UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL
INSTITUTO DE INFORMÁTICA
BACHARELADO EM CIÊNCIA DA COMPUTAÇÃO
STÉFANO DRIMON KURZ MOR
Emprego da Técnica de Workstealing:
Estudo de Caso com o Problema da Mochila
e MPI
Projeto de Diplomação
Prof. Dr. Nicolas Maillard
Orientador
Porto Alegre, Junho de 2007
UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL
Reitor: Prof. José Carlos Ferraz Hennemann
Vice-reitor: Prof. Pedro Cezar Dutra Fonseca
Pró-Reitor de Graduação: Prof. Carlos Alexandre Netto
Diretor do Instituto de Informática: Prof. Flávio Rech Wagner
Coordenador do CIC: Prof. Raul Fernando Weber
Bibliotecária-Chefe do Instituto de Informática: Beatriz Regina Bastos Haro
“Ouve e esquecerás, vê e recordarás, faz e saberás.”
— C ONFÚCIO
AGRADECIMENTOS
• Agradeço a Deus, por tudo nessa vida.
• Agradeço aos meus pais e meu irmão, que me fizeram chegar até aqui.
• Agradeço ao meu orientador, Nicolas Maillard, por sempre estar disposto a me
atender e por sempre respeitar minha opinião, sendo impecável durante todo este
processo.
• Agradeço à minha "mentora” Márcia Cera, por tudo que me ensinou, pelo apoio e
pelas correções.
• Agradeço à Jamile Moroszczuk, pelas discussões tão produtivas e o suporte inabalável.
SUMÁRIO
LISTA DE ABREVIATURAS E SIGLAS . . . . . . . . . . . . . . . . . . . .
8
LISTA DE FIGURAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
9
LISTA DE TABELAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
11
LISTA DE ALGORITMOS . . . . . . . . . . . . . . . . . . . . . . . . . . . .
12
RESUMO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
13
ABSTRACT
14
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1 INTRODUÇÃO . . . . . . . . . . . . . .
1.1
Atualidades . . . . . . . . . . . . . . .
1.2
Descrição do Problema . . . . . . . . .
1.3
Motivação . . . . . . . . . . . . . . . .
1.4
Trabalhos Anteriores . . . . . . . . . .
1.5
Ferramentas Empregadas . . . . . . .
1.6
Metodologia e Abordagem de Estudo .
1.7
Áreas de Interesse . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
15
15
15
16
17
18
18
19
2 CONTEXTO CIENTíFICO . . . . . . . . . .
2.1
Programação Paralela . . . . . . . . . . .
2.1.1
Hardware . . . . . . . . . . . . . . . . .
2.1.2
Modelos Computacionais e Comunicação
2.1.3
Desempenho . . . . . . . . . . . . . . . .
2.2
Introdução ao MPI . . . . . . . . . . . . .
2.2.1
Motivação . . . . . . . . . . . . . . . . .
2.2.2
História . . . . . . . . . . . . . . . . . .
2.2.3
Definição e Características . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
20
20
20
24
27
28
29
29
30
3 MPI . . . . . . . . . . . . . . . . . . . . . . . . . .
3.1
As Seis Primitivas Básicas . . . . . . . . . . . . .
3.1.1
Inicialização e Finalização . . . . . . . . . . . .
3.1.2
Identificação de Processos e Comunicadores . . .
3.1.3
Primeiro Exemplo . . . . . . . . . . . . . . . . .
3.1.4
Troca de Mensagens . . . . . . . . . . . . . . . .
3.1.5
Segundo Exemplo . . . . . . . . . . . . . . . . .
3.1.6
Programação Distribuída × Programação Paralela
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
32
32
32
33
33
36
38
38
3.2
Funcionalidades Adicionais . . . . . .
3.2.1
Comunicação Coletiva . . . . . . . .
3.2.2
Terceiro Exemplo . . . . . . . . . . .
3.2.3
Temporização . . . . . . . . . . . . .
3.2.4
Envio e Recebimento Não-bloqueantes
3.2.5
Quarto Exemplo . . . . . . . . . . . .
3.3
Multiplicação Matriz × Vetor . . . . .
3.3.1
Multiplicação Matriz × Matriz . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
40
40
43
45
45
47
48
48
4 PROBLEMA DA MOCHILA . .
4.1
Definição Intuitiva . . . . . . .
4.2
Definição Formal . . . . . . . .
4.3
Outras Definições . . . . . . . .
4.3.1
Problema da Mochila Limitado
4.3.2
Problema da Mochila 0-1 . . .
4.4
Complexidade . . . . . . . . . .
4.5
Solução . . . . . . . . . . . . .
4.5.1
Algoritmo . . . . . . . . . . .
4.5.2
MPI . . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
56
56
56
57
57
57
58
58
58
63
5 WORKSTEALING . . . . . . .
5.1
Difusão de Máximo Local . .
5.1.1
Algoritmo . . . . . . . . . .
5.1.2
Implementação . . . . . . .
5.2
Workstealing . . . . . . . . . .
5.2.1
Algoritmo . . . . . . . . . .
5.2.2
Considerações . . . . . . . .
5.2.3
Implementação . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
69
69
69
70
74
74
76
77
6 AVALIAÇÃO DE DESEMPENHO . . .
6.1
Implementação . . . . . . . . . . . . .
6.2
Elaboração dos Casos de Teste . . . .
6.3
Velocidade de Execução . . . . . . . .
6.3.1
Análise do Tempo de Execução . . . .
6.3.2
Speedup . . . . . . . . . . . . . . . .
6.3.3
Eficiência . . . . . . . . . . . . . . .
6.4
Consumo de Memória . . . . . . . . .
6.5
Balanceamento de Carga . . . . . . .
6.6
Impacto de Utilização do Workstealing
6.7
Deadlock . . . . . . . . . . . . . . . . .
6.7.1
Difusão de Máximo Local . . . . . . .
6.7.2
Workstealing . . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
84
84
85
87
87
88
89
90
92
96
96
97
98
7 CONCLUSÕES . . . . . . . . . . . . .
7.1
Problema da Mochila × Paralelização
7.2
Implementação . . . . . . . . . . . . .
7.3
Desempenho . . . . . . . . . . . . . . .
7.4
WS Clássico × Implementação . . . .
7.5
Escalabilidade . . . . . . . . . . . . .
7.6
Trabalhos Futuros . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
100
100
100
101
102
102
102
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
APÊNDICE A ANÁLISE DOS CASOS DE TESTE
A.1 Tempo de Execução . . . . . . . . . . . . . . .
A.2 Consumo de Memória . . . . . . . . . . . . . .
A.3 Balanceamento de Carga . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
. . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
. . . . . . . . . . .
104
104
107
107
REFERÊNCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
LISTA DE ABREVIATURAS E SIGLAS
AMD
Advanced Micro Devices.
DML
Difusão de Máximo Local.
E/S
Entrada/Saída.
GiB
Gigabyte (binário).
GPPD
Grupo de Processamento Paralelo e Distribuído.
IP
Internet Protocol.
LAM
Local Area Multicomputer.
MIMD
Multiple-Instruction, Multiple-Data.
MISD
Multiple-Instruction, Single-Data.
MPI
Message-Passing Interface.
PVM
Parallel Virtual Machine
RAM
Random Access Memory.
SIMD
Single-Instruction, Multiple-Data.
SISD
Single-Instruction, Single-Data.
TCP
Transmission Control Protocol.
UCP
Unidade Central de Processamento.
UFRGS
Universidade Federal do Rio Grande do Sul.
WS
Workstealing.
LISTA DE FIGURAS
Figura 2.1:
Figura 2.2:
Modelo clássico de multiprocessadores. . . . . . . . . . . . . . . . .
Modelo clássico de multicomputadores. . . . . . . . . . . . . . . . .
23
23
Figura 3.1:
Figura 3.2:
Figura 3.3:
Figura 3.4:
Figura 3.5:
Figura 3.6:
Figura 3.7:
Figura 3.8:
Figura 3.9:
Figura 3.10:
Figura 3.11:
Figura 3.12:
Figura 3.13:
Figura 3.14:
Figura 3.15:
Figura 3.16:
Figura 3.17:
Figura 3.18:
Figura 3.19:
Figura 3.20:
Figura 3.21:
Figura 3.22:
Figura 3.23:
Figura 3.24:
Figura 3.25:
Figura 3.26:
Figura 3.27:
Figura 3.28:
Figura 3.29:
Figura 3.30:
Figura 3.31:
Protótipos de MPI_Init e MPI_Finalize. . . . . . . . . . . . .
Protótipos de MPI_Comm_size() e MPI_Comm_rank(). . . . . . . .
Arquivos de inclusão MPI. . . . . . . . . . . . . . . . . . . . . . . .
Variáveis do programa Hello World MPI. . . . . . . . . . . . . . . .
Programa “Hello World” sem troca de mensagens. . . . . . . . . . .
Possibilidade de saída - primeiro exemplo. . . . . . . . . . . . . . .
Outra possibilidade de saída - primeiro exemplo. . . . . . . . . . . .
Protótipos de MPI_Send() e MPI_Recv(). . . . . . . . . . . . . . . .
Programa “Hello World” com troca de mensagens. . . . . . . . . . .
Saída - segundo exemplo. . . . . . . . . . . . . . . . . . . . . . . .
Diagrama do algoritmo de passagem de token. . . . . . . . . . . . .
Impressão seqüencial de rank com algoritmo de token em anel. . . . .
Resultado para a impressão seqüencial de identificadores. . . . . . .
Implementação direta de broadcast. . . . . . . . . . . . . . . . . . .
Protótipo de MPI_Broadcast(). . . . . . . . . . . . . . . . . . . . . .
Protótipo de MPI_Reduce(). . . . . . . . . . . . . . . . . . . . . . .
Programa para calcular uma aproximação de π. . . . . . . . . . . . .
Protótipos de MPI_Wtime() e MPI_Wtick(). . . . . . . . . . . . . .
Programa para calcular uma aproximação de π, com medição de tempo.
Protótipos de MPI_Isend() e MPI_Irecv(). . . . . . . . . . . . . . . .
Protótipos de MPI_Wait() e MPI_Test(). . . . . . . . . . . . . . . . .
Portótipos de MPI_Testany() e MPI_Waitany(). . . . . . . . . . . . .
Protótipo de MPI_Cancel(). . . . . . . . . . . . . . . . . . . . . . .
Recebimento de mensagem que pode ter exatas 2 tags. . . . . . . . .
Código para o programa de multiplicação matriz × vetor (início). . .
Código para o programa de multiplicação matriz × vetor (mestre). . .
Código para o programa de multiplicação matriz × vetor (escravo). .
Desempenho: multiplicação matriz × vetor – MPI-1.2 . . . . . . . .
Código para o programa de multiplicação matriz × matriz (início). . .
Código para o programa de multiplicação matriz × matriz (mestre). .
Código para o programa de multiplicação matriz × matriz (escravo). .
32
33
34
34
35
36
36
37
39
39
40
41
41
42
42
43
44
45
46
47
47
47
48
48
49
50
51
51
53
54
55
Figura 4.1:
Figura 4.2:
Formato de instância do problema da mochila. . . . . . . . . . . . .
Algoritmo Branch & Bound para o Problema da Mochila, em Python.
58
64
Figura 4.3:
Figura 4.4:
Figura 4.5:
Figura 4.6:
Figura 4.7:
Variáveis da implementação seqüencial que resolve o Problema da
Mochila (em C). . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Algoritmo Branch & Bound para o Problema da Mochila, em C . . .
Algoritmo C com primitivas básicas para o Problema da Mochila . .
Função que realiza a distribuição cíclica da entrada. . . . . . . . . . .
Algoritmo C/MPI paralelizado. . . . . . . . . . . . . . . . . . . . .
64
65
66
67
68
Figura 5.1:
Figura 5.2:
Figura 5.3:
Figura 5.4:
Figura 5.5:
Figura 5.6:
Figura 5.7:
Figura 5.8:
Figura 5.9:
Figura 5.10:
Figura 5.11:
Figura 5.12:
Implementação de broadcast assíncrono. . . . . . . . . . . . .
Implementação do gerenciador de difusão. . . . . . . . . . . .
Implementação de mpi_process_nonblocking(). . . . . . . . . .
Implementação do mecanismo de barreira. . . . . . . . . . . .
Algoritmo C/MPI paralelizado e com Difusão de Máximo Local.
Esquema de funcionamento – Fila de Distribuição Dupla . . . .
Implementação da fila de distribuição dupla. . . . . . . . . . .
Algoritmo C/MPI, versão com fila de distribuição dupla . . . .
Implementação do gerenciador de Workstealing. . . . . . . . .
Implementação da tabela de processos. . . . . . . . . . . . . .
Solicitação de tarefas - Workstealing. . . . . . . . . . . . . . .
Implementação MPI com Workstealing. . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
70
71
72
74
75
77
78
79
80
81
82
83
Formato do arquivo de saída. . . . . . . . . . . . . . . . . . . . . . .
Interface da estrutura de Benchmark. . . . . . . . . . . . . . . . . . .
Gráfico tempo de execução (número de elementos vs. tempo em segundos). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Figura 6.4: Gráfico tempo de execução (número de processos vs. tempo em segundos). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Figura 6.5: Gráfico Speedup. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Figura 6.6: Gráfico Eficiência. . . . . . . . . . . . . . . . . . . . . . . . . . . .
Figura 6.7: Gráfico Consumo de Memória (número de elementos vs. memória
em bytes). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Figura 6.8: Gráfico Consumo de Memória (número de processos vs. memória
em bytes). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Figura 6.9: Gráfico mensagens enviadas/recebidas (num. de elementos vs. num.
de mensagens). . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Figura 6.10: Gráfico mensagens enviadas/recebidas (num. de processos vs. num.
de mensagens). . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Figura 6.11: Impacto do WS: tempo de execução. . . . . . . . . . . . . . . . . . .
Figura 6.12: Impacto do WS: consumo de memória . . . . . . . . . . . . . . . . .
84
85
Figura 6.1:
Figura 6.2:
Figura 6.3:
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
88
89
90
91
92
93
94
95
97
98
LISTA DE TABELAS
Tabela 2.1:
Notação do cálculo do Speedup. . . . . . . . . . . . . . . . . . . . .
27
Tabela 3.1:
Tabela 3.2:
As seis funções básicas do MPI. . . . . . . . . . . . . . . . . . . . .
Tempos da multiplicação matriz × matriz paralela. . . . . . . . . . .
32
52
Tabela 4.1:
Significado das variáveis na função de distribuição cíclica da entrada.
67
Tabela 6.1:
Significado dos arquivos de saída do programa. . . . . . . . . . . . .
85
LISTA DE ALGORITMOS
1
2
3
4
Branch (um galho) . . . . . . . . . . . . . . . . . . .
Branch (toda a árvore). . . . . . . . . . . . . . . . . .
Bound . . . . . . . . . . . . . . . . . . . . . . . . . .
Solução Branch & Bound para o Problema da Mochila
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
59
60
61
62
RESUMO
O cerne da discussão aqui introduzida é o estudo do emprego da técnica de roubo de
tarefas (Workstealing) em programas paralelos, tomando-se como base a paralelização de
um algoritmo do tipo Branch & Bound que resolve o Problema da Mochila. Como principal ferramenta, utiliza-se uma implementação da especificação MPI (Message-Passing
Interface).
A monografia apresenta uma descrição detalhada da especificação MPI, com ênfase
nos recursos empregados na confecção do algoritmo. São introduzidas definições de
Workstealing e do Problema da Mochila, sendo apresentadas e comentadas as principais
partes do código do programa MPI que combina ambas. Além disso, são apresentadas
medições de desempenho, cujo objetivo é avaliar o impacto da solução apresentada sobre
diferentes aspectos (e.g., tempo de execução, consumo de memória, balanceamento de
carga, complexidade algorítmica, etc.) da execução de programas.
Ao final, são apresentadas conclusões gerais sobre o assunto e indicados trabalhos
futuros a serem realizados.
Palavras-chave: MPI, Problema da Mochila, Workstealing.
Use of The Workstealing Technique in Knapasack Problem’s Paralelization Using
MPI
ABSTRACT
The introduced discussion’s kernel is the study of the use of the task stealing (Workstealing) technique on programs’ paralelization process, taking as base the paralelization
of a Branch & Bound algorithm that solves the Knapsack Problem. As main tool, it utilizes a implementation of the MPI (Message-Passing Interface) specification.
The monography presents a detailed description of the MPI specification, giving emphasis at the resources used on algorithm’s confection. Definitons of the Workstealing
concept and Knapsack Problem are introduced, being presented and commented the MPI
program’s main parts of code, that combines both. Moreover, performance measurements
are presented, whose objective is to evaluate the presented solution’s impact on different
programs’ execution aspects (e.g., execution time, memory consumption, load balancing,
algorithmic complexity, etc.).
Finnaly, general conclusions are presented and future to-be-done work is pointed.
Keywords: MPI, Knapasack Problem, Workstealing.
15
1
INTRODUÇÃO
Programação paralela e arquiteturas paralelas de computadores representam um passo
natural na próxima geração da escala evolutiva da Computação. De fato,
[...] computadores paralelos evoluíram de bugigangas experimentais em
laboratórios para tornarem-se as ferramentas cotidianas dos Cientistas
da Computação, que precisam do que há de melhor em recursos computacionais, no intuito de resolver seus problemas. (GROPP; LUSK;
SKJELLUM, 1999, p.1)
1.1
Atualidades
Mesmo os processadores destinados ao uso pessoal começam a ganhar feições multiprocessadas; num estágio de transição de dual-core (dois núcleos) para quad-core (quatro
núcleos), fabricantes como Intel e AMD trazem para o cotidiano conceitos que antes faziam parte de empresas e universidades, apenas (CREEGER, 2005).
Recentemente, a Intel fez demonstração de um chip com oitenta núcleos e memória
RAM embutida, o TeraFLOP, capaz de processar um teraflop1 por segundo. Embora
não seja retrocompatível com qualquer arquitetura de microprocessador da empresa, protótipos como esse evidenciam os rumos que o mercado de microprocessadores (tanto
empresarial quanto doméstico) tenderá a adotar (MATTSON; HENRY, 1998).
1.2
Descrição do Problema
MPI é, desde 1996, o padrão de fato para a implementação do modelo de comunicação
por troca de mensagens em Computação de Alto Desempenho. MPI oferece um modelo
de replicação de processos (execução do mesmo código) em todas as UCPs que participam da computação, bem como primitivas de troca de mensagens entre estes processos
(GROPP; LUSK; SKJELLUM, 1999).
Um problema recorrente em aplicações paralelas é o balanceamento de carga de trabalho entre os processadores; para um melhor aproveitamento do paralelismo, é conveniente
que todos os processos tenham aproximadamente a mesma quantidade de tarefas a realizar. Qualquer desbalanceamento implica aumento do tempo de ociosidade, o que acaba
por afetar o desempenho. (PACHECO, 1997).
Uma técnica que visa obter o balanceamento de carga é o Workstealing. Esta abordagem consiste em fazer com que um processo que tenha esgotado sua carga computacional
1 Um
trilhão de operações em ponto flutuante.
16
“roube” tarefas de outros processos que ainda têm trabalho pendente, equilibrando a distribuição de tarefas (BLUMOFE; LEISERSON, 1994).
A utilização do Workstealing, no entanto, introduz questões relevantes para a computação. e.g.,
Impacto no desempenho. WS tenta diminuir o tempo de execução ao trocar tarefas entre os processos. Mas esse ganho pode não compensar o tempo perdido ao fazer as
operações de sincronização (trocas de mensagens) e o tempo agregado ao gerenciamento destas operações.
Escalabilidade. Quanto mais escalável o problema, mais difícil a sua implementação
através de Workstealing, visto que existem questões clássicas como ocorrência de
deadlocks, gerenciamento eficiente de memória (o consumo tende a ser elevado) e
adequação ao hardware utilizado.
Implementação Certos aspectos do algoritmo podem ser implementados de várias maneiras. Tais maneiras implicam, muitas vezes, em custos e dependências de certas
estruturas pré-definidas, que tornam o processo menos transparente. Em especial,
há a questão da portabilidade da solução para aplicações genéricas, que necessita
ser investigada, em decorrência da forte dependência em relação ao problema resolvido com o qual se pode construir o algoritmo.
Algumas destas questões ainda tem caráter em aberto; é difícil mensurar um caso
médio e eficiente, sendo necessário um estudo mais aprofundado.
1.3
Motivação
Estimar os possíveis benefícios da do emprego de Workstealing tem impacto forte
sobre questões relevantes da área. Traçar e resolver questões inerentes a este problema
introduz melhoramentos em áreas como:
Escalonadores de Processos. Implementações de escalonadores de processos MPI (e.g.,
LAM) não possuem um sistema de balanceamento de cargas eficiente2 e que conte
com recursos de roubo de processos3 (CERA et al., 2006), o que poderia ofertar
benefícios à computação realizada.
Bibliotecas Paralelas. Uma biblioteca genérica, eficiente e transparente ao máximo, que
realize Workstealing sobre tipos genéricos de dados pode garantir um ganho de
desempenho em aplicações paralelas de uma maneira ampla.
Otimização de Recursos. O balanceamento de cargas diminui ociosidade, otimizando o
uso de recursos.
Conforme já mencionado, o algoritmo utilizado para a aplicação da técnica e realização das medições foi um algoritmo do tipo Branch & Bound que resolve o Problema da
Mochila. Tal problema foi escolhido por uma série de motivos, a citar:
2 Carga,
neste caso, é a alocação do número de processos por processador.
tópico fundamental neste processo é a migração de processos, uma maneira eficiente e efetiva
de transferir os processos, uma vez que um algoritmo de Workstealing determine que é vantajoso fazê-lo.
3 Outro
17
• popularidade;
• escalabilidade; e
• relevância.
Nem todos os problemas possuem uma estrutura adequada ao uso de Workstealing
(BLUMOFE; LEISERSON, 1994). O Problema da Mochila, por sua estrutura combinatorial (KELLER; PFERSCHY; PISINGER, 2005), parece, a priori, apto a se beneficiar
do uso da técnica. Parte do estudo, portanto, consiste em determinar o quão o Problema
da Mochila é adequado para a aplicação de WS. Além disso, o Problema da Mochila é
especialmente interessante quando escrito em formas de maximização de lucros, como:
• decidir onde perfurar poços de petróleo;
• problemas de otimização de transporte de cargas;
• problemas de otimização de rotas aéreas.
Vale ressaltar que estes problemas são inerentemente intratáveis do ponto de vista
computacional, visto que o Problema da Mochila pertence à classe dos problemas NPCompletos4 (TOSCANI; VELOSO, 2002).
Esta monografia, portanto, preocupa-se em
1. Analisar e apresentar os principais recursos para se construir um programa paralelo
usando a especificação MPI;
2. Propor uma estratégia de paralelização do Problema da Mochila e fazê-lo através
de programação MPI;
3. Introduzir e dissertar sobre a técnica de Workstealing, apresentado vantagens e desvantagens, integrando esta característica ao programa construído; e
4. Fazer medições de diversas características na execução desta solução (e.g., tempo
de execução, memória, número de trocas de mensagens, etc.).
1.4
Trabalhos Anteriores
Parte dos assuntos abordados dão continuidade aos trabalhos do GPPD que tratam
do escalonamento dinâmico de processos. Em especial, os trabalhos de Guilherme Pezzi
sobre a implementação de Workstealing em algoritmos de divisão e conquista usando
MPI-2 (PEZZI et al., 2006) e os trabalhos de Márcia Cera sobre melhoras no escalonador
MPI para criação dinâmica de processos (CERA et al., 2006) são tomadas como referência
básica. Estende-se o primeiro, tentando estabelecer uma especificação de algoritmo de
Workstealing genérico (em contraposição ao caráter específico do programa apresentado)
e se objetiva, com os dados medidos, fornecer resultados que ampliem o leque de opções
na melhora do escalonador MPI que é proposta pelo segundo.
Resultados parciais deste trabalho foram publicados na Escola Regional de Alto Desempenho 2007 (ESCOLA REGIONAL DE ALTO DESEMPENHO, 2007) (no Fórum
de Iniciação Científica), em conjunto com uma abordagem introdutória sobre impacto da
criação dinâmica de processos com MPI-2, ausente nesta monografia.
4 Indica que a melhor solução só pode ser encontrada por meio da análise de todo o espaço combinatorial,
ou seja, possui complexidade exponencial quando executado em máquinas determinísticas.
18
1.5
Ferramentas Empregadas
Os exemplos e demonstrações cujos códigos são apresentados foram executados no
cluster labtec do GPPD da UFRGS. Ele executa sobre a distribuição LAM MPI 7.25 , uma
implementação de ambos os padrões MPI-1.2 e MPI-2.
Os códigos de programas expostos estão, predominantemente, em linguagem C. Em
alguns casos, quando o algoritmo seqüencial ganha foco, opta-se por mostrar sua implementação na linguagem Python, que fornece uma maneira mais próxima da descrição
matemática do problema. Os scripts apresentados são escritos em Bash Script6 . Estes
programas, por sua natureza e pelas características dos clusters, são executados em ambiente Linux.
1.6
Metodologia e Abordagem de Estudo
A cada capítulo apresentado procurou-se evidenciar o máximo de informações possíveis. No entanto, dependendo do interesse do leitor, pode-se dar enfoque a algum aspecto
específico da monografia. Por exemplo, se houver maior interesse na parte de implementação, os códigos do programa implementado estão disponíveis e comentados ao longo da
monografia. Se por outro lado, o interesse for na abordagem formal do problema e nos
resultados alcançados, não há necessidade marcante de se observar todos os trechos de
programa apresentados.
Procura-se tornar os capítulos o mais independentes possível, para se ajustar aos conhecimentos prévios que o leitor possui. Se já houver conhecimento da especificação MPI
ou do Problema da Mochila, por exemplo, pode-se dar um maior foco aos outros capítulos. Não se aconselha, no entanto, a omissão da leitura de algum capítulo; considerações
importantes sobre a implementação da solução do problema são feitas ao longo de todos
eles.
Os capítulos abordados, e seus respectivos temas, são:
Contexto Científico. Agrupa conceitos básicos e considerações relevantes encontradas
ao longo de todo o processo de montagem e seleção da bibliografia. Divide-se em
dois grandes tópicos (seções): Programação Paralela e Introdução ao MPI.
MPI. Aborda os comandos e primitivas básicas de MPI. Demonstra, através de exemplos,
as funções básicas e a construção de programas paralelos elementares no modelo
de troca de mensagens.
Problema da Mochila. Descreve detalhadamente o problema da Mochila, enumerando
sua definição e características. Apresenta uma solução seqüencial para este e também uma solução paralela, empregando MPI.
Workstealing. Introduz o conceito de Workstealing e discute seu emprego. Aborda, também, as modificações necessárias à resolução paralela do Problema da Mochila para
que se obtenha um algoritmo que aplique Workstealing.
Avaliação de Desempenho. Expõe os principais resultados obtidos na confecção da solução do problema. Vários aspectos são mensurados e, ao final, apresenta conclusões sobre estes resultados e o emprego da técnica proposta.
5 Mais
sobre a distribuição pode ser encontrado em http://www.lam-mpi.org/.
de script para o bash (bourne-again shell).
6 Linguagem
19
Conclusões. Enumera as principais conclusões inferidas ao longo do processo de confecção do trabalho. Relaciona conceitos e estabelece hipóteses sobre os resultados
apresentados. Ao término, traça um perfil dos trabalhos futuros a serem realizados.
1.7
Áreas de Interesse
Ao longo do desenvolvimento da monografia, são permeadas várias áreas da Ciência
da Computação e Matemática em geral; em especial, cada capítulo tem um foco distinto,
sendo interessante enumerar os conceitos básicos abordados ao longo de cada um:
Contexto Científico: Arquiteturas Paralelas, Programação Paralela, Programação Distribuída, Análise de Desempenho.
MPI: Programação Concorrente, Algoritmos e Programação, Estruturas de Dados, Classificação e Pesquisa de Dados, Técnicas de Construção de Programas, Algoritmos
Paralelos, Redes de Computadores.
Problema da Mochila: Programação Paralela e Distribuída, Complexidade de Algoritmos, Teoria da Computação, Pesquisa Operacional.
Workstealing: Algoritmos Paralelos, Sistemas Operacionais, Arquiteturas Paralelas, Técnicas de Otimização.
Avaliação de Desempenho: Probabilidade e Estatística, Complexidade de Algoritmos
Paralelos, Análise de Desempenho.
Conclusões: Teoria da Computação, Complexidade de Algoritmos, Arquiteturas Paralelas, Sistemas Operacionais, Programação Distribuída.
20
2
CONTEXTO CIENTÍFICO
Este capítulo descreve o atual estado da arte de tópicos fundamentais no desenvolvimento da monografia, sobretudo no que tange Programação Paralela e MPI. Dessa
maneira, o que se apresenta é a síntese e apontamento das direções da área, verificados na
bibliografia consultada; serve, ao mesmo tempo, de referência e de base para o restante
do conteúdo desenvolvido ao longo do estudo.
A abordagem adotada é mais conceitual. O leitor que deseje uma abordagem mais prática (sobretudo a presença de códigos) e focada em aplicações deve consultar os capítulos
posteriores.
2.1
Programação Paralela
Embora o enfoque do estudo seja a programação e codificação de algoritmos paralelos,
existe uma plataforma de hardware que desempenha papel essencial para o processamento
em alto desempenho e, sob certa perspectiva, torna-se o foco da área; a programação em
si passa a ser um artifício para se valer dos recursos disponíveis no hardware (GROPP;
LUSK; SKJELLUM, 1999).
Considerando esta importância, torna-se conveniente apresentar alguns conceitos da
parte física, a fim de contextualizar o leitor sobre o modelo de programação paralela e o
porquê deste modelo depender fortemente do hardware sobre o qual opera.
2.1.1
Hardware
A classificação original de computadores paralelos é conhecida como Taxonomia de
Flynn. Michael Flynn classificou as arquiteturas paralelas quanto ao número de fluxos
de dados e número de fluxo de instruções. A máquina de Von Neumman, precursora das
arquiteturas modernas, por exemplo, possui um fluxo de instrução e um fluxo de dados.
Desta maneira, é classificada como “single-instruction, single-data” (SISD). No extremo
oposto, temos o modelo “multiple-instruction, multiple-data” (MIMD), máquinas de vários processadores, executando instruções em paralelo sobre diferentes dados (FLYNN,
1972).
2.1.1.1
SISD
Máquinas nesta classificação remetem ao modelo clássico da máquina de Von Neumman; não há paralelismo e tudo é seqüencial. Neste modelo, há uma memória, representada por um grande bloco, e um processador. Entre processador e memória são movimentados dados e instruções, através de um barramento.
O “gargalo de Von Neumman” é justamente o acesso à memória. Por mais rápidos que
21
sejam os processadores, a latência de acesso à memória não decresce na mesma medida
em que a velocidade dos primeiros aumenta. Há, portanto, um decréscimo de desempenho
considerável. Como conseqüência, poucas máquinas, atualmente, seguem estritamente o
modelo de Von Neumman. Utilizam-se, na maioria das vezes, memórias hierárquicas, com
modelos baseados em memória cache1 , que aproveitam-se do princípio da localidade2
para aumentar o desempenho (PATTERSON; HENNESSY, 2005).
É possível estender a arquitetura SISD através de pipelining e o processamento vetorial. Pipelining é uma técnica bastante conhecida e melhora o aspecto do desempenho
ao quebrar instruções de máquina em microinstruções; dessa maneira, é possível começar
o processamento de uma instrução posterior sem que o ciclo da instrução corrente esteja
finalizado. Ser vetorial significa, em última instância, adicionar novas instruções ao conjunto de instruções da máquina para que ela forneça o processamento do mesmo comando
para vários dados em paralelo.(NAVAUX; ROSE, 2003)
É importante salientar que há certa discordância sobre a natureza dos processadores
vetoriais. Existem classificações em que, por exemplo, estes processadores capazes de
operar sobre vetores são vistos como máquinas SIMD (TANENBAUM, 1995). Esta classificação acaba variando entre autores; alguns afirmam que máquinas vetoriais são MISD,
outros que máquinas MISD sequer existem (são, portanto, variações de SIMD) e, ainda,
há aqueles que nem classificam as máquinas vetoriais como paralelas. Esta falta de uniformidade é natural; fluxos de instruções são abstrações em nível de hardware e, portanto,
são relativos (PACHECO, 1997).
O principal ponto fraco destas técnicas é que processadores vetorias e processadores
pipeline, em geral, não “escalam” bem, isto é, não são facilmente modificáveis, do ponto
de vista do hardware, para processar desafios maiores (NAVAUX; ROSE, 2003).
2.1.1.2
SIMD
Há distinção entre um sistema SIMD puro e processadores vetorias. A definição canônica de um processador SIMD é ter uma UCP mestra e várias subordinadas; a cada ciclo,
a UCP mestra faz o broadcast de uma instrução para as UCPs subordinadas operarem
sobre sua pequena porção de memória. Assim, as UCPs subordinadas ou executam essa
instrução ou ficam ociosas. Diante deste enquadramento, máquinas vetoriais são vistas
como monoprocessadas e este processador é que tem extensões multiprocessadas. Conforme mencionado anteriormente, no entanto, essa definição é relativa (NAVAUX; ROSE,
2003).
A desvantagem de sistemas SIMD reside nos códigos com muitos branches condicionais ou que dependam muito de estruturas condicionais. É muito provável que vários
processos fiquem ociosos por vários períodos de tempo. Seu principal trunfo é a fácil
programação (se o problema abordado possui uma estrutura regular). O custo de comunicação é alto, mas igual ao de máquinas MIMD de memória distribuída (revisadas adiante).
Por fim, elas possuem excelente escalabilidade (TANENBAUM, 2003).
2.1.1.3
MISD
De acordo com a Taxonomia de Flynn, não existem máquinas que satisfaçam esta
classificação (PATTERSON; HENNESSY, 2003). Alguns autores (ROOSTA, 1999) clas1 Memórias
de tamanho e velocidade de acesso intermediário entre memória principal e os registradores
(PATTERSON; HENNESSY, 2005).
2 Tal princípio enumera que dados utilizados em lugares próximos na execução do programa tendem a
estar dispostos assim também na memória (PATTERSON; HENNESSY, 2005).
22
sificam máquinas vetoriais como máquinas MISD, mas a bibliografia não é uniforme
sobre o assunto.
2.1.1.4
MIMD
A diferença fundamental entre máquinas MIMD e SIMD é que os processadores
MIMD são autônomos, não precisam todos executar o mesmo código (todos os processadores são UCPs individuais, com seus respectivos componentes). Ao contrário de máquinas SIMD, modelos MIMD são assíncronos (sem relógio global) e devem ser programados para se sincronizarem, se esta for a intenção. O mundo MIMD é dividido em dois
blocos: os de memória compartilhada (multiprocessadores) e os de memória distribuída
(multicomputadores) (TANENBAUM, 1995).
Multiprocessadores são um conjunto de processadores e módulos de memória ligados
por uma rede. Desta maneira, podem se classificar como (NAVAUX; ROSE, 2003):
Arquitetura baseada em barramento. É a mais simples forma de conexão. Acesso à
memória através de barramento. Não se comporta bem para um grande número de
processadores, visto que o barramento fica sobrecarregado. Justamente por isso,
não é uma solução escalável em grande porte. Para contornar este problema, usualmente os processadores têm grande quantidade de memória cache.
Arquitetura baseada em switches. Usa switches para gerenciar o acesso aos módulos
da memória. Um exemplo disso é uma arquitetura do tipo “cross-bar switch”. Esta
arquitetura se caracteriza por um engranzamento (mesh) retangular, com switches
nas intersecções e terminais nas bordas esquerda e superior. Processadores e módulos de memória podem ser conectados aos terminais. Os switches podem permitir
que um sinal se propague na vertical e horizontal simultaneamente ou redirecionar
o sinal de um eixo para o outro. Então, por exemplo, se tivermos processadores
à esquerda e memória acima, qualquer processador pode acessar qualquer módulo
de memória ao mesmo tempo que algum outro processador acessa algum outro
módulo. Assim, não se sofre com o problema de saturação encontrado em barramentos. Infelizmente, este tipo de arquitetura tende a ser muito caro. Uma matriz
m × n requereria m × n switches. Logo, a maioria destes sistema são pequenos.
Multiprocessadores, independentemente da disposição física dos módulos de memória, possuem um sistema de memória compartilhada, ou seja, todos os processadores têm
uma visão lógica de um único espaço de endereçamento pertencente a uma memória global (PATTERSON; HENNESSY, 2003). Um esquema de um multiprocessador clássico é
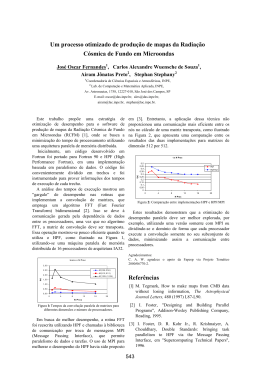
apresentado na Figura 2.1.
No sistema de Multicomputadores, cada processador tem sua memória privativa, ou
seja, é um sistema de memória distribuída. Isto significa, basicamente, que cada processador tem um espaço de endereçamento próprio e diferente dos demais (TANENBAUM,
1995). Se observarmos tais sistemas como grafos, veremos dois tipos de grafos: aqueles
cujos vértices correspondem ao par processador/memória (nodos) e aqueles em que alguns vértices são nodos e outros switches. Redes do primeiro tipo são “redes estáticas” e
do segundo tipo, “redes dinâmicas” (PATTERSON; HENNESSY, 2005). Uma ilustração
de um sistema multicomputador pode ser visto na Figura 2.2
Dos quatro modelos propostos pela Taxonomia de Flynn, o que se torna relevante
para o estudo são as máquinas MIMD; clusters e grids são exemplos clássicos de máquinas MIMD e, atualmente, são as estruturas funcionais que oferecem um maior poder de
processamento em razão de sua escalabilidade (DONGARRA et al., 2003).
23
Figura 2.1: Modelo clássico de multiprocessadores.
Figura 2.2: Modelo clássico de multicomputadores.
24
Um cluster é um computador paralelo, com um ponto de acesso centralizado. A visão
que o usuário tem ao programar é de um grande computador com vários processadores
paralelos. Grids, por outro lado, são computadores naturalmente heterogêneos, com pontos de acesso distribuídos. Além disso, a disposição e tipo dos nodos, dependendo da
arquitetura da máquina, pode sofrer alterações a qualquer momento. O usuário enxerga
o grid como um agregado de computadores que aproveitam os tempos ociosos uns dos
outros para melhorar o desempenho. (NAVAUX; ROSE, 2003).
2.1.2
Modelos Computacionais e Comunicação
Além de ter definido um hardware (máquinas MIMD, no caso), é necessário definir
um modelo de computação paralela que rode sobre este hardware. Modelos computacionais
[...] são uma visão conceitual dos tipos de operações disponíveis ao
programa. Estes não incluem sintaxe especifica de uma linguagem de
programação ou biblioteca em particular, e são (quase) independentes
do nível de hardware que os suporta (GROPP; LUSK; THAKUR, 1999,
p. 3).
Alguns exemplos de tópicos que influem sobre a classificação são o compartilhamento
(ou não) de memória, a quantidade de comunicação que está no hardware ou software, a
unidade de execução básica e etc.
Alguns modelos-exemplo são (GROPP; LUSK; THAKUR, 1999):
Paralelismo de Dados. Introduzido com os processadores vetoriais que, à época, ofereciam paralelismo apenas a nível de dados; o programa era, sob todos os outros
aspectos, seqüencial, com instruções que operassem em paralelo. Com o passar do
tempo, o paralelismo de dados passou a ser enquadrado mais como uma técnica
de programação do que uma arquitetura propriamente dita. O modelo, no entanto,
continua o mesmo: todo o paralelismo continua advindo dos dados. Muito desse
trabalho, hoje em dia, é feito pelo compilador.
Exemplo de implementação: HPF (High Performance FORTRAN) (KOELBEL;
LOVEMAN; SCHREIBER, 1993).
Memória Compartilhada. No modelo oposto ao Paralelismo de Dados, o paralelismo
não é extraído da independência implícita de certa parte do código seqüencial. Ao
invés disso, o paralelismo é explicitado diretamente pelo programador, sendo chamado de Paralelismo de Controle3 .
Memória compartilhada é uma técnica de comunicação no Paralelismo de Controle.
Através dela todos os processadores acessam todo o espaço de endereçamento da
memória e, portanto, compartilham variáveis. É um modelo extremamente eficiente, pois não envolve custos de comunicação, já que ela é toda feita através da
memória principal. Este modelo, no entanto, traz dois inconvenientes:
1. Repassa as questões de sincronização para o programador; a consistência das
variáveis deve ser garantida no nível de programação.
3 Muito
embora (GROPP; LUSK; THAKUR, 1999) omita qualquer referência, um modelo misto é perfeitamente factível; nada impede a existência de um modelo que possui, simultaneamente, paralelismo
implícito e explícito.
25
2. Para mais do que algumas dezenas de processadores o acesso à memória fica
comprometido, pois existe disputa pelo barramento e por células de armazenamento. Logo, o desempenho também acaba sofrendo um compromentimento.
Exemplo de implementação: OpenMP (Open Multi-Processing) (OPENMP C AND
C++ APPLICATION PROGRAM INTERFACE, 2002)
Troca de Mensagens. É um modelo conceitualmente oposto ao modelo de Memória
Compartilhada. Ao invés de uma memória global, acessada e compartilhada por
todos, existe apenas uma memória local para cada processador, cujo único postulante a acessar é o próprio. Qualquer troca de informações é feita pelo envio
e recebimento de mensagens, através de primitivas especiais. É um modelo mais
seguro em termos de sincronização, mas também é mais caro, pois trocas de mensagens são típicas operações de E/S. Baseia-se no uso de primitivas do tipo send()
e receive() sincronizadas entre processos. É, portanto, um modelo mais complexo do ponto de vista do programador.
Exemplo de implementação: PVM (Parallel Virtual Machine) (GEIST et al., 1994)
e MPI (GROPP; LUSK; SKJELLUM, 1999).
Operações em Memória Remota. É um misto dos modelos de Memória Compartilhada
e Troca de Mensagens. Existe uma única memória, acessada por todos (mas não diretamente), e cada processador também tem uma memória local disponível. A memória global é acessada via primitivas (tipicamente put() e get()) para escrita
e leitura. Esta medida implica, diretamente, que os processos não precisam mais
sincronizar-se para trocar informações; uma primitiva send() não mais necessita
de um correspondente receive(). Esta estrutura remete ao modelo clássico de
Distributed Shared Memory (NAVAUX; ROSE, 2003).
Este modelo consegue simplificar a complexidade da programação com troca de
mensagens e soma algum desempenho de um modelo com memória compartilhada,
uma vez que o acesso à memória passa a ser mais eficiente sem a sincronização
de primitivas de E/S. Além disso, tal modelo inclui um novo recurso chamado de
“Mensagem Ativa”, que consiste na execução de subrotinas de um processo no espaço de endereçamento de outro. Tal operação geralmente é usada para fins de cópia
de memória remota, emulando send() e receive() de maneira unilateral.
Exemplo de implementação: a especificação MPI-2 (GROPP; LUSK; THAKUR,
1999) fornece recursos para programação com operações em memória remota.
Threads. Os primeiros modelos de Memória Compartilhada usavam acessos a espaços
de endereçamento locais. A obtenção de memória compartilhada era feita através
de uma primitiva especial (parecido com malloc() da linguagem C). Hoje em
dia, no entanto, se assume um modelo onde toda a memória é distribuída. Isto dá
espaço para a aplicação do modelo em sistemas multithread.
Tendo-se um processo como a definição intuitiva de um programa em execução
(TOSCANI; OLIVEIRA; SILVA CARíSSIMI, 2002), uma thread é um fluxo de
execução de processo4 (TOSCANI; OLIVEIRA; SILVA CARíSSIMI, 2003). Qualquer comunicação entre threads é feita através da memória principal, compartilhada. Variáveis locais, no entanto, ainda permanecem privativas para cada thread.
4 Na
verdade, pode-se, ainda, definir um fluxo de execução como registradores, Program Counter, Stack
Pointer e alguns outros dados de contexto fortemente dependentes da arquitetura.
26
Como o chaveamento de uma thread para outra não requer ação explícita de programador, tal modelo aproxima-se de um modelo de Programação Paralela mesmo
que, muitas vezes, seja executado em máquinas monoprocessadas.
Exemplo de implementação: Pthreads (Posix Threads) (BUTENHOF, 1997).
Dentre os modelos de programação paralela, atualmente, o modelo mais utilizado na
programação de clusters é o de comunicação por troca de mensagens. Tal modelo também
é implementado pela MPI, como será visto adiante. Alguns fatores que contribuem para
esta estatística são (GROPP; LUSK; THAKUR, 1999):
Universalidade. A maioria das máquinas paralelas atuais são agregados de processadores conectados por uma rede de interconexão. Troca de mensagens ajusta-se bem
a este tipo lógica computacional; adapta-se, por tanto, com facilidade ao hardware
atual.
Expressividade. Algoritmos paralelos tendem a ser melhor expressos em termos de troca
de mensagens do que leituras/escritas em memória global, por permitirem certo
controle sobre a sincronização dos eventos.
Facilidade de depuração. Depurar programas paralelos permanece sendo um desafio
considerável na área. Embora depuradores sejam mais facilmente construídos no
modelo de memória distribuída, o processo de depuração, em si, é melhor realizado no modelo de troca de mensagens, visto que a maioria dos erros ocorre por
sobrescrita inesperada na memória.
Performance. No sistema de memória compartilhada existe apenas uma memória global, com uma hierarquia de cache e memória para todos os processos. Embora o
acesso a esta memória seja mais rápido que a sincronização por send()/
receive(), não é possível aproveitar todo o potencial do sistema de hierarquias,
causando sério prejuízo ao desempenho. O modelo de comunicação por troca de
mensagens associa trocas de dados e consultas à memória a cada processo; é uma
abordagem mais eficiente para o aproveitamento de princípio da localidade5 , fundamental para o melhor desempenho da cache do sistema.
2.1.2.1
Arquiteturas Multicore
Processadores da vários núcleos encontram-se numa fase de transição entre arquiteturas de 2 e arquiteturas de 4 núcleos. Atualmente a comunicação entre os núcleos é feita
via modelo de Memória Compartilhada (memória principal), variando o comportamento
da memória cache (compartilhada ou privativa) de acordo com o modelo de processador
(CREEGER, 2005).
No entanto, com o aumento considerável do número de núcleos, tal modelo se torna
problemático, visto que há disputa intensa por barramentos. O modelo de comunicação
que será adotado no futuro ainda é uma questão em aberto, mas há certas tendências de
que se adote um modelo próximo à troca de mensagens; o Intel TeraFLOP, máquina com
80 núcleos da Intel, adota uma abordagem NOC (Network on Chip) para fazer comunicação entre os seus processadores, com emprego de roteadores e switches, onde dados são
5 Baseia-se
no fato de que dados próximos tendem a ser usados em trechos próximos do código. Trata-se
de uma das bases da utilização de uma hierarquia de memória.
27
transferidos como numa rede de computadores clássica (TCP/IP) (MATTSON; HENRY,
1998).
Arquiteturas Multicore proporcionam abordagens mistas de alguns modelos. O uso
destes chips em clusters tende a seguir um destes modelos mistos. Internamente, em cada
chip multicore, usa-se o modelo de threads entre os processos do Sistema Operacional (e
um modelo de memória compartilhada entre os núcleos), o que garante uma comunicação
extremamente rápida. Cada nó, entretanto, comunica-se por um modelo de Troca de
Mensagens, através de uma rede específica.
2.1.3
Desempenho
Até agora todo embasamento apresentado para o uso de programação paralela foi
conceitual; organização do hardware e comunicação de processos foram o tema com
maior ênfase. Existe, no entanto, um embasamento teórico importante para o emprego de
Programação Paralela. É essencial que exista um modelo de referência para a medição e
formalização dos conceitos de desempenho e eficiência.
Um conceito fundamental na área de programação paralela é o conceito de speedup.
Speedup é o ganho de desempenho proporcionado pela adoção de um algoritmo paralelo
(DONGARRA et al., 2003); Uma abordagem para avaliação do speedup é a razão entre
o número de operações realizadas por uma execução seqüencial e o número de operações realizada por uma UCP na execução em paralelo (JAJA, 1992). Define-se a notação
utilizada na Tabela 2.1
Notação
P
A
n
p
T ∗ (n)
Tp (n)
S p (n)
Significado
Problema computacional.
Algoritmo paralelo utilizado.
Tamanho da entrada.
Número de processadores (UCPs)
Número de operações do melhor algoritmo
seqüencial para uma entrada de tamanho n.
Número de operações para cada UCP do algoritmo A para p processadores e uma entrada de
tamanho n.
Speedup obtido com p processadores e uma entrada de tamanho n.
Tabela 2.1: Notação do cálculo do Speedup.
A partir da notação empregada, define-se speedup como:
S p (n) =
T ∗ (n)
Tp (n)
(2.1)
É importante ressaltar que a base da fórmula é o melhor algoritmo seqüencial para o
problema (T ∗ (n)) e não o algoritmo paralelo executado com 1 processador (T1 (n)); embora seus tempos de execução sejam bem próximos, existem alguns testes feitos pelo algoritmo paralelo que independem do número de processadores que participarão da execução
(e.g., teste que determina o número de processadores ativos) e que adicionam elementos
ao cálculo da complexidade sem relação com o problema em si (JAJA, 1992). Outro
ponto que se faz destacar é que deve ser utilizado o melhor algoritmo seqüencial para este
28
mesmo cálculo. Dessa maneira, tal algoritmo não necessita seguir o modus-operandi do
algoritmo paralelo; ambos podem resolver o problema de maneira distinta.
Embora adequada, tal abordagem (número de operações executadas) é complexa de
ser precisada e medida, visto que é difícil definir precisamente o conceito de operação.
Logo, adota-se uma abordagem mais simples para o speedup, onde este é definido como
a razão entre tempo de processamento em um processador e o tempo de processamento
em uma configuração paralela (DONGARRA et al., 2003). Tem-se, então, a equação:
Speedup(n) =
T (1)
T (n)
(2.2)
A medida que n (número de processadores) cresce, T (n) (tempo de execução para n
processadores) decresce e o speedup aumenta.
É interessante, também, apresentar o conceito de eficiência. A eficiência é a medida
de utilização efetiva de todos os p processadores em uma execução paralela; representa,
conceitualmente, o quanto o desempenho se beneficia do aumento do número de processadores. Um índice de eficiência máximo (E p (n) = 1) é obtido quando a execução de A
com p processadores é p vezes mais rápida do que a execução de A com 1 processador
(JAJA, 1992).
Pode-se expressar eficiência pela fórmula
E(p) =
T (1)
p × T (p)
(2.3)
O ideal seria que o tempo de A se dividisse com o número de processadores; a execução com quatro 4 processadores, por exemplo, seria 4 vezes mais rápida que a execução
com 1 processador. Sob esta óptica, torna-se óbvio que, ao se multiplicar o tempo de
execução de A com 4 processadores pelo número total de processadores obtém-se, novamente, o tempo de execução com 1 processador.
Isto, no entanto, se configura somente numa situação ideal. Na maior parte dos casos,
0 < E p (n) < 1. Ocorre que existem custos de comunicação e sincronização que consomem tempo significativo durante a execução do algoritmo.
Por fim, é importante ressaltar que a eficiência é calculada com a base do algoritmo
paralelo com 1 processador e não com o algoritmo seqüencial; conforme explicitado na
parte sobre speedup, o algoritmo paralelo não necessita ser uma mera versão portada do
seqüencial e, dessa maneira, não discorre sobre a escalabilidade do algoritmo ao variarse o número de processadores. Esta abordagem está mais de acordo com o cálculo do
speedup simplificado apresentado anteriormente.
Com a base teórica sobre arquiteturas de computadores e análise de desempenho já
estabelecida, falta, ainda, apresentar o ferramental empregado em nível de software para
a programação paralela, o MPI. A próxima seção trata disso.
2.2
Introdução ao MPI
MPI não é uma biblioteca, uma linguagem ou um jeito novo de programar. MPI é, na
verdade, a especificação de uma interface para a implementação do modelo de comunicação por troca de mensagens (PACHECO, 1997). Esta seção foca a história, a filosofia
de implementação e as motivações que levaram à especificação. Um aprofundamento
técnico, com detalhes de implementação e primitivas básicas, pode ser visto no Capítulo
3.
29
2.2.1
Motivação
O padrão de comunicação por troca de mensagens demorou a se consolidar. A principal razão para essa situação ter ocorrido foi a falta de um padrão de fato a ser adotado
pelos usuários de máquinas paralelas. Desta maneira, cada vendedor implementava bibliotecas para troca de mensagens funcionais no seu sistema; emergia, assim, a falta de
portabilidade de tais sistemas, ao mesmo tempo em que, por se tratar de uma área nova, a
Computação Paralela não havia sido suficientemente experimentada para que se abstraíssem os conceitos mais úteis na implementação de algoritmos (GROPP; LUSK; THAKUR,
1999).
Surgiram muitas tentativas dentro da comunidade científica para a implementação de
um padrão (e.g., PVM). Tal diversidade foi proveitosa para o desenvolvimento do estado
da arte do tópico, mas acabou por gerar acirrado conflito e concorrência; cada novo padrão
vinha a fragmentar uma parcela dos usuários o que resultava em pessoas especialistas
em um ou outro destes padrões. Um grande entrave na utilização generalizada destas
bibliotecas é que elas não se comunicavam, ou seja, não havia portabilidade de um sistema
para o outro (DONGARRA et al., 2003).
Havia, então, uma dualidade na área, consistindo de adotar um sistema extremamente
portável (em geral, “meta-bibliotecas” sobre as bibliotecas existentes), mas escasso em
funcionalidades, ou um sistema robusto, com muitas funções, mas de uso muito específico. Sockets, por exemplo, consistem no uso mais generalizado que se poderia implementar troca de mensagens em Programação Paralela. No entanto, as mais diversas
implementações de sockets não oferecem qualquer facilidade em termos de algoritmos
paralelos. (GROPP; LUSK; THAKUR, 1999).
2.2.2
História
A diversidade de soluções para a implementação de um modelo de comunicação por
troca de mensagens, que introduziu as questões acima, atingiu um ponto largo de saturação; um padrão que aliasse portabilidade, performance e recursos passou ser um requisito
demandado pela comunidade de usuários e fornecedores.
Na conferência Supercomputing ’92 (em Novembro), formou-se um comitê para a
criação de um padrão a ser adotado na implementação do supracitado modelo. Uma enumeração dos principais objetivos deste comitê seria (GROPP; LUSK; THAKUR, 1999):
• definir um padrão portável para a troca de mensagens, que não seria uma padrão
oficial, mas que potencialmente atrairia implementadores e usuários;
• operar de uma maneira completamente aberta, permitindo a todos juntarem-se às
discussões; e
• ser terminado em um ano.
Dos contrastes entre os três objetivos, foi completado, em Maio de 1994, a referência
para o padrão MPI. O esforço para a criação do padrão foi vívido e ativo, fruto da participação ampla de uma comunidade focada. Adicionalmente, cumpriu sua meta ao atrair
tanto implementadores quanto usuários, em grande parte por ser aberto a qualquer opinião; ambos os pontos de vista puderam ser discutidos. Assim, após sucessivas reuniões
do fórum no período entre 1993 e 1995, surgia o MPI (GROPP; LUSK; THAKUR, 1999).
30
Em 1995-1997 o fórum tornou a deliberar sobre extensões à norma MPI original;
foram incluídos adventos para E/S paralela, gerenciamento dinâmico de processos, operações em memória remota e vários outros recursos. Como resultado deste esforço, o MPI
foi estendido para sua segunda versão, o MPI - 2.
2.2.3
Definição e Características
MPI é uma especificação de uma biblioteca para a troca de mensagens em C, C++
e FORTRAN, que especifica como devem ser (sintática e semanticamente) as estruturas
para estes fins nestas três linguagens (e.g., Funções, Classes, Subrotinas, etc.). MPI não
é uma implementação específica; qualquer interessado pode implementar o padrão da
maneira que preferir. Um programa MPI corretamente escrito deve rodar em todas as
implementações MPI (GROPP; LUSK; THAKUR, 1999).
Além das estruturas de send() e receive() básicos, MPI provê, também, estruturas para a comunicação coletiva, ou seja, computações que envolvem todos ou um grande
número de processos. Tal comunicação pode envolver o transporte de dados (e.g., primitivas do tipo send_broadcast()) ou computações coletivas (e.g., mínimos, máximos,
soma, etc.) (PACHECO, 1997).
MPI oferece suporte para vários tipos de primitivas send() e receive(). Pode-se
usá-las em modo bloqueante, esperando que a operação de comunicação se realize para o
prosseguimento da computação, ou não-bloqueante, caso contrário. Além disso, existem
outros modos, frutos da combinação dos anteriores, como (GROPP; LUSK; THAKUR,
1999)
Modo Síncrono. Primitivas do tipo send() só desbloqueiam quando o respectivo receive() houver ocorrido;
Modo de Prontidão (Ready). Para send(), provê ao programador maneiras de avisar
o sistema do uso de uma primitiva receive() já postada no processo destino,
para que a camada de baixo use um protocolo mais rápido, se disponível;
Modo Buffered. Operações de send() têm o controle de buffer feito pelo usuário; e
Modo Padrão. É a configuração normal das primitivas send() e receive() do MPI.
O receive() é bloqueante e o send() é bloqueante apenas enquanto o buffer
não for liberado.
Outra característica interessante do MPI são as topologias virtuais, ou seja, modelos
de disposição da comunicação entre processos (e.g., árvore, grafo, plano cartesiano, etc.)
independentes da real implementação (física) dos processadores sobre os quais estes rodam. Com elas, provém-se um método em alto-nível de manipular-se grupos de processos
e, ao mesmo tempo, abstrair sua localização real (DONGARRA et al., 2003).
Uma característica marcante, insistentemente trabalhada no desenvolvimento da especificação MPI, é o fato de que o suporte à múltiplos recursos é intrínseco à norma. Destes,
se destacam (GROPP; LUSK; SKJELLUM, 1999):
• O suporte à depuração nativo, através de ferramentas que permitem colocar “ganchos” ao longo do código e, posteriormente, interceptar chamadas MPI através desses mecanismos;
31
• O suporte à implementação de bibliotecas paralelas personalizadas, que usam o
MPI como base. Devido à noção de comunicadores, é possível construir bibliotecas independentes de código de usuário, com atributos e controladores de erros
personalizados.
Uma das capacidades-chave especificadas no MPI é sua característica de executar em
redes heterogêneas, pois tem uma definição de tipos portável e compatível com diferentes
arquiteturas. Desta maneira, diferentes tipos e estruturas de dados são convertidos de
acordo com a implementação do MPI; os implementadores têm total liberdade em decidir
como as conversões são realizadas, de acordo com a especificação.
Outra característica (que dá suporte a redes heterogêneas) é a abstração entre processadores e processos no sistema. A especificação MPI fala de processos e não de processadores; vai depender da implementação o número máximo de processos que podem
executar sobre um único processador. Além disso, também fica a cargo dos implementadores definir as fronteiras, para a respectiva biblioteca, entre nós (no caso clusters) e
processadores, pois um nó pode conter n processadores e é necessário estabelecer esta
relação com os processos MPI. Normalmente, um processo MPI corresponde a um processo de Sistema Operacional. No entanto, isto não é necessariamente verdade; existem
implementações sobre o UNIX em que vários processos MPI são mapeados sobre um
processo UNIX (GROPP; LUSK; THAKUR, 1999).
Unindo uma definição de tipos suficientemente portável e uma política flexível de
mapeamento processador-processo, MPI consegue dar uma visão de máquina virtual ao
usuário; pode-se enxergar apenas processos e mensagens, de acordo com a topologia
desejada (por meio das topologias virtuais) sem a preocupação do hardware sobre o qual
este sistema opera. Tal flexibilidade fornece ao MPI uma grande robustez no quesito
portabilidade, conforme almejado na sua feitura (PACHECO, 1997).
32
3
MPI
Este capítulo versa sobre aspectos mais técnicos e aplicados da especificação MPI
(versão 1.2). Serão apresentadas e descritas as primitivas básicas e exemplos de código
(comentados) serão utilizados para exemplificar seu uso.
3.1
As Seis Primitivas Básicas
MPI é uma especificação abrangente, com muitos recursos. No entanto, para qualquer
algoritmo paralelo que se queira utilizar, MPI pode ser tão simples quanto o uso de 6
funções básicas. Com estas funções, é possível implementar quase qualquer programa
MPI; a maioria das outras subrotinas são simplificações e combinações destas primitivas
de acordo com estruturas comuns em Programação Paralela.
A Tabela 3.1 mostra as seis primitivas principais usadas no MPI.
Primitiva
Função
MPI_Init
Inicializa o MPI
MPI_Finalize
Encerra o MPI.
MPI_Comm_size Retorna o número de processos rodando.
MPI_Comm_rank Retorna que processo eu sou.
MPI_Send
Manda uma mensagem.
MPI_Recv
Recebe uma mensagem.
Tabela 3.1: As seis funções básicas do MPI.
3.1.1
Inicialização e Finalização
MPI possui duas primitivas destinada a isso, cujo protótipo é apresentado na Figura
3.1.
int MPI_Init(int* argc char** argv[])
int MPI_Finalize()
Figura 3.1: Protótipos de MPI_Init e MPI_Finalize.
Todo o código MPI (ou seja, que se utilize de funções da biblioteca de implementação do MPI) utilizado deve estar contido entre estas duas primitivas; elas se encarregam
de inicializar e instanciar estruturas de dados em um nível de abstração transparente ao
usuário e também desalocam estas estruturas ao sair da área delimitada. Uma exceção a
33
esta regra é a função MPI_Wtime, utilizada para medição de tempos, que será visitada
mais adiante.
3.1.2
Identificação de Processos e Comunicadores
É muito útil agrupar-se os processos de um modo conveniente para a resolução do
problema (e.g., processos produtores e consumidores de recursos). MPI oferece duas
estruturas para esta manipulação: grupos e comunicadores.
Um grupo é simplesmente um conjunto de processos, sem qualquer propriedade sobre
sua disposição. Pode ser usado como referência para a inclusão ou exclusão de processos
em um canal e enxerga somente os processos de seu escopo. Grupos possuem um tipo
específico em MPI, o MPI_Group.
A peça fundamental para a execução de um programa MPI, no entanto, são os comunicadores. Pode-se entender um comunicador como um agregado que guarda informações
de um grupo de processos e da disposição (e.g., grafo, árvore, plano cartesiano) pela qual
estes processos relacionam-se. Desta maneira, esta estrutura permite referenciar um dado
processo através de um identificador de processo, que, a priori, deixa transparecer sua
topologia. Este é o mecanismo básico para se referenciar um processo; a fonte e o destino
de qualquer mensagem é identificado univocamente por um identificador e o comunicador
que fornece aquela referência.
A princípio, durante a execução de um programa MPI, todos os processos pertencem
ao comunicador MPI_COMM_WORLD, uma constante da especificação que fornece um
identificador de processo único e seqüencial (um inteiro) para todos os processos que
foram disparados na inicialização do programa. O usuário pode, quando desejar, criar
novos comunicadores, com todos ou com somente alguns processos, na topologia em
que preferir. Também é possível extrair o grupo de processos de qualquer comunicador,
inclusive o MPI_COMM_WORLD.
Existem duas funções de suma importância para o MPI que fazem uso de comunicadores. Elas são apresentadas na Figura 3.2
int MPI_Comm_size(MPI_Comm comm, int* size)
int MPI_Comm_rank(MPI_Comm comm, int* rank)
Figura 3.2: Protótipos de MPI_Comm_size() e MPI_Comm_rank().
A função MPI_Comm_size retorna o tamanho do comunicador (número de processos contidos) comm na variável size. Ao ser usado em conjunto com MPI_COMM_WORLD
como argumento, retorna o número total de processos participantes da execução.
MPI_Comm_rank retorna o identificador do processo dentro do comunicador passado como parâmetro. Se utilizado com MPI_COMM_WORLD, retorna o identificador do
processo dentre todos os processos que estão sendo executados. Neste caso, seu rank é
um número que varia, para p processos, de 0 até p − 1.
3.1.3
Primeiro Exemplo
A seguir é apresentado o código de um programa simples, que exibe uma mensagem
na tela no clássico estilo “Hello World”. O código não inclui troca de mensagens, a fim
de refletir o que foi apresentado até aqui e apresentar o uso das primitivas MPI_Init,
MPI_Finalize, MPI_Comm_size e MPI_Comm_rank.
34
Para executar o programa é necessário utilizar os arquivos de inclusão vistos na Figura
3.3.
#include <mpi.h>
#include <stdio.h>
Figura 3.3: Arquivos de inclusão MPI.
O arquivo mpi.h contém toda a especificação e os protótipos para a utilização das
bibliotecas MPI. O arquivo stdio.h, conforme conhecido, inclui funções para a manipulação de E/S num terminal de execução.
As variáveis utilizadas no código são vistas na Figura 3.4
int rank;
int p;
/* Rank of process. */
/* Number of processes. */
Figura 3.4: Variáveis do programa Hello World MPI.
A variável rank armazenará o identificador do processo. A variável p, por sua vez,
armazena o número de processos. O que o programa faz é, para cada processo, imprimir
seu identificador. Adicionalmente, faz distinção entre dois processos: o processo raiz e
o processo de maior rank. Esta divisão não é necessária no momento; mais adiante, nos
exemplos posteriores, ela revelará utilidade fundamental. O código do programa pode ser
visto na Figura 3.5.
Para compilar o programa, é necessário fazer a ligação com a biblioteca MPI, nomeada de maneira específica em cada distribuição. Para facilitar o trabalho de pesquisa,
existe um script, incluído na maioria das distribuições MPI, que faz essas ligações de
maneira transparente ao usuário, chamado mpicc. Para compilar o código apresentado, assumindo que o nome do arquivo seja hello_world.c e querendo um nome
de HelloWorld para o executável, basta invocar
mpicc -o HelloWorld hello_world.c
e, se nenhum erro ocorrer, o executável HelloWorld será criado.
No entanto, não basta apenas compilar o programa de maneira acertada; é preciso
executá-lo apropriadamente. Os processadores e arquiteturas atuais não “entendem” a
alocação de processos MPI; não há qualquer suporte no nível de hardware que distribua
os processos MPI e os mapeie sobre processos do Sistema Operacional. Logo, é necessário uma camada de software (em geral, um processo de Sistema Operacional no modo
daemon1 ) a qual se encarregará de realizar este mapeamento (e.g., o processo lamd na
distribuição LAM-MPI) e, também, de se comunicar com outras máquinas, com o mesmo
serviço, especificadas para participarem da computação.
Após o processo daemon ser executado e estiver rodando (tal processo e a maneira de
fazê-lo é específico de cada distribuição) é necessário utilizar um comando que diga a este
processo qual executável será disparado para a criação dos processos MPI. Para facilidade
1 Para
todos os efeitos, dizer que um processo está em modo daemon é o mesmo que dizer que sua
execução é feita em segundo plano pelo Sistema Operacional
35
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#include <mpi.h>
#include <stdio.h>
int
main(int argc, char *argv[])
{
int process_rank;
/* Rank of the process.
int p;
/* Number of processes.
*/
*/
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &process_rank);
MPI_Comm_size(MPI_COMM_WORLD, &p);
if ( process_rank == 0 ) {
printf("Greetings from process %d, the root!\n",
process_rank);
}
else if ( process_rank == p-1 ) {
printf("Greetings from process %d, the greatest rank!\n",
process_rank);
}
else {
printf("Greetings from process %d!\n", process_rank);
}
MPI_Finalize();
return 0;
}
Figura 3.5: Programa “Hello World” sem troca de mensagens.
36
do usuário, as distribuições conhecidas também utilizam-se de um script padrão para fazêlo, o mpiexec2 . A utilização do mpiexec, com o exemplo mostrado, é
mpiexec -n 4 HelloWorld
através do parâmetro -n, informa-se a quantidade de processos MPI que serão disparados.
Neste caso, são 4 processos.
MPI implementa um padrão de réplicas; todos os processos MPI rodam sobre exatamente o mesmo código e, por conseqüência, todos os processadores também. Se é necessário que algum processo específico tome ações diferentes dos demais, pode-se testar o
rank do processo, conforme demonstrado no exemplo. Em geral, a diferenciação mais recorrente é o processo zero ser o processo mestre em um algoritmo do tipo mestre-escravo
(DONGARRA et al., 2003).
A execução desse programa deve transcorrer sem complicações, produzindo o resultado esperado. Um exemplo de resultado de uma execução é visto na Figura 3.6. Outro
resultado de execução possível é mostrado na Figura 3.7.
Greetings
Greetings
Greetings
Greetings
from
from
from
from
process
process
process
process
0, the root!
1!
2!
3, the greatest rank!
Figura 3.6: Possibilidade de saída - primeiro exemplo.
Greetings
Greetings
Greetings
Greetings
from
from
from
from
process
process
process
process
1!
2!
3, the greatest rank!
0, the root!
Figura 3.7: Outra possibilidade de saída - primeiro exemplo.
A impressão da mensagem em console possui 1 ponteiro para a saída padrão, fornecido pela linguagem C e o Sistema Operacional. Logo, ocorre uma condição de corrida
(TOSCANI; OLIVEIRA; SILVA CARíSSIMI, 2002) entre os processos MPI, e a ordem
de impressão da mensagem pode variar entre uma execução e outra. Na verdade, o risco
da condição de corrida que se criou é ainda maior; devido à característica não-atômica
das primitivas de E/S em C é possível que as mensagens fossem escritas de forma embaralhada. Isto, no entanto, não acontece, pois estas mensagens são curtas e em pequena
quantidade, tendo uma execução rápida. MPI oferece mecanismos para o controle de condições de corridas, como barreiras (TOSCANI; OLIVEIRA; SILVA CARíSSIMI, 2002).
3.1.4
Troca de Mensagens
Para a troca de mensagens MPI se usa MPI_Send e MPI_Recv. Seus protótipos são
apresentados na Figura 3.8.
A literatura propõe uma discussão sobre a necessidade específica de cada parâmetro
(GROPP; LUSK; SKJELLUM, 1999), que foge deste escopo. Seu significado é
2 Em
referências mais antigas é utilizado o script mpirun (PACHECO, 1997). Embora a maioria das
distribuições ainda suportem esta sintaxe, ela está, agora, obsoleta (GROPP; LUSK; SKJELLUM, 1999).
37
int MPI_Send(void* buf, int count, MPI_Datatype dt, int dest,
int tag, MPI_Comm comm )
int MPI_Recv(void* buf, int count, MPI_Datatype dt, int source,
int tag, MPI_Comm comm, MPI_Status* status )
Figura 3.8: Protótipos de MPI_Send() e MPI_Recv().
void* buf : é o buffer de recepção/envio. É o endereço de memória que aponta para o
início da área de dados que será enviada (MPI_Send) ou recebida (MPI_Recv).
int count : é o número de variáveis de um certo tipo que será enviada/recebida. Pode
ser usada para indicar que se deseja receber, por exemplo, dois inteiros, ou enviar
três números em ponto flutuante, com a condição de que estes estejam contíguos na
memória (e.g., um vetor).
MPI_Datatype dt : é o que define o tipo das variáveis enviadas (e.g., MPI_INT para
inteiros). Presente por razões de portabilidade; nas arquiteturas de processadores,
o número de bytes (ou sua ordem de leitura) que representa uma variável de um
determinado tipo pode diferir. Desta maneira, o mapeamento é feito através de uma
camada inferior, pertencente ao MPI, e é transparente ao usuário, que o enxerga
por meio dos tipos da biblioteca. Por essa mesma razão não é recomendado enviar
fluxos de bytes baseado nos tamanhos-padrão de cada tipo; para isso, MPI oferece
o tipo MPI_BYTE.
int dest : é o identificador de processo, referente ao comunicador também passado por
parâmetro, que aponta a qual processo a mensagem será enviada no MPI_Send.
int source : é o identificador de processo, referente ao comunicador, também passado por
parâmetro, que aponta de qual processo a mensagem será recebida no MPI_Recv.
Para se receber uma mensagem de qualquer processo, usa-se a constante MPI_ANY
_SOURCE.
int tag : é uma marca identificadora para uma mensagem; serve para facilitar o controle do fluxo de mensagens entre dois ou mais processos. Pode, por exemplo, ser
usada para indicar a seqüência das mensagens a serem recebidas, se esta for importante; por mais que a rede, eventualmente, entregue as mensagens fora de ordem, se
houver uma seqüência de MPI_Recv que receba mensagens com tags seqüenciais
(mandas do mesmo modo pelo MPI_Send), então a entrega respeitará essa seqüência. A constante MPI_ANY_TAG pode ser usada para se receber uma mensagem
independentemente do valor da sua tag.
MPI_Comm comm : é o comunicador que dá semântica aos campos dest e source;
guarda a informação do grupo de processos e da topologia a qual se está fazendo
referência.
MPI_Status* status : é a variável que receberá uma estrutura de dados que contém informações diversas sobre a recepção da mensagem, incluindo quem a enviou e qual sua
tag. É especialmente útil quando é necessário usar as constantes MPI_ANY_SOURCE
ou MPI_ANY_TAG; embora possa-se receber a mensagem de qualquer fonte, com
38
qualquer marcação, é possível identificar quem enviou a mensagem (e em que contexto) para, por exemplo, enviar uma resposta. Abordagem muito usada em algoritmos do tipo mestre-escravo (DONGARRA et al., 2003).
A primitiva MPI_Recv é bloqueante e MPI_Send é bloqueante até que o buffer de
envio possa ser reaproveitado. Existem outros modos de envio/recepção, mencionados
anteriormente (e.g, send() bloqueante), que possuem uma correspondente primitiva em
MPI.
Existe um detalhe importante para a recepção e envio corretos de mensagem, que é a
questão do batimento dos parâmetros. Entre um MPI_Send e um MPI_Recv existem
certos argumentos que devem estar em concordância e outros que são completamente
independentes:
count, datatype : não necessariamente devem ser o mesmo; pode-se reinterpretar os
dados recebidos através das mudanças destes parâmetros.
tag, comm : devem ser o mesmo em ambos ou, no MPI_Recv, pode ser MPI_ANY_TAG.
dest, source : devem concordar (dest de um como o source do outro e vice-versa)
ou, no MPI_Recv, pode ser MPI_ANY_SOURCE.
buf : é completamente independente em ambas as primitivas.
3.1.5
Segundo Exemplo
Considerando o código de exemplo apresentado anteriormente, pode-se, agora, introduzir a troca de mensagens no corpo do algoritmo. O princípio, desta vez, é fazer com
que todos os processos enviem uma mensagem ao processo raiz e este as imprima na
tela, à medida que as for recebendo. O código resultante de aplicação de MPI_Send e
MPI_Recv pode ser visto na Figura 3.9 (PACHECO, 1998). A execução deste programa
deve ser semelhante à execução do programa anterior, conforme a Figura 3.10, com a diferença do processo de maior rank não estar identificado e o processo raiz (0) não imprimir
nada, pois sua única função é receber mensagens dos outros processos e imprimi-las.
Ainda existe uma condição de corrida, presente no recebimento das mensagens. No
entanto, não há mais o risco da impressão embaralhada: o processo raiz (0) imprimi as
mensagens seqüencialmente, na ordem em que forem chegando.
3.1.6
Programação Distribuída × Programação Paralela
A esta altura já existe ferramental suficiente para a apresentação de um exemplo importante para ilustrar as diferenças entre programação paralela e programação distribuída.
A programação distribuída ocorre quando o processamento não é realizado em apenas
uma unidade fundamental (UCP); a execução ocorre em vários processadores. Já a programação paralela, pressupõe que, além de existir uma distribuição da computação, estas
partes são executados ao mesmo tempo.
É difícil encontrar um exemplo de computação paralela pura. De fato, a maioria dos
programas ditos paralelos apresentam trechos que, embora distribuídos, são seqüenciais.
O exemplo a seguir mostra um programa MPI que ilustra a abordagem inversa, onde não
há processamento paralelo.
39
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include <stdio.h>
#include <mpi.h>
#include <string.h>
int
main(int argc, char *argv[])
{
int process_rank;
/*
int p;
/*
int source;
/*
int dest;
/*
int tag = 50;
/*
char message[100];
/*
MPI_Status status;
/*
*/
*/
*/
*/
*/
*/
*/
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &process_rank);
MPI_Comm_size(MPI_COMM_WORLD, &p);
if ( process_rank != 0 ) {
sprintf(message, "Greetings from process %d!", process_rank);
dest = 0;
MPI_Send(message, strlen(message) + 1, MPI_CHAR, dest, tag,
MPI_COMM_WORLD );
} else {
for (source = 1; source < p; source ++) {
MPI_Recv(message, 100, MPI_CHAR, source, tag,
MPI_COMM_WORLD, &status );
printf("%s\n", message);
}
}
MPI_Finalize();
return 0;
24
25
26
27
28
29
30
31
32
Rank of process.
Number of processes.
Rank of sender.
Rank of receiver.
Tag for messages.
Storage for the message.
Return status from receive.
}
Figura 3.9: Programa “Hello World” com troca de mensagens.
Greetings from process 1!
Greetings from process 2!
Greetings from process 3!
Figura 3.10: Saída - segundo exemplo.
40
3.1.6.1
Impressão Seqüencial
O exemplo apresentado aqui faz com que processos imprimam seu rank de maneira
garantidamente seqüencial, em ordem crescente. Para tanto, utiliza-se um algoritmo do
tipo passagem de token, onde um processo só imprime seu rank ao receber uma mensagem
do processo de identificador imediatamente anterior. A Figura 3.11 contém um diagrama
do algoritmo, enquanto a Figura 3.12 contém o código C.
Figura 3.11: Diagrama do algoritmo de passagem de token.
Neste caso, não há programação paralela; toda a computação é distribuída, porém
seqüencial. O resultado obtido, para 10 processos, é visto na Figura 3.13.
3.2
Funcionalidades Adicionais
Esta seção enumera algumas funcionalidades adicionais que o MPI oferece como ferramental ao programador paralelo. O objetivo não é exaurir a lista destas utilidades; são
apresentados os principais recursos que contribuirão, nos capítulos posteriores, para a
implementação do algoritmo que resolve o Problema da Mochila em paralelo.
3.2.1
Comunicação Coletiva
Além de operações MPI_Send e MPI_Recv, a especificação MPI oferece, também,
funções utilitárias, que implementam estruturas de comunicação para modos recorrentes
de transmitir mensagens entre processos.
Uma das principais comunicações coletivas é o broadcast, ou seja, mandar uma mensagem para todos os outros processos; de fato, tal tipo de envio é quase tão freqüentemente
usado quanto MPI_Send (GROPP; LUSK; SKJELLUM, 1999).
A primeira solução que ocorre para fazer comunicação broadcast entre os processos
seria a utilização de múltiplas chamadas MPI_Send, uma para cada processo, como na
estrutura vista na Figura 3.14, onde todos os processos, menos o que enviou a mensagem,
recebem os dados..
Existem, no entanto, dois motivos principais pelos quais esta abordagem não é a melhor:
Ineficiência. A rede de comunicação fica sobrecarregada de mensagens com o aumento
do número de processos participantes. Além disso, não há uma lógica para distribuir
as mensagens em uma hierarquia que aproveite topologias mais eficientes para a
41
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#include <mpi.h>
#include <stdio.h>
#define TOKEN 0
int
main(int argc, char *argv[])
{
int my_rank;
int num_procs;
int sender = -1;
MPI_Status status;
int first_proc;
int last_proc;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
first_proc = 0;
last_proc = num_procs - 1;
if ( my_rank != first_proc )
MPI_Recv(&sender, 1, MPI_INT, MPI_ANY_SOURCE, TOKEN,
MPI_COMM_WORLD, &status );
24
25
26
27
28
29
30
31
32
33
34
35
printf("Rank %d", my_rank);
if ( sender >= 0 )
printf(" sended by %d\n", sender);
else
printf("\n");
fflush(stdout);
if (my_rank != last_proc)
MPI_Send(&my_rank, 1, MPI_INT, my_rank + 1, TOKEN,
MPI_COMM_WORLD);
MPI_Finalize();
}
Figura 3.12: Impressão seqüencial de rank com algoritmo de token em anel.
Rank
Rank
Rank
Rank
Rank
Rank
Rank
Rank
Rank
Rank
0
1
2
3
4
5
6
7
8
9
sended
sended
sended
sended
sended
sended
sended
sended
sended
by
by
by
by
by
by
by
by
by
0
1
2
3
4
5
6
7
8
Figura 3.13: Resultado para a impressão seqüencial de identificadores.
42
for ( i = 0; i < num_procs; ++ i ) {
if ( i != my_rank )
MPI_Send(message,
size_message,
MPI_INT,
i,
tag,
MPI_COMM_WORLD);
}
Figura 3.14: Implementação direta de broadcast.
distribuição de mensagens (e.g., distribuir as mensagens numa topologia de árvore,
onde cada processo é um nó da árvore, faz com que o tempo de distribuição seja
logarítmico3 , enquanto o tempo seqüencial é linear4 ) (PACHECO, 1998).
Encapsulamento. Fazer uma distribuição mais eficiente promove muito trabalho ao programador (que não faz parte do algoritmo). Um detalhe importante a ser salientado
é o controle feito para que o processo que enviou não receba a própria mensagem,
fato que poderia causar deadlocks (TOSCANI; OLIVEIRA; SILVA CARíSSIMI,
2002) inesperados.
Em MPI, há uma primitiva específica para se implementar broadcast, a MPI_Bcast,
cujo protótipo é apresentado na Figura 3.15.
int MPI_Bcast(void* buf, int count, MPI_Datatype datatype, int root,
MPI_Comm comm )
Figura 3.15: Protótipo de MPI_Broadcast().
O significado dos parâmetros é o mesmo que em MPI_Send, com a diferença de que
não há um destino, mas sim a identificação do processo emissor das mensagens (root).
Existem dois motivos para a presença de tal informação:
• Conforme mencionado anteriormente, é necessário que o processo que emite as
mensagens não as envie para si mesmo; e
• Ao contrário do que se pensa inicialmente, não se recebe uma mensagem em broacast através de um MPI_Recv, mas sim através de outro MPI_Bcast. Logo, é
importante para o processo saber se é ele mesmo quem está mandando a mensagem
ou a recebendo.
O último item citado acima causa estranheza, a princípio, mas justifica-se pelo uso
eficiente da topologia; devido às otimizações topológicas que a primitiva pode fazer para
o envio eficiente das mensagens, a recepção lógica das mesmas difere da recepção física.
Em outras palavras, um processo pode estar recebendo a mensagem de um retransmissor,
precisamente, tenha uma complexidade média de, aproximadamente, log2 ( 2p ) ciclos, onde p é o
número de processos e 2p é o número de processos que apenas recebem mensagens, sem enviá-las (nodosfolha da árvore).
4 Complexidade de p − 1 envio de mensagens (ciclos), onde p é o número de processos.
3 Mais
43
ao invés da fonte. É importante, portanto, deixar a resolução física para um nível mais
baixo e transparente, ao invés de se adotar a abordagem padrão do MPI_Recv.
Um programa, ao utilizar um algoritmo do tipo mestre-escravo, elege um processo
como mestre. Este processo tem como função reunir as computações realizadas pelos
outros processos, efetuar uma operação sobre elas e devolvê-la ao usuário. Esta também
é uma operação muito freqüente em Programação Paralela.
Para simplificar este processo, MPI oferece maneiras de se unificar parcialmente o
trabalho do processo raiz. É possível, através de uma primitiva, unificar o processo de
receber uma mensagem de todos os processos, agrupá-las e realizar uma operação. Tal
primitiva é o MPI_Reduce, cujo protótipo é visto na Figura 3.16.
int MPI_Reduce(void* sendbuf, void* recvbuf, int count, MPI_Datatype
datatype, MPI_Op op, int root, MPI_Comm comm )
Figura 3.16: Protótipo de MPI_Reduce().
Da mesma maneira que MPI_Bcast, MPI_Reduce também deve ser invocada pelos processos que fizeram as computações parciais (onde terá um papel semelhante à
MPI_Send) e pelo processo raiz (como um MPI_Recv). Os parâmetros da função (inéditos) são
void* sendbuf, void* recvbuf : para o processo raiz, recvbuf será o buffer de recepção da mensagem. Para os outros processos, sendbuf será o buffer de envio. Isto
sugere que apenas uma variável do tipo buffer seria necessária, mas isso é incorreto;
é possível que o próprio processo raiz calcule alguma coisa e tenha que fundir seus
dados ao de todo o grupo, tendo de utilizar os dois buffers;
MPI_Op op : é uma constante da biblioteca que expressa qual operação deve ser feita
sobre os dados (e.g, MPI_SUM, para somar todos os dados e MPI_MAX para, dentre todos os dados recebidos, verificar qual é o maior) dentre as operações padrão
da especificação ou de operações construídas pelo usuário, cujo suporte é oferecido
pelo MPI, embora não seja detalhado aqui5
MPI_Reduce pode ser encarada como possuidora de uma lógica inversa à lógica de
envio/recepção do MPI_Bcast; aqui, o processo raiz espera que cheguem mensagens de
todos os processos, ao invés de enviá-las.
3.2.2
Terceiro Exemplo
O exemplo a seguir mostra a utilização das primitivas MPI_Bcast e MPI_Reduce
através de um programa que usa o método dos retângulos (CLáUDIO; MARINS, 1994)
para calcular um valor aproximado da constante π. O código foi retirado de (GROPP;
LUSK; THAKUR, 1999) e foi acrescido de algumas correções e otimizações6 . O algoritmo MPI pode ser visto na Figura 3.17
5 Em ambos os casos, com uma operação padrão ou personalizada, é importante que esta seja associativa,
ou seja, a ordem de realização da operação sobre os subconjuntos de um conjunto de dados não influa sobre
o resultado final.
6 A destacar, a inclusão dos cabeçalhos para E/S em C e a transaformação do valor de π com 25 (vinte e
cinco) dígitos em uma constante.
44
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
#include <mpi.h>
#include <math.h>
#include <stdio.h>
#define PI25DT 3.141592653589793238462643
int
main(int argc, char *argv[]) {
int n;
/* Number of intervals.
int myid;
/* ID of current process.
int numprocs;
/* Number of processes
int i;
/* "for" index.
double mypi;
/* Part of the sum of each process
double pi;
/* The final PI (sum) of all processes
double h;
/* Height of each sub-rectangle.
double sum;
/* Rectangle’s sum.
double x;
/* Middle value of the rectangle’s base.
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myId);
while (1) {
if ( myId == 0 ) {
printf("Enter the number of intervals: (0 quits) ");
scanf("%d", &n);
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if ( n == 0 ) {
break;
} else {
h = 1.0 / (double) n;
sum = 0.0;
for ( i = myid + 1; i <= n; i += numprocs ) {
x = h * ((double)i - 0.5 );
sum += (4.0 / (1.0 + x * x));
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0,
MPI_COMM_WORLD );
if ( myid == 0 )
printf("PI is approximately %.16f, Error is %.16f\n",
pi, fabs(pi - PI25DT) );
}
}
MPI_Finalize();
return 1;
39
40
41
42
43
44
45
*/
*/
*/
*/
*/
*/
*/
*/
*/
}
Figura 3.17: Programa para calcular uma aproximação de π.
45
Este método baseia-se no cálculo da integral da função 4/1 + x2 ; ela divide o eixo
x em tantos intervalos quanto o usuário requisitar. Após, envia esta informação via
MPI_Bcast, (altura, no eixo y, equivale ao valor de x constante naquele intervalo) para
que os processos façam o cálculo da área do respectivo retângulo e devolvem ao processo
raiz, que redistribui os intervalos pendentes. Após isso, todas as áreas são obtidas e somadas, através de MPI_Reduce. Para calcular o erro, é feita a comparação com um valor
π suficientemente grande e previamente definido.
3.2.3
Temporização
Parte fundamental da programação paralela consiste em mensurar o ganho de desempenho obtido com o emprego de uma solução multiprocessada; até agora, foram apresentadas soluções para a paralelização básica de algoritmos. Agora, é apresentado um
mecanismo simples para a medição do tempo de execução dos programas. Tal abordagem é útil para a confecção de comparativos e o estabelecimento de benchmarks, que
adquirem grande importância em capítulos posteriores.
Visando suprir estas necessidades, a especificação MPI oferece duas primitivas para a
medição de tempo, cujos protótipos são apresentados na Figura 3.18.
double MPI_Wtime()
double MPI_Wtick()
Figura 3.18: Protótipos de MPI_Wtime() e MPI_Wtick().
MPI_Wtime retorna o tempo transcorrido (em segundos) desde a última chamada
dela mesma ou, caso isto não tenha ocorrido, uma data padrão da implementação. De
qualquer modo, duas chamadas consecutivas revelam o tempo decorrido entre estas. Para
fins de uniformização da contagem de tempo, existe MPI_Wtick, que retorna o tempo
(em segundos) entre dois pulsos de clock consecutivos. Ambas as primitivas podem ser
usadas fora de MPI_Init(...) [...] MPI_Finalize(...), pois muitas vezes
é necessário medir a execução de um programa seqüencial com o mesmo ferramental.
Para exemplificar seu uso, apresenta-se uma versão com medição de tempo do código
apresentado na Figura 3.17. A Figura 3.19 contém o novo código.
3.2.4
Envio e Recebimento Não-bloqueantes
Conforme explanado anteriormente, existem vários modos no que se refere à espera
de uma operação de send ou receive em MPI. Um que desperta interesse especial para
fins da implementação que será desenvolvida é o envio e recebimento não-bloqueantes.
MPI possui MPI_Isend para envio e MPI_Irecv para recebimento não-bloqueante.
Seus protótipos são visualizados na Figura 3.20.
MPI_Isend é idêntico à sua versão bloqueante, mas a execução do programa prossegue mesmo que o buffer não tenha sido esvaziado. MPI_Irecv também é muito semelhante ao já apresentado, mas, ao invés de um ponteiro para a estrutura MPI_Status, há
um ponteiro para um outra estrutura, MPI_Request. Esta estrutura é um argumento que
guarda uma requisição após a chamada de um MPI_Irecv e pode ser testado a qualquer
momento para verificar se a mensagem já chegou.
Existem duas primitivas usadas para testar se um dada mensagem chegou, listadas na
Figura 3.21.
46
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
#include <mpi.h>
#include <math.h>
#include <stdio.h>
#define PI25DT 3.141592653589793238462643
int
main(int argc, char *argv[])
{
(...)
/* Time in seconds application started. */
double start_time;
/* Time in seconds application ended. */
double end_time;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank(MPI_COMM_WORLD, &myId);
while ( 1 ) {
if ( myid == 0 ) {
printf("Enter the number of intervals: (0 quits) ");
scanf("%d", &n);
}
/* Timing count begins. */
start_time = MPI_Wtime();
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if ( n == 0 ) {
break;
} else {
(...)
/* Timing count ends. */
end_time = MPI_Wtime();
if ( myid == 0 ) {
printf("PI is approximately %.16f, Error is %.16f\n",
pi,
fabs(pi - PI25DT) );
/* Timing and "clock tick" count. */
printf("Time is %.16f seconds or %.16f clock ticks.\n",
endTime - startTime,
(endTime - startTime)/MPI_Wtick() );
}
}
}
MPI_Finalize();
return 1;
}
Figura 3.19: Programa para calcular uma aproximação de π, com medição de tempo.
47
int MPI_Isend(void* buf, int count, MPI_Datatype dt, int dest,
int tag, MPI_Comm comm )
int MPI_Irecv(void* buf, int count, MPI_Datatype dt, int source,
int tag, MPI_Comm comm, MPI_Request* request )
Figura 3.20: Protótipos de MPI_Isend() e MPI_Irecv().
int MPI_Wait (MPI_Request *request, MPI_Status *status)
int MPI_Test (MPI_Request *request, int *flag, MPI_Status *status)
Figura 3.21: Protótipos de MPI_Wait() e MPI_Test().
MPI_Wait bloqueia até que a mensagem chegue, sendo útil para adiantar alguma
parte não-dependente da chegada da mensagem e, então, esperar. Quando a mensagem
chegar será como um MPI_Recv, entregando os dados nas variáveis indicadas e seu
status em status.
MPI_Test testa se a mensagem chegou, indicando tal fato na variável flag; em
seguida, testadando flag (e.g., if ( flag == 0 )), pode-se continuar de acordo
com as preferências do programador.
A estas primitivas tem versões que atuam sobre vetores de ponteiros do tipo MPI_Request;
estas funções têm o protótipo conforme visto na Figura 3.22.
int MPI_Testany(int count, MPI_Request* array_of_requests, int* index,
MPI_Status* status)
int MPI_Waitany(int count, MPI_Request* array_of_requests, int* index,
MPI_Status* status)
Figura 3.22: Portótipos de MPI_Testany() e MPI_Waitany().
index contém a posição do vetor que guarda o request da solicitação que foi
atendida. Uma aplicação disto será vista no próximo exemplo a ser mostrado.
Visto que as estruturas MPI tem um buffer, pode ser útil cancelar um MPI_Irecv,
que fica aguardando as mensagens; faz-se isso através de MPI_Cancel, descrito na Figura 3.23, que cancela uma requisição de aguardo de mensagem apontada por request.
3.2.5
Quarto Exemplo
Este exemplo ilustra o uso de primitivas não-bloqueantes. MPI fornece maneiras de se
receber uma mensagem com 1 determinado indicador (uma tag) ou de qualquer indicador (através da constante MPI_ANY_TAG). Não há, entretanto, um recurso para se receber
mensagens de um conjunto de tags. O código mostrado usa primitivas não-bloqueantes
para receber uma mensagem que pode ter exatamente 2 tipos de tag e pode ser visto
na Figura 3.24. O exemplo mostrado é claramente extensível para tantas tags quanto se
queira.
No exemplo apresentado, algum processamento é feito enquanto se espera a mensagem, geralmente para evitar uma condição de deadlock. No entanto, ao se remover este
processamento, tem-se o equivalente a um MPI_Recv, bloqueante, que aceita duas tags
no cabeçalho da mensagem.
48
int MPI_Cancel(MPI_Request *request)
Figura 3.23: Protótipo de MPI_Cancel().
1 MPI_Irecv(&msg, 1, MPI_INT, target_proc, TAG_ONE, MPI_COMM_WORLD,
2
&drequest[0]);
3 MPI_Irecv(&msg, 1, MPI_INT, target_proc, TAG_TWO, MPI_COMM_WORLD,
4
&drequest[1]);
5 flag = 0;
6 index = -1;
7 do {
8
MPI_Testany(2, drequest, &index, &flag, &status);
9
/* Some proc. */
10 } while ( flag == 0 );
11 MPI_Cancel(&(drequest[2-index]));
Figura 3.24: Recebimento de mensagem que pode ter exatas 2 tags.
3.3
Multiplicação Matriz × Vetor
Um estudo de caso a ser abordado é o algoritmo que realiza a multiplicação de uma
matriz por um vetor em paralelo. Lembrando, esta implementação é sobre MPI-1.2 e
é apresentada em (GROPP; LUSK; SKJELLUM, 1999), na linguagem FORTRAN. Para
fins desta monografia tal algoritmo foi convertido para a linguagem C.
Seja A uma matriz quadrada de ordem n e x um vetor de cumprimento n tal que
A × x = b, sendo b o vetor resultante da multiplicação, de tamanho n. O algoritmo é do
tipo mestre-escravo7 e decompõe A em linhas, que distribui ciclicamente a medida que os
escravos requisitam trabalho. Cada escravo, tendo recebido do mestre x (por broadcast),
faz a multiplicação do elemento de b correspondente.
Cada processo escravo, ao acabar a computação, requisita mais trabalho para o mestre,
que pode enviá-lo ou dizer ao escravo para terminar, pois não há mais tarefas. Ao final,
o processo mestre recolhe cada resultado e monta o vetor-reposta. O código está todo
contido em um arquivo mas, para melhor entendimento, subdividiu-se em três partes:
início (Figura 3.25), mestre (Figura 3.26) e escravo (Figura 3.27) .
Esta computação, para diferentes tamanhos de matriz e número de processos, teve seu
tempo de execução medido. As execuções são feitas para configurações utilizando de 2 a
10 nós. Para cada configuração, executou-se o mesmo programa com matrizes quadradas
de ordem 100 até 1000, incrementados de 100. O mesmo procedimento foi repetido 5
vezes e, ao final, tomou-se a média aritmética do tempo de execução. A Figura 3.28
apresenta os resultados obtidos. Estes resultados foram publicados, em conjunto com
medições sobre MPI-2 (com criação dinâmica dos processos) na Escola Regional de Alto
Desempenho 2007 (ESCOLA REGIONAL DE ALTO DESEMPENHO, 2007).
3.3.1
Multiplicação Matriz × Matriz
É interessante reparar que, com poucas extensões, é possível aproveitar o código apresentado e alterá-lo para produzir um programa que compute, paralelamente, a multiplicação de duas matrizes quadradas (A × B = C, com A, B e C de tamanho n).
O código estendido estava, originalmente, em FORTRAN (GROPP; LUSK; SKJEL7 Um
processo distribui tarefas a outros processos e colhe resultados (PACHECO, 1997).
49
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#include <mpi.h>
#include <stdio.h>
#include <unistd.h> /* GNU GetOpt library. */
#define MAX_ROWS 1001
#define MAX_COLS 1001
int
main(int argc, char *argv[])
{
int rows;
int cols;
double matrix[MAX_ROWS][MAX_COLS];
/* Matrix to be multiplied. */
double vectorA[MAX_COLS];
double vectorB[MAX_ROWS];
double buffer[MAX_COLS];
double answer;
int myid;
/* ID of current process.
*/
int master;
/* Master process ID.
*/
int numprocs;
/* Number of processes.
*/
int i, j;
/* Index for looping.
*/
int numsent;
int sender;
int anstype;
int row;
MPI_Status status;
/* Benchmark variables. */
double start_time;
(... GET PARAM ...)
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
Figura 3.25: Código para o programa de multiplicação matriz × vetor (início).
50
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
master = 0;
if ( myid == master ) {
/* Master’s part: */
/* Initializing vector and matrix. */
for (i = 0; i < cols; i = i + 1) {
vectorA[i] = 1;
for (j = 0; j < rows; j = j + 1)
matrix[j][i] = j;
}
start_time = MPI_Wtime();
/* Sends vectorA to each slave process. */
MPI_Bcast(vectorA, cols, MPI_DOUBLE, master, MPI_COMM_WORLD);
/* Sends a row for each slave process; tag with row number. */
numsent = 0;
for ( i = 0; i < numprocs-1; i = i + 1 ) {
for (j = 0; j < cols; j = j + 1)
buffer[j] = matrix[i][j];
MPI_Send(buffer, cols, MPI_DOUBLE, i + 1, i + 1,
MPI_COMM_WORLD);
numsent += 1;
}
for ( i = 0; i < rows; i = i + 1 ) {
MPI_Recv(&answer, 1, MPI_DOUBLE, MPI_ANY_SOURCE,
MPI_ANY_TAG, MPI_COMM_WORLD, &status);
sender = status.MPI_SOURCE;
anstype = status.MPI_TAG;
vectorB[anstype-1] = answer;
if ( numsent < rows ) {
for ( j = 0; j < cols; j = j + 1 ) {
buffer[j] = matrix[numsent][j];
}
MPI_Send(buffer, cols, MPI_DOUBLE, sender, numsent+1,
MPI_COMM_WORLD);
numsent += 1;
}
else
MPI_Send(MPI_BOTTOM, 0, MPI_DOUBLE, sender, 0,
MPI_COMM_WORLD);
}
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
/* Process 0 is the master process. */
printf("%d %d %f \n", rows, numprocs - 1,
MPI_Wtime() - start_time);
/* Prints solution */ (...)
}
Figura 3.26: Código para o programa de multiplicação matriz × vetor (mestre).
51
1
2
3
4
5
6
7
8
9
} else {
/* Slave’s part: */
MPI_Bcast(vectorA, cols, MPI_DOUBLE, master, MPI_COMM_WORLD);
if ( myid > rows ) {
MPI_Finalize();
return 0;
}
while (1) {
MPI_Recv(buffer, cols, MPI_DOUBLE, master, MPI_ANY_TAG,
MPI_COMM_WORLD, &status);
if ( status.MPI_TAG == 0 ) {
MPI_Finalize();
return 0;
} else {
row = status.MPI_TAG;
answer = 0.0;
for (i = 0; i < cols; i = i + 1)
answer += buffer[i] * vectorA[i];
MPI_Send(&answer, 1, MPI_DOUBLE, master, row,
MPI_COMM_WORLD);
}
}
}
MPI_Finalize();
return 0;
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
}
Figura 3.27: Código para o programa de multiplicação matriz × vetor (escravo).
Figura 3.28: Desempenho: multiplicação matriz × vetor – MPI-1.2
52
LUM, 1999) e foi portado para C. O código, como o anterior, também é apresentado em
três partes: início (Figura 3.29), mestre (Figura 3.30) e escravo (Figura 3.31)
As medições de tempo, tomadas variando-se apenas o número de processos para uma
matriz 1000 × 1000, foram realizadas 5 vezes e tomada a média aritmética; o número de
processos listados desconsidera o processo mestre (e.g., 0 significa o algoritmo seqüencial, rodado em separado da estrutura MPI), resultados apresentados na Tabela 3.2.
N. Proc.
0
1
2
3
4
5
6
7
Tempo (s)
0.026577
0.030405
0.069374
0.049342
0.054366
0.057348
0.076734
0.073961
N. Proc.
8
9
10
11
12
13
14
15
Tempo (s)
0.084667
0.110110
0.093460
0.103958
0.160807
0.141569
0.394071
0.258599
Tabela 3.2: Tempos da multiplicação matriz × matriz paralela.
É interessante notar que, contrariando a lógica, os tempos apresentados sobem com o
aumento do número de processos. Pode-se justificar isso através de três argumentos,
1. Com o aumento do número de processos, o número de troca de mensagens (operações de E/S, custosas em termos de tempo) sobe;
2. O fato da multiplicação envolver duas matrizes ao invés de um vetor e uma matriz
gera um aumento considerável no envio de mensagens (E/S); e
3. A matrizes não são grandes o suficiente para se beneficiar do aumento de processos
e sobrepujar o custo de comunicação.
53
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
#include <mpi.h>
#include <stdio.h>
#include <unistd.h> /* GNU GetOpt library. */
#define MAX_A_ROWS 100
#define MAX_A_COLS 100
#define MAX_B_COLS 100
int
main(int argc, char *argv[])
{
/* Algorithm variables. */
int a_rows;
int b_rows;
int c_rows;
int a_cols;
int b_cols;
int c_cols;
double matrixA[MAX_A_ROWS][MAX_A_COLS];
double matrixB[MAX_A_COLS][MAX_B_COLS];
double matrixC[MAX_A_ROWS][MAX_B_COLS];
double buffer[MAX_A_COLS]; /* Buffer for temp. multiplication. */
double answer[MAX_B_COLS];
int myid;
/* ID of current process. */
int master;
/* Master process ID. */
int numprocs;
/* Number of processes. */
int i;
/* Index for looping. */
int j;
/* Index for looping. */
int numsent;
/* Number of sent processes. */
int sender;
/* The sender identifier. */
int anstype;
/* Where the answer vector should be. */
int row;
/* Holds the row number. */
MPI_Status status;
double start_time;
(... GET PARAM ...)
/* Matrixes initialized sizes (indexes limits). */
master = 0;
/* Process 0 is the master process. */
a_rows = MAX_A_ROWS;
a_cols = MAX_A_COLS;
b_rows = MAX_A_COLS;
b_cols = MAX_B_COLS;
c_rows = a_rows;
c_cols = b_cols;
/* Initializating MPI. */
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
Figura 3.29: Código para o programa de multiplicação matriz × matriz (início).
54
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
if ( myid == master ) {
/** Master’s part: */
/* Initializing matrixes. */
(...)
start_time = MPI_Wtime();
/* Sends MatrixB to each slave process. */
for ( i = 0; i < b_rows; i = i + 1 )
MPI_Bcast(&(matrixB[i][0]), b_cols, MPI_DOUBLE, master,
MPI_COMM_WORLD);
/* Sends a row for each slave process; tag with row number. */
numsent = 0;
for ( i = 0; i < min(numprocs-1, a_rows); i = i + 1 ) {
for ( j = 0; j < a_cols; j = j + 1 )
buffer[j] = matrixA[i][j];
MPI_Send(buffer, a_cols, MPI_DOUBLE, i + 1, i + 1,
MPI_COMM_WORLD);
numsent = numsent + 1;
}
for ( i = 0; i < c_rows; i = i + 1 ) {
MPI_Recv(&answer, c_cols, MPI_DOUBLE, MPI_ANY_SOURCE,
MPI_ANY_TAG, MPI_COMM_WORLD, &status);
sender = status.MPI_SOURCE;
anstype = status.MPI_TAG;
for ( j = 0; j < c_cols; j = j + 1 )
matrixC[anstype-1][j] = answer[j];
if ( numsent < a_rows ) {
for ( j = 0; j < a_cols; j = j + 1 )
buffer[j] = matrixA[numsent][j];
MPI_Send(buffer, a_cols, MPI_DOUBLE, sender, numsent +
1, MPI_COMM_WORLD);
numsent = numsent + 1;
} else {
MPI_Send(MPI_BOTTOM, 0, MPI_DOUBLE, sender, 0,
MPI_COMM_WORLD);
}
}
/* Prints the data into the GNUPLOT format. */
printf("%d %f \n",numprocs - 1, MPI_Wtime() - start_time);
Figura 3.30: Código para o programa de multiplicação matriz × matriz (mestre).
55
1
2
3
4
} else {
/** Slave’s part: */
for ( i = 0; i < b_rows; i = i + 1 )
MPI_Bcast(&(matrixB[i][0]), b_cols, MPI_DOUBLE, master,
MPI_COMM_WORLD);
if ( myid > b_rows ) {
MPI_Finalize();
return 0;
}
while ( 1 ) {
MPI_Recv(buffer, a_cols, MPI_DOUBLE, master, MPI_ANY_TAG,
MPI_COMM_WORLD, &status);
if ( status.MPI_TAG == 0 ) {
MPI_Finalize();
return 0;
} else {
row = status.MPI_TAG;
for ( i = 0; i < b_cols; i = i + 1 ) {
answer[i] = 0.0;
for ( j = 0; j < a_cols; j = j + 1 )
answer[i] = answer[i]
+ buffer[j] * matrixB[j][i];
}
MPI_Send(&answer, b_cols, MPI_DOUBLE, master, row,
MPI_COMM_WORLD);
}
}
}
MPI_Finalize();
return 0;
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
}
Figura 3.31: Código para o programa de multiplicação matriz × matriz (escravo).
56
4
PROBLEMA DA MOCHILA
O Problema da Mochila é um problema de otimização combinatória de especial importância na Ciência da Computação, pois pertence à classe de problemas NP-Completos
(GAREY; JOHNSON, 1979). É, também, um dos principais problemas da área de Pesquisa Operacional, visto que muitas situações onde se busca maximizar o lucro podem
ser reduzidas a resolver este problema. Sua resolução demanda um grande esforço computacional, tornando-se especialmente interessante para a área de Programação Paralela.
O seguinte capítulo apresenta o Problema da Mochila e mostra um algoritmo paralelo que
o resolve, implementado em MPI.
4.1
Definição Intuitiva
O Problema da Mochila pode ser definido intuitivamente através de um cenário. Suponhase um ladrão que almeja roubar uma fábrica de peças de informática. Tudo de que o ladrão
dispõe para carregar o produto de seu furto é uma mochila escolar, de porte médio. Existem objetos das mais variadas dimensões, com os mais variados valores (e.g., placas-mãe,
memória de vídeo, memórias RAM, etc.). Caberá ao ladrão, portanto, escolher os itens a
carregar na sua mochila de modo que o valor a ser roubado seja máximo e que ele possa
carregar.
O Problema da Mochila, portanto, pode ser visto como o problema de preencher uma
mochila de capacidade limitada com itens que possuem um valor associado de modo a
não exceder esta capacidade e maximizar o valor resultante.
4.2
Definição Formal
A definição formal do Problema da Mochila é (KELLER; PFERSCHY; PISINGER,
2005):
Definição (Problema da Mochila Ilimitado). Sejam n tipos de itens (n ∈ N). Cada xi ∈ N
representa a quantidade de itens do tipo i, onde cada tipo tem associado um valor vi ∈ R+
e um peso pi ∈ R+ (i ∈ {1, . . . , n}). O máximo peso que a mochila pode carregar é C ∈ R+ .
O Problema da Mochila Ilimitado é, então,
n
maximizar
∑ xi × vi
i=1
n
|
∑ xi × pi ≤ C
i=1
Esta definição chama-se “Problema da Mochila Ilimitado” pois não há número de itens
de cada tipo (o valor de xi ) máximo. Este é o problema cuja implementação futuramente
apresentada resolve.
57
4.3
Outras Definições
Existem outros tipos de Problema da Mochila, com muitas variações nas restrições e
condições de execução (e.g., Problema da Mochila Compartimentada, Problema da Mochila Multidimensional, etc. ). É interessante analisar, entretanto, duas variações do Problema da Mochila que podem ser obtidas adicionando, cada uma, uma pequena restrição
no Problema da Mochila original. Estas variações são especialmente interessantes porque
podem ser facilmente adicionadas ao programa que resolve tal problema, por meio da
modificação de uma única função (branch).
4.3.1
Problema da Mochila Limitado
Retomando o exemplo do ladrão, este seria o caso do assaltante estar furtando uma
residência, ao invés de uma loja de computadores. Na residência, o número de itens que
pode ser levado do mesmo tipo tende a ser limitado1 ; é improvável, por exemplo, que
existam mais do que três ou quatro televisores. Assim cada item pode ser incluído no
somatório um número limitado de vezes. Formalmente (KELLER; PFERSCHY; PISINGER, 2005),
Definição (Problema da Mochila Limitado). Sejam n tipos de itens (n ∈ N). Cada xi ∈
{0, . . . , bi } representa a quantidade de itens do tipo i, onde cada tipo tem associado um
número de itens disponíveis máximo bi ∈ N, um valor vi ∈ R+ e um peso pi ∈ R+ (i ∈
{1, . . . , n}). O máximo peso que a mochila pode carregar é C ∈ R+ . O Problema da
Mochila Limitado é, então,
n
n
∑ xi × vi
maximizar
|
i=1
onde
4.3.2
∑ xi × pi ≤ C
i=1
0 ≤ xi ≤ bi
Problema da Mochila 0-1
No mesmo cenário dos anteriores, o ladrão, desta vez, atenta em roubar uma loja de
raros vasos chineses. Tal loja tem apenas um tipo de cada vaso e, deste modo, a decisão
do ladrão é entre levar o item ou não. Formalmente (KELLER; PFERSCHY; PISINGER,
2005),
Definição (Problema da Mochila 0-1). Sejam n tipos de itens (n ∈ N). Cada xi ∈ {0, 1}
representa a quantidade de itens do tipo i, um valor vi ∈ R+ e um peso pi ∈ R+ (i ∈
{1, . . . , n}). O máximo peso que a mochila pode carregar é C ∈ R+ . O Problema da
Mochila 0-1 é, então,
n
maximizar
n
∑ xi × vi
|
xi = 0
ou
i=1
onde
1A
∑ xi × pi ≤ C
i=1
xi = 1
priori, o número de itens da fábrica também é limitado. No entanto, pode-se considerar que o ladrão
tem tempo disponível para produzir quantas peças de um mesmo tipo quiser.
58
4.4
Complexidade
O Problema da Mochila é um problema NP-Completo. Portanto, o PM é resolvível
em tempo polinomial por um algoritmo não-determinístico. De fato, não há prova de
que existe algoritmo que resolva a o Problema da Mochila em tempo polinomial em uma
máquina determinística (pertence à classe NP) e qualquer outro problema NP pode ser
reduzido polinomialmente a um Problema da Mochila, sendo, assim, o problema NPCompleto (GAREY; JOHNSON, 1979) . A complexidade da solução adotada será apresentada junto com o código do algoritmo.
Devido à sua complexidade exponencial, uma solução eficiente para o problema deve
ser aquela que consegue reduzir, ao máximo, os termos da expressão exponencial. O
fato do Problema da Mochila ser NP-Completo permite que os resultados obtidos nesta
monografia possam ser generalizados para toda a classe de problemas NP-Completos.
Em outras palavras, é provável que o emprego de uma técnica de Workstealing produza
impacto semelhante quando aplicada à soluções paralelalas de outros algoritmos que resolvem problemas NP-Completos.
4.5
Solução
O algoritmo adotado para a solução do problema é do tipo Branch & Bound. Algoritmos desta natureza concentram-se em gerar ramos da árvore de possibilidades de
todas as soluções possíveis (branch) e cortam os ramos que não são promissores, ou seja,
garantidamente não vão gerar uma solução ótima (bound). Conforme explicitado, a enumeração de todas as soluções é feita em tempo exponencial, sendo de suma importância
a otimização do processo.
4.5.1
Algoritmo
Toma-se a Definição 4.2, “Problema da Mochila Ilimitado”. A solução apresentada
(KELLER; PFERSCHY; PISINGER, 2005) considera que a entrada está disposta de maneira decrescente em relação aos valores relativos dos objetos. Como valor relativo,
entende-se a razão entre o valor de um objeto do tipo i (vi ) e o peso do mesmo objeto
(pi ). Ou seja, há a relação
v2
vn
v1
≥
≥ ··· ≥
p1
p2
pn
Tal ordenamento, se desejado, pode ser feito com uma complexidade O(n × log2 (n))
(e.g., Quicksort). Para a implementação deste algoritmo construiu-se um gerador de casos
em Python, que gera arquivos de instâncias do Problema da Mochila com o formato apresentado na Figura 4.1. Esta medida garante a ordem decrescente dos valores relativos,
retirando este custo da implementação.
<número de elementos (n)> <capacidade da mochila (C)>
v1 v2 v3 v4 ... vn
p1 p2 p3 p4 ... pn
Figura 4.1: Formato de instância do problema da mochila.
A construção do algoritmo Branch & Bound que resolve o Problema da Mochila será
abordado em separado, para um melhor entendimento, já que as partes de branch e de
59
bound possuem certa independência.
4.5.1.1
Branch
Esta parte consiste em gerar os galhos da árvore de soluções (cada galho corresponde a
um conjunto {x1 , . . . , xn } candidato à solução ótima do problema), um a um. Para fazê-lo,
usa-se uma técnica de geração baseada em um algoritmo guloso.
Conforme foi estabelecido, os itens da entrada estão ordenados de acordo com seu
valor relativo. Logo, o primeiro item é o melhor em termos de custo/benefício. O algoritmo guloso atribui a este item (x1 ) o maior valor possível tal que o peso deste não
ultrapasse o limite da mochila, ou seja, tal que x1 × p1 ≤ C. Sobrando espaço na mochila
(C − x1 × p1 > 0), tenta-se preenchê-lo elevando-se ao máximo o valor de x2 respeitando
que (x1 × p1 ) + (x2 × p2 ) ≤ C. Sobrando espaço, ainda, na mochila, parte-se para x3 e
assim sucessivamente, até xn . Com isso, gera-se o primeiro galho da árvore de soluções
possíveis. Exemplo no Algoritmo 1.
Algoritmo 1 Branch (um galho)
1: x1 ← bC/p1 c
2: for j ← 2, n do
j
3:
x j ← b(C − ∑i=1 (pi × xi ))/p j c
4: end for
Fica evidente, assim, que é possível distribuir os itens a caberem na mochila simplesmente alterando o valor inicial de j; pode-se gerar um novo galho tanto da raiz (caso
apresentado), quanto de qualquer nodo intermediário. Isso implica que, para gerar a árvore toda, basta utilizar o algoritmo acima n − 1 vezes, onde, a cada execução o valor
inicial de j, inicializado com n, é decrescido de uma unidade.
O processo de gerar toda a árvore imediatamente remete a uma implementação recursiva. De fato, uma função recursiva é muito mais fácil de ser implementada e muito
mais legível. No entanto, para fins desta monografia, torna-se especialmente interessante
a abordagem iterativa, onde simula-se a pilha da recursividade. Os motivos para isso ficarão claros quando, ao implementar a solução baseada em MPI, as tarefas tiverem de ser
divididas, inviabilizando o uso da recursividade oferecida pelo Sistema Operacional. Por
hora, é apresentada a função iterativa. É importante notar que esta versão necessita que
se inicialize o primeiro galho conforme descrito acima antes de gerar todos os outros, que
usam este como base. Vê-se o resultado no Algoritmo 2.
4.5.1.2
Bound
Este procedimento faz com que galhos que comprovadamente não possam gerar o
valor ótimo não sejam nem expandidos. Basicamente, faz-se isso através da comparação
do máximo valor que ainda pode ser atingido com uma ramificação da árvore com o maior
valor corrente. Uma vez que o ponteiro k aponta para determinado nodo da árvore, acaba
particionando-a; todos os valores anteriores já foram estabelecidos, e os que estão à frente
ainda precisam ser expandidos iterativamente. Desse modo, tem-se
−−−−−→
{x1 , x2 , . . . , xk , −
x−
k+1 , . . . , xn }
Toma-se V e P como ∑ni=1 (xi × vi ) e ∑ni=1 (xi × pi ), respectivamente. Além disso,
sejam V ’ e P’ o valor e o peso, respectivamente, da partição {x1 , . . . , xk }. Dessa partição,
o espaço restante na mochila C − P’ (denotado, doravante, P”) deve ser preenchido com
60
Algoritmo 2 Branch (toda a árvore).
1: x1 ← bC/p1 c
2: for j ← 2, n do
j
3:
x j ← b(C − ∑i=1 (pi × xi ))/p j c
4: end for
5: k ← n
6: while true do
7:
k←n
8:
while (k ≥ 1) ∧ (xk = 0) do
9:
k ← k−1
10:
end while
11:
if then(k ≥ 1)
12:
exit
13:
end if
14:
if k = n then
15:
xk ← 0
16:
continue
17:
end if
18:
xk ← xk − 1
19:
for j ← k + 1, n do
j
20:
x j ← b(C − ∑i=1 (pi × xi ))/p j c
21:
end for
22:
V ← ∑ni=1 (vi × xi )
23:
if V > Vbest then
24:
xbest ← x
25:
Vbest ← V
26:
end if
27:
k←n
28: end while
61
a distribuição {xk+1 , . . . , xn } que maximize V − V ’. Note-se, também, que o maior valor
vk+1
relativo dos itens que restam é sk+1
, dado o ordenamento inicial dos valores relativos.
Para fazer a poda, basta supor o melhor caso possível para a partição não analisada e
verificar se esta situação supera ou não a melhor configuração corrente (xbest ), que tem o
valor Vbest . No caso, a melhor situação possível seria se todos os itens restantes possuísvk+1
. Basta, então, calcular a soma como se possuíssem este valor e
sem o valor relativo sk+1
comparar Vbest com este; caso não haja superação do primeiro pelo segundo, o algoritmo
prossegue sem abrir aquele ramo da árvore. Matematicamente, o Algoritmo 3 reflete estas
considerações.
Algoritmo 3 Bound
1: V 0 = ∑ki=1 (vi × xi )
2: P00 = P − ∑ki=1 (pi × xi )
3: if V 0 + (vk+1 /pk+1 × P00 ) ≤ Vbest then
4:
continue
5: else
6:
(branch)
7: end if
Para uma versão completa do algoritmo, basta adicionar o trecho de bound ao código já apresentado até aqui (MARTELLO; TOTH, 1990), o que pode ser visualizado no
Algoritmo 4.
O código apresentado resolve o Problema da Mochila. No entanto, uma abordagem
formal é por demais abstrata; é bom que se use uma abordagem mais prática para ilustrar o algoritmo. A Figura 4.2 mostra a mesmo algoritmo implementado na linguagem
Python. Com ela, há fácil compreensão das transcrições feitas, ao mesmo tempo em que
a análise fica mais limpa e clara. O módulo modknapsack contém apenas uma função
(readInstance(...)) que lê a entrada mostrada na Figura 4.1.
A demonstração formal da complexidade desta solução foge ao escopo desta monografia. No entanto, emxerga-se que:
1. O cálculo do valor total (V ) associado a um conjunto {x1 , . . . , xn } e a verificação da
obtenção de um novo maior (linhas 28-30) é realizada em tempo polinomial O(n);
2. A geração de um conjunto {x1 , . . . , xn } candidato à solução (linhas 24-26) é feito
em tempo polinomial O(n), mas depende da geração de todos os valores de k.
3. A geração de todos os conjuntos {x1 , . . . , xn } possíveis é exponencial; o número total de conjuntos que existem, pelo Princípio Fundamental da Contagem, é (considerase #xi como o número de valores que xi pode assumir)
n
#x1 × #x2 × #x3 × · · · × #xn = ∏ #xi
i=1
logo, como todos os conjuntos possíveis são gerados, este é o mínimo (exponencial)
de operações a serem realizadas.
De fato, a complexidade exata do Problema da Mochila é difícil de ser estimada, mas
podem-se traçar conjecturas em cima da complexidade pessimista e do tipo de Problema
da Mochila analisado:
62
Algoritmo 4 Solução Branch & Bound para o Problema da Mochila
1: procedure K NAPSACK B RANCH B OUND(C, n, {v1 , . . . , vn }, {p1 , . . . , pn })
2:
x1 ← bC/p1 c
3:
for j ← 2, n do
j
4:
x j ← b(C − ∑i=1 (pi × xi ))/p j c
5:
end for
6:
Vbest ← ∑ni=1 (vi × xi )
7:
xbest ← x
8:
while true do
. O laço será quebrado internamente, via break.
9:
k←n
10:
while (k ≥ 1) ∧ (xk = 0) do
11:
k ← k−1
12:
end while
13:
if k = n then
14:
xk ← 0
15:
continue
16:
end if
17:
if then(k ≥ 1)
18:
xk ← xk − 1
19:
V 0 = ∑ki=1 (vi × xi )
20:
P00 = P − ∑ki=1 (pi × xi )
21:
if V 0 + (vk+1 /pk+1 × P00 ) ≤ Vbest then
22:
continue
23:
else
24:
for j ← k + 1, n do
j
25:
x j ← b(C − ∑i=1 (pi × xi ))/p j c
26:
end for
27:
V ← ∑ni=1 (vi × xi )
28:
if V > Vbest then
29:
xbest ← x
30:
Vbest ← V
31:
end if
32:
k←n
33:
end if
34:
else
35:
break
36:
end if
37:
end while
38: end procedure
63
• O Problema da Mochila 0-1 possui complexidade pessimista O(2n ), pois cada xi
pode assumir dois valores, 0 e 1;
• O Problema da Mochila Limitado possui complexidade pessimista
O(max({b1 , . . . , bn })n ), pois, no pior caso, o número máximo de sub-árvores geradas é igual à maior quantidade de itens disponível;
• O Problema da Mochila Ilimitado possui complexidade pessimista
O((C/min({p1 , . . . , pn }))n ), pois, analogamente ao caso anterior, o número máximo de sub-árvores é determinado pelo maior xi possível, que, não possuindo limites explícitos, é determinado pela quantidade máxima do item que possui menor
peso (C/min({p1 , . . . , pn })).
tais considerações se mostram afinadas com a literatura (MARTELLO; TOTH, 1990).
Em geral, o Problema da Mochila é resolvido por Programação Dinâmica, técnica
algorítmica que utiliza recursões e uma estrutura de dados auxiliar que armazena os resultados parciais destas recursões para evitar a repetição de trabalho. No entanto, ambas
as soluções possuem a mesma complexidade (KELLER; PFERSCHY; PISINGER, 2005).
4.5.2
MPI
Uma vez que se tenha um algoritmo formal estabelecido e implementado em uma linguagem flexível, como Python, o próximo passo é paralelizar este algoritmo, através de
uma implementação da especificação MPI. No entanto, há um passo intermediário, que
é implementar o algoritmo seqüencial em C e, aí então, paralelizá-lo. Primeiramente,
apresenta-se a mera transcrição do programa em Python para C, na Figura 4.4. A declaração das variáveis é vista na Figura 4.3
A função read_instance(...) lê um arquivo (instance.txt) o qual contém
uma instância do Problema da Mochila, conforme a Figura 4.1. A função dotprod(...)
realiza o produto escalar entre dois vetores ou partes de vetores (indicados através dos
parâmetros int low e int high). O produto escalar corresponde ao somatório do
produto entre vetores (Algoritmo 4).
Para evidenciar um processo de paralelização mais claro, convém agrupar certas expressões em termos de operações fundamentais do algoritmo, como branch e bound, que
pudessem ser transformadas em funções independentes, trazendo mais clareza ao código.
Tal abordagem pode ser visualizada na Figura 4.5.
Para realizar a paralelização deste algoritmo usa-se uma técnica conhecida de programação paralela, a Decomposição Cíclica. Basicamente, esta técnica consiste em replicar
a entrada entre todos os processos participantes (processo realizado automaticamente pelo
MPI) e o processo selecionar, com base no seu identificador, que partes de entrada processará e que partes da entrada deixará que outros processos computem. O nome “cíclica”
advém do fato desejado que a distribuição da entrada seja cíclica, ou seja, que posições
sucessivas em um vetor de entrada sejam distribuídos dentre processos diferentes (PACHECO, 1997).
Existe outra abordagem para a Distribuição da entrada muito utilizada em programa
do tipo mestre-escravo, chamada Decomposição por Blocos; ao invés de enviar elementos
de um vetor sucessivos para processos diferentes, se enviam blocos de elementos sucessivos para processos diferentes. Tal abordagem visa economizar o custo da comunicação
envolvido no primeiro caso, visto que o envio de uma mensagem grande é mais eficiente
64
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
from modknapsack import readInstance
knapsack_instance = readInstance(sys.argv[1])
C = knapsackInstance[’size’]
v = knapsackInstance[’value’]
p = knapsackInstance[’weight’]
n = knapsackInstance[’itemnum’]
x = [0 for i in range(n)]
x[0] = C // p[0]
for j in range(1, n) :
x[j] = (C - sum([p[i]*x[i] for i in range(0, j)])) // s[j]
V_best = sum([v[i]*x[i] for i in range(0, n)])
x_best = x[:]
while True :
k = n-1
while (k >= 0) and (x[k] == 0) :
k = k - 1
if k == n-1 :
x[k] = 0
continue
if k >= 0 :
x[k] = x[k] - 1
V_temp = sum([v[i]*x[i] for i in range(0, k+1)])
P_temp = C - sum([p[i]*x[i] for i in range(0, k+1)])
if (V_temp + ((v[k+1] * P_temp) / p[k+1])) <= V_best :
continue
else :
k = k + 1
for j in range(k, n) :
x[j] = (C-sum([p[i]*x[i] for i in range(0, j)]))//p[j]
V = sum([v[i]*x[i] for i in range(0, n)])
if V > V_best :
x_best = x[:]
V_best = V
else :
break
Figura 4.2: Algoritmo Branch & Bound para o Problema da Mochila, em Python.
1
2
3
4
5
6
7
int i, j;
struct ks_instance_s ks_ins;
read_instance("instance.txt", &ks_ins);
int *x = (int *) calloc(ks_ins.item_num, sizeof(int));
int *x_best = (int *) calloc(ks_ins.item_num, sizeof(int));
int v_temp, b_temp;
int k;
Figura 4.3: Variáveis da implementação seqüencial que resolve o Problema da Mochila
(em C).
65
1 int
2 main(int argc, char* argv[])
3 {
4
(... VARS... )
5
x[0] = (int) (ks_ins.ks_capacity / ks_ins.item_weight[0]);
6
for ( j = 1; j < ks_ins.item_num; ++ j )
7
x[j] = (int) ((ks_ins.ks_capacity
8
- dotprod(ks_ins.item_weight, x, 0, j - 1))
9
/ ks_ins.item_weight[j]) ;
10
int v = 0;
11
int v_best = dotprod(ks_ins.item_value, x, 0, ks_ins.item_num - 1);
12
memcpy(x_best, x, ks_ins.item_num * sizeof(int) / sizeof(char));
13
14
k = ks_ins.item_num - 1;
15
while ( 1 ) {
16
while ( (k >= 0) && (x[k] == 0) )
17
k = k - 1;
18
if ( k == ks_ins.item_num - 1) {
19
x[k] = 0;
20
continue;
21
}
22
if ( k >= 0 ) {
23
x[k] = x[k] - 1;
24
v_temp = dotprod(ks_ins.item_value, x, 0, k);
25
b_temp = ks_ins.ks_capacity
26
- dotprod(ks_ins.item_weight, x, 0, k);
27
if ( (v_temp + ((ks_ins.item_value[k+1] * b_temp)
28
/ ks_ins.item_weight[k+1])) <= v_best ) {
29
printf("x[%d] = %d BOUND!\n", k, x[k]);
30
continue;
31
} else {
32
for ( j = k + 1; j < ks_ins.item_num; ++ j )
33
x[j] = (int) ((ks_ins.ks_capacity
34
- dotprod(ks_ins.item_weight, x, 0, j - 1))
35
/ ks_ins.item_weight[j]) ;
36
v= dotprod(ks_ins.item_value, x, 0, ks_ins.item_num-1);
37
if ( v > v_best ) {
38
memcpy(x_best,x, ks_ins.item_num
39
* sizeof(int)
40
/ sizeof(char));
41
v_best = v;
42
}
43
k = ks_ins.item_num -1;
44
}
45
} else {
46
break;
47
}
48
}
49 }
Figura 4.4: Algoritmo Branch & Bound para o Problema da Mochila, em C
66
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
read_instance(filename, &ks_ins);
x = (int *) calloc(ks_ins.item_num, sizeof(int));
branch(ks_ins, x, 0);
v = 0;
ks_sol.x = (int *) myalloc(ks_ins.item_num, sizeof(int));
ks_sol.v = dotprod(ks_ins.item_value, x, 0, ks_ins.item_num - 1);
memcpy(ks_sol.x, x, ks_ins.item_num * sizeof(int) / sizeof(char));
v = dotprod(ks_ins.item_value, x, 0, ks_ins.item_num - 1 );
k = ks_ins.item_num - 1;
while ( 1 ) {
while ( (k > 0) && (x[k] == 0) )
k = k - 1;
if ( k == ks_ins.item_num - 1) {
x[k] = 0;
continue;
}
if ( k > 0 ) {
x[k] = x[k] - 1;
if ( bound(ks_ins, x, k, ks_sol.v) ) {
continue;
} else {
branch(ks_ins, x, k + 1);
v = dotprod(ks_ins.item_value, x, 0, ks_ins.item_num - 1 );
update_best_sol(ks_ins, &ks_sol, x, v);
k = ks_ins.item_num - 1;
}
}
else
break;
}
free(x);
free(ks_sol.x);
free_instance(&ks_ins);
Figura 4.5: Algoritmo C com primitivas básicas para o Problema da Mochila
67
que o envio de várias pequenas, pois minimiza trocas de mensagens (DONGARRA et al.,
2003).
É nítido que, ao possibilitar o ajuste do tamanho do bloco enviado, na Decomposição
por Blocos, pode-se encarar a Decomposição Cíclica como um caso especial desta, onde
o tamanho do bloco é 1 (DONGARRA et al., 2003). Adicionalmente, para o Problema da
Mochila, é interessante distribuir um ramo da árvore, contado da raiz, para cada processo;
logo, o número de elementos que compõe a entrada para os processos do algoritmo paralelo que resolve o Problema da Mochila são os valores que x1 (doravante referenciado
como o código C, x[0]) pode assumir. A implementação da função de distribuição da
entrada é apresentada na Figura 4.6. A função retorna o identificador do processo que
deve processar aquele elemento da entrada e seu significado é apresentado na Tabela 4.1.
int
owner(int num_procs, int block_size, int index)
{
int block = (int) index/block_size;
int p = block % num_procs;
return p;
}
Figura 4.6: Função que realiza a distribuição cíclica da entrada.
Variável
Significado
int num_procs
Número total de processos.
int block_size Tamanho de bloco desejado.
int index
Posição da entrada a qual será distribuída.
Tabela 4.1: Significado das variáveis na função de distribuição cíclica da entrada.
Quando block_size é 1, há um simples hash da entrada, calculado através do módulo. Esta abordagem é a adotada, visto que o algoritmo não é do tipo mestre-escravo;
todos os processos calculam o valor ótimo de seus ramos, sem precisar receber a entrada
de alguém. Como não há envio (fora a distribuição inicial de dados que o MPI realiza
de forma transparente) de dados a processar e todos os processos possuem, inicialmente,
a entrada replicada, convém optar pela simples Distribuição Cíclica, visto os benefícios
óbvios que esta traz em relação ao balanceamento de carga; blocos muito grandes agregam fragmentação externa e, possivelmente, os processos de ranks (identificadores) mais
elevados computariam menos que processos de ranks mais baixos. A inserção desse mecanismo, bem como os preâmbulos MPI necessários à paralelização podem ser vistos
na Figura 4.7, onde a estrutura ks_sol guarda a solução (a distribuição em x[] que
apresenta o valor máximo, ks_sol.x e esse valor, ks_sol.v .).
A implementação apresentada do algoritmo que resolve o Problema da Mochila, paralelizado, ainda está incompleta; cada processo encontra sua distribuição de valor máximo
local, mas não há comunicação entre eles para determinar qual o melhor global, dentre
todos os ramos analisados. Este processo será abordado no capítulo seguinte, quando será
inserido num contexto mais complexo, ao se tratar de Difusão de Máximo Local, na parte
que tange o Workstealing.
68
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
read_instance(filename, &ks_ins);
x = (int *) calloc(ks_ins.item_num, sizeof(int));
branch(ks_ins, x, 0);
v = 0;
ks_sol.x = (int *) calloc(ks_ins.item_num, sizeof(int));
ks_sol.v = dotprod(ks_ins.item_value, x, 0, ks_ins.item_num - 1);
memcpy(ks_sol.x, x, ks_ins.item_num * sizeof(int) / sizeof(char));
int num_procs; // Number of procs.
int my_rank;
// Current proc’s rank.
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
v = dotprod(ks_ins.item_value, x, 0, ks_ins.item_num - 1 );
k = ks_ins.item_num - 1;
while ( 1 ) {
while ( (k > 0) && (x[k] == 0) )
k = k - 1;
if ( k == ks_ins.item_num - 1) {
x[k] = 0;
continue;
}
if ( k > 0 ) {
x[k] = x[k] - 1;
if ( my_rank == owner(num_procs, 1, x[0]) ) {
if ( bound(ks_ins, x, k, ks_sol.v) ) {
continue;
} else {
branch(ks_ins, x, k + 1);
v = dotprod(ks_ins.item_value, x, 0,
ks_ins.item_num - 1 );
update_best_sol(ks_ins, &ks_sol, x, v);
k = ks_ins.item_num - 1;
}
}
}
else
break;
}
free(x);
free(ks_sol.x);
free_instance(&ks_ins);
MPI_Finalize();
Figura 4.7: Algoritmo C/MPI paralelizado.
69
5
WORKSTEALING
Este capítulo se dedica a apresentar técnicas de otimização do algoritmo paralelo
Branch & Bound que resolve o Problema da Mochila apresentado nos capítulos anteriores. O foco dessas técnicas será a técnica de Workstealing (BLUMOFE; LEISERSON,
1994), que busca garantir um balanceamento de carga ideal e distribuição homogênea
das tarefas entre os processos. Antes disso, no entanto, é necessário corrigir a deficiência apresentada no final do Capítulo 4, Problema da Mochila, oferecendo uma maneira
de comparar os máximos locais e obter um máximo global. Essa correção não faz parte
do algoritmo de WS em si. No entanto, como ambos são implementados com a mesma
arquitetura, é interessante os colocar em seqüência.
5.1
Difusão de Máximo Local
A questão não é apenas a difusão dos máximos locais ao final da computação de todos
os processos. É interessante que os processos, durante a execução das tarefas a eles atribuídas, tenham a informação de qual é o atual valor máximo global; com isso, é possível
otimizar o uso do bound de forma a cortar um número maior de galhos que não apresentam potencial para obter uma solução ótima. Esta troca de informações, entretanto, deve
permitir que os processos continuem a computar, enquanto esperam por uma notificação
de que um novo melhor foi encontrado.
A maneira mais eficiente de esperar a notificação mencionada seria através do uso
de Threads. Entretanto, as implementações MPI ainda não conseguem ter um comportamento estável quando utilizam tal recurso. Uma solução paliativa, no caso, é o emprego
de comunicação não-bloqueante.
5.1.1
Algoritmo
O algoritmo empregado é bem simples, onde segue
1. Ao achar um novo máximo local, fazer um broadcast não-bloqueante a todos os
processos;
2. Um processo, ao receber uma notificação de que existe um novo melhor local, compara este, recebido na notificação, com o que possui (ks_sol.v). Então, duas
coisas podem ocorrer:
(a) Substituição do atual melhor, local, pelo melhor global. Neste caso uma indicação de que o atual melhor não foi encontrado pelo processo local é indicada zerando-se todos os elementos do vetor que fornece a melhor solução,
ks_sol.x;
70
(b) Não substituição do melhor local pelo global. Pode acontecer se os tempos
relativos entre a descoberta e o envio do novo máximo, entre dois ou mais
processos, for aproximado. Neste caso, a mensagem é simplesmente descartada.
3. Ao final de sua execução, um processo envia uma mensagem de fim de execução a
todos os outros.
4. Ao receber a mensagem de fim, o processo subtrai uma unidade do número de
processos ativos, que todos os processos guardam.
5.1.2
Implementação
A implementação desta difusão é de especial interesse, pois é construída com a mesma
arquitetura que é empregada na implementação do Workstealing.
MPI não possui uma implementação de broadcast assíncrono, por questões de deadlock. Logo, deve-se implementar tal recurso e, ainda, garantir que o deadlock não
ocorra. A prova formal de que ele não ocorre será apresentada no Capítulo 6, Avaliação
de Desempenho. Apenas sua implementação isenta de travas é mostrada. O broadcast
assíncrono, ao mandar uma mensagem, é implementado pela função vista na Figura 5.1,
onde MPI_Send(...) é usado no lugar de MPI_Isend porque poupa gerenciamento
de buffer e não depende de outros processos para se desbloquear. Apenas o recebimento
desta mensagem deve ser não-bloqueante, para a sincronização.
int
mpi_assync_broadcast(void *data, int num_item, MPI_Datatype datatype,
int tag, MPI_Comm comm, int num_procs, int my_rank)
{
int i;
for ( i = 0; i < num_procs; ++ i )
if ( i != my_rank )
MPI_Send(data, num_item, datatype, i, tag, comm);
return 1;
}
Figura 5.1: Implementação de broadcast assíncrono.
Para gerenciar o recebimento destes dados, é necessária uma lógica mais mais complexa. A opção escolhida foi montar um estrutura de dados gerenciadora, com todas as
variáveis e funções (interface) implementadas de maneira modular, por dois motivos:
1. Dar suporte futuro a uma biblioteca feita sobre MPI para a Difusão de Máximo
Local genérica; e
2. Melhor encapsulamento, controle e depuração, ao eliminar replicação de código.
A definição do gerenciador de difusão é dada na Figura 5.2. Os dois MPI_Request
atendem, cada um, um tipo de mensagem, em modelo semelhante ao que foi abordado na
Subseção 3.2.5. v_global guarda o atual melhor notificado e num_active_procs
guarda quantos processos ainda estão ativos, para prevenir o deadlock, através da primitiva1 mpi_process_nonblocking(...), explanada a seguir.
1 Note-se
que, até aqui, todas as funções implementadas que usem alguma primitiva MPI tem seu nome
71
/* Message Types. */
#define NEW_BEST_MSG
#define END_MSG
0
1
struct mpi_dif_manager_s {
MPI_Request request_end_msg;
MPI_Request request_new_best_msg;
int v_global;
int null; // For unimportant data.
int num_active_procs;
int whoinf; // Who gave this data.
};
void mpi_init_dif_manager(struct mpi_dif_manager_s *mpi_man,
int num_procs);
void mpi_free_dif_manager(struct mpi_dif_manager_s *mpi_man);
void mpi_process_nonblocking(struct mpi_dif_manager_s *mpi_man,
struct ks_solution_s *ks_sol,
struct ks_instance_s ks_ins);
int active_procs_remain(struct mpi_dif_manager_s mpi_man);
int mpi_nonblocking_broadcast(void *data,
int num_item,
MPI_Datatype datatype,
int tag,
MPI_Comm comm,
int num_procs,
int my_rank);
Figura 5.2: Implementação do gerenciador de difusão.
72
A função mpi_process_nonblocking(...) testa a recepção de uma mensagem de fim de computação ou de novo máximo local encontrado e deve ser invocada toda
vez que se quiser tratar o recebimento de uma mensagem de difusão ao longo do código.
Como o próprio nome já diz, ela é não bloqueante. Isso torna a verificação atômica e
garante tempo de processamento reservado. Em geral é útil invocá-la a cada nova geração
de um conjunto candidato a solução x[], dando-lhe periodicidade. O tratamento dessa
mensagem é feito automaticamente pela função, bem como a atualização do atual melhor
valor (através do ponteiro para ks_sol), de maneira transparente ao programador, que
não precisa adicionar linhas de código para tratar cada mensagem.
Esta transparência da mpi_process_nonblocking(...) tem pouco efeito sobre a lógica do algoritmo, simplificando a programação. No entanto, o tratamento destas
mensagens exige certos detalhes que a função deve atender, para que não haja deadlock.
A implementação desta função pode ser observada na Figura 5.3.
void
mpi_process_nonblocking(struct mpi_dif_manager_s *mpi_dif_man,
struct ks_solution_s *ks_sol,
struct ks_instance_s ks_ins )
{
int flag;
// Flag for non-blocking comm.
MPI_Status status; // Status for recv-like comm.
MPI_Test(&(mpi_dif_man -> request_new_best_msg), &flag, &status);
if ( flag != 0 ) {
if ( (mpi_dif_man -> v_global) >= (ks_sol -> v) ) {
ks_sol -> v = mpi_dif_man -> v_global;
mpi_dif_man -> whoinf = status.MPI_SOURCE;
}
MPI_Irecv(&(mpi_dif_man -> v_global),
1,
MPI_INT,
MPI_ANY_SOURCE,
NEW_BEST_MSG,
MPI_COMM_WORLD,
&(mpi_dif_man -> request_new_best_msg));
}
MPI_Test(&(mpi_dif_man -> request_end_msg), &flag, &status);
if ( flag != 0 ) {
-- (mpi_dif_man -> num_active_procs);
MPI_Irecv(&(mpi_dif_man -> null),
1,
MPI_INT,
MPI_ANY_SOURCE,
END_MSG,
MPI_COMM_WORLD,
&(mpi_dif_man -> request_end_msg));
}
}
Figura 5.3: Implementação de mpi_process_nonblocking().
precedido por mpi_. Faz-se isso para (a) diferenciar as funções implementadas na especificação MPI e as
específicas do problema, (b) identificar, facilmente, quais funções fazem E/S de troca de mensagens em alto
nível.
73
A função mpi_init_dif_manager(...) inicializa as requests e a função acima
testa o recebimento de mensagens sobre elas, chamando-as novamente após o recebimento de alguma mensagem. Ao receber uma mensagem de fim, simplesmente subtrai o
número de processos ativos de uma unidade.
Quando um processo acaba sua computação e envia sua mensagem de fim a todos
os outros, é necessário que ele cancele seus receives não-bloqueantes. No entanto, esta
abordagem simplista introduz alguns problemas, a saber:
1. Os processos não tem controle de quais outros processos acabam, apenas do número total dos processos ativos. Logo, os outros processos vão enviar mensagens
normalmente que, sem ninguém para recebê-las, esgotarão o buffer;
2. Mesmo que um controle seja implementado, pode ser que o processo se encerre
existindo mensagens destinadas a ele transitando na rede, lotando o buffer;
3. Se for optado por não cancelar os receives, então a LAM MPI travará quando chamar MPI_Finalize(...), pois ocorrerá deadlock dentre seus processos (para
que a LAM MPI encerre, é necessário que os buffers de mensagens estejam vazios,
ou seja, que todos os sends tenham um receive correspondente).
A solução para evitar o deadlock, neste caso, é fazer com que todos os processos só
cancelem as suas comunicações não-bloqueantes quando tiverem certeza de que nenhum
dos outros processos pode mandar mensagens ou que mensagens estão em trânsito; em
outras palavras, um processo só deve para de receber mensagens quando todos chegarem
ao final.
A solução óbvia que surge é a implementação de um algoritmo de detecção de término
distribuído (JAJA, 1992). No entanto, o cenário de aplicações de um algoritmo deste
tipo é mais restrito, sem comunicação broadcast, e, por isso, sua implementação é mais
complexa do que o necessário.
Algo que serve bem para sanar o problema apresentado é uma sincronização do tipo
barreira2 (TOSCANI; OLIVEIRA; SILVA CARíSSIMI, 2003). De fato, MPI oferece
MPI_Barrier(...) para esse propósito. No entanto, a solução MPI não é adequada;
os processos não podem ficar parados enquanto os outros processos computam, sendo
necessário que eles ainda possam receber notificações de novos melhores encontrados
para que, ao final da computação, todos tenham a mesma resposta (global) que soluciona
o problema.
É necessário implementar um mecanismo de barreira de mais alto nível, em que um
processo, ao acabar sua computação, fique apenas recebendo notificações de novo máximo ou de fim de processo. Apenas quando uma mensagem de fim é recebida de todos
os outros processos é que o processo se encerra. Tal mecanismo, no entanto, é de fácil
implementação (ao final do código), conforme a Figura 5.4. A cada mensagem de fim
que chega, o número de processos ativos é decrementado e, apenas quando todos informam isto é que todos estão livres para terminar a computação. Isto também garante que
condições de corrida não ocorram; um ponto de barreira, ao final, garante que todos os
processos de fato receberam a última mensagem de notificação, anterior à mensagem end
e que todos possuem a mesma resposta.
A integração do código mostrado com a Difusão de Máximo Local é mostrado na
Figura 5.5.
2 Uma
sincronização em que todos os fluxos de programa ficam parados ao atingirem certo ponto do
código e só prosseguem quando todos estiverem neste mesmo ponto.
74
/* Prevents deadlock and the race condition. */
while ( active_procs_remain(mpi_dif_man) )
mpi_process_nonblocking(&mpi_dif_man, &ks_sol, ks_ins);
Figura 5.4: Implementação do mecanismo de barreira.
5.2
Workstealing
A técnica de Workstealing (BLUMOFE; LEISERSON, 1994) é um conceito formalizado academicamente, mas que ainda não encontrou uma implementação genérica que
se estabelecesse como padrão de facto. Muitos autores publicaram sua síntese sob outros
nomes e.g., árvore de busca paralela (PACHECO, 1997), mas a essência do algoritmo é
mantida.
A técnica tem, por objetivo, obter uma balanceamento de carga entre os processos.
Isto significa que, ao garantir uma distribuição igualitária de tarefas, os processos ficarão menos ociosos e, portanto, será obtida uma exploração maior do paralelismo. Além
disso, o método possui robustez suficiente para equilibrar cargas que, pela definição do
problema, são naturalmente desbalanceadas (e.g., árvore degenerada). Esta monografia se
propõe a provar, na prática, se esta solução obtém o ganho de desempenho teórico a que
se propõe.
5.2.1
Algoritmo
Os elementos necessários para a implementação são:
1. Cada processo possuir uma pilha de tarefas. Estas tarefas são, ao longo da execução,
desempilhadas e processadas;
2. Mensagens específicas, definidas previamente, de solicitação de trabalho, de resposta com envio de trabalho e resposta vazia.
A seqüência clássica de operações (BLUMOFE; LEISERSON, 1994) realizadas pelos
processos consiste em
1. Caso a pilha de tarefas não esteja vazia, desempilhar as tarefas, seqüencialmente, e
realizá-las, uma a uma;
2. Caso a pilha estiver vazia, escolher aleatóriamente um processo e solicitar trabalho
para este;
3. Se o processo fornecer tarefas, empilha-las e ir para 1. Caso contrário, ir para 4;
4. Caso o processo não forneça tarefas, repetir 2 até que se receba uma tarefa ou um
timeout pré-definido seja atingido;
5. Parar.
No início do algoritmo tradicional, todos os processos começam com suas pilhas vazias, a exceção de um, cuja pilha contém todas as tarefas. Desta maneira, o balanceamento
de carga ocorre naturalmente, enquanto o algoritmo se desenvolve.
75
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
(...INIT VARs...)
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
v = dotprod(ks_ins.item_value, x, 0, ks_ins.item_num - 1 );
k = ks_ins.item_num - 1;
while ( 1 ) {
while ( (k > 0) && (x[k] == 0) )
k = k - 1;
if ( k == ks_ins.item_num - 1) {
x[k] = 0;
continue;
}
if ( k > 0 ) {
x[k] = x[k] - 1;
if ( my_rank == owner(num_procs, 1, x[0]) ) {
if ( bound(ks_ins, x, k, ks_sol.v) ) {
continue;
} else {
branch(ks_ins, x, k + 1);
v= dotprod(ks_ins.item_value, x, 0, ks_ins.item_num-1);
if ( update_best_sol(ks_ins, &ks_sol, x, v) ) {
/* The one that have the maximum is me! */
mpi_dif_man.whoinf = my_rank;
/* Broadcast the new local maximun. */
mpi_assync_broadcast(&(ks_sol.v), 1, MPI_INT,
NEW_BEST_MSG, MPI_COMM_WORLD, num_procs,
my_rank );
}
}
}
}
else
break;
}
mpi_nonblocking_broadcast(&(ks_sol.v), 1, MPI_INT, END_MSG,
MPI_COMM_WORLD, num_procs, my_rank);
38
39 /* Prevents deadlock and the race condition. */
40 while ( active_procs_remain(mpi_dif_man) )
41
mpi_process_nonblocking(&mpi_dif_man, &ks_sol, ks_ins);
42 /* Cancels the non-blocking comms. */
43 mpi_free_dif_manager(&mpi_dif_man);
44
45 free(x);
46 free(ks_sol.x);
47 free_instance(&ks_ins);
48 MPI_Finalize();
Figura 5.5: Algoritmo C/MPI paralelizado e com Difusão de Máximo Local.
76
5.2.2
Considerações
Para fins da aplicação neste trabalho, o algoritmo clássico sofreu algumas modificações. Tais modificações foram introduzidas visando obter maior desempenho, modificando certas premissas do algoritmo original. As alterações foram inseridas com especial
cuidado para evitar a ocorrência de deadlocks, já que tocam na questão da sincronização
do envio de mensagens.
Inicialmente, ao invés de um único processo possuir a pilha cheia, todas as pilhas são
abastecidas com tarefas via Distribuição Cíclica (vide Subseção 4.5.2). Isso faz com que
o fluxo de troca de mensagens grande que ocorre no início o Workstealing cesse, o que
provoca:
1. Menor execução de primitivas de troca de mensagens (E/S);
2. Menor tráfego na rede;
3. Balanceamento de carga inicial (diminui a necessidade de troca de mensagens ao
longo da execução);
4. Melhor aproveitamento do tipo de entrada do problema considerado (Problema da
Mochila).
Todos os fatores acima parecem contribuir para um aumento direto do desempenho (a
ser verificado no Capítulo 6, Avaliação de Desempenho.). Além disso, visando melhorar a
distribuição de processos, a estrutura de dados que armazena tarefas não é uma pilha, mas
sim uma fila de distribuição dupla (double sided queue3 ). Esta organização permite que
o a resolução das tarefas enxergue a estrutura de dados como uma pilha e que o roubo de
tarefas enxergue a mesma situação como uma fila (Figura 5.6). Como, heuristicamente,
as soluções que maximizam os elementos inicias de x[] oferecem maior potencialidade
de serem a solução ótima, pode-se empilhá-las por último. Isto garante um bom índice
de bound (pois serão desempilhadas primeiro) ao mesmo tempo em que, ao atender uma
solicitação de roubo, o processo fornecerá tarefas menos promissoras, que são ideais para
sofrerem um maior atraso, devido a latência de rede.
Outras alterações foram feitas para coibir a ocorrência de postergação indefinida. Ao
imaginar um cenário onde a mesma tarefa é repassada circularmente entre todos os processos, sem nunca ser processada e sem nunca atingir o timeout fica evidente que, dentro
do modelo clássico, a postergação indefinida é possível. Para contornar esta situação,
adotam-se duas medidas:
1. Apenas uma tarefa é passada por vez a cada solicitação de tarefas atendidas; e
2. Uma tarefa recebida por meio de workstealing é imediatamente processada e não
pode ser repassada.
O primeiro item tem implementação trivial. O segundo, no entanto, é mais complicado; a função que trata o recebimento de mensagens se comunica com os processos
apenas via pilha. Para contornar esta limitação, opta-se por restringir o uso da primeira
posição da pilha; qualquer tarefa alocada neste espaço nunca é enviada por Workstealing.
Como, ao solicitar tarefas, um processo indica que sua pilha está vazia, qualquer tarefa
recebida se alojará nesta posição e não correrá o risco de ser repassada.
3 Esta
estrutura de dados que possui característica de incluir dados somente através de um ponteiro para
início da fila, mas de retirar dados através de qualquer uma de suas extremidades.
77
Figura 5.6: Esquema de funcionamento – Fila de Distribuição Dupla
Estas simples medidas claramente (a) evitam que uma tarefa seja repassada ad infinitum (eliminando o risco de postergação indefinida) e (b) uniformizam e simplificam o
processo de implementação do Workstealing.
5.2.3
Implementação
Seguindo a ordem apresentada na subseção anterior, primeiramente deve-se modificar o código para que este processe o conceito de tarefas e consiga empilhar estas tarefas numa estrutura de fila de distribuição dupla. Inicialmente, o problema foi modelado
definindo-se uma tarefa como um conjunto x[] (galho) e a computação dessa tarefa como
o cálculo do valor de sua utilidade e sua comparação com a melhor utilidade local. Essa
abordagem, no entanto, revelou-se muito ruim, pois gera:
Mal aproveitamente de recursos computacionais. A complexidade do Problema da Mochila reside na geração de todos os conjuntos x[] e não no cálculo de seu valor.
Balancear a tarefa menos complexa é um grande fator de desperdício de recursos,
pois a tarefa mais pesada fica desbalanceada;
Consumo intratável de memória. Em testes realizado no cluster, a execução desse problema com 100 elementos consumiu memória RAM na ordem de 2GB. Como a
geração de conjuntos é uma operação exponencial e cada conjunto tem um grande
número de elementos, o consumo de memória torna-se, também, exponencial, o
que é intratável.
A abordagem alternativa (e que foi adotada), é considerar que uma tarefa é um número
inteiro, que representa um dos valores possíveis de x[0]. Com isso, cada tarefa passa a
ser o cálculo de todas as sub-árvores cujo primeiro elemento possui o valor associado ao
inteiro que representa a tarefa. Essa abordagem sana os defeitos da aproximação anterior
ao problema.
Definindo uma pilha e a noção de tarefa, a estrutura de dados (com a respectiva interface) é implementada conforme a Figura 5.7.
78
struct task_dfq_s {
struct task_dfq_node_s *start;
struct task_dfq_node_s *end;
int size;
};
struct task_dfq_node_s {
int task;
struct task_dfq_node_s *next;
struct task_dfq_node_s *previous;
};
int init_dfq(struct task_dfq_s* dfq);
int pop(struct task_dfq_s* dfq, int task);
int push_front(struct task_dfq_s* dfq);
int push_back(struct task_dfq_s* dfq);
int is_empty(struct task_dfq_s dfq);
int get_size(struct task_dfq_s dfq);
Figura 5.7: Implementação da fila de distribuição dupla.
A inserção do conceito de pilha no código é simples (Figura 5.8), mas tem uma consideração importante. Como agora os valores de x[0] não iniciam necessariamente no
máximo (pois esse valor representa uma tarefa), o valor de x[1] é que deve ser maximizado, visando uma execução correta do algoritmo guloso de geração de galhos.
O próximo passo é implementar a troca de mensagens em si. Para isso, usa-se uma
construção análoga ao gerenciador de difusão apresentado anteriormente. Conforme já
explicitado, um dos focos do trabalho realizado é oferecer as bases a um futuro suporte
de uma biblioteca Workstealing genérica. Embora alguns fatores ainda dependam fortemente de elementos do Problema da Mochila, sua generalização é simples, mesmo que
trabalhosa. Procurou-se, aqui, oferecer uma versão primitiva da abordagem de callbacks,
presente em linguagens de paradigma de Orientação a Objetos, que permite uma generalização fortíssima a qualquer aplicação, bastando reescrever algumas funções que são
chamadas internamente, em operações desta biblioteca.
Todas as considerações apresentadas sobre a construção de ambos os gerenciadores
mantém a validade, gerando, inclusive, funções colocadas nos mesmos lugares. A estrutura de dados do gerenciador Workstealing é visitada na Figura 5.9. As funções da interface do gerenciador mais importantes são mpi_ws_process_nonblocking(...)
(responsável por atender às requisições de roubo) e mpi_workstealing(...) (responsável por fazer as solicitações de roubo).
A função mpi_ws_process_nonblocking(...), como o próprio nome sugere, é extremamente semelhante a mpi_process_nonblocking(...), tendo modelos idênticos. É verificado se chegou mensagem de solicitação de tarefas
(WS_REQUEST_WORK_MSG) e o tratamento dado consiste em, verificando se a pilha do
atual processo tem tarefas, enviá-las ao processo solicitante (mensagem tipo
WS_TASK_MSG) ou enviar uma mensagem de que não há tarefa disponível
(WS_EMPTY_MSG). O cancelamento do receive é efetuado após a saída da barreira estabelecida pela Difusão de Máximo Local, aproveitando sua característica de ponto de
retenção, para também evitar deadlock.
A essência do algoritmo, no entanto, reside na função mpi_workstealing(...).
Procura-se, ao máximo, dar transparência a esta função, que intermedia o acesso à pilha
79
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
mpi_init_dif_manager(&mpi_dif_man, num_procs);
// Builds a task and initializes the "stack".
init_dfq(&task_stack);
for ( i = 0; i <= x[0]; i ++ )
if ( my_rank == owner(num_procs, 1, i) )
pop(&task_stack, i);
// Points to end of the array, for dissembling the recursivity.
k = ks_ins.item_num - 1;
while ( ! is_empty(&task_stack) ) {
x[0] = push_front(&task_stack);
branch(ks_ins, x, 1);
v = dotprod(ks_ins.item_value, x, 0, ks_ins.item_num - 1 );
while ( 1 ) {
mpi_process_nonblocking(&mpi_dif_man, &ks_sol, ks_ins);
while ( (k > 0) && (x[k] == 0) )
k = k - 1;
if ( k == ks_ins.item_num - 1) {
x[k] = 0;
continue;
}
if ( k > 0 ) {
x[k] = x[k] - 1;
if ( bound(ks_ins, x, k, ks_sol.v) ) {
continue;
} else {
branch(ks_ins, x, k + 1);
v = dotprod(ks_ins.item_value, 0, ks_ins.item_num-1 );
if ( update_best_sol(ks_ins, &ks_sol, x, v) ) {
mpi_dif_man.whoinf = my_rank;
mpi_nonblocking_broadcast(&(ks_sol.v), 1, MPI_INT,
NEW_BEST_MSG, MPI_COMM_WORLD, num_procs,
my_rank );
}
k = ks_ins.item_num - 1;
}
}
else
break;
}
}
mpi_assync_broadcast(&(ks_sol.v), 1, MPI_INT, END_MSG, MPI_COMM_WORLD,
num_procs, my_rank);
46
47 /* Prevents deadlock and the race condition. */
48 while ( active_procs_remain(mpi_dif_man) )
49
mpi_process_nonblocking(&mpi_dif_man, &ks_sol, ks_ins);
50 mpi_free_dif_manager(&mpi_dif_man);
51 (...)
52 MPI_Finalize();
Figura 5.8: Algoritmo C/MPI, versão com fila de distribuição dupla
80
/* Message Types */
#define WS_REQUEST_WORK_MSG
#define WS_TASK_MSG
#define WS_EMPTY_MSG
2
3
4
/* Request Types. */
#define WS_NUM_MSG_TYPE
#define WS_TASK_REQUEST
#define WS_EMPTY_REQUEST
2
0
1
struct mpi_ws_manager_s {
MPI_Request request_ws_work_msg;
struct ks_instance_s *ks_ins;
struct task_dfq_s *stack;
struct proc_table_s ws_proc_table;
int my_rank;
int num_procs;
int null;
};
int mpi_init_workstealing(struct mpi_ws_manager_s *workst, struct
task_dfq_s *stack, struct ks_instance_s *ks_ins, int my_rank, int
num_procs );
int mpi_workstealing(struct mpi_ws_manager_s *workst);
int mpi_free_workstealing(struct mpi_ws_manager_s *workst);
int mpi_ws_process_nonblocking(struct mpi_ws_manager_s *workst);
Figura 5.9: Implementação do gerenciador de Workstealing.
de tarefas e, se esta se encontra vazia, faz a solicitação de tarefas. Encarando-se como
uma máquina de estados, isso traz a seqüência:
1. Se existem tarefas na pilha, entrega a tarefa do topo da pilha ao processo;
2. Caso não exista tarefa na pilha, escolhe, dentre todos os processos, um, aleatoriamente;
3. Requisita-se tarefa ao processo escolhido;
4. Recebendo-se uma tarefa, entrega-a ao processo;
5. Recebendo uma negativa de tarefa, marca-se o processo em uma tabela como sem
tarefas, escolhe-se outro processo e repetindo-se a tentativa;
6. Caso todos os processos existentes estejam marcados como sem tarefas, acaba-se a
computação.
Note-se que o timeout é suprimido; é garantido, pela abordagem da implementação
(já apresentada), que não há risco de postergação indefinida. Adicionalmente, pode-se
notar que, uma vez que um processo seja identificado como sem tarefas, não há risco
de ignorar-se uma eventual realimentação da pilha; como já foi estatizado, o algoritmo é
implementado sem que esta ocorra, para que uma tarefa não seja repassada ad infinitum.
Na Figura 5.10, a estrutura de tabela de processos que foi empregada. O código da função
mpi_process_nonblocking(...) pode ser visto na Figura 5.11. O código do
programa com as partes relevantes, todo integrado com o que foi apresentado, pode ser
visto na Figura 5.12.
81
struct proc_table_s {
int *vector;
int size;
};
int init_proc_table(struct proc_table_s *table, int num_procs);
int free_proc_table(struct proc_table_s *table);
int set_all_active(struct proc_table_s *table);
int set_all_inactive(struct proc_table_s *table);
int set_proc_active(struct proc_table_s *table, int proc_rank);
int set_proc_inactive(struct proc_table_s *table, int proc_rank);
int is_proc_active(struct proc_table_s *table, int proc_rank);
int exist_active_proc(struct proc_table_s *table);
Figura 5.10: Implementação da tabela de processos.
82
1 int
2 mpi_workstealing(struct mpi_ws_manager_s *workst)
3 {
4
int i;
5
int msg;
6
int target_proc;
7
int task = 0;
8
int ws_flag;
9
MPI_Request ws_request[WS_NUM_MSG_TYPE];
10
MPI_Status ws_status;
11
int ws_index;
12
13
if ( ! is_empty(*(workst -> stack)) )
14
return 1;
15
set_all_active(&(workst -> ws_proc_table));
16
set_proc_inactive(&(workst -> ws_proc_table), workst -> my_rank);
17
18
while ( exist_active_proc(&(workst -> ws_proc_table)) ) {
19
20
do { target_proc = rand() % (workst -> num_procs); }
21
while ( ! is_proc_active(&(workst -> ws_proc_table),
target_proc) );
22
23
msg = WS_REQUEST_WORK_MSG;
24
MPI_Send(&msg, 1, MPI_INT, target_proc, WS_REQUEST_WORK_MSG,
MPI_COMM_WORLD);
25
MPI_Irecv(&task, 1, MPI_INT, target_proc, WS_TASK_MSG,
MPI_COMM_WORLD, &(ws_request[WS_TASK_REQUEST]) );
26
MPI_Irecv(&task, 1, MPI_INT, target_proc, WS_EMPTY_MSG,
MPI_COMM_WORLD, &(ws_request[WS_EMPTY_REQUEST]) );
27
28
ws_flag = 0;
29
do {
30
MPI_Testany(WS_NUM_MSG_TYPE, ws_request, &ws_index,
31
&ws_flag, &ws_status );
32
mpi_ws_process_nonblocking(workst, benchmark);
33
} while ( ws_flag == 0 );
34
for (i = 0; i < WS_NUM_MSG_TYPE; i ++)
35
if ( i != ws_index)
36
MPI_Cancel(&(ws_request[i]));
37
38
switch ( ws_status.MPI_TAG ) {
39
case WS_TASK_MSG :
40
pop(workst -> stack, task);
41
return 1;
42
43
case WS_EMPTY_MSG :
44
set_proc_inactive(&(workst -> ws_proc_table),
45
ws_status.MPI_SOURCE);
46
break;
47
}
48
}
49
return 0;
50 }
Figura 5.11: Solicitação de tarefas - Workstealing.
83
1 (...)
2 while ( mpi_workstealing(&workst) ) {
3
x[0] = push_front(&task_stack);
4
branch(ks_ins, x, 1);
5
v = dotprod(ks_ins.item_value, x, 0, ks_ins.item_num - 1 );
6
while ( 1 ) {
7
mpi_process_nonblocking(&mpi_dif_man, &ks_sol, ks_ins);
8
mpi_ws_process_nonblocking(&workst);
9
while ( (k > 0) && (x[k] == 0) )
10
k = k - 1;
11
if ( k == ks_ins.item_num - 1) {
12
x[k] = 0;
13
continue;
14
}
15
if ( k > 0 ) {
16
x[k] = x[k] - 1;
17
if ( bound(ks_ins, x, k, ks_sol.v) ) {
18
continue;
19
} else {
20
branch(ks_ins, x, k + 1);
21
v = dotprod(ks_ins.item_value, x, 0,
22
ks_ins.item_num - 1 );
23
if ( update_best_sol(ks_ins, &ks_sol, x, v) ) {
24
mpi_dif_man.whoinf = my_rank;
25
mpi_nonblocking_broadcast(&(ks_sol.v), 1, MPI_INT,
NEW_BEST_MSG, MPI_COMM_WORLD, num_procs,
my_rank );
26
}
27
k = ks_ins.item_num - 1;
28
}
29
}
30
else
31
break;
32
}
33 }
34 mpi_nonblocking_broadcast(&(ks_sol.v), 1, MPI_INT, END_MSG,
MPI_COMM_WORLD, num_procs, my_rank);
35
36 /* Prevents deadlock and the race condition. */
37 while ( active_procs_remain(mpi_dif_man) ) {
38
mpi_process_nonblocking(&mpi_dif_man, &ks_sol, ks_ins);
39
mpi_ws_process_nonblocking(&workst, &benchmark);
40 }
41 mpi_free_dif_manager(&mpi_dif_man);
42 mpi_free_workstealing(&workst);
43 (...)
Figura 5.12: Implementação MPI com Workstealing.
84
6
AVALIAÇÃO DE DESEMPENHO
Este capítulo dedica-se a medir e avaliar o desempenho da aplicação implementada e
discutida nos capítulos anteriores.
Os itens a serem avaliados foram:
1. velocidade de execução;
2. utilização de memória;
3. balanceamento de carga.
Todos os testes foram realizados no cluster labtec, do GPPD/UFRGS. Os experimentos foram realizados utilizando 10 UCPs Pentium III 1.1 GHz com 1 GiB de memória
RAM. A rede de comunicação é Gigabit Ethernet.
6.1
Implementação
Para se efetuar as medições, foi criada uma estrutura gerenciadora de benchmarks.
Certas funções desta estrutura são chamadas quando um evento ocorre e as medições
vão sendo registradas. Ao final da execução, tudo é impresso em um arquivo que tem o
formato visto na Figura 6.1 e cujo significado é descrito na Tabela 6.1.
EXTIME > xxxx
MUSAGE[0] > xxxx
STACK[0] > xxxx
WSSEND[0] > xxxx
WSRECV[0] > xxxx
.
.
.
MUSAGE[<num_proc-1>] > xxxx
STACK[<num_proc-1>] > xxxx
WSSEND[<num_proc-1>] > xxxx
WSRECV[<num_proc-1>] > xxxx
Figura 6.1: Formato do arquivo de saída.
Por condição de corrida, não se pode garantir que as medições serão impressas no arquivo na ordem desejada, visto que os tempos relativos dos processos variam. No entanto,
o script Python construído para processar os dados do benchmark faz uma análise léxica
do arquivo e obtém os dados corretos.
85
Item
EXTIME > xxxx
MUSAGE[n] > xxxx
STACK[n] > xxxx
Significado
Programa executado em xxxx segundos
Processo n consumiu xxxx bytes de memória.
Tamanho inicial da pilha de tarefas do processo
n em bytes.
WSSEND[n] > xxxx Número de tarefas enviadas por Workstealing
no processo n.
WSRECV[n] > xxxx Número de tarefas recebidas por Workstealing
no processo n.
Tabela 6.1: Significado dos arquivos de saída do programa.
A estrutura de benchmark deve ser passada como parâmetro em algumas funções,
modificando seu protótipo; as modificações introduzidas, no entanto, são mínimas. Considerações mais relevantes sobre esta implementação serão feitas quando necessário. A
interface da estrutura é apresentada na Figura 6.2. As funções do tipo set_flag informam se aquele parâmetro deve ser medido, enquanto as do tipo get têm função óbvia.
myalloc(...) tem função específica, abordada mais adiante.
struct benchmark_s {
int EXTIME_FLAG;
int MEM_FLAG;
int VERBOSE_FLAG;
int LOAD_FLAG;
double start_time;
int mem_usage;
int sstack;
int nwssend;
int nwsrecv;
};
void init_benchmark(struct benchmark_s *benchmark);
void set_extime_flag_on(struct benchmark_s *benchmark);
void set_mem_flag_on(struct benchmark_s *benchmark);
void set_verbose_flag_on(struct benchmark_s *benchmark);
void set_load_flag_on(struct benchmark_s *benchmark);
void *myalloc(int nvar, int svar, struct benchmark_s *benchmark);
int get_mem_usage(struct benchmark_s *benchmark);
void start_time_count(struct benchmark_s *benchmark);
double get_time_count(struct benchmark_s *benchmark);
int get_stack_size(struct benchmark_s *benchmark);
int get_wssend(struct benchmark_s *benchmark);
int get_wsrecv(struct benchmark_s *benchmark);
Figura 6.2: Interface da estrutura de Benchmark.
6.2
Elaboração dos Casos de Teste
Os casos de teste foram gerados automaticamente por um script Python escrito especialmente para isso. O script recebe como parâmetro o número de itens total e fornece, para
cada item, um valor de utilidade e um peso. Tal programa produz estes valores de maneira
86
aleatória, o que introduz um problema: é difícil gerar casos bem balanceados1 por causa
do advento do bound; não importa o quão grande seja uma entrada, bounds realizados
com sucesso no início da execução fazem o tempo de resolução ser muito pequeno2 .
É conveniente, para a análise de desempenho, que o tempo de resolução seja diretamente proporcional ao tamanho da entrada do algoritmo sempre e não apenas no pior
caso. Baseado nisso, as seguintes medidas são tomadas para obter o cenário da avaliação:
• Desabilitar o bound no programa sendo testado;
• O gerador de casos de teste gera itens com o peso máximo equivalente a metade
da capacidade da mochila para, heuristicamente, tentar usar mais itens distintos na
solução encontrada;
• O gerador de casos de teste gera utilidades diversas de 1 a 1000 para os itens,
para que, heursticamente, o espaço do valor de utilidades se distribua entre os itens
de maneira homogênea (sem muitas ocorrências de itens com o mesmo peso mas
utilidades diferentes), visando reduzir o número de itens “mortos”, quem sempre
são preteridos.
Por heurísticas se entendem medidas que produzem o efeito esperado intuitivamente
ou em um grande número de execuções, mas que não funcionam sempre.
É importante salientar que desenhar este cenário não é tendencioso; o que se faz é
uniformizar o número de operações realizadas com o tamanho da entrada para obter um
comportamento pessimista e com isso evidenciar a efetividade (ou não) dos mecanismos
implementados.
Para determinar um bom espaço de testes, foram feitos alguns testes preliminares, com
número, valores e pesos de elementos ajustados empiricamente e 10 UCPs. Em 10000 e
15000 encontrou-se um limite superior para o número de itens, graças à complexidade
exponencial do problema. O primeiro consumiu 7 horas de processamento do cluster e
o segundo, 2 dias3 . Com 2500 elementos, porém, o tempo de resolução foi de ∼ 20 segundos para 10 processos e ∼ 120 segundos para um processo. Como deve-se determinar
uma média dos tempos de execução via múltiplas execuções (vide Seção 6.3), este tempo
mostrou-se adequado ao número de testes realizados, elegendo-se este como o número de
elementos máximo empregado no teste.
Vale destacar que, como o valor total deve ser maximizado, sem estar sujeito a restrições, os valores individuais de cada item não tem relevância sobre a o número de conjuntos solução gerados. Ao contrário, o peso desses itens em relação ao peso da mochila
determina o número de galhos da árvore de possibilidades. Logo, é interessante se fixar
uma capacidade máxima da mochila de tal maneira que os pesos representem um espaço
de variedade grande, gerando conjuntos-solução diversificados. Através de alguns testes
com poucos elementos, chegou-se ao número fixo 5000 para a capacidade da mochila e
um valor de peso máximo igual à metade disso, de modo a gerar, no máximo, 2500 valores de pesos diferentes possíveis, o que, no pior caso (para os 2500 elementos postulados
1 Um
algoritmo que faça isso é, provavelmente, mais custoso computacionalmente do que resolver o
Problema da Mochila! Isso decorre de que, para verificar se um caso possui uma árvore bem-equilibrada, é
preciso executar n vezes um programa que resolva o Problema da Mochila.
2 Isto não diminui a complexidade do problema; no pior caso o bound é inefetivo.
3 Muito embora a política do cluster no que se refere a walltime não permita este período, resultados parciais foram guardados (estado das pilhas) e, após, a execução é retomada, carregando as pilhas armazenadas
ao invés de refazer a distribuição cíclica.
87
anteriormente), geram todos os itens de pesos diferentes. Em todas as execuções realizadas foram usados de 1 a 10 UCPs no processamento do problema, oferecidos pelo cluster
labtec.
O número de elementos iniciais escolhidos, empiricamente, foram 15, 50, 100, 1000,
2500, que apresentaram tempos mensuráveis de execução (a complexidade exponencial
faz com que cada elemento, ao ser elevado, aumente bastante o tempo de processamento).
Note-se que, na prática, a complexidade do algoritmo nunca atinge o valor pessimista
apresentado (O((C/min{p1 , . . . , pn })n )), pois muitos elementos, de valor relativo muito
baixo jamais são considerados para entrarem na mochila. Elevar a capacidade da mochila para considerar estes elementos é redundante, pois o limite superior de elementos
processados em tempo tratável seria apenas deslocado.
Para calcular-se os fatores medidos, toma-se a média aritmética das grandezas, visando uniformidade da medição. No entanto, a média só é confiável quando a análise do
desvio padrão é feita; se os valores, a cada execução, forem muito distantes da média, ela
não representará o tempo de execução do caso normal, pois pode ser o reflexo de uma
deturpação muito grande em alguns dos dados. Para fins de execução deste programa,
o seguinte algoritmo é adotado, visando determinar o número de execuções necessárias
para a obtenção de uma média confiável:
1. Escolher uma constante N (e.g, 20), que representa o número inicial de execuções;
2. Elege-se um número ε (e.g, 0.01), que representa a margem de distância desejada
em relação à média;
3. Roda-se N testes, calculando a média (x) e o desvio padrão (s) destes;
4. Se s < ε × x, então acabou. Caso contrário faz-se N ← N + k (e.g, k = 10) e volta-se
a 3.
Após algumas execuções, discutidas no Apêndice A, montou-se os casos de teste com
• 30 execuções;
• conjuntos de 1000, 1500, 1800, 2000 e 2500 elementos; e
• número de UCPs utilizadas variando de 1 a 10.
6.3
Velocidade de Execução
Esta seção dedica-se a avaliar três aspectos da velocidade de execução do programa
apresentado: a análise do tempo de execução, o speedup e a eficiência.
6.3.1
Análise do Tempo de Execução
A Figura 6.3 mostra os tempos de execução em contraste com o número de elementos processados, para execuções de 1 a 10 processos. É interessante observar que com
1800 elementos o comportamento sofre uma leve distorção, seja qual for o número de
processos. Como foram procedidas várias execuções, é evidente que não se trata de uma
anomalia isolada. Surge a hipótese de que o advento da aplicação do Workstealing tenha
surtido tal efeito, visto que o roubo de tarefas não tem um comportamento constante, pois
é modificado por uma condição de corrida entre a execução dos processos. Um fator mais
88
forte, no entanto, para esta distorção, seria o caráter aleatório do gerador de casos de teste;
mesmo com o bound desabilitado, é possível que os valores relativos se distribuam de tal
forma que a capacidade da mochila seja exaurida facilmente logo no início do algoritmo,
gerando uma árvore degenerada, com um conjunto de possíveis soluções muito menor a
ser gerado. Contudo, como, ao aumentar o número de processos, a anomalia se torna mais
evidente, não se pode descartar a influência do workstealing, pois o aumento do número
de processos leva a tamanhos iniciais de pilha menores, mais mensagens do protocolo de
roubo de tarefas trocadas e, por conseqüência, maior impacto no desempenho.
O ganho de desempenho obtido ao aumentar-se o número de processos é progressivamente menor, graças ao custo de comunicação que cresce; esse valor tende a convergir
para um valor ótimo a partir do qual o aumento do número de processos é inefetivo. Tal
fato é evidenciado pela Figura 6.4.
Figura 6.3: Gráfico tempo de execução (número de elementos vs. tempo em segundos).
6.3.2
Speedup
Conforme apresentado anteriormente, o speedup, ou seja, o ganho de desempenho
relativo ao uso de vários processadores, pode ser calculado por
Sp =
T (1)
T (n)
usando-se n processadores. Numa situação ideal, S p = n.
Por usar-se a função MPI_Wtime(...) para o cálculo do tempo e pela necessidade
de igualar os ambientes de execução (que é a noção de máquina virtual oferecida pelo
89
Figura 6.4: Gráfico tempo de execução (número de processos vs. tempo em segundos).
MPI), a versão seqüencial é executada em ambiente MPI, mas não faz testes de verificação
de ranking ou de comunicação. O gráfico correspondente pode ser visto na Figura 6.5.
A imagem que representa o speedup agrega pouca informação de desperdício de
tempo, pois as retas são na maior parte do tempo constantes, paralelas e sobrepostas,
exceto quando o número de processos fica perto de 10, onde começam a se diferenciar,
sinal de que a comunicação (incluindo aí o Workstealing) começa a pesar (de fato, mais
para frente é mostrado que, quanto maior o número de processos, mais tarefas tendem a
ser roubadas). Essa constatação mostra que o comportamento do algoritmo proposto se
aproxima do ideal.
Pode-se usar o gráfico de speedup como um teste de regressão linear e verificar que,
comparados com a função pt (t sendo o tempo de execução e p o número de processos),
as retas apresentadas aproximam-se da reta que o teste gera para a mesma função. Em
outras palavras, o speedup evidencia que até que se atinja o valor ótimo no qual não se
ganha velocidade, o gráfico do número de processos pelo tempo se comporta como uma
parábola e, após, o tempo de execução tende a ser constante.
6.3.3
Eficiência
O conceito de eficiência é dado por:
Ep =
T (1)
T (p) × p
Para uma entrada de tamanho n e usando-se p processadores. Numa situação ideal,
90
Figura 6.5: Gráfico Speedup.
E p = 1. O gráfico correspondente pode ser observado na Figura 6.6.
A imagem da Eficiência, ao contrário do speedup, consegue evidenciar melhor as discrepâncias introduzidas pela comunicação (troca de mensagens). Até um número razoável
de processos empregados (∼ 5) o decaimento é o esperado, em virtude da comunicação
normal da distribuição cíclica da entrada. No entanto, para um número de processos maiores, começa-se a observar distorções fora do padrão, provavelmente introduzidas pelo
advento do Workstealing. Uma análise mais consistente será feita na Seção 6.5, Balanceamento de Carga.
6.4
Consumo de Memória
O consumo de memória representa parte importante da avaliação de desempenho,
pois tem impacto direto na velocidade de execução e no esforço computacional realizado.
Além disso, através dessa medição, pode-se estimar se a técnica de Workstealing, em
troca de balanceamento de carga, não eleva o consumo de memória consideravelmente4 .
Um programa corretamente escrito libera toda a memória que aloca. Este fator desagrega a capacidade de medição do uso de memória. Além disso, não adianta estabelecer
um “checkpoint” no código, pois a memória é alocada e desalocada em posições diferentes da programação. Para solucionar este dilema, aborda-se o pior caso e avalia-se o
4 Disso
também depende a boa implementação do algoritmo; o mesmo problema pode gerar consumo
linear(e.g, cada tarefa é um inteiro, como nesta implementação) ou exponencial (e.g., cada tarefa é um
conjunto candidato à solução) da memória.
91
Figura 6.6: Gráfico Eficiência.
somatório de toda a memória alocada do programa.
Para se registrar a memória alocada, na implementação em C, construiu-se a primitiva
myalloc(...), que substitui malloc(...), registra na estrutura de benchmark a
quantidade de memória requerida e, somente após, aloca essa memória ao usuário. Ao
final da execução, tem-se o somatório de todas as chamadas de alocação de memória
realizadas pelo usuário.
Foi verificado, através do framework para a supervisão de execução de programas
Valgrind (NETHERCOTE; SEWARD, 2003), que não existe memória não-liberada ao
final da execução do programa e, portanto, não compromete a máquina em que está sendo
executado.
É importante observar que a memória usada por um processo nem sempre é constante; como a função usada para fazer as medições é uma função do tipo somatório, há
certa irregularidade na obtenção do consumo total de memória por culpa do Workstealing.
Quando se rouba tarefas, mais memória é alocada em função das tarefas recebidas e isso
desbalanceia o somatório. No entanto, dado o tamanho restrito das mensagens, essa diferença é pequena (mas, como já mencionado anteriormente, aumenta com o aumento do
número de processos). Naturalmente para a execução com 1 processo o desvio padrão é
0, visto que não há Workstealing (a memória ocupada é constante para cada entrada.).
Ao final, a memória consumida por todos os processos é somada. Obtém-se o consumo de memória médio por processo dividindo-se esse somatório pelo número total de
processos. Os gráficos que ilustram o consumo de memória (média por processo) são
vistos nas Figuras 6.7 e 6.8.
É evidente que quanto mais processos, mais se divide a entrada dentre as pilhas de
92
Figura 6.7: Gráfico Consumo de Memória (número de elementos vs. memória em bytes).
tarefas e o consumo de memória diminui. Pode-se notar, por observação, que o empilhamento das tarefas por Workstealing não tem contribuição significativa, para poucos
processos. Isso, pela análise das estruturas de dados, é normal; como há uma distribuição
cíclica da entrada (que contém centenas de elementos) no início, a troca de alguns inteiros tem influência pequena sobre o somatório final, a não ser que sejam muitas trocas,
que ocorrem mais freqüentemente com o aumento do número de processos. A Figura 6.7
mostra que o aumento de consumo de memória é linear; ao se adicionar um elemento, as
estruturas de dados empregadas crescem proporcionalmente, resultando numa reta dentro
da comparação gráfica. A Figura 6.8 mostra o mesmo cenário, pela óptica do número de
processos utilizado em função da memória alocada.
6.5
Balanceamento de Carga
Para medir a efetividade do balanceamento de carga é importante, antes, relembrar
que, diferentemente do WS original (BLUMOFE; LEISERSON, 1994), aqui se faz uma
distribuição cíclica da entrada antes da execução do algoritmo, para otimizá-lo. Isso implica num impacto menor da adoção da técnica no algoritmo. Além disso, as pilhas entre
os processos sempre serão carregadas com b ep c ou d ep e (onde p é o número de processos
e e o número de elementos da entrada).
As medições são feitas quanto ao número de tarefas efetivamente recebidas e efetivamente enviadas5 ; requisições não são levadas em conta, pois pode ser que não sejam
5 Este
é um número total de mensagens, e não a média. Logo, não faz sentido falar em desvio-padrão,
93
Figura 6.8: Gráfico Consumo de Memória (número de processos vs. memória em bytes).
atendidas. Devido às requisições não atendidas, o tempo de obtenção de uma tarefa pode
variar pois, tanto o primeiro quanto o último processo tentado pode possuir as tarefas,
sendo impossível medir o tempo associado à obtenção da tarefa, mesmo em uma rede
ideal.
Ao invés de medir as requisições não atendidas, adota-se um simplificação matemática para o problema: pode-se mensura o caso médio do atendimento de uma solicitação
(atendida com p−1
2 tentativas) ou o pior caso da mesma situação (atendimento em p − 1
tentativas), de modo a adequar a análise ao grau de pessimismo que se quer empregar.
Para fins desta monografia, trata-se apenas das tarefas recebidas e enviadas.
É interessante observar a heterogeneidade do comportamento, frente à variação do
número de elementos e processos, conforme as Figuras 6.9 e 6.10. Como sends e receives
são complementares, basta avaliar uma das operações e considerá-la em dobro caso queira
se avaliar ambas.
Fica claro o não-determinismo implícito da ocorrência de Workstealing ao se comparar os gráficos apresentados. Embora não sirvam para se traçar uma função, é importante
ressaltar que eles não tem utilidade nula; dadas alterações não esperadas nas medições
de desempenho e/ou consumo de memória, é possível, usando os dados apresentados, ter
evidências de que as alterações são provocadas pela ocorrência de atividades de roubo de
tarefas, naquele contexto. Por exemplo, ao observar a Figura 6.6, Eficiência, observa-se
que, para 1800 elementos, na transição do proessamento com 8 para o processamento
com 9 processadores, há uma queda abrupta de eficiência, que foge ao padrão teórico.
neste caso
94
Figura 6.9: Gráfico mensagens enviadas/recebidas (num. de elementos vs. num. de
mensagens).
95
Figura 6.10: Gráfico mensagens enviadas/recebidas (num. de processos vs. num. de
mensagens).
96
Ao verificar a Figura 6.10, Mensagens Enviadas/Recebidas vemos que, com 9 processos houve um acréscimo considerável de troca de mensagens por causa do Workstealing
implementado, justificando o comportamente observado.
É importante salientar que as observações mostradas são válidas apenas para o Workstealing como foi implementado aqui. A técnica original (BLUMOFE; LEISERSON,
1994) difere em vários aspectos dessa versão e pode não responder da mesma maneira
ao testes realizados.
6.6
Impacto de Utilização do Workstealing
Até agora, todas as medições apresentadas e análises se valiam do programa implementado com os recursos de WS habilitados e funcionando. No entanto, uma das propostas da monografia é responder se o Workstealing traz ganho real de desempenho ao
buscar o balanceamento de carga em um ambiente paralelo. Além disso, caso este benefício seja percebido é necessário, também, determinar o quanto de memória pode ter sido
sacrificado em prol do aumento de desempenho.
Conforme já mencionado, a ocorrência de roubo de tarefas aumenta com o aumento do
número de processos. Além disso, um cenário com bastantes elementos também oferece
uma maior chance de que aconteçam roubos. Desta maneira, os testes foram feitos com
2500 elementos e variando-se de 1 a 10 processos, o máximo de elementos e processos
das medições anteriores. Além disso, foi calculada a média de execução que satisfez
um desvio padrão menor ou igual que 0.01, obtida com 30 execuções. O resultado das
comparações pode ser observado nas Figuras 6.11 (tempo de execução) e 6.12 (consumo
de memória).
Observando as Figuras, é fácil perceber que a introdução de Workstealing traz um
grande ganho de desempenho para um número elevado de processos, visto que o tempo
de execução passou de ∼ 80 segundos para ∼ 20 segundos com 10 UCPs, um aumento de
velocidade de aproximadamente 25%, sem, no entanto, apresentar diferença significativa
no consumo de memória.
Vale destacar que o ganho obtido vale para essa implementação do Problema da Mochila; não é garantido que a técnica traga o mesmo ganho quando aplicadas em outros
problemas; fatores como o encapsulamento da noção de tarefas, latência da rede e natureza do problema podem afetar este resultado.
Devido ao emprego de Workstealing, os tempo de execução, com carga balanceada,
são menos suscetíveis a atrasos de uma UCP, pois o trabalho desta, no meio tempo, é distribuído entre as outras, enquanto na abordagem convencional as UCPs que já acabaram
o trabalho ficam ociosas.
6.7
Deadlock
Para validar todas as medições encontradas, é importante provar a corretude do programa, em especial a ausência de deadlocks. Lembrando, existem 3 condições básicas
para a ocorrência de deadlock (TOSCANI; OLIVEIRA; SILVA CARíSSIMI, 2003):
1. quando um processo que já possui um recurso pode requisitar outro recurso;
2. quando os recursos alocados a um processo não podem ser preemptados;
3. quando é possível a formação de um ciclo (cadeia fechada) no qual cada processo
97
Figura 6.11: Impacto do WS: tempo de execução.
está bloqueado à espera de recursos que estão alocados para outros processos do
mesmo ciclo.
Inexistindo uma destas condições, garante-se que não ocorrer deadlock. No programa
que resolve o Problema da Mochila (versão final), existem duas partes passíveis da ocorrência da trava: a Difusão de Máximo Local e o Workstealing. A prova formal de que
estes trechos não apresentam deadlock é apresentada a seguir.
Fica claro, também, a capacidade de adaptação que o algoritmo tem em ambientes
heterogêneos; quanto maior a discrepância entre a eficiência dos processadores de uma
máquina paralela, mais Workstealing tende a ser realizado, visto que os processos possuirão velocidades de esvaziamento da pilha diferentes e os processos mais lentos tendem a
doar tarefas a processos mais rápidos.
6.7.1
Difusão de Máximo Local
Neste algoritmo, como foi implementado, a única chance de um processo se bloquear
é na barreira, ao final do programa; ao longo da execução não há dependência alguma
do recebimento de mensagens para a computação; a barreira é o único ponto onde um
processo fica bloqueado.
Pode-se entender o bloqueio do processo como uma entrada em um estado de espera
do qual só é libera (sendo p o número de processos) ao receber os p−1 tokens informando
o fim dos outros processos; neste caso, o recurso a ser consumido são tokens de final, ao
qual cada processo possui, inicialmente, p − 1 tokens que distribui ao fim de sua computação e espera pelo recebimento de outros p − 1 tokens, oriundos um de cada processo. A
98
Figura 6.12: Impacto do WS: consumo de memória
prova da não-ocorrência deadlock baseia-se no fato de que (1) não procede e é feita por
absurdo:
Teorema (Algoritmo DML × Deadlock). O algoritmo de Difusão de Máximo Local implementado não entra em deadlock.
Prova. (absurdo). Sejam um processo pi e um número de processos n tal que i ∈ {1, . . . , n}.
Supõe-se que (1) é válido:
(1) é válido
∃pi | (pi possui token não-enviado) ∧ (pi espera por tokens de outros processos)
pi possui token não-enviado
pi não acabou a computação.
−→
−→
−→
no entanto,
(1) é válido
∃pi | (pi possui token não-enviado) ∧ (pi espera por tokens de outros processos)
pi espera por tokens de outros processos
pi acabou a computação.
−→
−→
−→
o que é um absurdo; logo, (1) deve se falso.
6.7.2
Workstealing
O algoritmo de Workstealing tem dois pontos críticos, que podem originar deadlock:
a barreira ao final do programa e a solicitação de uma tarefa. Muito embora o programa
99
possa se bloquear no primeiro caso, a barreira não depende de recursos da parte de Workstealing, mas sim exclusivamente dos recursos do algoritmo DML; a prova de que esta
parte não entra em trava mortal foi apresentada no Teorema “Algoritmo DML × Deadlock”.
Resta provar que, ao solicitar uma tarefa de outro processo, é impossível ocorrer um
ciclo entre todos os processos, logo (3) não é válido. Nos casos apresentados a seguir, o
recurso a ser consumido é uma tarefa como definida anteriormente, que pode ser empilhada (recurso disponível) ou executada (recurso consumido). É importante lembrar que
algumas implicações são válida pois partem dos códigos já apresentados do programa;
em especial, é importante relembrar
1. um processo que está no aguardo de uma solcitação de Workstealing pode atender
sempre requisições de tarefas de outros processos; e
2. há sincronização sobre a pilha de tarefas.
Teorema (Algoritmo WS × Deadlock). O algoritmo de Workstealing implementado não
entra em deadlock.
Prova. (direta) Quer se provar que (3) é inválido pois um processo pode atender outro
mesmo que esteja na esperando por tarefas. Seja um número de processos n e a ← b
significa que “a está bloqueado, à espera de uma resposta de b”.
∀i ∈ {1, . . . , n}(pi ← pi+1 )
−→
(p1 ← p2 ) ∧ (p2 ← p3 ) ∧ · · · ∧ (pn−1 ← pn ) ∧ (pn ← p1 )
no entanto, p1 responde à solicitação de pn , conforme postulado:
(p1 responde a pn )
∀i ∈ {1, . . . , n}(pi ) é desbloqueado
(3) não ocorre.
−→
−→
100
7
CONCLUSÕES
Este capítulo apresenta conclusões construídas sobre todo o processo definido ao
longo desta monografia, baseado nos capítulos anteriores.
7.1
Problema da Mochila × Paralelização
Conforme referido no Capítulo 4, o Problema da Mochila é um problema NP-Completo,
o que significa que possui complexidade exponencial quando processado por uma máquina não-determinística. O advento da paralelização consegue diminuir o tempo de execução do algoritmo. No entanto, tal advento não reduz a complexidade do problema; a
curva de crescimento exponencial persiste para soluções paralelas do problema.
A paralelização, no entanto, mostra-se especialmente relevante na execução prática
do problema. Relativamente ao número de elementos apresentados, o ganho no tempo de
execução foi grande para o escopo experimentado.
O resultado mais importante obtido nesta área, no entanto, foi a constatação de que
é possível paralelizar o Problema da Mochila e esta solução paralela se beneficia do emprego de WS, verificando a hipótese apresentada no Capítulo 1.
7.2
Implementação
Um dos pontos a serem verificados é a possibilidade de se construir uma biblioteca
que implemente o Workstealing de maneira transparente ao usuário; por ser um algoritmo
que depende fortemente das estruturas de dados sobre as quais atua, existe a possibilidade
de que não se possa construir uma biblioteca robusta e portável simultaneamente.
Verifica-se que a construção da biblioteca é viável e, ao longo da monografia, propô-se
estruturas de dados e interfaces para essas estruturas genéricas. Tais construções conseguiram mostrar, na implementação do código:
Encapsulamento. As funções a serem chamadas englobam detalhes de protocolos que
não são interessantes aos usuários, permitindo que este se foque na resolução do
problema a que se propõe.
Portabilidade. Como usa apenas bibliotecas-padrão da linguagem C e MPI, a solução é
portável para a maioria dos sistemas que ofereçam suporte a ambos os padrões.
No entanto, a implementação ainda não está em estágio satisfatório para a montagem
de uma biblioteca autônoma; existem fortes dependências das estruturas em relação à
paralelização específica do Problema da Mochila. Tais dependências impedem que a
abordagem seja genérica o suficiente em relação aos tipos de problema utilizados.
101
A solução para o problema da dependência das estruturas de dados foi prototipada
apenas, pois sua implementação foge ao escopo da monografia. Para atender ao problema,
utiliza-se de estruturas de dados (e.g, pilha de tarefas) e funções-chave (interfaces para as
estruturas) que necessitam ser reescritas pelo usuário e fornecidas como parâmetros para
certas subrotinas que atendem ao protocolo. Tal abordagem é conhecida como “utilização
de callbacks” e é especialmente popular no contexto de linguagens orientadas a objetos.
A biblioteca padrão de C (stdlib.h) usa a mesma abordagem para prover funções de
ordenamento genéricas.
7.3
Desempenho
Uma das questões-chave do trabalho desenvolvido é o impacto do uso da técnica de
Workstealing no desempenho de um programa paralelo. Objetiva-se verificar se a adoção
do método impacta num ganho (pelo balanceamento de carga) ou num custo (pelos custos
de comunicação) adicional ao programa paralelo sendo executado.
O capítulo 6 mostrou que há uma ganho perceptível de desempenho ao se utilizar a
técnica de WS nesta implementação. Este não é um resultado absoluto, pois depende,
também, da eficiência com que as estruturas de dados de pilhas de tarefas é gerenciada
e das características das máquinas que executam o programa. Em outras palavras, esse
ganho não pode ser generalizado para qualquer aplicação que, porventura, utilize uma biblioteca genérica baseada no algoritmo apresentado, muito embora um largo contingente
de aplicações possa se beneficiar disto.
O trabalho é desenvolvido sobre máquinas homogêneas (clusters homogêneos). Essa
fato é importante, como evidencia a seguinte linha de pensamento:
1. o Workstealing clássico tem um alto custo de comunicação no início, tendo desempenho inferior ao obtido ao se fazer uma simples decomposição cíclica da entrada;
2. o Workstealing sobre a decomposição cíclica (conforme apresentado aqui) é efetivo
quando existe disparidade entre as velocidades de processamento dos nós, pois processos ociosos (mais rápidos) roubam carga dos processos cheios de tarefas (mais
lentos), o que incrementa a velocidade global de resolução do problema.
O último item implica que quanto mais diferença houver entre as velocidades dos
vários processadores, mais o efeito do Workstealing será proveitoso. Para um cluster
homogêneo, a velocidade de processamento de pilhas do mesmo tamanho tende a ser a
mesma, deixando um número pequeno de tempo ocioso e, ainda, tendo de arcar com o
custo de comunicação de requisições não atendidas, fazendo do WS, apesar de efetivo,
uma técnica que não desenvolve todo o seu potencial.
Grids e clusters heterogêneos, por outro lado, permitem que a técnica atinja seu ápice
de eficiência (mesmo que isto implique, no caso de grids, um perda de desempenho nãodesejável para o usuário); existe bastante diferença entre a capacidade de cada nó e isso
provoca a ociosidade latente de aplicações paralelas, sanada adequadamente pelo Workstealing clássico.
Vale lembrar que implementação apresentada, não oferece um suporte consistente para
a execução em Grids, conforme discutido na próxima seção.
102
7.4
WS Clássico × Implementação
Conforme referido, o algoritmo implementado difere do algoritmo clássico do WS,
pois, na implementação apresentada, em especial, há distribuição cíclica da entrada.
Tal medida é implementada para fins de desempenho, visto que a execução em ambiente MPI (em arquiteturas do tipo cluster) possui uma replicação natural de processos
e entradas que evita o grande número de solicitações iniciais feitas para o processo que
possui todas as tarefas, no algoritmo clássico.
Tal ganho, entretanto, desagrega flexibilidade ao modelo original. Embora otimize
o desempenho num contexto MPI/cluster, tal implementação não é facilmente generalizada para outros tipo de arquiteturas (e.g., grids), que tem um caráter mais dinâmico
das máquinas e processos que participam da computação e, portanto, não há garantia da
replicação de entrada que MPI proporciona. No contexto onde os processos só recebem
informações da entrada via troca de mensagens, a implementação apresentada falha (pois
se baseia fortemente na replicação da entrada), enquanto o WS clássico funciona sem
problemas.
7.5
Escalabilidade
Para um número de elementos elevado, surgem duas questões referentes à escalabilidade da solução quando o problema cresce: a ocorrência de deadlocks e o consumo
elevado de memória.
Demonstrou-se formalmente, no Capítulo 6, que o algoritmo implementado não entra
em deadlock. Além disso, o controle de deadlock não impacta em redução de desempenho significativa, conforme apresentado. A inexistência de travas mortais comprovada
genéricamente faz com que o ambiente de execução ganhe heterogeneidade; é altamente
provável que o algoritmo se comporte como o esperado independentemente do ambiente
sobre o qual executa.
Já o consumo de memória não é inerente à implementação. Por mais que a solução
desenvolvida consuma pouca memória e mantenha um patamar aceitável, uma biblioteca
genérica não pode gozar da mesma propriedade; a implementação dos callbacks de pilha
de tarefas, a cargo do usuário, é quem gerencia a quantidade de memória ocupada por
cada pilha. É importante destacar que isso exige especial atenção na implementação de
um programa NP-Completo; como deve haver a geração de todos os conjuntos-solução
possíveis (que crescem exponencialmente), é altamente aconselhável que não se empilhem estes conjuntos, sob risco de uso exponencial da memória.
Além de ser escalável (comporta-se como esperado quando o problema aumenta),
a solução apresentada também é bem-escalável, ou seja, continua eficiente quando se
aumenta o tamanho do problema. Além disso, o algoritmo apresentado tende a ser mais
eficiente para tamanhos de problema maiores, onde o percentual de tempo gasto com a
comunicação é percentualmente menor.
7.6
Trabalhos Futuros
Alguns trabalhos futuros relacionados a esta monografia incluem
Construção da Biblioteca. O trabalho apresentado mostra um esqueleto e guias para a
construção de uma biblioteca genérica e transparente de Workstealing. O próximo
passo, natural, é a construção desta biblioteca.
103
Uso de MPI-2. A especificação MPI-2 oferece a criação dinâmica de processos, ou seja,
novos processos podem ser criados e alocados a processadores a medida em que
surge a necessidade. É interessante investigar até onde esta possibilidade contribui
para a realização do WS, sobretudo no caso de Grids.
Medição em Grids e Clusters Heterogêneos. As medições foram realizadas em um cluster homogêneo. Seria interessante fornecer dados precisos sobre a performance do
algoritmo em um cluster heterogêneo ou grid, visando comprovar a sua escalabilidade e enumerando as modificações necessárias que o código deve sofrer para
suportar este contexto;
Migração de Processos. Seria interessante agregar o algoritmo de Workstealing a um escalonador de processos MPI. Para tanto, deve-se trabalhar na construção específica
de um gerenciador de escalonamento que consiga abstrair processos como tarefas
e, com isso, comutar tarefas através do uso de algoritmos de migração de processos.
104
APÊNDICE A
ANÁLISE DOS CASOS DE TESTE
Este anexo dedica-se a discutir a obtenção dos valores apresentados no Capítulo 6,
Avaliação de Desempenho, utilizados para a realização dos testes envolvendo tempo de
execução, consumo de memória e troca de mensagens. Para todas as medições, ε = 0.01.
A.1
Tempo de Execução
A Figura A.2 ilustra os resultados de tempo de execução para todos os números de
elementos (15, 50, 100, 2500), de 1 a 10 processos com . O formato apresentado é visto
na Figura A.1 e seu significado na Tabela A.1.
[<num_elem>,<num_proc>] [EXT = xxx] [DPAD = xxx] <state>
Figura A.1: Formato da tabela de resultados do benchmark.
Item
<num_elem>
<num_proc>
EXT = xxx
DPAD = xxx
<state>
Significado
Número de elementos.
Número de processadores.
Média dos tempos de execução para as N execuções.
Desvio padrão.
OK, caso s < ε × x. FAIL, caso contrário.
Tabela A.1: Significado dos símbolos da tabela de resultados do benchmark.
A Figura A.2 mostra que, para menos do que 1000 elementos e tomando-se ε = 0.01,
a média obtida não é satisfatória. Nos casos onde o número de processos é igual a 1,
a média, óbviamente, é satisfatória sempre, visto que ela é igual às suas parcelas e, por
isso, o desvio padrão é o menor possível. Aparentemente há certa dificuldade em obter
um valor médio satisfatório para um número reduzido de elementos. Para verificar isso,
segue-se o algoritmo proposto no Capítulo 6 para obtenção da média, define-se o valor de
k = 20 e se faz uma nova bateria de testes, com N = 30 (Figura)
A situação torna a não convergir para poucos elementos. Pode-se traçar duas possibilidades para tal ocorrência:
1. Para casos muito pequenos, o tempo de execução também é muito pequeno. Logo,
o poder de representação da arquitetura do processador não consegue representar
os números decimais que representam os desvios-padrão, muito baixos;
105
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
[15,1]
[EXT
[15,2]
[EXT
[15,3]
[EXT
[15,4]
[EXT
[15,5]
[EXT
[15,6]
[EXT
[15,7]
[EXT
[15,8]
[EXT
[15,9]
[EXT
[15,10] [EXT
[50,1]
[EXT
[50,2]
[EXT
[50,3]
[EXT
[50,4]
[EXT
[50,5]
[EXT
[50,6]
[EXT
[50,7]
[EXT
[50,8]
[EXT
[50,9]
[EXT
[50,10] [EXT
[100,1] [EXT
[100,2] [EXT
[100,3] [EXT
[100,4] [EXT
[100,5] [EXT
[100,6] [EXT
[100,7] [EXT
[100,8] [EXT
[100,9] [EXT
[100,10] [EXT
[1000,1] [EXT
[1000,2] [EXT
[1000,3] [EXT
[1000,4] [EXT
[1000,5] [EXT
[1000,6] [EXT
[1000,7] [EXT
[1000,8] [EXT
[1000,9] [EXT
[1000,10][EXT
[2500,1] [EXT
[2500,2] [EXT
[2500,3] [EXT
[2500,4] [EXT
[2500,5] [EXT
[2500,6] [EXT
[2500,7] [EXT
[2500,8] [EXT
[2500,9] [EXT
[2500,10][EXT
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
0.0107576]
0.02639]
0.0337298]
0.0447095]
0.044959]
0.0528291]
0.0609]
0.063024]
0.0700221]
0.0717377]
0.0142862]
0.0198123]
0.029569]
0.029055]
0.0387701]
0.0374721]
0.0438698]
0.0534928]
0.053187]
0.0631203]
0.0422086]
0.0342021]
0.0339237]
0.0364187]
0.0418637]
0.0439955]
0.0498867]
0.0534728]
0.0591513]
0.0632516]
26.849526]
13.4566571]
8.9943672]
6.7585116]
5.4241147]
4.5401515]
3.9027259]
3.4260675]
3.0589852]
2.7664852]
167.2858947]
83.717032]
55.8893633]
42.01759]
33.757429]
28.2815779]
24.4468126]
21.6946972]
19.5886754]
18.0523394]
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
0.000339238100586]
0.0109487714887]
0.00142401832073]
0.00205701230213]
0.00293363771148]
0.00245342918517]
0.00304944956782]
0.00272217258005]
0.00449719044269]
0.00858316771426]
5.63674452927e-05]
0.00259086798197]
0.019246385144]
0.00157378242178]
0.0193391512077]
0.00132459750281]
0.00128360333091]
0.0140158684497]
0.00149727448682]
0.01259240406]
0.00016504558293]
0.00117051521894]
0.000824536779046]
0.00126314449336]
0.00586649501738]
0.00121264973875]
0.00798741355787]
0.00256856586877]
0.0113798287826]
0.00382172800358]
0.0288982616629]
0.0143115247608]
0.00888024790306]
0.00891155488583]
0.00422864740978]
0.00968449113249]
0.00457775945818]
0.00494981492928]
0.00351585073676]
0.00631425626465]
0.0752806144414]
0.0390441750138]
0.0191406907589]
0.0171415084713]
0.0236446289749]
0.0116703285491]
0.0212549473136]
0.0450827801559]
0.0490940156333]
0.0456056258905]
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
OK
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
OK
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
Figura A.2: Medição dos tempos de execução (10 execuções).
106
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
[15,1]
[15,2]
[15,3]
[15,4]
[15,5]
[15,6]
[15,7]
[15,8]
[15,9]
[15,10]
[50,1]
[50,2]
[50,3]
[50,4]
[50,5]
[50,6]
[50,7]
[50,8]
[50,9]
[50,10]
[100,1]
[100,2]
[100,3]
[100,4]
[100,5]
[100,6]
[100,7]
[100,8]
[100,9]
[100,10]
[1000,1]
[1000,2]
[1000,3]
[1000,4]
[1000,5]
[1000,6]
[1000,7]
[1000,8]
[1000,9]
[1000,10]
[2500,1]
[2500,2]
[2500,3]
[2500,4]
[2500,5]
[2500,6]
[2500,7]
[2500,8]
[2500,9]
[2500,10]
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
0.0106930666667]
0.0263158333333]
0.0324301666667]
0.0452368]
0.0498012333333]
0.0519160666667]
0.0605000333333]
0.0656367666667]
0.072859]
0.0689583333333]
0.0142467]
0.0194492333333]
0.0258476666667]
0.0291807666667]
0.0359899]
0.0392619333333]
0.0441116333333]
0.0520438333333]
0.0556016666667]
0.0610661]
0.0421672333333]
0.0343344666667]
0.0341094333333]
0.0367348666667]
0.0410060666667]
0.0441573333333]
0.0479009666667]
0.0547305]
0.0617156666667]
0.0650695]
26.852102]
13.4561770333]
8.99220156667]
6.76308713333]
5.42681156667]
4.53885793333]
3.9043424]
3.42688143333]
3.06061966667]
2.76708153333]
167.264477267]
83.7193909]
55.8895467667]
42.0201783333]
33.7555503]
28.2830196667]
24.4531655333]
21.6740607]
19.5902117]
18.0564178]
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
0.000203823441739]
0.0068566158642]
0.00233781246237]
0.00614348694315]
0.025044165907]
0.00242229953348]
0.00228690821979]
0.012495231404]
0.0213064093255]
0.00629709258765]
7.58270036523e-05]
0.00217931858511]
0.0111155109623]
0.0025677076679]
0.0125894234519]
0.00945302219484]
0.00212798322011]
0.0111664808153]
0.00802547821041]
0.0123452958802]
0.000132810646467]
0.00133704134858]
0.00102807274274]
0.00215245599472]
0.00399603013289]
0.00144612567616]
0.00479299221553]
0.0100921236402]
0.0141683640146]
0.0140342567454]
0.0288489445812]
0.0146939932812]
0.00827961494725]
0.0134307544759]
0.00856314744591]
0.0117236657087]
0.00794709719687]
0.00750067155899]
0.00946464069412]
0.0125237204887]
0.0972753907263]
0.0391541690631]
0.0250703633823]
0.0156450808144]
0.0266859214887]
0.0211015637273]
0.0331389888623]
0.0368826845733]
0.0419581238801]
0.0427533562805]
Figura A.3: Medição dos tempos de execução (30 execuções).
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
OK
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
OK
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
FAIL
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
107
2. O tempo de processamento é muito pequeno frente ao tempo de comunicação; o
programa gasta mais tempo na troca de mensagens do que fazendo o processamento
em si.
A primeira hipótese pode parecer razoável, mas basta uma olhada nos desvios-padrão
apresentados para verificar que ela falha; o menor desvio padrão apresentado (∼ 7.5827 ×
10−5 ) é verificado positivamente. A hipótese, portanto, é falha. A segunda hipótese parece ser a mais razoável; o alto tempo de latência que a troca de mensagens provoca supera
o tempo de processamento. Como os tempos de troca de mensagens dependem de uma
série da fatores quase aleatórios (carga da rede, ocupação dos buffers, etc.), os custos de
comunicação também são determinados aleatoriamente, o que faz com que estes números
nunca convirjam para uma média1 . Estes custos, de fato, são problemas recorrentes em
programação paralela, abordada em vários eventos da área (ESCOLA REGIONAL DE
ALTO DESEMPENHO, 2007).
Mediante isto, é útil, para fins de análise, usar mais elementos, afim de confirmar o
postulado. Baseado nos dados apresentados, tendo certeza que os valores, para mais de
1000 elementos, convergem, é conveniente escolher mais elementos do que este valor,
no caso, 1000, 1500, 1800, 2000, 2500. Para evitar a repetição desnecessária de testes,
usam-se, novamente, 30 execuções. Estes elementos, de fato, confirmam a conclusão
apresentada, como pode ser visto na Figura A.4.
A.2
Consumo de Memória
A Figura A.5 mostra o consumo de memória no mesmo formato em que é feita
a avaliação de desempenho, substituindo EXT (tempo de execução em segundos) por
MEM (memória consumida em bytes). As medições foram feitas, tal qual anteriormente,
respeitando-se a máxima distancia da média dada pelo desvio padrão.
A.3
Balanceamento de Carga
O recebimento e envio de tarefas é um fator aleatório, pois é resultado de uma condição de corrida. Isto pode ser evidenciado pela Figura A.6, onde se mostra o resultado
das 30 execuções para 2500 elementos e 10 processos, onde o referencial é o processo de
número 10.
De fato, como mencionado anteriormente, o envio e recebimento de tarefas ocorre
mais facilmente com o aumento do número de processos. A Figura A.7 mostra a execução
do programa para 2500 elementos e 3 processos, tomando o processo 2 como referência.
Dessa maneira, fica difícil precisar corretamente uma função que expresse a taxa de
envio ou recebimento de tarefas. Contornos para esta situação são descritos no Capítulo
6.
1 Esta
conclusão deve ser válida, mesmo com o Workstealing (que implica maiores custos de comunicação) desabilitado, pois há o custo de comunicação MPI natural às aplicações. Mesmo que isso eventualmente permita que uma faixa do número de elementos menor venha a convergir, matematicamente sempre
irá existir uma faixa de número de custo elevado de comunicação, que não convergem.
108
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
[1000,1]
[1000,2]
[1000,3]
[1000,4]
[1000,5]
[1000,6]
[1000,7]
[1000,8]
[1000,9]
[1000,10]
[1500,1]
[1500,2]
[1500,3]
[1500,4]
[1500,5]
[1500,6]
[1500,7]
[1500,8]
[1500,9]
[1500,10]
[1800,1]
[1800,2]
[1800,3]
[1800,4]
[1800,5]
[1800,6]
[1800,7]
[1800,8]
[1800,9]
[1800,10]
[2000,1]
[2000,2]
[2000,3]
[2000,4]
[2000,5]
[2000,6]
[2000,7]
[2000,8]
[2000,9]
[2000,10]
[2500,1]
[2500,2]
[2500,3]
[2500,4]
[2500,5]
[2500,6]
[2500,7]
[2500,8]
[2500,9]
[2500,10]
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
[EXT
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
26.8528707333] [DPAD = 0.0333933707441]
13.4683186667] [DPAD = 0.0129807776576]
9.00799513333] [DPAD = 0.00749613369631]
6.77735542857] [DPAD = 0.00612728575351]
5.44311833333] [DPAD = 0.00552155552148]
4.55871196429] [DPAD = 0.00644472073056]
3.92496076667] [DPAD = 0.00841211594081]
3.45192932143] [DPAD = 0.00463376159555]
3.07427937931] [DPAD = 0.00462139043263]
2.7850921]
[DPAD = 0.0132990536696]
60.1102189]
[DPAD = 0.0721571054224]
30.0877856]
[DPAD = 0.0194270428265]
20.0838294333] [DPAD = 0.0113542488599]
15.0915499524] [DPAD = 0.0106060842986]
12.0909193846] [DPAD = 0.00664547562375]
10.1025945714] [DPAD = 0.00674633604601]
8.68623239286] [DPAD = 0.00706197531535]
7.62627093333] [DPAD = 0.0105303161567]
6.81066524138] [DPAD = 0.0126470038737]
6.18087403448] [DPAD = 0.0597001885098]
81.2249111333] [DPAD = 0.0372123445571]
40.6557511]
[DPAD = 0.0159091125928]
26.4657286]
[DPAD = 0.0096779610483]
21.8746560714] [DPAD = 0.0185950807239]
15.73247146667] [DPAD = 0.0264851551593]
13.32193596667] [DPAD = 0.0159201086801]
11.3027701]
[DPAD = 0.0102274948979]
10.5480813]
[DPAD = 0.00928848878609]
9.0141603]
[DPAD = 0.00977744383077]
8.5509957]
[DPAD = 0.0170690271447]
106.5561137]
[DPAD = 0.0926798866441]
53.3542754667] [DPAD = 0.0320474529672]
35.6413687]
[DPAD = 0.0267787454417]
26.7958899231] [DPAD = 0.0177569118023]
21.5221352]
[DPAD = 0.0149270678017]
18.0358812667] [DPAD = 0.0144334347093]
15.6029128667] [DPAD = 0.0213496455353]
13.7993478333] [DPAD = 0.0228852701203]
12.4591445667] [DPAD = 0.0304073834422]
11.4293376667] [DPAD = 0.0288214095991]
167.294710867] [DPAD = 0.104966505727]
83.7104580333] [DPAD = 0.044471359152]
55.8979496667] [DPAD = 0.0243657349261]
42.02193104]
[DPAD = 0.0173290449507]
33.7411595882] [DPAD = 0.0180413635638]
28.2778684828] [DPAD = 0.0136757405541]
24.4634930667] [DPAD = 0.0312944140158]
21.6711581429] [DPAD = 0.030941047535]
19.5753810345] [DPAD = 0.0397428517781]
18.0408034333] [DPAD = 0.0555629899421]
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
Figura A.4: Medição dos tempos de execução (30 execuções) – versão final.
109
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
[1000,1]
[1000,2]
[1000,3]
[1000,4]
[1000,5]
[1000,6]
[1000,7]
[1000,8]
[1000,9]
[1000,10]
[1500,1]
[1500,2]
[1500,3]
[1500,4]
[1500,5]
[1500,6]
[1500,7]
[1500,8]
[1500,9]
[1500,10]
[1800,1]
[1800,2]
[1800,3]
[1800,4]
[1800,5]
[1800,6]
[1800,7]
[1800,8]
[1800,9]
[1800,10]
[2000,1]
[2000,2]
[2000,3]
[2000,4]
[2000,5]
[2000,6]
[2000,7]
[2000,8]
[2000,9]
[2000,10]
[2500,1]
[2500,2]
[2500,3]
[2500,4]
[2500,5]
[2500,6]
[2500,7]
[2500,8]
[2500,9]
[2500,10]
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
[MEM
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
76016.0]
46019.6]
36019.6]
31022.0]
28024.0]
26032.8]
24608.4]
23543.2]
22710.4]
22045.2]
84016.0]
54016.0]
44018.4]
39016.8]
36024.0]
34034.8]
32614.8]
31541.2]
30713.6]
30056.8]
88816.0]
58811.2]
48816.8]
43321.6]
40822.0]
38831.2]
36133.6]
35598.0]
34178.0]
33857.2]
92016.0]
62011.2]
52022.4]
47017.2]
44038.4]
42061.2]
40653.6]
39589.6]
38761.2]
38103.2]
100016.0]
70010.8]
60022.0]
55019.6]
52030.8]
50061.6]
48651.6]
47596.0]
46764.0]
46124.8]
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
[DPAD
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
0.0]
11.5716657588]
6.41979697976]
8.18745887065]
5.75355961782]
5.39731735105]
2.190890206]
4.38178045704]
4.88205721529]
6.81984932394]
0.0]
11.9308351588]
5.81081036828]
3.04449755451]
7.27774121836]
5.16219679054]
7.51274779396]
12.8717814849]
6.08899516302]
19.0650429331]
0.0]
5.39731735105]
6.24996550452]
6.08899517382]
4.54858826147]
5.39731736324]
9.13349274993]
7.77263102839]
6.10257153259]
19.3451410626]
0.0]
5.3973173998]
8.1773446431]
4.83093483736]
21.5432203888]
8.73518450756]
14.5782076432]
47.4171509799]
18.5591319683]
71.7881942083]
0.0]
5.16219676505]
6.10257153259]
9.532521489]
17.6447706308]
9.83168697937]
18.5055443667]
44.7151906611]
13.4932933533]
80.6484067858]
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
OK
Figura A.5: Consumo de memória (30 execuções).
110
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
PROC.:10
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
0
17
9
0
11
0
0
22
0
13
0
25
0
0
0
0
24
0
0
4
0
0
3
11
14
24
25
15
26
14
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
14
1
2
13
3
13
12
0
14
0
13
0
12
14
12
14
0
13
13
3
14
11
5
2
0
0
0
0
0
0
Figura A.6: Tarefas enviadas e recebidas do processo 10 (2500 elementos, 10 processos).
111
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
NUM.
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
ELEM.:2500
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
PROC.:2
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
SEND:
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
1
1
0
0
1
0
0
1
0
0
0
0
0
0
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
RECEIVED:
1
0
1
0
0
0
1
1
0
1
0
0
0
0
0
0
0
0
0
0
0
0
1
0
0
0
0
1
0
0
Figura A.7: Tarefas enviadas e recebidas do processo 2 (2500 elementos, 3 processos).
112
REFERÊNCIAS
BLUMOFE, R. D.; LEISERSON, C. E. Scheduling Multithread Computations by Work
Stealing. In: ANNUAL SYMPOSIUM ON FOUNDATIONS OF COMPUTER SCIENCE, 35., 1994. Proceedings. . . [S.l.: s.n.], 1994.
BUTENHOF, D. R. Programming with POSIX Threads. [S.l.]: Addison-Wesley Professional, 1997.
CERA, M. C.; PEZZI, G. P.; MATHIAS, E. N.; MAILLARD, N.; NAVAUX, P. O. A.
Improving the Dynamic Creation of Processes in MPI-2. In: EURO-PVM/MPI, 2006,
2006. Proceedings. . . [S.l.: s.n.], 2006. p.8.
CLáUDIO, D. M.; MARINS, J. M. Cálculo Numérico Computacional : teoria e prática.
2.ed. [S.l.]: Atlas, 1994.
CREEGER, M. Multicore CPUs for the masses. Queue, New York, NY, USA, v.3, n.7,
p.64–ff, 2005.
DONGARRA, J.; FOSTER, I.; FOX, G.; GROPP, W.; KENNEDY, K.; TORCZON, L.;
WHITE, A. Sourcebook of Parallel Computing. 1.ed. São Francisco: Morgan Kaufmann Publishers, 2003.
ESCOLA REGIONAL DE ALTO DESEMPENHO, 2007. Anais. . . [S.l.: s.n.], 2007. n.7.
FLYNN, M. J. Some Computer Organization and Their Effectiveness. In: IEEE Transactions on Computers. [S.l.: s.n.], 1972. v.C-21, n.9.
GAREY, M. R.; JOHNSON, D. S. Computers and Intractability: a guide to the theory
of np-completeness. [S.l.]: W. H. Freeman, 1979. (Series of Books in the Mathematical
Sciences).
GEIST, A.; BEGUELIN, A.; DONGARRA, J.; JIANG, W.; MANCHEK, R.; SUNDERAM, V. PVM: parallel virtual machine a users’ guide and tutorial for networked parallel
computing. 1.ed. [S.l.]: MIT Press, 1994. (The Scientific and Engineering Computation
series).
GROPP, W.; LUSK, E.; SKJELLUM, A. Using MPI - Portable Parallel Programming
with Message-Passing Interface. 2.ed. Massachusetts Institue of Technology - Cambridge, Massachusetts 02142: The MIT Press, 1999. (Scientific and Engineering Computation Series).
113
GROPP, W.; LUSK, E.; THAKUR, R. Using MPI-2: advanced features of the messagepassing interface. Massachusetts Institue of Technology - Cambridge, Massachusetts
02142: The MIT Press, 1999. (Scientific and Engineering Computation Series).
JAJA, J. An Introduction to Paralell Algorithms. [S.l.]: Addinson-Wesley, 1992.
KELLER, H.; PFERSCHY, U.; PISINGER, D. Knapsack Problems. [S.l.]: Springer,
2005. 546p.
KOELBEL, C. H.; LOVEMAN, D. B.; SCHREIBER, R. S. The High Performance Fortran Handbook. [S.l.]: The MIT Press, 1993. (Scientific and Engineering Computation).
MARTELLO, S.; TOTH, P. Knapsack Problems: algorithms and computer implementations. [S.l.]: John Wiley & Sons Inc, 1990. (Wiley Interscience Series in Discrete Mathematics and Optimization).
MATTSON, T. G.; HENRY, G. An Overview of the Intel TFLOPS Supercomputer. Intel
Technology Journal, [S.l.], n.Q1, p.12, 1998.
NAVAUX, P. O. A.; ROSE, C. A. F. D. Arquiteturas Paralelas. 1.ed. [S.l.]: Editora Sagra
Luzzato, 2003. n.15. (Série Livros Didáticos).
NETHERCOTE, N.; SEWARD, J. Valgrind: a program supervision framework. Eletronic
Notes in Theoretical Computer Science, [S.l.], v.89, n.2, p.23, 2003.
OPENMP C and C++ Application Program Interface. 2.ed. [S.l.]: OpenMP Architecture
Review Board, 2002.
PACHECO, P. S. Paralell Programming With MPI. 1.ed. [S.l.]: Morgan Kaufmann
Publishers, 1997.
PACHECO, P. S. A User’s Guide to MPI. 1998.
PATTERSON, D. A.; HENNESSY, J. L. Arquitetura de Computadores: uma abordagem quantitativa. 3.ed. [S.l.]: Editora Campus, 2003.
PATTERSON, D. A.; HENNESSY, J. L. Organização e Projeto de Computadores: a
interface hardware software. 3.ed. [S.l.]: Editora Campus, 2005.
PEZZI, G. P.; CERA, M. C.; MATHIAS, E. N.; MAILLARD, N.; NAVAUX, P.
O. A. Escalonamento Dinâmico de programas MPI-2 utilizando Divisão e Conquista. In:
WORKSHOP EM SISTEMAS COMPUTACIONAIS DE ALTO DESEMPENHO 2006 WSCAD, 2006, 2006. Proceedings. . . [S.l.: s.n.], 2006.
ROOSTA, S. H. Parallel Processing and Parallel Algorithms: theory and computation.
1.ed. [S.l.]: Springer, 1999.
TANENBAUM, A. S. Distributed Operating Systems. [S.l.]: Prentice-Hall, 1995.
TANENBAUM, A. S. Sistemas Operacionais Modernos. 2.ed. [S.l.]: Prentice-Hall,
2003.
TOSCANI, L. V.; VELOSO, P. Complexidade de Algoritmos. 2.ed. [S.l.]: Editora Sagra
Luzzato, 2002. n.13. (Série Livros Didáticos).
114
TOSCANI, S. S.; OLIVEIRA, R. S. de; SILVA CARíSSIMI, A. da. Sistemas Operacionais. 2.ed. [S.l.]: Editora Sagra Luzzato, 2002. n.11. (Série Livros Didáticos).
TOSCANI, S. S.; OLIVEIRA, R. S. de; SILVA CARíSSIMI, A. da. Sistemas Operacionais e Programação Concorrente. 1.ed. [S.l.]: Editora Sagra Luzzato, 2003. n.14. (Série
Livros Didáticos).
Baixar