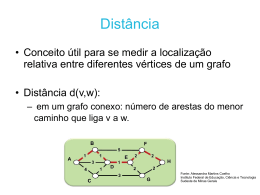
Anais do XVI Encontro de Iniciação Científica e Pós-Graduação do ITA – XVI ENCITA / 2010 Instituto Tecnológico de Aeronáutica, São José dos Campos, SP, Brasil, 20 de outubro de 2010 DESENVOLVIMENTO DE REPOSITÓRIO DE DADOS E MÉTODOS DE EXTRAÇÃO E PRÉ-PROCESSAMENTO PARA APOIO A PROJETOS DE PESQUISA EM REDES COMPLEXAS Marcos Ricardo Omena de Albuquerque Maximo Instituto Tecnológico de Aeronáutica - ITA Rua H8B, apartamento 214, CEP: 12228-461, Campus do CTA, São José dos Campos, SP, Brasil Bolsista PIBIC-CNPq [email protected] Cinara Guellner Ghedini Instituto Tecnológico de Aeronáutica - ITA Praça Marechal Eduardo Gomes, 50, Vila das Acácias, CEP: 12.228-900, São José dos Campos, SP, Brasil [email protected] Carlos Henrique Costa Ribeiro Divisão de Ciência da Computação Instituto Tecnológico de Aeronáutica Praça Marechal Eduardo Gomes, 50, Vila das Acácias, CEP: 12.228-900, São José dos Campos, SP, Brasil [email protected] Resumo. A proposta desse projeto é a criação de um repositório de redes complexas reais para apoio a pesquisas. Como etapa inicial, fez-se aquisição de bases de domínio público, através de varredura pela Internet ou por pedidos diretos a pesquisadores da área. A análise das redes realizada através da ferramenta "Network Workbench Tool". Posteriormente, foi feito estudo e implementação de métodos de extração de amostras de redes complexas e análise da confiabilidade destes. Para o repositório, foi proposto um ambiente web dinâmico, em que estariam disponíveis as bases para download juntamente com a documentação gerada nas etapas anteriores com opções de filtragem e exibição dos resultados de interesse do usuário. Palavras chave: codificação de software, mineração de dados, bases de dados, amostragem em redes complexas. 1. Introdução O estudo de redes é necessário quando há propriedades não dedutíveis apenas a partir da análise das propriedades de indivíduos, pois dependem das interações entre estes. Encontra-se redes em sistemas biológicos (cadeias alimentares, sistemas nervosos etc.), construções tecnológicas (redes de distribuição de energia, sistemas de transporte e de telecomunicações etc.), na sociedade (redes sociais), entre outros sistemas de entidades conectadas (Barabási, 2002). Denomina-se complexas redes caracterizadas por uma topologia não-trivial, em que a disposição de seus elementos não é completamente regular nem aleatória. Isso está em geral associado a interações complexas e de difícil previsibilidade. Quase todas as redes reais se encaixam nessa classificação, daí a importância do estudo de redes complexas (Barabási, 2002). Embora antigo, o estudo de redes teve maior avanço recentemente, dado que novos recursos tecnológicos permitem aquisição e análise de dados em escalas sem precedentes (Newman, 2003). Assim, foi possível verificar empiricamente que redes de natureza e propósitos distintos apresentam propriedades topológicas recorrentes (Ghedini, et al., 2009), (Newman, 2003), (Barabási, 2002), (Albert, et al., 2002), o que sugere semelhanças na formação e evolução desses sistemas. O campo de aplicação do tema é vasto e pouco conhecido (Newman, 2003). Por exemplo, espera-se que conhecimentos sobre redes complexas permitam melhor controle da propagação de doenças e a criação de sistemas de transmissão mais eficientes e robustos (Ghedini, et al., 2009), (Barabási, 2002). 1.1. Representação de Redes Matematicamente, redes são modeladas por grafos: vértices representam indivíduos e as arestas relações entre estes. Um grafo é um par ordenado ࡳ = (ࢂ, ࡱ), ࢂ conjunto dos vértices e ࡱ ⊆ ࢂ × ࢂ de arestas (Ghedini, et al., 2009). Assim, se é o número de vértices, o grafo fica bem representado por uma matriz × , denominada matriz de adjacências, em que ࢇ = se há aresta do vértice i ao j e ࢇ = se não há. Se ࢇ = ࢇ , ∀, ∈ ࢂ, trata-se de grafo direcionado; caso contrário, o grafo é não-direcionado. Anais do XVI ENCITA, ITA,20 de outubro de 2010 , Há redes em que é interessante ter informações adicionais nas ligações: numa rede social, pode-se associar um número à "intensidade" do relacionamento. Nesses casos, associa-se uma segunda matriz ࢃ ( × ) de pesos, em que cada ࢝ guarda o valor adicional associado à aresta ࢇ (Ghedini, et al., 2009). Outros termos comuns na teoria de grafos são descritos na Tab. 1. Tabela 1. alguns termos comuns em teoria de grafos. Grau (vértice/grafo): número de arestas conectadas a um vértice. Para um grafo, esse termo significa o grau médio dos vértices desse grafo. No caso de grafos orientados, fala-se também de grau das arestas que chegam ao vértice (grau de entrada) e das que saem (grau de saída). Vizinhança (vértice): conjunto dos vértices que possuem alguma aresta em comum com o vértice em questão. Caminho (de um vértice a outro): seqüência de arestas que levam de um determinado vértice um a outro. Caminho mínimo (de um vértice a outro): caminho com menor número de arestas que leve de um vértice a outro; note que esse não é necessariamente único (ver Fig. 1). Distância (de um vértice a outro): número de arestas do caminho mínimo. Diâmetro (grafo): maior distância do grafo. As Figs. 1 e 2 ilustram alguns dos conceitos discutidos. aresta vértice Figura 1. Grafo não-direcionado. Observe que há dois caminhos mínimos entre os vértices marcados. Figura 2. Grafo direcionado (flechas indicam orientações das arestas). 1.2. Propriedades e Métricas Como salientado, as redes complexas freqüentemente apresentam propriedades semelhantes. As mais importantes são descritas a seguir. Small world (mundo pequeno, numa tradução literal): fenômeno associado ao fato de que mesmo que as redes contenham muitos vértices, a distância média entre dois vértices quaisquer pode ser considerada pequena. Na WWW há bilhões de páginas, mas as páginas estão distantes umas das outras por um número relativamente pequeno de cliques. A métrica utilizada para avaliar essa propriedade é o comprimento de caminho mínimo médio (र), uma média das distâncias entre dois vértices quaisquer do grafo (Albert, et al., 2002). Mais formalmente: considere um vértice qualquer; seja र(, ) a distância entre e outro vértice qualquer do grafo. Calcule então a média das र(, )’s sobre todos os vértices diferentes de e chame र(). Assim, o comprimento de caminho mínimo médio é a média dos र()’s assim calculados sobre todos os vértices . Clustering: refere-se à tendência das redes de formar aglomerados de indivíduos, porções em que todos ou quase todos estão conectados entre si (Albert, et al., 2002). Em redes sociais, amizades são mais freqüentes entre pessoas com Anais do XVI ENCITA, ITA,20 de outubro de 2010 , interesses comuns ou que trabalham ou estudam juntas, assim há círculos de amizade, profissional, entre outros, que foram aglomerados. A métrica associada é o clustering coefficient () do grafo. Considere um vértice i de grau ; se ሺ ିሻ todos os vértices da vizinhança estiverem conectados entre si, existem ൫ ൯ = arestas. O clustering coefficient do vértice é definido como a razão entre o número de arestas (ࡱ ) que realmente existem e o máximo possível (Albert, ࡱ et al., 2002): = ሺ ିሻ . O clustering coeficient do grafo é a média dos ’s assim calculados. Distribuição de grau: a distribuição de grau é uma função distribuição de probabilidade que dá a probabilidade de um vértice escolhido aleatoriamente ter exatamente vértices. Nas redes reais, é comum encontrar uma distribuição de grau da forma ࡼሺሻ~ିࢽ . Essas redes são chamadas de scale-free. Em redes scale-free, encontram-se vértices com um número muito grande de ligações, embora poucos, e muitos vértices com poucas arestas (Barabási, 2002), (Ghedini, et al., 2009), (Albert, et al., 2002). 1.3. Modelos de Redes Complexas O estudo de modelos de redes complexas é importante no entendimento da construção e evolução destas. Nessa secção, são apresentados os modelos mais famosos de geração de redes complexas. Grafo aleatório: começa-se com um grafo com o número desejado de vértices e sem arestas. Então, para cada par de vértices, com uma probabilidade predefinida de sucesso é criada uma aresta entre esses. Grafos aleatórios têm a propriedade small world, porém seu clustering coefficient é bem menor que o de redes complexas reais e a distribuição de grau segue uma distribuição de Poisson (Albert, et al., 2002). Mesmo quando não é scale-free, a distribuição de grau de uma rede real costuma se desviar consideravelmente de uma Poisson. Modelo Small World de Watts-Strogatz: começa-se com um anel ordenado com o número desejado de vértices em que cada vértice está conectado aos primeiros / vizinhos de cada lado (ver Fig. 3). Em seguida, cada aresta tem uma probabilidade de ser religada aleatoriamente (Albert, et al., 2002). Além de satisfazer a propriedade small world, possui um clustering coefficient alto. Entretanto, ainda falha em ter uma distribuição de grau condizente com a encontrada na maioria das redes reais (Albert, et al., 2002). Figura 3. Anel ordenado inicial do modelo de Watts-Strogatz. Modelo Scale-free de Barabási-Álbert: começa-se com um pequeno número de vértices. Então, a cada passo, adiciona-se um novo vértice que será ligado a (≤ ) outros vértices já presentes no grafo. A cada nova aresta adicionada, a escolha do vértice é tal que a probabilidade de um vértice ser escolhido é proporcional ao seu grau. Após ࢚ passos, há + ࢚ vértices e ࢚ arestas no grafo (Albert, et al., 2002). Nos modelos anteriores, iniciava-se com um número fixo de vértices e um algoritmo gerava uma topologia estática; nesse modelo propõe-se um "algoritmo evolucionário". A motivação dessa mudança de abordagem foi a busca pelo entendimento de como as redes complexas são construídas. Redes reais são sistemas que crescem com a adição de novos vértices, em que há preferência na formação de novas ligações (preferential attachment): por exemplo, pessoas com mais amigos têm maior chance de fazer novas amizades. Isso é simulado com a probabilidade de um vértice ser escolhido para uma nova conexão proporcional ao seu grau (Albert, et al., 2002). Esse modelo gera uma rede com distribuição de graus scale-free, porém com clustering coefficient baixo. 1.4. Amostragem Anais do XVI ENCITA, ITA,20 de outubro de 2010 , Algumas redes podem ter bilhões de elementos. Isso não apenas dificulta a aquisição dos dados, mas também pode inviabilizar simulações e análises por limitações de recursos computacionais. Nesse contexto, surge a necessidade de amostras. A amostragem de redes complexas traz complicações extras, já que o enfoque está nas características topológicas da rede e não aos indivíduos em si. Na tentativa de capturar essas propriedades, alguns métodos de geração de amostras foram propostos na Literatura. Seguem descrições dos mais comumente utilizados. 1. Amostragem por vértices (node sampling): seleciona-se (parâmetro de entrada) vértices do grafo aleatoriamente. Todas as arestas entre esses são mantidas. Os desconectados são descartados. 2. Amostragem por arestas (edge sampling): seleciona-se aleatoriamente (parâmetro de entrada) arestas do grafo. Todos os vértices conectados por essas são mantidos. Como o algoritmo foca nas arestas, é mais sensível a estrutura do grafo que o anterior. Tem a desvantagem de privilegiar a escolha de vértices com grau alto. 3. Amostragem "bola de neve" (snowball sampling): pega-se um vértice aleatoriamente e considera-se o subgrafo formado por apenas este. Assim, pega-se sucessivamente todos os vértices ligados aos vértices do subgrafo de uma dada iteração. O algoritmo continua enquanto houver um número de vértices menor que (parâmetro de entrada) no subgrafo. Se, numa dada iteração, nem todos os vértices ligados aos vértices do subgrafo precisem ser pegos para atingir ݊, os vértices faltantes são escolhidos aleatoriamente. 2. Aquisição e Análises de Bases Na varredura pela Internet, encontrou-se bases disponíveis publicamente nos seguintes links: • http://www.nd.edu/~networks/resources.htm (CCNR) (Barabási, et al.). • http://www-personal.umich.edu/~mejn/netdata/ (Newman) (Newman). • http://vlado.fmf.uni-lj.si/pub/networks/data/ (Pajek) (Batagelj, et al., 2006). Essas páginas são coleções de bases. Assim, algumas das bases não são dos autores das coleções e os devidos créditos pela aquisição e compilação dos dados devem ser dados aos autores originais. As devidas referências podem ser encontradas nos respectivos links acima. As bases das cidades suecas foram obtidas por pedido direto ao senhor Martin Rosvall do Departamento de Biologia da Universidade de Washington. O uso das bases e a disponibilização pública foram permitidas pelo pesquisador. Para análise, foram selecionadas as seguintes bases (conforme nomes geralmente encontrados na Literatura): • Adjacência de palavras no romance "David Copperfield" de Charles Dickens; • Blogs políticos durante a eleição dos EUA de 2004; • Cidades suecas (Estocolmo, Gotemburgo, Malmö e Umeå); • Clube de Caratê de Zachary; • Coautorias em Ciências de Redes; • Colaborações em Alta Energia; • Colaborações em Astrofísica; • Colaborações em Matéria Condensada (versões de 1999, 2003 e 2005); • Internet a nível de sistemas autônomos; • Coaparência dos personagens do romance Les Miserables de Victor Hugo; • Linhas aéreas americanas; • Livros políticos; • Rede de distribuição elétrica dos EUA; • Rede neural da minhoca C. Elegans; • Rede social de golfinhos de uma comunidade da Nova Zelândia; • WWW (como levantada pelo cientista Barabási). A análise foi realizada com a ferramenta "Network Workbench Tool" (NWB) (NWB Team, 2006). Muitas estavam em formato GML, não suportado pelo NWB, e para conversão foi utilizado o software “Simple GML to XGMML Convertor” (Punin, 2000). Algumas delas apresentaram problemas para serem convertidas por possuírem caracteres não suportados (bases das cidades suecas) ou valores infinitos (Colaborações em Matéria Condensada, versão 2005). A solução encontrada foi implementar rotinas em C++ para convertê-las para lista de adjacências (Edge list), formato simples que consiste de uma listagem das arestas do grafo. Os resultados das análises estão nas Tabs. 2, 3 e 4. Destacamos que as métricas "comprimento de caminho mínimo médio" e "clustering coefficient" são em geral definidas e aplicadas para bases não-direcionadas. Assim, quando esses resultados aparecerem para bases direcionadas, significa que foram obtidas da base não-direcionada gerada a partir da Anais do XVI ENCITA, ITA,20 de outubro de 2010 , direcionada (considera-se uma aresta entre ݅ e ݆ se há pelo menos um dos arcos ݅ para ݆ ou ݆ para ݅). Aparentemente, essa é uma metodologia comumente adotada. Tabela 2. Bases obtidas e algumas informações. Base Arquivo Descrição Rede de adjacência de adjetivos comuns e Adjacência de adjnoun.gml substantivos no romance “David Copperfield” palavras de Charles Dickens Rede dos hyperlinks entre blogs sobre política Blogs políticos polblogs.gml americana Rede social de amizades entre membros de um Clube de Caratê karate.gml clube de caratê em uma universidade de Zachary americana na década de 70 Coautorias em Coautoria entre cientistas que trabalharam em Ciências de netscience.gml teoria ou experimentos de redes Redes Colaborações em Coautoria entre cientistas de Alta Energia hep-th.gml Alta Energia Colaborações em Coautoria entre cientistas de Astrofísica astro-ph.gml Astrofísica Colaborações em Coautoria entre cientistas de Matéria Matéria Condensada (1/1/1995-31/3/2005) cond-mat.gml Condensada (1999) Colaborações em Coautoria entre cientistas de Matéria Matéria Condensada (1/1/1995-31/12/1999) cond-mat-2003.gml Condensada (2003) Colaborações em Coautoria entre cientistas de Matéria Matéria Condensada (1/1/1995-30/6/2003) cond-mat-2005.gml Condensada (2005) Rede de informações da cidade sueca de Estocolmo LC_clean_sthlm.gml Estocolmo (maior componente conectado) Rede de informações da cidade sueca de Gotemburgo LC_clean_gbg.gml Gotemburgo (maior componente conectado) Internet (sistemas Internet no nível de sistemas autônomos as-22july06.gml autônomos) Coaparência de personagens do romance “Les Les Miserables lesmis.gml Miserables” Linhas áreas Rede de aeroportos americanos (1997) USAir97.net americanas Livros sobre política americana vendidos no tempo da eleição presidencial de 2004 e vendidos pela Amazon.com. Uma aresta é Livros políticos polbooks.gml colocada se os dois livros são comprados frequentemente juntos por um mesmo comprador Rede de informações da cidade sueca de Malmö LC_clean_malmo.gml Malmö (maior componente conectado) Rede de Topologia da Rede de Distribuição Elétrica do distribuição power.gml Oeste dos Estados Unidos elétrica Rede neural da C. Rede neural da minhoca C. Elegans celegansneural.gml Elegans Rede social de Rede de associações frequentes entre dolphins.gml golfinhos golfinhos numa comunidade na Nova Zelândia Rede de informações da cidade sueca de Umeå LC_clean_umea.gml Umeå (maior componente conectado) Formato* Fonte GML Newman GML Newman GML Newman GML Newman GML Newman GML Newman GML Newman GML Newman GML Newman GML Rosvall GML Rosvall GML Newman GML Newman Pajek Pajek GML Newman GML Rosvall GML Newman GML Newman GML Newman GML Rosvall Anais do XVI ENCITA, ITA,20 de outubro de 2010 , WWW (Barabási) Parte da WWW no domínio das páginas estudada em 1999 www.dat Edge list CCNR * Informações sobre formatos de bases podem ser encontrados em (Punin, et al., 2001) e (NWB Community). Tabela 3. Características das bases. Número de Base Vértices Adjacência de 112 palavras Blogs políticos Clube de Caratê de Zachary Coautorias em Ciências de Redes Colaborações em Alta Energia Colaborações em Astrofísica Colaborações em Matéria Condensada (1999) Colaborações em Matéria Condensada (2003) Colaborações em Matéria Condensada (2005) Estocolmo Gotemburgo Internet (sistemas autônomos) Les Miserables Linhas áreas americanas Livros políticos Malmö Rede de distribuição elétrica Rede neural da C. Elegans Rede social de golfinhos Umeå WWW (Barabási) Número de Arestas Direcionada Atributos dos Vértices Atributos das Arestas 425 Não rótulo (string), valor (int) 1490 19025 Sim rótulo (string), valor (int), fonte (string) 34 78 Não 1589 2742 Não rótulo (string) 8361 15751 Não rótulo (string) peso (float) 16706 121251 Não rótulo (string) peso (float) 16726 47594 Não rótulo (string) peso (float) 31163 120029 Não rótulo (string) 40421 175693 Não rótulo (string) 10713 7470 23422 11975 Não Não 22963 48436 Não rótulo (int) 77 254 Não 332 2126 Não peso (float) 105 3735 441 7384 Não Não rótulo (string) rótulo (string), posição XYZ (float,float,float) rótulo (string), valor (char) 4941 6594 Não 297 2345 Sim rótulo (int) peso (int) 62 159 Não rótulo (string) 566 325729 1090 1497135 Não Sim peso (float) valor (int) Tabela 4. Resultados das análises das bases: grau médio total, grau de entrada (apenas grafos direcionados), grau de saída (idem), clustering coefficient, caminho mínimo médio, diâmetro. Observação: para cálculo de C, र e D de bases direcionadas, foi considerado o grafo não-direcionado gerado a partir desta. Base <݇> < > < ࢛࢚ > र ࡰ Adjacência de 7,5893 0,1898 2,5356 46 palavras Blogs políticos 25,5369 12,7685 12,7685 0,3600 2,7375 8 Anais do XVI ENCITA, ITA,20 de outubro de 2010 , Clube de Caratê de Zachary Coautorias em Ciências de Redes Colaborações em Alta Energia Colaborações em Astrofísica Colaborações em Matéria Condensada (1999) Colaborações em Matéria Condensada (2003) Colaborações em Matéria Condensada (2005) Estocolmo Gotemburgo Internet (sistemas autônomos) Les Miserables Linhas áreas americanas Livros políticos Malmö Rede de distribuição elétrica Rede neural da C. Elegans Rede social de golfinhos Umeå WWW (Barabási) 4,5882 0,5879 2,4082 5 3,4512 0,8782 5,8232 17 3,7677 0,6365 7,0254 19 14,5159 0,7262 4,7980 14 5,6910 0,7371 6,6276 18 7,7033 0,7232 5,7667 16 8,6932 0,7185 5,4993 18 4,3726 3,2062 0,2787 0,2744 5,721 7,8448 15 24 4,2186 0,3499 3,8424 11 6,5974 0,7355 2,6411 5 12,8072 0,7494 2,7381 6 8,4000 3,9539 0,4875 0,2697 3,0788 6,0857 7 14 2,6691 0,1065 18,9892 46 0,3079 2,4553 5 5,1290 0,3029 3,3570 8 3,8516 9,1925 0,3076 5,6345 11 15,7912 7,8956 7,8956 Com base nos resultados das análises e com os critérios de dar preferência a bases recorrentes em referências da área e com valores heterogêneos das propriedades (, र e < ݇ >), selecionou-se as seguintes bases para focar nos trabalhos das etapas seguintes: 1. Rede neural da C. Elegans; 2. Coautorias em ciências de rede; 3. Estocolmo (cidade sueca); 4. Gotemburgo (cidade sueca); 5. Rede de distribuição elétrica dos EUA; 6. Internet (sistemas autônomos); 7. WWW (Barabási). 3. Amostragem Para comparar os métodos, decidiu-se por amostragem com 1%, 5% e 10% dos vértices ou das arestas (conforme o exigido pelo método) como parâmetro (ver seção 1.4) e verificação de como as métricas se desviam nas amostras em relação ao valor da base original. Fez-se um trabalho de geração e análise de amostras inicial com o NWB. Entretanto, este no seu estágio atual de desenvolvimento não permite a automatização das simulações. Assim, o trabalho com um número grande de dados se Anais do XVI ENCITA, ITA,20 de outubro de 2010 , torna excessivamente mecânico e custoso para o operador. Além disso, após ter os resultados iniciais prontos, surgiu a necessidade de adicionar uma nova métrica na análise, o que exigiria refazer o trabalho feito até então. Devido a isso, decidiu-se gerar códigos para tornar a automatização possível. Como já dispunha-se de rotinas das principais métricas implementadas em MATLAB, optou-se pela plataforma. O trabalho inicial feito no NWB ajudou na criação de uma noção do comportamento dos métodos de amostragem e como guia na aferição das rotinas implementadas. As rotinas de geração das amostras foram feitas com base nas descrições dos métodos no NWB (ver seção 1.4). Amostragens das bases direcionadas ("C. Elegans" e "WWW") levaram a orientação das arestas em consideração. Optou-se por 10 amostras para cada base, método e percentagem (no caso das 6 primeiras bases escolhidas) para se ter alguma confiabilidade estatística. As métricas escolhidas para trabalho foram "clustering coefficient", comprimento de caminho mínimo médio, diâmetro e comprimento de caminho mínimo normalizado (razão entre as duas anteriores). Após a geração e análise das amostras, fez-se um tratamento estatístico e a geração de gráficos para facilitar a interpretação dos resultados. Nesse artigo, são apresentados apenas alguns dos resultados finais devido a limitações de espaço. No caso da WWW, mesmo com amostras, a análise requer um tempo de processamento muito grande ou é inviabilizada devido a limitação de memória. Por isso, um trabalho especial foi feito com essa base. Para ela, a análise foi limitada a 5 amostras apenas para os métodos de amostragem por vértices e "bola de neve"; amostragem por arestas gerou amostras inviáveis de serem simuladas devido a limitações de memória mesmo com 1% . Os resultados para amostragem da WWW estão mais abaixo nessa seção. Para ilustrar a diferença entre os métodos, a Tab. 5 traz os resultados da amostragem para a base "Rede de Distribuição Elétrica". O comportamento dos métodos para as demais bases seguiu em geral aproximadamente o mesmo padrão. Tabela 5. Análise estatística dos resultados para a base "Rede de Distribuição Elétrica". Parâmetro n Medida da <> र Base Amostragem estatística amostragem original 2,6691 0,1065 18,9892 Mínimo 0 0 0 Máximo 1 0 1 49 (1%) Média 0,4 0 0,186667 Desvio 0,516398 0 0,318639 padrão Mínimo 1,032258 0 0,025098 Máximo 1,230769 0,058824 0,080882 nodesampling 247 (5%) Média 1,085943 0,005882 0,0535 Desvio 0,054645 0,018602 0,018676 padrão Mínimo 1,092593 0 0,013673 Máximo 1,219512 0,04878 0,039585 494 (10%) Média 1,156259 0,012856 0,020942 powergrid Desvio 0,042956 0,018 0,008347 padrão Mínimo 1 0 0,007634 Máximo 1,03937 0 0,009499 66 (1%) Média 1,017867 0 0,008495 Desvio 0,01233 0 0,0006 padrão Mínimo 1,061093 0 0,002144 edgesampling Máximo 1,085526 0 0,002677 330 (5%) Média 1,072708 0 0,002432 Desvio 0,008514 0 0,000172 padrão Mínimo 1,123615 0 0,001619 659 (10%) Máximo 1,166372 0,00717 0,002456 ࡰ र/ࡰ 46 0 1 0,4 0,4128 0 1 0,186667 0,516398 0,318639 2 3 2,2 0,012549 0,040441 0,024282 0,421637 0,007611 2 5 3,9 0,003571 0,007917 0,005363 0,994429 0,001288 1 2 1,9 0,003993 0,007634 0,004629 0,316228 0,001087 3 7 3,8 0,00038 0,000806 0,000676 1,229273 0,000128 5 8 0,00023 0,000409 Anais do XVI ENCITA, ITA,20 de outubro de 2010 , 49 (1%) snowball 247 (5%) 494 (10%) Média Desvio padrão Mínimo Máximo Média Desvio padrão Mínimo Máximo Média Desvio padrão Mínimo Máximo Média Desvio padrão 1,143353 0,001833 0,00195 5,9 0,000336 0,013755 0,002674 0,000256 0,994429 5,32E-05 2,081633 2,693878 2,322449 0 0,291929 0,063432 3,353741 5,113946 4,295918 6 12 8,2 0,417871 0,58309 0,532361 0,207633 0,089457 0,541743 1,75119 0,050687 2,340081 2,979757 2,565992 0,025541 0,175239 0,087531 6,357362 8,244594 7,138406 12 15 13,7 0,468185 0,569637 0,521686 0,184662 0,051725 0,66245 1,159502 0,032413 2,396761 2,825911 2,610526 0,028036 0,226949 0,075486 7,504841 9,205476 8,324303 14 18 15,9 0,476443 0,603701 0,52541 0,114667 0,059884 0,494274 1,37032 0,033616 A escolha do MATLAB ainda se mostrou interessante por este já possuir medidas estatísticas e geração de gráficos prontos. O que dispensou bastante trabalho, dado que foi possível automatizar todo esse processo com programação. Dos resultados, pode-se extrair as seguinte conclusões: • Para bases muito pequenas, o número de vértices e arestas na amostra é muito pequeno ao se trabalhar com percentagens, assim as métricas falham ou geram resultados muito destoantes entre as amostras. À medida que trabalhamos com bases maiores, que são as bases em que métodos de amostragem se fazem verdadeiramente necessários, os resultados obtidos são mais confiáveis; • De modo geral, o método de amostragem por vértices gera os piores resultados, enquanto a amostragem "bola de neve" gera os mais condizentes; • Os desvios entre as amostras é considerável, de modo que a geração de um número razoável de amostras é recomendada; • Para as métricas "grau médio", "clustering coefficient" e "comprimento de caminho mínimo médio normalizado" (fração entre "comprimento de caminho mínimo médio" e "diâmetro"), que são pouco dependentes do tamanho da rede, a melhor amostra considerada entre as 10 para o método "bola de neve" possui em geral valores muito próximos da rede real, mesmo em percentagens baixas. • Embora resulte nos melhores valores, a amostragem "bola de neve" ainda possui desvios entre as amostras alto, pois é fortemente dependente da vizinhança do vértice inicialmente escolhido e, portanto, muito sensível a heterogeneidades na rede. Ainda tem o inconveniente de falhar caso seja escolhido um vértice inicial isolado ou acabar por extrair um cluster isolado, pequeno e pouco representativo. A questão do problema de se escolher bases pequenas pode ser claramente verificada ao considerarmos o método "bola de neve" com as melhores amostras (que seria o melhor caso de amostragem dentre os que consideramos) para a rede da C. Elegans e para a de Gotemburgo. Mesmo nessa condição e com 10%, o "grau médio" para a C. Elegans se desvia bastante do esperado, enquanto para Gotemburgo, os valores em todas as métricas pouco dependentes de tamanho são próximos dos da original mesmo com 1%. Essa situação é ilustrada nos gráficos das Figs. 4 e 5. Anais do XVI ENCITA, ITA,20 de outubro de 2010 , Figura 4. Resultados das métricas analisadas para a melhor amostra gerada com o método "bola de neve" para a base "rede neural da C. Elegans". Figura 5. Resultados das métricas analisadas para a melhor amostra gerada com o método "bola de neve" para a base "Gotemburgo". Um fato interessante é observado na amostragem da WWW (ver Tab. 5). Embora seja uma base grande, os valores são muito destoantes entre as amostras. Tem-se problema especialmente com o método "bola de neve". Este falha nas 3ª e 4ª tentativas (um vértices isolado deve ter sido escolhido), e apenas a 5ª amostra tem um número de vértices frente à percentagem e base escolhidas. O motivo desse comportamento deve estar associado a WWW ser uma rede direcionada com muitas partes isoladas, em que há muitas páginas sem links que levem ao restante da rede. Tabela 5. Resultados da amostragem para a rede "WWW". Parâmetro Número Número Amostragem n da de de arestas amostragem vértices 399 438 407 471 nodesampling 3257 (1%) 382 439 333 432 368 422 300 1972 11 11 snowball 3257 (1%) 0 0 0 0 र <݇> ࡰ 0,003665 0,005192 0,006747 0,015503 0,01044 2,021026 3 0 0 0,040434 0,033295 0,05069 0,077896 0,041004 0,67869 0 0 0 0,551378 0,653563 0,638743 0,798799 0,657609 7,74 2 0 0 3 2 3 2 2 4 5 0 0 Anais do XVI ENCITA, ITA,20 de outubro de 2010 , 3257 16334 3,767779 0,342148 8,248081 6 4. Ambiente do Repositório 4.1. Motivação Durante o trabalho de busca pelas bases de domínio público, percebeu-se que não existe uma centralização destas bases e a documentação é escassa. Desse modo, pesquisadores que necessitem de redes reais para validar suas pesquisas enfrentam dificuldades para encontrar redes adequadas. O desafio é a construção de uma plataforma em que resultados e bases de interesse estejam facilmente acessíveis e adequadamente documentadas. Para isso, é desejável a criação de uma plataforma web dinâmica, em que ferramentas de filtragem estejam disponíveis. Essa foi justamente a etapa final do projeto. 4.2. Conceituação 1. 2. 3. Plataforma: há necessidade de uso de banco de dados num servidor para que os dados do repositório sejam acessados, isso cria flexibilidade de modificação no repositório sem necessidade de alteração no código do ambiente. O trabalho com banco de dados será feito com a framework "Django", baseada em "Python". Para que responda a comandos de imediato, a interface deve ser implementada em "Javascript". Funcionalidade: exibe as informações escolhidas nas opções de exibição das bases que satisfaçam as restrições da filtragem. Permite downloads da base e de amostras em diversos formatos. Interface: num menu lateral devem ficar as opções de filtragem e de exibição. Na página principal, exibe-se tabelas com as informações das bases e as opções de download conforme as opções de filtragem e exibição. Pode-se ordenar as bases de acordo com determinado parâmetro ao se clicar na célula que contém o nome desse no topo da tabela. Um clique na linha correspondente a uma determinada base deve expandir essa linha para uma ficha com todas as informações da rede. 4.3. Comentários Para esclarecimento da proposta de interface, foi gerada uma página exemplo em HTML, a captura da tela desta exibida em um browser está na Fig. 6. Embora tenha-se cogitado análises e geração de amostras "on-the-fly", ou seja, em tempo de execução, percebeu-se que era inviável com os recursos disponíveis. Ambas exigem grande capacidade de processamento, assim haveria facilmente sobrecarga do servidor. Caso haja necessidade real de sua implementação, deve-se buscar meios de executálo fora do código próprio da plataforma em linguagens mais rápidas como "C/C++". Ainda não foi idealizado, mas acoplar um sistema para cadastramento de novas bases por usuários também é interessante. A plataforma ainda está em desenvolvimento, porém acredita-se que a documentação feita neste artigo seja suficiente para a continuação num futuro projeto. É de interesse do orientado a conclusão deste ambiente, mesmo após o fim do prazo da bolsa. Opções de exibição Filtros Lista de bases com as opções de exibição selecionadas e que satisfazem as condições de filtragem. Anais do XVI ENCITA, ITA,20 de outubro de 2010 , Figura 6. Página exemplo para ilustrar o conceito proposto de interface. 5. Conclusões Foram obtidas e analisadas as bases disponíveis publicamente. Muito do trabalho de programação foi dispensado, pois o "Network Workbench Toll" (NWB Team, 2006) já tinha disponível a maioria das rotinas. Durante a busca das bases, chegou-se a conclusão de que pesquisadores que necessitem de redes reais para validar suas teses ainda encontram dificuldades para encontrar as redes adequadas ao seu trabalho, dada a falta de centralização e documentação. Assim, foi proposta uma plataforma web dinâmica para cobrir essa falta, dado que a disponibilização bruta das bases e dos resultados das análises não é tão interessante. Embora ainda não completamente implementada, sua funcionalidade e interface já estão definidas e documentadas nesse artigo. O estudo de amostragem foi concluído como previsto. Percebeu-se que extração de amostras em redes complexas traz complicações extras. Portanto, dependendo da topologia da rede, pode-se ter dificuldades em obter amostras confiáveis. Observou-se que para redes grandes, os resultados obtidos com um dos métodos ("Snowball") foram razoáveis para as métricas pouco dependentes do tamanho da rede. Entretanto, se a rede contém muitas partes isoladas, esse método costuma falhar ou levar a valores muito destoantes. Para os demais métodos, análises das amostras revelaram em geral valores dispersos e distantes dos da base original. 6. Agradecimentos Agradeço primeiramente à doutoranda Cinara Ghedini e ao professor Carlos Henrique, ambos do Instituto Tecnológico de Aeronáutica, pela orientação. Em especial à Cinara, pela dedicação e paciência comigo na etapa final do projeto. Ao senhor Daniel O. Cajueiro (Departamento de Economia, Universidade de Brasília), pelo envio de algumas bases e dicas sobre o trabalho. Ao senhor Martin Rosvall, (Departamento de Biologia, Universidade de Washington) pelo envio da rede das cidades suecas e por ter concedido permissão para usá-la no trabalho e disponibilizá-la publicamente. À família, pela compreensão no período de Férias. Por fim, agradeço ao CNPq pelo apoio financeiro concedido. 7. Referências Albert, Réka e Barabási, Albert-László. 2002. Statistical Mechanics of Complex Networks. 2002, Vol. v. 74, n. 1. Barabási, A.-L. e Toroczkai, Z. CCNR - Resources. site do Center for Complex Network Research (CCNR). [Online] [Citado em: 28 de Janeiro de 2010.] http://www.nd.edu/~networks/resources.htm. Barabási, Albert-László. 2002. Linked: The New Science of Networks. Cambridge, MA : Perseus, 2002. Batagelj, Vladimir e Mrvar, Andrej. 2006. Pajek datasets. [Online] 2006. http://vlado.fmf.unilj.si/pub/networks/data/. Ghedini, Cinara G. e Ribeiro, Carlos Henrique Costa. 2009. Detecting Global Efficiency in Complex Networks Using Local Measurements and Neighborgood Information. 2009. CSBC - XXIX Congresso da Sociedade Brasileira de Computação, 2009, Bento Gonçalves. WPerformance 2009 - VIII Workshop em Desempenho de Sistemas Computacionais e de Comunicação, 2009.. Newman, M. E. J. Network data. página pessoal de Mark Newman, University of Michigan. [Online] [Citado em: 28 de Janeiro de 2010.] http://www-personal.umich.edu/~mejn/netdata/. —. 2003. The structure and function of complex networks. 2003. NWB Community. NWB Community Wiki. [Online] https://nwb.slis.indiana.edu/community/?n=Main.HomePage. NWB Team. 2006. Network Workbench Tool. 2006. Indiana University, Northeastern University, and University of Michigan, http://nwb.slis.indiana.edu. Punin, John e Krishnamoorthy, Mukkai. 2001. XGMML. [Online] 8 de Julho de 2001. http://www.cs.rpi.edu/~puninj/XGMML/. Punin, John. 2000. Simple GML to XGMML Convertor. 5 de Março de 2000.
Baixar