth, he had sold his heart for multiple editions of a Discussão Gigerenzer et al. famous book whose message he did not believe in. He had sacrificed his intellectual integrity for success. Ten thousands of students have read his text, believing that it reveals the method of science. Dozens of less informed textbook writers copied from his text, churning out a flood of offspring textbooks, and not noticing the mess. 1. The null ritual Textbooks and curricula in psychology almost never teach the statistical toolbox, which contains tools such as descriptive statistics, Tukey’s exploratory methods, Bayesian statistics, Neyman–Pearson decision theory and Wald’s sequential analysis. Knowing the contents of a toolbox, of course, requires statistical thinking, that is, the art of choosing a proper tool for a given problem. Instead, one single procedure that I call the “null ritual” tends to be featured in texts and practiced by researchers. Its essence can be summarized in a few lines: The null ritual: 1. Set up a statistical null hypothesis of “no mean difference” or “zero correlation.” Don’t specify the predictions of your research hypothesis or of any alternative substantive hypotheses. 2. Use 5% as a convention for rejecting the null. If significant, accept your research hypothesis. Report the result as p < 0.05, p < 0.01, or p < 0.001 (whichever comes next to the obtained p-value). 3. Always perform this procedure. The null ritual has sophisticated aspects I will not cover here, such as alpha adjustment and ANOVA procedures. But these do not change its essence. Often, textbooks also teach concepts alien to the ritual, such as statistical power and effect sizes, but these additions tend Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Geraisof Socio-Economics 33 (2004) 587–606 G. Gigerenzer / The Journal Modelagem Estatística Discussão - Gigerenzer et al. (2004) Página 3 589 to disappear when examples are given. They just don’t fit. More recently, the ritual has been labeled null hypothesis significance testing, for short, NHST or sometimes NHSTP (with P for “procedure”). It became institutionalized in curricula, editorials, and professional associations in psychology in the mid-1950s (Gigerenzer, 1987, 1993). The 16th edition of a highly influential textbook, Gerrig and Zimbardo’s Psychology and Life (2002), portrays the null ritual as statistics per se and calls it the “backbone of psychological research” (p. 46). Its mechanical nature is sometimes presented like the rules of grammar. For instance, the 1974 Publication Manual of the American Psychological Association told authors what to capitalize, when to use a semicolon, and how to abbreviate states and territories. It also told authors how to interpret p-values: “Caution: Do not infer trends from data that fail by a small margin to meet the usual levels of significance. Such results are best interpreted as caused by chance and are best reported as such. Treat the result section like an income tax return. Take what’s coming to you, but no more” (p. 19; this passage was deleted in the 3rd ed., 1983). Judgment is not invited. This reminds me of a maxim regarding the critical ratio, the predecessor of the significance level: “A critical ratio of three, or no Ph.D.” Anonymity is essential. The ritual is virtually always presented without names, as statistics per se. If names such as Fisher or Pearson are mentioned in textbooks in psychology, they are usually done so in connection with a minor detail, such as to thank E.S. Pearson for the permission to reprint a table. The major ideas are presented anonymously, as if they were given truths. Which text written for psychologists points out that null hypothesis testing was Fisher’s idea? And that Neyman and Pearson argued against null hypothesis testing? If names of statisticians surface, the reader is typically told that they are all of one mind. For instance, in response to a paper of mine (Gigerenzer, 1993), the author of a statistical textbook, S.L. Chow (1998), acknowledged that different methods of statistical inference in fact exist. But a few lines later he fell back into the “it’s-all-the-same” fable: “To K. Pearson, R. Fisher, J. Neyman, and E.S. Pearson, NHSTP was what the empirical research was all about” (Chow, 1998, p. xi). Reader beware. Each of these eminent statisticians would have rejected the null ritual as bad statistics. Fisher is mostly blamed for the null ritual. But toward the end of his life, Fisher (1955, 1956) rejected each of its three steps. First, “null” does not refer to a nil mean difference or S. F. but Silva Aula 1: AIntrodução zeroThiago correlation, to [email protected] any hypothesis to be “nullified.” correlationàofModelagem 0.5, or a reduction Será que não podemos realmente inferir nada a partir de dados que não atingem significância estatística (especialmente por uma pequena margem?) Outline Apresentações Informações Geraisof Socio-Economics 33 (2004) 587–606 G. Gigerenzer / The Journal Modelagem Estatística Discussão - Gigerenzer et al. (2004) Página 3 589 to disappear when examples are given. They just don’t fit. More recently, the ritual has been labeled null hypothesis significance testing, for short, NHST or sometimes NHSTP (with P for “procedure”). It became institutionalized in curricula, editorials, and professional associations in psychology in the mid-1950s (Gigerenzer, 1987, 1993). The 16th edition of a highly influential textbook, Gerrig and Zimbardo’s Psychology and Life (2002), portrays the null ritual as statistics per se and calls it the “backbone of psychological research” (p. 46). Its mechanical nature is sometimes presented like the rules of grammar. For instance, the 1974 Publication Manual of the American Psychological Association told authors what to capitalize, when to use a semicolon, and how to abbreviate states and territories. It also told authors how to interpret p-values: “Caution: Do not infer trends from data that fail by a small margin to meet the usual levels of significance. Such results are best interpreted as caused by chance and are best reported as such. Treat the result section like an income tax return. Take what’s coming to you, but no more” (p. 19; this passage was deleted in the 3rd ed., 1983). Judgment is not invited. This reminds me of a maxim regarding the critical ratio, the predecessor of the significance level: “A critical ratio of three, or no Ph.D.” Anonymity is essential. The ritual is virtually always presented without names, as statistics per se. If names such as Fisher or Pearson are mentioned in textbooks in psychology, they are usually done so in connection with a minor detail, such as to thank E.S. Pearson for the permission to reprint a table. The major ideas are presented anonymously, as if they were given truths. Which text written for psychologists points out that null hypothesis testing was Fisher’s idea? And that Neyman and Pearson argued against null hypothesis testing? If names of statisticians surface, the reader is typically told that they are all of one mind. For instance, in response to a paper of mine (Gigerenzer, 1993), the author of a statistical textbook, S.L. Chow (1998), acknowledged that different methods of statistical inference in fact exist. But a few lines later he fell back into the “it’s-all-the-same” fable: “To K. Pearson, R. Fisher, J. Neyman, and E.S. Pearson, NHSTP was what the empirical research was all about” (Chow, 1998, p. xi). Reader beware. Each of these eminent statisticians would have rejected the null ritual as bad statistics. Fisher is mostly blamed for the null ritual. But toward the end of his life, Fisher (1955, 1956) rejected each of its three steps. First, “null” does not refer to a nil mean difference or S. F. but Silva Aula 1: AIntrodução zeroThiago correlation, to [email protected] any hypothesis to be “nullified.” correlationàofModelagem 0.5, or a reduction Será que não podemos realmente inferir nada a partir de dados que não atingem significância estatística (especialmente por uma pequena margem?) "Judgement is not invited". Então por que vocês estão aqui? Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) p < 0.05 ? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) p < 0.05 ? P(D | H) < 0.05 ? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) p < 0.05 ? P(D | H) < 0.05 ? ou P(H | D) < 0.05 ? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Teorema de Bayes P(A | B) = P(B | A)P(A) P(B) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Teorema de Bayes P(H | D) = P(D | H)P(H) P(D) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Teorema de Bayes P(H | D) = P(D | H)P(H) P(D) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem p-valor Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Teorema de Bayes P(H | D) = P(D | H)P(H) P(D) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Normalização Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Teorema de Bayes P(H | D) = P(D | H)P(H) P(D) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Priori Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Mas se P(D | H) está proximo de zero, não é razoável imaginar que P(H | D) também? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Fixa a a geração de números aleatórios set.seed(30) Cria uma amostra com n=30, e distribuição normal média = 5, d.p. =2 p1 <- rnorm(30,5,2) Segunda amostra, Uma transformação conhecida da primeira p2 <- p1 + 0.5 Histogram of p2 2 3 Frequency 4 3 1 2 0 1 0 Frequency 4 5 5 6 7 6 Histogram of p1 2 4 6 8 p1 Thiago S. F. Silva [email protected] 2 4 6 8 p2 Aula 1: Introdução à Modelagem 10 Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) # Teste t para diferença t.test(p1, p2, alternative = "two.sided", var.equal = TRUE) ## ## ## ## ## ## ## ## ## ## ## Two Sample t-test data: p1 and p2 t = -0.9889, df = 58, p-value = 0.3268 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -1.5121 0.5121 sample estimates: mean of x mean of y 4.339 4.839 Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) # Cria outra amostra com os mesmos parâmetros, n # = 300 p1.big <- rnorm(300, 5, 2) p2.big <- p1.big + 0.5 # teste t novamente t.test(p1.big, p2.big, alternative = "two.sided", var.equal = TRUE) ## ## ## ## ## ## ## ## ## ## ## Two Sample t-test data: p1.big and p2.big t = -2.905, df = 598, p-value = 0.003811 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -0.8381 -0.1619 sample estimates: mean of x mean of y 4.791 5.291 Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) # E se a diferença fosse menor? p3.big <- p1.big + 0.1 t.test(p1.big, p3.big, alternative = "two.sided", var.equal = TRUE) ## ## ## ## ## ## ## ## ## ## ## Two Sample t-test data: p1.big and p3.big t = -0.5809, df = 598, p-value = 0.5615 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -0.4381 0.2381 sample estimates: mean of x mean of y 4.791 4.891 Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) # Será? p1.gigante <- rnorm(30000, 5, 2) p3.gigante <- p1.gigante + 0.1 # Nope. t.test(p1.gigante, p3.gigante, alternative = "two.sided", var.equal = TRUE) ## ## ## ## ## ## ## ## ## ## ## Two Sample t-test data: p1.gigante and p3.gigante t = -6.126, df = 59998, p-value = 9.061e-10 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -0.13199 -0.06801 sample estimates: mean of x mean of y 5.019 5.119 Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem 0.6 p−valor, teste t 0.4 0.2 0.0 # De fato, podemos simular # a relação entre n e p-val: pvals <- rep(0,5000) for (i in c(3:5000)){ p1.sim <- rnorm(i,5,2) p3.sim <- p1.sim + 0.1 t <- t.test(p1.sim,p3.sim, alt="two.sided",var.equal=TRUE)$p.value pvals[i] <- t } 0.8 Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) 0 1000 2000 3000 n Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem 4000 5000 Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) # Dando um 'zoom' de 300 a 500 plot(300:500, pvals[300:500], type = "l", xlab = "n", ylab = "p-valor, teste t") 0.50 p−valor, teste t 0.42 0.46 0.6 0.4 0.2 0.0 p−valor, teste t 0.8 0.54 # Todos os valores de 3 a 3000 plot(3:5000, pvals[3:5000], type = "l", xlab = "n", ylab = "p-valor, teste t") abline(v = c(300, 500), col = "red") 0 1000 2000 3000 4000 5000 n Thiago S. F. Silva [email protected] 300 350 400 n Aula 1: Introdução à Modelagem 450 500 Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Quanto menor o n, maior a chance de que você tenha uma amostra que aproxima mal a população, causando flutuações no seu valor p! # Simulação de múltiplas instancias, para # n=10,50,100,500 e 5000 psim <- data.frame(n = rep(c(10, 50, 100, 500, 5000), each = 500), p = rep(NA, 2500)) for (i in c(1, 500, 1000, 1500, 2000)) { for (j in c(0:499)) { ind <- i + j p1.sim2 <- rnorm(psim$n[ind], 5, 2) p3.sim2 <- p1.sim2 + 0.1 t2 <- t.test(p1.sim2, p3.sim2, alternative = "two.sided", var.equal = TRUE)$p.value psim$p[ind] <- t2 } } psim$nfac <- as.factor(psim$n) boxplot(p ~ nfac, data = psim, xlab = "n", ylab = "p-valor, teste t (500 replica??es)") Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) 0.8 0.6 0.4 0.2 0.0 p−valor, teste t (500 replicações) Quanto menor o n, maior a chance de que você tenha uma amostra que aproxima mal a população, causando flutuações no seu valor p! 10 50 100 500 5000 n Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Os três métodos Ritual Nulo: 1 2 3 Fisher: Set up a statistical null hypothesis of "no mean difference"or "zero correlation."Don’t specify the predictions of your research hypothesis or of any alternative substantive hypotheses. Use 5% as a convention for rejecting the null. If significant, accept your research hypothesis. Report the result as p < 0.05, p < 0.01, or p < 0.001 (whichever comes next to the obtained p-value). Neyman-Pearson: 1 Set up a statistical null hypothesis. The null need not be a nil hypothesis (i.e., zero difference). 2 Report the exact level of significance (e.g., p = 0.051 or p = 0.049). Do not use a conventional 5% level, and do not talk about accepting or rejecting hypotheses. 3 1 Set up two statistical hypotheses, H1 and H2 , and decide about α, β, and n before the experiment, based on subjective cost-benefit considerations. These define a rejection region for each hypothesis. 2 If the data falls into the rejection region of H1 , accept H2 ; otherwise accept H1 . Note that accepting a hypothesis does not mean that you believe in it, but only that you act as if it were true. 3 The usefulness of the procedure is limited to situations where you have a disjunction of hypotheses (e.g., either µ1 = 8 or µ2 = 8 is true) and you can make meaningful cost-benefit trade-offs for alpha and beta. Use this procedure only if you know very little about the problem at hand. Always perform this procedure. Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Níveis de significância Nível de Significância = α (Neyman-Pearson) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Níveis de significância Nível de Significância = α (Neyman-Pearson) Deve ser pré-definido, junto com β, especificando os erros Tipo I e Tipo II que você considera toleráveis, e então estabelecer o n necessário para detectar um certo tamanho de efeito com essas probabilidades de erro. Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Níveis de significância Nível de Significância = α (Neyman-Pearson) Deve ser pré-definido, junto com β, especificando os erros Tipo I e Tipo II que você considera toleráveis, e então estabelecer o n necessário para detectar um certo tamanho de efeito com essas probabilidades de erro. Nível de Significância = valor exato (Fisher) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Níveis de significância Nível de Significância = α (Neyman-Pearson) Deve ser pré-definido, junto com β, especificando os erros Tipo I e Tipo II que você considera toleráveis, e então estabelecer o n necessário para detectar um certo tamanho de efeito com essas probabilidades de erro. Nível de Significância = valor exato (Fisher) Grau de certeza que você tem sobre a relação entre os dados observados e uma certa hipótese (geralmente a hipótese nula) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Níveis de significância Nível de Significância = α (Neyman-Pearson) Deve ser pré-definido, junto com β, especificando os erros Tipo I e Tipo II que você considera toleráveis, e então estabelecer o n necessário para detectar um certo tamanho de efeito com essas probabilidades de erro. Nível de Significância = valor exato (Fisher) Grau de certeza que você tem sobre a relação entre os dados observados e uma certa hipótese (geralmente a hipótese nula) p → 1 não significa "aceito H0 ", e sim "Não posso dizer com certeza que H0 é falsa". Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Níveis de significância Nível de Significância = α (Neyman-Pearson) Deve ser pré-definido, junto com β, especificando os erros Tipo I e Tipo II que você considera toleráveis, e então estabelecer o n necessário para detectar um certo tamanho de efeito com essas probabilidades de erro. Nível de Significância = valor exato (Fisher) Grau de certeza que você tem sobre a relação entre os dados observados e uma certa hipótese (geralmente a hipótese nula) p → 1 não significa "aceito H0 ", e sim "Não posso dizer com certeza que H0 é falsa". Para Fisher, p é uma propriedade da amostra; para N-P, é uma propriedade to teste! Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Tamanho (magnitude) do efeito = valor de real interesse científico 25 y1 20 Pearson's product-moment correlation 15 data: x1 and y1 t = 1.679, df = 8, p-value = 0.1318 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.1758 0.8627 sample estimates: cor 0.5103 10 ## ## ## ## ## ## ## ## ## ## ## 30 set.seed(1979) x1 <- runif(10, 1, 10) y1 <- 10 + 2 * x1 + rnorm(10, 0, 4) cor.test(x1, y1) 3 4 5 6 x1 Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem 7 8 9 Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Tamanho (magnitude) do efeito = valor de real interesse científico Interpretação errada: Não existe efeito de X sobre Y 25 y1 20 Pearson's product-moment correlation 15 data: x1 and y1 t = 1.679, df = 8, p-value = 0.1318 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.1758 0.8627 sample estimates: cor 0.5103 10 ## ## ## ## ## ## ## ## ## ## ## 30 set.seed(1979) x1 <- runif(10, 1, 10) y1 <- 10 + 2 * x1 + rnorm(10, 0, 4) cor.test(x1, y1) 3 4 5 6 x1 Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem 7 8 9 Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Tamanho (magnitude) do efeito = valor de real interesse científico Interpretação correta: é provável que haja efeito de X sobre Y , porém mais amostras são necessárias para que se tenha certeza 25 y1 20 Pearson's product-moment correlation 15 data: x1 and y1 t = 1.679, df = 8, p-value = 0.1318 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: -0.1758 0.8627 sample estimates: cor 0.5103 10 ## ## ## ## ## ## ## ## ## ## ## 30 set.seed(1979) x1 <- runif(10, 1, 10) y1 <- 10 + 2 * x1 + rnorm(10, 0, 4) cor.test(x1, y1) 3 4 5 6 x1 Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem 7 8 9 Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Tamanho (magnitude) do efeito = valor de real interesse científico y2 10.2 Pearson's product-moment correlation 9.8 data: x2 and y2 t = 14.34, df = 498, p-value < 2.2e-16 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: 0.4755 0.5999 sample estimates: cor 0.5406 9.6 ## ## ## ## ## ## ## ## ## ## ## 10.6 x2 <- runif(500, 1, 10) y2 <- 10 + 0.05 * x2 + rnorm(500, 0, 0.2) cor.test(x2, y2) 2 4 6 x2 Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem 8 10 Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Tamanho (magnitude) do efeito = valor de real interesse científico Interpretação errada: X tem um forte efeito sobre Y , porque p 0.05 y2 10.2 Pearson's product-moment correlation 9.8 data: x2 and y2 t = 14.34, df = 498, p-value < 2.2e-16 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: 0.4755 0.5999 sample estimates: cor 0.5406 9.6 ## ## ## ## ## ## ## ## ## ## ## 10.6 x2 <- runif(500, 1, 10) y2 <- 10 + 0.05 * x2 + rnorm(500, 0, 0.2) cor.test(x2, y2) 2 4 6 x2 Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem 8 10 Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Tamanho (magnitude) do efeito = valor de real interesse científico Interpretação correta: Afirmo que X possui um fraco efeito sobre Y , com alto grau de certeza y2 10.2 Pearson's product-moment correlation 9.8 data: x2 and y2 t = 14.34, df = 498, p-value < 2.2e-16 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: 0.4755 0.5999 sample estimates: cor 0.5406 9.6 ## ## ## ## ## ## ## ## ## ## ## 10.6 x2 <- runif(500, 1, 10) y2 <- 10 + 0.05 * x2 + rnorm(500, 0, 0.2) cor.test(x2, y2) 2 4 6 x2 Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem 8 10 Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Tamanho do efeito y2 10.2 9.6 9.8 15 10 y1 20 25 10.6 30 Algo errado? 0 2 4 6 8 10 x1 Thiago S. F. Silva [email protected] 0 2 4 6 x2 Aula 1: Introdução à Modelagem 8 10 30 25 y2 20 15 10 15 10 y1 20 25 30 Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) 0 2 4 6 8 10 x1 Thiago S. F. Silva [email protected] 0 2 4 6 x2 Aula 1: Introdução à Modelagem 8 10 Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Se os exemplos anteriores fossem resultados preliminares do teste de duas drogas, capazes de aumentar o seu desempenho na prova de Princípios Físicos. . . Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Se os exemplos anteriores fossem resultados preliminares do teste de duas drogas, capazes de aumentar o seu desempenho na prova de Princípios Físicos. . . . . . qual droga você tomaria? Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) 30 25 y2 20 15 10 15 10 y1 20 25 30 Tamanho do efeito 0 2 4 6 8 10 x1 0 2 4 6 8 x2 Para dose = 8, a droga 1 te dá uma performance entre 17 - 26. Talvez. Para dose = 8, a droga 2 te dá uma performance entre 10.1 - 10.6. Com certeza. Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem 10 a bit harsh on blaming Fisher rather the null ritual; recall that Fisher also proposed other Outline statistical tools, and in the 1950s, he thought of null hypothesis testing as adequate only for situations in which we know nothing or little. Meehl (1978) made a challenging prediction concerning null hypothesis tests in nonexperimental settings, where random assignment to treatment and control group is not possible, due to ethical or practical constraints. It can be summarized as follows: Páginas 15 e 16 Meehl’s conjecture: A conjectura de Meehl In nonexperimental settings with large sample sizes, the probability of rejecting the null hypothesis of nil group differences in favor of a directional alternative is about 0.50. Isn’t that good news? We guess that X is larger than Y—and we get it right half of the time. For instance, if we make up the story that Protestants have a higher memory span than Catholics, slower reaction times, smaller shoe size, and higher testosterone levels, each of these hypotheses has about a 50% chance of being accepted by a null hypothesis test. If we do not commit to the direction and just guess that X and Y are different, we get it right virtually 100% of the time. Meehl reasoned that in the real world––as opposed to experimental settings––the null hypothesis (“nil” as defined by the null ritual, not by Fisher) is always wrong. Some difference exists between any natural groups. Therefore, with sufficient statistical power, one will almost always find a significant result. If one randomly guesses the direction of the difference, it follows that one will be correct in about 50% of the cases (with a unidirectional alternative hypothesis, one will be correct in about 100% of them). Niels Waller (2004) set out to test Meehl’s conjecture empirically. He had access to the data of more than 81,000 individuals who had completed the 567 items of the Minnesota Multiphase Personality Inventory—Revised (MMPI-2). The MMPI-2 asks people about a broad range of contents, including health, personal habits, attitudes toward sex, and extreme manifestations of psychopathology. Imagine a gender theorist who has concocted a new theory that predicts directional gender differences, that is, women will score higher on some item than men, or vice versa. Can we predict the probability of rejecting the null hypothesis in favor of the new theory? According to Meehl’s conjecture, it is about 50%. In Waller’s simulation, the computer picked the first of the 511 items of the MMPI-2 (excluding 56 for their known ability to discriminate between the sexes), determined randomly the direction of the alternative hypothesis, and computed whether the difference was significant in the predicted This procedure was repeatedAula with1:allIntrodução 511 items. The result: 46% of the Thiagodirection. S. F. Silva [email protected] à Modelagem a bit harsh on blaming Fisher rather the null ritual; recall that Fisher also proposed other The routine reliance on the nullOutline ritual discourages not only statistical thinking but also statistical tools, and in the 1950s, he thought of null hypothesis testing as adequate only for theoretical thinking. One does not need to specify one’s hypothesis, nor any challenging situations in which we know nothing or little. Meehl (1978) made a challenging prediction alternative hypothesis. There is no premium on “bold” hypotheses, in the sense of Karl concerning null hypothesis tests in nonexperimental settings, where random assignment to Popper or Bayesian model comparison (MacKay, 1995). In many experimental papers in treatment and control group is not possible, due to ethical or practical constraints. It can be social and cognitive psychology, there is no theory in shooting distance, but only surrogates summarized as follows: such as redescription of the results (Gigerenzer, 2000, chapter 14). The sole requirement is to reject a null that is identified with “chance.” Statistical theories such as Neyman–Pearson Meehl’s conjecture: theory and Wald’s theory, in contrast, begin with two or more statistical hypotheses. In the absence of theory, the temptation is to look first at the data and then see what In nonexperimental settings with large sample sizes, the probability of rejecting the null is significant. The physicist Richard Feynman (1998, pp. 80–81) has taken notice of this hypothesis of nil group differences in favor of a directional alternative is about 0.50. misuse of hypothesis testing. I summarize his argument. Páginas 15 e 16 A conjectura de Meehl Isn’t that good news? We guess that X is larger than Y—and we get it right half of the Feynman’s conjecture: time. For instance, if we make up the story that Protestants have a higher memory span than Catholics, slower reaction times, smaller shoe size, and higher testosterone levels, each of To report a significant result and reject the null in favor of an alternative hypothesis is these hypotheses has about a 50% chance of being accepted by a null hypothesis test. If we meaningless unless the alternative hypothesis has been stated before the data was obtained. do not commit to the direction and just guess that X and Y are different, we get it right virtually 100% of the time. Meehl reasoned that in the real world––as opposed to experimental settings––the null hypothesis (“nil” as defined by the null ritual, not by Fisher) is always wrong. Some difference exists between any natural groups. Therefore, with sufficient statistical power, one will almost always find a significant result. If one randomly guesses the direction of the difference, it follows that one will be correct in about 50% of the cases (with a unidirectional alternative hypothesis, one will be correct in about 100% of them). Niels Waller (2004) set out to test Meehl’s conjecture empirically. He had access to the data of more than 81,000 individuals who had completed the 567 items of the Minnesota Multiphase Personality Inventory—Revised (MMPI-2). The MMPI-2 asks people about a broad range of contents, including health, personal habits, attitudes toward sex, and extreme manifestations of psychopathology. Imagine a gender theorist who has concocted a new theory that predicts directional gender differences, that is, women will score higher on some item than men, or vice versa. Can we predict the probability of rejecting the null hypothesis in favor of the new theory? According to Meehl’s conjecture, it is about 50%. In Waller’s simulation, the computer picked the first of the 511 items of the MMPI-2 (excluding 56 for their known ability to discriminate between the sexes), determined randomly the direction of the alternative hypothesis, and computed whether the difference was significant in the predicted This procedure was repeatedAula with1:allIntrodução 511 items. The result: 46% of the Thiagodirection. S. F. Silva [email protected] à Modelagem A conjectura de Feynman a bit harsh on blaming Fisher rather the null ritual; recall that Fisher also proposed other The routine reliance on the nullOutline ritual discourages not only statistical thinking but also statistical tools, and in the 1950s, he thought of null hypothesis testing as adequate only for theoretical thinking. One does not need to specify one’s hypothesis, nor any challenging situations in which we know nothing or little. Meehl (1978) made a challenging prediction alternative hypothesis. There is no premium on “bold” hypotheses, in the sense of Karl concerning null hypothesis tests in nonexperimental settings, where random assignment to Popper or Bayesian model comparison (MacKay, 1995). In many experimental papers in treatment and control group is not possible, due to ethical or practical constraints. It can be social and cognitive psychology, there is no theory in shooting distance, but only surrogates summarized as follows: such as redescription of the results (Gigerenzer, 2000, chapter 14). The sole requirement is to reject a null that is identified with “chance.” Statistical theories such as Neyman–Pearson Meehl’s conjecture: theory and Wald’s theory, in contrast, begin with two or more statistical hypotheses. In the absence of theory, the temptation is to look first at the data and then see what In nonexperimental settings with large sample sizes, the probability of rejecting the null is significant. The physicist Richard Feynman (1998, pp. 80–81) has taken notice of this hypothesis of nil group differences in favor of a directional alternative is about 0.50. misuse of hypothesis testing. I summarize his argument. Páginas 15 e 16 A conjectura de Meehl Isn’t that good news? We guess that X is larger than Y—and we get it right half of the Feynman’s conjecture: time. For instance, if we make up the story that Protestants have a higher memory span than Catholics, slower reaction times, smaller shoe size, and higher testosterone levels, each of To report a significant result and reject the null in favor of an alternative hypothesis is these hypotheses has about a 50% chance of being accepted by a null hypothesis test. If we meaningless unless the alternative hypothesis has been stated before the data was obtained. do not commit to the direction and just guess that X and Y are different, we get it right virtually 100% of the time. Meehl reasoned that in the real world––as opposed to experimental settings––the null hypothesis (“nil” as defined by the null ritual, not by Fisher) is always wrong. Some difference exists between any natural groups. Therefore, with sufficient statistical power, one will almost always find a significant result. If one randomly guesses the direction of the difference, it follows that one will be correct in about 50% of the cases (with a unidirectional alternative hypothesis, one will be correct in about 100% of them). Niels Waller (2004) set out to test Meehl’s conjecture empirically. He had access to the data of more than 81,000 individuals who had completed the 567 items of the Minnesota Multiphase Personality Inventory—Revised (MMPI-2). The MMPI-2 asks people about a broad range of contents, including health, personal habits, attitudes toward sex, and extreme manifestations of psychopathology. Imagine a gender theorist who has concocted a new theory that predicts directional gender differences, that is, women will score higher on some item than men, or vice versa. Can we predict the probability of rejecting the null hypothesis in favor of the new theory? According to Meehl’s conjecture, it is about 50%. In Waller’s simulation, the computer picked the first of the 511 items of the MMPI-2 (excluding 56 for their known ability to discriminate between the sexes), determined randomly the direction of the alternative hypothesis, and computed whether the difference was significant in the predicted This procedure was repeatedAula with1:allIntrodução 511 items. The result: 46% of the Thiagodirection. S. F. Silva [email protected] à Modelagem A conjectura de Feynman No mundo real, nunca existe diferença ou relação verdadeiramente zero O interesse, desta maneira, está em determinar o tamanho da distância entre esta diferença/relação e zero (ou algum outro valor basal). Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Em resumo O p-valor é uma medida de confiança, não de impacto Se você está realmente fazendo um experimento, pré-defina α, β e n, para ter certeza de que vai conseguir medir o efeito esperado Se é um estudo observacional, reporte os p-valores exatos. . . . . . e interprete-os apenas como uma medida de certeza O mais importante sempre será o tamanho do efeito! Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Em resumo O p-valor é uma medida de confiança, não de impacto Se você está realmente fazendo um experimento, pré-defina α, β e n, para ter certeza de que vai conseguir medir o efeito esperado Se é um estudo observacional, reporte os p-valores exatos. . . . . . e interprete-os apenas como uma medida de certeza O mais importante sempre será o tamanho do efeito! Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Em resumo O p-valor é uma medida de confiança, não de impacto Se você está realmente fazendo um experimento, pré-defina α, β e n, para ter certeza de que vai conseguir medir o efeito esperado Se é um estudo observacional, reporte os p-valores exatos. . . . . . e interprete-os apenas como uma medida de certeza O mais importante sempre será o tamanho do efeito! Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Em resumo O p-valor é uma medida de confiança, não de impacto Se você está realmente fazendo um experimento, pré-defina α, β e n, para ter certeza de que vai conseguir medir o efeito esperado Se é um estudo observacional, reporte os p-valores exatos. . . . . . e interprete-os apenas como uma medida de certeza O mais importante sempre será o tamanho do efeito! Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Em resumo O p-valor é uma medida de confiança, não de impacto Se você está realmente fazendo um experimento, pré-defina α, β e n, para ter certeza de que vai conseguir medir o efeito esperado Se é um estudo observacional, reporte os p-valores exatos. . . . . . e interprete-os apenas como uma medida de certeza O mais importante sempre será o tamanho do efeito! Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem Outline Apresentações Informações Gerais Modelagem Estatística Discussão - Gigerenzer et al. (2004) Thiago S. F. Silva [email protected] Aula 1: Introdução à Modelagem
Download