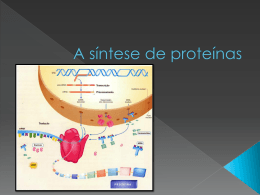
Genes Menor porção do DNA capaz de produzir um efeito que pode ser detectado no organismo. Região do DNA que pode ser transcrita em moléculas de RNA. Ácidos nucleicos Os ácidos nucléicos são macromoléculas de natureza química, formadas por nucleotídeos, grupamento fosfórico (fosfato), glicídio (monossacarídeo / pentoses) e uma base nitrogenada, compondo o material genético contido nas células de todos os seres vivos. Presentes no núcleo dos eucariotos e dispersos no hialoplasma dos procariotos, os ácidos nucléicos podem ser de dois tipos: ácido desoxirribonucléico (DNA) e ácido ribonucléico (RNA), ambos relacionados ao mecanismo de controle metabólico celular (funcionamento da célula) e transmissão hereditária das características. Os Ácidos Nucléicos: DNA e RNA O DNA se diferencia do RNA por possuir o açúcar desoxirribose e os nucleotídeos adenina, citosina, guanina e timina. No RNA, o açúcar é a ribose e os nucleotídeos são adenina, citosina, guanina e uracila (a uracila entra no lugar da timina). O modelo do DNA A partir de experimentos feitos por vários pesquisadores e utilizando os resultados da complexa técnica de difração com raios X, Watson e Crick concluíram que, no DNA, as cadeias complementares são helicoidais, sugerindo a idéia de uma escada retorcida. Nessa escada, os corrimãos são formados por fosfatos e desoxirribose, enquanto os degraus são constituídos pelos pares de bases nitrogenadas. Os átomos de carbono das moléculas de ribose e desoxirribose são numerados conforme a figura abaixo. Observe que os carbonos do açúcar são numerados com uma linha (‘) a fim de distinguilos dos outros carbonos do nucleotídeo. Em cada fita do DNA, o “corrimão” é formado por ligações entre moléculas de açúcar e radicais fosfato. Note que o radical fosfato se liga ao carbono 3’ de um açúcar e ao carbono 5’ do seguinte. As duas cadeias de nucleotídeos do DNA são unidas uma à outra por ligações chamadas de pontes de hidrogênio, que se formam entre as bases nitrogenadas de cada fita. O pareamento de bases ocorre de maneira precisa: uma base púrica se liga a uma pirimídica – adenina (A) de uma cadeia pareia com a timina (T) da outra e guanina (G) pareia com citosina (C). O DNA controla toda a atividade celular. Ele possui a “receita” para o funcionamento de uma célula. Toda vez que uma célula se divide, a “receita” deve ser passada para as células-filhas. Todo o “arquivo” contendo as informações sobre o funcionamento celular precisa ser duplicado para que cada célulafilha receba o mesmo tipo de informação que existe na célula-mãe. Para que isso ocorra, é fundamental que o DNA sofra “auto-duplicação”. A duplicação do DNA O modelo estrutural do DNA proposto por Watson e Crick explica a duplicação dos genes: as duas cadeias do DNA se separam e cada uma delas orienta a fabricação de uma metade complementar. O experimento dos pesquisadores Meselson e Stahl confirmou que a duplicação do DNA é semiconservativa, isto é, que metade da molécula original se conserva íntegra em cada uma das duas moléculas-filhas. No processo de duplicação do DNA, as pontes de hidrogênio entre as bases se rompem e as duas cadeias começam a se separar. À medida que as bases vão sendo expostas, nucleotídeos que vagam pelo meio ao redor vão se unindo a elas, sempre respeitando a especificidade de emparelhamento: A com T, T com A, C com G e G com C. Uma vez ordenados sobre a cadeia que está que está servindo de modelo, os nucleotídeos se ligam em seqüência e formam uma cadeia complementar dobre cada uma das cadias da molécula original. Assim, uma molécula de DNA reproduz duas moléculas idênticas a ela. A enzima DNA-polimerase Diversos aspectos da duplicação do DNA já foram desvendados pelos cientistas. Hoje, sabe-se que há diversas enzimas envolvidas nesse processo. Certas enzimas desemparelham as duas cadeias de DNA, abrindo a molécula. Outras desenrolam a hélice dupla, e há, ainda, aquelas que unem os nucleotídeos entre si. A enzima que promove a ligação dos nucleotídeos é conhecida como DNA polimerase, pois sua função é construir um polímero (do grego poli, muitas, e meros, parte) de nucleotídeos. Essas enzimas adicionam nucleotídeos complementares somente no sentido 5’ 3’. Como as cadeias de DNA são invertidas, a síntese em uma cadeia acontece em um sentido e, na outra, acontece em sentido oposto. A transcrição do DNA O material genético representado pelo DNA contém uma mensagem em código que precisa ser decifrada e traduzida em proteínas, muitas das quais atuarão nas reações metabólicas da célula. A mensagem contida no DNA deve, inicialmente, ser passada para moléculas de RNA que, por sua vez, orientarão a síntese de proteínas. O controle da atividade celular pelo DNA, portanto, é indireto e ocorre por meio da fabricação de moléculas de RNA, em um processo conhecido como transcrição. O trecho da molécula de DNA onde está localizado um gene a ser transcrito abre-se por ação da enzima RNA polimerase e nesse ponto inicia-se o emparelhamento de nucleotídeos do RNA por ação da mesma enzima. A transcrição do ocorre sempre no sentido 5’ 3’. As moléculas de RNA são constituídas por uma seqüência de ribonucleotídeos, formando uma cadeia (fita) simples. Existem três tipos básicos de RNA, que diferem um do outro no peso molecular: o RNA ribossômico, representado por RNAr (ou rRNA), o RNA mensageiro, representado por RNAm (ou mRNA) e o RNA transportador, representado por RNAt (ou tRNA). 1) O RNA ribossômico é o de maior peso molecular e constituinte majoritário do ribossomo, organóide relacionado à síntese de proteínas na célula. 2) O RNA mensageiro é o de peso molecular intermediário e atua conjuntamente com os ribossomos na síntese protéica. 3) O RNA transportador é o mais leve dos três e encarregado de transportar os aminoácidos que serão utilizados na síntese de proteínas. A síntese de RNA (mensageiro, por exemplo) se inicia com a separação das duas fitas de DNA. Apenas uma das fitas do DNA serve de molde para a produção da molécula de RNAm. A outra fita não é transcrita. Essa é uma das diferenças entre a duplicação do DNA e a produção do RNA. As outras diferenças são: os nucleotídeos utilizados possuem o açúcar ribose no lugar da desoxirribose; há a participação de nucleotídeos de uracila no lugar de nucleotídeos de timina. Assim, se na fita de DNA que está sendo transcrita aparecer adenina, encaminha-se para ela um nucleotídeo complementar contendo uracila; Imaginando um segmento hipotético de um filamento de DNA com a seqüência de bases: DNA- ATGCCGAAATTTGCG O segmento de RNAm formado na transcrição terá a seqüência de bases: RNA- UACGGCUUUAAACGC Em uma célula eucariótica, o RNAm produzido destaca-se de seu molde e, após passar por um processamento, atravessa a carioteca e se dirige para o citoplasma, onde se dará a síntese protéica. Com o fim da transcrição, as duas fitas de DNA seu unem novamente, refazendo-se a dupla hélice. OBS para os eucariontes!!! As sequências codificantes são chamadas de éxons. Elas são intercaladas por regiões não codificantes, chamadas de íntrons, que são inicialmente transcritas em RNA no núcleo, mas não estão presentes no RNAm final no citoplasma, não sendo representada no produto protéico final. Em muitos genes, o tamanho cumulativo dos exóns é muito menor que o de íntrons. Splicing – remoção acontece ainda no núcleo Tradução da informação Uma proposta brilhante sugerida por vários pesquisadores, e depois confirmada por métodos experimentais, foi a de que cada três letras (uma trinca de bases) do DNA corresponderia um aminoácido. Nesse caso, haveria 64 combinações possíveis de três letras, o que seria mais do que suficiente para codificar os vinte tipos diferentes de aminoácidos (matematicamente, utilizando o método das combinações seriam, então, 4 letras combinadas 3 a 3, ou seja, 64 combinações possíveis). O código genético do DNA se expressa por trincas de bases, que foram denominadas códons. Cada códon, formado por três letras, corresponde a um certo aminoácido. A correspondência entre o trio de bases do DNA, o trio de bases do RNA e os aminoácidos por eles especificados constitui uma mensagem em código que passou a ser conhecida como “código genético”. Mas, surge um problema. Como são vinte os diferentes aminoácidos, há mais códons do que tipos de aminoácidos! Deve-se concluir, então, que há aminoácidos que são especificados por mais de um códon, o que foi confirmado. A tabela abaixo, especifica os códons de RNAm que podem ser formados e os correspondentes aminoácidos que especificam. A sequência que marca o início do gene recebe o nome de região promotora, e a que marca o final é chamada sequência de término da transcrição. Dizemos que o código genético é universal, pois em todos os organismos da Terra atual ele funciona da mesma maneira, quer seja em bactérias, em uma cenoura ou no homem. O códon AUG, que codifica para o aminoácido metionina, também significa início de leitura, ou seja, é um códon que indica aos ribossomos que é por esse trio de bases qe deve ser iniciada a leitura do RNAm. Note que três códons não especificam nenhum aminoácido. São os códons UAA, UAG e UGA, chamados de códons e parada durante a “leitura” (ou stop códons) do RNA pelos ribossomos, na síntese protéica. Diz-se que o código genético é degenerado porque cada “palavra” (entenda-se aminoácido) pode ser especificada por mais de uma trinca. Exemplificando Um RNAm, processado no núcleo, contendo sete códons (21 bases hidrogenadas) se dirige ao citoplasma. No citoplasma, um ribossomo se liga ao RNAm na extremidade correspondente ao início da leitura. Dois RNAt, carregando os seus respectivos aminoácidos (metionina e alanina), prendem-se ao ribossomo. Cada RNAt liga-se ao seu trio de bases (anticódon) ao trio de bases correspondentes ao códon do RNAm. Uma ligação peptídica une a metionina à alanina. O ribossomo se desloca ao longo do RNAm. O RNAt que carregava a metionina se desliga do ribossomo. O quarto RNAt, transportando o aminoácido leucina, une o seu anticódon ao códon correspondente do RNAm. Uma ligação peptídica é feita entre a leucina e a alanina. O ribossomo novamente se desloca. O RNAt que carregava a alanina se desliga do ribossomo. O quarto RNAt, transportando o aminoácido ácido glutâmico encaixa-se no ribossomo. Ocorre a união do anticódon desse RNAt com o códon correspondente do RNAm. Uma ligação peptídica une o ácido glutâmico à leucina. Novo deslocamento do ribossomo. O quinto RNAt, carregando a aminoácido glicina, se encaixa no ribossomo. Ocorre a ligação peptídica da glicina com o ácido glutâmico. Continua o deslocamento do ribossomo ao longo do RNAm. O sexto RNAt, carregando o aminoácido serina, se encaixa no ribossomo. Uma liogação peptídica une a serina à glicina. Fim do deslocamento do ribossomo. O último transportador , carregando o aminoácido triptofano, encaixa-se no ribossomo. Ocorre a ligação peptídica do triptofano com a serina. O RNAt que carrega o triptofano se separa do ribossomo. O mesmo ocorre com o transportador que portava a serina. O peptídeo contendo sete aminoácidos fica livre no citoplasma. Claro que outro ribossomo pode se ligar ao RNAm, reiniciando o processo de tradução, que resultará em um novo peptídio. Perceba, assim, que o RNAm contendo sete códons (21 bases nitrogenadas) conduziu a síntese de um peptídeo formado por sete aminoácidos. Mutações De maneira geral, as mutações ocorrem como conseqüência de erro no processo de duplicação do DNA. Acontecem em uma baixíssima freqüência. Muitas delas, inclusive, são corrigidas por mecanismos especiais, como, por exemplo, a ação do gene p53 que evita a formação de tumores. Há, no entanto, certos agentes do ambiente que podem aumentar a taxa de ocorrência de erros genéticos. Entre esses agentes mutagênicos podemos citar: substâncias existentes no fumo, os raios X, a luz ultravioleta, ácido nitroso e algumas corantes existentes nos alimentos. Não é à toa que, em muitos países, é crescente a preocupação com a diminuição da espessura da camada do gás ozônio (O3), que circunda a atmosfera terrestre. Esse gás atua como filtro de luz ultravioleta proveniente do Sol. Com a diminuição da sua espessura, aumenta a incidência desse tipo de radiação, o que pode afetar a pele das pessoas. Ocorrem lesões no material genético, que podem levar a certos tipos de câncer de pele. As mutações gênicas são mudanças ocasionais que ocorrem nos genes, ou seja, é o procedimento pelo qual um gene sofre uma mudança estrutural. As mutações envolvem a adição, eliminação ou substituição de um ou poucos nucleotídeos da fita de DNA. A mutação proporciona o aparecimento de novas formas de um gene e, consequentemente, é responsável pela variabilidade gênica. Quando ocorre por adição ou subtração (mutações deletérias) de bases, altera o código genético, definindo uma nova sequência de bases, que consequentemente poderá alterar o tipo de aminoácido incluído na cadeia proteica, tendo a proteína outra função ou mesmo inativação da expressão fenotípica. Por substituição, ocorre em razão da troca de uma base nitrogenada purina (adenina e guanina) por outra purina, ou de uma pirimidina (citosina e timina) por outra pirimidina, sendo esse processo denominado de transição e a substituição de uma purina por uma pirimidina, ou vice-versa, denominada de transversão.
Download