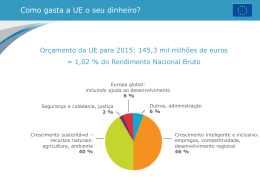
Seleção de Características através de Nearest Shrunken Centroids DIEGO RICARDO DE ARAUJO DEPARTAMENTO DE CIÊNCIA DA COMPUTAÇÃO INSTITUTO DE CIÊNCIA EXATAS UNIVERSIDADE FEDERAL DE JUIZ DE FORA Introdução Classificação de Dados Seleção de Características Sistema Inteligente Testes Comparativos Resultados Considerações Finais 2 Descoberta de Conhecimento em Bases de Dados Crescente fluxo de dados Dados coletados e acumulados rapidamente Transformação de informação em conhecimento útil 4 Descoberta de Conhecimento em Bases de Dados Pré-processamento: dados preparados para mineração Mineração de dados: extração de conhecimento através de métodos inteligentes Avaliação Apresentação: representação e visualização do conhecimento para o usuário 5 Mineração de Dados Análise de grandes base de dados Extração de padrões de interesse do modelo de dados Conjunto de dados Domínio de conhecimento Métodos de mineração Avaliação de padrões 7 Mineração de Dados 8 Introdução Classificação de Dados Seleção de Características Sistema Inteligente Testes Comparativos Resultados Considerações Finais 9 Processo de classificação Treinamento Aprendizado de conhecimento a partir de amostras com classes conhecidas 11 Processo de classificação Teste Avaliação do conhecimento descoberto pelo treinamento através da predição de classe de amostras desconhecidas 12 Avaliação dos Métodos de Classificação Acurácia: índice de exatidão de classificação de amostras desconhecidas Desempenho: velocidade e custo computacional referente a utilização do classificador 14 Avaliação dos Métodos de Classificação Robustez: capacidade de realizar predições corretas a partir de conjuntos de dados com amostras incompletas ou com ruído Escalabilidade: eficiência do modelo de conhecimento a partir de uma grande quantidade de dados Interpretabilidade: compreensão do modelo de conhecimento extraído do modelo de dados 15 Método Nearest Centroid Centróide Centro de distribuição de um conjunto de amostras Amostras de treinamento: centróide geral Amostras de determinada classe: centróide de classe 17 Método Nearest Centroid Matematicamente um espaço p-dimensional, sendo p o numero de atributos i = 1, 2, ... , p presentes num conjunto de dados composto de n amostras j = 1, 2, ... , n Seja xij a expressão do i-ésimo atributo da amostra j. Cada amostra está associada a uma classe k, pertencente a um conjunto discreto de K classes, Ck = (1, 2, ... ,K) cada classe k, estão associadas nk amostras que compõem o modelo de dados. A 18 Método Nearest Centroid Matematicamente O i-ésimo componente dos centróides Geral x i j 1 xij / n n De classe xik i C xij / nk k 19 Método Nearest Centroid Função de distância k x p * i 1 x * i x ik si2 2 2 log k Sendo 2 1 s xij xik n K k i Ck 2 i k nk / n K k 1 k 1 Classificação 20 Introdução Classificação de Dados Seleção de Características Sistema Inteligente Testes Comparativos Resultados Considerações Finais 21 Seleção de Características Teoria Maior quantidade de atributos: maior poder de discernimento Prática Informações irrelevantes confundem e retardam os sistemas de aprendizado 22 Seleção de Características Motivação Existência de bases de dados com alto nível dimensional que acarretam alto custo computacional (baixo desempenho) e/ou pouca acurácia no processo de mineração de dados 23 Seleção de Características Eliminação de atributos irrelevantes/redundantes do modelo de dados Busca da melhoria do processo de descoberta de conhecimento 24 Método Nearest Shrunken Centroid Distância estatística xik xi dik mk si xik xi mk si dik Sendo mk 1/ nk 1/ n 26 Método Nearest Shrunken Centroid Função de limiarização suave d 'ik sign dik . dik 27 Método Nearest Shrunken Centroid Dessa forma x'ik xi mk si d 'ik Se dado atributo i, ∃∆ tal que ∀k tem-se d’ik = 0, então o i-ésimo componente dos centróides são eliminados pois não interferem na tarefa de classificação k x p * i 1 x * i x ik si2 2 2 log k 28 Shrunken Centroids 29 Introdução Classificação de Dados Seleção de Características Sistema Inteligente Testes Comparativos Resultados Considerações Finais 30 Sistema Inteligente 31 Sistema Inteligente File: arquivo físico da base de dados *.arff *.dat Sample: amostra da base de dados. Composta por seus atributos (values) e identificada por sua classe 32 Sistema Inteligente DataBase: representação da base de dados. Composta de um conjuntos de amostras (samples) Centroid: centróide de um conjunto de amostras 33 Sistema Inteligente NearestCentroidClassifier: classificador NSC de treinamento: trainingSet Conjunto de teste: testSet Centróides de classe: classCentroids Centróide geral: overallCentroids Classificação de amostra: classify(sample) Conjunto 34 Sistema Inteligente Shrinker Seleção de características Realiza a redução dos centróides shrinkCentroids() NearestCentroidClassifier searchDelta() crossValidation() de kfolds 35 Introdução Classificação de Dados Seleção de Características Sistema Inteligente Testes Comparativos Resultados Considerações Finais 36 Metodologia Sub-divisão das bases de dados Testes de classificação 75% conjunto de treinamento 25% conjunto de teste Seleção de características Dados originais Dados reduzidos 38 Metodologia Validação Cruzada 39 Metodologia Validação Cruzada Neste trabalho convencionou-se a utilização de validação cruzada de 10 folhas como ponto de partida para o processo de avaliação de classificação 40 Metodologia Bases de dados utilizadas Breast Colon Glasses Iris Leukemia Lymphoma Prostate 41 Metodologia Classificadores utilizados NSC Weka: suíte de mineração de dados Naive-Bayes SMO Multilayer Perceptron J48 Random Forest 42 Testes Comparativos Por Base de Dados 43 Breast 44 Colon 45 Glasses 46 Iris 47 Leukemia 48 Lymphoma 49 Prostate 50 Testes Comparativos Por Classificador 51 NSC 52 Naive-Bayes 53 SMO 54 Multilayer Perceptron 55 J48 56 Random Forest 57 Introdução Classificação de Dados Seleção de Características Sistema Inteligente Testes Comparativos Resultados Considerações Finais 58 Resultados Média por Base de Dados Média por Classificador 59 Resultados Numero de Atributos x Desempenho Grande redução do número de atributos Ganho considerável de desempenho Maiores índices Bases de dados de alto nível dimensional 60 Resultados Acurácia Perda pouco significativa de acurácia Melhores índices Base de dados: Leukemia (+2,22%) Classificador: Multilayer Perceptron (+0,96%) Piores índices Base de dados: Breast (-8%) Classificador: Random Forest (-3,43%) 61 Resultados Desempenho x Acurácia Ganho de desempenho e de acurácia Bases de dados de alto nível dimensional 62 Introdução Classificação de Dados Seleção de Características Sistema Inteligente Testes Comparativos Resultados Considerações Finais 63 Considerações Finais Ganho considerável de desempenho Queda pouco significativa de acurácia Melhores resultados em bases de dados de alto nível dimensional 64 Considerações Finais Trabalhos Futuros Estudos Outros comparativos métodos de seleção de características Variação da proporção entre número de amostras de treinamento e teste 65
Download