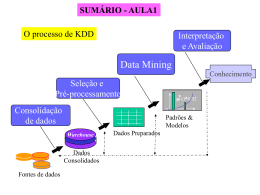
Universidade Federal do Estado do Rio de Janeiro Centro de Ciências Exatas e Tecnologia Escola de Informática Aplicada Análise do perfil de uma comunidade científica através de mineração de texto. Brunno Athayde Silveira Thiago Yusuke Muramatsu Orientador Kate Cerqueira Revoredo i Rio de Janeiro, RJ – Brasil Dezembro de 2011 Análise do perfil de uma comunidade científica através de mineração de texto. Brunno Athayde Silveira e Thiago Yusuke Muramatsu Aprovada por: __________________________________________________ Prof. Kate Cerqueira Revoredo, DSc. (UNIRIO) __________________________________________________ Prof. Fernanda Araujo Baião, DSc. (UNIRIO) ______________________________________________ Prof. Renata Mendes de Araujo, DSc. (UNIRIO) ii Rio de Janeiro, RJ – Brasil. Dezembro de 2011 iii Agradecimentos Agradecemos ao corpo docente da UNIRIO, em especial à professora Kate, pela paciência e diálogo franco. Agradecemos nossas famílias e amigos, que nos tornaram quem somos. 1 RESUMO O trabalho apresenta uma forma de análise de uma comunidade científica através de suas publicações, possibilitando traçar o perfil da mesma, ao gerar indicadores que auxiliam no entendimento dos diferentes tópicos abordados pelos pesquisadores. Os indicadores são gerados de forma automática, sendo: uma rede de colaboração, uma rede com as instituições envolvidas e o contexto (classificação) dessas publicações. Um sistema foi desenvolvido para auxílio da análise, sendo dividido em dois módulos principais: geração de grafos e classificação automática de texto. Realizou-se um estudo de caso com uma comunidade de Sistemas de Informação. Este trabalho está inserido no escopo do projeto “Redes Sociais de Pesquisa em Sistemas de Informação” o qual tem apoio da FAPERJ (processo número E26/111484/2010) Palavras-chave: Descoberta de conhecimento, mineração de texto, classificação automática de texto, categorização, redes sociais, grafos. 2 ABSTRACT This works presents an analysis of a scientific community through its publications, enabling the design of its profile, generating indicators that assist in the understanding of the different topics covered by the researchers. These indicators are generated automatically, as follows: a collaborative network, a network of institutions involved and the context (classification) of the publications. A system was developed to support the analysis and was divided into two main modules: generating graphs and document classification. A case study with a community of Information Systems was conducted. This work is inserted into the scope of the project "Social Networks Research in Information Systems" which is supported by FAPERJ (process number E26/111484/2010) Keywords: Knowledge-discovery in databases - KDD, text mining, Document classification/categorization, social network, graphs. 3 Índice 1 Introdução ......................................................................................................... 7 2 Conhecimento preliminar ............................................................................... 11 2.1 Análise de redes sociais................................................................................ 11 2.1.1 2.2 Grafos ................................................................................................ 12 Mineração de texto ....................................................................................... 14 2.2.1 Classificação automática de texto ..................................................... 15 2.2.2 Pré-processamento ............................................................................ 18 2.2.2.1 Identificação de termos: o conceito de dicionário ......................... 20 2.2.2.2 Stopwords e termos de pouco valor preditivo ............................... 21 2.2.2.3 Stemming e Lemmatisation ........................................................... 22 2.2.2.4 N-gram ........................................................................................... 23 2.2.3 Seleção das características ................................................................ 24 2.2.3.1 Representação dos documentos ..................................................... 24 2.2.3.2 Redução ......................................................................................... 25 2.2.3.3 Determinação do peso dos termos ................................................. 26 2.2.3.3.1 Frequência relativa do termo ................................................. 26 2.2.3.3.2 TF-IDF................................................................................... 27 2.2.3.3.3 Escore de relevância .............................................................. 28 2.2.3.4 Truncagem ..................................................................................... 30 2.2.3.5 Normalização ................................................................................. 31 2.2.4 Métodos de categorização ................................................................. 31 4 3 3.1 4 2.2.4.1 Modelos difusos ............................................................................ 32 2.2.4.2 Algoritmo de categorização - Calculando o grau de similaridade 34 Proposta .......................................................................................................... 36 Proposta de classificação automática de artigos .......................................... 38 Estudo de caso ................................................................................................ 39 4.1 Extração das informações............................................................................. 39 4.2 Geração de grafos de colaboração da comunidade do SBSI ........................ 39 4.3 4.2.1 Pajek .................................................................................................. 39 4.2.2 Preparação dos dados ........................................................................ 41 Classificação automática de artigos do SBSI ............................................... 43 4.3.1 5 Escolha dos algoritmos...................................................................... 45 4.3.1.1 Escore de relevância ...................................................................... 45 4.3.1.2 Algoritmo de categorização ........................................................... 46 4.3.2 Pré-processamento realizado ............................................................. 47 4.3.3 Seleção das características realizada ................................................. 48 4.3.4 Método de categorização utilizado.................................................... 48 Análise dos resultados .................................................................................... 49 5.1 Resultado da geração de grafos .................................................................... 49 5.2 Resultados da classificação automática........................................................ 52 5.2.1.1 Outro experimento- Melhorando o resultado ................................ 54 5.3 Análise da classificação automática ............................................................. 56 5.4 Dificuldades encontradas e limitações ......................................................... 58 5 5.4.1 Problemas na extração das informações............................................ 58 5.4.2 Problemas na definição das categorias .............................................. 58 5.5 Trabalhos Relacionados ............................................................................... 59 5.6 Trabalhos Futuros ......................................................................................... 60 6 Anexo A - Stoplist .......................................................................................... 61 7 Referencias ..................................................................................................... 62 Índice de Tabelas Tabela 1 - Matriz de similaridade entre objetos (Fonte: Wives, 1999) ................... 33 Tabela 2 - Primeiro resultado gerado ...................................................................... 52 Tabela 3 - Resultado do classificador levando em consideração uma categoria por artigo para geração da lista de termos ............................................................................ 55 6 1 Introdução Mineração de texto, como é conhecido o processo de descoberta de informação a partir de dados não estruturados, inspira-se na mineração de dados, utilizando técnicas lingüísticas para tratamento de informações a partir de texto em línguas naturais, produzindo informação textual de alta qualidade. Comumente, através da mineração, busca-se a classificação automática de texto e agrupamento por semelhança. A classificação ou agrupamento podem sempre ser feitos de maneira manual, mas com a grande quantidade de informação disponível a ser tratada, demandariam muito tempo. A divisão de documentos em categorias, realizada de modo manual por um especialista, é algo muito comum em diversos sistemas. Dessa maneira, a tarefa de recuperação de informação é facilitada, pois possibilita a busca em domínios específicos em uma base mais concisa de documentos. Podemos imaginar esta aplicação em diversos cenários: bibliotecas, sites web, entre outros. Com o grande volume de dados, tornam-se necessárias as técnicas de classificação e agrupamento de textos de forma automática, tornando possível, por exemplo, a correta distribuição das informações dentro de uma empresa. Este cenário, de muita informação necessitando de tratamento, influenciou estudos que possibilitam a classificação automática de textos com bons resultados, 7 diminuindo a necessidade de especialistas, que, por exemplo, participariam do processo de validação do resultado. (Schiminovich, 1971) afirma que a classificação automática de textos pode ser tão ou mais precisa que a classificação manual, com um custo potencialmente menor. Um sistema de classificação automática de documentos deve então ser capaz de associar um documento a uma ou mais categorias prédefinidas. O processamento de linguagem natural estuda a compreensão automática de linguagens humanas naturais, convertendo-as, por exemplo, em representações manipuláveis por programas de computador, envolvendo campos da lingüística, inteligência artificial, ciência da computação e lexicografia (Bates, 1995). A classificação de documentos de texto (document classification/categorization) como problema da ciência da informação estuda todo o processo de transformação da informação em dados e conhecimento, com o objetivo de classificar o documento em uma ou mais categorias. Uma técnica não supervisionada mais específica é a de agrupamento de documentos (document clustering), intimamente relacionada ao agrupamento de dados (data clustering), utilizando-se das técnicas de processamento de linguagem natural para o tratamento dos dados não estruturados. Técnicas de determinação do peso dos termos medem a importância de uma determinada palavra em um documento de texto. TF-IDF (Sparck Jones, 1972) é uma das medidas de importância mais utilizadas na recuperação da informação em mineração de texto. Basicamente, baseando-se na freqüência da palavra no documento e na coleção, é atribuído um peso indicando sua representatividade. Toda esta tecnologia permitiria a classificação automática de artigos científicos. A classificação destes artigos em categorias pré-definidas facilitaria não só a recuperação 8 de informação, por estarem em domínios específicos, mas também a percepção de trabalhos associados, a classificação por parte dos autores e os possíveis erros de classificação e a análise dos tópicos e seus relacionamentos para possíveis sugestões de temas para os simpósios. De maneira mais macro, geraria indicadores que seriam utilizados para análise do simpósio, bem como da comunidade como um todo. Outra forma de analisar uma determinada comunidade é através de sua rede social de colaboração. Redes sociais são estruturas sociais compostas por pessoas e/ou organizações que se conectam através de relações e compartilham interesses comuns – informação, conhecimento e esforços em busca do mesmo objetivo. A intensificação das redes sociais reflete um processo de maior participação democrática e mobilização social (Barnes, 1954). A análise de redes sociais facilita o acompanhamento das discussões, permitindo a percepção de tendências de opiniões e apoiando o processo colaborativo. Este trabalho tem por objetivo analisar uma comunidade científica através de suas publicações científicas. Esta análise é feita utilizando técnicas de mineração de textos para identificação do contexto da publicação e geração da rede de colaboração. A proposta foi avaliada considerando publicações feitas no Simpósio Brasileiro de Sistemas de Informação (SBSI). O presente trabalho está estruturado em capítulos e será desenvolvido da seguinte forma: Capítulo II: Apresenta o conhecimento preliminar referente à classificação automática de texto através da mineração de texto e a análise de rede sociais através da geração de grafos. Capítulo III: Apresenta a proposta de maneira generalizada. 9 Capítulo IV: Descreve o estudo de caso realizado para a classificação automática dos artigos científicos e a geração dos grafos da rede de colaboração do simpósio. Capítulo V: Resultados finais e conclusões – Reúne as considerações finais, assinala as contribuições da pesquisa e sugere possibilidades de aprofundamento posterior. Capítulo VI: Anexos. 10 2 Conhecimento preliminar Este capítulo visa apresentar e descrever todo o conhecimento preliminar relevante para o trabalho: a análise de redes sociais e sua relação com a teoria dos grafos e a classificação automática de texto através de técnicas de mineração de texto. 2.1 Análise de redes sociais Análise de redes sociais pode ser caracterizada como uma abordagem composta de quatro propriedades básicas (Freeman, 2011): 1. Envolve a intuição de que as ligações entre os atores sociais são importantes; 2. É baseada na coleção e análise de dados que registram as relações sociais que ligam os atores; 3. Baseia-se fortemente em imagens gráficas que revelam e mostram os padrões das ligações; 4. Desenvolve modelos computacionais e matemáticos para descrever e explicar os padrões. 11 Até a década de 1930, nenhum autor havia produzido um trabalho com as quatro propriedades listadas acima. O moderno campo da análise de redes sociais surgiu então na década de 1930 (Freeman, 2011). Na análise das redes sociais, muitos conceitos e terminologias são originários da teoria dos grafos. A linguagem dos grafos pode ser utilizada para modelar idéias que eram conhecidas antes da teoria dos grafos. Por exemplo, diagramas genealógicos são grafos onde nós representam indivíduos ligados por relações de parentesco ou afinidade. Diagramas deste tipo são utilizados de maneira prática há muito tempo, então, desde que se percebeu a relevância dos grafos para a análise de redes sociais, surgiu um campo vasto para a aplicação desta teoria (Barnes and Harary, 1983). 2.1.1 Grafos O uso de imagens visuais é comum em vários campos da ciência sendo importante para o desenvolvimento dos mesmos (Freeman, 2000). São identificadas duas maneiras distintas de exibição usadas na construção de imagens de redes sociais, uma baseada em pontos e linhas, outra em matrizes. Nas representações por linhas e pontos, os pontos representam os atores e as linhas as conexões. Na representação por matrizes, linhas e colunas, ambas, representam os atores, e números ou símbolos nas células representam as relações sociais que ligam os atores. A grande maioria das imagens representando redes sociais envolve o uso dos pontos e linhas, assim como neste trabalho. No estudo da estrutura das redes sociais é necessário incluir as relações entre os atores, têm-se então três elementos básicos: 1. Atores (nós) 12 2. Relações (arestas) 3. Fluxos de informação (unidirecionais ou bidirecionais) Figura 1 - Imagem de um padrão de vínculos (Moreno apud Freeman, 2000) A Figura 1 mostra um grafo, conjunto de pontos e um conjunto de linhas conectando pares de pontos, que sugere que os indivíduos do topo e da base seriam os “dominantes”, pois se conectam aos demais pontos, e teriam uma ligação “direta” e “indireta”. (Moreno, 1934) sugere a utilização de setas para representar as ligações entre os atores. Numa ligação entre os atores A e B, se A responde B e B não responde A, a seta apontaria do ator A para o B. Caso cada um deles responda para o outro, a linha não seria uma seta, mas teria uma pequena linha cruzando sua metade, são os chamados grafos direcionados. Isso pode ser visto na Figura 2. Figura 2 - Quem reconheceu quem em uma coleção de bebês (Moreno apud Freeman, 2000) 13 Na Figura 2, o bebê A, por exemplo, está aparentemente na base de uma possível hierarquia de reconhecimento, pois não foi reconhecido por nenhum dos outros. Por outro lado, B, D G e H estão no topo, sendo reconhecido cada um por outros dois. C, E, F e I estão no meio: sendo cada um reconhecido por outro. Porém a hierarquia está longe de ser estrita; C e E reconheceram um ao outro, já G, H e I formaram um círculo, onde G reconheceu I, I reconheceu H e H reconheceu G (Moreno apud Freeman, 2000). A análise visual de redes sociais tem dois objetivos principais (Freeman, 2001): 1. Revelar clusters de atores fortemente ligados, os chamados grupos sociais; 2. Revelar o conjunto de atores que interpreta papéis especiais na rede social (como exemplo, um ou mais atores proeminentes que ligam dois distintos grupos sociais); 2.2 Mineração de texto A Figura 3 ilustra as etapas operacionais executadas em processos de Descoberta de conhecimento (Knowledge-discovery in databases - KDD). O processo de KDD é um processo iterativo onde as três primeiras etapas podem ser interpretadas como a análise exploratória dos dados. As etapas de seleção, pré–processamento e transformação compreendem as funções relacionadas à captação, à organização e ao tratamento dos dados, com os objetivos de encontrar as características mais relevantes, reduzir a dimensionalidade e criar o conjunto de dados de entrada, preparando os dados para os algoritmos da etapa seguinte, a mineração de dados. 14 Figura 3 - Etapas operacionais do processo KDD (Fonte: FAYYAD ET AL., 1996) A mineração de dados é considerada a etapa mais importante do processo de KDD, pois é nela que é realizada a busca efetiva por conhecimentos úteis através da extração de padrões. A última etapa é a de pós-processamento e interpretação, abrangendo a apresentação e o tratamento do conhecimento obtido na mineração de dados, viabilizando a avaliação dos padrões e a utilidade do conhecimento. Baseada na mineração de dados, a mineração de texto busca obter informação útil (conhecimento) a partir de dados não estruturados. Para isso, utiliza técnicas lingüísticas para tratamento de informações a partir de texto em línguas naturais. Sendo assim, as fases anteriores à aplicação da técnica de mineração em si ganham destaque. 2.2.1 Classificação automática de texto Segundo (Moens apud Galho and Moraes, 2003), “o homem executa a categorização de texto lendo o texto e deduzindo as classes de expressões específicas e seus padrões de contexto. A classificação automática de texto simula este processo e reconhece os padrões de classificação como uma combinação de características de texto. Estes padrões devem ser gerais o bastante para ter grande aplicabilidade, mas 15 específicos o suficiente para serem seguros quanto à categorização de uma grande quantidade de textos”. (Rizzi apud Galho and Moraes, 2003) afirma que “a categorização de textos é uma técnica utilizada para classificar um conjunto de documentos em uma ou mais categorias existentes. Ela é geralmente utilizada para classificar mensagens, notícias, resumos e publicações. A categorização também pode ser utilizada para organizar e filtrar informações. Essa capacidade faz com que esta técnica possa ser aplicada em empresas, contribuindo no processo de coleta, análise e distribuição de informações e, conseqüentemente, na gestão e na estratégia competitiva de uma empresa”. A classificação automática de texto utiliza o processamento de linguagem natural para associar um documento de texto a um conjunto de documentos conhecido como categoria, além de permitir a definição automática destas categorias. Assim, organiza os documentos para armazenagem e recuperação, limitando o espaço de busca e facilitando o acesso à informação. Ao invés de selecionar um documento de texto entre milhares disponíveis, analisa-se somente a categoria de interesse. Basicamente, classificação de texto pode ser dividida em dois tipos: supervisionada, onde um mecanismo externo (interação humana, por exemplo) fornece informação para a correta classificação dos documentos (Document classification/categorization), e não supervisionada (também chamada de agrupamento (Document clustering)), onde a classificação deve ser realizada sem nenhuma referência de informação externa (Fabrizio Sebastiani, 2002). Quando não se conhece previamente as categorias nas quais os textos devem ser classificados, utiliza-se então a técnica de agrupamento (Document clustering). Assim, como possíveis aplicações para o agrupamento de texto, surgem cenários onde não se 16 dispõe de nenhuma informação sobre os textos e o volume de dados é muito grande, tornando inviável a classificação manual (Solange ET AL, 2011). Quando as categorias são previamente conhecidas, utiliza-se a classificação de texto (Document classification/categorization). Este é o tipo de classificação que será tratada a partir de agora e utilizada neste trabalho. Um sistema de classificação automática de texto através de métodos supervisionados compreende duas fases: definição das categorias e classificação dos novos documentos de texto (Galho and Moraes, 2003). A fase de definição das categorias é normalmente realizada em três etapas: preparação dos textos, seleção de características e definição da lista de termos relevantes das categorias. Figura 4 - Esquema de definição de categorias (Adaptado de Galho and Moraes, 2003) Sobre uma coleção de documentos de texto conhecidos e pertencentes a uma mesma categoria, aplica-se a etapa de preparação do texto. Nessa etapa, cada documento dessa coleção é analisado. São aplicadas algumas técnicas que facilitam o processo de seleção de características dos textos, tais como: retirada de todas as palavras que não influenciam para a definição da categoria do texto, retirada de símbolos (ex: #,#,$,%,¨,&,*,(,), etc.), conversão de termos em radicais, entre outras. 17 Logo após, são localizadas (através de medidas que determinam os pesos dos termos), nos textos, todas as palavras que expressam melhor suas características, ou seja, as palavras ou conceitos que podem definir sua categoria. A partir destes conceitos, é gerada uma lista de termos comuns a todos os documentos de cada categoria. Um termo comum aos documentos de uma mesma categoria e incomum aos documentos das outras categorias seria um bom preditor desta categoria. Essa lista de termos compõe o índice que representa a categoria. Figura 5 - Esquema de categorização de novos documentos (Adaptado de Galho and Moraes, 2003) Na fase de categorização, o novo texto a ser classificado também passa pela etapa de preparação já mencionada. Após essa etapa também é necessário descobrir as características desse documento para definir a sua lista de termos. A categorização ocorre através de uma comparação entre a lista de termos das categorias e a lista de termos do novo documento (através da utilização de um método de categorização). A categoria que possuir a lista de termos mais similar à lista do documento novo será escolhida como sua classe. A Figura 5 apresenta o esquema de categorização de novos documentos. 2.2.2 Pré-processamento 18 Os sistemas de classificação automática de texto identificam padrões através de exemplos de treinamento que serão utilizados para classificar novos documentos em relação à coleção. Diferente dos dados armazenados em bancos de dados relacionais, onde estão organizados em forma de linhas e colunas, e cada linha representa uma tupla e cada coluna um atributo (característica), ou seja, estão estruturados, os dados em textos estão dispostos de maneira não estruturada. Neste caso, os documentos são as instâncias e as palavras os atributos. Então, a etapa de preparação do texto ou etapa de pré-processamento é uma das mais importantes da mineração de texto, pois determina os valores das características (atributos) que representarão os documentos dentro da base a ser considerada. Os dados precisam ser analisados, selecionados, uniformizados e formatados através de técnicas de preparação do texto. Retirar o que não é significativo para a classificação torna o texto mais enxuto e a lista de palavras das categorias mais sucinta. Isto reduz expressivamente o trabalho a ser realizado nas etapas de seleção das características e categorização, e, conseqüentemente, diminui significativamente o tempo de processamento. Apesar das vantagens, a possível eliminação de termos relevantes comprometeria o resultado final. As iniciais dificuldades em tratar os dados não estruturados motivaram estudos para o desenvolvimento de técnicas de análise de texto para transformação dos documentos. As técnicas de processamento de linguagem natural são úteis no campo da mineração de texto para “entender o texto”, extraindo a sintaxe e semântica, o 19 texto deixa de ser tratado como “uma grande bolsa de seqüência de caracteres” (Harris, 1954). 2.2.2.1 Identificação de termos: o conceito de dicionário Como supracitado, os documentos são representados por palavras, que são os atributos utilizados pelos sistemas de classificação automática de texto. Estes sistemas buscam e identificam padrões que associem os documentos as categorias, que são conceitos definidos pelo usuário. Acontece que, nem sempre, palavras são conceitos. Algumas representam mais de um conceito, enquanto certos conceitos necessitam de mais de uma palavra para a sua representação. Por exemplo, a palavra “banco” representa mais de um conceito, enquanto o conceito de “banco de areia” precisa de mais de uma palavra para ser representado. Ainda assim, (Salton e Buckley, 1988) concluíram que muitas vezes a definição de termos simples pode ter os melhores resultados. Outras palavras não possuem valor semântico, como as preposições e artigos. Enquanto as pessoas são capazes de identificar facilmente os conceitos relacionados às palavras em um documento, por percepção do mundo e conhecimento da linguagem, os sistemas de classificação automática de texto não possuem esta capacidade, ou seja, o conhecimento dos conceitos. Para que um sistema destes possa inferir um conceito de maneira correta, tendo como base apenas os documentos da coleção, é necessário realizar uma seleção para obtenção de um conjunto de palavras que minimizaria o erro. Este conjunto de palavras é conhecido como dicionário, abordagem convencional neste tipo de trabalho. Produz-se uma lista de palavras através da varredura da coleção de documentos, sendo as palavras qualquer seqüência 20 de caracteres separados por espaço em branco ou sinais de pontuação. É comum, durante o momento de criação desta lista, realizar a conversão de todos os caracteres para maiúsculas ou minúsculas. Assim, a mesma seqüência de caracteres sempre seria reconhecida pelo algoritmo como sendo o mesmo termo. Duas possíveis abordagens para a criação do dicionário são: 1. Dicionário local a. Formado por termos de documentos de uma mesma categoria. Deve possuir uma quantidade fixa de termos simples, selecionados de acordo com suas freqüências de ocorrência. 2. Dicionário geral ou universal a. Formado a partir de todos os documentos da coleção. Durante o processo de criação do dicionário entram as técnicas de análise de texto, que visam justamente retirar o que não é significativo para a tarefa de classificação dos documentos de texto. As técnicas podem alterar dependendo da abordagem, mas algumas são consideradas convencionais. A ordem de aplicação das mesmas também pode ser diferente. Para identificação individual das palavras, costuma-se aplicar a retirada de pontuação, algarismos e caracteres inválidos ou inconsistentes. Outras técnicas de processamento de linguagem natural serão vistas a seguir. 2.2.2.2 Stopwords e termos de pouco valor preditivo Palavras que pertençam a uma lista de stopwords são retiradas. Representam palavras que não possuem valor semântico (geralmente artigos, advérbios, 21 preposições e conjunções), ou seja, não possuem valor preditivo para a tarefa de classificação e, portanto, devem ser descartadas (Luhn, 1958). São definidas de maneira manual e não existe uma lista definitiva de stopwords. Cada ferramenta pode utilizar uma determinada lista de stopwords e qualquer grupo de palavras pode ser escolhido para um determinado propósito. Por exemplo, the é uma das mais comuns function word da língua inglesa e no caso particular de nomes como The Who, sua remoção causaria problemas. Palavras que ocorrem muito ou pouco freqüentemente em determinado texto, também podem ser retiradas. São termos incapazes de distinguir este documento perante os outros documentos da base, assim como palavras que ocorrem em grande quantidade de documentos (se uma palavra aparece em diversos textos da coleção, não é ela que será capaz de diferenciá-los entre si). A escolha do número para palavras que ocorrem menos de um determinado número de vezes é resultado de testes empíricos, mas estudos sugerem que varia entre três (Mladenic apud, Castro, P. F., 2000) e cinco (Apté apud Castro, P. F., 2000), (Lewis apud Castro, P. F., 2000). O descarte destas palavras já gera uma considerável diminuição dos termos a serem considerados, estes termos restantes por sua vez ganham em relevância. 2.2.2.3 Stemming e Lemmatisation Geralmente, variantes do mesmo termo podem ser consideradas com um único item, tratando implicações lingüísticas (Luhn, 1958). “Diferença”, “diferente”, “diferentemente” e “diferencial” teriam o mesmo significado. 22 Lemmatisation é um conceito da lingüística que representa o processo de agrupar diferentes formas da mesma palavra para que sejam considerados com único item. Na lingüística computacional, representa a determinação do lema, forma canônica, de uma palavra. Verbos, então, são transformados no infinitivo e substantivos vão para o masculino singular. Stemming é o processo de redução de uma palavra suprimindo seu sufixo, assim as diferentes formas da mesma palavra seriam agrupadas e analisadas como um único item (Weiss apud Castro, P. F., 2000). Não é necessário que o stem seja o radical da palavra, bastando que as palavras relacionadas estejam associadas ao mesmo stem. A diferença entre o as duas técnicas é que o stemming analisa as palavras individualmente, sendo incapaz de diferenciar o significado do termo de acordo com o contexto. Por sua vez, é mais fácil de implementar e exige menos processamento computacional, sendo utilizado quando sua menor precisão não influencia negativamente o resultado. Um exemplo é a palavra inglesa “better” que possui como lema “good”. Um algoritmo stemming seria incapaz de perceber a relação. 2.2.2.4 N-gram N-gram é uma subseqüência de itens de uma dada seqüência. Os itens podem ser fonemas, sílabas, palavras, entre outros, de acordo com a aplicação. Um n-gram de tamanho um é conhecido como “unigram”; tamanho dois como “bigram”; três como “trigram”; quatro como “fourgram” e cinco ou mais como “n-gram”. Um modelo n-gram é um modelo probabilístico de predição utilizado no processamento de linguagem natural. Na preparação do texto, os termos são definidos para que cada n-gram seja composto de n palavras. 23 A utilização de modelos n-gram possibilita a obtenção de conceitos mais concretos, através do reconhecimento de tuplas de palavras conhecidas. De maneira concisa, um modelo n-gram prediz o termo seguinte baseado no anterior. O objetivo principal da aplicação da técnica seria a obtenção de seqüências de palavras que formem termos únicos com grande valor preditivo. No contexto analisado, “text mining” teria maior relevância que os termos “text” e “mining” analisados individualmente. 2.2.3 Seleção das características Nesta etapa, os termos pré-processados são escolhidos para representar os documentos. Para isso, segue-se um critério previamente estabelecido que deva ser capaz de determinar a relevância de cada termo quanto a sua expressividade semântica. Em outras palavras, termos que devam ser capaz de expressar o conteúdo dos documentos. Estes critérios são lingüísticos, estatísticos ou uma combinação de ambos. Nos critérios lingüísticos, o significado do conteúdo do documento é representado através de processamento de linguagem natural. Já a abordagem estatística é feita através de cálculos matemáticos aplicados as palavras do documento ou da coleção. Basicamente, atribui-se peso às palavras definindo sua importância. Os atributos de melhor pontuação formam a lista de palavras. 2.2.3.1 Representação dos documentos Os documentos de texto são representados como vetores de termos denominados bag-of-words. 24 Figura 6 - Exemplo da representação como bag-of-words usando um vetor de frequências (Castro, P. F., 2000) A Figura 6 mostra um exemplo de bag-of-words. As palavras são mantidas sem qualquer ordem pré-estabelecida e, neste exemplo, possuem sua correspondente frequência no documento de texto. A partir do dicionário, vetores representando documentos de texto ou conjuntos de documentos podem conter valores binários, onde 1 representa a presença da palavra e 0 indica a ausência, ou números indicando a quantidade de ocorrências (ou frequência) de cada palavra no texto. 2.2.3.2 Redução O processo de criação do dicionário pode não ser suficiente para a produção de dados tratáveis pelo método de aprendizado. O conjunto de características resultantes pode, em muitos casos, ser enumerada em centenas de milhares (Yang apud Castro, P. F., 2000) (Pazzani apud, Castro, P. F., 2000). Poucos métodos de aprendizado são capazes de lidar com esta quantidade de dados e, mais ainda, o desempenho de alguns é muito prejudicado quando este número é muito elevado. 25 Sendo assim, uma segunda etapa de seleção das características é indispensável. Esta consiste na redução do conjunto de palavras originais, conhecida como redução de dimensionalidade na área de reconhecimento de padrões. Apresentaremos na seção 2.2.3.4 a técnica de truncagem, uma das mais simples e mais utilizadas visando diminuir o número de termos relevantes considerados. 2.2.3.3 Determinação do peso dos termos A principal função de um term-weighting system é o aumento da recuperação da informação desejada. Isto depende basicamente de dois fatores: 1. Os itens que o usuário deseja recuperar precisam ser recuperados; 2. Os itens estranhos devem ser rejeitados. A princípio, um bom sistema deve produzir ambas as recuperações, conseguindo alta precisão na recuperação de itens desejáveis e a mesma alta precisão na recuperação de itens indesejáveis. O estudo de (Salton e Buckley, 1988) apresenta diferentes abordagens na determinação automática de peso de termos (automatic term weight-ing). 2.2.3.3.1 Frequência relativa do termo Após a fase de pré-processamento do texto e aplicação das técnicas como a eliminação de stopwords, algumas palavras comuns em determinado assunto costumam se repetir com frequência. A técnica de frequência relativa é uma das mais comuns no processo de seleção de características em mineração de texto. Partindo do princípio de que quanto mais vezes uma palavra aparece em um determinado texto, mais importante ela é, a técnica define a importância do termo encontrado no texto. O número de vezes em que um 26 termo aparece em um texto é chamado de frequência do termo (term frequency) e esta pode ser uma maneira direta de calcular a frequência relativa. No entanto, a fórmula apresentada na Equação 1 permite a normalização do resultado, diminuindo a influência dos tamanhos dos textos no resultado (um texto grande poderia ter um maior valor de ocorrência de determinado termo que não necessariamente reflita sua importância para o mesmo) (Salton, 1983). Frel X = Fabs X N Equação 1 - Frequência relativa do termo Onde: Frel X = frequência relativa de X; Fabs X = a frequência absoluta de X, quantidade de vezes que X aparece no documento; Ν = o número total de termos do texto. Outra maneira de calcular a frequência do termo dentro de um documento é apresentada na fórmula a seguir (Salton and Buckley, 1988): 0 .5 + 0.5tf Maxtf Chamada de frequência do termo normalizada aumentada, a frequência do termo é normalizada pela frequência máxima encontrada no documento e normalizada novamente para que o valor fique entre 0.5 e 1. 2.2.3.3.2 TF-IDF A técnica de seleção TF-IDF (Term Frequency–Inverse Document Frequency) é outra técnica de seleção de características frequentemente usada na mineração de 27 texto. É uma abordagem estatística utilizada para definir o quão relevante é um termo em relação a uma coleção. A relevância do termo discriminatório sobe à medida que a palavra aparece mais vezes no texto e diminui à medida que aparece nos outros documentos da coleção (Sparck Jones, 1972). A partir da frequência relativa do termo, importância do termo d em um texto t, e da frequência inversa de documentos, medida de importância geral do termo obtida dividindo-se o número total de documentos pelo número de documentos em que o termo aparece (Equação 1), chega-se a fórmula apresentada na Equação 2: N log ni Equação 2 - Frequência inversa dos documentos Onde: Ν = Número de documentos na coleção de referência; ni = número de documentos na coleção de referência que tem o termo de índice i. N ft i × log ni Equação 3 - TF-IDF: frequência relativa do termo X frequência inversa de documentos Onde: ft i = frequência relativa do termo i; Ν = número de documentos na coleção de referência; ni = número de documentos na coleção de referência que tem o termo de índice i. 2.2.3.3.3 Escore de relevância 28 A técnica do escore de relevância foi apresentada e aplicada no estudo de (Wiener ET AL, 1995). A seleção dos termos deve ter como objetivo encontrar um subconjunto de termos que se mostre o mais eficiente para a tarefa de classificação. Os termos, então, devem ser adequadamente discriminativos entre as categorias. Cada categoria é analisada individualmente, através de seus documentos de texto, criando-se tarefas de classificação independentes para a seleção dos subconjuntos de termos que melhor discriminam documentos sobre aquele tópico. Para a seleção dos termos representantes de uma categoria, todos os termos recebem um valor de quão bem servem como preditores individuais do assunto. Este valor é chamado de escore de relevância em relação ao que (Salton and Buckley, 1988) chamaram de peso de relevância. O cálculo é apresentado na Equação 4. wtk 1 + dt 6 rk = log wt k 1 + dt 6 Equação 4 - Escore de relevância Onde: rk = o escore de relevância do t ermo k; wtk = número de documentos pertencentes a uma dada categoria t que contém o termo k; wt k = número de documentos de outras categorias que contém o termo k; d t = o número total de documentos de outras categorias; d t = o número total de documentos da categoria t; 29 wt k é o número de documentos da categoria contendo o termo, dt é o total de documentos da categoria, etc. Valores altamente positivos e altamente negativos indicam termos úteis para a discriminação. 2.2.3.4 Truncagem A técnica de truncagem visa diminuir o número de termos relevantes a serem considerados. Também chamada de seleção por peso do termo, após o calculo do peso termo, são escolhidos apenas os que possuem os maiores valores calculados. Palavras com pouca frequência não caracterizam um documento ou categoria, sendo irrelevantes para a classificação. A princípio, a técnica pode ser necessariamente utilizada para, ao reduzir o escopo, tornar o conjunto de características tratável pela máquina. Isso ocorre, pois o tempo necessário para obtenção da classificação ou agrupamento é diretamente proporcional ao número de características analisadas. Porém, o estudo de (Wiener ET AL, 1995) mostra que passar de uma determinada faixa de termos considerados, analisando um número maior, pode piorar a precisão do classificador automático. Ao analisar 20 termos, a melhor precisão foi encontrada, piorando o resultado ao se incluir mais termos. Isso mostra que identificar adequadamente os termos mais relevantes é uma tarefa crucial para a classificação automática. A explicação para o resultado é a ocorrência de overfitting, quando a alimentação da base de treinamento começa a gerar peculiaridades. É importante ressaltar que o número mínimo ou máximo de características relevantes a serem analisados para um resultado satisfatório varia de coleção para coleção, bem como não é trivial estabelecê-lo. 30 A truncagem, bem como a fase de pré-processamento, é desencorajada por alguns autores. Wives (1999) afirma que quanto maior o número de características utilizadas no processo de calculo da similaridade, mais confiável é o grau de similaridade, quanto menos se abstrai do mundo real, mais condizente com o mundo real consegue-se ser. Por sua vez, a identificação das características e definição da relevância dos termos para o calculo de similaridade é considerada parte chave nos estudos analisados (Salton, 1988), (Wiener ET AL, 1995), (Wives, 1999), (Castro, P. F., 2000), (Galho and Moraes, 2003). 2.2.3.5 Normalização Como citado na seção 2.2.3.3.1, a técnica de normalização do resultado visa tratar as diferenças de tamanho entre os diversos documentos de texto considerados. Basicamente, os valores representando as frequências dos termos são normalizados para ficarem entre zero e um, dividindo-se a frequência relativa do termo pela sua frequência máxima. Existem variações para o cálculo da normalização. As funções apresentadas e utilizadas neste trabalho utilizam a técnica de normalização. 2.2.4 Métodos de categorização Nesta fase, são utilizados métodos que identificam os conceitos no texto e efetuam a categorização de fato. Esses métodos podem classificar os documentos em nenhuma, uma ou mais categorias existentes. Quando um método efetua a categorização de textos em apenas uma categoria, diz-se que este método é de classificação binária. E, quando os textos podem ser classificados em mais de uma categoria, diz-se que foi aplicado um método de categorização graduada, podendo 31 definir o grau de pertinência do documento a cada uma das categorias para as quais ele foi classificado (Lewis apud Galho and Moraes, 2003). Existem vários métodos de categorização, mas basicamente o processo é comparar a lista de termos do texto e da categoria, definir se eles são semelhantes e a partir deste resultado decidir se o texto pertence à categoria. Algumas funções utilizam valores indicando a presença ou não da palavra, 1 para presente e 0 para ausente. Estes valores são atribuídos independentemente do termo aparecer mais de uma vez no documento de texto. Outras funções são capazes de utilizar valores informando o quanto um termo é discriminativo em relação ao documento de texto, baseando-se na frequência da palavra no mesmo (outros podem levar em consideração a coleção inteira ou assuntos (categorias)). 2.2.4.1 Modelos difusos A lógica difusa, ou lógica fuzzy, diferente da lógica tradicional, permite valores lógicos intermediários entre o “falso” (0) e o “verdadeiro” (1). Assim, um valor como 0,5 poderia ser considerado médio, como um “talvez”. Ou seja, um valor lógico difuso poderia ser qualquer valor entre 0 e 1. Pode-se dizer que a lógica fuzzy está para o raciocínio aproximado assim como a lógica tradicional está para o raciocínio preciso (Oliveira apud Wives, 1999). Um modelo fuzzy simples é o de inclusão simples (Valerie Cross apud Wives, 1999), que avalia a presença da mesma palavra em dois objetos comparados. Caso o termo apareça nos dois, soma-se o valor 1 ao contador, do contrário soma-se 0. Ao final, o valor encontrado é divido pelo número total de termos não repetidos 32 encontrados nos dois documentos, resultando em um valor entre 0 e 1. O problema deste modelo é que, ao analisar e considerar somente o fato da palavra aparecer em ambos os objetos, não considerar a relevância maior que uma palavra pode ter um dos deles. Outras funções, que consideram a frequência da palavra no documento, utilizam pesos para o cálculo do valor fuzzy, contornando o fato de termos possuírem importâncias diferentes nos dois objetos comparados. Neste caso, os termos possuem um peso que pode ser a frequência relativa ou outro valor de discriminação. O valor de similaridade é calculado pela média entre os pesos médios dos termos comuns, ou seja, para cada termo comum a ambos os objetos, soma-se a média dos pesos e ao final a média é calculada sobre o total de termos não repetidos em ambos os objetos. Apesar de considerar a frequência da palavra nos objetos comparados, esta ultima função pode trazer distorções. Ao contar a média dos termos, dois pesos extremos terão o mesmo resultado que dois pesos médios, quando na verdade indicam que os termos possuem níveis de relevância diferentes nos dois objetos. A Tabela 1 apresenta uma matriz de similaridade entre objetos. Tabela 1 - Matriz de similaridade entre objetos (Fonte: Wives, 1999) Obj1 Obj2 Obj3 Obj4 Obj5 Obj1 1.0 0.3 0.2 0.7 0.6 Obj2 0.3 1.0 0.5 0.3 0.9 Obj3 0.2 0.5 1.0 0.3 0.4 Obj4 0.7 0.3 0.3 1.0 0.8 Obj5 0.6 0.9 0.4 0.8 1.0 33 Normalmente, quando adotadas as medidas de similaridade fuzzy, os valores apresentados na tabela possuem as seguintes peculiaridades: 1. Os graus variam entre 0 (sem similaridade) e 1 (totalmente similar); 2. Um objeto é totalmente similar a ele mesmo; 3. Se o objeto X é 20% similar a Y, então Y também é 20% similar a X. Com isso, tem se uma matriz triangular, onde os elementos acima da diagonal principal devem ser armazenados. As situações ambíguas enfrentadas na definição da relevância dos termos encorajam o uso da lógica fuzzy, pois a mesma se propõe a tratar situações imprecisas, oferecendo melhores resultados através do cálculo de pertinência de um elemento a um conjunto, tendo sua aplicação resultados satisfatórios em diversos estudos (Wives, 1999) (Loh, 2001) (Galho and Moraes, 2003). 2.2.4.2 Algoritmo de categorização - Calculando o grau de similaridade Para a categorização, o processo consiste em determinar o grau de semelhança da lista de termos de um novo documento de texto com a lista de termos de uma categoria. Para cada termo comum à lista de termos do novo texto e de uma determinada categoria, calcula-se o grau de igualdade de seu escore de relevância com sua frequência relativa. As funções utilizadas no cálculo são apresentadas na Equação 5, sendo as variáveis “ a ” o escore de relevância do termo na categoria e “ b ” a frequência relativa no novo documento, por exemplo. gi (a, b) = [ ] 1 (a → b ) ∧ (b → a ) + (a → b ) ∧ (b → a ) 2 Equação 5 - Algoritmo de categorização 34 Onde: a→b= b ; a , b = 1 − a ou 1 − b ; a O grau de similaridade do texto em relação à categoria é calculado após o cálculo do grau de igualdade de todos os termos comuns entre os dois. A fórmula apresentada na Equação 6 mostra que o grau de igualdade do texto em relação à categoria é o somatório de todos os graus de igualdades dos termos comuns a ambos, dividindo-se este valor pelo total de termos distintos em relação às duas listas. k gs ( X , Y ) = ∑ gi (a, b) h =1 h N Equação 6 - Cálculo do grau de similaridade do texto em relação à categoria Onde: gs = o grau de similaridade entre os documentos X e Y ; gi = o grau de igualdade entre os pesos do termo h (peso a no documento X e peso b no documento Y ); h = índice para os termos comuns aos dois documentos; k = número total de termos comuns aos dois documentos; N = número total de termos nos dois documentos sem contagem repetida. O processo deve ser repetido para cada categoria. Os maiores valores obtidos são as categorias mais pertinentes ao texto, os menores valores representam as menos pertinentes (Galho and Moraes, 2003), (Wives, 1999), (Loh, 2001). 35 3 Proposta Neste trabalho, pretendemos aplicar a mineração de texto para ajudar na análise de uma comunidade cientifica seguindo duas vertentes sendo a primeira a geração de uma rede social de colaboração e a segunda a classificação automática de artigos científicos. As informações de entrada relevantes são os artigos científicos da comunidade que se deseja avaliar. Estes artigos são estruturados em titulo, autores, instituições envolvidas, abstract, resumo e o texto do artigo. Figura 7 - Modelo do sistema para módulo de geração de grafos. Para o módulo de geração de grafos, foram identificados como essenciais os nomes dos autores e das instituições envolvidas. Já para o módulo de classificação, o resumo. O resumo tem como característica ser conciso, expressando em poucas palavras o objetivo dos trabalhos. Sendo assim, é natural pensar que as palavras apresentadas no 36 resumo de um artigo sejam de importância para o entendimento do mesmo, o que viria a facilitar a identificação dos termos relevantes. Figura 8 - Modelo do sistema para o módulo de classificação. Para o módulo de classificação, também é necessário entrar com as respectivas categorias às quais cada artigo, que serão utilizadas na definição das listas de termos relevantes de cada categoria, está associado. A proposta é se possível, utilizar a mesma classificação dada pelos autores dos artigos. Isso evitaria a necessidade de uma classificação manual de um grande conjunto de artigos e possibilitaria a descoberta de possíveis erros de classificação por parte dos autores. Em muitos casos, um artigo pode estar relacionado a uma, nenhuma, ou mais categorias, fazendo com que algumas vezes o mesmo artigo seja analisado para definição dos termos de duas ou mais categorias diferentes. Além disso, pode ser necessário realizar um tratamento dos tópicos abordados pelas categorias, relacionando os que forem exatamente o mesmo assunto ou muito próximos para que sejam tratados como uma única categoria. Pode ser realizada uma 37 validação com o usuário indicando sinônimos ou fornecendo uma lista de sinônimos previamente. Com estas informações, já seria possível gerar grafos de colaboração da comunidade, bem como extrair a lista de termos das categorias. Para finalizar a classificação, seriam então necessários os artigos que se deseja classificar. 3.1 Proposta de classificação automática de artigos Após a formação da lista de termos de cada categoria, através da utilização da técnica de escore de relevância, seção 2.2.3.3.3, e da formação das listas de termos dos novos textos a serem classificados, através da técnica de frequência relativa do termo, seção 2.2.3.3.1, é aplicada a técnica de similaridade difusa apresentada na seção 2.2.4.1. Classificadores automáticos de artigos científicos são descritos em (Schiminovich, 1971) e (Bichteler and Parsons, 1974) – numa modificação do algoritmo original, utilizando o conteúdo de citação dos mesmos para identificação dos padrões e artigos relacionados. (Garfield, Malin and Small, 1975) também descrevem um sistema computacional para classificação automática de artigos científicos através dos padrões das citações, para isso utilizam uma base de dados de 13 anos de arquivos com 3,4 milhões de artigos e 40 milhões de citações. Ao final do processo de classificação dos novos documentos, teríamos uma lista de categorias mais semelhantes a cada artigo. 38 4 Estudo de caso Nesta seção é apresentada a fase de extração das informações, feita de uma única maneira para os dois módulos do sistema implementado, e o estudo de caso realizado. 4.1 Extração das informações A primeira etapa do sistema a ser implementada é a de extração das informações, também chamada de coleta. As informações de entrada são os artigos científicos das edições 2008, 2009, 2010 e 2011 do SBSI, armazenadas em formato PDF, dos quais são extraídos os nomes dos autores e das instituições envolvidas e o abstract. A escolha de trabalhar apenas com o abstract tem como objetivos diminuir a quantidade de informação relevante a ser considerada e facilitar a etapa de préprocessamento. A aplicação das técnicas de processamento de linguagem natural (como, por exemplo, a técnica “stemming”) se mostrou facilitada ao tratar da língua inglesa. 4.2 Geração de grafos de colaboração da comunidade do SBSI 4.2.1 Pajek 39 Existem diversas ferramentas disponíveis para geração de grafos de redes sociais. A ferramenta Pajek1 foi desenvolvida para análise e visualização de grandes redes, com milhares ou milhões de vértices, motivada pela observação de que existem várias fontes de grandes redes possíveis de serem lidas por máquina (V. Batagelj, A. Mrvar, 2011). Os principais objetivos da ferramenta Pajek são: • Suportar abstração por decomposição recursiva de uma grande rede em diversas redes menores que, então, podem ser tratadas por métodos mais sofisticados; • Prover ao usuário ferramentas poderosas de visualização; • Implementar uma seleção de algoritmos eficientes para análise de grandes redes. Torna-se possível a identificação de clusters (vizinhos “importantes”), extração de vértices pertencentes ao mesmo cluster para análise individual, visualizar conjuntos de vértices como clusters (visualização global), entre outras abordagens. 1 http://pajek.imfm.si/doku.php?id=start 40 Figura 9 - Abordagens para lidar com grandes redes (V. Batagelj, A. Mrvar, 2011) 4.2.2 Preparação dos dados A ferramenta Pajek aceita como entrada um arquivo do tipo texto formatado. Alterações simples na formatação permitem a manipulação dos nós e arestas, como alteração de cor, tamanho e posição dos nós no espaço. A Figura 10 mostra um exemplo de arquivo de entrada aceito pela ferramenta pajek. 41 Figura 10 - Arquivo exemplo da ferramenta Pajek A Figura 11 mostra o grafo gerado pelo arquivo de exemplo. Figura 11 - Rede gerada pelo arquivo de exemplo A Figura 12 mostra uma rede de notícias sobre terrorismo. 42 Figura 12 - Parte da rede Reuters Terror News (V. Batagelj, A. Mrvar, 2011) O sistema então gera um arquivo de saída em formato de texto, formatado de maneira a ser reconhecido pelo Pajek. 4.3 Classificação automática de artigos do SBSI Os artigos de 2008, 2009 e 2010 são analisados para a formação das listas de termos relevantes das categorias (base de treinamento), enquanto os artigos da edição 2011 serão os classificados automaticamente (base de teste). Também é entrada do sistema uma planilha em formato XLS. Esta planilha é uma adaptação da planilha gerada como relatório da ferramenta de controle de submissão JEMS, com a identificação dos artigos que serviram como treinamento para o algoritmo de classificação e seus respectivos tópicos de interesse, associados pelos autores no momento da submissão. A planilha foi utilizada, pois os artigos em formato 43 PDF não possuem seus tópicos de interesse, utilizados para a definição das categorias. A planilha teve que ser adaptada basicamente por dois motivos: Os títulos dos artigos nos arquivos PDF podem não ser os mesmos da planilha de relatório gerada pelo JEMS; Foi necessário realizar um tratamento dos tópicos, considerando os que fossem exatamente o mesmo assunto ou muito próximos como uma única categoria, por exemplo: “Estudos de caso de aplicação de SI” e “Estudos de caso de Sistemas de Informação”. Este tratamento foi realizado de maneira empírica e alterado várias vezes até a versão final. Definição e busca por palavras chave foram utilizadas para extração das informações, sendo o respeito ao padrão da Sociedade Brasileira de Computação (SBC) considerado crucial. Alguns artigos então tiveram de ser descartados por, ao estarem fora do padrão, dificultarem a definição dos critérios de parada e, conseqüentemente, a extração automática das informações. Figura 13 - Tela principal 44 4.3.1 Escolha dos algoritmos O presente trabalho utiliza na etapa de seleção de características as técnicas de escore de relevância e truncagem para a criação das listas de termos representativos das categorias e a técnica de frequência relativa do termo para a criação da lista de termos representativos dos novos textos a serem classificados. Para a classificação dos novos documentos de texto, o método de categorização é o de similaridade difusa. 4.3.1.1 Escore de relevância O algoritmo escolhido para a seleção das características, chamado de escore de relevância (Wiener ET AL, 1995), visa encontrar o subconjunto de termos originais que seja o mais útil possível no processo de classificação. Para selecionar um conjunto de termos de uma categoria, os termos recebem um valor determinando o quão relevantes são como preditores individuais desta categoria, selecionando-se os mais relevantes. O escore de relevância mede quanto o termo é “desbalanceado” entre os documentos das diferentes categorias. A aplicação da técnica é essencial para a análise da similaridade, pois diferentes categorias podem possuir os mesmos termos como relevantes e o escore de relevância permitira a percepção de graus de importância diferentes. O escore de relevância é tratado na seção 2.2.3.3.3 e sua fórmula apresentada na Equação 4. Para a criação das listas de termos é utilizada a técnica de truncagem, ou seleção por peso do termo, os termos do texto são ordenados por valor e apenas os mais relevantes são selecionados, sendo o resto eliminado. É uma técnica bastante utilizada, pois otimiza a performance do classificador ao reduzir a dimensionalidade 45 dos termos considerados para classificação. Os dados devem estar normalizados, removendo o efeito de variação no tamanho dos documentos tratados. A lista com os termos representantes de cada categoria foi definida com 50 termos, o que na grande maioria dos casos é suficiente (Shütze apud Wives, 1999). 4.3.1.2 Algoritmo de categorização Como apresentado na seção 2.2.4.1, a lógica difusa, ou lógica fuzzy, diferente da lógica tradicional, permite valores lógicos intermediários entre o “falso” (0) e o “verdadeiro” (1). Assim, um valor como 0,5 poderia ser considerado médio, como um “talvez”. Ou seja, um valor lógico difuso poderia ser qualquer valor entre 0 e 1. Uma técnica difusa, então, permitiria a categorização graduada de um texto em mais categorias. Isto motivou a escolha de uma técnica de lógica difusa, pois os artigos podem estar associados a mais de um tópico de interesse. A fórmula do algoritmo de categorização utilizado é apresentada na Equação 5. Supondo que o termo comum em análise seja “modelagem” e que sua frequência relativa em um novo texto seja 0.4331 e seu escore de relevância na categoria, 0.1857. Aplicando-se a fórmula dada e considerando-se a = 0.4331 e b = 0.1857, tem-se: a → b = 0.4288 e b → a = 2.3323 . Como dito, os valores devem estar normalizados, ou seja, devem pertencer ao intervalo [0,1]. Para isso, caso o valor encontrado seja maior que 1, assume-se 1. Quando for menor que 0, assume-se 0. Portanto, neste caso b → a é definido como 1. Realizando-se os demais cálculos da mesma forma, tem-se: a = 1 − a = 0,5669 b = 1 − b = 0.8143 46 b →a = a = 0,6962 para b ≠ 0 ; b a →b = b = 1,4364 para a ≠ 0 ; a A partir desses resultados, pode-se calcular, então, o grau de igualdade do termo: gi (0.4331, 0.1857 ) = [min(0.4288, 1) + min(1, 0.6962)] = [0.4288 + 0.6962] = 0.5625 2 2 Assim, o termo “modelagem” do novo texto obteve como grau de igualdade 0.5625 em relação à categoria analisada. O grau de similaridade do texto em relação à categoria é calculado após o calculo do grau de igualdade de todos os termos comuns entre os dois. A formula utilizada é apresentada na Equação 6. 4.3.2 Pré-processamento realizado Na etapa de pré-processamento do texto são realizadas as atividades de identificação dos termos (descrita na seção 2.2.2.1), onde foram definidos termos simples (unigram), remoção de stopwords (a stoplist encontra-se no Anexo A - Stoplist) e remoção de pontuação (numéricos pontos e acentos). Também foram removidas palavras com menos de dois caracteres. Uma prática comum na mineração de texto é a remoção de palavras consideradas pequenas antes da indexação dos termos (Hill and Lewicki, 2011). Todo este tratamento resolveu problemas como a remoção de apóstrofes e termos antes identificados como “s” ou “’s”, comuns na língua inglesa. A técnica de stemming, remoção de sufixo, seção 2.2.2.3, foi escolhida pela facilidade de implementação em relação à lemmatisation, pois não foi encontrada uma biblioteca para processamento de linguagem natural na linguagem de programação desejada. 47 Após a aplicação das técnicas citadas acima, os termos estavam prontos para a etapa de seleção das características e geração dos dicionários. 4.3.3 Seleção das características realizada Após o pré-processamento, é realizada a etapa de seleção das características para a criação das categorias Nesta fase, através da aplicação do escore de relevância, são geradas as listas de termos significativos a partir dos abstracts. A seção 5.4.2 trata das dificuldades encontradas na definição prévia das categorias. Possíveis problemas nesta definição podem gerar listas de termos indesejáveis, afinal o domínio deve ser explicitado o mais corretamente possível, para que se determine que tipo de informação é relevante (Castro, P. F., 2000). Uma informação relevante para a definição de uma categoria é justamente a que a distingue de outra categoria. Ou seja, erros gerados ainda na fase extração de informações afetam negativamente a fase de seleção de termos e assim sucessivamente. 4.3.4 Método de categorização utilizado Após a formação da lista de termos de cada categoria, através da utilização da técnica de escore de relevância, seção 2.2.3.3.3, e da formação das listas de termos dos novos textos a serem classificados, através da técnica de frequência relativa do termo, seção 2.2.3.3.1, é aplicada a técnica de similaridade difusa apresentada na seção 2.2.4.1. Os resultados serão apresentados na seção abaixo. 48 5 Análise dos resultados Esta seção visa apresentar e discutir os resultados encontrados, tanto para a geração dos grafos, quanto para a classificação automática de artigos científicos. Os problemas encontrados, suas possíveis soluções e propostas de trabalhos futuros também se encontram nesta seção. 5.1 Resultado da geração de grafos Foram gerados dois tipos de grafos, grafos de colaboração entre os autores e grafos de colaboração entre as instituições. Foi necessário realizar um pequeno tratamento antes da geração dos arquivos em formato aceito pela ferramenta Pajek. Alguns nomes de autores não apresentavam a mesma grafia em diferentes artigos e o sistema não conseguia associá-los. Após o tratamento realizado, o sistema passou a associar os que puderam ser identificados manualmente como um único autor. O grafo apresentado na Figura 14 mostra a colaboração entre os autores do SBSI 2008, onde 21 artigos foram considerados. O peso da aresta representa o número de vezes em que os autores colaboraram entre si nestas edições do SBSI. 49 Figura 14 - Grafo de colaboração entre autores do SBSI 2008 O grafo apresentado na figura faz a separação dos componentes. Os nomes dos autores foram omitidos. Podemos perceber pela análise do grafo que, nos 21 artigos analisados, nenhum autor foi responsável por mais de um. Isso porque nenhuma das arestas assume o valor dois, ou seja, nenhum dos autores colaborou duas vezes com o mesmo autor. Além disso, os clusters apresentados são redes totalmente distribuídas (Franco, 2009), nenhum dos nós é descentralizador, separando outros clusters, ou seja, nenhum dos nós é ligado a outros dois nós que não se ligam entre si. Isso significa que nenhum dos nós, ou seja, nenhum dos autores tem uma posição centralizadora, de poder, sobre os outros. Em relação ao número de publicações, nenhum dos autores obteve destaque sobre os outros. A Figura 15 a seguir apresenta o grafo de colaboração de instituições para as edições 2008, 2009 e 2010 do SBSI. 50 Figura 15 - Grafo de colaboração de instituições SBSI O grafo de colaboração de instituições exigiu um tratamento muito maior se comparado ao grafo de autores. Isso porque os nomes das instituições costumam aparecer das mais variadas maneiras, muitas vezes contendo o departamento, por exemplo, enquanto os nomes dos autores costumam seguir o padrão escolhido por eles para publicação. Apesar da geração de um arquivo no formato aceito pelo Pajek, o tratamento foi realizado de forma manual, dada a dificuldade. Foram descartadas informações como: A empresa onde o autor trabalha, a não ser que esta seja a única referência; O artigo possui um único autor, mas são identificadas mais de uma instituição; O autor trabalhando sozinho não caracteriza uma colaboração; Duas pessoas da mesma instituição colaborando entre si não caracteriza uma colaboração entre instituições; UNIRIO não colabora com UNIRIO. Neste grafo, já podemos perceber a existência de clusters ligados entre si, com nós possuindo um papel de maior destaque, por exemplo, a UFMA colabora com a UFBA, 51 esta última por sua vez colabora com outras três instituições, sendo o elo entre estas e a UFMA. 5.2 Resultados da classificação automática A seguir é apresentada a Tabela 2, com o primeiro resultado gerado, mostrando uma análise macro do classificador. A segunda coluna mostra o total de artigos em que o classificar encontrou semelhança (ou seja, valor maior que 0 para o resultado do algoritmo de categorização mostrado na seção 2.2.4.1) entre o artigo e pelo menos um dos tópicos de interesses cadastrados pelo autor. Este resultado não significa que o algoritmo sugeriu como categoria mais semelhante uma das referentes ao tópico de interesse cadastrado pelo autor. Na verdade, este resultado aconteceu duas vezes, sendo que em outras três vezes a segunda ou terceira categoria mais semelhante segundo o classificador fazia referência a um dos tópicos de interesse. Ao todo, foram levadas em consideração 30 categorias, que são as categorias criadas a partir da análise da base formada pelos artigos de 2008, 2009 e 2010. Tabela 2 - Primeiro resultado gerado Total analisados de artigos Total de artigos em que Porcentagem o classificador sugeriu um dos temas do autor 27 22 81% A partir do resultado apresentado, foram analisados os tópicos de interesse que o classificador não conseguiu relacionar aos artigos, ou seja, os tópicos cadastrados pelos autores e que não apareceram como semelhante (valor maior que 0 para o 52 resultado do algoritmo de categorização) no resultado. Por exemplo, a categoria formada pelos tópicos “E-Business, E-Commerce e E-Government” e “Tecnologia da Informação no Governo Federal” foi citada quatro vezes pelos autores, porém somente em um dos casos o classificador citou o artigo como relevante à categoria. A mesma dificuldade ocorreu, por exemplo, com a categoria "Modelagem conceitual de Sistemas de Informação" (citada seis vezes pelos autores e em três destes casos pelo classificador), com a categoria "Gerência de dados e metadados / Representação e gerência informação, dados e metadados" (citada três vezes pelos autores e em nenhum destes casos pelo classificador), com a categoria "Sistemas de apoio à decisão" (citada sete vezes pelos autores e em somente um destes casos pelo classificador) e finalmente com a categoria "Planejamento estratégico de Sistemas e Tecnologia da Informação" (citada quatro vezes pelos autores e em nenhum destes casos pelo classificador). A explicação pode estar no tamanho reduzido da base de treinamento para formação da lista de termos de cada categoria. Por exemplo, a categoria formada pelos tópicos “E-Business, E-Commerce e E-Government” e “Tecnologia da Informação no Governo Federal” teve sua lista de termos formada apenas por três artigos (ou seja, apenas três dos artigos do SBSI (edições 2008, 2009 e 2010) foram cadastrados pelos autores como referentes a estes tópicos. A seção 5.5 trata de trabalhos relacionados, citando diferenças de abordagem deste trabalho a uma das abordagens mais comumente encontrada na literatura, tratando inclusive o tamanho indesejável da base de treinamento disponível. Das outras categorias citadas em que o classificador mostrou dificuldade para assinalar artigos como semelhantes, a que obteve o melhor desempenho foi 53 "Modelagem conceitual de Sistemas de Informação” (sendo citada pelo classificador 50% das vezes em que foi citada pelo autor). Esta categoria foi formada após a análise de sete artigos, sendo destas citadas a que possuiu o maior número de artigos para a formação de sua lista de termos relevantes. Relaciona-se o desempenho superior ao maior número de artigos de entrada, possibilitando a criação de um dicionário mais relevante para diferenciação da categoria em relação às demais. Já uma categoria que teve sua lista de termos formada por um grande número de artigos obteve um comportamento diferente do classificador. A categoria "Metodologias e abordagens para engenharia de Sistemas de Informação" foi formada pelos termos de 17 artigos, sendo a categoria mais relacionada pelos autores no período. Citada oito vezes pelos autores de 2011, em todas estas vezes o classificador citou a categoria como uma das mais semelhantes, sendo duas vezes como a mais semelhante. Outro comportamento notado foi que, mesmo quando o autor não classificava seu artigo como pertencente ao tópico "Metodologias e abordagens para engenharia de Sistemas de Informação", o classificador tendia a apresentá-lo como semelhante. Um número baixo de artigos para a formação de uma categoria se mostrou extremamente insatisfatório, enquanto o classificador mostrou tendência a encontrar semelhanças com as categorias que possuíram mais artigos para treinamento. 5.2.1.1 Outro experimento- Melhorando o resultado Para melhorar o resultado, houve uma mudança na abordagem. Isso ocorreu porque, como citado na seção 4.3.3, as categorias são formadas de acordo com os tópicos de interesses cadastrados pelos autores no momento da submissão, sendo que 54 cada artigo pode estar associado a mais de um tópico, portanto a mais de uma categoria. Como citado na seção 2.2.4.1, a técnica de similaridade difusa considera relevante para diferenciação da categoria um termo que seja, não só relevante para a categoria em si, mas não ocorra com frequência nas outras categorias. Esta sobreposição de termos comuns causa a diminuição da relevância ou até mesmo a exclusão da lista de termos importantes. Partindo do pressuposto que, ao marcar o tópico de interesse ao qual seu artigo é relevante, o autor sempre escolhe primeiro aquele com o qual o artigo possui mais semelhança, as categorias então passaram a ser formadas por artigos exclusivos. Isso quer dizer que cada artigo passa a ser relacionado a uma única categoria para formação da lista dos termos relevantes. Nesta situação, o número de categorias levadas em consideração (ou seja, o número de categorias utilizadas no treinamento, portanto o número de categorias às quais o classificador pode relacionar) diminuiu para 24, isso porque, se antes podiam ser consideradas quatro categorias por artigo e agora apenas uma, algumas foram descartadas. Tabela 3 - Resultado do classificador levando em consideração uma categoria por artigo para geração da lista de termos Total analisados de artigos Total de artigos em que Porcentagem o classificador sugeriu um dos temas do autor 27 24 89% O resultado apresentado na Tabela 3 não é necessariamente melhor. O que aconteceu é que, ao mudar a abordagem, considerando que cada artigo de 55 treinamento é único a uma categoria, o classificador teve maior facilidade para diferenciar uma categoria em relação à outra. Ao mesmo tempo, a dificuldade inicial citada na seção acima se acentuou, passando o classificador a ter mais dificuldade de identificar as categorias pouco citadas durante o treinamento. Ao conseguir diferenciar mais as categorias entre si, o total de artigos em que o classificador sugeriu um dos temas do autor aumentou, à medida que o classificador passou a conseguir relacionar mais facilmente o artigo a uma de suas categorias mais semelhantes. Porém, apresentou mais dificuldade em citar como mais semelhante um dos tópicos citados pelo autor. Na primeira abordagem foram duas vezes (sendo em outras três oportunidades a segunda ou terceira), nesta segunda abordagem, isso ocorreu apenas uma vez para a categoria mais semelhante (sendo cinco para a segunda ou terceira). Uma maior diferença entre as listas de termos tornou mais fácil a diferenciação das categorias para o classificador, em compensação o menor número de artigos para formação de cada categoria individualmente dificultou a identificação exata da categoria referente ao artigo. 5.3 Análise da classificação automática Os resultados mostrados na seção 5.2 mostram que o sistema classificador automático implementado poderia ser utilizado para sugestão de tópicos aos autores no momento da classificação, tendo a possibilidade de sugerir em quase 90% das vezes um tópico de interesse relevante ao autor, que muitas vezes em um primeiro momento poderia não associar aquele tópico ao artigo. Isso facilitaria a classificação do artigo pelo autor e poderia diminuir possíveis erros de classificação. Mesmo que um 56 tópico de interesse não possua grande similaridade com outro, a ocorrência de termos parecidos nos nomes dos tópicos pode confundir o autor, gerando um erro durante a classificação manual. Estes erros influenciariam negativamente no desempenho do classificador. O sistema, no entanto, se mostrou ineficiente para uma classificação definitiva do artigo, ou seja, ao analisar o artigo, conseguir retornar uma classificação relevante com alto índice de acerto. Neste último caso, acredita-se, no entanto, que a pequena base utilizada tenha sido a principal razão. Classificadores são implementados e testados geralmente utilizando como base o corpus de notícia Reuters, com mais de 20000 notícias disponíveis (Weiss apud Castro, P. F., 2000). Visando aumentar o número de artigos possivelmente considerados para a formação de uma categoria, poderia ser necessário exigir que o autor sempre classifique o artigo em mais de um tópico de interesse, afinal é normal imaginar que um artigo cubra mais de um tópico de interesse, por mais restrito que seja o assunto do tópico. Também é normal pensar que o artigo, apesar de fazer referência a mais de um tópico, faz mais referência a um específico, sendo assim o autor no momento da classificação indicaria um grau de relevância do artigo em relação ao tópico. Depois, seria necessário mudar a abordagem, utilizando esse grau de relevância como peso do artigo em relação à categoria. Ainda seguindo esta visão de sugestão do tópico de interesse pelo classificador automático, a partir de cada artigo submetido, as listas de termos das categorias seriam atualizadas automaticamente, aumentando a base e melhorando, portanto, a capacidade de categorização do classificador automático. 57 5.4 Dificuldades encontradas e limitações 5.4.1 Problemas na extração das informações A primeira grande dificuldade apresentada foi na etapa de extração das informações. Os artigos devem seguir o padrão SBC, mas pequenas variações no padrão, ou mesmo pequenos erros, relevados pelas comissões julgadoras, atrapalharam o processo. Como exemplo, um dos artigos vinha com o termo “abstract” escrito de maneira incorreta. O algoritmo, ao verificar caractere por caractere, não encontrava a palavra desejada, não conseguindo definir o momento de coletar a informação. Sendo assim, alguns dos artigos tiveram de ser descartados. Foram considerados então 57 artigos aceitos das edições 2008, 2009 e 2010, que formaram a base de treinamento, e 27 artigos aceitos da edição 2011, que formaram a base de testes. Considera-se utilizar os artigos descartados em uma futura versão do classificador. Outra possibilidade para atenuação e/ou resolução do problema, seria a informação por parte do sistema dos artigos com problemas na padronização. 5.4.2 Problemas na definição das categorias A definição das categorias nunca é uma tarefa trivial, ela demanda a análise manual e é essencial para um bom resultado. Como citado anteriormente, diferente dos estudos analisados como referência, neste trabalho os artigos são relacionados muitas vezes a mais de uma categoria, havendo uma sobreposição de idéias. Na definição das listas de termos relevantes das categorias, são levados em consideração os termos das outras categorias, sendo que muitas vezes estamos falando de artigos comuns a ambas as categorias. 58 Na classificação automática de texto, informações relevantes são justamente as que distinguem uma categoria de outra, mas, no caso de artigos comuns a diversas categorias, uma informação pode ser relevante a mais de uma categoria, dificultando o estabelecimento do domínio. Além disso, os artigos da base de treinamento tiveram suas categorias, definidas a partir dos tópicos de interesse, assinaladas pelos autores no momento da submissão. Um possível erro de classificação dos autores gera resultados indesejados. Esta foi uma das motivações para o desenvolvimento do classificador, identificar possíveis erros de classificação e sugerir automaticamente novas categorias. 5.5 Trabalhos Relacionados O fato de um artigo poder estar relacionado a mais de uma categoria, difere da maioria dos estudos utilizados como referência que utilizam o corpus Reuters Corpus (Weiss apud Castro, P. F., 2000) - coleção de notícias da agência Reuters lançada em 2000, onde cada notícia em questão é pertinente a apenas uma das categorias analisadas - ou outras coleções de notícias (Pazzim, 2007). A coleção Reuters Corpus se tornou padrão para este tipo de estudo, porque um classificador automático de texto só poderia ter seu resultado comparado a outro que utilizasse a mesma base. Outra questão a ser analisada é a quantidade de artigos formando cada categoria. Nos estudos com a Reuters Corpus, pode-se facilmente selecionar muitas notícias de treinamento para formação de cada categoria, enquanto neste trabalho um tópico pode ter vários artigos e outro um ou dois, ocasionando uma dimensionalidade insuficiente (indesejável) para o aprendizado da máquina. 59 5.6 Trabalhos Futuros Como trabalho futuro, considera-se a utilização de referências consolidadas da área ao invés dos tópicos de referência do SBSI. Ou seja, seriam analisadas as principais referências de cada área para definição das categorias e dos vocabulários. A motivação para esta mudança na abordagem é a dificuldade dos autores em classificar o próprio artigo. 60 6 Anexo A - Stoplist A stoplist contém as palavras de pouco valor preditivo, retiradas durante a fase de pré-processamento dos textos, as chamadas stopwords. A stoplist foi retirada da biblioteca de processamento de linguagem natural NLTK. 'all', 'just', 'being', 'over', 'both', 'through', 'yourselves', 'its', 'before', 'herself', 'had', 'should', 'to', 'only', 'under', 'ours', 'has', 'do', 'them', 'his', 'very', 'they', 'not', 'during', 'now', 'him', 'nor', 'did', 'this', 'she', 'each', 'further', 'where', 'few', 'because', 'doing', 'some', 'are', 'our', 'ourselves', 'out', 'what', 'for', 'while', 'does', 'above', 'between', 't', 'be', 'we', 'who', 'were', 'here', 'hers', 'by', 'on', 'about', 'of', 'against', 's', 'or', 'own', 'into', 'yourself', 'down', 'your', 'from', 'her', 'their', 'there', 'been', 'whom', 'too', 'themselves', 'was', 'until', 'more', 'himself', 'that', 'but', 'don', 'with', 'than', 'those', 'he', 'me', 'myself', 'these', 'up', 'will', 'below', 'can', 'theirs', 'my', 'and', 'then', 'is', 'am', 'it', 'an', 'as', 'itself', 'at', 'have', 'in', 'any', 'if', 'again', 'no', 'when', 'same', 'how', 'other', 'which', 'you', 'after', 'most', 'such', 'why', 'a', 'off', 'i', 'yours', 'so', 'the', 'having', 'once' 61 7 Referencias Bates, M. (1995). Models of natural language understanding. Proceedings of the National Academy of Sciences of the United States of America, Vol. 92, No. 22 (Oct. 24, 1995), pp. 9977–9982. Castro, P. F. (2000) Categorização Automática de Textos. Instituto Militar de Engenharia, IME, Brasil. Eugene Garfield, Morton V. Malin and Henry Small. A System for Automatic Classification of Scientific Literature. Institute for Scientific Information 325 Chestnut Street Philadelphia, Pa. 19106. Reprinted from Journal of the Indian Institute of Science 57(2):61-74, 1975 Fabrizio Sebastiani. Machine learning in automated text categorization. ACM Computing Surveys, 34(1):1–47, 2002. Franco, Augusto de. O poder nas redes sociais. Carta Rede Social 192 (18/06/09) Freeman, L. C.: Visualizing social networks. Journal of Social Structure, 1, 2000. G. Salton and C. Buckley. Term weighting approaches in automatic text retrieval. Information Processing and Management, 24(5):513-523, 1988. Galho, Thaís S.; MORAES, Sílvia M. W. (2003) Categorização Automática de Documentos de Texto Utilizando Lógica Difusa. Gravataí: ULBRA. Trabalho de Conclusão de Curso. 62 Harris, Zellig (1954). "Distributional Structure". Word 10 (2/3): 146–62. "And this stock of combinations of elements becomes a factor in the way later choices are made ... for language is not merely a bag of words but a tool with particular properties which have been fashioned in the course of its use". Hill, T.; Lewicki, P. Statistics: methods and applications. A comprehensive reference for science, industry and data mining. 1.ed. Tulsa: StaSoft, 2006. p485. Prévia disponível em: <http://books.google.com.br/books?id=TI2TGjeilMAC>. Acesso em: 27 jul. 2011. J. A. Barnes. Class and Committees in a Norwegian Island Parish. Human Relations February 1954 7: 39-58 J.A. Barnes and Frank Harary. 1983. "Graph theory in network analysis" Social Networks 5: 235-244. Julie Bichteler; Ronald G. Parsons. Document retrieval by means of an automatic classification algorithm for citations. Graduate School of Library Science, The University of Texas at Austin, USA. The Library, Computation Center, Department of Physics, The University of Texas at Austin, USA. Received 1 May 1974 Linton Freeman, Graphical Techniques for Exploring Social Network Data. University of California, Irvine, 2001. Linton Freeman, The Development of Social Network Analysis—with an Emphasis on Recent Events. University of California, Irvine, 2011. Loh, Stanley (2001) Abordagem Baseada em Conceitos para Descoberta de Conhecimento em Textos. Porto Alegre: UFRGS. Requisito Parcial ao Grau de Doutor em Ciência da Computação, Instituto de Informática, Universidade Federal do Rio Grande do Sul. 63 Luhn, H.P., 'The automatic creation of literature abstracts', IBM Journal of Research and Development, 2, 159-165 (1958). Pazzim, Débora. Machado Clusterização de Textos Utilizando o Algoritmo k-Means / Débora. Machado Pazzim [orientada por] Silvia Maria Wanderley Moraes –. Gravataí: 2007. 38 p.: il. S. Schiminovich. American Institute of Physics, 335 East 45 Street, New York, N.Y. 10017, USA. 1971 Solange O. Rezende, Ricardo M. Marcacini, Maria F. Moura , O uso da Mineração de Textos para Extração e Organização Não Supervisionada de Conhecimento, 2011 Sparck Jones, K. (1972), “A statistical interpretation of term specificity and its application in retrieval”, Journal of Documentation, Vol. 28, pp. 11–21. V. Batagelj, A. MRVAR: Pajek – Program for Large Network Analysis. Connections, 2011. Valerie Cross. Fuzzy Information Retrieval. Systems Analysis Department, Miami University, Oxford, OH 45056. Journal of Intelligent Information Systems, 3, 29-56 (1994). Wiener, Erick; Pedersen, Jan O.; Weigend, Andreas S. (1995) A Neural Network Approach to Topic Sppoting. Wives, Leandro Krug (1999) Um estudo sobre Agrupamento de Documentos Textuais em Processamento de Informações não Estruturadas Usando Técnicas de “Clustering”. Porto Alegre: UFRGS. Dissertação (Mestrado em Ciência da Computação), Instituto de Informática, Universidade Federal do Rio Grande do Sul. 64
Baixar