FACULDADE DE TECNOLOGIA DE SÃO JOSÉ DOS CAMPOS
LUIZ HENRIQUE NOGUEIRA LORENA
UTILIZAÇÃO DE TÉCNICAS DE BUSINESS INTELLIGENCE PARA AVALIAR O
PROCESSO SELETIVO FATEC-SJC
SÃO JOSÉ DOS CAMPOS
2011
i
LUIZ HENRIQUE NOGUEIRA LORENA
UTILIZAÇÃO DE TÉCNICAS DE BUSINESS INTELLIGENCE PARA AVALIAR O
PROCESSO SELETIVO FATEC-SJC
Trabalho de graduação apresentado à
Faculdade de Tecnologia de São José dos
Campos, como parte dos requisitos necessários
para obtenção de título de Tecnólogo em
Banco de Dados.
Orientador: Fernando Masanori Ashikaga, Me
SÃO JOSÉ DOS CAMPOS
2011
ii
LUIZ HENRIQUE NOGUEIRA LORENA
UTILIZAÇÃO DE TÉCNICAS DE BUSINESS INTELLIGENCE PARA AVALIAR O
PROCESSO SELETIVO FATEC-SJC
Trabalho de graduação apresentado à
Faculdade de Tecnologia de São José dos
Campos, como parte dos requisitos necessários
para obtenção de título de Tecnólogo em
Banco de Dados.
____________________________________________________________________
ANDERSON VIÇOSO DE ARAÚJO, ME
____________________________________________________________________
JULIANA FORIN PASQUINI MARTINEZ, ME
____________________________________________________________________
FERNANDO MASANORI ASHIKAGA, ME
__/__/__
DATA DE APROVAÇÃO
iii
Dedico este trabalho a meus pais e irmã que amo incondicionalmente,
a memória de meus avós que não tiveram as mesmas oportunidades que tive
mas me deram exemplos de caráter e integridade que levarei por toda a vida,
a meu orientador por sua eterna paciência e apoio durante o curso deste trabalho,
a minha querida sobrinha Amanda que conseguiu, através de seus olhos e sorriso,
me motivar quando me achava perdido ou cansado e a todos aqueles que não tiveram as
oportunidades de estudo que tive em vida, espero retribuí-los na forma de contribuições que
possa deixar na área de tecnologia da informação assim como na de saúde.
iv
AGRADECIMENTOS
Agradeço primeiramente a Deus pela oportunidade de estar vivo e pela capacidade de
poder concretizar mais este projeto. Agradeço novamente a Ele por me colocar para caminhar
ao lado de pessoas tão especiais como meus pais, que sempre me deram os exemplos, suporte
e a principal ferramenta em minha vida, o estudo.
À minha irmã por ser uma fonte inesgotável de inspiração e orgulho.
À meu orientador Prof. Fernando Masanori pela orientação neste trabalho e
principalmente por sua paciência.
À FATEC por seu apoio em relação à infra estrutura, materiais didáticos, professores e
funcionários, que ajudaram a tornar este trabalho realidade.
Aos professores Anderson Viçoso De Araújo e Juliana Forin Pasquini Martinez pelas
sugestões e comentários que muito enriqueceram este trabalho.
v
"Sou o que quero ser, porque possuo apenas uma vida
e nela só tenho uma chance de fazer o que quero.
Tenho felicidade o bastante para fazê-la doce,
dificuldades para fazê-la forte,
tristeza para fazê-la humana e esperança suficiente para fazê-la feliz.
As pessoas mais felizes não tem as melhores coisas,
elas sabem fazer o melhor das oportunidades que aparecem em seus caminhos."
Clarice Lispector
vi
RESUMO
A Faculdade de Tecnologia de São José dos Campos (FATEC-SJC) recebe, a cada processo
seletivo, dados sobre os candidatos que optaram por um de seus cursos. Estes dados são
disponibilizados pelo Centro Paula Souza em formato de planilha eletrônica, contendo os
dados submetidos pelo candidato via formulário eletrônico de cadastro disponibilizado no
endereço eletrônico do processo seletivo da instituição, assim como o desempenho destes
candidatos. Apesar disto, não existe atualmente uma iniciativa específica para se analisar estes
dados de forma analítica na instituição. Desta maneira, informações importantes sobre o
processo seletivo podem ser desperdiçadas, tais como o perfil destes candidatos e os seus
respectivos desempenhos. Uma das áreas da Tecnologia da Informação que mais se destaca e
pode auxiliar no processo de avaliação destes dados é a área de Business Intelligence, sendo o
Data Warehouse uma de suas principais técnicas. Através desta técnica pode-se criar um
Banco de Dados modelado de forma analítica, com a finalidade de responder questionamentos
sobre o processo seletivo. Sendo assim, o objetivo deste trabalho é utilizar técnicas e
ferramentas da área de Business Intelligence para extrair, modelar e exibir analiticamente os
dados sobre o processo seletivo da instituição, obtendo informações que sejam relevantes aos
responsáveis pela promoção de melhorias deste processo dentro da instituição.
Palavras - chave: Business Intelligence, Data Warehouse, Processo seletivo.
vii
ABSTRACT
The Faculdade de Tecnologia de São José dos Campos (FATEC-SJC) receives, at each
selection process, data from the applicants who have chosen one of the courses. Those data
are provided by Centro Paula Souza on spreadsheet format, containing the data submitted by
the applicant via electronic registration form available on the selection process website of the
institution, as well as the performance of these candidates. Despite this, there is no currently
initiative to analyze these data in an analytical way. Thus, important information about the
selection process can be wasted, like the applicants profile and their respective performances.
One of the areas of Information Technology that stands out and can assist in the evaluation of
these data is the area of Business Intelligence, being the Data Warehouse one of its main
techniques. Through this technique one can create an analytically modeled database, in order
to answer questions about the selection process. Therefore, the objective of this work is to use
techniques
and
tools of
display analytical data
the
of the
Business
institution
Intelligence area
selection
to
process,
extract,
retrieving
model and
relevant
information to people responsible for promoting improvements on the process within the
institution.
Keywords: Business Intelligence, Data Warehouse, Selection process
viii
LISTA DE FIGURAS
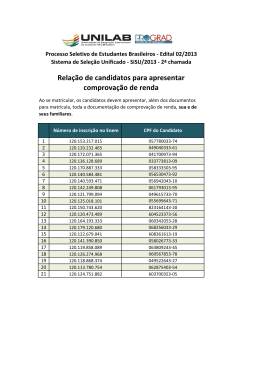
Figura 1.1 - SpatialKey: alia dados demográficos a uma plataforma de mapas. ...................... 14
Figura 1.2 - SpatialKey: comparação da mesma região em tempos distintos. ......................... 14
Figura 2.1 - Visão geral do Data Warehouse. .......................................................................... 21
Figura 2.2 - Arquitetura Genérica de um DW. ......................................................................... 25
Figura 3.1 - O Data Warehouse: onde a Modelagem Dimensional é o destaque. .................... 26
Figura 3.2 - Fatos e Dimensões em um Esquema em Estrela................................................... 27
Figura 3.3 - Exemplo de um Esquema em Estrela com dados do setor de vendas................... 27
Figura 3.4 - Esquema em Estrela para o processo de Vendas. ................................................. 30
Figura 3.5 - Exemplo de Snowflake e Outriggers. ................................................................... 33
Figura 4.1 - Ambiente de Atuação do ETL. ............................................................................. 38
Figura 4.2 - Visão geral do processo de ETL. .......................................................................... 41
Figura 5.1 - Sequência a ser executada a carga do Modelo em Estrela. ................................... 47
Figura 5.2 - Processo de Carga de uma Tabela de Dimensão. ................................................. 50
Figura 5.3 - Sequência do processo de carga de uma Tabela de Fatos.................................... 53
Figura 6.1 - Questionário Sócio Econômico: comparação do número de questões. ................ 60
Figura 6.2 - Manuais do Candidato ao Vestibular .................................................................... 63
Figura 6.3 - Disciplinas com peso 2, processo seletivo 1º Semestre de 2011. ......................... 65
Figura 6.4 - Software DataCleaner: Avaliação do CEP frente a uma Expressão Regular. ...... 67
Figura 6.5 - Arquitetura Geral da Solução Proposta neste Trabalho. ....................................... 69
Figura 6.6 - Resultado: Afrodescendência e Escolaridade Pública. ......................................... 72
ix
LISTA DE TABELAS
Tabela 2.1 - Sistemas de Suporte ao Operacional X Analíticos ............................................... 20
Tabela 3.1 - Tipos de Mudanças possíveis em atributos de uma tabela de dimensões. ........... 37
Tabela 4.1 - Exemplos de Desafios da Integração de Dados.................................................... 42
Tabela 4.2 - Cuidados durante o processo de ETL ................................................................... 43
Tabela 6.1 - Formulário Processo Seletivo FATEC - Etapas de preenchimento ..................... 59
Tabela 6.2 - Planilhas Disponíveis - Inconsistências encontradas. .......................................... 62
Tabela 6.3 - Gabaritos: diferenças na composição das provas. ................................................ 63
Tabela 6.4 - Disciplina que compõem a prova 2011 primeiro semestre. ................................. 64
Tabela 6.5 – Todos os candidatos de Escolas Públicas (Afro ou não) por cidade. .................. 73
Tabela 6.6 - Dados Demográficos: Total de candidatos por Estado. ....................................... 74
Tabela 6.7 - Dados Demográficos: Quantidade de candidatos por cidade. .............................. 75
Tabela 6.8 - Quantidade de candidatos por deficiência física. ................................................. 76
Tabela 6.9 - Quantidade candidatos por estado civil. ............................................................... 76
Tabela 6.10 - Quantidade de candidatos por faixa etária. ........................................................ 77
Tabela 6.11 - Quantidade de candidatos entre 15-24 anos. ...................................................... 78
Tabela 6.12 - Quantidade de candidatos por resposta à questão 2. .......................................... 80
Tabela 6.13 - Quantidade de alunos por resposta à questão 11. ............................................... 82
Tabela 6.14 - Quantidade de candidatos de 15-19 por resposta à questão 11. ......................... 83
Tabela 6.15 - Quantidade de candidatos de 20-24 por resposta à questão 11. ......................... 83
Tabela 6.16 - Quantidade de candidatos por opção de curso ................................................... 84
Tabela 6.17 - Quantidade de candidatos de 15-19 por opção de curso. ................................... 85
Tabela 6.18 - Quantidade de candidatos de 20-24 por opção de curso. ................................... 86
Tabela 6.19 - Quantidade de alunos de escola pública aprovados em 1º chamada por curso. . 87
Tabela 6.20 - Média dos Candidatos - Banco de Dados ou Redes ........................................... 88
Tabela 6.21 - Média dos Candidatos - Logística por disciplina ............................................... 88
Tabela 6.22 - Média dos Candidatos - Manutenção e Manufatura de aeronaves ..................... 89
Tabela 6.23 - Comparação das médias nas disciplinas de todos os candidatos por curso........ 89
Tabela 6.24 - Comparação das médias nas disciplinas dos candidatos de 1ª chamada. ........... 90
x
LISTA DE ABREVIATURAS E SIGLAS
BI - Business Intelligence
DW - Data Warehouse
DSS - Decision Support Systems
ETL - Extract, Transform, Load
EIS – Executive Support System
FAT - Fundação de Apoio à Tecnologia
FATEC - Faculdade de Tecnologia do Estado de São Paulo
FATEC-SJC - Faculdade de Tecnologia de São José dos Campos
UFSC - Universidade Federal de Santa Catarina
CEETEPS - Centro Estadual de Educação Tecnológica Paula Souza
xi
SUMÁRIO
1
INTRODUÇÃO ............................................................................................................... 13
1.1
1.2
1.3
1.4
2
MOTIVAÇÃO ............................................................................................................... 13
DEFINIÇÃO DO PROBLEMA .......................................................................................... 15
PROPOSTA DE SOLUÇÃO .............................................................................................. 15
ORGANIZAÇÃO DO TRABALHO .................................................................................... 16
BUSINESS INTELLIGENCE E DATA WAREHOUSE ............................................ 17
2.1 BUSINESS INTELLIGENCE .............................................................................................. 17
2.2 A EVOLUÇÃO DOS COMPONENTES DO BUSINESS INTELLIGENCE ................................... 18
2.3 FATORES QUE COLABORARAM PARA ORIGEM DO DW ................................................. 20
2.4 DATA WAREHOUSE: O NOVO PARADIGMA..................................................................... 21
2.4.1
Data Warehouse .................................................................................................. 22
2.4.2
Arquitetura Genérica de um DW ........................................................................ 23
2.5 CONSIDERAÇÕES FINAIS ............................................................................................. 24
3
MODELAGEM DIMENSIONAL ................................................................................. 26
3.1 DESIGN MULTIDIMENSIONAL ...................................................................................... 26
3.1.1
Medidas e Contexto ............................................................................................ 27
3.1.2
Reconhecendo Fatos e Dimensões ..................................................................... 28
3.2 O ESQUEMA EM ESTRELA ........................................................................................... 30
3.2.1
Tabela de Dimensão ........................................................................................... 31
3.2.2
Tabelas de Fatos ................................................................................................. 34
3.3 SLOWLY CHANGING DIMENSIONS .................................................................................. 36
3.4 CONSIDERAÇÕES FINAIS ............................................................................................. 37
4
ETL (EXTRACT, TRANSFORM, LOADING) .............................................................. 38
4.1 DEFINIÇÃO .................................................................................................................. 38
4.2 BLOCOS BASE DO ETL ................................................................................................ 39
4.3 DESAFIOS DA INTEGRAÇÃO DE DADOS ....................................................................... 40
4.4 CUIDADOS NO PLANEJAMENTO DO PROCESSO DE ETL................................................ 42
4.5 CDC (CHANGE DATA CAPTURE) ................................................................................ 44
4.6 QUALIDADE DOS DADOS ............................................................................................. 44
4.6.1
Profilling de Dados............................................................................................. 45
4.6.2
Validação de Dados ............................................................................................ 46
4.7 CONSIDERAÇÕES FINAIS ............................................................................................. 46
5
PROCESSO DE CONSTRUÇÃO DE UM DATA WAREHOUSE ........................... 47
5.1 ATIVIDADES ENVOLVIDAS........................................................................................... 47
5.2 CARREGANDO AS TABELAS DE DIMENSÃO ................................................................. 48
5.2.1
Pré-Processamento dos dados ............................................................................. 48
5.2.2
Processamento de Novos Registros .................................................................... 49
xii
5.2.3
Processamento de Mudanças do Tipo 1 ............................................................. 51
5.2.4
Processamento de Mudanças do Tipo 2 ............................................................. 51
5.3 PROCESSO DE CARGA DA TABELA DE FATOS .............................................................. 52
5.3.1
Requisitos a serem atendidos .............................................................................. 52
5.3.2
Pré-Processamento dos dados ............................................................................. 53
5.4 IDENTIFICAÇÃO DAS CHAVES SUBSTITUTAS ............................................................... 54
5.5 CONSIDERAÇÕES FINAIS ............................................................................................. 55
6
PROPOSTA DE SOLUÇÃO .......................................................................................... 56
6.1 O PROBLEMA ANALISADO .......................................................................................... 56
6.1.1
O Processo Seletivo da FATEC ......................................................................... 57
6.2 ESCOPO DO TRABALHO ............................................................................................... 65
6.3 FERRAMENTAS UTILIZADAS NO PROJETO ................................................................... 66
6.3.1
Qualidade dos dados ........................................................................................... 66
6.3.2
ETL ..................................................................................................................... 68
6.3.3
Banco de Dados: MySQL ................................................................................... 68
6.4 ARQUITETURA DO PROTÓTIPO ..................................................................................... 69
6.4.1
Primeira Etapa: FONTE DE DADOS ................................................................ 70
6.4.2
Segunda Etapa: PROCESSO DE ETL ............................................................... 70
6.4.3
Terceira Etapa: DATA WAREHOUSE ............................................................. 70
6.4.4
Quarta Etapa: APRESENTAÇÃO...................................................................... 71
6.5 DOCUMENTAÇÃO DO MODELO DIMENSIONAL ............................................................ 71
6.6 RESULTADOS OBTIDOS ............................................................................................... 71
6.6.1
Afrodescendência e Escolaridade Pública .......................................................... 72
6.6.2
Dados Demográficos .......................................................................................... 74
6.6.3
Dados Sócio Econômicos ................................................................................... 79
6.6.4
Opção de Curso e Desempenho do Candidato .................................................. 84
6.7 CONSIDERAÇÕES FINAIS ............................................................................................. 90
7
CONSIDERAÇÕES FINAIS SOBRE O PRESENTE TRABALHO ......................... 91
7.1
7.2
CONTRIBUIÇÕES E CONCLUSÕES ................................................................................. 91
TRABALHOS FUTUROS ................................................................................................ 92
13
1
INTRODUÇÃO
1.1
Motivação
A diminuição do custo de dispositivos de armazenamento e a internet disponibilizaram
uma quantidade enorme de recursos que foram acumulados por organizações em diversos
campos de atuação durante os anos. As instituições que foram capazes de transformar estes
dados em informação e conhecimento conseguiram tomar decisões mais efetivas ganhando
vantagem competitiva (VERCELLIS, 2009).
Para as empresas, segundo Reeves (REEVES, 2009), o principal foco é aumentar as
receitas e/ou reduzir custos, melhorando assim seu desempenho e aumentado o lucro. Para o
setor público, o foco principal é o serviço oferecido aos cidadãos, assim como lidar com
restrições orçamentárias e usar recursos sabiamente.
Golfarelli (GOLFARELLI, 2009), por sua vez, afirma que existe uma propriedade
comum aos ramos de atuação públicos e privados: a necessidade de ferramentas para extrair
informações desta grande quantidade de dados de maneira rápida e fácil. As informações
retiradas podem ajudar a estudar o funcionamento de uma organização, as correlações entre
seus processos internos e auxiliar em seu processo de tomada de decisões estratégicas.
Neste intuito muitos esforços vêm sendo aplicados na tentativa de reunir estas
informações assim como facilitar as suas interpretações, tendo os sistemas de Business
Intelligence (BI) alcançado sucesso no mercado empresarial com ferramentas de previsão de
custos, relatórios e tomada de decisões (WILLIAMS, 2007).
Na área da educação, os sistemas de BI podem ser utilizados em diferentes contextos.
No trabalho proposto por Piedade (PIEDADE, 2009), por exemplo, o intuito foi identificar
fatores que promovem o sucesso dos estudantes, para que sejam planejadas estratégias para se
evitar a evasão escolar. Outro exemplo na área educacional pode ser encontrado no trabalho
realizado por Shigunov (SHIGUNOV, 2007). Neste trabalho, as técnicas de BI foram
utilizadas para avaliar o desempenho dos candidatos ao vestibular da Universidade Federal de
Santa Catarina (UFSC, 2010), de maneira a facilitar a detecção de possíveis deficiências em
seu processo seletivo.
Seguindo os exemplos citados acima, este trabalho terá como objetivo final a
utilização de técnicas de BI sobre os dados provenientes das fichas de inscrição, assim como
14
os de desempenho dos candidatos ao vestibular da Faculdade de Tecnologia de São José dos
Campos (FATEC-SJC, 2010), de maneira a se extrair informações que auxiliem a tomada de
decisões estratégicas pelas pessoas responsáveis pelo planejamento educacional da instituição.
As informações provenientes desta análise podem facilitar, por exemplo, a observação
de deficiências em uma determinada disciplina nos alunos entrantes, auxiliando a instituição a
tomar uma decisão como ministrar aulas iniciais de reforço, fazendo com que os alunos se
motivem mais com o curso, evitando assim o aumento nas evasões. As mesmas informações
podem direcionar os esforços de iniciativas como o VESTEC (VESTEC, 2010), um curso
pré-vestibular gratuito criado por iniciativa de alunos da FATEC-SJC, servindo de base para
avaliar quais matérias seriam candidatas a grupos de reforço ou estudos, direcionados ao
vestibular da instituição.
Conhecer o perfil do candidato é outro fator que motiva este trabalho. Sua idade,
localização, faixa etária, assim como outras informações são importantes para o planejamento
estratégico da FATEC-SJC como instituição pública de ensino superior, responsável por
oferecer currículos que respondem ao desenvolvimento tecnológico e econômico do país e
que se adéquam às demandas sociais de bens e serviços.
Tendo em mãos dados regionais e aliando-os a um mapa (Figura 1.1), por exemplo,
tanto a instituição quanto os responsáveis por políticas públicas no setor educacional no
estado, poderiam avaliar a eficiência de suas ações, assim como conhecer a distribuição
geográfica de seus candidatos e compará-la em tempos distintos (Figura 1.2), avaliando a
eficiência na operação de divulgação de seu vestibular por exemplo.
Figura 1.1 - SpatialKey: alia dados Figura 1.2 - SpatialKey: comparação da
demográficos a uma plataforma de mapas.
mesma região em tempos distintos.
Fonte: SPATIALKEY (2010).
Fonte: SPATIALKEY (2010).
15
Este mesmo recurso citado aliado a outras informações e técnicas podem evidenciar
demandas a serem supridas por novos investimentos ou políticas educacionais por parte do
estado por exemplo.
Portanto, este trabalho vem atender essa necessidade apresentada pela instituição
FATEC-SJC em relação à análise de seus dados de uma maneira estratégica, propondo para
isso uma solução, que poderá ser enriquecida em trabalhos futuros utilizando-se outras
técnicas que se beneficiarão da arquitetura proposta neste projeto.
1.2
Definição do Problema
A FATEC-SJC acumula a cada processo seletivo, um conjunto de dados referentes à
ficha de inscrição e desempenho de seus candidatos. Entretanto, inexiste atualmente uma
forma eficiente de se analisar e interpretar estes dados históricos dentro da instituição. Desta
maneira, muitas informações estratégicas
poderiam auxiliar no processo decisório da
instituição são mal aproveitadas.
O presente trabalho visa suprir esta necessidade, sendo uma primeira etapa, que poderá
ser complementada com trabalhos futuros, focado em outras áreas, que não a de análise do
processo seletivo da instituição.
1.3
Proposta de Solução
Este trabalho propõe a modelagem dos dados provenientes do vestibular FATEC-SJC
de maneira a utilizá-los de forma analítica, utilizando para isto técnicas de modelagem e
ferramentas disponíveis na área de BI.
Os dados coletados no processo seletivo da instituição serão preparados e modelados
de forma a facilitar e auxiliar à tomada de decisão quanto ao planejamento educacional e
estratégico da instituição.
O primeiro passo para o desenvolvimento da solução proposta é extrair os dados
relevantes à construção de um modelo analítico. Estes dados se encontram em arquivos que
contém o cadastro dos candidatos assim como os seus respectivos desempenhos no processo
16
seletivo da FATEC-SJC. Deverá ser realizada uma seleção, padronização e filtragem de
maneira que se possam retirar possíveis inconsistências.
O segundo passo é a construção do modelo analítico a ser aplicado sobre estes dados
extraídos, para que seja montada uma arquitetura baseada na técnica de Data Warehouse.
O terceiro e último passo é o desenvolvimento de um protótipo usado para exibir os
relatórios usados pelos usuários finais que desejarem melhorar seu processo decisório.
1.4
Organização do Trabalho
Este trabalho está organizado da seguinte forma:
a) Os Capítulos de número 2 ao 5 são dedicados a Revisão da Literatura referente ao
tema do trabalho:
Capítulo 2: apresenta o conceito de Business Intelligence, sua evolução e
principais componentes constituintes, dando ênfase à técnica de Data
Warehouse;
Capítulo 3: apresenta a técnica de Modelagem Dimensional e os principais
conceitos que serviram de base para a criação da solução proposta neste
trabalho;
Capítulo 4: aborda os principais conceitos e técnicas dentro de um dos
principais processos envolvidos na construção de um Data Warehouse, o
processo de ETL (Extract, Transform, Loading);
Capítulo 5: aborda a sequência em que será realizada a criação do Data
Warehouse
proposto assim como os principais detalhes e conceitos
envolvidos.
b) O Capítulo 6 aborda os detalhes do problema a ser resolvido pela solução proposta,
a arquitetura da solução, as ferramentas utilizadas em cada etapa de seu
desenvolvimento, assim como toda a documentação que foi criada sobre a análise
dos requisitos;
c) O Capítulo 7 apresenta as considerações finais deste trabalho.
17
2
BUSINESS INTELLIGENCE E DATA WAREHOUSE
2.1
Business Intelligence
Business Intelligence é um termo abrangente, utilizado para descrever uma variedade
de técnicas voltadas a identificar, extrair e analisar dados de modo a se obter informações
importantes sobre o desempenho empresarial. O objetivo final é utilizar estas informações
para tornar mais eficiente o processo de tomada de decisões pelos gestores das empresas
(Willians 2007).
A origem do conceito de BI remete ao artigo “A Business Intelligence System”,
escrito por Hans Peter Luhn no jornal IBM System Journal em 1958 (LUHN, 1958). Neste
artigo, o termo inteligência foi definido como:
“A habilidade de encontrar relações presentes em fatos de maneira a guiar ações a
determinado objetivo”.
Segundo Bouman e Dongen (BOUMAN, 2010), este artigo é considerado hoje em dia
por muitos o marco para o desenvolvimento dos atuais sistemas de BI.
A definição dada por Luhn (LUHN, 1958) ainda é válida, entretanto, o termo BI foi
reintroduzido e popularizado por Howard Dresner em 1989, na época trabalhando como
analista do grupo de pesquisa Gartner Inc (GARTNER, 2011). Naquele tempo, a indústria de
software estava focada em acrônimos como DSS (Decision Support Sytem) e EIS (Executive
Support System), mas Dresner estava procurando um termo mais geral, que unificasse e
definisse melhor o conceito de se analisar dados para tomadas de decisões no contexto
empresarial. Deste modo, ele definiu BI como sendo:
“Conceitos e métodos para melhorar o processo de tomada de decisão em negócios
utilizando-se sistemas de suporte baseados em fatos”.
As definições de Hans Peter Luhn e Howard Dresner têm em comum a característica
de serem gerais, não focando em uma tecnologia específica, e de terem o foco na resolução de
problemas utilizando-se sistemas baseados em fatos.
Uma característica importante em comum entre as diferentes definições apresentadas a tomada de decisões a partir da análise de fatos - é justamente a base para os atuais sistemas
de BI. Desta maneira, para tomar melhores decisões baseadas em fatos, os sistemas atuais
devem retirar a informação factual de um ou mais sistemas de informação, integrá-las, e
18
apresentá-las ao usuário final de uma maneira útil, em relatórios ou análises que ajudarão a
compreender o desempenho passado e presente da organização analisada.
2.2
A evolução dos componentes do Business Intelligence
Segundo Ponniah (PONNIAH, 2010), as organizações usam sistemas computacionais
desde a década de 60 e conforme foram crescendo se tornaram completamente dependentes
destes para suportar seus processos de negócio. Estes sistemas são efetivos para o que foram
criados, suportando com sucesso as rotinas operacionais do dia a dia.
Na década de 90 as organizações começaram a ficar mais complexas, corporações se
expandiram globalmente, e a concorrência entre empresas se tornou mais acirrada, com
executivos buscando cada vez mais informações para se manterem competitivos. Os sistemas
que suportam o dia a dia operacional continuaram a fornecer a base necessária para o correto
funcionamento das empresas, entretanto, o que os executivos necessitavam eram diferentes
tipos de informações em um formato próprio que pudessem auxiliá-los no processo decisório.
Desta maneira, várias soluções foram propostas dentro das empresas com este enfoque, como
pode ser visto a seguir nos estágios evolutivos dos Sistemas de Suporte a Decisão:
Relatórios: Foi uma tentativa inicial de fornecer informações estratégicas.
Usuários fazem requisição para o departamento de Tecnologia da Informação (TI)
que programará os relatórios especialmente para aquela requisição;
Programas de Extração de Dados: Tentativa das equipes de TI em antecipar
alguns tipos de relatórios. Os profissionais de TI criam uma série de programas
especializados em extrair os dados de suas respectivas fontes de tempo em tempo;
Pequenas Aplicações: O processo de extração dos dados já está formalizado,
podendo-se criar aplicações. Os profissionais de TI podem criar aplicações em
que o usuário possa estipular parâmetros para cada relatório tendo a opção de
impressão ou visualização dos resultados filtrados de acordo com parâmetros;
Centros de Informação: No início da década de 70, algumas grandes corporações
criaram o que se denominou de “Centros de Informação”. Os usuários poderiam ir
19
até estes centros e requisitar relatórios específicos ou ver informações de
relatórios pré-definidos em telas informativas.
Decision-Support Systems (DSS): Surgem aplicações mais sofisticadas com
intenção de fornecer algo que pode se caracterizar como informações estratégicas.
Novamente, parecido com as outras iniciativas anteriores, estes sistemas eram
baseados nos dados extraídos de arquivos. Os sistemas eram orientados a menus e
proviam informações online e habilidade de se criar relatórios específicos.
Executive Information Systems (EIS): Tentativa de levar as informações
estratégicas ao computador dos executivos de focando na simplicidade e
facilidade de uso. O sistema exibe informações chaves todos os dias e provê a
habilidade de se construir relatórios de maneira simplificada. Entretanto, apenas
telas e relatórios pré-programados eram disponíveis.
Segundo Ponniah (PONNIAH, 2010), todas as estratégias apresentadas foram
insatisfatórias em fornecerem as informações estratégicas que os gestores necessitavam. Os
seguintes fatores colaboraram para que estas técnicas não obtivessem o sucesso previsto:
Os usuários finais dependem totalmente dos profissionais de TI para lhes prover a
informação, pois não acessam a informação diretamente, apenas por relatórios
pré-programados;
As informações requisitadas podem mudar de tempos em tempos, necessitando
reformular programas e relatórios.
Além dos fatores listados anteriormente, a razão fundamental para que estas
estratégias não tenham sido bem sucedidas é que todas procuraram prover as informações
estratégicas usando diretamente os dados na forma em que eram usados nos sistemas de
suporte ao operacional. Estes sistemas, tais como os responsáveis pelo controle de estoque,
pagamento de contas, processamento de pedidos, e outros, não foram criados de forma a
prover informações estratégicas em sua concepção original.
Na seção que segue será dada sequência dos principais fatores que contribuíram para o
nascimento da técnica de DW como uma solução analítica.
20
2.3
Fatores que colaboraram para origem do DW
Os sistemas de suporte ao operacional são classificados como Online Transaction
Processing Systems (OLTP), especializados em transações que processam informações sobre
uma entidade única como uma ordem de compra, um pagamento, ou um cliente específico.
Portanto, estes sistemas são tipicamente modelados e especializados em inserir e atualizar
dados nos bancos de dados (DATE, 2003).
Baseado nas diferenças expostas entre os sistemas de suporte operacionais e os
sistemas analíticos procurou-se modelar e criar um sistema de informação que tivesse escopo,
propósitos, conteúdo, padrão de uso e tipos de acesso diferentes dos sistemas propostos
anteriormente. Desta maneira, nasce o DW como um novo paradigma, voltado
especificamente para sanar a necessidade dos gestores por informações estratégicas.
Segundo Adamson (ADAMSON, 2010), as principais diferenças entre os sistemas de
suporte operacional e o analítico podem ser vistas na Tabela 2.2.
Tabela 2.1 - Sistemas de Suporte ao Operacional X Analíticos
OPERACIONAL
ANALÍTICO
Propósito
Execução dos processos de
negócio
Avaliação dos processos da
empresa
Conteúdo dos dados
Valores recentes
Valores recentes e passados
Estrutura dos dados
Otimizada para transações
individuais
Otimizada para consultas
complexas (agregações)
Frequência de Acesso
Alta
Média a Baixa
Tipo de Acesso
Leitura, Atualização,
Eliminação
Leitura
Uso
Previsível e Repetitivo
Randômico, Heurístico
Tempo de Resposta
Milissegundos
Alguns segundos a minutos
Usuários
Grande Número
Número Relativamente Pequeno
Fonte: Adaptado de Adamson (2010).
21
2.4
Data Warehouse: o novo paradigma
Este novo modelo começou a ser implementado nas empresas no final da década de 80
e início dos anos 90, preconizando que o DW deve ser mantido separado dos sistemas que
suportam a rotina operacional da empresa, dedicado exclusivamente a tomada de decisões
estratégicas (Ponniah, 2010). Uma visão geral do DW como fonte de informações estratégicas
pode ser visto na Figura 2.1.
De uma maneira bem geral o DW contém as métricas críticas dos processos de
negócio da empresa guardados em diferentes contextos. Por exemplo, unidade de vendas por
produto, dia, grupo de clientes, região, promoção etc. A unidade de vendas representa a
métrica sendo medida, enquanto que produto, dia e os demais atributos demonstram o
contexto em que essa medida está sendo avaliada (Adamson, 2010).
DADOS OPERACIONAIS
EXTRAÇÃO, LIMPEZA E
AGREGAÇÃO
INFORMAÇÕES
ESTRATÉGICAS
Medidas Chave /
Dimensões de Negócio
SISTEMAS
OPERACIONAIS
TRANSFORMAÇÃO DOS
DADOS
DATA WAREHOUSE
Figura 2.1 - Visão geral do Data Warehouse.
Fonte: Adaptado de Ponniah (2010).
Nas subseções que seguem serão apresentadas definições mais formais para o termo
DW assim como os seus principais componentes desta técnica.
22
2.4.1
Data Warehouse
De acordo com Bouman e Dougen (2010), assim como BI, os conceitos utilizados em
um Data Warehouse foram utilizados antes mesmo de o termo ter sido definido por Willian
H. Inmon (INMON, 1990).
Barry Devlin e Paul Murphy, em 1988, expuseram os conceitos fundamentais usados
até hoje nos sistemas de DW (DEVLIN e MURPHY, 1988). Eles definiram o conceito de um
Business Data Warehouse (BDW) como sendo:
“Um local único de armazenamento lógico de toda a informação utilizada para
extrair relatórios sobre um determinado negócio”
Inmon (INMON, 1990) por sua vez, contribuiu com sua definição dizendo que o DW é
uma coleção de dados que suporta decisões gerenciais e que possui as seguintes
características:
Orientado a Assuntos : Todas as entidades e eventos estão relacionadas a
determinado assunto, por exemplo, vendas;
Variante com o Tempo : Todas as mudanças nos dados são guardadas para
permitir relatórios que mostram mudanças ao longo do tempo;
Não volátil : Os dados que entram em um DW nunca são sobrepostos ou
eliminados (apenas no caso de falhas);
Integrado : contém dado de múltiplas fontes de dados depois de serem limpos e
padronizados, mostrando uma visão única sobre determinado assunto “Single
version of the truth”.
Segundo Ponniah (2010), a criação de um ambiente separado para o DW acarretou em
benefícios tais como:
Visão integrada e total dos dados da empresa;
Dados recentes e históricos facilmente acessíveis para a tomada de decisão;
Tornar possíveis Sistemas de Suporte a Decisão sem sobrecarregar os Sistemas de
Suporte ao Operacional;
Tornar a informação consistente dentro de toda a organização.
23
Ao longo dos anos, para se garantir os princípios enunciados acima, diferentes
arquiteturas foram propostas, assim como formas de se modelar os dados em um DW,
entretanto, uma característica que todos os autores concordam é que o DW deve ser um
repositório de dados separado, dedicado a análise e relatórios, assim como preconizado no
trabalho feito por Devlin e Murphy (1988).
A subseção que segue apresenta uma arquitetura genérica para o ambiente do DW
assim como seus componentes principais.
2.4.2
Arquitetura Genérica de um DW
Segundo Kimball (2002), existem quatro componentes separados e distintos a serem
considerados em um ambiente de DW – sistemas de suporte ao operacional, uma área de
estágio de dados, uma área de representação de dados, e uma ferramenta de acesso.
Existem diversas arquiteturas específicas para um DW. Bouman e Dongen (2010)
apresentam uma arquitetura genérica explicando cada um de seus componentes. O diagrama
utilizado por ele foi adaptado e pode ser visto na Figura 2.2. Este mesmo diagrama pode ser
analisado e interpretado como o descrito abaixo:
FONTE DE DADOS : Uma ou mais fontes de dados provenientes de diferentes
sistemas dentro da empresa;
PROCESSO DE ETL : Um processo para extrair, transformar e carregar os dados
no DW denominado ETL (Extract, Transform, Loading). Utilizando-se para isso
uma área intermediária denominada área de estágio. Este componente e o
processo de ETL serão apresentados em maiores detalhes no Capítulo 4;
DATA WAREHOUSE : Composto pelo DW, que consiste em um banco de dados
central e zero ou mais Data Marts. Data Marts, segundo Inmon (1990), são um
subconjunto de dados presentes no DW que foram modelados de forma a atender
as necessidades analíticas de uma determinada área de negócio, por exemplo,
vendas;
24
APRESENTAÇÃO : Uma camada composta de várias ferramentas para trabalhar
com os dados e exibi-los ao usuário final. Extraindo os dados diretamente do DW.
Este tópico, entretanto, estará fora do escopo deste trabalho.
2.5
Considerações Finais
Este capítulo abordou um resumo dos principais conceitos de Business Intelligence e o
nascimento de uma de suas técnicas mais importantes atualmente, o Data Warehouse, que
consiste na base da solução proposta neste trabalho, sendo a utilização desta técnica um de
seus objetivos específicos.
O capítulo que segue apresentará o assunto Modelagem Dimensional, cujos conceitos
elucidam como o DW organiza seus dados e funcionamento de forma a cumprir seu papel
analítico.
25
Figura 2.2 - Arquitetura Genérica de um DW.
Fonte: Adaptado de (BOUMAN e DONGEN, 2010).
26
3
MODELAGEM DIMENSIONAL
O presente capítulo apresenta o assunto Modelagem Dimensional dentro do processo
de criação de uma DW. Este capítulo tem como base teórica os livros dos autores Ralph
Kimball (2002) e Christopher Adamson (2010). O primeiro autor foi escolhido por ser criador
da base de quase tudo que é utilizado hoje em Modelagem Dimensional, enquanto o segundo
foi escolhido por possuir uma abordagem didática única dentre os livros de Modelagem
Dimensional utilizados como referência neste trabalho.
A Figura 3.1 isola os tópicos a serem abordados.
Figura 3.1 - O Data Warehouse: onde a Modelagem Dimensional é o destaque.
Fonte: Adaptado de Bouman e Dongen (2010).
3.1
Design Multidimensional
Conforme foi apresentado no Capítulo 2, os Sistemas de Informação são classificados
em duas categorias principais: os que suportam a execução dos processos de negócio e
aqueles que suportam a análise dos processos de negócio. Seus propósitos distintos refletem
diferentes perfis de uso, sugerindo assim que diferentes princípios irão guiar seu design.
27
Kimball (2002) explica que a Modelagem Dimensional (MD) é o nome dado a uma
técnica de design lógico diferente do tradicional modelo utilizado nos sistemas de caráter
operacional. O autor afirma ser uma técnica que procura apresentar os dados em uma maneira
padronizada, intuitiva e que permita um acesso de alto-desempenho.
A técnica de MD ajuda na análise de negócios de uma maneira simples: ela modela a
medida dos processos de negócios. Desta maneira, o modelo dimensional de um processo de
negócios é composto por dois componentes: medidas e seu contexto (ADAMSON, 2010).
3.1.1
Medidas e Contexto
As medidas são denominadas fatos, e o contexto dimensões. Estes componentes são
organizados em um design de banco de dados que facilita uma variedade de usos analíticos
(BOUMAN e DONGEM, 2010).
Segundo Adamson (2010), se implementado em um Banco de Dados Relacional, este
modelo será chamado de Esquema em Estrela, mas se implementado em um Banco de Dados
Multidimensional, será chamado de Cubo. O nome “Esquema em Estrela” foi dado porque a
disposição dos componentes constituintes deste modelo se parece com o formato de uma
estrela (Figura 3.2).
(Contexto)
DIMENSÃO
TEMPO
(Contexto)
DIMENSÃO
(Contexto)
DIMENSÃO
CLIENTE
PRODUTO
(Medidas)
FATOS
(Contexto)
DIMENSÃO
VENDAS
(Contexto)
DIMENSÃO
PROMOÇÃO
LOJA
Figura 3.2 - Fatos e Dimensões em um Figura 3.3 - Exemplo de um Esquema em
Esquema em Estrela.
Estrela com dados do setor de vendas.
Fonte: Adaptado de Bouman (2010).
Fonte: Adaptado de Bouman (2010).
28
O centro de cada modelo dimensional é um conjunto de métricas de negócio que
demonstram como o processo é avaliado, ligado a uma ou mais tabelas que garantem o
contexto em que cada medida central foi avaliada (Figuras 3.2 e 3.3).
O presente trabalho irá se focar na modelagem dimensional utilizando-se um Banco de
Dados Relacional, portanto, mais informações sobre a modelagem dimensional em Banco de
Dados Multidimensionais podem ser encontradas em Bouman (2010), Adamson (2010) ou
Kimball (2002).
3.1.2
Reconhecendo Fatos e Dimensões
Segundo Bouman (2010), a distinção entre o que é fato e o que é dimensão dentro da
análise de um problema nem sempre é clara, mas uma explicação simples dada pelo autor é de
que as tabelas de dimensão contêm informações qualitativas sobre as entidades de negócio
(clientes, produtos, lojas) e as tabelas de fatos sobre eventos de negócios (vendas, compras,
pedidos), ou seja, dados quantitativos em geral.
Adamson
(2010)
explica
que
por
se
tratarem
de
medidas,
os
fatos
tendem a ser numéricos em valor, e as pessoas querem vê-los em vários níveis de detalhes.
Kimball (2002) afirma que os fatos mais úteis são numéricos e aditivos, tais como a
quantidade vendida de determinado produto. A propriedade aditiva do fato é crucial porque
aplicações de DW quase nunca trabalham em cima de uma única linha do Banco de Dados, ao
invés disso trabalham com centenas, milhares e até milhões de linhas de ao mesmo tempo, e a
operação mais útil de ser realizada com tantas linhas é somá-las.
Podem-se identificar fatos olhando para as coisas que as pessoas querem
medir. Enquanto que em uma declaração escrita ou falada, a palavra "por" e “para”
é quase sempre seguida de uma dimensão (ADAMSON, 2010). Considere a questão abaixo:
“Qual a quantidade de pedidos em dólares por categoria de produto para janeiro?”
Neste caso a pessoa que solicita esta pergunta quer uma medição separada para
cada categoria
de
produto, como
indica
a expressão "por
categoria
de
produto".
A categoria de produto é uma dimensão, assim como janeiro é um valor ou instância de uma
dimensão. Apesar da dimensão tempo não ter sido nomeada, pode-se inferir que é mês e o que
29
se quer medir é a “quantidade de pedidos em dólares”, representando desta maneira o fato a
ser analisado.
“Qual a quantidade de pedidos em dólares por categoria de produto para Janeiro?”
FATO
Mas,
nem
tudo
o que é numérico é
DIMENSÃO
DIMENSÃO
um fato. Às
vezes, um elemento
de dados numérico é uma dimensão. Adamson (2010) explica que a chave é determinar como
o atributo está sendo usado. É algo que pode ser especificado em diferentes níveis
de detalhe? Se assim for, é um fato. Esta fornecendo um contexto? Se assim for, é uma
dimensão. Exemplo:
"Mostre-me a margem em dólares por número de pedido"
A sentença acima contém dois elementos numéricos. A margem em dólares pode
ser especificada em diferentes níveis de detalhe, e quem pergunta está pedindo que seja
agrupado pelo número do pedido.
Sendo assim a "margem em dólares" é um fato. Mas e o número do pedido? Ele
também é numérico, mas o falante não está pedindo que os
números
de
pedido sejam
somados. Em vez disso, o número do pedido está sendo usado para especificar o contexto para
a margem em dólares. Neste caso o número do pedido é uma dimensão.
"Mostre-me a margem em dólares por número de pedido"
FATO
DIMENSÃO
Outros exemplos de dados numéricos comportando-se como dimensões incluem o
tamanho, idade, números de telefone, números de documentos, e os montantes unitários,
tais como
custo
unitário ou preço
unitário.
elementos são dimensões reside em sua utilização.
A
dica
de
que
estes
30
3.2
O Esquema em Estrela
No Modelo Dimensional denominado de “Esquema em Estrela”, os contextos são
agrupadas em tabelas de dimensão e os fatos são armazenados nas colunas de uma tabela de
fatos.
A Figura 3.4 mostra um Esquema em Estrela simples baseado nos fatos e dimensões
para o processo de vendas.
Figura 3.4 - Esquema em Estrela para o processo de Vendas.
Fonte: Adaptado de Adamson (2010).
31
As seções que seguem descrevem os componentes principais que compõem a
modelagem dimensional e um Esquema em Estrela em maiores detalhes.
3.2.1
Tabela de Dimensão
As Tabelas de Dimensão possuem as colunas que serão usadas para fornecer um rico
contexto necessário para o estudo dos fatos, geralmente sob a forma de rótulos textuais que
antecedem
os
fatos em
cada linha de
um relatório. Elas também
podem ser
usadas
para conduzir as relações de maior ou menor detalhe, subtotalização ou ordenações
(Adamson, 2010).
Segundo Kimball (2002), os atributos das Tabelas de Dimensão têm um papel vital
dentro de um DW, pois são fonte de todo o tipo de filtragem que pode ser realizada nos dados
analisados. O autor afirma que o poder de um DW é diretamente proporcional à qualidade e
abrangência de seus atributos dimensionais.
Estas tabelas apresentam uma série de características:
Contém descritores textuais do negócio;
Costumam ter muitas colunas ou atributos (de 50 a 100);
Os campos devem ser palavras reais evitando-se utilizar códigos ou abreviações;
Geralmente o número de linhas é menor que um milhão, representando no total de
espaço consumido por tabelas geralmente igual a 10% do tamanho do banco;
Informações descritivas hierárquicas são armazenadas de modo redundante. Ex.:
categoria de produto presente na tabela “DIM_PRODUTO” (Figura 3.4).
Tabelas de Dimensão conseguem representar relações hierárquicas dos negócios, mas
colocando-as em uma mesma tabela. A Figura 3.4 mostra o atributo categoria na tabela de
dimensão produto. Para cada linha da tabela produto, a informação descritiva sobre a
categoria do produto é guardada de forma redundante. É realizado desta maneira para facilitar
o uso e por motivos de performance.
Uma característica marcante das tabelas de dimensão é que são tipicamente
desnormalizadas (Kimbal, 2002). Como geralmente são pequenas e geometricamente menores
32
que as tabelas de fatos, a melhora na eficiência de armazenamento ao se normalizar não terá
impacto significante sobre o tamanho global do Banco de Dados. Além disso, o impacto
causado ao ter que fazer uma junção com esta tabela inserida não compensa a quantidade de
espaço ganho. Prefere-se então não se preocupar com o tamanho da Tabela de Dimensão,
priorizando-se assim a simplicidade e acessibilidade.
3.2.1.1 Outriggers e Snowflakes
A normalização trás benefícios para os sistemas operacionais, que devem suportar a
uma variedade de transações concorrentes, sendo fator decisivo para que seja mantida a
integridade dos dados. Os sistemas analíticos por sua vez são usados de maneira diferente,
possuindo um comportamento de uso normalmente focado em consultas. Desta maneira, as
Tabelas de Dimensão contém várias redundâncias.
Entretanto existem algumas situações onde o uso limitado de normalizações trás
benefícios analíticos. Neste tipo de normalização a tabela que se liga a dimensão recebe o
nome de Outrigger, enquanto que o modelo final recebe o nome de Snowflake devido à forma
da disposição de suas tabelas (Figura 3.5).
Na Figura 3.5 a tabela “Categoria” seria apenas requerida se a categoria do produto
mudasse demais em tempos relativamente curtos, o que faria com que um número grande de
linhas repetidas para guardar o histórico de mudanças fosse gerado. Desta maneira o atributo
de categoria poderia ser colocado em uma tabela denominada Outrigger.
Outro tipo de Outrigger válido é visto na tabela de dimensão DIM_PROMOCAO
(Figura 3.5). Os atributos “Promocao_Data_Inicio” e “Promocao_Data_Fim” são links para
visões da tabela Data, a visão “VIEW_DATA_PROMOCAO” é um Outrigger neste modelo.
3.2.1.2 Chaves e história
Em um Esquema em Estrela, cada tabela de dimensão recebe uma Chave Substituta
(Surrogate Key). Esta coluna é um identificador único, criado exclusivamente para o DW
e são atribuídas e mantidas como parte do processo de carga do Esquema em Estrela.
33
Figura 3.5 - Exemplo de Snowflake e Outriggers.
Fonte: Adaptado de Adamson (2010).
A chave substituta não tem um significado intrínseco; ela é tipicamente um número
inteiro sendo a chave primária da tabela de dimensão.
As tabelas de dimensão também contêm colunas chave que identificam unicamente
algo em um sistema de suporte ao operacional. Encontramos exemplos na Figura 3.4:
Cliente_ID, Loja_ID, Promocao_ID e Produto_SKU. Nestes sistemas, estas colunas
identificam clientes específicos, lojas, promoções e produtos respectivamente. Estas colunas
chave são referidas como Chaves Naturais.
A separação das Chaves Substitutas e Chaves Naturais permite que o armazém de
dados possa rastrear mudanças, mesmo que o sistema operacional original não possa. Por
exemplo, suponha que o cliente de nome “Ana Maria” seja identificado pelo valor de
Cliente_ID 10 em um sistema operacional. Se o cliente muda sua sede local, o sistema
operacional pode simplesmente sobrescrever o endereço do Cliente_ID 10. Para fins de
análise, no entanto, pode ser útil rastrear a história do consumidor “Ana Maria”. Como o
modelo em estrela não utiliza Cliente_ID para identificar uma linha única na dimensão do
34
Cliente, é possível armazenar várias versões de ABC, embora ambos tenham o mesmo
Cliente_ID igual a 10. As duas versões podem ser distinguidas por diferentes valores de
Chave Substituta.
3.2.2
Tabelas de Fatos
O núcleo de um modelo em estrela é a Tabela de Fatos. Além de apresentar os fatos
ela inclui Chaves Substitutas que a ligam às tabelas de dimensões. O Esquema em
Estrela simples da Figura 3.5, por exemplo, inclui os fatos “Venda_Valor”, “Venda_Custo”,
“Venda_Lucro” e “Venda_Quantidade”. A tabela inclui também chaves substitutas que se
referem a clientes, datas, produtos, lojas e promoções que ocorreram as vendas.
Juntas, as chaves estrangeiras de uma tabela de fatos são consideradas às vezes para
identificar uma única linha na tabela fato. Isto é certamente verdadeiro na Figura 3.4,
onde cada linha da tabela fato representa pedidos de um produto vendido por um vendedor a
um cliente em um determinado dia. Em outros casos, no entanto, as chaves estrangeiras de
uma tabela de fatos não são suficientes para identificar uma linha única.
Cada linha na tabela de fatos armazena dados em um determinado nível de detalhe.
Este nível de detalhe é conhecido como granularidade da tabela de fato. A lista de dimensões
define a granularidade em que as medidas na tabela de fatos estão e todas as medidas em uma
tabela de fatos devem estar no mesmo nível de detalhe.
As informações contidas nas tabelas de fatos podem ser consumidas em uma
variedade de níveis diferentes, no entanto, deve-se previamente agregar os dados a um mesmo
nível de detalhe.
Os fatos nestas tabelas são medições realizadas em negócios representando uma
quantidade. Em sua maioria os fatos são aditivos, entretanto existem fatos semi-aditivos e até
não aditivos. No caso dos semi-aditivos podemos utilizar contagens e médias para resumir
linhas.
As tabelas de fatos possuem algumas características:
Tendem a ser complexas no número de linhas, mas simples no número de colunas;
35
Granularidades: existem três tipos de tabelas de fatos que serão descritas com
mais detalhes na subseção que se segue. Os tipos são: Transação, Instantâneo
Periódico e Instantâneo Acumulado;
Possui uma chave composta formada pela chave substituta de cada uma de
dimensões que formam o modelo;
Expressam relações de muitos-para-muitos em modelos dimensionais;
Costumam consumir 90% do espaço de um Banco de Dados.
3.2.2.1 Tipos de Tabelas de Fatos
Existem três tipos de Tabelas de Fatos:
Transacionais: acompanham as atividades individuais que definem um processo
de negócio e suportam diversos fatos que descrevem estas características;
Instantâneo Periódico: amostras de medidas periódicas de estado tais como
balanços ou níveis. Estas medidas podem ser equivalentes ao efeito cumulativo de
uma série de transações, mas não são fáceis de estudar neste formato. Algumas
medidas como temperatura não podem ser modeladas como transações, por
exemplo;
Instantâneo Acumulativo: é usado para acompanhar o progresso de um item
individual durante uma série de passos de processamento. Permite o estudo do
tempo passado entre etapas chaves de um processo ou eventos. Este tipo de tabela
de fato correlaciona várias atividades diferentes em uma única linha.
Segundo Adamson (2010), para criaro melhor Modelo Dimensional para um processo
de negócio deve-se pensar em algum destes tipos de Tabela de Fatos. Alguns processos de
negócios pode requerer apenas uma Tabela de Fatos, mas outras podem requerer mais de uma.
Portanto, deve-se escolher o tipo de tabela certa para cada situação.
36
3.3
Slowly Changing Dimensions
Segundo Kimball (2002), inicialmente assume-se que as Tabelas de Dimensões sejam
logicamente independentes entre si e que em particular sejam independentes do tempo.
Entretanto, isto não acontece no mundo real. Apesar dos atributos em uma tabela de dimensão
se manterem relativamente estáticos, não são fixos indefinidamente. Os atributos das
dimensões mudam, embora em uma velocidade relativamente baixa ao longo do tempo.
Quando necessitamos monitorar as mudanças que ocorrem nos atributos das
dimensões é inaceitável colocar tudo na tabela de fatos ou fazer com que cada dimensão se
torne dependente do tempo. Estaríamos normalizado-a e consequentemente perdendo a
facilidade de entendimento do modelo e performance. Ao invés disso, aproveitamos o fato
que a maioria das dimensões são aproximadamente constantes ao longo do tempo. Desta
maneira, podemos preservar esta estrutura de dimensões independentes com relativamente
poucos ajustes para lidar com estas mudanças.
O termo Slowly Changing Dimensions (Dimensões que Mudam Lentamente) refere-se
exatamente à frequência relativamente baixa em que as dimensões acumulam mudanças se
comparada com as tabelas de fatos, que acumulam linhas a uma velocidade maior
(KIMBALL, 2002).
À medida que os dados são atualizados nos sistemas operacionais deve-se tomar
alguma atitude do lado do DW nas tabelas que são alimentadas por estes sistemas. Segundo
Kimball (KIMBALL, 2002), devemos especificar uma estratégia para lidar com a mudança de
cada atributo das tabelas de dimensão. Desta maneira, os sistemas analíticos deverão adequar
seus modelos dimensionais às mudanças vindas do ambiente operacional..
Existem três técnicas básicas para lidar com mudanças de atributos, assim como um
conjunto de técnicas híbridas. Pode-se decidir aplicar uma ou mais técnicas destas, por
exemplo, em uma única tabela:
1. Sobrescreve-se o valor do atributo na tabela de dimensão
2. Insere uma nova linha na tabela de dimensão
3. Insere uma nova coluna na tabela de dimensão
Cada uma destas técnicas possuem vantagens e desvantagens que são apresentadas na
tabela 3.1:
37
Tabela 3.1 - Tipos de Mudanças possíveis em atributos de uma tabela de dimensões.
TIPOS DE MUDANÇAS
Tipo 1
Tipo 2
Tipo 3
Dificuldade de
Implementação
Baixa
Média
Média
Frequência no
DW
Baixa
Alta
Baixa
Descrição
O atributo é
sobrescrito
Inserir um novo registro
Adicionar nova coluna a
com nova chave substituta
cada mudança
Guardar o histórico
Quando não conseguimos
associar o novo valor do
atributo ao antigo histórico
de fatos ou vice-versa
Quando Usar?
Correção
Desvantagem
Perdemos o
Histórico
Muitas mudanças
causam impacto em
armazenamento
Impacto em
armazenamento, pois
repete-se dados da coluna
para cada registro no banco
Fonte: Adaptado de Adamson (2010).
3.4
Considerações Finais
Este capítulo abordou um resumo dos principais conceitos sobre o assunto Modelagem
Dimensional e que foram importantes para o desenvolvimento da solução proposta neste
trabalho.
O capítulo que segue apresentará o assunto ETL, cujos conceitos elucidam o processo
de obtenção a manipulação e a carga de dados no DW.
38
4
ETL (EXTRACT, TRANSFORM, LOADING)
O presente capítulo apresenta o assunto ETL dentro do processo de criação de uma
DW. Este capítulo tem como base teórica os livros dos autores Ralph Kimball e Joe Caserta
(2004) e Caster et al. (2010).
A figura abaixo isolam os tópicos a serem abordados.
Figura 4.1 - Ambiente de Atuação do ETL.
Fonte: Adaptado de Adamson (2010).
4.1
Definição
O acrônimo ETL (Extract, Transform, Load) corresponde especificamente a Extração,
Transformação e Carga. Uma definição mais formal seria: “um conjunto de processos para
retirar dados dos sistemas OLTP (Online Transaction Processing) e colocá-los em um Data
Warehouse” (KIMBALL e CASERTA, 2004).
Os passos principais do ETL podem ser agrupados como segue:
39
1. Extração: Todo o processamento requerido para se conectar a vários sistemas
fontes, extrair os dados das fontes de dados, e deixá-los disponíveis para os passos
subsequentes.
2. Transformação: Qualquer função aplicada ao dado extraído no momento em que
estes saem do sistema fonte e são carregados em seu objetivo final. Essas funções podem
conter (mas não são limitadas) as seguintes operações:
Validação dos dados frente a regras de qualidade;
Modificação do conteúdo ou estrutura dos dados;
Integração com dados de diferentes fontes;
Cálculo de valores derivados e agregados baseados nos dados processados.
3. Carga: Todo o processamento requerido para carregar os dados no sistema alvo.
Esta parte do processo consiste em mais do que a carga em massa dos dados transformados na
tabela alvo. As partes deste processo incluem, por exemplo, gerenciamento de Chaves
Substitutas (Surrogate Keys) e gerenciamento de tabelas dimensionais.
4.2
Blocos base do ETL
Segundo Kimball e Caserta (2004) a melhor forma de compreender uma solução de
ETL é vê-la como um processo. Um processo tem entrada, saída, e uma ou mais unidades de
trabalho, os passos do processo. Estes passos, entretanto, têm entradas e saídas, e executam
uma operação para transformar a entrada em uma saída (Figura 4.2).
As funções dos principais passos constituintes do processo de ETL demonstrados na
Figura 4.2 acima são apresentadas a seguir:
EXTRAÇÃO: os dados brutos vindos dos sistemas fonte são guardados em uma
área de estágio onde serão manipulados como arquivos ou em um banco de dados.
A área de estágio dará flexibilidade de se recomeçar todo o processo se ocorrer
40
uma interrupção, evitando a sobrecarga que o reinício do processo pode causar
sobre os sistemas de suporte ao operacional;
LIMPEZA : execução de testes para checar a qualidade dos dados que pode
envolver vários passos incluindo a checagem de valores válidos, garantia da
consistência entre valores, remoção de dados duplicados, e checagem se regras e
procedimentos de negócio foram seguidos. Esta limpeza pode envolver a
intervenção humana;
CONFORMIZAÇÃO : A conformidade dos dados é requerida sempre que duas
ou mais fontes de dados são unidos em um DW. Dados de fontes separadas não
podem ser usados juntos a menos que alguns ou todos os rótulos textuais destas
fontes sejam feitas idênticas e medidas numéricas sejam matematicamente
racionalizadas de maneira que as medidas unidas façam sentido. A padronização
requer um acordo dentro da empresa para se usar domínios e medidas
padronizados;
CARGA : estruturar fisicamente os dados em um conjunto de modelos simples e
simétricos denominados modelos dimensionais, ou equivalentemente, esquemas
em estrela.
4.3
Desafios da Integração de Dados
Os desafios podem ser políticos, organizacionais, funcionais ou de natureza
tecnológica.
Segundo Kimball e Caserta (2004) as barreiras tecnológicas são um desafio, mas na
maioria das vezes removíveis; barreiras organizacionais são muito mais difíceis de vencer.
A Tabela 4.2 resume algumas das barreiras que podem ser encontradas.
41
Figura 4.2 - Visão geral do processo de ETL.
Fonte: Adaptado de Kimball e Caserta (2004).
42
Tabela 4.1 - Exemplos de Desafios da Integração de Dados.
TIPOS DE DESAFIOS
Políticos
Organizacionais
DESCRIÇÃO
regras e políticas internas de acesso aos dados
quais dados são necessários para responder as questões da
organização
a metodologia de desenvolvimento usada pode dificultar o
processo
Tecnológicos
grande quantidade de dados para extrair de uma vez
encontrar mudanças que ocorreram nos dados
integração entre sistemas diferentes
lidar com dados incompletos e inconsistentes
definir quais trabalhos e transformações serão construídos
não puramente pelo lado técnico, mas pelo lado funcional
Funcionais
o mesmo modelo conceitual deve ser usado para resolver
problemas similares
Fonte: Adaptado de Kimball e Caserta (2004).
Após resolver os desafios organizacionais, de projeto e de design, a primeira tarefa
técnica é ver de que lugar os dados serão retirados, em que forma estão disponíveis e o que
exatamente faz parte dos dados que você está interessado. Estes passos fazem parte do
processo de design do ETL, que será abordado na próxima subseção.
4.4
Cuidados no Planejamento do processo de ETL
Deve-se ter o cuidado para que sejam criadas transformações que saibam lidar com as
possíveis falhas durante o processo de ETL.
43
A tabela a seguir lista alguns dos cuidados mais importantes a se tomar durante este
processo.
Tabela 4.2 - Cuidados durante o processo de ETL
CUIDADO
DESCRIÇÃO
Ter acesso a sistemas fontes proprietários. Exemplo: ERP´s
comerciais
Aquisição de Dados
Políticas Internas que impeçam acesso direto aos dados
Problemas com a flexibilidade dada ao usuário final que poderá
renomear, excluir ou mover colunas prejudicando o processo
Cuidado com
Planilhas
de ETL
Configurações de Internacionalização
Pode-se aceitar planilhas desde que criadas por um processo
automatizado ou em formato padronizado
Testar a conexão com o repositório
Checar se um host está disponível
Espera para que o comando SQL retornar o sucesso/falha
baseado na condição de contagem de linha
Design para Falhas
Checar por diretórios vazios
Checar pela existência de um arquivo, tabela, ou coluna
Comparar os arquivos e diretórios
Configurar um timeout em conexões FTP e SSH
Criar saídas sucesso/falhas para cada passo disponível
Tratamento de exceção no nível de trabalhos e transformações
Tabelas de Fatos devem ser carregadas depois que todas as
dimensões sejam carregadas.
Se o processo de carga de uma dimensão falhar, permite-se
reiniciá-lo apenas nas partes que deram falhas e não foram
executados ainda
Fonte: Caster et al. (2010).
44
4.5
CDC (Change Data Capture)
O primeiro passo em um processo de ETL é a extração de dados de vários sistemas e a
passagem destes para o processo seguinte. A melhor prática é utilizar uma área intermediária
denominada área de estágio (Staging Area). Os dados extraídos podem ser armazenados em
banco de dados ou arquivos nesta área para que se possa recomeçar sem a necessidade de
pegar todos os dados novamente, sobrecarregando os sistemas de suporte ao operacional.
Ao carregar pela primeira vez um DW todos os dados serão carregados nesta área de
estágio. A partir da primeira carga necessitamos apenas atualizar os dados para refletir o seu
estado atual. Tudo que estamos interessados é no que mudou desde a última vez que foi
realizada uma carga, desta maneira deve-se identificar quais registros foram inseridos,
modificados, ou até eliminados nos sistemas fonte. O processo de identificação destas
mudanças e apenas retornar os registros que são diferentes dos que você já carregou no DW é
chamado de Change Data Capture ou CDC.
Basicamente, existem duas categorias principais de processos CDC, intrusivos ou não
intrusivos. Considera-se intrusivo aqueles em que a operação CDC tem um possível impacto
na performance do sistema que os dados são retirados. A maioria dos métodos usados para
capturar a mudança dos dados é intrusiva, deixando apenas uma opção não intrusiva.
4.6
Qualidade dos Dados
Deve-se assumir que sempre existem problemas de qualidade nos dados extraídos,
desta maneira é necessário fazer o planejamento de uma transformação para lidar com estes
problemas.
O ideal é que problemas de qualidade de dados sejam resolvidos nos sistemas fonte,
não no processo ETL (KIMBALL; CASERTA, 2004). Entretanto, arrumar a qualidade de
dados antes de começar um projeto de DW é um luxo que muitas organizações não podem
arcar.
Duas categorias de ferramentas estão disponíveis para lidar com os problemas de
qualidade:
45
1. Ferramentas de Profilling: usadas para investigar a qualidade dos dados,
buscando-se dois objetivos: o primeiro é comunicar os resultados deste exercício
para o dono dos dados; o segundo é servir de entrada para a validação dos passos
de um processo ETL;
2. Ferramentas de Monitoramento: usadas para constantemente monitorar e avaliar
os dados baseados em regras de negócio e qualidade.
4.6.1
Profilling de Dados
Uma das primeiras coisas a se fazer ao começar um projeto de ETL é realizar o profile
nos dados. Este processo dirá quantos dados existem e sua semelhança, tanto tecnicamente
quanto estatisticamente. A forma mais comum de profilling é o realizado por coluna, onde
para cada coluna em uma tabela, estatísticas são criadas. Dependendo do tipo de dados
consegue-se obter as seguintes informações::
Número de valores nulos ou vazios;
Número de valores distintos;
Valores Mínimo, Máximo e Médio (campos numéricos);
Tamanhos Mínimo, Máximo e Médio (campos string);
Padrões (Por exemplo, ###-###-#### para números);
Distribuição dos Dados.
Deve-se tomar cuidado, pois o profile de dados levará apenas às conclusões listadas
acima, problemas de qualidade lógicos e entre sistemas não podem ser detectados pela
maioria das ferramentas de profilling. Para detectá-las, deve existir em um primeiro momento
um glossário de negócios e um sistema de metadados, entretanto, estes sistemas ainda são
muito raros.
46
4.6.2
Validação de Dados
A validação é usada para conferir se as regras de negócio estão sendo respeitadas
durante o processo de ETL.
Usado dentro do processo para marcar, por exemplo, a ausência de elementos em um
sistema fonte representada por valores nulos, substituindo-o por um valor padrão como
Desconhecido, Ilegível ou qualquer outra forma que for necessária.
4.7
Considerações Finais
Este capítulo abordou um resumo dos principais conceitos da técnica denominada
ETL, responsável pela obtenção, transformação e carga dos dados na forma preconizada pela
Modelagem Dimensional dentro do DW.
O capítulo que segue apresentará o processo de Construção de um DW Modelagem
Dimensional e a descrição de seus principais passos que serão seguidos para confecção da
solução proposta neste trabalho.
47
5
PROCESSO DE CONSTRUÇÃO DE UM DATA WAREHOUSE
O presente capítulo apresenta de forma detalhada o processo de Construção do Data
Warehouse e os principais passos envolvidos.
O conteúdo exposto tem como base teórica o livro do autor Adamson (2010) que
propõem a sequência de construção do DW que deverá ser seguida pelo presente projeto.
5.1
Atividades envolvidas
O processo de construção de um DW envolve duas categorias principais de atividades:
processar os dados para armazená-los nas Tabelas de Dimensão e nas Tabelas de Fatos.
Carregar uma tabela de dimensão é um processo incremental, que envolve tarefas
como reconhecer novos dados e dados que mudaram; gerenciar chaves substitutas e inserir ou
fazer a atualizações de registros de uma dimensão se apropriado.
No caso das Tabelas de Fatos o processo de carga só pode ser executado se todas as
dimensões com que a mesma se relaciona já tiverem sido carregadas (Figura 5.1), pois existe
uma dependência fundamental em um Modelo Estrela: cada tabela de fatos possui uma chave
estrangeira que referencia linhas das tabelas de dimensão.
Figura 5.1 - Sequência a ser executada a carga do Modelo em Estrela.
Fonte: Adaptado de Adamson (2010).
48
O passo 1 da Figura 5.1 será decomposto em uma série de atividades que deverão ser
executadas para cada tabela de dimensão. Assim como o passo 2 será decomposto em uma
série de atividades que deverão ser executadas para carregar as tabelas de fatos.
5.2
Carregando as Tabelas de Dimensão
Deve-se tomar cuidado para inspecionar os sistemas fontes das tabelas de dimensão
por mudanças na informação de tempos em tempos e inserir registros assim que apropriado.
A lista que segue enumera os requisitos que deverão ser atendidos durante o processo
de carga de uma tabela de dimensão:
Extrair dados dos sistemas fontes;
Selecionar os atributos da dimensão;
Identificar novos registros de tabelas de dimensão que mudaram;
Gerenciar chaves substitutas;
Processar novos registros;
Processar mudanças do Tipo 1;
Processar mudanças do Tipo 2.
Devido a complexidade do processo de carga de tabelas de Dimensão é interessante
quebrá-lo em uma série de passos individuais, sendo que cada um deles deve ser executado
para cada tabela de dimensão no esquema em estrela.
5.2.1
Pré-Processamento dos dados
Inicialmente os dados devem ser obtidos de uma fonte e formatados como
especificado no design das tabelas alvo. Estas atividades são representadas pelos três
primeiros passos na Figura 5.2.
49
O passo 1.1 representa a aquisição dos dados dos sistemas fonte. Uma vez extraído, os
dados devem ser reorganizados de forma a serem processados uma linha por vez (passo 1.2 da
Figura 5.2).
Assim que os dados estão estruturados para serem lidos uma linha por vez, o passo 1.3
da Figura 5.2 separa os atributos de Dimensão de cada uma delas. Os seguintes processos
podem ser executados neste passo:
Os códigos devem ser decodificados em valores descritivos;
Campos com atributos compostos devem ser separados em uma série de atributos;
Conjunto de campos podem ser concatenados;
Valores nulos podem ser substituídos com textos mais compreensivos com
“Indisponível” ou “Desconhecido”;
Pode-se formatar os atributos em maiúsculo assim como outras operações podem
ser executadas.
O passo 1.3 pode ser quebrado para incluir tarefas de limpeza de dados, tais como
padronização de nomes e endereço.
Assim que as tarefas de 1.1 a 1.3 estiverem completas, um ou mais potenciais registros
para as dimensões estarão prontos para processamento futuro. Os próximos passos
determinarão como um registro em potencial é analisado, se ele se encaixa como um novo
registro ou possui mudanças do Tipo 1 ou Tipo 2 ou ambas.
5.2.2
Processamento de Novos Registros
Os novos registros serão os com Chave Natural que ainda não exista no esquema em
estrela. A cada novo valor encontrado, deve-se atribuir uma chave substituta e inseri-la
diretamente na respectiva Tabela de Dimensão. Na Figura 5.2 este processo é representado
pelos passos 1.4, 1.9 e 1.10.
50
Figura 5.2 - Processo de Carga de uma Tabela de Dimensão.
Fonte: Adaptado de Adamson (2010).
51
Para determinar se um registro que chega é novo, o passo 1.4 busca por sua chave
natural na Tabela de Dimensão. Este processo de checagem é referido como lookup. Se o
valor da Chave Natural não é encontrado na tabela existente, o registro é novo devendo-se
designar a próxima chave substituta para o registro (passo 1.9), a partir deste momento podese carregá-lo na Tabela de Dimensão (passo 1.10). Se, por outro lado, um registro é
encontrado como resultado do processo de lookup feito no passo 1.4, a Chave Natural já está
presente na Dimensão e o registro deve ser analisado com mais calma para determinar se
aconteceram mudanças do Tipo 1 e 2.
5.2.3
Processamento de Mudanças do Tipo 1
Todo registro que não é novo pode conter mudanças do Tipo 1. Quando um atributo
muda no lado do sistema fonte e se comporta como uma mudança deste tipo, seu valor é
sobreposto no DW. Para identificar uma mudança do Tipo 1, um registro que chega é
comparado com o valor de Chave Natural do registro mais atual no DW. Os atributos do Tipo
1 são comparados, se não são iguais, uma mudança do Tipo 1 foi identificada. Na Figura 5.2
esta comparação é realizada no passo 1.5.
No passo 1.6 da Figura 5.2, as mudanças do Tipo 1 são aplicadas para todos os
registros de tabelas dimensionais que compartilham uma Chave Natural – não somente o
registro com a versão mais atual.
Assim que as mudanças do Tipo 1 forem aplicadas, o processo deste novo registro
fonte ainda não está completo. Deve-se checar para ver se mudanças do Tipo 2 ocorreram.
5.2.4
Processamento de Mudanças do Tipo 2
Depois que uma mudança do Tipo 1 foi identificada e aplicada, o registro a ser
inserido deve ser checado por mudanças do Tipo 2. Na Figura 5.2, isso acontece no passo 1.7.
Esta tarefa pode ser completa por um terceiro lookup, usando a combinação da Chave Natural
e todos os atributos do Tipo 2 deste registro. Se pelo menos um dos atributos de Tipo 2 tiver
sido modificado, uma mudança de Tipo 2 ocorreu, senão o processo é finalizado.
52
Ao ocorrer uma mudança, o registro anterior não será mais o atual, portanto, o passo
1.8 é utilizado para atualizar o campo de controle de versão do registro anterior para o valor
“Não é mais o atual”, enquanto que o novo registro atual recebe uma nova Chave Substituta
(Passo 1.9) e é carregado na tabela do DW (Passo 1.10).
Um registro único pode conter tanto uma mudança do Tipo 1 e 2. Isto explica porque o
passo 1.6 é conectado ao passo 1.7, e não ao final do processo de fluxo.
5.3
Processo de Carga da Tabela de Fatos
O processo de carga da Tabela de Fatos pega as transações dos sistemas fonte, calcula
os fatos, identifica as chaves estrangeiras apropriadas e insere os registros em um esquema em
estrela. A parte mais complexa deste processo envolve identificar os valores de chaves
estrangeiras apropriados.
Os sistemas fonte fornecem apenas a chave natural, mas as tabelas de fato devem usar
chaves estrangeiras para referir-se a dimensões. Para cada fato no sistema fonte, as chaves
naturais que identificam o contexto dimensional devem ser substituídas por Chaves
Substitutas que identificam linhas nas Tabelas de Dimensão.
Como mudanças do Tipo 2 são possíveis, existem múltiplas linhas em uma tabela de
dimensão para um valor particular.
5.3.1
Requisitos a serem atendidos
A Tabela de Fatos é governada pelos seguintes requisitos:
Extrair dados dos sistemas fonte;
Computar os Fatos;
Agregar os novos fatos à granularidade da tabela de fatos;
Obter Chaves Substitutas para cada uma das Dimensões;
Carregar os registros das Tabelas de Fato dentro de um DW.
53
O fluxo de processo para suportar estes requisitos é mostrado na Figura 5.3.
Novamente, estes passos são lógicos, que servem para guiar a discussão do processo de carga.
As tarefas e técnicas específicas usadas irão variar baseadas nos sistemas fonte, design, as
capacidades da ferramenta ETL sendo usada e as preferências do desenvolvedor.
5.3.2
Pré-Processamento dos dados
O primeiro passo é extração dos dados dos sistemas fonte, representado pelo passo 2.1
da Figura 5.3. As informações necessárias para carregar as transações em uma tabela de fatos
incluem os elementos de dados que serão usados para criar os fatos e as chaves naturais que
serão usadas para identificar as dimensões associadas.
Depois que os dados são adquiridos, pode ser necessário reestruturar os dados de
modo que possam ser processados uma linha por vez. Isto é representado pelo passo 2.2 na
Figura 5.3.
Figura 5.3 - Sequência do processo de carga de uma Tabela de Fatos.
Fonte: Adaptado de Adamson (2010).
Depois que os dados são extraídos e organizados por linha, os fatos devem ser
calculados a partir dos dados disponibilizados pelo sistema fonte. Fatos aditivos como valores
monetários e quantidade de itens em linhas separadas. Para cada linha de pedido, estes
registros devem ser consolidados em uma única linha. Esta atividade é representada pelo
passo 2.3 na Figura 5.3.
54
Alguns cuidados devem ser tomados no processo de carga das tabelas de fatos:
Se as fontes de dados proverem dados em uma granularidade menor que o de uma
tabela de fatos existente estes deverão ser agregados ao mesmo nível de detalhe;
Deve-se tomar cuidado para não agregar fatos semi aditivos impropriamente;
Fatos não aditivos devem ser quebrados em componentes totalmente aditivos no
design do esquema.
Na Figura 5.3, a agregação é realizada no Passo 2.4. Quando existem múltiplos
sistemas fonte, este processo pode ser repetido para cada um. Alternativamente, extrações
iniciais podem ser realizadas separadamente com dados sendo consolidados em uma Área de
Estágio única. Tarefas subsequentes são executadas usando este conjunto consolidado de
dados.
Quando existe uma fonte única que é relacional, estes quatro primeiros passos podem
ser executados em apenas uma consulta. As consultas selecionam as chaves naturais
relevantes e depois agregam e calculam os fatos. O próximo passo é atribuir as Chaves
Substitutas.
5.4
Identificação das Chaves Substitutas
Cada transação do sistema fonte é extraída com valores de Chave Natural que
descrevem seu contexto. Nas Tabelas de Fatos, as chaves estrangeiras que se referem às
tabelas dimensionais não contêm os valores de Chaves Naturais. Os valores de chave dos
sistemas fonte são substituídos por Chaves Substitutas (Surrogate Keys) para que se
carreguem os registros na tabela de fatos. Este processo é representado na Figura 5.3 pelo
passo 2.5 e deve ser feito uma vez para cada Dimensão referenciada na Tabela de Fatos.
A identificação dos valores de Chave Substituta é realizada em um processo de
lookup. Busca-se na tabela de Dimensão por uma linha que contém valores de Chave Natural
providas pelos sistemas fonte. Assim que a Dimensão apropriada é encontrada, sua chave
substituta é obtida.
Para garantir uma Chave de Dimensão correta o processo de lookup deve ser refinado
em uma das seguintes formas:
55
Se o Design Dimensional inclui uma coluna de controle de versão de registro
atual, pode-se utilizá-la para identificar a versão mais recente.
Se o Design Dimensional inclui campos para datas efetivas e de expiração, a data
de transação pode ser comparada com estas datas para identificar a versão correta.
Se nenhuma das ferramentas de design acima está disponível, todos os atributos
do Tipo 2 deverão ser extraídos com as transações fonte junto com as chaves
naturais, e serão usadas no processo de lookup.
Se um dado fonte passa por múltiplas mudanças do Tipo 2 entre as cargas, ou se for
necessário carregar a história passada nas Tabelas de Fatos, o procedimento não será efetivo,
sendo necessário tratar este atributo como sendo uma mudança do Tipo 3 e atualizando-o de
acordo ou, se necessário, deve-se utilizar algum tipo de técnica híbrida para lidar com
mudanças. Maiores detalhes sobre técnicas híbridas podem ser consultados no livro “The
Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning, Conforming,
and Delivering Data” (KIMBALL; CASERTA, 2004).
5.5
Considerações Finais
Este capítulo abordou o processo de construção de um DW e seus principais passos. O
processo enunciado neste capítulo será seguido para o desenvolvimento da solução proposta
neste trabalho.
O capítulo que segue apresentará a proposta de solução deste trabalho, abordando-se o
problema analisado, o escopo deste trabalho, ferramentas utilizadas assim como os modelos
criados.
56
6
PROPOSTA DE SOLUÇÃO
O objetivo deste capítulo é apresentar o problema escolhido para ser solucionado neste
trabalho, assim como apresentar os processos envolvidos no desenvolvimento da solução
proposta.
Este capítulo está dividido como segue:
A seção 6.1 abordará o problema a ser solucionado, detalhando-o, a seção 6.2
apresentará o escopo deste trabalho, a seção 6.3 mostra as ferramentas utilizadas neste
projeto, a seção 6.4 detalha a arquitetura proposta para a solução, a seção 6.5 descreve o
processo de implementação da solução, a seção 6.6 apresenta os resultados obtidos, enquanto
que a seção 6.7 tece as considerações finais deste capítulo.
6.1
O Problema Analisado
A cada semestre a instituição FATEC-SJC acumula arquivos em formato de planilhas,
contendo as informações dos candidatos que participam do processo seletivo. Os dados
armazenados são tanto os que o candidato preenche na ficha de inscrição do respectivo
vestibular, assim como os referentes a seu desempenho neste.
Apesar de receber estes dados do CEETEPS, a instituição FATEC-SJC não efetua uma
análise para que possa extrair algum tipo de conhecimento em relação aos seus candidatos, tal
como o perfil demográfico, seu desempenho assim como a quantidade de alunos que passam
se tornam efetivamente alunos da instituição.
A ideia deste trabalho nasceu a partir do resultado obtido pelo professor da FATECSJC Fernando Masanori Ashikaga que, por iniciativa própria, avaliando o desempenho dos
alunos nas disciplinas que possuem ponderações diferenciadas (peso 2), descobriu que
candidatos que vieram do cursinho pré-vestibular VESTEC (VESTEC, 2010) poderiam
melhorar seu desempenho se o cursinho desse ênfase nestas matérias, de maneira a ajudá-los a
ingressar na instituição FATEC-SJC. Ao analisar os dados históricos ele constatou que os
alunos ingressantes costumavam acertar apenas 30% das questões de matemática. Em
contrapartida, os mesmos candidatos acertavam em média 70% dos pontos de História. Essa
informação o ajudou no planejamento pedagógico do cursinho oferecido pelo VESTEC, que
57
possui uma restrição de tempo, espaço físico e de profissionais, pois é oferecido aos sábados
(7h00-19h20), no prédio da faculdade UNESP e é ministrado por alunos voluntários de
renomadas instituições de ensino do Estado de São Paulo, como a UNICAMP, ITA, USP,
UFABC, UNIFESP, FATEC.
O resultado da iniciativa descrita acima foi que com estas informações em mãos e
dentro do contexto apresentado, decidiu-se aumentar a carga de aulas de Matemática e
realizar aulas de nivelamento nesta disciplina.
Da mesma forma, este trabalho é uma iniciativa para que estes dados possam ser
aproveitados de uma maneira mais eficiente, de forma a obter informações importantes sobre
os candidatos que participam do processo seletivo da instituição. Para isso as subseções que
seguem irão descrever em mais detalhes o problema analisado neste trabalho.
6.1.1
O Processo Seletivo da FATEC
Semestralmente as Faculdades de Tecnologia do Estado de São Paulo oferecem
atualmente 10.860 vagas, distribuídas entre 60 cursos de graduação tecnológica e 51 unidades
pelo estado de São Paulo (CEETEPS, 2011).
O candidato que deseja ingressar na instituição deverá participar de um processo
seletivo (VESTIBULAR, 2011), realizado semestralmente de maneira unificada pela FAT
(Fundação de Apoio a Tecnologia), uma fundação de direito privado sem fins lucrativos,
criada por professores da Faculdade de Tecnologia de São Paulo - FATEC-SP, mais detalhes
podem ser encontrados em FAT, 2011.
A FATEC-SJC em específico (FATEC-SJC, 2010a) foi criada em 2 de março de 2006
conforme o Decreto Nº 50.580 publicado no Diário Oficial, mais detalhes podem ser
encontrados no website da instituição ao se acessar o menu “Sobre a FATEC” (FATEC-SJC,
2010b).
A instituição iniciou suas atividades no primeiro semestre de 2006 e de acordo com o
tempo ofereceu os seguintes cursos:
No 1º semestre de 2006, iniciou suas atividades com a implantação do Curso
de Logística com Ênfase em Transportes;
58
No 1º semestre de 2007, foi implantado o curso de Tecnologia em Informática Ênfases em Banco de Dados e Redes de Computadores;
No 1º semestre de 2009, foi implantado o curso de Tecnologia em Sistemas
Aeronáuticos.
Uma característica marcante da instituição e que influi também em seu processo
seletivo é a liberdade que possui para adequar a estrutura de seus cursos ao perfil de
profissional que o mercado procura, agora de uma maneira ainda mais significativa, após a
conquista de sua autonomia acadêmica (CLARA, 2011). Esta característica importante para a
instituição também é um dos fatores que dificultaram uma parte do processo de
desenvolvimento da solução proposta neste trabalho, já que o processo seletivo mudou com o
decorrer dos anos e estas mudanças começaram a ficar difíceis de serem evidenciadas
somente verificando os dados brutos já consolidados nos arquivos em formato de planilhas
enviados pelo CEETEPS.
Mais detalhes sobre as dificuldades encontradas durante o processo de estudo dos
dados obtidos para a realização do desenvolvimento deste projeto serão apresentados nas
subseções que seguem.
6.1.1.1 Ficha de inscrição (dados a serem analisados)
A ficha de inscrição do vestibular atual FATEC (segundo semestre de 2011) é
composta por um formulário eletrônico que deve ser preenchido em cinco etapas. O apêndice
A (FICHA DE INSCRIÇÃO 2º SEMESTRE DE 2011) apresenta o passo a passo do processo
de preenchimento (Figuras A1 até A20).
Os dados preenchidos pelo candidato neste formulário são importantes para o presente
trabalho, pois fornecem um rico contexto a um dos fatos que se desejam analisar: o perfil
demográfico do candidato, entretanto problemas foram encontrados.
A Tabela 6.1 apresenta um resumo dos principais detalhes de cada uma das cinco
etapas envolvidas no preenchimento da ficha de inscrição ao processo seletivo FATEC.
59
Tabela 6.1 - Formulário Processo Seletivo FATEC - Etapas de preenchimento
ETAPAS
CONTEÚDO
Data de nascimento, Documento
de
Identidade,
Nome
do
Candidato, CPF, Email e outros
1. Dados Pessoais
(Mais detalhes no ANEXO A )
Dados Cadastrais Gerais:
Dados sobre o ENEM
Dados sobre Necessidades Especiais
Declarações sobre:
2. Pontuação Acrescida
Afrodescendência
(Mais detalhes no ANEXO A)
3. Fatec, curso e período
(Mais detalhes no ANEXO A)
4. Confirmação
Escolaridade Pública
Seleção da unidade Fatec
Curso e período
Confirmação do cadastro
veracidade das informações
17 questões sócio econômicas
e
da
(Mais detalhes no ANEXO A)
5. Questionário Sócio Econômico
(Mais detalhes no ANEXO A)
Fonte: Autoria própria.
Uma dificuldade com os dados refere-se ao questionário sócio econômico. Os
formulários dos processos seletivos anteriores (2009 e 2010, primeiro e segundo semestres
assim como o do primeiro semestre de 2011) não estão mais disponíveis na internet para
consulta. A Figura 6.1 que segue demonstra este problema.
60
Figura 6.1 - Questionário Sócio Econômico: comparação do número de questões.
Fonte: Autoria própria.
Sem os formulários originais e os respectivos enunciados das perguntas referentes ao
questionário sócio econômico não podemos afirmar, olhando apenas para os dados
apresentados na Figura 6.1, que o enunciado da questão 15 do questionário do 1º semestre de
2009 é o mesmo que o da questão 15 do 1º semestre de 2011. Só conseguiríamos aceitar tal
proposição se tivéssemos acesso ao enunciado das questões de cada processo seletivo
elencado na Figura 6.1, senão estaríamos a assumir um risco desnecessário, inserindo
possivelmente uma inconsistência no DW e comprometendo a sua validade como ferramenta
analítica.
Ressalta-se que apenas o formulário correspondente ao processo seletivo FATEC para
o segundo semestre de 2011 está disponível na internet, disponibilizando as seguintes
questões sócio econômicas:
1. Você já prestou Vestibular da Fatec anteriormente?
2. Como você ficou conhecendo a Fatec?
3. Por que você deseja fazer um curso tecnológico na Fatec?
4. Você já iniciou algum curso superior?
5. Onde você mora?
6. Que tipo de curso de ensino médio (antigo 2º grau) você concluiu ou concluirá?
7. Onde você cursa ou cursou o ensino médio (antigo 2º grau) ou equivalente?
8. Em que período você cursa ou cursou o ensino médio (antigo 2º grau) ou
equivalente?
61
9. Você exerce atualmente atividade remunerada?
10. Que tipo de atividade profissional você exerce?
11. Qual a sua participação na vida econômica da família?
12. Qual é a renda familiar mensal de seu domicílio? (considere a soma de todos os
salários dos membros de sua família e assinale a alternativa que mais se aproxima do
valor total)
13. Quantas pessoas contribuem para obtenção dessa renda familiar, incluindo você?
14. Qual é o nível de instrução de seu pai?
15. Qual é o nível de instrução de sua mãe?
16. Você acessa a Internet em sua casa?
17. Você pretende futuramente ingressar em outro curso superior?
Possivelmente, olhando para as questões acima, poderíamos concluir que a questão 15
dos formulários antigos poderia ser a mesma que a do formulário atual, entretanto, não é
compensador levar esta dúvida para dentro do ambiente do DW, pois uma inconsistência
como essa pode comprometer a qualidade dos dados e gerar um esforço adicional para sua
correção.
Se as questões de número 1 à 15 fossem iguais para todos os processos seletivos da
Figura 6.1 e as novas questões anexadas durante o tempo fossem sempre colocadas ao final do
formulário, o questionário poderia ser modelado analiticamente, colocando-se o valor “Não
aplicável” nas questões dos candidatos que responderam formulários mais antigos.
Outro problema encontrado foi referente à maneira como os dados desta ficha de
inscrição foram disponibilizados pelo CEETEPS à FATEC-SJC. O formato planilha, como
explicado no Capítulo 4 – Tabela 4.3, possui uma série de desvantagens se não utilizado
adequadamente. A Tabela 6.2 expõe alguns destes problemas.
Como enfatizado no Capítulo 4, podemos confiar nos dados em planilhas desde que a
planilha tenha sido criada a partir de um processo automatizado ou se estiver em um formato
padronizado. Podemos corrigir este problema de dois modos: corrigindo na fonte que gera
esta inconsistência ou através de scripts ETL personalizados para lidar com cada uma destas
inconsistências. O ideal e recomendado sempre é corrigir o processo de obtenção destes
dados, pois ele é a fonte de toda as inconsistências presentes. Desta maneira, recomenda-se
que os próximos arquivos venham seguindo algum padrão definido pela instituição FATECSJC e o CEETEPS, de maneira a facilitar o processo automatizado de ETL.
62
Tabela 6.2 - Planilhas Disponíveis - Inconsistências encontradas.
PLANILHAS DISPONÍVEIS – INCONSISTÊNCIAS
1s2009.xls
2s2009.xls
1s2010.xls
2s2010.xls
1s2011.xls
85
76
85
86
90
AFRODESCEN
DENTE
AFRODESCEN
AFRODESCEN
DENTE
AFRODESCEN
DENTE
AFRODESCEN
DENTE
de colunas
NOME_CURSO
HISTÓRIA
QUÍMICA
INGLÊS
MATEMÁTICA
FISICA
GEOGRAFIA
BIOLOGIA
PORTUGUÊS
...
NOME_CURSO
HIST
QUIM
INGL
MATE
FISI
GEOG
BIOL
PORT
ANOENEM
NOME_CURSO
HISTÓRIA
QUÍMICA
INGLÊS
MATEMÁTICA
FISICA
GEOGRAFIA
BIOLOGIA
PORTUGUÊS
....
NOME_CURSO
HISTÓRIA
QUÍMICA
INGLÊS
MATEMÁTICA
FISICA
GEOGRAFIA
BIOLOGIA
PORTUGUÊS
...
Colunas
...
...
...
NOTAPARCIAL
NOTAFINAL
NOTAPARCIAL
NOTAFINAL
CURSO_1
HISTÓRIA
QUÍMICA
INGLÊS
MATEMÁTICA
FISICA
GEOGRAFIA
BIOLOGIA
PORTUGUÊS
...
MULTIDISCIPLI
NAR
NOTAPARCIAL
NOTAFINAL
Número de
Colunas
Nome
Divergente
Inexistentes
NOTAPARCIAL
NOTAFINAL
MULT
...
...
Fonte: Autoria própria.
6.1.1.2 A composição da Prova e o desempenho dos alunos
Para avaliar o desempenho dos candidatos foi necessário entender como este processo
é feito. A melhor fonte para este tipo de informação encontra-se nos manuais do candidato de
cada processo seletivo.
Foram encontrados os manuais dos candidatos apenas dos processos seletivos do
primeiro semestre de 2010, assim como os de primeiro e segundo semestres de 2011 (Figura
6.2). Sendo assim, as provas dos processos seletivos do segundo semestre de 2010 e primeiros
e segundos semestres de 2009 não puderem ser avaliadas da forma mais adequada.
Os processos seletivos anteriores a 2009 não farão parte do escopo da solução
proposta, pois não fizeram parte das planilhas disponibilizadas para a implementação da
solução.
63
Figura 6.2 - Manuais do Candidato ao Vestibular
Fonte : MANUAL (2010, 2011a, 2011b).
Foram feitas avaliações sobre os dados encontrados nos gabaritos disponibilizados na
seção “Provas e Gabaritos” do website do processo seletivo FATEC (VESTIBULAR, 2011),
para compreender melhor os detalhes do processo seletivo e do cálculo das notas das provas
correspondentes aos manuais que não foram encontrados.
Tabela 6.3 - Gabaritos: diferenças na composição das provas.
PROCESSOS SELETIVOS
1s2009
2s2009
1s2010
2s2010
1s2011
Número total de
Questões (48)
Novo total de
Questões (54) e
Disciplina
Número total de
Questões (54) e
Disciplina iguais
Número total de
Questões (54) e
Disciplina iguais
Número total de
Questões (54) e
Disciplina iguais
Fonte: GABARITOS (2009a, 2009b, 2010a, 2010b, 2011).
64
Os gabaritos dos processos seletivos estudados neste trabalho foram encontrados no
website ajudaram a avaliar um pouco das mudanças que ocorreram na prova ao longo dos
processos seletivos.
Nota-se na Tabela 6.2 que no processo seletivo de 2009, ocorreram mudanças entre os
semestres: o número de questões passou de 48 para 54 enquanto que uma nova disciplina foi
adicionada. A partir do segundo semestre de 2009 não houve mudanças no número de
questões e disciplinas.
Por falta dos manuais do candidato relativos aos anos de 2009 e do 1º semestre de
2010, além de novas mudanças previstas nos manuais dos semestres de 2011 em relação ao
número de questões (MANUAL 2011a e 2011b), decidiu-se analisar o desempenho dos candidatos
somente no processo seletivo referente ao 1º semestre de 2011.
Analisando os dados disponíveis, a prova escolhida para avaliação foi composta por
uma redação e por 54 (cinquenta e quatro) questões, cada uma com 5 (cinco) alternativas (A,
B, C, D e E), com 6 (seis) questões de cada uma das disciplinas a seguir relacionadas:
Tabela 6.4 - Disciplina que compõem a prova 2011 primeiro semestre.
DISCIPLINA
NÚMERO DE QUESTÕES
Biologia
6
Física
6
Geografia
6
História
6
Matemática
6
Química
6
Inglês
6
Português
6
Multidisciplinar (Raciocínio Lógico)
6
TOTAL DE QUESTÕES
54
Fonte: MANUAL, 2011a.
65
Existe uma ponderação diferente para duas disciplinas das elencadas acima de acordo
com o escopo do curso escolhido como é visto na Figura 6.3.
A nota final do candidato é calculada conforme instruções do manual (MANUAL,
2011a).
Figura 6.3 - Disciplinas com peso 2, processo seletivo 1º Semestre de 2011.
Fonte: MANUAL, 2011a.
6.2
Escopo do Trabalho
De acordo com os resultados da avaliação realizada na seção anterior, o escopo deste
trabalho ficou reduzido à avaliação do processo seletivo do 1º semestre de 2011 com relação
ao desempenho dos candidatos e questionário sócio econômico. Uma análise demográfica dos
candidatos será realizada usando todos os arquivos de processo seletivo disponíveis.
Para que o escopo deste projeto seja atingido serão utilizados conceitos e técnicas da
área de BI para a extração, modelagem e consulta dos dados, assim como para a consulta dos
resultados em um banco de dados analítico.
A extração dos dados terá como base os princípios enunciados nos capítulos 4 deste
trabalho. A modelagem dos dados de acordo com o Modelo Dimensional se apoiará sobre os
princípios enunciados no capítulo 3 e a sequência para a construção do ambiente analítico do
DW seguirá os princípios enunciados no capítulo 5.
A seção que segue apresentará as ferramentas que foram utilizadas em cada etapa da
montagem do ambiente do DW.
66
6.3
Ferramentas Utilizadas no Projeto
As subseções que se seguem trazem um breve resumo das tecnologias, suas principais
características e as vantagens de utilização dentro do processo de montagem de um DW.
6.3.1
Qualidade dos dados
O software DataCleaner (DATACLEANER, 2011) é uma aplicação de código
livre utilizada para analisar, avaliar a qualidade, transformar e limpar dados. É uma alternativa
livre (LGPL) aos softwares de gerenciamento de dados usados em projetos de DW, pesquisas
estatísticas e outras.
A versão deste software utilizada neste projeto foi: DataCleaner 2.1.1 (stable) para
Windows.
O DataCleaner foi importante no processo de avaliação da qualidade dos dados fonte
a serem usados na solução proposta neste trabalho.
A Figura 6.4 corresponde ao resultado obtido pela ferramenta DataCleaner após uma
busca utilizado-se um filtro para procurar valores que seguem uma determinada expressão
regular. A expressão regular deste exemplo em particular é a seguinte:
^([0-9]{5})-([0-9]{3})$
No contexto da Figura 6.4 a expressão regular foi usada para checar se os valores de
CEP do arquivo “1s2009” (Seta 1 – Figura 6.4) estão de acordo com a simples regra: cinco
algarismos numéricos seguidos de um hífen e mais três algarismos numéricos. Neste caso a
ferramenta DataCleaner obteve os resultados e os apresentou em uma tabela indicada pela
Seta 2 – Figura 6.4.
67
1
2
3
Figura 6.4 - Software DataCleaner: Avaliação do CEP frente a uma Expressão Regular.
Fonte: Autoria própria.
Esta tabela apresenta os resultados da operação em quatro linhas distintas:
Número de linhas: 1232
Número de Valores Nulos: 0
Número de resultados que seguem a expressão regular: 1231
Número de resultados que não seguem a expressão regular: 1
Ao clicar no botão que fica ao lado direito do valor da linha que não segue a expressão
regular (última linha da tabela), o software exibe em uma nova janela quais os valores não
seguem o formato definido na expressão regular (Seta 3 – Figura 6.4), neste caso apenas um
elemento “12237-70”, que não possui o último algarismo numérico do CEP.
Resultados como este nos ajudaram a ter mais confiança na confecção dos scripts
envolvidos na fase de ETL do sistema proposto, expondo a qualidade dos dados em termos de
integridade, padrões seguidos, possíveis surpresas e desafios a serem encontrados na
transformação e limpeza de dados incompletos ou até mesmo inexistentes.
68
6.3.2
ETL
Para a execução do processo de ETL o conjunto de ferramentas escolhido foi o
Pentaho Data Integration (PDI, 2011). O PDI oferece uma série de ferramentas poderosas
para os processos de Extração, Transformação e Carga (ETL) de dados, seguindo uma
abordagem de construção de código orientada a metadados e visual.
O software possui uma interface intuitiva, baseada em drag-and-drop e blocos base.
Estes blocos base proveem uma quantidade enorme de possibilidades ao profissional de ETL
em termos de construção de transformações.
A versão do software utilizada neste projeto foi: Pentaho Data Integration Community
Edition 4.1.0 (stable) para Microsoft Windows.
O PDI foi fundamental como ferramenta em todo o processo de ETL, desde a extração
dos dados dos arquivos em formato Microsoft Excel à construção do DW com suas
respectivas tabelas de Fatos, Dimensões e Chaves Substitutas.
6.3.3
Banco de Dados: MySQL
O MySQL (MYSQL, 2011) é um dos Bancos de Dados de código livre mais populares
devido a sua performance, alta confiabilidade e facilidade de uso. É utilizado em muitos
projetos construídos em uma arquitetura LAMP (Linux, Apache, MySQL, PHP/Perl/Python).
O trabalho proposto utilizará o Banco de Dados Relacional MySQL para armazenar o
DW, entretanto, qualquer outro Banco de Dados Relacional poderia ou pode ser utilizado para
o mesmo sem muitas modificações.
A versão do MySQL utilizada no projeto foi: MySQL 5.5.8. A justificativa para a
utilização do MySQL advém do artigo escrito por Jos Van Dongen (DONGEN, 2009) . Sendo
o autor um consultor de BI, dono de uma empresa de Consultoria desde 1999 e autor de livros
como “Pentaho Kettle Solutions“ (CASTER; BOUMAN; DONGEN, 2010) e “Pentaho
Solutions” (BOUMAN; DONGEN, 2010).
Neste artigo ele questiona sobre quais são as opções que existem em Bancos de Dados
Analíticos de código livre e se impressiona com o levantamento realizado pelo Instituto
Gartner. A pesquisa feita pelo instituto apresentou que na época 18% das empresas
69
entrevistadas continuavam a utilizar o MySQL como Banco de Dados para Data Warehouse.
O autor então testou as opções de código livre oferecidas como o PostgreSQL, LucidDB,
MonetDB, MySQL 5.0 e 5.1 fazendo um comparativo dos recursos oferecidos e desempenho
frente a uma instância de teste. O resultado é que o MySQL em sua versão 5.1 apresentou no
quesito recursos uma quantidade maior de opções que seus concorrentes enquanto que, no
quesito desempenho, não apresentou uma diferença que justificasse a adoção de um banco de
dados como o LucidDB.
Trabalhos futuros podem explorar uma gama de Banco de Dados que seguem
arquiteturas diferentes da Relacional, como os Bancos de Dados Colunares Open Source
como o MonetDB (MONODB, 2011), Infobright Community Edition (INFOBRIGHT, 2011),
HBase (HBASE, 2011) entre outros.
6.4
Arquitetura do protótipo
A arquitetura a ser utilizada neste projeto é mostrada na Figura 6.5. A figura
demonstra os principais componentes envolvidos no processo de construção da solução de BI
proposta neste trabalho.
O processo de construção pode ser visto em quatro etapas. As subseções que seguem
explicam os componentes utilizados em cada uma.
Figura 6.5 - Arquitetura Geral da Solução Proposta neste Trabalho.
70
6.4.1
Primeira Etapa: FONTE DE DADOS
A fonte de dados para este sistema foi composta por cinco arquivos em planilhas com
os dados cadastrais dos candidatos assim como os seus respectivos desempenhos nas provas
do vestibular FATEC-SJC.
Outra fonte de dados para o sistema advém de arquivos no formato separado por
vírgulas (CSV) que serão obtidos durante o processo de ETL diretamente do site do IBGE
(IBGE, 2011).
6.4.2
Segunda Etapa: PROCESSO DE ETL
Os dados dos arquivos fonte foram extraídos em uma Área de Estágio construída
como um Banco de Dados Relacional, em nosso caso o MySQL. O modelo relacional desta
área de estágio se encontra no Apêndice A2.
Nesta região os dados foram limpos, padronizados e transformados de forma a serem
utilizados analiticamente, seguindo os princípios da Modelagem Dimensional descritos no
Capítulo 4 da Revisão Bibliográfica. Um esquema sobre como foi feito o processo de ETL é
apresentado no Apêndice A1.
6.4.3
Terceira Etapa: DATA WAREHOUSE
Nesta etapa já temos o Bando de Dado Analítico montado, com seus principais
componentes como: Tabelas de Fatos, Dimensões, Chaves Substitutas e outros modelados
dimensionalmente. Maiores detalhes sobre a Modelagem Dimensional podem ser encontrados
no Apêndice C.
A Figura 6.5 mostra que teremos no DW apenas um Data Mart, que será o que avalia
o Processo Seletivo da FATEC-SJC.
71
6.4.4
Quarta Etapa: APRESENTAÇÃO
A quarta etapa apresenta os relatórios obtidos a partir da análise feitas sobre os dados.
Os relatórios serão realizados manualmente, através de buscas realizadas diretamente no DW.
6.5
Documentação do Modelo Dimensional
Os requisitos de negócio da solução proposta estão descritos em detalhes nos
apêndices deste trabalho. O Apêndice B.1 refere-se ao documento de requisitos, enumerando
os requisitos de negócio do projeto proposto.
No Apêndice B.2 apresenta-se a Matriz de referência cruzada de requisitos que
descreverá como as principais Dimensões do Modelo Dimensional se relacionarão com cada
uma das medidas avaliadas.
O Apêndice C.1 apresenta o Modelo Dimensional da solução proposta, enquanto que o
Apêndice C.2 apresenta o Dicionário de Dados das tabelas de Dimensão e da Tabela de Fatos.
6.6
Resultados Obtidos
As subseções a seguir apresentam os resultados obtidos ao se analisar os dados do
processo seletivo FATEC - 1º semestre de 2011.
Os dados foram analisados de acordo com os seguintes tópicos:
Afrodescendência e Escolaridade Pública;
Dados Demográficos;
Dados Sócio Econômicos;
Opção de Curso e Desempenho do Candidato.
72
6.6.1
Afrodescendência e Escolaridade Pública
A seguir serão apresentados os resultados obtidos na avaliação feita em relação ao
número de candidatos que possuem características importantes para o cálculo de seu
desempenho final.
Segundo o manual do candidato do processo seletivo FATEC 2011 - primeiro
semestre (MANUAL 2011a), os candidatos que declararam as características que seguem
puderam participar do seu Sistema de Pontuação Acrescida:
Afrodescendente: acréscimo de 3% sobre a nota final;
Apenas Escolaridade Pública: acréscimo de 10% sobre a nota final;
Afrodescendente e Escolaridade Pública: acréscimo de 13% sobre a nota final.
A Figura 6.6 mostra a quantidade de candidatos para cada uma das características que
participam do Sistema de Pontuação Acrescida.
471
28%
259
15%
Afrodescendente e Escolaridade
Pública
Apenas Escolaridade Pública
Apenas Afrodescendente
70
4%
Nenhuma das Opções
899
53%
Figura 6.6 - Resultado: Afrodescendência e Escolaridade Pública.
Conforme a Figura 6.6 nota-se que a maioria dos candidatos é originária de escola
pública, representando 68% (afrodescendentes ou não). Esta informação pode ser importante
mais adiante para avaliar uma possível causa do fraco desempenho apresentado em
determinadas disciplinas.
73
Os mesmos resultados obtidos na Figura 6.6 podem ser enriquecidos agregando
informações geográficas. A Tabela 6.5, por exemplo, apresenta o importante resultado obtido
anteriormente referente à quantidade de candidatos que responderam ter cursado todo o
ensino médio em escola pública localizando-os geograficamente.
Tabela 6.5 – Todos os candidatos de Escolas Públicas (Afro ou não) por cidade.
TOTAL DE CANDIDATOS AGRUPADOS POR MUNICÍPIO
CIDADES
TOTAL
São José dos Campos
805
69,52%
Caçapava
108
9,33%
Jacareí
104
8,98%
Taubaté
33
2,85%
São Paulo
12
1,04%
Jambeiro
8
0,69%
Pindamonhangaba
6
0,52%
Tremembé
5
0,43%
Caraguatatuba
4
0,35%
São José dos Campos
Caçapava
Jacareí
Taubate
São Paulo
Jambeiro
Pindamonhangaba
Tremenbé
Ilhabela
4
0,35%
Caraguatatuba
Ilhabela
OUTRAS
69
5,96%
1158
100%
OUTRAS
74
6.6.2
Dados Demográficos
A seguir serão apresentadas algumas características dos candidatos escolhidas para
serem analisadas:
Distribuição Geográfica: Tabelas 6.6 e 6.7;
Deficiência Física: Tabela 6.8;
Estado Civil: Tabela 6.9;
Faixa-Etária: Tabela 6.10.
Tabela 6.6 - Dados Demográficos: Total de candidatos por Estado.
TOTAL DE ALUNOS POR ESTADO
ESTADO
TOTAL
SP
1684
99,12%
MG
14
0,82%
DF
1
0,06%
1699
100%
SP
MG
DF
75
Tabela 6.7 - Dados Demográficos: Quantidade de candidatos por cidade.
TOTAL DE CANDIDATOS POR CIDADE
TOP 10 Cidades
CIDADE
UF
São José dos Campos SP
São José dos Campos
Caçapava
Jacareí
Taubaté
São Paulo
Pindamonhangaba
Caraguatatuba
Jambeiro
Guaratinguetá
Tremembé
OUTRAS
TOTAL
1149
67,62%
Caçapava
SP
169
9,95%
Jacareí
SP
161
9,48%
Taubaté
SP
58
3,41%
São Paulo
SP
21
1,24%
Pindamonhangaba
SP
11
0,65%
Caraguatatuba
SP
8
0,47%
Jambeiro
SP
8
0,47%
Guaratinguetá
SP
6
0,35%
Tremembé
SP
6
0,35%
OUTRAS
-
102
6,00%
1699
100%
76
Tabela 6.8 - Quantidade de candidatos por deficiência física.
QUANTIDADE DE CANDIDATOS POR DEFICIÊNCIA
TIPO DE
DEFICIÊNCIA
Nenhuma
TOTAL
Nenhuma
1696
99,82%
Motora
1
0,06%
Visual
1
0,06%
Dislexia
1
0,06%
1699
100%
Motora
Visual
Dislexia
Tabela 6.9 - Quantidade candidatos por estado civil.
QUANTIDADE DE CANDIDATOS POR ESTADO CIVIL
ESTADO CIVIL
TOTAL
SOLTEIRO
1226
72,16%
CASADO
393
23,13%
OUTROS
80
4,71%
1699
100%
SOLTEIRO
CASADO
OUTROS
77
Tabela 6.10 - Quantidade de candidatos por faixa etária.
QUANTIDADE DE CANDIDATOS POR FAIXA ETÁRIA
FAIXA ETÁRIA
15 - 19
40 - 44
20 - 24
45 - 49
25 - 29
50 - 54
30 - 34
55 - 59
TOTAL
15 - 19
448
26,37%
20 - 24
461
27,13%
25 - 29
348
20,48%
30 - 34
226
13,30%
35 - 39
104
6,12%
40 - 44
66
3,88%
45 – 49
35
2,06%
50 - 54
8
0,47%
55 - 59
2
0,12%
60 - 64
1
0,06%
1699
100%
35 - 39
60 - 64
78
Tabela 6.11 - Quantidade de candidatos entre 15-24 anos.
QUANTIDADE DE CANDIDATOS ENTRE IDADES 15 – 24
FAIXA ETÁRIA
IDADE
TOTAL
15
1
0,22%
16
0
0,00%
17
62
13,84%
18
223
49,78%
19
162
36,16%
448
100%
20
121
26,25%
21
99
21,48%
22
90
19,52%
23
73
15,84%
24
78
16,92%
461
100%
15-19
15
16
17
18
19
20-24
20
21
22
23
24
79
A partir dos resultados apresentados anteriormente podemos concluir que:
Distribuição Geográfica: existe uma predominância de candidatos do Estado de
São Paulo, mais específicamente da região do Vale do Paraíba;
Deficiência Física: o número de candidatos que possuem algum tipo de
deficiência física é relativamente baixo se comparado com o total;
Estado civil: predomina candidatos solteiros;
Faixa-Etária: existe uma proximidade na quantidade de alunos nas faixas etárias
de 15-19 e 20-24 (Tabela 6.10). Além disso, estas duas faixas etárias
correspondem a 53,50% do total de candidatos, por isso para descobrir o quanto
cada idade dentro destas faixas etárias contribui para este percentual foi criada a
Tabela 6.11. O maior valor é justamente na idade de 18 anos, idade em que
candidatos que não foram aprovados com 17 anos em nenhum vestibular está em
algum cursinho preparatório para o vestibular.
Devido à quantidade representativa de candidatos entre nas faixas etárias 15-19 e 2024, os resultados referentes aos dados sócios econômicos da subseção que segue serão
apresentados também para estas faixas etárias.
6.6.3
Dados Sócio Econômicos
A seguir seguem exemplos de resultados obtidos na análise realizada sobre os dados
sócio econômicos dos candidatos.
Foram selecionadas duas questões do questionário sócio econômico presente no
formulário do processo seletivo 2011 – primeiro semestre.
A primeira questão refere-se à forma em que o candidato tomou conhecimento da
FATEC. Esta questão foi selecionada para avaliar a eficiência do processo de divulgação do
processo seletivo da instituição. Os resultados obtidos são apresentados nas Tabelas 6.12 à
6.14.
A segunda questão selecionada pretende avaliar a participação do candidato na vida
econômica de sua família. As Tabelas 6.15 à 6.17 apresentam os resultados obtidos.
80
Questão 2: Como você ficou conhecendo a Fatec?
A. Por intermédio de aluno ou de ex-aluno da Fatec
B. Na empresa em que trabalho
C. Por jornal, televisão, rádio ou INTERNET
D. Na escola ou cursinho
E. Por cartazes ou faixas
F. Outros
Tabela 6.12 - Quantidade de candidatos por resposta à questão 2.
QUANTIDADE DE CANDIDATOS POR RESPOSTA
C
A
D
F
B
E
ITEM
RESPOSTA
TOTAL
C
Por jornal televisão rádio ou
INTERNET
614
36,14%
A
Por intermédio de aluno ou de
ex-aluno da Fatec
481
28,31%
D
Na escola ou cursinho
209
12,30%
F
Outros
190
11,18%
B
Na empresa em que trabalho
108
6,36%
E
Por cartazes ou faixas
97
5,71%
1699
100%
81
Tabela 6.13 - Quantidade de candidatos de 15-19 por resposta à questão 2.
QUANTIDADE DE CANDIDATOS DE 15 – 19 POR RESPOSTA
ITEM
C
A
D
F
B
RESPOSTA
TOTAL
D
Na escola ou cursinho
126
28,13%
C
Por jornal televisão rádio ou
INTERNET
126
28,13%
A
Por intermédio de aluno ou de
ex-aluno da Fatec
105
23,44%
F
Outros
58
12,95%
E
Por cartazes ou faixas
25
5,58%
B
Na empresa em que trabalho
8
1,79%
448
100%
E
Tabela 6.14 - Quantidade de candidatos de 20-24 por resposta à questão 2.
QUANTIDADE DE CANDIDATOS DE 20 – 24 POR RESPOSTA
A
C
D
F
E
ITEM
RESPOSTA
TOTAL
A
Por intermédio de aluno ou de
ex-aluno da Fatec
156
33,84%
C
Por jornal televisão rádio ou
INTERNET
149
32,32%
D
Na escola ou cursinho
59
12,80%
F
Outros
46
9,98%
E
Por cartazes ou faixas
27
5,86%
B
Na empresa em que trabalho
24
5,21%
461
100%
82
Questões 11: Qual a sua participação na vida econômica da família?
A. Não trabalho e meus gastos são financiados por minha família ou outras
pessoas;
B. Trabalho para custear meus estudos;
C. Trabalho para custear os meus estudos e recebo ajuda da família;
D. Trabalho para minha própria manutenção e para auxiliar no orçamento familiar
ou de outras pessoas;
E. Trabalho e sou responsável pelo sustento de minha família.
Tabela 6.13 - Quantidade de alunos por resposta à questão 11.
QUANTIDADE DE CANDIDATOS POR RESPOSTA
A
D
E
B
C
ITEM
RESPOSTA
TOTAL
A
Não trabalho e meus gastos
são financiados por minha
família ou outras pessoas
527
31,02%
D
Trabalho para minha própria
manutenção e para auxiliar no
orçamento familiar ou de
outras pessoas
513
30,19%
E
Trabalho e sou responsável
pelo sustento de minha família
442
26,02%
B
Trabalho para custear meus
estudos
129
7,59%
C
Trabalho para custear os meus
estudos e recebo ajuda da
família
88
5,18%
1699
100%
83
Tabela 6.14 - Quantidade de candidatos de 15-19 por resposta à questão 11.
QUANTIDADE DE CANDIDATOS DE 15-19 POR RESPOSTA
ITEM
RESPOSTA
A
Não trabalho e meus gastos
são financiados por minha
família ou outras pessoas
311
69,42%
Trabalho para minha própria
manutenção e para auxiliar no
orçamento familiar ou de
outras pessoas
71
15,85%
B
Trabalho para custear meus
estudos
32
7,14%
C
Trabalho para custear os meus
estudos e recebo ajuda da
família
31
6,92%
Trabalho e sou responsável
pelo sustento de minha família
3
0,67%
448
100%
D
E
A
D
B
C
E
TOTAL
Tabela 6.15 - Quantidade de candidatos de 20-24 por resposta à questão 11.
QUANTIDADE DE ALUNOS DE 20-24 POR RESPOSTA
ITEM
D
A
D
A
B
E
C
RESPOSTA
Trabalho para minha própria manutenção
e para auxiliar no orçamento familiar ou
de outras pessoas
Não trabalho e meus gastos são
financiados por minha família ou outras
pessoas
TOTAL
184
39,91%
133
28,85%
B
Trabalho para custear meus estudos
63
13,67%
E
Trabalho e sou responsável pelo sustento
de minha família
41
8,89%
C
Trabalho para custear os meus estudos e
recebo ajuda da família
40
8,68%
461
100%
84
6.6.4
Opção de Curso e Desempenho do Candidato
Tabela 6.16 - Quantidade de candidatos por opção de curso
QUANTIDADE DE CANDIDATOS POR OPÇÃO DE CURSO
1
2
3
4
5
6
7
ITEM
CURSOS
VAGAS
CANDIDATO
TOTAL
VAGA
1
LOGÍSTICA (NOITE)
40
8,725
349
20,54%
2
MANUTENÇÃO DE AERONAVES (NOITE)
40
7,4
296
17,42%
3
BANCO DE DADOS OU REDES DE
COMPUTADORES (NOITE)
40
7,375
295
17,36%
4
MANUFATURA AERONÁUTICA (NOITE)
80
2,85
228
13,42%
5
MANUTENÇÃO DE AERONAVES (MANHÃ)
40
5,25
210
12,36%
6
LOGÍSTICA (MANHÃ)
40
4,975
199
11,71%
7
BANCO DE DADOS OU REDES DE
COMPUTADORES (TARDE)
40
3,05
122
7,18%
1699
100%
85
Tabela 6.17 - Quantidade de candidatos de 15-19 por opção de curso.
QUANTIDADE DE CANDIDATOS DE 15-19 POR OPÇÃO DE CURSO
1
2
3
4
5
6
7
ITEM
CURSOS
TOTAL
1
BANCO DE DADOS OU REDES DE COMPUTADORES (NOITE)
80
17,86%
2
LOGÍSTICA (NOITE)
78
17,41%
3
MANUTENÇÃO DE AERONAVES (MANHÃ)
72
16,07%
4
MANUTENÇÃO DE AERONAVES (NOITE)
66
14,73%
5
LOGÍSTICA (MANHÃ)
66
14,73%
6
MANUFATURA AERONÁUTICA (NOITE)
50
11,16%
7
BANCO DE DADOS OU REDES DE COMPUTADORES (TARDE)
36
8,04%
448
100%
86
Tabela 6.18 - Quantidade de candidatos de 20-24 por opção de curso.
QUANTIDADE DE CANDIDATOS DE 20-24 POR OPÇÃO DE CURSO
1
2
3
4
5
6
7
ITEM
TOTAL
CURSOS
1
LOGÍSTICA (NOITE)
108
23,43%
2
BANCO DE DADOS OU REDES DE COMPUTADORES (NOITE)
85
18,44%
3
MANUTENÇÃO DE AERONAVES (NOITE)
79
17,14%
4
MANUFATURA AERONÁUTICA (NOITE)
55
11,93%
5
LOGÍSTICA (MANHÃ)
46
9,98%
6
MANUTENÇÃO DE AERONAVES (MANHÃ)
44
9,54%
7
BANCO DE DADOS OU REDES DE COMPUTADORES (TARDE)
44
9,54%
461
100%
87
Tabela 6.19 - Quantidade de alunos de escola pública aprovados em 1º chamada por curso.
QUANTIDADE DE CANDIDATOS DE ESCOLA PÚBLICA APROVADOS NA 1º CHAMADA
90
80
80
70
60
50
40
40
40
40
40
40
40
31
31
30
27
25
24
22
21
20
10
0
1
2
3
Escola Pública
ITEM
4
5
6
7
Total Vagas
CURSOS
VAGAS
TOTAL
1
MANUTENÇÃO DE AERONAVES (NOITE)
40
31
77,50%
2
LOGÍSTICA (MANHÃ)
40
31
77,50%
3
MANUFATURA AERONÁUTICA (NOITE)
80
27
33,75%
4
LOGÍSTICA (NOITE)
40
25
62,50%
5
BANCO DE DADOS OU REDES DE COMPUTADORES (TARDE)
40
24
60,00%
6
MANUTENÇÃO DE AERONAVES (MANHÃ)
40
22
55,00%
7
BANCO DE DADOS OU REDES DE COMPUTADORES (NOITE)
40
21
52,50%
88
Tabela 6.20 - Média dos Candidatos - Banco de Dados ou Redes
Cursos
Banco de Dados ou
Redes (Tarde)
Peso
2
Banco de Dados ou
Redes (Tarde e Noite)
Todos
1ª
Chamada
Todos
1ª
Chamada
Todos
1ª
Chamada
Historia
4.75
5.92
4.99
6.96
4.87
6.44
Química
4.03
5.46
4.28
6.04
4.16
5.75
Inglês
3.48
4.96
3.89
6.87
3.69
5.92
Geografia
4.44
6.08
4.33
6.75
4.39
6.42
Biologia
3.66
5.25
3.80
5.88
3.73
5.57
Português
4.37
5.54
4.26
5.25
4.93
5.40
Física
3.46
4.25
3.36
4.42
3.41
4.34
Matemática
2.02
3.08
2.05
4.38
2.04
3.73
Multidisciplinar
3.89
6.25
4.05
7.67
3.97
6.96
Disciplinas
Peso
1
Banco de Dados ou
Redes (Noite)
Tabela 6.21 - Média dos Candidatos - Logística por disciplina
Cursos
Logística (Manhã)
Disciplinas
Peso
1
Peso
2
Todos
Historia
4.73
Química
4.02
Inglês
2.79
Geografia
3.94
Biologia
3.50
Física
2.65
Multidisciplinar
3.22
Matemática
1.93
Português
4.15
Logística (Noite)
1ª
Chamada
Todos
1ª
Chamada
6.29
5.29
3.83
5.96
5.29
3.46
5.25
3.38
5.33
4.53
4.11
3.01
3.68
3.44
2.86
3.30
2.06
4.13
6.63
5.38
4.67
5.96
5.04
4.21
6.21
4.08
6.04
Logística (Manhã e
Noite)
Todos
1ª
Chamada
4.63
6.46
4.07
5.34
2.90
4.25
3.81
5.96
3.47
5.17
2.76
3.84
3.26
5.73
2.00
3.73
4.14
5.69
89
Tabela 6.22 - Média dos Candidatos - Manutenção e Manufatura de aeronaves
Cursos
Manutenção
de Aeronaves
(Manhã)
Peso
1
Peso
2
Manutenção de
Aeronaves
(Noite)
Manufatura
Aeronáutica
(Noite)
Disciplinas
Todo
s
1ª
Chama
da
Todos
1ª
Chama
da
Todos
1ª
Chama
da
Historia
Química
Inglês
Geografia
Biologia
Multidisciplinar
Português
Matemática
Física
4.39
3.88
3.14
3.73
3.22
3.52
3.88
2.20
3.17
6.08
5.46
5.00
6.67
5.13
6.42
5.54
3.83
5.00
4.74
4.21
3.12
3.97
3.50
4.08
4.06
2.23
3.47
6.79
6.21
5.17
6.29
5.67
6.50
5.42
4.00
5.46
4.77
4.41
3.11
4.40
3.67
4.06
4.21
2.42
3.60
6.58
5.92
4.62
6.50
5.37
6.54
5.67
4.38
5.33
Manutenção de
Aeronaves
(Manhã e Noite)
+
Manufatura
Aeronáutica
(Noite)
1ª
Todos Chama
da
4,63
6,48
4,17
5,86
3,12
4,93
4,03
6,49
3,46
5,39
3,89
6,49
4,05
5,54
2,28
4,07
3,41
5,26
Tabela 6.23 - Comparação das médias nas disciplinas de todos os candidatos por curso.
Disciplinas
Cursos
História Química Inglês Geografia Biologia Português Física Matemática Multidisciplinar
BD ou REDES
(TARDE)
4,75
4,03
3,48
4,44
3,66
4,37
3,46
2,02
3,89
BD ou REDES
(NOITE)
4,99
4,28
3,89
4,33
3,80
4,26
3,36
2,05
4,05
LOGÍSTICA
(MANHÃ)
4,73
4,02
2,79
3,94
3,50
4,15
2,65
1,93
3,22
LOGÍSTICA
(NOITE)
4,53
4,10
3,01
3,68
3,44
4,13
2,86
2,06
3,30
MANUFATURA
(NOITE)
4,77
4,41
3,11
4,40
3,67
4,21
3,60
2,42
4,06
MANUTENÇÃO
(MANHÃ)
4,39
3,89
3,14
3,73
3,22
3,82
3,17
2,20
3,52
MANUTENÇÃO
(NOITE)
4,74
4,21
3,12
3,97
3,50
4,06
3,46
2,23
4,08
Legenda
Matérias Peso 2
Maior Média
Menor Média
90
Tabela 6.24 - Comparação das médias nas disciplinas dos candidatos de 1ª chamada.
Disciplinas
Cursos
História Química
Inglês
Geografia Biologia Português
Física
Matemática Multidisciplinar
BD ou REDES
(TARDE)
5.92
5.46
4.96
6.08
5.25
5.54
4.25
3.08
6.25
BD ou REDES
(NOITE)
6.96
6.04
6.87
6.75
5.88
5.25
4.42
4.38
7.67
LOGÍSTICA
(MANHÃ)
6.29
5.29
3.83
5.96
5.29
5.33
3.46
3.38
5.25
LOGÍSTICA
(NOITE)
6.63
5.38
4.67
5.96
5.04
6.04
4.21
4.08
6.21
MANUFATURA
(NOITE)
6.58
5.92
4.62
6.50
5.37
5.67
5.33
4.38
6.54
MANUTENÇÃO
(MANHÃ)
6.08
5.46
5.00
6.67
5.13
5.54
5.00
3.83
6.42
MANUTENÇÃO
(NOITE)
6.79
6.21
5.17
6.29
5.67
5.42
5.46
4.00
6.50
Legenda
6.7
Matérias Peso 2
Maior Média
Menor Média
Considerações Finais
Este capítulo descreveu o problema analisado pelo presente trabalho, detalhando os
passos envolvidos na concepção da solução, análise dos dados, modelagem, proposta da
arquitetura, ferramentas utilizadas, assim como os resultados obtidos.
O próximo capítulo apresentará as conclusões finais deste trabalho, as principais
contribuições, assim como seus trabalhos futuros.
91
7
CONSIDERAÇÕES FINAIS SOBRE O PRESENTE TRABALHO
Este trabalho apresentou a modelagem dos dados provenientes do vestibular FATECSJC de maneira a utilizá-los de forma analítica, utilizando para isto técnicas de modelagem e
ferramentas disponíveis na área de BI.
Os dados coletados no processo seletivo da instituição foram preparados e modelados
de forma a facilitar e auxiliar à tomada de decisão quanto ao planejamento educacional e
estratégico da instituição. Estes dados se encontram em arquivos que contém o cadastro dos
candidatos assim como os seus respectivos desempenhos no processo seletivo da FATECSJC.
Foi realizada uma seleção, padronização e filtragem visando retirar possíveis
inconsistências. O modelo analítico foi aplicado sobre estes dados extraídos, montando uma
arquitetura baseada na técnica de Data Warehouse. Finalmente foram realizadas algumas
consultas sobre o DW de forma a extrair resultados.
7.1
Contribuições e Conclusões
As principais contribuições deste trabalho foram:
Descoberta de inconsistências nos arquivos disponibilizados pelo CEETEPS, que poderão
ser aprimorados ao se utilizar algum tipo de modelo ou uma padronização em sua criação;
Análise, preparação e modelagem dimensional dos dados disponibilizados pelos
CEETEPS apresentando uma análise superficial do perfil do candidato FATEC, e que
poderá servir de base para novos projetos dentro da instituição;
O potencial das análises apresentadas nos resultados do capítulo 6, que mostra
informações sócio econômicas, demográficas e de desempenho dos candidatos que
realizaram o processo seletivo de 2011;
Ressaltar a importância de se analisar dados acumulados e não aproveitados.
92
A partir destas contribuições pode-se concluir que:
No processo ETL foram encontradas dificuldades devido à falta de padronização na
composição das planilhas que contém os dados disponibilizados. Algumas colunas
apresentaram inconsistências em nome de colunas, falta de campos, e surgimento de
novos, o que torna o processo de criação de scripts de ETL imprevisível e sujeito a
retrabalhos a cada novo processo seletivo;
A partir dos resultados da análise realizada podem-se traçar iniciativas de melhorar o
processo seletivo com maior e melhor divulgação, verificar se os incentivos de cotas estão
sendo atingidos, além de outros indicadores sócio econômicos e sociais;
Embora o modelo tenha sido criado para analisar dados de processos seletivos, poderá ser
ampliado em trabalhos futuros para acompanhamento do aluno durante o curso.
7.2
Trabalhos Futuros
As contribuições alcançadas com este Trabalho não encerram as pesquisas
relacionadas à área de BI e sua utilização para avaliar o processo seletivo FATEC-SJC, mas
abrem oportunidades para alguns trabalhos futuros:
Novas áreas podem ser avaliadas além do processo seletivo, tais como desempenho dos
alunos durante o curso assim como o período de um ano após a sua saída da instituição,
mapeando assim toda a sua trajetória desde a entrada até a saída da instituição;
Pode-se empregar outras técnicas de BI para se extrair informações sobre estes dados,
como o Data Mining, de forma a se descobrir padrões e correlações desconhecidos entre
os dados, assim como outras técnicas de visualização de dados.
93
REFERÊNCIAS BIBLIOGRÁFICAS
ADAMSON, C.; Star Schema: The Complete Reference. 1st ed. McGraw-Hill, 2010. ISBN:
978-0-07-174432-4
BOUMAN, R.; DONGEN, J. van; Pentaho Solutions: Business Intelligence and Data
Warehousing with Pentaho and MySQL® . 1 ed. Indianapolis: Wiley Publishing, 2010. ISBN:
978-0-470-48432-6.
CASTER, M.; BOUMAN, R.; DONGEN, J. van; Pentaho Kettle Solutions: Building Open
Source ETL Solutions with Pentaho Data Integration. 1st ed. Indianapolis: Wiley Publishing,
2010. ISBN: 978-0470635179.
CLARA, G. S.; A maioridade acadêmica. Revista do Centro Paula Souza, Print Com, n. 22, p.
8-10. 2011.
Disponível em: <http://www.centropaulasouza.sp.gov.br/publicacoes/revista/2011/edicao-22maio-junho.pdf>. Acesso em: 18 mai, 2011.
CEETEPS: Centro Estadual de Educação Tecnológica Paula Souza. 2010. Disponível em:
<http://www.centropaulasouza.sp.gov.br>. Acesso em: 10 ago. 2010.
CEETEPS: Vestibular - Centro Estadual de Educação Tecnológica Paula Souza. 2011.
Disponível em: <http://www.centropaulasouza.sp.gov.br/Vestibular>. Acesso em: 7 mai.
2011.
DATACLEANER: Software para Análise, Profiling, Transformação e Limpeza de Dados.
2011. Disponível em: <http://www.datacleaner.eobjects.org>. Acesso em: 4 mar. 2011.
DATE, C. J.; An Introduction to Database Systems. 8 th ed. Addison Wesley, 2003. ISBN10: 9780321197849
DEVLIN, B. A.; MURPHY, P. T.; An Architecture for a Business and Information System.
IBM Systems Journal, IBM, v.27, n.1, p.60-80, 1988. ISSN: 0018-8670.
DONGEN:
Open
Source
Data
Warehousing?
Disponível
em:
<http://www.tholis.com/news/open-source-data-warehousing>. Acesso em: 10 mai, 2011.
FAT: Fundação de Apoio à Tecnologia. 2011. Disponível em: <http://www.fatgestao.org.br>.
Acesso em: 18 maio, 2011.
94
FATEC-SJC: Faculdade de Tecnologia de São José dos Campos. 2010a. Disponível em:
<http://www.fatecsjc.edu.br>. Acesso em: 6 ago. 2010.
FATEC-SJC: Sobre a Fatec São José dos Campos. 2010b.
<http://www.fatecsjc.edu.br/?cont=fatec>. Acesso em: 6 ago. 2010.
Disponível
em:
GABARITOS: Gabarito Vestibular Fatec 2009 – primeiro semestre. 2009a. Disponível em:
<http://www.vestibularfatec.com.br/download/prova_ant/62.pdf>. Acesso em: 18 mai, 2011.
GABARITOS: Gabarito Vestibular Fatec 2009 – segundo semestre. 2009b. Disponível em:
<http://www.vestibularfatec.com.br/download/prova_ant/67.pdf>. Acesso em: 18 mai, 2011.
GABARITOS: Gabarito Vestibular Fatec 2010 – primeiro semestre. 2010a. Disponível em:
<http://www.vestibularfatec.com.br/download/prova_ant/68.pdf>. Acesso em: 18 mai, 2011.
GABARITOS: Gabarito Vestibular Fatec 2010 – segundo semestre. 2010b. Disponível em:
<http://www.vestibularfatec.com.br/download/prova_ant/71.pdf>. Acesso em: 18 mai, 2011.
GABARITOS: Gabarito Vestibular Fatec 2011 – primeiro semestre. 2011. Disponível em:
<http://www.vestibularfatec.com.br/download/prova_ant/72.pdf>. Acesso em: 18 mai, 2011.
GARTNER: Gartner Group. Disponível em: <http://www.gartner.com>. Acesso em: 3 fev,
2011
GOLFARELLI, M.; RIZZI, S.; Data Warehouse Design: Modern Principles and
Methodologies. 1st ed. McGraw-Hill Osborne, 2009. ISBN-10: 0071610391
HBASE: Open-source, distributed, versioned, column-oriented store Database. Disponível
em: <http://hbase.apache.org>. Acesso em: 18 mai, 2011.
IBGE:
Instituto
Brasileiro
de
Geografia
<http://www.ibge.gov.br>. Acesso em: 18 mai, 2011.
e
Estatística.
Disponível
em:
INFOBRIGHT: The Open-Source Database for Ad hoc Analytics. Disponível em:
<http://www.infobright.org>. Acesso em: 18 mai, 2011.
INMON, W. H.; Building the Data Warehouse. 1st ed. John Wiley & Sons, Inc, 1990. ISBN:
0-471-08130-2.
95
KIMBALL, R.; CASERTA, J.; The Data Warehouse ETL Toolkit: Practical Techniques for
Extracting, Cleaning, Conforming, and Delivering Data. 2nd ed. John Wiley and Sons, 2004.
eISBN: 0-764-57923-1.
KIMBALL, R.; ROSS, M.; The Data Warehouse Toolkit: the complete guide to Dimensional
Modeling. 2nd ed. John Wiley and Sons, 2002. ISBN: 0-471-20024-7.
LUHN, H. P.; A Business Intelligence System. IBM Journal of Research and Development,
IBM, v.2, n.4, p. 314 – 319, 1958. ISSN: 0018-8646.
MANUAL: Manual do Candidato ao Vestibular FATEC 2010 - primeiro semestre. 2010.
Disponível em: <http://www.centropaulasouza.sp.gov.br/Vestibular/manual/2010/manualvestibular-1s-2010.pdf>. Acesso em: 18 mai, 2011.
MANUAL: Manual do Candidato ao Vestibular FATEC 2011 - primeiro semestre. 2011a.
Disponível em: <http://www.centropaulasouza.sp.gov.br/Vestibular/manual/2011/manualvestibular-1s-2011.pdf>. Acesso em: 18 mai, 2011.
MANUAL: Manual do Candidato ao Vestibular FATEC 2011 - segundo semestre. 2011b.
Disponível em: <http://www.centropaulasouza.sp.gov.br/Vestibular/manual/2011/manualvestibular-2s-2011.pdf>. Acesso em: 18 mai, 2011.
MONODB: Column-Store Pionner. Disponível em: <http://www.monodb.org>. Acesso em:
18 mai, 2011.
MYSQL: The world’s most popular open source
<http://www.mysql.com>. Acesso em: 18 mai, 2011.
database.
Disponível
em:
PDI: Pentaho Data Integration Project. 2011. Disponível em: <http://kettle.pentaho.com>.
Acesso em: 5 mar. 2011.
PIEDADE, M. B.; SANTOS, M. Y.; Business intelligence supporting the teaching-learning
process. In: Proceedings of the 9th WSEAS international Conference on Simulation,
Modeling and Optimization (Budapest, Hungary, September 03 - 05, 2009). R. Imre, M.
Demiralp, and N. Mastorakis, Eds. Mathematics And Computers In Science And Engineering.
World Scientific and Engineering Academy and Society (WSEAS), Stevens Point, Wisconsin,
2009. 292-297.
96
PONNIAH, P.; Data Warehouse Fundamentals For IT Professionals. 2nd ed. John Wiley and
Sons, 2010. ISBN 978-0-470-46207-2.
REEVES, L.; A Managers Guide to Data Warehousing. 1st ed. Wiley, 2009. ISBN10: 0470176385
SHIGUNOV, F.; Uma Aplicação OLAP sobre a Web para Análise dos Dados do Vestibular
da UFSC e Diretrizes para a sua Integração com GIS. 2007. 88f., Trabalho de conclusão de
curso de Bacharel em Sistemas de Informação – UFSC, Santa Catarina, 2007
SPATIALKEY: Location Intelligence for Decision
<http://www.spatialkey.com>. Acesso em: 4 set, 2010.
Makers.
Disponível
em:
UFSC: Universidade Federal de Santa Catarina. Disponível em: < http://ufsc.br/ >. Acesso
em: 10 ago, 2010.
WILLIAMS, S.; WILLIAMS N.; The profit impact of Business Intelligence. 1st ed. San
Francisco: Morgan Kaufmann, 2007. ISBN10: 0-12-372499-6
VERCELLIS, C.; Business Intelligence: Data Mining and Optimization for Decision Making.
Milano: John Wiley & Sons, Ltd., 2009. ISBN: 978-0-470-51138-1
VESTEC: Curso Pré-Vestibular. Disponível em: <http://www.vestec.hdfree.com.br >. Acesso
em: 12 ago. 2010.
VESTIBULAR: Website do Processo Seletivo FATEC. 2011.
<http://www.vestibularfatec.com.br/home/>. Acesso em: 18 mai, 2011.
Disponível
em:
97
APÊNDICE A: DOCUMENTAÇÃO ÁREA DE ESTÁGIO
A.1 Etapas do processo de ETL usado para carregar Área de Estágio:
A.2 Modelo Entidade Relacionamento da Área de Estágio:
98
APÊNDICE B: DOCUMENTAÇÃO DE REQUISITOS
B.1 Documento de Requisitos
Documento de Requisitos para o Processo Seletivo FATEC-SJC
Área Avaliada:
Processo Seletivo FATEC-SJC
Descrição:
Avaliação do desempenho dos candidatos no processo seletivo assim como o seu perfil
demográfico.
Papéis dos Usuários Finais:
Diretor
Tomar decisões estratégicas.
Coordenadores de Curso
Tomar decisões estratégicas.
Professores FATEC-SJC
Tomar decisões estratégicas.
Representantes
Municipais, Estaduais e
Federais
Tomar decisões estratégicas.
Requisitos Analíticos:
1. Visualizar o desempenho do candidato por matéria, curso, prova.
2. Quantidade total de candidatos por município, prova, deficiência.
3. Quantidade total de candidatos por questão do questionário sócio econômico.
99
Medidas de Processo:
PROCESSO
MEDIDAS
Desempenho do
Candidato
Média
Processo Seletivo
Quantidade de Candidatos
Questionário Sócio
Econômico (17
questões)
Quantidade de candidatos
por Resposta das questões
CONTEXTO DA MEDIDA
Curso
Prova
Semestre
Disciplina
Área da Disciplina
Curso
Prova
Semestre
Candidato:
Inscrição
Sexo
Estado Civil
Raça
Bairro
Município
Estado
UF
Provedor de Email
Situação
DDD
Escola Pública
Faixa Etária IBGE
Necessidade Especial
ENEM
Curso
Prova
Semestre
Candidato:
Inscrição
Sexo
Estado Civil
Raça
Bairro
Município
Estado
UF
Provedor de Email
Situação
DDD
Escola Pública
Faixa Etária IBGE
Necessidade Especial
ENEM
100
B.2 Matriz de Referência Cruzada de Requisitos
Processo Seletivo FATEC-SJC
Medidas
Avaliadas
Dimensões
Envolvidas
Curso
Prova
Semestre
Disciplina
Disciplina
Área da Disciplina
ENEM
Faixa Etária IBGE
Necessidade Especial
Inscrição
Sexo
Estado Civil
Raça
Bairro
Candidato
Município
Estado
UF
Provedor de Email
Situação
DDD
Escola Pública
Desempenho
do Candidato
Processo Seletivo
Questionário Sócio
Econômico
101
APÊNDICE C: DOCUMENTAÇÃO DIMENSIONAL
C.1 Modelo Dimensional
Processo:
Desempenho do Aluno
Tipo:
Instantâneo Periódico
102
Semestre
Granularidade:
Fatos:
numero_candidatos
Quantidade total de candidatos que se
enquadram
Fatos Não Aditivos:
media_candidatos (Semi Aditivo)
Média dos candidatos
Tabelas de Dimensão:
candidato
curso
disciplina
enem
faixa_etaria_IBGE
necessidade_especial
prova
questao
resposta
semestre
Candidato ao vestibular
Curso escolhido pelo candidato
Disciplina da prova analisada
Dados sobre o enem
Faixa etária em que o candidato se
encaixa
Detalhes sobre deficiência física
Detalhes sobre a prova
Questões do questionário sócio
econômico
Respostas do questionário sócio
econômico
Semestre em que a prova foi realizada
Frequência de Carga:
Semestral
Interação com outras Estrelas:
-
103
C.2 Dicionário de Dados do Modelo Dimensional
C.2.1 Documentação Tabelas de Dimensão
Tabela: candidato
Fonte:
Tabela stg_candidato da área de estágio
Relacionamentos: Relacionada com cada uma das tabelas da área de estágio.
Regras de
Processamento:
Requisitos de
Segurança:
Intervalo de
Carga:
Número Inicial
de linhas:
Crescimento
Anual:
Existe um pré-processamento necessário em alguns campos e na retirada
de outros que não são necessários à análise.
Dados que identifiquem o candidato (RG, nome) e que o localize
fisicamente foram suprimidos do modelo.
Semestral
1800 registros em média
4000 registros em média
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
id_candidato
unsigned int
0 a 4294967295
SK (Surrogate Key)
Chave substituta para a dimensão candidato.
1
Inserido automaticamente à cada carga.
Nenhuma.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
candidato_numero_inscricao
varchar
45
Tipo 1
Chave Natural do candidato no Sistema Fonte.
28.01400-4
Campo INSCRICAO da planilha 1s2011.xls.
Nenhuma.
Campo:
Tipo de Dado:
Tamanho:
candidato_data_nascimento
DATE
-
104
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Tipo 1
Data de nascimento do Candidato.
10/06/1997
Campo NASCIMENTO da planilha 1s2011.xls
Utilizado para colocar o candidato dentro de sua faixa etária
correspondente do IBGE.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
candidato_afrodescendencia
CHAR
3
Tipo 1
Confirmação ou não de afrodescendência.
SIM
Campo AFRODESCENDENTE da planilha 1s2011.xls
Nenhuma
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
candidato_escola_publica
CHAR
3
Tipo 1
Confirmação ou não de escolaridade pública.
SIM
Campo ESCOLARIDADE da planilha 1s2011.xls
Nenhuma
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
candidato_estado_civil
VARCHAR
10
Tipo 1
Estado civil do candidato.
SOLTEIRO
Campo ESTADO_CIV da planilha 1s2011.xls
Nenhuma
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Campo:
candidato_genero
VARCHAR
10
Tipo 1
Gênero do candidato.
FEMININO
Campo SEXO da planilha 1s2011.xls
Nenhuma
candidato_servidor_email
105
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
VARCHAR
50
Tipo 1
Provedor de email do candidato.
@gmail.com
Campo EMAIL da planilha 1s2011.xls
Retirada do primeiro pedaço que corresponde ao email do candidato,
isolando apenas o provedor de email.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
candidato_classificacao
unsigned short int
0 a 65535
Tipo 1
Classificação final do candidato.
1
Campo CLASS da planilha 1s2011.xls
Colocar zero nos locais onde existem valores nulos.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
candidato_situacao_vestibular
VARCHAR
10
Tipo 1
Situação final do candidato no processo seletivo.
AUSENTE
Campo SITUACAO da planilha 1s2011.xls
Substituição dos códigos:
A => AUSENTE
1 => APROVADO
S => SUPLENTES
C => CLASSIFICADO
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
candidato_bairro
VARCHAR
100
Tipo 1
Bairro onde reside o candidato.
JARDIM DA GRANJA
Campo BAIRRO da planilha 1s2011.xls
Nenhuma
candidato_municipio
VARCHAR
100
Tipo 1
Município onde reside o candidato.
106
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
São José dos Campos
Campo MUNICIPIO da planilha 1s2011.xls
Nenhuma
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
candidato_estado
VARCHAR
100
Tipo 1
Estado onde reside o candidato.
SÃO PAULO
Campo ESTADO da planilha 1s2011.xls
Conversão de código para valor por extenso:
SP => SÃO PAULO
Tabela: curso
Fonte:
Tabela stg_curso da área de estágio
Relacionamentos: Relacionada com a tabela stg_candidato
Regras de
Processamento:
Requisitos de
Segurança:
Intervalo de
Carga:
Número Inicial
de linhas:
Crescimento
Anual:
Existe um pré-processamento necessário apenas para isolar os campos
necessários.
Semestral
7 registros em média
1 registros em média por ano.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
id_curso
unsigned int
0 a 4294967295
SK (Surrogate Key)
Chave substituta para a dimensão curso.
1
Inserido automaticamente à cada carga.
Nenhuma.
curso_nome
VARCHAR
100
Tipo 1
Nome do curso escolhido pelo candidato.
BANCO DE DADOS OU REDES DE COMPUTADORES
107
Elementos Fonte:
Regras de
Transformação:
Campo CURSO1 da planilha 1s2011.xls
Conversão de código para valor por extenso:
SP => São Paulo
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
curso_periodo
VARCHAR
10
Tipo 1
Período do curso escolhido pelo candidato.
NOITE
Campo CURSO1 da planilha 1s2011.xls
Pré-processamento em cima do nome do curso para extração do valor de
período.
Tabela: disciplina
Fonte:
Tabela stg_desempenho da área de estágio
Relacionamentos: Relacionada com a tabela stg_candidato
Regras de
Processamento:
Requisitos de
Segurança:
Intervalo de
Carga:
Número Inicial
de linhas:
Crescimento
Anual:
Existe um pré-processamento necessário para isolar seus campos.
Semestral
9 registros em média
1 registros em média por ano.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
id_disciplina
unsigned int
0 a 4294967295
SK (Surrogate Key)
Chave substituta para a dimensão disciplina.
1
Inserido automaticamente à cada carga.
Nenhuma.
disciplina_nome
VARCHAR
50
Tipo 1
Nome da disciplina da prova.
PORTUGUÊS
Cada campo com nome de disciplina na planilha 1s2011.xls
108
Regras de
Transformação:
Pré-processamento para extração do nome de cada disciplina.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
disciplina_grupo
VARCHAR
50
Tipo 1
Grupo que a disciplina pertence.
EXATAS
Criado dinamicamente no ETL.
Pré-processamento para ligar as disciplinas aos grupos.
Tabela: enem
Fonte:
Tabela stg_enem da área de estágio
Relacionamentos: Relacionada com a tabela stg_candidato
Regras de
Processamento:
Requisitos de
Segurança:
Intervalo de
Carga:
Número Inicial
de linhas:
Crescimento
Anual:
Existe um pré-processamento necessário para isolar seus campos.
Semestral
1800 registros em média
4000 registros em média
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
id_enem
unsigned int
0 a 4294967295
SK (Surrogate Key)
Chave substituta para a dimensão enem.
1
Inserido automaticamente à cada carga.
Nenhuma.
enem_codigo
VARCHAR
50
Tipo 1
Chave Natural do candidato no ENEM.
201001041019
Campo ENEM da planilha 1s2011.xls
Nenhuma.
109
Transformação:
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
enem_nota
DOUBLE
5,3
Tipo 1
Chave Natural do candidato no ENEM.
55,15
Campo NOTAENEM da planilha 1s2011.xls
Nenhuma.
Tabela: faixa_etaria_IBGE
Fonte:
Arquivo separado por vírgulas (csv) direto do IBGE.
Relacionamentos: Regras de
Processamento:
Requisitos de
Segurança:
Intervalo de
Carga:
Número Inicial
de linhas:
Crescimento
Anual:
Existe um pré-processamento necessário para isolar seus campos.
Semestral
10 registros em média
1 registros em média
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
id_faixa_etaria
unsigned int
0 a 4294967295
SK (Surrogate Key)
Chave substituta para a dimensão faixa_etaria_ibge.
1
Inserido automaticamente à cada carga.
Nenhuma.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
faxia_etaria
VARCHAR
45
Tipo 1
Intervalo de idade do IBGE.
15-19
Direto de arquivo separado por vírgulas (csv) do IGBE
Nenhuma.
110
Tabela: necessidade_especial
Fonte:
Tabela stg_necessidade da área de estágio
Relacionamentos: Relacionada com a tabela stg_candidato
Regras de
Processamento:
Requisitos de
Segurança:
Intervalo de
Carga:
Número Inicial
de linhas:
Crescimento
Anual:
Existe um pré-processamento necessário para isolar seus campos.
Semestral
13 registros em média
1 registros em média
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
id_necessidade
unsigned int
0 a 4294967295
SK (Surrogate Key)
Chave substituta para a dimensão necessidade.
1
Inserido automaticamente à cada carga.
Nenhuma.
necessidade_nome
VARCHAR
50
Tipo 1
Nome do tipo de deficiência do candidato.
Visual
Campo NECESSIDADE da planilha 1s2011.xls
Substituição do valor “-“ que representa nulo por Não possui.
necessidade_grau_deficiencia
VARCHAR
50
Tipo 1
Grau de deficiência do candidato.
Parcial
Campo NECESSIDADE_TIPO da planilha 1s2011.xls
Substituição do valor “-“ que representa nulo por Não possui.
111
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
necessidade_tipo_prova
VARCHAR
50
Tipo 1
Tipo de prova especial necessária.
Prova ledor (fiscal para ler e transcrever a prova)
Campo NECESSIDADE_TIPO_PROVA da planilha 1s2011.xls
Substituição do valor “-“ que representa nulo por Não possui.
Tabela: prova
Fonte:
Dados contidos na planilha 1s2011.xls
Relacionamentos: Relacionada com a tabela stg_candidato
Regras de
Processamento:
Requisitos de
Segurança:
Intervalo de
Carga:
Número Inicial
de linhas:
Crescimento
Anual:
Existe um pré-processamento necessário para isolar seus campos.
Semestral
1 registros em média
2 registros em média
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
id_prova
unsigned int
0 a 4294967295
SK (Surrogate Key)
Chave substituta para a dimensão prova.
1
Inserido automaticamente à cada carga.
Nenhuma.
prova_numero_questoes
Int
Tipo 1
Número de questões da prova.
54
Retirado através do processo de ETL feito sobre o formulário de inscrição
do processo seletivo Fatec.
Pré-processamento para inserção no Modelo Dimensional.
112
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
prova_data
DATE
Tipo 1
Data da prova.
05/12/2010
Campo DTPROVA da planilha 1s2011.xls
Nenhuma.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
prova_hora
TIMESTAMP
Tipo 1
Hora da prova.
05/12/2010
Campo DTPROVA da planilha 1s2011.xls
Nenhuma.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
prova_envelope
VARCHAR
45
Tipo 1
Código do envelope que veio a prova.
1137
Campo ENVELOPE da planilha 1s2011.xls
Nenhuma.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
prova_sala
VARCHAR
45
Tipo 1
Código da sala da prova.
012
Campo SALA da planilha 1s2011.xls
Nenhuma.
prova_codigo_local_exame
VARCHAR
45
Tipo 1
Código da local da prova. Chave Natural.
28
113
Elementos Fonte:
Regras de
Transformação:
Campo CODLOC da planilha 1s2011.xls
Nenhuma.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
prova_local_exame
VARCHAR
45
Tipo 1
Nome do local da prova.
FATEC SÃO JOSÉ DOS CAMPOS - PROF. JESSEN VIDAL
Campo CODLOC da planilha 1s2011.xls
Nenhuma.
Tabela: questao
Fonte:
Tabela stg_questao da área de estágio
Relacionamentos: Relacionada com a tabela stg_questionario
Regras de
Processamento:
Requisitos de
Segurança:
Intervalo de
Carga:
Número Inicial
de linhas:
Crescimento
Anual:
Existe um pré-processamento necessário para isolar seus campos.
Semestral
17 registros em média
1 registros em média
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
id_questao
unsigned int
0 a 4294967295
SK (Surrogate Key)
Chave substituta para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
questao
VARCHAR
250
Tipo 1
Enunciado da questão sócio econômica.
Como você ficou conhecendo a Fatec?
Retirado do formulário de inscrição do processo seletivo Fatec.
114
Regras de
Transformação:
Pré-processamento para inserção na Área de Estágio.
Tabela: resposta
Fonte:
Tabela stg_resposta da área de estágio
Relacionamentos: Relacionada com a tabela stg_questionario
Regras de
Processamento:
Requisitos de
Segurança:
Intervalo de
Carga:
Número Inicial
de linhas:
Crescimento
Anual:
Existe um pré-processamento necessário para isolar seus campos.
Semestral
87 registros em média
5 registros em média
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
id_resposta
unsigned int
0 a 4294967295
SK (Surrogate Key)
Chave substituta para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
resposta_item
VARCHAR
45
Tipo 1
Item correspondente à resposta da questão sócio econômica.
A
Retirado do formulário de inscrição do processo seletivo Fatec.
Pré-processamento para inserção na Área de Estágio.
resposta
VARCHAR
250
Tipo 1
Resposta da questão sócio econômica.
Na empresa em que trabalho
Retirado do formulário de inscrição do processo seletivo Fatec.
Pré-processamento para inserção na Área de Estágio.
115
Transformação:
Tabela: semestre
Fonte:
Criado via ETL.
Relacionamentos:
-
Regras de
Processamento:
Requisitos de
Segurança:
Intervalo de
Carga:
Número Inicial
de linhas:
Crescimento
Anual:
Existe um pré-processamento necessário para isolar seus campos.
Semestral
60 registros em média
2 registros em média
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
id_semestre
unsigned int
0 a 4294967295
SK (Surrogate Key)
Chave substituta para a dimensão semestre.
1
Inserido automaticamente à cada carga.
Nenhuma.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
semestre_ano
int
Tipo 1
Ano correspondente ao semestre.
2011
Criado via ETL.
Criado via ETL.
Campo:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
semestre_numero
int
Tipo 1
Código do semestre.
1
Criado via ETL.
Criado via ETL.
116
Campo:
semestre_formatado
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de
Transformação:
VARCHAR
45
Tipo 1
Semestre formatado.
1º Semestre
Criado via ETL.
Criado via ETL.
C.2.2 Documentação Tabela de Fatos
Tabela: fato_desempenho
Fontes:
Tabela stg_desempenho na Área de estágio
Relacionamentos:
Com todas as outras dimensões do modelo.
Regras de Processamento:
Requisitos de Segurança:
Existem regras no ETL para o cálculo das
notas de cada aluno
Nenhuma já que os dados que identificam o
aluno não serão visíveis a todos.
Intervalo de Carga:
Semestral
Número de Linhas Iniciais:
2000 em média.
Crescimento Anual:
4000 em média.
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
numero_candidatos
int
Tipo 1
Quantidade de candidatos que se enquadram nas características
procuradas
1
Criado via ETL.
Nenhuma.
Coluna:
Tipo de Dado:
media_candidatos
DOUBLE
117
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
5,2
Tipo 1
Média dos candidatos
8,52
Obtido através de cálculos feitos na fase de ETL.
Regras utilizadas na fase de ETL para cálculo de nota.
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
id_candidato
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão candidato.
1
Inserido automaticamente à cada carga.
Nenhuma.
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
id_curso
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão curso.
1
Inserido automaticamente à cada carga.
Nenhuma.
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
id_disciplina
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão disciplina.
1
Inserido automaticamente à cada carga.
Nenhuma.
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
id_necessidade_especial
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão necessidade_especial.
1
Inserido automaticamente à cada carga.
Nenhuma.
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
id_faxia_etaria
unsigned int
0 a 4294967295
FK (Foreign Key)
118
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Chave Estrangeira para a dimensão necessidade_especial.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_1
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_1
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_2
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_2
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_3
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
119
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_3
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_4
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_4
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_5
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_5
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
120
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
id_questao_6
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_6
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_7
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_7
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_8
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_8
121
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
id_questao_9
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
id_resposta_9
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
id_questao_10
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
id_resposta_10
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
Coluna:
Tipo de Dado:
Tamanho:
id_questao_11
unsigned int
0 a 4294967295
122
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_11
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_12
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_12
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_13
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_13
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
123
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_14
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_14
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_15
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_15
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_16
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
124
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Coluna:
Tipo de Dado:
Tamanho:
Tipo de Coluna:
Definição:
Dados Exemplo:
Elementos Fonte:
Regras de Transformação:
Nenhuma.
id_resposta_16
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_questao_17
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão questao.
1
Inserido automaticamente à cada carga.
Nenhuma.
id_resposta_17
unsigned int
0 a 4294967295
FK (Foreign Key)
Chave Estrangeira para a dimensão resposta.
1
Inserido automaticamente à cada carga.
Nenhuma.
125
ANEXO A: FICHA DE INSCRIÇÃO 2º SEMESTRE DE 2011
A.1 Captura de Tela: Formulário de Inscrição do Processo Seletivo FATEC 2º SEM/11
Figura A.1 – INÍCIO DO PROCESSO: Documento de Identidade e Data de Nascimento
Figura A.2 - PASSO 1: Dados Pessoais
126
Figura A.3 - PASSO 1: Dados Pessoais (Tipos de Documento de Identidade)
Figura A.4 - PASSO 1: Dados Pessoais (Continuação)
127
Figura A.5 - PASSO 1: Dados Pessoais (ENEM)
Figura A.5 - PASSO 1: Dados Pessoais (Deficiência: Motora - grau)
128
Figura A.6 - PASSO 1: Dados Pessoais (Deficiência: Motora - tipo de prova)
Figura A.7 - PASSO 1: Dados Pessoais (Deficiência: Visual - grau)
129
Figura A.8 - PASSO 1: Dados Pessoais (Deficiência: Visual - tipo de prova)
Figura A.8 - PASSO 1: Dados Pessoais (Deficiência: Auditiva - grau)
130
Figura A.9 - PASSO 1: Dados Pessoais (Deficiência: Auditiva - tipo de prova)
Figura A.10 - PASSO 1: Dados Pessoais (Deficiência: Dislexia - grau)
131
Figura A.11 - PASSO 1: Dados Pessoais (Deficiência: Dislexia – tipo de prova)
Figura A.12 - PASSO 2: Pontuação Acrescida (Afrodescendência)
132
Figura A.13 - PASSO 2: Pontuação Acrescida (Escolaridade Pública)
Figura A.14 - PASSO 2: Pontuação Acrescida (Escolaridade Pública - continuação)
133
Figura A.15 - PASSO 3: Fatec, curso e período (Fatec)
Figura A.16 - PASSO 3: Fatec, curso e período (Curso)
134
Figura A.17 - PASSO 3: Fatec, curso e período (Período)
Figura A.18 - PASSO 5: Questionário Sócio Econômico
135
Figura A.19 - PASSO 5: Questionário Sócio Econômico (Continuação)
Figura A.20 - PASSO 5: Questionário Sócio Econômico (Fim)
Baixar