Uma Biblioteca Digital para Depósito,
Gestão e Acesso a Teses e Dissertações
Resumo
Descreve-se o desenvolvimento de uma biblioteca digital de teses e dissertações. Esta
biblioteca é um sistema distribuído, baseando-se na existência de servidores locais nas
bibliotecas das universidades e de um servidor central na Biblioteca Nacional, onde são
depositadas todas as teses e dissertações publicadas nas universidades portuguesas.
São abordadas as questões do armazenamento destas publicações, o seu acesso, a sua
identificação de forma persistente, os seus formatos, a sua preservação, e a sua visibilidade
para o exterior, entre outras.
A inter-operação com outros sistemas é abordada com especial detalhe, sendo vista como
essencial para tornar estas publicações visíveis para todos potenciais interessados, que por sua
vez, podem estar espalhados pelo mundo inteiro. Para conseguir a inter-operação são
implementadas várias interfaces, que disponibilizam a metadata sobre as teses e dissertações
em diferentes formatos, os quais são gerados por conversão a partir do formato de metadata
próprio desta biblioteca digital.
Palavras-chave
Bibliotecas Digitais, Internet, Metadata, Publicação Digital, Sistemas Distribuídos,
Inter-operação.
A Digital Library for Deposit, Management
and Access to digital Theses and
Dissertations
Abstract
This work describes the development of a digital library of theses and dissertations. This
library is a distributed system, based on the existence of local servers in the university’s
libraries and a central server in the Portuguese National Library, where are deposited all
theses and dissertations published in the Portuguese universities.
This work approaches the issues of storage of these publications, their access, their persistent
identification, their formats, their long-term preservation, and their visibility to the exterior..
There has been particular interest in the issue of interoperability with other systems.
Interoperability is essential to make these publications visible to all potential readers, which
may be spread around the world. To achieve interoperability several interfaces are
implemented, which make available the document’s metadata in different formats. Those
metadata formats are generated automatically by conversion from the own metadata format of
this digital library.
Keywords
Digital Libraries, Digital Publishing, Distributed Systems, Interoperability, Internet,
Metadata.
Agradecimentos
À Rita, à minha Família, a José Borbinha e a todos aqueles que tornaram
possível este trabalho.
Índice Geral
ÍNDICE GERAL..................................................................................................I
LISTA DE FIGURAS ......................................................................................... V
LISTA DE TABELAS ...................................................................................... VII
NOTAÇÕES E REFERÊNCIAS ..........................................................................IX
1. INTRODUÇÃO ................................................................................................... 1
1.1 Motivação................................................................................................................... 1
1.2 Depósito de Publicações............................................................................................. 2
1.2.1
Paradigmas de Depósito ..................................................................................... 2
1.2.2
O depósito legal em Portugal ............................................................................. 3
1.2.3
Depósito de publicações electrónicas................................................................. 4
1.3 Resultados .................................................................................................................. 5
1.4 Organização e Estrutura da Tese .............................................................................5
2. O ESTADO DA ARTE E TECNOLOGIA RELEVANTE ........................................... 7
2.1 Introdução................................................................................................................... 7
2.2 Iniciativas relevantes .................................................................................................. 8
2.2.1
Networked Computer Science Technical Reference Library............................. 8
2.2.2
Networked Digital Library of Theses and Dissertations .................................... 9
2.2.3
Open Archives Initiative .................................................................................. 10
2.3 Identificadores de publicações digitais .................................................................... 12
2.4 Condições de acesso e uso de publicações digitais .................................................. 13
2.4.1
Mecanismos de controlo de acesso .................................................................. 15
2.4.2
Metadata para acesso........................................................................................ 16
2.5 Formatos de documentos digitais ............................................................................. 16
2.5.1
Formatos de trabalho........................................................................................ 17
2.5.2
Formatos de apresentação ................................................................................ 18
2.5.3
Formatos orientados para a estrutura ............................................................... 19
2.5.3.1 Standard Generalized Markup Language..................................................... 20
I
II
ÍNDICE
2.5.3.2 Extensible Markup Language....................................................................... 20
2.6 Metadata nas bibliotecas .......................................................................................... 21
2.6.1
O Formato MARC............................................................................................ 23
2.6.2
A norma ISO 2709 ........................................................................................... 24
3. REQUISITOS DA BIBLIOTECA DIGITAL DE TESES E DISSERTAÇÕES .............. 31
3.1 Introdução................................................................................................................. 31
3.2 Reconhecimento do problema .................................................................................. 31
3.2.1
Os autores ......................................................................................................... 33
3.2.2
As bibliotecas das universidades...................................................................... 33
3.2.3
A Biblioteca Nacional ...................................................................................... 34
3.2.4
Os leitores......................................................................................................... 34
3.3 Casos de uso ............................................................................................................. 34
3.4 Acesso às dissertações.............................................................................................. 36
3.5 Identificadores .......................................................................................................... 37
3.6 Formatos das dissertações ........................................................................................ 37
3.7 Análise dos dados..................................................................................................... 38
3.8 Síntese da análise ..................................................................................................... 39
4. DESENHO DO SISTEMA .................................................................................. 41
4.1 Introdução................................................................................................................. 41
4.2 Arquitectura de alto nível......................................................................................... 41
4.3 Tecnologia................................................................................................................ 44
4.3.1
O Sistema DIENST .......................................................................................... 44
4.3.2
Aplicação do DIENST no DiTeD .................................................................... 48
4.3.3
Outras tecnologias ............................................................................................ 49
4.4 Estruturas de dados................................................................................................... 50
4.4.1
Metadata ........................................................................................................... 50
4.4.2
Implicações funcionais ..................................................................................... 54
4.4.2.1 A estrutura de metadata................................................................................ 56
4.4.2.2 Interface de utilizador................................................................................... 57
4.4.2.3 Índices de pesquisa....................................................................................... 59
4.4.2.4 Interfaces para inter-operação ...................................................................... 60
ÍNDICE
III
5. CONCRETIZAÇÃO DO SISTEMA ..................................................................... 61
5.1 Introdução................................................................................................................. 61
5.2 Arquitectura detalhada ............................................................................................. 61
5.3 O sistema de repositório ........................................................................................... 64
5.4 O sistema de pesquisa federada................................................................................ 66
5.4.1
A colecção virtual de teses e dissertações ........................................................ 66
5.4.2
Indexação e pesquisa........................................................................................ 67
5.5 O serviço de depósito ............................................................................................... 70
5.6 Resolução de URNs ................................................................................................. 72
5.7 O módulo de conversão de registos de metadata ..................................................... 74
5.8 Interfaces de utilizador ............................................................................................. 81
5.8.1
Interface de depósito ........................................................................................ 81
5.8.2
Interface de pesquisa e acesso .......................................................................... 86
5.8.3
Interface de administração ............................................................................... 89
6. INTER-OPERAÇÃO COM OUTROS SISTEMAS .................................................. 93
6.1 Introdução................................................................................................................. 93
6.2 Interface com o UNIMARC ..................................................................................... 94
6.3 Interface com a Networked Computer Science Technical Report Library............... 98
6.4 Interface com a Open Archives Initiative ............................................................... 101
6.5 Interface com o protocolo Z39.50 .......................................................................... 104
6.6 Inter-operação na Networked Digital Library of Theses and Dissertations........... 107
7. CONCLUSÕES E TRABALHO FUTURO ........................................................... 113
7.1 Introdução............................................................................................................... 113
7.2 Formato para dissertações e teses digitais.............................................................. 113
7.2.1
Estrutura do formato....................................................................................... 114
7.2.2
Apresentação do formato ............................................................................... 116
7.2.3
Síntese e aplicabilidade do formato ............................................................... 118
7.3 infra-estruturas emergentes para inter-operação .................................................... 119
7.3.1
Iniciativa Dublin Core.................................................................................... 119
7.3.2
Resource Description Framework ................................................................. 122
7.4 Avaliação da biblioteca digital de teses e dissertações .......................................... 123
IV
ÍNDICE
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E
TESES DIGITAIS ......................................................................... 125
A. DTD – Definição de Tipo de Documento para o formato para dissertações e
teses digitais ............................................................................................................... 125
B. Folha de estilo para a apresentação do formato.......................................................... 129
C. Exemplo de um documento fictício............................................................................ 138
D. Apresentação do documento....................................................................................... 143
REFERÊNCIAS .............................................................................................. 149
Lista de Figuras
Figura 1 – Interacção entre o bibliotecário e o catálogo para a troca de registos ......................... 22
Figura 2 – Principais componentes de um registo ISO 2709 ........................................................ 25
Figura 3 – Etiqueta de registo ISO 2709 ....................................................................................... 26
Figura 4 – Directoria de um registo ISO 2709 .............................................................................. 27
Figura 5 – Campos variáveis de um registo ISO 2709.................................................................. 28
Figura 6 – Casos de uso da biblioteca digital de teses e dissertações ........................................... 35
Figura 7 – Processo de depósito das teses e dissertações digitais................................................. 38
Figura 8 – Arquitectura de alto nível do sistema DiTeD .............................................................. 42
Figura 9 – Componentes de um servidor local.............................................................................. 43
Figura 10 – Componentes do servidor central .............................................................................. 44
Figura 11 – Configuração dos serviços DIENST para um servidor isolado ................................. 46
Figura 12 – Exemplo de uma configuração de serviços DIENST ................................................ 47
Figura 13 – Definição do formato de metadata DiTeD................................................................. 53
Figura 14 – Estrutura de dados da configuração do sistema DiTeD ............................................. 55
Figura 15 – Diagrama da interface de depósito de documentos ................................................... 57
Figura 16 – Interface HTML gerada a partir interface de recolha da estrutura de
metadata sobre o autor .................................................................................................. 58
Figura 17 – Visualização de um registo de metadata.................................................................... 59
Figura 18 – Visualização resumida de dois registos de metadata ................................................. 59
Figura 19 – Configuração de serviços do servidor central............................................................ 63
Figura 20 – Configuração de serviços de um servidor local ......................................................... 64
Figura 21 – Execução de uma pesquisa ........................................................................................ 68
Figura 22 – Diagrama do processo de recolha de metadata para indexação................................. 69
Figura 23 – Diagrama do processo de recolha de novas dissertações........................................... 71
Figura 24 – Exemplo de resolução de um URN............................................................................ 72
Figura 25 – Arquitectura do servidor URN................................................................................... 73
Figura 26 – Exemplo do registo, alteração ou remoção de um URN............................................ 74
Figura 27 – Acesso aos vários formatos de metadata ................................................................... 76
Figura 28 – Representação generalizada de um registo de metadata ............................................ 76
Figura 29 – Exemplo de conversão de um registo de metadata .................................................... 77
Figura 30 – Processo de conversão de registos de metadata......................................................... 77
V
VI
LISTA DE FIGURAS
Figura 31 – Diagrama da conversão de registos de metadata ....................................................... 78
Figura 32 – Registo no formato DiTeD ........................................................................................ 80
Figura 33 – Registo convertido para UNIMARC.......................................................................... 81
Figura 34 – Interface de depósito (1º passo) ................................................................................. 82
Figura 35 – Interface de depósito (2º passo) ................................................................................. 83
Figura 36 – Interface de depósito (3º passo) ................................................................................. 84
Figura 37 – Interface de depósito (4º passo) ................................................................................. 85
Figura 38 – Interface de depósito (5º passo, envio dos ficheiros)................................................. 86
Figura 39 – Interface de pesquisa.................................................................................................. 87
Figura 40 – Interface de navegação............................................................................................... 87
Figura 41 – Resultados de uma pesquisa ...................................................................................... 88
Figura 42 – Interface de acesso às dissertações ............................................................................ 89
Figura 43 –Interface de aprovação de documentos ....................................................................... 90
Figura 44 – Interface de pesquisa para visualização dos conteúdos do repositório ...................... 90
Figura 45 – Interface de visualização dos conteúdos e extracção de metadata............................. 91
Figura 46 –Visualização da metadata dos documentos nos vários formatos suportados.............. 91
Figura 47 – Especificação da conversão DiTeD
UNIMARC .................................................. 95
Figura 48 – Especificação da conversão DiTeD
RFC 1807................................................... 100
Figura 49 – Especificação da conversão DiTeD
OAMS........................................................ 104
Figura 50 – Estrutura da DTD..................................................................................................... 114
Figura 51 – Funcionamento da XSL ........................................................................................... 116
Figura 52 – Apresentação de um documento XML .................................................................... 117
Lista de Tabelas
Tabela 1 – Cenários de condições de acesso e uso ....................................................................... 14
Tabela 2 – Campo UNIMARC...................................................................................................... 23
Tabela 3 – Registo bibliográfico UNIMARC ............................................................................... 24
Tabela 4 – Caracteres separadores e terminadores da norma ISO 2709 ....................................... 29
Tabela 5 – As principais operações dos serviços definidos pelo DIENST ................................... 48
Tabela 6 – Estrutura de metadata usada no projecto DiTeD......................................................... 52
Tabela 7 –Interfaces de recolha da metadata sobre o autor........................................................... 58
Tabela 8 – Exemplo de uma configuração dos índices de pesquisa.............................................. 60
Tabela 9 – Interface HTTP do sistema URN ................................................................................ 73
Tabela 10 – O formato de metadata definido no RFC 1807 ......................................................... 99
Tabela 11 – Pedidos do protocolo Open Archives Initiative....................................................... 102
Tabela 12 – Open Arquives Metadata Set................................................................................... 103
Tabela 13 – Comparação entre a metadata utilizada por quatro membros da NDLTD .............. 109
Tabela 14 – Núcleo de elementos para interoperabilidade no NDLTD ...................................... 110
Tabela 15 – Elementos do núcleo de metadata Dublin Core. ..................................................... 121
VII
Notações e referências
As referências bibliográficas seguem os critérios baseados no sistema autor-data, tal como é
referido por João Frada no Capítulo 3 da sua obra “Guia prático para elaboração e
apresentação de trabalhos científicos”. Assim, uma referência na forma (Frada, 97) poderá
corresponder à obra:
“Frada, João José Cúcio (1997). Guia prático para elaboração e apresentação de trabalhos científico. 7ª
Edição, Edições Cosmos, 1997.”
No caso de publicações acessíveis na Internet, em exclusivo ou em complemento de edições
impressas, fornece-se ainda o seu endereço nesse espaço. Na ausência de normas universalmente
aceites, seguem-se as recomendações da MLA – Modern Language Association. Estas reflectem
uma tendência geral de apresentar o endereço da obra delimitado pelos caracteres “<” e “>”,
recomendando ainda a apresentação da data da última vez que esse endereço foi verificado,
escrita delimitada pelos caracteres “[“ e “]”. Deste modo a referência (MLA, 1998)
corresponderia à publicação:
“MLA (1998). MLA Style. Modern Language Association. <http://www.mla.org> [16 de Fevereiro de 1998].”
Na presente dissertação considera-se como data dessa verificação para todas as referências
precisamente a data de conclusão desta obra, conforme apresentada na capa, decidindo-se por
isso simplificar as referências omitindo a referida data. Assim, a referência (MLA, 1998) será
escrita simplesmente como:
“MLA (1998). MLA Style. Modern Language Association. <http://www.mla.org>"
Ainda sobre recursos na Internet relevantes como referência para este trabalho, outros há de
manifesto interesse mas que não correspondem em rigor a referências bibliográficas formais de,
tais como endereços de serviços (como por exemplo o <http://google.com>). Nestes casos a
opção foi referenciá-los apenas no próprio texto, na forma de notas.
Finalmente, e no que respeita à notação gráfica utilizada nos diagramas, utiliza-se sempre que
possível, a notação associada à linguagem UML – Unified Modeling Language, conforme
definida pela Rational1, a empresa que tem liderado os esforços da definição, tendo sido ainda
usadas como referência as publicações (Erikson & Penker, 1998) e (Rosenberg & Scott, 1999).
1
<http://www.rational.com/uml>
IX
Capítulo 1
INTRODUÇÃO
1.1
MOTIVAÇÃO
As teses e dissertações levadas a cabo nas universidades portuguesas, são hoje um trabalho de
investigação de grande valor, mas quase sempre pouco visível para o mundo. Estas publicações
são impressas em papel e depositadas nas bibliotecas das universidades e na Biblioteca Nacional,
onde permanecem, muitas vezes no anonimato, sendo consultadas apenas esporadicamente.
Hoje em dia, as dissertações2, apesar de ainda se destinarem a ser impressas, são criadas pelos
seus autores em formato digital. Alguns autores disponibilizam as suas dissertações nas suas
páginas pessoais na Internet, mas, embora isto permita o acesso online à dissertação, a
descoberta da existência deste trabalho, por parte dos potenciais interessados, continua a ser
difícil. Os motores de pesquisa da Internet apenas permitem pesquisar em páginas de hipertexto
e, salvo raras excepções, não é este o formato em que as dissertações são disponibilizadas.
A criação de uma biblioteca digital de teses e dissertações surge assim como uma oportunidade
para “libertar” este trabalho de investigação, e permitir a sua disseminação ao nível mundial.
Espera-se assim, permitir que as universidades tornem disponível de forma imediata, sem
grandes custos adicionais, os resultados da investigação dos seus estudantes, como uma
importante contribuição para o progresso da educação e, consequentemente, da humanidade.
2
Por forma a facilitar a leitura, a palavra “dissertações” é utilizada ao longo deste trabalho, para referir “teses e dissertações”.
1
2
INTRODUÇÃO
No contexto actual em que a publicação digital começa a tornar-se um movimento cultural de
grande importância, a Biblioteca Nacional escolheu o género das teses e dissertações como o seu
primeiro caso de estudo sobre o depósito de publicações digitais, mantendo-se assim fiel à sua
principal missão, a de reunir e preservar todas as publicações do país.
Surge assim o enquadramento da biblioteca digital de teses e dissertações, com o objectivo de
aproximar as bibliotecas das universidades, a Biblioteca Nacional, os autores e os leitores, de
modo a permitir uma melhor divulgação destes trabalhos, bem como facilitar o processo do seu
depósito.
1.2
DEPÓSITO DE PUBLICAÇÕES
O depósito das publicações (Borbinha, Freire, Cardoso, Campos & Castanheira, 1998) editadas
num determinado país é uma disposição legislativa existente na maioria dos respectivos Estados.
O alcance desta medida legal é garantir que uma organização, regra geral uma biblioteca
nacional, receba, organize e arquive o repositório bibliográfico do respectivo país e responda,
perante a sociedade, pela manutenção, ao longo dos tempos, desse património.
Nalguns países, como por exemplo nos Estados Unidos ou França, esta medida tem ainda um
alcance mais alargado, já que visa funcionar também como mecanismo de registo intelectual da
obra (sendo por vezes este mesmo o primeiro objectivo formal anunciado).
1.2.1 PARADIGMAS DE DEPÓSITO
Existem na prática mundial três modelos fundamentais relativamente à forma como se
constituem as colecções de depósito: depósito legal, depósito voluntário e aquisição.
O modelo de depósito legal caracteriza-se pela existência de um contexto legal que força os
agentes responsáveis pela produção de publicações a depositar um determinado número de
cópias das mesmas junto de entidades beneficiárias desse depósito. Este é o modelo seguido em
Portugal relativamente ao material impresso, cabendo a obrigação desse depósito às tipografias.
O depósito voluntário corresponde a um modelo baseado normalmente em acordos entre
entidades beneficiárias desse depósito e os agentes responsáveis pela produção de publicações
INTRODUÇÃO
3
(feitos normalmente através das suas organizações representativas). Este modelo é seguido
tradicionalmente, por exemplo, na Holanda, com uma taxa de sucesso considerável (estimada
como superior a 90%).
O modelo baseado na aquisição consiste, regra geral, na compra directa ou indirecta das
publicações relevantes, pela entidade interessada na constituição de uma colecção de depósito.
Esta opção é seguida por instituições e países onde contextos legais e culturais complexos
tornam intrincado ou mesmo impossível, qualquer um dos outros modelos. É este o exemplo da
Suíça, um país de relativa reduzida dimensão, uma grande abertura ao exterior e contexto
fortemente multilíngue, sendo ainda praticado em Portugal pela Biblioteca Nacional, como
opção para completar a sua colecção com obras relevantes sobre a nossa cultura produzidas no
estrangeiro.
1.2.2 O DEPÓSITO LEGAL EM PORTUGAL
Após algumas tentativas de depósito parcial, foi em 1933 que se instituiu em Portugal a
obrigação legal para as tipografias portuguesas depositarem, na Biblioteca Nacional, um número
fixo de exemplares de cada publicação que imprimem.
Esta lei foi revista em 1982 dando origem ao diploma legal pelo qual hoje se rege a actividade de
depósito da bibliografia portuguesa na Biblioteca Nacional (Decreto-Lei Nº74/82).
Em comparação com outros países, nomeadamente os da Comunidade Europeia, a lei portuguesa
apresenta muitas diferenças: o depósito é efectuado pela tipografia, enquanto que na maioria dos
casos compete ao editor garantir o cumprimento da lei, e o número de exemplares a depositar é
de 14 quando o que se verifica noutros países é um mínimo de 1 e um máximo de 4.
Dos exemplares depositados na Biblioteca Nacional, um destina-se a arquivo e o outro a
empréstimo, sendo os restantes doze enviados para outras tantas instituições igualmente
beneficiárias desse depósito3.
3
A saber, as Bibliotecas do Real Gabinete Português de Leitura do Rio de Janeiro, da Academia de Ciências de Lisboa, Gerais da Universidade
de Coimbra e da Universidade do Minho, Municipais de Lisboa, Coimbra e Porto, Distrital de Évora, Popular de Lisboa, e ainda as Regiões
Autónomas dos Açores e da Madeira.
4
INTRODUÇÃO
1.2.3 DEPÓSITO DE PUBLICAÇÕES ELECTRÓNICAS
De enciclopédias a jogos, passando por programas de computador, discos compactos, cassetes
vídeo, etc., temos vindo a assistir, nos últimos anos ao surgimento de novas preocupações e de
novas legislações tendentes a abranger também o depósito de publicações electrónicas.
A verdade, porém, é que se de início se falava quase exclusivamente em publicações com
suporte "físico" manuseável, sujeito a instalação e “arrumável”, rapidamente se começou a falar
também das publicações "virtuais", as quais podem ir de emissões públicas de televisão e rádio a
conteúdos tornados públicos na Internet.
Tentando sumariar as tendências actuais, verifica-se que a legislação proposta nos últimos 4 a 5
anos nos países mais desenvolvidos encara quase sempre a hipótese de um depósito de
publicações off-line e online, apresentando, no entanto, listas por tipo de publicação de forma a
eliminar, sobretudo no caso da Internet, o que se considera efémero.
Focando a nossa atenção na Internet, não é assim, como se calcula, uma tarefa fácil a de
controlar o que já por si é tão pouco controlável como as publicações que aí vão aparecendo. A
abordagem deste problema implica uma necessidade de redefinição de conceitos básicos (onde
se incluem os próprios conceitos de "publicação" e "acto de publicar"), assim como de uma
didáctica a fazer junto dos produtores de informação para os sensibilizar a um depósito que
garanta, inclusive, os seus interesses como autores ou detentores de direitos e a permanência da
informação que produziram.
Por outro lado, e do ponto de vista das bibliotecas nacionais, há que criar as condições para que o
depósito se efectue e que passam pela identificação e um certo "controlo" do que se vai
publicando, pela descrição e criação de pontos de acesso para que essas publicações sejam
coerentemente pesquisáveis e localizáveis e pela preservação, a longo prazo, da informação nelas
constante.
A preservação a longo prazo destas publicações vai de certeza levantar toda uma nova gama de
problemas técnicos e económicos às bibliotecas, resultantes não só da natural obsolescência dos
formatos de codificação desses conteúdos (aparentemente cada vez em maior número e
diversidade), como também dos equipamentos necessários à sua reprodução (tendo vindo no
entanto a assistir-se aqui, felizmente, a uma maior independência dos conteúdos relativamente
aos dispositivos ou mesmo aos sistema operativos).
INTRODUÇÃO
1.3
5
RESULTADOS
Um género de publicação que em Portugal se encontra sujeito ao depósito legal é o das teses e
dissertações produzidas nas universidades e instituições de investigação nacionais.
O depósito dessas publicações em formato digital foi objecto de um protocolo de cooperação
entre a Biblioteca Nacional, o INESC (Instituto de Engenharia de Sistemas e Computadores) e o
Instituto Superior Técnico, o qual deu origem ao projecto DiTeD e ao trabalho descrito nesta
tese. Este trabalho foi também enquadrado com o projecto NEDLIB4 (Networked European
Deposit Libraries). Este projecto foi iniciado em Janeiro de 1998 e teve a duração de três anos,
tendo sido suportado pelo programa Telematics for Libraries da Comissão Europeia. O projecto
NEDLIB teve como objectivo "encontrar formas de tornar possível que publicações digitais
criadas hoje venham a ser usadas agora e no futuro".
Os resultados do projecto DiTeD são assim usados pela Biblioteca Nacional e pelas
universidades portuguesas para suportar um sistema operacional de depósito de teses e
dissertações.
1.4
ORGANIZAÇÃO E ESTRUTURA DA TESE
Este documento foi elaborado por forma a apresentar o trabalho realizado de uma forma clara e
perceptível, apresentando assim a informação estruturada de acordo com o processo de
desenvolvimento seguido.
O capítulo 2 pode ser visto como uma síntese do trabalho de investigação inicial realizado, onde
são apresentados conceitos e projectos relevantes para o desenvolvimento do presente trabalho.
Nos capítulos 3, 4 e 5 são expostas as principais fases do processo de desenvolvimento da
biblioteca digital de teses e dissertações. Assim, no capítulo 3 é apresentada em detalhe a análise
efectuada ao problema, apresentando os requisitos que a solução deverá cobrir. No capítulo 4, é
descrito o desenho do sistema, no qual são expostas as arquitecturas do sistema e de dados
propostas para a solução. No capítulo 5 apresenta-se em detalhe a concretização dos
componentes da arquitectura.
4
<http://www.konbib.nl/nedlib>
6
INTRODUÇÃO
No capítulo 6, são apresentadas as características de inter-operação da biblioteca digital de teses
e dissertações com outros sistemas.
Por fim, no capítulo 7 são apresentadas as conclusões ao presente trabalho, descrevendo-se
também os temas em aberto para realização futura.
Capítulo 2
O ESTADO DA ARTE E TECNOLOGIA
RELEVANTE
2.1
INTRODUÇÃO
Nos últimos anos, três iniciativas distinguiram-se pelo seu trabalho inovador na área das
bibliotecas digitais: a Networked Computer Science Technical Reference Library e o seu trabalho
desenvolvido em bibliotecas digitais distribuídas; a Networked Digital Library of Theses and
Dissertations e a sua experiência, não só em bibliotecas digitais, mas mais especificamente com
teses e dissertações digitais; e a Open Archives Initiative e a sua proposta para a inter-operação
entre bibliotecas digitais como forma de aumentar a “visibilidade” dos seus conteúdos. O
trabalho desenvolvido por estas iniciativas foi assim um excelente ponto de partida para o
presente trabalho, e é desta forma brevemente apresentado neste capítulo pela sua relevância
para o bom entendimento do mesmo.
Este capítulo pretende assim, apresentar o enquadramento para este trabalho, introduzindo para
além de alguns conceitos, outros assuntos relevantes para a análise do problema em questão.
7
8
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
2.2
INICIATIVAS RELEVANTES
2.2.1 NETWORKED COMPUTER SCIENCE TECHNICAL REFERENCE LIBRARY
A Networked Computer Science Technical Reference Library (NCSTRL)5 foi um esforço
pioneiro na criação de uma colecção virtual de publicações digitais, baseada em colecções
distribuídas, através da implementação de um conjunto de serviços básicos (Lagoze 1996).
A NCSTRL é hoje uma federação de mais de 100 instituições com o objectivo de providenciar
uma biblioteca digital federada de materiais sobre ciência da computação.
A NCSTRL age principalmente em três áreas de actividade:
•
Construção da federação de bibliotecas digitais;
•
Desenvolvimento de uma arquitectura aberta como uma base técnica que permite
alcançar a federação de colecções, servindo também como uma proposta de arquitectura
para federações de bibliotecas digitais mais gerais;
•
Desenvolvimento e demonstração de uma “implementação de referência” dos seus
protocolos/serviços.
O elemento chave da actividade da NCSTRL é o desenvolvimento e demonstração de uma
aproximação para a biblioteca digital federada através de uma arquitectura aberta. Esta
arquitectura aberta baseia-se na ideia de que a funcionalidade das bibliotecas digitais poder ser
separada num conjunto de serviços ou funções bem definidas, cada serviço com um protocolo
bem definido que especifica a interface para esse serviço. Alguns destes serviços interagem com
os utilizadores; outros interagem com máquinas. Esta arquitectura oferece às organizações
participantes a liberdade de utilização de diferentes desenhos e concretizações dos serviços desde
que as suas interfaces sigam o protocolo.
A concretização de referência deste protocolo é o sistema DIENST (Lagoze & Davis 1995).
5
<http://www.ncstrl.org>
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
9
2.2.2 NETWORKED DIGITAL LIBRARY OF THESES AND DISSERTATIONS
O conceito de teses e dissertações digitais começou por ser discutido em 1987 nos Estados
Unidos da América entre a UMI6, a universidade Virginia Tech, e a Universidade do Michigan.
Desde esta altura diversos projectos têm sido desenvolvidos nesta área.
O primeiro trabalho de investigação e, também o mais relevante, foi levado a cabo na
universidade de Virginia Tech em 1991, onde foram abordados os problemas associados à
produção, arquivo e acesso das teses e dissertações em formato digital. Como resultado, desde
1994 que o Virginia Tech tem em funcionamento um sistema que cobre o processo
administrativo da entrega de uma tese ou dissertação em formato digital, que permite aos
estudantes efectuar o envio online dos seus documentos no formato PDF, por FTP, ou em mão,
por disquete ou CD-ROM. Em 1997, após um período de transição, foi decretada a
obrigatoriedade, para todos os estudantes, de efectuarem a submissão dos seus trabalhos em
formato digital.
Como resultado dos esforços desenvolvidos pelo Virginia Tech, bem como do interesse
demonstrado por outras organizações mundiais, nasceu a Networked Digital Library of Theses
and Dissertations (NDLTD), um esforço internacional que procura melhorar a educação
académica através do encorajamento de todas as universidades a requererem a submissão de
teses e dissertações em formato digital (Constantinos, Kipp, Sornil, Mather & Fox, 1999).
Desde a sua criação, a NDLTD tem vindo a ganhar relevância internacional, com impacto no
trabalho de milhares de estudantes e investigadores. Conta hoje com cerca de 60 instituições
representando 13 países, dos quais a maioria são universidades e, as restantes, organizações sem
fim lucrativo e corporações. A Biblioteca Nacional é o único participante português,
representando as universidades portuguesas.
Até à data, a entrega em formato digital é obrigatória em cinco universidades, das quais, quatro
nos EUA (Virginia Tech, Universidade do West Virginia, Universidade do East Tenessee, e
Universidade do North Texas), e uma na África do Sul (Universidade de Rhodesna).
Presentemente, o NDLTD promove actividades de investigação e desenvolvimento em áreas
como a aplicação de métodos de automatização para simplificar o processamento dos
6
A UMI é uma editora que publica teses e dissertações. <http://www.umi.com>
10
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
documentos, a utilização de normas para preservação e inter-operação entre sistemas, e a
especificação da utilização de metadata7 para a pesquisa e navegação de colecções de teses.
2.2.3 OPEN ARCHIVES INITIATIVE
A Open Archives Iniciative (OAI) tem desenvolvido um trabalho muito importante para facilitar
a descoberta de conteúdos guardados em arquivos de publicações digitais, geralmente
provenientes de áreas técnicas e científicas.
Os primeiros resultados práticos da Open Archives Initiative surgiram em Outubro de 1999, com
a Convenção de Santa Fé, tendo-se seguido a discussão em sessões especiais em Junho de 2000
em San Antonio no Texas, e em Setembro de 2000 na 4ª Conferência Europeia sobre Bibliotecas
digitais, em Lisboa).
Esta convenção é uma combinação de princípios organizacionais e de especificações técnicas
para facilitar um nível de inter-operação mínima mas potencialmente muito funcional entre
arquivos de publicações digitais. A convenção oferece aos arquivos um mecanismo
relativamente fácil de concretizar, que lhes permite disponibilizar a sua informação abertamente.
Esta abertura permite que sejam construídos níveis superiores de funcionalidade utilizando a
informação tornada disponível pelos arquivos que adoptem a convenção.
As origens da OAI vêm do número crescente de arquivos de publicações digitais. Muito destes
arquivos começaram como veículos informais para a disseminação de resultados preliminares.
Entre estes, muitos evoluíram para um médium orientado para a partilha de resultados de
investigação entre colegas do mesmo campo de investigação.
Estes arquivos surgiram como uma evolução da publicação em jornais científicos formais,
devido às facilidades dadas pela Internet como médium para partilha de resultados de pesquisa e
à não cedência dos direitos do autor para o editor. Estes arquivos são vistos como uma forma
mais justa e eficiente para a disseminação de resultados de investigação.
As aproximações adoptadas pelos vários arquivos diferem bastante entre si. Algumas baseiam-se
num modelo centralizado, outras num modelo institucional distribuído por departamentos ou
extensões. Alguns lidam apenas com metadata, outros com metadata e com o conteúdo. No
7
Entende-se por metadata, como informação descritiva sobre um recurso.
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
11
entanto todos visam partilhar os resultados de investigação de uma forma conveniente e
imediata. Esta é a razão porque a OAI acredita que a inter-operação entre arquivos é a chave para
aumentar o impacto dos mesmos e ajudar na sua missão.
Inter-operação é um termo que toca em diversos aspectos dos arquivos. Incluindo os seus
formatos de metadata, a sua arquitectura, a sua abertura à criação de serviços externos, etc. A
inter-operação entre arquivos oferece benefícios substancias para os seus utilizadores. Talvez o
ponto mais importante seja o de criar um ponto de entrada para uma variedade de recursos de
informação sem barreiras entre diferentes domínios. Mecanismos para inter-operação oferecem o
potencial para ferramentas de descoberta e colecções virtuais que se estendem através do
conteúdo de múltiplos arquivos. Os autores também beneficiam deste ponto de entrada comum,
uma vez que os seus trabalhos estarão acessíveis para uma maior audiência.
A OAI representa uma aproximação pragmática e incremental para conseguir inter-operação
entre arquivos. Uma das preocupações da OAI foi balancear entre a necessidade de
funcionalidade com o requisito de manter os custos de entrada suficientemente baixos para os
arquivos participantes. Esta foi uma questão que deitou por terra outros esforços anteriores de
inter-operação; por exemplo, a utilização do extremamente funcional protocolo Z39.50 tem sido
limitado às bibliotecas, devido aos custos da sua complexidade (Stubley, Peter. 1999).
A inter-operação é assim restringida ao nível de recolha de metadata, que consiste na extracção
da descrição de documentos. Uma aproximação já antes demonstrada com sucesso pelo projecto
Harvest (Bowman, C.M., 1995). Os mecanismos utilizados pela OAI para estabelecer esta interoperação são os seguintes:
•
Definição de um conjunto simples de elementos de metadata, com o objectivo de permitir
alguma granularidade na descoberta de documentos entre arquivos. O Open Archives
Metadata Set.
•
Utilização de uma sintaxe comum para representar e transportar metadata.
•
Definição de um protocolo comum para permitir a extracção de metadata dos arquivos
participantes.
O OAI trata os documentos como caixas pretas, permitindo aos arquivos terem a sua própria
representação dos documentos, sendo apenas necessário para o OAI, que seja especificado o
ponto de acesso através de um URL.
12
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
Em resumo, a OAI oferece recomendações técnicas de concretização simples para os arquivos.
Estas permitem que os conteúdos dos arquivos se tornem disponíveis globalmente através sua
integração numa variedade de serviços orientados para o utilizador, como motores de pesquisa,
sistemas de recomendação, e sistemas para a interligação de documentos.
2.3
IDENTIFICADORES DE PUBLICAÇÕES DIGITAIS
A identificação de recursos na Internet é um desafio mais complicado do que normalmente se
supõe. Os “Uniform Resource Locators” (URLs) estão ligados a um ficheiro num computador
específico e tem que ser modificado quando o sistema de ficheiros ou o servidor de Internet são
reorganizados, ou quando o ficheiro é transferido para outra organização. É por isso necessário
um sistema de identificadores lógicos que sejam persistentes, independentes da sua localização e
globalmente únicos. Este identificador é descrito pela comunidade da Internet/WWW como um
“Uniform Resource Name” (URN). No entanto os URNs não têm sido muito utilizados, não
devido a dificuldades de concepção de tal sistema, mas devido a dificuldades da sua aplicação no
mundo da Internet. A ideia geral por detrás dos URNs é a de que é necessário um sistema que
faça a resolução de qualquer URN para o URL (ou outra forma futura de localizador) válido
actualmente.
Duas concretizações de URNs surgiram nos últimos anos: o sistema “handle8” desenvolvido pela
Corporation for National Research Initiatives9, e o sistema PURL (Persistent Uniform Resource
Locators) desenvolvido pela OCLC10 (Online Computer Library Center Inc.).
O sistema “handle” (Sun & Lannom 2000; Sun, Lannom & Shi 2000; Sun, Reilly & Lannom
2000) é um sistema distribuído desenhado para suportar inter-operação global. Incorpora um
conjunto expansível dos servidores e caches, que permitem o registo e a resolução de “handles”
a partir de qualquer um desses servidores. O problema do sistema “handle” é que para a sua
completa realização, é necessário que os browsers de Internet reconheçam os URN, ou os
“handles” em particular. A forma ideal de o conseguir seria que o “World Wide Web
8
<http://www.handle.net>
<http://www.cnri.reston.va.us>
10
<http://www.oclc.org>
9
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
13
Consortion11” recomendasse o suporte para os URNs pelos browsers. O que não se prevê que
venha a acontecer num futuro próximo, devido à prioridade de outros assuntos. Enquanto isso
não acontecer a resolução de “handles” é feita através de proxies que fazem de porta de entrada
entre o protocolo HTTP e o protocolo de resolução de “handles”.
O sistema PURL cria URLs persistentes, endereços lógicos que são traduzidos através do
sistema de resolução PURL no URL da localização física actual. O sistema PURL é uma solução
que pode ser concretizada nos dias de hoje. Pode ser utilizados com os browsers mas não satisfaz
todos os requisitos de um sistema URN. Um PURL não é completamente independente da
localização, isto acontece porque os servidores PURL são sistemas independentes o que faz com
que o local onde se encontra o sistema de resolução faça parte do PURL.
Embora o sistema “handle” aparente ser o melhor sistema URN, o sistema PURL apresenta-se
como uma solução mais fácil de concretizar, e que serve as necessidades dos nossos dias.
O sistema “handle”, enquanto não forem suportados pelos browsers e se mantiver a sua
resolução através de proxies, não oferece muito mais funcionalidade do que um PURL oferece
hoje em dia. O sistema PURL oferece a mesma funcionalidade que um “handle” com a
tecnologia actual, mas tem custos de concretização mais baixos, sem comprometer o futuro.
Caso a resolução de URNs venha a ser suportada pelos browser (ou outra tecnologia futura) os
URNs hoje resolvidos através de um PURL poderão igualmente vir a ser resolvidos nessa
tecnologia futura.
2.4
CONDIÇÕES DE ACESSO E USO DE PUBLICAÇÕES DIGITAIS
As condições de acesso e uso de um recurso ou colecção digital de uma biblioteca, podem ser
especificadas de várias formas. Dependendo do contexto legal ou do licenciamento de cada caso,
três cenários genéricos podem ser identificados.
No primeiro cenário, o acesso é completamente livre e os recursos podem ser utilizados
livremente para qualquer fim. Num cenário mais restrito, os recursos podem ser acedidos e
replicados apenas para uso pessoal. No terceiro cenário, o utilizador pode apenas interagir com o
conteúdo do recurso, a replicação ou qualquer utilização adicional do recurso não é permitida.
11
<http://www.w3c.org>
14
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
A partir destes cenários, três propriedades são identificadas para as condições de acesso e uso:
•
Acesso – a possibilidade de aceder a um recurso e interagir com o seu conteúdo
intelectual ou artístico (por exemplo, ler uma publicação digital, ou interagir com uma
aplicação multimédia).
•
Replicação - a possibilidade de replicar um recurso e/ou utilizá-lo para uso pessoal (por
exemplo, fazer uma cópia impressa ou digital do recurso para uso pessoal).
•
Utilização - a possibilidade de reutilizar o conteúdo intelectual ou artístico do recurso
(por exemplo, reutilizar o recurso, ou parte dele, numa publicação comercial).
A Tabela 1 resume os três cenários e as suas propriedades.
A – Completo
Livre
Livre
Livre
B – Limitado
Livre
Livre
Não
C – Mínimo
Livre
Não
Não
Tabela 1 – Cenários de condições de acesso e uso
As condições de acesso e uso podem ser uniformes para todos os utilizadores caso as colecções
não requeiram qualquer diferenciação entre eles, no entanto, este não é o caso que se verifica
sempre. Para diferentes tipos de utilizadores são, por vezes necessárias diferentes condições de
acesso e uso. Por exemplo, os recursos de uma colecção podem ter diferentes condições para um
utilizador anónimo, um utilizador registado e um bibliotecário. O utilizador anónimo poderá
pertencer ao cenário C, o utilizador registado e o bibliotecário no cenário B.
Ao mesmo tempo, diferentes colecções ou publicações podem apresentar diferentes condições
para utilizadores diferentes. Isto torna possível, por exemplo, que para uma sessão específica,
para um utilizador específico, este pode ter acesso a uma colecção onde parte pertence ao cenário
A, outra parte ao cenário B, e outra ao cenário C.
Um cenário com diferentes condições de acesso e uso para cada utilizador é um caso mais
complexo com necessidades de informação mais exigentes. Este cenário pode incluir um ou
todos os cenários descritos acima, sendo assim necessária informação sobre os utilizadores, as
suas condições de acesso e um mecanismo de controlo de acesso.
A secção seguinte apresenta possíveis métodos de controlo de acesso.
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
15
2.4.1 MECANISMOS DE CONTROLO DE ACESSO
Para os cenários onde o controlo de acesso é necessário, um ou mais dos métodos aqui descritos
podem ser utilizados:
•
Acesso controlado através dos endereços de rede – Utilizando o endereço de rede
(endereço IP) do computador a partir do qual o utilizador pede o acesso, podem ser-lhe
apresentadas diferentes condições de acesso e uso. Por exemplo, uma biblioteca pode
autorizar o acesso aos utilizadores que acedem a partir da rede da biblioteca e permitir
apenas a pesquisa a utilizadores de fora da sua rede. Com este método, é possível
concretizar os cenários A e B.
•
O acesso é permitido apenas a partir de um espaço controlado – O acesso aos recursos
digitais é restrito a um local onde apenas utilizadores autorizados têm acesso, assim
nenhum sistema de controlo de acesso é necessário. Por exemplo, uma rede local
acessível a partir de uma sala nas instalações de uma biblioteca, onde apenas alguns
utilizadores têm acesso. Com este método, é possível concretizar qualquer um dos três
cenários.
•
Acesso controlado por autenticação de utilizador – Cada utilizador é autenticado antes
de lhe ser autorizado o acesso aos recursos. Desta forma podem ser concretizadas
condições de acesso e uso para cada indivíduo. Com este método, é possível concretizar
os cenários A e B.
No entanto, é importante notar que os requisitos para o controlo automático da utilização do
recurso não pode ser garantido com a tecnologia actual. Assim, este é um requisito legal sem
implicações técnicas.
A autenticação de utilizador é o modo mais completo, mas também mais complexo, de
controlar o acesso. È o único método capaz de controlar as condições de acesso e uso para cada
utilizador. Normalmente os sistemas de autenticação utilizam o conceito de grupos ou classes de
utilizadores. Cada utilizador pode pertencer a um ou mais grupos, que têm associados as
condições de acesso e uso para todos os recursos, a aplicar aos membros do seu grupo.
16
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
2.4.2 METADATA PARA ACESSO
Nas duas subsecções anteriores foram descritos os cenários possíveis para condições de acesso e
uso numa biblioteca, e as formas de controlar o acesso. Esta análise permitiu a identificação dos
requisitos de metadata para acesso.
A metadata para acesso deve consistir na seguinte informação:
•
Mensagem geral de direitos de autor
•
Descrição do acordo de copyright – Descrição dos termos e condições do acordo entre o
detentor dos direitos de autor e a biblioteca.
•
Data de início do acordo de copyright – Data a partir de quando o acordo é válido.
•
Data de fim do acordo de copyright – Data até quando o acordo é válido
•
Contacto do detentor dos direitos de autor - uma forma de contacto com o detentor dos
direitos de autor, isto é um endereço postal ou de correio electrónico, ou um número de
telefone.
•
Condições de utilização – Especificação, para cada grupo de utilizadores, das condições
de acesso e uso. Deve indicar em qual dos cenários da Tabela 1, o grupo pertence.
2.5
FORMATOS DE DOCUMENTOS DIGITAIS
Com a explosão da Internet como um repositório global de informação contendo uma grande
quantidade e variedade de materiais, têm-se multiplicado os formatos de documentos utilizados
para o seu armazenamento e acesso.
Do ponto de vista da biblioteca digital, podemos considerar 2 grupos principais entre os
possíveis formatos de representação dos documentos: os «formatos de imagem» (em que o texto
do documento se encontra na forma de imagem); e os «formatos de documentos» (onde o texto
do documento está disponível para indexação e pesquisa). As teses e dissertações digitais
encontram-se quase sempre em «formatos de documentos», isto é no formato original em que
foram escritas (o formato do processador de texto), ou num formato próprio para o seu acesso e
leitura (criado a partir do seu formato original). Os «formatos de imagem» são utilizados nos
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
17
casos em que a versão digital da dissertação é criada a partir da sua versão impressa em papel,
através de um processo de digitalização.
No caso em estudo neste trabalho, as dissertações nascem digitais, pois mesmo que sejam criadas
com o intuito de serem impressas, as dissertações são criadas nos processadores de texto, e são,
por isso, digitais. Por esta razão, aqui são apenas abordados os «formatos de documentos».
Para facilitar a análise, podemos subdividir os «formatos de documentos» em três grupos
principais:
•
Formatos de trabalho – formatos específicos dos processadores de texto em que os
documentos são escritos.
•
Formatos de apresentação – formatos que foram desenvolvidos para impressão ou
visualização no écran.
•
Formatos estruturados – formatos que se baseiam no facto da estrutura dos documentos
ser a fundação de onde a aparência é deduzida.
Esta divisão visa ajudar na análise da escolha do(s) formato(s) mais indicado(s) para o género
das teses e dissertações. No entanto, esta divisão não implica que um formato não tenha
características de mais de um grupo.
Nas três secções seguintes é analisada a aplicabilidade dos três tipos de formatos nas teses e
dissertações digitais, sendo analisados em três aspectos: facilidade de criação, facilidade de
acesso, e a preservação da dissertação
2.5.1 FORMATOS DE TRABALHO
Nos formatos de trabalho consideram-se aqueles que são específicos dos processadores de texto
em que os documentos são escritos. A aplicação de leitura destes formatos é geralmente o
próprio processador de texto, o que, juntamente com o facto da especificação destes formatos
não ser pública, torna o documento apenas acessível para aqueles que possuem a mesma
aplicação de processamento de texto.
Estes formatos são geralmente proprietários, cuja especificação não é pública. Além disso, estes
formatos mudam constantemente com cada versão da aplicação, tornando a leitura do formato só
possível com uma versão igual ou superior, à versão em que foi criado. Muitas vezes, a leitura do
18
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
formato a partir de versões superiores da aplicação, gera visualizações ligeiramente diferentes da
versão em que foi criado.
Por estas razões, o armazenamento numa biblioteca digital de dissertações nestes formatos não
garante a sua preservação, nem a facilidade do acesso e leitura por parte dos utilizadores.
2.5.2 FORMATOS DE APRESENTAÇÃO
Os formatos de apresentação foram desenvolvidos para a impressão ou visualização no écran.
Normalmente, são constituídos por um ficheiro, não são editáveis, e não contêm informação
sobre a estrutura do documento. Estes formatos são também chamados de Linguagens de
Descrição de Páginas (LDP). Estas linguagens são “... linguagens de programação desenhadas
para proporcionar uma descrição de qualquer página a uma impressora.” (Adobe Systems Inc.
1985).
As LDPs mais utilizadas hoje em dia são o Postscript e o PDF (Portable Document Format). O
Postscript é uma LDP pura, que não oferece qualquer funcionalidade adicional para além da
descrição das páginas. O PDF contem a toda funcionalidade do Postscript, descrevendo as
páginas com rigor matemático, e ainda com outras funcionalidades que visam facilitar a leitura
de documentos no écran, através de ligações, anotações, e outras. O PDF é um formato
pertencente à Adobe mas, embora, seja um formato proprietário, a sua especificação é pública
(pelo que, é considerada, por alguns, como uma norma). A aplicação necessária para o ler é
distribuída gratuitamente estando disponível para todas as principais plataformas. A criação de
dissertações no formato PDF é também bastante fácil para o autor, pois a dissertação pode ser
escrita no seu processador de texto favorito, e a criação do PDF é efectuada através de um
comando de impressão para uma “impressora” que é na realidade o gerador do formato PDF. O
autor poderá em seguida trabalhar o formato PDF, acrescentando algumas funcionalidades para a
leitura do PDF no écran.
O formato PDF apresenta-se assim como uma boa solução para o formato digital das
dissertações. É fácil de criar pelo autor, e bastante acessível para o leitor. Em questões de
preservação, devido ao seu rigor matemático, e ao facto da sua especificação ser pública, oferece
boas garantias de que o formato poderá ser preservado durante pelo menos os próximos
cinquenta anos.
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
19
2.5.3 FORMATOS ORIENTADOS PARA A ESTRUTURA
Estes formatos baseiam-se no facto da estrutura dos documentos e a sua aparência estarem muito
relacionados. De facto, o texto é formatado de modo mostrar a sua estrutura ao leitor, e quando
uma formatação é aplicada de forma constante a um documento, a tarefa do leitor é facilitada. É
por esta razão que é pratica comum escrever os títulos e cabeçalhos dos documentos com letra
mais carregada. Durante a leitura, nós dependemos destas convenções tipográficas para construir
uma imagem mental da estrutura do documento. Do mesmo modo, as revistas e os jornais tentam
construir o seu estilo visual, escolhendo um conjunto de tipos de letra e utilizando-o
constantemente durante anos, de modo que os seus leitores sejam capazes de a identificar apenas
pelo seu aspecto tipográfico. Isto dá conforto ao leitor regular, e ajuda a diferenciar dos
competidores. Da mesma forma as companhias tendem a criar um estilo próprio utilizando
logotipos e cabeçalhos próprios.
Neste aspecto, as Generalized Markup Languages (GML) tem um papel muito importante. O
fundamento principal das GMLs é o facto da estrutura dos documentos ser a fundação de onde a
aparência é deduzida, o que se aplica a todos os tipos de documentos incluindo teses,
dissertações, livros, cartas, relatórios, revistas, etc.
Nos formatos que se concentram na apresentação dos documentos, só com grande esforço se
consegue garantir uma aparência idêntica em diferentes plataformas. A aproximação das GMLs
guarda a estrutura dos documentos a partir da qual a apresentação é deduzida. Embora esta
diferença aparente ser trivial, ela comporta bastantes implicações, pois a utilização das GMLs
garante uma maior portabilidade e flexibilidade dos documentos, está menos sujeita a erros, e no
ponto de vista da biblioteca/arquivo, é mais fácil de utilizar.
Estes formatos, oferecem as melhores garantias de preservação que algum formato pode dar. No
entanto, a criação de documentos nestes formatos trás grandes dificuldades aos autores, devido à
inexistência de boas ferramentas para o efeito.
Nas secções seguintes são descritas duas GMLs, a Standard Generalized Markup Language e a
mais recente Extensible Markup Language.
20
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
2.5.3.1 STANDARD GENERALIZED MARKUP LANGUAGE
A SGML (Standard Generalized Markup Language) é a norma internacional para a definição de
descrições de estruturas e conteúdos de variados tipos de documentos.
A SGML não é uma estrutura de documento standard. De facto, é irrealista pensar que uma única
estrutura possa satisfazer as necessidades de todos os autores. De facto, livros, cartas,
dicionários, memorandos, dissertações, etc., são demasiado diferentes para serem todos incluídos
na mesma estrutura sem colocar demasiadas restrições aos autores.
A SGML não pretende impor o seu próprio conjunto de “etiquetas”, mas sim propor uma
linguagem para os autores descreverem a estrutura dos seus documentos. A força da SGML é
que ela é uma linguagem para descrever documentos, estando assim aberta a novas aplicações de
uma forma muito flexível.
A estrutura dos documentos é escrita numa Descrição de Tipo de Documento (Document Type
Definition - DTD). Uma DTD especifica um conjunto de elementos, como estes se relacionam, e
o conjunto de “etiquetas” (tags) para marcar o documento.
Embora o SGML não imponha a estrutura para documentos algumas DTDs podem ser mantidas
como normas públicas. Alguns dos exemplos mais conhecidos são:
•
Três DTDs desenvolvidas pela Associação Americana de editoras para livros, artigos e
publicações em folhetins. Esta foi a primeira grande aplicação da SGML.
•
A HTML, que é uma DTD para documentos hipermédia, publicados na Internet.
2.5.3.2 EXTENSIBLE MARKUP LANGUAGE
A XML (Extensible Markup Language) foi desenhada para permitir a utilização da SGML na
Internet. Relativamente à SGML, a XML facilita a definição de tipos de documentos, e a escrita
e gestão de documentos, oferecendo ainda funcionalidades para a transmissão e partilha dos
documentos na Internet. O XML define um dialecto mais simples do que o SGML, com o
objectivo de permitir que o SGML possa ser processado na Internet do mesmo modo que é hoje
possível fazer com o HTML.
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
21
A XML simplifica significativamente a SGML em vários aspectos:
•
Foi feita uma escolha específica de caracteres de sintaxe. Foi escolhida para que todos os
utilizadores do XML usem a mesma sintaxe. Por exemplo, todas as “etiquetas” iniciais
começam com “<” e acabam com “>”.
•
Foi introduzida uma “etiqueta” que representa um elemento vazio.
•
Não é permitida a omissão de etiquetas finais. O que indica que todos os elementos não
vazios terão uma etiqueta inicial e uma final.
•
Não é obrigatória a presença de uma DTD.
A XML é hoje muito aplicada na Internet, não só como uma linguagem para descrever a
estrutura de documentos, mas também para representar informação de uma forma geral.
2.6
METADATA NAS BIBLIOTECAS
Utilizando uma definição simples, metadata são dados sobre dados, ou seja, é a descrição do
conteúdo e das características de um documento ou trabalho. O objecto da metadata podem ser
texto, imagens, conjuntos de dados, música, etc. O objectivo da sua utilização é o de libertar os
potenciais utilizadores da necessidade de ter conhecimento prévio da existência do “objecto” e
das suas características. A metadata é fundamental para a procura de informação, e tem sido
utilizada e aperfeiçoada nas bibliotecas desde à séculos.
O processo pelo qual o bibliotecário cria e gere registos de metadata é chamado catalogação.
Esta é uma das tarefas principais das bibliotecas, pois é através dela que se torna possível numa
biblioteca encontrar as obras, através do nome do autor, do assunto, do título, etc. O resultado da
catalogação é o catálogo e os registos de metadata das obras chamam-se registos bibliográficos.
O catálogo consiste numa típica base de dados, destinada ao registo e pesquisa das obras
existentes, com referência à sua localização física nas estantes (Borbinha 2000). O acesso ao
catálogo de uma biblioteca é geralmente efectuado nas instalações da biblioteca através do seu
sistema informático, onde os leitores encontram as obras que procuram efectuando pesquisas no
catálogo. Algumas bibliotecas disponibilizam o acesso aos seus catálogos via Internet. Estes
catálogos são chamados de OPAC – Public Online Access Catalog.
22
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
A catalogação é um processo complexo e com custos muito elevados, pois exige pessoal
especializado. Um estudo efectuado na Biblioteca Nacional estimou o custo de 3500$00 apenas
para a integração e verificação de registos bibliográficos no catálogo (Borbinha 2000). Estes
elevados custos, levam as bibliotecas a procurar formas de cooperação. Esta é conseguida através
de catálogos colectivos partilhados por várias bibliotecas, e através da troca de registos
bibliográficos. Em Portugal foi criado tem sido promovido desde o início da década de oitenta o
catálogo nacional PORBASE, um catálogo partilhado por mais de cento e cinquenta bibliotecas.
Como forma de garantir a qualidade dos registos e permitir a sua troca, foi criado em 1965 o
formato MARC (Machine Readable Catalog) através da conjugação de esforços da Biblioteca do
Congresso nos Estado Unidos e do Council of the British National Bibliography, do Reino
Unido. Diferentes formatos MARC nacionais foram criados em resposta às necessidades
nacionais de acordo com as suas regras de catalogação locais e ambientes de operação. Existem
hoje em dia cerca de 50 variantes do formato MARC.
A troca de registos é efectuada através das funcionalidades de importação/exportação de registos
dos catálogos (Figura 1). Os registos são exportados nos formatos MARC utilizando a norma
ISO 2709 para a sua representação e transporte.
Catálogo
Importação de
registos
Bibliotecario
Exportação de
registos
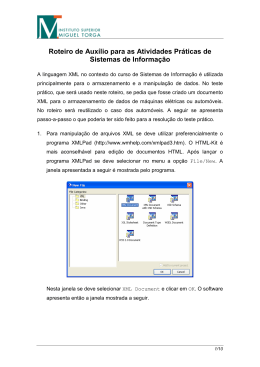
Figura 1 – Interacção entre o bibliotecário e o catálogo para a troca de registos
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
23
Com o intuito de criar a possibilidade de interacção entre as várias variantes do formato MARC,
a IFLA12 (International Federation of Library Associations and Institutions) definiu o formato
UNIMARC. Este foi criado com o objectivo de, no mínimo, poder servir de solução de interação
entre as variantes do MARC, devendo por isso ser compatível com todos eles (IFLA 1996). Mais
tarde este formato veio a ser adoptado por alguns países, tal como Portugal.
2.6.1 O FORMATO MARC
Os princípios por detrás do formato MARC é o de estruturar os dados bibliográficos em campos
e sub-campos13 como na Tabela 2.
200
1#
$a
UNIMARC
$e
Manual de catalogação
Tabela 2 – Campo UNIMARC
Um campo é um número de três dígitos que define uma condição bibliográfica. Os indicadores
são dois números com um dígito que oferecem informação adicional sobre o conteúdo do campo.
Quando um indicador não está definido a sua posição contem um espaço (no exemplo acima
representado pelo caracter “#”). Os sub-campos são introduzidos por um caracter especial de
controlo (geralmente representado por $) seguido de uma letra ou número qualificando o
elemento dentro do campo (por exemplo, $a, $b, $1, $4). Alguns campos contêm um único subcampo com os dados codificados em posições fixas (por exemplo, o campo 100 do UNIMARC).
O formato especifica ainda se cada campo e sub-campo são obrigatórios, opcionais ou
condicionais de outro elemento, e se pode ser repetido.
Na Tabela 3 encontra-se um exemplo detalhado dum registo UNIMARC. Este registo descreve
uma tese de mestrado intitulada “Cultura organizacional” pelo autor João Bilhim.
12
<http://www.ifla.org>
Na literatura sobre o UNIMARC é utilizada a expressão “campo de metadata” em vez de “elemento de metadata”, embora ambas as
expressões se refiram ao mesmo.
13
24
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
!
100
0#
$a19890317d1988####k##y0pora0103####ba
Dados gerais de processamento
101
##
$apor
Língua da publicação
102
##
$aPT
País de publicação ou produção
105
##
$aa###m###001yy
Dados codificados: livros
106
##
$ar
Dados codificados: material textual - atributos
físicos
200
1#
$aCultura organizacional$bTexto
policopiado$eestudo do Instituto de Engenharia
de Sistemas e Computadores (INESC)$fJoão
Abreu de Faria Bilhim
Título e menção de responsabilidade
210
##
$aLisboa$c[s.n.]$d1988
Publicação, distribuição
215
##
$a[5], 207,[24] f.$cil.$d30 cm
Descrição física
320
##
$aBibliografia, p. 197-207
Nota relativa a bibliografias e índices internos
328
##
$aTese de mestrado em Ciências
Antropológicas, apresentada ao Inst. Sup. de
Ciências Sociais e Políticas, Univ. Técnica de
Lisboa
Nota de dissertação ou tese
675
##
$a39(043.2)$vBN$zpor
Classificação Decimal Universal (CDU)
700
#1
$aBilhim$bJoão Abreu de Faria
Nome de autor-pessoa física (responsabilidade
intelectual principal)
801
#0
$aPT$bBN$gRPC
Fonte de origem
Tabela 3 – Registo bibliográfico UNIMARC
A representação e transporte de registos MARC é feita através do formato definido pela norma
ISO 2709, descrito na secção seguinte.
2.6.2 A NORMA ISO 2709
O formato definido pela norma ISO 2709 foi desenhado para armazenamento de dados em
bandas magnéticas, embora hoje em dia se mantenha a sua utilização para transporte de registos
online. Têm no entanto surgido alguns esforços para o transporte de registos MARC em formatos
mais fáceis de manipular e mais adequados às tecnologias actuais, como por exemplo em SGML
(Library of Congress, 1998) ou mais recentemente em XML (Virginia Tech, 2000).
O UNIMARC define uma concretização da norma ISO 2709, ,o entanto, em Portugal a sua
utilização não é totalmente correcta. Por esta razão é aqui dada uma curta explicação da norma
ISO 2709, sendo também referidos detalhes da concretização do UNIMARC, sempre que sejam
relevantes. No final desta secção são apresentadas as incompatibilidades entre a concretização
UNIMARC e a utilizada em Portugal.
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
25
A norma ISO 2709 indica que cada registo bibliográfico preparado para troca terá de ser
constituído por (Figura 2):
•
Uma etiqueta de registo que consiste em 24 caracteres;
•
Uma directoria que consiste numa etiqueta de 3 dígitos para cada campo de dados bem
como o respectivo comprimento e a posição do caracter de início relativa ao primeiro
campo de dados;
•
Campos de dados de comprimento variável, separados individualmente por um separador
de campo.
ETIQUETA DE
REGISTO
DIRECTORIA
CAMPOS VARIÁVEIS
T/R
LEGENDA
T/R - terminador de registo
Figura 2 – Principais componentes de um registo ISO 2709
A primeira componente de um registo codificado segundo a norma ISO 2709 é a etiqueta de
registo. Esta contém informação geral necessária para o processamento do registo.
A etiqueta de registo é constituída por vários elementos de comprimento fixo que são
identificados pela posição dentro da etiqueta (Figura 3). A etiqueta como um todo, tem sempre
24 caracteres de comprimento. Convencionalmente as posições dos caracteres são numeradas de
0 a 23.
26
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
ETIQUETA DE
REGISTO
DIRECTORIA
CAMPOS VARIÁVEIS
T/R
24 Caracteres
0
5 6
10 11 12
17
20
24
Mapa da directoria
Definição adicional de registo
Endreço base dos dados
Comprimento do indentificador de subcampo
Comprimento do indicador
Códigos de implementação
Estado do registo
Tamanho do registo
LEGENDA
T/R - terminador de registo
Figura 3 – Etiqueta de registo ISO 2709
O conteúdo das 24 posições da etiqueta de registo é o seguinte:
•
Comprimento do registo (posições 0-4) – Contém o número de caracteres de que se
compõe todo o registo. É constituído por cinco dígitos justificados à direita, preenchidos
com zeros quando necessário.
•
Estado do registo (posição 5) – Um só caracter que indica o estado do registo. c = registo
corrigido, d = registo anulado, n = registo novo, o = registo de nível mais elevado, p =
registo anterior incompleto ou de pré-publicação.
•
Códigos de concretização (posições 6-9) – Os códigos a utilizar nestas posições não são
definidos pela norma ISO 2709. Estes dependem da concretização individual da norma.
No caso da concretização do UNIMARC contém o tipo de registo (posição 6), o nível
bibliográfico (posição 7) e o código de nível hierárquico (posição 8). A posição nove não
está definida, sendo preenchida por um espaço.
•
Comprimento do indicador (posição 10) – Um dígito que regista o comprimento dos
indicadores. Na concretização do UNIMARC, o comprimento dos indicadores é 2.
•
Comprimento do identificador de sub-campo (posição 11) – Um dígito que regista o
comprimento do identificador de sub-campo. Na concretização do UNIMARC, esta
posição tem o valor 2.
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
•
27
Endereço base dos dados (posições 12-16) - Contém a posição do caracter de início do
primeiro campo de dados relativamente ao início do registo. É constituído por cinco
dígitos justificados à direita, preenchidos com zeros quando necessário.
•
A definir pelas concretizações (posições 17-19) – Os códigos a utilizar nestas posições
não são definidos pela norma ISO 2709. Na concretização UNIMARC estas posições
contêm a definição adicional de registo. Estes consistem em códigos relativos a outros
pormenores necessários para o processamento do registo. A posição 17 contém o nível da
codificação; a posição 18 contém a forma de descrição da catalogação; a posição 19 não
está definida.
•
Mapa da directoria (posições 20-23) – Contém pormenores sobre o comprimento e
estrutura para a entrada de directoria de cada campo de dados. Na posição 20 encontra-se
o comprimento do “comprimento do campo”. A posição 21 contém o comprimento da
“posição do caracter de início. Na posição 22 está o comprimento da parte definida para a
concretização. A posição 23 não está definida pela norma. Na concretização UNIMARC
o comprimento do “comprimento de campo” é 4, o comprimento da “posição do caracter
inicial” é 5, o comprimento da parte definida para a concretização é 0, e a ultima posição
não se encontra definida, sendo preenchida por um espaço.
ETIQUETA DE
REGISTO
DIRECTORIA
CAMPOS VARIÁVEIS
T/R
LEGENDA
T/R - terminador de registo
T/C - terminador de campo
0
3
Etiqueta
7
Comprimento
12
Posição de início
Entrada do
primeiro campo
15
Etiqueta
19
Comprimento
Posição de início
Entrada do
segundo campo
T/C
Entradas de
outros campos
Figura 4 – Directoria de um registo ISO 2709
28
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
A seguir à etiqueta de registo, um registo ISO 2709 tem uma directoria. Cada entrada de
directoria consiste em três partes (Figura 4). A primeira é a etiqueta do campo seguida do
número de caracteres (ou comprimento) desse campo. Este inclui todos os caracteres referentes a
indicadores, identificadores de sub-campos, os dados propriamente ditos, e o terminador de
campo.
O comprimento do campo é seguido da posição do caracter de início do campo em relação à
posição do primeiro caracter da parte de campos variáveis do registo. O primeiro caracter do
primeiro campo variável tem a posição 0, e a sua posição dentro de todo o registo é dada nas
posições 12-16 da etiqueta de registo.
A etiqueta tem 3 caracteres de comprimento. O “comprimento dos dados” tem o comprimento
definido na posição 20 da etiqueta de registo. O comprimento da “posição inicial” é definido da
posição 21 da etiqueta de registo.
A concretização UNIMARC define o tamanho de 4 caracteres para o “comprimento dos dados” e
de 5 caracteres para a “posição inicial”.
A directoria termina com o caracter “terminador de campo”.
Entrada do
primeiro campo
ETIQUETA
DE
REGISTO
Etiqueta
Comprimento
Posição de início
Etiqueta
Comprimento
Posição de início
Entradas de
outros campos
DIRECTORIA
LEGENDA
T/R - terminador de registo
T/C - terminador de campo
S/S - separador de subcampo
Ind. - indicador
Id/S - Identificador de subcampo
CAMPOS
VARIÁVEIS
Ind. Ind.
Id/
S/S
1 2
S
T/R
T/C
Dados do
Id/
S/S
subcampo
S
Dados do
primeiro campo
Dados do
Ind. Ind.
Id/
T/C
S/S
subcampo
1 2
S
Dados do
subcampo
Dados de
outros campos
Figura 5 – Campos variáveis de um registo ISO 2709
T/C
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
29
Os campos de dados de comprimento variável seguem a directoria (Figura 5) e contêm os dados
propriamente ditos (dados bibliográficos no caso do UNIMARC) por oposição aos dados de
processamento. As etiquetas não são carregadas nos campos de dados pois estas aparecem
apenas na directoria.
Na concretização do UNIMARC, cada campo de dados, consiste em dois indicadores seguidos
de um número variável de sub-campos. Cada sub-campo começa com um identificador de subcampo que consiste num “separador de sub-campo” e um código de sub-campo que o identifica.
Os identificadores de sub-campos são seguidos de dados codificados ou textuais de qualquer
comprimento, a não ser que a descrição do campo determine em contrário. O sub-campo final
termina com o caracter “terminador de campo”.
Na Tabela 4 encontram-se os códigos ASCII dos caracteres terminadores e separadores
especificados pela norma ISO 2709.
!
Terminador de registo
Terminador de campo
Separador de subcampo
036
036
037
Tabela 4 – Caracteres separadores e terminadores da norma ISO 2709
Em Portugal os registos UNIMARC são geralmente codificados, para exportação, segundo a
variante da norma ISO 2709 utilizada na aplicação Micro CDS/ISIS.
O Micro CDS/ISIS é um sistema de armazenamento e recuperação de informação não-numérica
desenvolvido pela UNESCO desde 1985 para satisfazer a necessidade expressa por muitas
instituições, especialmente de países em vias de desenvolvimento, para poderem gerir este tipo
de informação, utilizando as novas tecnologias.
A Biblioteca Nacional adaptou o Micro CDS/ISIS às regras de catalogação portuguesas, e este
tem sido a aplicação mais utilizada para gerir os catálogos das bibliotecas portuguesas. Este
formato tem funcionado com o formato de troca de registos em Portugal. Surgem no entanto
problemas quando se pretende trocar registos, devido à incompatibilidade entre as concretizações
do Micro CDS/ISIS e do ISO 2709 do UNIMARC. Esta incompatibilidade torna difícil a
importação dos registos portugueses no estrangeiro, e vice versa.
30
O ESTADO DA ARTE E TECNOLOGIA RELEVANTE
Estes problemas foram identificados pelo autor durante o seu trabalho no projecto europeu
MALVINE14. Neste projecto pretende-se criar um ponto de acesso na Internet para as colecções
de manuscritos modernos guardados e catalogados em bibliotecas, arquivos, centros de
documentação e museus europeus. Durante o desenvolvimento do projecto, surgiram problemas
no acesso ao catálogo dos manuscritos da Biblioteca Nacional, devido à incompatibilidade entre
as concretizações do ISO 2709 do Micro CDS/ISIS e do UNIMARC.
Os problemas identificados com a variante do Micro CDS/ISIS são os seguintes:
1. O Micro CDS/ISIS introduz quebras de linha de 80 em 80 caracteres. O caracter de
quebra de linha aumenta o tamanho do registo e dos campos, tornando a etiqueta de
registo e a directoria inválidas. Para se efectuar a sua leitura é necessário retirar as
quebras de linha antes de processar o registo.
2. A norma ISO 2709 utiliza como terminador de registo e de campo os caracteres com os
códigos ASCII “035” e “036”, respectivamente. O Micro CDS/ISIS utiliza por defeito o
caracter “#” para ambos. O que, para além de não seguir a norma, pode danificar os
registos que contenham este caracter no valor de algum campo.
3. O Micro CDS/ISIS não considera a utilização de separadores de sub-campo, o que levou
à adopção em Portugal do caracter “^” como separador de sub-campo. O valor correcto
do separador de sub-campo é o caracter com o código ASCII “037”.
4. O Micro CDS/ISIS atribui às posições 10 (comprimento do indicador) e 11 (comprimento
do identificador de sub-campo) da etiqueta de registo o valor 0. Este valor é incorrecto
pois os registos UNIMARC utilizam indicadores de comprimento 2 e identificadores de
sub-campo com comprimento 2.
14
<http://www.malvine.org>
Capítulo 3
REQUISITOS DA BIBLIOTECA DIGITAL DE
TESES E DISSERTAÇÕES
3.1
INTRODUÇÃO
Neste capítulo são descritos os problemas a solucionar pela biblioteca digital de teses e
dissertações, e os requisitos que esta deve preencher. Começa-se por identificar o processo de
depósito das dissertações, os seus actores e os requisitos impostos por eles. Em seguida, são
analisados alguns aspectos relativos ao processamento das publicações, quando em formato
digital (a sua identificação, acesso, e formato). É então feita uma análise dos dados que a
biblioteca digital deve processar e finaliza-se com uma síntese da análise.
3.2
RECONHECIMENTO DO PROBLEMA
Tendo como ponto de referência, o processo das dissertações em papel, o sistema deve criar um
processo paralelo para as dissertações em formato digital. O processo utilizado para as
dissertações em papel é o seguinte:
31
32
REQUISITOS DA BIBLIOTECA DIGITAL DE TESES E DISSERTAÇÕES
1. Após a avaliação do seu trabalho, o autor entrega um número de cópias15 em papel da
versão final da sua dissertação na universidade.
2. Dessas cópias, algumas são enviadas para a biblioteca da universidade e outras para a
Biblioteca Nacional.
3. A biblioteca da universidade processa o depósito local da dissertação.
4. A Biblioteca Nacional processa o depósito legal da dissertação.
5. Os leitores podem então aceder às dissertações a partir das instalações da biblioteca da
universidade ou da Biblioteca Nacional.
De notar que o problema aqui em estudo é apenas o de depositar as dissertações digitais na
biblioteca da universidade e na Biblioteca Nacional, após a aprovação das dissertações. Um
sistema interno às universidades com o objectivo de cobrir todo o processo administrativo das
dissertações em formato digital (como o utilizados por algumas universidades membros da
NDLTD), não é o objectivo deste trabalho.
Pode-se concluir que, após terminada e aprovada, uma dissertação passa a um estado que
envolve quatro actores:
•
O autor da dissertação – entrega a dissertação na sua universidade.
•
A biblioteca da universidade – responsáveis pelo depósito local das dissertações, aí
entregues pelos autores ou pelas estruturas administrativas locais.
•
A Biblioteca Nacional – responsável pelo depósito legal das teses e dissertações
entregues em todas as universidades portuguesas.
•
Os leitores – as pessoas que pretendem consultar as dissertações.
Na restante parte desta secção são analisados os requisitos de cada um dos actores, mas partindo
do princípio que as dissertações deixam de ser impressas, passando a ser processadas em formato
digital.
15
O número de cópias a entregar pode variar conforme a universidade e o grau da dissertação. Para os vários casos este número varia,
aproximadamente, entre as 8 e as 15 cópias.
REQUISITOS DA BIBLIOTECA DIGITAL DE TESES E DISSERTAÇÕES
33
3.2.1 OS AUTORES
Os autores criam as suas dissertações em formato digital e entregam-nas na sua universidade ou
directamente para a biblioteca aí localizada. Para o autor o sistema deve preencher os seguintes
requisitos:
•
Permitir a entrega das dissertações através da Internet, ou por mão própria (em disquete,
CD-ROM, etc.).
•
Permitir a especificação de condições de acesso à dissertação ou a partes dela.
•
Permitir a disseminação do seu trabalho mundialmente.
3.2.2 AS BIBLIOTECAS DAS UNIVERSIDADES
As biblioteca das universidades são responsáveis pelo depósito local das dissertações, aí
entregues pelos autores ou pelas estruturas administrativas locais. Para as bibliotecas das
universidades o sistema deve preencher os seguintes requisitos:
•
Aceitar submissões das dissertações em formato digital, e efectuar o seu armazenamento.
A submissão poderá ser efectuada pelo autor ou por um funcionário da biblioteca.
•
Permitir ao bibliotecário efectuar um controlo de qualidade sobre as dissertações
entregues.
•
Facilitar o processo de catalogação das dissertações.
•
Processar automaticamente o depósito legal na Biblioteca Nacional, mas apenas para as
dissertações verificadas pelo bibliotecário e aceites como válidas.
•
Facilitar a pesquisa e o acesso às dissertações
•
Permitir a disseminação mundial do trabalho de investigação levado a cabo na
universidade.
34
REQUISITOS DA BIBLIOTECA DIGITAL DE TESES E DISSERTAÇÕES
3.2.3 A BIBLIOTECA NACIONAL
A Biblioteca Nacional é responsável pelo depósito legal das teses e dissertações realizadas em
todas as universidades portuguesas. Para a Biblioteca Nacional o sistema deve preencher os
seguintes requisitos:
•
Receber as dissertações enviadas pelas bibliotecas universitárias para efeitos de depósito
legal, e efectuar o seu registo e armazenamento.
•
Permitir ao bibliotecário efectuar um controlo de qualidade sobre as dissertações
enviadas.
•
Facilitar a pesquisa e o acesso das dissertações.
•
Poder identificar as dissertações de um modo persistente e independente da sua
localização na Internet.
•
Oferecer meios que permitam contribuir para preservar a longo prazo as dissertações.
•
Deve ser possível a inter-operação com o catálogo nacional Porbase.
3.2.4 OS LEITORES
Os leitores pretendem aceder às dissertações. Para eles, o sistema deve preencher os seguintes
requisitos:
•
Permitir um processo fácil e eficaz de pesquisa e acesso.
•
Obter as dissertações em formatos fáceis de utilizar.
•
Ter um ponto de acesso a partir do qual seja possível pesquisar todas as dissertações
digitais existentes em Portugal.
3.3
CASOS DE USO
A partir do reconhecimento do problema feito na secção anterior, foi identificada a necessidade
de dois sistemas informáticos: o primeiro pata as bibliotecas universitárias e o segundo para a
REQUISITOS DA BIBLIOTECA DIGITAL DE TESES E DISSERTAÇÕES
35
Biblioteca Nacional. Foi também identificado mais um actor – o bibliotecário; este visa
preencher os requisitos apresentados pelas bibliotecas para o controlo de qualidade das
dissertações entregues pelos autores. As acções dos vários actores encontra-se representadas no
caso da Figura 6.
Biblioteca Universitária
Notificação de
novas dissertações
Aceitação/rejeição
de dissertações
Depósito da dissertação
Exportação de
metadata
Autor
Bibliotecário da universidade
Pesquisa de dis-sertações
Acesso a dissertações
Envio de novas
dissertações
Biblioteca Nacional
Bibliotecário
Leitor
Pesquisa de dis-sertações
Recolha de novas
dissertações
Aceitar/rejeitar
documento
Notificação de
novos documentos
Acesso a dissertações
Exportar metadata
Bibliotecário da Bib. Nacional
Figura 6 – Casos de uso da biblioteca digital de teses e dissertações
O autor interage com a biblioteca universitária quando efectua o depósito da sua dissertação.
Ao efectuar o depósito, o autor fornece metadata sobre a dissertação, que entre outra
informação, deve conter a especificação das condições de acesso à dissertação. O autor deve ser
notificado quando a sua dissertação é aceite (ou rejeitada) pelo bibliotecário da biblioteca
universitária.
36
REQUISITOS DA BIBLIOTECA DIGITAL DE TESES E DISSERTAÇÕES
O bibliotecário interage com o sistema da sua biblioteca principalmente para efectuar o controlo
de qualidade das dissertações aí depositadas. Sempre que são depositadas no sistema novas
dissertações, o bibliotecário deverá ser automaticamente notificado. Após efectuado o controlo
de qualidade, a pessoa depositou a dissertação deve ser notificada da aceitação/rejeição; no caso
das bibliotecas das universidades deve ser notificado o autor, e no caso da Biblioteca Nacional
deve ser notificado o bibliotecário da universidade de origem da dissertação. O bibliotecário
também interage com o sistema para extrair a metadata sobre as dissertações armazenadas. A
metadata deve ser extraída num formato que o bibliotecário possa utilizar para incluir as
dissertações depositadas no catálogo da sua biblioteca.
Periodicamente, a Biblioteca Nacional deve recolher as dissertações depositadas localmente nas
bibliotecas das universidades. As dissertações só devem ser recolhidas após o bibliotecário ter
verificado a sua qualidade.
O leitor pesquisa e acede às dissertações depositadas tanto através dos sistemas das bibliotecas
universitárias como do sistema da Biblioteca Nacional. Em qualquer um dos pontos de acesso
para o leitor, este deve poder pesquisar e aceder às dissertações de todas as bibliotecas das
universidades.
3.4
ACESSO ÀS DISSERTAÇÕES
Sobre o acesso, pretende-se que estas publicações estejam acessíveis na Internet tanto local (isto
é, nas bibliotecas) como remotamente. Este acesso tem que obedecer no entanto a um conjunto
de requisitos básicos mas muito importantes, já que estas obras têm muitas vezes características
que podem exigir que a consulta seja condicionada na sua totalidade ou apenas a determinadas
partes da mesma (normalmente capítulos ou páginas, que podem estar relacionadas com
inovações industriais, conteúdos patenteados, etc). Para estes casos deve ser possível especificar
as partes do conteúdo a que se deseja restringir o acesso.
As condições de acesso devem ser especificadas durante o depósito do documento, devendo estar
à disposição do autor os seguintes tipos de acesso:
•
Acesso livre – o acesso à publicação é autorizado a todos os utilizadores.
REQUISITOS DA BIBLIOTECA DIGITAL DE TESES E DISSERTAÇÕES
•
37
Acesso local – o acesso à publicação é autorizado apenas a utilizadores dentro da
universidade.
•
Inacessível – o acesso à publicação é negado a qualquer utilizador. Apenas a metadata do
documento pode ser acedida.
Uma dissertação com apenas acesso local, quando é depositada na Biblioteca Nacional, poderá
também ser acedida de dentro da rede da Biblioteca Nacional.
Para os casos que exigem que a consulta seja condicionada a determinadas partes da publicação,
as condições de acesso devem poder ser especificadas ao nível do ficheiro. Por exemplo, para
uma publicação que contêm num capítulo conteúdos patenteados, e que seja constituída por dois
ficheiros, um com o capítulo em questão, e outro com os restantes capítulos, o primeiro ficheiro
ficará inacessível e o segundo ficará com acesso livre.
As restrições ao acesso, quando especificadas, devem ser mantidas por um período de tempo
necessário para que o autor publique o seu trabalho. Após este período o bibliotecário deverá
entrar em contacto com o autor com o objectivo de retirar as restrições ao acesso.
3.5
IDENTIFICADORES
Cada dissertação depositada deve receber um identificador URN. Para tal, deve ser atribuído a
cada dissertação um identificador único baseado no número de depósito (ou outra forma de a
identificar univocamente dentro do sistema), o qual deverá assim ser usado para a determinação
automática de um URN.
3.6
FORMATOS DAS DISSERTAÇÕES
No ponto de vista do sistema DiTeD, o formato em que os documentos são arquivados deve
oferecer alguma segurança em relação à preservação a longo prazo das dissertações, e permitir a
sua fácil leitura pelos utilizadores finais. Estes dois factores podem por vezes entrar em conflito,
pois um formato que hoje é facilmente lido em qualquer computador, pode não oferecer
garantias de que o poderá vir a ser no futuro. O caso oposto também não é desejável, pois um
formato que garanta a preservação a longo prazo, mas que as aplicações de leitura não estejam
38
REQUISITOS DA BIBLIOTECA DIGITAL DE TESES E DISSERTAÇÕES
facilmente disponíveis para o leitor, também não é uma situação desejável. É portanto,
necessário utilizar formatos que garantam o acesso fácil, e a preservação a longo prazo das
dissertações, ou que pelo menos não comprometam nenhum destes dois factores.
3.7
ANÁLISE DOS DADOS
Podemos identificar a partir da análise anterior, que as dissertações e a sua metadata são os dados
a processar pelo sistema. O fluxo de acções do que representam o processo de depósito das
dissertações, desde que são entregues pelo autor, encontra-se representado na Figura 7. Os
primeiros três passos referem-se ao depósito local das dissertações nas bibliotecas das
universidades, e os passos seguintes ao depósito legal na Biblioteca Nacional.
Autor ou
funcionário
Bibliotecário
Repositório da
biblioteca da
universidade
Verificação
Bibliotecário
Recolha
[válida]
Submissão
Biblioteca
Nacional
Depósito local
Repositório
da Biblioteca
Nacional
Depósito central
[válida]
Verificação
[inválida]
[inválida]
Figura 7 – Processo de depósito das teses e dissertações digitais
As dissertações são submetidas pelos autores ou por funcionários da biblioteca, sendo de seguida
verificada a sua validade por um bibliotecário local. Caso se verifique a sua validade, as
dissertações são armazenadas num repositório do sistema da biblioteca da universidade. A partir
deste passo, a dissertação fica acessível a partir do sistema da biblioteca. Periodicamente, o
sistema da Biblioteca Nacional verifica a existência novas dissertações nos sistemas das
universidades, recolhendo-as automaticamente. Finalmente, as dissertações são verificadas pelos
bibliotecários da Biblioteca Nacional e, caso sejam válidas, elas são armazenadas no sistema da
REQUISITOS DA BIBLIOTECA DIGITAL DE TESES E DISSERTAÇÕES
39
Biblioteca Nacional. Após este passo, a dissertação fica acessível também a partir do sistema da
Biblioteca Nacional. Note-se que a metadata acompanha a da dissertação durante todo este
processo.
O controlo de qualidade é assim efectuado em dois pontos: aquando do depósito local na
biblioteca universitária, e aquando do depósito legal na Biblioteca Nacional. As duas
verificações aparentam ser necessárias pois o nível de qualidade exigido pela Biblioteca
Nacional é diferente do nível exigido pelas bibliotecas universitárias. No entanto, esta situação
deverá ser avaliada durante os primeiros meses de funcionamento do sistema, podendo vir a
mostrar-se desnecessária a segunda verificação.
As dissertações e a sua metadata são também o objecto alvo das pesquisas e acessos às
dissertações por parte do leitor. A pesquisa, processando a metadata, e o acesso, processando
tanto a metadata como a própria dissertação.
Devido à grande dimensão das dissertações, o seu conteúdo pode estar dividido por vários
ficheiros. Permitir esta divisão é também importante, como forma de permitir a especificação de
condições de acesso a partes de uma dissertação, de acordo com o que foi dito na secção “3.4 Acesso às dissertações”.
3.8
SÍNTESE DA ANÁLISE
Para satisfazer as necessidades acima citadas foram identificados os seguintes componentes para
a biblioteca digital de teses e dissertações:
•
Sistema de repositório – Este sistema é responsável por armazenar as dissertações e a
metadata a elas associada. O sistema de repositório deve concretizar um sistema de
controlo de acesso. Este deve garantir o cumprimento das condições de acesso às
dissertações de acordo com as especificações dos respectivos autores. O acesso às
dissertações e à sua metadata deve ser feito de uma forma aberta, através de protocolos
para inter-operação, de forma a tornar as dissertações mais visíveis tanto nacionalmente
como internacionalmente. As dissertações armazenadas num repositório podem ser
compostas por vários ficheiros, e devem ser identificadas segundo o sistema de
identificação de publicações independente da localização, descrito mais abaixo nesta
secção.
40
REQUISITOS DA BIBLIOTECA DIGITAL DE TESES E DISSERTAÇÕES
•
Sistema de administração de repositórios – este sistema deve concretizar uma interface
de utilizador para interacção com o bibliotecário e com o autor. Esta interface deve
permitir a recepção das dissertações, da metadata e das condições de acesso, enviadas
através da Internet pelo autor ou por um funcionário da biblioteca. Deve também permitir
que o bibliotecário efectue o controlo de qualidade das dissertações recebidas. Esta
interface deve ainda permitir ao bibliotecário extrair registos metadata no formato
utilizado no catálogo da sua biblioteca e no catálogo nacional PORBASE.
•
Interface de utilizador para o leitor – Esta interface deve permitir ao leitor pesquisar, e
navegar, na metadata das dissertações depositadas em qualquer uma das universidades. É
também através desta interface que o leitor deve poder consultar as dissertações e a
respectiva metadata. Uma vez que o público alvo das tese e dissertações não se restringe
ao nível nacional, esta interface deverá ser multilíngue, devendo suportar pelo menos as
línguas portuguesa e inglesa.
•
Sistema de pesquisa federada – Este sistema deve tornar possível pesquisar as
dissertações de todas as universidades a partir de qualquer uma das interfaces com o
leitor nos sistemas das bibliotecas das universidades e da Biblioteca Nacional.
•
Sistema de depósito – Este sistema deve recolher periodicamente as dissertações
depositadas localmente nas bibliotecas das universidades, e envia-las para a Biblioteca
Nacional, onde é efectuado o seu depósito legal.
•
Sistema de identificação de publicações independente da localização – Deve ser um
sistema de identificadores lógicos que sejam persistentes, independentes da sua
localização e globalmente únicos, isto é, devem preencher os requisitos de um URN
(Uniform Resource Locator) de acordo com o RFC 2141 (Moats, 1997). Este sistema
deve incluir um sistema de resolução dos identificadores em URLs que localizam as
dissertações.
Capítulo 4
DESENHO DO SISTEMA
4.1
INTRODUÇÃO
Neste capítulo, é apresentada a arquitectura do sistema e de dados apresentadas como solução
baseada nos requisitos descritos no capítulo anterior. Na primeira parte, é apresentada a
arquitectura de alto nível, sendo discutida, na segunda parte, a tecnologia utilizada para pôr em
prática esta arquitectura. Finalmente, na terceira parte, é descrita a estrutura de dados utilizada no
sistema.
4.2
ARQUITECTURA DE ALTO NÍVEL
O sistema DiTeD baseia-se na existência de servidores locais instalados normalmente nas
bibliotecas das universidades, e um servidor central instalado na Biblioteca Nacional (Figura 8).
A comunicação com, e entre, os servidores é feita pela da Internet, através do protocolo HTTP.
41
42
DESENHO DO SISTEMA
SERVIDOR CENTRAL
(Biblioteca Nacional)
H
T
T
P
INTERNET
H
T
T
P
H
T
T
P
SERVIDOR LOCAL
(Biblioteca A)
SERVIDOR LOCAL
(Biblioteca B)
H
T
T
P
SERVIDOR LOCAL
(Biblioteca Z)
Figura 8 – Arquitectura de alto nível do sistema DiTeD
A interacção dos vários utilizadores (isto é, os leitores, os autores e os bibliotecários) com o
sistema é feita através de um browser de Internet.
Os servidores locais (na Figura 9) são constituídos por quatro componentes:
•
Um sistema de repositório onde são armazenadas as dissertações depositadas na
biblioteca da universidade.
•
Um sistema de administração do repositório. Através desta componente o bibliotecário
efectua o controlo de qualidade das dissertações depositadas. O bibliotecário pode
também extrair os registos metadata no formato utilizado no catálogo da sua biblioteca.
•
Uma interface de utilizador multilíngue a partir da qual os utilizadores podem pesquisar
e aceder às dissertações de todas as universidades.
•
Um sistema de pesquisa federada que permite pesquisar as dissertações armazenadas
nos repositórios de todas as universidades, a partir da interface de utilizador.
DESENHO DO SISTEMA
43
SERVIDOR
LOCAL
1
1
SISTEMA DE
REPOSITÓRIO
1
SISTEMA DE
ADMINISTRAÇÃO
1
INTERFACE DE
UTILIZADOR
SISTEMA DE
PESQUISA
FEDERADA
DE
REPOSITÓRIO
Figura 9 – Componentes de um servidor local
O servidor central (na Figura 10) é constituído por seis componentes:
•
Um sistema de repositório onde são armazenadas as dissertações e a metadata
recolhidas dos servidores locais das universidades.
•
Um sistema de administração do repositório. Através desta componente o bibliotecário
efectua o controlo de qualidade das dissertações recolhidas dos servidores locais das
universidades. O bibliotecário pode também extrair os registos metadata no formato
utilizado no catálogo nacional PORBASE.
•
Uma interface de utilizador multilíngue a partir da qual os utilizadores podem pesquisar
e aceder às dissertações de todas as universidades.
•
Um sistema de identificação de publicações que permite a ao sistema identificar as
dissertações de um modo independente da localização. Este sistema permite o registo, a
alteração e a resolução dos identificadores.
•
Um sistema de pesquisa federada que permite pesquisar as dissertações armazenadas
nos repositórios de todas as universidades, a partir da interface de utilizador .
•
Um sistema de depósito responsável pela recolha das dissertações depositadas
localmente nas bibliotecas das universidades.
44
DESENHO DO SISTEMA
SERVIDOR
CENTRAL
SISTEMA DE
REPOSITÓRIO
1
1
1
1
SISTEMA DE
ADMINISTRAÇÃO
DE
REPOSITÓRIO
SISTEMA DE
DEPÓSITO
1
INTERFACE DE
UTILIZADOR
1
SISTEMA DE
IDENTIFICAÇÃO
SISTEMA DE
PESQUISA
FEDERADA
DE
PUBLICAÇÕES
Figura 10 – Componentes do servidor central
4.3
TECNOLOGIA
Nesta secção são descritas as tecnologias escolhidas para concretizar a arquitectura descrita
anteriormente.
4.3.1 O SISTEMA DIENST
Conceptualmente, o DIENST é um sistema que permite configurar um conjunto de serviços
individuais que são executados em servidores distribuídos, que em cooperação oferecem os
serviços de uma biblioteca digital (Lagoze & Davis, 1995).
Os principais componentes da sua arquitectura são:
•
Um modelo para documentos que incorpora identificação dos conteúdos, estrutura lógica
e disseminação dos conteúdos em múltiplos formatos.
•
Um conjunto de serviços.
•
Um mecanismo para combinar os vários serviços em variadas colecções.
•
Um mecanismo de distribuição de colecções por regiões, para facilitar a distribuição
global.
DESENHO DO SISTEMA
45
A arquitectura do DIENST é baseada na noção de serviços definidos individualmente que
quando combinados criam um biblioteca digital distribuída. A palavra distribuída é aqui
utilizada, porque os serviços podem estar localizados em qualquer local na Internet. A
funcionalidade do DIENST inclui o armazenamento e acesso a documentos digitais, o
armazenamento de novos recursos, e a indexação e pesquisa dos mesmos.
A comunicação entre os vários serviços é feita através de um protocolo aberto (também chamado
protocolo DIENST), que torna possível a combinação dos serviços de acordo com as
necessidades da colecção e também a construção de novos serviços que tiram partido dos
serviços definidos pelo DIENST. Os principais serviços definidos no DIENST são os seguintes:
•
Serviço de Repositório – Oferece os meios para o armazenamento e acesso a documentos
digitais. Oferece ainda meios para a organização e disseminação dos seus conteúdos.
•
Serviço de Indexação – Oferece os mecanismos para a pesquisa de documentos digitais.
É responsável pela indexação da informação sobre conjuntos de documentos digitais, que
podem estar dispersos em vários repositórios.
•
Serviço de Mediação de Pesquisa – Este serviço é responsável por decidir quais os
servidores de indexação mais indicados para enviar os pedidos de pesquisa. A decisão
baseia-se no conteúdo dos servidores de indexação, e no desempenho da ligação.
•
Serviço de Colecção – Fornece informação sobre como um conjunto de serviços
interagem entre si para formar uma colecção lógica.
•
Serviço de Administração – Oferece uma interface homem-máquina para a administração
de repositórios.
•
Serviço de Interface de Utilizador – Trata de interacção, directa ou indirecta, entre os
utilizadores e os restantes serviços da biblioteca digital.
46
DESENHO DO SISTEMA
BROWSER DE
INTERNET
HTTP
HTTP
SERVIÇO DE
INTERFACE DE
UTILIZADOR
SERVIÇO DE
ADMINISTRAÇÃO
HTTP
SERVIÇO DE
MEDIAÇÃO DE
PESQUISA
HTTP
HTTP
HTTP
SERVIÇO DE
INDEXAÇÃO
HTTP
SERVIÇO DE
REPOSITÓRIO
Figura 11 – Configuração dos serviços DIENST para um servidor isolado
Na Figura 11 encontra-se a configuração mínima de serviços DIENST. Esta figura representa
uma biblioteca digital com apenas um repositório, não havendo por isso a necessidade de criar
uma colecção; por esta razão o serviço de colecção não é utilizado. Podemos ainda observar
como os serviços se relacionam entre si. O serviço de interface de utilizador comunica com o
serviço de Mediação de Pesquisa (para efectuar pesquisas na colecção) e com o serviço de
repositório (para aceder a documentos e à metadata dos mesmos). O serviço de Administração
comunica com o serviço de repositório para enviar novos documentos, retirar documentos, etc. O
serviço de mediação de pesquisa envia pedidos de pesquisa para o serviço de indexação. O
serviço de indexação mantém sempre actualizados os índices da metadata dos documentos
armazenados no repositório.
DESENHO DO SISTEMA
47
Na Figura 12 encontra-se um exemplo de configuração dos serviços definidos pelo DIENST de
modo a criar uma colecção virtual a partir de serviços instalados em duas instituições.
Relativamente ao exemplo anterior, importa salientar que o serviço de indexação mantém os
índices conjuntos dos conteúdos de ambos os repositórios. O serviço de mediação de pesquisa
dirige os pedidos de pesquisa para o serviço de indexação. O serviço de colecção dá a conhecer
aos serviços de interface de utilizador a localização do serviço de mediação de pesquisa; por sua
vez o serviço de mediação de pesquisa, é informado da localização do serviço de indexação; e os
servidores de indexação são informados da localização dos repositórios que devem indexar.
SERVIÇO DE COLECÇÃO
INSTITUIÇÃO A
SERVIÇO DE
ADMINISTRAÇÃO
SERVIÇO DE
REPOSITÓRIO
SERVIÇO DE
INTERFACE DE
UTILIZADOR
INSTITUIÇÃO B
SERVIÇO DE
MEDIAÇÃO DE
PESQUISA
SERVIÇO DE
INDEXAÇÃO
SERVIÇO DE
INTERFACE DE
UTILIZADOR
SERVIÇO DE
ADMINISTRAÇÃO
SERVIÇO DE
REPOSITÓRIO
Figura 12 – Exemplo de uma configuração de serviços DIENST
Como foi dito atrás, a comunicação com os vários serviços é feita através de um protocolo
aberto, também chamado DIENST. Este protocolo expõe a funcionalidade dos serviços através
da definição de operações para cada um deles. As principais operações definidas pelo protocolo
DIENST encontram-se na Tabela 5 (Davis, Lagoze, Fielding & Marisa, 2000).
48
DESENHO DO SISTEMA
#
"
$
Serviço de repositório
•
•
•
•
•
listar conteúdos
listar formatos de metadata suportados
listar partições
submeter novo documento
retirar documento
Serviço de pesquisa
•
efectuar uma pesquisa
Serviço de mediação de pesquisa
•
efectuar uma pesquisa
Serviço de colecção
•
•
•
•
listar todos os serviços da colecção
listar repositórios
listar mediadores de pesquisa
listar servidores de indexação
Serviço de administração
•
•
•
submissão de novos documentos
aprovação de documentos submetidos
rejeição de documentos submetidos
Serviço de interface de utilizador
•
•
•
•
gerar interface de pesquisa
gerar interface de navegação de colecções
efectuar uma pesquisa/navegação
aceder a um documento
Tabela 5 – As principais operações dos serviços definidos pelo DIENST
4.3.2 APLICAÇÃO DO DIENST NO DITED
O sistema DIENST oferece várias características que o tornam uma boa escolha como a
ferramenta base para o desenvolvimento de uma biblioteca digital distribuída de teses e
dissertações. Em primeiro lugar, os serviços do DIENST podem ser combinados de uma forma
muito flexível permitindo a satisfazer as necessidades da arquitectura distribuída que se pretende
para a biblioteca digital de teses e dissertações. Em segundo lugar, o sistema DIENST pode ser
adaptado para as necessidades das dissertações, pois o seu código fonte encontra-se disponível
livremente com licença para utilização e modificação. Em terceiro lugar, é possível a
concretização de serviços adicionais que utilizam os serviços definidos pelo DIENST. Isto
devido ao facto das funcionalidades dos seus serviços estar exposta através do protocolo
DIENST.
Um outro aspecto importante, é a importância da investigação por detrás do sistema DIENST,
principalmente nos tópicos de arquitecturas de bibliotecas digitais distribuídas (Lagoze, Davis &
James 1995) (Lagoze & Davis 2000), colecções virtuais (Lagoze, Fielding & Payette 1998)
(Lagoze & Fielding 1998) e pesquisa federada (Dushay & French, 1999) (Dushay, French,
DESENHO DO SISTEMA
49
Lagoze, 1999a) (Dushay, French, Lagoze, 1999b). O DIENST não é apenas uma ferramenta a
partir da qual se construiu o DiTeD. O DIENST é também um trabalho de referência na
construção de bibliotecas digitais distribuídas, oferecendo tanto as bases para o sistema, como a
teoria resultante de anos de experiência na Networked Computer Science Technical Reference
Library.
4.3.3 OUTRAS TECNOLOGIAS
O sistema DIENST foi desenvolvido na linguagem de programação Perl, o que levou a que o
sistema DiTeD também o tenha sido.
O Perl16 (Practical Extraction and Report Language) é uma linguagem de programação muito
prática, fácil de usar, eficiente e completa. É uma linguagem interpretada17, frequentemente
utilizada para a criação de páginas dinâmicas na Internet. É bastante utilizada no manuseamento
e extracção de informação de ficheiros (de texto ou binários), devido essencialmente a técnicas
sofisticadas de processamento de padrões por intermédio de expressões regulares. Outras
vantagens desta linguagem são a sua modularidade e possibilidade de reutilização, e nas versões
mais recentes, a possibilidade de utilização de programação orientada a objectos. É uma das
linguagens mais utilizadas para a Internet no mundo inteiro, o que por sua vez, levou ao
desenvolvimento, por parte de vários programadores, de muitas e variadas bibliotecas para a
linguagem. Esta é talvez a maior vantagem do Perl relativamente aos seus concorrentes, pois
existem bibliotecas que facilitam a programação em quase tudo o que possa estar relacionado
com a Internet, como por exemplo as bibliotecas de HTTP, SSL, correio electrónico, NNTP,
ligação a bases de dados, compressão de ficheiros, processadores de HTML e XML, entre outras.
O sistema DIENST foi inicialmente desenvolvido para ser executado como uma aplicação CGI18
(Common Gateway Interface). Nas versões mais recentes, o DIENST foi desenvolvido como um
módulo do servidor de HTTP Apache19, utilizando o módulo “mod_perl” como interpretador de
Perl. O servidor Apache é o servidor de HTTP mais utilizado no mundo, sendo distribuído
gratuitamente, juntamente com o seu código fonte e sem restrições de utilização. É
16
<http://www.perl.com>
Apesar do Perl ser uma linguagem interpretada, já foram desenvolvidos compiladores como forma de melhorar o desempenho dos programas.
18
O CGI foi uma das primeiras soluções utilizadas para a geração de páginas de Internet dinâmicas.
19
<http://www.apache.org>
17
50
DESENHO DO SISTEMA
extremamente configurável e extensível através da sua interface para o desenvolvimento de
módulos.
O mod_perl é um módulo do Apache que permite o desenvolvimento de módulos para o Apache
completamente em Perl. Para além disso, permite evitar os custos no desempenho de iniciar o
interpretador de Perl, sempre que um programa Perl é executado. Isto através da inclusão no
servidor Apache de um interpretador de Perl.
4.4
ESTRUTURAS DE DADOS
4.4.1 METADATA
Como foi dito atrás, a metadata é fundamental para a procura de informação. O objectivo da sua
utilização é o de libertar os potenciais utilizadores da necessidade de ter conhecimento prévio da
existência dos recursos e das suas características.
A metadata tem sido utilizada e aperfeiçoada nas bibliotecas desde à séculos, no entanto, hoje em
dia a sua necessidade aparece também na Internet onde geralmente, a procura de informação é
feita através de motores de pesquisa que procuram palavras no texto das páginas da Internet. Esta
técnica, embora muito útil, apresenta algumas limitações, por exemplo, podemos fazer pesquisas
por palavras que aparecem em inúmeras páginas, embora estas não se debrucem sobre as
palavras pesquisadas. Outro exemplo é a da procura de documentos de um autor, o único modo
de efectuar essa pesquisa é esperando que o nome do autor apareça nos seus documentos, mas o
resultado será constituído na maioria por documentos em que o nome do autor aparece no texto,
embora ele não seja o seu autor.
Uma vez que as pesquisas são efectuadas comparando as palavras a pesquisar com as palavras no
texto não estruturado de documentos, a utilização de metadata para normalizar a estrutura e o
conteúdo dos objectos da pesquisa, melhora o processo de pesquisa de informação. O popular
motor de pesquisa “Yahoo!”20 é um exemplo da utilidade que mesmo uma simples estrutura de
metadata pode ter. Apenas utilizando um assunto e uma descrição como metadata para cada
20
<http://www.yahoo.com>
DESENHO DO SISTEMA
51
“local na Internet”, a facilidade acrescida na pesquisa é muito significativa. No entanto a
utilização de metadata na Internet (mais especificamente na World Wide Web) é problemática,
uma vez que normalmente é o autor quem fornece a metadata, cuja compreensão sobre o assunto
é limitada, não tem à sua disposição um guia ou uma norma para a aplicar. No entanto, de uma
forma geral, estes problemas não se verificam nas bibliotecas digitais, pois nestas, é possível
guiar o autor no fornecimento da metadata, ou mesmo ser o próprio bibliotecário a aplicar a
metadata, permitindo desta forma, o uso de um formato normalizado, definido para as
necessidades da biblioteca digital. Este é o caso da biblioteca digital de teses e dissertações
descrita neste trabalho. Nesta biblioteca, a estrutura de metadata usada para descrever uma
dissertação é definida como se apresenta na Tabela 6. Na primeira coluna encontram-se os
nomes dos blocos (agrupamentos lógicos de elementos de metadata), e na coluna da direita os
elementos pertences a cada bloco.
%
&
Titulo
- Título em Português
- Título em Inglês
- Título em terceira língua (língua original se diferente de Português e Inglês)
- Subtítulo em Português
- Subtítulo em Inglês
- Subtítulo em terceira língua (língua original se diferente de Português e Inglês)
Autor
- Nome do autor
- Instituição do autor
- Departamento do autor
- Área ou curso do autor
- Ano de nascimento do autor
- Correio electrónico do autor
- Endereço postal do autor
- Telefone do autor
Género
- Género da manifestação (tese ou dissertação)
Língua
- Língua da manifestação (código a extrair de lista controlada ISO 639-2)
Resumo
- Resumo em Português
- Resumo em Inglês
- Resumo numa terceira língua
Indexação
(pode repetir)
- Termo em Português (pode repetir)
- Termo em Inglês (pode repetir)
- Termo numa terceira língua (pode repetir)
Orientador
- Nome do orientador
- Instituição do orientador
- Ano de nascimento do orientador
- Correio electrónico do orientador
- Endereço postal do orientador
Júri
(pode repetir)
- Nome do elemento do júri
- Ano de nascimento do elemento do júri
- Instituição do elemento do júri
52
DESENHO DO SISTEMA
%
&
Aprovação
- Data de aprovação (em formato ISO 8601)
Notas
- Notas gerais
Ficheiros
(pode repetir)
- Nome de ficheiro
- Formato de ficheiro
- Termos e condições de acesso ao ficheiro
- Data da revisão das condições (em formato ISO 8601)
- Chave MD5 do ficheiro
- Notas ao ficheiro
Biblioteca
- Identificação da biblioteca depositante
- Correio electrónico da biblioteca depositante
- Endereço postal da biblioteca depositante
- Data de depósito (em formato ISO 8601)
- Identificador URN
Direitos
- Declaração geral de direitos de autor
Nota: Os elementos obrigatórios encontram-se escritos a
elementos a sublinhado são preenchidos automaticamente pelo sistema.
grosso,
e
os
facultativos
a
fino.
Os
Tabela 6 – Estrutura de metadata usada no projecto DiTeD
Os elementos apresentados nesta tabela pertencem a três classes de metadata sobre uma
dissertação:
•
Descrição bibliográfica – A esta categoria pertencem os elementos contidos nos blocos
“título”, “autor”, “género”, “língua”, “resumo”, “indexação”, “orientador”, “júri”,
“aprovação”, “notas” e “biblioteca”.
•
Descrição estrutural e técnica – Nesta classe encontram-se os elementos “nome de
ficheiro”, “formato de ficheiro”, “notas ao ficheiro” e “chave MD5 do ficheiro” (este
elemento é utilizado para verificar a transmissão correcta do ficheiro através da rede).
•
Acesso e uso – A esta classe pertencem os elementos “declaração geral de direitos de
autor”, “termos e condições de acesso ao ficheiro” e “data da revisão das condições”.
A definição formal e completa do formato, encontra-se na Figura 13. Esta consiste numa
Definição de Tipo de Documento XML21.
21
O mérito da codificação da estrutura de metadata do DiTeD deve-se a José Borbinha.
DESENHO DO SISTEMA
53
<?xml version="1.0" encoding="ISO-8859-1"?>
<!-- Declaração DTD para o formato de metadata DiTeD - V2.0 (05/09/2000) -->
<!-- Definição da estrutura de um bloco de um registo -->
<!ELEMENT
ditedmeta (record+) >
<!ELEMENT
record
( work | author | genre | language| adviser | juri | approval | note
| file | library | copyright )+ >
<!-- Definição dos elementos constituintes de um registo -->
<!ELEMENT
work ( title | subtitle | abstract | indexing )+ >
<!ATTLIST work lang NMTOKEN #REQUIRED>
<!ELEMENT
title (#PCDATA) >
<!ELEMENT
subtitle
(#PCDATA) >
<!ELEMENT
abstract
(#PCDATA) >
<!ELEMENT
indexing (term+) >
<!ELEMENT
term (#PCDATA) >
<!ATTLIST
term control NMTOKEN #IMPLIED>
<!ELEMENT
name (#PCDATA) >
<!ELEMENT
org (#PCDATA) >
<!ELEMENT
birthyear (#PCDATA) >
<!ELEMENT
email (#PCDATA) >
<!ELEMENT
address
(#PCDATA) >
<!ELEMENT
dep (#PCDATA) >
<!ELEMENT
area (#PCDATA) >
<!ELEMENT
phone(#PCDATA) >
<!—Definição de elementos auxiliares... -->
<!ENTITY % person "name | org | birthyear?">
<!ENTITY % p-adviser "%person; | email? | address? ">
<!ENTITY % p-author "%p-adviser; | dep? | area? | phone?">
<!-- Definição dos elementos constituintes de um registo (contrinuação) -->
<!ELEMENT
genre (#PCDATA) >
<!ELEMENT
language (#PCDATA) >
<!ELEMENT
note (#PCDATA) >
<!ELEMENT
date (#PCDATA) >
<!ELEMENT
author
(%p-author;)+ >
<!ELEMENT
adviser
(%p-adviser;)+ >
<!ELEMENT
juri (%person;)* >
<!ELEMENT
approval (date)? >
<!ELEMENT
deposit
(date) >
<!ELEMENT
library
( name | email | address | deposit | identifier | note)+ >
<!ELEMENT
file ( name | type | access | md5 | note?)+ >
<!ELEMENT
access
(#PCDATA) >
<!ATTLIST access mode ( Livre | Local | Reservado ) "Local" period
( 0 | 3 | 6 | 12 | 24 ) "6">
<!ELEMENT
type (#PCDATA) >
<!ELEMENT
md5 (#PCDATA) >
<!ELEMENT
urn (#PCDATA) >
<!ELEMENT
copyright (#PCDATA) >
<!ELEMENT
identifier (urn) >
Figura 13 – Definição do formato de metadata DiTeD
Os valores a atribuir a alguns elementos devem ser normalizados. As datas devem usar o formato
normalizado ISO 860122, e o elemento “língua da manifestação” deve usar os códigos das línguas
definidos na norma ISO 639. O elemento “género” deve ter um dos seguintes valores: “tese de
doutoramento”, “tese de mestrado”, “trabalho de aptidão pedagógica e capacidade científica” ou
“cursos de estudos superiores especializados”. Os elementos “instituição do autor”,
22
Segundo a norma ISO 8601 as datas são representadas segundo o formato “CCYY-MM-DD”, em que CC é o século, YY o ano, MM o mês, e
DD o dia.
54
DESENHO DO SISTEMA
“departamento do autor” e “área ou curso do autor” também devem ter valores normalizados,
configurados para cada universidade individualmente.
De notar que o sistema DiTeD é basicamente um sistema que oferece um conjunto de
funcionalidades para o processamento das dissertações em formato digital, associando-lhes uma
estrutura de metadata. Ora se tivermos em conta que as dissertações digitais são compostas por
ficheiros, tal como outros géneros de publicações digitais, então, para utilizar o sistema DiTeD
com outros géneros de publicações digitais que possuam requisitos funcionais, seria apenas
necessário mudar a estrutura da metadata. Por esta razão, e porque existem de facto outros
géneros de publicações digitais pelos quais existe interesse por parte da Biblioteca Nacional em
efectuar o seu depósito, o sistema DiTeD foi desenvolvido de forma a ser uma biblioteca digital
distribuída que oferece um conjunto de funcionalidades para o processamento de “objectos
digitais” que têm uma estrutura de metadata associada. Ou seja o sistema DiTeD permite que a
estrutura de metadata, e algumas das suas funcionalidades, sejam configuradas durante a
instalação. Desta forma o sistema DiTeD pode ser utilizado com dissertações, com outros
géneros de publicações ou noutros países, sem que sejam necessárias alterações do seu código
fonte ou, com poucas alterações.
Na secção seguinte são descritas as implicações funcionais que a configuração da estrutura de
metadata acarreta, e a estrutura de dados que a suporta.
4.4.2 IMPLICAÇÕES FUNCIONAIS
A estrutura de metadata condiciona o funcionamento de quase todo o sistema. Por esta razão é
necessário configurar não só a estrutura de metadata, mas também o seu comportamento para as
funcionalidades dela dependentes
Uma vez que esta estrutura de dados visa permitir a utilização do sistema DiTeD com outros
géneros de publicações, nesta secção é utilizada a palavra “documento”, em vez da palavra
“dissertação”.
DESENHO DO SISTEMA
55
Configuração
do sistema
1
1
1
Estrutura de
metadata
1
1
1
1
Índices de
pesquisa
Interface de utilizador
Interfaces de
inter-operação
1 1
1
1
Metadata
do documento
*
Formato de metadata
*
identificador
Índice
Metadata
dos ficheiros
1
1
visualização()
identificador
*
1
1
1
1..*
Bloco
1
1
nome
nome_em_inglês
repetível [s|n]
1..*
1
1
{ou}
1..*
Visualização
1..*
1
1
1
*
Páginas
*
1
1
*
Interface de recolha
*
*
1
Conversor
Interface de
submissão
*
Elemento
identificador
nome
repetível [s|n]
obrigatório [s|n]
valor_por_defeito
valores possíveis
1
Visualização
resumida dos registos
de metadata
Visualização
dos elementos
de metadata
Formato de
codificação
1
1
texto_ajuda
tipo_de_interface
verificações
*
Elemento gerado
automaticamente
evento
gerador_de_valor()
Figura 14 – Estrutura de dados da configuração do sistema DiTeD
Na Figura 14 encontra-se representada a estrutura de dados que suporta a configuração do
sistema DiTeD. As suas componentes são as seguintes:
•
A estrutura de metadata.
•
A interface de utilizador, ou seja como os elementos de metadata devem ser utilizados na
interacção com os utilizadores.
•
Os índices de pesquisa, indicam como deve ser utilizada a metadata na pesquisa por
documentos.
•
As interfaces para inter-operação, definem como outros formatos de metadata para interoperação, devem ser gerados a partir da estrutura de metadata.
Cada uma destas componentes é descrita em detalhe nas subsecções seguintes.
56
DESENHO DO SISTEMA
4.4.2.1 A ESTRUTURA DE METADATA
A estrutura de metadata define os elementos de metadata sobre cada documento no sistema, e
sobre os ficheiros que os constituem. Os elementos relativos ao documento são agrupados em
blocos de elementos de acordo com a estrutura lógica da metadata. Os elementos têm os
seguintes atributos:
•
Identificador – O nome pelo qual o elemento é conhecido dentro da estrutura de
metadata.
•
Nome – O nome “amigável” do elemento. Este nome é fornecido para cada uma das
línguas da interface de utilizador.
•
Repetível – Indica se o elemento pode ser repetido.
•
Obrigatório – Indica se o elemento é de preenchimento obrigatório durante a submissão.
•
Valor por defeito – Indica o valor por defeito deste elemento.
•
Valores possíveis do elemento – Indica uma lista com os possíveis valores deste
elemento.
Existem ainda elementos que são gerados automaticamente pelo sistema. Estes elementos têm
todas as características de um elemento normal, mais as seguintes funcionalidades:
•
O evento que activa a sua geração – Indica em que altura do processo de gestão do
documento (e.g. submissão, aceitação pelo administrador, depósito), é gerado o valor do
elemento.
•
A função que gera o seu valor – Esta é a função que é chamada quando o evento é
activado. Esta função gera o valor a atribuir ao elemento.
Um exemplo de geração automática de um elemento, durante a submissão de uma dissertação, é
o elemento “data de submissão”. Neste caso, o evento que activa a sua geração é a submissão, e a
função que o gera, atribui-lhe a data actual.
DESENHO DO SISTEMA
57
4.4.2.2 INTERFACE DE UTILIZADOR
A interface de utilizador define como os elementos de metadata devem ser utilizados na
interacção com os utilizadores (incluindo o bibliotecário). Esta divide-se na interface de depósito
de documentos, e na visualização resumida e completa de registos de metadata.
A interface de depósito consiste na organização, em páginas de recolha, dos blocos definidos na
estrutura de metadata, e na interface utilizada para o utilizador introduzir os dados de cada
elemento.
A interface de depósito de documentos (Figura 15) consiste em várias páginas HTML que
recebem do utilizador a metadata sobre o documento, seguida de uma página onde são enviados
os ficheiros e preenchida a metadata relativa a cada um deles. No final é gerada uma página de
confirmação do depósito.
:PÁGINA INICIAL
Depósito de documentos
:PÁGINA DE SUBMISSÃO Nº1
Página seguinte
Página anterior
:PÁGINA DE SUBMISSÃO Nº2
Página anterior
Página seguinte
:PÁGINA DE SUBMISSÃO Nº X
Página seguinte
Página anterior
:PÁGINA DE SUBMISSÃO DE FICHEIROS
Finalizar depósito
:PÁGINA DE CONFIRMAÇÃO
Figura 15 – Diagrama da interface de depósito de documentos
A interface de recolha de cada elemento da estrutura de metadata, tem os seguintes atributos:
•
Tipo de interface – indica o tipo de interface para a recolha do valor do elemento.
•
Verificações - indica as verificações a efectuar aos dados introduzidos pelo utilizador.
58
DESENHO DO SISTEMA
•
Texto de ajuda – contém o texto de ajuda que auxilia o utilizador no preenchimento do
elemento.
A Tabela 7 contém um exemplo com oito elementos e as suas interfaces de recolha. Os
elementos na tabela são relativos ao autor de uma dissertação.
'
(
)
)
*
+
$
Nome completo
Texto, 80, 1
Está preenchido
Instituição
Texto, 80, 1
Está preenchido
Departamento
Texto com lista de valores
possíveis, é possível especificar
outro valor, 30, 1
Está preenchido
Área
Texto, 80, 1
Está preenchido
Ano de nascimento
Inteiro, 4
Está preenchido, é um
inteiro
E-mail
E-mail, 50, 1
Contém um e-mail, está
preenchido
Morada
Texto, 90, 3
Telefone
Texto, 40, 1
,
-
Introduza o seu nome
completo.
Insira apenas o ano do
seu nascimento
Tabela 7 –Interfaces de recolha da metadata sobre o autor
A partir da informação da interface e do elemento é gerada a interface HTML, uma janela de
ajuda, e o código “javascript” que efectua as verificações dos dados inseridos pelo utilizador. A
interface gerada para os elementos do exemplo da Tabela 7, encontra-se na Figura 16. O texto de
ajuda está acessível através do ponto de interrogação que se encontra no lado direito de cada
elemento.
Figura 16 – Interface HTML gerada a partir interface de recolha da estrutura de metadata sobre o autor
DESENHO DO SISTEMA
59
A interface de visualização consiste numa página HTML onde é mostrada ao utilizador toda o
conteúdo de um registo de metadata, incluindo também os pontos de acesso aos ficheiros que
compõem o documento. Alguns elementos são visualizados de formas especiais, como por
exemplo o “endereço de correio electrónico” do exemplo da Figura 17.
Figura 17 – Visualização de um registo de metadata
A interface de visualização resumida consiste na visualização dos elementos mais
representativos da estrutura de metadata – normalmente constituída pelo título, o nome do autor,
e a data. É utilizada na interface de pesquisa e navegação, para mostrar nos resultados da
operação, uma versão resumida do registo de metadata do documento. Esta interface consiste na
visualização de apenas alguns elementos da estrutura de metadata como se mostra na Figura 18.
Figura 18 – Visualização resumida de dois registos de metadata
4.4.2.3 ÍNDICES DE PESQUISA
A pesquisa por documentos é efectuada em três índices chamados título, autor e descrição. Estes
índices contêm um ou mais elementos da estrutura de metadata. Desta forma quando um
utilizador lança uma pesquisa num índice, a pesquisa é feita no(s) elemento(s) incluído(s) nesse
índice. Na Tabela 8 encontra-se um exemplo, em que o índice “título” contém os elementos
60
DESENHO DO SISTEMA
“título” e “subtítulo”, o índice “autor” contém o elemento “nome completo do autor”, e o índice
“descrição” contém os elementos “resumo” e “palavra-chave”.
'
&
,
Título
Título, subtítulo
Autor
Nome completo do autor
Descrição
Resumo, palavras-chave
Tabela 8 – Exemplo de uma configuração dos índices de pesquisa
4.4.2.4 INTERFACES PARA INTER-OPERAÇÃO
As interfaces para inter-operação, utilizam geralmente formatos de metadata específicos23 (por
exemplo, o formato Open Archives Metadata Set é utilizado para a inter-operação com a Open
Archives Inicitaive). Estes formatos necessitam de ser criados a partir da estrutura de metadata
do sistema DiTeD. Para esse efeito, cada formato disponível para inter-operação, é composto por
três componentes:
•
Regras de conversão – Consiste num conjunto de regras que convertem um registo
DiTeD num registo deste formato. A regras de conversão são especificadas segundo uma
linguagem que é descrita na secção “5.7 - O módulo de conversão de registos de
metadata”.
•
Formato de codificação – Este é o formato em que o registo é codificado. Os formatos de
codificação necessários para as interfaces definidas são a norma ISO 2709 e a codificação
em XML.
•
Definição da visualização – Consiste numa função que gera a visualização do registo no
formato convertido para a interface de utilizador.
23
As interfaces para inter-operação concretizadas no sistema DiTeD são descritas no “Capítulo 7 - Inter-operação com outros sistemas”
Capítulo 5
CONCRETIZAÇÃO DO SISTEMA
5.1
INTRODUÇÃO
Neste capítulo é aprofundado o desenho do sistema apresentado no capítulo anterior, e detalhada
a concretização dos componentes da arquitectura.
5.2
ARQUITECTURA DETALHADA
Os servidores locais e central são constituídos por uma combinação dos serviços definidos pelo
DIENST. Embora todos os serviços tenham sido adaptados para as teses e dissertações, a
funcionalidade básica dos serviços definida no DIENST foi mantida.
Para o servidor central foi definido um serviço adicional que não é definido pelo DIENST, o
serviço de depósito. Este serviço está encarregue de verificar periodicamente a existência de
novas dissertações nos servidores locais. As novas dissertações são recolhidas e submetidas para
o servidor de depósito. A funcionalidade deste serviço encontra-se descrita em detalhe na secção
“5.5 - O serviço de depósito”.
A configuração de serviços DIENST do servidor central encontra-se representada na Figura 19.
O servidor central é na realidade constituído por três servidores independentes, o servidor de
depósito, o servidor de colecção, e o servidor de identificação de publicações. O servidor de
61
62
CONCRETIZAÇÃO DO SISTEMA
identificação de publicações foi desenvolvido como um servidor independente, pois ele pode ser
utilizado conjuntamente com outros géneros de publicação, não apenas com as dissertações
digitais. Em relação à separação dos servidores de depósito e de colecção24, esta deve-se às
implicações da utilização do mecanismo de pesquisa federada do sistema DiTeD (descrito na
secção “5.4 - O sistema de pesquisa federada”).
O servidor de colecção é constituído por quatro serviços:
•
O serviço de colecção - fornece informação a todos os servidores locais sobre todos os
servidores existentes e os serviços neles instalados.
•
Um serviço de indexação – responsável pela indexação da metadata sobre as dissertações
que se encontram nos vários repositórios.
•
Um serviço de mediação de pesquisa – faz o encaminhamento das pesquisas para o
servidor de indexação mais indicado.
•
O serviço de depósito - verifica periodicamente a existência de novas dissertações nos
servidores locais. Recolhe as novas dissertações e submete-as para o servidor de
depósito.
O servidor de depósito é um servidor isolado, isto é, ele não se encontra dentro da colecção
virtual definida no servidor de colecção. Ele tem, portanto, a configuração de serviços mínima de
serviços DIENST para um servidor isolado. Ou seja é constituído por um repositório, um serviço
de indexação, um serviço de mediação de pesquisa, um serviço de administração e um serviço de
interface de utilizador.
24
Embora estes servidores estejam separados na arquitectura, ambos podem coexistir na mesma máquina.
CONCRETIZAÇÃO DO SISTEMA
63
SERVIÇO DE
ADMINISTRAÇÃO 1
SERVIÇO DE
INTERFACE DE
UTILIZADOR
SERVIDOR
CENTRAL
SERVIÇO DE
1 DEPÓSITO
1
1
SERVIÇO DE
MEDIAÇÃO DE
PESQUISA
SERVIÇO DE
INDEXAÇÃO
1 SERVIÇO DE
COLECÇÃO
1
SERVIDOR DE
DEPÓSITO
(INDEPENDENTE)
1
SERVIDOR DE
COLECÇÃO
1 SERVIÇO DE
MEDIAÇÃO DE
PESQUISA
1
1
1
SERVIDOR DE
IDENTIFICAÇÃO
SERVIÇO DE
INDEXAÇÃO
DE
PUBLICAÇÕES
1
1
SERVIÇO DE
REPOSITÓRIO
SERVIÇO DE
INTERFACE DE
UTILIZADOR
Figura 19 – Configuração de serviços do servidor central
Fazendo uma ligação à arquitectura de alto nível, descrita anteriormente na “Figura 9 –
Componentes de um servidor local”, os componentes do servidor central são constituídos da
seguinte forma:
•
Sistema de repositório – é composto pelo serviço de repositório do servidor de depósito.
•
Sistema de administração de repositório – é composto pelo serviço administração do
servidor de depósito.
•
Interface de utilizador – existem duas interfaces com o utilizador no servidor central: uma
interface para o servidor de depósito e uma outra interface que dá acesso às colecções dos
servidores locais.
•
Sistema de pesquisa federada – é composto por três serviços do servidor de colecção: os
serviços de colecção, de mediação de pesquisa, e de indexação. Os serviços de indexação
e mediação de pesquisa do servidor de depósito não fazem parte do sistema de pesquisa
federada, estes destinam-se apenas para pesquisas no servidor de depósito.
•
Sistema de depósito – é composto pelo serviço de depósito do servidor de colecção.
64
CONCRETIZAÇÃO DO SISTEMA
Os servidores locais são constituídos pelos seguintes componentes:
•
Sistema de repositório – é composto pelo serviço de repositório.
•
Sistema de administração de repositório – é composto pelo serviço administração.
•
Interface de utilizador – é composto pelo serviço de interface de utilizador.
•
Sistema de pesquisa federada – uma vez que o mecanismo de pesquisa federada do
DIENST é feito através da recolha de metadata dos repositórios, os servidores locais não
necessitam de conter nenhum outro mecanismo para o efeito. Apenas necessitam de
disponibilizar a metadata dos documentos do seu repositório, através do protocolo
DIENST. Opcionalmente, os servidores locais podem conter os serviços de indexação e
de mediação de pesquisa. Este servidor de indexação indexa os conteúdos de todos os
repositórios, não apenas o repositório do servidor local. A sua utilização oferece aos
utilizadores, um melhor desempenho na execução de pesquisas.
SERVIDOR
LOCAL
SERVIÇO DE
ADMINISTRAÇÃO
1
0..1
0..1
1
SERVIÇO DE
INTERFACE DE
UTILIZADOR
SERVIÇO DE
MEDIAÇÃO DE
PESQUISA
1
SERVIÇO DE
REPOSITÓRIO
SERVIÇO DE
INDEXAÇÃO
Figura 20 – Configuração de serviços de um servidor local
5.3
O SISTEMA DE REPOSITÓRIO
O modelo de documentos utilizado no projecto DiTeD permite o armazenamento de conteúdos
constituídos por vários ficheiros em várias formas (isto é, texto, imagens, vídeo, áudio). Cada
CONCRETIZAÇÃO DO SISTEMA
65
documento tem associado um registo de metadata (no formato DiTeD) que descreve o
documento e cada um dos ficheiros que o constituem.
O acesso às dissertações é controlado através do endereço de rede (endereço IP) do computador a
partir do qual é pedido o acesso. Em cada pedido de acesso a um ficheiro, é comparado endereço
IP de origem do pedido, com as condições de acesso ao ficheiro, e com a lista de endereços IP da
rede da universidade ou biblioteca. O acesso é negado caso se verifiquem as restrições
especificadas pelo autor. As restrições de acesso não são aplicadas quando o pedido de acesso é
feito a partir do servidor central da Biblioteca Nacional. O depósito legal é sempre feito na
Biblioteca Nacional independentemente das restrições de acesso especificadas pelo autor.
Cada documento depositado recebe um identificador URN, que deve ser resolvido através do
servidor de identificação de publicações. Para suportar este processo, é atribuído a cada
publicação um identificador único baseado no número de depósito, o qual irá assim ser usado
para a determinação automática do URN. Usam-se ainda as seguintes regras ABNF para a
especificação desse identificador (Borbinha 2000) (Gulik, Iannella & Faltstrom 2000):
PURL
URN
urn-n
inst
= “http://purl.pt/” ( urn-n / URN )
= “urn:bnpt:” urn-n
= “dited:” inst “/” 1 *DIGIT
= 1 *( DIGIT / ALPHA / ”-“ )
O elemento “inst” pretende representar nos identificadores a instituição depositante, a controlar
de acordo com uma tabela mantida pelo sistema (esse elemento serve de identificador da
instituição em todo o serviço DiTeD). Neste caso, exemplos de identificadores URN poderão ser:
urn:bnpt:dited:utl-ist/123
urn:bnpt:dited:uminho/123
Por sua vez exemplos de identificadores PURL derivados deste processo serão25:
http://purl.pt/urn:bnpt:dited:utl-ist/123
http://purl.pt/urn:bnpt:dited:uminho/123
http://purl.pt/dited:utl-ist/123
http://purl.pt/dited:uminho/123
25
Para mais detalhes, consultar em “A URN Namespace for resources maintained by the National Library of Portugal” (Borbinha, 2000).
66
CONCRETIZAÇÃO DO SISTEMA
A resolução destes identificadores levam o utilizador a uma página HTML, onde se encontra a
descrição do documento (metadata), e a partir da qual se pode aceder aos ficheiros que o
constituem. A forma como estes identificadores são registados e resolvidos no servidor de
identificação de publicações, é descrita na secção “5.6 - Resolução de URNs”.
5.4
O SISTEMA DE PESQUISA FEDERADA
A funcionalidade do sistema de pesquisa federada é aqui descrita em duas partes. Primeiro é
descrito como os serviços interagem entre si para conseguir a pesquisa federada, sendo depois
descrito o processo de indexação de metadata e de execução de pesquisas.
5.4.1 A COLECÇÃO VIRTUAL DE TESES E DISSERTAÇÕES
A colecção de teses e dissertações está logicamente e administrativamente dividida em
autoridades de publicação (por exemplo, universidades, departamentos). Cada autoridade tem o
controlo sobre a adição e administração de documentos no(s) seu(s) repositórios. A metadata dos
documentos nestes repositórios são indexadas por um ou mais servidores de indexação. A
metadata é acedida através de pedidos do protocolo DIENST ao repositório respectivo. O serviço
de colecção permite a federação dos servidores de indexação e dos repositórios numa única
colecção uniforme (Lagoze & Fielding, 1998). Os pedidos do protocolo DIENST definidos para
o serviço de colecção permitem o acesso à seguinte informação (Davis, Lagoze, Fielding &
Marisa, 2000):
•
A lista de autoridades de publicação que compõem a colecção. Estas são as
universidades, ou os seus departamentos.
•
A localização na rede (isto é, endereço e número de porto) dos servidores de indexação
que contêm os índices da informação das autoridades de publicação. Por exemplo, os
índices da informação das teses e dissertações do Instituto Superior Técnico, pode estar
no seu servidor de indexação e no servidor da Biblioteca Nacional.
•
A correspondência entre os servidores de indexação e os servidores de repositório. Esta
informação indica aos servidores de indexação quais os repositórios que estes devem
indexar.
CONCRETIZAÇÃO DO SISTEMA
•
67
A localização na rede dos servidores de mediação de pesquisa. Esta informação indica
aos servidores de interface de utilizador para onde devem enviar as pesquisas.
A informação do serviço de colecção é utilizada pelo serviço de interface de utilizador. Cada
serviço de interface de utilizador é configurado com a localização na rede do serviço de
colecção. Periodicamente cada servidor de interface de utilizador contacta o servidor de colecção
para obter a informação sobre a colecção. Esta informação é então guardada internamente.
Depois a informação sobre a colecção, é utilizada para criar a interface de pesquisa. Por
exemplo, para criar a uma lista das autoridades de publicação que o utilizador pode escolher para
pesquisar.
O serviço de mediação de pesquisa obtêm a informação de colecção da mesma forma. A
informação é então utilizada para decidir para quais dos servidores de indexação devem ser
enviadas as pesquisas recebidas do servidores de interface de utilizador.
5.4.2 INDEXAÇÃO E PESQUISA
No processo de pesquisa existem quatro serviços intervenientes:
•
Serviço de interface de utilizador – responsável pela interacção com o utilizador, de
quem recebem os pedidos de pesquisa. As pesquisas são enviadas para um mediador de
pesquisa.
•
Serviço de mediação de pesquisa – encaminha as pesquisas para os servidores de
indexação mais indicados.
•
Serviço de indexação – indexa a metadata das dissertações de um ou mais repositórios, e
efectua as pesquisas na metadata.
•
Serviço de repositório – contém as dissertações e a correspondente metadata.
Os vários servidores sabem da existência e localização dos outros servidores através do serviço
de colecção da forma que foi descrita na secção 5.4.1.
Uma pesquisa lançada por um utilizador é processada como se mostra na Figura 21. A pesquisa é
recebida no serviço de interface de utilizador que a envia para o serviço de mediação de pesquisa
mais próximo. A pesquisa é então enviada para um servidor de indexação que contenha os
68
CONCRETIZAÇÃO DO SISTEMA
índices da colecção pesquisada. Aqui a pesquisa é executada e os resultados enviados para o
mediador de pesquisa, que por sua vez, os reenvia para o servidor de interface de utilizador.
Object5
:Browser
:Utilizador
Serviço de interface
de utilizador
:Serviço de mediação
de pesquisa
Serviço de indexação
pesquisa
pesquisa
pesquisa
visualização dos
resultados
resultados da
pesquisa
resultados da
pesquisa
resultados da
pesquisa
Figura 21 – Execução de uma pesquisa
Não se prevê que num futuro próximo a colecção de teses e dissertações atinja uma dimensão
insustentável para um servidor de indexação. Assim um servidor de indexação tem capacidade
para indexar o conteúdo de todos os repositórios existentes. No entanto, os servidores locais das
universidades podem incluir o seu servidor de indexação por questões de desempenho. Caso seja
utilizado, este servidor indexa os conteúdos de todos os repositórios, não apenas o repositório do
servidor local.
Uma vez que toda a colecção de teses e dissertações é indexada num único servidor, o serviço de
mediação de pesquisa referido tem aqui um papel que não tira proveito de todas as suas
funcionalidades26.
Para indexar a metadata das dissertações, o serviço de indexação recolhe periodicamente a
metadata das novas dissertações que vão sendo armazenadas nos repositórios, conforme se
mostra na Figura 22. Para cada um dos repositórios é pedida a metadata de todas as dissertações
entradas desde a última recolha. O servidor de repositório responde enviando a metadata das
26
O serviço de mediação também oferece mecanismos para o envio de uma pesquisa para vários servidores de indexação, e outros mediadores de
pesquisa, e a agregação dos vários resultados de pesquisa recebidos.
CONCRETIZAÇÃO DO SISTEMA
69
novas dissertações, caso existam. Após a recolha da metadata, os novos registos são incluídos no
índice.
SERVIÇO DE INDEXAÇÃO
SERVIÇO DE REPOSITÓRIO
Obter lista de repositórios
* para cada repositório
Pedir metadata dos novos documentos
Verificar a existência de novos documentos
Verificar existência de novos documentos
Enviar lista de novos documentos e a sua metadata
[existem documentos novos]
[não existem documentos novos]
Indexar metadata recebida
Figura 22 – Diagrama do processo de recolha de metadata para indexação
O motor de indexação utilizado no serviço de indexação é o freeWAIS-sf27. Este é uma extensão
do pacote freeWAIS desenvolvido pela Clearinghouse for Networked Information Discovery and
Retrieval28 (CNIDR) e que se encontra documentado em (Pfeifer 1995). O sufixo “sf” no nome
do pacote, quer dizer campos estruturados (structured fields), uma característica que o distingue
do seu predecessor. Os documentos são representados como um conjunto de campos, que podem
conter diferentes tipos de dados como datas, texto e valores numéricos.
A capacidade de utilizar a estrutura lógica dos documentos torna o freeWAIS-sf a tecnologia
indicada para indexar registos de metadata, uma vez que estes são constituídos por vários
campos.
27
<http://ls6-www.informatik.uni-dortmund.de/ir/projects/freeWAIS-sf/>
70
CONCRETIZAÇÃO DO SISTEMA
O freeWAIS-sf é uma tecnologia de recuperação de informação avançada, cujo código fonte se
encontra disponível. Utiliza algoritmos de análise fonética29, stemming30, e pesquisas booleanas
complexas. Sendo uma ferramenta conhecida pelas suas grandes capacidades na análise da
relevância de documentos em pesquisas.
No entanto, o freeWAIS-sf não se encontra preparado para a língua portuguesa, o que reduz o
seu desempenho. A análise fonética e stemming não são por isso utilizados no projecto DiTeD.
Mesmo assim o freeWAIS-sf continua a ser a melhor opção para o motor de indexação, uma vez
que não se encontram disponíveis livremente ferramentas de indexação com as suas capacidades,
e adaptadas à língua portuguesa.
5.5
O SERVIÇO DE DEPÓSITO
O serviço de depósito é um serviço que não está definido no DIENST. Este serviço foi criado
para satisfazer os requisitos da lei de depósito legal portuguesa. A lei de depósito legal requer
que todas as teses e dissertações entregues nas universidades portuguesas sejam depositadas na
Biblioteca Nacional.
Como foi mostrado na Figura 7, a recolha das dissertações que se encontram depositadas nos
servidores locais é feita pelo servidor central através do serviço de depósito. As dissertações
recolhidas são depois verificadas por um bibliotecário e caso estejam válidas são então
depositadas no servidor de depósito.
O processo de recolha efectuado pelo serviço de depósito encontra-se representado na Figura 23.
O serviço de depósito começa por obter a lista dos repositórios da colecção, contactando o
serviço de colecção. Para cada um dos repositórios, é pedida a metadata de todas as dissertações
entrados no repositório desde a última recolha. O servidor de repositório responde enviando a
metadata das novas dissertações, caso existam. Em seguida, o serviço de depósito analisa a
metadata recebida e para cada nova publicação pede ao repositório os ficheiros que a compõem.
28
<http://www.cnidr.org>
A análise fonética consiste em mapear as palavras para um código do seu som, antes de ser inserida ou pesquisada no índice. Assim, palavras
com sons iguais ou semelhantes são tratadas como se fossem idênticas.
30
A técnica de stemming consiste em reduzir as palavras para a sua forma mais simples, antes de ser inserida ou pesquisada no índice. Assim, as
palavras ‘computador’, ‘computadores’ e ‘computação’ são tratadas como se fossem idênticas.
29
CONCRETIZAÇÃO DO SISTEMA
71
Após a recolha completa da publicação, e da respectiva metadata, o serviço de depósito envia a
publicação para o servidor de depósito, simulando um depósito feito por um utilizador.
Para tornar este processo mais robusto o servidor mantém, de forma persistente, o estado das
dissertações já depositadas com sucesso. Permitindo ao sistema recuperar de falhas que ocorram
durante o processo de depósito.
SERVIÇO DE DEPÓSITO
SERVIÇO
DE REPOSITÓRIO
Obter lista de repositórios
* para cada repositório
Pedir metadata dos novos documentos
Verificar a existência de novos documentos
Verificar existência de novos documentos
Enviar lista de novos documentos e a sua metadata
* para cada novo documento
Pedir ficheiros
Verificar condições de acesso
Submeter documento para o servidor de depósito
Enviar Ficheiros
Figura 23 – Diagrama do processo de recolha de novas dissertações
Após a submissão das dissertações para o servidor de depósito, a sua validade é verificada por
um bibliotecário (através do serviço de administração do repositório), e caso sejam válidas são
finalmente depositadas no repositório de servidor de depósito.
72
5.6
CONCRETIZAÇÃO DO SISTEMA
RESOLUÇÃO DE URNS
Para a resolução de URNs optou-se pela tecnologia PURL (Permanent URL). Um servidor de
PURL é, na prática, um servidor de HTTP, de que se pretende de elevada fiabilidade, associado a
uma base de dados de resolução de URNs em URLs.
Para cada URN registado numa dessas bases de dados associa-se um URL real, o qual é
devolvido pelo servidor num comando HTTP de redireccionamento, para cada cliente que lhe
aceda. Esse redireccionamento é processado assim automaticamente sem necessidade de
qualquer intervenção ou conhecimento da parte do utilizador, conforme se ilustra na Figura 24.
Object5
:Browser Cliente
:Utilizador
:Servidor URN
acesso ao URN
:Base de dados URN
:Servidor Destino
pedido de tradução
do URN num URL
Comando de
redireccionamento
URL de destino
acesso ao URL de destino
visualização do
conteúdo do URL
de destino
retorno do conteúdo do URL de destino
Figura 24 – Exemplo de resolução de um URN
Na Figura 25 encontra-se representada a arquitectura do servidor de resolução de URNs. Este é
constituído pelo sistema de resolução encarregue de traduzir URNs em URLs, e por um sistema
de gestão, oferecendo funcionalidades para a gestão da base de dados de URNs.
CONCRETIZAÇÃO DO SISTEMA
73
ServidorBD:MySQL
<<base de dados>>
BD URN
<<base de dados>>
BD autenticação
Servidor HTTP:Apache + mod_perl
Sistema de autenticação
Sistema de resolução
interface HTTP
Sistema de gestão
Interface HTTP
Figura 25 – Arquitectura do servidor URN
Tanto o sistema de resolução como o de gestão concretizam uma interface por HTTP definida
por um protocolo aberto de modo a tornar o mais simples possível a interacção com o servidor
URN. A interface encontra-se definida na Tabela 9.
.
/
Resolução de um URN
#
http://purl.pt/<urn>
Registo de um novo URN
http://purl.pt/register?urn=<urn>&url=<url>
Modificação de um URN
http://purl.pt/update?urn=<urn>&newurl=<url>
Remoção de um URN
http://purl.pt/delete?urn=<urn>
Tabela 9 – Interface HTTP do sistema URN
A gestão dos URNs é controlada por um sistema de autenticação. Cada espaço de nomes URN
tem associado a si informação de autorização para a sua manutenção. Esta informação é utilizada
para controlar as operações de gestão de URNs por nome de utilizador e palavra-chave, ou por
endereço IP (Figura 26).
74
CONCRETIZAÇÃO DO SISTEMA
:Cliente
:Servidor URN
pedito de registo,
alteração ou remoção
de um URN
:autenticador
:Base de dados URN
:Base de dados autenticação
pedido de
autenticação do cliente
verificação da
autorização
resultado da autorização
resultado da
autorização
execução do pedido
resultado do
pedido
resultado da
execução
Figura 26 – Exemplo do registo, alteração ou remoção de um URN
O servidor aqui especificado foi apenas concretizado parcialmente (apenas com o registo e
resolução de URNs), uma vez que o serviço purl.pt está a ser concretizado pela Biblioteca
Nacional31. Este protótipo encontra-se implementado em Perl com uma base de dados MySQL.
Para melhorar o seu desempenho, o Perl é executado num servidor Apache compilado com
suporte para o mod_perl. O mod_perl integra o interpretador de Perl no apache evitando que seja
iniciado o interpretador de Perl em cada chamada ao servidor URN. Outro factor que poderia
degradar o desempenho do sistema seria a necessidade de efectuar a ligação à base de dados em
cada chamada ao servidor URN, por esta razão é utilizado o módulo Apache::DBI. Este módulo
mantém a ligação à base de dados aberta entre chamadas.
5.7
O MÓDULO DE CONVERSÃO DE REGISTOS DE METADATA
A interoperabilidade entre formatos de metadata é um assunto que tem despertado um grande
interesse na comunidade das bibliotecas digitais (Bearman, Miller, Rust, Trant & Weibel, 1999)
(Lagoze & Lynch, 1996) (Lagoze, Hunter, Brickley, 2000) (Library of Congress, 1997).
31
À data de edição desta dissertação, encontra-se a decorrer um projecto com a Universidade de Lisboa para a concretização completa do
servidor PURL, associado a um sistema de depósito mais vasto.
CONCRETIZAÇÃO DO SISTEMA
75
Dentro do projecto DiTeD foram identificados três casos onde a conversão de registos de
metadata era necessária:
•
Na inter-operação com o catálogo da biblioteca, através da exportação de registos
UNIMARC (o formato de metadata utilizado no catálogo das bibliotecas portuguesas e
no catálogo nacional PORBASE);
•
Na inter-operação ao nível de pesquisa através da disponibilização de registos OAMS
(Open Archives Metadata Set) através do protocolo Open Archives;
•
Na inter-operação ao nível de pesquisa através da disponibilização de registos RFC 1807
(formato utilizado pelo DIENST) através do protocolo DIENST.
Para satisfazer estas necessidades o DiTeD concretiza um módulo de conversão de metadata cujo
funcionamento se mostra na Figura 27. A metadata é armazenada no formato próprio do DiTeD
e é convertida, pelo módulo de conversão, para outros formatos quando necessário.
No sistema DiTeD, um registo de metadata, independentemente do seu formato, tem sempre uma
estrutura como a apresentada na Figura 28. Nesta estrutura, um registo é composto por uma lista
ordenada de elementos que, por sua vez, têm um nome e podem ter um valor e/ou uma lista
ordenada de elementos.
Tecnicamente, a conversão de registos de metadata consiste na transformação de uma destas
estruturas numa outra destas estruturas. Ambas as estruturas têm um significado semântico
semelhante dentro do contexto do seu formato de metadata. A Figura 29 ilustra um exemplo da
conversão de registos de metadata.
76
CONCRETIZAÇÃO DO SISTEMA
BIBLIOTECÁRIO
APLICAÇÃO CLIENTE
OAI OU NCSTRL
CLIENTE DIT ED
Pedido de
registo
UNIMARC
SERVIÇO DE
ADMINISTRAÇÃO
SERVIÇO DE
REPOSITÓRIO
Pedir registo
no formato
UNIMARC
Obter
registo no
repositório
Pedido de
registo OAI
ou RFC 1807
Pedir
Conversão
do registo
Converter
registo
Devolver
registo
convertido
Devolver
registo
convertido
Obter
registo no
repositório
Pedido de
registo
DiTeD
Pedir
Conversão
do registo
Converter
registo
Devolver
registo
convertido
Devolver
registo
convertido
Obter
registo no
repositório
Devolver
registo
Figura 27 – Acesso aos vários formatos de metadata
Registo Metadata
MÓDULO DE
CONVERSÃO
contém
{ordenados}
*
Elemento
Nome
Valor
*
contém
{ordenados}
Figura 28 – Representação generalizada de um registo de metadata
CONCRETIZAÇÃO DO SISTEMA
77
Título
Bibliotecas Digitais
Autor
Fernando José
Título
CONVERSÃO
Data aprovação
2000-11-25
Palavras-chave
Internet, Publicação
Bibliotecas Digitais
Criador
Fernando José
Data
25 de Novembro, 2000
REGISTO DE METADATA (CONVERTIDO)
REGISTO DE METADATA
Figura 29 – Exemplo de conversão de um registo de metadata
Cada formato de metadata tem associado a si um formato de codificação. Assim, antes de
converter um registo de metadata este tem de ser descodificado e, após a conversão, novamente
codificado no formato pretendido.
:Módulo de conversão
Registo A : Registo de
metadata
Registo B : Registo de
metadata
ler registo
descodificar
registo
registo descodificado
converter
registo
escrever registo
convertido
codificar
registo
Figura 30 – Processo de conversão de registos de metadata
Como se pode observar na Figura 30, o processo responsável pela conversão de registos de
metadata é sempre composto por três passos:
1. Descodificar registo - O registo de origem é lido a partir do seu formato codificado
(exemplo: ISO 2709, XML, etc.) e representado numa estrutura de dados como a
apresentada na Figura 28.
78
CONCRETIZAÇÃO DO SISTEMA
2. Converter registo - A conversão é aplicada pelo módulo de conversão e o registo de
destino gerado.
3. Codificar registo - O registo de destino é codificado no formato de metadata pretendido.
O módulo de conversão assenta sobre uma infra-estrutura técnica desenvolvida com o objectivo
de facilitar a especificação de conversões entre diferentes formatos de metadata, composta por
uma linguagem de conversão, e por um interpretador. A linguagem de conversão permite
especificar, para cada elemento do formato, uma regra constituída por um par «elemento» «acções», na qual as «acções» são despoletadas pelo interpretador sempre que é identificada a
existência do «elemento» no registo a converter. A linguagem de conversão permite ainda
especificar um conjunto de acções, despoletadas pelo início da conversão.
O modo de funcionamento do interpretador do módulo de conversão é representado na Figura
31.
Executar regras de conversão iniciais
[Não existem mais elementos]
Passar para o próximo elemento
[Não existe regra de conversão]
[Existem mais elementos]
[Existe regra de conversão]
Executa regra de conversão
Figura 31 – Diagrama da conversão de registos de metadata
O registo a converter é enviado para o interpretador, juntamente com as regras de conversão. O
interpretador começa por executar as regras de conversão iniciais, percorrendo de seguida os
elementos do registo, executando para cada um, as regras de conversão correspondentes, caso
existam. Após ter percorrido todos os elementos, o registo encontra-se convertido para o formato
pretendido.
CONCRETIZAÇÃO DO SISTEMA
79
A linguagem de conversão é constituída por um pequeno subconjunto de comandos da
linguagem Perl e não utiliza variáveis, pelo que estas são substituídas por “localizadores” que
referenciam elementos nos registos de metadata de origem e destino.
A linguagem de conversão tem a seguinte especificação ABNF (Crocker & Overell 1997):
conversao = 1*(regra) / regra_arranque 1*(regra)
regra_arranque = “_init_” “{” instrucoes “}”
regra =localizador “{” instrucoes “}”
localizador = “/” caminho / caminho /
localizador-destino = “d:” localizador
localizador-origem = “o:” localizador
caminho = nome-elemento / nome-elemento “/” caminho
instrucoes = instrucoes “;” instrucao / instrucao
instrucao = i-if / i-atrib
i-atrib = localizador-destino atrib-op expr
i-if = “if (“ expr ”) {“ instruções “}” /
“if (“ expr ”) {“ instruções “}else {“ instruções “}”
expr =
expr op-bin expr / “not” expr / “(“expr”)” / EXPRESSAO-REGULAR /
localizador / “defined (” nome-elemento “)” / “’” 1*CHAR “’”
; EXPRESSAO-REGULAR corresponde a uma expressão regular com a
; sintaxe especificada na linguagem de programação perl
atrib-op = “=” / “.=” / “+=” / “-=”
op-bin = “eq” / “ne” / “==” / “!=” / “and” / “or” / “.” / “+” / “-” /
“*” / “/”
nome-elemento = string / “_”
string = 1*(DIGIT / ALFA / “-“)
As instruções e expressões especificadas nesta linguagem, assumem o significado semântico que
normalmente lhes é atribuído nas linguagem de programação procedimentais. Assim, para
especificar condições para a conversão de elementos utiliza-se a instrução “if” (regra i-if), e para
verificar a existência de um elemento utiliza-se a expressão “defined”. A utilização de
expressões regulares32 permite a completa manipulação do conteúdo dos elementos, tornando
assim possível a conversão de campos codificados ou com formatos distintos, possibilitando
ainda referenciar posições dentro de um elemento.
O interpretador da linguagem de conversão foi concretizado através da interpretação das regras
em Perl. Assim, antes de uma regra ser executada, os “localizadores” são substituídos pelas
estruturas de dados do interpretador que representam os registos de origem e destino. Em
32
As expressões regulares seguem a sintaxe e a funcionalidade da linguagem Perl.
80
CONCRETIZAÇÃO DO SISTEMA
seguida, a regra é interpretada. À medida que as regras vão sendo executadas o registo de destino
vai sendo construído.
A especificação das conversões do formato DiTeD para os vários formatos de inter-operação são
apresentados no “Inter-operação com outros sistemas”. Como exemplo, é apresentado na Figura
32 a visualização de um registo no formato DiTeD, e na Figura 33, a visualização do mesmo
registo convertido para UNIMARC.
Figura 32 – Registo no formato DiTeD
CONCRETIZAÇÃO DO SISTEMA
81
Figura 33 – Registo convertido para UNIMARC
5.8
INTERFACES DE UTILIZADOR
O sistema DiTeD contém três interfaces de utilizador distintas:
•
A interface de depósito, utilizada pelo autor ou por um funcionário da biblioteca, para
enviar para o sistema uma dissertação;
•
A interface de pesquisa e acesso, utilizada pelos leitores descobrirem e consultarem as
dissertações;
•
A interface de administração, utilizada pelo bibliotecário para controlar os documentos
que são depositados, no repositório por ele administrado. Esta interface permite-lhe
também consultar e extrair a metadata dos documentos armazenados
5.8.1 INTERFACE DE DEPÓSITO
A interface de depósito de documentos consiste em várias páginas HTML que recebem do
utilizador a metadata sobre o documento, seguida de uma página onde são enviados os ficheiros
e preenchida a metadata relativa a cada um deles (Figura 34, Figura 35, Figura 36, Figura 37 e
Figura 38). No final é gerada um página de confirmação do depósito. Em todas as páginas da
interface o utilizador pode escolher a língua da interface (no canto superior direito da página), e
voltar a uma página anterior sem perder os dados já introduzidos (no topo, ao centro da página).
82
CONCRETIZAÇÃO DO SISTEMA
Figura 34 – Interface de depósito (1º passo)
Na primeira página, o utilizador introduz a metadata sobre o título e o autor da dissertação. Na
interface de depósito, os elementos de preenchimento obrigatório, são indicados com a palavra
“obrigatório”, por baixo do nome do elemento.
CONCRETIZAÇÃO DO SISTEMA
83
Figura 35 – Interface de depósito (2º passo)
Na segunda página, o utilizador introduz a metadata descritiva da dissertação e as notas. No topo
da página, o utilizador têm a possibilidade de voltar atrás, para a primeira página
84
CONCRETIZAÇÃO DO SISTEMA
Figura 36 – Interface de depósito (3º passo)
Na terceira página, o utilizador introduz a metadata sobre os membros do júri.
CONCRETIZAÇÃO DO SISTEMA
85
Figura 37 – Interface de depósito (4º passo)
Na quarta página, o utilizador introduz a metadata sobre o supervisor da dissertação, e indica o
número de ficheiros que irá submeter. O número de ficheiros aqui indicado é utilizado para gerar
a página de envio dos ficheiros.
86
CONCRETIZAÇÃO DO SISTEMA
Figura 38 – Interface de depósito (5º passo, envio dos ficheiros)
Na quinta página, o utilizador introduz a metadata sobre cada um dos ficheiros, as condições de
acesso ao ficheiro, e, caso haja restrições ao acesso, qual a sua duração. Após o preenchimento
desta página, os ficheiros e a metadata são transmitidos para o sistema de administração do
repositório, finalizando-se assim o processo de depósito.
5.8.2 INTERFACE DE PESQUISA E ACESSO
A procura por documentos pode ser feita de duas formas: através de pesquisas ou através de
navegação da colecção.
CONCRETIZAÇÃO DO SISTEMA
87
Figura 39 – Interface de pesquisa
No caso da pesquisa, esta pode ser feita por campos bibliográficos (ou seja, especificamente nos
índices de pesquisa definidos) com a possibilidade de combinar pesquisas em múltiplos campos
bibliográficos (na Figura 39 em baixo). O utilizador pode também utilizar a pesquisa simples (na
Figura 39 em cima), esta consiste em pesquisar todos os campos bibliográficos da pesquisa por
campos.
Figura 40 – Interface de navegação
88
CONCRETIZAÇÃO DO SISTEMA
A interface de navegação na colecção (na Figura 40) permite ao utilizador navegar por ano ou
por nome de autor.
Figura 41 – Resultados de uma pesquisa
Após o utilizador introduzir uma pesquisa (ou uma navegação), recebe uma página com os
resultados (Figura 41), a partir da qual pode aceder aos documentos.
CONCRETIZAÇÃO DO SISTEMA
89
Figura 42 – Interface de acesso às dissertações
Na Figura 42 encontra-se a interface de acesso a um documento. Esta é a página que o URN de
uma publicação referencia. A partir daqui o utilizador pode aceder aos ficheiros que constituem o
documento, sendo apenas permitido o acesso aos ficheiros que o utilizador pode ter acesso.
5.8.3 INTERFACE DE ADMINISTRAÇÃO
A interface de administração permite ao bibliotecário controlar os documentos que são
depositados no seu repositório, e também consultar e extrair a metadata dos documentos
armazenados.
90
CONCRETIZAÇÃO DO SISTEMA
Figura 43 –Interface de aprovação de documentos
Na Figura 43 encontra-se a interface para aprovação de documentos submetidos. O bibliotecário
pode consultar a metadata e os ficheiros dos documentos. Para os documentos aceites, ele
selecciona uma partição do repositório e uma autoridade (caso o repositório esteja dividido em
várias partições e/ou existam várias autoridades) onde o documento será depositado.
Figura 44 – Interface de pesquisa para visualização dos conteúdos do repositório
A interface da Figura 44 é utilizada para seleccionar os documentos a consultar. O utilizador
pode consultar um documento específico (introduzindo o seu identificador) ou um grupo de
CONCRETIZAÇÃO DO SISTEMA
91
documentos (introduzindo um intervalo de tempo relativo à entrada de documentos no
repositório). No écran seguinte, mostrado na Figura 45, o utilizador pode observar a resultante
lista de documentos. Aqui o utilizador pode obter a metadata de todos os documentos listados em
formato UNIMARC num ficheiro ISO 2709 (através da ligação no canto superior direito da
Figura 45).
O utilizador pode também consultar a metadata de um documento em todos os formatos
suportados pelo repositório, como se mostra na Figura 46.
Figura 45 – Interface de visualização dos conteúdos e extracção de metadata
Figura 46 –Visualização da metadata dos documentos nos vários formatos suportados
Capítulo 6
INTER-OPERAÇÃO COM OUTROS
SISTEMAS
6.1
INTRODUÇÃO
Embora a inter-operação tenha sido considerado um aspecto importante em diversos esforços
desenvolvidos na área das bibliotecas digitais, (Paepcke, Chang, 1998), o seu significado e a sua
concretização não tem sido muito bem sucedida.
As questões mais relevantes neste contexto deverão ser a que nível se deve ter a inter-operação, e
o que é necessário para o conseguir. Elevando muito a fasquia da inter-operação, torna-se difícil
de chegar a um consenso sobre como tornar possível a inter-operação a esse nível. Casos como o
projecto UPS (Van de Sompel, Krichel, Nelson, 2000), ou do NSCTRL demonstram as
potencialidades da inter-operação, no entanto, também deixam clara a dificuldade em chegar a
um consenso sobre o nível de inter-operação a atingir, como se pode observar nas diferentes
opções tomadas nestes dois projectos, para níveis semelhantes de inter-operação.
Outro aspecto importante a ter em conta na definição de formas de inter-operação é a facilidade
de as pôr em prática. Ou seja, para que um mecanismo de inter-operação venha a ser adoptado
em larga escala, este deverá ser fácil de compreender e utilizar, caso contrário os custos da sua
aplicação podem impedir ou desmotivar a sua adopção.
93
94
INTER-OPERAÇÃO COM OUTROS SISTEMAS
A inter-operação é um factor essencial para a biblioteca digital de teses e dissertações, pois sem
uma abertura do sistema ao exterior as dissertações continuariam difíceis de encontrar para os
potenciais leitores espalhados por todo o mundo.
Com objectivo de permitir a melhor disseminação das dissertações, o sistema DiTeD concretiza
várias interfaces para inter-operação ao nível da pesquisa. Uma outra interface, esta para interoperação com o catálogo das bibliotecas e com o catálogo nacional PORBASE, é concretizada
para facilitar a catalogação das dissertações nas bibliotecas.
Este capítulo descreve estas interfaces para inter-operação.
6.2
INTERFACE COM O UNIMARC
O UNIMARC é o formato de metadata utilizado nas bibliotecas portuguesas para registo e
pesquisa das obras existentes.
A interface com o UNIMARC serve essencialmente para a inter-operação entre o sistema DiTeD
e o catálogo da biblioteca ou o catálogo nacional PORBASE. Esta interface permite que o
bibliotecário extraia a metadata das dissertações, armazenadas no repositório da sua biblioteca,
em formato UNIMARC. O bibliotecário extrai a metadata através da interface de administração,
efectuando, posteriormente, a importação da metadata no catálogo.
INTER-OPERAÇÃO COM OUTROS SISTEMAS
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
_init_ {
d:102.a
d:105.a
d:320.a
}
entry {
if (o:_
95
= 'PT';
= 'a
m
001yy';
= "Contém referências bibliográficas";
=~ /(\d+)-(\d+)-(\d+)/) {
d:100.a = $1 . $2 . $3;
} else{
d:100.a = ‘
‘;
}
d:100.a .= ‘d’;
if (o:approval =~ /(\d+)-\d+-\d+/) {
d:100.a .= "$1
";
}else{
d:100.a .= "
" ;
}
d:100.a .= 'k y0pory0103
ba';
}
language {
d:101.i1 = '0';
d:101.a = o:_;
d:101.d = 'eng';
d:101.d = 'por';
}
title {
d:200.i1 = '1';
d:200.a = o:_;
if ( defined(o:subtitle) ) { d:200.a .= ', ' . o:subtitle };
d:200.f = o:author;
if ( defined(o:titleeng) ) { d:200.d = o:titleeng; d:200.z=\"eng\" }
if ( defined(o:subtitleeng) ) { d:200.d .= ', ' . o:subtitleeng }
if ( defined(o:titleother) ) {
d:200.d = o:titleother;
d:200.z=o:language
}
if ( defined(o:subtitleother) ) { d:200.d .= ', ' . o:subtitleother }
}
genre {
d:328.a = o:_;
if ( defined(o:authordep) ) { d:328.a .= ', ' . o:authordep };
if ( defined(o:publisher) ) { d:328.a .= ', ' . o:publisher };
if ( o:approval =~ /(\d+)-\d+-\d+/) { d:328.a .= ', ' . "$1" };
}
author {
d:700.i2 = '1';
if ( o:_ =~ /^(.+)\s([^\s]+)$/){ d:700.a = $2; d:700.b = $1; };
}
keywords {
d:610.i1 = '0' ;
d:610.a = o:_ ;
}
abstract { d:330.a = o:_ }
adviser {
d:702.i2 = '1';
if ( o:_ =~ /^(.+)\s([^\s]+)$/){ d:702.a = $2; d:702.b = $1; };
}
docid { d:856.i1 = ‘4’; d:856.g = ‘urn:bnpt:dited:’o:_;
d:856.u = ‘http://purl.pt/urn:bnpt:dited:’.o:_; }
Figura 47 – Especificação da conversão DiTeD
UNIMARC
A metadata é convertida, para o formato UNIMARC, a partir do formato DiTeD. A conversão é
feita pelo módulo de conversão de metadata, e define-se como se mostra na Figura 47, segundo a
linguagem de conversão especificada na “secção 5.7“. Assim, a conversão consiste no seguinte:
•
Linhas 1 a 5 – estas regras são as primeiras a ser executas, pois não estão dependentes de
nenhum elemento DiTeD. São executadas 3 regras:
96
INTER-OPERAÇÃO COM OUTROS SISTEMAS
o O sub-campo “$a” do campo “102” (país de publicação) é preenchido com o valor
“PT” (o código de Portugal).
o O sub-campo “$a” do campo “105” (informação codificada sobre livros) é
preenchida com o valor “a
m
001yy”, este valor é igual em todas as
dissertações.
o O sub-campo “$a” do campo “320” (nota relativa a bibliografias) é preenchida
com a frase "Contém referências bibliográficas".
•
Linhas 6 a 19 - o sub-campo “$a” do campo “100” (dados gerais de processamento), é
um sub-campo codificado de comprimento fixo, cujas posições têm um conteúdo
designado pelo UNIMARC. As suas posições são preenchidas da seguinte forma:
o Posições 0 a 7 (data de entrada) – é preenchida pelo elemento “entry” (data de
submissão).
o Posição 8 (tipo de data de publicação) – é preenchida com o valor “d”
(monografia completa quando publicada).
o Posições 9 a 16 (data de publicação) – são preenchidas com o ano de aprovação
da dissertação (retirado do elemento “approval”), o mês e o dia são deixados em
branco.
o Posições 17 a 19 (código de audiência) – são preenchidas com o valor “k “
(adulto, sério).
o Posição 20 (código de publicação oficial) - é preenchida com o valor “y”
(publicação não oficial).
o Posição 21 (código de registo modificado) - é preenchida com o valor “0” (registo
não modificado).
o Posições 22 a 24 (língua da catalogação) - são preenchidas com o valor “por”, o
código da língua portuguesa.
o Posição 25 (código de transliteração) - é preenchida com o valor “y” (não é
utilizada transliteração).
INTER-OPERAÇÃO COM OUTROS SISTEMAS
97
o Posições 26 a 29 (conjuntos de caracteres) - são preenchidas com o valor “0103”
(conjunto latino básico, conjunto latino estendido).
o Posições 30 a 33 (conjuntos de caracteres adicionais) - são preenchidas em
branco.
o Posições 34 e 35 (alfabeto do título) - são preenchidas com o valor “ba” (alfabeto
latino).
•
Linhas 20 a 25 – estas linhas preenchem o campo “101” (língua da publicação). O
primeiro indicador é preenchido com o valor “0” (o documento está escrito na sua língua
original). O sub-campo “$a” (língua do texto) é preenchido com o valor do elemento
“language”. O sub-campo “$d” (língua do resumo) é preenchido com os códigos da
língua portuguesa e inglesa.
•
Linhas 26 a 38 – estas linhas preenchem o campo “200” (título). O primeiro indicador é
preenchido com o valor “1” (título significativo). O sub-campo “$a” (titulo próprio) é
preenchido com o valor do elemento “title” (título) seguido do elemento “subtitle”
(subtítulo) caso este exista. O sub-campo “$f” (primeira menção de responsabilidade) é
preenchido com o elemento “author” (nome do autor). As restantes regras preenchem os
sub-campos “$d” (título paralelo) e “$z” (língua do título paralelo) para o título e
subtítulo em inglês (elementos “titleeng” e “subtitleeng”)e noutra língua (elementos
“titleother” e “subtitleother”).
•
Linhas 39 a 44 – estas linhas preenchem o campo “328” (nota de tese ou dissertação). O
sub-campo “$a” (texto da nota) é preenchido com o valor do elemento “genre” (género da
publicação), seguida do elemento “authordep” (departamento do autor), do elemento
“publisher” (a biblioteca da universidade), e do ano de aprovação (retirado da data de
aprovação - elemento “approval”).
•
Linhas 45 a 48 – estas linhas preenchem o campo “700” (nome de autor – pessoa física).
O segundo indicador é preenchido com o valor “1” (entrada pelo apelido). Os subcampos “$a” (palavra de ordem) e “$b” (outra parte do nome) são preenchidos a partir do
elemento “author” (nome do autor).
•
Linhas 49 a 52 – estas linhas preenchem o campo “610” (termos de indexação não
controlados). O primeiro indicador é preenchido com o valor “0” (nível do termo não
98
INTER-OPERAÇÃO COM OUTROS SISTEMAS
especificado). O sub-campo “$a” (termo de indexação) é preenchido com o valor do
elemento “keywords” (termos de indexação).
•
Linha 53 - o sub-campo “$a” do campo “330” (sumário ou resumo), é preenchido com o
valor do elemento “abstract” (resumo da dissertação).
•
Linhas 54 a 57 – estas linhas preenchem o campo “702” (nome de autor –
responsabilidade intelectual secundária). O segundo indicador é preenchido com o valor
“1” (entrada pelo apelido). Os sub-campos “$a” (palavra de ordem) e “$b” (outra parte do
nome) são preenchidos a partir do elemento “adviser” (nome do supervisor).
•
Linhas 58 e 59 – o primeiro indicador do campo “856” (localização e acesso electrónico)
é preenchido com o valor “4” (acesso por HTTP). Nos sub-campos “$g” e “$u” são
preenchidos com o URN e o URL da dissertação (criados a partir do elemento “docid”).
6.3
INTERFACE COM A NETWORKED COMPUTER SCIENCE
TECHNICAL REPORT LIBRARY
O sistema DiTeD é inter-operável com a Networked Computer Science Technical Report Library
(NCSTRL) através do protocolo DIENST. A inter-operação é completa ao nível da pesquisa, e
parcial ao nível do modelo de documentos. O modelo de documentos do DIENST não preenche
todos os requisitos das dissertações e teses digitais (isto é, múltiplos ficheiros por documento).
Por esta razão algumas operações de acesso ao repositório do protocolo DIENST não são
suportadas pelo DiTeD, no entanto a operações básicas e essenciais para a inter-operação são
compatíveis.
A NCSTRL utiliza o formato de metadata definido no RFC 1807 (Lasher & Cohen, 1995). Este
formato bibliográfico visa descrever relatórios técnicos, como se mostra na Tabela 10. Para interoperação com a NCSTRL, os repositórios do sistema DiTeD permitem o acesso à metadata das
dissertações no formato do RFC 1807, através do protocolo DIENST.
INTER-OPERAÇÃO COM OUTROS SISTEMAS
'
99
& 0
Identificador
id
Identificador do registo.
Data de entrada
entry
Data de criação do registo.
Organização
organization
O nome da organização publicadora.
Título
title
O título do trabalho, atribuído pelo autor.
Tipo de publicação
type
Indica o tipo de publicação.
Data de revisão
revision
Ultima data de revisão do registo.
Autor
author
Nome do(s) autor(e).
Colectividade-autor
corp-author
Nome do autor-colectividade.
Contacto do autor
contact
Forma de contacto com o(s) autores.
Data de publicação
date
A data de publicação.
Direitos de autor
copyright
Informação sobre os direitos de autor.
URN
handle
O URN da publicação.
Palavras-chave
keyword
Palavras-chave livres ou retiradas de um vocabulário controlado.
Cobertura temporal
period
O período de tempo coberto pela publicação.
Informação de série
series
Informação sobre a série. (volume, número, etc.).
Organização monitora
monitoring
O nome das organizações monitoras.
Organização financiadora
funding
O nome das organizações financiadoras.
Número do contrato
contract
O número do contrato.
Língua
language
Língua em que a publicação está escrita.
Notas
notes
Notas adicionais.
Resumo
abstract
Resumo do conteúdo da publicação.
Tabela 10 – O formato de metadata definido no RFC 1807
A metadata é convertida a partir do formato DiTeD, pelo módulo de conversão de metadata. A
conversão do formato DiTeD para o formato do RFC 1807, segundo a linguagem de conversão
especificada na “secção 5.7“, define-se como se mostra na Figura 48. Esta conversão consiste
num mapeamento simples de alguns elementos do formato DiTeD para os elementos com o
mesmo significado semântico no formato do RFC 1807. O mapeamento é o seguinte:
•
Linha 1 – o elemento “id” (identificador do registo) é preenchido com o elemento
“docid” (identificador da dissertação).
•
Linha 3 - o elemento “entry” (data de criação do registo) é preenchido com o elemento
“entry” (data de submissão).
•
Linha 5 - o elemento “organization” (organização publicadora) é preenchido com o
elemento “publisher” (nome da biblioteca universitária).
•
Linhas 7 a 11 - o elemento “title” (título do trabalho) é preenchido com o elemento
“titleeng” (título em inglês) seguido do elemento “subtitleeng” (subtítulo em inglês) caso
exista o elemento.
100
INTER-OPERAÇÃO COM OUTROS SISTEMAS
•
Linha 13 - o elemento “author” (nome do autor) é preenchido com o elemento “author”
(nome do autor).
•
Linha 15 - o elemento “contact” é preenchido com o elemento “authoremail”.
•
Linha 17 - o elemento “date” (data de publicação) é preenchido com o elemento
“approval” (data de aprovação).
•
Linha 19 - o elemento “copyright” é preenchido com o elemento “copyright”.
•
Linha 21 - o elemento “language” (língua da publicação) é preenchido com o elemento
“language” (língua da manifestação).
•
Linha 23 - o elemento “abstract” (resumo) é preenchido com o elemento “abstracteng”
(resumo em inglês).
•
Linha 25 - o elemento “notes” (notas) é preenchido com o elemento “notes” (notas).
•
Linha 27 - o elemento “keywords” (palavras-chave) é preenchido com o elemento
“keywordseng” (palavras-chave em inglês).
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
docid { d:id = o:_ }
entry { d:entry = o:_ }
publisher { d:organization = o:_ }
titleeng {
d:title = o:_ ;
if ( defined(o:subtitleeng) ) {
d:title .= ', ' . o:subtitleeng
}}
author { d:author = o:_ }
authoremail { d:contact = o:_ }
approval { d:date = o:_ }
copyright { d:copyright = o:_ }
language { d:language = o:_ }
abstracteng { d:abstract = o:_ }
notes { d:notes = o:_ }
keywordseng { d:keyword = o:_ }
Figura 48 – Especificação da conversão DiTeD
RFC 1807
INTER-OPERAÇÃO COM OUTROS SISTEMAS
6.4
101
INTERFACE COM A OPEN ARCHIVES INITIATIVE
O objectivo do protocolo OAI (protocolo Open Archives Initiative) é oferecer e promover uma
estrutura para inter-operação independente das aplicações ou plataformas usadas; e que pode ser
usada por uma variedade de comunidades que publicam conteúdos na Internet. O protocolo OAI
baseia-se no conceito de “recolha de metadata” (metadata harvesting), uma aproximação
demonstrada com sucesso pelo projecto Harvest alguns anos atrás (Bowman, 1995). O resultado
é uma estrutura com duas classes de participantes:
•
Fornecedores de Dados que suportam o protocolo OAI como um meio de expor a
metadata sobre os seus conteúdos.
•
Fornecedores de Serviços que enviam pedidos do protocolo OAI para os fornecedores
de dados e utilizam a sua metadata como a base para construir serviços de valor
acrescentado.
O protocolo assenta em cinco conceitos básicos:
•
Repositório – um servidor acessível por rede, para o qual podem ser enviados pedidos do
protocolo OAI, embebidos em HTTP.
•
Registo – uma sequência de bytes codificada em XML que é retornada por um
repositório em resposta a um pedido de metadata do protocolo OAI para um item nesse
repositório.
•
Identificador único – uma chave para extrair metadata de um item num repositório.
•
Selo de data – A data de criação, remoção ou última data de modificação de um item,
cujo efeito é uma mudança na metadata de um registo disseminado desse item.
•
Conjunto – Uma forma opcional de agrupar itens num repositório, com o objectivo de
efectuar a recolha selectiva de registos.
O protocolo define seis tipos de pedidos (Tabela 11) que permitem aos fornecedores de serviços
obter informação sobre um repositório e recolher os registos de metadata sobre os seus
conteúdos.
102
INTER-OPERAÇÃO COM OUTROS SISTEMAS
# 1
!
#
GetRecord
Obtém um registo de metadata de um
item num repositório.
Identify
Obtém informação sobre o repositório,
incluindo informação administrativa,
identidade e informação específica da sua
comunidade.
Obtém os identificadores dos registos que
podem ser recolhidos do repositório.
Obtém os formatos de metadata
disponíveis no repositório, ou para um
item específico.
Recolhe registos de metadata do
repositório.
Obtém a estrutura dos conjuntos do
repositório
ListIdentifiers
ListMetadataFormats
ListRecords
ListSets
# 1
Identificador do item
Formato de metadata
Filtro de data
Filtro de conjunto
Identificador do item
Filtro de data
Filtro de conjunto
Tabela 11 – Pedidos do protocolo Open Archives Initiative
O protocolo OAI oferece os meios para a inter-operação de uma forma simples e fácil de
concretizar. Desta forma os fornecedores de dados podem facilmente expor os seus conteúdos
através da concretização do protocolo33 OAI no seus sistemas. A simplicidade do protocolo OAI
baixa significativamente os custos da adopção do protocolo, o que se espera que leve a uma
maior aceitação do protocolo, o que por sua vez permitirá que em cima destes, venham a ser
criados serviços que acrescentem valor aos fornecedores de dados.
O protocolo OAI consiste num subconjunto do protocolo DIENST, utilizando um formato de
metadata próprio, o OAMS (Open Archives Metadata Set) codificado em XML. Este formato é o
requisito mínimo para inter-operação, sendo permitida e encorajada a utilização de outros
formatos.
Os repositórios do sistema DiTeD concretizam o protocolo OAI, sendo os registos OAMS
gerados pelo módulo de conversão de metadata, sempre que são requisitados através do
protocolo OAI.
O OAMS é um formato muito simples com apenas nove elementos (Tabela 12). Estes elementos
contêm apenas a informação mais relevante para a inter-operação na pesquisa.
33
A OAI disponibiliza de forma livre concretizações do protocolo para os fornecedores de dados. Estes têm apenas que adaptar estas
concretizações ao seu sistema.
INTER-OPERAÇÃO COM OUTROS SISTEMAS
&
103
'
Title
Date of Accession
Título
Data de entrada
Display ID
Identificador
Full ID
Identificador
completo
Author
Autor
Abstract
Subject
Resumo
Assunto
Comment
Comentário
Date for Discovery
Data
O título dado ao registo
A data de quando o registo foi inserido no
arquivo.
Um URL identificando uma página que oferece
o acesso às possíveis manifestações do registo.
O identificador completo do registo. Este
identificador é composto pelo identificador do
arquivo, seguido do identificador do registo
dentro do arquivo.
O autor responsável pela criação do conteúdo
intelectual do registo. O autor pode também ter
associada uma instituição.
Resumo do conteúdo do registo.
O tópico do conteúdo do registo expresso por
palavras-chave.
Texto contendo informação adicional relevante
para a pesquisa do registo.
Um data normalmente associada ao registo.
Tabela 12 – Open Arquives Metadata Set
A metadata é convertida a partir do formato DiTeD, pelo módulo de conversão de metadata. A
conversão do formato DiTeD para o formato do OAMS, segundo a linguagem de conversão
especificada na “secção 5.7“, define-se como se mostra na Figura 49. Assim, a conversão
consiste no seguinte:
•
Linhas 1 a 5 - o elemento “title” (título do trabalho) é preenchido com o elemento
“titleeng” (título em inglês) seguido do elemento “subtitleeng” (subtítulo em inglês) caso
este exista.
•
Linhas 6 e 7 – o elemento “accession.date” (data de entrada) é preenchido com o
elemento “entry” (data de submissão).
•
Linhas 8 a 12 – o elemento “discovery.date” (data associada ao registo) é preenchido com
o elemento “approval” (data de aprovação), caso o elemento “approval” não exista ele é
preenchido com o elemento “entry” (data de submissão).
•
Linha 14 - o elemento “displayID” (identificador) é preenchido com o elemento “docid”
(identificador da dissertação).
•
Linha 15 - o elemento “fullID” (identificador) é preenchido com o elemento “docid”
(identificador da dissertação) precedido do identificador do arquivo (“DiTeD”) e um
separador (“#”).
•
Linha 18 - o elemento “author.name” (nome do autor) é preenchido com o elemento
“author” (nome do autor).
104
INTER-OPERAÇÃO COM OUTROS SISTEMAS
•
Linha 19 - o elemento “author.instituição” (instituição do autor) é preenchido com o
elemento “authororg” (instituição do autor).
•
Linha 21 - o elemento “abstract” (resumo) é preenchido com o elemento “abstracteng”
(resumo em inglês).
•
Linha 22 - o elemento “subject” (assunto) é preenchido com o elemento “keywordseng”
(palavras-chave em inglês).
•
Linhas 23 a 30 - o elemento “comment” é preenchido com um comentário em inglês
indicando a língua em que o documento está escrito, obtida do elemento “language”
(língua).
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
titleeng {
d:title = o:_;
if ( defined(o:subtitleeng) ) {
d:title .= ', ' . o:subtitleeng ;
}}
entry {
d:accession.date = o:_;
if (defined(o:approval)) {
d:discovery.date = o:approval;
}else {
d:discovery.date = o:_;
}}
docid {
d:displayid = o:_;
d:fullid = 'DiTeD#' . o:_;
}
author
d:author.name = o:_;
d:author.institution = o:_.authororg;
}
abstracteng { d:abstract = o:_ }
keywordseng { d:subject = o:_ }
language {
if (o:_ eq 'por') { d:comment = 'Document
if (o:_ eq 'eng') { d:comment = 'Document
if (o:_ eq 'ger') { d:comment = 'Document
if (o:_ eq 'fre') { d:comment = 'Document
if (o:_ eq 'spa') { d:comment = 'Document
if (o:_ eq 'ita') { d:comment = 'Document
}
Figura 49 – Especificação da conversão DiTeD
6.5
written
written
written
written
written
written
in
in
in
in
in
in
Portuguese' };
English' };
German' };
French' };
Spanish' };
Italian' };
OAMS
INTERFACE COM O PROTOCOLO Z39.50
O Z39.50 (Lynch, 1997) é um protocolo que especifica estruturas de dados e regras de
comunicação que permitem a uma máquina cliente (chamada “origem” na norma) pesquisar
INTER-OPERAÇÃO COM OUTROS SISTEMAS
105
bases de dados numa máquina servidora (chamada “alvo” na norma) e obter registos que são
identificados como um resultado de uma pesquisa.
O nome “Z39.50” vem do facto de ter sido desenvolvido pela NISO (National Information
Standards Organization), organização de desenvolvimento de normas que servem as bibliotecas,
as editoras e os serviços de informação. As normas NISO são numerados sequencialmente e o
Z39.50 é a 50º norma desenvolvida pela NISO. A versão actual do Z39.50 foi adoptada em 1995,
substituindo as versões anteriores adoptadas em 1992 e 1988. É por vezes referido como o
Z39.50 Versão 3 (NISO/ANSI, 1995).
É um protocolo com ligação que mantém estado e define interacções entre duas máquinas.
A arquitectura básica do Z39.50 é a seguinte: Um servidor hospeda uma ou mais bases de dados
contendo registos. Associado com cada base de dados estão um conjunto de pontos de acesso
(índices) que podem ser utilizados para pesquisa. Esta é uma visão mais abstracta de uma base de
dados, que esconde os detalhes do SQL, por exemplo. É apenas necessário tratar com as
entidades lógicas baseadas no tipo de informação que está guardada na base de dados, não o
detalhes da concretização da base de dados.
Uma das funções básicas do Z39.50 permite ao cliente transmitir uma pesquisa para o servidor
(search request). A pesquisa produz um conjunto de registos, chamado um “conjunto de
resultados” (result set), que é mantido no servidor; o resultado de uma pesquisa é um relatório do
número de registos no conjunto de resultados. Os conjuntos de resultados podem ser combinados
ou restringidos por pesquisas subsequentes. Note-se que esta característica é substancialmente
diferente dos servidores SQL, que não utilizam conjuntos de resultados.
Registos do conjunto de resultados podem ser subsequentemente obtidos através de um pedido
de apresentação (present). O pedido de apresentação oferece opções elaboradas para controlar o
conteúdo e o formato dos registos que são retornados. O pedido de apresentação especifica quais
os registos do conjunto de resultados a enviar.
O Z39.50 também contém funções para a gestão de pesquisas. Por exemplo, um servidor pode
dar informação sobre o progresso de uma pesquisa em execução; um cliente pode abortar uma
pesquisa em execução.
O Z39.50 contêm funcionalidades para gerir conjuntos de resultados, para ordenar conjuntos de
resultados, para navegar os valores dos pontos de acesso associados com uma base de dados,
para abrir e fechar ligações, e também um mecanismo geral chamado “serviços estendidos”
106
INTER-OPERAÇÃO COM OUTROS SISTEMAS
(extended services), que são essencialmente uma chamada de procedimento remota assíncrona
que o cliente pode utilizar para invocar serviços no servidor.
O protocolo também define o seguinte:
•
Uma linguagem para especificar pesquisas, que por seu lado utiliza definições registadas
para conjuntos de atributos (attribute sets) que especificam os nomes dos pontos de
acesso.
•
Várias sintaxes que podem ser usadas para transferir registos do servidor para cliente,
incluindo tanto sintaxes específicas de alguns domínios (como por exemplo o MARC
para dados bibliográficos), como uma complexa sintaxe de utilização geral chamada
Generalized Record Syntax One (GRS-1).
•
Uma linguagem para descrever como construir registos para serem transferidos do
conjunto de resultados para o cliente.
•
Uma funcionalidade de explicação (explain) que permite aos clientes obter uma grande
variedade de informação de um servidor, sobre as bases de dados disponíveis, e quais os
pontos de acesso suportados em cada base de dados, entre outros. Esta funcionalidade
visa permitir o desenvolvimento de clientes que se auto-configuram quando se ligam a
variados servidores.
O Z39.50 utiliza um registo para vários tipos de objectos, como conjuntos de atributos utilizados
em comandos de pesquisa (queries) e sintaxes de registos usadas nos pedidos de apresentação.
Estes são referidos através de identificadores de objecto que são utilizados como parâmetros nos
vários pedidos e respostas do protocolo. Alguns identificadores de objecto são designados pela
norma. A designação de identificadores é feita pela Z39.50 Maitnance Agency34.
Em qualquer norma existem opções de concretização, e o significado de algumas especificações
pode admitir várias interpretações. As concretizações do Z39.50 seguiram diferentes
interpretações da norma. Como resultado os utilizadores sentem dificuldades em pesquisar
múltiplas bases de dados onde diferentes interpretações de várias funcionalidades do Z39.50
foram concretizadas.
34
<http://lcweb.loc.gov/z3950/agency/>
INTER-OPERAÇÃO COM OUTROS SISTEMAS
107
Os utilizadores de produtos Z39.50 identificaram vários problemas que levam à sua insatisfação.
Alguns dos problemas encontrados são (Lunau, 2000):
1. Um utilizador não sabe quais os atributos ou combinações de atributos que foi
concretizada e consequentemente, não sabe como construir os termos de pesquisa.
2. As bases de dados concretizam índices diferentes originando pesquisas em índices
desapropriados, como por exemplo, no índice “nome” em vez do índice “autor”.
3. Geração de conjuntos de resultados muito grandes, causados pela não aceitação por parte
do servidor de uma pesquisa precisa, tratando todas as pesquisas como pesquisas por
palavras-chave.
Estes problemas também se põem no lado de quem concretiza o sistema. A grande complexidade
da norma torna-o difícil de pôr em prática da forma ideal, comprometendo a correcta interoperação.
A colecção de dissertações do servidor central encontra-se acessível através do protocolo
Z39.50. Para este efeito foi utilizado o sistema Zebra da Indexdata35, uma concretização do
protocolo Z39-50, gratuita para fins não comerciais (Indexdata, 1999). O sistema Zebra inclui
uma sistema de base de dados, com suporte para a importação de registos MARC, o que permite
a actualização desta base de dados através da interface com o UNIMARC do sistema DiTeD.
6.6
INTER-OPERAÇÃO NA NETWORKED DIGITAL LIBRARY OF
THESES AND DISSERTATIONS
Um objectivo perseguido na iniciativa NDLTD tem sido o de conseguir uma forma de pesquisa
federada entre as colecções dos seus membros, utilizando como base um formato de metadata
comum. Esta secção contém os resultados dos estudos de algumas estruturas de metadata
utilizadas em diversos países, e das discussões que têm sido levadas a cabo dentro da iniciativa
NDLTD. Esta secção conclui-se com uma proposta para um núcleo de elementos de metadata
para teses e dissertações para inter-operação ao nível da pesquisa.
35
<http://www.indexdata.org>
108
INTER-OPERAÇÃO COM OUTROS SISTEMAS
Os formatos de metadata utilizados nas iniciativas locais espelham muitas vezes as necessidades
da sua organização, dos seus processos de trabalho, e do seu sistema informático. Isto leva a que
a definição de um formato de metadata normalizado com o objectivo de ser usado como formato
principal em cada um dos sistemas informáticos locais seja um pouco irrealista, pois ele não
conseguirá satisfazer as necessidades específicas de cada um.
O formato deverá então ser visto como um formato para inter-operação. Este deverá consistir
num núcleo de elementos de utilização generalizada e com conteúdos algo flexíveis, de modo a
possibilitar a sua utilização mesmo nas interpretações mais exigentes, seguindo assim, a filosofia
do Dublin Core. O formato deverá ser o mais específico possível tendo sempre em conta o
requisito anterior.
Para melhor entender os requisitos de um tal formato, foi feita uma comparação entre a metadata
utilizada por quatro membros da NDLTD (Tabela 13). Esta comparação permite identificar a
informação contida nos registos de metadata sobre teses e dissertações das várias iniciativas
(Freire, 2000).
&
#
!
+ !
(&
2
*
Titulo
Sub titulo
Titulo traduzido para Inglês
Subtitulo traduzido para Inglês
Notas sobre o título
Obrigatório
Opcional
Obrigatório
Opcional
Obrigatório
Nome do autor
Morada do autor
Email do autor
Número de telefone do autor
Instituição do autor
Departamento do autor
Curso do autor
Data de Nacimento do autor
Local de Nascimento do autor
Obrigatório
Obrigatório
Opcional
Opcional
Obrigatório
Obrigatório
Obrigatório
Opcional
Obrigatório
Opcional
Opcional
Área do documento
Palavras-chave
Palavras-chave controladas
Palavras-chave traduzidas para Inglês
N/A
N/A
Opcional
.
(
2*
3
3
*
Obrigatório
Opcional
Obrigatório
Opcional
Obrigatório
Opcional
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Recomendado
Recomendado
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Opcional
Obrigatório
Opcional
Opcional
N/A
Recomendado
Recomendado
Recomendado
Recomendado
Resumo do documento
Resumo do documento traduzido para
Inglês
Notas do autor
Obrigatório
Obrigatório
Recomendado
N/A
Recomendado
Opcional
Opcional
Opcional
Nome do orientador
Título do orientador
Afiliação do orientador
Email do orientador
Morada do orientador
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Opcional
Opcional
"
4
(
Obrigatório
Obrigatório
Obrigatório
INTER-OPERAÇÃO COM OUTROS SISTEMAS
&
109
#
!
Nome do membro do Juri
Titulo do membro do Juri
Afiliação do membro do Juri
Email do membro do Juri
Morada do membro do Juri
Nome do presidente do Juri
Titulo do presidente do Juri
Afiliação do presidente do Juri
Email do presidente do Juri
Morada do presidente do Juri
+ !
(&
2
*
Recomendado
Opcional
Recomendado
Opcional
.
(
2*
"
4
(
3
3
*
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Editora
Email da editora
Morada da editora
Obrigatório
Opcional
Opcional
Recomendado
Opcional
Opcional
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Data em que é válida
Data da defesa
Data de criação
Data de submissão para avaliação
Data de submissão para o sistema
informático
Obrigatório
Obrigatório
Opcional
Obrigatório
Obrigatório
Tipo de Tese ou Dissertação
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Identificador URI
Identificador local
Obrigatório
Obrigatório
Opcional
Obrigatório
Obrigatório
Língua
Obrigatório
Opcional
Obrigatório
Obrigatório
Fonte
Opcional
Opcional
Obrigatório
Cobertura geográfica
Cobertura temporal
Opcional
Opcional
Opcional
Opcional
Obrigatório
Obrigatório
Obrigatório
Declaração de direitos de autor
Condições de acesso
Data de revisão das condições de acesso
Obrigatório
Obrigatório
Opcional
Opcional
Obrigatório
Opcional
Obrigatório
Obrigatório
Obrigatório
Formato dos ficheiros
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Obrigatório
Opcional
Partes da publicação
Tabela 13 – Comparação entre a metadata utilizada por quatro membros da NDLTD
Como resultado é aqui proposto um núcleo de elementos considerados relevantes para a pesquisa
de teses e dissertações. Este núcleo de elementos encontra-se descrito na Tabela 14; esta contêm
o nome do elemento na primeira coluna, e uma descrição do seu conteúdo na coluna seguinte. As
restantes colunas indicam a(s) razão(ões) pela qual o elemento é considerado relevante para o
processo de pesquisa de teses e dissertações. Os três pontos de avaliação são:
•
Pesquisa – indica se existe um potencial interesse, por parte dos utilizadores, em efectuar
pesquisas neste elemento.
110
INTER-OPERAÇÃO COM OUTROS SISTEMAS
•
Avaliação – indica se o elemento é potencialmente importante para um utilizador que
tenta avaliar a relevância de uma publicação apenas através da metadata.
•
Acesso – indica a importância do elemento para um utilizador conseguir o acesso à
publicação.
Considera-se que os elementos referidos na Tabela 13 e que não estejam incluídos na Tabela 14,
não têm um peso significativo nos três pontos referidos acima.
&
# 0
Titulo*
O título e o subtitulo do documento.
Nome do autor
O nome do autor
Organização
A organização(ões) e respectivo departamento(s).
Deve incluir a universidade e outras organizações
que estejam ligadas ao trabalho levado a cabo
pelo autor
Contactos do autor
Contactos do autor (email, morada, telefone)
Grau académico
O grau académico associado ao documento
Área científica
Curso ou área científica do documento
Nome da editora
Editora responsável pela publicação da tese. A
biblioteca da universidade pode ser considerada a
editora
Contactos da editora
Contactos da editora (email, morada, telefone)
Palavras-chave*
Lista de palavras ou frases chave que descrevem
o conteúdo do documento
Palavras-chave controladas
Lista de códigos de sistemas de classificação,
e/ou de palavras ou frases chave obtidas através
dos mesmos
Resumo*
Texto que resume o conteúdo do documento
Índice
Índice do documento
Orientador
Nome do Orientador
Data
A data que é geralmente associada ao documento.
Pode conter a data de defesa, de aprovação, ou de
criação. Deve ser utilizada a data que geralmente
aparece associada ao documento.
Identificador (URI)
O URI que aponta directamente para o
documento ou para o ponto de entrada para o
mesmo
Língua
Língua em que está escrito o documento
Declaração de direitos de
autor
Declaração geral de direitos de autor do
documento
Condições de acesso
Descrição das condições de acesso ao documento
(por exemplo, acesso livre, accesso restrito à
universidade, etc.)
Formatos de ficheiros
Formatos dos ficheiros que constituem o
documento
"
* - Para os documentos que não estão escritos em inglês, também deve ser fornecida uma tradução deste elemento em inglês.
Tabela 14 – Núcleo de elementos para interoperabilidade no NDLTD
INTER-OPERAÇÃO COM OUTROS SISTEMAS
111
Para este núcleo ser posto em prática é ainda necessário definir o seu formato de codificação
(talvez baseado em Dublin Core, com uma sintaxe XML/RDF), e um mecanismo para tornar a
inter-operação possível (muito provavelmente, através do protocolo Open Archives). As maiores
dificuldades sentidas neste tema não se focam nas questões técnicas, mas sim em como conciliar
as necessidades e os conceitos de diferentes culturas, neste tema em que cada instituição tem as
suas regras, as quais são tradicionalmente postas em prática de uma forma bastante rígida.
A continuação da investigação neste tema é aqui deixada como trabalho futuro.
Capítulo 7
CONCLUSÕES E TRABALHO FUTURO
7.1
INTRODUÇÃO
Neste capítulo são apresentadas algumas conclusões finais, temas em aberto e trabalho futuro.
7.2
FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
As teses e dissertações têm características próprias que as distinguem das outras publicações
digitais. O tipo destas publicações é bem definido: as teses e dissertações têm estruturas
tradicionais, normalmente definidas pelos conselhos científicos das universidades, e destinam-se,
principalmente, a serem impressas. Deste modo o formato destas publicações consiste
essencialmente em texto e imagens fixas, correspondendo ao formato tradicional das
dissertações, mas no caso das versões digitais poderão ser aceites conteúdos multimédia. Os
formatos orientados à estrutura (descritos na “subsecção 2.5.3 - Formatos orientados para a
estrutura”), aplicam-se muito bem às dissertações, uma vez que o conteúdo destas é, geralmente,
muito estruturado.
Neste capítulo é descrito um trabalho exploratório levado a cabo pelo autor para criar um
formato orientado à estrutura para teses e dissertações, com o intuito de facilitar e melhorar, a
113
114
CONCLUSÕES E TRABALHO FUTURO
manipulação das dissertações nos repositórios das biblioteca digitais. Este formato é definido
através da Extensible Markup Language (XML), tendo também associada uma folha de estilo36,
responsável pela apresentação do formato. Uma folha de estilo contém instruções que indicam a
um processador (um Web browser por exemplo) como traduzir a estrutura lógica de um
documento fonte, numa estrutura para apresentação. Tipicamente, as folhas de estilo contêm
instruções como as seguintes: “mostrar as ligações hipertexto a azul”; “começar os capítulos no
lado esquerdo de uma nova página”; “numerar as figuras sequencialmente”.
Este formato é constituído por duas componentes: uma Definição de Tipo de Documento (DTD)
em XML; e pela folha de estilo que permite visualizar os documentos escritos segundo o formato
definido pela DTD.
7.2.1 ESTRUTURA DO FORMATO
A DTD desenvolvida especifica o formato das teses e dissertações digitais. A estrutura definida
na DTD divide-se em três partes principais, a frente, o corpo e as costas. Uma visão geral da
DTD encontra-se na Figura 50.
FRENTE
CORPO
COSTAS
Universidade
Capítulo
Referências
Figura de capa
Capítulo
Apêndices
Título
Capítulo
Currículo
Autor
Grau Académico
Blocos
Data
Resumo
Parágrafos
Resumo em Inglês
Palavras Chave
Notas de rodapé
Palavras Chave em Inglês
Agradecimentos
Objectos multimédia
Figura 50 – Estrutura da DTD
36
O termo “folha de estilo” refere-se ao termo “stylesheet” utilizado na língua inglesa.
CONCLUSÕES E TRABALHO FUTURO
115
Na “frente” encontra-se informação sobre a tese ou dissertação (título, autor, universidade,
resumo, etc.). O “corpo” é a parte principal da publicação, onde se encontra a maior parte do seu
conteúdo. O corpo está dividido em capítulos, secções, subsecções, blocos e sub-blocos. O
conteúdo destes elementos pode ser texto, tabelas, objectos multimédia, etc. Os elementos
principais do corpo são:
•
Capítulos
•
Blocos
•
Parágrafos
•
Listas (ordenadas, desordenadas, descritivas)
•
Notas de rodapé
•
Ligações
•
Objectos multimédia
•
Tabelas
Finalmente vêm as costas, onde se inclui a bibliografia, os apêndices e o currículo do autor. A
bibliografia é constituída principalmente por citações. Os apêndices têm uma estrutura idêntica à
dos capítulos. O currículo do autor é constituído principalmente por parágrafos.
A maioria dos elementos da estrutura definida incluem texto. O texto pode incluir os seguintes
elementos:
•
Ênfase
•
Texto carregado
•
Texto dactilografado
•
Citação
•
Texto em língua estrangeira
•
Ligação hipertexto
•
Sobrescrita
•
Subscrita
•
Títulos de trabalhos ou de artigos
116
CONCLUSÕES E TRABALHO FUTURO
7.2.2 APRESENTAÇÃO DO FORMATO
A apresentação do formato é efectuada através de uma folha de estilo, definida na Extensible
Style Language (XSL), a linguagem de estilo para o XML. Com o XML um documento pode ser
escrito utilizando um conjunto de etiquetas (tags) próprio – estes elementos têm o seu
significado no contexto do assunto do documento e permite um melhor controlo sobre a
apresentação. No entanto, existem custos associados, pois os elementos XML não têm uma
semântica predefinida. Por exemplo, a etiqueta <IMG> pode ser uma imagem ou um número
imaginário, dependendo do assunto do documento. O papel da XSL é exprimir as folhas de estilo
que descrevem as regras de apresentação das etiquetas XML.
O processo de apresentação está dividido em duas partes (Figura 51). Primeiro é construída uma
árvore de resultados a partir da árvore fonte (o próprio documento). Depois, a árvore de
resultados é interpretada para produzir o output no écran, ou em papel, ou em fala, ou em
qualquer outro tipo de média.
MOTOR XSL
1ª
XML
2ª FASE
FASE
Construção da
árvore de
resultados
Frente
Formatação
INDICE
T ÍTULO
Capítulo 1……….….........…x
Capítulo 2………..........……x
2.1 Secção …..................x
Bibliografia ……….…..........x
CAPÍTULO 1
Título
ÁRVORE DE
RESULTADOS
Corpo
Capítulo
Capítulo
Secção
CAPÍTULO 2
2.1 Secção
BIBLIOGRAFIA
Título
Índice
Capítulo
Capítulo
Costas
Secção
Bibliografia
Bibliografia
Figura 51 – Funcionamento da XSL
A construção da árvore de resultados é efectuada associando moldes a padrões do documento
fonte. Os moldes são aplicados no documento fonte para criar a árvore de resultados. A estrutura
da árvore de resultados pode ser completamente diferente da estrutura da árvore fonte. Durante a
CONCLUSÕES E TRABALHO FUTURO
117
construção da árvore de resultados, a árvore fonte pode ser filtrada e reordenada, e pode ser
acrescentada uma estrutura arbitrária. A segunda fase da actuação da XSL, a formatação, é
efectuada utilizando o vocabulário de formatação especificado pela XSL. A XSL não exige a
utilização deste vocabulário, e pode ser utilizado para transformações gerais do XML. Por
exemplo, a XSL pode ser utilizada para transformar XML em HTML, ou seja, XML que utiliza
os elementos e atributos definidos pelo HTML.
A folha de estilo definida para o formato de teses e dissertações, utiliza a XSL para apresentar os
documentos em HTML, ou seja, em vez de ser utilizado o vocabulário de formatação da XSL foi
utilizado o HTML. Esta escolha deve-se ao facto dos browsers da Internet não suportarem a
versão 1.0 da XSL, aquando da realização deste trabalho, e também ao facto de existirem
servidores de WWW37 que suportam a utilização da XSL para enviar, pela Internet, documentos
XML transformados em HTML.
Para apresentar um documento ao leitor, os vários componentes do formato interagem entre si
como se mostra na Figura 52. Um documento é processado por um motor de XML e XSL,
juntamente com a DTD e a folha de estilo. O resultado do processamento é um documento
HTML.
DTD
Folha de
estilo
HTML
Documento
XML
Motor XML
+
Motor XSL
Figura 52 – Apresentação de um documento XML
Uma definição formal e completa do formato, com um exemplo, encontra-se no “Apêndice A Definição XML do formato para dissertações e teses digitais”. Aí se apresentam sucessivamente:
37
•
Definição de Tipo de documento dos elementos e seus atributos.
•
Definição da folha de estilo
•
Exemplo de um ficheiro com uma dissertação fictícia de demonstração.
A saber, o servidor Apache. <http://www.apache.org>
118
CONCLUSÕES E TRABALHO FUTURO
•
Sequência de imagens de visualização da dissertação usada no exemplo, apresentada
segundo a folha de estilo anterior.
7.2.3 SÍNTESE E APLICABILIDADE DO FORMATO
Este formato traz novas possibilidades para a manipulação das teses e dissertações digitais. Em
primeiro lugar a utilização deste formato garante a preservação a longo prazo destas publicações,
pois o formato não está dependente de nenhum dispositivo ou aplicação para ser visualizado.
Mesmo que deixem de existir as aplicações que visualizam o formato, a informação para sua
apresentação pode ser extraída a partir da estrutura do documento. No entanto, os conteúdos
multimédia incluídos nos documentos continuam sujeitos ao problema da preservação, pelo que,
se sugere que os autores os incluam num formato popular, de uso generalizado, pois dessa forma
as possibilidades de que esse formato deixe de ser suportado são mais baixas. Finalmente, este
formato permite especificar mais detalhadamente as condições de acesso que os autores desejam
para a sua dissertação. O autor poderá especificar quais os elementos (capítulos, parágrafos,
tabelas, figuras, etc.) a que pretende restringir o acesso. O mesmo se aplica à recuperação de
informação, pois este formato possibilita a pesquisa em títulos, cabeçalhos, etc.
No entanto, existem sérias dificuldades em levar à prática um formato deste tipo. Não existem
ferramentas para os autores criarem os seus documentos neste formato, nem os processadores de
texto actuais suportam o XML, ao nível exigido para a sua utilização eficaz com este formato.
Algumas experiências têm sido feitas em várias universidades europeias e americanas, no sentido
de criar «formatos guias» (templates) para os processadores de texto, baseados numa DTD.
Obtendo-se o formato estruturado a partir de uma conversão do formato do processador de texto.
No entanto, mesmo com a utilização de «formatos guias», não é possível controlar totalmente as
acções dos autores, pelo que mesmo assim a conversão necessita de ser guiada por uma pessoa, o
que torna o processo de conversão muito dispendioso. Nas áreas científicas em que a
apresentação da dissertação é essencial, a imposição de um formato estruturado poderá também
não ser bem aceite, pois em áreas como a arquitectura, os autores exigem o controlo total sobre a
apresentação do documento.
Finalizando, uma outra questão em aberto, é como se poderá incluir neste formato conteúdos
como fórmulas matemáticas ou químicas (ou outras), sem perder a estrutura da fórmula. A
representação destas fórmulas em XML já tem sido estudada, existindo propostas concretas em
CONCLUSÕES E TRABALHO FUTURO
119
MathML38 e QML39. No entanto a sua integração num formato estruturado para dissertações,
continua em aberto.
Em resumo, um formato estruturado para teses e dissertações está ainda longe de poder ser posto
em prática, apesar das suas grandes vantagens em termos de preservação e na recuperação de
informação, a sua utilização na prática é difícil devido, principalmente, à falta de ferramentas
para a sua criação.
7.3
INFRA-ESTRUTURAS EMERGENTES PARA INTER-OPERAÇÃO
Embora tenham sido abordados, neste trabalho, vários mecanismos de inter-operação, um
aspecto essencial que ainda não foi referido é a necessidade de metadata normalizada na Internet
como factor essencial para a inter-operação. São aqui descritas duas peças fundamentais: a
iniciativa Dublin Core e a Resource Description Framework (RDF). Estes deverão ter um papel
muito importante na continuação do trabalho aqui descrito, para atingir um bom nível de interoperação dentro da Networked Digital Library of Theses and Dissertations (NDLTD).
7.3.1 INICIATIVA DUBLIN CORE
A necessidade por metadata descritiva normalizada tem sido explorada pelo Dublin Core. Este
consiste num simples, mas eficiente conjunto de elementos para descrever vários tipos de
recursos digitais. O Dublin Core é constituído por quinze elementos, cuja semântica tem sido
definida por um grupo de profissionais de vários campos e de vários países vindos das
bibliotecas, da ciência da computação, da codificação de texto, dos museus, e outros campos
relacionados.
Pretende-se do Dublin Core as seguintes características (Hillmann, 2000):
•
Simplicidade de criação e manutenção – Os elementos são poucos e simples de forma a
permitir que mesmo um utilizador sem especialização possa criar simples registos
descritivos facilmente e sem grandes custos, oferecendo ao mesmo tempo, melhores
possibilidades para a pesquisa desses recursos num ambiente em rede.
38
<http://www.w3.org/TR/REC-MathML/>
120
CONCLUSÕES E TRABALHO FUTURO
•
Semântica facilmente compreensível – a descoberta de informação na Internet é afectada
pelas diferenças em terminologia e práticas descritivas das várias áreas de conhecimento.
O Dublin Core pode ajudar um utilizador inexperiente na descoberta de recursos através
de um conjunto de elementos comuns cuja semântica é universalmente conhecida. Por
exemplo, cientistas interessados em artigos por um determinado autor, e ou designers
interessados em trabalhos de um artista, ambos concordaram na importância do elemento
criador (creator).
•
Interesse internacional – O conjunto de elementos do Dublin Core foi originalmente
desenvolvido em inglês, mas várias versões têm sido criadas em outras línguas, existindo
hoje versões em mais de 20 línguas.
•
Extensibilidade – Na procura do equilíbrio entre a necessidade para descrever recursos
digitais de uma forma simples, e a necessidade de precisão na sua procura, o Dublin Core
reconhece a necessidade de oferecer um mecanismo para estender o conjunto de
elementos para as necessidades de procura adicionais.
A semântica dos quinze elementos do Dublin Core encontra-se descrita na Tabela 15 (DCMI,
1999). Nesta tabela encontra-se o nome do elemento na primeira coluna. Na coluna “etiqueta”
está representado o identificador universal do elemento que, na prática, corresponde ao seu nome
na língua inglesa. A descrição do elemento encontra-se na terceira coluna.
39
<http://www.xml-cml.org>
CONCLUSÕES E TRABALHO FUTURO
'
121
& 0
Título
title
O nome dado ao recurso pelo criador ou editor.
Criador
creator
A pessoa ou organização responsável em primeira instância pelo conteúdo intelectual do recurso. Por
exemplo, os autores no caso de textos, ou os artistas, fotógrafos ou desenhadores no caso de outros
recursos visuais.
Assunto
subject
Os tópicos do recurso. Tipicamente, os assuntos irão ser expressos por palavras chave ou frases que
descrevam o assunto ou o conteúdo do recurso. Encoraja-se a utilização de vocabulários controlados e de
sistemas de classificação formais.
Descrição
description
Uma descrição textual do recurso, tal como um resumo no caso de um documento ou a descrição do
conteúdo no caso de outros recursos visuais.
Editor
publisher
A entidade responsável por tornar o recurso disponível no formato actual, tal como por exemplo a
empresa editora, um departamento universitário ou outro tipo de organização.
Contribuinte
contributor
Uma pessoa ou organização que tenha dado uma contribuição intelectual significativa para a criação do
recurso mas num plano secundário, e que por isso não é especificada no elemento criador.
Data
date
A data em que o recurso foi tornado público na forma actual.
Tipo
type
A categoria do recurso, tal como por exemplo página pessoal, romance, poema, minuta, ensaio,
dicionário.
Formato
format
Os formatos de dados do recurso, utilizado para identificar as aplicações ou os equipamentos que possam
vir a ser necessários para mostrar ou operar com o recurso.
Identificador
identifier
Sequência de caracteres (palavra, número ou combinação de ambos) utilizado para identificar
univocamente o recurso. Exemplos para recursos em linha (disponíveis em redes) podem ser URLs e
URNs (estes quando disponíveis e concretizados). Para outros recursos podem ser usados outros
identificadores formais, tais como por exemplo o ISBN ("International Standard Book Number"- Número
Internacional Normalizado para Livro).
Fonte
source
Sequência de caracteres (palavra, número ou combinação de ambos) utilizado para identificar
univocamente um trabalho a partir do qual o recurso actual possa ter derivado (se aplicável). Por
exemplo, a versão PDF de um romance pode ter como valor para este elemento fonte o número ISBN do
livro impresso que deu origem a essa versão PDF.
Língua
language
Língua(s) do conteúdo intelectual do recurso.
Relação
relation
As relações deste recurso com outros recursos. A intenção deste elemento é a de oferecer uma forma de
expressar relações entre recursos que tenham um relacionamento formal entre si mas que ao mesmo
tempo existam como recursos discretos em si mesmos. Por exemplo, imagens de um documento,
capítulos de um livro ou itens de uma colecção.
Cobertura
coverage
As características da cobertura espacial e/ou temporal do recurso.
Direitos
rights
Informação de direitos sobre o recurso ou relativos ao mesmo.
Tabela 15 – Elementos do núcleo de metadata Dublin Core.
A utilização prática não se tem dado como era esperado inicialmente no Dublin Core. Ao invés
de ser utilizado como formato de metadata que pudesse gerir a metadata associada a cada página
da Internet, o Dublin Core tem sido utilizado em vários projectos e iniciativas para representação
de metadata. A utilização de metadata para descrever páginas da Internet, não tem sido
largamente utilizada, devido à sua utilização indevida, com o intuito de atrair os leitores para
páginas cujas descrições nada têm a ver com o seu conteúdo real. Alguns motores de pesquisa
ignoram mesmo as etiquetas “<META>” das páginas HTML.
Um aspecto que ainda deverá merecer maior atenção pelo Dublin Core são os mecanismos de
extensibilidade do Dublin Core. Pois não existe ainda qualquer guia sobre como criar extensões.
O Dublin Core tem sido estendido para colmatar necessidades de procura não cobertas pelos seus
15 elementos. Estas extensões têm sido feitas de diversas formas, criando dúvidas sobre como
estas extensões devem ser utilizadas para inter-operação em conjunto com o Dublin Core simples
ou com outras extensões. Por exemplo, imaginemos um caso em que se pretende ter na metadata
122
CONCLUSÕES E TRABALHO FUTURO
o primeiro e último nome do autor, e a sua morada. Uma forma aparente de o fazer seria criando
os elementos creator.firstname, creator.lastname e creator.postaladdress. Como deveria então
ser indexados estes elementos por um serviço de pesquisa que desconhece esta extensão?
Deveria indexar todos os três campos no índice creator (o que levaria à inclusão da morada neste
índice)? Ou deveria ignorar todos os elementos (ficando sem conteúdo para indexar no índice
creator)?
7.3.2 RESOURCE DESCRIPTION FRAMEWORK
Uma das questões que se põe hoje em dia na Internet, é a dificuldade de automatizar as tarefas
que todos nós aí executamos. O objectivo da definição da Resource Description Framework
(RDF), é o de permitir a descrição de recursos por estruturas formais de metadata que possam vir
a ser criadas e processadas automaticamente (Miller, 1998). É uma infra-estrutura que permite a
codificação, troca e reutilização de metadata estruturada. Esta infra-estrutura permite a interoperação ao nível da metadata através dos seus mecanismos que suportam convenções
semânticas comuns, sintaxes e estruturas. O RDF não define a semântica a utilizar, mas sim a
forma de definir elementos de metadata. O RDF utiliza a XML como sintaxe comum para a troca
e o processamento de metadata.
O RDF oferece assim os meios para a criação de metadata que pode ser processada
automaticamente, de forma a encorajar a troca, utilização e extensão de semânticas de metadata
entre diferentes comunidades.
Entre as potenciais implicações da utilização generalizada de metadata RDF, podemos
considerar: uma maior facilidade na pesquisa de informação na Internet, pois os motores de
pesquisa terão mais informação estruturada disponível; automatizar das nossas tarefas na Internet
será mais fácil;. e a grande quantidade de informação não estruturada na Internet poderá tornarse em algo com mais significado (Lassila, 1997).
Fica ainda em aberto, a questão da aplicabilidade prática do RDF, mas esta poderá vir a tornar-se
numa ferramenta com grande impacto para as bibliotecas digitais.
CONCLUSÕES E TRABALHO FUTURO
7.4
123
AVALIAÇÃO DA BIBLIOTECA DIGITAL DE TESES E DISSERTAÇÕES
A biblioteca digital de teses e dissertações descrita neste trabalho consegue preencher os
requisitos que lhe foram postos, entre os quais se destaca a inter-operação. Esta foi atingida
através da concretização de várias interfaces, e dos seus formatos de metadata associados. Estes
formatos são gerados por conversão a partir do formato de metadata DiTeD. Considera-se assim,
que as dissertações depositadas neste sistema estão tão visíveis para o exterior quanto é possível
com a tecnologia actual.
Todas as tecnologias aplicadas nesta biblioteca permitem a sua utilização gratuita, possibilitando
a sua aplicação sem grandes custos para todos os actores do processo da vida de uma dissertação.
Para alguns dos actores os custos de execução do seu papel, são mesmo reduzidos:
•
Para o autor, os custos são reduzidos, pois este já cria a sua dissertação em formato
digital, e sendo o depósito feito em formato digital, serão menos cópias impressas que o
autor terá que entregar. Para além disso o autor pode tornar o seu trabalho visível para o
exterior.
•
As bibliotecas das universidades, podem utilizar o sistema DiTeD livremente (tanto o
sistema DiTeD como as aplicações que ele utiliza são distribuídos gratuitamente) tendo
apenas os custos associados ao equipamento informático necessário, e de pessoal
qualificado para manter o sistema em funcionamento. Como contrapartida, as bibliotecas
pouparão espaço nas prateleiras (um recurso muito importante nas bibliotecas), o
depósito legal na Biblioteca Nacional será mais fácil, desempenharão melhor a sua
missão, e melhorar a visibilidade do trabalho de investigação da sua universidade.
•
Para a Biblioteca Nacional pode-se indicar os mesmos custos e vantagens associadas às
bibliotecas das universidades. No entanto a Biblioteca obtém do sistema a experiência no
depósito de publicações digitais, tendo em mão um sistema adaptável a outros géneros de
publicações electrónicas.
•
Para o leitor, surge agora a possibilidade de encontrar e aceder facilmente às
dissertações, apenas com os custos de uma ligação à Internet.
124
CONCLUSÕES E TRABALHO FUTURO
O sistema DiTeD será disponibilizado sob uma licença pública GNU (GNU general public
license40). Este factor em conjunção com a adaptabilidade do sistema, possibilitará a sua
utilização noutros países, ou com outros géneros de publicação digital, que possuam requisitos
semelhantes aos aqui apresentados.
40
<http://www.gnu.org/copyleft/gpl.html>
Apêndice A - Definição XML do
formato para dissertações e
teses digitais
A.
DTD – DEFINIÇÃO DE TIPO DE DOCUMENTO PARA O FORMATO
PARA DISSERTAÇÕES E TESES DIGITAIS
<?xml version="1.0" encoding="ISO-8859-1"?>
<!-- Declaração DTD para o formato para dissertações e teses digitais – V1.0 (10/10/1999) -->
<!ELEMENT dited ( front, body, back )>
<!-- Front -->
<!ELEMENT front ( school, mm*, title, author, degree, city, date,
abstract, keywords, abstracten, keywordsen, grant?, dedication?, acknowledgments? )>
<!ELEMENT title ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle )*>
<!ELEMENT author ( given, surname, suffix? ) >
<!ELEMENT given ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT surname ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT suffix ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT organization ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT submission ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT school ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT degree ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT major ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT date ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT city ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT keywords ( keyword+ )>
<!ELEMENT keywordsen ( keyword+ )>
<!ELEMENT keyword ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle )*>
<!ELEMENT copyright ( #PCDATA | em | strong | tt | q | term | foreign |
125
126
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
im | link | target | a | sup | sub | br |
worktitle | articletitle )*>
<!ELEMENT abstract ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | p | citation | table | mm )*>
<!ATTLIST abstract
id ID #IMPLIED>
<!ELEMENT abstracten ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | p | citation | table | mm )*>
<!ATTLIST abstracten
id ID #IMPLIED>
<!ELEMENT grant ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | p | citation | table | mm )*>
<!ATTLIST grant
id ID #IMPLIED>
<!ELEMENT dedication ( head?, ( p | citation | table | mm)* )>
<!ATTLIST dedication
id ID #IMPLIED>
<!ELEMENT acknowledgments ( head?, ( p | citation | table | mm)* )>
<!ATTLIST acknowledgments
id ID #IMPLIED>
<!-- Body -->
<!ELEMENT body ( chapter+ )>
<!-- 1. -->
<!ELEMENT chapter ( head?, ( p | citation | table | mm | footnote )*, section* )>
<!ATTLIST chapter
id ID #IMPLIED>
<!-- 1.2 -->
<!ELEMENT section ( head?, ( p | citation | table | mm | footnote )*, subsection* )>
<!ATTLIST section
id ID #IMPLIED>
<!-- 1.2.3 -->
<!ELEMENT subsection ( head?, ( p | citation | table | mm | footnote )*, block* )>
<!ATTLIST subsection
id ID #IMPLIED>
<!-- 1.2.3.4 -->
<!ELEMENT block ( head?, ( p | citation | table | mm | footnote )*, subblock* )>
<!ATTLIST block
id ID #IMPLIED>
<!-- 1.2.3.4.5 -->
<!ELEMENT subblock ( head?, ( p | citation | table | mm | footnote )* )>
<!ATTLIST subblock
id ID #IMPLIED>
<!ELEMENT p ( #PCDATA | head | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle |
ol | ul | dl | pre | verse | blockquote | attrib | math | footnote )*>
<!ELEMENT head ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle )*>
<!ELEMENT em ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ELEMENT strong ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ELEMENT br EMPTY>
<!ELEMENT tt ( #PCDATA | footnote )*>
<!ELEMENT q ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ELEMENT term ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ELEMENT foreign ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ELEMENT im ( #PCDATA | footnote )*>
<!ATTLIST im
id ID #IMPLIED>
<!ELEMENT sup ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
<!ELEMENT sub ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ELEMENT pre ( #PCDATA | footnote )*>
<!ATTLIST pre
id ID #IMPLIED
outfile CDATA #IMPLIED>
<!ELEMENT blockquote ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | p | citation | table | mm | footnote )*>
<!ELEMENT attrib ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ELEMENT verse ( head?, stanza+ )>
<!ATTLIST verse
id ID #IMPLIED>
<!ELEMENT stanza ( speaker | line | stage )+>
<!ELEMENT speaker ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ELEMENT line ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ATTLIST line
id ID #IMPLIED
indented (indent|noindent) "noindent"
number CDATA #IMPLIED>
<!ELEMENT stage ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ATTLIST stage
id ID #IMPLIED>
<!ELEMENT ol ( li )+>
<!ATTLIST ol
id ID #IMPLIED
numbering ( arabic | lalpha | lroman | uroman | ualpha ) #IMPLIED>
<!ELEMENT ul ( li )+>
<!ATTLIST ul
id ID #IMPLIED>
<!ELEMENT li ( #PCDATA | head | ol | ul | dl |
em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | p | citation | table | mm | footnote )*>
<!ELEMENT dl ( dt, dd )+>
<!ELEMENT dt ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ELEMENT dd ( #PCDATA | head | ol | ul | dl |
em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | p | citation | table | mm | footnote )*>
<!ELEMENT a ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ATTLIST a
href CDATA #REQUIRED>
<!ELEMENT link ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle )*>
<!ATTLIST link
id ID #IMPLIED
HyTime CDATA "clink"
goesto IDREF #REQUIRED>
<!ELEMENT target ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ATTLIST target
id ID #IMPLIED>
<!ELEMENT footnote ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | p | citation | table | mm )*>
<!ATTLIST footnote
id ID #REQUIRED>
<!ELEMENT caption ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
127
128
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
<!ELEMENT table ( caption?, row* )>
<!ATTLIST table
id ID #IMPLIED>
<!ELEMENT colhead ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ELEMENT rowhead ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ELEMENT row ( rowhead?, ( c* | colhead* ))>
<!ELEMENT c ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle | footnote )*>
<!ELEMENT mm ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br |
worktitle | articletitle)*>
<!ATTLIST mm
id ID #IMPLIED
inline (true|false) "true"
object CDATA #REQUIRED>
<!ELEMENT worktitle ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br | footnote )*>
<!ELEMENT articletitle ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br | footnote )*>
<!-- Back -->
<!ELEMENT back ( bibliography, appendix*, vita )>
<!ELEMENT bibliography ( head?, ( p | citation | table | mm | footnote )* )>
<!ELEMENT citation ( address | articletitle | bible | court | edition | editor | email |
handle | note | number | pages | pubdate | publisher | url | version |
volume | workauthor | worktitle | footnote )*>
<!ATTLIST citation
id ID #IMPLIED
worktype CDATA #REQUIRED
published ( published | unpublished ) "published">
<!ELEMENT appendix ( head?, ( p | citation | table | mm | footnote )*, section* )>
<!ATTLIST appendix
id ID #IMPLIED>
<!ELEMENT vita ( head?, ( p | citation | table | mm | footnote )* )>
<!ELEMENT address ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT bible ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT court ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT edition ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT editor ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT email ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT handle ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT note ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT number ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT pages ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT pubdate ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT publisher ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT url ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT version ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT volume ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
<!ELEMENT workauthor ( #PCDATA | em | strong | tt | q | term | foreign |
im | link | target | a | sup | sub | br )*>
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
B.
129
FOLHA DE ESTILO PARA A APRESENTAÇÃO DO FORMATO
<?xml version="1.0" encoding="iso-8859-1"?>
</xsl:template>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/TR/WD-xsl"
xmlns="http://www.w3.org/TR/REChtml40" result-ns=""
indent-result="yes">
<xsl:template match="suffix">
<br/>
(<xsl:apply-templates/>)
</xsl:template>
<xsl:template match="dtd">
<html>
<head>
<title>
<xsl:value-of
select="front/title"/>
</title>
</head>
<body>
<xsl:apply-templates/>
</body>
</html>
</xsl:template>
<xsl:template match="front">
<center>
<xsl:apply-templates/>
</center>
</xsl:template>
<xsl:template match="school">
<table>
<tr>
<td>
<IMG
align="left"
alt="Instituto Superior Técnico" border="0"
src="istlogo.gif" />
</td>
<td
valign="center"
align="center">
<h1>
<xsl:apply-templates/>
</h1>
</td>
</tr>
</table>
</xsl:template>
<xsl:template match="title">
<br/>
<h1>
<xsl:apply-templates/>
</h1>
</xsl:template>
<xsl:template match="author">
<h2>
<xsl:apply-templates/>
</h2>
</xsl:template>
<xsl:template match="given">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="surname">
<xsl:apply-templates/>
<xsl:template match="degree">
<br/>
<h4>
Dissertação para obtenção do Grau
de Mestrado em
<br/>
<xsl:apply-templates/>
</h4>
</xsl:template>
<xsl:template match="date">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="city">
<br/>
<xsl:apply-templates/>,
</xsl:template>
<xsl:template match="keywordsen">
<h3>KEYWORDS:</h3>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="keywords">
<h3>Palavras-chave:</h3>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="keyword">
<xsl:apply-templates/>
<xsl:if
test=".[not(last-oftype())]">, </xsl:if>
</xsl:template>
<xsl:template match="abstract">
<hr/>
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<h3>Resumo:</h3>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="abstracten">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<h3>ABSTRACT:</h3>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="grant">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<h3>Reconhecimentos:</h3>
<xsl:apply-templates/>
130
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
</xsl:template>
<xsl:template match="dedication">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<h3>Dedicatória:</h3>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="acknowledgments">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<h3>Agradecimentos:</h3>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="body">
<hr/>
<h2>Índice</h2>
<xsl:apply-templates select="chapter"
mode="toc"/>
<xsl:apply-templates
select="//bibliography" mode="toc"/>
<xsl:apply-templates
select="//appendix" mode="toc"/>
<hr/>
<h2>Índice de figuras e multimédia</h2>
<xsl:apply-templates
select="//mm"
mode="toc"/>
<hr/>
<h2>Índice de tabelas</h2>
<xsl:apply-templates select="//table"
mode="toc"/>
<hr/>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="chapter">
<br/>
<xsl:choose>
<xsl:when test='.[@id]'>
<a name="{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="name">xmlcptcnt<xsl:number level="any"
count="chapter"
format="A"/></xsl:attribute></a>
</xsl:otherwise>
</xsl:choose>
<center>
<h2>
Capítulo <xsl:number level="multi"
count="chapter|section|subsection|block|subb
lock" format="1.1: "/> <xsl:apply-templates
select="head" mode="visible"/>
</h2>
</center>
<xsl:apply-templates/>
<xsl:if test='.//footnote'>
<hr/>
<big><b>Notas:</b></big><br/>
<xsl:apply-templates
select=".//footnote" mode="notas"/>
</xsl:if>
</xsl:template>
<xsl:template match="chapter" mode="toc">
<strong>
Capítulo <xsl:number level="multi"
count="chapter|section|subsection|block|subb
lock" format="1.1: "/>
<xsl:choose>
<xsl:when test='.[@id]'>
<a href="#{@id}">
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="href">#xmlcptcnt<xsl:number
level="any"
count="chapter"
format="A"/></xsl:attribute>
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:otherwise>
</xsl:choose>
</strong>
<br/>
<p style="margin-left: 3em">
<xsl:apply-templates
select="section" mode="tocc"/>
</p>
</xsl:template>
<xsl:template
match="section"
mode="anexo">
<xsl:choose>
<xsl:when test='.[@id]'>
<a name="{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="name">xmlsctcnt<xsl:number level="any"
count="section"
format="A"/></xsl:attribute></a>
</xsl:otherwise>
</xsl:choose>
<h3><xsl:number
level="multi"
count="appendix|section|subsection|block|sub
block"
format="A.1
"/>
<xsl:applytemplates select="head" mode="visible"/>
</h3>
<xsl:apply-templates mode="anexo"/>
</xsl:template>
<xsl:template match="section">
<xsl:choose>
<xsl:when test='.[@id]'>
<a name="{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="name">xmlsctcnt<xsl:number level="any"
count="section"
format="A"/></xsl:attribute></a>
</xsl:otherwise>
</xsl:choose>
<h3><xsl:number
level="multi"
count="chapter|section|subsection|block|subb
lock" format="1.1 "/> <xsl:apply-templates
select="head" mode="visible"/>
</h3>
<xsl:apply-templates/>
</xsl:template>
<xsl:template
match="section"
mode="tocc">
<xsl:number
level="multi"
count="chapter|section|subsection|block|subb
lock" format="1.1 "/>
<xsl:choose>
<xsl:when test='.[@id]'>
<a href="#{@id}">
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="href">#xmlsctcnt<xsl:number
level="any"
count="section"
format="A"/></xsl:attribute>
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:otherwise>
</xsl:choose>
<br/>
<xsl:apply-templates select="subsection"
mode="tocc"/>
</xsl:template>
<xsl:template
match="section"
mode="toca">
<xsl:number
level="multi"
count="appendix|section|subsection|block|sub
block" format="A.1 "/>
<xsl:choose>
<xsl:when test='.[@id]'>
<a href="#{@id}">
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="href">#xmlsctcnt<xsl:number
level="any"
count="section"
format="A"/></xsl:attribute>
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:otherwise>
</xsl:choose>
<br/>
<xsl:apply-templates select="subsection"
mode="toca"/>
</xsl:template>
<xsl:template
match="subsection"
mode="anexo">
<xsl:choose>
<xsl:when test='.[@id]'>
<a name="{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="name">xmlsbscnt<xsl:number level="any"
count="subsection"
format="A"/></xsl:attribute></a>
</xsl:otherwise>
</xsl:choose>
<h4><xsl:number
level="multi"
count="appendix|section|subsection|block|sub
block" format="A.1.1
"/>
<xsl:applytemplates select="head" mode="visible"/>
</h4>
<xsl:apply-templates mode="anexo"/>
</xsl:template>
<xsl:template match="subsection">
<xsl:choose>
<xsl:when test='.[@id]'>
<a name="{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="name">xmlsbscnt<xsl:number level="any"
count="subsection"
format="A"/></xsl:attribute></a>
131
</xsl:otherwise>
</xsl:choose>
<h4><xsl:number
level="multi"
count="chapter|section|subsection|block|subb
lock" format="1.1.1
"/>
<xsl:applytemplates select="head" mode="visible"/>
</h4>
<xsl:apply-templates/>
</xsl:template>
<xsl:template
match="subsection"
mode="tocc">
<xsl:number
level="multi"
count="chapter|section|subsection|block|subb
lock" format="1.1.1 "/>
<xsl:choose>
<xsl:when test='.[@id]'>
<a href="#{@id}">
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="href">#xmlsbscnt<xsl:number
level="any"
count="subsection"
format="A"/></xsl:attribute>
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:otherwise>
</xsl:choose>
<br/>
<xsl:apply-templates
select="block"
mode="tocc"/>
</xsl:template>
<xsl:template
match="subsection"
mode="toca">
<xsl:number
level="multi"
count="appendix|section|subsection|block|sub
block" format="A.1.1 "/>
<xsl:choose>
<xsl:when test='.[@id]'>
<a href="#{@id}">
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="href">#xmlsbscnt<xsl:number
level="any"
count="subsection"
format="A"/></xsl:attribute>
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:otherwise>
</xsl:choose>
<br/>
<xsl:apply-templates
select="block"
mode="toca"/>
</xsl:template>
<xsl:template match="block" mode="anexo">
<xsl:choose>
<xsl:when test='.[@id]'>
<a name="{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="name">xmlblkcnt<xsl:number level="any"
count="block"
format="A"/></xsl:attribute></a>
</xsl:otherwise>
</xsl:choose>
132
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
<h5><xsl:number
level="multi"
count="appendix|section|subsection|block|sub
block" format="A.1.1.1
"/>
<xsl:applytemplates select="head" mode="visible"/>
</h5>
<xsl:apply-templates mode="anexo"/>
</xsl:template>
<xsl:template match="block">
<xsl:choose>
<xsl:when test='.[@id]'>
<a name="{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="name">xmlblkcnt<xsl:number level="any"
count="block"
format="A"/></xsl:attribute></a>
</xsl:otherwise>
</xsl:choose>
<h5><xsl:number
level="multi"
count="chapter|section|subsection|block|subb
lock" format="1.1.1.1
"/>
<xsl:applytemplates select="head" mode="visible"/>
</h5>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="block" mode="tocc">
<xsl:number
level="multi"
count="chapter|section|subsection|block|subb
lock" format="1.1.1.1 "/>
<xsl:choose>
<xsl:when test='.[@id]'>
<a href="#{@id}">
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="href">#xmlblkcnt<xsl:number
level="any"
count="block"
format="A"/></xsl:attribute>
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:otherwise>
</xsl:choose>
<br/>
<xsl:apply-templates
select="subblock"
mode="tocc"/>
</xsl:template>
<xsl:template match="block" mode="toca">
<xsl:number
level="multi"
count="appendix|section|subsection|block|sub
block" format="A.1.1.1 "/>
<xsl:choose>
<xsl:when test='.[@id]'>
<a href="#{@id}">
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="href">#xmlblkcnt<xsl:number
level="any"
count="block"
format="A"/></xsl:attribute>
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:otherwise>
</xsl:choose>
<br/>
<xsl:apply-templates
mode="toca"/>
</xsl:template>
select="subblock"
<xsl:template
match="subblock"
mode="anexo">
<xsl:choose>
<xsl:when test='.[@id]'>
<a name="{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="name">xmlsbbcnt<xsl:number level="any"
count="subblock"
format="A"/></xsl:attribute></a>
</xsl:otherwise>
</xsl:choose>
<h6><xsl:number
level="multi"
count="appendix|section|subsection|block|sub
block" format="A.1.1.1.1
"/>
<xsl:applytemplates select="head" mode="visible"/>
</h6>
<xsl:apply-templates mode="anexo"/>
</xsl:template>
<xsl:template match="subblock">
<xsl:choose>
<xsl:when test='.[@id]'>
<a name="{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="name">xmlsbbcnt<xsl:number level="any"
count="subblock"
format="A"/></xsl:attribute></a>
</xsl:otherwise>
</xsl:choose>
<h6><xsl:number
level="multi"
count="chapter|section|subsection|block|subb
lock" format="1.1.1.1.1
"/>
<xsl:applytemplates select="head" mode="visible"/>
</h6>
<xsl:apply-templates/>
</xsl:template>
<xsl:template
match="subblock"
mode="tocc">
<xsl:number
level="multi"
count="chapter|section|subsection|block|subb
lock" format="1.1.1.1.1 "/>
<xsl:choose>
<xsl:when test='.[@id]'>
<a href="#{@id}">
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="href">#xmlsbbcnt<xsl:number
level="any"
count="subblock"
format="A"/></xsl:attribute>
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:otherwise>
</xsl:choose>
<br/>
</xsl:template>
<xsl:template
mode="toca">
match="subblock"
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
<xsl:number
level="multi"
count="appendix|section|subsection|block|sub
block" format="A.1.1.1.1 "/>
<xsl:choose>
<xsl:when test='.[@id]'>
<a href="#{@id}">
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="href">#xmlsbbcnt<xsl:number
level="any"
count="subblock"
format="A"/></xsl:attribute>
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:otherwise>
</xsl:choose>
<br/>
</xsl:template>
<xsl:template match="p">
<p>
<xsl:apply-templates/>
</p>
</xsl:template>
<xsl:template
match="chapter/head|section/head|subsection/
head|block/head|subblock/head|bibliography/h
ead|appendix/head|vita/head" mode="visible">
<xsl:apply-templates/>
</xsl:template>
<xsl:template
match="appendix/head|section/head|subsection
/head|block/head|subblock/head"
mode="anexo">
</xsl:template>
<xsl:template
match="chapter/head|section/head|subsection/
head|block/head|subblock/head|bibliography/h
ead|appendix/head|vita/head">
</xsl:template>
<xsl:template
match="dedication/head|acknowledgments/head|
p/head">
<strong>
<xsl:apply-templates/>
</strong>
</xsl:template>
<xsl:template
match="verse/head|li/head|dd/head">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="em">
<em>
<xsl:apply-templates/>
</em>
</xsl:template>
<xsl:template match="strong">
<strong>
<xsl:apply-templates/>
</strong>
</xsl:template>
<xsl:template match="br">
<br>
<xsl:apply-templates/>
</br>
</xsl:template>
<xsl:template match="tt">
<tt>
<xsl:apply-templates/>
</tt>
</xsl:template>
<xsl:template match="q">
<q>
<xsl:apply-templates/>
</q>
</xsl:template>
<xsl:template match="term">
<strong>
<xsl:apply-templates/>
</strong>
</xsl:template>
<xsl:template match="foreign">
<em>
<xsl:apply-templates/>
</em>
</xsl:template>
<xsl:template match="im">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<code>
<xsl:apply-templates/>
</code>
</xsl:template>
<xsl:template match="sup">
<sup>
<xsl:apply-templates/>
</sup>
</xsl:template>
<xsl:template match="sub">
<sub>
<xsl:apply-templates/>
</sub>
</xsl:template>
<xsl:template match="pre">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<pre>
<xsl:apply-templates/>
</pre>
</xsl:template>
<xsl:template match="blockquote">
<blockquote>
<xsl:apply-templates/>
</blockquote>
</xsl:template>
<xsl:template match="attrib">
<blockquote>
<xsl:apply-templates/>
</blockquote>
</xsl:template>
<xsl:template match="verse">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="stanza">
<dl>
<xsl:apply-templates/>
133
134
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
</dl>
</xsl:template>
<xsl:template match="speaker">
<dt>
<xsl:apply-templates/>
</dt>
</xsl:template>
<xsl:template match="stage">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<dd>
<em>
<xsl:apply-templates/>
</em>
</dd>
</xsl:template>
<xsl:template match="line">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<dd>
<em>
<xsl:apply-templates/>
</em>
</dd>
</xsl:template>
<xsl:template match="br">
<br/>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="ol">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<ol>
<xsl:apply-templates/>
</ol>
</xsl:template>
<xsl:template match="ul">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<ul>
<xsl:apply-templates/>
</ul>
</xsl:template>
<xsl:template match="li">
<li>
<xsl:apply-templates/>
</li>
</xsl:template>
<xsl:template match="dl">
<dl>
<xsl:apply-templates/>
</dl>
</xsl:template>
<xsl:template match="dt">
<dt>
<strong>
<xsl:apply-templates/>
</strong>
</dt>
</xsl:template>
<xsl:template match="dd">
<dd>
<xsl:apply-templates/>
</dd>
</xsl:template>
<xsl:template match="a">
<a href="{@href}">
<xsl:apply-templates/>
</a>
</xsl:template>
<xsl:template match="link">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
[<a href="#{@goesto}">
<xsl:apply-templates/>
</a>]
</xsl:template>
<xsl:template match="target">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<a name="{@goesto}">
<xsl:apply-templates/>
</a>
</xsl:template>
<xsl:template match="footnote">
</xsl:template>
<xsl:template
match="footnote"
mode="notas">
<a name="{@id}"/>
<tr valign="top">
<td>
<font size="2">
<a name="{@id}">
[<em>
<xsl:number
level="any"
count="footnote" format="1"/>
</em>]
</a>
</font>
</td>
<font size="2">
<xsl:apply-templates/>
</font>
</tr>
<br/>
</xsl:template>
<xsl:template match="float">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="caption">
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="table">
<xsl:choose>
<xsl:when test='.[@id]'>
<a name="{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="name">xmltblcnt<xsl:number level="any"
count="table"
format="A"/></xsl:attribute></a>
</xsl:otherwise>
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
</xsl:choose>
<table
border="1"
cellpadding="4"
align="center">
<caption align="bottom">
Tabela <xsl:number level="any"
count="table" format="1"/> <xsl:apply-templates
select="caption"/>
</caption>
<xsl:apply-templates select="row"/>
</table>
</xsl:template>
<xsl:template match="table" mode="toc">
<xsl:choose>
Tabela
<xsl:number
level="any"
count="table" format="1"/> <xsl:when test='.[@id]'>
<a href="#{@id}">
<xsl:apply-templates
select="caption"/>
</a>
</xsl:when>
<xsl:otherwise>
Tabela <xsl:number level="any"
count="table" format="1"/> <a><xsl:attribute
name="href">#xmltblcnt<xsl:number
level="any"
count="table"
format="A"/></xsl:attribute>
<xsl:apply-templates
select="caption"/>
</a>
</xsl:otherwise>
</xsl:choose>
<br/>
</xsl:template>
<xsl:template match="colhead">
<th>
<xsl:apply-templates/>
</th>
</xsl:template>
<xsl:template match="rowhead">
<th>
<xsl:apply-templates/>
</th>
</xsl:template>
<xsl:template match="collumn">
<tr>
<xsl:apply-templates/>
</tr>
</xsl:template>
<xsl:template match="row">
<tr>
<xsl:apply-templates/>
</tr>
</xsl:template>
<xsl:template match="c">
<td>
<xsl:apply-templates/>
</td>
</xsl:template>
<xsl:template match="mm">
<xsl:counter-increment name="mm"/>
<xsl:choose>
<xsl:when test='.[@id]'>
<a name="{@id}"></a>
</xsl:when>
<xsl:otherwise>
135
<a><xsl:attribute
name="name">xmlmmcnt<xsl:number level="any"
count="mm" format="A"/></xsl:attribute></a>
</xsl:otherwise>
</xsl:choose>
<center>
<xsl:choose>
<xsl:when test='.[@inline="false"]'>
<p>
Multimédia
<xsl:number
level="any" count="mm" format="1"/> <a href="{@object}">
<xsl:apply-templates/>
</a>
</p>
</xsl:when>
<xsl:otherwise>
<p>
<img src="{@object}"/>
<br/>
Figura
<xsl:number
level="any" count="mm" format="1"/>
- <xsl:apply-templates/>
</p>
</xsl:otherwise>
</xsl:choose>
</center>
</xsl:template>
<xsl:template match="mm" mode="toc">
<xsl:counter-increment name="mm"/>
<xsl:choose>
<xsl:when test='.[@inline="false"]'>
Multimédia
<xsl:number
level="any" count="mm" format="1"/> <xsl:choose>
<xsl:when test='.[@id]'>
<a href="#{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="href">#xmlmmcnt<xsl:number level="any"
count="mm" format="A"/></xsl:attribute>
<xsl:applytemplates/>
</a>
</xsl:otherwise>
</xsl:choose>
</xsl:when>
<xsl:otherwise>
Figura <xsl:number level="any"
count="mm" format="1"/> <xsl:choose>
<xsl:when test='.[@id]'>
<a href="#{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="href">#xmlmmcnt<xsl:number level="any"
count="mm" format="A"/></xsl:attribute>
<xsl:applytemplates/>
</a>
</xsl:otherwise>
</xsl:choose>
</xsl:otherwise>
</xsl:choose>
<br/>
</xsl:template>
<xsl:template match="worktitle">
<em>
<xsl:apply-templates/>
</em>
</xsl:template>
<xsl:template match="articletitle">
136
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
``<xsl:apply-templates/>''
</xsl:template>
<xsl:template match="back">
<hr/>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="bibliography">
<a name="xmlbblcnt"/>
<h2><xsl:apply-templates select="head"
mode="visible"/></h2>
<xsl:apply-templates/>
<xsl:if test='.//footnote'>
<hr/>
<big><b>Notas:</b></big><br/>
<xsl:apply-templates
select=".//footnote" mode="notas"/>
</xsl:if>
</xsl:template>
<xsl:template
match="bibliography"
mode="toc">
<strong>
<a
href="#xmlbblcnt"><xsl:applytemplates select="head" mode="visible"/></a>
</strong>
<p/>
</xsl:template>
<xsl:template match="citation">
<xsl:if test='.[@id]'>
<a name="{@id}"></a>
</xsl:if>
<p>
<xsl:apply-templates/>
</p>
</xsl:template>
<xsl:template match="appendix">
<br/>
<xsl:choose>
<xsl:when test='.[@id]'>
<a name="{@id}"></a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="name">xmlapdcnt<xsl:number level="any"
count="appendix"
format="A"/></xsl:attribute></a>
</xsl:otherwise>
</xsl:choose>
<h2>
Anexo
<xsl:number
level="multi"
count="appendix|section|subsection|block|sub
block" format="A.1"/>: <xsl:apply-templates
select="head" mode="visible"/>
</h2>
<xsl:apply-templates mode="anexo"/>
<xsl:if test='.//footnote'>
<hr/>
<big><b>Notas:</b></big><br/>
<xsl:apply-templates
select=".//footnote" mode="notas"/>
</xsl:if>
</xsl:template>
<xsl:template
match="appendix"
mode="toc">
<strong>
Anexo
<xsl:number
level="multi"
count="appendix|section|subsection|block|sub
block" format="A.1 "/>:
<xsl:choose>
<xsl:when test='.[@id]'>
<a href="#{@id}">
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:when>
<xsl:otherwise>
<a><xsl:attribute
name="href">#xmlapdcnt<xsl:number
level="any"
count="appendix"
format="A"/></xsl:attribute>
<xsl:apply-templates
select="head" mode="visible"/>
</a>
</xsl:otherwise>
</xsl:choose>
</strong>
<br/>
<p style="margin-left: 3em">
<xsl:apply-templates
select="section" mode="toca"/>
</p>
</xsl:template>
<xsl:template match="vita">
<br/>
<br/>
<h2><xsl:apply-templates select="head"
mode="visible"/></h2>
<xsl:apply-templates/>
<xsl:if test='.//footnote'>
<hr/>
<big><b>Notas:</b></big><br/>
<xsl:apply-templates
select=".//footnote" mode="notas"/>
</xsl:if>
</xsl:template>
<xsl:template match="address">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="bible">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="court">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="edition">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="editor">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="email">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="handle">
<xsl:apply-templates/>
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="note">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="number">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="pages">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="pubdate">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="publisher">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="url">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
137
</xsl:template>
<xsl:template match="version">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="volume">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="workauthor">
<xsl:apply-templates/>
</xsl:template>
<xsl:template
match="citation/workauthor">
<xsl:apply-templates/>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="citation/worktitle">
<em><xsl:apply-templates/></em>
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
<xsl:template match="articletitle">
``<xsl:apply-templates/>''
<xsl:if test=".[not(last-of-any())]">,
</xsl:if>
</xsl:template>
</xsl:stylesheet>
138
C.
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
EXEMPLO DE UM DOCUMENTO FICTÍCIO
De seguida apresenta-se um exemplo de uma dissertação completa (fictícia), codificada segundo
o formato definido.
<?xml version="1.0" encoding="ISO-8859-1"?>
<!-- <?xml-stylesheet href="dtd.xsl" type="text/xsl"?> -->
<!DOCTYPE dtd SYSTEM "dtd.dtd" [
]>
<dtd>
<front>
<school>
UNIVERSIDADE TÉCNICA DE LISBOA <br/>
INSTITUTO SUPERIOR TÉCNICO
</school>
<title> Tese de Demonstração </title>
<author>
<given>Nuno</given>
<surname>Freire</surname>
<suffix>Engenheiro</suffix>
</author>
<degree>Engenharia Electrotécnica e de Computadores</degree>
<city>Lisboa</city>
<date>1 de Março de 1999</date>
<abstract>
<p>Esta tese de teste serve apenas para demonstrar o formato de uma tese em <strong>
XML</strong>.</p>
</abstract>
<keywords>
<keyword>Hipermédia</keyword>
<keyword>Dissertações e Teses Digitais</keyword>
<keyword>XML</keyword>
</keywords>
<abstracten>
<p>This thesis pupose is to demonstrate the format of a <strong>XML</strong>
thesis.</p>
</abstracten>
<keywordsen>
<keyword>Hipermedia</keyword>
<keyword>Digital Theses and Dissertations</keyword>
<keyword>XML</keyword>
</keywordsen>
<dedication>
<p>Este trabalho é dedicado a quem deseje aprender XML.</p>
</dedication>
<acknowledgments>
<p>Quero agradecer a todos os que me apoiaram.</p>
<p>E a todos os meus amigos.</p>
</acknowledgments>
</front>
<body>
<chapter id="linkdemo">
<head>Introdução</head>
<p>As teses digitais servem para têm características próprias que as diferenciam dos
outros géneros de publicações digitais. Esta tese de teste irá demonstrar o funcionamento deste
formato digital.</p>
</chapter>
<chapter>
<head>Demonstração das secções</head>
<p>Este é um capítulo...</p>
<section>
<head>Secção</head>
<p>Esta é uma secção...</p>
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
139
<subsection>
<head>Sub-secção</head>
<p>Esta é uma sub-secção...</p>
<block>
<head>Bloco</head>
<p>Este é um bloco...</p>
<subblock>
<head>Sub-bloco</head>
<p>Este é um sub-bloco...</p>
</subblock>
</block>
</subsection>
</section>
</chapter>
<chapter>
<head>Texto</head>
<p>Todas as secções que contenham texto podem conter os seguintes elementos:
<ul>
<li>Texto normal</li>
<li>
<em>Enfâse</em>
</li>
<li>
<strong>Carregado</strong>
</li>
<li>
<tt>Texto datilografado</tt>
</li>
<li>
<q>Citação</q>
</li>
<li>
<foreign>Texto em língua estrangeira</foreign>
</li>
</ul>
</p>
<p>Os elementos seguintes também podem ocorrer onde existir texto<ul>
<li>Ligação hipertexto <link goesto="linkchapter">(ver mais detalhes sobre
ligações)</link>
</li>
<li>O alvo de uma ligação hipertexto.<link goesto="foot1">1</link></li>
<li>Sobrescrita (a<sup>2</sup>+b<sup>2</sup>=c<sup>2</sup>)</li>
<li>Subescrita (H<sub>2</sub>O)</li>
<li>
<worktitle>Título de um trabalho</worktitle>
</li>
<li>
<articletitle>Título
de
um
artigo<link
goesto="foot2">2</link></articletitle>
</li>
</ul>
</p>
<footnote id="foot1"> Primeiro exemplo de uma nota </footnote>
<footnote id="foot2"> Este artigo não se encontra disponível livremente</footnote>
</chapter>
<chapter>
<head>Paragrafos</head>
<p>Os parágrafos podem conter os elementos anteriores e mais os que se encontram
descritos nas secções seguintes.</p>
<section>
<head>Cabeçalho</head>
<p>
<head>Cabeçalho do parágrafo.</head>O Cabeçalho de um parágrafo.<link
goesto="foot3">3</link></p>
<footnote id="foot3"> Outro exemplo de uma nota </footnote>
</section>
<section>
<head>Listas ordenadas</head>
<p>
<ol>
<li>elemento</li>
<li>elemento</li>
<li>elemento</li>
<li>elemento</li>
</ol>
</p>
</section>
140
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
<section>
<head>Listas não ordenadas</head>
<p>
<ul>
<li>elemento</li>
<li>elemento</li>
<li>elemento</li>
<li>elemento</li>
</ul>
</p>
</section>
<section>
<head>Listas descritivas</head>
<p>
<dl>
<dt>elemento</dt>
<dd>descrição</dd>
<dt>elemento</dt>
<dd>descrição</dd>
<dt>elemento</dt>
<dd>descrição</dd>
<dt>elemento</dt>
<dd>descrição</dd>
</dl>
</p>
</section>
<section>
<head>Texto preformatado</head>
<p>
<pre>Isto
é
texto
preformatado.</pre>
</p>
</section>
<section>
<head>Verso</head>
<p>
<verse>
<head>Um pequeno verso</head>
<stanza>
<speaker>Isto é um speaker</speaker>
<line>Isto é um line</line>
<stage>Isto é um stage</stage>
</stanza>
</verse>
</p>
</section>
<section>
<head>Citação de um bloco</head>
<p>O bloco seguinte é uma citação:<blockquote>
<p>bla, bla, bla, bla, bla, bla, bla, bla, bla, bla </p>
<p>bla, bla, bla, bla, bla, bla, bla, bla, bla, bla</p>
</blockquote>
</p>
</section>
</chapter>
<chapter id="linkchapter">
<head>Ligações hipertexto</head>
<p>As ligações hipertexto permitem ligar capítulos, seccções, figuras, tabelas,
...<link goesto="linkdemo">Siga esta ligação para voltar ao 1º capítulo</link>
</p>
</chapter>
<chapter>
<head>Multimédia</head>
<p>Aqui temos uma imagem</p>
<mm object="istlogo.gif">Exemplo de uma imagem</mm>
<p>Aqui temos mais multimédia</p>
<mm object="drum.wav" inline="false">Algum som (tambor)</mm>
</chapter>
<chapter>
<head>Tabelas</head>
<table>
<caption> Exemplo de uma tabela </caption>
<row>
<rowhead>Palavra</rowhead>
<colhead>olá</colhead>
<colhead>adeus</colhead>
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
141
</row>
<row>
<rowhead>Francês</rowhead>
<c>bonjour</c>
<c>au revoir</c>
</row>
<row>
<rowhead>Inglês</rowhead>
<c>hello</c>
<c>goodbye</c>
</row>
</table>
<table>
<caption>Segundo exemplo de uma tabela</caption>
<row>
<rowhead>Palavra</rowhead>
<colhead>hoje</colhead>
<colhead>amanhã</colhead>
</row>
<row>
<rowhead>Francês</rowhead>
<c>aujourdui</c>
<c>demain</c>
</row>
<row>
<rowhead>Inglês</rowhead>
<c>today</c>
<c>tomorow</c>
</row>
</table>
</chapter>
</body>
<back>
<bibliography>
<head>Referências e Bibliografia</head>
<citation worktype="newspaper">
<address>endereco</address>
<articletitle>titulo de artigo</articletitle>
<bible>biblia</bible>
<court>tribunal</court>
<edition>edição</edition>
<editor>editor</editor>
<email>email</email>
<handle>handle</handle>
<note>nota</note>
<number>numero</number>
<pages>paginas</pages>
<pubdate>data da publicação</pubdate>
<publisher>publisher</publisher>
<url>url</url>
<version>versão</version>
<volume>volume</volume>
<workauthor>autor do trabalho</workauthor>
<worktitle>titulo do trabalho</worktitle>
</citation>
<citation worktype="book">
<workauthor>Stallings, W.</workauthor>
<worktitle>Network
and
internetwork
security
:
principles
practice</worktitle>
<pubdate>1995</pubdate>
</citation>
</bibliography>
<appendix>
<head>Exemplo de um apêndice</head>
<p>Os apêndices funcionam como capítulos. Apenas muda a sua numeração.</p>
<section>
<head>Secção de um apêndice</head>
<p>Aqui temos uma secção de um apêndice</p>
<subsection>
<head>Subsecção de um apêndice</head>
<p>Aqui temos uma subsecção de um apêndice...</p>
</subsection>
</section>
</appendix>
<appendix>
<head>Exemplo de um apêndice</head>
and
142
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
<p>Os apêndices funcionam como capítulos. Apenas muda a sua numeração.</p>
</appendix>
<vita>
<head>O meu currículo</head>
<p>Eu nasci em Lisboa num dia de sol...</p>
<p>Depois,...</p>
</vita>
</back>
</dtd>
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
D.
143
APRESENTAÇÃO DO DOCUMENTO
Apresenta-se de seguida uma sequência de 9 imagens ilustrando a visualização completa da
dissertação do exemplo que tem sido utilizado. A visualização obedece ao formato definido pela
folha de estilo anterior.
A sequência de imagens corresponde a uma mesma janela (janela do cliente Internet Explorer, da
Microsoft), mostrada em 9 momentos diferentes de focagem.
144
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
145
146
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
APÊNDICE A - DEFINIÇÃO XML DO FORMATO PARA DISSERTAÇÕES E TESES DIGITAIS
147
Referências
Adobe Systems Inc. (1985). Postscript Language Tutorial and Cookbook. Fifteenth printing, April 1990. Reading
(MA): Addison Wesley Publishing.
Anderson, G.; Lasher, R.; Reich, V. (1996). The Computer Science Technical Report (CS-TR) Project: A
Pioneering Digital Library Project Viewed from a Library Perspective. The Public-Access Computer
Systems Review 7, No 2, 1996. <http://info.lib.uh.edu/pr/v7/n2/ande7n2.html>
Arms, Caroline; Klavans, Judith; Waters, Donald (1999). Enabling Access in Digital Libraries: A Report on a
Workshop on Access Management. February 1999. The Digital Library Federation, Council on Library and
Information Resources. Washington, DC, USA.
Bearman, D.; Miller, E.; Rust, G.; Trant, J.; Weibel, S. (1999). A Common Model to Support Interoperable
Metadata. D-Lib Magazine, vol 5, nº1. Janeiro 1999.
Borbinha, J.L. (2000). A URN Namespace for resources maintained by the National Library of Portugal.
Proposta de RFC.
Borbinha, J.L.; Ferreira, J.; Jorge, J; Delgado, J. (1998). A Digital Library for a Virtual Organization.
Proceedings of the Hawai’i International Conference On System Sciences, 6-9 Janeiro 1998, Khoala Coast,
Hawai’i, USA. <http://bruxelas.inesc.pt/~jlb/publica/hicss31/hicss31c.ps.gz>
Borbinha, J.L.; Ferreira, J.; Jorge, J; Delgado, J. (1997). Networked Digital Libraries: the Concept and a Case
Study. ACM SIGIR-97 - Workshop on Networked Information Retrieval, 31 Julho 1997, Philadelphia, USA.
Borbinha, José; Freire, Nuno; Cardoso, Fernando; Campos, Fernanda; Castanheira, Luisa (1998). Depósito de
Publicações Digitais. EEI'
98 – Encontro de Engenharia Informática – Colégio de Engenharia Informática –
Ordem dos Engenheiros, Aveiro, 10 a 12 de Dezembro de 1998.
Borbinha, José. (2000). Bibliotecas Digitais – O Futuro Através da Biblioteca Tradicional. Tese de
doutoramento. Intituto Superior Técnico. 2000.
Bowman, C.M., et al. 1995. The Harvest Information Discovery and Access System. Computer Networks and
ISDN Systems. 28 no. 1 & 2: pp. 119-125.
Crocker, D.; Overell, P.. (1997). Augmented BNF for Syntax Specifications: ABNF, RFC 2234, Novembro 1997.
Davis, J.; Lagoze, C.; Fielding, D.; Marisa, R. (2000). DIENST Protocol Specification.
<http://www.cs.cornell.edu/cdlrg/dienst/protocols/DienstProtocol.htm>
Davis, J. R.; Lagoze, C. (2000). NCSTRL: Design and Deployment of a Globally Distributed Digital Library.
Journal of the American Society for Information Science (JASIS), 2000.
<http://www.cs.cornell.edu/lagoze/papers/NCSTRL-IEEE3.doc>
Decreto-Lei Nº74/82 de 3 de Março (Depósito Legal)
<http://www.biblioteca-nacional.pt/bn/biblioteca/legislação/dep_leg.html>
Dublin Core Metadata Initiative, Dublin Core Metadata Element Set, Version 1.1,
<http://purl.org/dc/documents/rec-dces-19990702.htm>
Dushay, N. ;French, J. C. (1999). Using Query Mediators for Distributed Searching in Federated Digital
Libraries, Digital Libraries '
99: The Fourth ACM Conference on Digital Libraries, Berkeley, 1999.
< http://cs-tr.cs.cornell.edu/Dienst/UI/1.0/Display/xxx.cs.DL/9902020>
Dushay, N. ;French, J. C.; Lagoze, C. (1999a).Predicting Performance of Indexers in a Distributed Digital
Library. Cornell University Computer Science, Ithaca, NY, Technical Report TR99-1743, Maio 1999.
<http://cs-tr.cs.cornell.edu/Dienst/UI/1.0/Display/ncstrl.cornell/TR99-1743>
Dushay, N. ;French, J. C.; Lagoze, C. (1999b). A Characterization Study of NCSTRL Distributed Searching.
Cornell University Computer Science, Technical Report TR99-1725, Janeiro 1999.
<http://cs-tr.cs.cornell.edu/Dienst/UI/1.0/Display/ncstrl.cornell/TR99-1725>
Erikson, Hans-Erik; Penker, Magnus (1998). UML Toolkit. John Wiley & Sons, Inc., New York, USA.
Frada, João José Cúcio (1997). Guia prático para elaboração e apresentação de trabalhos científico. 7ª Edição,
Edições Cosmos.
Freire, Nuno (1998). Integration of Multilingual Classification Systems with the Dienst digital library system.
Eighth DELOS workshop, Estocolmo, Suécia, 21-23 de Outubro de 1998.
149
150
REFERÊNCIAS
Freire, Nuno (2000). Interoperability Metadata Set for NDLTD. Workshop DTDs and the usage of new XMLtechnologies for electronic theses and dissertations.Berlim, Alemanha, Maio de 2000.
Fox, Edward A.; Eaton, J. L.; McMillan, G.; Kipp, N. A.; Weiss, L.; Arce, E.; Guyer, S. (1996). National Digital
Library of Theses and Dissertations. D-Lib Magazine, September 1996.
<http://www.dlib.org/dlib/september96/theses/09fox.html>
Goldfarb, Charles F. (1990). The SGML Handbook. Oxford University Press, New York, USA.
Graham, Peter, S. (1994). Intellectual Preservation and Electronic Intellectual Property. Proceedings:
Technological Strategies for Protecting Intellectual Property in the Networked Multimedia Environment
Coalition for Networked Information. <http://www.cni.org/docs/ima.ip-workshop/Graham.html>
Gulik, D. van; Iannella, R.; Faltstrom, P. (2000). URN Namespace Definition Mechanisms. RFC 2611. Novembro
2000. <http://www.ietf.org/internet-drafts/draft-ietf-urn-rfc2611bis-00.txt>
Hakli, Esko; Hakala, Juha (1998). URN Implementation in National Libraries. Discussion paper – Conference of
European National Libraries, Prague, October 1, 1998.
Haynes, David (1998). Electronic publications – an agenda for publishers and national libraries. Report of the
CoBRA+ Concerted Action to the CENL/FEP Joint Committee on electronic publications. InfoConsult (Europe)
Ltd. November 1998.
Hillmann, Diane. (2000). Using Dublin Core. <http://purl.oclc.org/dc/documents/wd/usageguide-20000716.htm>
Holt, Brian P.; McCallum, Sally H.; Long, A. B.; Campos, Fernanda (1989). Manual UNIMARC. Biblioteca
Nacional, Lisboa.
IFLA. (1996). UNIMARC: An Introduction. International Federation of Library Associations and Institutions.
1996. <http://www.nlx-bnc.ca/ifla/VI/p1996-1/unimarc.htm>
IFLA (1998). Functional requirements for bibliographic records: final report. IFLA Study Group on the
Functional Requirements for Bibliographic Records, International Federeration of Library Associations and
Institutions, The Hague, The Netherlands.
Indexdata. (1999). Zebra Server - Administrators's Guide and Reference. Indexdata. 1999
<http://www.indexdata.com/zebra/zebra.ps.gz>
Lagoze, Carl; Davis, James R. (1995). Dienst - An Architecture for Distributed Document Libraries.
Communications of the ACM, Abril de 1995, Vol 38. <http://www.cs.cornell.edu/cdlrg/dienst/papers/cacm.htm>
Lagoze, C. (1996). The Networked Computer Science Technical Reports Library. Cornell Computer Science
Technical Report, Julho 1996. <http://cs-tr.cs.cornell.edu/Dienst/UI/2.0/Describe/ncstrl.cornell/TR96-1595>
Lagoze, C.; Fielding, D. (1998). Defining Collections in Distributed Digital Libraries. D-Lib Magazine, 1998.
<http://www.dlib.org/dlib/november98/lagoze/11lagoze.html>
Lagoze, C.; Fielding, D.; Payette, S. (1998). Making Global Digital Libraries Work: Collection Service,
Connectivity Regions, and Collection Views. ACM Digital Libraries '
98, Pittsburgh, 1998.
<http://www.cs.cornell.edu/lagoze/papers/lagoze.pdf>
Lagoze, C.;Lynch, C.; Jr, R. (1996). The Warwick Framework: A Container Architecture for Aggregating Sets
of Metadata. Cornell University Computer Science, Technical Report TR-96-1593. Junho 1996.
<http://cs-tr.cs.cornel.edu/Dienst/UI/2.0/Describe/ncstrl.cornell/TR96-1593>
Lagoze, C.; Hunter, J.; Brickley, D. (2000). An Event-Aware Model for Metadata Interoperability. Proceedings
of the 4th European Conference, ECDL 2000. Lisbon, Portugal. Setembro 2000.
Lasher, R.; Cohen, D. (1995). A Format for Bibliographic Records. RFC 1807. Junho 1995.
<http://www.cis.ohio-state.edu/htbin/rfc/rfc1807.html>
Library of Congress. (1997). Dublin Core/MARC/GILS Crosswalk. <http://lcweb.loc.gov/marc.dccross.html>
1997.
Library of Congress. (1998). MARC DTDs Document Type Definitions: Background and Development. Library
of Congress, United States, 1998. <http://lcweb.loc.gov/faq/catfaq.html>
Lunau, C. (2000). The Bath Profile: what is it and why should I care? National Library of Canada. Março 2000.
<http://www.nlc-bnc.ca/bath/prof.pdf>
Lynch, Clifford A. (1997). The Z39.50 Information Retrieval Standard. Part I: A Strategic View of Its Past,
Present and Future. D-Lib Magazine, Abril 1997. <http://www.dlib.org/dlib/april97/04lynch.html>
MLA (1998). MLA Style. Modern Language Association. <http://www.mla.org>
Miller, Eric (1998). An Introduction to the Resource Description Framework. D-Lib Magazine, May 1998.
<http://www.dlib.org/dlib/may98/miller/05miller.html>
REFERÊNCIAS
151
Moats, R. (1997). URN Syntax. IETF Network Working Group, May 1997.
NISO/ANSI. (1995). Information Retrieval (Z39.50): Application Service Definition and Protocol
Specification. NISO/ANSI, 1995. <http://lcweb.loc.gov/z3950/agency/document.html>
Ora, L. (1997). Introduction to RDF Metadata. W3C NOTE. Novembro de 1997.
<http://www.w3.org/TR/NOTE-rdf-simple-intro>
Paepcke, Andreas, Chen-Chuan Chang, Hector Garcia-Molina, and Terry Winograd. (1998). Interoperability for
Digital Libraries Worldwide. Communications of the ACM 41, no 4. 1998.
Phanouriou, Constantinos; Kipp, Neill A.; Sornil, Ohm; Mather, Paul; Fox, Edward A. (1999). A Digital Library
for Authors: Recent Progress of the Networked digital Library of Theses and Dissertations. Proceedings of
the Digital Libraries ’99, Agosto 1999.
Pfeifer, U. (1995). The enhanced freeWAIS distribution Edition 0.5, for freeWAIS-sf 2.0. Outubro 1995
<http://ls6-www.informatik.uni-dortmund.de/ir/projects/freeWAIS-sf/fwsf.html>
Rosenberg, Doug; Scott, Kendall (1999). Use Case Driven Object Modeling with UML: A Practical Approach.
Addison Wesley Longman, Inc., USA.
Sompel, Herbert; Lagoze, Carl; The Santa Fe Convention of the Open Archives Initiative. D-Lib Magazine 6, no.
2. <http://www.openarchives.org/sfc/sfc_entry.htm>
Stubley, Peter. (1999). Clumps as Catalogues. Ariadne no. 22.
<http://www.ariadne.ac.uk/issue22/distributed/distukcat2.html>
Sun, S. X.; Lannom, L. (2000) Handle system overview. IETF Draft, Agosto 2000
<http://www.ietf.org/internet-drafts/draft-sun-handle-system-05.txt>
Sun, S. X.; Lannom, L.; Shi, J. (2000) Handle System Protocol (ver 2.0) Specification. IETF Draft, Outubro
2000
<http://www.ietf.org/internet-drafts/draft-sun-handle-system-protocol-00.txt>
Sun, S. X.; Reilly, S.; Lannom, L. (2000) Handle System Protocol (ver 2.0) Specification. IETF Draft, Outubro
2000 <http://www.ietf.org/internet-drafts/draft-sun-handle-system-def-03.txt>
Baker, Thomas. (1998). Languages for Dublin Core. D-Lib Magazine, Dezembro 1998,
< http://www.dlib.org/dlib/december98/12baker.html>
Baker, Thomas. (2000). A Grammar of Dublin Core. D-Lib Magazine, vol. 6, n 10, Outubro 2000.
<http://www.dlib.org/dlib/october00/baker/10baker.html>
USEMARCON. (1997). USEMARCON Technical Manual. Projecto USEMARCON. 1997.
Van de Sompel, Herbert; Thomas Krichel, Michael L. Nelson e outros (2000). The UPS Prototype: An
Experimental End-User Service across E-Print Archives. D-Lib Magazine 6, no. 2.
<http://www.dlib.org/dlib/february00/vandesompel-ups/02vandesompel-ups.html>
Virginia Tech. (2000). MARC as an Open Archives Metadata Standard. Digital Libraries Research Laboratory,
Virginia Tech, United States. Agosto 2000. <http://www.dlib.vt.edu/projects/OAi/marcxml/marcxml.html>
Weibel, Stuart; Lagoze, Carl. (1997). An element set to support resource discovery. International Journal on
Digital Libraries 1997.
Young, Jefrey R. (1998). Requiring Theses in Digital Format: the First Year at Virgina Tech. The Chronicle of
Higher Education, February 13, 1998, pp. A29.
Baixar