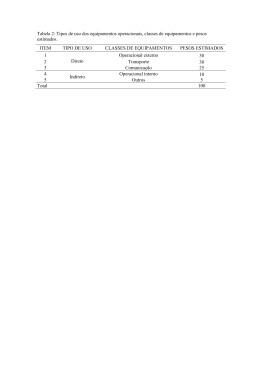
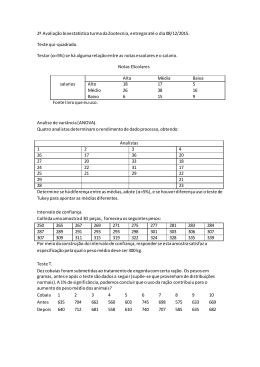
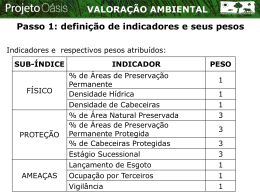
Recuperação
de Informação
Estrutura de Dados II
Mariella Berger
1
Roteiro
Tarefas
de Recuperação de Informação
Modelos
de Recuperação de Documentos
cv
Modelo Booleano
Modelo Espaço Vetorial
Recuperaçãocvde Informação
Sistemas de Recuperação de
Informação
Um sistema automático para RI pode ser visto como a parte do
sistema de informação responsável pelo armazenamento ordenado
dos documentos em um BD e sua posterior recuperação para
responder a consulta do usuário
Etapas principais:
cv
Preparação dos documentos
Indexação dos documentos
Busca (casamento com a consulta do usuário)
Ordenação dos documentos recuperados
Representação do Documento
Visão Lógica
Cada
documento da base pode ser representado
por:
um conjunto de termos (ou palavras) que melhor
cv
representam seus tópicos (geralmente, substantivos e verbos)
seu texto completo (todos os termos que aparecem no
documento, incluindo artigos, preposições,...)
seu texto completo + estrutura (títulos, fonte (negrito,
itálico), hiperlinks...)
Modelos Clássicos de
Recuperação de Documentos
Veremos
inicialmente os seguintes modelos:
Modelo Booleano e Modelo Espaço Vetorial
Para
cada modelo, veremos: cv
A representação do documento
A representação da consulta
A noção de relevância dos documentos em relação à
consulta utilizada na recuperação
pode ser binária (sim/não) ou ordenada
Modelos Clássicos
Conceitos Básicos
Considere
uma base qualquer de documentos
Cada
documento na base é representado por um
conjunto de n termos (ou palavras isoladas)
cv
k1, k2,...,kn
Esses
termos são escolhidos a partir da base de
documentos completa
cada base terá seu conjunto de termos
representativos
Modelos Clássicos
Conceitos Básicos
Cada
documento (dj) é representado por termos da base
associados a pesos
d1 = k1 (w1), k2 (w2),..., kn (wn)
Peso
cv
Importância da palavra para descrever o documento
Quando o termo não aparece no documento, o peso
associado é zero
Cada modelo de recuperação define pesos de uma
maneira diferente
Modelos Clássicos
Conceitos Básicos
As
consultas podem ser representadas pelo mesmo
conjunto de termos da base
Alguns
modelos permitem
cvassociar pesos aos termos
da consulta
Modelo cvBooleano
Modelo Booleano
Representação do documento
Dado o conjunto de termos representativos para a base em questão
K = {k1, k2,...,kn}
Os documentos são representados como vetores de pesos binários de
tamanho n
cv
Cada posição no vetor corresponde a um termo usado na
indexação dos documentos da base
A representação indica apenas se o termo está ou não presente
no documento
d1 = {1,1,0}
documento d1 contém os termos k1 e k2, e não contém o termo k3
Modelo Booleano
Representação da consulta
Consulta:
Termos conectados por AND, OR e/ou NOT
Exemplo: k1 AND (k2 OR NOT k3)
cv
A consulta é transformada em uma fórmula normal disjuntiva (DNF)
objetivo: facilitar o casamento entre documento e consulta
Exemplo: (1,1,1) OR (1,1,0) OR (1,0,0)
Documento casa com a consulta se ele casa com algum dos
componentes da consulta
O documento d1 = {1,1,0} casa com a consulta
Modelo Booleano
Relevância
Relevância
“binária”:
O documento é considerado relevante se seu
“casamento” com a consulta é verdadeiro
cv
Não é possível ordenar os documentos recuperados
Exemplo
Base de
Documentos
de consulta
K1
k2
Consulta
k 1 k2 k3
k3
Documentos
apresentados ao
usuário
Modelo Booleano
Vantagens
Modelo
simples baseado em teoria bem
fundamentada
Fácil
de implementar
cv
Modelo Booleano
Desvantagens
Não
permite casamento parcial entre consulta e
documento
Não
permite ordenação dos documentos
cv
recuperados
A
necessidade de informação do usuário deve ser
expressa em termos de uma expressão booleana
(nem todo usuário é capaz disso)
Em
consequência, este modelo geralmente retorna
ou poucos documentos ou documentos demais
Modelo Espaço
vetorial
cv
Modelo Espaço Vetorial
Associa
pesos positivos não-binários aos termos,
permitindo o casamento “parcial” entre consulta e
documento
Esses pesos são usadoscv
para calcular um “grau de
similaridade” entre consulta e documento
O
usuário recebe um conjunto ordenado de
documentos como resposta à sua consulta
Mais interessante do que apenas uma lista
desordenada de documentos
Modelo Espaço Vetorial
Este
modelo pode utilizar diferentes fórmulas para:
Calcular os pesos dos vetores
Freqüência de ocorrência do termo no documento
cv
TF-IDF (mais usado)
Calcular a medida de similaridade entre consulta e
documentos
Co-seno (mais usado)
Jaccard, Coeficiente de Pearson, etc...
Representação do documento
e da consulta
Dado
o conjunto de termos representativos para a
base em questão K = {k1, k2,...,kn}
cada termo de K é um eixo de um espaço vetorial
cv
Consultas (q) e documentos (d) são representados
como vetores nesse espaço n-dimensional
Representação do documento
e da consulta
cv
Representação do documento
e da consulta
Consulta q
:
Brasil Olimpíadas Sidney
Documento d
Brasil em Sidney 2000
:
O Brasil não foi bem no quadra
das medalhas da Olimpíada de
Sidney 2000 ...
Sidne
y
Representação de
cv Brasil q 0.4
q
Olimpíadas 0.3
Sidney
0.3
Representação de
Brasil d 0.5
Olimpíadas 0.3
Sidney
0.2
0.
2
0.
3
Olimpíada
s
d
0.
5
Brasi
l
Modelo Espaço Vetorial
Pesos
Os
pesos são usados para computar a similaridade
O
peso de um termo em um documento pode ser
calculado de diversas formas:
cv
Frequência no documento
Balancear características em comum (intradocumentos) e características para fazer a distinção
entre documentos (inter-documentos)
Pesos - Frequência
Exemplo
Documento A: “A dog and a cat.”
cv
Documento B: “A frog.”
Pesos - Frequência
O
vocabulário contém todas as palavras utilizadas
a, dog, and, cat, frog
cv
O vocabulário necessita ser ordenado
a, and, cat, dog, frog
Pesos - Frequência
Documento
A: “A dog and a cat.”
Vetor: (2,1,1,1,0)
cv
Documento
B: “A frog.”
Vetor: (1,0,0,0,1)
Pesos - Frequência
Queries
também podem ser representadas como
vetores:
Dog = (0,0,0,1,0)
cv
Frog = (0,0,0,0,1)
Dog and frog = (0,1,0,1,1)
Pesos - Frequência
Doc original
Doc : www.filosofia.com
“Se o desonesto soubesse a
vantagem de ser honesto,
ele seria honesto ao menos
por desonestidade.”
Sócrates
Operações de Texto
Doc : www.filosofia.com
desonesto / soubesse /
cv /
vantagem / honesto
seria / honesto /
menos/desonestidade/
socrates
Representação
Doc : www.filosofia.com
honesto
desonesto
soubesse
vantagem
seria
menos
desonestidade
socrates
2
1
1
1
1
1
1
1
Pesos – TF-IDF
Método TF-IDF leva em consideração:
Frequência do termo no documento
Term Frequency (TF)
cv
Quanto maior, mais relevante é o termo para descrever o documento
Inverso da frequência do termo entre os documentos da coleção
Inverse Document Frequency (IDF)
Termo que aparece em muitos documentos não é útil para distinguir
relevância
Peso associado ao termo tenta balancear esses dois fatores
Pesos – TF-IDF
tf_i(frequência do termo) = o número de vezes que o termo i ocorre
no documento (reflete a informação local)
df_i(frequência do documento) = o número de documentos que
contém o termo i.
cv
D = número total de documentos
Pesos – TF-IDF
A fração df_i/D é a probabilidade de selecionar um documento que
contém o termo i.
log(D/df_i) é o Inverse Document Frequency (IDFi ) e reflete a
informação global
cv
Se o termo aparece pouco nos documentos, então este é mais
relevante.
Pesos – TF-IDF
cv
Similaridade
cv
Similaridade
cv
Similaridade
Cada
dimensão corresponde a um termo, e o valor
do documento em cada dimensão varia entre 0
(irrelevante ou não presente) e 1 (totalmente
relevante).
cv
As
distâncias entre um documento e outro indicam
seu grau de similaridade, ou seja, documentos que
possuem os mesmos termos acabam sendo
colocados em uma mesma região do espaço e, em
teoria, tratam de assuntos similares.
Similaridade - consulta
Os
vetores dos documentos podem ser comparados
com o vetor da consulta e o grau de similaridade
entre cada um deles pode ser identificado.
cv
Os documentos mais similares (mais próximos no
espaço) à consulta são considerados relevantes
para o usuário e retornados como resposta
Similaridade - consulta
Uma
das formas de calcular a proximidade entre os
vetores é testar o ângulo entre estes vetores.
No
modelo original, é utilizada
uma função batizada
cv
de cosine vector similarity
K
d
1
Similaridade(q,d) = cos()
q
K
2
Relevancia
Similaridade
pode ser medida pelo coseno do
ângulo entre q e d
Quanto menor é o ângulo
cventre os documentos, maior
o coseno (E maior é a similaridade entre d e q)
Exemplo:
para 2 vetores d e d’, a similaridade é
calculada pelo coseno, ou seja:
d d'
d d'
Relevancia
Depois
dos graus de similaridade terem sido
calculados, é possível montar uma lista ordenada
(ranking) de todos os documentos e seus respectivos
graus de relevância à consulta,
da maior para a
cv
menor relevância
Similaridade
cv
Similaridade
Similaridade
= produto interno / produto das normas
0.2
0
.4
0.4
0
.1
0.1
0
.2
0
.3
0
.3
sim
0
.
83
2
2 2 2
2 2 2 2
(0.2)
(0.4)
(0.1)
(0.3)
(0.4)
(0.1)
(0.2
(0.
cv
Exemplo 1
Query:
"gold silver truck"
A
coleção possui 3 documentos (D = 3)
cv
D1: "Shipment of gold damaged in a fire"
D2:
"Delivery of silver arrived in a silver truck"
D3:
"Shipment of gold arrived in a truck"
cv
Similaridade
cv
Similaridade
cv
Similaridade
cv
Similaridade
Resultado
Rank
1: Doc 2 = 0.8246
Rank
2: Doc 3 = 0.3271
Rank
3: Doc 1 = 0.0801
cv
Vantagens
Oferecer
Atribuir
um framework simples e elegante
pesos aos termos melhora o desempenho
É
uma estratégia de encontrocv
parcial (função de similaridade),
que é melhor que a exatidão do modelo booleano;
Os
documentos são ordenados de acordo com seu grau de
similaridade com a consulta.
Em
geral, seu desempenho (precisão e recall) supera todos os
outros modelos
Desvantagens
Ausência
de ortogonalidade entre os termos. Isso poderia
encontrar relações entre termos que aparentemente não têm
nada em comum;
É
um modelo generalizado;
cv
Um
documento relevante pode não conter termos da
consulta;
Documentos
similaridade.
muito longos podem dificultar na medida da
Ideias para melhorar o modelo
Apontar
um conjunto de palavras-chaves nos
documentos
Eliminar
artigos)
palavras muito comuns
(como exemplo
cv
Limitar
o vetor espaço em substantivos e poucos
verbos ou adjetivos
Criar
subvetores para documentos muito grandes
Baixar