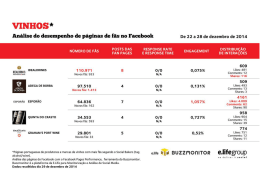
Pós-Graduação em Ciência da Computação “ASDP: Um Processo de Análise de Sentimento em Debates Polarizados não Ideológicos” Por Francisco Assis Ricarte Neto Dissertação de Mestrado Universidade Federal de Pernambuco [email protected] www.cin.ufpe.br/~posgraduacao RECIFE, FEVEREIRO/2014 UNIVERSIDADE FEDERAL DE PERNAMBUCO CENTRO DE INFORMÁTICA PÓS-GRADUAÇÃO EM CIÊNCIA DA COMPUTAÇÃO FRANCISCO ASSIS RICARTE NETO “ASDP: Um Processo de Análise de Sentimento em Debates Polarizados não Ideológicos " ESTE TRABALHO FOI APRESENTADO À PÓS-GRADUAÇÃO EM CIÊNCIA DA COMPUTAÇÃO DO CENTRO DE INFORMÁTICA DA UNIVERSIDADE FEDERAL DE PERNAMBUCO COMO REQUISITO PARCIAL PARA OBTENÇÃO DO GRAU DE MESTRE EM CIÊNCIA DA COMPUTAÇÃO. ORIENTADOR(A): Flávia de Almeida Barros RECIFE, FEVEREIRO/2014 Catalogação na fonte Bibliotecário Jefferson Luiz Alves Nazareno, CRB 4-1758 Ricarte Neto, Francisco Assis. ADSP: um processo de análise de sentimento em debates polarizados não ideológicos. – Recife: O Autor, 2014. 121f. : fig. Orientadora: Flávia de Almeida Barros. Dissertação (Mestrado) - Universidade Federal de Pernambuco. Cin. Ciência da computação , 2014. Inclui referências e apêndice. 1. Ciência da computação . 2Inteligência Artificial. I. Barros, Flávia de Almeida. (orientador). II. Título. 004 (22. ed.) MEI 2014-55 Dissertação de Mestrado apresentada por Francisco Assis Ricarte Neto à Pós-Graduação em Ciência da Computação do Centro de Informática da Universidade Federal de Pernambuco, sob o título “ASDP: Um Processo de Análise de Sentimento em Debates Polarizados não Ideológicos” orientada pela Profa. Flávia de Almeida Barros e aprovada pela Banca Examinadora formada pelos professores: ______________________________________________ Profa. Patricia Cabral de Azevedo Restelli Tedesco Centro de Informática / UFPE ______________________________________________ Prof. Raimundo Santos Moura Departamento de Computação / UFPI _______________________________________________ Profa. Flávia de Almeida Barros Centro de Informática / UFPE Visto e permitida a impressão. Recife, 18 de fevereiro de 2014. ___________________________________________________ Profa. Edna Natividade da Silva Barros Coordenadora da Pós-Graduação em Ciência da Computação do Centro de Informática da Universidade Federal de Pernambuco. À minha avó Maria Iracema (in memoriam), que foi e sempre será minha referência para agir com responsabilidade, dignidade e justiça. Agradecimentos Agradeço primeiramente a Deus, pois sem fé nele nada é possível. Às minhas amadas mães Francimar (in memoriam) e Iracema (in memoriam) que sempre serão meus maiores exemplos de vida. Sei que estão orgulhosas, e todas as minhas conquistas são dedicadas inteiramente às senhoras. À minha família que, apesar da distância, sempre está me incentivando aos estudos. Agradeço em especial aos meus tios-pais Francira e Elio por todo os conselhos e suportes; aos meus primos-irmãos Irapuá e Egbara que sempre me apoiaram. À minha amada noiva Dracy por toda sua paciência, carinho e amor durante todo esse tempo em que estive longe. Dificilmente esse trabalho seria concluído sem suas palavras amorosas. À minha orientadora Flavia, por toda sua atenção, incentivo e orientação. Seu conhecimento e experiência foram decisivos no decorrer do mestrado. Serei eternamente grato. Às amizades formadas em Recife: Evandro, Elvio, Jean, Jefferson, Luiza, Raphael e Társis. E por fim, agradeço aos professores do Centro de Informática– UFPE, e do Departamento de Computação –UFPI , que contribuíram com minha formação acadêmica. A todos, o meu muito obrigado. Resumo Cada vez mais, pessoas recorrem a reviews, fóruns ou redes sociais em busca de opiniões sobre produtos e serviços, para embasar suas decisões. Contudo, a análise manual dessas opiniões não é um processo trivial, devido à enorme quantidade de informações disponíveis. Outro problema comum são as opiniões falsas, ou propositadamente tendenciosas sobre algum produto. Nestes casos, para se obter uma posição “confiável” dos usuário acerca de algum item, é necessário buscar e analisar uma grande quantidade de opiniões. Neste contexto, a Mineração de Opinião ou Análise de Sentimento (AS), vem auxiliar os usuários que buscam opiniões na Web. A AS é a área de estudo que analisa opiniões, sentimentos e emoções de pessoas acerca de algum tópico (produto, serviço, evento). Este trabalho de Mestrado teve como objetivo principal a Análise de Sentimentos em Debates Polarizados (e.g., iPhone x Blackberry), um domínio ainda pouco explorado pela AS. O foco central é a classificação da postura dos participantes do debate (i.e., se apóiam o produto A ou B). A partir dos resultados dessa análise, pode-se identificar, por exemplo, que produto é o preferido no mercado. Contudo, esta é uma tarefa complexa, pois esses debates são longos, e apresentam elementos que dificultam a classificação automática do sentimento, tais como ironias ou ofensas direcionadas a outros participantes ou produtos. Apresentamos aqui o ASDP, um Processo de Análise de Sentimento em Debates Polarizados, com foco nos debates não ideológicos. Aqui, a classificação da postura dos posts é feita com base na identificação de padrões linguísticos que foram observados em corpora de debates polarizados. Esses padrões recuperam triplas do tipo <produto, palavra opinativa, sentença>, que consideram o contexto de ocorrência dos termos para a atribuição da classe do post. O ASDP também trata a ocorrência de referências anafóricas e de concessões. O protótipo implementado conta ainda com um módulo para a criação e análise de uma rede de replies em forma de grafo, a fim de auxiliar no processo de classificação final da postura dos posts. Os resultados dos experimentos revelam taxas de 73,91% de acerto na classificação dos posts. Os padrões linguísticos implementados neste trabalho foram desenvolvidos dentro da abordagem de Sistemas Baseados em Conhecimento, o que torna fácil a reusabilidade desta técnica em outros domínios, bem como garante uma fácil extensibilidade dos padrões. Também foram desenvolvidas e utilizadas técnicas Linguísticas para auxiliar a classificação dos posts dos debates. Palavras-chave: Análise de Sentimento, Debates Polarizados, Postura do Post, Padrões Linguísticos. Abstract Nowadays it is common for people to seek for opinions in online reviews, forums and social networks to make their decisions. However, manual analysis of these opinions it is not a trivial process due the huge amount of information available. Another problem are fake or intentionally biased opinions about a product/service. In these cases, to obtain a general “realible” stance about an item it is necessary to analyze a large amount of data. In this context, the Opinion Mining or Sentiment Analysis (SA) has been assisting users to find opinions on Web. SA is research area that analyzes opinions, emotions and feelings of people about some topic (product, service, event). This Master Thesis had as core objective to study the Sentiment Analysis on two-side debates (e.g., iPhone vs. Blackberry) a field yet unexplored by SA. The goal is to provide the classification of users stances on debate (i.e., which side they support, product A or product B). From these results, one can identify for example, the preferred product in the market. However, this is a complex task because these debates are too longs, and present elements (e.g., irony, insults) that complicate even more the task of automatic sentiment classification. In this thesis we present ASDP, a process of sentiment analysis on two-side debates focusing on non-ideological debates. The classification of posts stance is based on linguistic patterns that were observed on corpora debate. These patterns extract triples <product, opinion word, sentence> which are used to assignment the post stance. The ASDP also treats of anaphora resolution, concessions and has a module for creating and analyzing a graph of replies presents on debate, in order to assist the final stance classification. The experiment results show 73,91% of precision on classification of posts. The linguistics patterns implemented in this work were developed within approach Knowledge Based, which makes quite simple the reusability of this technique in other different domains as well as ensure easy extensibility of the patterns. Were also developed and used linguistic techniques to assist the stance classification. Keywords: Sentiment Analysis, Non-Ideological debates, stance, linguistic patterns Lista de Figuras Figura 2.1 Resultado comparativo entre duas câmeras digitais representadas por cores distintas (Liu, 2012) . . . . . . . . . . . . . . . . . . . . . . Figura 3.1 Exemplos de trechos argumentações polarizadas retirados de (Somasundaran e Wiebe, 2010). A coluna da esquerda apresenta o trecho da argumentação positiva/negativa, e a coluna da direita mostra os marcadores de argumentação. . . . . . . . . . . . . . . . . . . . . . . . . . . . Figura 3.2 Lista de atributos utilizados pelo classificador do trabalho de (Walker et al., 2012). Na coluna da esquerda estão os atributos, e na coluna da direita, existe uma breve explanação sobre cada um dos atributos. Figura 3.3 Resultados do primeiro experimento desenvolvido em (Walker et al., 2012). Os primeiros quatro debates que estão sobre a linha horizontal são debates não ideológicos. Na coluna da esquerda são apresentados os valores das acurácias relacionadas aos atributos utilizados na classifiação. Os demais debates apresentados são ideológicos. . . . . . . . . . . Figura 3.4 Resultados do segundo experimento desenvolvido em (Walker et al., 2012). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Figura 3.5 Exemplos de regras sintáticas utilizadas por Somasundaran e Weibe. Figura 3.6 Resultados das probabilidades apresentadas no trabalho de Somasundaran e Weibe sobre o debate iPhone vs. Blackberry . . . . . . . . . Figura 3.7 Resultados de Somasundaran e Wiebe (2009) . . . . . . . . . . . Figura 3.8 Estrutura do léxico subjetivo MPQA com exemplos de palavras. . Figura 3.9 Estrutura do léxico SentiWordNet contendo exemplos de palavras opinativas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Figura 4.1 Figura 4.2 Figura 4.3 Figura 4.4 Figura 4.5 Figura 4.6 Figura 4.7 Figura 4.8 Figura 4.9 Arquitetura geral do protótipo ASDP. . . . . . . . . . . . . . . Arquitetura da etapa de pré-processamento do protótipo ASDP. Lista de abreviações presentes na base de subtituição. . . . . . Lista de contrações presentes na base de subtituição. . . . . . . Lista de sinônimos presentes na base de subtituição. . . . . . . Etiquetas presentes no POS-tagger de Stanford. . . . . . . . . Arquitetura da etapa de classificação de sentimento do ASDP. . Lista de expressões negativas . . . . . . . . . . . . . . . . . . Lista de conectivos utilizados para a análise de concessões. . . . . . . . . . . . 32 39 41 41 42 43 44 45 46 47 53 55 57 57 58 61 62 65 65 Figura 5.1 Rede de Replies do debate Playstation 3 vs. Nintendo Wii . . . . 89 Lista de Tabelas Tabela 3.1 Quantidade de posts nos corpora de debates de Somasundaran e Weibe (Somasundaran e Wiebe, 2009). . . . . . . . . . . . . . . . . . . Tabela 5.1 Quantidade de posts extraídos por debate. . . . . . . . . . . . . Tabela 5.2 Matriz de confusão para o cálculo do erro de classificação . . . . Tabela 5.3 Matriz confusão da classificação dos posts do debate Firefox vs. Internet Explorer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.4 Matriz confusão da classificação dos posts no debate Iphone vs. Blackberry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.5 Matriz confusão da classificação dos posts no domínio Opera vs. Firefox . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.6 Matriz confusão da classificação dos posts no domínio Playstation 3 vs. Nintendo Wii . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.7 Matriz confusão da classificação dos posts no domínio Playstation 3 vs. Xbox 360 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.8 Resultado da classificação por posts do debate Firefox vs. Internet Explorer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.9 Resultado da classificação por posts do debate Iphone vs. Blackberry Tabela 5.10 Resultado da classificação por posts do debate Opera vs. Firefox Tabela 5.11 Resultado da classificação por posts do debate Playstation 3 vs. Nintendo Wii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.12 Resultado da classificação por posts do debate Firefox vs. Internet Explorer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.13 Resultado das classificações dos debates . . . . . . . . . . . . . Tabela 5.14 Matriz confusão da classificação dos posts do debate Firefox vs. Internet Explorer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.15 Matriz confusão da classificação dos posts no debate Iphone vs. Blackberry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.16 Matriz confusão da classificação dos posts no domínio Opera vs. Firefox . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.17 Matriz confusão da classificação dos posts no domínio Playstation 3 vs. Nintendo Wii . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.18 Matriz confusão da classificação dos posts no domínio Playstation 3 vs. Xbox 360 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 73 76 78 79 79 79 80 81 81 81 81 82 82 83 83 84 84 84 Tabela 5.19 Resultado da classificação por posts do debate Firefox vs. Internet Explorer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.20 Resultado da classificação por posts do debate Iphone vs. Blackberry Tabela 5.21 Resultado da classificação por posts do debate Opera vs. Firefox Tabela 5.22 Resultado da classificação por posts do debate Playstation 3 vs. Nintendo Wii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.23 Resultado da classificação por posts do debate Firefox vs. Internet Explorer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.24 Resultado das classificações dos debates . . . . . . . . . . . . . Tabela 5.25 Matriz confusão da classificação dos posts do debate Firefox vs. Internet Explorer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.26 Matriz confusão da classificação dos posts no debate Iphone vs. Blackberry . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.27 Matriz confusão da classificação dos posts no domínio Opera vs. Firefox . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.28 Matriz confusão da classificação dos posts no domínio Playstation 3 vs. Nintendo Wii . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.29 Resultado da classificação por posts do debate Firefox vs. Internet Explorer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.30 Resultado da classificação por posts do debate Iphone vs. Blackberry Tabela 5.31 Resultado da classificação por posts do debate Opera vs. Firefox Tabela 5.32 Resultado da classificação por posts do debate Playstation 3 vs. Nintendo Wii . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.33 Resultado das classificações dos debates . . . . . . . . . . . . . Tabela 5.34 Resultados de Somasundaran e Wieber (2009) . . . . . . . . . . Tabela 5.35 Comparação na quantidade de posts utilizados no ASDP, no trabalho de Somasundaran e Wiebe (2009) e no trabalho de Walker et al. (2012) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Tabela 5.36 Apresentação dos resultados dos trabalhos de Somasundaran e Wiebe (2009), Walker et al. (2012) e o ASDP . . . . . . . . . . . . . . 85 85 85 86 86 86 90 90 90 91 92 92 92 92 93 94 95 96 Sumário 1 Introdução 1.1 Motivação e Contexto . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.2 Trabalho Realizado . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3 Organização do Trabalho . . . . . . . . . . . . . . . . . . . . . . . . . 13 14 15 16 2 Análise de Sentimento 2.1 Áreas Correlatas . . . . . . . . . . . . . . . . . . . . . 2.1.1 Mineração de Texto . . . . . . . . . . . . . . . 2.1.2 Mineração da Web . . . . . . . . . . . . . . . 2.1.3 Mineração de Opiniões/ Análise de Sentimentos 2.2 Análise de Sentimento – Detalhamento . . . . . . . . . 2.2.1 Nomenclatura adotada e Definições . . . . . . 2.2.2 Níveis da AS . . . . . . . . . . . . . . . . . . 2.3 Etapas da Análise de Sentimentos . . . . . . . . . . . 2.3.1 Detecção de subjetividade . . . . . . . . . . . 2.3.2 Extração de atributos . . . . . . . . . . . . . . 2.3.3 Classificação de sentimentos . . . . . . . . . . 2.3.4 Apresentação dos resultados . . . . . . . . . . 2.4 Aplicações e Ferramentas da AS . . . . . . . . . . . . 2.5 Desafios . . . . . . . . . . . . . . . . . . . . . . . . . 2.6 Conclusão . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 19 19 21 22 23 23 26 27 28 28 29 31 32 33 34 . . . . . . . . 35 35 38 40 45 46 47 48 49 4 ASDP: Um Processo de Análise de Sentimento em Debates Polarizados 4.1 Caracterização do Problema . . . . . . . . . . . . . . . . . . . . . . . . 51 52 3 Análise de Sentimento em Debates Polarizados 3.1 Visão Geral . . . . . . . . . . . . . . . . . 3.2 AS em Debates Ideológicos . . . . . . . . . 3.3 AS em Debate Não Ideológicos . . . . . . . 3.4 Léxicos Subjetivos . . . . . . . . . . . . . 3.5 Fenômenos Linguísticos em debates . . . . 3.5.1 Anáforas . . . . . . . . . . . . . . 3.5.2 Concessões . . . . . . . . . . . . . 3.6 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.2 4.3 . . . . . . . . . . . . . . . . . . . 53 54 55 56 56 56 58 58 58 59 59 61 62 63 64 65 67 69 71 . . . . . . . . . . . 72 73 75 77 77 78 82 83 88 89 93 97 6 Conclusão 6.1 Contribuições finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6.2 Trabalhos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98 98 99 4.4 4.5 Arquitetura do Sistema . . . . . . . . . . . . Pré-processamento dos Posts . . . . . . . . . 4.3.1 Eliminação de posts não opinativos . . Léxico Subjetivo . . . . . . . . . . . Exemplos de posts eliminados . . . . 4.3.2 Normalização dos textos . . . . . . . Base de substituições . . . . . . . . . Exemplos de posts normalizados . . . 4.3.3 POS-Tagging . . . . . . . . . . . . . Exemplos de posts etiquetados . . . . Classificação de Sentimento . . . . . . . . . . 4.4.1 Resolução de Anáfora . . . . . . . . . 4.4.2 Atribuição Inicial de Polaridade . . . Formação das triplas . . . . . . . . . Atribuição de Polaridade da Tripla . . 4.4.3 Análise de Concessões . . . . . . . . 4.4.4 Classificação das Posturas dos Posts . 4.4.5 Criação e Análise do Grafo de Replies Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 Experimentos e Resultados 5.1 Corpora de Debates . . . . . . . . . . . . . . . . . . . . . . . . . . . 5.2 Métricas de Avaliação . . . . . . . . . . . . . . . . . . . . . . . . . . 5.3 Classificação de Opinião em Debates de Produtos . . . . . . . . . . . 5.3.1 Atribuição de Polaridade utilizando o Léxico Subjetivo . . . . Resultados Obtidos . . . . . . . . . . . . . . . . . . . . . . . 5.3.2 Classificação com o uso de Resolução de Anáfora e Concessão Resultados Obtidos . . . . . . . . . . . . . . . . . . . . . . . 5.3.3 Classificação do Grafo de Replies . . . . . . . . . . . . . . . Resultados Obtidos . . . . . . . . . . . . . . . . . . . . . . . 5.4 Análise de Trabalhos Relacionados . . . . . . . . . . . . . . . . . . . 5.5 Considerações Finais . . . . . . . . . . . . . . . . . . . . . . . . . . Referências 101 Apêndice 109 A Bases de Substituições 110 A.1 Contrações . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 110 A.2 Abrevições . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112 A.3 Sinônimos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117 B Dicionário de Gírias 119 1 Introdução A Web 2.0 desencadeou uma explosão de serviços disponíveis na Internet, bem como um grande aumento de usuários na rede. Difundiu-se a criação de blogs, fóruns de discussão, sites de debates, redes sociais e sites de compras, favorecendo o aumento na interação entre os indivíduos. Neste cenário, uma atividade que se tornou bastante frequente é a busca por opiniões sobre produtos e/ou serviços. De forma geral, todos os usuários recorrem a sites de opiniões (reviews), fóruns de discussão ou até mesmo às redes sociais em busca da experiência de outras pessoas antes de tomar suas decisões. Uma pesquisa de opinião realizada nos EUA revelou que entre 73% a 87% das pessoas que buscam opiniões na Web se disseram fortemente influenciadas pelas reviews1 . Os entrevistados afirmaram ainda que estariam dispostos a pagar até 99% a mais por um serviço avaliado como "excelente"em relação a outro avaliado como "bom". Os dados acima confirmam o fato de que a Internet se transformou em um poderosíssimo meio de transmissão de opiniões sobre produtos e serviços. Contudo, apesar de ser fácil encontrar opiniões na grande rede, a sua análise manual não é um processo trivial. Isso se deve a dois fatores principais: a abundância de informações disponíveis, e a dificuldade de se interpretar linguagem natural, que é imprecisa e ambígua por natureza. Uma tendência atual das pessoas é expressar seus pensamentos e pontos de vistas em micro blogs, redes sociais, ou em sites de debates2 , opinando sobre os mais diversos assuntos, desde temas relacionados a política (e.g., guerras, direito sobre armas, aborto) a temas sobre opiniões acerca de produtos. Este comportamento gera oportunidades para empresas de marketing, que buscam gerir a publicidade de políticos em campanhas eleitorais, ou de marcas de produtos no mercado consumidor, analisando o pensamento 1 http://www.comscore.com/press/release.asp?press=1928 2 www.createdebate.com, www.convinceme.net, www.politicalforum.com, www.forandagainst.com 14 1.1. MOTIVAÇÃO E CONTEXTO geral expresso nessas mídias sociais3 . Nesse contexto, a Análise de Sentimento busca extrair a postura/posicionamento (do inglês, stance) de um indivíduo a partir de textos polarizados. Somasundaran e Wiebe (2009) definem stance como uma opinião geral de uma pessoa sobre um objeto, idéia ou posição. Walker et al. (2012) defendem que este ponto de vista (postura) pode ser utilizado na identificação de qual lado um indivíduo está em um debate polarizado, e.g., a favor ou contra a legalização do aborto. A Análise de Sentimento (AS) pode ser definida como a área de estudo que analisa opiniões, sentimentos, atitudes, e emoções de pessoas acerca de produtos, serviços, indivíduos, empresas e eventos (Liu, 2012). O objetivo central é determinar automaticamente a polaridade das opiniões emitidas (se positivas ou negativas). A AS se utiliza de técnicas e métodos de diversas áreas de pesquisa, com destaque para Processamento de Linguagem Natural (PLN) ((Allen, 1995), (Manning e Schütze, 1999)), Mineração de Texto (Feldman e Sanger, 2006), Mineração da Web ((Cooley et al., 1997), (Kosala e Blockeel, 2000), (Liu, 2006)), Recuperação da Informação ((Baeza-Yates e Ribeiro-Neto, 1999), (Manning et al., 2008)) e Inteligência Artificial (Russell e Norvig, 2003) (mais especificamente classificação automática de texto). 1.1 Motivação e Contexto A análise de sentimento é uma área recente na comunidade científica. Os primeiros trabalhos sobre opiniões buscavam investigar o sentimento expresso em textos de reviews) de produtos e filmes ((Pang et al., 2002), (Turney e Littman, 2003), (Dave et al., 2003), (Morinaga et al., 2002)). Desde então, muito já se desenvolveu nessa área, e as abordagens que classificam sentimento em reviews já conseguem realizar esta tarefa com ótimas taxas de precisão ((Silva et al., 2012), (Popescu e Etzioni, 2005), (Qiu et al., 2011), (Hu e Liu, 2004)). Contudo, a AS tradicional não consegue tratar adequadamente um fenômeno relativamente recente: Análise das opiniões em debates online. Os principais fatores que agregam desafios a esta atividade estão associados à dificuldade de interpretar as opiniões nos discursos nos debates. Durante o debate, os participantes apresentam suas preferências e justificam o porquê de suas opiniões estarem corretas. Além disso, para fortalecer seus pontos de vista, alguns 3 http://data-informed.com/presidential-debates-provide-living-laboratory-for-marketers-studying- sentiment-analysis/ 15 1.2. TRABALHO REALIZADO debatedores apresentam argumentações negativas sobre seus adversários ou sobre as opiniões deles. É comum também que durante a evolução do discurso, alguns participantes mudem de opinião, e portanto, passem a defender o lado a qual eram adversários. Complicando ainda mais este cenário, os usuários presentes no debate podem apresentar opiniões positivas sobre alguns aspectos do objeto (produto ou tópico) sendo apoiado pelo lado adversário, sem realmente mudar sua postura no debate. Além disso, alguns debatedores chegam a manifestar opiniões negativas sobre aspectos dos tópicos que defendem. A estes fatores, damos o nome de concessões (Robaldo et al., 2010). A fim de demonstrar a dificuldade de realizar Análise de Sentimento em debates online, Walker et al. (2012) examinaram a classificação da postura dos participantes dentro do corpus de 14 debates distintos, 10 debates ideológicos, e 4 debates não ideológicos. Os autores conduziram um experimento através do Mechanical Turk4 onde a classificação dos posts de debate foi feita por humanos. Eles observaram que apenas 78,26% das pessoas que participaram desse experimento coincidiram sua classificação com a marcação original do post no debate, demonstrando que classificar os posts isoladamente não é uma tarefa trivial nem para humanos. 1.2 Trabalho Realizado Diante do que foi apresentado, esta pesquisa de mestrado tem como objetivo classificar a postura dos participantes de um debate não ideológico mediante a um tema (e.g., qual o melhor Sistema Operacional: Windows ou OSX (Apple)). Para a realização desta tarefa criamos o processo de Análise de Sentimento denominado ASDP que, por meio de técnicas e ferramentas linguísticas, determina a polaridade dos posts do debate através da identificação das palavras opinativas e das entidades associadas a elas. A realização da etapa de classificação de sentimentos é bastante complexa, pois os textos de debate costumam ser longos, e algumas vezes apresentam ironias, ou até mesmo ofensas direcionadas a outros participantes ou produtos. Os indivíduos que participam do debate além de argumentarem sobre a razão de suas preferências serem melhores, podem também tecer críticas sobre as argumentações e preferências dos adversários. Nesse contexto, elaboramos um processo de classificação através de padrões linguísticos que foram observados nos textos. Esses padrões recuperam triplas do tipo <produto, palavra opinativa, sentença> que servirão para a atribuição inicial da polaridade, análise de anáforas, concessões, e com esses e outros fatores associados, poderão definir as 4 https://www.mturk.com/mturk/welcome 16 1.3. ORGANIZAÇÃO DO TRABALHO classes dos posts. O protótipo desenvolvido foi codificado na linguagem de programação Java5 . Para a classificação de sentimentos foram utilizados 807 posts sobre temas de debates não ideológicos. Os experimentos realizados mostram uma classificação de 73,91% de precisão. Dois outros trabalhos conhecidos na literatura e que também fazem a classificação da postura dos posts dentro de debates não ideológicos, são os trabalhos de Somasundaran e Wiebe (2009) e Walker et al. (2012). Através de uma abordagem não supervisionada, Somasundaran e Wiebe (2009) conseguem 68,75% de precisão sobre a análise de posts em debates polarizados não ideológicos. Já o método supervisionado de Walker et al. (2012) obteve 75,38% de acurácia na classificação da postura dos posts em debates não ideológicos. A técnica proposta nesta dissertação de Mestrado, o ASDP, obeteve taxas de precisão e acurácia semelhantes aos resultados de Somasundaran e Wiebe (2009), e Walker et al. (2012), através do uso de padrões linguísticos que podem ser facilmente extendidos e reutilizáveis em outros domínios. Este trabalho foi desenvolvido seguindo a abordagem de Sistemas Baseados em Conhecimento, utilizando-se de técnicas Linguísticas para a classificação dos posts dos debates. 1.3 Organização do Trabalho A presente dissertação está dividida em seis capítulos. Após este capítulo de Introdução, os capítulos seguintes tratam sobre os conceitos de AS, revisões bibliográficas, descrição da abordagem proposta e detalhamento dos experimentos. O capítulo 2 apresenta os principais termos e conceitos sobre Análise de Sentimentos. Este capítulo descreve também os níveis e as etapas que são abordados nos trabalhos relacionados à Mineração de Opiniões. Também apresentamos algumas aplicações existentes no mercado que fazem AS. O capítulo 3 apresenta o estado da arte da Análise de Sentimento em debates online. São descritos os principais desafios desta área, bem como as contribuições existentes na literatura. Apresentamos dois fenômenos linguísticos comuns em debates e que foram tratados nesta pesquisa. Por último, foi mostrado os dois principais léxicos subjetivos presentes na literatura, o léxico MPQA, e o léxico SentiWordNet. O capítulo 4 descreve o processo de AS proposto nesta pesquisa de Mestrado. São 5 http://www.oracle.com/technetwork/java/javase/overview/index.html 17 1.3. ORGANIZAÇÃO DO TRABALHO descritas as técnicas e algoritmos utilizados no desenvolvimento do trabalho. No capítulo 5 apresentamos a metodologia e experimentos realizados. Foi feito também uma comparação entre os resultados obtidos pelo ASDP e duas outras técnicas da literatura. O capítulo 6 apresenta a conclusão deste trabalho juntamente com uma análise dos resultados obtidos. Neste capítulo, propusemos algumas extensões para o ASDP como trabalhos futuros. 18 2 Análise de Sentimento Uma atividade bastante comum hoje em dia é nos depararmos navegando na Web em busca de opiniões sobre produtos e/ou serviços. De forma geral, usuários recorrem a reviews, fóruns ou até mesmo as redes sociais, em busca da experiência de outras pessoas para que possam tomar suas decisões. Apesar de ser fácil encontrar opiniões na Internet, a sua análise manual não é um processo trivial, devido à enorme quantidade de informações disponíveis na Web. Além disso, temos também outros problemas para realizar essa análise: as opiniões falsas, ou propositadamente tendenciosas sobre algum produto (Jindal e Liu, 2007). Logo, para se obter uma posição geral “confiável” dos usuário acerca de algum produto, é necessário buscar e analisar uma quantidade significativa de opiniões na Web. Nesse contexto, a Mineração de Opinião, também conhecida como Análise de Sentimento (AS), vem facilitar a vida dos usuários que buscam opiniões na Web. A Análise de Sentimento é a área de estudo que analisa opiniões, sentimentos, atitudes e emoções de pessoas acerca de produtos, serviços, tópicos, eventos e/ou alguns de seus atributos (Liu, 2012). A AS procura realizar, de forma rápida e automática, a análise das opiniões disponíveis acerca de um produto ou serviço, e retornar para o usuário a opinião geral sobre o objeto de seu interesse. Sempre que queremos tomar decisões importantes buscamos saber o que outras pessoas pensam. As opiniões são fundamentais em várias atividades humanas pois elas são capazes de manipular nosso comportamento. Como já dito, a AS é uma área de pesquisa relativamente recente. O grande impulso para o crescimento dessa área foi o surgimento explosivo dos meios de comunicações sociais (e.g., fóruns de discussão, reviews, blogs, redes sociais, etc.) na Web, onde o público em geral utiliza estes conteúdos para suas tomadas de decisões. Contudo, o foco da AS não é somente voltado para auxiliar usuários. Entre os 19 2.1. ÁREAS CORRELATAS trabalhos que deram início às investigações nessa área, citamos (Wiebe, 1994), cujo foco era reconhecer sentenças subjetivas1 em textos de narrações fictícias em terceira pessoa, para então identificar o ponto de vista psicológico do personagem. A AS também é muito útil em áreas como Marketing, Bolsa de Valores, eleições políticas, entre outros. Existem trabalhos que buscam identificar as opiniões dos eleitores sobre políticos e seus projetos (e.g., (Mullen e Malouf, 2006), (Wang et al., 2012)). Neste capítulo, mostraremos uma visão geral da Mineração de Opinião/AS. A seção 2.1 define o conceito de Análise de Sentimento, como também algumas noções básicas de áreas correlatas, que são necessários para a compreensão do restante do trabalho. A seção 2.2 apresenta os principais termos e conceitos utilizados na área de Análise de Sentimento, e os níveis em que a AS é abordada. A seção 2.3 introduz as etapas da análise de sentimento. Na seção 2.4, apresentamos alguns produtos existentes para AS, e algumas possíveis aplicações dessa técnica. A seção 2.5 mostra alguns dos desafios e limitações encontrados na AS. Por fim, a seção 2.6 encerra este capítulo com a conclusão. 2.1 Áreas Correlatas Por ser uma área relativamente recente e sem uma nomenclatura padrão, a AS possui termos distintos para conceitos semelhantes. Desta forma, neste documento, iremos utilizar os termos e seus conceitos apresentados nesta seção. As seções 2.1.1, e 2.1.2 apresentarão alguns dos principais termos e definições sobre áreas bastante relacionadas com a AS, e que auxiliarão no entendimento do conteúdo desta dissertação. A seção 2.1.3 mostrará os principais conceitos abordados na área de Análise de Sentimento. 2.1.1 Mineração de Texto Mineração de Texto (Text Mining), também conhecida como Descoberta de Conhecimento em Textos (Knowlegde Discovered in Texts – KDT), busca extrair informações através da identificação e exploração de padrões em uma coleção de documentos de textos (Feldman e Sanger, 2006). Os documentos de textos podem ser encontrados em duas formas distintas: textos semi-estruturados (e.g., documentos de especificação de requisitos, páginas HTML) e textos não estruturados (e.g., reviews, posts em fóruns, etc.). Para a mineração de grandes coleções de documentos, é necessário realizar um pré-processamentos nos textos e armazenar as informações como dados estruturados, 1 Sentenças subjetivas são aquelas que apresentam pensamentos, opiniões, e percepções do personagem na narrativa. 20 2.1. ÁREAS CORRELATAS que são mais fáceis de processar do que arquivos de texto. Dessa forma, grande parte das abordagens de Mineração de Texto representa cada documento como uma lista das palavras (bag of words) que estão contidas no texto. Para isso, métodos clássicos de Recuperação de Informação são utilizados (e.g., modelo espaço vetorial, modelo booleano, modelo probabilista), definindo um grau de importância de cada palavra em relação ao documento (Hotho et al., 2005). Hotho et al. (2005) descrevem três tarefas de pré-processamento para os documentos de textos, cujo objetivo é de reduzir a dimensão da lista inicial de palavras do texto, a fim de obter uma lista mais representativa do documento: • Filtragem (Filtering): Métodos de filtragem removem as stop words do texto, que são as palavras que não possuem conteúdo semântico/informação (e.g., artigos, conjunções, preposições, etc) • Lematização (Lemmatization): O objetivo deste método é mapear todas as formas verbais para o seu modo infinitivo, e mapear os substantivos no plural para a forma no singular. Para a realização dessa tarefa, a classe gramatical de cada palavra tem que ser fornecida. • Stemming: Este método tenta obter o stem (semelhante ou igual ao radical) das palavras retirando prefixos e sufixos. Por exemplo, retira-se o sufixo ‘s’ dos plurais, as terminações verbais dos verbos (e.g., terminação “ing” para a língua inglesa), ou outros sufixos. O stem então representa todas as palavras derivadas desse memso radical. Em (Hotho et al., 2005), os autores destacam que não existe um procedimento único para a Mineração de Textos, e enumeram as principais tarefas relacionadas à área: • Classificação de textos: Tem o objetivo de atribuir classes pré-definidas aos documentos de uma coleção. Esses documentos são classificados a partir de informações presentes no texto (e.g., termos, palavras). Para a realização desta tarefa, podem ser utilizados classificadores baseados em conhecimento explícito (i.e., baseados em regras que são definidas por um especialista) (Feldman e Sanger, 2006), ou algoritmos supervisionados de aprendizagem de máquina (e.g., KNN, NaiveBayes, Support Vector Machine, etc) (Mitchell, 1997). • Agrupamento de textos: esta tarefa tem o objetivo de encontrar grupos (clusters) de documentos com conteúdos similares, ou seja, encontrar as classes de documentos que não são conhecidas a priori. Geralmente a qualidade dos clusters é 21 2.1. ÁREAS CORRELATAS considerada boa se os documentos dentro de um mesmo grupo são similares entre si, e ao mesmo tempo dissimilares dos documentos de outro cluster. Os principais algoritmos para a realização desta tarefa são os algoritmos de aprendizagem nãosupervisionada (e.g., K-means, Bisecting K-means, Self Organizing Map, Fuzzy Clustering) (Steinbach et al., 2000). • Extração de Informação: O objetivo principal desta tarefa é extrair dados/informação do texto, atribuindo conceitos específicos a estes dados, mapeando a informação contida em um documento em uma estrutura tabular (Silva, 2004). Para a realização de Extração de Informação, podem ser utilizados algoritmos de aprendizagem de máquina supervisionados, e Processamento de Linguagem Natural (e.g., Reconhecimento de Entidades Nomeadas, POS-Tagger, Tokenização) (Allen, 1995). 2.1.2 Mineração da Web A Mineração da Web (Web Mining) pode ser definida como a tarefa de descobrir e analisar quaisquer tipos de informações/conhecimentos úteis a partir de serviços ou documentos da Web (Cooley et al., 1997), (Kosala e Blockeel, 2000). Esta área surgiu devido ao incrível crescimento das fontes de informações disponíveis na Internet (e.g., blogs, fóruns, sites de notícias, reviews e etc.), juntamente com a necessidade de ferramentas automáticas que facilitem a busca de informações desejadas pelos os usuários. Para facilitar esta atividade, Kosala e Blockeel (2000) propuseram etapas para a realização de Web Mining: • Coleta de Recursos: Esta etapa é responsável por recuperar da Web os documentos de interesse do usuário. • Seleção de informação e pré-processamento: Esta etapa faz a seleção automática de dados específicos dos documentos recuperados, e faz o pré-processamento destes dados. • Generalização: Etapa responsável por identificar, de forma automática, padrões existentes em websites selecionados. • Análise: Etapa que faz a validação ou interpretação dos padrões encontrados. Baseado nos tipos de dados que podem ser utilizados no processo de mineração, Liu (2006) divide a Web Mining em três categorias: Mineração da estrutura da Web (Web 22 2.1. ÁREAS CORRELATAS Structure Mining), Mineração do Uso da Web (Web Usage Mining) e por fim, a Mineração de Conteúdo da Web (Web Content Mining). • Mineração da Estrutura na Web: A Mineração da Estrutura da Web é capaz de descobrir informações úteis a partir dos hyperlinks. Analisando os links, é possível criar mecanismos capazes de identificar web pages importantes (semelhante ao trabalho dos engenhos de busca), e detectar comunidades ou indivíduos que possam compartilhar interesses em comum. • Mineração do Uso da Web: Esta categoria de Web Mining se refere à descoberta de padrões de acesso dos usuários através de seus logs, cookies, perfis em redes sociais, consultas, enfim, qualquer interação do usuário com a Web. Através destas informações é possível detectar os serviços ou produtos que um indivíduo acessou na Internet, e apresentar informações relacionadas a estas consultas aos potenciais clientes (e.g., promoções, descontos, outros serviços/produtos semelhantes). • Mineração de Conteúdo da Web: Esta área trata da extração dos conteúdos presentes nos websites. É possível descobrir padrões em páginas Web para a extração de dados úteis, como descrição de produtos, posts em fóruns, em blogs ou em redes sociais. Através desses dados podemos averiguar, por exemplo, o sentimento expresso por uma pessoa em um debate sobre qual seria o melhor navegador para Internet, Firefox ou Internet Explorer. Contudo, note que a análise de sentimento dos dados extraídos da Web já é tarefa de outra área de trabalho (como será visto a seguir). 2.1.3 Mineração de Opiniões/ Análise de Sentimentos Esta seção traz uma visão superficial da AS, com o objetivo de distinguir esta área das duas áreas correlatas apresentadas anteriormente. Os conceitos aqui apresentados serão aprofundados na seção 2.2 a seguir. Como já visto, a Análise de Sentimento é responsável por identificar as opiniões sobre um determinado assunto (i.e., do objeto sob análise), e avaliar a polaridade dessas opiniãos (ou seja, classificar as opinões entre positivas, negativas ou neutras) (Tsytsarau e Palpanas, 2012). Segundo Liu (2010) a AS pode ser tratada em três níveis de granularidade: no nível do documento, no nível da sentença, ou no nível do atributo2 . 2 atributos podem ser componentes, aspectos ou características do objeto sendo avaliado (e.g., produto=celular, componentes={bateria, tela, tamanho, preço, etc}). 23 2.2. ANÁLISE DE SENTIMENTO – DETALHAMENTO Um processo completo de AS pode contar com quatro etapas principais: • Detecção de subjetividade, que classifica os textos entre subjetivos e objetivos, sendo considerado subjetivo o texto que contém alguma opinião; • Extração de atributos, responsável por identificar no texto os aspectos ou características do objeto sob análise; • Classificação de sentimento/polaridade, que busca determinar a polaridade do texto; e • Apresentação dos resultados. Para realização de AS utilizamos técnicas de diversas áreas de pesquisa, com destaque para Processamento de Linguagem Natural (PLN) ((Allen, 1995), (Manning e Schütze, 1999)), Mineração de Texto (Text Mining)(Feldman e Sanger, 2006), Mineração da Web (Web Mining)((Cooley et al., 1997), (Kosala e Blockeel, 2000), (Liu, 2006)),Recuperação da Informação ((Baeza-Yates e Ribeiro-Neto, 1999), (Manning et al., 2008)) e Inteligência Artificial (Russell e Norvig, 2003). Por fim, destacamos algumas das principais aplicações da AS, que estão presentes no mercado ou são objeto de pesquisa na academia. A análise de opiniões de consumidores e do público em geral tem sido um grande negócio para o marketing de empresas, relações públicas e campanhas políticas. A seção 2.4 irá apresentar mais detalhes sobre aplicações e ferrmanetas para AS. 2.2 Análise de Sentimento – Detalhamento Nesta seção, aprofundaremos alguns conceitos fundamentais associados à área de Análise de Sentimento automatica, que é o foco principal desta dissertação. A Análise de Sentimento, também chamada de Mineração de Opinião, é uma área ainda recente (Pang e Lee, 2008), (Tsytsarau e Palpanas, 2012). Assim, ainda não existe um consenso quanto à sua nomenclatura, e alguns de seus conceitos ainda estão sendo consolidados. 2.2.1 Nomenclatura adotada e Definições Neste trabalho, adotamos o padrão proposto por Liu (2010), que é o mais encontrado na literatura relacionada. Os exemplos 2.1 a 2.4 irão ajudar na ilustração dos conceitos 24 2.2. ANÁLISE DE SENTIMENTO – DETALHAMENTO apresentados. Como os corpora usados nesta dissertação estão em inglês, os exemplos também estarão nesse mesmo idioma. Para facilitar a ilustração dos conceitos, nos exemplos, cada sentença está numerada sequencialmente, a partir de (1). Exemplo 2.1: Comentário retirado do corpus do debate Firefox vs. Internet Explorer. “(1) Firefox’s tab interface is much smoother than IE’s. (2) Heck, up until a few weeks ago, IE didn’t HAVE tabs. (3) Firefox also doesn’t have anywhere near the security problems that IE has. (4) IE is a bloated, cruddy little shred of software that should be forgotten immediately and brought up only when remembering the worst ideas ever.” Exemplo 2.2: Comentário retirado do corpus do debate iPhone vs. Blackberry. “(1) Not a "huge"difference, but yes, it’s more expensive. (2) I should not that I own both. (3) I upgraded from my Pearl to the iPhone shortly after it came out. (4) What’s this about the iPhone being a brick? (5) It’s 3/4 an inch taller and 1/4 an inch wider. (6) It’s just as thin (exactly) and it’s slightly heavier which makes it feel more solid and durable. (7) And sure you can carry around your iPod and your Pearl - I’ll carry my iPhone. (8) I mean you’re complaining about bulge and you’re okay with having 2 devices to do the work of 1? (9) Yes, the iPhone is limited to 8GB, but if you’re so in need of 30GB of music then you might have some issues. (10) I mean I have 5 GB of music on my phone and that’s 2.6 days worth of continual playing. (11) I’m sorry AT&T/Cingular sucksin your area - definitely a reason not to get an iPhone, but don’t blame the phone for that. (12) I mean Verizon is terrible in my area with AT&T beingexcellent, so it’s all relative.” A seguir, serão apresentados os conceitos básicos mais importantes para a área de AS. • Objeto: Um objeto é uma entidade que pode ser um produto, serviço, pessoa, evento, organização ou tópico que seja alvo de um comentário. Na sentença (1) do exemplo 2.1 temos “Firefox” e “IE” como exemplos de objetos analisados. • Atributos ou Características: São componentes ou aspectos de um dado objeto e que podem ser referenciados no texto. Existem dois tipos de atributos: atributos explícitos, atributos implícitos. Os atributos explícitos são aqueles que aparecem em evidência no texto (e.g., a palavra “tab” na sentença (1) do exemplo 2.1). Já os atributos implícitos estão ‘escondidos’ no texto (e.g., o atributo capacity (capacidade de armazenamento) do objeto iPhone, na sentença (9) do exemplo 2.2). • Autor (opinion holder): É a pessoa ou organização que expressa a opinião. Para os exemplos acima, os autores são as pessoas que escreveram os posts. 25 2.2. ANÁLISE DE SENTIMENTO – DETALHAMENTO • Opinião: É uma visão, atitude, emoção ou avaliação sobre um objeto, ou sobre seus atributos, por parte de um autor. A sentença 5 do exemplo 2.2 é uma ilustração de uma opinião. • Orientação da Opinião: A orientação da opinião acerca de um objeto (ou de seus atributos) pode ser positiva ,negativa ou neutra. • Palavras Opinativas: São as palavras que qualificam os objetos e/ou seus atributos. Geralmente, são palavras das classes gramaticais dos adjetivos e advérbios, porém, pode-se encontrar verbos e substantivos com o sentido de qualificação. No exemplo 2.2, terrible (12), solid (6), e durable (6), são exemplos de palavras opinativas. Descreveremos a seguir dois tipos de opiniões que foram frequentemente encontrados em nossos corpora de debates sobre produtos: • Opiniões Diretas: São os casos de opiniões que fazem referência a apenas um objeto ou atributo. A sentença (11) do exemplo 2.2 é uma ilustração desse tipo de opinião. • Opiniões Comparativas: Opiniões comparativas expressam relações de similaridade ou diferença entre dois ou mais objetos, ou atributos comuns a dois objetos, que foram destacados pelo autor. As opiniões comparativas geralmente são expressas no texto na forma de adjetivos comparativos, ou adjetivos superlativos. A primeira sentença do exemplo 2.1 é um caso desse tipo de opinião. Exemplo 2.3: Comentário retirado do corpus de debate Mac vs. Windows “(1) The whole windows v. mac debate has become a debate thats not meant to convince anyone or change anyone’s opinion,but to simply throw insults at the OS that you do not have, or the one that you are less comfortable with. (2) Therefore I will not try to convert you mac lovers, but simply silence you. (3) Lets look at the facts: Windows has a larger market share. (4) not twice mac’s share, nor 5 times it, but over 10 times the mac market share. (5) This fact is what guarantee’s customers that they will have and extensive software library to choose from. (6) Windows does have its shortcomings, the biggest (arguably) of which is the extensive library of viruses and#$ware, no choice involved in this. (7) With the introduction of Windows Vista, the "pretty"look is no longer exclusive to macs. (8) Instant search is available on both, and the list of similarities goes on... (9) The end result is the fact that most of us will not think "mac or windows"next time we buy a computer, but "vista premium or ultimate?” 26 2.2. ANÁLISE DE SENTIMENTO – DETALHAMENTO Exemplo 2.4: Comentário retirado do corpus de debate Mac vs. Windows. “(1) mac´s are lame, build your own computer” Como é possível perceber através desses exemplos, nem todas as sentenças emitem opiniões sobre algum produto sob análise. Dessa forma, para realizar AS é importante termos capacidade de distinguir uma sentença com opinião de uma sentença sem opinião. A seguir, definiremos alguns termos importantes para distinguir sentenças e opiniões. • Sentença Subjetivas: São sentenças que expressam sentimentos ou crenças pessoais (e.g., a sentença (1) no exemplo 2.4). • Sentenças Objetivas: As sentenças objetivas expressam informações factuais sobre o mundo, ou sobre o objeto sob análise (e.g., a sentença (1) do exemplo 2.3). • Opinião Implicíta: Uma opinião implícita é aquela que está embutida em sentenças objetivas (e.g., a sentença (9) do exemplo 2.2). Embora essa sentença apresente um fato, ela também indica uma opinião negativa sobre o produto iPhone. • Opinião Explícita: Ao contrário da anterior, as opiniões explícitas são aquelas expressadas através de sentenças subjetivas (e.g., o exemplo 2.4). • Sentenças Opinativas: São aquelas que podem apresentar tanto opiniões explícitas como opiniões implícitas. A AS é responsável por identificar as opiniões sobre um determinado objeto, e avaliar a polaridade dessas opiniões, ou seja, classificar as opiniões entre positivas e negativas (Tsytsarau e Palpanas, 2012). 2.2.2 Níveis da AS Segundo Liu (2010) a classificação de sentimento pode ser tratada em três níveis de granularidade: no nível do documento, no nível da sentença e no nível do atributo. Dado um conjunto de documentos opinativos, a Classificação de Sentimento no nível do Documento busca determinar se cada documento expressa uma opinião geral positiva, negativa ou neutra a respeito do objeto sob análise. Note que a polaridade de um documento opinativo é considerada neutra quando ele traz a mesma quantidade de avaliações positivas e negativas sobre o objeto sob análise. Como exemplo de trabalho 27 2.3. ETAPAS DA ANÁLISE DE SENTIMENTOS neste nível de classificação, citamos Pang (Pang et al., 2002) que utilizaram algoritmos de aprendizagem de máquina para classificar reviews de filmes entre positivos ou negativos. Outros exemplos deste nível de AS são (Sebastiani, 2002) e (Dave et al., 2003). A Classificação de Sentimento no nível da Sentença geralmente se divide em duas etapas. Primeiramente, busca-se identificar se cada sentença do texto é subjetiva ou objetiva. Em seguida, procura-se determinar se as sentenças subjetivas expressam opiniões positivas, negativas ou neutras. Podemos citar trabalhos de AS nesse nível de classificação: (Yu e Hatzivassiloglou, 2003) e (Kim e Hovy, 2004). Exemplo 2.5: Comentário retirado do corpus de debate Sony Ps3 vs. Nintendo Wii. “(1) PS controllers have always been lame. (2) Most game controllers have sucked. (3) The Wii is the first truly intuitive controller ever. (4) As a non-console gamer, I love the my Wiimote, it’s the first thing that’s ever felt ’right’.” Por fim, na Classificação de Sentimento no nível do Aspecto, os atributos são analisados isoladamente. Esse tipo de classificação é realizado por aplicações que procuram um nível maior de refinamento na AS. Depois de determinar (manualmente ou automaticamente) os atributos dos objetos sob análise, é realizada a classificação das opiniões sobre cada um dos atributos mencionados. No exemplo 2.5, existe na sentença (1) uma opinião negativa sobre o atributo controller do console Sony Ps3, e na sentença (4), outro atributo (Wiimote) está associado a uma palavra positiva. Por fim, e possível determinar o sentimento geral sobre cada atributo do objeto sob análise com base nas polaridades das opiniões já classificadas. Um exemplo de AS nesse nível é o trabalho de (Silva et al., 2012) A seção 2.3 a seguir apresenta as etapas de um processo completo de AS. 2.3 Etapas da Análise de Sentimentos Um processo completo de AS engloba quatro etapas principais: detecção de subjetividade, que classifica os textos entre subjetivos e objetivos; extração de atributos, responsável por identificar os atributos do objeto em análise; classificação de sentimento/polaridade, que busca determinar a polaridade do texto; e apresentação dos resultados. As seções a seguir dão mais detalhes sobre cada uma dessas etapas. 28 2.3. ETAPAS DA ANÁLISE DE SENTIMENTOS 2.3.1 Detecção de subjetividade A etapa de detecção de subjetividade é responsável por identificar as sentenças subjetivas no texto. Essa etapa é fundamental para o processo de AS, pois as sentenças subjetivas apresentam de forma explícita os sentimentos, crenças, e emoções sobre um determinado objeto. Existem duas abordagens principais para a detecção automática de subjetividade na literatura: os métodos baseados em técnicas linguísticas e estatísticas ((Castro, 2011), (Hatzivassiloglou e Wiebe, 2000)); e os métodos baseados em algoritmos de aprendizagem de máquina (Yu e Hatzivassiloglou, 2003). Como exemplo de métodos linguisticos e estatísticos, citamos o trabalho de Hatzivassiloglou e Wiebe (2000). Os autores defendem que os adjetivos são fortes indicadores de subjetividade. Dessa forma, eles determinam a subjetividade das sentenças com base na orientação semântica dos adjetivos. Em outra pesquisa, Castro (2011) realiza detecção de subjetividade em cima de um corpus de review de filmes. Com o uso de uma ferramenta de POS-Tagging e o léxico SentiWordNet (Esuli e Sebastiani, 2006), Castro identifica a subjetividade em sentenças do corpus e as classifica como sentenças objetivas e sentenças subjetivas, alcançando taxas de acerto de até 74,5%. Do outro lado, Yu e Hatzivassiloglou (2003) utilizaram um classificador NaiveBayes em um corpus composto por artigos do Wall Street Journal. O classificador separa sentenças objetivas (notícias e negócios) de sentenças subjetivas (artigos do editor e resposta às cartas de leitores). 2.3.2 Extração de atributos A etapa de extração de atributos é responsável por identificar e extrair dos textos disponíveis os aspectos, componentes ou características associados ao objeto sob análise. Na ausência de um processo automático de extração, os atributos devem ser infomados manualmente. Esta etapa é obrigatória quando se deseja realizar uma AS no nível de atributo, visto que na AS no nível de sentença e de documento, as características dos objetos não são analisadas individualmente. As principais pesquisas sobre extração de atributos são conduzidas sobre corpus de reviews de produtos (Liu, 2012). Liu destaca que existem dois tipos mais comuns de reviews: • Tipo 1 – Pros, contras e review detalhado: É pedido ao autor do comentário 29 2.3. ETAPAS DA ANÁLISE DE SENTIMENTOS que descreva os atributos favoráveis e os não favoráveis separadamente, além de descrever um review detalhado posteriormente. • Tipo 2 – Reviews de formato livre: O autor do comentário pode escrever livremente, sem ter que explicitar os prós e contras do produto ou serviço. A extração de atributos nos comentários do Tipo 1 pode ser conduzida por diversos métodos (e.g., Aprendizagem de Máquina, PLN). Este tipo de review geralmente consiste em frases curtas, e cada uma das sentença trata somente de um único atributo. Os reviews do Tipo 2 são mais complexos para processar, pois apresentam frases completas, podendo ser encontrados vários atributos em uma única sentença. Silva (2013) foi capaz de identificar os aspectos de produtos e suas opiniões a partir de padrões linguísticos, e posteriormente classificar esses pares como positivos, negativos ou neutros. Hu e Liu (2004) descrevem uma abordagem não-supervisionada para extração de aspectos em reviews do Tipo 2. Esta abordagem requer uma grande quantidade de reviews, e consiste em dois passos: • Identificar os substantivos e sintagmas nominais mais frequentes: Hu e Liu defendem que os atributos dos objetos nos reviews são substantivos ou sintagmas nominais. Desta forma, o uso de um POS-Tagger é de grande utilidade. A razão para a extração dos substantivos mais frequentes é que, quando as pessoas comentam sobre produtos e seus atributos, o vocabulário utilizado tende a coincidir. • Identificar os atributos menos frequentes utilizando palavras opinativas: As palavras opinativas geralmente são adjetivos ou advérbios que expressam opiniões positivas e/ou negativas. A justificativa para este passo é que uma mesma palavra opinativa pode ser utilizada para descrever diferentes atributos (e.g., a palavra opinativa lame no exemplo 2.4 e na senteça (1) do exemplo 2.5, qualifica dois atributos/entidades distintos). Dessa forma, as palavra opinativas que avaliam os atributos frequentes podem avaliar os atributos não-frequentes, portanto, podem ser utilizadas para a extração destes atributos. Como exemplos de outros trabalhos que fazem extração de atributos sobre reviews do tipo 2, podemos citar (Siqueira, 2010) e (Lima, 2011). 2.3.3 Classificação de sentimentos Esta é a etapa do processo de AS onde são classificadas as opiniões no texto. Cada opinião possui um valor associado, que corresponde a sua orientação/polaridade (positiva, 30 2.3. ETAPAS DA ANÁLISE DE SENTIMENTOS negativa ou neutra). Aqui, também contamos com diferentes abordagens para realizar esta etapa da AS, sendo as principais delas a Aprendizagem de Máquina e a Abordagem baseada em Léxicos Subjetivos. Como exemplos de trabalhos que utilizam Aprendizagem de Máquina para classificação de sentimento, citamos (Pang et al., 2002), (Wilson et al., 2005), (Mullen e Malouf, 2006) e (Walker et al., 2012). Apesar de obterem uma ótima precisão na classificação, tais soluções são muito dependentes do corpus de treinamento do classificador, apresentando dificuldades no processamento de textos de outros domínios. Como alternativa, temos a abordagem baseada no uso de Léxicos Subjetivos. Tais léxicos apresentam uma lista de palavras opinativas com suas polaridades associadas. Como exemplos, citamos o SentiWordNet ((Baccianella et al., 2010), (Esuli e Sebastiani, 2006)) e o léxico subjetivo MPQA (Wilson et al., 2005). Esta abordagem utiliza as polaridades associadas às palavras opinativas para determinar a polaridade das opiniões no texto. Contudo, o uso de Léxicos Subjetivos para a classificação de sentimento pode não ser suficiente. É importante também considerar outros elementos presentes no texto que alteram a polaridade das opiniões, como por exemplo, expressões negativas, cláusulas adversativas, concessões etc. Exemplo 2.6: Comentário retirado do corpus do debate Windows vs. Mac. “(1) I’m not going into the details of why Macs are better, but I will say this: (2) Any person who switches to a Mac, I guarantee will never go back voluntarily.” Liu (2010) descreve uma abordagem genérica para esta etapa de classificação de sentimentos: • Identificação de palavras opinativas: Este passo corresponde a identificação de todas as palavras opinativas presentes no texto. A seguir, para as palavras positivas, negativas e neutras são atribuídos os valores [+1], [-1], e [0] respectivamente. • Expressões negativas: As expressões negativas, quando presentes no texto, invertem a polaridade das opiniões associadas a elas (e.g., not, none, neither, nothing). Geralmente, utilizam-se valores empíricos para determinar o tamanho da janela que será utilizada para verificar se existe uma expressão negativa próxima a uma opinião. Um exemplo de sentença onde a negação não está próxima da palavra opinativa é a sentença (1) do exemplo 2.6. 31 2.3. ETAPAS DA ANÁLISE DE SENTIMENTOS • Cláusulas adversativas: Sentenças que possuem cláusulas adversativas, em geral, trazem opiniões contrárias. Dessa forma, considera-se que a polaridade da opinião antes da cláusula adversativa é contrária à polaridade da opinião depois desta cláusula. É possível averiguar uma cláusula adversativa na segunda sentença do exemplo 2.7. Exemplo 2.7: Comentário retirado do corpus do debate Windows vs. Mac . “(1) Apples are nice computers with an exceptional interface. (2) Vista will close the gap on the interface some but Apple still has the prettiest, most pleasing interface and most likely will for the next several years. ” 2.3.4 Apresentação dos resultados A apresentação dos resultados é a última etapa do processo de AS. Esta etapa é responsável por analisar os dados de saída das etapas anteriores e apresentar, de forma simples e clara, os resultados para o usuário final. As informações obtidas a partir da classificação dos comentários podem ser mostradas de diversas formas, desde textos descrevendo os resultados da análise, a gráficos que fazem comparações entre dois ou mais produtos do mesmo domínio (ver figura 2.1). A figura 2.1 mostra um gráfico resultante da AS no nível de atributo em textos sobre duas câmeras digitais de marcas distintas. São apresentadas duas barras de cores diferentes para cada atributo das câmeras (foto, bateria, lentes, peso e tamanho), e o sentimento geral sobre os produtos - quanto mais acima da linha horizontal a barra estiver, maior é a avaliação positiva; quanto mais abaixo da linha horizontal, maior é a avaliação negativa. Pang e Lee (2008) dividem a Visualização e Sumarização em dois tipos distintos: • Sumarização de documento único: Este primeiro tipo de sumarização trata apenas das entidades de um único documento. O objetivo é apresentar o resultado da análise de sentenças extraídas, ou de unidades similares de textos, que relatam opiniões semelhantes ou que falem de um mesmo atributo, e a partir daí, apresentar os pontos positvos e os pontos negativos deste atributo. • Sumarização Multi-documento: Este tipo de sumarização apresenta o resultado da análise dos objetos sobre diversos documentos de um mesmo domínio. O intuito dessa análise não é apenas mostrar ao usuário os pontos positivos e negativos de cada aspecto, como também comparar os aspectos dos dois objetos. 32 2.4. APLICAÇÕES E FERRAMENTAS DA AS Figura 2.1 Resultado comparativo entre duas câmeras digitais representadas por cores distintas (Liu, 2012) 2.4 Aplicações e Ferramentas da AS Esta seção apresenta algumas das aplicações mais comuns da AS, bem como cita algumas ferramentas que auxiliam na realização automática desta tarefa. Como dito, a AS das opiniões de consumidores tem sido foco de atenção para o pessoal de marketing de empresas, relações públicas e campanhas políticas. Claramente, a AS sobre produtos é o tipo de aplicação mais comum nessa área. Um exemplo clássico desse tipo de aplicação é o Google Product Search3 , um website que fornece sumários de reviews sobre produtos e seus aspectos. Contudo, a AS não trata somente desses casos. Outro importante domínio para mineração de opinião é o mercado financeiro. Através da análise de artigos, blogs e jornais, sistemas como The Stock Sonar4 são capazes de avaliar o sentimento em torno de companhias, e tenta prever o impacto positivo/negativo sobre o preço de suas ações no mercado financeiro. As redes sociais são o foco de várias aplicações de AS, devido à sua capacidade de cobrir diversos tópicos como política, mercado financeiro, reputação de produtos e marcas. Citamos aqui o tweetfeel5 , uma ferramenta capaz de analisar o sentimento a respeito de uma marca ou produto no Twitter6 . Outra ferramenta com a funcionalidade voltada para a monitoração de opiniões sobre marcas e empresas nas redes sociais é a 3 http://www.google.com/shopping 4 http://www.thestocksonar.com/ 5 http://www.tweetfeel.com/ 6 http://twitter.com/ 33 2.5. DESAFIOS Viralheat7 . Na área da política citamos o sistema de Wang et al. (2012), que teve como objetivo a AS nos tweets relacionados às eleições presidenciais dos Estados Unidos no ano de 2012. Além das aplicações citadas, existem ainda ferramentas que podem auxiliar na construção de aplicações de AS. Citamos como exemplos a NLTK8 (Natural Language Tool Kit) e a Alchemy API9 . A NLTK é exclusiva para a linguagem de programação Python e possui importantes funcionalidades para o Processamento de Linguagem Natural, dentre elas, corpora de textos, classificadores de texto, sendo também capaz de detectar textos opinativos e classificá-los. A Alchemy API é um Web service capaz de identificar sentimento positivo/negativo em textos e páginas Web da língua inglesa ou alemã. Este serviço pode ser utilizado por qualquer linguagem de programação que seja capaz de fornecer implementações para arquitetura REST. 2.5 Desafios O crescente interesse do mercado sobre Análise de Sentimento é devido ao potencial de suas aplicações. Igualmente importantes são os desafios que esta área apresenta para a comunidade científica. As principais dificuldades em minerar opiniões estão relacionadas aos elementos associados aos textos (e.g., erros gramaticais, erros de grafia, sarcasmos, etc). Listaremos a seguir alguns fatores que tornam a AS um processo não trivial: • Named-Entity Recognition (NER): Reconhecimento de entidades nomeadas é a tarefa responsável por identificar as entidades que estão sendo avaliadas no texto (Nadeau e Sekine, 2007). Em textos opinativos como reviews de filmes, ou de debates ideológicos, a NER se torna uma tarefa bastante difícil, pois as entidades aqui referenciadas podem ser de diversos tipos (e.g., pessoas, lugares, organizações). Outro fator que aumenta a dificuldade dessa tarefa são as anáforas. Nos textos opinativos, comumente os autores utilizam pronomes para fazer referência a objetos já citados. Para solucionar este problema, é necessário desenvolver um método para Resolução de Anáfora (Jakob e Gurevych, 2010). • Léxicos Subjetivos: Uma das principais fontes de erro em abordagens que utilizam léxicos subjetivos são os falsos hits com as palavras do léxico (Somasundaran e 7 https://www.viralheat.com/ 8 http://nltk.org/ 9 http://www.alchemyapi.com/ 34 2.6. CONCLUSÃO Wiebe, 2009). Muitas destas palavras, de acordo com o contexto em que se encontram no texto, podem ter conotação subjetiva ou objetiva, e portanto, adicionam ruído à classificação de sentimento. • Detecção de Subjetividade: Um terceiro desafio é determinar quais documentos ou partes de documentos possuem conteúdo opinativo. A detecção de subjetividade em textos extraídos de reviews de produtos é simples, visto que esses textos são estritamente opinativos. Já em textos extraídos de debates ideológicos, fóruns, redes sociais, a detecção de subjetividade torna-se bastante complicada, pois além da estrutura do texto ser diferente dos reviews, é comum a ocorrência de ironias, sarcasmos, metáforas. Esses elementos podem ser erroneamente interpretados como opiniões positivas, sendo que na realidade são opiniões negativas. • Textos Opinativos com Ruídos: Textos com erros de grafia, erros gramaticais, falta de pontuação e gírias ainda representam grandes desafios para os sistemas de AS. Alguns desses problemas são solucionados a partir de um bom préprocessamento no texto. 2.6 Conclusão Neste capítulo, apresentamos os principais conceitos relacionados à área de Análise de Sentimentos (e.g., níveis da AS, tipos de opiniões, etc), além das etapas de um sistema de Mineração da Opinião. Por fim, citamos alguns desafios que fazem com que a Análise de Sentimento seja uma das áreas mais pesquisadas no momento. No próximo capítulo, apresentaremos com mais detalhes o processo de Análise de Sentimento em cima de textos de debates de produtos. 35 3 Análise de Sentimento em Debates Polarizados Neste capítulo, veremos com mais profundidade a classificação de sentimento em debates polarizados, por este ser o foco do nosso trabalho. Apresentaremos as principais contribuições da AS em debates ideológicos e debates não-ideológicos, descrevendo com maiores detalhes as abordagens e recursos utilizados nesses trabalhos. A seção 3.1 mostrará uma visão geral sobre os problemas de realizar AS em textos de debates polarizados. As seções 3.2, e 3.3 apresentarão algumas abordagens utilizadas para classificação de sentimentos em debates polarizados. A seção 3.4 descreve brevemente dois léxicos subjetivos bastante citados na literatura de AS. Na seção 3.5 apresentamos dois fenômenos liguísticos comuns em debates online e que foram tratados neste trabalho de mestrado. Por fim, a seção 3.6 apresentará as considerações finais. 3.1 Visão Geral Uma tendência atual das pessoas é expressar seus pensamentos e pontos de vistas em micro blogs, redes sociais, ou em sites de debates1 , opinando sobre os mais diversos assuntos, desde temas relacionados a política (e.g., guerras, direito sobre armas, aborto) a temas sobre opiniões acerca de produtos. Este comportamento gera oportunidades para empresas de marketing, que buscam gerir a publicidade de políticos em campanhas eleitorais, ou de marcas de produtos no mercado consumidor2 , analisando o pensamento geral expresso nessas mídias sociais. 1 www.createdebate.com, www.convinceme.net, www.politicalforum.com, www.forandagainst.com 2 http://data-informed.com/presidential-debates-provide-living-laboratory-for-marketers-studying- sentiment-analysis/ 36 3.1. VISÃO GERAL Quadro 3.1:Exemplos de posts do debate sobre a Existência de Deus Postura Posts God does not exist Before I began, let’s create three base ideas about God: A. God is perfect B. God sees all C. God can do whatever he/she wants Now, based on those, we can create the following: 1. God sees evil in the world (B), but despite having the power to stop it (C), does not. 2. Any being that sees wrong, knows it can be stopped by him or her, and takes no action is flawed on some level. 3. This is contradictory to letter A, as in the scripture it is said that God is perfect. 4. Therefore, God doesn’t exist. God does exist God sees all, God is perfect, God can do whatever He wants, Now..God sees evil but doesn’t stop it. So, therefore he is not real. When a murderer sees evil and does not stop it does that mean he doesn’t exist? When I see evil in the government or anything, and do nothing, because I can’t. Does that mean I am not real? Sometimes we can’t stop evil, and must let it happen. Everything happens for a reason the good and the bad. He is not responsible for Evil, Lucifer is. He may try to stop evil, but whether evil is stopped or not depends on if the person or being who is doing it is pure and good. Who is to say He didn’t try. You can’t prove he didn;t without some more details. God does not exist To prove there is not a God,you must prove that God does not exist Unless you can present evidence that God does not exist, than your argument is no better than your opposition. God does exist Prove to me that the Flying Spaghetti Monster doesn’t exist. No sir it doesn’t work that way. If you are asserting something exists you are required to back it up with evidence. Nothing can be disproved, your must do your best to PROVE your stance using logic, reason and evidence. Things can be found to be VERY VERYVERY unlikely. Saying something exists doesn’t make it so. 37 3.1. VISÃO GERAL Nesse contexto, a Análise de Sentimento busca extrair a postura/posicionamento (do inglês, stance) de um indivíduo a partir de textos polarizados. Somasundaran e Wiebe (2009) definem stance como uma opinião geral de uma pessoa sobre um objeto, idéia ou posição. Walker et al. (2012) defendem que este ponto de vista (postura) pode ser utilizado na identificação de qual lado um indivíduo está em um debate polarizado, e.g., a favor ou contra a existência de Deus, como ilustrado no quadro 3.13 . Discussões em fóruns, ou em sites de debates na Web sobre tópicos atuais (e.g., Qual o melhor console: PS3 ou Xbox?, Casamento Gay, etc.) são bem populares, e costumam ter uma forte carga emotiva. Os participantes desses debates apresentam suas preferências e justificam o porquê de suas opiniões estarem corretas. Além disso, para fortalecer seus pontos de vista, alguns debatedores apresentam argumentações negativas sobre seus adversários ou sobre as opiniões deles. Outra ocorrência comum é a mudança de opinião de alguns participantes durante a evolução do debate, chegando até a trocar de lado na discussão. Complicando ainda mais este cenário, os participantes do debate ainda podem apresentar opiniões positivas sobre alguns aspectos do objeto (produto ou tópico) sendo apoiado pelo lado adversário, sem realmente mudar sua postura no debate. Além disso, alguns debatedores chegam a manifestar opiniões negativas sobre aspectos dos tópicos que defendem no debate. A estes fatores, damos o nome de concessões (Robaldo et al., 2010). Existem alguns outros elementos presentes em debates polarizados que acrescentam dificuldades à realização da AS. A linguagem informal predominante nestes tipos de textos, e a grande quantidade de gírias, são fortes fontes de ruído na etapa de classificação de sentimento. Assim, para determinar a polaridade nesses debates, é necessário, além de identificar as opiniões positivas e as negativas, determinar sobre o que essas opiniões estão tratando, ou seja, as entidades que estão sendo avaliadas. Nesses debates, algumas das entidades presentes são citadas por referências anafóricas (Somasundaran e Wiebe, 2009), o que pode dificultar a tarefa de associar uma palavra opinativa a um objeto em discussão. Walker et al. (2012) examinaram a classificação da postura dos participantes dentro do corpus de 14 debates distintos, 10 debates ideológicos, e 4 debates não ideológicos. A fim de demonstrar a dificuldade da AS nesses tipos de textos, os autores conduziram um experimento através do Mechanical Turk4 onde a classificação dos posts de debate foi 3 http://www.convinceme.net/debates/150/Existence-of-God.html 4 https://www.mturk.com/mturk/welcome 38 3.2. AS EM DEBATES IDEOLÓGICOS feita por humanos. Eles observaram que apenas 78,26% das pessoas que participaram desse experimento coincidiram sua classificação com a marcação original do post no debate, demonstrando que classificar os posts isoladamente não é uma tarefa trivial nem para humanos. Nas próximas seções, apresentaremos as principais contribuições relacionadas a AS em textos de debates ideológicos e debates não-ideológicos. 3.2 AS em Debates Ideológicos Existem diversos trabalhos relacionados à AS com o objetivo de classificar a stance de pessoas dentro de um debate, sejam debates de cunho formal, como por exemplo debates sobre resoluções e projetos de leis discutidos no Congresso dos Estados Unidos5 , ou sejam debates informais, como vemos nos fóruns online e sites de debates. Uma das primeiras investigações sobre AS em textos de debates políticos foi realizada por Thomas et al. (2006). Analisando um corpus de debate do congresso americano, os autores inferiram relacionamentos entre os debatedores que faziam replies a outros participantes que compartilhavam a mesma opinião. Para a classificação das stances dos debatedores, os autores utilizaram um classificador baseado em Support Vector Machine (SVM). O melhor resultado obtido pelos autores foi 76,05% de acurácia. Outro trabalho que utiliza uma estrutura de relacionamentos entre os participantes de um debate é Malouf e Mullen (2008). Esse trabalho reuniu um corpus de debate com 77.854 posts sobre tópicos políticos do site politics.com6 . Os participantes do debate informam sua orientação política em relação ao posts, e através disso, os autores agruparam todos os integrantes em três classes, com base em suas orientações: Left (liberal, democrat, l-fringe); Right (conservative, republican, r-fringe); e Other (centrist, green, libertarian, independent). Malouf e Mullen conduziram três experimentos utilizando esse corpus de debates políticos. O primeiro experimento buscou medir a Orientação Semântica política dos textos reproduzindo a técnica PMI-IR descrita no trabalho de Turney (2002). Os autores alcançaram a acurácia de 40,76% nesta primeira experimentação. O segundo experimento foi realizado utilizando o algoritmo de classificação de texto Naive Bayes. Malouf e Mullen obtiveram melhor acurácia no segundo experimento em relação ao anterior, alcançando 63,46%. No último experimento, foi criada uma matriz de adjacência de 5 https://www.govtrack.us/ 6 www.politics.com 39 3.2. AS EM DEBATES IDEOLÓGICOS co-citações entre os participantes do debate para a representação do corpus no formato de um grafo. Em seguida, foi medida a distância entre dois pares desta estrutura para tentar inferir clusters de debatedores com padrões de citações semelhantes. Após a criação dos clusters, Malouf e Mullen aplicam o algoritmo de classificação utilizado no experimento anterior para inferir as posturas dos grupos. Das três configurações, o último experimento obteve o melhor resultado, onde a acurácia chegou aos 68,48%. Já a pesquisa (Wang e Rosé, 2010) foi conduzida com base em textos de fóruns7 , analisando a estrutura de co-citações e repostas presentes nas discussões. Os autores tentaram inferir relacionamentos entre pares de citações do corpus utilizando uma variação de Análise de Semântica Latente (do inglês, Latent Semantic Analysis), ao invés de tentar inferir conformidade ou discórdia entre os autores dos posts. Com essa abordagem, Wang e Rosé conseguiram 71% de acurácia em seus resultados. Somasundaran e Weibe também classificaram as posturas de usuários em debates ideológicos (Somasundaran e Wiebe, 2010). Neste trabalho as autoras buscaram inovar, criando um dicionário de argumentações polarizadas (positivas ou negativas). Somasundaran e Weibe defendem que existem expressões que dão indícios de que um dado trecho do texto contém uma argumentação polarizada. As autoras construíram seu dicionário com base no corpus MPQA8 , que possui argumentações polarizadas. A figura 3.1 ilustra alguns exemplos de trechos de argumentações e as expressões que são indicadores de argumentação. Note que os indicadores de argumentações positivas (no topo da figura) são diferentes dos indicadores de argumentações negativas. Figura 3.1 Exemplos de trechos argumentações polarizadas retirados de (Somasundaran e Wiebe, 2010). A coluna da esquerda apresenta o trecho da argumentação positiva/negativa, e a coluna da direita mostra os marcadores de argumentação. 7 alt.politics.usaUsenet 8 http://mpqa.cs.pitt.edu/corpora/mpqa_corpus 40 3.3. AS EM DEBATE NÃO IDEOLÓGICOS Somasundaran e Weibe conduziram duas experimentações com seus corpora de debates. A primeira configuração utiliza somente as informações do dicionário de argumentações polarizadas. Na segunda configuração, as autoras buscam identificar a polaridade(positiva , negativa , ou neutra) de cada sentença dos posts e então, atribuir esta polaridade às palavras de classes abertas presentes em cada sentença analisada. Para esta tarefa, Somasundaran e Weibe identificaram as palavras opinativas presentes nas sentenças dos posts com o auxílio do léxico MPQA (Wilson et al., 2005). Assim, a polaridade de cada sentença é definida pela soma da polaridade das palavras opinativas. Para a classificação das posturas dos posts nos debate, Somasundaran e Weibe utilizaram o algoritmo de aprendizagem supervisionada SVM da ferramenta Weka9 (Hall et al., 2009). O melhor resultado obtido pelas autores foi 70,59% de acurácia. Outra linha de trabalho relacionada à AS em debates ideológicos é a detecção de subgrupos de debatedores que possuem pontos de vista distintos (Abu-Jbara et al., 2012). Para detectar as posturas dos usuários, o sistema de Abu-Jbara et al. utiliza uma abordagem baseada em regras para a identificar as opiniões relacionadas, bem como os tópicos sendo discutidos. Posteriormente, os autores contabilizam a frequência com que cada usuário interage ou menciona um assunto, e a quantidade de vezes que os usuários expressam aspectos positivos e negativos sobre cada tópico do debate. Os clusters são formados através de algoritmos de aprendizagem não supervisionada10 . 3.3 AS em Debate Não Ideológicos Esta seção apresentará duas abordagens para Análise de Sentimento em debates nãoideológicos, i.e., aqueles debates sem conteúdo político (e.g., debates sobre produtos/marcas, animais, personagens de filmes, etc.). O trabalho de Walker et al. (2012), já mencionado aqui nesta dissertação, investigou a polaridade de 14 debates distintos, sendo 10 debates ideológicos, e 4 não ideológicos. Para a classificação automática, Walker et al. conduziram dois experimentos utilizando diversos algoritmos de Aprendizagem Supervisionada. O primeiro experimento foi conduzido baseado nos atributos ilustrados na figura 3.2, com exceção do último atributo. Para a segunda experimentação, os autores construíram um grafo para representar os replies presentes nos debates, e além disso acrescentaram o atributo contexto, que foi excluído no primeiro momento. Este atributo é responsável por adicionar as informações 9 http://www.cs.waikato.ac.nz/ml/weka/ 10 http://java-ml.sourceforge.net/ 41 3.3. AS EM DEBATE NÃO IDEOLÓGICOS Figura 3.2 Lista de atributos utilizados pelo classificador do trabalho de (Walker et al., 2012). Na coluna da esquerda estão os atributos, e na coluna da direita, existe uma breve explanação sobre cada um dos atributos. do post pai, i.e., o comentário que está no nível logo acima no grafo. Figura 3.3 Resultados do primeiro experimento desenvolvido em (Walker et al., 2012). Os primeiros quatro debates que estão sobre a linha horizontal são debates não ideológicos. Na coluna da esquerda são apresentados os valores das acurácias relacionadas aos atributos utilizados na classifiação. Os demais debates apresentados são ideológicos. Inspirado no trabalho de Thomas et al. (2006), um outro experimento teve como foco a classificação dos posts agrupados por autores. Em seguida, eles estenderam o experimento aplicando o algoritmo MinCut (Bansal et al., 2008). Contudo, os resultados dessa experimentação não foram divulgados pelos autores pois, segundo eles próprios, não houve melhoras na acurácia desta experimentação. As figuras 3.3 e 3.4 apresentam os resultados de Walker et al. (2012). Como é possível ser observado na figura 3.3, os resultados obtidos sobre os debates não ideológicos (67,69%) são ligeiramente superiores em relação aos resultados obtidos com os debates ideológicos (65,38%). Já a figura 3.4 mostra os resultados do segundo experimento, e como é possível ver, este resultados se mostraram superiores em relação aos valores 42 3.3. AS EM DEBATE NÃO IDEOLÓGICOS Figura 3.4 Resultados do segundo experimento desenvolvido em (Walker et al., 2012). apresentados no experimento anterior. As melhores taxas de acurária foram: 75,38% nos debates não ideológicos, e 69,23% nos debates ideológicos. Em relação ao corpus Firefox vs. Internet Explorer, que é explorado tanto nesta dissertação como no trabalho de Somasundaran e Wiebe (2009), obtive 63,75% na classificação sem contexto. Já na classificação com contexto, sua melhor acurácia foi 66,25%. Uma das principais contribuições da área, e referência base para esta pesquisa de mestrado, é o trabalho de Somasundaran e Wiebe (2009). As autoras desenvolveram uma abordagem não-supervisionada para a classificação das posturas em posts de debates polarizados com dois tópicos (e.g., iPhone x Blackberry). Para a realização deste trabalho, elas coletaram textos de debates sobre produtos no site convinceme11 . Tabela 3.1 Quantidade de posts nos corpora de debates de Somasundaran e Weibe (Somasundaran e Wiebe, 2009). Tópicos dos debates Firefox vs. Internet Explorer Blackberry vs. iPhone Sony Ps3 vs. Nintendo Wii Opera vs. Firefox Windows vs. Mac Total de Posts utilizados de cada debate 169 24 68 16 27 As autoras disponibilizaram seus corpora para livre download12 . A tabela 3.1 apresenta os tópicos dos debates dos corpora, e a quantidade posts em cada corpus. As informações aqui apresentadas fazem referência aos dados divulgados pelas autoras. 11 www.convinceme.net 12 http://mpqa.cs.pitt.edu/corpora/product_debates 43 3.3. AS EM DEBATE NÃO IDEOLÓGICOS Para identificar as opiniões contidas nos debates, as autoras buscaram no texto palavras que estão contidas no léxico subjetivo MPQA (Wilson et al., 2005). Se uma palavra desse léxico é identificada no texto, logo, atribui-se a esssa palavra a sua polaridade no dicionário, podendo ser positiva (+), negativa (-), ou neutra (*). A seção 3.4 irá apresentar esse dicionário com mais detalhes, uma vez que esse léxico foi utilizado neste trabalho de mestrado na etapa de classificação de sentimento. Para emparelhar essas opiniões às entidades (atributos) que elas avaliam, Somasundaran e Weibe criaram um sistema baseado em regras sintáticas, e utilizaram o parser de dependência de Stanford13 para extrair essas informações. A figura 3.5 apresenta algumas das regras desenvolvidas pelas autoras. Figura 3.5 Exemplos de regras sintáticas utilizadas por Somasundaran e Weibe. Assim que os pares (aspecto-opinião) são criados, as autoras abstraem suas representações para aspecto+ ou aspecto-, de acordo com a polaridade das opiniões. Logo, o par (popup-annoying) será reescrito como popup-. Em uma segunda etapa do trabalho, Somasundaran e Weibe mineram a Web em busca de identificar as preferências expressas pelos participantes dos debates em suas argumentações. As autoras defendem que os participantes de debates tendem a destacar os atributos que são fundamentais para suas posturas, expressando opiniões positivas sobre os aspectos que os agradam, e opiniões negativas sobre os atributos que os desagradam. Para realização desta tarefa, as autoras reuniram textos de weblogs e fóruns sobre os tópicos relacionados aos debates sendo analisados (e.g., iPhone e Blackberry), e identificaram os pares (aspecto-opinião) de maneira semelhante ao procedimento usado nos textos dos debates. Para cada aspecto-i dos pares encontrados no corpus da Web, é 13 http://nlp.stanford.edu/software/lex-parser.shtml 44 3.3. AS EM DEBATE NÃO IDEOLÓGICOS calculada a seguinte probabilidade condicional (Eq. 3.1): P q ! t ópico j = aspectoip q p # t ópico j , aspectoi #aspectoip 3.1 Onde p = q = +, -, * denotam a polaridade dos aspectos e tópicos, respectivamente; j = 1 , 2 e i = 1 ... M, onde M representa o número de aspectos individuais dentro do corpus. A figura 3.6 apresenta os resultados de algumas dessas probabilidades. De acordo com a figura, podemos destacar que o atributo email+ é mais frequente em textos com aspectos positivo sobre o tópico Blackberry do que do tópico iPhone. De maneira semelhante, o atributo keyboard+ também é mais comum em textos sobre Blackberry do que em textos relacionados ao iPhone. Figura 3.6 Resultados das probabilidades apresentadas no trabalho de Somasundaran e Weibe sobre o debate iPhone vs. Blackberry Na etapa de classificação dos posts, as autoras formularam um problema de Programação Linear Inteira14 . Em um de seus experimentos, elas contabilizam as concessões encontradas nos corpora com o auxílio de uma lista de conectivos de discurso Penn Discourse Treebank (Prasad et al., 2008). A estratégia básica deste procedimento foi determinar a posição dos conectivos no texto, e inverter a(s) polaridade(s) do(s) par(es) de uma das sentenças. Se o conectivo estiver no meio da sentença, os pares pertencentes à sentença que precede o conectivo terão suas polaridades invertidas. Se o conectivo estiver no início da sentença, esta é separa em uma sub-sentença até primeira vírgula encontrada, e todos os pares nesta sub-sentença terão suas polaridades invertidas. A contribuição Somasundaran e Wiebe (2009) foi apresentada em dois experimentos (OpPr, e OpPr + Disc) . Como visto na figura 3.7, no OpPr onde a classificação dos posts é conduzida sem a análise de concessões, e o melhor resultado obtido foi 66,67% de acurácia no corpus Windows vs.Mac. Já o OpPr + Disc faz a análise de concessões 14 Maiores detalhes no artigo (Somasundaran e Wiebe, 2009) 45 3.4. LÉXICOS SUBJETIVOS Figura 3.7 Resultados de Somasundaran e Wiebe (2009) e também obteve o resultado de 66,67% de acurácia no mesmo corpus. Os números apresentados no corpus Opera vs. Firefox são superiores em relação aos outros corpora, porém esses resultados são obtidos sobre a análise de quatro posts deste debate. 3.4 Léxicos Subjetivos Léxicos subjetivos são recursos essenciais para diversas abordagens de Análise de Sentimento (Turney, 2002), (Taboada et al., 2011), (Silva et al., 2012). Esses dicionários podem ser criados manualmente ((Wilson et al., 2005), (Taboada et al., 2011)), ou podem ser gerados automaticamente, a partir de um conjunto de inicial de palavras opinativas (seed words) (Turney e Littman, 2003), (Qiu et al., 2011). O léxico subjetivo utilizado no trabalho de Somasundaran e Wiebe (2009) e neste 46 3.5. FENÔMENOS LINGUÍSTICOS EM DEBATES trabalho de mestrado é o léxico MPQA (Wilson et al., 2005)15 . Este recurso possui cerca de 8 mil palavras opinativas, contendo, além da polaridade, o grau de subjetividade das palavras (forte ou fraco), o tamanho (indica se a palavra é ou não uma palavra composta), a classe gramatical, e se palavra está reduzida ao stem. A figura 3.8 apresenta como é a estrutura deste dicionário. Figura 3.8 Estrutura do léxico subjetivo MPQA com exemplos de palavras. Esse léxico subjetivo foi compilado a partir de uma lista de palavras do trabalho de Riloff e Wiebe (2003), e posteriormente, expandido com o auxílio um dicionário, um thesaurus, e uma lista de palavras positivas e negativas do léxico General Inquirer 16 . Outro léxico de destaque na literatura de AS é o SentiWordNet ((Esuli e Sebastiani, 2006), (Baccianella et al., 2010)). Este dicionário foi criado a partir da base lexical do WordNet17 , e contém cerca de 110 mil palavras da língua inglesa, sendo das seguintes classes gramaticais: verbos, substantivos, advérbios e adjetivos. A cada palavra é associado um valor positivo e um valor negativo, e o valor neutro é obtido pelo complemento da soma dos dois scores anteriores. Também são indicadas as classes gramaticais das palavras, bem como informações sobre o uso e cada palavra na língua inglesa. A figura 3.9 apresenta a estrutura do SentiWordNet. 3.5 Fenômenos Linguísticos em debates Esta seção apresenta uma breve fundamentação sobre dois fenômenos linguísticos presentes em debates: as anáforas (seção 3.5.1), e as concessões (seção 3.5.2). Esses fenômenos foram considerados e tratados neste trabalho de mestrado. 15 Disponível em: http://mpqa.cs.pitt.edu/lexicons/ inquirer/ 17 http://wordnet.princeton.edu/ 16 http://www.wjh.harvard.edu/ 47 3.5. FENÔMENOS LINGUÍSTICOS EM DEBATES Figura 3.9 Estrutura do léxico SentiWordNet contendo exemplos de palavras opinativas. 3.5.1 Anáforas Um elemento pouco abordado em sistemas de Análise de Sentimento e que é capaz de auxiliar na identificação de entidades associadas às opiniões são as anáforas (Jakob e Gurevych, 2010). Este fenômeno é um elemento linguístico de coesão que faz referência a alguma entidade anteriormente expressa no texto (Mitkov, 1999). Mitkov também explica que a entidade que é referenciada pela anáfora é conhecida como antecedente. De acordo essa definição, podemos dizer que a resolução de anáfora pode ser definida como o processo de identificar o antecedente de um referente anafórico ((Mitkov, 1999), (Kabadjov, 2007)). Mitkov descreve os três tipos de anáforas mais difundidos na literatura de Linguística Computacional: • Anáfora pronominal é o tipo de anáfora mais conhecido e estudado dentro da literatura. Os pronomes anafóricos podem ser dos tipos pessoal, possessivo, reflexivo e demonstrativo. O exemplo 3.1 apresenta o antecedente em negrito na primeira sentença, e seu referente anafórico sublinhado na segunda sentença. • Anáfora de Sintagma Nominal é tipo de anáfora onde o antecedente é referenciado por um sintagma nominal que deve ser semanticamente próximo ao antecedente (e.g., sinônimo). Este caso de anáfora é demonstrado no exemplo 3.2 . • Anáfora One é o caso onde a anáfora é concedida pelo sintagma nominal formado com o termo “one”. O exemplo 3.3 apresenta uma ilustração desta ocorrência. 48 3.5. FENÔMENOS LINGUÍSTICOS EM DEBATES Exemplo 3.1: Caso de anáfora pronominal retirado de (Mitkov, 1999) Computational Linguists from many different countries attended the tutorial. They took extensive notes. Exemplo 3.2: Caso de anáfora de sintagma nominal retirado de (Mitkov, 1999) Computational Linguists from many different countries attended the tutorial. The participants found it hard to cope with the speed of the presentation. 3.5.2 Concessões Em debates, é comum encontrarmos participantes que, durante a evolução da discussão, mudam de opinião sobre um determinado tópico e passam a defender o lado do debate que antes criticavam. Outro fenômeno também comum em debates ocorre quando um participante reconhece o ponto de vista de um adversário no debate, mas, apesar disso, permanece com sua opinião. A este último fenômeno damos o nome de concessão (Concession). Por definição, concessão é um tipo particular de relação semântica entre a interpretação de um argumento que cria uma expectativa e um segundo argumento que explicitamente contradiz o primeiro (Kruijff-Korbayova e Webber, 2007). A primeira sentença do exemplo 3.4 mostra um caso de concessão retirado no nosso corpora de debates. O usuário, apesar de se expressar de forma favorável ao iPhone, demonstra em sua argumentação que prefere o Blackberry. Robaldo et al. (2010) destacam dois tipos de concessão: a que instancia uma relação direta entre a expectativa e a contradição desta, e a que instancia uma relação indireta entre esses elementos que estão presentes em um determinado trecho do texto. Para melhor compreensão dos tipos de concessão, utilizaremos os exemplos 3.5 e 3.6 a seguir. Considere a seguinte suposição: “Mulheres bonitas geralmente não ficam solteiras, todas se casam”. No exemplo 3.5, levando em consideração a suposição anterior, o trecho em negrito gera uma expectativa direta, que é claramente negada na sentença seguinte. Já no exemplo 3.6, se uma pessoa não possuir um carro, não implica que esta mesma pessoa não tenha uma bicicleta. Neste caso a concessão é indireta, pois supondo que “uma pessoa que não possui carro é uma pessoa sem muita mobilidade”, a sentença em negrito gera uma expectativa que é indiretamente negada na sentença em itálico. 49 3.6. CONSIDERAÇÕES FINAIS Exemplo 3.3: Caso de anáfora com o referente one retirado de (Mitkov, 1999) If you cannot attend a tutorial in the morning, you can go for an afternoon one. Exemplo 3.4: Post retirado do debate iPhone vs. Blackberry. (1)While the iPhone may appeal to younger generations and the BB to older, there is no way it is geared towards a less rich population. (2) In fact it’s exactly the opposite.(3) It’s a gimmick. (4) The initial purchase may be half the price, but when all is said and done you pay at least $200 more for the 3g. 3.6 Considerações Finais Como foi visto neste capítulo, a Análise de Sentimento em debates polarizados apresenta alguns desafios que não estão presentes na mineração de opiniões em reviews. Para melhor organização do capítulo, dividimos as abordagens de AS em dois tipos de debates polarizados: debates ideológicos e debates não ideológicos. Como dito anteriormente, os debates ideológicos apresentam conteúdos políticos, discussões sobre direitos relacionados a armas, crenças religiosas, aborto e etc. Já os debates não ideológicos são sobre temas sem conotação política, como por exemplo, qual o melhor navegador web, o melhor console de vídeo games, o melhor aparelho celular, etc. Alguns trabalhos sobre debates polarizados consideraram as estruturas de replies importantes para a classificação da postura de cada participante no debate. Estas abordagens utilizaram essa estrutura para formar clusters de debatedores que possuíssem a mesma opinião. Os replies dentro do debate realmente podem definir relacionamentos de conformidade/discórdia entre os debatedores, sendo, portanto, estruturas que devem ser consideradas no processo de classificação de sentimento. Contudo, utilizá-los como meio para agrupar os participantes de mesma opinião pode não ser uma boa prática, pois durante a evolução do debate, os participantes podem mudar de opinião e trocar de posição no debate. Outra abordagem bem interessante e inovadora é o trabalho de Somasundaran e Wiebe (2009). Este trabalho obteve bons resultados realizando uma mineração na Web, juntamente com a utilização de uma abordagem não supervisionada para determinar as preferências dos participantes do debate. Contudo, as autoras não trataram um elemento essencial, muito comum em debates, e que faz parte da análise do discurso, que são as 50 3.6. CONSIDERAÇÕES FINAIS Exemplo 3.5: Ilustração de um caso de concessão direta Although Greta Garbo was considered the yardstick of beauty, she never married. Exemplo 3.6: Ilustração de um caso de concessão indireta Although he does not have a car, he has a bike. anáforas. A abordagem desenvolvida durante este trabalho de mestrado implementou um algoritmo simples de resolução de anáforas que melhorou o desempenho da abordagem de Somasundaran e Wiebe (2009). Mesmo com o crescente número de pesquisas tratando sentimento em debates polarizados, os resultados ainda estão longe do estado da arte da AS em geral. Como os pesquisadores citados neste capítulo destacam, ainda há muito o que evoluir neste campo da AS. O capítulo a seguir apresentará nossa abordagem para a classificação de sentimento em debates não ideológicos. O capítulo 5 traz os experimentos realizados em cima desta abordagem. 51 4 ASDP: Um Processo de Análise de Sentimento em Debates Polarizados Nos capítulos anteriores, foram apresentados os conceitos e desafios gerais encontrados no universo de Análise de Sentimento. No capítulo 2, ilustramos algumas áreas de aplicação para sistemas de AS, e descrevemos as motivações para a criação de tais sistemas. No capítulo 3, voltamos nossa atenção a uma área de pesquisa crescente em mineração de opiniões, que é a AS em debates on-line. Este capítulo é destinado à apresentação do trabalho desenvolvido nesta pesquisa de mestrado, com foco na AS em debates polarizados não ideológicos. Observando a necessidade de sistemas mais eficazes na classificação de sentimentos em debates polarizados, apresentamos o ASDP, um processo de Análise de Sentimento em Debates Polarizados. Segundo Sommerville (1995), processo é um conjunto de atividades e resultados associados que levam à produção de um produto de software. Complementando essa definição, temos que processo é “qualquer atividade ou conjunto de atividades que toma um input, adiciona valor a ele e fornece um output a um cliente específico” (Gonçalves, 2000). Dentro dessa ótica, nosso processo recebe como input posts de debates polarizados, acresecenta a cada posts sua polaridade (stance), e retorna esse resultado ao usuário do sistema implementado. Ainda segundo o Sommerville (1995), os processos são compostos por tarefas ou atividades fundamenteais inter-relacionadas, que buscam a solução de uma questão específica. No nosso caso, o ASDP conta com três tarefas/atividades pricipais: pré-processamento dos posts de entrada, classificação de sentimento, apresentação dos resultados. Essas atividades foram consideradas como etapas de processamento dos posts, tendo sido implementadas em módulos separados no protótipo do sistema. A classificação de sentimento do ASDP é baseada em padrões linguísticos e em um 52 4.1. CARACTERIZAÇÃO DO PROBLEMA léxico subjetivo, que consiste no MPQA (Wilson et al., 2005) (ver seção 3.4) juntamente com um léxico de gírias criado durante o desenvolvimento deste trabalho. Esta etapa dispõe também de um submódulo para resolução de anáfora, um submódulo para a análise de concessões, e por último, um submódulo para análise dos posts usando uma representação em forma de grafo de replies. A seguir, a seção 4.1 apresenta com mais clareza o problema que o ASDP busca resolver. Na seção 4.2, é definida a arquitetura do sistema que implementa o ASDP. A seção 4.3 descreve a etapa de normalização dos posts dos debates. A seção 4.4 apresenta o processo de classificação de sentimento, explicando o funcionamento de cada um dos seus submódulos. Por fim, a seção 4.5 apresenta as considerações finais deste capítulo. 4.1 Caracterização do Problema No capítulo 2, mostramos que um processo de Análise de Sentimento completo é bastante complexo, podendo ser dividido em quatro tarefas/etapas: detecção de subjetividade (2.3.1), extração de atributos (2.3.2), classificação de sentimentos (2.3.3) e apresentação de resultados (2.3.4). Como apresentado nos capítulos 2 e 3, nem todos os trabalhos relacionados a AS implementam todas as etapas mencionadas anteriormente, devido à sua grande complexidade. Escolhemos como foco do ASDP a etapa de classificação de sentimentos. A princípio, a etapa de detecção de subjetividade não seria necessária, uma vez que os posts de debates polarizados deveriam sempre carregar conteúdo subjetivo. Apesar disso, detectamos alguns comentários sem conteúdo opinativo que foram considerados como ruído, e foram automaticamente removidos (ver seção 4.3). A etapa de extração automática de atributos, que é uma das mais complexas da AS, foi deixada como trabalho futuro. Assim, os atributos foram manualmente informados para o sistema implementado. Por fim, a etapa de visualização de resultados foi implementada de forma bastante simples, e consiste apenas na apresentação dos resultados da classificação em uma caixa de diálogo gerada a partir da Linguagem de Programação JAVA 1 . Como dito anteriormente, o objetivo central deste trabalho é a classificação de sentimentos em debates polarizados não ideológicos. Esta tarefa é bastante complexa, pois os textos dos debates costumam ser longos, e algumas vezes apresentam ironias, ou até mesmo ofensas direcionadas a outros participantes ou produtos/marcas/empresas. Os indivíduos que participam do debate, além de argumentarem em favor de suas preferên1 www.oracle.com/technetwork/java/javase/downloads/ 53 4.2. ARQUITETURA DO SISTEMA cias, podem também tecer críticas sobre as argumentações e preferências dos adversários. Isso dificulta muito a classificação automática do post, uma vez que podemos encontrar palavras opinativas positivas e negativas no mesmo post. Este trabalho foi desenvolvido seguindo a abordagem de Sistemas Baseados em Conhecimento, utilizando-se de técnicas Linguísticas para a classificação dos posts dos debates. Elaboramos um processo de classificação que utiliza padrões linguísticos que foram observados nos textos. Esses padrões montam triplas do tipo <produto, palavra opinativa, sentença>, que são usadas para a atribuição inicial da polaridade, análise de anáforas e concessões. Com esses e outros fatores associados, essa triplas definem as classes dos posts. Figura 4.1 Arquitetura geral do protótipo ASDP. 4.2 Arquitetura do Sistema A figura 4.1 apresenta a arquitetura do protótipo do ASDP, e as fases para o processo de classificação de sentimentos nos debates polarizados. O protótipo atual do ASDP foi desenvolvido para a língua inglesa, devido à dificuldade em encontrar sites de debates na língua portuguesa, bem como recursos e ferramentas linguísticas para o português. Assim sendo, todos os exemplos utilizados neste trabalho estão na língua inglesa, bem como as regras utilizadas para a classificação de sentimento. Como é possível ver na figura 4.1, o ASDP possui duas etapas principais: o préprocessamento dos posts, responsável pela normalização e etiquetagem dos posts que 54 4.3. PRÉ-PROCESSAMENTO DOS POSTS serão as entradas para a classificação de sentimentos; e a classificação de sentimento, que por sua vez é composta pelos submódulos de atribuição de polaridade através do léxico subjetivo, resolução de anáfora, análise de concessões, e análise do grafo de replies. Todas essas atividades serão aprofundadas nas seções seguintes. O ASDP conta com três bases de conhecimento, que auxiliam no processamento do posts: base de substituições, léxico subjetivo e base de padrões linguísticos. Essas bases serão descritas em seções diferentes, à medida que forem sendo usadas no processamento dos posts. Assim, o Léxico subjetivo será discutido na seção 4.3.1; a base de substituições é vista na seção 4.3.2; e a Base de padrões linguísticos será apresentada na seção 4.4.2. Para ilustrar o processo geral do ASDP, iremos utilizar três (posts), que demonstrarão a execução de todas as etapas do ASDP. Os posts que serão utilizados são os exemplos 4.1 ,4.2 e 4.3. Exemplo 4.1: Comentário retirado do corpus do debate iPhone vs. Blackberry. “Rebuttal to: soso While the iPhone may appeal to younger generations and the BB to older, there is no way it is geared towards a less rich population. In fact it’s exactly the opposite. It’s a gimmick. The initial purchase may be half the price, but when all is said and done you pay at least $200 more for the 3g. ” Exemplo 4.2: Comentário retirado do corpus do debate iPhone vs. Blackberry. “Rebuttal to: coop I’ve never understood the appeal of the Blackberry in the first place. I’m a Treo 650 user myself, but as for iPhone - it gets my vote over Blackberry. I love the idea of not having to carry 2-3 devices. As it is, I carry a 60 GB iPod AND my phone. However, my Treo 650 plays music, plays movies, has Bluetooth, runs 3rd party apps, etc.... I love it. I may not switch at all, but if I had to pick Blackberry or iPhone - the chocie is clear.” Exemplo 4.3: Comentário retirado do corpus do debate Firefox vs. Internet Explorer2 . “i love firefox and defended it, but what is odd is that this site is breaking in it.” 4.3 Pré-processamento dos Posts A etapa de pré-processamento é responsável por três tarefas distintas. Inicialmente, é feita uma análise automática dos posts de entrada a fim de descartar os posts que não 55 4.3. PRÉ-PROCESSAMENTO DOS POSTS possuem palavras opinativas, ou não fazem referência a nenhum dos tópicos do debate (ver seção 4.3.1). Essa tarefa equivale à etapa de detecção de subjetividade nos processos comuns de AS. A seguir, os textos dos posts opinativos passam por uma fase de normalização, a fim de eliminar abreviações e contrações (que introduzem ruído na AS). Por fim, os posts normalizados passam por um processo de etiquetagem com o uso do POS-Tagger de Stanford (Toutanova et al., 2003). A figura 4.2 ilustra os submódulos desta etapa. A saída deste módulo é usada como entrada para o módulo de Classificação de sentimento. Figura 4.2 Arquitetura da etapa de pré-processamento do protótipo ASDP. 4.3.1 Eliminação de posts não opinativos A eliminação dos posts sem conteúdo opinativo foi feita automaticamente de forma ad-hoc, com base apenas nas características dos posts usados nos nossos experimentos. Assim, foram eliminados os posts que não continham nenhuma palavra opinativa (com auxílio do léxico subjetivo), bem como os posts que não mencionavam no texto nenhum dos tópicos em debate. 56 4.3. PRÉ-PROCESSAMENTO DOS POSTS Léxico Subjetivo O léxico subjetivo utilizado nesta pesquisa de mestrado consiste no léxico MPQA aumentado por gírias, que foram encontradas nos textos comuns de debates polarizados. Exemplos de entradas do léxico MPQA podem ser vistos na seção 3.4, no capítulo 3, enquanto que alguns exemplos de entradas do léxicos de gírias são mostradas no quadro 4.1. O léxico de gírias completo pode ser visto no apêndice B. Quadro 4.1: Lista de gírias presentes no léxico de gírias criado. Tipo Tamanho Palavra Classe Gramatical Stemmed Polaridade weaksubj 1 rox adjetivo não postiva weaksubj 1 pwns verbo não positiva weaksubj 1 crap substantivo não negativa Exemplos de posts eliminados O quadro 4.2 apresenta alguns exemplos de posts eliminados no pré-processamento. Quadro 4.2: Exemplos de posts que foram descartados na etapa pré-processamento. Debate Iphone vs. Blackberry Firefox vs. Internet Explorer Firefox vs. Internet Explorer Sony Ps3 vs. Nintendo Wii 4.3.2 Post and your point is ? thats the funniest thing i ’ ve read today . hey nobrob wasnt ie invented before firefox ah derrrr ! ! ! ! ! ! ! ! online is free and demos dont cost you anything Normalização dos textos É comum encontrarmos em sites de debates on line, fóruns de discussões, e blogs, textos com erros de grafia, abreviações, gírias, entre outros elementos que caracterizam a linguagem informal dominante nesses sites. Para a realização de um processo de AS mais preciso, é interessante que esses elementos sejam tratados no texto sob análise, pois a presença destes pode acarretar na perda de informações do texto, ou até mesmo na inclusão de ruídos no processo de AS. O submódulo de Normalização é responsável por filtrar os posts de entrada, substituindo as contrações, abreviações pelas palavras correspondentes na linguagem formal. 57 4.3. PRÉ-PROCESSAMENTO DOS POSTS Figura 4.3 Lista de abreviações presentes na base de subtituição. Figura 4.4 Lista de contrações presentes na base de subtituição. Para isto, foram utilizadas bases de substituições que contém esses termos e suas respectivas palavras na forma padrão. As bases de substituições foram criadas a partir da análise dos posts dos corpora de debates usados nos nossos experimentos (ver Apêndice A). Tanto no Quadro 4.1, como nos exemplos 4.1 e 4.2 é possível verificar a presença de abreviações e contrações nos posts. Além disso, nos posts, é comum os participantes se referirem às entidades em debate ora por sua nomenclatura oficial, ora por uma abreviação, ou até mesmo um apelido. O exemplo 4.1 ilustra uma ocorrência dessa natureza, quando o produto Blackberry é referenciado por BB. Para tratar esses fatores recorrentes nos textos, foi criada uma base de sinônimos com as principais palavras que referenciam oficialmente os produtos em debate no nosso corpora. Assim, apelidos e abreviações foram substituídos por suas 58 4.3. PRÉ-PROCESSAMENTO DOS POSTS Figura 4.5 Lista de sinônimos presentes na base de subtituição. nomenclaturas oficiais. Base de substituições As figuras 4.3, 4.4 e 4.5 apresentam exemplos de entradas de abreviações, contrações e sinônimos respectivamente. A base completa de sinônimos pode ser vista na seção A.3 do apêndice A. Exemplos de posts normalizados Os exemplos 4.4 e 4.5 apresentam as modificações nos posts dos exemplos 4.1 e 4.2, respectivamente, após a execução do submódulo de Normalização. Como é possível verificar, todas as contrações foram tratadas, bem como a abreviação do produto Blackberry. Exemplo 4.4: Comentário retirado do corpus do debate iPhone vs. Blackberry. “rebuttal to : soso while the iphone may appeal to younger generations and the blackberry to older , there is no way it is geared towards a less rich population . in fact it is exactly the opposite . it is a gimmick . the initial purchase may be half the price , but when all is said and done you pay at least $ 200 more for the 3g . ” 4.3.3 POS-Tagging Após concluída a normalização dos posts, o passo seguinte é a etiquetagem das palavras do texto segundo sua classe gramatical. A importância dessa etiquetagem é que, em geral, 59 4.4. CLASSIFICAÇÃO DE SENTIMENTO Exemplo 4.5: Comentário retirado do corpus do debate iPhone vs. Blackberry. “rebuttal to : coop i have never understood the appeal of the blackberry in the first place . i am a treo 650 user myself , but as for iphone - it gets my vote over blackberry . i love the idea of not having to carry 2 - 3 devices . as it is , i carry a 60 gb iphone and my phone . however , my treo 650 plays music , plays movies , has bluetooth , runs 3rd party application , etc . . . . i love it . i may not switch at all , but if i had to pick blackberry or iphone - the chocie is clear . ” as palavras opinativas correspondem a adjetivos e advérbios, podendo também incluir alguns substantivos (e.g., amigo/inimigo) e verbos (e.g., gosto, detesto). Para isto, utilizamos POS-taggers (do inglês, Parts-Of-Speech taggers), que são ferramentas que têm como objetivo etiquetar vocábulos com sua classe gramatical, levando em conta o contexto de ocorrência do vocábulo na sentença. São vários os POS-taggers que podem ser encontrados na literatura, porém o mais utilizado é o Stanford POS-tagger (Toutanova et al., 2003). Segundo Silva (2013), os POS-tagger são bastante úteis em diversas etapas da AS. No ASDP, o Stanford POS-tagger é utilizado apenas na fase de pré-processamento dos posts. Contudo, esta etiquetagem é crucial para a etapa de classificação de sentimento, como veremos na seção 4.4.2. Nesta fase de processamento, os textos dos posts já normalizados são segmentados em sentenças, e em seguida, utiliza-se o Stanford POS-Tagger (Toutanova et al., 2003) para a etiquetagem das palavras. A figura 4.6 ilustra as etiquetas utilizadas pelo Stanford POS-tagger. Exemplos de posts etiquetados O quadro 4.3 apresenta as transformações ocorridas nos posts dos exemplos 4.3, 4.4 e 4.5. 4.4 Classificação de Sentimento A etapa de classificação de sentimento é responsável por definir a postura (stance) de cada post do debate. Para isso, é necessário identificar os produtos/tópicos em discussão e as palavras opinativas associadas a estas entidades. Após a análise da polaridade das palavras opinativas, esta etapa define a stance de cada post como pro-produto_1 ou pro-produto_2. 60 4.4. CLASSIFICAÇÃO DE SENTIMENTO Quadro 4.3:Exemplos de entradas e saídas no processo de etiquetagem. Post Original while the iphone may appeal to younger generations and the blackberry to older , there is no way it is geared towards a less rich population . in fact it is exactly the opposite . it is a gimmick . the initial purchase may be half the price , but when all is said and done you pay at least $ 200 more for the 3g . Post etiquetado pelo Stanford POS-Tagger while_IN the_DT iphone_NN may_MD appeal_VB to_TO younger_JJR generations_NNS and_CC the_DT blackberry_NN to_TO older_JJR ,_, there_EX is_VBZ no_DT way_NN it_PRP is_VBZ geared_VBN towards_IN a_DT less_JJR rich_JJ population_NN ._. in_IN fact_NN it_PRP is_VBZ exactly_RB the_DT opposite_NN ._. it_PRP is_VBZ a_DT gimmick_NN ._. the_DT initial_JJ purchase_NN may_MD be_VB half_PDT the_DT price_NN ,_, but_CC when_WRB all_DT is_VBZ said_VBN and_CC done_VBN you_PRP pay_VBP at_IN least_JJS $_$ 200_CD more_JJR for_IN the_DT 3g_NN ._. i have never understood the appeal of the blackberry in the first place . i am a treo 650 user myself , but as for iphone - it gets my vote over blackberry . i love the idea of not having to carry 2 - 3 devices . as it is , i carry a 60 gb iphone and my phone . however , my treo 650 plays music , plays movies , has bluetooth , runs 3rd party application , etc . . . . i love it . i may not switch at all , but if i had to pick blackberry or iphone the chocie is clear . i_FW have_VBP never_RB understood_VBN the_DT appeal_NN of_IN the_DT blackberry_NN in_IN the_DT first_JJ place_NN ._. i_FW am_VBP a_DT treo_NN 650_CD user_NN myself_PRP ,_, but_CC as_IN for_IN iphone_NN -_: it_PRP gets_VBZ my_PRP$ vote_NN over_IN blackberry_NN ._. i_FW love_VBP the_DT idea_NN of_IN not_RB having_VBG to_TO carry_VB 2_LS -_: 3_CD devices_NNS ._. as_IN it_PRP is_VBZ ,_, i_FW carry_VB a_DT 60_CD gb_NN iphone_NN and_CC my_PRP$ phone_NN ._. however_RB ,_, my_PRP$ treo_NN 650_CD plays_NNS music_NN ,_, plays_VBZ movies_NNS ,_, has_VBZ bluetooth_NN ,_, runs_VBZ 3rd_CD party_NN application_NN ,_, etc_FW ._. ._. ._. ._. i_FW love_VBP it_PRP ._. i_FW may_MD not_RB switch_VB at_IN all_DT ,_, but_CC if_IN i_FW had_VBD to_TO pick_VB blackberry_NN or_CC iphone_NN -_: the_DT chocie_NN is_VBZ clear_JJ ._. i love firefox and defended it, but what i_FW love_NN firefox_NN and_CC defended_VBD is odd is that this site is breaking in it. firefox_NN ,_, but_CC what_WP is_VBZ odd_JJ is_VBZ that_IN this_DT site_NN is_VBZ breaking_VBG in_IN firefox_NN ._. 61 4.4. CLASSIFICAÇÃO DE SENTIMENTO Figura 4.6 Etiquetas presentes no POS-tagger de Stanford. O módulo do protótipo que implementa a etapa de classificação de sentimento contempla cinco submódulos, como é possível verificar na figura 4.7. O primeiro submódulo (SM1) trata da resolução de anáforas nos post. O SM2 é responsável por identificar as opiniões presentes nestes textos. O SM3 irá tratar das concessões, um fenômeno linguístico comum em debates. O quarto submódulo (SM4) define a postura dos posts, e o SM5 finaliza a etapa de classificação de sentimentos com a criação e análise do grafo dos replies presentes nos corpora de debates. 4.4.1 Resolução de Anáfora O primeiro submódulo da classificação de sentimento do ASDP é responsável por tratar os pronomes anafóricos (SM1). As anáforas são elementos linguísticos de coesão que fazem referência a alguma entidade anteriormente expressa no texto (Mitkov, 1999). Segundo Jakob e Gurevych (2010), estes elementos contribuem no processo de Análise de Sentimento, pois auxiliam no processo de identificação de entidades relacionadas a opiniões através da resolução dos referenciais anafóricos. Como apresentado na figura 4.7, o procedimento de resolução de anáfora é logo após a etapa de pré-processamento. O algoritmo desenvolvido para resolução de anáfora é 62 4.4. CLASSIFICAÇÃO DE SENTIMENTO Figura 4.7 Arquitetura da etapa de classificação de sentimento do ASDP. bem simples, e consiste apenas na averiguação da última entidade que foi citada antes da ocorrência do pronome anafórico “it”. A lógica por trás deste método é que após uma entidade ser citada no texto, é comum o indivíduo referenciar esta entidade com o uso de algum pronome. A evolução deste processo de resolução de anáfora é uma das recomendações de trabalhos futuros. A primeira sentença do quadro 4.3 tem uma ocorrência de um referencial anafórico “it”. Após o submódulo de resolução de anáfora, o referencial anafórico é substituído pelo produto mais próximo, i.e., blackberry. A sentença deve ficar como ilustrado no exemplo 4.6. Exemplo 4.6: Primeira sentença do exemplo 4.2 após a resolução de anáfora. ““while the iphone may appeal to younger generations and the blackberry to older , there is no way blackberry is geared towards a less rich population .”” 4.4.2 Atribuição Inicial de Polaridade O segundo submódulo da classificação de sentimentos do ASDP é a Atribuição Inicial de Polaridade. O objetivo deste submódulo é extrair triplas <produto, palavra opinativa, senteça> que serão responsáveis por identificar a postura dos posts dos debates. 63 4.4. CLASSIFICAÇÃO DE SENTIMENTO Para a extração das triplas foram desenvolvidos padrões linguísticos a partir da observação de três debates que integram os corpora utilizados neste trabalho: o debate Mac OS X Leopard vs. Windows Vista3 , o debate PC vs. Mac 4 , e o debate Windows vs. Mac5 . Os padrões linguísticos foram elaborados com o auxílio de uma gramática da língua inglesa (Carter e McCarthy, 2006) e com o uso da ferramenta POS-tagger de Stanford (Toutanova et al., 2003). O quadro 4.5 descreve os padrões que foram aplicados para extração das triplas. Note que os produtos/tópicos são respresentados pelas etiquetas PSubstantivo e as palavras opinativas são as classes gramaticais que estão sublinhadas. O símbolo “|” sinaliza que o padrão pode ter mais de uma classe gramatical para representar uma palavra opinativa, ou seja, o padrão (5) pode ser PSubstantivo + Verbo + Advérbio, ou PSubstantivo + Verbo Substantivo. Formação das triplas Conforme a figura 4.7, a entrada deste submódulo são os posts etiquetados pelo POSTagger de Stanford (Toutanova et al., 2003), juntamente com as anáforas resolvidas. O quadro 4.4 apresenta as classes gramaticais utilzadas nos padrões linguísticos, e as etiquetas associadas que foram utilizadas para este processo de extração. Quadro 4.4: Classes Gramaticais e as etiquetas do Stanford Pos-tagger. Classe Gramatical Substantivo Adjetivo Advérbio Verbo Etiqueta NN, NNS, NNP, NNPS JJ, JJS, JJR RB, RBR, RBS VB, VBD, VBG, VBN, VBZ, VBP Para demonstrar o procedimento de extração das triplas<produto, palavra opinativa, sentença> iremos utilizar o exemplo 4.3 após o POS-tagging (ver quadro 4.3). Inicialmente, identifica-se um dos produtos/tópicos do debate (PSubstantivo) dado uma sentença do post como entrada. Conforme o exemplo 4.3, o produto identificado seria o “firefox”. Após a identificação do tópico/produto, o método tenta encontrar alguma palavra opinativa (candidata) com o uso dos padrões linguísticos descritos no quadro 4.5. Caso a 3 http://www.convinceme.net/debates/55/Mac-OS-X-Leopard-vs-Windows-Vista.html 4 http://www.convinceme.net/debates/7509/PC-vs-MAC.html 5 http://www.convinceme.net/debates/335/Windows-v-Mac.html 64 4.4. CLASSIFICAÇÃO DE SENTIMENTO palavra encontrada esteja presente no léxico subjetivo, a tripla <produto, palavra opinativa, sentença> é formada. Se esta palavra não estiver contida no léxico subjetivo, a tripla não é formada. Este método repete esses passos para cada sentença em todos os posts do debate. Dado o exemplo 4.3, as triplas formadas seriam: <firefox, love, i love firefox and defended it, but what is odd is that this site is breaking in it.> e <firefox, odd, i love firefox and defended it, but what is odd is that this site is breaking in it.>. Os padrões responsáveis pela extração dessas triplas são indicados no quadro 4.6. Quadro 4.5: Padrões Linguísticos. Palavra Opinativa anterior ao Produto (1) Advérbio + Adjetivo + PSubstantivo (2) ( Adjetivo | Substantivo | Verbo) + PSubstantivo Palavra Opinativa após o Produto (3) PSubstantivo + ( Adjetivo | Advérbio | Verbo | Substantivo ) (4) PSubstantivo + Verbo + Advérbio + ( Adjetivo | Verbo ) (5) PSubstantivo + Verbo + ( Adjetivo | Advérbio | Substantivo ) (6) PSubstantivo + Advérbio + Verbo + Adjetivo (7) PSubstantivo + Advérbio + ( Verbo | Substantivo | Adjetivo ) Para o processo de formação das triplas<produto, palavra opinativa, senteça> foram desconsiderados os stopwords, que são palavras de classes gramaticais consideradas irrelevantes para o desenvolvimento deste trabalho, como artigos, pronomes, preposições, etc. Atribuição de Polaridade da Tripla Como dito anteriormente, o objetivo desse módulo é atribuir uma polaridade inicial (positiva +, negativa -, neutra*) às palavras opinativas das triplas formadas pelos padrões linguísticos. Logo, é analisado nesse módulo, apenas as palavras opinativas e as sentenças onde se encontram, pois estes são os fatores que irão definir a polaridade da tripla. Inicialmente, a atribuição de polaridade é realizada com base no léxico subjetivo (léxico MPQA (Wilson et al., 2005) + léxico de Gírias). Após a formação das triplas, substituímos as palavras opinativas de acordo com as suas polaridades associadas no léxico subjetivo, +1 caso a polaridade da palavra seja positiva, -1 caso a polaridade seja negativa e 0 caso a polaridade seja neutra. Como apresentado na subseção 3.4, este dicionário fornece a cada palavra a sua polaridade e seu grau de subjetividade (forte ou fraca). Contudo, neste trabalho os graus 65 4.4. CLASSIFICAÇÃO DE SENTIMENTO de subjetividade não foram considerados, e portanto, tanto as palavras de subjetividade fraca quanto as palavras de subjetividade forte recebem polaridades +1 , e -1 para as palavras positivas e negativas respectivamente. Outro fator de influencia neste módulo são as expressões negativas dentro das sentenças. Para esta análise, considera-se uma janela de tamanho 5 a partir da palavra opinativa, e se por ventura, no intervalo de palavras dentro desta janela possuir algumas das expressões negativas da figura 4.4.2, a polaridade da tripla é invertida. Observe que nas duas primeiras sentenças no quadro 4.6, as expressões negativas invertem a polaridade das palavras opinativas, definindo assim a nova polaridade da tripla. not, none, nothing, neither, hardly, never, no one, cannot, nor, nowhere, against, absurd, except, without Figura 4.8 Lista de expressões negativas 4.4.3 Análise de Concessões O terceiro submódulo da classificação de sentimento trata da análise de concessões (SM3). As concessões são relações semânticas que ocorrem entre sentenças, onde a primeira sentença apresenta uma relação de expectativa que é claramente negada na sentença seguinte (Robaldo et al., 2010). O algoritmo proposto para esta análise é similar ao introduzido em (Somasundaran e Wiebe, 2009). Para o funcionamento deste procedimento, foi gerada uma lista de conectivos a partir das categorias “Concession” e “Contra-expectation” do corpus Penn Discourse Treebank, que é apresentada no figura 4.4.3. • Se o conectivo estiver no início da sentença, esta é separada na primeira ocorrência da virgula que estiver no meio da sentença. A primeira parte é considerada a expectativa, e a segunda a não-expectativa. • Se o conectivo for encontrado no meio da sentença, a parte do texto anterior a sentença é considerada expectativa, e parte seguinte considerada não-expectativa. • As opiniões presentes nas partes consideradas expectativas terão sua polaridade invertida. although, but ,even if, even though, however, still, though, while, yet, nonetheless Figura 4.9 Lista de conectivos utilizados para a análise de concessões. 66 4.4. CLASSIFICAÇÃO DE SENTIMENTO Quadro 4.6: Exemplo de padrões linguísticos, e dos produtos associados a palavras opinativas que são identificados na etapa de criação de triplas. Os termos “PSUBTANTIVO” presentes na segunda coluna são referentes ao produtos em debate. 67 4.4. CLASSIFICAÇÃO DE SENTIMENTO No exemplo 4.2 é possível verificar a ocorrência de concessão na segunda sentença do post. No início desta sentença a expectativa é criada no momento em que o autor afirma ser usuário do aparelho Blackberry. Porém, logo em seguida, o autor expressa uma opinião positiva sobre o produto da Apple, adversário da Blackberry no debate. Se uma tripla fosse identificada na primeira parte desta sentença, a sua polaridade seria invertida. No exemplo 4.3, o autor do post começa enaltecendo o Firefox. Contudo, na sentença seguinte o autor define qual é sua real posição sobre o produto no debate. Neste caso, como houve uma tripla formada na primeira parte da sentença, a polaridade inicial dessa tripla foi invertida, conforme mostra o quadro 4.7. 4.4.4 Classificação das Posturas dos Posts Para a classificação das posturas dos posts do debate desenvolvemos as equações 4.1, 4.2 e 4.3. 4.1 stance = max(w, u) 4.2 u = Σ p j , +1 + Σ (pi , −1) 4.3 w = Σ (pi , +1) + Σ p j , −1 As equações 4.2 e 4.3 calculam a postura do post a partir da soma das polaridades atribuídas às triplas que foram identificadas em cada comentário, onde pi e p j representam os produtos (de cada tripla) debatidos no texto. A equação 4.1 define qual a postura de cada post: caso w > u, a postura do comentário será pro-produto_1, já se u > w, a postura do post receberá a classe pro-produto_2. Se o valor de u for igual ao valor de w, atribuímos a classe empate ao post. Aplicando as equações 4.1, 4.2 e 4.3 sobre o post ilustrado no exemplo 4.3, e com as triplas formadas a partir dos submódulos de resolução de anáfora e análise de concessões (ver quadro 4.7), onde, a variável pi representa o produto Firefox, e variável pj, por sua vez, representa o produto Internet Explorer, teremos o seguinte cenário: a quantidade de triplas favoráveis ao Firefox é 0 (u = 0), e a quantidade de triplas favoráveis ao Internet Explorer é três (w = 3). Logo, de acordo com a equação 4.1, a postura desse post será pro-internet explorer. 68 4.4. CLASSIFICAÇÃO DE SENTIMENTO Quadro 4.7: Exemplo de triplas e as polaridades associadas após os submódulos SM1, SM2 e SM3. 69 4.4. CLASSIFICAÇÃO DE SENTIMENTO 4.4.5 Criação e Análise do Grafo de Replies O último submódulo deste processo de classificação de sentimento analisa as estruturas de replies presentes nos debates. Como visto no capítulo 3, alguns trabalhos já utilizaram esta estrutura para tentar inferir concordância/discórdia entre os participantes no debate. Contudo, neste módulo, os replies irão formar uma rede de discórdia entre os participantes do debate. Um dos sites de debates que foram utilizados para a criação dos corpora possui uma característica peculiar quanto a estrutura de replies. No site convinceme.net, quando um indivíduo discorda do ponto de vista de outro participante do debate, o usuário pode enviar uma mensagem direcionada ao post do participante em que ele discorda. Se houver uma réplica, esta mensagem será uma nova thread com o link rebuttal, que é uma mensagem de discórdia à argumentação prévia dentro do debate. Desta forma, o convinceme.net garante que a estrutura de replies só tenha um nível. Dentro desse contexto, o método proposto pra este módulo é responsável por identificar quais posts são do tipo rebuttal, e a quais comentários estes replies se direcionam, e assim, inferir a classificação dos posts. Como visto na figura 4.7, a entrada deste submódulo recebe a classificação dos posts, juntamente com os links de replies, i.e. os posts identificados como rebuttal são novamente analisados a fim de identificar a qual comentário este reply foi direcionado. O quadro 4.8 apresenta exemplos de comentários e de replies do debate Windows vs. Mac6 . Após esta análise nos replies, cria-se uma matriz de adjacência para a representação do grafo. A matriz de adjacência é definida como uma matriz n x n A(G)=[aij], onde i = j = 0 ... n, sendo n o número de vértices, e aij a aresta que liga os vértices vi e vj. Nesta matriz, se aij tiver valor igual a 1, isso significa que os vértices vi e vj são adjacentes. Caso aij seja igual a 0, os vértices vi e vj não são vértices adjacentes, e dessa forma não haverá ligação entre eles. Os vértices do grafo formado pela matriz de adjacência são os posts dos debates, e as arestas são as ligações entre os posts e os replies identificados nesta rede de discórdia. Após a fase de criação do grafo, o passo seguinte é classificar os posts do debate de acordo com a de entrada deste submódulo (classicação do submódulo anterior), levando em conta as ligações formadas na fase de criação do grafo. Como dito anteriormente, os replies presentes no convinceme.net são mensagens de dicórdia a outros comentários dentro do debate, e portanto, suas stance são contrárias. Dessa forma, a análise feita sobre o grafo de replies percorre todos vértices do grafo, e verifica a existência de alguma 6 http://www.convinceme.net/debates/335/Windows-v-Mac.html 70 4.4. CLASSIFICAÇÃO DE SENTIMENTO Quadro 4.8:Exemplos de posts e replies do debate Windows vs. Mac Usuário shem Postura Rebuttal para Posts Windows is Better —— For all my gaming needs, windows has kept me happy for a long long time. xboteb13 Mac is Better gaara42 shem You can dual-boot Windows on a Mac (though I don’t see why you would). The only reason you think games are better on a PC is because they have better graphics cards. BUT this does NOT prove that Windows (an operating system) is better than Mac OS (an operating system). You are saying that the hardware that has Windows installed on it is better. That’s fine. Windows is Better —— Forgot to add this in my last argument, but Windows also has games, were as Macs don’t have nearly as many. For many people, such as myself, this is a big differentiator for with less games the Macs don’t fulfil the needs of certain people. xboteb13 Mac is Better gaara42 "Forgot to add this in my last argument, but Windows also has games, were as Macs don’t have nearly as many. For many people, such as myself, this is a big differentiator for with less games the Macs don’t fulfil the needs of certain people." Off of this... 1) Many game developers create games for Windows, but many also create games for universal platforms, meaning Mac and Windows. 2) You can dual-boot Windows on a computer running Mac OS. 71 4.5. CONSIDERAÇÕES FINAIS ligação a outro vértice. Se o vértice (origem) possuir uma arestra (i.e. é um comentário que recebeu um reply), é verificado a stance do vértice adjacente, esta postura é invertida e então é atribuída ao vértice origem. 4.5 Considerações Finais Neste capítulo, foi apresentado o ASDP, um processo de Análise de Sentimento em cima de debates não ideológicos. Através do uso de padrões linguísticos, o protótipo ASDP propõe um método para a classificação de sentimento em debates polarizados. As principais características deste protótipo são: a utilização de padrões linguísticos para identificação de opiniões em debates não polarizados, uma abordagem para Resolução de Anáfora, a Análise de Concessões, e por último, uma Análise em cima da Rede de Rebuttal. Como foi abordado anteriormente, o ASDP não possui a etapa de extração de característica, sendo uma tarefa proposta como trabalho futuro. A etapa de detecção de subjetividade consiste apenas em verificar se os posts possuem ou não opiniões através do uso do léxico subjetivo. Os posts que contêm palavras opinativas serão analisados, e os comentários sem opiniões serão automaticamente removidos. No próximo capítulo, serão apresentados os resultados dos experimentos, como também comparações com outras duas abordagens encontradas na literatura, o trabalho de (Somasundaran e Wiebe, 2009), e o trabalho de (Walker et al., 2012). 72 5 Experimentos e Resultados Este capítulo apresenta os experimentos realizados para avaliação da ASDP, processo proposto para Análise de Sentimento em Debates Polarizados. Primeiramente, a seção 5.1 detalha a base de dados utilizada para a experimentação. Em seguida, a seção 5.2 apresenta as métricas usadas na avaliação dos experimentos realizados. A seção 5.3 descreve os experimentos e os resultados obtidos, e a seção 5.4 mostra que os resultados obtidos pelo ASDP estão próximos aos resultados de outros trabalhos da literatura. Finalmente, a seção 5.5 traz as considerações finais deste capítulo. Foram realizados três experimentos, sempre utilizando um léxico (dicionário) subjetivo para auxiliar a determinar a polaridade dos textos. Utilizamos o léxico MPQA (Wilson et al., 2005) ampliado por um pequeno dicionário auxiliar de gírias com polaridades. Esse dicionário de gírias foi criado durante a realização do mestrado, com base nos textos dos debates estudados. Nesses textos, o uso de gírias é bastante comum, pois os participantes dos debates tendem a usarem gíria com uma carga opinativa. Conforme foi apresentado no capítulo 4, a etapa de classificação de sentimento do ASDP possui cinco submódulos (ver figura 4.7). Para a realização dos testes foram propostas três configurações diferentes. O primeiro experimento classifica o sentimento dos posts de debates somente com base no léxico subjetivo. O segundo experimento trata da resolução de anáfora e faz a análise de concessões dos textos dos debates. A resolução de anáfora é responsável por determinar a qual entidade um determinado pronome se refere (Mitkov, 1999). Já concessões ocorrem quando um autor, apesar de enaltecer alguns pontos de vista do lado oposto do debate, permanece fiel às suas convicções, e não troca de lado no debate. No terceiro experimento, adicionamos a informação dos links de rebuttal dos debates do site convinceme.net. Estes links são replies sobre alguns comentários nos quais o autor pode discordar diretamente de uma argumentação dada por outro participante do debate. 73 5.1. CORPORA DE DEBATES Para analisar essa informação, foi necessário mapear todos os posts do debate em um grafo. Cada nó do grafo representa o post e o respectivo autor. As arestas diretamente conectadas representam as ligações entre os posts e os replies, os quais, por sua vez, representam quem direcionou um critica para outrem. 5.1 Corpora de Debates Os corpora de debates foram criados a partir dos sites de discussão online convinceme1 e createdebate2 . Outros sites de debates polarizados são: forandagainst.com, e debatepolitics.com. Os textos extraídos foram sobre debates não ideológicos, que são argumentações contra ou a favor entre tópicos referentes a produtos/marcas e detalhes técnicos. Os textos dos debates foram extraídos da Web por um crawler. Ao total, foram reunidos cerca de 807 posts de debates entre produtos como: 225 comentários no debate Internet Explorer vs. Firefox, 88 comentários no debate PlayStation 3 vs. Nintendo WII, entre outros. A tabela 5.1 apresenta a quantidade de posts extraídos por debate pelo Webcrawler. Tabela 5.1 Quantidade de posts extraídos por debate. Debate Desenvolvimento Mac OS X Leopard vs. Windows Vista Mac vs. Pc Windows vs. Mac Experimentos Firefox vs. Internet Explorer iPhone vs. Blackberry Opera vs. Firefox Sony Ps3 vs. Nintendo Wii Sony Ps3 vs. Xbox 360 Número de Posts 58 17 27 225 27 16 88 349 Nos sites convinceme.net e createdebate.com, o usuário que iniciar um debate deve fornecer um título que irá informar o tópico em discussão no debate. Em cada debate, existem duas colunas que servem para separar as argumentações a favor das argumentações contrárias sobre o mesmo tema. Além disso, o usuário tem direito de discordar 1 www.convinceme.net 2 www.createdebate.com 74 5.1. CORPORA DE DEBATES diretamente de uma argumentação do debate utilizando os replies. No convinceme.net, o rebuttal é um reply direto ao post, no qual o autor pode argumentar diretamente sobre o post em questão, ou até mesmo sobre o autor deste. O quadro 5.1 apresenta alguns posts que são rebuttals presentes no debate Internet Explorer vs. Firefox, e o quadro 5.2 apresenta exemplos de posts comuns, ou seja, não são do tipo rebuttal. Quadro 5.1: Exemplos de posts de rebuttal do debate Firefox vs. Internet Explorer. Stance Post Pro-Firefox Firefox is Free Software. Nothing more. Pro-Internet Explorer when have you ever paid for MSIE? lol. Pro-Firefox Thats the funniest thing i’ve read today. Pro-Internet Explorer I like those cute little popup windows. You don’t get those with Firefox. Quadro 5.2: Exemplos de posts Pro-Firefox, Pro-Internet Explorer. Stance Pro-Firefox Post Beginner use IE, Advance user choose Firefox! Pro-Internet Explorer IE is much easier to use. It also is more visually pleasing. It is much more secure as well. Pro-Firefox I can reconfigure Firefox very easily to meet my needs as my life changes. If I need great SEO extensions I can get them. If I need an HTML color picker instead when I get more involved with other elements of site development, FF is easily remodeled to suit my new browsing needs. The breadth and variety of FF add-ons is a critical advantage. Pro-Internet Explorer I used to be a firefox user but I only have 2GBs of RAM on my system and I like to use more than one program at a time. Firefox sucks up way too much memory to justify the one or two advantages. Apesar dos sites de debate convince.net e createdebate.com fornecerem uma marcação inicial determinada pela coluna escolhida pelo usuário, todos os posts foram marcados manualmente com uma das seguintes classificações: pro-produt_1, pro-produto_2, sem_opinião (none). A marcação dos textos foi feita manualmente porque, apesar dos posts estarem organizados no site de forma que suas localizações nas colunas do site 75 5.2. MÉTRICAS DE AVALIAÇÃO representem sua marcação, muitos usuários, por falta de conhecimento ou por negligência, acabam argumentando a favor de (ou contra) um produto na coluna onde deveriam argumentar contra o (ou a favor do) outro produto. Além disso, foram também retiradas manualmente as ironias, visto que esse tipo de post não são tratados neste trabalho. Para facilitar a realização dos experimentos, todos os posts selecionados foram armazenados em planilhas excel. Para trabalhar com esses dados nesse tipo de arquivo, utilizamos a API Apache POI 3 . Todos os dados de cada post são armazenados em uma linha da planilha, que está organizada em cinco colunas. O quadro 5.3 mostra quais são as informações armazenadas para cada post. Todas as planilhas com os corpora estão disponíveis na Web4 . Quadro 5.3: Dados armazenados sobre cada post na base de dados. Número Autor Título Marcação manual Texto A primeira coluna representa somente a numeração do post no arquivo, a fim de manter uma ordem. A segunda coluna contém o nome do autor. Esta informação é utilizada para geração da rede de rebuttal, para auxiliar a classificação dos posts no debate. O nome do autor é utilizado para identificar para qual postagem está sendo direcionado o rebuttal. As colunas título e texto são referentes ao título e ao texto do post respectivamente. A coluna da marcação manual representa a categoria de cada post definida manualmente. Por exemplo, no debate “Internet Explorer vs. Firefox”, um post que é favorável ao Firefox receberá marcação de “firefox”, e caso o post seja pró-Internet Explorer, sua marcação será “internetexplorer”. 5.2 Métricas de Avaliação Para a avaliação dos nossos resultados, as métricas utilizadas foram as tradicionalmente utilizadas em Classificações de Texto, que são ilustradas nas equações 5.1 a 5.6. A tabela 5.2 apresenta a matriz de confusão utilizada no cálculo dessas equações. O termo true Ci (true positive) representa a quantidade de pares da classe i corretamente classificados, e o termo erro(Cj, Ci) é a quantidade de pares da Classe i erroneamente classificados como sendo da classe Cj. 3 http://poi.apache.org/ 4 https://www.dropbox.com/s/w50q7g4mnsjfc2a/corpora.zip 76 5.2. MÉTRICAS DE AVALIAÇÃO Tabela 5.2 Matriz de confusão para o cálculo do erro de classificação A partir da tabela 5.2 é possível calcular a precisão (Ps), a cobertura (Cs) e o Fmeasure (Fms) por classe. Psi = trueCi (trueCi + erro (Ci,C j) + erro (Ci,Ck)) 5.1 Csi = trueCi (trueCi + erro (C j,Ci) + erro (Ck,Ci)) 5.2 2 ∗ Ps ∗Cs 5.3 Ps +Cs As fórmulas 5.1, 5.2 e 5.3 são para a avaliação da classificação dos posts por classe, ou seja, pro-produto_1, pro-produto_2, sem opinião (none). Conforme apresentado na seção 4.4.4, durante a fase de classificação das posturas dos posts é possível que a quantidade de triplas a favor de um produto seja igual à quantidade de triplas a favor do produto adversário. A estes casos de posts foi determinado a classe empate/não determinado (tie). Para a classificação dos posts em relação ao debate, utilizamos as fórmulas 5.4, 5.5 e 5.6. Fms(1)i = Pe = trueCi + trueC j + trueCk totaldeposts − nodeterminados(empate) 5.4 Ce = trueCi + trueC j + trueCk totaldeposts 5.5 Acc = trueCi + trueC j + trueCk totaldeposts 5.6 A precisão em relação ao debate é determinada através da quantidade de posts corretamente classificados sobre a quantidade total de posts que foram classificados. Aqui desconsideramos os posts que recebem classe empate, pois são os posts que o nosso 77 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS classificador não consegue associar uma categoria. A cobertura é determinada de forma idêntica à acurácia (Acc). Ambas são a razão entre o número de posts classificados corretamente sobre a quantidade total de posts. Portanto, daqui pra frente será utilizado apenas o termo cobertura. 5.3 Classificação de Opinião em Debates de Produtos Como visto no capítulo 4, o processo de classificação de sentimento possui algumas etapas. O primeiro passo é o pré-processamento do texto, responsável por normalizar os textos dos debates de entrada e remover os posts sem palavras opinativas. O segundo passo é a classificação de sentimento, que é responsável pela identificação das triplas <produto, palavra opinativa, sentença> através de padrões linguísticos e da consulta ao dicionário subjetivo. Ainda neste passo, são feitas as resoluções de anáforas, as análises de concessões, e a criação e análise do grafo de replies. Para avaliar o desempenho do processo de Análise de Sentimentos do ASDP, realizamos três experimentos com três configurações distintas. O primeiro experimento classifica os posts somente com base nas polaridades das palavras opinativas, de acordo com o léxico subjetivo utilizado (Seção 5.3.1). No segundo experimento foi acrescentada a resolução de anáfora e análise de concessões (Seçõe 5.3.2). O último experimento considera também as informações dos rebuttal links dos posts do debate (Seção 5.3.3). A partir desses replies, construímos uma rede de posts que discordam diretamente de outros comentários no debate. As taxas de desempenho de cada configuração serão apresentadas na seções abaixo 5.3.1 Atribuição de Polaridade utilizando o Léxico Subjetivo O primeiro experimento propõe classificar a postura dos posts apenas extraindo as triplas <produto, palavra opinativa, sentença> através dos padrões linguísticos. Em seguida, as palavras opinativas das triplas são substituídas pela sua polaridade, de acordo com o dicionário subjetivo. São atribuídos os valores +1, -1 e 0, que representam as palavras positivas e negativas respectivamente. Por fim, a classificação geral do post é calculada a partir da soma da polaridade dos pares que seriam favoráveis a cada lado do debate, segundo as equações 4.2 e 4.3, conforme a seção 4.4.4. A equação que possuir maior valor numérico irá determinar a classe do post, como mostra a equação 4.1. Por exemplo, se um dado post é representado 78 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS pelos pares (Firefox, +1), (Firefox, +1) e (Internet Explorer, -1), sua classificação final será pro-firefox. Como visto na seção 4.4.2, utilizamos neste experimento um parâmetro para a definir o tamanho da janela de análise de expressões negativas. O valor empiricamente atribuído aqui, assim como nos outros experimentos, foi o valor cinco. Resultados Obtidos Os dados apresentados nas tabelas 5.3 a 5.7 são as matrizes confusão com os resultados para os corpora de debates Firefox vs. Internet Explorer5 , Iphone vs. BlackBerry6 , Opera vs. Firefox7 , Playstation 3 vs. Xbox 3608 e Playstation 3 vs. Nintendo Wii9 . Como visto anteriormente nesse capítulo, as métricas utilizadas foram Precisão, Cobertura e F-Measure. A matriz confusão foi calculada considerando as três classes em que o post pode ser classificado: pro-produto_1, pro-produto_2, objetivo/sem_opinião (none). Tabela 5.3 Matriz confusão da classificação dos posts do debate Firefox vs. Internet Explorer Como é possível observar nas tabelas 5.3, 5.4, 5.5, 5.6 e 5.7, essa primeira configuração do experimento classificou ao total 123 posts como None incorretamente. Alguns posts são difíceis de serem classificados, mesmo que manualmente, e em alguns casos, os padrões linguísticos não foram capazes de identificar opiniões nos textos, seja devido a limitação dos padrões, ou devido a etiquetagem incorreta de palavras na etapa de pré-processamento no texto. Alguns exemplos de posts classificados automaticamente como None são ilustrados no quadro 5.4. 5 http://www.convinceme.net/debates/58/Firefox-vs-Internet-Explorer.html 6 http://www.convinceme.net/debates/109/iPhone-vs-Blackberry.html 7 http://www.convinceme.net/debates/214/Opera-vs-Firefox.html 8 http://www.createdebate.com/debate/show/Is_PS3_better_than_Xbox_360 9 http://www.convinceme.net/debates/20/Sony-PS3-vs-Nintendo-Wii.html 79 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS Tabela 5.4 Matriz confusão da classificação dos posts no debate Iphone vs. Blackberry Tabela 5.5 Matriz confusão da classificação dos posts no domínio Opera vs. Firefox Tabela 5.6 Matriz confusão da classificação dos posts no domínio Playstation 3 vs. Nintendo Wii 80 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS Tabela 5.7 Matriz confusão da classificação dos posts no domínio Playstation 3 vs. Xbox 360 Quadro 5.4: Exemplos de posts classificados automaticamente como None pelo ASDP. Marcação Manual pro-firefox Marcação Automática none pro-firefox none pro-internet explorer none Post ie is full of bugs , glitches , and horrible slowness . . . . firefox has add ons and better security and stability fixes : d rebuttal to : rezmang apple doesn ’ t make firefox . apple makes safari , an entirely unrelated browser , which incidentally is also light years ahead of ie . ie is in fact mainstream , with more than 85 % of online users . only among the technically literate do better alternatives such as firefox , safari and opera begin to dominate . not that i really think that you ’ re being serious here , but one never knows . besides , even if you ’ re not serious , some poor soul might take you seriously ! till there comes a time when ff come preinstall in pcs . . . . ie will continue to dominate . enuff said Outro fator que deve ser considerado é a limitação do léxico utilizado Wilson et al. (2005). Existe uma grande quantidade de adjetivos comparativos, e adjetivos superlativos que não estão presentes no dicionário subjetivo (e.g. trendiest, slowest, faster, bigger, smoother, prettier,entre outros). Estas palavras são muito comuns nos corpora, devido a grande quantidade de comparações existentes nos debates. Ainda outra provável causa é a existência de opiniões que utilizam pronomes para se referir a algum produto (anáforas). 81 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS A ocorrência desses pronomes motivou a criação de um módulo para resolução de anáfora (Mitkov, 1999), como será visto no segundo experimento (Seção 5.3.2). Tabela 5.8 Resultado da classificação por posts do debate Firefox vs. Internet Explorer Pro-Firefox Pro-Internet Explorer None Precisão 0,8851 0,4571 0,2157 Cobertura 0,5923 0,50 1,0 F(1)-Measure 0,7097 0,4776 0,3548 Tabela 5.9 Resultado da classificação por posts do debate Iphone vs. Blackberry Precisão 0,8851 0,90 0,25 Pro-iPhone Pro-Blackberry None Cobertura 0,5923 0,75 1,0 F(1)-Measure 0,7097 0,8182 0,4 Tabela 5.10 Resultado da classificação por posts do debate Opera vs. Firefox Pro-Opera Pro-Firefox None Precisão 0,60 0,3333 0,0 Cobertura 0,3333 0,2857 0,0 F(1)-Measure 0,4286 0,3077 0,0 Tabela 5.11 Resultado da classificação por posts do debate Playstation 3 vs. Nintendo Wii Pro-Playstation 3 Pro-Nintendo Wii None Precisão 0,5600 0,60 0,20 Cobertura 0,4375 0,3947 1,0 F(1)-Measure 0,4912 0,4762 0,3333 As tabelas 5.8 a 5.12 mostram os resultados em relação aos posts (postura do participante). As baixas taxas de precisão apresentadas na classe None para todos os debates são devidas à baixa quantidade de posts marcados manualmente com esta classe. O classificador consegue identificar os posts que são realmente da classe None, porém 82 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS Tabela 5.12 Resultado da classificação por posts do debate Firefox vs. Internet Explorer Pro-Playstation 3 Pro-Xbox 360 None Precisão 0,7632 0,4918 0,5299 Cobertura 0,5878 0,4412 0,8158 F(1)-Measure 0,6641 0,4651 0,6425 Tabela 5.13 Resultado das classificações dos debates Firefox vs. Internet Explorer iPhone vs. Blackberry Opera vs. Firefox Playstation 3 vs. Nintendo Wii Playstation 3 vs. Xbox 360 Precisão 0,6012 0,7500 0,3125 0,4533 0,6130 Cobertura 0,5417 0,5769 0,3125 0,4250 0,5576 F(1)-Measure 0,5699 0,6522 0,3125 0,4387 0,5840 classifica outros posts que seriam das classes pro-produto_1 , ou pro-produto_2 como None incorretamente. Esse comportamento se repete nos demais experimentos. É possível verificar que, apenas com o uso do léxico subjetivo, o nosso classificador não foi capaz de obter resultados satisfatórios. O melhor resultado foi no debate Iphone vs. Blackberry (ver tabelas 5.9 e 5.13). 5.3.2 Classificação com o uso de Resolução de Anáfora e Concessão Nesse segundo experimento, além do léxico polarizado, foi também utilizado um algoritmo simples para resolução de anáfora (ver seção 4.4.1), bem como um método para contabilizar concessões nos posts (seção 4.4.3). Por fim, utilizamos as equações 5.1, 5.2 e 5.3 para determinar a classificação do post. A anáfora é um tipo de referência textual que aponta para alguma entidade mencionada anteriormente no texto (Kabadjov, 2007). De acordo essa definição, podemos dizer que a “resolução de anáfora” pode ser definida como o processo de identificar o antecedente de uma anáfora (Mitkov, 1999). Existem vários tipos de anáforas (Mitkov, 1999), porém este trabalho se restringe a tratar anáfora pronominal. Mais precisamente, buscou-se tratar apenas o pronome pessoal “it”, pois as entidades que queremos cobrir são os produtos dos debates. Após as resoluções de anáforas, são feitas as análises de concessões nos posts dos 83 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS debates. Conforme já definido na seção 3.5.2, concessão é uma relação semântica que ocorre entre uma argumentação que cria uma expectativa sobre algo, e uma segunda argumentação que explicitamente nega a primeira (Robaldo et al., 2010). Para tratar as ocorrências das concessões nos posts, criamos uma lista de conectivos inspirados no trabalho de Somasundaran e Wiebe (2009). Os conectivos foram selecionados a partir da lista de conectivos das categorias “Concession” e “Contra-expectiation” do Penn Discourse Treebank (Prasad et al., 2008). Resultados Obtidos As tabelas 5.14 a 5.18 apresentam as matrizes confusão de cada debate. Em seqüência as tabelas 5.19 a 5.24 mostram os resultados utilizando as métricas já apresentadas anteriormente. Tabela 5.14 Matriz confusão da classificação dos posts do debate Firefox vs. Internet Explorer Tabela 5.15 Matriz confusão da classificação dos posts no debate Iphone vs. Blackberry 84 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS Tabela 5.16 Matriz confusão da classificação dos posts no domínio Opera vs. Firefox Tabela 5.17 Matriz confusão da classificação dos posts no domínio Playstation 3 vs. Nintendo Wii Tabela 5.18 Matriz confusão da classificação dos posts no domínio Playstation 3 vs. Xbox 360 85 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS Os resultados deste experimento em alguns debates apresentaram uma pequena melhora em relação aos resultados do experimento anterior. As tabelas 5.19 a 5.23 mostram pequenas evoluções em relação às tabelas 5.8 a 5.12. A classe pro-iphone obteve 100% na precisão, porém sua cobertura obteve uma queda, visto que neste experimento, três posts da classe pro-iphone foram classificados erroneamente como pro-blackberry. De modo geral, nas demais classes houve um aumento na cobertura, e acreditamos que isso seja graças ao uso da resolução de anáfora. Tabela 5.19 Resultado da classificação por posts do debate Firefox vs. Internet Explorer Pro-Firefox Pro-Internet Explorer None Precisão 0,8977 0,4211 0,2340 Cobertura 0,6031 0,5161 1,0 F(1)-Measure 0,7215 0,4638 0,3793 Tabela 5.20 Resultado da classificação por posts do debate Iphone vs. Blackberry Pro-iPhone Pro-Blackberry None Precisão 1,0 0,75 0,3333 Cobertura 0,3750 0,9231 1,0 F(1)-Measure 0,5455 0,8276 0,5 Tabela 5.21 Resultado da classificação por posts do debate Opera vs. Firefox Pro-Opera Pro-Firefox None Precisão 0,6667 0,3333 0,0 Cobertura 0,50 0,3333 0,0 F(1)-Measure 0,5714 0,3333 0,0 De forma geral, a cobertura em todos os debates obtiveram melhoras, graças ao algoritmo de resolução de anáforas, como demonstrado na tabela 5.24. O debate Firefox vs. Internet Explorer mostrou melhora de 1,15% na precisão, 1,04% na acurácia e cobertura, e 1,09% no f-measure em relação ao experimento anterior (ver tabela 5.13). Pouquíssimos posts tiveram sua classificação diferente em relação ao primeiro experimento. No debate Iphone vs. Blackberry, a precisão teve uma piora de 2,27%, porém sua cobertura obteve 86 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS Tabela 5.22 Resultado da classificação por posts do debate Playstation 3 vs. Nintendo Wii Pro-Playstation 3 Pro-Nintendo Wii None Precisão 0,6818 0,6667 0,2083 Cobertura 0,4688 0,50 1,0 F(1)-Measure 0,5556 0,5714 0,3448 Tabela 5.23 Resultado da classificação por posts do debate Firefox vs. Internet Explorer Pro-Playstation 3 Pro-Xbox 360 None Precisão 0,7436 0,4058 0,5688 Cobertura 0,5800 0,4000 0,8267 F(1)-Measure 0,6517 0,4029 0,6739 Tabela 5.24 Resultado das classificações dos debates Firefox vs. Internet Explorer iPhone vs. Blackberry Opera vs. Firefox Playstation 3 vs. Nintendo Wii Playstation 3 vs. Xbox 360 Precisão 0,6127 0,7273 0,4286 0,5205 0,60 Cobertura 0,5521 0,6154 0,3750 0,4750 0,5514 F(1)-Measure 0,5808 0,6667 0,40 0,4967 0,5747 uma melhora de 3,85%, e a f-measure melhorou 1,45%. Mesmo tendo uma melhora em alguns resultados em relação ao debate, a cobertura da classe pro-iphone teve uma queda de 21,73%. Alguns posts que não foram corretamente classificados no primeiro experimento, tiveram sua classe corretamente atribuída neste segundo momento. Ainda assim, em pouquíssimos comentários este experimento definiu incorretamente a stance de posts que foram classificados de forma correta no primeiro experimento, principalmente devido à resolução de anáfora. A segunda linha do quadro 5.5 apresenta em destaque uma anáfora que foi resolvida e adicionou ruído na classificação. O debate Opera vs. Firefox teve uma melhora de 11,61% na precisão, 6,25% na cobertura e 8,75% no f-measure. A análise das concessões contribuíram para o aumento nas taxas de precisão e cobertura deste debate. A quarta linha do quadro 5.5 apresenta em destaque uma sentença de um comentário do debate Opera vs. Firefox, que foi 87 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS Quadro 5.5:Exemplos de posts tratados no segundo experimento. Debate Firefox vs. Internet Explorer Postura pro-ie Posts i love firefox and defended firefox, but what is odd is that this site is breaking in firefox. iPhone vs. Blackberry pro-blackberry rebuttal to : coop show the iphone is $ 399 and the pearl is $199 . not a "huge "difference , but yes , iphone is more expensive . i should not that i own both . i upgraded from my pearl to the iphone shortly after iphone came out . what ’ s this about the iphone being a brick ? iphone ’ s 3 / 4 an inch taller and 1 / 4 an inch wider . iphone ’ s just as thin ( exactly ) and iphone ’ s slightly heavier which makes iphone feel more solid and durable . and sure you can carry around your ipod and your pearl - i ’ ll carry my iphone . i mean you ’ re complaining about bulge and you ’ re okay with having 2 devices to do the work of 1 ? yes , the iphone is limited to 8gb , but if you ’ re so in need of 30gb of music then you might have some issues . (...). Playstation 3 vs. Nintendo Wii pro-wii wii is a revolutionary system . nintendo has always been the company to come out with something new ; usually ahead of time with their new product . this time , wii has actually turned out pretty damn good , rather than the horrible turn out of the power glove which was a good idea , but couldn ’ t be properly made because the censors couldn ’ t direct the character in the right direction two thirds of the time . anyways , to get to the point , sure , the ps3 has great graphics but when ps3 all comes down to ps3 , aren ; t video games meant to be fun , rather than good to look at ? if you want something good to look at , go look at porn or some shiny object ; not some really good looking video game . wii = better . deal with wii . Opera vs. Firefox pro-opera having used both browsers extensively , opera in my eyes is the better browser . it loads faster , generally seems to load pages faster , has a slicker interface by default , has a number of really nice features built in that firefox doesn ’ t ( hover previews of tabs , for example ) , bittorrent support . . . . a better download manager . much prefer the password manager ( wand ) as well . opera also doesn ’ t seem to hog as much memory as firefox . the main disadvantage of opera for me is that the widgets simply don ’ t match the extensions in firefox , but this is the fact that firefox has a much larger following , not a direct failure of opera . 88 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS classificado como sem opinião no primeiro experimento e foi corretamente classificado neste experimento, graças a análise de concessões. O debate Playstation 3 vs. Nintendo Wii teve uma melhora de 6,72% na precisão, 5% na cobertura e 5,8% no f-measure. O principal destaque no aumento das precisão no debate Playstation 3 vs. Nintendo Wii se deve ao fato de alguns posts classificados erroneamente no primeiro experimento, terem sido classificados de forma correta ou com a classe “tie” (empate) neste segundo momento. Na terceira linha do quadro 5.5 apresenta um exemplo de post do debate Playstation 3 vs. Nintendo Wii que foi classificado corretamente graças ao algoritmo de resolução de anáfora e uma concessão identificada. O debate Ps3 vs. Xbox 360 apresentou uma pequena queda nos resultados em relação ao experimento anterior. A justificativa para este fato está associada ao algoritmo simplista de resolução de anáfora, que tratou pronomes que não eram anáforas, e desta forma, adicionou ruídos à classificação de sentimentos. 5.3.3 Classificação do Grafo de Replies O terceiro experimento consiste na composição do segundo experimento, mais as informações dos replies dos debates. Como dito anteriormente, no site convinceme.net os autores têm a opção de fazer “rebuttal” a comentários de outro participante do debate, isto é, o usuário pode argumentar contra outro comentário do debate de forma direta. Desta forma, apenas os debates extraídos do convinceme.net foram utilizados neste experimento, visto que apenas neste, podemos criar um grafo de replies de apenas um nível, conforme apresentado na seção 4.4.5 do capítulo 4. Logo, o corpus de debate Playstation 3 vs. Xbox 36010 não é utilizado neste experimento, pois não é possível gerar o grafo de replies dos posts deste debate. A partir desses replies, construímos uma rede com os posts dos debates, onde apenas os comentários de usuários que discordam de outros posts possuem ligações. Os vértices da rede são os posts e os autores associados. As arestas possuem sentido, já que os “rebuttals” são direcionados. A figura 5.3.3 é um exemplo de como fica nossa rede de “rebuttal”. A partir da figura 5.3.3, é possível observar que a rede gerada é razoavelmente conectada, e através dessas ligações podemos inferir as classes dos vértices olhando a postura de seu vizinho. Cada um dos vértices do grafo de replies já possuem uma classificação prévia oriunda dos submódulos SM1, SM2, SM3 e SM4 (ver figura 4.7). 10 http://www.createdebate.com/debate/show/Is_PS3_better_than_Xbox_360 89 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS Figura 5.1 Rede de Replies do debate Playstation 3 vs. Nintendo Wii Dessa forma, a análise no grafo de replies consiste em, dado um vértice com ligação, verificar qual a postura do vértice vizinho, para então atribuir a stance contrária ao vértice em análise. Resultados Obtidos A seguir, as tabelas 5.25 a 5.28 ilustram a matriz confusão da classificação de cada um dos corpus de debate. A seguir, os resultados das métricas de avaliação são apresentados nas tabelas 5.29 a 5.33. Como esperado, os resultados deste experimento superaram os anteriores (vide tabelas 5.29 a 5.33). Com o uso dos links de rebuttal, além de conseguir reduzir a quantidade de posts não determinados (empate), foi obtida também a classificação correta vários comentários dos debates que não foram corretamente classificados no experimento anterior. O quadro 5.6 apresenta alguns exemplos de posts que tiveram suas posturas corretamente modificadas graças à analise nos links de replies. A primeira coluna apresenta a postura inicial do post. A segunda coluna mostra a stance do post após a consulta ao vértice vizinho. A terceira e quarta colunas apresentam os comentários referente ao vértice em análise e o adjacente respectivamente. As tabelas com os resultados por classe demonstram melhora nos resultados em 90 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS Tabela 5.25 Matriz confusão da classificação dos posts do debate Firefox vs. Internet Explorer Tabela 5.26 Matriz confusão da classificação dos posts no debate Iphone vs. Blackberry Tabela 5.27 Matriz confusão da classificação dos posts no domínio Opera vs. Firefox 91 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS Tabela 5.28 Matriz confusão da classificação dos posts no domínio Playstation 3 vs. Nintendo Wii Quadro 5.6:Exemplos de posts que foram modificados com a análise nos replies. Stance Inicial Stance após análise Posts do Vértice none pro-firefox rebuttal to : kgbudz that form of argument degrades this forum , and will cause the arguments to fall to the lowest common denominator . this word , "indisputable ", i do not think it means what you think it does . i dispute your claim from personal experience , if nothing else . that makes it disputable . i think yahoo ! has chat rooms more attuned to your style of debate . check them out . Posts do Vizinho Its an indisputable fact that the average IE user gets laid 2500% more than the average firefox user. tie Opera Rules, I hate firefox. It looks horrible (even with themes), It is a lot slower than Opera! pro-firefox rebuttal to : nexus450 show ironic thing : opera pioneered tabbed browsing , but firefox handles large amounts of open tabs much better that opera does . sorry firefox losers... game set match go cry about IE somewhere else 8ˆ( Opera RULES, no competition!! 92 5.3. CLASSIFICAÇÃO DE OPINIÃO EM DEBATES DE PRODUTOS relação ao experimento anterior (tabelas 5.29 a 5.32), com destaque para o aumento de 12,5% na cobertura dos posts pro-iphone. A precisão e a cobertura dos posts pro-firefox e dos posts pro-wii também tiveram um aumento significativo nos valores. Tabela 5.29 Resultado da classificação por posts do debate Firefox vs. Internet Explorer Pro-Firefox Pro-Internet Explorer None Precisão 0,9029 0,4318 0,3140 Cobertura 0,6788 0,5588 1,0 F(1)-Measure 0,7750 0,4872 0,4783 Tabela 5.30 Resultado da classificação por posts do debate Iphone vs. Blackberry Precisão 0,6667 0,75 1,0 Pro-iPhone Pro-Blackberry None Cobertura 0,50 0,8571 1,0 F(1)-Measure 0,5714 0,80 1,0 Tabela 5.31 Resultado da classificação por posts do debate Opera vs. Firefox Pro-Opera Pro-Firefox None Precisão 0,6667 0,5 0,0 Cobertura 0,50 0,5714 0,0 F(1)-Measure 0,5714 0,5333 0,0 Tabela 5.32 Resultado da classificação por posts do debate Playstation 3 vs. Nintendo Wii Pro-Playstation 3 Pro-Nintendo Wii None Precisão 0,6667 0,7222 0,3846 Cobertura 0,5294 0,7027 1,0 F(1)-Measure 0,5902 0,7123 0,5556 É importante ressaltar que todos os debates tiveram suas taxas de precisão superior à classificação randômica (caso base), como pode ser verificado na tabela 5.33. O debate Firefox vs. Internet Explorer teve um aumento 6,31% na precisão em relação 93 5.4. ANÁLISE DE TRABALHOS RELACIONADOS Tabela 5.33 Resultado das classificações dos debates Firefox vs. Internet Explorer iPhone vs. Blackberry Opera vs. Firefox Playstation 3 vs. Nintendo Wii Precisão 0,6758 0,7391 0,5333 0,6447 Cobertura 0,6406 0,6538 0,50 0,6125 F(1)-Measure 0,6578 0,6939 0,5161 0,6282 ao segundo experimento, e um aumento de 7,46% na precisão em relação ao primeiro experimento. Sua cobertura aumentou em 8,85% e 9,89% em relação ao primeiro e ao segundo experimento respectivamente. No debate Iphone vs. Blackberry, a precisão melhorou em relação ao segundo experimento, porém ainda está inferior ao primeiro experimento. Em compensação, a cobertura e o F-measure superaram em 7,69% e 4,17% respectivamente os resultados apresentados no primeiro experimento. Os piores resultados nos três experimentos foram obtidos no debate Opera vs. Firefox. Essa configuração obteve o melhor resultado em relação às outras duas. A precisão alcançou 53,33%, a cobertura 50% e o F-measure 51,61%. No debate Playstation 3 vs. Nintendo Wii, essa configuração obteve melhora acima de 10% em todas as medidas em relação ao segundo experimento. Em relação ao primeiro experimento, as taxas foram superiores em quase 15% em comparação com a primeira configuração. 5.4 Análise de Trabalhos Relacionados Esta seção tem como foco apresentar que, os resultados obtidos no ASDP são semelhantes aos resultados encontrados na literatura da área. Apesar de Somasundaran e Wiebe (2009) e Walker et al. (2012) formarem seus corpora a partir do convinceme.net, não iremos fazer comparações entre nossos resultados pois a quantidade de posts analisados (ver tabela 5.35), e a época de extração destes comentários utilizados pelos trabalhos são distintas. No trabalho de Somasundaran e Wiebe (2009), os resultados demonstrados foram obtidos com os debates Firefox vs. Internet Explorer, Windows vs. Mac, Playstation 3 vs. Nintendo Wii e Opera vs. Firefox. A tabela 5.34 apresenta os resultados dos experimentos realizados por Somasundaran e Wiebe. 94 5.4. ANÁLISE DE TRABALHOS RELACIONADOS Tabela 5.34 Resultados de Somasundaran e Wieber (2009) 95 5.4. ANÁLISE DE TRABALHOS RELACIONADOS Os melhores resultados de Somasundaran e Weibe são com o experimento OpPr + Disc na tabela 5.34. Segundo as autoras, essa configuração tem uma etapa inicial em que identificam-se os targets, que seriam as features ou tópicos do debate, e utiliza um corpus de textos da Web para relacionar esses targets à postura dos comentários no debate. Em seguida, para efetuar a classificação, Somasundaran e Wiebe formulam um problema de Programação Linear Inteira. A diferença do experimento OpPr + Disc para o experimento OpPr é que o primeiro faz uma análise de concessões semelhante ao nosso trabalho. Como é possível observar nas tabelas 5.33 e 5.34, apesar de utilizarmos técnicas e corpora distintos, os nossos resultados são bem próximos. Tabela 5.35 Comparação na quantidade de posts utilizados no ASDP, no trabalho de Somasundaran e Wiebe (2009) e no trabalho de Walker et al. (2012) Outro trabalho voltado para a classificação de sentimento em debates é o de Walker et al. (2012). Diferente da nossa abordagem e da abordagem de Somasundaran e Weibe, Walker et al. utilizaram algoritmos de Aprendizagem de Máquina na classificação dos posts (relatando apenas os resultados obtidos pelo algoritmo NaiveBayes). Outra peculiaridade desse trabalho é a construção da rede de posts do debate. Walker et al. apresentaram dois grupos de resultados, sendo uma classificação com contexto e uma classificação sem contexto. Na classificação com contexto, eles utilizaram os atributos do post corrente e do seu pai no grafo para a classificação. Na classificação sem contexto, os autores não utilizaram os atributos do post pai. Nesses dois experimentos, cada classificador é executado apenas com seus atributos, e posteriormente com todos os atributos juntos (mais detalhes sobre os atributos ver em (Walker et al., 2012)). A melhor acurácia no corpus Firefox vs. Internet Explorer obtida por Walker et al. foi 63,75% na classificação sem contexto. Já na classificação com contexto, sua melhor acurácia foi 66,25%. Para o debate Firefox vs. Internet Explorer, todos os 14 resultados 96 5.4. ANÁLISE DE TRABALHOS RELACIONADOS apresentados pelos autores são próximos às nossas taxas de acurácias (ver seção 3.3), sendo que, apenas um resultado de Walker et al. (2012) consegue superar a nossa acurácia (ver tabela 5.33). A tabela 5.36 apresenta um comparativo entre os melhores resultados obtidos pelo ASDP, o trabalho de Somasundaran e Wiebe (2009) e a contribuição de Walker et al. (2012). Somasundaran e Weibe apresentam resultados que alcançam o estado da arte no debate Opera vs. Firefox. Contudo, as autoras utilizaram um corpus muito pequeno (ver tabela 5.35) na classificação, e portanto, é possível afirmar que a quantidade de amostras não é suficiente para boa inferência. Tabela 5.36 Apresentação dos resultados dos trabalhos de Somasundaran e Wiebe (2009), Walker et al. (2012) e o ASDP 97 5.5. CONSIDERAÇÕES FINAIS 5.5 Considerações Finais Neste capítulo foram apresentados os resultados dos três experimentos conduzidos na nossa pesquisa. Após a descrição de cada uma das configurações, apresentamos os resultados e comparamos os valores entre si. Posteriormente citamos dois trabalhos encontrados na literatura e comparamos cada um deles com nossa melhor configuração. Conforme foi apresentado na seção 5.4, os resultados obtidos pelo ASDP são semelhantes aos resultados demonstrados por Somasundaran e Wiebe (2009) e Walker et al. (2012). Apenas dois corpora utilizados são comuns ao ASDP e à contribuição de Somasundaran e Wiebe (2009), e o corpus de debate Firefox vs. Internet Explorer utilizado pelo ASDP também foi trabalhado por Walker et al. (2012). Nossos melhores resultados foram 73,91% de precisão, 65,38% de acurácia e 69,39% no f-measure sobre o corpus de debate iPhone vs. Blackberry. Também foi demonstrado uma melhora nas taxas dos resultados com o uso de um algoritmo de resolução de anáforas e análise de concessões, sendo 66,67% a melhor f-measure obtida. O próximo capítulo irá apresentar a conclusão deste trabalho, indicando as principais contribuições para a Análise de Sentimentos, bem como as dificuldades encontradas, possíveis melhorias e trabalhos futuros. 98 6 Conclusão Esta dissertação apresentou o ASDP, um processo de classificação de sentimentos baseado em regras linguísticas, responsável por capturar as palavras opinativas, os tópicos associados e as sentenças onde estes dois termos foram encontrados. Através desses dados, o ASDP consegue classificar sentimentos em debates não ideológicos com taxas de até 73,91% de precisão. O ASDP foi testado em três configurações distintas. A primeira, a classificação de sentimento é feita apenas com o uso do léxico subjetivo, e dos padrões linguísticos. No segundo experimento foi acrescentado um método para resolução de anáforas e análise de concessões. O terceiro e último experiemnto, foi inserido uma abordagem que tenta inferir a classe dos posts de acordo com os seus vizinhos no grafo. Como visto nos capítulos 5 e 3, o ASDP foi capaz de apresentar resultados semelhantes em alguns corpora em comparação a dois trabalhos bem conhecidos na literatura ((Somasundaran e Wiebe, 2009), (Walker et al., 2012)). Além disso, o ASDP possui um método de resolução de anáfora, que é um fenômeno linguístico comum em debates e importante para o reconhecimento de entidades nomeadas. Nenhum dos dois trabalhos citados anteriormente desenvolveram métodos para solucionar referenciais anafóricos. A seguir, a seção 6.1 apresenta as principais contribuições do método aqui proposto, e a seção 6.2 descreve propostas de trabalhos futuros a serem conduzidos a partir do que já foi feito nesta pesquisa. 6.1 Contribuições finais Destacamos abaixo as principais contribuições do trabalho realizado nesta pesquisa de Mestrado: 99 6.2. TRABALHOS FUTUROS • Realização de uma revisão bibliográfica extensa sobre Análise de Sentimentos, incluindo os principais conceitos e etapas para o desenvolvimento de um sistema completo de AS, bem como os principais trabalhos relacionados à classificação de sentimento voltada a debates polarizados não ideológicos – foco do nosso trabalho. • Desenvolvimento de padrões linguísticos, que podem ser facilmente expandidos e refatorados, para a identificação de palavras opinativas em textos de debates não ideológicos. As palavras opinativas são validadas com o uso do léxico subjetivo MPQA (Wilson et al., 2005). • Apresentação de fenômenos linguísticos pouco abordados na literatura de AS e a apresentação de um mecanismo que lida com estes fenômenos. • Proposta de um representação da estrutura de replies de um debate em forma de grafo. • Utilização da Abordagem Baseada em Conhecimento para AS em contraste com a utilização dominante de técnicas de Aprendizagem de Máquina. • Construção de um protótipo de sistema de AS que realiza a classificação de sentimentos, e apresenta taxas de desempenho semelhantes a trabalhos relacionados da literatura ((Somasundaran e Wiebe, 2009), (Walker et al., 2012)). 6.2 Trabalhos Futuros Como trabalhos futuros pretendemos desenvolver algumas extensões com o objetivo de melhorar a pesquisa relatada nesta dissertação. A seguir, apresentaremos as propostas para extensão: • Extração de aspectos: esta importante etapa no processo de Análise de Sentimento ficou ausente no ASDP. Contudo, o próximo passo é o desenvolvimento de um método para a extração automática de atributos e/ou tópicos relacionados aos debates não ideológicos, com o objetivo de transformar o ASDP em um processo completo de AS. • Resolução de Anáforas: apesar de estar implementado no ASDP, não foi feita uma avaliação profunda sobre o algoritmo simplista de resolução de anáfora. Durante uma avaliação superficial, foram identificados algumas resoluções erradas, e que acrescentaram ruídos aos resultados. 100 6.2. TRABALHOS FUTUROS • Utilização de um corretor ortográfico: a linguagem predominante nestes debates online é uma linguagem informal, com a grande ocorrência de erros ortográficos, visto que os usuários não se preocupam em escrever de forma correta. O uso de um corretor ortográfico auxiliaria o pré-processamento do texto podendo melhorar a precisão do ASDP. • Análise dos posts no grafo: o quinto submódulo da etapa de classificação de postura do ASDP apresentado no capítulo 4, cria um grafo a partir dos replies identificados nos debates do site convinceme1 . Porém outros sites de debates possuem mecanismos próprios para os usuários apresentarem críticas direcionadas a outros comentários. Dessa forma, pretendemos criar um novo método para a criação do grafo dos posts, e juntamente com esta nova estrutura, um mecanismo para auxiliar no processo de classificação de sentimento através dos grafos criados. 1 www.convinceme.net 101 Referências Abu-Jbara, A., Diab, M., Dasigi, P. e Radev, D. Subgroup Detection in Ideological Discussions. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers - Volume 1, ACL ’12. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 399–409. URL http://dl.acm.org/citation.cfm?id=2390524.2390580, 2012. Allen, J. Natural Language Understanding (2Nd Ed.). Benjamin-Cummings Publishing Co., Inc., Redwood City, CA, USA, 1995. Baccianella, S., Esuli, A. e Sebastiani, F. SentiWordNet 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining. N. C. C. Chair), K. Choukri, B. Maegaard, J. Mariani, J. Odijk, S. Piperidis, M. Rosner e D. Tapias (editores), Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10). European Language Resources Association (ELRA), Valletta, Malta, 2010. Baeza-Yates, R. A. e Ribeiro-Neto, B. Modern Information Retrieval. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 1999. Bansal, M., Cardie, C. e Lee, L. The Power of Negative Thinking: Exploiting Label Disagreement in the Min-cut Classification Framework. D. Scott e H. Uszkoreit (editores), COLING (Posters), páginas 15–18. URL http://dblp.uni-trier. de/db/conf/coling/coling2008p.html#BansalCL08, 2008. Carter, R. e McCarthy, M. Cambridge Grammar of English: A Comprehensive Guide : Spoken and Written English Grammar and Usage. Cambridge University Press, 2006. Castro, A. Detecção Automática de Subjetividade: Aprendizagem de Máquina Versus Ferramentas Linguísticas. Trabalho de Graduação em Ciência da Computação - Centro de Informática/UFPE, Recife, 2011. Cooley, R., Mobasher, B. e Srivastava, J. Web Mining: Information and Pattern Discovery on the World Wide Web. ICTAI ’97: Proceedings of the 9th International Conference on Tools with Artificial Intelligence, ICTAI ’97. IEEE Computer Society, Washington, DC, USA, página 558, 1997. Dave, K., Lawrence, S. e Pennock, D. M. Mining the peanut gallery: opinion extraction and semantic classification of product reviews. Proceedings of the 12th international 102 REFERÊNCIAS conference on World Wide Web, WWW ’03. ACM, New York, NY, USA, páginas 519–528. URL http://doi.acm.org/10.1145/775152.775226, 2003. Esuli, A. e Sebastiani, F. SENTIWORDNET: A Publicly Available Lexical Resource for Opinion Mining. In Proceedings of the 5th Conference on Language Resources and Evaluation (LREC’06, páginas 417–422, 2006. Feldman, R. e Sanger, J. Text Mining Handbook: Advanced Approaches in Analyzing Unstructured Data. Cambridge University Press, New York, NY, USA, 2006. Gonçalves, J. E. L. As empresas são grandes coleções de processos. Revista de Administração de Empresas, 40:6 – 9. URL http://www.scielo.br/scielo.php? script=sci_arttext&pid=S0034-75902000000100002&nrm=iso, 2000. Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P. e Witten, I. H. The WEKA Data Mining Software: An Update. SIGKDD Explor. Newsl., 11(1):10–18. URL http://doi.acm.org/10.1145/1656274.1656278, 2009. Hatzivassiloglou, V. e Wiebe, J. M. Effects of Adjective Orientation and Gradability on Sentence Subjectivity. Proceedings of the 18th Conference on Computational Linguistics - Volume 1, COLING ’00. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 299–305. URL http://dx.doi.org/10.3115/ 990820.990864, 2000. Hotho, A., Nürnberger, A. e Paaß, G. A Brief Survey of Text Mining. LDV Forum - GLDV Journal for Computational Linguistics and Language Technology, 20(1):19–62. URL http://www.kde.cs.uni-kassel.de/hotho/pub/ 2005/hotho05TextMining.pdf, 2005. Hu, M. e Liu, B. Mining and summarizing customer reviews. Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, KDD ’04. ACM, New York, NY, USA, páginas 168–177. URL http: //doi.acm.org/10.1145/1014052.1014073, 2004. Jakob, N. e Gurevych, I. Using Anaphora Resolution to Improve Opinion Target Identification in Movie Reviews. Proceedings of the ACL 2010 Conference Short Papers, ACLShort ’10. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 263–268. URL http://dl.acm.org/citation.cfm?id=1858842. 1858891, 2010. 103 REFERÊNCIAS Jindal, N. e Liu, B. Review spam detection. Proceedings of the 16th international conference on World Wide Web, WWW ’07. ACM, New York, NY, USA, páginas 1189– 1190. URL http://doi.acm.org/10.1145/1242572.1242759, 2007. Kabadjov, M. A. A Comprehensive Evaluation of Anaphora Resolution and Discoursenew Classification. Department of Computer Science - University of Essex, United Kingdom, 2007. Kim, S.-M. e Hovy, E. Determining the Sentiment of Opinions. Proceedings of the 20th International Conference on Computational Linguistics, COLING ’04. Association for Computational Linguistics, Stroudsburg, PA, USA. URL http://dx.doi.org/ 10.3115/1220355.1220555, 2004. Kosala, R. e Blockeel, H. Web Mining Research: A Survey. SIGKDD Explor. Newsl., 2(1):1–15. URL http://doi.acm.org/10.1145/360402.360406, 2000. Kruijff-Korbayova, I. e Webber, B. Interpreting concession statements in light of information structure, volume 3. Kluwer Academic Publishers, 2007. Lima, D. PairExtractor: Extração de Pares Livre de Domínio para Análise de Sentimentos. Trabalho de Graduação em Ciência da Computação - Centro de Informática/UFPE, Recife, 2011. Liu, B. Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data (DataCentric Systems and Applications). Springer-Verlag New York, Inc., Secaucus, NJ, USA, 2006. Liu, B. Sentiment Analysis and Subjectivity. Handbook of Natural Language Processing, 2nd ed, 2010. Liu, B. Sentiment Analysis and Opinion Mining. Morgan & Claypool Publishers, 1 edição, 2012. Malouf, R. e Mullen, T. Taking sides: User classification for informal online political discourse. Internet Research, 2008. Manning, C. D., Raghavan, P. e Schütze, H. Introduction to Information Retrieval. Cambridge University Press, New York, NY, USA, 2008. Manning, C. D. e Schütze, H. Foundations of statistical natural language processing. MIT Press, Cambridge, MA, USA, 1999. 104 REFERÊNCIAS Mitchell, T. M. Machine Learning. McGraw-Hill, Inc., New York, NY, USA, 1 edição, 1997. Mitkov, R. Relatório Técnico Anaphora Resolution: The State Of The Art, School of Languages and European Studies, University of Wolverhampton, 1999. Morinaga, S., Yamanishi, K., Tateishi, K. e Fukushima, T. Mining Product Reputations on the Web. Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’02. ACM, New York, NY, USA, páginas 341–349. URL http://doi.acm.org/10.1145/775047.775098, 2002. Mullen, T. e Malouf, R. A preliminary investigation into sentiment analysis of informal political discourse. AAAI Symposium on Computational Approaches to Analysing Weblogs (AAAI-CAAW, páginas 159–162, 2006. Nadeau, D. e Sekine, S. A survey of named entity recognition and classification. Lingvisticae Investigationes, 30(1):3–26. URL http://www.ingentaconnect.com/ content/jbp/li/2007/00000030/00000001/art00002, 2007. Pang, B. e Lee, L. Opinion Mining and Sentiment Analysis. Found. Trends Inf. Retr., 2(1-2):1–135. URL http://dx.doi.org/10.1561/1500000011, 2008. Pang, B., Lee, L. e Vaithyanathan, S. Thumbs up?: sentiment classification using machine learning techniques. Proceedings of the ACL-02 conference on Empirical methods in natural language processing - Volume 10, EMNLP ’02. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 79–86. URL http: //dx.doi.org/10.3115/1118693.1118704, 2002. Popescu, A.-M. e Etzioni, O. Extracting product features and opinions from reviews. Proceedings of the conference on Human Language Technology and Empirical Methods in Natural Language Processing, HLT ’05. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 339–346. URL http://dx.doi.org/10.3115/ 1220575.1220618, 2005. Prasad, R., Miltsakaki, E., Dinesh, N., Lee, A., Joshi, L., A.and Robaldo e Webber, B. Relatório Técnico PDTB 2.0 Annotation Manual, Institute for Research in Cognitive Science, University of Pennsylvania, http://www.seas.upenn.edu/ pdtb/PDTBAPI/pdtbannotation-manual.pdf, 2008. 105 REFERÊNCIAS Qiu, G., Liu, B., Bu, J. e Chen, C. Opinion word expansion and target extraction through double propagation. Comput. Linguist., 37(1):9–27. URL http://dx.doi.org/ 10.1162/coli_a_00034, 2011. Riloff, E. e Wiebe, J. Learning extraction patterns for subjective expressions. Proceedings of the 2003 conference on Empirical methods in natural language processing, EMNLP ’03. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 105– 112. URL http://dx.doi.org/10.3115/1119355.1119369, 2003. Robaldo, L., Miltsakaki, E. e Bianchini, A. Corpus-based Semantics of Concession: Where do Expectations Come from? N. C. C. Chair), K. Choukri, B. Maegaard, J. Mariani, J. Odijk, S. Piperidis, M. Rosner e D. Tapias (editores), Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10). European Language Resources Association (ELRA), Valletta, Malta, 2010. Russell, S. J. e Norvig, P. Artificial Intelligence: A Modern Approach. Pearson Education, 2 edição, 2003. Sebastiani, F. Machine Learning in Automated Text Categorization. ACM Comput. Surv., 34(1):1–47. URL http://doi.acm.org/10.1145/505282.505283, 2002. Silva, E. Um sistema para extração de informação em referências bibliográficas baseado em aprendizagem de máquina. Dissertação de Mestrado - Centro de Informática/UFPE, Recife, 2004. Silva, G., N. PairClassif - Um Método para Classificação de Sentimentos Baseado em Pares. Dissertação de Mestrado - Centro de Informática/UFPE, Recife, 2013. Silva, N., Lima, D. e Barros, F. SAPair: Um processo de Análise de Sentimento no Nível de Característica. IV International Workshop on Web and Text Intelligence (WTI – 2012). Proc of the Brazilian Conference on Iteligent Systems, Curitiba, PR, Brasil, páginas 1–10, 2012. Siqueira, H. WhatMatter: Extração e visualização de características em opiniões sobre serviços. Dissertação de Mestrado - Centro de Informática/UFPE, Recife, 2010. Somasundaran, S. e Wiebe, J. Recognizing Stances in Online Debates. Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 1 - Volume 1, ACL 106 REFERÊNCIAS ’09. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 226– 234. URL http://dl.acm.org/citation.cfm?id=1687878.1687912, 2009. Somasundaran, S. e Wiebe, J. Recognizing Stances in Ideological On-line Debates. Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, CAAGET ’10. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 116–124. URL http://dl.acm.org/citation.cfm?id=1860631.1860645, 2010. Sommerville, I. Software Engineering (5th Ed.). Addison Wesley Longman Publishing Co., Inc., Redwood City, CA, USA, 1995. Steinbach, M., Karypis, G. e Kumar, V. A Comparison of Document Clustering Techniques. M. Grobelnik, D. Mladenic e N. Milic-Frayling (editores), KDD-2000 Workshop on Text Mining, August 20. Boston, MA, páginas 109–111. URL http: //www-users.cs.umn.edu/~karypis/publications/ir.html, 2000. Taboada, M., Brooke, J., Tofiloski, M., Voll, K. e Stede, M. Lexicon-based Methods for Sentiment Analysis. Comput. Linguist., 37(2):267–307. URL http://dx.doi. org/10.1162/COLI_a_00049, 2011. Thomas, M., Pang, B. e Lee, L. Get out the Vote: Determining Support or Opposition from Congressional Floor-debate Transcripts. Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, EMNLP ’06. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 327–335. URL http: //dl.acm.org/citation.cfm?id=1610075.1610122, 2006. Toutanova, K., Klein, D., Manning, C. D. e Singer, Y. Feature-rich Part-of-speech Tagging with a Cyclic Dependency Network. Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology - Volume 1, NAACL ’03. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 173–180. URL http://dx.doi.org/ 10.3115/1073445.1073478, 2003. Tsytsarau, M. e Palpanas, T. Survey on Mining Subjective Data on the Web. Data Min. Knowl. Discov., 24(3):478–514. URL http://dx.doi.org/10.1007/ s10618-011-0238-6, 2012. 107 REFERÊNCIAS Turney, P. D. Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, ACL ’02. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 417–424. URL http://dx.doi.org/10.3115/ 1073083.1073153, 2002. Turney, P. D. e Littman, M. L. Measuring Praise and Criticism: Inference of Semantic Orientation from Association. ACM Trans. Inf. Syst., 21(4):315–346. URL http: //doi.acm.org/10.1145/944012.944013, 2003. Walker, M. A., Anand, P., Abbott, R., Tree, J. E. F., Martell, C. e King, J. That is Your Evidence?: Classifying Stance in Online Political Debate. Decis. Support Syst., 53(4):719– 729. URL http://dx.doi.org/10.1016/j.dss.2012.05.032, 2012. Wang, H., Can, D., Kazemzadeh, A., Bar, F. e Narayanan, S. A System for Real-time Twitter Sentiment Analysis of 2012 U.S. Presidential Election Cycle. Proceedings of the ACL 2012 System Demonstrations, ACL ’12. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 115–120. URL http://dl.acm.org/ citation.cfm?id=2390470.2390490, 2012. Wang, Y.-C. e Rosé, C. P. Making Conversational Structure Explicit: Identification of Initiation-response Pairs Within Online Discussions. Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, HLT ’10. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 673–676. URL http://dl.acm.org/ citation.cfm?id=1857999.1858096, 2010. Wiebe, J. M. Tracking Point of View in Narrative. Comput. Linguist., 20(2):233–287. URL http://dl.acm.org/citation.cfm?id=972525.972529, 1994. Wilson, T., Wiebe, J. e Hoffmann, P. Recognizing Contextual Polarity in Phrase-level Sentiment Analysis. Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, HLT ’05. Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 347–354. URL http: //dx.doi.org/10.3115/1220575.1220619, 2005. Yu, H. e Hatzivassiloglou, V. Towards answering opinion questions: separating facts from opinions and identifying the polarity of opinion sentences. Proceedings of the 2003 conference on Empirical methods in natural language processing, EMNLP ’03. 108 REFERÊNCIAS Association for Computational Linguistics, Stroudsburg, PA, USA, páginas 129–136. URL http://dx.doi.org/10.3115/1119355.1119372, 2003. 109 Apêndice 110 A Bases de Substituições A.1 Contrações Contração Palavra Real i’m i am i’ll i will i’d i had i’ve i have you’re you are you’ll you will you’d you had you’ve you have he’s he is he’ll he will he’d he had she’s she is she’ll she will she’d she had it’s it is it’d it had we’re we are we’ll we will we’d we had we’ve we have they’re they are they’ll they will they’d they had they’ve they have there’s there is there’ll there will there’d there had that’s that is that’ll that will aren’t are not can’t can not Continua na próxima página 111 A.1. CONTRAÇÕES Contração Palavra Real couldn’t could not didn’t did not doesn’t does not don’t do not hadn’t had not hasn’t has not isn’t is not mustn’t must not needn’t need not shouldn’t should not wasn’t was not weren’t were not won’t will not wouldn’t would not aren ’ t are not can ’ t can not couldn ’ t could not didn ’ t did not doesn ’ t does not don ’ t do not hadn ’ t had not hasn ’ t has not isn ’ t is not mustn ’ t must not needn ’ t need not shouldn ’ t should not wasn ’ t was not weren ’ t were not won ’ t will not wouldn ’ t would not they ’ re they are haven ’t have not don ’ t do not i ’ ll i will i’m i am i’d i had i ’ ve i have you ’ re you are you ’ ll you will you ’ d you had you ’ ve you have he ’ s he is he ’ ll he will he ’ d he had she ’ s she is she ’ ll she will she ’ d she had it ’ s it is it ’ d it had we ’ re we are Continua na próxima página 112 A.2. ABREVIÇÕES A.2 Contração Palavra Real we ’ ll we will we ’ d we had we ’ ve we have they ’ re they are they ’ ll they will they ’ d they had they ’ ve they have there ’ s there is there ’ ll there will there ’ d there had that ’ s that is that ’ ll that will aren ’ t are not can ’ t can not couldn ’ t could not didn ’ t did not doesn ’ t does not don ’ t do not hadn ’ t had not hasn ’ t has not isn ’ t is not mustn ’ t must not needn ’ t need not shouldn ’ t should not wasn ’ t was not weren ’ t were not won ’ t will not wouldn ’ t would not Abrevições Abreviação Palavra Real a.c. before christ a.m. ante meridiem abbrev. abbreviation ac. before christ acc. account acct. account adj. adjective adm. administrator adv. adverb am. ante meridiem app application app. application program applic. application apps application assoc. association aug. august Continua na próxima página 113 A.2. ABREVIÇÕES Abreviação Palavra Real bbm blackberry messenger bhd. bulkhead brit. british bros. brother cap. civil air patrol capt. captain ceo. chief executive officer cia. central intelligence agency comm. commercial communic. communications compan. companion conf. conference const. construction contr. contrast contrib. contribution corp. corporation corresp. corresponding d.c. after christ dc. after christ dec. december def. definition dept. department descr. description dict. dictionary dr. doctor drs. doctresse ecol. ecology econ. economy ed. edition educ. education electr. electricity electron. eletronic elem. element encycl. encyclopaedia eng. english etc. et cetera exc. except exerc. exercise faq. frequently asked question feb. february fem. feminine fig. figurative fr. french freq. frequent fund. fundamental geogr. geography geol. geology geom. geometry gov. government govt. government Continua na próxima página 114 A.2. ABREVIÇÕES Abreviação Palavra Real hist. history i.e. that is ie. that is illustr. illustration inc. incorporated ind. industry industr. industry infl. influenced inst. institute introd. introduction irreg. irregular jr. junior lang. language lt. local time ltd. limited company man. manual managem. management masc. masculine math. mathematics med. medicine mem. memory mr. mister mrs. mistress ms. miss nat. natural no. number nov. november nucl. nuclear o.e. old english obj. object oct. october oe. old english opt. optics org. organization orig. origin outl. outline oxf. oxford p.m. post meridiem pers. person photogr. photography phr. phrase phys. physical pict. picture pl. plural plur. plural pm. post meridiem pol. politics pop. popular pract. practice prec. preceding Continua na próxima página 115 A.2. ABREVIÇÕES Abreviação Palavra Real prep. preposition pres. present princ. principle priv. privative prob. probably probl. problem proc. proceeding prof. professor pron. pronoun prop. properly ptt push to talk publ. publications quot. quotation rec. record ref. reference reg. register rel. related rep. report repr. representative res. research rev. review sel. selection sens. sense sept. september soc. society sociol. sociology spec. specification st. saint struct. structure subj. subject subord. subordinate subseq. subsequently subst. substantively superl. superlative surg. surgery syst. system techn. technology technol. technological teleph. telephony trans. transactions transf. transferred transl. translation trav. travel treas. treasury treatm. treatment u.s. united states u.s.s.r. union of soviet socialist republics us. united states ussr. union of soviet socialist republics vertebr. vertebrate Continua na próxima página 116 A.2. ABREVIÇÕES Abreviação Palavra Real vet. veterinary vs. versus vulg. vulgar wd. word westm. westminster wks. works yrs. years zoogeogr. zoogeography zool. zoology yr year cuz because open-source opensource open - source opensource next - gen next-gen next - gen next-gen atleast at least dosnt does not cuz because cant can not dont do not ive i have crash bandicoot crashbandicoot cannot can not pop ups popups becuz because 2b to be 2bh to be honest 2day today 2ez too easy 2g too good 2g2bt too good to be true 2l8 too late 2m tomorrow 2moro tomorrow 2moz tomorrow 2mrw tomorrow 2u to you 2u2 to you too 2-you to you a/w anyway afaik as far as i know allshare all share alltel all phone alot a lot asap as soon as possible atb all the best batt battery biz business brb be right back bt bluetooth Continua na próxima página 117 A.3. SINÔNIMOS Abreviação A.3 Palavra Real btfl beautiful btw by the way couldnt could not cya see you dat that dats that is didn did not didnt did not dis this doesnot does not doesnt does not dont do not dunno do not know dupe duplicate ftw for the win fyi for your information gfu good for you gimme give me gj good job gl good luck gratz congratulations havent have not idk i do not know idunno i do not know im i am imo in my opinion iow in other words isnt is not its it is its it is lmk let me know mic microphone micro microusb micro microsd moto motorola nite night np no problem omg oh my god otoh on the other hand ppl people tbh to be honest thats that is thx thanks txt text ty thank you whats what is Sinônimos 118 A.3. SINÔNIMOS Sinônimo Palavra Real mozilla foundation firefox fire fox firefox firefox 3 firefox ff2 firefox ff firefox fx firefox microsoft internetexplorer internet explore internetexplorer ie’s internetexplorer ie internetexplorer msie’s internetexplorer msie internetexplorer m$ internetexplorer ie6 internetexplorer ie 6 internetexplorer ie7 internetexplorer ie 7 internetexplorer windows internetexplorer ms internetexplorer apple iphone ipod iphone blackberry pearl blackberry pearl blackberry bb blackberry iphones iphone curve blackberry playstation3 ps3 playstation3’s ps3 playstation 3 ps3 ps 3 ps3 sony ps3 nintendo wii wii wii’s wii box xbox360 psn ps3 x box xbox360 x box 360 xbox360 x box360 xbox360 xbox 360 xbox360 xbox live xbox360 xbox xbox360 x-box xbox360 x-boxes xbox360 ps ps3 xbox360s xbox360 playstation ps3 119 B Dicionário de Gírias type=weaksubj len=1 word1=sucks pos1=verb stemmed1=y priorpolarity=negative type=weaksubj len=1 word1=hype pos1=noun stemmed1=y priorpolarity=negative type=weaksubj len=1 word1=pick pos1=verb stemmed1=y priorpolarity=positive type=weaksubj len=1 word1=babble pos1=noun stemmed1=y priorpolarity=negative type=weaksubj len=1 word1=pwns pos1=adj stemmed1=n priorpolarity=positive type=weaksubj len=1 word1=breaks pos1=verb stemmed1=y priorpolarity=negative type=weaksubj len=1 word1=freaking pos1=verb stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=preferring pos1=verb stemmed1=y priorpolarity=positive type=weaksubj len=1 word1=copycat pos1=noun stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=rocks pos1=adj stemmed1=n priorpolarity=positive type=weaksubj len=1 word1=rox pos1=adj stemmed1=n priorpolarity=positive type=weaksubj len=1 word1=sucks pos1=verb stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=sux pos1=verb stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=sucked pos1=verb stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=copies pos1=verb stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=copied pos1=adj stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=crash pos1=verb stemmed1=y priorpolarity=negative type=weaksubj len=1 word1=crashes pos1=verb stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=crashed pos1=adj stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=turds pos1=adj stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=breaking pos1=noun stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=diehard pos1=noun stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=crap pos1=noun stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=dropped pos1=verb stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=buddy pos1=noun stemmed1=n priorpolarity=positive type=weaksubj len=1 word1=shiny pos1=adj stemmed1=n priorpolarity=positive type=weaksubj len=1 word1=heavy pos1=verb stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=fad pos1=noun stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=gutted pos1=verb stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=bash pos1=verb stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=bashes pos1=verb stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=bug pos1=noun stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=bugs pos1=noun stemmed1=n priorpolarity=negative type=weaksubj len=1 word1=rules pos1=noun stemmed1=n priorpolarity=positive type=weaksubj len=1 word1=noob pos1=noun stemmed1=y priorpolarity=negative type=weaksubj len=1 word1=noobs pos1=noun stemmed1=y priorpolarity=negative type=weaksubj len=1 word1=n00b pos1=noun stemmed1=y priorpolarity=negative type=weaksubj len=1 word1=n00bs pos1=noun stemmed1=y priorpolarity=negative 120 type=weaksubj len=1 word1=bloody pos1=adj stemmed1=y priorpolarity=negative type=weaksubj len=1 word1=flawfree pos1=noun stemmed1=n priorpolarity=positive type=weaksubj len=1 word1=sleeker pos1=noun stemmed1=n priorpolarity=positive type= weaksubj len=1 word1=losers pos1=noun stemmed1=n priorpolarity=negative 121
Baixar